We automated the evaluation and made the code out there on GitHub.
got here to me after I tried to breed the paper “Studying Phrase Vectors for Sentiment Evaluation” by Maas et al. (2011).
On the time, I used to be nonetheless in my remaining yr of engineering college. The objective was to breed the paper, problem the authors’ strategies, and, if attainable, evaluate them with different phrase representations, together with LLM-based approaches.
What struck me was how easy and stylish the tactic was. In a approach, it jogged my memory of logistic regression in credit score scoring: easy, interpretable, and nonetheless highly effective when used appropriately.
I loved studying this paper a lot that I made a decision to share what I discovered from it.
I strongly advocate studying the unique paper. It’s going to enable you perceive what’s at stake in phrase illustration, particularly how one can analyze the proximity between two phrases from each a semantic perspective and a sentiment polarity perspective, given the particular contexts by which these phrases are used.
At first, the mannequin appears easy: construct a vocabulary, be taught phrase vectors, incorporate sentiment info, and consider the outcomes on IMDb critiques.
However after I began implementing it, I spotted that a number of particulars matter lots: how the vocabulary is constructed, how doc vectors are represented, how the semantic goal is optimized, and the way the sentiment sign is injected into the phrase vectors.
On this article, we are going to reproduce the primary concepts of the paper utilizing Python.
We’ll first clarify the instinct behind the mannequin. Then we are going to current the construction of knowledge used within the article, assemble the vocabulary, implement the semantic element, add the sentiment goal, and at last consider the discovered representations utilizing the linear SVM classifier.
The SVM will enable us to measure the classification accuracy and evaluate our outcomes with these reported within the paper.
What downside does the paper clear up?
Conventional Bag of Phrases fashions are helpful for classification, however they don’t be taught significant relationships between phrases. For instance, the phrases great and superb must be shut as a result of they categorical comparable that means and comparable sentiment. However, great and horrible could seem in comparable film evaluate contexts, however they categorical reverse sentiments.
The objective of the paper is to be taught phrase vectors that seize each semantic similarity and sentiment orientation.
Knowledge construction
The dataset accommodates:
25,000 labeled coaching critiques or paperwork
50,000 unlabeled coaching critiques
25,000 labeled check critiques
The labeled critiques are polarized:
Detrimental critiques have rankings from 1 to 4
Optimistic critiques have rankings from 7 to 10
The rankings are linearly mapped to the interval [0, 1], which permits the mannequin to deal with sentiment as a steady likelihood of optimistic polarity.
aclImdb/
├── prepare/
│ ├── pos/ "0_10.txt" -> evaluate #0, 10 stars, very optimistic
│ │ "1_7.txt" -> evaluate #1, 7 stars, optimistic
│ ├── neg/ "10_2.txt" -> evaluate #10, 2 stars, very unfavourable
│ │ "25_4.txt" -> evaluate #25, 4 stars, unfavourable
│ └── unsup/ "938_0.txt" -> evaluate #938, 0 stars, unlabeled
└── check/
├── pos/ optimistic critiques, by no means seen throughout coaching
└── neg/ unfavourable critiques, by no means seen throughout coaching
We will due to this fact retailer every doc in a Evaluate class with the next attributes: textual content, stars, label, and bucket.
In fact, it doesn’t must be a category particularly named Evaluate. Any object can be utilized so long as it offers no less than these attributes.
from dataclasses import dataclass
from typing import Optionally available
@dataclass
class Evaluate:
textual content: str
stars: int
label: str
bucket: str
Vocabulary building
The paper builds a hard and fast vocabulary by first ignoring the 50 most frequent phrases, then conserving the following 5,000 most frequent tokens.
No stemming is utilized. No customary stopword removing is used. That is essential as a result of some stopwords, particularly negations, can carry sentiment info.
Earlier than constructing this vocabulary, we first want to take a look at the uncooked knowledge.
We seen that the critiques will not be absolutely cleaned. Some paperwork include HTML tags, so we take away them throughout the knowledge loading step. We additionally take away punctuation connected to phrases, corresponding to ".", ",", "!", or "?".
This can be a slight distinction from the unique paper. The authors preserve some non-word tokens as a result of they might assist seize sentiment. For instance, "!" or ":-)" can carry emotional info. In our implementation, we select to take away this punctuation and later consider how a lot this choice impacts the ultimate mannequin efficiency.
When working with textual content knowledge, the following query is all the time the identical:
How ought to we characterize paperwork and phrases numerically?
The authors begin by gathering all tokens from the coaching set, together with each labeled and unlabeled critiques. We will consider this as placing all phrases from the coaching paperwork into one giant basket.
Then, to characterize phrases in an area the place we will prepare a mannequin, they construct a set of phrases referred to as the vocabulary.
The authors construct a dictionary that maps every token, which we are going to loosely name a phrase, to its frequency. This frequency is solely the variety of occasions the token seems within the full coaching set, together with each labeled and unlabeled critiques.
Then they choose the 5,000 most frequent phrases, after eradicating the 50 most frequent phrases.
These 5,000 phrases kind the vocabulary V.
Every phrase in V will correspond to 1 column of the illustration matrix R. The authors select to characterize every phrase in a 50-dimensional area. Due to this fact, the matrix R has the next form:
Every column of R is the vector illustration of 1 phrase:
The objective of the mannequin is to be taught this matrix R in order that the phrase vectors seize two issues on the similar time:
Semantic info, that means phrases utilized in comparable contexts must be shut;
Sentiment info, that means phrases carrying comparable polarity, must also be shut.
That is the central concept of the paper.
As soon as the information is loaded, cleaned, and the vocabulary is constructed, we will transfer to the development of the mannequin itself.
The primary a part of the mannequin is unsupervised. It learns semantic phrase representations from each labeled and unlabeled critiques.
Then, the second half provides supervision through the use of the star rankings to inject sentiment into the identical vector area.
Semantic element
The semantic element defines a probabilistic mannequin of a doc.
Every doc is related to a latent vector theta. This vector represents the semantic path of the doc.
Every phrase has a vector illustration , saved as a column of the matrix R.
The likelihood of observing a phrase w in a doc is given by a softmax mannequin:
Intuitively, a phrase turns into possible when its vector is nicely aligned with the doc vector theta.
MAP estimation of theta
The mannequin alternates between two steps.
First, it fixes R and b and estimates one theta vector for every doc.
Then, it fixes theta and updates R and b.
The theta vectors will not be saved as remaining parameters. They’re momentary document-specific variables used to replace the phrase representations.
To estimate the parameters of the mannequin, the authors use most probability.
The thought is easy: we need to discover the parameters R and b that make the noticed paperwork as possible as attainable underneath the mannequin.
Ranging from the probabilistic formulation of a doc, they introduce a MAP estimate θ̂ₖ for every doc dₖ. Then, by taking the logarithm of the probability and including regularization phrases, they acquire the target perform used to be taught the phrase illustration matrix R and the bias vector b:
which is maximized with respect to R and b. The hyperparameters within the mannequin are the regularization weights (λ and ν) and the phrase vector dimensionality β.
On this step, we be taught the semantic illustration matrix. This matrix captures how phrases relate to one another based mostly on the contexts by which they seem.
Sentiment element
The semantic mannequin alone can be taught that phrases happen in comparable contexts. However this isn’t sufficient to seize sentiment.
For instance, great and horrible could each happen in film critiques, however they categorical reverse opinions.
To resolve this, the paper provides a supervised sentiment goal:
The vector ψ defines a sentiment path within the phrase vector area. Right here, solely the labelled knowledge are used.
If a phrase vector lies on one facet of the hyperplane, it’s thought of optimistic. If it lies on the opposite facet, it’s thought of unfavourable.
They mixed the sentiment goal and the sentiment half to construct the ultimate and the complete goal studying:
The primary half learns semantic similarity. The second half injects sentiment info. The regularization phrases stop the vectors from rising too giant.
|| denotes the variety of paperwork within the dataset with the identical rounded worth of . The weighting is launched to fight the well-known imbalance in rankings current in evaluate collections.
Classification and outcomes
As soon as the phrase illustration matrix R has been discovered, we will use it to construct document-level options.
The target is now to categorise every film evaluate as optimistic or unfavourable.
To do that, the authors prepare a linear SVM on the 25,000 labeled coaching critiques and consider it on the 25,000 labeled check critiques.
The essential query is just not solely whether or not the phrase vectors are significant, however whether or not they assist enhance sentiment classification.
To reply this query, we consider a number of doc representations and evaluate them with the outcomes reported in Desk 2 of the paper.
The one factor that adjustments from one configuration to a different is the best way every evaluate is represented earlier than being handed to the classifier.
1. Bag of Phrases baseline
The primary illustration is an ordinary Bag of Phrases. Within the paper, this baseline is reported as Bag of Phrases (bnc). The notation means:
b = binary weighting
n = no IDF weighting
c = cosine normalization
A evaluate or doc is represented by a vector v of measurement 5000, as a result of the vocabulary accommodates 5,000 phrases.
For every phrase j within the vocabulary:
So this illustration solely data whether or not a phrase seems no less than as soon as. It doesn’t depend what number of occasions it seems.
Then the vector is normalized by its Euclidean norm:
This offers the Bag of Phrases baseline used to coach the SVM.
This baseline is powerful as a result of sentiment classification usually depends on direct lexical clues. Phrases corresponding to glorious, boring, terrible, or nice already carry helpful sentiment info.
2. Semantic-only phrase vector illustration
The second illustration makes use of the phrase vectors discovered by the semantic-only mannequin.
The authors first characterize a doc as a Bag of Phrases vector v. Then they compute a dense doc illustration by multiplying this vector by the discovered matrix:
The place
This vector could be interpreted as a weighted mixture of the phrase vectors that seem within the evaluate.
Within the paper, when producing doc options by way of the product Rv, the authors use bnn weighting for v. This implies:
b = binary weighting
n = no IDF weighting
n = no cosine normalization earlier than projection
Then, after computing Rv, they apply cosine normalization to the ultimate dense vector.
So the ultimate illustration is:
This illustration makes use of semantic info discovered from the coaching critiques, together with each labeled and unlabeled paperwork.
3. Full semantic + sentiment illustration
The third illustration follows the identical building, however makes use of the complete matrix Rfull.
