Samsung’s newly launched $1,800 Galaxy XR headset contains help for bootloader unlocking.
In contrast to opponents like Meta Quest or Apple Imaginative and prescient Professional, this makes the Galaxy XR uniquely accessible for fanatics and builders.
It’s unclear whether or not this was supposed by Samsung or an oversight that will probably be patched, however it opens doorways for customized ROMs and different software program mods.
Samsung simply launched the Undertaking Moohan headset this week, rebranding it because the Samsung Galaxy XR. It’s the primary Android XR headset that individuals should purchase, so there’s lots of pleasure behind the product regardless of its $1,800 price ticket. It appears Samsung has given customers another reason to be excited: bootloader unlocking.
Don’t need to miss one of the best from Android Authority?
As X consumer Brad Lynch discovered, the Galaxy XR features a toggle for OEM unlocking in Developer Choices:
Shock, shock — not solely does the toggle work, however you can even really go forward and unlock the bootloader.
Bootloader unlocking on the Galaxy XR is a breath of contemporary air, particularly when you think about how Samsung went out of its method to take away the bootloader unlock possibility from One UI 8 throughout its telephones and tablets, even from units that beforehand supported it.
It’s much more stunning, contemplating that the majority mainstream opponents within the AR/XR area, such because the Apple Imaginative and prescient Professional and the Meta Quest lineup, don’t formally permit bootloader unlocking. You possibly can unlock the bootloader on some older and unpatched firmware variations of the Meta Quest 2 and three by exploits. To one of the best of my information, that is the primary time an AR/VR/XR headset has had an unlocked bootloader/OS for the reason that Oculus Go. This makes the Galaxy XR a very distinctive system in latest occasions, one which surprisingly doesn’t supremely penalize fanatics and energy customers from tinkering with the software program (but).
Will you purchase the Samsung Galaxy XR?
308 votes
It stays to be seen whether or not Samsung really supposed the Galaxy XR’s bootloader to be unlockable, or if this was merely an oversight that will probably be mounted with a future software program replace. Provided that the Android XR platform may use all of the push it may get proper now from builders and fanatics, it does really feel intentional and never unintentional.
I’m preserving my fingers crossed that builders will discover new and progressive makes use of for the {hardware}, due to the unlocked bootloader. Time for some Android XR customized ROMs? Heck yeah!
Extra pixels, and weighs lower than the Imaginative and prescient Professional
The Samsung Galaxy XR is a formidable first try at a hybrid AR / VR headset. Strap the lightweight unit to your head to take pleasure in video games, films, or use your favourite productiveness apps in giant format for as much as 2.5 hours per cost. 4K micro-LED shows provide 4,032 PPI of decision.
Thanks for being a part of our group. Learn our Remark Coverage earlier than posting.
Close to-Hurricane Melissa Will Drop Thoughts-Boggling Rain on Jamaica
Melissa is presently a slow-moving tropical storm that’s anticipated to quickly intensify to a serious hurricane—a brutal mixture will drench Jamaica and different Caribbean islands
Tropical Storm Melissa swirling slowly over the Caribbean Sea on October 23, 2025.
Tropical Storm Melissa is poised to devastate Jamaica and elements of Haiti this weekend because the slow-moving storm quickly explodes into a serious hurricane and dumps enormous quantities of rain on the Caribbean islands. Some areas may see as a lot as 20 inches of rainfall in just some days. With that depth, an Olympic swimming pool’s price of water would cowl scarcely lower than the realm of a soccer subject.
Winds are the menace that’s most related to hurricanes, adopted by storm surge. However rain is an typically ignored peril of such storms—and will be essentially the most harmful one. That was the case with 2017’s Hurricane Harvey—which established the document for rainfall in a single storm within the continental U.S. when it dropped greater than 48 inches of rain close to Houston—and with final yr’s Hurricane Helene—which dropped as a lot as two toes of rain in Appalachia simply days after earlier rainfall of roughly one foot within the area.
For those who’re having fun with this text, take into account supporting our award-winning journalism by subscribing. By buying a subscription you might be serving to to make sure the way forward for impactful tales concerning the discoveries and concepts shaping our world at present.
As of the afternoon of October 23, Melissa is a tropical storm with a peak sustained wind velocity of 45 miles per hour, in line with the Nationwide Oceanic and Atmospheric Administration’s Nationwide Hurricane Middle, which is working regardless of the now three-week-long, persevering with shutdown of the federal authorities. The storm is anticipated to change into a hurricane inside 48 hours and to accentuate to a serious Class 3 hurricane by Sunday—after which it’ll maybe prime out as a Class 4 hurricane by Monday. (Forecasters are nonetheless watching to see whether or not Melissa may threaten the continental U.S. subsequent week.)
However even because the winds inside Melissa are forecast to change into highly effective gusts, the ambiance across the storm is calm, leaving the would-be hurricane meandering via the Caribbean. Melissa’s eye is presently transferring at a velocity of simply two miles per hour. “You or I may stroll quicker than it’s transferring,” says Brian McNoldy, a hurricane researcher on the College of Miami. The entire threats of a severe hurricane are exacerbated when a storm strikes slowly as a result of any given place is uncovered to hurricane circumstances for extra time. “Getting hit by a hurricane is rarely good,” McNoldy says. “However getting hit by a hurricane that’s not transferring is a lot worse.”
As Melissa crawls by, it’ll dump enormous quantities of rain on the islands in its path. The Nationwide Hurricane Middle’s rainfall forecasts presently see western Jamaica getting practically a foot of rain inside the subsequent three days, with some places surpassing that. However the storm’s timeline is presently longer than the forecast’s; former NOAA meteorologist Alan Gerard expects some elements of the Caribbean to see at the least 20 inches of rain from Melissa.
Extra intense rainfall occasions from storms of all types have gotten extra possible as warming temperatures prime the ambiance to carry extra water vapor. “That’s the fingerprint that local weather change has on storms—usually, extra moisture, extra rain,” McNoldy says.
He worries that Melissa’s devastation within the Caribbean can be worsened by the mountainous terrain of islands reminiscent of Jamaica and Hispaniola, which is split between Haiti and the Dominican Republic. Such a panorama is especially weak to flash floods and landslides as a result of water rushes to the bottom elevation it will possibly discover—take into account the horrible flooding Hurricane Helene dropped at Appalachia final autumn. As well as, mountainous landscapes can worsen rainfall itself as a result of when an air mass hits a mountainside, it’s compelled upward, which causes it to drop extra of the water inside it, McNoldy says.
The mixture could possibly be a recipe for dire flash flooding, which is especially harmful in steep terrain that funnels enormous quantities of water into small areas. “When you’re over even half a foot of rain, it’s a ridiculous quantity of rain,” McNoldy says. “If you’re entering into 12-plus inches of rain, it’s simply an excessive amount of for wherever to deal with, irrespective of how good your infrastructure is.”
It’s Time to Stand Up for Science
For those who loved this text, I’d prefer to ask on your assist. Scientific American has served as an advocate for science and trade for 180 years, and proper now would be the most crucial second in that two-century historical past.
I’ve been a Scientific American subscriber since I used to be 12 years outdated, and it helped form the best way I take a look at the world. SciAm at all times educates and delights me, and evokes a way of awe for our huge, lovely universe. I hope it does that for you, too.
For those who subscribe to Scientific American, you assist be sure that our protection is centered on significant analysis and discovery; that we have now the sources to report on the selections that threaten labs throughout the U.S.; and that we assist each budding and dealing scientists at a time when the worth of science itself too typically goes unrecognized.
The weblog is about estimation of genetic parameters like genotypic variance, phenotypic variance, heritability, genetic advance, genetic advance as a share of imply, phenotypic coefficient of variation (PCV), genotypic coefficient of variation (GCV) for the RCBD trails of genotypes. (Studying time 20 minutes).
1. INTRODUCTION
In a normal
statistical context, a parameter
refers to a numerical attribute or attribute that describes a inhabitants.
It may be a hard and fast worth or an unknown amount that helps to explain or
summarize a particular side of a inhabitants. Genetic Parameter
is a statistical measure that quantifies the genetic contributions to traits
inside a inhabitants of an organism. Genetic parameter estimation in plant
breeding entails quantifying varied genetic elements that affect traits
of curiosity, comparable to yield, illness resistance or high quality attributes. These
parameters present important insights into the genetic foundation of those traits,
informing breeding selections geared toward bettering crop varieties.
Genetic parameters embody a
vary of measurements, together with heritability, genetic variance and genetic
advance. Heritability signifies the proportion of phenotypic
variation in a trait that’s attributable to genetic components, guiding breeders
on the potential response to choice. Genetic variance
quantifies the variability in traits because of genetic variations amongst
people, essential for understanding trait inheritance patterns. Genetic
advance measures the anticipated enchancment from choice, facilitating
environment friendly breeding methods. Understanding these genetic parameters empowers
plant breeders to develop improved cultivars tailor-made to particular agricultural
wants, enhancing crop productiveness, resilience and high quality. These parameters
are estimated via statistical analyses of trait knowledge collected from
breeding experiments, using methodologies comparable to variance element
evaluation and heritability estimation. The experiments are laid in varied experimental
designs that ensures legitimate and interpretable outcomes via randomization,
replication and management. Designs vary from easy fully randomized
designs to advanced ones like randomized full block designs (RCBD), factorial designs and Latin
squares. These designs assist isolate variable results and perceive their
interactions.
1.RANDOMIZED
COMPLETE BLOCK DESIGN
Randomized
Full Block Design (RCBD) is a basic experimental design used
extensively in plant breeding analysis to regulate for variability inside
experimental models. In RCBD, every block accommodates all genotypes, with random
project inside blocks, controlling for variability and making certain
complete genotype comparability. Therefore, it’s referred to as “Randomized
Full Block Design.” This design reduces experimental error and enhances
the precision of genotype imply comparisons by accounting for block-to-block
variability. It’s important for drawing legitimate inferences about genotype
results whereas minimizing the affect of extraneous components.
2.1When
RCBD is used?
The
RCBD is employed in agricultural analysis underneath particular situations to realize
dependable and exact outcomes. Listed here are eventualities when RCBD is used: heterogeneous experimental models, identified gradients, a number of genotypes, restricted experimental models, small-scale
trials and so forth.
2.2Assumptions
of RCBD
The
RCBD operates underneath a number of key assumptions to make sure legitimate and dependable
outcomes: homogeneity inside blocks,
independence of observations, additivity of results, random project,
normality, equal variance, no lacking knowledge and so forth.
2.3 Randomization steps in RCBD
Randomization
in a Randomized Full Block Design (RCBD) is a vital step to make sure
unbiased allocation of therapies to experimental models inside every block. Right here
are the detailed steps for randomization in RCBD:
1. Determine the Remedies
2. Outline the Blocks
3. Assign Remedies Randomly inside Every Block
4. Document the Project
5. Repeat for All Blocks
6. Confirm Randomization
7. Create a Structure Plan
2.4 Evaluation
of Variance (ANOVA) for RCBD
In a RCRD, the Evaluation of Variance
(ANOVA) mannequin offers a
comparability by partitioning of variance because of varied sources.
It’s used to research the info and check the importance of genotype results. The statistical mannequin for ANOVA in RCBD is as
underneath:
Right here the null speculation is about as all genotypes means are equal
and the choice speculation is at the least one genotype pair differs
considerably. Significance of the imply sum of squares because of replications (Mr)
and genotypes (Mg) is examined towards error imply squares (Me). A comparability of
the calculated F (Mg/Me) with the important worth of F similar to genotype
levels of freedom and error levels of freedom provides the thought to just accept or
reject the null speculation.
