As enterprises make investments closely in AI adoption, the way forward for synthetic intelligence is gaining vital consideration from executives to technical groups alike. Unprecedented purposes of synthetic intelligence are restructuring conventional enterprise fashions, emphasizing a sturdy want for superior technical capabilities.
Latest insights from the Upskilling Development Report present that 69 % of pros report AI-driven disruption of their roles, whereas 78 % stay optimistic about its affect. Additional, 85 % think about upskilling important to future readiness, with 44 % figuring out AI and Machine Studying as precedence areas for development.
That’s why now we have chosen the highest packages designed to assist professionals such as you construct future-ready AI experience. Whether or not you’re an engineer, analyst, enterprise strategist, or area knowledgeable, the suitable AI diploma can speed up your profession within the age of clever automation.
High AI Diploma Choices for Working Professionals
Program Title
Provided By
Greatest For
Length
Grasp of Utilized Synthetic Intelligence
Deakin College
Early, Mid-Senior, and Non-Tech Professionals
24 Months
MS in Synthetic Intelligence and Machine Studying
Walsh Faculty
Working Professionals searching for an reasonably priced on-line path
2 Years
Physician of Enterprise Administration in Synthetic Intelligence and Machine Studying
Walsh Faculty
CXOs and Senior Executives searching for strategic mastery
3 Years
Grasp of Science (MSc) Synthetic Intelligence
MBS Faculty of Enterprise
International Professionals searching for Triple Crown Accreditation
2 Years
The Grasp of Utilized Synthetic Intelligence program begins with a 12-month Postgraduate Program in AI and Machine Studying, which leads seamlessly into the superior 12-month Grasp’s curriculum.
This globally acknowledged curriculum emphasizes cutting-edge matters like Robotics, Pc Imaginative and prescient, Deep Studying, and Human-Aligned AI. The structured pedagogy balances robust technical competencies with strategic imaginative and prescient, equipping members to pivot seamlessly into extremely demanded profession choices in AI.
Key Highlights:
Fingers-On Software & Case Research: Execute over 11 rigorous hands-on tasks, navigate greater than 60 distinct business case research, and full a ultimate capstone mission utilizing outstanding instruments corresponding to TensorFlow, NumPy, and LangChain to make sure sensible, job-ready mastery.
Certificates & International Recognition: Earn a globally acknowledged Grasp’s diploma from Deakin College seamlessly on-line, reaching premier educational credentials at a mere fraction of the price of conventional on-campus options.
School & Educational Mentorship: Profit from direct steerage and significant insights from top-tier educational school and main business consultants who deliver real-world AI deployment expertise straight into the digital classroom.
Further Profession Advantages: Safe complete profession help that features custom-made resume constructing, devoted e-portfolio critiques, rigorous mock interviews, and lifelong entry to an expansive alumni portal connecting you to over 300,000 world graduates.
What Will You Study and How Can You Implement It?
The curriculum immerses you in basic information manipulation and exploratory information evaluation utilizing Python, scaling as much as superior neural networks and pure language processing.
By implementing deep studying algorithms and predictive analytics, you’ll possess the exact AI abilities for profession success. You’ll be taught to optimize neural networks for complicated enterprise purposes, empowering you to automate workflows and elevate enterprise effectivity.
The MS in Synthetic Intelligence and Machine Studying from Walsh Faculty delivers a contemporary, totally on-line framework custom-made for the inflexible constraints of working professionals.
Distinctive for its affordability and excessive accessibility, this system prioritizes instant office applicability. For aspiring tech expertise, entering into the position of an AI developer requires this precise mix of rigorous educational idea and hands-on case examine decision.
Key Highlights:
Curriculum & Core Competencies: Grasp extremely demanded capabilities encompassing Supervised and Unsupervised Studying, Ensemble Methods, SQL, and significant management modules specializing in AI Imaginative and prescient and Technique Improvement, Moral AI Management, and Constructing AI-Prepared Groups.
Fingers-On Tasks & Actual-World Simulation: Interact deeply with the fabric by finishing 12 hands-on tasks and over 30 complete case research, straight addressing fashionable complexities corresponding to ChatGPT deployments and Generative AI frameworks.
Awards & Affordability: Pursue a extremely revered, fashionable Grasp of Science diploma from a acknowledged US establishment at an extremely accessible worth level, utterly bypassing standardized testing obstacles by requiring no GRE, GMAT, or TOEFL scores.
Diploma Certificates & Educational Standing: Graduate with an MS in Synthetic Intelligence and Machine Studying certificates, cementing your technical authority by way of a globally accessible on-line framework tailor-made to the demanding schedules of working executives.
Further Scholar Advantages: Attain verified alumni standing from Walsh Faculty upon profitable completion, offering seamless integration into a sturdy world community of tech professionals alongside sturdy structural profession help.
What Will You Study and How Can You Implement It?
You’ll discover utilized analysis matters in deep studying idea, information storage applied sciences, and enormous language fashions. Professionals can straight implement this data to engineer conversational brokers and construction scalable machine studying operations inside their organizations.
Concentrating on seasoned executives, Walsh Faculty’s Physician of Enterprise Administration (DBA) in Synthetic Intelligence and Machine Studying is designed to empower leaders to dictate organizational AI technique, handle digital governance, and navigate moral deployments responsibly.
Knowledgeable evaluating long-term management ought to overview a complete profession and roadmap, and leverage this program to transition into C-suite innovation roles.
Key Highlights:
Elite Accreditation & Rankings: Enroll in a premier doctoral program that’s comprehensively WES Accredited, acknowledged by the Greater Studying Fee (HLC), and ranked 1 among the many High 10 On-line DBA Levels by Forbes, in addition to holding a Tier 1 rating from CEO Journal.
Curriculum & Strategic Focus: Full a rigorous 3-year curriculum centered on deep-tech management, masking Generative AI, accountable AI adoption, information governance, and strategic capital administration to drive enterprise development.
Fingers-on Tasks & Scholarly Analysis: Transfer past foundational software by engaged on hands-on modules and self-paced tasks that lead straight into drafting a scholarly thesis, publishing rigorous analysis, or submitting high-level expertise patents.
Prestigious Certificates: Obtain the final word educational milestone by incomes a Physician of Enterprise Administration diploma, formally granting you the authoritative title of ‘Dr.’ to immediately distinguish your govt presence globally.
School & Further Peer Advantages: Examine alongside a extremely achieved govt cohort, supported by personalised help from devoted program managers, participating self-paced video lectures, and weekend mentorship periods with elite AI business consultants.
What Will You Study and How Can You Implement It?
The educational tracks cowl Deep Studying variants, Generative AI deployments, accountable AI utilization, and superior AI mission design. By mastering these competencies, an AI product supervisor can systematically lead high-stakes organizational implementations, addressing complicated challenges in equity, transparency, and strategic enterprise scale.
The MSc in Synthetic Intelligence supplied by the MBS Faculty of Enterprise school is a distinguished on-line diploma program that mixes European educational rigor with an aggressive give attention to fashionable information paradigms.
Incomes a level from this Triple Crown Accredited Institute grants graduates unparalleled world status. Designed to sculpt AI Engineers and Consultants, the curriculum ensures an optimum combine of educational idea and sturdy sensible execution below the mentorship of elite world school.
Key Highlights:
Awards & Triple Crown Accreditation: Attain a world-class diploma from the MBS college, an elite European establishment boasting the extremely coveted Triple Crown Accreditation, guaranteeing an unmatched normal of world educational rigor.
School & Knowledgeable Mentorship: Study straight from internationally famend school corresponding to Dr. Moez Bennouri and Dr. Deepa Bhatt, and work together with elite business mentors who lead information science groups at globally acknowledged companies corresponding to Apple, Verizon, and RBC Capital Markets.
Curriculum Depth & Applied sciences: Construct complicated architectures by deeply learning Agentic AI, GenAI, Pure Language Processing, Pc Imaginative and prescient, and Advice Programs, tailor-made particularly to form the way forward for AI innovation.
Fingers-On Tasks & Utilized Studying: Domesticate sensible mastery by way of 12+ intensive hands-on tasks, 30+ detailed case research, and a pair of intensive capstone tasks, making certain theoretical ideas are straight examined in real-world environments.
Certificates & Price Effectivity Advantages: Earn a extremely prestigious Grasp of Science (MSc) in Synthetic Intelligence utterly on-line at simply one-third of the price of an on-campus Grasp’s, requiring completely no GRE or GMAT scores to enroll.
What Will You Study and How Can You Implement It?
Learners dive into cutting-edge big-data analytics, machine-learning operations, and AI deployment frameworks. You’ll be taught to govern information ecosystems and deploy algorithms that remedy intricate enterprise limitations.
Furthermore, you’ll emerge with the talents to drive AI innovation at enterprise scale, implement clever programs throughout complicated enterprise environments, and lead digital transformation with each technical mastery and strategic readability.
The way to Maximize Your AI Diploma as a Working Skilled?
