

{kind=link}
A 12 months of constructing a video caption pipeline with 100+ skilled creators, and what it taught us about scaling supervision as an alternative of fashions.
By Zhiqiu Lin and Chancharik Mitra. Based mostly on our CVPR 2026 work, Constructing a Exact Video Language with Human-AI Oversight (Spotlight, High 3%).
How shut is in the present day’s video generator to a Hollywood cinematographer?
Hollywood administrators attain for sure pictures as a result of they make a scene land. They cue a selected feeling within the viewer that flat protection can not. Open your favourite video generator (Veo 3.1, Seedance 2, or any of the newest open-source fashions) and ask it for a dolly zoom of a person standing in the midst of a bustling road, the way in which Hitchcock used the shot to make the world really feel like it’s collapsing inward. Or a rack focus pulling from a espresso cup to the lady behind it, the form of focus pull that quietly tells the viewers the place to look. Or a Dutch-angle shot of a nervous particular person staring into the void, a tilted body that places the viewer on edge.
Most mills will hand again one thing near a generic dolly-in, or a slow-motion clip with the improper focal topic. The output is normally visually competent, however it doesn’t do the factor. The mannequin has clearly seen movies that comprise these methods. It simply doesn’t know how one can act on the phrases.
We predict that is symptomatic of a broader hole. Filmmakers talk with a shared, exact vocabulary: shot measurement, body place, focus sort, lens distortion, digital camera peak, video velocity. Immediately’s vision-language fashions (VLMs), and the captioning datasets that feed them, principally don’t.
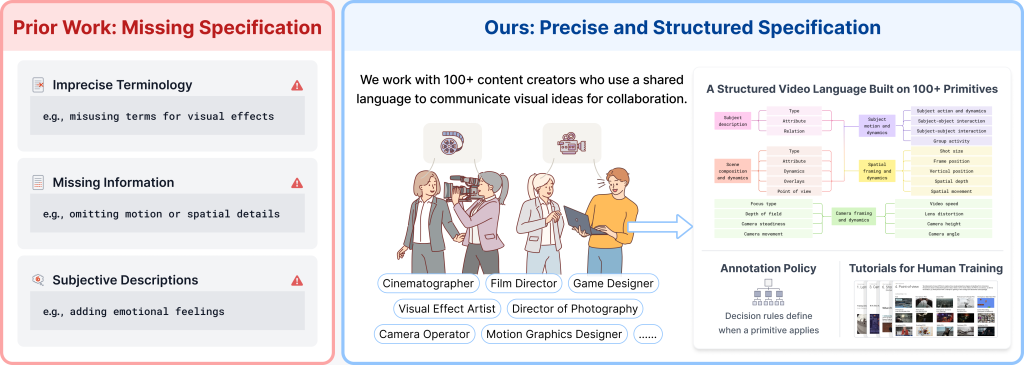
On this put up we describe CHAI, a captioning pipeline (in our utilization, a caption is an extended, structured paragraph describing a video’s content material, movement, and digital camera work — not a subtitle monitor) that we constructed over the previous 12 months with 100+ skilled video creators. The acronym stands for Critique-based Human-AI Oversight. Present video caption datasets are usually written both by crowdworkers, who lack the cinematic vocabulary to explain a shot exactly, or by giant vision-language fashions, whose captions learn easily (fluent — no grammatical or stylistic errors) however routinely describe objects and motions that aren’t within the video (hallucinated). The central concept behind CHAI is to mix the 2: the captioner mannequin (e.g., a big video-language mannequin equivalent to Gemini-2.5-Professional) writes the draft, a educated human critiques it, and the mannequin revises in opposition to that critique.
This put up works by means of 4 questions:
1. Why do VLMs battle with cinematic prompts?
2. How ought to people and fashions divide the captioning work?
3. Does the standard of human critique change what the mannequin can be taught?
4. Do higher captions within the coaching knowledge give us a greater video generator?
Query 1: Why do VLMs battle with cinematic prompts?
A pure first speculation is that this can be a capability downside — that the present technology of vision-language fashions is just too small, has too little context, or has not been pretrained on sufficient video to deal with cinematic prompts, and that the following technology will clear up it. However after auditing eight well-liked video-text datasets from 2016 to 2025 (ActivityNet Captions, MSR-VTT, DREAM-1K, ShareGPT4Video, PerceptionLM, and others), we predict the bottleneck is elsewhere. The visible content material is within the movies these fashions practice on, and trendy VLMs understand it effectively. What’s lacking is the language: the captions paired with these movies don’t comprise the exact vocabulary wanted to explain cinematic method. In our experiments, coaching bigger fashions on extra of the identical knowledge solely marginally improved these points. They look like issues of annotation coverage, not of capability.