2.5 Completely different statistic associated to RBD design
2.5.1 Commonplace error of imply (SEm):
2.5.2 Coefficient of Variation (CV%):
2.5.3 Important distinction at 5% stage of
significance
2.6 What if replication supply of
variation discovered vital in RCBD?
2.6.1 Causes for Important Replication in Plant Genotype Experiments
This contains environmental micro-variation (soil heterogeneity, microclimatic situations, and so forth.,), administration and cultural practices (inconsistent utility of therapies, variations in planting depth and spacing and so forth.,), biotic components (pest and illness strain, microbial exercise and so forth.,), phenotypic plasticity (adaptive responses), measurement and sampling error (human error in measurement, instrument calibration and so forth.,)
2.6.2 Addressing Important Replication in Plant Genotype Experiments
This may be achieved by bettering experimental design (improve block homogeneity, improve variety of replicates and so forth.,), standardize cultural practices (constant therapy utility, uniform planting strategies and so forth.,), management environmental components (monitor and handle microclimate, soil administration and so forth.,), common monitoring for biotic components (pest and illness administration, microbial inoculants and so forth.,), refine measurement strategies (coaching and calibration, automated measurements and so forth.,)
3 CALCULATION OF SIMPLE MEASURES OF VARIABILITY
Easy measures of
variability embrace vary, normal deviation, variance, normal deviation and
coefficient of variation. These measures assist in understanding the distribution
and unfold of knowledge, that are important for statistical evaluation and
decoding the variability inside an information set for given character.
3.1 Vary: The distinction
between the utmost and minimal values in an information set. Offers a fast sense of
the unfold of the info, however is delicate to outliers.
Vary = Most Worth – Minimal Worth
3.2 Commonplace Deviation (SD): A
measure of the typical distance of every knowledge level from the imply. Signifies how
unfold out the info factors are across the imply. A smaller SD signifies knowledge
factors are near the imply, whereas a bigger SD signifies they’re extra unfold
out.
The place, xi is every knowledge level, x ̅ is the imply of the info and n is the variety of knowledge factors
3.3 Variance: The
common of the squared variations from the imply. It measures the dispersion
of knowledge factors. It is the sq. of the usual deviation.
3.4 Coefficient of Variation (CV): The
ratio of the usual deviation to the imply, expressed as a share. It standardizes
the measure of variability by evaluating the usual deviation relative to the
imply. Helpful for evaluating the diploma of variation between completely different knowledge units,
particularly these with completely different models or broadly completely different means.
4.Variance
Parts
Within the context of plant breeding and genetics, ANOVA (Evaluation of
Variance) is commonly used to partition the noticed variance into completely different
elements: phenotypic variance, genotypic variance, and environmental
variance. These elements are essential for understanding the underlying
variability and for estimating the respective coefficients of variation.
4.4What if genotypic variance is detrimental?
If σ2g
(genotypic variance) is detrimental, it signifies that the calculated worth just isn’t
possible since variance, by definition, can’t be detrimental. This example
sometimes arises because of small pattern dimension, massive experimental error, incorrect
knowledge or calculation and so forth.To deal with this points improve replications, enhance experimental design,re-evaluate
knowledge and so forth. In abstract, a detrimental genotypic variance suggests the
want for a reassessment of the experimental design, knowledge high quality and evaluation
strategies.
5. COEFFICIENTS OF VARIATION
5.1 Phenotypic Coefficient of Variation (PCV): Measures the extent of phenotypic variability relative to the imply of the trait.
5.2 Genotypic Coefficient of Variation (GCV): Measures the extent of genotypic variability relative to the imply of the trait.
5.3 Tips on how to Interpret the Relative
Values of GCV, PCV and ECV?
The relative values of
Genotypic Coefficient of Variation (GCV), Phenotypic Coefficient of Variation
(PCV), and Environmental Coefficient of Variation (ECV) present insights into
the sources and magnitude of variability inside a genetic inhabitants.
GCV is Excessive In comparison with PCV: PCV sometimes exceeds or equals GCV because it
contains each genetic and environmental variance. If GCV surpasses PCV,
this implies a calculation error; evaluate for accuracy.
PCV is Excessive In comparison with GCV: PCV is larger than GCV, indicating
substantial environmental affect on the trait. The distinction suggests
vital environmental variance. Regardless of genetic variability, breeders
should reduce environmental results to pick successfully based mostly on genetic
potential.
ECV is Increased than GCV: The trait is closely influenced by
environmental components, with minimal genetic variability. Phenotypic
choice could also be tough. Introducing new genetic materials may assist
improve genetic variability and enhance choice effectivity for the
trait.
5.4Tips on how to
Interpret Mixture of Values of GCV and PCV
Excessive GCV and Excessive PCV: This
signifies that the trait is strongly influenced by genetic components, however
environmental components additionally play a big position. Regardless of the
environmental affect, the excessive genetic variability suggests good
potential for enchancment via choice. Deal with stabilizing the
setting to harness the genetic potential successfully. Breeders can
make vital progress by deciding on superior genotypes.
Excessive GCV and Low PCV: This
means that the trait is predominantly influenced by genetic components,
with minimal environmental influence. The excessive genetic variability just isn’t
masked by environmental results. This is a perfect scenario for breeders.
Choice can be extremely efficient for the reason that phenotypic efficiency
instantly displays the genetic potential.
Low GCV and Excessive PCV: This
signifies that the trait is basically influenced by environmental components,
with little genetic variability. The excessive phenotypic variability is usually
because of environmental results. Choice could be much less efficient as a result of
low genetic variability. Breeders could have to concentrate on bettering
environmental situations or administration practices to cut back the
environmental variance. Moreover, exploring wider genetic bases or
introducing new germplasm may very well be thought-about to extend genetic
variability.
Low GCV and Low PCV: This
means that the trait is comparatively secure with minimal affect from
each genetic and environmental components. The shortage of variability may
point out that the trait is both extremely conserved or has reached a
choice plateau. Restricted scope for enchancment via choice.
Breeders may have to introduce new genetic materials to extend
variability. Alternatively, focus may shift to different traits with larger
variability and potential for enchancment.
6. Heritability and Genetic advance
Heritability and Genetic advance are vital
choice parameters. Heritability estimates together with the genetic advance are
usually extra useful in predicting genetic achieve underneath choice than
heritability estimates alone. Nonetheless, it isn’t needed {that a} character
exhibiting excessive heritability will even exhibit excessive genetic advance.
6.2 Tips on how to interpret the results of heritability in broad sense?
1.Low
Heritability (0-30%): A low share of phenotypic variation within the
trait is because of genetic components. A lot of the noticed variation is probably going due
to environmental influences. Selective breeding for this trait could be much less
efficient as a result of genetic variations contribute minimally to the trait’s
expression. As an alternative, concentrate on optimizing environmental situations to enhance
the trait.
2.Average Heritability (30-60%): A
average share of phenotypic variation is because of genetic components. Each
genetics and setting play vital roles in influencing the trait. Selective
breeding can result in average enhancements within the trait. Genetic good points may be
achieved, however additionally it is important to handle environmental components to totally
categorical the genetic potential.
Excessive Heritability (60% and above): A excessive
share of phenotypic variation is because of genetic components. A lot of the
variation within the trait may be attributed to genetic variations amongst
people. Selective breeding is extremely efficient for this trait. Important
genetic enhancements may be made, and the trait is much less influenced by
environmental components.
6.3 Estimation of Genetic advance (GA)
Genetic advance refers back to the enchancment in a trait achieved via choice. It is determined by the choice depth, heritability and phenotypic normal deviation of the trait. The anticipated genetic advance (GA) may be calculated for every character by adopting the next system at 5 % choice depth utilizing the fixed ‘Ok’ as 2.06.
6.5 Tips on how to Interpret the Results of Genetic Advance as Per Cent of Imply?
1.Low Genetic Advance (0-10%): The trait is much less aware of choice. Reaching vital genetic enchancment via choice alone could be difficult. It could be needed to think about different methods comparable to hybridization or bettering environmental situations.
2.Average Genetic Advance (10-20%): The trait reveals an inexpensive response to choice. Choice can result in noticeable enhancements within the trait. A balanced strategy of choice and environmental administration may be efficient.
3. Excessive Genetic Advance (20% and above): The trait is extremely aware of choice. Important genetic good points may be achieved via choice. This trait is a main candidate for intensive choice packages to realize speedy enchancment.
6.6 Combining The Outcomes of Heritability (Broad Sense) And Genetic Advance (As P.c of Imply)
Combining heritability (broad-sense heritability) and genetic advance as % of imply (GAM) offers a extra complete understanding of the potential for enchancment of traits in a breeding program. This mix helps in figuring out traits that aren’t solely genetically managed but in addition aware of choice.
SOLVED EXAMPLE
Dataset: The
experiment was laid in Randomized Full Block Design with three replications
in maize (Zea mays L.) by utilizing 30 genotypes. The info have been noticed
from every replication by randomly chosen vegetation for days to 50% flowering. Hyperlink of Dataset
Genotypes
Replications
Genotype whole
Genotype imply
R1
R2
R3
G1
66
75
75
216.00
72.00
G2
68
75
76
219.00
73.00
G3
70
75
80
225.00
75.00
G4
70
81
86
237.00
79.00
G5
72
68
74
214.00
71.33
G6
66
72
80
218.00
72.67
G7
59
63
74
196.00
65.33
G8
66
69
79
214.00
71.33
G9
72
80
78
230.00
76.67
G10
64
66
83
213.00
71.00
G11
84
72
74
230.00
76.67
G12
60
64
75
199.00
66.33
G13
62
68
65
195.00
65.00
G14
63
72
75
210.00
70.00
G15
73
81
70
224.00
74.67
G16
58
84
70
212.00
70.67
G17
77
82
86
245.00
81.67
G18
64
69
75
208.00
69.33
G19
82
82
84
248.00
82.67
G20
72
74
75
221.00
73.67
G21
75
80
78
233.00
77.67
G22
70
76
82
228.00
76.00
G23
76
83
82
241.00
80.33
G24
77
76
75
228.00
76.00
G25
77
83
70
230.00
76.67
G26
76
84
86
246.00
82.00
G27
83
68
72
223.00
74.33
G28
61
75
84
220.00
73.33
G29
67
78
60
205.00
68.33
G30
67
70
78
215.00
71.67
Replication whole
2097
2245
2301
Grand whole
6643
7.1 Evaluation of Variance
Null speculation for genotypes and replication
H0: There are not any vital variations amongst technique of genotypes underneath examine.
Ha: There are not any vital variations amongst technique of replications underneath examine.
Conclusion:
• Low GCV and low PCV for days to 50% flowering point out low variability. The shortage of variability may point out that the trait is both extremely conserved or has reached a variety plateau.
• Heritability is <30 indicated extra affect of setting within the inheritance of the trait
• Low heritability coupled with low genetic advance as per cent of imply point out the choice wouldn’t be rewarding because of environmental fluctuations
7. STEPS TO
PERFORM ANALYSIS OF GENETIC PARAMETER ESTIMATION IN AGRI ANALYZE
Step 1: To create a CSV file with columns for Genotype, replication and trait
(DFF). Hyperlink of Dataset
“Cardiovascular ailments (CVDs),” Who.int. [Online]. Out there: https://www.who.int/news-room/fact-sheets/element/cardiovascular-diseases-(cvds). [Accessed: 25-Sep-2024].
[2]
S. James Sales space, “Fusobacterium infections☆,” in Reference Module in Biomedical Sciences, Elsevier, 2014.
[3]
Y. W. Han, “Fusobacterium nucleatum Interplay with Host Cells,” Oral Microbial Communities. Wiley, p. 221, 02-Aug-2011.
[4]
S. Chaushu et al., “Direct recognition of Fusobacterium nucleatum by the NK cell pure cytotoxicity receptor NKp46 aggravates periodontal illness,” PLoS Pathog., vol. 8, no. 3, p. e1002601, 2012.
