

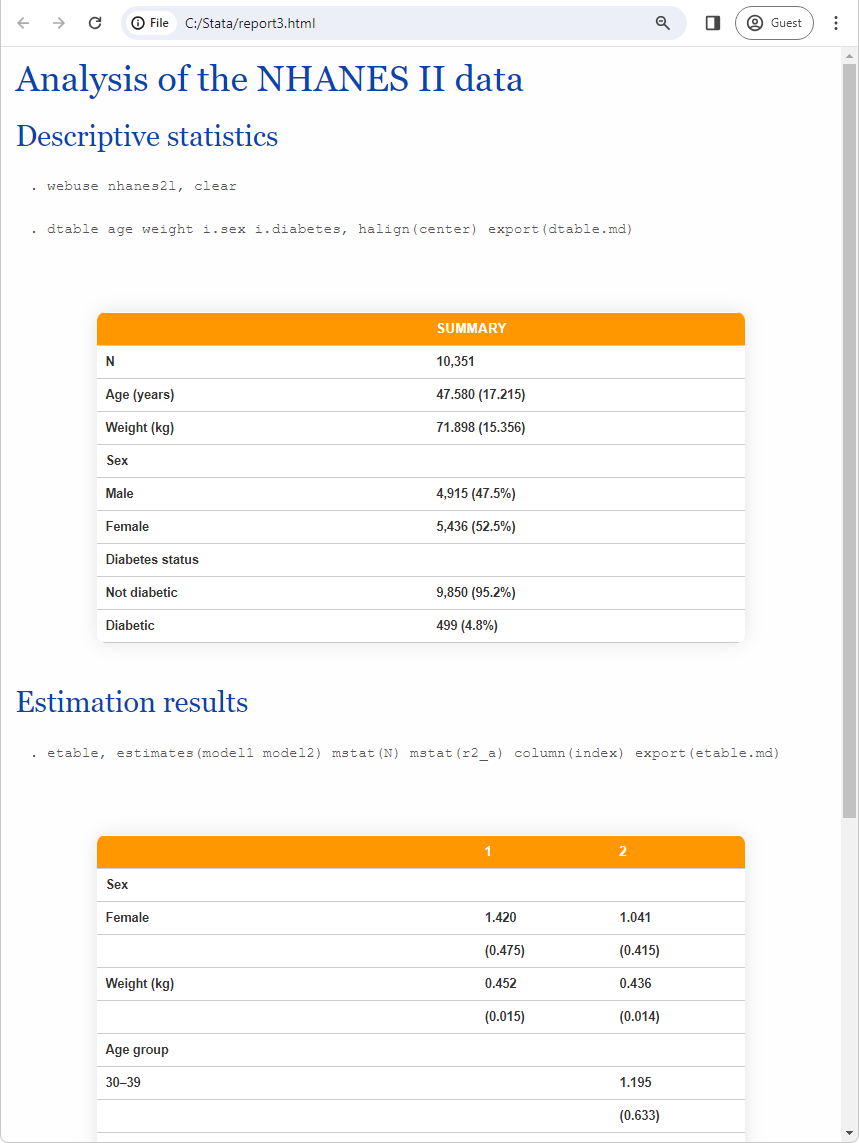
An Asian palm civet
Kurit afshen/Shutterstock
Espresso beans collected from the faeces of civets have a novel chemistry that will clarify why such beans are prized for his or her flavour.
Asian palm civets (Paradoxurus hermaphroditus) are mongoose-like animals native to South and South-East Asia. Civet espresso, also called kopi luwak, is without doubt one of the world’s most useful and strangest luxurious drinks. A kilogram of beans which have handed via a civet’s digestive tract will be price over $1000.
Kopi luwak is produced primarily in Indonesia, the Philippines and Vietnam, however it is usually made on a smaller scale in different nations, together with India and East Timor. Nevertheless, animal welfare teams urge shoppers to keep away from the business, accusing it of preserving 1000’s of civets caged in horrible circumstances.
To learn the way espresso beans are remodeled after passing via a civet, Palatty Allesh Sinu at Central College of Kerala, India, and his colleagues collected espresso samples from 5 coffee-growing farms close to Kodagu within the Western Ghats mountain vary of India.
Civets stay wild inside these farms, and not one of the operations maintain the animals caged. Staff routinely acquire the beans from the scats after which add them to the harvest of tree-grown espresso beans. “The locations we labored have a harmonious interplay between planters and civets,” says Sinu. “We need to convey the details in regards to the chemical composition to the planters.”
The researchers collected almost 70 civet scats containing espresso beans and in addition manually harvested beans from the plantations’ robusta espresso bushes, earlier than operating a set of checks that checked out key chemical parts, like fat and caffeine.
Whole fats was considerably larger within the civet beans than in these harvested from the bushes, whereas caffeine, protein and acid content material had been barely decrease. The decrease acidity was possible because of the fermentation throughout digestion, the researchers say.
The risky natural compounds within the civet espresso additionally confirmed important variations relative to common espresso beans. A few of these parts, that are routinely present in common espresso beans, had been both lacking outright from the civet beans or current in solely minimal portions.
The staff means that the upper fats content material in civet espresso could contribute to its distinctive aroma and flavour profile, and the decrease degree of proteins could end in decreased bitterness.
Sinu says caging civets to make kopi luwak is merciless, and the hope is that additional work might assist develop synthetic fermentation processes that end in espresso with an equivalent chemical composition.
“We assume that the intestine microbiome may assist a way within the fermentation course of,” Sinu says. “As soon as we all know the enzymes concerned in digestion and fermentation, we could possibly artificially make civet espresso.”
Matters:













{kind=link}
{kind=link}