This matrix is discovered with each elements of the mannequin:
the semantic goal, which learns contextual similarity between phrases;
The sentiment goal, which injects polarity info from the star rankings.
For every doc, we compute:
Then we normalize:
The instinct is that ought to produce doc options that seize each what the evaluate is about and whether or not the language is optimistic or unfavourable.
That is the primary contribution of the paper: studying phrase vectors that mix semantic similarity and sentiment orientation.
4. Full illustration + Bag of Phrases
The ultimate configuration combines the discovered dense illustration with the unique Bag of Phrases illustration.
We concatenate the 2 representations to acquire:
This offers the classifier two complementary sources of knowledge:
a dense 50-dimensional illustration discovered by the mannequin;
a sparse lexical illustration that preserves precise word-presence info.
This mixture is beneficial as a result of phrase vectors can generalize throughout comparable phrases, whereas Bag of Phrases options preserve exact lexical proof.
For instance, the dense illustration could be taught that great and superb are shut, whereas the Bag of Phrases illustration nonetheless preserves the precise presence of every phrase.
We then prepare a linear SVM on the labeled coaching set and consider it on the check set.
This permits us to reply two questions.
First, do the discovered phrase vectors enhance sentiment classification?
Second, does including sentiment info to the phrase vectors assist past semantic info alone?
Implementation in Python
We implement the mannequin in 5 steps:
Load and clear the IMDb dataset
Construct the vocabulary
Prepare the semantic element
Prepare the complete semantic + sentiment mannequin
Consider the discovered representations utilizing SVM
The desk under reveals the closest neighbors of chosen goal phrases within the discovered vector area.
For every goal phrase, we report the 5 most comparable phrases in line with cosine similarity. The complete mannequin, which mixes the semantic and sentiment goals, tends to retrieve phrases which are shut each in that means and in sentiment orientation. The semantic-only mannequin captures contextual and lexical similarity, nevertheless it doesn’t explicitly use sentiment labels throughout coaching.
The desk under compares our outcomes with the outcomes reported within the paper. For every illustration, we prepare a linear SVM on the labeled coaching critiques and report the classification accuracy on the check set. This permits us to judge how nicely every doc illustration performs on the IMDb sentiment classification process.
Our consequence vs outcomes paper.
The complete mannequin could be very near the consequence reported within the paper. This implies that the sentiment goal is carried out appropriately.
The biggest hole seems within the semantic-only mannequin. This will likely come from optimization particulars, preprocessing, or the best way document-level options are constructed for classification.
Conclusion
On this article, we reproduced the primary elements of the mannequin proposed by Maas et al. (2011).
We carried out the semantic goal, added the sentiment goal, and evaluated the discovered phrase vectors on IMDb sentiment classification.
The mannequin reveals how unlabeled knowledge can assist be taught semantic construction, whereas labeled knowledge can inject sentiment info into the identical vector area.
This can be a easy however highly effective concept: phrase vectors shouldn’t solely seize what phrases imply, but in addition how they really feel.
Whereas this publish doesn’t cowl each element of the paper, we extremely advocate studying the authors’ unique work. Our objective was to share the concepts that impressed us and the enjoyment we discovered each in studying the paper and scripting this publish.
We hope you take pleasure in it as a lot as we did.
Picture Credit
All photos and visualizations on this article have been created by the creator utilizing Python (pandas, matplotlib, seaborn, and plotly) and excel, except in any other case said.
References
[1] 𝗔𝗻𝗱𝗿𝗲𝘄 𝗟. 𝗠𝗮𝗮𝘀, 𝗥𝗮𝘆𝗺𝗼𝗻𝗱 𝗘. 𝗗𝗮𝗹𝘆, 𝗣𝗲𝘁𝗲𝗿 𝗧. 𝗣𝗵𝗮𝗺, 𝗗𝗮𝗻 𝗛𝘂𝗮𝗻𝗴, 𝗔𝗻𝗱𝗿𝗲𝘄 𝗬. 𝗡𝗴, 𝗮𝗻𝗱 𝗖𝗵𝗿𝗶𝘀𝘁𝗼𝗽𝗵𝗲𝗿 𝗣𝗼𝘁𝘁𝘀. 2011. Studying Phrase Vectors for Sentiment Evaluation. In Proceedings of the forty ninth Annual Assembly of the Affiliation for Computational Linguistics: Human Language Applied sciences, pages 142–150, Portland, Oregon, USA. Affiliation for Computational Linguistics.
A requirement sign drops. A provider goes darkish. A competitor cuts costs. Your planning system provides you a dashboard. What you really need is a call in minutes, not weeks. That’s the hole SAP and DataRobot are closing collectively.
Enterprise planning is present process a elementary shift. For many years, organizations have relied on structured planning cycles, quarterly forecasts, annual budgets, and periodic situation evaluation. However in at this time’s atmosphere of fixed disruption, that mannequin is not sufficient. Companies don’t simply want higher plans, they want the flexibility to sense, purpose, and act in actual time.
SAP acknowledges this shift. SAP’s Enterprise Planning providing delivers important worth by unifying fragmented planning processes right into a single, related system that hyperlinks technique, planning, and execution. Historically, organizations wrestle with siloed knowledge, handbook processes, and delayed decision-making, which limits their means to reply to change. SAP addresses this by offering a basis of semantically aligned knowledge, built-in planning fashions, and real-time KPI visibility throughout finance, provide chain, and operations. This allows companies to maneuver past static reporting and forecasting towards a extra cohesive, enterprise-wide view of efficiency, bettering alignment throughout capabilities and guaranteeing that choices are grounded in constant, trusted knowledge.
The true worth of SAP’s method lies in its means to rework planning right into a steady, real-time decisioning functionality by means of its Agentic Proactive Steering framework. By embedding intelligence straight into planning workflows, SAP permits organizations to watch efficiency, consider eventualities, and act on insights in minutes relatively than weeks. The Sense–Purpose–Act mannequin ensures that choices are usually not solely data-driven but additionally context-aware and execution-ready, with a clear “glass field” view into key drivers and outcomes. This leads to quicker response to disruptions, improved operational effectivity, and the flexibility to repeatedly optimize enterprise efficiency—turning planning from a periodic train right into a strategic benefit that drives agility, resilience, and higher enterprise outcomes.
Collectively we’re redefining enterprise planning for the age of AI, shifting away from sluggish, handbook cycles towards a world the place organizations can detect and act on disruptions in minutes.
The Downside: Planning is Nonetheless Too Sluggish
On the coronary heart of SAP’s enterprise planning imaginative and prescient is a essential problem: shifting from plan to execution is difficult. It takes a very long time to align inner and exterior knowledge, enhanced it, construct normal experiences, after which run deeper evaluation and forecasts.
This lag is brought on by:
Guide knowledge aggregation throughout inner and exterior methods.
Static forecasts that develop into outdated nearly as quickly as they’re generated.
Restricted flexibility to mannequin eventualities exterior normal buildings.
Inadequate visibility into cross-functional and group-level impacts.
This hole is the place aggressive benefit is now received or misplaced. Organizations at the moment function in “weeks” primarily based on previous knowledge.
What Modifications with Agentic Proactive Steering?
Agentic Proactive Steering takes us from weeks to minutes. It permits true cross-functional plan propagation by changing static knowledge handoffs with event-driven, AI-powered brokers that perceive causal relationships throughout enterprise domains. It eliminates the necessity for over-sized, inefficient fashions that try to map the complicated relationships between the completely different planning verticals. In conventional SAP environments, a change in provide chain planning—similar to a disruption in IBP—would take weeks to ripple into monetary forecasts, requiring handbook intervention and leading to choices primarily based on outdated knowledge.
With agentic AI, a sign in provide chain (e.g., diminished provide or demand shift) mechanically triggers a Provide Chain Agent to rebalance the plan, which in flip prompts a Finance Agent that recalculates income, prices, margins, and money movement in actual time utilizing embedded monetary fashions. This creates a dynamic, closed-loop system the place choices propagate immediately throughout capabilities—guaranteeing that operational modifications are instantly mirrored in monetary outcomes.
Constructed on a “Glass Field” method
One concern with AI-driven automation is justified: how have you learnt it’s proper? The reply right here is full transparency. Each agent choice — each KPI delta, each simulated consequence, each optimized suggestion — comes with a visual clarification of the way it was reached. This isn’t black-box automation. It’s AI your finance and operations groups can audit, defend, and belief.
How we shut the hole between Plan and Execution
SAP’s roadmap is concentrated on closing the hole between strategic planning and operational execution to drive higher efficiency. This imaginative and prescient is constructed upon an built-in framework throughout three layers:
Sense (SAP): perceive the impacts on KPIs in real-time, with brokers monitoring each inner and exterior indicators.
Purpose (SAP): to elucidate these impacts, the brokers present clear explanations as to how the deltas to the KPIs are calculated, whereas offering context.
Act (SAP): Based mostly on the “Sense and Purpose” phases, SAP’s brokers then construct out forecast eventualities which are primarily based on the recognized most important drivers. Customers can leverage the Joule conversational interface to make modifications to forecast variations, for instance adjusting enter components, and even including further dimension members.
Act (enhanced with DataRobot): Constructing off the preliminary derived forecast eventualities, DataRobot enhances the “Act” part by orchestrating three specialised brokers: a Predictive Agent that may enhance the accuracy of forecasts even additional, a Simulation Agent that evaluates a number of doable eventualities and their trade-offs, and an Optimization Agent that determines the perfect plan of action underneath real-world constraints.
DataRobot: the way it enhances the “Act” part
As a substitute of stopping at static forecasts and dashboards, organizations can now simulate a number of future eventualities dynamically, optimize choices throughout complicated constraints, and execute actions straight inside SAP functions. On the core of this transformation are the next parts:
The Predictive Agent
Typical forecasts have a shelf life, The Predictive agent eliminates it with…
Mannequin Blueprint Analysis: Constructed on the DataRobot platform, it evaluates a various set of mannequin blueprints towards stay SAP knowledge.
Dwell Leaderboard: Utilizing DataRobot’s key capabilities, it applies a aggressive method to check dozens of modeling blueprints and ranks fashions on a stay Leaderboard to determine the Champion mannequin.
Progressive Retraining: The agent progressively retrains prime performers on rising knowledge volumes (16% → 32% → 64% → 100%) earlier than selecting the right mannequin for full retraining on 100% of the information.