[5]
J. Zhou, L. Liu, P. Wu, L. Zhao, and Y. Wu, “Fusobacterium nucleatum accelerates atherosclerosis through macrophage-driven aberrant proinflammatory response and lipid metabolism,” Entrance. Microbiol., vol. 13, 2022.
[6]
A. L. Truant, S. Menge, Ok. Milliorn, R. Lairscey, and M. T. Kelly, “Fusobacterium nucleatum pericarditis,” J. Clin. Microbiol., vol. 17, no. 2, pp. 349–351, 1983.
[7]
M. Febbraio, C. B. Roy, and L. Levin, “Is there a causal hyperlink between periodontitis and heart problems? A concise assessment of current findings,” Int. Dent. J., vol. 72, no. 1, pp. 37–51, 2022.
[8]
H. Liu, Y. Liu, W. Fan, and B. Fan, “Fusobacterium nucleatum triggers proinflammatory cell demise through Z-DNA binding protein 1 in apical periodontitis,” Cell Commun. Sign., vol. 20, no. 1, 2022.
[9]
J. O’Brien, H. Hayder, Y. Zayed, and C. Peng, “Overview of MicroRNA biogenesis, mechanisms of actions, and circulation,” Entrance. Endocrinol. (Lausanne), vol. 9, 2018.
[10]
S. Liu et al., “The host shapes the intestine Microbiota through fecal MicroRNA,” Cell Host Microbe, vol. 19, no. 1, pp. 32–43, 2016.
[11]
A. Swidsinski et al., “Acute appendicitis is characterised by native invasion with Fusobacterium nucleatum/necrophorum,” Intestine, vol. 60, no. 1, pp. 34–40, 2009.
[12]
I. Brook, “Fusobacterial infections in kids,” Curr. Infect. Dis. Rep., vol. 15, no. 3, pp. 288–294, 2013.
[13]
L. Wolff, D. Martiny, V. Y. M. Deyi, E. Maillart, P. Clevenbergh, and N. Dauby, “COVID-19-associated Fusobacterium nucleatum bacteremia, Belgium,” Emerg. Infect. Dis., vol. 27, no. 3, pp. 975–977, 2020.
[14]
P. J. Ford et al., “Irritation, warmth shock proteins and periodontal pathogens in atherosclerosis: an immunohistologic examine,” Oral Microbiol. Immunol., vol. 21, no. 4, pp. 206–211, 2006.
[15]
C. A. Brennan and W. S. Garrett, “Fusobacterium nucleatum — symbiont, opportunist and oncobacterium,” Nat. Rev. Microbiol., vol. 17, no. 3, pp. 156–166, 2019.
[16]
Y. W. Han, “Fusobacterium nucleatum: a commensal-turned pathogen,” Curr. Opin. Microbiol., vol. 23, pp. 141–147, 2015.
[17]
S. Hopkins et al., “Oral well being and heart problems,” Am. J. Med., vol. 137, no. 4, pp. 304–307, 2024.
[18]
“Life’s Important 8TM Your guidelines for lifelong good well being,” Coronary heart.org. [Online]. Out there: https://www.coronary heart.org/en/healthy-living/healthy-lifestyle/lifes-essential-8. [Accessed: 25-Sep-2024].
Studying and understanding econometrics papers will be arduous work. Most revealed articles, even evaluation articles, are written by specialists for specialists. Until you’re already accustomed to the literature, it may be an actual uphill battle to make it by means of a current paper. In grad faculty I keep in mind our professors repeatedly admonishing me and the remainder of the cohort to “learn the papers!” However once I did my greatest to comply with this recommendation, I practically all the time felt like I used to be banging my head towards a wall.
Efficient studying is a ability that may be realized, and the one option to study is thru observe. However you possibly can study the simple method or the arduous method. The arduous method is to maintain making an attempt and hope for the most effective; the simple method is to regulate your strategy based mostly on the experiences of others. With that in thoughts, this publish gives some suggestions and methods that I’ve picked up by means of the years for studying technical materials effectively and successfully. My audience is PhD college students in Economics, particularly college students within the Econometrics Studying Group at Oxford, however I hope that a number of the following suggestions shall be useful for others as nicely.
You probably have any suggestions of your personal, or when you violently agree or disagree with any of mine, I hope to listen to from you within the feedback part beneath!
Learn One thing Else As a substitute
The primary query to ask your self is whether or not you need to even be studying this paper within the first place. Simply because White’s (1980) paper on heteroskedasticity-robust commonplace errors is a “traditional” in econometrics, that doesn’t imply that you need to learn it. In actual fact, as a graduate pupil simply beginning out, you most likely shouldn’t! The paper that introduces a brand new concept or process isn’t the paper that provides the clearest clarification. Studying an excellent textbook clarification is a way more efficient option to become familiar with a brand new concept. You would possibly, for instance, attempt studying the related chapters in White’s textbook Asymptotic Concept for Econometricians as an alternative.
However generally it’s important to learn a specific paper. Perhaps it’s the paper you’ve been assigned to current in a studying group, or perhaps it’s extremely related to your personal analysis. In that case you should still need to begin by studying one thing else. For instance, there could be a more moderen paper or evaluation article that provides an excellent abstract of the concept or methodology in query. Studying this paper first could make it a lot simpler so that you can sort out the unique paper.
So to all these professors on the market who hold telling their college students to “learn the papers!” I say: “learn the papers, however solely after you’ve learn one thing else first!”
Don’t Assume You Should Perceive the Complete Factor
As a basic rule you need to not anticipate to grasp all the things if you learn a paper. Chances are you’ll solely get 10% on the primary learn, however that’s advantageous! In addition to papers I’ve written myself, there are comparatively few articles that I’ve checked line-by-line from begin to end. Even when you’ve been assigned to current a paper that doesn’t imply that it’s essential perceive each element of each lemma within the on-line technical appendix. As a substitute your aim needs to be to grasp the key concepts and contributions of the paper. Like something in life, there are diminishing returns to effort in studying a paper. When studying papers to help your personal analysis, you will be much more selective. The important thing query turns into: “how is that this related for what I’m doing?” It could be that you simply solely want to grasp a small a part of the paper to get what you want.
Don’t Assume You’re Silly
In case you’re confused, don’t assume that it’s your fault. Discover your confusion and attempt to unravel it with out taking issues as a right or participating in unfavorable self-talk. The one option to study is by getting confused after which unconfusing your self!
Chances are you’ll be confused as a result of the authors assume one thing that you simply don’t. They’re probably specialists within the discipline who’ve spent years desirous about this explicit query. You, however, are simply beginning out. As you achieve a bit extra context, issues might fall quickly into place. (See my subsequent tip beneath.)
Chances are you’ll be confused as a result of the paper is confusingly written. Writing is tough, and technical writing is particularly arduous. The referee course of may even make papers extra complicated, since our current system for evaluating analysis includes a number of rounds of revisions through which the authors should attempt to fulfill referees with differing views. The result’s that revealed papers usually include a considerable component of “cruft” that distracts from the primary message.
Chances are you’ll even be confused as a result of the paper is incorrect! As an excellent Bayesian, you shouldn’t instantly soar to the conclusion that you simply, a newcomer to this discipline, have stumbled upon an important error that everybody else has missed. Alternatively, you positively shouldn’t consider all the things that you simply see in print! All papers are incorrect indirectly, and a few papers are incorrect in critical and essential methods. In case you’re confused, it’s value contemplating whether or not the authors have been confused too!
Unfold Your self Skinny
Let’s say you actually need to become familiar with paper X on matter Y. You’ve learn the related textbook materials, you’ve tried a evaluation article, and also you’re nonetheless struggling. What now? Unusual although it could sound, one useful reply is to learn extra papers on matter Y in an especially shallow method. Skim the abstracts, introductions, and conclusions. Be aware any phrases or ideas that hold showing, particularly ones that you simply don’t perceive.
I can consider many events once I skimmed 9 papers and didn’t perceive any of them, however then learn a tenth and instantly all the things clicked. The important thing right here is context. If you’re new to matter Y, there shall be numerous little issues that you simply’ve by no means considered earlier than however that the literature takes as a right. Since most papers are written for specialists by specialists, essential particulars are sometimes not noted or glossed over as in the event that they have been apparent. Simply as fish don’t notice that they’re in water, specialists usually fail to understand that they’re taking quite a lot of issues as a right. The explanation that studying many papers will help is that completely different specialists will miss completely different particulars. The important thing that it’s essential perceive paper X could be a seemingly throwaway remark in paper Z!
Clarify It to Somebody Else
One of the simplest ways to grasp one thing is by making an attempt to clarify it to another person. This holds true even when the “another person” in query is only a figment of your creativeness. As you learn, begin by making an attempt to clarify the paper to your self in your personal phrases. I discover it useful to jot down within the margins of the paper as I’m going, summarizing the important thing concepts with much less jargon and less complicated terminology and notation. If you’re confused about one thing, attempt to put your confusion into phrases; make it concrete and write it down.
Speaking to an actual particular person will be much more useful. In case you’re in a studying group, attempt discussing the paper informally with one your friends who has additionally learn it. Chances are you’ll be stunned at how a lot two individuals, neither of whom understands one thing on their very own, can study from one another. On this courageous new world of LLMs like Claude and GPT4o, you can even attempt importing your paper and discussing it with an AI. You can’t assume that the AI will essentially offer you dependable details about the paper, however identical to a peer who solely partially understands it, an AI is usually a helpful sounding board on your personal concepts and confusions. Noticing errors within the AI’s understanding, pointing them out and persevering with the dialog may also be an effective way to make clear your personal considering.
Head Straight for the Simulation / Empirical Instance
Ideally each paper would have a implausible introduction that makes it clear what the paper is about and why it’s essential. In actual life, introductions will be hit-or-miss. So after studying the introduction, you would possibly think about heading straight for the simulation research and/or empirical instance. Most econometrics papers suggest a technique that solves a specific downside. What’s the downside, and why does the actual information producing course of (DGP) within the simulation (or the actual information within the empirical instance) exhibit it? What parameters of the simulation DGP management the extent of the issue? What’s the “previous” methodology on which the paper improves? That is prone to be one thing acquainted comparable to a “textbook” methodology. How precisely is the brand new methodology applied? In different phrases, how precisely is it computed from actual or simulated information? Attempt to write down all of the steps within the implementation in a sufficiently exact method that you can code it your self.
As soon as you know the way to reply these questions you’re in a a lot better place to grasp the remainder of the paper. As you learn by means of the assumptions and theorems, refer again to the simulation research. Why does the DGP fulfill the assumptions? Are you able to consider a unique DGP through which the assumptions fail? Is there something “fishy” concerning the simulation instance? Does it look like the authors have cooked the books indirectly, e.g. by introducing a really “delicate” model of the central downside, or one thing else that will be unrealistic in observe? Answering these questions will assist you to consider the paper, perceive its limitations and presumably take into consideration learn how to enhance upon it.
Make Issues Less complicated
Many econometrics papers current outcomes at an especially excessive degree of generality. On the one hand this can be a good factor. A lot of the ability of arithmetic comes from abstraction and basic outcomes are extra widely-applicable. However from an expositional standpoint, that is horrible. This historical past of arithmetic is a historical past of concrete issues to particular issues that have been progressively generalized and expanded over time. The historical past of concepts mirrors the best way that the typical particular person learns most successfully: by beginning with concrete examples after which generalizing.
With this in thoughts, attempt to simplify the theorems and examples within the paper. Eliminating covariates usually cuts down on each algebra and notation, so begin with this. Attempt re-writing the assumptions and theorems on this less complicated notation. Are a number of the assumptions complicated? Attempt strengthening them or attempt to see if you’ll find a concrete instance through which they maintain, presumably taken from the simulation DGP.
