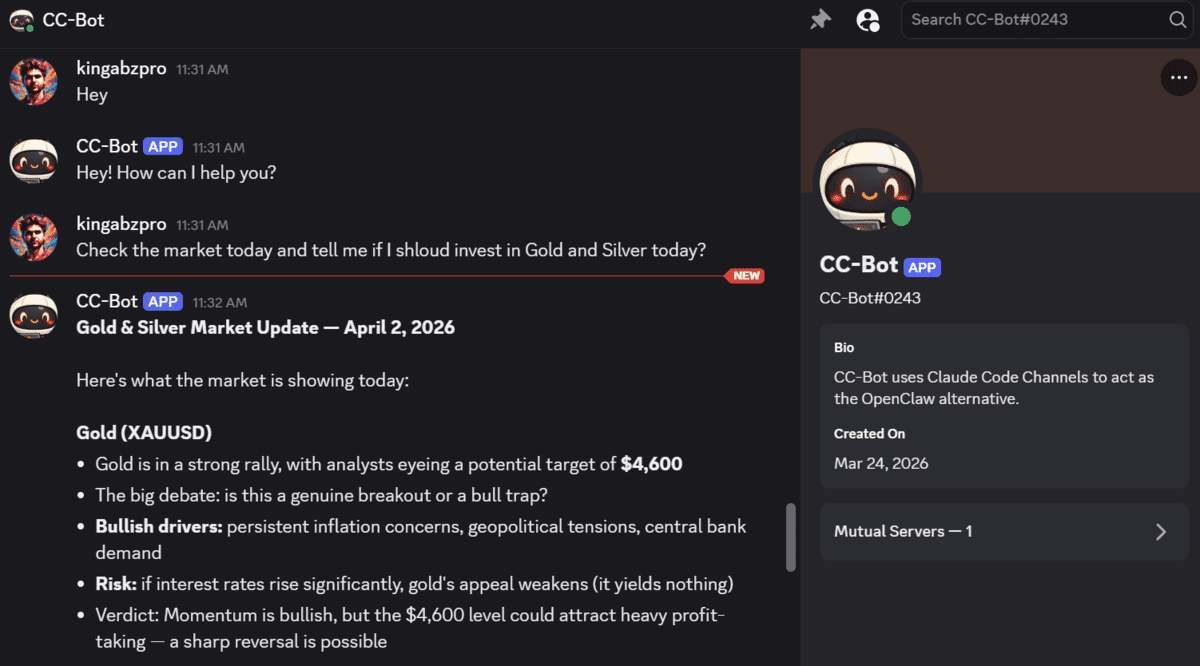
Claude Code Channels is rapidly changing into a sensible various to OpenClaw for individuals who wish to join Claude to talk platforms with out establishing a heavier agent framework. It’s easier to get working, works with a Claude subscription out of the field, and provides you an easy option to work together with a neighborhood Claude Code session via Discord.
On this article, you’ll learn to arrange Claude Code Channels domestically and join it to your Discord server. The important thing factor to grasp from the beginning is that this setup will depend on a stay native Claude Code session. The bot solely works whereas that session is actively working in your machine.
# What You Want Earlier than You Begin
Earlier than setting all the things up, ensure you have:
You must also know that Channels requires a Claude.ai login and doesn’t work with API-key-only authentication.
Notice: This information makes use of Home windows 11 because the working system for the setup steps and instructions, however the identical total course of can be adopted on Linux and macOS.
