

{kind=link}
Desk of Contents
- Constructing and Coaching a Kimi-K2 Mannequin Utilizing DeepSeek-V3 Elements
- Kimi-K2 vs DeepSeek-V3: Key Structure Variations in LLM Design
- Combination of Specialists Scaling in Kimi-K2: Mannequin Measurement, Sparsity, and Effectivity
- Consideration Head Optimization in Kimi-K2 for Environment friendly Lengthy-Context LLMs
- MuonClip Optimizer: Stabilizing Giant-Scale LLM Coaching in Kimi-K2
- Token Effectivity in LLM Coaching: Why It Issues for Kimi-K2
- Consideration Logit Explosion in LLMs: Coaching Instability and Challenges
- QK-Clip: Stopping Consideration Logit Explosion in Kimi-K2 Coaching
- Coaching Knowledge Optimization for Kimi-K2: Bettering Token Utility in LLMs
- Token Utility in LLM Coaching: Maximizing Studying per Token
- Information Knowledge Rephrasing for LLMs: Bettering Coaching Knowledge High quality
- Kimi-K2 Implementation: Coaching an Open-Supply LLM with DeepSeek-V3
- Multi-Head Latent Consideration (MLA) with Max Logit Monitoring in Kimi-K2
- Implementing the MuonClip Optimizer for Secure LLM Coaching
- Full Kimi-K2 Coaching Pipeline: Setup, Config, and Optimization
- Abstract
Constructing and Coaching a Kimi-K2 Mannequin Utilizing DeepSeek-V3 Elements
The panorama of enormous language fashions (LLMs) is present process a elementary transformation towards agentic intelligence, the place fashions can autonomously understand, plan, cause, and act inside complicated and dynamic environments. This paradigm shift strikes past conventional static imitation studying towards fashions that actively study by interplay, purchase expertise past their coaching distribution, and adapt their habits primarily based on expertise. Agentic intelligence represents a vital functionality for the following technology of basis fashions, with transformative implications for instrument use, software program improvement, and real-world autonomy.
Kimi-K2 stands on the forefront of this revolution. As a 1.04 trillion-parameter Combination-of-Specialists (MoE) language mannequin with 32 billion activated parameters, Kimi-K2 was purposefully designed to deal with the core challenges of agentic functionality improvement. The mannequin achieves outstanding efficiency throughout numerous benchmarks:
- 66.1 on Tau2-bench
- 76.5 on ACEBench (en)
- 65.8 on SWE-bench Verified
- 53.7 on LiveCodeBench v6
- 75.1 on GPQA-Diamond
On the LMSYS (Giant Mannequin Techniques Group) Area leaderboard, Kimi-K2 ranks as the highest open-source mannequin and fifth general, competing intently with Claude 4 Opus and Claude 4 Sonnet.
On this lesson, we dive deep into the technical improvements behind Kimi-K2, specializing in its architectural variations from DeepSeek-V3, the revolutionary MuonClip optimizer, and coaching knowledge enhancements. We additionally present a whole implementation information utilizing DeepSeek-V3 elements as constructing blocks.
Kimi-K2 vs DeepSeek-V3: Key Structure Variations in LLM Design
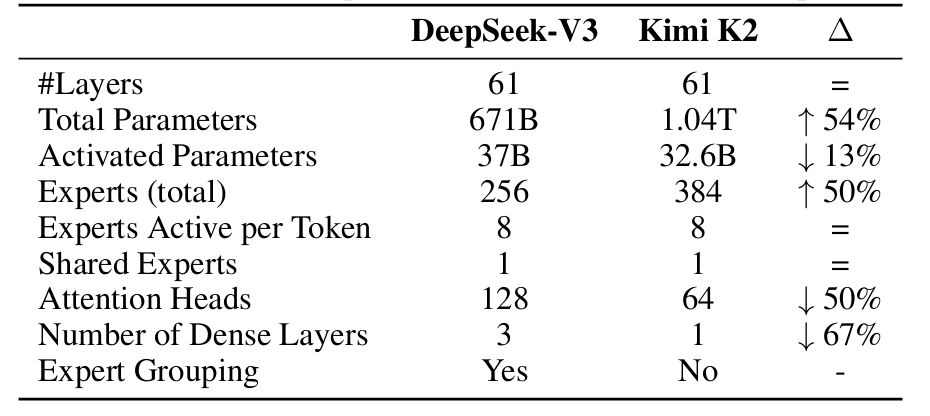
Whereas Kimi-K2 builds on DeepSeek-V3’s structure, a number of strategic modifications have been made to optimize agentic capabilities and inference effectivity. Understanding these architectural variations is essential for implementing the mannequin successfully (Desk 1).
Combination of Specialists Scaling in Kimi-K2: Mannequin Measurement, Sparsity, and Effectivity
Essentially the most vital architectural departure lies in Kimi-K2’s aggressive sparsity scaling. By way of fastidiously managed small-scale experiments, the Kimi workforce developed a sparsity scaling legislation that demonstrated a transparent relationship: with the variety of activated parameters held fixed (i.e., fixed FLOPs), rising the overall variety of specialists constantly lowers each coaching and validation loss. This discovering led to a dramatic improve in mannequin sparsity.