Don’t Get Hung Up on Technicalities
Some components of a paper are “core materials” and a few components are “technicalities”. Maintaining these separate in your thoughts will make it a lot simpler to grasp a paper. One useful strategy is to make a dependency tree of the assumptions, lemmas, and theorems earlier than making an attempt to grasp them. When you see how issues match collectively you might discover, for instance, that the one position of Proposition 3 is to determine that an acceptable Central Restrict Theorem holds and the one position of Assumptions 2-6 is to show Proposition 3. Improbable! On this case, simply assume the conclusion of Proposition 3 and transfer on to see the place that is wanted within the core outcomes. Even if you’re studying assumptions, lemmas, propositions, theorems, and proofs, try to be aiming to get the “large image” fairly than to assimilate each tiny element.
Be Appropriately Skeptical of Asymptotics
Asymptotics are an important device in econometrics however keep in mind that it’s finite pattern properties that we really care about. The “asymptotic distribution” of an estimator is only a thought experiment, not one thing you possibly can take to the financial institution. An asymptotic argument is a form of approximation that in impact supposes that sure issues are “negligible.” This approximation may very well be implausible or it may very well be horrible. It’s solely by means of simulation research that we are able to actually know which is the case. Or, to cite van der Vaart (1998),
strictly talking, most asymptotic outcomes which can be presently accessible are logically ineffective. It’s because most asymptotic outcomes are restrict outcomes, fairly than approximations consisting of an approximating system plus an correct error sure … Because of this there’s good asymptotics and unhealthy asymptotics and why two forms of asymptotics generally result in conflicting claims … As a result of it could be theoretically very arduous to determine that approximation errors are small, one usually takes recourse to simulation research
For an instance of “good” versus “unhealthy” asymptotics utilized to energy evaluation, see this publish.
Graph databases have revolutionized how organizations handle advanced, interconnected information. Nevertheless, specialised question languages reminiscent of Gremlin usually create a barrier for groups trying to extract insights effectively. Not like conventional relational databases with well-defined schemas, graph databases lack a centralized schema, requiring deep technical experience for efficient querying.
To deal with this problem, we discover an method that converts pure language to Gremlin queries, utilizing Amazon Bedrock fashions reminiscent of Amazon Nova Professional. This method helps enterprise analysts, information scientists, and different non-technical customers entry and work together with graph databases seamlessly.
On this submit, we define our methodology for producing Gremlin queries from pure language, evaluating totally different methods and demonstrating how one can consider the effectiveness of those generated queries utilizing giant language fashions (LLMs) as judges.
Answer overview
Reworking pure language queries into Gremlin queries requires a deep understanding of graph buildings and the domain-specific data encapsulated throughout the graph database. To attain this, we divided our method into three key steps:
Understanding and extracting graph data
Structuring the graph just like text-to-SQL processing
Producing and executing Gremlin queries
The next diagram illustrates this workflow.
Step 1: Extract graph data
A profitable question technology framework should combine each graph data and area data to precisely translate pure language queries. Graph data encompasses structural and semantic info extracted immediately from the graph database. Particularly, it contains:
Vertex labels and properties – A list of vertex sorts, names, and their related attributes
Edge labels and properties – Details about edge sorts and their attributes
One-hop neighbors for every vertex – Capturing native connectivity info, reminiscent of direct relationships between vertices
With this graph-specific data, the framework can successfully cause concerning the heterogeneous properties and sophisticated connections inherent to graph databases.
Area data captures extra context that augments the graph data and is tailor-made particularly to the applying area. It’s sourced in two methods:
Buyer-provided area data – For instance, the shopper kscope.ai helped specify these vertices that symbolize metadata and will by no means be queried. Such constraints are encoded to information the question technology course of.
LLM-generated descriptions – To reinforce the system’s understanding of vertex labels and their relevance to particular questions, we use an LLM to generate detailed semantic descriptions of vertex names, properties, and edges. These descriptions are saved throughout the area data repository and supply extra context to enhance the relevance of the generated queries.
Step 2: Construction the graph as a text-to-SQL schema
To enhance the mannequin’s comprehension of graph buildings, we undertake an method just like text-to-SQL processing, the place we assemble a schema representing vertex sorts, edges, and properties. This structured illustration enhances the mannequin’s potential to interpret and generate significant queries.
The query processing part transforms pure language enter into structured components for question technology. It operates in three levels:
Entity recognition and classification – Identifies key database components within the enter query (reminiscent of vertices, edges, and properties) and categorizes the query primarily based on its intent
Context enhancement – Enriches the query with related info from the data part, so each graph-specific and domain-specific context is correctly captured
Question planning – Maps the improved query to particular database components wanted for question execution
The context technology part makes positive the generated queries precisely mirror the underlying graph construction by assembling the next:
Ingredient properties – Retrieves attributes of vertices and edges together with their information sorts
Graph construction – Facilitates alignment with the database’s topology
Area guidelines – Applies enterprise constraints and logic
Step 3: Generate and execute Gremlin queries
The ultimate step is question technology, the place the LLM constructs a Gremlin question primarily based on the extracted context. The method follows these steps:
The LLM generates an preliminary Gremlin question.
The question is executed inside a Gremlin engine.
If the execution is profitable, outcomes are returned.
If execution fails, an error message parsing mechanism analyzes the returned errors and refines the question utilizing LLM-based suggestions.
This iterative refinement makes positive the generated queries align with the database’s construction and constraints, bettering general accuracy and usefulness.
Immediate template
Our closing immediate template is as follows:
## Request
Please write a gremlin question to reply the given query:
{{query}}
You may be supplied with couple related vertices, along with their
schema and different info.
Please select essentially the most related vertex in accordance with its schema and different
info to make the gremlin question appropriate.
## Directions
1. Listed below are associated vertices and their particulars:
{{schema}}
2. Do not rename properties.
3. Do not change strains (utilizing slash n) within the generated question.
## IMPORTANT
Return the ends in the next XML format:
INSERT YOUR QUERY HERE
PROVIDE YOUR EXPLANATION ON HOW THIS QUERY WAS GENERATED
AND HOW THE PROVIDED SCHEMA WAS LEVERAGED
Evaluating LLM-generated queries to floor fact
We carried out an LLM-based analysis system utilizing Anthropic’s Claude 3.5 Sonnet on Amazon Bedrock as a choose to evaluate each question technology and execution outcomes for Amazon Nova Professional and a benchmark mannequin. The system operates in two key areas:
Question analysis – Assesses correctness, effectivity, and similarity to ground-truth queries; calculates precise matching part percentages; and gives an general score primarily based on predefined guidelines developed with area specialists
Execution analysis – Initially used a single-stage method to check generated outcomes with floor fact, then enhanced to a two-stage analysis course of:
Merchandise-by-item verification towards floor fact
Calculation of general match share
Testing throughout 120 questions demonstrated the framework’s potential to successfully distinguish appropriate from incorrect queries. The 2-stage method notably improved the reliability of execution outcome analysis by conducting thorough comparability earlier than scoring.
Experiments and outcomes
On this part, we focus on the experiments we performed and their outcomes.
Question similarity
Within the question analysis case, we suggest two metrics: question precise match and question general score. A precise match rating is calculated by figuring out matching vs. non-matching elements between generated and floor fact queries. The next desk summarizes the scores for question precise match.
Simple
Medium
Exhausting
General
Amazon Nova Professional
82.70%
61%
46.60%
70.36%
Benchmark Mannequin
92.60%
68.70%
56.20%
78.93%
An general score is supplied after contemplating elements together with question correctness, effectivity, and completeness as instructed within the immediate. The general score is on scale 1–10. The next desk summarizes the scores for question general score.
Simple
Medium
Exhausting
General
Amazon Nova Professional
8.7
7
5.3
7.6
Benchmark Mannequin
9.7
8
6.1
8.5
One limitation within the present question analysis setup is that we rely solely on the LLM’s potential to check floor fact towards LLM-generated queries and arrive on the closing scores. Consequently, the LLM can fail to align with human preferences and under- or over-penalize the generated question. To deal with this, we advocate working with a topic professional to incorporate domain-specific guidelines within the analysis immediate.
Execution accuracy
To calculate accuracy, we examine the outcomes of the LLM-generated Gremlin queries towards the outcomes of floor fact queries. If the outcomes from each queries match precisely, we rely the occasion as appropriate; in any other case, it’s thought of incorrect. Accuracy is then computed because the ratio of appropriate question executions to the full variety of queries examined. This metric gives an easy analysis of how nicely the model-generated queries retrieve the anticipated info from the graph database, facilitating alignment with the supposed question logic.
The next desk summarizes the scores for execution outcomes rely match.
Simple
Medium
Exhausting
General
Amazon Nova Professional
80%
50%
10%
60.42%
Benchmark Mannequin
90%
70%
30%
74.83%
Question execution latency
Along with accuracy, we consider the effectivity of generated queries by measuring their runtime and evaluating it with the bottom fact queries. For every question, we file the runtime in milliseconds and analyze the distinction between the generated question and the corresponding floor fact question. A decrease runtime signifies a extra optimized question, whereas vital deviations may recommend inefficiencies in question construction or execution planning. By contemplating each accuracy and runtime, we achieve a extra complete evaluation of question high quality, ensuring the generated queries are appropriate and performant throughout the graph database. The next field plot showcases question execution latency with respect to time for the bottom fact question and the question generated by Amazon Nova Professional. As illustrated, all three kinds of queries exhibit comparable runtimes, with related median latencies and overlapping interquartile ranges. Though the bottom fact queries show a barely wider vary and the next outlier, the median values throughout all three teams stay shut. This implies that the model-generated queries are on the similar stage as human-written ones by way of execution effectivity, supporting the declare that AI-generated queries are of comparable high quality and don’t incur extra latency overhead.
Question technology latency and price
Lastly, we examine the time taken to generate every question and calculate the associated fee primarily based on token consumption. Extra particularly, we measure the question technology time and observe the variety of tokens used, as a result of most LLM-based APIs cost primarily based on token utilization. By analyzing each the technology velocity and token price, we are able to decide whether or not the mannequin is environment friendly and cost-effective. These outcomes present insights in deciding on the optimum mannequin that balances question accuracy, execution effectivity, and financial feasibility.
As proven within the following plots, Amazon Nova Professional persistently outperforms the benchmark mannequin in each technology latency and price. Within the left plot, which depicts question technology latency, Amazon Nova Professional demonstrates a considerably decrease median technology time, with most values clustered between 1.8–4 seconds, in comparison with the benchmark mannequin’s broader vary from round 5–11 seconds. The precise plot, illustrating question technology price, exhibits that Amazon Nova Professional maintains a a lot smaller price per question—centered nicely under $0.005—whereas the benchmark mannequin incurs increased and extra variable prices, reaching as much as $0.025 in some instances. These outcomes spotlight Amazon Nova Professional’s benefit by way of each velocity and affordability, making it a powerful candidate for deployment in time-sensitive or large-scale techniques.
Conclusion
We experimented with all 120 floor fact queries supplied to us by kscope.ai and achieved an general accuracy of 74.17% in producing appropriate outcomes. The proposed framework demonstrates its potential by successfully addressing the distinctive challenges of graph question technology, together with dealing with heterogeneous vertex and edge properties, reasoning over advanced graph buildings, and incorporating area data. Key elements of the framework, reminiscent of the mixing of graph and area data, the usage of Retrieval Augmented Technology (RAG) for question plan creation, and the iterative error-handling mechanism for question refinement, have been instrumental in reaching this efficiency.