# Putting in Claude Code and Signing In
First, set up Claude Code in PowerShell:
irm https://claude.ai/set up.ps1 | iex
Then create a working folder, transfer into it, and begin Claude Code:
mkdir my-channels
cd my-channels
claude
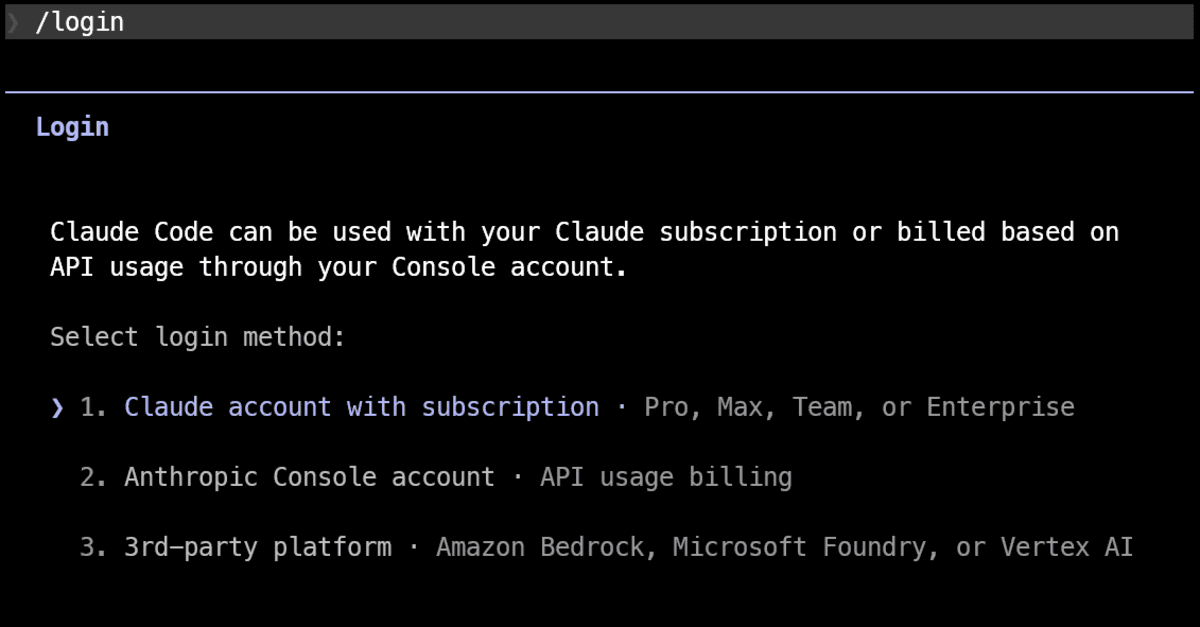
As soon as Claude Code opens, log in along with your Claude.ai account:
This step is required earlier than Channels will work.
# Putting in Bun and Including the Discord Plugin
Claude Code’s official Channels plugins use Bun, so set up it subsequent:
irm bun.sh/set up.ps1 | iex
You may affirm the set up with:
After that, inside Claude Code, run the next instructions one after the other in the identical sequence. Every command prepares the subsequent step, so it is necessary to not skip the order.
Subsequent, replace {the marketplace} so Claude Code can fetch the newest out there plugins:
/plugin market replace claude-plugins-official
Then set up the official Discord plugin:
/plugin set up discord@claude-plugins-official
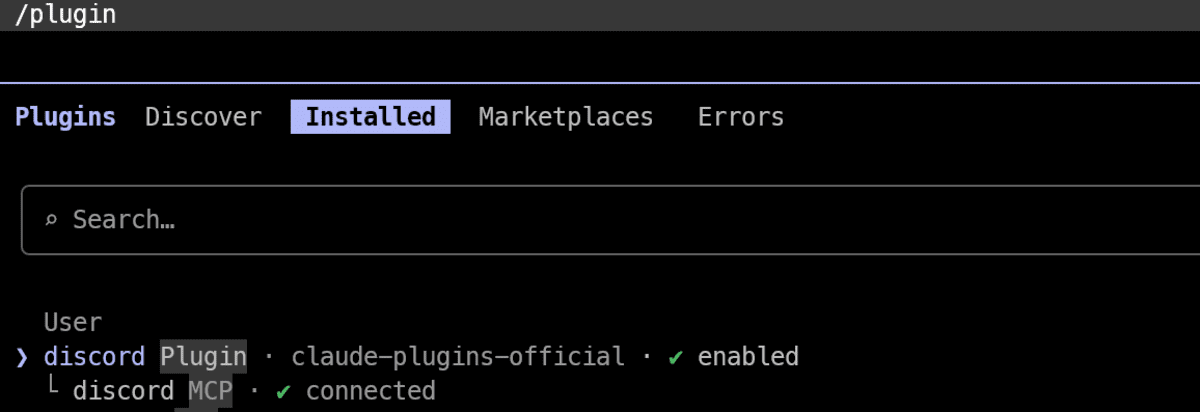
Lastly, reload plugins so the newly put in Discord integration turns into out there in your present Claude Code session:
At this level, Claude Code is able to use the Discord channel integration.