Steady Enchancment: This ensures essentially the most correct mannequin is at all times chosen and that forecasts enhance repeatedly as new knowledge turns into accessible.
Outcome: A dwelling forecast that displays the very best view of actuality.
The Simulator Agent
The Simulator Agent enhances planning by shifting past static, rule-based “what-if” and one-time eventualities. The Agent runs all of them — concurrently, probabilistically, and ranked by consequence.
Probabilistic Analysis: It evaluates a number of response methods probabilistically relatively than counting on predefined assumptions.
Consequence Distributions: By utilizing stay machine studying outputs, it evaluates a number of response methods probabilistically relatively than counting on predefined assumptions.
Commerce-off Evaluation: It quantifies trade-offs throughout competing choices, offering clear and defensible choice logic.
Outcome: Planning grounded in chance that gives a full vary of outcomes, not only a single projection.
The Optimizer Agent
Realizing the perfect reply is ineffective when you can’t act on it. The Optimizer Agent closes that hole — evaluating actual constraints in actual time and delivering choices which are able to execute.
Excessive Efficiency (GPU-Accelerated) Optimization: It makes use of high-performance computation to guage complicated, multi-variable environments.
Constraint Administration: The agent evaluates complicated constraints, together with prices, provide chain limitations, and regulatory necessities.
Dynamic Updating: It repeatedly updates choices primarily based on the present greatest view of actuality, drawing straight from stay Predictive and Simulator agent outputs.
Outcome: Execution choices which are possible, optimized for optimum worth, and completely aligned with enterprise targets.
The Future: The Autonomous Enterprise
That is the route SAP is heading: an Autonomous Enterprise the place knowledge is repeatedly sensed, choices are dynamically simulated, and actions are executed inside a unified platform. By aligning finance, provide chain, and operations in actual time, organizations can reply to disruptions in minutes. The Agentic Proactive Steering layer is main instance of how we carry this imaginative and prescient to life.
The businesses that pull forward received’t have higher spreadsheets. They’ll have methods that sense disruption earlier than it turns into a disaster, simulate responses earlier than a gathering is known as, and execute choices earlier than a competitor even is aware of there’s an issue.
Able to Shut the Loop? Your subsequent disruption received’t wait to your subsequent planning cycle. Learn how to get forward of it.
Winhanced is a controller-first gaming shell for Home windows. It unifies your total recreation library throughout Steam, Xbox, Epic, GOG, and PlayStation into one superbly designed interface, fixes Home windows sleep and resume conduct, and supplies clever efficiency administration, all with out changing Home windows itself.
Does Winhanced change Steam Massive Image or Armoury Crate?
Not totally. Winhanced works extra like a unified frontend that may launch and set up video games throughout a number of platforms whereas including a extra console-like expertise to Home windows handhelds.
Why Winhanced as a substitute of Armoury Crate or Playnite?
OEM instruments like Armoury Crate and Legion House primarily deal with device-specific {hardware} controls and settings administration. Group-driven launchers corresponding to Playnite emphasize library group and customization, whereas Winhanced goals to mix recreation library administration, handheld-focused optimizations, and controller-friendly navigation right into a extra unified gaming expertise.
Can Winhanced enhance gaming efficiency on handheld PCs?
It would not immediately enhance FPS, however its streamlined interface and quick-access controls could make handheld gaming really feel smoother and fewer cluttered.
Is Winhanced just for handheld gaming gadgets?
No, whereas it’s designed with gadgets just like the ROG Ally and Legion Go in thoughts, it can be used on common Home windows gaming PCs with a controller.
Options
Each recreation you personal, one place
Each storefront. Each library. Unified, superbly offered, and all the time present. No launcher switching, no gaps.
Put it down. Decide it up. It is there.
Dependable droop and resume throughout each supported gadget and title. The promise no different Home windows app makes. And retains.
The gadget optimizes itself
Autopilot, WARP upscaling, Good Profiles, Dynamic TDP. When it really works it is invisible. When it is seen, it is pleasant.
Play regionally or within the cloud.
Native xCloud streaming constructed proper in. No browser. No workarounds. Full controller assist, direct launch.
Make Winhanced your Home windows dwelling display screen.
Winhanced is the primary third-party app that may register as your Home windows Full Display Expertise dwelling app. One setting, and you might be in Winhanced the second you decide up your gadget, no Xbox app required.
Decide up the place you left off. Each time.
Sleep your gadget. Come again. Your recreation is precisely the place you left it. As much as 80% much less battery drain whereas asleep. No compromises.
Full management. With out leaving your recreation.
TDP, decision, body fee targets, and Lossless Scaling controls are all accessible mid-game by way of the Winhanced HUD, a local Xbox Recreation Bar widget that lives inside your recreation with out interrupting it.
What’s New
Redesigned First-Run Onboarder
The primary-run setup bought a full visible rewrite. 5 targeted steps: Welcome, Machine, Libraries, Customise, Achieved
New dynamic backdrop tinted by your Home windows accent shade, actual gadget renders for each supported gadget, and controller-driven navigation all through
Per-step micro-interactions make first-run setup really feel smoother and extra seamless
System Accent Theme & In-App Shade Picker
Backdrop and accent highlights retint stay to match your Home windows accent shade
The Customise step within the onboarder and Settings → Basic each embrace a 48-color picker that overrides simply inside Winhanced
Decide a shade and all the UI follows, producing a dynamic 3-color theme backdrop primarily based in your choice
Adaptive Show Scaling
Massive rewrite below the hood. The launcher now scales as a single canvas with one root remodel as a substitute of compensating per-element
UI fills any side ratio (16:9, 16:10, 21:9 ultrawide) with out letterboxing or bizarre textual content sizing bugs
Recreation particulars panel respects the footer and sizes canvas-relative
Seven of the widest dialogs (recreation choices, batch import, Steam QR, and so forth.) bought correct width caps so that they by no means stretch off-screen
Per-Recreation Executable Path & Launch Arguments
Recreation Choices on any tile now exposes two new fields: an Executable Path override and Customized Launch Arguments
Level a recreation at a modded .exe, alt construct, or customized launcher, with per-game command line assist
Hidden for Xbox UWP titles the place the package deal household drives launch
Steam exhibits a heads-up in case your override would break overlay injection
Get the Widespread Science every day e-newsletter💡
Breakthroughs, discoveries, and DIY ideas despatched six days per week.
In December 2010, Michael Faherty died in his dwelling in Galway, Eire. His physique was burned and the fireside was lit, however there was no different supply of flames or gas. The home was largely uncharred. The one injury was soot marks on the ceiling and flooring, proper the place the 76-year-old retiree expired.
At a loss for an alternate clarification, the coroner chalked up Faherty’s demise to: Spontaneous. Combustion.
Sooo…reality? Fiction? One thing in between? Within the newest video from Widespread Science, we separate the very fact from the fiction relating to spontaneous combustion.
The Baffling Circumstances of Spontaneous Human Combustion
When you’d wish to see extra Widespread Science movies, subscribe on YouTube. We’ll be bringing you explainers and explorations of our bizarre world.
Google House is rolling out new Gemini for Dwelling early entry updates and Google Dwelling app 4.16 enhancements.
Gemini can now join saved family particulars, like a nanny’s title, to camera-history questions, with timers and alarms additionally getting velocity enhancements.
Sensible shows are getting thumbs-up/down suggestions buttons for voice command responses, whereas the app provides thermostat and QR-code setup enhancements.
Google Dwelling’s massive Gemini improve all the time had a sure attract. We’ve seen sufficient sci-fi films to know the way helpful an all-knowing assistant working your own home may be, however Gemini for Dwelling hasn’t reached that futuristic stage simply but. One motive is that it hasn’t all the time obtained the context proper, and asking a speaker about “the nanny” or “my spouse’s automotive” solely works if the assistant is aware of who and what you imply. Nonetheless, Google seems to be transferring in the appropriate path, with the most recent Google Dwelling updates aimed squarely at making these family questions much less robotic.
Google detailed the adjustments in its Might 11 launch notes and a Nest Group publish, with the Gemini for Dwelling updates rolling out to voice assistant early entry customers. The Google Dwelling app can be getting a couple of enhancements of its personal as a part of model 4.16, which begins rolling out right this moment.
Gemini is getting higher at family context
Probably the most attention-grabbing practical improve is that Gemini can now use data you’ve saved in Ask Dwelling when answering digital camera historical past questions on sensible audio system and shows. Google offers the instance of saving a element like “our nanny’s title is Alice,” then later asking when the nanny got here dwelling. Gemini might then use that saved context to seek for a well-known face tagged as Alice.
That will get nearer to the form of sensible dwelling assistant Google has been promising: one which understands the way you speak about your family, somewhat than forcing you to recollect the precise names and labels your units anticipate. You may as well now ask for a Dwelling Transient in your speaker or show to get a fast recap of what occurred at dwelling when you have been away.
Don’t wish to miss the very best from Android Authority?
Google can be making it simpler to inform the corporate when Gemini will get issues proper or mistaken. Sensible shows will now present thumbs-up and thumbs-down buttons after most voice interactions, providing you with a faster option to ship suggestions. Given the shaky begin to the early entry interval, latest updates appear extra attentive to consumer requests, and this seems to be the most recent effort by Google to point out that the corporate is listening to customers.
Gemini must also really feel sooner for some primary requests. Google says it has optimized backend processing for sensible dwelling instructions, making actions like turning on lights extra responsive. Alarms and timers must also be noticeably faster, with Google saying it has streamlined how these instructions are processed to scale back wait instances and the necessity to repeat your self.
There are a few different Gemini tweaks. Google says grownup customers ought to now get extra useful solutions to benign queries that will beforehand have been caught up in age-restriction filters, like asking it the way to make a margarita. Gemini must also be higher at serving to you get began, with clearer and extra tailor-made options if you ask questions like “What are you able to do?”
The Google Dwelling app will get some sensible enhancements
The Google Dwelling app aspect of the replace is simply as sensible, particularly for sensible thermostat house owners. Nest Thermostat house owners can now immediately pause utilizing out of doors temperatures to warmth or cool their dwelling immediately from the thermostat, with out altering their longer-term automated settings. Google says thermostat schedule banners must also show extra well timed, related recommendation.