Three patterns confirmed up again and again:
• Imprecise terminology. Captions conflate dolly-in (the digital camera bodily strikes ahead) with zoom-in (the focal size modifications), or describe a fisheye distortion as “round constructing.”
• Lacking data. Captions describe what’s within the body and skip all the pieces else: movement, digital camera shake, focus modifications, shot measurement. Something temporal, something concerning the digital camera, will get dropped.
• Subjective descriptions. “An atmospheric shot filled with stress” tells a mannequin nothing it could possibly floor in pixels.
A pure subsequent thought: simply rent crowdworkers to jot down extra cautious captions. We tried that. Crowdworkers nonetheless confused dolly-in with zoom-in, known as broad pictures “close-ups,” and described fisheye distortion as “a spherical constructing.” Seeing is just not the identical as understanding how one can describe.
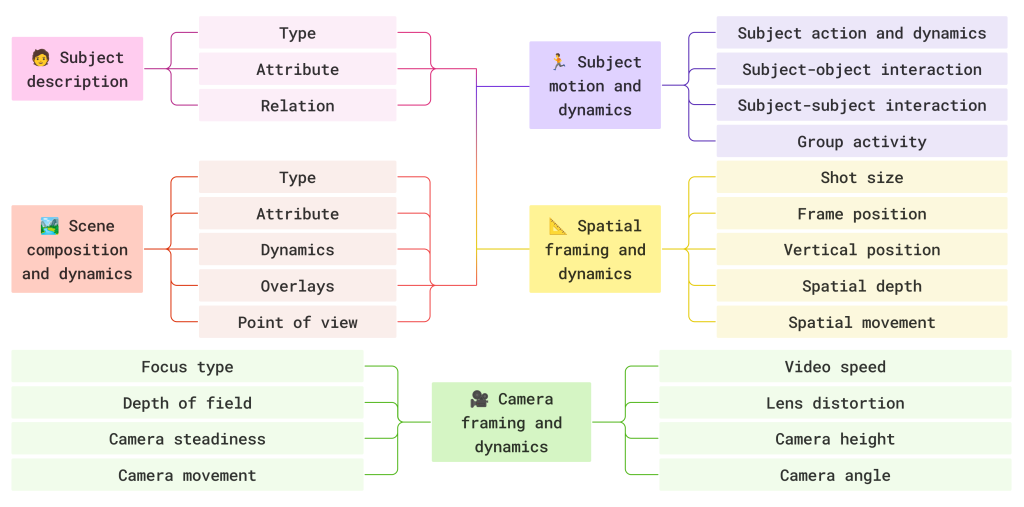
What labored, finally, was bringing in folks whose job requires this vocabulary: cinematographers, administrators of images, movement graphics designers, VFX artists, recreation designers, digital camera operators. Over the previous 12 months, we constructed a structured caption specification with 100+ such collaborators. The specification has 5 elements:
• Topic (sort, attribute, relations)
• Scene (composition, dynamics, overlays, perspective)
• Movement (topic actions, interactions, group exercise)
• Spatial (shot measurement, body place, depth, spatial motion)
• Digicam (focus sort, depth of area, steadiness, motion, video velocity, lens distortion, peak, angle)
All 5 elements collectively contain roughly 200 low-level visible primitives, each one with a definition and a choice rule for when it applies. This prevents annotators from freelancing terminology, as all they must do is tag in opposition to the spec.
Takeaway: VLMs battle with cinematic prompts as a result of the captions they had been educated on don’t comprise the exact vocabulary professionals use. In our experiments, scaling fashions or knowledge alone gave solely marginal good points; specifying the language fastidiously made a a lot larger distinction.
Query 2: How ought to people and fashions divide the captioning work?
As soon as we made the spec, we nonetheless needed to determine who would write the lengthy captions. The 2 apparent decisions, people or fashions, every include well-known limitations.
People alone produce captions with typos, grammatical errors, and inconsistent occasion ordering. In addition they fatigue: 200 to 400 phrases of cautious prose per video, whereas wanting up the spec, is exhausting and costly.
Fashions alone produce captions that learn fantastically however that, on a miserable fraction of clips, confidently describe objects and motions that aren’t there. In addition they steadily combine up left and proper.
What we observed in pilot research is that the failure modes are uneven in a helpful approach. Immediately’s LLMs write higher prose than most people. However people, particularly educated ones, are a lot better than LLMs at noticing visible or movement errors in a draft, the sort the place the caption says “shifting left” however the topic is shifting proper. So we constructed the pipeline round that asymmetry. The mannequin drafts, the human critiques, the mannequin revises. That is conceptually just like Saunders et al. (2022)‘s self-critiquing fashions for summarization, however utilized to long-form video captioning the place the human nonetheless does the arduous half: catching grounded errors in opposition to the precise video.