# Creating and Configuring Your Discord Bot
Now go to the Discord Developer Portal and create a brand new utility. Inside that utility, open the Bot part, reset the token, and replica it someplace secure.
You additionally must allow Message Content material Intent, as a result of with out it the bot won’t be able to learn the textual content folks ship.
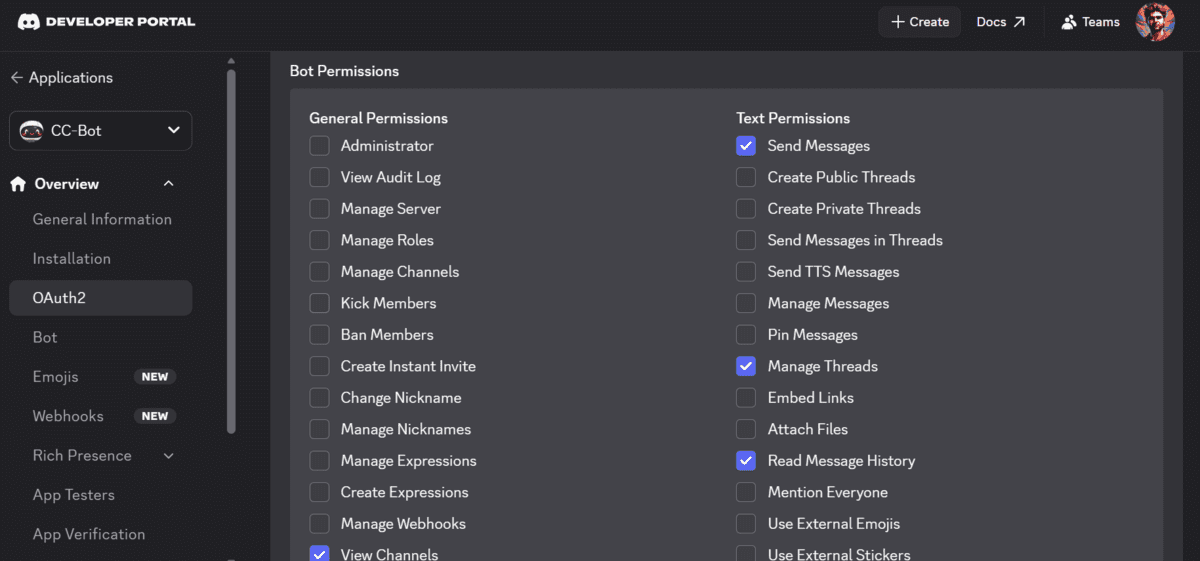
Subsequent, generate an invitation hyperlink for the bot utilizing the OAuth2 URL Generator. Give it the permissions it wants, reminiscent of:
View Channels
Ship Messages
Ship Messages in Threads
Learn Message Historical past
Connect Information
Add Reactions
Ship Voice Messages
Then use the generated hyperlink so as to add the bot to your Discord server.
# Connecting Claude Code to Discord
Return to Claude Code and configure the Discord plugin utilizing your bot token:
/discord:configure YOUR_DISCORD_BOT_TOKEN
Claude Code often shops this token robotically in its Channels config listing.