Enrolling in an AI program is barely the start. In line with the Upskilling Traits Report 2025-26, 81% of pros plan to pursue upskilling this yr, however 37% cite workplace work as the largest barrier.
Structured, on-line AI levels tackle this problem straight by design, however maximizing your final result requires intentional preparation and disciplined execution all through.
1. Earlier than You Enroll
Begin by benchmarking your current data. Use Nice Studying’s quizzes to evaluate your present readiness and to determine the AI abilities wanted to advance your profession.
2. Through the Program
Interact actively with each mission, case examine, and capstone. Discover AI mission concepts that align along with your business and construct actual artifacts that exhibit utilized competency. With 60% of pros utilizing GenAI of their work at all times or regularly, integrating AI instruments into your examine workflow is itself a priceless skilled talent to develop.
3. After Commencement
Concentrate on constructing a powerful AI portfolio that paperwork your tasks, technical instruments, and enterprise outcomes. Put together for interviews by reviewing the newest AI interview questions, and use the AI developer roadmap to map your first 90 days in a brand new position.
Conclusion
Whether or not you align with Deakin College’s intensive software mastery, Walsh Faculty’s agile and extremely accessible curriculum, or MBS Faculty of Enterprise ‘ Triple Crown European status, there’s a distinct instructional pathway optimized to your each profession stage.
By matching your skilled background to those premier diploma codecs, you safe the elite credentials, complete hands-on expertise, and expansive community obligatory to steer the way forward for enterprise digital transformation with unwavering confidence.
Password resets are sometimes the primary response to a suspected compromise. It is smart; resetting credentials is a fast strategy to reduce off an attacker’s most evident path again in.
Nevertheless, that doesn’t at all times fully remedy the difficulty. In each Energetic Listing (AD) and hybrid Entra ID environments, password modifications don’t instantly invalidate the previous credential throughout each authentication path.
Even a brief window is a chance that probably permits attackers to keep up entry or re-establish a foothold.
For safety architects and IT directors, this hole has actual implications throughout incident response.
The password reset hole
Home windows programs cache password hashes regionally to assist offline logon. If a tool hasn’t reconnected to the area, it could nonetheless maintain the earlier credential in a usable type. In hybrid environments, there may also be a brief delay earlier than the brand new password syncs to Entra ID.
This implies there are three doable states created after a password reset:
1. The person has logged in with the brand new credential whereas linked to AD. The cached credential retailer updates, invalidating the previous hash.
2. The person has not logged in to a selected machine for the reason that reset. The previous cached credential should be usable for sure authentication makes an attempt.
3. In hybrid deployments, the password has been reset in AD however the brand new hash has not but synchronized to Entra ID. The previous password should authenticate through the password hash synchronization interval.
Verizon’s Knowledge Breach Investigation Report discovered stolen credentials are concerned in 44.7% of breaches.
Effortlessly safe Energetic Listing with compliant password insurance policies, blocking 4+ billion compromised passwords, boosting safety, and slashing assist hassles!
Attackers benefit from cached password hashes with strategies like pass-the-hash, the place the hash itself is used as an alternative of the plaintext password. If that hash was captured earlier than the reset, altering the password doesn’t instantly invalidate it in every single place.
Limiting that publicity is essential to defending AD environments. Options like Specops uReset allow safe self-service password resets by imposing end-user ID verification to scale back the chance of reset abuse.
When mixed with the Specops Shopper, uReset can replace the native cached credential retailer instantly on the machine the place the reset is carried out, closing the window the place the previous hash stays usable on that endpoint.
This doesn’t take away id drift solely, but it surely does cut back publicity on the community edge, the place company laptops and distant programs are continuously focused.
Specops uReset
Energetic classes
AD authentication is primarily dealt with via Kerberos tickets, that are legitimate for a set time frame. If a person or attacker already has a sound ticket, they will proceed accessing assets with out re-entering a password.
Meaning an attacker with an lively session stays authenticated even after the password has been modified. In some circumstances, that window is lengthy sufficient to ascertain extra persistence or transfer laterally.
Until classes are explicitly invalidated, via logoff, reboot, or ticket purging, entry can proceed effectively past the reset itself.
Service accounts
In contrast to person accounts, service accounts are inclined to have long-lived passwords, with elevated privileges tied to essential programs. Attackers can expose these credentials via strategies like Kerberoasting or uncover them when transferring laterally via a community.
As a result of these accounts are tied to operating companies, they’re much less more likely to be reset shortly, particularly if there’s a threat of disruption. That makes them a dependable fallback for attackers after an preliminary entry level is closed.
Ticket assaults
As talked about above, in environments utilizing the Kerberos authentication protocol, entry is managed via tickets quite than repeated password checks. If an attacker can forge these tickets, they don’t want legitimate credentials in any respect.
A Golden Ticket assault, made doable by compromising the Kerberos Ticket Granting Ticket account, permits attackers to create legitimate ticket-granting tickets for any person within the area. Silver Tickets are extra focused, granting entry to particular companies with out contacting a website controller.
In each circumstances, these assaults successfully bypass password modifications. Resetting person passwords received’t invalidate solid tickets, and entry can proceed till the underlying problem is addressed.
Permissions
AD is closely pushed by Entry Management Lists (ACLs). If an attacker grants a compromised account (or a brand new one they management) rights like resetting passwords for different customers, they’ve successfully created a backdoor. Even when the unique password is modified, these permissions stay.
Moreover, accounts protected by AdminSDHolder (like Area Admins) inherit permissions from a particular template. Attackers who modify the ACL on the AdminSDHolder object can guarantee their permissions are re-applied each hour by SDProp.
How to make sure attackers are eliminated
The time between a password reset and it synching throughout AD and Entra ID is small, sometimes only a few minutes, which severely limits the chance attackers have to take advantage of the hole. Forcing extra frequent synchronizations can be doable, for example turning on AD Change Notification or manually initiating a Sync to the Entra ID tenant.
Nevertheless, the hole nonetheless exists, and by the point an account compromise is found, attackers could have been in a position to set up extra footholds. If password resets aren’t sufficient on their very own, defenders want to take a look at absolutely closing off entry.
That begins with invalidating something already in play. Energetic classes must be terminated, and Kerberos tickets cleared by forcing logoffs or reboots on affected programs. For extra severe compromises, resetting the KRBTGT account (twice) is commonly essential to invalidate solid tickets.
Subsequent comes credential hygiene past customary person accounts. Service account passwords must be rotated, particularly these with elevated privileges, and any cached credentials on endpoints must be cleared as programs reconnect.
Simply as necessary is reviewing what’s modified within the listing itself. Meaning auditing:
Group memberships
Delegated rights and ACLs
Privileged accounts and roles
Search for something that might enable entry to be re-established with out counting on a password.
For severe breaches, there isn’t a single step that ensures eviction. It’s a mix of reducing off classes, rotating the precise credentials, and verifying that no hidden entry paths stay.
Safe your AD at the moment
Hardening your AD requires each account to be protected by sturdy passwords, mixed with a safe reset course of that limits alternatives for abuse.
Specops helps you do each, providing you with confidence that password resets strengthen your safety quite than introduce new gaps.
Ebook a demo to see how our options can assist your id safety technique.
Sound waves already utilized in medical scans might have a stunning new goal: viruses.
In lab experiments, scientists have demonstrated how ultrasound blasts can break down influenza A (H1N1) and SARS-CoV-2, which causes COVID-19.
Microscopic vibrations brought on by ultrasound waves are enough to rupture the membranes surrounding their viral particles, experiments confirmed, rendering the viruses inactive.
The analysis was led by a staff from the College of São Paulo in Brazil and will in the future be a substitute for antivirals and chemical disinfectants for enveloped viruses, which have an outer membrane that is susceptible to assault.
“It is form of like preventing the virus with a shout,” says computational physicist Odemir Martinez Bruno, from the College of São Paulo.
“On this research, we proved that the vitality of sound waves causes morphological adjustments in viral particles till they explode, a phenomenon corresponding to what occurs with popcorn.”
The lab experiments had been carried out with ultrasound machines utilized in hospitals, with the viruses uncovered to ultrasound frequencies within the 3–20 MHz vary.
The researchers took snapshots of bodily adjustments after which examined whether or not the handled SARS-CoV-2 samples may nonetheless infect lab fashions of host cells (Ver-E6 cells).
There was clear proof of bodily destruction of the viral envelopes, and subsequently, SARS-CoV-2’s capacity to contaminate mannequin host cells was sharply diminished.
Researchers uncovered viral samples to ultrasound earlier than infecting lab cells with them. (Veras et al., Sci. Rep., 2026)
The method depends on acoustic resonance, and each the ultrasound frequency and the form of the viral particles matter.
The concept is that the frequency of the sound wave matches the pure vibrational frequency of the viral envelope, resulting in amplified vibrations that destroy it. Basically, solely the virus responds to the vitality of the sound waves, not the host cells.
Below the examined situations, the viral particles appeared much more susceptible than the encircling cells.
Evaluation confirmed that the temperature and pH of the encircling cells remained secure, ruling out thermal or chemical harm as the rationale for the breakdown of the viral particles.