Concretely, the loop:
1. Primitives. A educated annotator labels which visible and movement primitives are current within the clip.
2. Pre-caption. The mannequin generates an extended caption from these primitives, following the spec.
3. Critique. An annotator reads the pre-caption in opposition to the video and writes a critique stating what’s improper and what ought to change. The critique needs to be correct (the issues it flags are improper), full (it doesn’t miss errors), and constructive (it tells the mannequin what to do, not simply that one thing is dangerous).
4. Put up-caption. The mannequin revises its draft utilizing the critique.
5. Refinement. If the post-caption remains to be off, the human refines the critique relatively than rewriting the caption.
We tasked reviewers (top-performing annotators promoted to a quality-control function) with checking each critique and post-caption in opposition to the video. This fashion annotators had been scored based mostly on their accuracy, whereas reviewers earned rewards for catching the errors they discovered. Each precision (don’t flag issues that aren’t improper) and recall (don’t miss issues which might be improper) had been incentivized on the knowledge stage, earlier than any modeling occurred.
Shifting the human’s job from writing to proofreading has a facet profit we underestimated: every video takes far much less cognitive effort, and the ensuing 200 to 400 phrase captions find yourself extra correct than what both people or fashions produce alone.
Takeaway: LLMs and people have uneven strengths in long-form video captioning. Designing the pipeline round that asymmetry, relatively than making an attempt to switch one with the opposite, offers each higher captions and a extra sustainable annotation course of.
Query 3: Does the standard of human critique change what the mannequin can be taught?
The pipeline produces a triple for each video: (pre-caption, critique, post-caption). That triple is extra than simply an annotated caption. It’s supervision for 3 completely different post-training duties without delay:
• Captioning. Practice the mannequin to provide lengthy, devoted captions.
• Reward modeling. Deal with (pre-caption, post-caption) as a (rejected, most well-liked) pair.
• Critique technology. Practice the mannequin to jot down the critique itself, given the video and the draft.
We post-trained Qwen3-VL-8B on all three codecs collectively utilizing customary supervised fine-tuning (SFT). We additionally tried reinforcement studying (RL) strategies like Direct Choice Optimization (DPO), however discovered that easy SFT on the total triplet knowledge is the strongest. The detailed numbers are within the paper; the headline is that including express desire and critique alerts improves each technique we examined.
We had been curious whether or not the high quality of the critique mattered to downstream efficiency, or whether or not any “that is improper” sign would do. So we ran an ablation: take a clear CHAI critique, intentionally degrade one property at a time (accuracy, recall, constructiveness), and see how the post-trained captioner performs on every process.

Outcomes for an 8B Qwen3-VL post-trained on every variant are offered in Desk 1. Caption and Critique are BLEU-4 scores (a normal text-generation metric measuring n-gram overlap with reference textual content on a 0–100 scale; larger means nearer to the human reference) in opposition to held-out reference captions and critiques. For the Reward process, we report binary accuracy on whether or not the captioner scores the post-caption larger than the pre-caption (likelihood = 50). Increased is healthier on all three.
| Critique variant | Acc. | Rec. | Constr. | Caption | Reward | Critique |
| Blind Gemini-2.5 | — | — | — | 10.9 | 44.5 | 21.1 |
| Gemini-2.5 | — | — | — | 12.7 | 62.0 | 26.2 |
| Inaccurate critique | ✗ | ✓ | ✓ | 12.1 | 47.1 | 21.9 |
| Incomplete critique | ✓ | ✗ | ✓ | 12.5 | 56.6 | 28.7 |
| Non-constructive critique | ✓ | ✓ | ✗ | 13.4 | 67.2 | 32.9 |
| CHAI (with QC) | ✓ | ✓ | ✓ | 18.2 | 89.8 | 41.7 |
Three issues stand out:
1. High quality is just not optionally available. Dropping any one of many three properties materially hurts each downstream process. Non-constructive critiques (the most affordable to gather, because you should not have to say what’s improper) harm the least however nonetheless go away a big hole.
2. Present knowledge is generally non-constructive. We checked the critiques in publicly launched datasets like Saunders et al.’s GDC launch and MM-RLHF. Greater than half are non-constructive in our sense (“that is improper” with no prompt repair). That helps clarify why coaching on these datasets leaves efficiency on the desk.