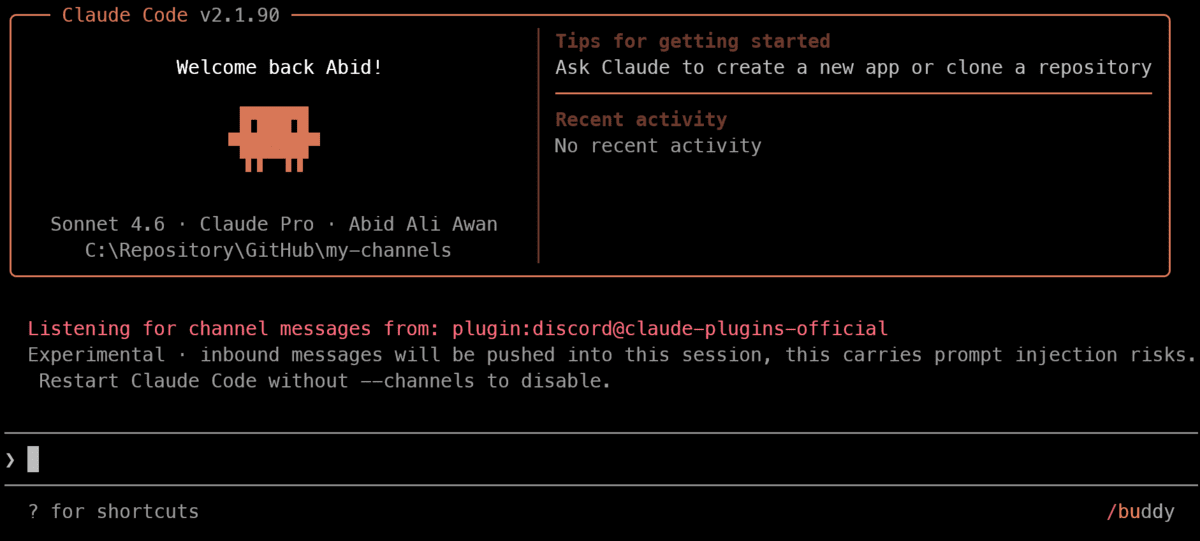
After configuring the token, restart Claude Code with Channels enabled:
claude --channels plugin:discord@claude-plugins-official
This begins Claude Code with the Discord Channels plugin turned on.
If you do not need Claude Code to ask for permission every time it wants to make use of a software or take a brand new motion, you can begin it with the auto-approve flag as an alternative:
claude --dangerously-skip-permissions --channels plugin:discord@claude-plugins-official
This makes the session extra automated, which might be helpful for a smoother Discord expertise. Nonetheless, it’s best to solely use this in case you belief the surroundings and perceive that Claude Code will probably be allowed to behave with out asking for affirmation every time.
# Pairing Your Discord Account and Beginning to Use It
As soon as Claude Code is working with Channels enabled, ship your bot a direct message in Discord. It ought to reply with a pairing code.
Take that code and enter it inside Claude Code:
/discord:entry pair YOUR_PAIRING_CODE
Then lock entry to accredited customers solely:
/discord:entry coverage allowlist
After that, you possibly can message the bot in Discord and Claude Code will reply via your native session.
# Ultimate Notes and Troubleshooting
If one thing is just not working as anticipated, the factors beneath cowl the most typical Claude Code Channels points and the quickest methods to repair them.
Bot is on-line however says nothing: Allow Message Content material Intent in your Discord bot settings. With out it, the bot receives empty message content material.
Claude by no means connects to Discord: Restart Claude Code with the --channels plugin:discord@claude-plugins-official flag. The Discord plugin won’t work until Channels is enabled at launch.
Bot doesn’t reply after setup: Full the pairing step by sending the bot a DM, copying the pairing code, and working the pair command inside Claude Code.
DMs don’t work in any respect: Ensure your Discord account and the bot are in the identical server, since Discord requires that for direct messages to work.
Plugin instructions don’t seem: Run /reload-plugins after putting in or updating the plugin so the present session picks it up.
Replies break after resuming a session: Keep away from counting on --resume for now, as a result of a latest Claude Code difficulty reviews that channel plugins might not restart appropriately after resume.
Claude says it’s listening, however nothing arrives: Verify /mcp to verify the Discord plugin is definitely related. Latest reviews present instances the place the plugin fails on startup though Claude Code seems to be prepared.
Messages arrive however Claude stays idle: This can be a present channel notification bug. Restarting the session is the only workaround for now.
Replies cease after an Permit or Deny immediate: This can be a lately reported Discord permission relay difficulty. Restart the session if it occurs.
If the bot stops working whenever you shut the terminal, that’s regular. Claude Code Channels solely works whereas your native Claude Code session remains to be working.
Abid Ali Awan (@1abidaliawan) is a licensed knowledge scientist skilled who loves constructing machine studying fashions. At present, he’s specializing in content material creation and writing technical blogs on machine studying and knowledge science applied sciences. Abid holds a Grasp’s diploma in know-how administration and a bachelor’s diploma in telecommunication engineering. His imaginative and prescient is to construct an AI product utilizing a graph neural community for college students fighting psychological sickness.
“Unlocking the ability of brokers requires reminiscence,” Pete Johnson, MongoDB’s subject CTO of AI, mentioned throughout a press briefing. “Similar to human reminiscence, a very good agentic reminiscence organizes information. It helps brokers retrieve the best information primarily based on context and be taught to make smarter choices and take optimized actions over time.”