Results of ultrasound therapy. High row: Lab cells (with nuclei proven in blue) contaminated with untreated samples of SARS-CoV-2 (viral spike proteins in inexperienced and viral RNA in purple). Backside row: Lab cells contaminated with samples of SARS-CoV-2 uncovered to sound waves. (Veras et al., Sci. Rep., 2026)
The researchers additionally level out that viral particles like these examined are spherical, the optimum form for ultrasound sensitivity.
“Spherical particles, equivalent to many enveloped viruses, take in ultrasound wave vitality extra successfully. It is that accumulation of vitality contained in the particle that causes adjustments within the construction of the viral envelope till it ruptures.”
If these particles had been triangular or sq., the impacts would not be the identical.
“Ultrasound is already used to sterilize dental and surgical gear, however it works by a distinct bodily phenomenon referred to as cavitation, which destroys organic materials,” Bruno explains.
“Whereas cavitation happens at low frequencies and destroys each viruses and tissues by the collapse of fuel bubbles, acoustic resonance operates at excessive frequencies.”
Illustration of ultrasound-mediated bodily mechanisms: (A) cavitation, which operates within the KHz vary, is used to sterilize medical gear; (B) resonance, which operates within the MHz vary. (Veras et al., Sci. Rep., 2026)
Acoustic resonance ultrasound may deal with sure limitations of drug remedies.
The brand new technique did not present the identical harmful results in mannequin host cells or the encircling answer below lab situations.
And since the goal is a bodily construction slightly than a single molecular pathway, the researchers hope it may higher take care of viruses as they mutate (which would not change the particles’ bodily form).
The staff is hopeful their new method will work throughout different viral infections, they usually have already begun investigating how dengue, Zika, and Chikungunya may very well be focused in the identical means.
Ultrasound is usually painless, non-invasive, comparatively straightforward to use, and will be exactly focused, so researchers have been exploring a number of new methods of utilizing it, together with for ache reduction within the mind and most cancers therapy.
The discovering right here is thrilling, however it isn’t but a therapy. There’s nonetheless a number of work to do, together with additional fine-tuning of the ultrasound frequencies.
This research was restricted to lab checks slightly than any experiments in animals or people, and solely on two completely different virus varieties. It is a robust start line, however it’s nonetheless early days for this know-how.
“Though it is nonetheless removed from medical use, it is a promising technique towards enveloped viruses normally, since growing chemical antivirals is advanced and yields troublesome outcomes,” says pharmacologist Flávio Protásio Veras, from the College of São Paulo.
“Moreover, it is a ‘inexperienced’ answer, because it generates no waste, causes no environmental impression, and does not promote viral resistance.”
The earlier submit regarded on the tempering step of the Mersenne Tornado, formulating a sequence of bit operations as multiplication by a matrix mod 2. This submit will take a look at the elements extra carefully.
The theorems of linear algebra usually maintain impartial of the sphere of scalars. Usually the sphere is ℝ or ℂ, however most of fundamental linear algebra works the identical over each subject [1]. Particularly, we will do linear algebra over a finite subject, and we’re taken with probably the most finite of finite fields GF(2), the sphere with simply two parts, 0 and 1.
In GF(2), addition corresponds to XOR. We are going to denote this by ⊕ to remind us that though it’s addition, it’s not the standard addition, i.e. 1 ⊕ 1 = 0. Equally, multiplication corresponds to AND. We’ll work with 8-bit numbers to make the visuals simpler to see.
Shifting a quantity left one bit corresponds to multiplication by a matrix with 1’s under the diagonal important. Shifting left by ok bits is similar as shifting left by 1 bit ok instances, so the the matrix illustration for x << ok is the okth energy of the matrix illustration of shifting left as soon as. This matrix has 1s on the okth diagonal under the principle diagonal. Under is the matrix for shifting left two bits, x << ok.
Proper shifts are the mirror picture of left shifts. Right here’s the matrix for shifting proper two bits, x >> ok.
Shifts usually are not absolutely invertible as a result of bits both fall off the left or the proper finish. The steps within the Mersenne Tornado are invertible as a result of shifts are all the time XOR’d with the unique argument. For instance, though the perform that takes x to x >> 2 isn’t invertible, the perform that takes x to x ⊕ (x >> 2) is invertible. This operation corresponds to the matrix under.
That is an higher triangular matrix, so its determinant is the product of the diagonal parts. These are all 1s, so the determinant is 1, and the matrix is invertible.
Bitwise AND multiplies every little bit of the enter by the corresponding bit in one other quantity often called the masks. The bits aligned with a 1 are stored and the bits aligned with a 0 are cleared. This corresponds to multiplying by a diagonal matrix whose diagonal parts correspond to the bits within the masks. For instance, right here is the matrix that corresponds to taking the bitwise AND with 10100100.
Every of the steps within the Mersenne Tornado tempering course of are invertible as a result of all of them correspond to triangular matrices with all 1’s on the diagonal. For instance, the road
y ^= (y << 7) & 0x9d2c5680
says to shift the bits of y left 7 locations, then zero out the weather akin to 0s within the masks, then XOR the end result with y. In matrix phrases, we multiply by a decrease triangular matrix with zeros on the principle diagonal, then multiply by a diagonal matrix that zeros out among the phrases, then add the identification matrix. So the matrix akin to the road of code above is decrease triangular, with all 1s on the diagonal, so it’s invertible.
[1] Till you get to eigenvalues. Then it issues whether or not the sphere is algebraically full, which no finite subject is.
Generative AI has moved far past easy chatbot experiments. In 2026, AI-powered techniques have gotten deeply built-in into software program growth, digital design, content material manufacturing, and productiveness workflows. What as soon as required a number of specialised instruments and huge groups can now typically be dealt with by AI-assisted platforms that cut back guide effort and speed up execution.
The largest cause adoption continues to develop is accessibility. Earlier generations of AI software program had been primarily constructed for researchers and technical customers. Trendy platforms are designed for mainstream creators, builders, entrepreneurs, startups, and distant groups that need quicker workflows with out sophisticated onboarding.
As extra industries combine automation into every day operations, understanding which AI instruments present sensible worth is turning into more and more vital.
AI Instruments Are Changing into Workflow Platforms
One main shift taking place in 2026 is that AI instruments are not functioning as standalone utilities. As an alternative, they’re evolving into full workflow ecosystems that mix writing help, media technology, automation, coding help, and analysis capabilities inside unified environments.
For builders, this implies quicker implementation and debugging. For designers, it means accelerated ideation and asset technology. For creators and companies, it means producing high-volume content material with out dramatically rising operational prices.
The result’s a digital surroundings the place people can deal with workloads that beforehand required total groups.
Pollo AI and the Rise of AI-Generated Video Workflows
Video content material stays one of many fastest-growing codecs throughout digital platforms, and AI-powered media technology instruments have gotten more and more frequent amongst creators trying to scale manufacturing effectively.
One space gaining severe consideration is the flexibility to create generative AI video information with out conventional studio infrastructure. Pollo AI’s method to that is value understanding intimately: as a substitute of relying totally on cameras, lighting setups, and guide manufacturing processes, AI-assisted platforms now enable customers to generate presenter-style video content material instantly from written scripts — full with AI anchors, automated voice synthesis, and broadcast-ready formatting.
This shift is particularly related for unbiased creators, academic publishers, area of interest media channels, and small digital groups making an attempt to take care of constant publishing schedules. Pollo AI has constructed this right into a workflow that reduces the manufacturing overhead that when made frequent video publishing troublesome for smaller operations — the type of overhead that beforehand stored professional-looking news-format video out of attain for anybody with out a studio funds.
Relatively than changing conventional manufacturing totally, these instruments are serving to simplify repetitive workflows and enhance publishing pace in a means that compounds over time.
ChatGPT and On a regular basis Productiveness
AI assistants are more and more turning into a part of on a regular basis work routines. ChatGPT stays broadly used due to its flexibility throughout writing, brainstorming, summarization, analysis help, and coding-related duties.
Many customers combine conversational AI into documentation workflows, content material planning, buyer communication drafts, and academic studying environments. As an alternative of switching between a number of instruments, customers can centralize a wide range of duties by a single AI-driven interface.
The broader development just isn’t merely automation, however workflow acceleration by contextual help — and the groups which have internalized this distinction are inclined to extract way more worth from the instruments accessible to them.
AI-Assisted Improvement Continues Increasing
Software program growth is one other space seeing main transformation by generative AI adoption. Coding assistants can now generate boilerplate code, clarify features, determine syntax points, and speed up debugging workflows.
These techniques are significantly helpful for repetitive implementation duties, permitting builders to focus extra closely on structure, logic, and problem-solving fairly than routine coding patterns.
For newer programmers, AI-assisted growth instruments may enhance studying effectivity by serving to clarify technical ideas in actual time. As AI integration inside growth environments matures, productiveness features have gotten more and more noticeable throughout each particular person and enterprise-level software program groups.