Kimi-K2 employs 384 specialists in comparison with DeepSeek-V3’s 256 specialists, representing a 50% improve. Regardless of this, the mannequin maintains 8 energetic specialists per token, leading to a sparsity ratio of 48 (384/8) versus DeepSeek-V3’s 32 (256/8). This elevated sparsity comes with a trade-off: whereas whole parameters develop to 1.04 trillion (54% greater than DeepSeek-V3’s 671B), the variety of activated parameters truly decreases to 32.6B (13% lower than DeepSeek-V3’s 37B). This design selection optimizes the compute-performance frontier, reaching superior mannequin high quality whereas sustaining environment friendly inference.
Consideration Head Optimization in Kimi-K2 for Environment friendly Lengthy-Context LLMs
A vital optimization for agentic purposes entails the variety of consideration heads. DeepSeek-V3 units the variety of consideration heads to roughly twice the variety of mannequin layers (128 heads for 61 layers) to raised make the most of reminiscence bandwidth. Nevertheless, as context size will increase, this design incurs vital inference overhead.
For agentic purposes requiring environment friendly long-context processing, this turns into prohibitive. With a 128k sequence size, rising consideration heads from 64 to 128 (whereas holding 384 whole specialists) results in an 83% improve in inference FLOPs. By way of managed experiments, the Kimi workforce discovered that doubling the variety of consideration heads yields solely modest enhancements in validation loss (0.5% to 1.2%) underneath iso-token coaching situations.
Provided that sparsity 48 already offers sturdy efficiency, the marginal good points from doubling consideration heads don’t justify the inference value. Kimi-K2 due to this fact makes use of 64 consideration heads (half of DeepSeek-V3’s 128), dramatically lowering inference prices for long-context agentic workloads whereas sustaining aggressive efficiency.
MuonClip Optimizer: Stabilizing Giant-Scale LLM Coaching in Kimi-K2
The MuonClip optimizer represents some of the vital improvements in Kimi-K2’s improvement, addressing the basic problem of coaching stability at trillion-parameter scale whereas sustaining token effectivity. Understanding MuonClip requires analyzing each the underlying Muon optimizer and the novel QK-Clip mechanism that makes it secure for large-scale coaching.
Token Effectivity in LLM Coaching: Why It Issues for Kimi-K2
Given the more and more restricted availability of high-quality human knowledge, token effectivity has emerged as a vital consider LLM scaling. Token effectivity refers to how a lot efficiency enchancment is achieved per token consumed throughout coaching. The Muon optimizer, launched by Jordan et al. (2024), considerably outperforms AdamW underneath the identical compute funds, mannequin measurement, and coaching knowledge quantity.
Earlier work in Moonlight demonstrated that Muon’s token effectivity good points make it a perfect selection for maximizing the intelligence extracted from restricted high-quality tokens. Nevertheless, scaling Muon to trillion-parameter fashions revealed a vital problem: coaching instability as a consequence of exploding consideration logits.
Consideration Logit Explosion in LLMs: Coaching Instability and Challenges
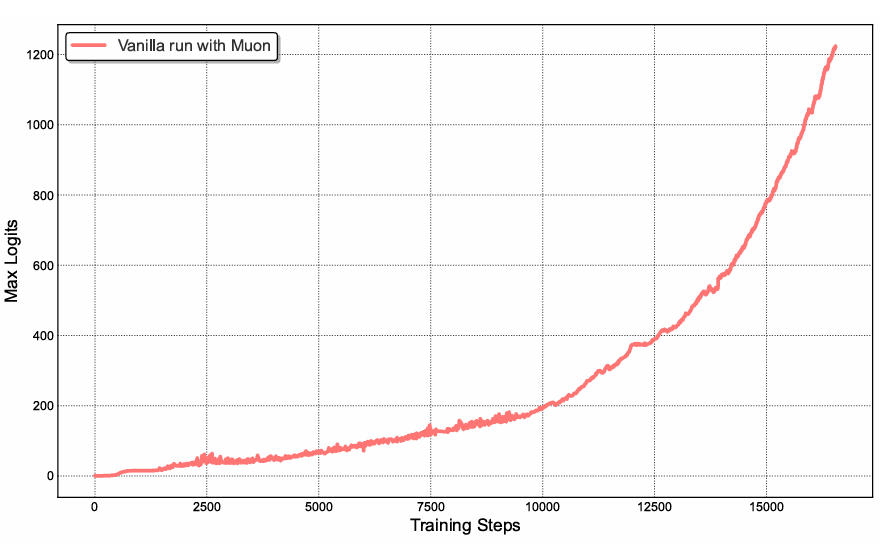
Throughout medium-scale coaching runs utilizing vanilla Muon, consideration logits quickly exceeded magnitudes of 1000, resulting in numerical instabilities and occasional coaching divergence (Determine 1). This phenomenon occurred extra incessantly with Muon than with AdamW, suggesting that Muon’s aggressive optimization dynamics amplify instabilities within the consideration mechanism.