There’s additionally a helpful iOS enchancment for sensible dwelling customers with suitable third-party thermostats and air conditioners. Google says now you can handle these units immediately within the Google Dwelling app on iOS, simply as you may on Android.
Lastly, Google is altering the machine setup stream within the Dwelling app. The outdated multi-option setup menu has been changed with a QR code scanner that guides you to the appropriate setup path on your machine, whether or not it’s a Matter-enabled product, a Works with Google Dwelling machine, or a Google Nest machine.
Gemini for Dwelling remains to be a work-in-progress, however to be honest, that’s why it’s in early entry. Google is rolling out the updates thick and quick lately, and each appears to supply smart iterations towards the setup we all the time hoped it could be.
Thanks for being a part of our group. Learn our Remark Coverage earlier than posting.
Elon Musk’s trial towards OpenAI and Microsoft entered its remaining stretch on Monday, with testimony from Microsoft CEO Satya Nadella, former OpenAI chief scientist Ilya Sutskever, and present OpenAI chairman Bret Taylor.
Sutskever drew the highlight, revealing an possession stake in OpenAI’s $850-billion for-profit arm that’s at the moment price about $7 billion. That makes him one of many largest recognized particular person shareholders of OpenAI. Earlier within the trial, OpenAI president Greg Brockman acknowledged for the primary time that he has round $30 billion price of OpenAI shares.
Brockman was one of many analysis lab’s authentic cofounders, and Sutskever joined shortly afterward, turning down a $6 million annual compensation provide from Google. Brockman mentioned he and Sutskever have been “joined on the hip,” till Sutskever helped lead Sam Altman’s transient removing as OpenAI CEO in 2023. Sutskever had helped gather proof to indicate Altman’s alleged historical past of deception, and even assisted in drafting a memo to the board. Although they tried to restore the connection, Sutskever has been estranged from Brockman and Altman ever since, a lawyer for OpenAI mentioned on Monday.
Sutskever, who arrived within the courtroom carrying a costume shirt and slacks, the primary male witness to testify with no swimsuit jacket, gave the impression to be dejected about not being concerned with OpenAI. (He left and shaped a competing AI lab in 2024.) “I felt a substantial amount of possession of OpenAI,” he mentioned at one level Monday. “I felt like I put my life into it, and I merely cared for it, and I didn’t need it to be destroyed.”
Sutskever’s testimony bolstered Musk’s rivalry that Altman shouldn’t be the correct individual to steer an AI lab that might create synthetic common intelligence. As well as, Sutskever talked about how the superalignment workforce he helped lead, which centered on the security of future fashions, was doing a very powerful work at OpenAI “for the long run.” The workforce was disbanded in Might 2024, shortly after Sutskever left the corporate.
However Sutskever additionally added to OpenAI’s protection that Musk by no means negotiated any particular guarantees when funding the OpenAI nonprofit. Musk’s allegation that such commitments existed and that Altman and Brockman violated them by pursuing a profitable for-profit arm are the core of his claims within the lawsuit. Sutskever mentioned OpenAI wanted “numerous {dollars}” to construct a pc as huge because the human mind, and whereas looking for donations had some “affordable success,” turning into a for-profit was the consensus manner ahead.
“I might describe it because the distinction between an ant and a cat,” Sutskever mentioned in response to a query from US district choose Yvonne Gonzalez Rogers about how extra computing helped OpenAI degree up. “If there’s no funding, there isn’t a huge laptop.”
Ultimately, Sutskever, a outstanding AI scientist who paints in his spare time, testified for about an hour, barely making eye contact with anybody throughout his time on the witness stand.
Musk’s authorized workforce had unsuccessfully sought to deal with Sutskever as a hostile witness due to his monetary stake in OpenAI. However Gonzalez Rogers agreed to offer attorneys for each Musk and OpenAI additional leeway of their questioning of Sutskever attributable to what she described as his “distinctive place” within the case.
The Blip
A lot of Monday’s testimony centered across the well-covered occasions of Altman’s ouster and reinstatement as CEO in November 2023. Nadella described Sutskever and different board members firing Altman as “novice metropolis” and reiterated that he “by no means obtained readability” concerning the lack of candor that led to their resolution. Nadella additionally acknowledged throughout his testimony that he and colleagues mentioned 14 potential board members who would be part of OpenAI if Altman returned, together with at the least two whom the Microsoft group vetoed and one who later joined. Nadella described Microsoft’s enter as solutions.
Sutskever mentioned he supported firing Altman as a result of an “surroundings the place executives don’t have the proper info” shouldn’t be “conducive to succeed in any grand objective.” However he criticized his board colleagues for dashing the method, missing expertise, and accepting “authorized recommendation that wasn’t excellent.”
Microsoft’s Wager
In his lawsuit, Musk accused Microsoft of serving to to remodel OpenAI right into a moneymaking machine past what Musk supposed. Nadella testified that Microsoft had first supported OpenAI with discounted cloud computing nevertheless it may not afford to take action “as soon as the invoice began going up.” A for-profit arm that Microsoft may put money into, in change for a possible monetary return, was extra palatable.
However because the years progressed and the payments saved rising, Microsoft needed extra out of the partnership. Microsoft “will lose 4 bil subsequent 12 months!!!” Nadella exclaimed in an e mail in 2022 to his lieutenants concerning the OpenAI partnership. He referred to as for a brand new settlement guaranteeing Microsoft would additionally get AI “know-how” from the startup, which he saved spelling as “Open AI.”
The panorama of enormous language fashions (LLMs) is present process a elementary transformation towards agentic intelligence, the place fashions can autonomously understand, plan, cause, and act inside complicated and dynamic environments. This paradigm shift strikes past conventional static imitation studying towards fashions that actively study by interplay, purchase expertise past their coaching distribution, and adapt their habits primarily based on expertise. Agentic intelligence represents a vital functionality for the following technology of basis fashions, with transformative implications for instrument use, software program improvement, and real-world autonomy.
Kimi-K2 stands on the forefront of this revolution. As a 1.04 trillion-parameter Combination-of-Specialists (MoE) language mannequin with 32 billion activated parameters, Kimi-K2 was purposefully designed to deal with the core challenges of agentic functionality improvement. The mannequin achieves outstanding efficiency throughout numerous benchmarks:
66.1 on Tau2-bench
76.5 on ACEBench (en)
65.8 on SWE-bench Verified
53.7 on LiveCodeBench v6
75.1 on GPQA-Diamond
On the LMSYS (Giant Mannequin Techniques Group) Area leaderboard, Kimi-K2 ranks as the highest open-source mannequin and fifth general, competing intently with Claude 4 Opus and Claude 4 Sonnet.
On this lesson, we dive deep into the technical improvements behind Kimi-K2, specializing in its architectural variations from DeepSeek-V3, the revolutionary MuonClip optimizer, and coaching knowledge enhancements. We additionally present a whole implementation information utilizing DeepSeek-V3 elements as constructing blocks.
Whereas Kimi-K2 builds on DeepSeek-V3’s structure, a number of strategic modifications have been made to optimize agentic capabilities and inference effectivity. Understanding these architectural variations is essential for implementing the mannequin successfully (Desk 1).
Essentially the most vital architectural departure lies in Kimi-K2’s aggressive sparsity scaling. By way of fastidiously managed small-scale experiments, the Kimi workforce developed a sparsity scaling legislation that demonstrated a transparent relationship: with the variety of activated parameters held fixed (i.e., fixed FLOPs), rising the overall variety of specialists constantly lowers each coaching and validation loss. This discovering led to a dramatic improve in mannequin sparsity.
Kimi-K2 employs 384 specialists in comparison with DeepSeek-V3’s 256 specialists, representing a 50% improve. Regardless of this, the mannequin maintains 8 energetic specialists per token, leading to a sparsity ratio of 48 (384/8) versus DeepSeek-V3’s 32 (256/8). This elevated sparsity comes with a trade-off: whereas whole parameters develop to 1.04 trillion (54% greater than DeepSeek-V3’s 671B), the variety of activated parameters truly decreases to 32.6B (13% lower than DeepSeek-V3’s 37B). This design selection optimizes the compute-performance frontier, reaching superior mannequin high quality whereas sustaining environment friendly inference.
A vital optimization for agentic purposes entails the variety of consideration heads. DeepSeek-V3 units the variety of consideration heads to roughly twice the variety of mannequin layers (128 heads for 61 layers) to raised make the most of reminiscence bandwidth. Nevertheless, as context size will increase, this design incurs vital inference overhead.
For agentic purposes requiring environment friendly long-context processing, this turns into prohibitive. With a 128k sequence size, rising consideration heads from 64 to 128 (whereas holding 384 whole specialists) results in an 83% improve in inference FLOPs. By way of managed experiments, the Kimi workforce discovered that doubling the variety of consideration heads yields solely modest enhancements in validation loss (0.5% to 1.2%) underneath iso-token coaching situations.
Provided that sparsity 48 already offers sturdy efficiency, the marginal good points from doubling consideration heads don’t justify the inference value. Kimi-K2 due to this fact makes use of 64 consideration heads (half of DeepSeek-V3’s 128), dramatically lowering inference prices for long-context agentic workloads whereas sustaining aggressive efficiency.
The MuonClip optimizer represents some of the vital improvements in Kimi-K2’s improvement, addressing the basic problem of coaching stability at trillion-parameter scale whereas sustaining token effectivity. Understanding MuonClip requires analyzing each the underlying Muon optimizer and the novel QK-Clip mechanism that makes it secure for large-scale coaching.
Given the more and more restricted availability of high-quality human knowledge, token effectivity has emerged as a vital consider LLM scaling. Token effectivity refers to how a lot efficiency enchancment is achieved per token consumed throughout coaching. The Muon optimizer, launched by Jordan et al. (2024), considerably outperforms AdamW underneath the identical compute funds, mannequin measurement, and coaching knowledge quantity.
Earlier work in Moonlight demonstrated that Muon’s token effectivity good points make it a perfect selection for maximizing the intelligence extracted from restricted high-quality tokens. Nevertheless, scaling Muon to trillion-parameter fashions revealed a vital problem: coaching instability as a consequence of exploding consideration logits.