Along with bettering accuracy, we’re actively engaged on a number of enhancements. These embody refining the analysis methodology to deal with deeply nested question outcomes extra successfully and additional optimizing the usage of LLMs for question technology. Furthermore, we’re utilizing the RAGAS-faithfulness metric to enhance the automated analysis of question outcomes, leading to higher reliability and consistency in assessing the framework’s outputs.
Concerning the authors
Mengdie (Flora) Wang is a Information Scientist at AWS Generative AI Innovation Middle, the place she works with clients to architect and implement scalable Generative AI options that handle their distinctive enterprise challenges. She focuses on mannequin customization methods and agent-based AI techniques, serving to organizations harness the total potential of generative AI expertise. Previous to AWS, Flora earned her Grasp’s diploma in Laptop Science from the College of Minnesota, the place she developed her experience in machine studying and synthetic intelligence.
Jason Zhang has experience in machine studying, reinforcement studying, and generative AI. He earned his Ph.D. in Mechanical Engineering in 2014, the place his analysis targeted on making use of reinforcement studying to real-time optimum management issues. He started his profession at Tesla, making use of machine studying to automobile diagnostics, then superior NLP analysis at Apple and Amazon Alexa. At AWS, he labored as a Senior Information Scientist on generative AI options for purchasers.
Rachel Hanspal is a Deep Studying Architect at AWS Generative AI Innovation Middle, specializing in end-to-end GenAI options with a give attention to frontend structure and LLM integration. She excels in translating advanced enterprise necessities into progressive functions, leveraging experience in pure language processing, automated visualization, and safe cloud architectures.
Zubair Nabi is the CTO and Co-Founding father of Kscope, an Built-in Safety Posture Administration (ISPM) platform. His experience lies on the intersection of Huge Information, Machine Studying, and Distributed Programs, with over a decade of expertise constructing software program, information, and AI platforms. Zubair can also be an adjunct school member at George Washington College and the writer of Professional Spark Streaming: The Zen of Actual-Time Analytics Utilizing Apache Spark. He holds an MPhil from the College of Cambridge.
Suparna Pal – CEO & Co-Founding father of kscope.ai – 20+ years of journey of constructing progressive platforms & options for Industrial, Well being Care and IT operations at PTC, GE, and Cisco.
Wan Chen is an Utilized Science Supervisor at AWS Generative AI Innovation Middle. As a ML/AI veteran in tech trade, she has wide selection of experience on conventional machine studying, recommender system, deep studying and Generative AI. She is a stronger believer of Superintelligence and may be very passionate to push the boundary of AI analysis and software to reinforce human life and drive enterprise development. She holds Ph.D in Utilized Arithmetic from College of British Columbia and had labored as postdoctoral fellow in Oxford College.
Mu Li is a Principal Options Architect with AWS Vitality. He’s additionally the Worldwide Tech Chief for the AWS Vitality & Utilities Technical Subject Group (TFC), a neighborhood of 300+ trade and technical specialists. Li is obsessed with working with clients to realize enterprise outcomes utilizing expertise. Li has labored with clients emigrate all-in to AWS from on-prem and Azure, launch the Manufacturing Monitoring and Surveillance trade answer, deploy ION/OpenLink Endur on AWS, and implement AWS-based IoT and machine studying workloads. Outdoors of labor, Li enjoys spending time together with his household, investing, following Houston sports activities groups, and catching up on enterprise and expertise.
AI is in each boardroom dialog, and enterprise leaders all over the place are feeling the stress to get it proper. However as adoption hastens, so do the questions.
Which use circumstances are delivering actual outcomes? How are organizations balancing velocity with governance? Are most constructing from scratch, shopping for off the shelf, or discovering a center path? And most significantly, what’s really working in observe for world enterprises?
Drawing insights from over 1000+ enterprise leaders throughout industries and areas, it paints an actual image of what AI experimentation and adoption seem like in 2025, not simply in headlines, however on the bottom.
On this weblog, you’ll get a peek into what’s prime of thoughts for world AI leaders – the priorities, challenges, investments, and expertise methods shaping the subsequent part of enterprise AI.
Let’s dive in
(Concerning the report: Surveyed in March 2025 by Paradoxes and supported by Kore.ai, ‘Sensible Insights from AI Leaders – 2025’ reveals how enterprise leaders are adopting AI, tackling challenges, investing budgets, and driving innovation to reshape enterprise and achieve a aggressive edge.
The survey gathered insights from over 1000 senior enterprise and expertise leaders throughout 12 nations, together with the U.S., UK, Germany, UAE, India, Singapore, Philippines, Japan, Korea, Australia, and New Zealand. Obtain the whole report.)
How deep AI adoption runs throughout enterprises?
Enterprises are experimenting with AI throughout a number of practical areas, however typically in silos. What’s lacking is a cohesive technique to scale AI impression throughout the enterprise.
Based on the Kore.ai survey, 71% of enterprise leaders report that their organizations are actively utilizing or piloting AI throughout a number of departments, like buyer help, IT, HR, finance, operations, and advertising and marketing.
This surge in adoption aligns with Gartner’s forecast that, by 2026, greater than 80% of enterprises may have deployed generative AI functions in manufacturing, a dramatic rise from lower than 5% in early 2023. The survey exhibits that use circumstances particular to IT help, customer support, and advertising and marketing lead in AI automation. Product, HR, finance, operations, and engineering present sturdy uptake, whereas capabilities like admin, procurement, authorized, and gross sales stay in early or experimental levels.
Regionally, North America (79%), Western Europe (70%), and India (87%) lead in AI adoption, pushed by sturdy govt help. In distinction, components of APAC, notably Japan (56%), South Korea (64%), and Southeast Asia (59%), present a slower uptake, reflecting extra cautious management. With AI adoption accelerating worldwide, the subsequent query is obvious: Which use circumstances are driving leaders to double down on AI?
What’s fueling the AI agenda within the C-suite?
Throughout boardrooms, the AI dialog is shifting from ‘why’ to ‘the place subsequent’. The analysis highlights that almost all leaders are specializing in use circumstances at present that ship tangible enterprise worth:
1. 44% are making use of AI for course of automation, masking areas like compliance, danger administration, and workflow optimization. 2. 31% of organizations are utilizing AI to reinforce office productiveness, from automating duties and surfacing insights to enabling sooner content material creation and summarization. 3. 24% are deploying AI to reinforce customer support and self-service experiences.
Know-how (77%) and monetary companies (72%) are doubling down on AI for insights and analytics, treating knowledge as a aggressive edge. Retail (77%), enterprise companies (75%), and healthcare (69%) are targeted on AI-powered buyer engagement. In the meantime, use circumstances like search and knowledge discovery are gaining floor throughout expertise (64%), finance (66%), retail (71%), and enterprise companies (62%).
Nearly all of enterprises are already seeing early wins with AI. Actually, 93% of leaders report that their pilot initiatives met or exceeded expectations. Nonetheless, transferring from profitable pilots to organization-wide AI transformation introduces a brand new set of hurdles.
The analysis means that enterprises are going through just a few challenges which might be slowing down their momentum. A few of these challenges are:
1. The AI expertise hole – This stays probably the most important problem enterprises face at present. Bain & Co. additionally recognized that 44% of executives really feel an absence of in-house experience is slowing AI adoption. 2. Excessive LLM prices – with 42% respondents citing it, ongoing token-based prices for LLMs additionally emerged as a big problem to scaling AI within the examine. This implies that usage-based prices grow to be extra related as organizations scale. 3. Knowledge safety and belief – 41% of the decision-makers within the survey reported that they face the problem of safeguarding proprietary and first-party knowledge.
Given these challenges, many organizations are rethinking their strategy to AI adoption: Ought to they construct customized options in-house, or is it more practical to purchase? 👇
Purchase or construct? Strategic trade-offs shaping enterprise AI
Let’s dive into the intriguing story revealed by Kore.ai analysis—the story of how enterprises are navigating the traditional purchase vs. construct dilemma for AI.
The survey exhibits that enterprises clearly favor simplicity and velocity over complexity. Solely 28% of organizations mentioned they’d favor to construct their very own AI options from the bottom up, whereas the remaining 72% are choosing numerous purchase-led methods. This contains ready-to-deploy options (31%), customizable third-party choices (25%), or integrating best-of-breed options (16%).
This pattern is per the McKinsey report, which says that AI methods that mix vendor instruments with inside capabilities allow enterprises to scale AI 1.5X sooner than these constructing totally personalized options.
Selecting distributors: worth over price
The selection of AI vendor is not only a procurement choice, however a make-or-break choice. The place the suitable associate can speed up outcomes and scale innovation, whereas the fallacious one can introduce friction, delays, and technical debt. Based on the analysis, decision-makers constantly prioritize output high quality and accuracy (45%), AI resolution effectivity and efficiency (34%), domain-specific experience (28%), and ease of integration with current methods (28%).
Notably, vendor pricing (24%) ranks a lot decrease on the checklist. These priorities replicate a maturing market the place leaders are on the lookout for long-term companions that may evolve with their wants, perceive their {industry}, and ship measurable worth at scale.
Need a full breakdown of which shopping for methods enterprises are utilizing for AI? Obtain the complete report for all particulars right here.
Need a full breakdown of which shopping for methods enterprises are utilizing for AI? Obtain the Full Report for all particulars.
What are hard-earned classes from previous AI initiatives?
As enterprise AI strikes past pilots, leaders are asking onerous questions: What actually issues to scale? The place are we underprepared? And what can we enhance? The analysis highlights vital areas that repeatedly emerge because the spine of profitable AI deployments:
Greater than 50% of the respondents cited knowledge high quality as an space needing critical enchancment in future AI initiatives. In any case, AI’s impression is barely as sturdy as the info it learns from.
Industries equivalent to retail, manufacturing, and expertise are doubling down on first-party knowledge, recognizing its position in enabling differentiated, AI-driven experiences. In the meantime, regulated sectors equivalent to healthcare, monetary companies, authorities, and enterprise companies are putting higher concentrate on the safe dealing with of consumer and third-party knowledge.
Safety and knowledge privateness are non-negotiable
With AI methods permeating enterprise operations, knowledge safety and privateness are greater than technical containers; they’re belief and compliance necessities. Practically 40% of leaders view safety and knowledge privateness as the highest space to strengthen in upcoming AI initiatives.
Tech infrastructure is a strategic enabler
Many organizations, within the survey, admit their present tech stacks aren’t constructed to help enterprise-grade AI. AI workloads demand important compute energy, scalable pipelines, and sturdy mannequin governance.
AI expertise is a make-or-break for AI success
Kore.ai analysis suggests that just about two-thirds of organizations admit they want stronger AI experience, however they’re divided on whether or not to rent new expertise or upskill current groups. The numbers underscore a broader expertise crunch that impacts each scale-up.
“AI success hinges on partnering knowledge and enterprise groups and constructing a data-literate tradition.” – Vanguard’s Chief Knowledge Officer.
The place are the investments headed in 2025 and past?
When requested, “How do you anticipate your AI price range will change over the subsequent three years?” A exceptional 90% leaders say their AI budgets will enhance, with 75% planning to allocate greater than half of their IT spending to AI initiatives.
The report additionally highlights industry-specific price range patterns. As an example, monetary companies and expertise sectors are main the cost with over 50% of their tech price range going in direction of AI expertise. Enterprise companies and healthcare are following intently with substantial allocations, whereas manufacturing (25%) tends to be extra conservative in its AI spending.
Remaining ideas: the enterprise AI story is simply starting
If there’s one factor this analysis makes clear, it’s that AI is changing into a core a part of how organizations work, compete, and develop.
And as extra enterprises embrace agentic AI, the numbers inform a transparent story: leaders are pushing past pilots, budgets are scaling quick, and AI is making its presence felt throughout departments, from buyer help to finance to advertising and marketing. Expertise methods are evolving, infrastructure is being modernized, and knowledge is lastly getting the eye it deserves.