Present mitigation methods proved inadequate:
- Logit soft-capping (utilized in Gemma) immediately clips consideration logits, however the dot merchandise between queries and keys can nonetheless develop excessively earlier than capping is utilized
- Question-Key Normalization (QK-Norm) (Dehghani et al., 2023) is incompatible with Multi-head Latent Consideration (MLA) as a result of full key matrices aren’t explicitly materialized throughout inference
QK-Clip: Stopping Consideration Logit Explosion in Kimi-K2 Coaching
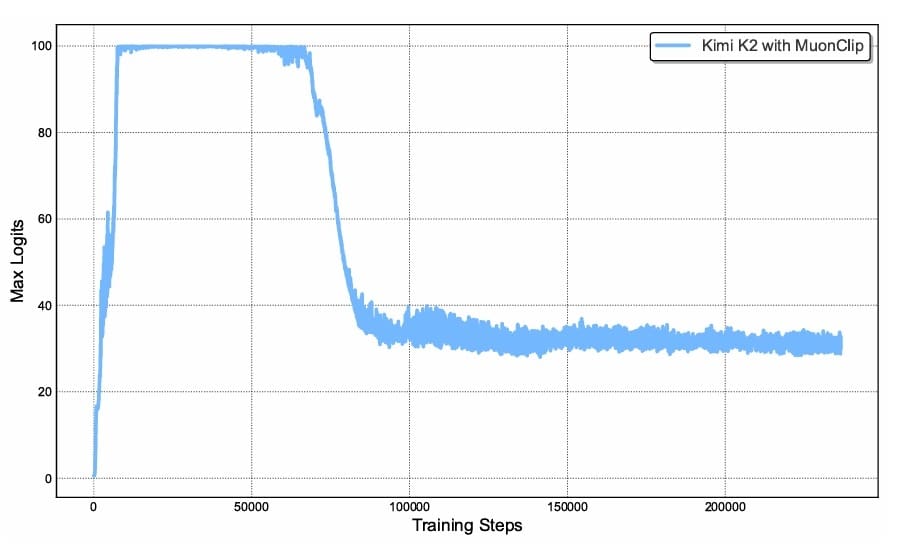
To deal with this elementary problem, the Kimi workforce proposed QK-Clip, a novel weight-clipping mechanism that explicitly constrains consideration logits by rescaling the question and key projection weights post-update. The class of QK-Clip lies in its simplicity: it doesn’t alter ahead and backward computation within the present step however as a substitute makes use of most logits as a guiding sign to manage weight development (Determine 2).
For every consideration head  , the eye mechanism computes:
, the eye mechanism computes:

The eye output is:
^topright) V^h")
QK-Clip defines the max logit per head as:
^top")
the place  is the present batch and
is the present batch and  index completely different tokens.
index completely different tokens.
When  exceeds a threshold
exceeds a threshold  (set to 100 for Kimi-K2), QK-Clip rescales the weights. Critically, the rescaling is utilized per-head reasonably than globally, minimizing intervention on heads that stay secure:
(set to 100 for Kimi-K2), QK-Clip rescales the weights. Critically, the rescaling is utilized per-head reasonably than globally, minimizing intervention on heads that stay secure:
") .
.
This per-head, component-aware clipping represents a considerable refinement over naive world clipping methods.
Determine 3 describes the entire algorithm for MuonClip Optimizer.

Coaching Knowledge Optimization for Kimi-K2: Bettering Token Utility in LLMs
Past architectural and optimizer improvements, Kimi-K2’s superior efficiency stems considerably from strategic enhancements in coaching knowledge. With high-quality human-generated knowledge changing into more and more scarce, the main target shifts to rising token utility, outlined because the efficient studying sign every token contributes to mannequin updates.
Token Utility in LLM Coaching: Maximizing Studying per Token
Token effectivity in pre-training encompasses 2 associated however distinct ideas:
- Optimizer effectivity: How successfully the optimizer extracts sign from every gradient replace (addressed by MuonClip)
- Token utility: The inherent info density and studying sign in every token
Rising token utility immediately improves token effectivity. A naive strategy entails repeated publicity to the identical tokens throughout a number of epochs, however this results in overfitting and lowered generalization. The important thing innovation in Kimi-K2 lies in a complicated artificial knowledge technology technique that amplifies high-quality tokens with out inducing overfitting.
Information Knowledge Rephrasing for LLMs: Bettering Coaching Knowledge High quality
Pre-training on knowledge-intensive textual content presents a elementary trade-off: a single epoch is inadequate for complete data absorption, whereas multi-epoch repetition yields diminishing returns. To resolve this rigidity, Kimi-K2 employs an artificial rephrasing framework with the next 3 key elements.
Fashion- and Perspective-Numerous Prompting
To reinforce linguistic range whereas sustaining factual integrity, fastidiously engineered prompts information a big language mannequin to generate trustworthy rephrasings in various kinds and views. This strategy ensures that whereas surface-level linguistic options change, the underlying factual content material stays constant. The range of expressions forces the mannequin to study strong representations of the identical data throughout a number of linguistic realizations.
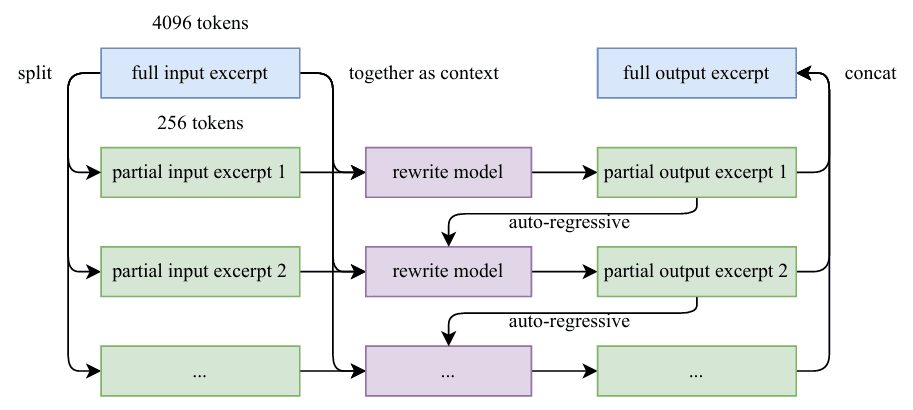
Chunk-wise Autoregressive Era
Lengthy paperwork pose a problem for traditional LLM-based rewriting as a consequence of implicit output size limitations. Kimi-K2 addresses this by a chunk-based autoregressive technique: paperwork are segmented, every section is rephrased individually with preserved context, and segments are stitched again collectively to kind full passages. This technique prevents info loss and maintains world coherence throughout prolonged texts (Determine 4).