Throughout medium-scale coaching runs utilizing vanilla Muon, consideration logits quickly exceeded magnitudes of 1000, resulting in numerical instabilities and occasional coaching divergence (Determine 1). This phenomenon occurred extra incessantly with Muon than with AdamW, suggesting that Muon’s aggressive optimization dynamics amplify instabilities within the consideration mechanism.
Determine 1: Consideration logits quickly exceed 1000, which may result in potential numerical instabilities and even coaching divergence (supply: Kimi Workforce, 2026).
Present mitigation methods proved inadequate:
Logit soft-capping (utilized in Gemma) immediately clips consideration logits, however the dot merchandise between queries and keys can nonetheless develop excessively earlier than capping is utilized
Question-Key Normalization (QK-Norm) (Dehghani et al., 2023) is incompatible with Multi-head Latent Consideration (MLA) as a result of full key matrices aren’t explicitly materialized throughout inference
To deal with this elementary problem, the Kimi workforce proposed QK-Clip, a novel weight-clipping mechanism that explicitly constrains consideration logits by rescaling the question and key projection weights post-update. The class of QK-Clip lies in its simplicity: it doesn’t alter ahead and backward computation within the present step however as a substitute makes use of most logits as a guiding sign to manage weight development (Determine 2).
Determine 2: Most logits for Kimi-K2 with MuonClip and τ = 100 over the whole coaching run. The max logits quickly improve to the capped worth of 100 earlier than decaying to a secure vary (supply: Kimi Workforce, 2026).
For every consideration head , the eye mechanism computes:
The eye output is:
QK-Clip defines the max logit per head as:
the place is the present batch and index completely different tokens.
When exceeds a threshold (set to 100 for Kimi-K2), QK-Clip rescales the weights. Critically, the rescaling is utilized per-head reasonably than globally, minimizing intervention on heads that stay secure:
.
This per-head, component-aware clipping represents a considerable refinement over naive world clipping methods.
Determine 3 describes the entire algorithm for MuonClip Optimizer.
Past architectural and optimizer improvements, Kimi-K2’s superior efficiency stems considerably from strategic enhancements in coaching knowledge. With high-quality human-generated knowledge changing into more and more scarce, the main target shifts to rising token utility, outlined because the efficient studying sign every token contributes to mannequin updates.
Token effectivity in pre-training encompasses 2 associated however distinct ideas:
Optimizer effectivity: How successfully the optimizer extracts sign from every gradient replace (addressed by MuonClip)
Token utility: The inherent info density and studying sign in every token
Rising token utility immediately improves token effectivity. A naive strategy entails repeated publicity to the identical tokens throughout a number of epochs, however this results in overfitting and lowered generalization. The important thing innovation in Kimi-K2 lies in a complicated artificial knowledge technology technique that amplifies high-quality tokens with out inducing overfitting.
Pre-training on knowledge-intensive textual content presents a elementary trade-off: a single epoch is inadequate for complete data absorption, whereas multi-epoch repetition yields diminishing returns. To resolve this rigidity, Kimi-K2 employs an artificial rephrasing framework with the next 3 key elements.
Fashion- and Perspective-Numerous Prompting
To reinforce linguistic range whereas sustaining factual integrity, fastidiously engineered prompts information a big language mannequin to generate trustworthy rephrasings in various kinds and views. This strategy ensures that whereas surface-level linguistic options change, the underlying factual content material stays constant. The range of expressions forces the mannequin to study strong representations of the identical data throughout a number of linguistic realizations.
Chunk-wise Autoregressive Era
Lengthy paperwork pose a problem for traditional LLM-based rewriting as a consequence of implicit output size limitations. Kimi-K2 addresses this by a chunk-based autoregressive technique: paperwork are segmented, every section is rephrased individually with preserved context, and segments are stitched again collectively to kind full passages. This technique prevents info loss and maintains world coherence throughout prolonged texts (Determine 4).
Constancy Verification
To make sure consistency between unique and rewritten content material, constancy checks examine the semantic alignment of every rephrased passage with its supply. This high quality management step prevents the introduction of hallucinations or factual errors throughout the rephrasing course of.
Determine 4: Auto-regressive chunk-wise rephrasing pipeline for lengthy enter excerpts (supply: Kimi Workforce, 2026).
Arithmetic Knowledge Rephrasing
To reinforce mathematical reasoning capabilities, high-quality mathematical paperwork are rewritten right into a “learning-note” type following SwallowMath methodology (Determine 5). This transformation converts dense mathematical exposition into extra pedagogical codecs that higher help studying. Moreover, knowledge range is elevated by the interpretation of high-quality mathematical supplies from different languages into English, successfully multiplying the accessible high-quality mathematical coaching knowledge.
Determine 5: 4-stage pipeline for developing SwallowMath (supply: Fujii et al., 2026).
Total Pre-training Corpus
The whole Kimi-K2 pre-training corpus includes 15.5 trillion tokens of curated, high-quality knowledge spanning 4 major domains:
Net Textual content: Normal data and pure language understanding
Code: Programming and structured reasoning
Arithmetic: Quantitative reasoning and formal problem-solving
Information: Area-specific experience and factual info
On this part, we stroll by the important thing implementation particulars for coaching Kimi-K2, focusing particularly on the elements that differ from the usual DeepSeek-V3 implementation. We’ll study the improved Multi-head Latent Consideration with max logit monitoring, the MuonClip optimizer implementation, and the customized coaching setup.
The Multi-head Latent Consideration (MLA) mechanism in Kimi-K2 extends DeepSeek-V3’s implementation with vital modifications to help QK-Clip. The important thing enhancement is per-head max-logit monitoring throughout the ahead go, which offers the sign wanted for weight clipping by the optimizer.
On Strains 1-47, we outline the MLA structure following DeepSeek-V3’s design with compression and decompression of queries and key-values by low-rank projections. The important thing innovation seems on Line 49, the place we initialize self.max_logits = 0.0, a vital state variable that tracks the utmost consideration logits throughout heads. This monitoring mechanism is important for QK-Clip to operate correctly.
On Strains 52-82, we implement the usual ahead go by the compression-decompression pipeline. The enter undergoes compression by way of kv_proj and q_proj, adopted by decompression by devoted linear layers. We then reshape tensors for multi-head processing and apply Rotary Place Embeddings (RoPE) individually to content material and positional elements. This separation permits per-head QK-Clip to focus on solely the suitable elements with out affecting shared rotary embeddings.
# Concatenate content material and cord components
q = torch.cat([q_content, q_rope], dim=-1)
ok = torch.cat([k_content, k_rope], dim=-1)
# Consideration computation
scale = 1.0 / math.sqrt(q.measurement(-1))
scores = torch.matmul(q, ok.transpose(-2, -1)) * scale
with torch.no_grad():
# self.max_logits = torch.max(scores, dim=1).merchandise()
self.max_logits = listing(torch.max(scores.transpose(1, 0).contiguous().view(scores.form[1], -1), dim=-1)[0])
# Apply causal masks
scores = scores.masked_fill(self.causal_mask[:, :, :T, :T] == 0, float('-inf'))
# Apply padding masks if offered
if attention_mask isn't None:
padding_mask_additive = (1 - attention_mask).unsqueeze(1).unsqueeze(2) * float('-inf')
scores = scores + padding_mask_additive
# Softmax and dropout
attn_weights = F.softmax(scores, dim=-1)
attn_weights = self.attn_dropout(attn_weights)
# Apply consideration to values
out = torch.matmul(attn_weights, v)
# Reshape and venture
out = out.transpose(1, 2).contiguous().view(B, T, self.n_head * self.head_dim)
out = self.resid_dropout(self.o_proj(out))
return out
On Strains 89-94, we compute consideration scores and implement the essential max logit monitoring. The rating computation follows normal scaled dot-product consideration. Nevertheless, Strains 92-94 signify a key departure from vanilla DeepSeek-V3: we observe the utmost consideration logit per head utilizing torch.no_grad() to keep away from affecting gradients. The scores tensor has form [batch, num_heads, seq_len, seq_len], and we transpose and reshape to extract per-head most values. This per-head granularity allows focused intervention solely on heads exhibiting logit explosion, minimizing disruption to secure heads.
On Strains 97-113, we full the eye mechanism with causal masking, elective padding masks, softmax normalization, and dropout. The ultimate output projection maintains the usual MLA structure. The class of this implementation lies in its non-invasiveness: max logit monitoring provides minimal computational overhead (a single max operation underneath torch.no_grad) whereas offering the vital sign for optimizer-level weight clipping.
The MuonClip optimizer represents the core innovation enabling secure trillion-parameter coaching. Our implementation integrates Newton-Schulz orthogonalization, RMS matching, weight decay, and per-head QK-Clip right into a unified optimizer.
On Strains 1-13, we outline the entry level for the QK-Clip utility. The operate accepts question and key projection weights together with per-head max logits and a threshold (defaulting to 100). We deal with each listing and tensor inputs for flexibility, changing lists to tensors on the suitable machine with matching dtype. The vital design selection right here is in-place modification: we immediately modify weight tensors to keep away from reminiscence allocation overhead throughout optimization.
On Strains 15-48, we extract dimensions and guarantee tensor kind compatibility. We first extract dimensions and compute the per-head scaling issue just for heads the place .