However the journey is way from over.
The analysis additionally highlights that whereas enthusiasm runs excessive, so do the expectations and the stress to show worth, defend knowledge, and scale responsibly. The choices leaders make now, equivalent to what to construct, what to purchase, the place to speculate, and how one can measure success, will form the trajectory of AI for years to come back.
This weblog solely scratches the floor. The total Kore.ai Sensible Insights from AI Leaders – 2025 report dives deeper into the benchmarks, methods, and classes that at present’s decision-makers are utilizing to show AI potential into enterprise efficiency. 👇
The concept of extinction — the everlasting lack of life — is horrifying. But the stakes of dropping crops and animals are sometimes unclear. If an already-rare chicken vanishes from the forest, most individuals in all probability gained’t really feel the affect.
However a troubling scenario unfolding in Florida is totally different. Following a record-shattering warmth wave in 2023, two marine species at the moment are practically extinct within the state — and the affect of that loss on human life will probably be felt for generations.
In a brand new examine revealed this week in Science, researchers discovered that elkhorn and staghorn corals — two species as soon as elementary to the construction of Florida’s reef — at the moment are “functionally extinct” within the state. Which means these animals are so uncommon that they now not serve a perform in Florida’s marine ecosystem.
Why excessive warmth kills corals
Corals are colonies of residing animals, referred to as polyps, which have a symbiotic relationship with a form of algae that lives inside their cells. The algae give coral meals — and their shade — in change for vitamins and a spot to soak up daylight.
When the ocean will get too scorching, nevertheless, this symbiotic relationship breaks down, and the polyps expel the algae and switch white. That is bleaching. When a coral is bleached, it’s basically weak and ravenous, and if the warmth persists, it may possibly die.
Throughout excessive marine warmth waves — like what Florida noticed in summer time 2023 — corals can die in a matter of days, generally with out bleaching. Warmth shock kills the polyps and causes their comfortable tissue to slough off their skeleton.
Beginning in July 2023, water temperatures in Southeast Florida, dwelling to the one barrier reef within the continental US, began rising to record-breaking ranges, partly on account of local weather change. Sensors recorded temperatures above 93 levels in some components of the reef. And corals had been finally uncovered to warmth that was as a lot as 4 instances higher than “all prior years on document,” the authors write. That worn out 97.8 p.c to 100% of staghorn and elkhorn corals within the Florida Keys, the place most of them had been discovered, in keeping with the examine, which was led by Derek Manzello, a coral researcher on the Nationwide Oceanic and Atmospheric Administration.
“What we noticed occur was an excessive warmth wave the place circumstances surpassed the thresholds of survival of an entire, whole species — two species — throughout all of Florida’s coral reef,” mentioned Ross Crafty, a coral biologist at Chicago’s Shedd Aquarium, who was carefully concerned within the analysis. “That’s one thing we haven’t seen earlier than. We had been in shock.”
These outcomes ought to alarm anybody residing in coastal Florida. Staghorn and elkhorn corals — native to Florida and the Caribbean, the place their populations have additionally plummeted — usually are not solely fairly to have a look at however assist maintain human life.
Olivia M. Williamson/Science
Olivia M. Williamson/Science
Elkhorn coral within the Florida Keys progressed from wholesome (prime left) to bleached (prime proper) to useless (backside) in a matter of months in the summertime of 2023.Dana E. Williams/Science
These species create advanced buildings that appeal to fish by offering them with a spot to cover from predators and meals to eat. These embrace fish comparable to snappers and groupers that folks catch and devour in Florida, the place one evaluation reveals fishing is a whopping $24.6 billion trade. Then there’s the worth that corals present for nature-related tourism. Diving and snorkeling generate some $900 million a yr in Southeast Florida. While you go snorkeling, there’s usually an expectation that you simply’ll see coral or the animals it helps, from eels to octopuses.
However maybe most significantly, these two coral species safeguard coastlines from flooding throughout hurricanes. Or a minimum of they did. Staghorn and elkhorn develop within the shallows, the place their many giant branches assist cut back wave power, very like a seawall. Waves with much less power are smaller and slower and don’t deal as a lot harm after they attain the shore. A 2014 meta-analysis discovered that coral reefs — which comprise different species past staghorn and elkhorn — can cut back wave power by a mean of 97 p.c. That interprets to cash: A 2019 authorities examine discovered that Florida’s coral reefs avert $675 million price of flood harm every year.
Now that these coral species are principally useless, staghorn and elkhorn skeletons in Florida will ultimately wither away, leaving the shoreline much less engaging to fish and vacationers, and extra susceptible to storms.
What occurred in Florida isn’t a one-off occasion. High scientists are assured that excessive marine warmth waves are changing into extra frequent. And whereas staghorn and elkhorn are particularly delicate to warming, they actually aren’t the one species that warmth places in danger. The planet has already misplaced roughly half of its stay coral cowl, and local weather change — and the bleaching of corals it causes — has emerged as the highest risk. In Australia, for instance, a 2024 bleaching occasion killed off roughly 1 / 4 of the corals within the northern Nice Barrier Reef, a document decline.
The state of coral reefs is so bleak, in truth, that a big, worldwide workforce of scientists just lately introduced that these ecosystems worldwide have surpassed a local weather tipping level, past which they will now not survive.
That implies that until rich economies cease burning fossil fuels, it’s unlikely that Florida will ever be capable to deliver again ample colonies of elkhorn and staghorn corals, even with aggressive restoration efforts. Certainly, most of the corals that died within the 2023 warmth wave had been planted on the reef by conservation teams. (I detailed that in a separate story right here.)
Even when the world’s prime polluters slashed their emissions instantly — which, in the mean time, seems anathema to US power coverage — coral reefs would nonetheless face dramatic losses. The ocean is already far too scorching. Restoring the life-supporting advantages that reefs as soon as supplied in locations like Florida now requires superior expertise to breed heat-tolerant corals, whereas additionally tackling different threats like overfishing and air pollution.
“We have to do one thing to throw corals a lifeline,” Crafty advised me. “We are able to’t simply cease and say, ‘Oh, the federal authorities isn’t doing what we’d prefer to see occur on this entrance, so we’re simply going to surrender.’ We are able to’t cease. We now have to maintain making an attempt.”
A scientific trial testing a diabetes medicine and an insulin nasal spray has discovered that each medicine, together and alone, safely sort out totally different facets of gentle cognitive decline that’s typically seen in early Alzheimer’s illness, with none dangerous unwanted side effects.
We all know Alzheimer’s illness and different types of dementia are extremely advanced circumstances, and a number of remedy approaches are doubtless wanted to raised handle them.
The 2 medicines examined on this trial goal a number of totally different organic processes: Empagliflozin, an current diabetes drug, reduces irritation, which has been linked to Alzheimer’s onset, amongst different issues. The insulin nasal spray, which delivers insulin straight to the mind, has additionally been proven to maintain mind cells wholesome.
Carried out within the US, the trial reveals some early indicators of progress in sustaining mind well being in these vulnerable to Alzheimer’s. It enrolled 47 older adults aged 55 to 85 years, 42 of whom accomplished remedy.
The contributors had been recognized with gentle cognitive impairment or gentle dementia, or have been cognitively nice however confirmed indicators of molecular modifications linked to Alzheimer’s illness.
They got both empagliflozin alone, the insulin spray by itself, each medicines collectively, or a placebo, for 4 weeks. The trial was too small to detect any statistically vital variations between the teams (its fundamental intention was testing security); nevertheless, some tendencies have been noticed.
“For the primary time, we discovered that empagliflozin, a longtime diabetes and coronary heart medicine, decreased markers of mind damage whereas restoring blood stream in crucial mind areas,” says neuroscientist Suzanne Craft from the Wake Forest College Faculty of Medication within the US.
“We additionally confirmed that delivering insulin on to the mind with a newly validated machine enhances cognition, neurovascular well being, and immune perform.”
One of many advantages seen with empagliflozin (EMPA-Solely) was indicators of much less tau build-up in cerebrospinal fluid (CSF). (Erichsen et al., A&D, 2025)
As a diabetes drug, empagliflozin improves the best way the physique handles glucose and sodium. This has numerous additional results, together with decrease irritation and stress on cells, higher vitality effectivity, and improved insulin sensitivity.
Right here, the medicine was proven to cut back the degrees of the tau protein in cerebrospinal fluid, a protein that we all know can kind dangerous clumps in Alzheimer’s brains. It additionally had advantages by way of blood stream and levels of cholesterol, and several other different biomarkers linked to Alzheimer’s development.
The insulin nasal spray was chosen as a result of insulin resistance has beforehand been linked to Alzheimer’s, and former analysis reveals insulin’s results on mind cells will help enhance immune responses, white matter construction, and blood stream.
On this research, contributors given the insulin spray noticed higher scores on cognitive assessments measuring reminiscence and considering. Via mind scans, the researchers noticed advantages in white matter connectivity and blood stream linked to reminiscence.
The physique’s metabolism, or the best way it turns gasoline into vitality, is essential to good well being, and these therapies focus extra on that, slightly than a few of the later, end-stage results of Alzheimer’s we see in individuals with the illness.
“Our research means that concentrating on metabolism can change the course of Alzheimer’s illness,” says Craft. “Collectively, these findings spotlight metabolism as a robust new frontier in Alzheimer’s remedy.”
This was a comparatively fast and small trial, achieved to construct on earlier analysis and run additional security assessments.
Whereas a lot additional testing is required to gauge how efficient these medicine could also be in mitigating Alzheimer’s illness, the outcomes present an encouraging stability in boosting the best way the immune system fights illness, whereas additionally reducing the danger of overactive immune responses resulting in irritation and harm.
“We plan to construct on these promising outcomes with bigger, longer research in individuals with early and preclinical Alzheimer’s illness,” says Craft.
“We consider these therapies might provide actual therapeutic potential, both on their very own or together with different Alzheimer’s therapies.”
With Leah South from QUT we’re organizing an internet workshop on the subject of “Measuring the standard of MCMC output”. The occasion web site is right here with extra data:
That is a part of ISBABayesComp part’s efforts to prepare actions whereas ready for the following “large” in-person assembly, hopefully in 2023. The occasion advantages from the beneficiant help of QUT Centre for Knowledge Science. The occasion’s web site shall be often up to date between now and the occasion in October 2021, with three reside classes:
11am-2pm UTC on Wednesday sixth October,
1pm-4pm UTC on Thursday 14th October,
3pm-6pm UTC on Friday twenty second October.
Registration is free however obligatory (kind right here) as we need to be sure the reside classes stay convivial and centered; therefore the somewhat particular theme, nevertheless it’s an thrilling matter with a number of very a lot open questions, which we hope will appeal to each practitioners and methodologists. In the meantime some materials shall be obtainable on the web site to everybody, together with video recordings of shows, and posters, in order that the workshop hopefully advantages the broader group.
In case you have recommendations for this occasion, or want to set up an identical occasion sooner or later, on one other “BayesComp” matter, don’t hesitate to get in contact. Our contact particulars are on the workshop’s web site.