Constancy Verification
To make sure consistency between unique and rewritten content material, constancy checks examine the semantic alignment of every rephrased passage with its supply. This high quality management step prevents the introduction of hallucinations or factual errors throughout the rephrasing course of.
Arithmetic Knowledge Rephrasing
To reinforce mathematical reasoning capabilities, high-quality mathematical paperwork are rewritten right into a “learning-note” type following SwallowMath methodology (Determine 5). This transformation converts dense mathematical exposition into extra pedagogical codecs that higher help studying. Moreover, knowledge range is elevated by the interpretation of high-quality mathematical supplies from different languages into English, successfully multiplying the accessible high-quality mathematical coaching knowledge.

Total Pre-training Corpus
The whole Kimi-K2 pre-training corpus includes 15.5 trillion tokens of curated, high-quality knowledge spanning 4 major domains:
- Net Textual content: Normal data and pure language understanding
- Code: Programming and structured reasoning
- Arithmetic: Quantitative reasoning and formal problem-solving
- Information: Area-specific experience and factual info
Kimi-K2 Implementation: Coaching an Open-Supply LLM with DeepSeek-V3
On this part, we stroll by the important thing implementation particulars for coaching Kimi-K2, focusing particularly on the elements that differ from the usual DeepSeek-V3 implementation. We’ll study the improved Multi-head Latent Consideration with max logit monitoring, the MuonClip optimizer implementation, and the customized coaching setup.
Multi-Head Latent Consideration (MLA) with Max Logit Monitoring in Kimi-K2
The Multi-head Latent Consideration (MLA) mechanism in Kimi-K2 extends DeepSeek-V3’s implementation with vital modifications to help QK-Clip. The important thing enhancement is per-head max-logit monitoring throughout the ahead go, which offers the sign wanted for weight clipping by the optimizer.
class MultiheadLatentAttention(nn.Module):
def __init__(self, config: DeepSeekConfig):
tremendous().__init__()
self.config = config
self.n_embd = config.n_embd
self.n_head = config.n_head
self.head_dim = config.n_embd // config.n_head
# Compression dimensions
self.kv_lora_rank = config.kv_lora_rank
self.q_lora_rank = config.q_lora_rank
self.rope_dim = config.rope_dim
# KV compression
self.kv_proj = nn.Linear(self.n_embd, self.kv_lora_rank, bias=False)
self.kv_norm = RMSNorm(self.kv_lora_rank)
# KV decompression
self.k_decompress = nn.Linear(self.kv_lora_rank, self.n_head * self.head_dim, bias=False)
self.v_decompress = nn.Linear(self.kv_lora_rank, self.n_head * self.head_dim, bias=False)
# Question compression
self.q_proj = nn.Linear(self.n_embd, self.q_lora_rank, bias=False)
self.q_decompress = nn.Linear(self.q_lora_rank, self.n_head * self.head_dim, bias=False)
# RoPE projections
self.k_rope_proj = nn.Linear(self.n_embd, self.n_head * self.rope_dim, bias=False)
self.q_rope_proj = nn.Linear(self.q_lora_rank, self.n_head * self.rope_dim, bias=False)
# Output projection
self.o_proj = nn.Linear(self.n_head * self.head_dim, self.n_embd, bias=config.bias)
# Dropout
self.attn_dropout = nn.Dropout(config.dropout)
self.resid_dropout = nn.Dropout(config.dropout)
# RoPE
self.rope = RotaryEmbedding(self.rope_dim, config.block_size)
# Causal masks
self.register_buffer(
"causal_mask",
torch.tril(torch.ones(config.block_size, config.block_size)).view(
1, 1, config.block_size, config.block_size
)
)
self.max_logits = 0.0 # Monitor most consideration logits
On Strains 1-47, we outline the MLA structure following DeepSeek-V3’s design with compression and decompression of queries and key-values by low-rank projections. The important thing innovation seems on Line 49, the place we initialize self.max_logits = 0.0, a vital state variable that tracks the utmost consideration logits throughout heads. This monitoring mechanism is important for QK-Clip to operate correctly.