@torch.no_grad()
def apply_qk_clip_vectorized(
query_weights: torch.Tensor,
key_weights: torch.Tensor,
max_logits_per_head: torch.Tensor,
tau: float = 100.0
) -> None:
q_out, q_in = query_weights.form[0], query_weights.form[1]
k_out, k_in = key_weights.form[0], key_weights.form[1]
num_heads = len(max_logits_per_head)
d_k = q_out // num_heads
# Guarantee tensor kind
if not isinstance(max_logits_per_head, torch.Tensor):
max_logits_per_head = torch.tensor(
max_logits_per_head,
machine=query_weights.machine,
dtype=query_weights.dtype
)
# Compute scaling elements: gamma = tau / max_logit the place max_logit > tau
needs_clip = max_logits_per_head > tau
# If no clipping wanted, return early
if not needs_clip.any():
return
gamma = torch.the place(
needs_clip,
tau / max_logits_per_head.clamp(min=1e-8),
torch.ones_like(max_logits_per_head)
)
sqrt_gamma = torch.sqrt(gamma)
# Reshape weights to [d_model, num_heads, d_k] for per-head scaling
# Views share underlying storage, so in-place ops modify unique tensor
q_reshaped = query_weights.view(q_out // num_heads, num_heads, q_in)
k_reshaped = key_weights.view(k_out // num_heads, num_heads, k_in)
# Apply per-head scaling IN-PLACE: broadcast sqrt_gamma [num_heads] over [d_model, num_heads, d_k]
q_reshaped.mul_(sqrt_gamma.view(1, num_heads, 1))
k_reshaped.mul_(sqrt_gamma.view(1, num_heads, 1))
q_reshaped = q_reshaped.view(q_out, q_in)
k_reshaped = k_reshaped.view(k_out, k_in)
On Strains 52-60, we restart the operate definition and extract dimensions. On Strains 80-97, we carry out the precise weight clipping by cautious tensor reshaping and in-place multiplication. The weights are reshaped from [d_model, d_model] to [d_model/num_heads, num_heads, d_k] to show the pinnacle dimension. We then apply scaling utilizing in-place multiplication (mul_) with broadcasting. The sq. root scaling ensures that when question and key each obtain , their dot product receives the total scaling. This elegant mathematical property permits us to clip consideration logits by rescaling the weights that produce them, reasonably than clipping logits immediately after they’re computed.
Strains77 and 78 implement early exit if no head requires clipping, which turns into a standard case later in coaching when consideration logits stabilize. This optimization avoids pointless computation when the mannequin is well-behaved.
class MuonClip(torch.optim.Optimizer):
def __init__(
self,
params,
lr: float = 1e-3,
momentum: float = 0.95,
weight_decay: float = 0.01,
tau: float = 100.0,
ns_steps: int = 5,
eps: float = 1e-7
):
if lr < 0.0:
elevate ValueError(f"Invalid studying price: {lr}")
if not 0.0 <= momentum <= 1.0:
elevate ValueError(f"Invalid momentum worth: {momentum}")
if weight_decay < 0.0:
elevate ValueError(f"Invalid weight_decay worth: {weight_decay}")
if tau <= 0.0:
elevate ValueError(f"Invalid tau worth: {tau}")
defaults = dict(
lr=lr,
momentum=momentum,
weight_decay=weight_decay,
tau=tau,
ns_steps=ns_steps,
eps=eps
)
tremendous().__init__(params, defaults)
# For QK-Clip performance
self.mannequin = None
self.attention_layers = []
def set_model(self, mannequin: nn.Module):
self.mannequin = mannequin
if hasattr(mannequin, 'get_attention_layers'):
self.attention_layers = mannequin.get_attention_layers()
On Strains 1-33, we outline the MuonClip optimizer class, inheriting from PyTorch’s base Optimizer. The constructor accepts normal hyperparameters (studying price, momentum, weight decay) plus QK-Clip-specific parameters ( and Newton-Schulz steps). We validate all parameters and initialize state monitoring. Critically, Strains 35-38 implement mannequin registration by set_model(), which extracts consideration layers for later QK-Clip utility. This design separates optimizer logic from mannequin structure, permitting the optimizer to function on any mannequin exposing a get_attention_layers() methodology.
@torch.no_grad()
def step(self, closure: Non-compulsory[Callable] = None) -> Non-compulsory[float]:
loss = None
if closure isn't None:
with torch.enable_grad():
loss = closure()
for group in self.param_groups:
lr = group['lr']
momentum = group['momentum']
weight_decay = group['weight_decay']
ns_steps = group['ns_steps']
eps = group['eps']
for p in group['params']:
if p.grad is None:
proceed
grad = p.grad
state = self.state[p]
# Initialize momentum buffer
if len(state) == 0:
state['momentum_buffer'] = torch.zeros_like(p)
buf = state['momentum_buffer']
# Apply momentum: Mt = μMt−1 + Gt
buf.mul_(momentum).add_(grad)
if p.ndim >= 2: # 2D+ parameters - use Muon
# Apply Newton-Schulz orthogonalization
if p.ndim > 2:
original_shape = buf.form
buf_2d = buf.view(buf.form[0], -1)
orthogonal_update = newton_schulz(buf_2d, ns_steps, eps)
orthogonal_update = orthogonal_update.view(original_shape)
else:
orthogonal_update = newton_schulz(buf, ns_steps, eps)
# RMS matching issue: √(max(n,m) × 0.2)
n, m = p.form[0], p.form[1] if p.ndim > 1 else 1
rms_factor = math.sqrt(max(n, m) * 0.2)
orthogonal_update = orthogonal_update * rms_factor
# Replace: Wt = Wt−1 − η(Ot + λWt−1)
p.add_(orthogonal_update + weight_decay * p, alpha=-lr)
else:
# 1D parameters - normal momentum
p.add_(buf + weight_decay * p, alpha=-lr)
# Apply QK-Clip
self._apply_qk_clip()
return loss
On Strains 41-94, we implement the core optimization step integrating Muon updates with QK-Clip. The step begins with normal closure dealing with and parameter group iteration. Strains 41-68 implement momentum accumulation () utilizing in-place operations for reminiscence effectivity. The vital branching happens at Line 70: parameters with 2+ dimensions obtain Muon remedy.
On Strains 72-83, we apply the Muon replace for matrix parameters. Newton-Schulz orthogonalization produces an orthogonal approximation of the momentum buffer, which we then scale by to match AdamW’s RMS traits. This scaling ensures Muon’s updates have comparable magnitudes to AdamW, enabling simpler hyperparameter switch. Lastly, Line 86 applies the replace with weight decay: . Line 89 applies normal momentum updates to 1D parameters resembling biases and normalization layers.
def _apply_qk_clip(self):
"""Apply QK-Clip to consideration layers to forestall logit explosion."""
if not self.attention_layers:
return
tau = self.param_groups[0]['tau']
for attention_layer in self.attention_layers:
if not hasattr(attention_layer, 'max_logits'):
proceed
max_logits = attention_layer.max_logits
if not max_logits:
proceed
# Deal with each scalar and per-head max logits
if isinstance(max_logits, (int, float)):
max_logits = [max_logits]
apply_qk_clip_per_head(
attention_layer.k_decompress.weight.knowledge,
attention_layer.q_decompress.weight.knowledge,
max_logits,
tau
)
On Strains 96-122, we apply QK-Clip in spite of everything weight updates. The _apply_qk_clip() methodology iterates by all registered consideration layers, extracts their max_logits attribute (populated throughout ahead go), and applies per-head clipping to the question and key decompression weights. This post-update clipping ensures weights don’t develop unboundedly throughout coaching steps whereas preserving gradient info inside every step.
On Strains 1-4, we configure the mannequin structure. Kimi-K2 doesn’t use Multi-Token Prediction, so we disable multi-token prediction (multi_token_predict=0) to simplify coaching and give attention to core capabilities. We use 8 specialists for this academic implementation reasonably than the tons of utilized in production-scale Kimi-K2 and DeepSeek-V3 fashions. We additionally use 4 consideration heads for this small-scale academic implementation, in comparison with the production-scale configurations utilized in DeepSeek-V3 and Kimi-K2.
On Strains 6-30, we outline coaching arguments following greatest practices for small-scale experiments. We use gradient accumulation (4 steps) to simulate bigger batch sizes with restricted GPU reminiscence, allow mixed-precision coaching (fp16=True) for pace and reminiscence effectivity, and configure common analysis and checkpointing each 50 steps. The educational price of 5e-4 is conservative for secure coaching, with a short 10-step warmup.
On Strains 31-36, we initialize the mannequin and create a MuonClip optimizer. Critically, Line 36 registers the mannequin with the optimizer utilizing set_model(), enabling QK-Clip to entry consideration layers. This registration should happen earlier than coaching begins.
On Strains 39-60, we instantiate the customized coach with all elements and launch coaching. The optimizers=(optimizer, None) argument offers our customized optimizer to Hugging Face Coach, overriding its default optimizer creation. After coaching completes, we save each the mannequin weights and tokenizer for later inference.
Course info:
86+ whole courses • 115+ hours hours of on-demand code walkthrough movies • Final up to date: Could 2026 ★★★★★ 4.84 (128 Scores) • 16,000+ College students Enrolled
I strongly consider that should you had the correct instructor you could possibly grasp pc imaginative and prescient and deep studying.
Do you assume studying pc imaginative and prescient and deep studying needs to be time-consuming, overwhelming, and complex? Or has to contain complicated arithmetic and equations? Or requires a level in pc science?
That’s not the case.
All you could grasp pc imaginative and prescient and deep studying is for somebody to clarify issues to you in easy, intuitive phrases. And that’s precisely what I do. My mission is to alter schooling and the way complicated Synthetic Intelligence subjects are taught.
In the event you’re severe about studying pc imaginative and prescient, your subsequent cease must be PyImageSearch College, essentially the most complete pc imaginative and prescient, deep studying, and OpenCV course on-line right this moment. Right here you’ll discover ways to efficiently and confidently apply pc imaginative and prescient to your work, analysis, and initiatives. Be part of me in pc imaginative and prescient mastery.
Inside PyImageSearch College you may discover:
&verify; 86+ programs on important pc imaginative and prescient, deep studying, and OpenCV subjects
&verify; 86 Certificates of Completion
&verify; 115+ hours hours of on-demand video
&verify; Model new programs launched usually, making certain you may sustain with state-of-the-art methods
&verify; Pre-configured Jupyter Notebooks in Google Colab
&verify; Run all code examples in your net browser — works on Home windows, macOS, and Linux (no dev atmosphere configuration required!)
&verify; Entry to centralized code repos for all 540+ tutorials on PyImageSearch
&verify; Straightforward one-click downloads for code, datasets, pre-trained fashions, and many others.
&verify; Entry on cell, laptop computer, desktop, and many others.
We started by detailing the best way to practice Kimi-K2 from scratch utilizing DeepSeek-V3 elements, emphasizing the architectural variations that set Kimi-K2 aside. We explored the mannequin’s scale and sparsity, exhibiting that lowering the variety of consideration heads allowed us to steadiness effectivity and efficiency. A key a part of this journey was the introduction of the MuonClip optimizer, which stabilizes coaching whereas pushing the boundaries of large-scale language modeling.