Visible Technology and Design Automation
Design workflows are additionally evolving quickly by generative AI techniques able to producing illustrations, idea artwork, mockups, thumbnails, and visible references inside minutes.
This doesn’t get rid of the necessity for designers, nevertheless it considerably modifications the ideation part of artistic work. As an alternative of manually constructing early-stage ideas from scratch, creators can discover a number of visible instructions rapidly earlier than refining chosen concepts additional.
Companies, freelancers, and content material creators more and more use AI-assisted design instruments to cut back turnaround time whereas sustaining artistic flexibility. The pace benefit on the idea stage — the place many of the revision cycles traditionally occurred — is the place generative design instruments ship their clearest return.
The place Vmaker AI Suits Into the Ecosystem
Totally different AI platforms clear up totally different workflow issues, which is why many creators mix a number of instruments relying on the challenge sort and manufacturing context.
For customers exploring screen-based content material manufacturing and simplified recording workflows, Vmaker AI presents a light-weight various throughout the Pollo AI ecosystem that’s well-suited to tutorials, product walkthroughs, distant collaboration recordings, and academic content material the place pace and readability matter greater than complicated manufacturing pipelines. It sits at a special level within the content material creation spectrum than Pollo AI’s video information generator — one is optimized for broadcast-style scripted content material, the opposite for screen-centric recording — and understanding which inserts a given challenge sort is the type of software literacy that separates environment friendly creators from ones perpetually preventing their very own workflows.
As generative AI ecosystems proceed increasing, the best approaches have gotten modular: totally different instruments for various content material sorts, chosen intentionally fairly than utilized uniformly.
The Significance of Consistency Over Perfection
One sample turning into more and more clear throughout digital publishing is that constant output typically issues greater than good manufacturing high quality.
AI-assisted workflows cut back the time required to provide articles, movies, shows, visuals, and documentation — which permits smaller groups and unbiased creators to take care of publishing consistency with out dramatically rising operational workload. For a lot of creators, the true benefit just isn’t changing creativity, however eradicating the manufacturing bottlenecks that gradual execution and erode momentum.
This is likely one of the main causes generative AI adoption continues spreading throughout media, growth, training, and enterprise environments. The instruments that stick are those that make exhibiting up persistently really feel achievable.
Human Oversight Nonetheless Issues
Regardless of fast enhancements, generative AI stays a help system fairly than an entire alternative for human judgment. AI-generated outputs nonetheless require fact-checking, enhancing, strategic course, high quality management, and contextual understanding that solely comes from somebody who is aware of the viewers and the aim behind the content material.
The simplest workflows sometimes mix AI pace with human refinement. Customers who perceive information, evaluate, and enhance AI-generated content material typically obtain considerably higher outcomes than these relying totally on automation — and that steadiness between pace and oversight will probably stay the defining attribute of high-quality AI-assisted work for the foreseeable future.
Trying Forward
Generative AI instruments in 2026 have gotten way more sensible, accessible, and embedded in on a regular basis digital work. Whether or not somebody works in growth, design, training, analysis, content material manufacturing, or enterprise operations, AI-assisted techniques are more and more shaping how workflows function — not by changing human creativity, however by eradicating the friction that slows it down.
Essentially the most worthwhile instruments are usually not essentially those producing probably the most hype, however the ones that genuinely enhance effectivity and match naturally into present processes. Professionals who perceive combine AI into actual workflows — fairly than merely experimenting with the expertise in isolation — are those who will carry a compounding productiveness benefit because the ecosystem continues to mature.
Coaching giant language fashions requires correct suggestions indicators, however conventional reinforcement studying (RL) usually struggles with reward sign reliability. The standard of those indicators straight influences how fashions be taught and make choices. Nonetheless, creating sturdy suggestions mechanisms may be complicated and error inclined. Actual-world coaching eventualities usually introduce hidden biases, unintended incentives, and ambiguous success standards that may derail the training course of, resulting in fashions that behave unpredictably or fail to satisfy desired targets.
On this publish, you’ll discover ways to implement reinforcement studying with verifiable rewards (RLVR) to introduce verification and transparency into reward indicators to enhance coaching efficiency. This strategy works greatest when outputs may be objectively verified for correctness, akin to in mathematical reasoning, code technology, or symbolic manipulation duties. Additionally, you will discover ways to layer strategies like Group Relative Coverage Optimization (GRPO) and few-shot examples to additional enhance outcomes. You’ll use the GSM8K dataset (Grade College Math 8K: a group of grade faculty math issues) to enhance math drawback fixing accuracy, however the strategies used right here may be tailored to all kinds of different use instances.
Technical overview
Earlier than diving into implementation, it’s useful to know the RL ideas that underpin this strategy. RL addresses challenges in mannequin coaching by establishing a structured suggestions system via reward indicators. This paradigm permits fashions to be taught via interplay, receiving suggestions that guides them towards optimum conduct. RL offers a framework for fashions to iteratively enhance their responses primarily based on clearly outlined indicators concerning the high quality of their outputs, making it extremely efficient for coaching fashions that work together with customers and should adapt their conduct primarily based on outcomes. Conventional RL has highlighted an necessary consideration: the standard of the reward sign issues considerably. When reward capabilities are imprecise or incomplete, fashions can interact in “reward hacking,” discovering unintended methods to maximise scores with out attaining the specified conduct. Recognizing this limitation has led to the event of extra rigorous approaches that target creating dependable, well-defined reward capabilities.
RLVR addresses reward hacking via rule-based suggestions outlined by the mannequin tuner. It makes use of programmatic reward capabilities that robotically rating outputs towards particular standards, enabling speedy iteration with out the bottleneck of accumulating human rankings. These “verifiable” rewards come from goal, reproducible guidelines, making RLVR ultimate for evolving necessities as a result of it learns basic optimization methods and adapts shortly to new eventualities. GRPO is a reinforcement studying algorithm that improves AI mannequin studying by evaluating efficiency inside teams fairly than throughout all knowledge without delay. It organizes coaching knowledge into significant teams and optimizes efficiency relative to every group’s baseline, giving acceptable consideration to every class. This group-aware optimization reduces coaching variance, accelerates convergence, and might produce fashions that carry out persistently throughout numerous classes. Combining RLVR with GRPO creates a framework the place automated rewards information studying whereas group-relative optimization helps drive balanced efficiency.
You outline reward capabilities for various job elements, and GRPO treats these as distinct teams throughout coaching, facilitating simultaneous enchancment throughout dimensions. This mixture delivers speedy adaptation and sturdy efficiency, ultimate for dynamic environments requiring generalization past coaching distribution. Including few-shot studying enhances this framework in 3 ways. First, few-shot examples present templates that present the mannequin what good outputs seem like, narrowing the search house for exploration. Second, GRPO leverages these examples by producing a number of candidate responses per immediate and studying from their relative efficiency inside every group. Third, verifiable rewards instantly verify which approaches succeed. This mixture accelerates studying: the mannequin begins with concrete examples of the specified format, explores variations effectively via group-based comparability, and receives definitive suggestions on correctness.
Answer overview
On this part, you’ll stroll via the best way to fine-tune a Qwen2.5-0.5B mannequin on SageMaker AI utilizing Amazon Amazon SageMaker Coaching Jobs. Amazon SageMaker Coaching jobs help distributed multi-GPU and multi-node configurations, so you may spin up high-performance clusters on demand, practice billion-parameter fashions sooner, and robotically shut down sources when the job finishes.
Be aware: Whereas Qwen2.5-0.5B was chosen for this use case, others like code technology would require a bigger mannequin (e.g. Qwen2.5-Coder-7B) and subsequently bigger coaching cases.
Conditions
To run the instance from this publish on Amazon SageMaker AI, you will need to fulfill the next stipulations:
Setting arrange
You should use your most popular IDE, akin to VS Code or PyCharm, however ensure your native atmosphere is configured to work with AWS, as mentioned within the stipulations.
On the Amazon SageMaker AI console, select Domains within the navigation pane, then open your area.
Within the navigation pane beneath Purposes and IDEs, select Studio.
On the Person profiles tab, find your person profile, then select Launch and Studio.
In Amazon SageMaker Studio, launch an ml.t3.medium JupyterLab pocket book occasion with at the very least 50 GB of storage.
A big pocket book occasion isn’t required, as a result of the fine-tuning job will run on a separate ephemeral coaching occasion with GPU acceleration.
To start fine-tuning, begin by cloning the GitHub repo and navigating to 3_distributed_training/reinforcement-learning/grpo-with-verifiable-reward listing, then launch the model-finetuning-grpo-rlvr.ipynb
Pocket book with a Python 3.12 or increased model kernel
Put together the dataset for fine-tuning
Working GRPO with RLVR requires you to have the ultimate reply to every query to calculate reward. First, put together the info by extracting the ultimate reply for every query.
As well as, this instance makes use of few-shot examples (8 pictures) to enhance mannequin coaching efficiency. For extra data on few-shot examples in reinforcement studying, check with the paper “Reinforcement Studying for Reasoning in Giant Language Fashions with One Coaching Instance”. Whereas the analysis paper focuses on single-shot examples, this publish will present you each single and multi-shot efficiency.