def ahead(self, x: torch.Tensor, attention_mask: Non-compulsory[torch.Tensor] = None):
B, T, C = x.measurement()
# Compression section
kv_compressed = self.kv_norm(self.kv_proj(x))
q_compressed = self.q_proj(x)
# Decompression section
k_content = self.k_decompress(kv_compressed)
v = self.v_decompress(kv_compressed)
q_content = self.q_decompress(q_compressed)
# RoPE elements
k_rope = self.k_rope_proj(x)
q_rope = self.q_rope_proj(q_compressed)
# Reshape for multi-head consideration
k_content = k_content.view(B, T, self.n_head, self.head_dim).transpose(1, 2)
v = v.view(B, T, self.n_head, self.head_dim).transpose(1, 2)
q_content = q_content.view(B, T, self.n_head, self.head_dim).transpose(1, 2)
k_rope = k_rope.view(B, T, self.n_head, self.rope_dim).transpose(1, 2)
q_rope = q_rope.view(B, T, self.n_head, self.rope_dim).transpose(1, 2)
# Apply RoPE
cos, sin = self.rope(x, T)
q_rope = apply_rope(q_rope, cos, sin)
k_rope = apply_rope(k_rope, cos, sin)
# Concatenate content material and cord components
q = torch.cat([q_content, q_rope], dim=-1)
ok = torch.cat([k_content, k_rope], dim=-1)
On Strains 52-82, we implement the usual ahead go by the compression-decompression pipeline. The enter undergoes compression by way of kv_proj and q_proj, adopted by decompression by devoted linear layers. We then reshape tensors for multi-head processing and apply Rotary Place Embeddings (RoPE) individually to content material and positional elements. This separation permits per-head QK-Clip to focus on solely the suitable elements with out affecting shared rotary embeddings.
# Concatenate content material and cord components
q = torch.cat([q_content, q_rope], dim=-1)
ok = torch.cat([k_content, k_rope], dim=-1)
# Consideration computation
scale = 1.0 / math.sqrt(q.measurement(-1))
scores = torch.matmul(q, ok.transpose(-2, -1)) * scale
with torch.no_grad():
# self.max_logits = torch.max(scores, dim=1).merchandise()
self.max_logits = listing(torch.max(scores.transpose(1, 0).contiguous().view(scores.form[1], -1), dim=-1)[0])
# Apply causal masks
scores = scores.masked_fill(self.causal_mask[:, :, :T, :T] == 0, float('-inf'))
# Apply padding masks if offered
if attention_mask isn't None:
padding_mask_additive = (1 - attention_mask).unsqueeze(1).unsqueeze(2) * float('-inf')
scores = scores + padding_mask_additive
# Softmax and dropout
attn_weights = F.softmax(scores, dim=-1)
attn_weights = self.attn_dropout(attn_weights)
# Apply consideration to values
out = torch.matmul(attn_weights, v)
# Reshape and venture
out = out.transpose(1, 2).contiguous().view(B, T, self.n_head * self.head_dim)
out = self.resid_dropout(self.o_proj(out))
return out
On Strains 89-94, we compute consideration scores and implement the essential max logit monitoring. The rating computation follows normal scaled dot-product consideration. Nevertheless, Strains 92-94 signify a key departure from vanilla DeepSeek-V3: we observe the utmost consideration logit per head utilizing torch.no_grad() to keep away from affecting gradients. The scores tensor has form [batch, num_heads, seq_len, seq_len], and we transpose and reshape to extract per-head most values. This per-head granularity allows focused intervention solely on heads exhibiting logit explosion, minimizing disruption to secure heads.
On Strains 97-113, we full the eye mechanism with causal masking, elective padding masks, softmax normalization, and dropout. The ultimate output projection maintains the usual MLA structure. The class of this implementation lies in its non-invasiveness: max logit monitoring provides minimal computational overhead (a single max operation underneath torch.no_grad) whereas offering the vital sign for optimizer-level weight clipping.
Implementing the MuonClip Optimizer for Secure LLM Coaching
The MuonClip optimizer represents the core innovation enabling secure trillion-parameter coaching. Our implementation integrates Newton-Schulz orthogonalization, RMS matching, weight decay, and per-head QK-Clip right into a unified optimizer.
def apply_qk_clip_per_head(
query_weights: torch.Tensor,
key_weights: torch.Tensor,
max_logits_per_head: Union[List[float], torch.Tensor],
tau: float = 100.0
) -> None:
if isinstance(max_logits_per_head, listing):
max_logits_per_head = torch.tensor(
max_logits_per_head,
machine=query_weights.machine,
dtype=query_weights.dtype
)
apply_qk_clip_vectorized(query_weights, key_weights, max_logits_per_head, tau)
On Strains 1-13, we outline the entry level for the QK-Clip utility. The operate accepts question and key projection weights together with per-head max logits and a threshold (defaulting to 100). We deal with each listing and tensor inputs for flexibility, changing lists to tensors on the suitable machine with matching dtype. The vital design selection right here is in-place modification: we immediately modify weight tensors to keep away from reminiscence allocation overhead throughout optimization.
def apply_qk_clip_per_head(
query_weights: torch.Tensor,
key_weights: torch.Tensor,
max_logits_per_head: Union[List[float], torch.Tensor],
tau: float = 100.0
) -> None:
if isinstance(max_logits_per_head, listing):
max_logits_per_head = torch.tensor(
max_logits_per_head,
machine=query_weights.machine,
dtype=query_weights.dtype
)
apply_qk_clip_vectorized(query_weights, key_weights, max_logits_per_head, tau)
@torch.no_grad()
def apply_qk_clip_vectorized(
query_weights: torch.Tensor,
key_weights: torch.Tensor,
max_logits_per_head: torch.Tensor,
tau: float = 100.0
) -> None:
q_out, q_in = query_weights.form[0], query_weights.form[1]
k_out, k_in = key_weights.form[0], key_weights.form[1]
num_heads = len(max_logits_per_head)
d_k = q_out // num_heads
# Guarantee tensor kind
if not isinstance(max_logits_per_head, torch.Tensor):
max_logits_per_head = torch.tensor(
max_logits_per_head,
machine=query_weights.machine,
dtype=query_weights.dtype
)
# Compute scaling elements: gamma = tau / max_logit the place max_logit > tau
needs_clip = max_logits_per_head > tau
On Strains 15-48, we extract dimensions and guarantee tensor kind compatibility. We first extract dimensions and compute the per-head scaling issue just for heads the place  .