To advance automated retrieval and chronic agent reminiscence, the corporate is including Automated Voyage AI Embeddings in MongoDB Vector Search. The aptitude is now accessible in public preview.
Fragmented AI stacks current one other problem. As builders grapple with them, they’re typically caught paying what Ben Cefalo, MongoDB CPO, known as the “synchronization tax.” To make information agent-searchable, builders should sew collectively issue search, operational information shops, embedded fashions, and caches, then take the time to construct advanced information pipelines that hold every part in sync throughout techniques.
However by natively integrating Voyage AI into Atlas, MongoDB has turned a “multi week engineering venture right into a two minute configuration,” Cefalo claimed. Builders can ship dependable, reliable brokers rather more shortly and simply, and “with out all of the advanced information plumbing.”
Vector databases have graduated from experimental tooling to mission-critical infrastructure. In 2026, vector databases function the core retrieval layer for RAG pipelines, semantic search techniques, and agentic AI workflows — and selecting the incorrect one has actual price and efficiency penalties. This information breaks down the highest vector databases obtainable as we speak, overlaying structure, efficiency, pricing, and the best use circumstances for every.
Why Vector Databases Matter Extra Than Ever in 2026
The shift is structural. As LLMs develop into customary in enterprise software program, the necessity to retailer, index, and retrieve high-dimensional embeddings at scale has develop into unavoidable. RAG (Retrieval-Augmented Technology) has develop into one of many dominant architectures for grounding LLM outputs in non-public or real-time information, and plenty of manufacturing RAG techniques use vector databases as a core retrieval layer. The query is now not whether or not you want a vector database — it’s which one matches your infrastructure, scale, and funds.
MARKTECHPOST · UPDATED MAY 2026 · 9 DATABASES REVIEWED · FACT-CHECKED AGAINST PRIMARY SOURCES
▸ Greatest Managed, Zero-Ops Vector DB
Pricing
Free / $20 / $50 / $500 min
CEO (Sep 2025)
Ash Ashutosh
Strongest totally managed possibility for low operational overhead. New Builder tier ($20/mo) added 2026. Nexus & KnowQL launched Could 2026 Launch Week.
Go-to for billion-scale with GPU acceleration. Zilliz Cloud’s Cardinal engine delivers as much as 10x throughput and 3x quicker index builds vs OSS options.
Engineers’ selection. Composable vector search: dense + sparse + filters + customized scoring in a single question. Rust-native. Self-host handles thousands and thousands of vectors at $30–50/mo.
Hybrid search champion. Processes BM25, vector similarity, and metadata filters concurrently in a single question. Observe: $25/mo pricing is retired since Oct 2025.
For those who’re on PostgreSQL and underneath 10M vectors, add pgvector earlier than including a brand new database. Vectors and relational information in the identical transaction, zero new infrastructure.
Zero information sprawl — vectors, JSON docs, and metadata in a single assortment. Automated Embedding (Voyage AI) permits one-click semantic search. Integrates with LangChain & LlamaIndex natively.
Quickest path from zero to working vector search. Runs in-process or as client-server. Not optimized for excessive manufacturing scale — purpose-built for LLM utility scaffolding.
Sits immediately on object storage — no always-on server. AWS-validated for serverless stacks at billion-vector scale. Robust multimodal help for cross-modal retrieval pipelines.
A library, not a database — no persistence, question API, or operational tooling. The inspiration many manufacturing techniques construct on. For ML researchers and customized similarity search pipelines.
Already working MongoDB? You don’t want a second database.
Atlas Vector Search retains operational information, metadata, and vector embeddings in a single assortment — no sync lag, no dual-write, no further billing envelope. Automated Embedding through Voyage AI provides one-click semantic search. Flex tier caps at $30/month. M0 free tier obtainable with no bank card.
Pinecone stays one of many strongest totally managed choices for groups that need low operational overhead. Its serverless structure permits builders to retailer billions of vectors with out provisioning a single server, with robust multi-tenant isolation and high-availability SLAs.