3. An 8B mannequin will be aggressive with a lot bigger closed fashions when the info is true. On the identical captioning, reward, and critique benchmarks, the post-trained 8B Qwen3-VL matches or exceeds GPT-5 and Gemini-3.1-Professional on the metrics we report. The mannequin measurement has not modified; the supervision sign has.
A small bonus: the identical reward mannequin additionally helps at inference time. Finest-of-N decoding with the educated reward mannequin continues to enhance efficiency with no further human labels.
Takeaway: The type of the critique is just not a stylistic element. A mannequin collectively post-trained on captions, preferences, and critiques performs materially higher on all three duties when the critiques it’s educated on are correct, full, and constructive — and materially worse when any a type of properties is lacking.
Query 4: Do higher captions within the coaching knowledge give us a greater video generator?
A skeptical reader may say: that is all very good, however captioning is upstream of what most individuals really need, which is technology. So we examined whether or not the improved captioner strikes the needle on a downstream video generator. We took a big corpus {of professional} video (movies, adverts, music movies, gameplay), re-captioned it with the post-trained 8B mannequin, and used these new captions to fine-tune Wan2.2.
The fine-tuned mannequin can act on detailed prompts (as much as roughly 400 phrases) for methods that off-the-shelf mills reliably get improper:
We didn’t change the generator structure or coaching goal. The one factor that modified was the language used to explain the movies within the coaching set. That was sufficient to show an present generator a category of methods it beforehand couldn’t articulate.
Takeaway: A extra exact caption vocabulary upstream interprets into extra controllable technology downstream, with the identical mannequin structure and coaching recipe. The bottleneck for cinematic management was within the supervision, not the mannequin.
Dialogue
We began this mission assuming we had been going to coach a captioner mannequin. We ended up spending a lot of the 12 months on the pipeline round it: what to jot down captions about, who ought to write them, who ought to examine them, and what the checks ought to appear to be. The mannequin contributions really feel virtually downstream of these decisions.
Three issues we want we had appreciated earlier:
• Specification earlier than scale. Coaching bigger fashions on noisier knowledge gave solely marginal good points. As soon as the spec was in place, smaller fashions began wanting very aggressive.
• “Crowdsource it” is just not a baseline; it’s a completely different downside. Annotating cinematic method accurately requires the identical vocabulary the sector already makes use of. Asking untrained staff to invent that vocabulary on the fly is just not a budget model of asking educated staff to use it.
• Critiques are coaching knowledge. The type of the critique we accumulate in the present day decides how successfully fashions will be educated tomorrow. Datasets that file solely thumbs-up / thumbs-down are leaving plenty of post-training sign on the desk.
CHAI is one piece of an extended effort on exact video language. The closest companion is CameraBench (NeurIPS’25 Highlight), our earlier benchmark on digital camera movement, which seeded the camera-side primitives within the spec.
Assets
We’re releasing the specification, coaching tutorials, annotation platform, quality-control circulation, knowledge, code, and fashions. If you’re engaged on video understanding or technology and need to use any of those, please do.
Undertaking web page: https://linzhiqiu.github.io/papers/chai/
Paper: https://arxiv.org/abs/2604.21718
Code: https://github.com/chancharikmitra/CHAI
References
Krishna et al., 2017. Dense-Captioning Occasions in Movies (ActivityNet Captions). ICCV. arXiv:1705.00754.
Xu et al., 2016. MSR-VTT: A Massive Video Description Dataset for Bridging Video and Language. CVPR.
Wang et al., 2024. Tarsier: Recipes for Coaching and Evaluating Massive Video Description Fashions (DREAM-1K). arXiv:2407.00634.
Chen et al., 2024. ShareGPT4Video: Enhancing Video Understanding and Technology with Higher Captions. NeurIPS. arXiv:2406.04325.
Cho et al., 2025. PerceptionLM: Open-Entry Information and Fashions for Detailed Visible Understanding. arXiv:2504.13180.
Saunders et al., 2022. Self-critiquing Fashions for Helping Human Evaluators. arXiv:2206.05802.
Zhang et al., 2025. MM-RLHF: The Subsequent Step Ahead in Multimodal LLM Alignment. arXiv:2502.10391.
Lin et al., 2025. In direction of Understanding Digicam Motions in Any Video (CameraBench). NeurIPS Highlight. arXiv:2504.15376.
Wan Crew, 2025. Wan: Open and Superior Massive-Scale Video Generative Fashions (Wan2.2). arXiv:2503.20314.
Bai et al., 2025. Qwen3-VL Technical Report. arXiv:2511.21631.
All opinions expressed on this put up are these of the authors and don’t signify the views of CMU.