We then turned to the challenges of token effectivity and the eye logit explosion drawback. To deal with these, we launched the QK-Clip innovation, which helped us management runaway logits and enhance general stability. Alongside this, we refined our coaching knowledge pipeline, specializing in token utility and data knowledge rephrasing to make sure that each token contributed meaningfully to the mannequin’s studying course of. These enhancements allowed us to maximise the worth of the info whereas holding coaching environment friendly.
Lastly, we described the implementation particulars, together with enhanced multi-head latent consideration with max logit monitoring and the sensible integration of the MuonClip optimizer. We concluded with a whole coaching setup, exhibiting how all these improvements got here collectively to make Kimi-K2 a sturdy, environment friendly, and scalable mannequin. By combining architectural refinements, optimizer breakthroughs, and knowledge enhancements, this lesson demonstrated how these methods push the boundaries of what’s attainable in fashionable language mannequin coaching.
Mangla, P. “Constructing and Coaching a Kimi-K2 Mannequin Utilizing DeepSeek-V3 Elements,” PyImageSearch, S. Huot, A. Sharma, and P. Thakur, eds., 2026, https://pyimg.co/d3tge
@incollection{Mangla_2026_building-training-kimi-k2-model-using-deepseek-v3,
writer = {Puneet Mangla},
title = {{Constructing and Coaching a Kimi-K2 Mannequin Utilizing DeepSeek-V3 Elements}},
booktitle = {PyImageSearch},
editor = {Susan Huot and Aditya Sharma and Piyush Thakur},
12 months = {2026},
url = {https://pyimg.co/d3tge},
}
To obtain the supply code to this put up (and be notified when future tutorials are revealed right here on PyImageSearch), merely enter your e mail deal with within the kind beneath!
Obtain the Supply Code and FREE 17-page Useful resource Information
Enter your e mail deal with beneath to get a .zip of the code and a FREE 17-page Useful resource Information on Laptop Imaginative and prescient, OpenCV, and Deep Studying. Inside you may discover my hand-picked tutorials, books, programs, and libraries that can assist you grasp CV and DL!
Because of this, finish customers are souring on “AI all over the place, on a regular basis.” Solely 8% of Individuals would pay further for AI, in line with ZDNET-Aberdeen analysis. Amid rising AI slop considerations and rising shopper pushback, The Wall Road Journal experiences that firms have gotten extra cautious about how they promote AI in merchandise.
“The most important anti-pattern is AI all over the place with out context,” says Neeraj Abhyankar, VP of information and AI at R Techniques, a digital product engineering firm. “Groups bolt chatbots or auto-generated content material onto established merchandise and workflows in ways in which disrupt the consumer’s movement moderately than improve it.”
Sudden closures, such because the sunsetting of video technology app Sora, spotlight the brittleness of AI choices available in the market. Enthusiasm for AI-generated content material can also be declining: 46% of customers dislike firms that use AI to generate content material, and 43% are much less more likely to buy from them, in line with SurveyMonkey’s State of Advertising and marketing 2025 report.
So, on the danger of dropping potential enterprise, is including AI to your software program services or products actually price it? And if that’s the case, how do you do it proper? Under, we examine in with consultants to look at the downsides of unexpectedly bolting AI onto present merchandise, in addition to constructive examples with measurable advantages, to assist draw the road between helpful AI and AI that simply will get in the best way.
Giant language fashions (LLMs) have a style for utilizing “flowery”, generally overly verbose language of their responses. Ask a easy query, and chances are high you might get flooded with paragraphs of overly detailed, enthusiastic, and sophisticated prose. This standard habits is rooted of their coaching, as they’re optimized to be as useful and conversational as potential.
Sadly, verbosity is a severe side to have beneath the radar, and could be argued to typically correlate with an elevated odds of a serious subject: hallucinations. The extra phrases are generated in a response, the upper the probabilities of drifting from grounded data and venturing into “the artwork of fabrication”.
In sum, strong guardrails are wanted to forestall this double-sided downside, beginning with verbosity checks. This text reveals the way to use the Textstat Python library to measure readability and detect overly complicated responses earlier than they attain the top consumer, forcing the mannequin to refine its response.
# Setting a Complexity Finances with Textstat
The Textstat Python library can be utilized to compute scores such because the automated readability index (ARI); it estimates the grade degree (degree of examine) wanted to grasp a bit of textual content, reminiscent of a mannequin response. If this complexity metric exceeds a price range or threshold — reminiscent of 10.0, equal to a Tenth-grade studying degree — a re-prompting loop could be routinely triggered to require a extra concise, less complicated response. This technique not solely dispels flowery language however may additionally assist cut back hallucination dangers, as a result of the mannequin adheres to core information extra strictly in consequence.
# Implementing the LangChain Pipeline
Let’s examine the way to implement the above-described technique and combine it right into a LangChain pipeline that may be simply run in a Google Colab pocket book. You will want a Hugging Face API token, obtainable at no cost at https://huggingface.co/settings/tokens. Create a brand new “secret” named HF_TOKEN on the left-hand aspect menu of Colab by clicking on the “Secrets and techniques” icon (it appears like a key). Paste the generated API token within the “Worth” discipline, and you’re all arrange!
To start out, set up the required libraries:
!pip set up textstat langchain_huggingface langchain_community
The next code is Google Colab-specific, and you might want to regulate it accordingly if you’re working in a special atmosphere. It focuses on recovering the saved API token:
from google.colab import userdata
# Get hold of Hugging Face API token saved in your Colab session's Secrets and techniques
HF_TOKEN = userdata.get('HF_TOKEN')
# Confirm token restoration
if not HF_TOKEN:
print("WARNING: The token 'HF_TOKEN' wasn't discovered. This may increasingly trigger errors.")
else:
print("Hugging Face Token loaded efficiently.")
Within the following piece of code, we carry out a number of actions. First, it units up parts for native textual content era by way of a pre-trained Hugging Face mannequin — particularly distilgpt2. After that, the mannequin is built-in right into a LangChain pipeline.
import textstat
from langchain_core.prompts import PromptTemplate
# Importing mandatory courses for native Hugging Face pipelines
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
from langchain_community.llms import HuggingFacePipeline
# Initializing a free-tier, local-friendly, appropriate LLM for textual content era
model_id = "distilgpt2"
tokenizer = AutoTokenizer.from_pretrained(model_id)
mannequin = AutoModelForCausalLM.from_pretrained(model_id)
# Making a text-generation pipeline
pipe = pipeline(
"text-generation",
mannequin=mannequin,
tokenizer=tokenizer,
max_new_tokens=100,
system=0 # Use GPU if obtainable, in any other case it would default to CPU
)
# Wrapping the pipeline in HuggingFacePipeline
llm = HuggingFacePipeline(pipeline=pipe)
Our core mechanism for measuring and managing verbosity is applied subsequent. The next perform generates a abstract of textual content handed to it (assumed to be an LLM’s response) and tries to make sure the abstract doesn’t exceed a threshold degree of complexity. Observe that when utilizing an acceptable immediate template, era fashions like distilgpt2 can be utilized for acquiring textual content summaries, though the standard of such summarizations might not match that of heavier, summarization-focused fashions. We selected this mannequin as a consequence of its reliability for native execution in a constrained atmosphere.
def safe_summarize(text_input, complexity_budget=10.0):
print("n--- Beginning Abstract Course of ---")
print(f"Enter textual content size: {len(text_input)} characters")
print(f"Goal complexity price range (ARI rating): {complexity_budget}")
# Step 1: Preliminary Abstract Era
print("Producing preliminary complete abstract...")
base_prompt = PromptTemplate.from_template(
"Present a complete abstract of the next: {textual content}"
)
chain = base_prompt | llm
abstract = chain.invoke({"textual content": text_input})
print("Preliminary Abstract generated:")
print("-------------------------")
print(abstract)
print("-------------------------")
# Step 2: Measure Readability
ari_score = textstat.automated_readability_index(abstract)
print(f"Preliminary ARI Rating: {ari_score:.2f}")
# Step 3: Implement Complexity Finances
if ari_score > complexity_budget:
print("Finances exceeded! Preliminary abstract is simply too complicated.")
print("Triggering simplification guardrail...")
simplification_prompt = PromptTemplate.from_template(
"The next textual content is simply too verbose. Rewrite it concisely "
"utilizing easy vocabulary, stripping away flowery language:nn{textual content}"
)
simplify_chain = simplification_prompt | llm
simplified_summary = simplify_chain.invoke({"textual content": abstract})
new_ari = textstat.automated_readability_index(simplified_summary)
print("Simplified Abstract generated:")
print("-------------------------")
print(simplified_summary)
print("-------------------------")
print(f"Revised ARI Rating: {new_ari:.2f}")
abstract = simplified_summary
else:
print("Preliminary abstract is inside complexity price range. No simplification wanted.")
print("--- Abstract Course of Completed ---")
return abstract
Discover additionally within the code above that ARI scores are calculated to estimate textual content complexity.
The ultimate a part of the code instance exams the perform outlined beforehand, passing pattern textual content and a complexity price range of 10.0, and printing the ultimate outcomes.
# 1. Offering some extremely verbose, complicated pattern textual content
sample_text = """
The inextricably intertwined permutations of cognitive computational arrays inside the
realm of Giant Language Fashions typically precipitate a cascade of unnecessarily labyrinthine
lexical constructions. This propensity for circumlocution, while seemingly indicative of
profound erudition, incessantly obfuscates the foundational semantic payload, thereby
rendering the generated discourse considerably much less accessible to the quintessential layperson.
"""
# 2. Calling the perform
print("Operating summarizer pipeline...n")
final_output = safe_summarize(sample_text, complexity_budget=10.0)
# 3. Printing the ultimate end result
print("n--- Closing Guardrailed Abstract ---")
print(final_output)
The ensuing printed messages could also be fairly prolonged, however you will notice a delicate lower within the ARI rating after calling the pre-trained mannequin for summarization. Don’t count on miraculous outcomes, although: the mannequin chosen, whereas light-weight, is just not nice at summarizing textual content, so the ARI rating discount is reasonably modest. You possibly can strive utilizing different fashions like google/flan-t5-small to see how they carry out for textual content summarization, however be warned — these fashions will likely be heavier and tougher to run.