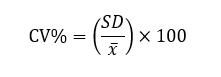



















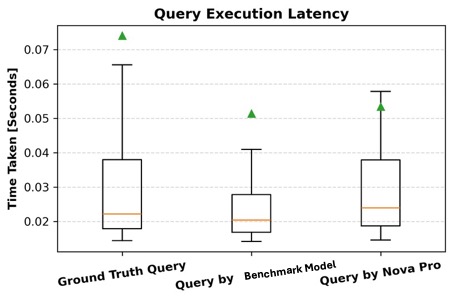
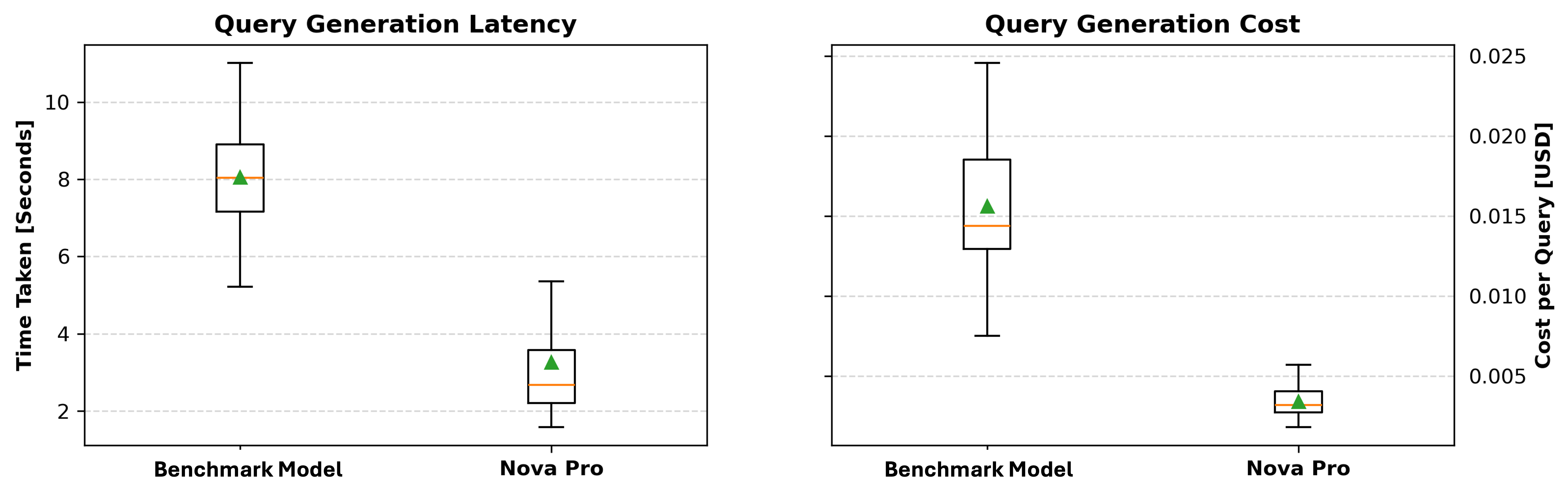
 Mengdie (Flora) Wang is a Information Scientist at AWS Generative AI Innovation Middle, the place she works with clients to architect and implement scalable Generative AI options that handle their distinctive enterprise challenges. She focuses on mannequin customization methods and agent-based AI techniques, serving to organizations harness the total potential of generative AI expertise. Previous to AWS, Flora earned her Grasp’s diploma in Laptop Science from the College of Minnesota, the place she developed her experience in machine studying and synthetic intelligence.
Mengdie (Flora) Wang is a Information Scientist at AWS Generative AI Innovation Middle, the place she works with clients to architect and implement scalable Generative AI options that handle their distinctive enterprise challenges. She focuses on mannequin customization methods and agent-based AI techniques, serving to organizations harness the total potential of generative AI expertise. Previous to AWS, Flora earned her Grasp’s diploma in Laptop Science from the College of Minnesota, the place she developed her experience in machine studying and synthetic intelligence. Jason Zhang has experience in machine studying, reinforcement studying, and generative AI. He earned his Ph.D. in Mechanical Engineering in 2014, the place his analysis targeted on making use of reinforcement studying to real-time optimum management issues. He started his profession at Tesla, making use of machine studying to automobile diagnostics, then superior NLP analysis at Apple and Amazon Alexa. At AWS, he labored as a Senior Information Scientist on generative AI options for purchasers.
Jason Zhang has experience in machine studying, reinforcement studying, and generative AI. He earned his Ph.D. in Mechanical Engineering in 2014, the place his analysis targeted on making use of reinforcement studying to real-time optimum management issues. He started his profession at Tesla, making use of machine studying to automobile diagnostics, then superior NLP analysis at Apple and Amazon Alexa. At AWS, he labored as a Senior Information Scientist on generative AI options for purchasers. Rachel Hanspal is a Deep Studying Architect at AWS Generative AI Innovation Middle, specializing in end-to-end GenAI options with a give attention to frontend structure and LLM integration. She excels in translating advanced enterprise necessities into progressive functions, leveraging experience in pure language processing, automated visualization, and safe cloud architectures.
Rachel Hanspal is a Deep Studying Architect at AWS Generative AI Innovation Middle, specializing in end-to-end GenAI options with a give attention to frontend structure and LLM integration. She excels in translating advanced enterprise necessities into progressive functions, leveraging experience in pure language processing, automated visualization, and safe cloud architectures. Zubair Nabi is the CTO and Co-Founding father of Kscope, an Built-in Safety Posture Administration (ISPM) platform. His experience lies on the intersection of Huge Information, Machine Studying, and Distributed Programs, with over a decade of expertise constructing software program, information, and AI platforms. Zubair can also be an adjunct school member at George Washington College and the writer of Professional Spark Streaming: The Zen of Actual-Time Analytics Utilizing Apache Spark. He holds an MPhil from the College of Cambridge.
Zubair Nabi is the CTO and Co-Founding father of Kscope, an Built-in Safety Posture Administration (ISPM) platform. His experience lies on the intersection of Huge Information, Machine Studying, and Distributed Programs, with over a decade of expertise constructing software program, information, and AI platforms. Zubair can also be an adjunct school member at George Washington College and the writer of Professional Spark Streaming: The Zen of Actual-Time Analytics Utilizing Apache Spark. He holds an MPhil from the College of Cambridge. Suparna Pal – CEO & Co-Founding father of kscope.ai – 20+ years of journey of constructing progressive platforms & options for Industrial, Well being Care and IT operations at PTC, GE, and Cisco.
Suparna Pal – CEO & Co-Founding father of kscope.ai – 20+ years of journey of constructing progressive platforms & options for Industrial, Well being Care and IT operations at PTC, GE, and Cisco. Wan Chen is an Utilized Science Supervisor at AWS Generative AI Innovation Middle. As a ML/AI veteran in tech trade, she has wide selection of experience on conventional machine studying, recommender system, deep studying and Generative AI. She is a stronger believer of Superintelligence and may be very passionate to push the boundary of AI analysis and software to reinforce human life and drive enterprise development. She holds Ph.D in Utilized Arithmetic from College of British Columbia and had labored as postdoctoral fellow in Oxford College.
Wan Chen is an Utilized Science Supervisor at AWS Generative AI Innovation Middle. As a ML/AI veteran in tech trade, she has wide selection of experience on conventional machine studying, recommender system, deep studying and Generative AI. She is a stronger believer of Superintelligence and may be very passionate to push the boundary of AI analysis and software to reinforce human life and drive enterprise development. She holds Ph.D in Utilized Arithmetic from College of British Columbia and had labored as postdoctoral fellow in Oxford College. Mu Li is a Principal Options Architect with AWS Vitality. He’s additionally the Worldwide Tech Chief for the AWS Vitality & Utilities Technical Subject Group (TFC), a neighborhood of 300+ trade and technical specialists. Li is obsessed with working with clients to realize enterprise outcomes utilizing expertise. Li has labored with clients emigrate all-in to AWS from on-prem and Azure, launch the Manufacturing Monitoring and Surveillance trade answer, deploy ION/OpenLink Endur on AWS, and implement AWS-based IoT and machine studying workloads. Outdoors of labor, Li enjoys spending time together with his household, investing, following Houston sports activities groups, and catching up on enterprise and expertise.
Mu Li is a Principal Options Architect with AWS Vitality. He’s additionally the Worldwide Tech Chief for the AWS Vitality & Utilities Technical Subject Group (TFC), a neighborhood of 300+ trade and technical specialists. Li is obsessed with working with clients to realize enterprise outcomes utilizing expertise. Li has labored with clients emigrate all-in to AWS from on-prem and Azure, launch the Manufacturing Monitoring and Surveillance trade answer, deploy ION/OpenLink Endur on AWS, and implement AWS-based IoT and machine studying workloads. Outdoors of labor, Li enjoys spending time together with his household, investing, following Houston sports activities groups, and catching up on enterprise and expertise.