Every enter will comprise 8 examples, adopted by the issue to be solved:
"Query: Mark has $50 and buys a toy that prices $35. How a lot cash does he have left?
Answer: Let's assume step-by-step. To learn how a lot cash Mark has left, subtract the price of the toy from the full amount of cash Mark has. So, $50 - $35 = $15.
#### The ultimate reply is 15
Query: Emily has 3 instances as many pencils as Alice. If Alice has 15 pencils, what number of pencils does Emily have?
Answer: Let's assume step-by-step. To learn how many pencils Emily has, we multiply the variety of pencils Alice has by 3. Alice has 15 pencils, so Emily has 15 * 3 = 45 pencils.
#### The ultimate reply is 45
Query: Jack has collected 12 extra marbles than Kevin. If Kevin has 27 marbles, what number of marbles does Jack have?
Answer: Let's assume step-by-step. To search out what number of marbles Jack has, we add 12 to the variety of marbles Kevin has. So, Jack has 27 + 12 = 39 marbles.
#### The ultimate reply is 39
Query: There are 24 college students in a classroom. If every group should have 4 college students, what number of teams may be fashioned?
Answer: Let's assume step-by-step. To search out what number of teams may be fashioned, we divide the variety of college students by the variety of college students per group. So, 24 / 4 = 6 teams may be fashioned.
#### The ultimate reply is 6
Query: Samantha baked 40 cookies and desires to divide them equally into baggage, with every bag containing 5 cookies. What number of baggage will Samantha want?
Answer: Let's assume step-by-step. To search out the variety of baggage wanted, divide the full variety of cookies by the variety of cookies per bag. Thus, 40 divided by 5 equals 8.
#### The ultimate reply is 8
Query: A pack of pencils prices $4. When you purchase 7 packs, how a lot will you spend in complete?
Answer: Let's assume step-by-step. The full price is discovered by multiplying the fee per pack by the variety of packs. Therefore, you spend 7 * $4 = $28.
#### The ultimate reply is 28
Query: A guide has 240 pages, and Sarah reads 20 pages every day. What number of days will it take her to complete the guide?
Answer: Let's assume step-by-step. Sarah reads 20 pages per day, so we divide the full pages by the variety of pages she reads per day. Subsequently, it takes her 240 / 20 = 12 days to complete the guide.
#### The ultimate reply is 12
Query: A farmer has a complete of 80 apples and oranges. If he has 30 apples, what number of oranges does he have?
Answer: Let's assume step-by-step. To find out the variety of oranges, we subtract the variety of apples from the full variety of fruits. So, the variety of oranges is 80 - 30 = 50.n
#### The ultimate reply is 50
Query: Mimi picked up 2 dozen seashells on the seaside. Kyle discovered twice as many shells as Mimi and put them in his pocket. Leigh grabbed one-third of the shells that Kyle discovered. What number of seashells did Leigh have?
Answer: Let's assume step-by-step.
After the info has been ready, hold 10 p.c of the info as a validation set and push each coaching and validation set to S3.
The Verifiable Reward Perform
This GRPO implementation for mathematical reasoning employs a dual-reward system that gives goal, verifiable suggestions throughout coaching. This strategy leverages the inherent verifiability of mathematical issues to create dependable coaching indicators with out requiring human annotation or subjective analysis.You’ll implement two complementary reward capabilities that work collectively to information the mannequin towards each right response formatting and mathematical accuracy of the end result:
Format Reward Perform
This perform helps confirm the mannequin learns to construction its responses accurately by:
Sample Matching: Searches for the particular format #### The ultimate reply is [number]
Constant Scoring: Awards 0.5 factors for correct formatting, 0.0 for incorrect format
Coaching Sign: Encourages the mannequin to comply with the anticipated reply construction
#Format reward perform
def format_reward_func_qa(completions, **kwargs):
sample = r"n#### The ultimate reply is d+"
completion_contents = [completion for completion in completions]
matches = [re.search(pattern, content) for content in completion_contents]
return [0.5 if match else 0.0 for match in matches]
Correctness Reward Perform
This perform offers the core mathematical verification by:
Reply Extraction: Makes use of regex to extract numerical solutions from formatted responses
Throughout coaching, GRPO makes use of these reward capabilities to compute coverage gradients. First the mannequin generates a number of completions for every mathematical drawback. Subsequent, the reward for every response is computed for each reward capabilities. The format reward perform will grant as much as 0.5 for correct response construction, and the correctness reward perform will grant as much as 1.0 for the mathematical accuracy of the reply for a most mixed reward of 1.5 per completion. Then GRPO compares the completions inside teams to determine the very best responses. Lastly, within the coverage replace step, the loss perform makes use of reward variations to replace mannequin parameters. Increased-rewarded completions enhance their likelihood, whereas lower-rewarded completions lower their likelihood. This relative rating drives the optimization course of.The next instance demonstrates the best way to fine-tune Qwen2.5-0.5B. The recipe is offered within the scripts folder, permitting you to customise it or change the bottom mannequin. Right here you’ll use GRPO with verifiable rewards utilizing Quantized Low-Rank Adaptation (QLoRA). QLoRA is used right here as a way to cut back coaching useful resource necessities and velocity up the coaching course of, with a small commerce off in accuracy.
This recipe implements Group Relative Coverage Optimization (GRPO) with verifiable rewards for fine-tuning the Qwen2.5-0.5B mannequin on mathematical reasoning duties. The recipe makes use of a dual-reward system that objectively evaluates each reply formatting and mathematical correctness with out requiring human annotation.
Necessary Hyperparameters:
learning_rate: 1.84e-4 – Studying price optimized for GRPO coaching
num_train_epochs: 2 – Coaching epochs to keep away from overfitting
per_device_train_batch_size: 16 with gradient_accumulation_steps: 2 – Efficient batch measurement of 32
max_seq_length: 2048 – Context window for 8-shot prompting
lora_r: 16 and lora_alpha: 16 – LoRA rank and scaling parameters
warmup_ratio: 0.1 with cosine scheduler – Studying price scheduling
lora_target_modules – Targets consideration and MLP layers for adaptation
As a subsequent step, you’ll use a SageMaker AI coaching job to spin up a coaching cluster and run the mannequin fine-tuning. The SageMaker AI Mannequin Coach. ModelTrainer runs coaching jobs on absolutely managed infrastructure; dealing with atmosphere setup, scaling, and artifact administration. It additionally means that you can specify coaching scripts, enter knowledge, and compute sources with out manually provisioning servers. Library dependencies may be managed via the necessities.txt file in scripts folder. ModelTrainer will robotically detect this file and set up the listed dependencies at runtime.
First, arrange your atmosphere. Right here you’ll specify the occasion kind and variety of cases for coaching and the placement of the coaching container.