# Wrapping Up
This text reveals the way to implement an infrastructure for measuring and controlling overly verbose LLM responses by calling an auxiliary mannequin to summarize them earlier than approving their degree of complexity. Hallucinations are a byproduct of excessive verbosity in lots of eventualities. Whereas the implementation proven right here focuses on assessing verbosity, there are particular checks that will also be used for measuring hallucinations — reminiscent of semantic consistency checks, pure language inference (NLI) cross-encoders, and LLM-as-a-judge options.
Iván Palomares Carrascosa is a frontrunner, author, speaker, and adviser in AI, machine studying, deep studying & LLMs. He trains and guides others in harnessing AI in the actual world.
This story appeared in The Logoff, a day by day e-newsletter that helps you keep knowledgeable in regards to the Trump administration with out letting political information take over your life. Subscribe right here.
Welcome to The Logoff: President Donald Trump hopes to droop the federal gasoline tax as his struggle with Iran drives costs ever increased.
Can he do this? Not by himself, although it’s not clear Trump is aware of that: He unequivocally instructed a reporter this morning that “we’re going to take off the gasoline tax for a time frame.”
As a substitute, he’ll want Congress to cross a invoice — which it’d. Democratic lawmakers have beforehand launched laws to take action, and a number of Republican members signaled their help on Monday (it’s additionally already changing into a marketing campaign subject).
It’s certainly not a certain factor, although: Congress has by no means handed a gasoline tax vacation, together with when President Joe Biden known as for one in 2022. On Monday, Senate Majority Chief John Thune instructed reporters that “I’ve not previously clearly been a fan of that concept,” however that he would hear out senators who supported it.
How a lot wouldn’t it assist? The federal gasoline tax is eighteen.4 cents per gallon, so suspending it will make a distinction on the margin. It might do little to actually normalize costs, nevertheless; gasoline is $4.52/gallon on common, up 38.5 cents from only a month in the past and greater than $1.50 from the beginning of the struggle.
Suspending the gasoline tax would additionally price the Freeway Belief Fund billions in income. And there’s the issue of creating certain the tax break truly advantages customers: Because the Washington Put up factors out, the gasoline tax isn’t collected instantly on the pump, so some financial savings may movement to grease firms as a substitute.
What in regards to the struggle? Essentially the most direct strategy to ease gasoline costs can be to finish the struggle in Iran (although it wouldn’t repair the issue instantly, and even shortly). On Sunday, nevertheless, Trump rejected an Iranian response to the most recent US peace proposal as “TOTALLY UNACCEPTABLE.”
And with that, it’s time to sign off…
Right here’s some unalloyed, grade-A excellent news: Espresso, it seems, is just not merely okay for us, however affirmatively good for us. My colleague Bryan Walsh breaks down what it does for us and the lengthy scientific journey to figuring it out — you’ll be able to learn his full article right here with a present hyperlink.
Have an important night, and we’ll see you again right here tomorrow!










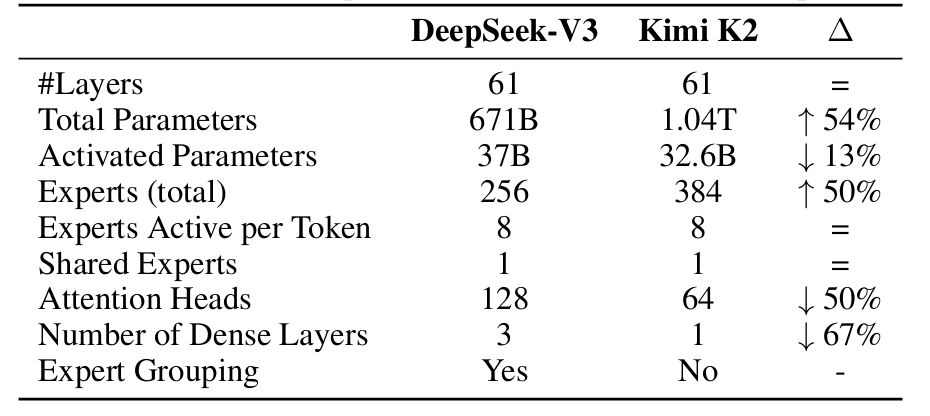
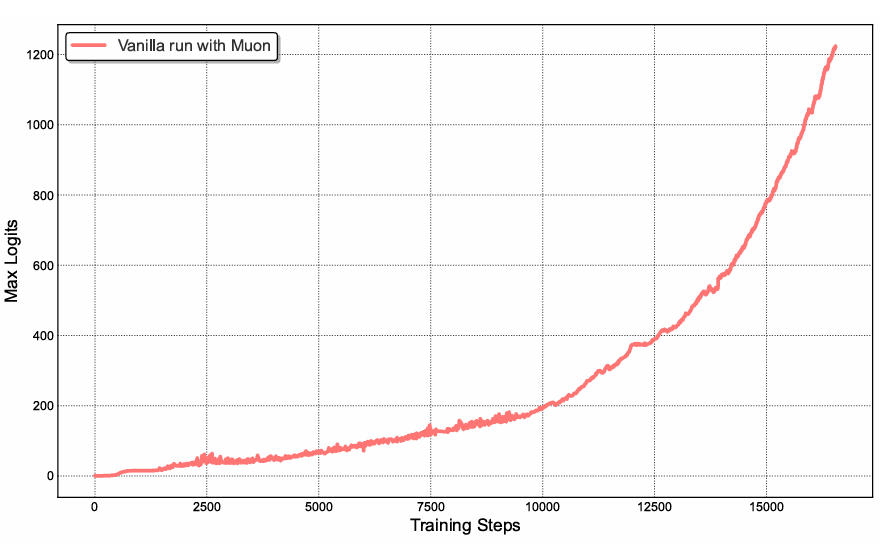
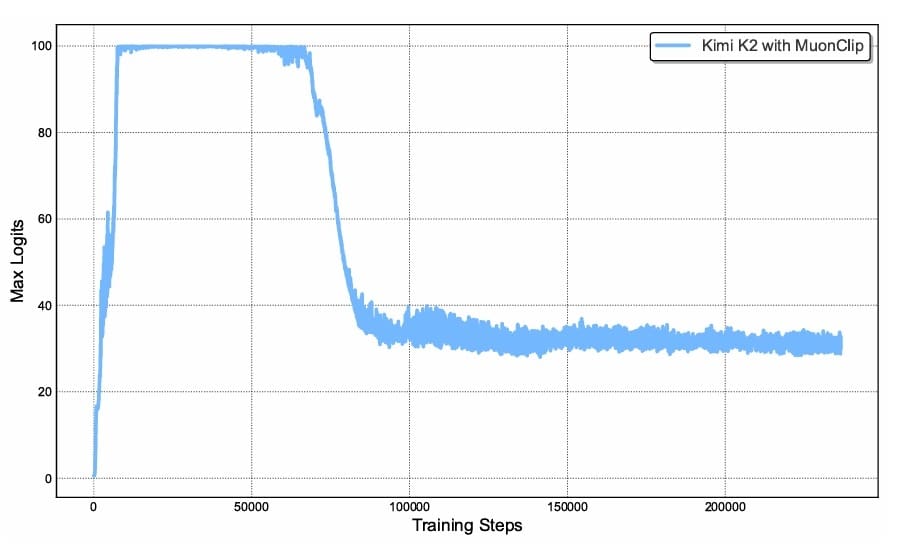
 , the eye mechanism computes:
, the eye mechanism computes:
^topright) V^h")
^top")
 is the present batch and
is the present batch and  index completely different tokens.
index completely different tokens. exceeds a threshold
exceeds a threshold  (set to 100 for Kimi-K2), QK-Clip rescales the weights. Critically, the rescaling is utilized per-head reasonably than globally, minimizing intervention on heads that stay secure:
(set to 100 for Kimi-K2), QK-Clip rescales the weights. Critically, the rescaling is utilized per-head reasonably than globally, minimizing intervention on heads that stay secure:") .
.
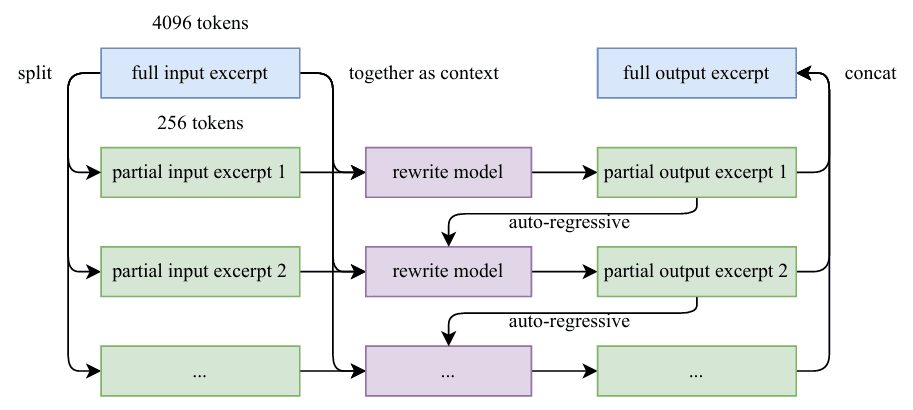

 .
. scaling utilizing in-place multiplication (
scaling utilizing in-place multiplication ( , their dot product receives the total
, their dot product receives the total  scaling. This elegant mathematical property permits us to clip consideration logits by rescaling the weights that produce them, reasonably than clipping logits immediately after they’re computed.
scaling. This elegant mathematical property permits us to clip consideration logits by rescaling the weights that produce them, reasonably than clipping logits immediately after they’re computed. ) utilizing in-place operations for reminiscence effectivity. The vital branching happens at Line 70: parameters with 2+ dimensions obtain Muon remedy.
) utilizing in-place operations for reminiscence effectivity. The vital branching happens at Line 70: parameters with 2+ dimensions obtain Muon remedy. } times 0.2") to match AdamW’s RMS traits. This scaling ensures Muon’s updates have comparable magnitudes to AdamW, enabling simpler hyperparameter switch. Lastly, Line 86 applies the replace with weight decay:
to match AdamW’s RMS traits. This scaling ensures Muon’s updates have comparable magnitudes to AdamW, enabling simpler hyperparameter switch. Lastly, Line 86 applies the replace with weight decay: ") . Line 89 applies normal momentum updates to 1D parameters resembling biases and normalization layers.
. Line 89 applies normal momentum updates to 1D parameters resembling biases and normalization layers.
")