In 2025–2026, Pinecone optimized its serverless structure to satisfy rising demand for large-scale agentic workloads. Key capabilities embrace Pinecone Inference (hosted embedding and reranking fashions built-in into the pipeline), Pinecone Assistant for production-grade chat and agent functions, Devoted Learn Nodes (DRN) for read-heavy workloads, and native full-text search in public preview. BYOC (Convey Your Personal Cloud) — now in public preview on AWS, GCP, and Azure — runs the info aircraft contained in the buyer’s personal cloud account. Pinecone additionally launched Nexus and KnowQL in early entry as a part of its Could 2026 Launch Week.
Pricing: Pinecone has 4 tiers: Starter (free), Builder ($20/month flat), Commonplace ($50/month minimal utilization), and Enterprise ($500/month minimal utilization). The Builder tier is new in 2026, concentrating on solo builders and small groups. At manufacturing scale, prices can climb considerably — however the zero-DevOps overhead justifies it for groups with out devoted infrastructure engineers.
Milvus is the dominant open-source selection for billion-scale deployments. Its managed counterpart, Zilliz Cloud, makes use of Cardinal — a proprietary vector search engine that Zilliz says delivers as much as 10x greater question throughput and 3x quicker index constructing in comparison with open-source HNSW-based options — with native integration with streaming information platforms like Kafka and Spark.
Milvus is designed for environment friendly vector embedding and similarity searches, supporting GPU acceleration, distributed querying, and environment friendly indexing. It’s extremely configurable and helps a spread of indexing strategies equivalent to IVF, HNSW, and PQ, permitting customers to stability accuracy and velocity in response to their wants. The database provides wonderful scalability with environment friendly index storage and shard administration.
In distributed mode, Milvus introduces further operational dependencies — together with metadata storage, object storage, and WAL/message-log infrastructure — relying on the deployment configuration. For many groups, it’s extra infrastructure than the workload calls for.
Its 2026 differentiator is composable vector search: each side of retrieval is a composable primitive engineers management immediately — indexing, scoring, filtering, and rating are all tunable, none opaque. Operators can compose dense vectors, sparse vectors, metadata filters, multi-vector retrieval, and customized scoring in a single question.
Qdrant provides one of the best price-performance ratio in 2026. Self-hosted on a small VPS, it handles thousands and thousands of vectors at $30–$50/month.
The free tier gives 1GB RAM and 4GB disk storage with no bank card required. Paid cloud plans are resource-based quite than a flat charge — pricing scales with compute and storage provisioned. Filtering is the place Qdrant stands out — the database helps wealthy JSON-based filters that combine with vector search effectively. Select Qdrant if you’re budget-conscious, want advanced filtering at reasonable scale (underneath 50 million vectors), need edge or on-device deployment through Qdrant Edge, or desire a stable stability of options with out breaking the financial institution.
Weaviate is the hybrid search champion in 2026, delivering native BM25 + dense vectors + metadata filtering in a single question. Constructed-in vectorization through built-in embedding fashions eliminates exterior pipelines. Multi-modal help handles textual content, pictures, and audio in the identical vector area.
Whereas Pinecone and Milvus give attention to pure vector search, Weaviate does one factor higher than every other database on this comparability: hybrid search. You question with a vector embedding, add key phrase filters utilizing BM25, and apply metadata constraints — Weaviate processes all three concurrently and returns ranked outcomes. Different databases add these options individually or require combining separate queries; Weaviate builds it into the core structure.
The modular structure lets groups swap in several embedding fashions, vectorizers, and rerankers with out rebuilding an utility — important when fashions replace continuously.
Pricing:Weaviate restructured its cloud pricing in October 2025. The outdated Serverless tier ($25/month) was retired and changed with Flex at $45/month minimal (shared cloud, 99.5% SLA, pay-as-you-go), together with from $280/month (annual dedication, 99.9% SLA), and Premium from $400/month (devoted infrastructure, 99.95% SLA). A free 14-day sandbox is offered with no bank card required, but it surely expires mechanically and can’t be prolonged. Any supply nonetheless citing $25/month is referencing pre-October 2025 pricing.
Kind: PostgreSQL extension | Greatest for: Groups wanting a unified relational + vector information stack
Probably the most vital pattern in present structure is the rising adoption of pgvector. If you’re already utilizing PostgreSQL, you seemingly don’t want a brand new database. It has pushed its capability to thousands and thousands of vectors with production-grade velocity. It provides full ACID compliance for each conventional relational and vector information.
pgvector provides a vector column kind to PostgreSQL with help for cosine similarity, L2 distance, and inside product operations. It helps each HNSW and IVFFlat indexing.