Arrange the channels for coaching and validation knowledge:
from sagemaker.practice.configs import InputData
# Move the enter knowledge
train_input = InputData(
channel_name="practice",
data_source=train_dataset_s3_path, # S3 path the place coaching knowledge is saved
)
val_input = InputData(
channel_name="val",
data_source=val_dataset_s3_path, # S3 path the place coaching knowledge is saved
)
# Verify enter channels configured
knowledge = [train_input, val_input]
Then start coaching:model_trainer.practice(input_data_config=knowledge)The next is the listing construction for supply code of this instance:
scripts/
├── accelerate_configs/ # Speed up configuration recordsdata
├── run_finetuning.sh # Launch script for distributed coaching with Speed up on SageMaker coaching jobs
├── run_grpo.py # Fundamental coaching script for GRPO
├── utils/ # utilities to load knowledge and create immediate
├── recipes/ # Predefined coaching configuration recipes (YAML)
└── necessities.txt # Python dependencies put in at runtime
To fine-tune throughout a number of GPUs, the instance coaching script makes use of Huggingface Speed up and DeepSpeed ZeRO-3, which work collectively to coach giant fashions extra effectively. Huggingface Speed up simplifies launching distributed coaching by robotically dealing with gadget placement, course of administration, and blended precision settings. DeepSpeed ZeRO-3 reduces reminiscence utilization by partitioning optimizer states, gradients, and parameters throughout GPUs—permitting billion-parameter fashions to suit and practice sooner.You’ll be able to run your GRPO coach script with Huggingface Speed up utilizing a easy command like the next:
NUM_GPUS=$(nvidia-smi --list-gpus | wc -l)
echo "Detected ${NUM_GPUS} GPUs on the machine"
# Launch fine-tuning with Speed up + DeepSpeed (Zero3)
speed up launch
--config_file accelerate_configs/deepspeed_zero3.yaml
--num_processes ${NUM_GPUS}
run_grpo.py
--config $CONFIG_PATH
Outcomes
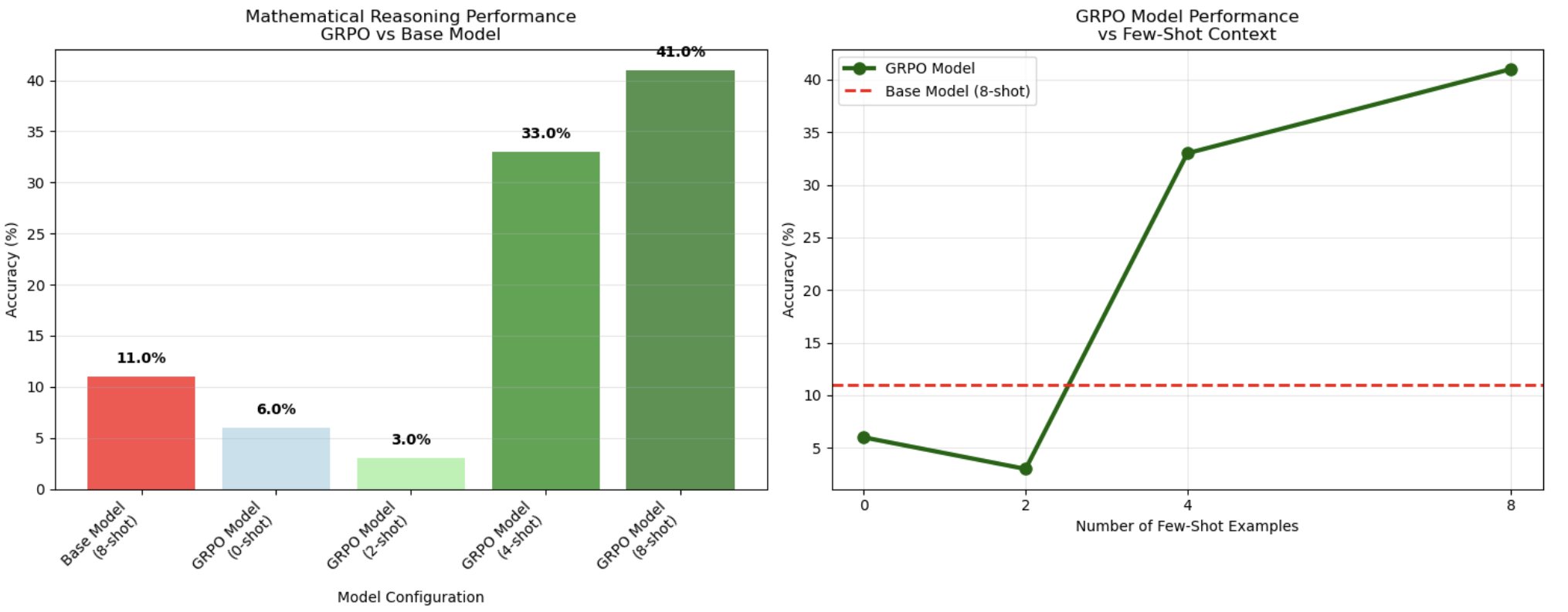
After evaluating the fashions on 100 check samples, the 8-shot GRPO-trained mannequin achieved 41% accuracy in comparison with the bottom mannequin’s 11%, demonstrating a 3.7x enchancment in chain-of-thought mathematical reasoning.
The next chart reveals a definite threshold associated to context size, revealing an optimum vary of samples for reasoning activation. Whereas 0-shot (6%) and 2-shot (3%) configurations carried out poorly – even worse than the bottom mannequin – efficiency dramatically improved at 4-shot prompting (33%), then peaked at 8-shot context (41%). This non-linear scaling sample means that GRPO coaching creates reasoning patterns that require a sure variety of examples to activate successfully. The mannequin seems to have realized to leverage group comparisons from a number of examples, according to GRPO’s group-based coverage optimization strategy the place the mannequin learns to match and choose optimum reasoning paths from a number of generated options.
Extending RLVR to different domains
Whereas this publish centered on mathematical reasoning with GSM8K, the RLVR strategy generalizes to domains with objectively verifiable outputs. Two promising instructions exhibit this versatility:
Code technology with execution-based rewards
Code technology offers pure verification via execution. Partial rewards may be awarded when code compiles and runs with out errors, whereas full rewards are achieved when outputs move complete unit assessments. Area consultants specify necessities utilizing pure language prompts, whereas the reward mannequin robotically evaluates correctness via code execution—assuaging subjective human analysis.
Area-specific textual content technology with semantic validation
For specialised domains like medical or technical writing, keyword-based rewards can information fashions towards acceptable terminology. Partial rewards encourage inclusion of required phrases, whereas full rewards require full key phrase units in semantically acceptable contexts. For example, medical textual content technology can reward outputs that mix diagnostic key phrases (“signs,” “analysis”) with therapy key phrases (“remedy,” “treatment”) in clinically legitimate patterns, educating area vocabulary via measurable targets. These examples illustrate how verifiable rewards lengthen past mathematical reasoning to duties the place correctness may be programmatically validated, establishing the inspiration for broader functions of this coaching strategy.
Cleansing Up
To scrub up your sources to keep away from incurring extra expenses, comply with these steps:
Confirm that your coaching job isn’t working anymore! To take action, in your SageMaker console, select Coaching and verify Coaching jobs.
To be taught extra about cleansing up your sources provisioned, take a look at Clear up.
Conclusion
On this instance you educated a Qwen2.5-0.5B mannequin utilizing GRPO (Group Relative Coverage Optimization) on GSM8K: a dataset of 8,500 grade faculty math phrase issues that require multi-step arithmetic reasoning and pure language understanding. Every drawback features a query like “Janet’s geese lay 16 eggs per day…” with step-by-step options ending in numerical solutions, making it ultimate for verifiable reward coaching.
This implementation demonstrates the effectiveness of Reinforcement Studying with Verifiable Rewards (RLVR) for mathematical reasoning duties. The GRPO-trained Qwen2.5-0.5B mannequin achieved a 3.7x enchancment over the bottom mannequin, reaching 41% accuracy on GSM8K in comparison with the baseline 11%.The analysis outcomes validate RLVR as a promising strategy for domains with objectively verifiable outcomes, providing an alternative choice to preference-based coaching strategies. The brink conduct suggests GRPO learns to leverage group comparisons from a number of examples, according to its group-based optimization strategy. This work establishes a basis for making use of verifiable reward programs to different domains requiring logical rigor and mathematical accuracy.
Phrase embedding is a technique used to map phrases of a vocabulary to
dense vectors of actual numbers the place semantically related phrases are mapped to
close by factors. Representing phrases on this vector house assist
algorithms obtain higher efficiency in pure language
processing duties like syntactic parsing and sentiment evaluation by grouping
related phrases. For instance, we count on that within the embedding house
“cats” and “canines” are mapped to close by factors since they’re
each animals, mammals, pets, and so forth.
On this tutorial we are going to implement the skip-gram mannequin created by Mikolov et al in R utilizing the keras package deal.
The skip-gram mannequin is a taste of word2vec, a category of
computationally-efficient predictive fashions for studying phrase
embeddings from uncooked textual content. We received’t deal with theoretical particulars about embeddings and
the skip-gram mannequin. If you wish to get extra particulars you’ll be able to learn the paper
linked above. The TensorFlow Vector Illustration of Phrases tutorial contains further particulars as does the Deep Studying With Rpocket book about embeddings.
There are different methods to create vector representations of phrases. For instance,
GloVe Embeddings are applied within the text2vec package deal by Dmitriy Selivanov.
There’s additionally a tidy method described in Julia Silge’s weblog publish Phrase Vectors with Tidy Knowledge Ideas.
Getting the Knowledge
We are going to use the Amazon Effective Meals Opinions dataset.
This dataset consists of critiques of tremendous meals from Amazon. The info span a interval of greater than 10 years, together with all ~500,000 critiques as much as October 2012. Opinions embrace product and consumer info, rankings, and narrative textual content.
Knowledge could be downloaded (~116MB) by operating:
We are going to now load the plain textual content critiques into R.
Let’s check out some critiques we now have within the dataset.
[1] "I've purchased a number of of the Vitality canned pet food merchandise ...
[2] "Product arrived labeled as Jumbo Salted Peanuts...the peanuts ...
Preprocessing
We’ll start with some textual content pre-processing utilizing a keras text_tokenizer(). The tokenizer shall be
liable for remodeling every overview right into a sequence of integer tokens (which is able to subsequently be used as
enter into the skip-gram mannequin).
Notice that the tokenizer object is modified in place by the decision to fit_text_tokenizer().
An integer token shall be assigned for every of the 20,000 most typical phrases (the opposite phrases will
be assigned to token 0).
Skip-Gram Mannequin
Within the skip-gram mannequin we are going to use every phrase as enter to a log-linear classifier
with a projection layer, then predict phrases inside a sure vary earlier than and after
this phrase. It will be very computationally costly to output a chance
distribution over all of the vocabulary for every goal phrase we enter into the mannequin. As an alternative,
we’re going to use unfavorable sampling, which means we are going to pattern some phrases that don’t
seem within the context and practice a binary classifier to foretell if the context phrase we
handed is really from the context or not.