.
@torch.no_grad()
def apply_qk_clip_vectorized(
query_weights: torch.Tensor,
key_weights: torch.Tensor,
max_logits_per_head: torch.Tensor,
tau: float = 100.0
) -> None:
q_out, q_in = query_weights.form[0], query_weights.form[1]
k_out, k_in = key_weights.form[0], key_weights.form[1]
num_heads = len(max_logits_per_head)
d_k = q_out // num_heads
# Guarantee tensor kind
if not isinstance(max_logits_per_head, torch.Tensor):
max_logits_per_head = torch.tensor(
max_logits_per_head,
machine=query_weights.machine,
dtype=query_weights.dtype
)
# Compute scaling elements: gamma = tau / max_logit the place max_logit > tau
needs_clip = max_logits_per_head > tau
# If no clipping wanted, return early
if not needs_clip.any():
return
gamma = torch.the place(
needs_clip,
tau / max_logits_per_head.clamp(min=1e-8),
torch.ones_like(max_logits_per_head)
)
sqrt_gamma = torch.sqrt(gamma)
# Reshape weights to [d_model, num_heads, d_k] for per-head scaling
# Views share underlying storage, so in-place ops modify unique tensor
q_reshaped = query_weights.view(q_out // num_heads, num_heads, q_in)
k_reshaped = key_weights.view(k_out // num_heads, num_heads, k_in)
# Apply per-head scaling IN-PLACE: broadcast sqrt_gamma [num_heads] over [d_model, num_heads, d_k]
q_reshaped.mul_(sqrt_gamma.view(1, num_heads, 1))
k_reshaped.mul_(sqrt_gamma.view(1, num_heads, 1))
q_reshaped = q_reshaped.view(q_out, q_in)
k_reshaped = k_reshaped.view(k_out, k_in)
On Strains 52-60, we restart the operate definition and extract dimensions. On Strains 80-97, we carry out the precise weight clipping by cautious tensor reshaping and in-place multiplication. The weights are reshaped from [d_model, d_model] to [d_model/num_heads, num_heads, d_k] to show the pinnacle dimension. We then apply  scaling utilizing in-place multiplication (
scaling utilizing in-place multiplication (mul_) with broadcasting. The sq. root scaling ensures that when question and key each obtain  , their dot product receives the total
, their dot product receives the total  scaling. This elegant mathematical property permits us to clip consideration logits by rescaling the weights that produce them, reasonably than clipping logits immediately after they’re computed.
scaling. This elegant mathematical property permits us to clip consideration logits by rescaling the weights that produce them, reasonably than clipping logits immediately after they’re computed.
Strains 77 and 78 implement early exit if no head requires clipping, which turns into a standard case later in coaching when consideration logits stabilize. This optimization avoids pointless computation when the mannequin is well-behaved.
class MuonClip(torch.optim.Optimizer):
def __init__(
self,
params,
lr: float = 1e-3,
momentum: float = 0.95,
weight_decay: float = 0.01,
tau: float = 100.0,
ns_steps: int = 5,
eps: float = 1e-7
):
if lr < 0.0:
elevate ValueError(f"Invalid studying price: {lr}")
if not 0.0 <= momentum <= 1.0:
elevate ValueError(f"Invalid momentum worth: {momentum}")
if weight_decay < 0.0:
elevate ValueError(f"Invalid weight_decay worth: {weight_decay}")
if tau <= 0.0:
elevate ValueError(f"Invalid tau worth: {tau}")
defaults = dict(
lr=lr,
momentum=momentum,
weight_decay=weight_decay,
tau=tau,
ns_steps=ns_steps,
eps=eps
)
tremendous().__init__(params, defaults)
# For QK-Clip performance
self.mannequin = None
self.attention_layers = []
def set_model(self, mannequin: nn.Module):
self.mannequin = mannequin
if hasattr(mannequin, 'get_attention_layers'):
self.attention_layers = mannequin.get_attention_layers()
On Strains 1-33, we outline the MuonClip optimizer class, inheriting from PyTorch’s base Optimizer. The constructor accepts normal hyperparameters (studying price, momentum, weight decay) plus QK-Clip-specific parameters ( and Newton-Schulz steps). We validate all parameters and initialize state monitoring. Critically, Strains 35-38 implement mannequin registration by set_model(), which extracts consideration layers for later QK-Clip utility. This design separates optimizer logic from mannequin structure, permitting the optimizer to function on any mannequin exposing a get_attention_layers() methodology.