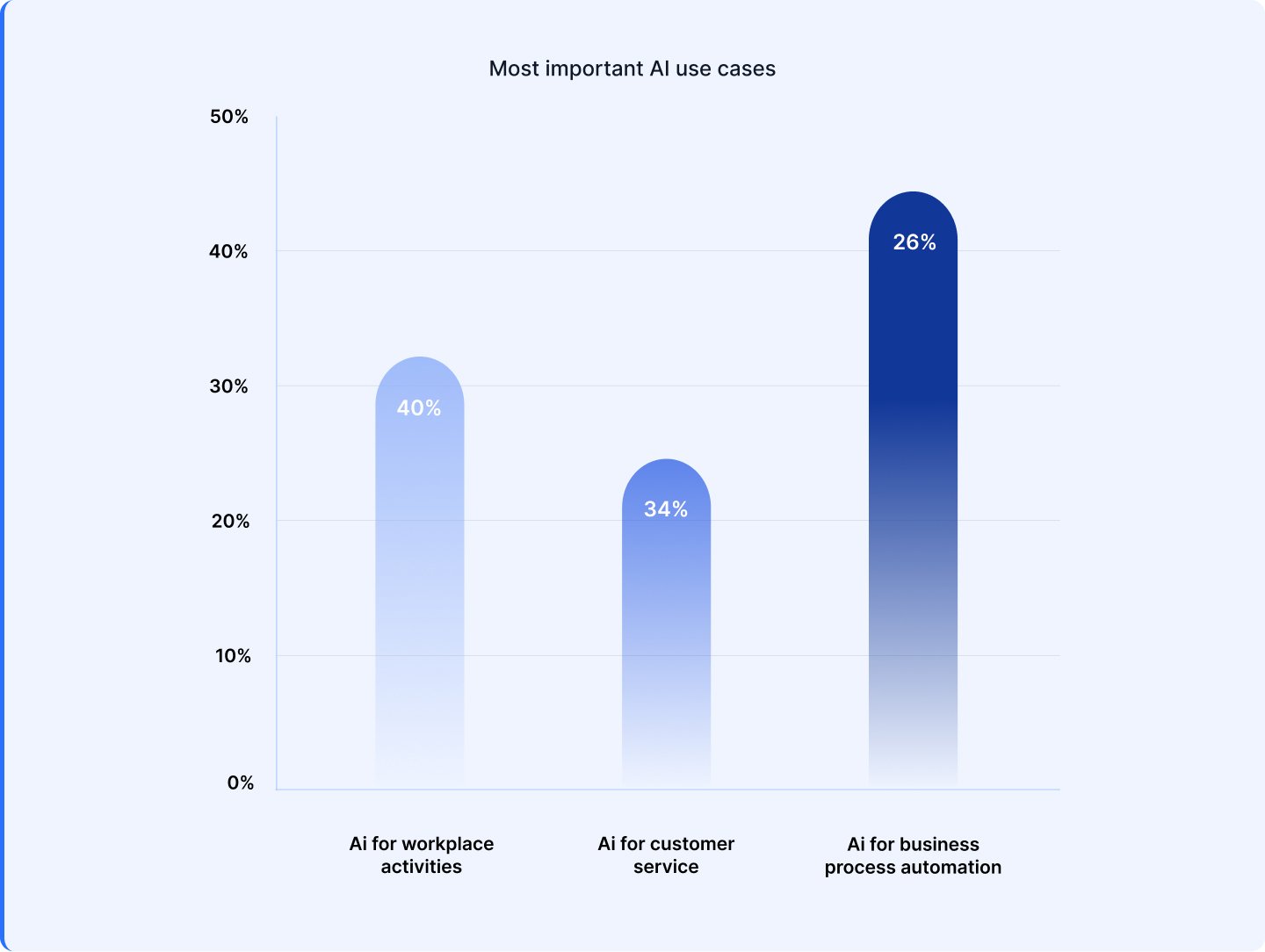
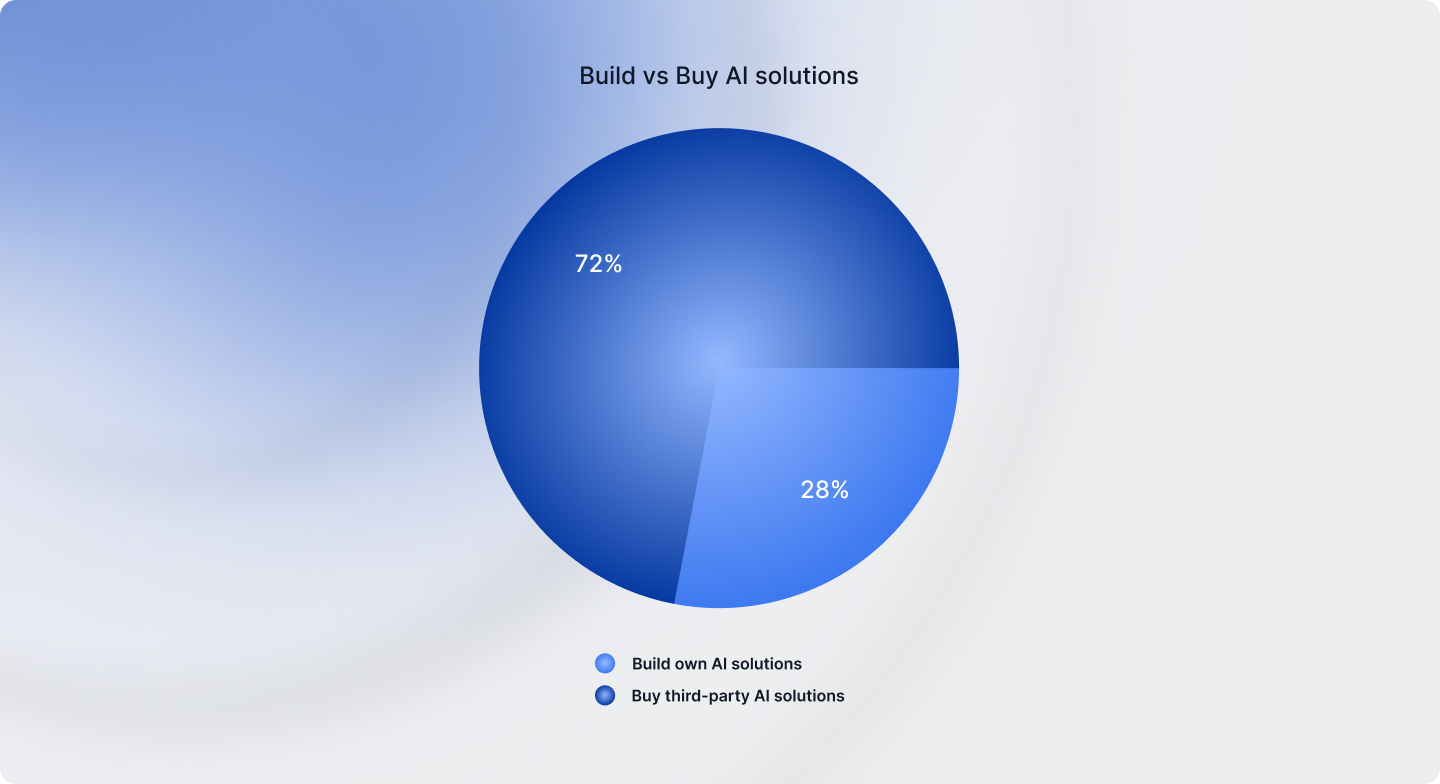
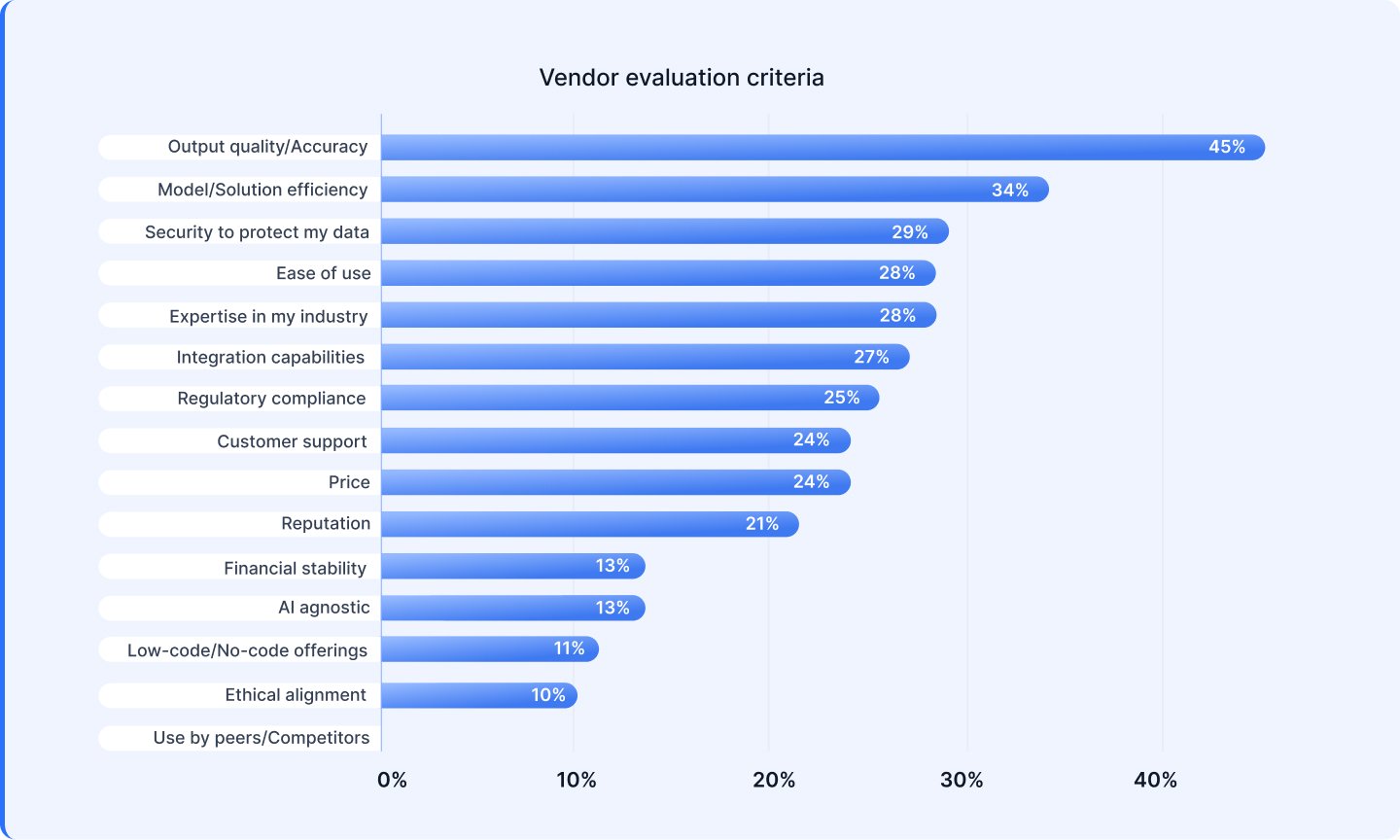
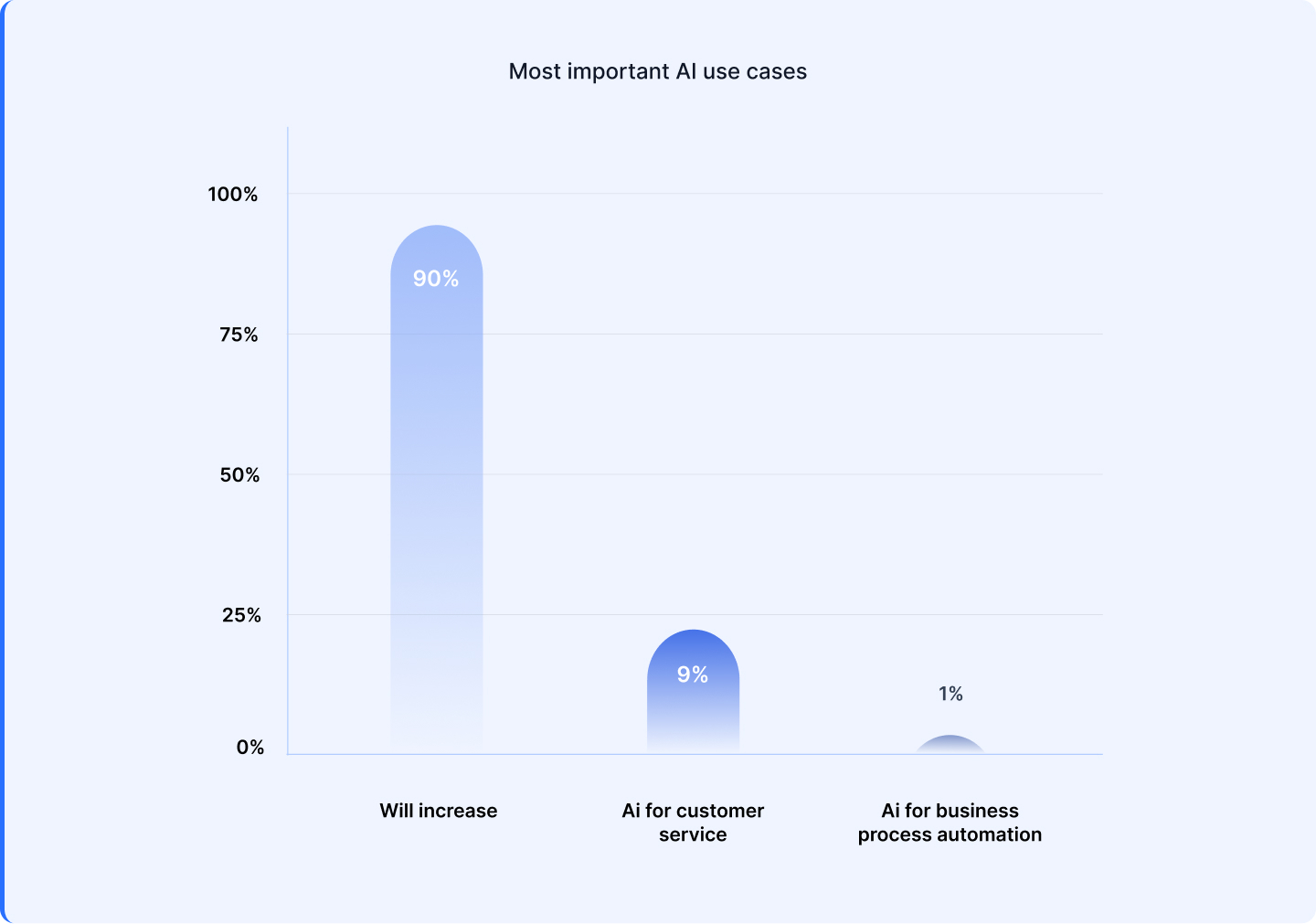






{kind=link}