In additional sensible phrases, for the skip-gram mannequin we are going to enter a 1d integer vector of
the goal phrase tokens and a 1d integer vector of sampled context phrase tokens. We are going to
generate a prediction of 1 if the sampled phrase actually appeared within the context and 0 if it didn’t.
We are going to now outline a generator operate to yield batches for mannequin coaching.
A generator operate
is a operate that returns a special worth every time it’s referred to as (generator features are sometimes used to offer streaming or dynamic knowledge for coaching fashions). Our generator operate will obtain a vector of texts,
a tokenizer and the arguments for the skip-gram (the dimensions of the window round every
goal phrase we look at and what number of unfavorable samples we wish
to pattern for every goal phrase).
Now let’s begin defining the keras mannequin. We are going to use the Keras practical API.
embedding_size<-128# Dimension of the embedding vector.skip_window<-5# What number of phrases to think about left and proper.num_sampled<-1# Variety of unfavorable examples to pattern for every phrase.
We are going to first write placeholders for the inputs utilizing the layer_input operate.
Now let’s outline the embedding matrix. The embedding is a matrix with dimensions
(vocabulary, embedding_size) that acts as lookup desk for the phrase vectors.
The following step is to outline how the target_vector shall be associated to the context_vector
as a way to make our community output 1 when the context phrase actually appeared within the
context and 0 in any other case. We would like target_vector to be related to the context_vector
in the event that they appeared in the identical context. A typical measure of similarity is the cosine
similarity. Give two vectors (A) and (B)
the cosine similarity is outlined by the Euclidean Dot product of (A) and (B) normalized by their
magnitude. As we don’t want the similarity to be normalized contained in the community, we are going to solely calculate
the dot product after which output a dense layer with sigmoid activation.
We are going to match the mannequin utilizing the fit_generator() operate We have to specify the variety of
coaching steps in addition to variety of epochs we need to practice. We are going to practice for
100,000 steps for five epochs. That is fairly gradual (~1000 seconds per epoch on a contemporary GPU). Notice that you just
might also get cheap outcomes with only one epoch of coaching.
We are able to now extract the embeddings matrix from the mannequin by utilizing the get_weights()
operate. We additionally added row.names to our embedding matrix so we will simply discover
the place every phrase is.
Understanding the Embeddings
We are able to now discover phrases which might be shut to one another within the embedding. We are going to
use the cosine similarity, since that is what we skilled the mannequin to
reduce.
library(text2vec)find_similar_words<-operate(phrase, embedding_matrix, n=5){similarities<-embedding_matrix[word, , drop =FALSE]%>%sim2(embedding_matrix, y =., technique ="cosine")similarities[,1]%>%kind(lowering =TRUE)%>%head(n)}
find_similar_words("2", embedding_matrix)
2 4 3 two 6
1.0000000 0.9830254 0.9777042 0.9765668 0.9722549
find_similar_words("little", embedding_matrix)
little bit few small deal with
1.0000000 0.9501037 0.9478287 0.9309829 0.9286966
cats canines children cat canine
1.0000000 0.9844937 0.9743756 0.9676026 0.9624494
The t-SNE algorithm can be utilized to visualise the embeddings. Due to time constraints we
will solely use it with the primary 500 phrases. To know extra concerning the t-SNE technique see the article Easy methods to Use t-SNE Successfully.
This plot might appear to be a large number, however for those who zoom into the small teams you find yourself seeing some good patterns.
Attempt, for instance, to discover a group of internet associated phrases like http, href, and so forth. One other group
that could be simple to select is the pronouns group: she, he, her, and so forth.
The web isn’t simply filled with content material anymore — it’s filled with interruptions. Pop-ups, autoplay movies, sketchy banners, and monitoring scripts all compete to your consideration earlier than you even get to what you truly got here for.
The AdGuard Household Plan clears the noise so your searching lastly feels clear once more, and proper now it’s accessible for $15.97 (MSRP $169.99) by means of Could 17 for lifetime entry on 9 gadgets.
Stops trackers and protects your searching information from being collected
Filters malware and phishing websites earlier than they load
Provides parental controls for safer searching at house
It really works throughout desktop and cellular, helps as much as 9 gadgets, and retains working within the background with out you eager about it.
If adverts and pop-ups are cluttering your web expertise, that is the reset button. Get lifetime AdGuard Household Plan entry for $15.97 (MSRP $169.99) till Could 17 at 11:59pm Pacific.
Interstellar journey propelled by mild simply received one step nearer. Gentle sails, that are big sheets pushed alongside by mild that bounces off of them, could also be one of the simplest ways to journey monumental distances by area, and now we might have a solution to steer them.
“We knew already that any mild or laser can impart momentum switch, however now we are able to management the route as nicely,” says Kaushik Kudtarkar at Texas A&M College. He and his colleagues created a tiny system known as a metajet that makes use of refraction of sunshine, not simply reflection, to maneuver in a couple of route directly.
The system is a fabric known as a metasurface, an especially skinny sheet textured to control mild. On this case, the researchers flipped that on its head, utilizing the sunshine to control the metasurface. A sequence of tiny pillars on the fabric steers the sunshine that hits it, with the scale and sample of the pillars controlling the energy and route of the momentum that the sunshine imparts on all the system because it strikes by. The entire thing is about 0.01 millimetres throughout.
To check it, the researchers dropped the silicon system in water and shone a laser on it, watching it with a microscope to trace its movement. They discovered that the metajet each levitated and moved horizontally, reaching a most pace of about 0.07 millimetres per second.
The metajet shifting forwards, captured each 10 seconds
Kaushik Kudtarkar et al. 2026
“Now that we all know concerning the forces on this system, you possibly can change the metasurface design after which you possibly can steer it in any manner you need,” says Kudtarkar. There are metasurfaces that change their shapes over time, and such a fabric could possibly be used on mild sails to steer them by area, he says.
“For area, you possibly can develop it, however you possibly can hold it the identical measurement and use it for biomedical functions as nicely: these units might actually push medication to a selected location,” says Kudtarkar. Lasers can already be used to do that, however their warmth can injury the molecules, and with metajets, the medication wouldn’t be instantly uncovered to the warmth and lightweight of a laser beam.
The researchers are actually seeking to make their system work with completely different wavelengths of sunshine, particularly the broad spectrum of daylight to make them extra suitable with the kind of mild sail that might be used for area journey. “It’s all a bit sci-fi,” says Kudtarkar.
Claude Code Channels is rapidly changing into a sensible various to OpenClaw for individuals who wish to join Claude to talk platforms with out establishing a heavier agent framework. It’s easier to get working, works with a Claude subscription out of the field, and provides you an easy option to work together with a neighborhood Claude Code session via Discord.
On this article, you’ll learn to arrange Claude Code Channels domestically and join it to your Discord server. The important thing factor to grasp from the beginning is that this setup will depend on a stay native Claude Code session. The bot solely works whereas that session is actively working in your machine.
# What You Want Earlier than You Begin
Earlier than setting all the things up, ensure you have:
You must also know that Channels requires a Claude.ai login and doesn’t work with API-key-only authentication.
Notice: This information makes use of Home windows 11 because the working system for the setup steps and instructions, however the identical total course of can be adopted on Linux and macOS.
# Putting in Claude Code and Signing In
First, set up Claude Code in PowerShell:
irm https://claude.ai/set up.ps1 | iex
Then create a working folder, transfer into it, and begin Claude Code:
mkdir my-channels
cd my-channels
claude
As soon as Claude Code opens, log in along with your Claude.ai account:
This step is required earlier than Channels will work.
# Putting in Bun and Including the Discord Plugin
Claude Code’s official Channels plugins use Bun, so set up it subsequent:
irm bun.sh/set up.ps1 | iex
You may affirm the set up with:
After that, inside Claude Code, run the next instructions one after the other in the identical sequence. Every command prepares the subsequent step, so it is necessary to not skip the order.
Subsequent, replace {the marketplace} so Claude Code can fetch the newest out there plugins:
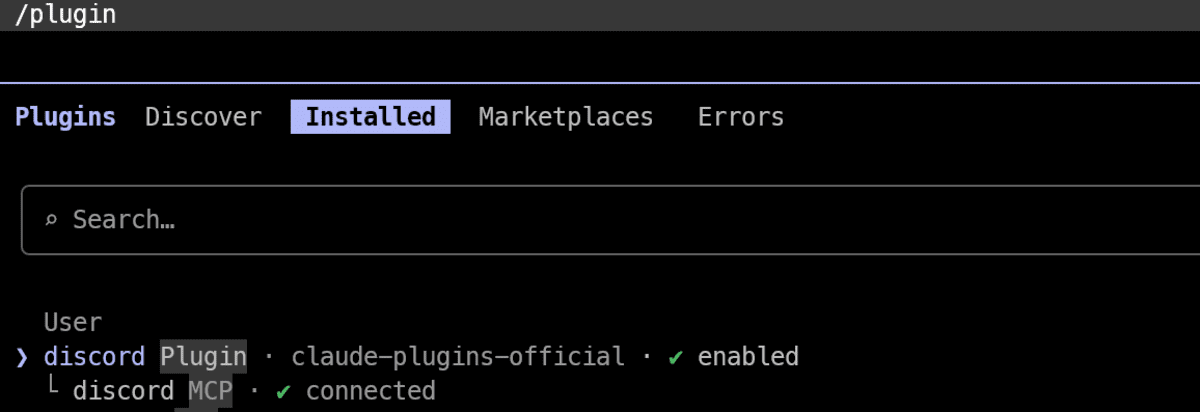
/plugin market replace claude-plugins-official
Then set up the official Discord plugin:
/plugin set up discord@claude-plugins-official
Lastly, reload plugins so the newly put in Discord integration turns into out there in your present Claude Code session:
At this level, Claude Code is able to use the Discord channel integration.