@torch.no_grad()
def step(self, closure: Non-compulsory[Callable] = None) -> Non-compulsory[float]:
loss = None
if closure isn't None:
with torch.enable_grad():
loss = closure()
for group in self.param_groups:
lr = group['lr']
momentum = group['momentum']
weight_decay = group['weight_decay']
ns_steps = group['ns_steps']
eps = group['eps']
for p in group['params']:
if p.grad is None:
proceed
grad = p.grad
state = self.state[p]
# Initialize momentum buffer
if len(state) == 0:
state['momentum_buffer'] = torch.zeros_like(p)
buf = state['momentum_buffer']
# Apply momentum: Mt = μMt−1 + Gt
buf.mul_(momentum).add_(grad)
if p.ndim >= 2: # 2D+ parameters - use Muon
# Apply Newton-Schulz orthogonalization
if p.ndim > 2:
original_shape = buf.form
buf_2d = buf.view(buf.form[0], -1)
orthogonal_update = newton_schulz(buf_2d, ns_steps, eps)
orthogonal_update = orthogonal_update.view(original_shape)
else:
orthogonal_update = newton_schulz(buf, ns_steps, eps)
# RMS matching issue: √(max(n,m) × 0.2)
n, m = p.form[0], p.form[1] if p.ndim > 1 else 1
rms_factor = math.sqrt(max(n, m) * 0.2)
orthogonal_update = orthogonal_update * rms_factor
# Replace: Wt = Wt−1 − η(Ot + λWt−1)
p.add_(orthogonal_update + weight_decay * p, alpha=-lr)
else:
# 1D parameters - normal momentum
p.add_(buf + weight_decay * p, alpha=-lr)
# Apply QK-Clip
self._apply_qk_clip()
return loss
On Strains 41-94, we implement the core optimization step integrating Muon updates with QK-Clip. The step begins with normal closure dealing with and parameter group iteration. Strains 41-68 implement momentum accumulation ( ) utilizing in-place operations for reminiscence effectivity. The vital branching happens at Line 70: parameters with 2+ dimensions obtain Muon remedy.
) utilizing in-place operations for reminiscence effectivity. The vital branching happens at Line 70: parameters with 2+ dimensions obtain Muon remedy.
On Strains 72-83, we apply the Muon replace for matrix parameters. Newton-Schulz orthogonalization produces an orthogonal approximation of the momentum buffer, which we then scale by } times 0.2") to match AdamW’s RMS traits. This scaling ensures Muon’s updates have comparable magnitudes to AdamW, enabling simpler hyperparameter switch. Lastly, Line 86 applies the replace with weight decay:
to match AdamW’s RMS traits. This scaling ensures Muon’s updates have comparable magnitudes to AdamW, enabling simpler hyperparameter switch. Lastly, Line 86 applies the replace with weight decay: ") . Line 89 applies normal momentum updates to 1D parameters resembling biases and normalization layers.
. Line 89 applies normal momentum updates to 1D parameters resembling biases and normalization layers.
def _apply_qk_clip(self):
"""Apply QK-Clip to consideration layers to forestall logit explosion."""
if not self.attention_layers:
return
tau = self.param_groups[0]['tau']
for attention_layer in self.attention_layers:
if not hasattr(attention_layer, 'max_logits'):
proceed
max_logits = attention_layer.max_logits
if not max_logits:
proceed
# Deal with each scalar and per-head max logits
if isinstance(max_logits, (int, float)):
max_logits = [max_logits]
apply_qk_clip_per_head(
attention_layer.k_decompress.weight.knowledge,
attention_layer.q_decompress.weight.knowledge,
max_logits,
tau
)
On Strains 96-122, we apply QK-Clip in spite of everything weight updates. The _apply_qk_clip() methodology iterates by all registered consideration layers, extracts their max_logits attribute (populated throughout ahead go), and applies per-head clipping to the question and key decompression weights. This post-update clipping ensures weights don’t develop unboundedly throughout coaching steps whereas preserving gradient info inside every step.
Full Kimi-K2 Coaching Pipeline: Setup, Config, and Optimization
Lastly, we carry every little thing collectively in a whole coaching configuration:
config = DeepSeekConfig()
config.multi_token_predict = 0
config.n_experts = 8
config.n_head = 4
training_args = TrainingArguments(
output_dir="./kimik2_checkpoints",
num_train_epochs=2,
per_device_train_batch_size=8,
per_device_eval_batch_size=4,
learning_rate=5e-4,
warmup_steps=10,
weight_decay=0.01,
logging_dir="./kimik2_checkpoints/logs",
logging_steps=50,
save_steps=50,
save_total_limit=3,
eval_steps=50,
eval_strategy="steps",
save_strategy="steps",
metric_for_best_model="eval_loss",
greater_is_better=False,
gradient_accumulation_steps=4,
fp16=True,
dataloader_num_workers=2,
remove_unused_columns=False,
report_to="none",
push_to_hub=False,
save_safetensors=False,
)
On Strains 1-4, we configure the mannequin structure. Kimi-K2 doesn’t use Multi-Token Prediction, so we disable multi-token prediction (multi_token_predict=0) to simplify coaching and give attention to core capabilities. We use 8 specialists for this academic implementation reasonably than the tons of utilized in production-scale Kimi-K2 and DeepSeek-V3 fashions. We additionally use 4 consideration heads for this small-scale academic implementation, in comparison with the production-scale configurations utilized in DeepSeek-V3 and Kimi-K2.
On Strains 6-30, we outline coaching arguments following greatest practices for small-scale experiments. We use gradient accumulation (4 steps) to simulate bigger batch sizes with restricted GPU reminiscence, allow mixed-precision coaching (fp16=True) for pace and reminiscence effectivity, and configure common analysis and checkpointing each 50 steps. The educational price of 5e-4 is conservative for secure coaching, with a short 10-step warmup.
mannequin = DeepSeek(config)
data_collator = DeepSeekDataCollator(tokenizer)
optimizer = MuonClip(mannequin.parameters(), lr=5e-3)
optimizer.set_model(mannequin)
# Create coach
coach = DeepSeekTrainer(
mannequin=mannequin,
args=training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
data_collator=data_collator,
optimizers=(optimizer, None)
)
print("✓ Coach created. Beginning coaching...")
print("=" * 80)
# Prepare!
coach.practice()
print("=" * 80)
print("✓ Coaching full!")