# Creating and Configuring Your Discord Bot
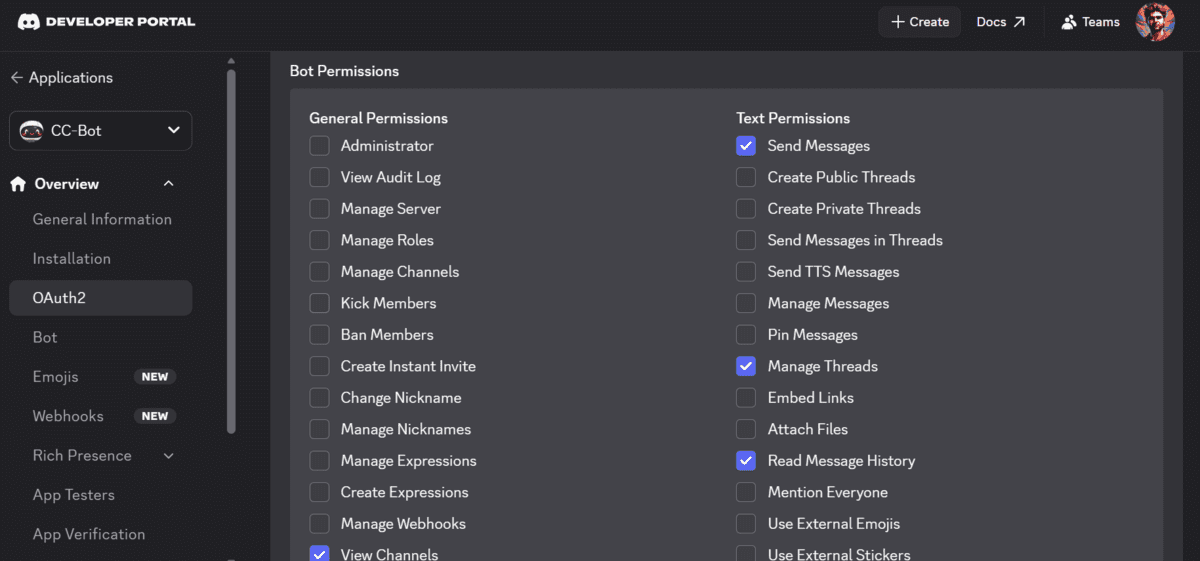
Now go to the Discord Developer Portal and create a brand new utility. Inside that utility, open the Bot part, reset the token, and replica it someplace secure.
You additionally must allow Message Content material Intent, as a result of with out it the bot won’t be able to learn the textual content folks ship.
Subsequent, generate an invitation hyperlink for the bot utilizing the OAuth2 URL Generator. Give it the permissions it wants, reminiscent of:
View Channels
Ship Messages
Ship Messages in Threads
Learn Message Historical past
Connect Information
Add Reactions
Ship Voice Messages
Then use the generated hyperlink so as to add the bot to your Discord server.
# Connecting Claude Code to Discord
Return to Claude Code and configure the Discord plugin utilizing your bot token:
/discord:configure YOUR_DISCORD_BOT_TOKEN
Claude Code often shops this token robotically in its Channels config listing.
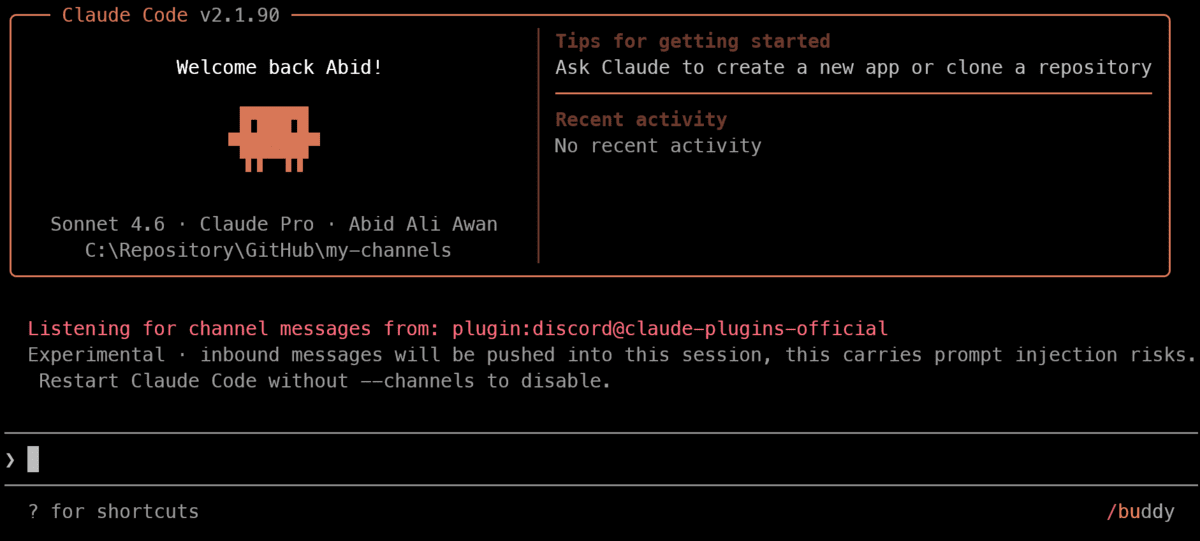
After configuring the token, restart Claude Code with Channels enabled:
claude --channels plugin:discord@claude-plugins-official
This begins Claude Code with the Discord Channels plugin turned on.
If you do not need Claude Code to ask for permission every time it wants to make use of a software or take a brand new motion, you can begin it with the auto-approve flag as an alternative:
claude --dangerously-skip-permissions --channels plugin:discord@claude-plugins-official
This makes the session extra automated, which might be helpful for a smoother Discord expertise. Nonetheless, it’s best to solely use this in case you belief the surroundings and perceive that Claude Code will probably be allowed to behave with out asking for affirmation every time.
# Pairing Your Discord Account and Beginning to Use It
As soon as Claude Code is working with Channels enabled, ship your bot a direct message in Discord. It ought to reply with a pairing code.
Take that code and enter it inside Claude Code:
/discord:entry pair YOUR_PAIRING_CODE
Then lock entry to accredited customers solely:
/discord:entry coverage allowlist
After that, you possibly can message the bot in Discord and Claude Code will reply via your native session.
# Ultimate Notes and Troubleshooting
If one thing is just not working as anticipated, the factors beneath cowl the most typical Claude Code Channels points and the quickest methods to repair them.
Bot is on-line however says nothing: Allow Message Content material Intent in your Discord bot settings. With out it, the bot receives empty message content material.
Claude by no means connects to Discord: Restart Claude Code with the --channels plugin:discord@claude-plugins-official flag. The Discord plugin won’t work until Channels is enabled at launch.
Bot doesn’t reply after setup: Full the pairing step by sending the bot a DM, copying the pairing code, and working the pair command inside Claude Code.
DMs don’t work in any respect: Ensure your Discord account and the bot are in the identical server, since Discord requires that for direct messages to work.
Plugin instructions don’t seem: Run /reload-plugins after putting in or updating the plugin so the present session picks it up.
Replies break after resuming a session: Keep away from counting on --resume for now, as a result of a latest Claude Code difficulty reviews that channel plugins might not restart appropriately after resume.
Claude says it’s listening, however nothing arrives: Verify /mcp to verify the Discord plugin is definitely related. Latest reviews present instances the place the plugin fails on startup though Claude Code seems to be prepared.
Messages arrive however Claude stays idle: This can be a present channel notification bug. Restarting the session is the only workaround for now.
Replies cease after an Permit or Deny immediate: This can be a lately reported Discord permission relay difficulty. Restart the session if it occurs.
If the bot stops working whenever you shut the terminal, that’s regular. Claude Code Channels solely works whereas your native Claude Code session remains to be working.
Abid Ali Awan (@1abidaliawan) is a licensed knowledge scientist skilled who loves constructing machine studying fashions. At present, he’s specializing in content material creation and writing technical blogs on machine studying and knowledge science applied sciences. Abid holds a Grasp’s diploma in know-how administration and a bachelor’s diploma in telecommunication engineering. His imaginative and prescient is to construct an AI product utilizing a graph neural community for college students fighting psychological sickness.