# Save remaining mannequin
coach.save_model("./kimik2_final")
tokenizer.save_pretrained("./kimik2_final")
print("✓ Mannequin saved to ./kimik2_final")
On Strains 31-36, we initialize the mannequin and create a MuonClip optimizer. Critically, Line 36 registers the mannequin with the optimizer utilizing set_model(), enabling QK-Clip to entry consideration layers. This registration should happen earlier than coaching begins.
On Strains 39-60, we instantiate the customized coach with all elements and launch coaching. The optimizers=(optimizer, None) argument offers our customized optimizer to Hugging Face Coach, overriding its default optimizer creation. After coaching completes, we save each the mannequin weights and tokenizer for later inference.
What’s subsequent? We suggest PyImageSearch College.
86+ whole courses • 115+ hours hours of on-demand code walkthrough movies • Final up to date: Could 2026
★★★★★ 4.84 (128 Scores) • 16,000+ College students Enrolled
I strongly consider that should you had the correct instructor you could possibly grasp pc imaginative and prescient and deep studying.
Do you assume studying pc imaginative and prescient and deep studying needs to be time-consuming, overwhelming, and complex? Or has to contain complicated arithmetic and equations? Or requires a level in pc science?
That’s not the case.
All you could grasp pc imaginative and prescient and deep studying is for somebody to clarify issues to you in easy, intuitive phrases. And that’s precisely what I do. My mission is to alter schooling and the way complicated Synthetic Intelligence subjects are taught.
In the event you’re severe about studying pc imaginative and prescient, your subsequent cease must be PyImageSearch College, essentially the most complete pc imaginative and prescient, deep studying, and OpenCV course on-line right this moment. Right here you’ll discover ways to efficiently and confidently apply pc imaginative and prescient to your work, analysis, and initiatives. Be part of me in pc imaginative and prescient mastery.
Inside PyImageSearch College you may discover:
- &verify; 86+ programs on important pc imaginative and prescient, deep studying, and OpenCV subjects
- &verify; 86 Certificates of Completion
- &verify; 115+ hours hours of on-demand video
- &verify; Model new programs launched usually, making certain you may sustain with state-of-the-art methods
- &verify; Pre-configured Jupyter Notebooks in Google Colab
- &verify; Run all code examples in your net browser — works on Home windows, macOS, and Linux (no dev atmosphere configuration required!)
- &verify; Entry to centralized code repos for all 540+ tutorials on PyImageSearch
- &verify; Straightforward one-click downloads for code, datasets, pre-trained fashions, and many others.
- &verify; Entry on cell, laptop computer, desktop, and many others.
Abstract
We started by detailing the best way to practice Kimi-K2 from scratch utilizing DeepSeek-V3 elements, emphasizing the architectural variations that set Kimi-K2 aside. We explored the mannequin’s scale and sparsity, exhibiting that lowering the variety of consideration heads allowed us to steadiness effectivity and efficiency. A key a part of this journey was the introduction of the MuonClip optimizer, which stabilizes coaching whereas pushing the boundaries of large-scale language modeling.
We then turned to the challenges of token effectivity and the eye logit explosion drawback. To deal with these, we launched the QK-Clip innovation, which helped us management runaway logits and enhance general stability. Alongside this, we refined our coaching knowledge pipeline, specializing in token utility and data knowledge rephrasing to make sure that each token contributed meaningfully to the mannequin’s studying course of. These enhancements allowed us to maximise the worth of the info whereas holding coaching environment friendly.
Lastly, we described the implementation particulars, together with enhanced multi-head latent consideration with max logit monitoring and the sensible integration of the MuonClip optimizer. We concluded with a whole coaching setup, exhibiting how all these improvements got here collectively to make Kimi-K2 a sturdy, environment friendly, and scalable mannequin. By combining architectural refinements, optimizer breakthroughs, and knowledge enhancements, this lesson demonstrated how these methods push the boundaries of what’s attainable in fashionable language mannequin coaching.
Quotation Info
Mangla, P. “Constructing and Coaching a Kimi-K2 Mannequin Utilizing DeepSeek-V3 Elements,” PyImageSearch, S. Huot, A. Sharma, and P. Thakur, eds., 2026, https://pyimg.co/d3tge
@incollection{Mangla_2026_building-training-kimi-k2-model-using-deepseek-v3,
writer = {Puneet Mangla},
title = {{Constructing and Coaching a Kimi-K2 Mannequin Utilizing DeepSeek-V3 Elements}},
booktitle = {PyImageSearch},
editor = {Susan Huot and Aditya Sharma and Piyush Thakur},
12 months = {2026},
url = {https://pyimg.co/d3tge},
}
To obtain the supply code to this put up (and be notified when future tutorials are revealed right here on PyImageSearch), merely enter your e mail deal with within the kind beneath!

Obtain the Supply Code and FREE 17-page Useful resource Information
Enter your e mail deal with beneath to get a .zip of the code and a FREE 17-page Useful resource Information on Laptop Imaginative and prescient, OpenCV, and Deep Studying. Inside you may discover my hand-picked tutorials, books, programs, and libraries that can assist you grasp CV and DL!
The put up Constructing and Coaching a Kimi-K2 Mannequin Utilizing DeepSeek-V3 Elements appeared first on PyImageSearch.