The operational benefit is important: vectors stay subsequent to relational information, each might be queried in the identical transaction, and groups handle one system as an alternative of two. For functions the place vector search is one characteristic amongst many — quite than the core workload — that is usually the best name.
Kind: Absolutely managed SaaS (Atlas) | Greatest for: Full-stack functions the place vectors should stay alongside JSON paperwork and operational information
MongoDB Atlas Vector Search brings vector retrieval immediately into the Atlas managed database platform — eliminating the “information sprawl” drawback of sustaining a separate vector retailer alongside a main database. Operational information, metadata, and vector embeddings all stay in the identical assortment, queryable in a single pipeline. That is the strongest argument for MongoDB within the vector area: zero synchronization lag between doc updates and their vector index.
Atlas Vector Search makes use of HNSW-based ANN indexing and helps embeddings as much as 4,096 dimensions, with scalar and binary quantization for price and efficiency optimization. Search Nodes enable groups to scale their vector search workload independently from their transactional cluster — important for read-heavy RAG functions. The platform integrates natively with LangChain, LlamaIndex, and Microsoft Semantic Kernel, and helps RAG, semantic search, advice engines, and agentic AI patterns out of the field.
A standout 2026 characteristic is Automated Embedding — a one-click semantic search functionality powered by Voyage AI that generates and manages vector embeddings mechanically, with out requiring groups to jot down embedding code or handle mannequin infrastructure.
Atlas Vector Search is built-in into Atlas cluster pricing — there is no such thing as a separate cost for the vector search characteristic itself. The M0 tier is free endlessly (512MB storage). The Flex tier (GA February 2025) helps Vector Search and caps at $30/month, changing the older Serverless and Shared tiers. Devoted clusters begin at roughly $57/month (M10) for manufacturing workloads.
Chroma — Greatest for Prototyping and LLM-Native Improvement
Kind: Open-source, embedded or client-server | Greatest for: Early growth, native prototyping, LLM utility scaffolding
Chroma is an open-source embedding database centered on developer expertise. It runs in-process (embedded) or as a client-server setup, making it the quickest path from zero to a working vector search.
Chroma has an intuitive API that simplifies integration into functions, making it accessible for builders and researchers with out requiring intensive database administration experience. It delivers excessive accuracy with spectacular recall charges, supporting embedding-based search and superior ANN (Approximate Nearest Neighbor) strategies.
Chroma DB’s mixture of simplicity, flexibility, and AI-native design makes it a wonderful selection for builders engaged on LLM-powered functions. Its open-source nature and energetic group contribute to its fast evolution.
Chroma Cloud is offered with a Starter plan ($0/month + utilization), Workforce plan ($250/month + utilization), and Enterprise customized pricing — that means Chroma is now not purely self-hosted.
LanceDB — Greatest for Serverless, Object-Storage-Backed, and Multimodal Retrieval
LanceDB is an open-source, serverless vector database that shops information within the Lance columnar format, designed to take a seat immediately on object storage (S3, GCS, and so on.) with out requiring an always-on server. AWS particularly calls out LanceDB as well-suited for serverless stacks as a result of it’s file-based and integrates natively with S3 — enabling elastic, pay-per-query retrieval at billion-vector scale with no persistent infrastructure to handle.
LanceDB’s columnar format permits quick random entry and environment friendly filtering immediately on-disk, avoiding the reminiscence overhead that almost all different vector databases require at question time. It additionally has robust multimodal help, making it related for pipelines that work throughout textual content, pictures, and structured information.
Faiss (Meta AI) — Greatest for Analysis and Customized Pipelines
Kind: Open-source library (not a full database) | Greatest for: Analysis, customized similarity search, GPU-accelerated batch workloads
Faiss‘s mixture of velocity, scalability, and suppleness positions it as a high contender for tasks requiring high-performance similarity search capabilities. When working with Faiss, finest practices embrace selecting the suitable index kind based mostly on dataset dimension and search necessities, experimenting with parameters like nlist and nprobe for IVF indexes, and utilizing GPU acceleration for vital efficiency boosts on giant datasets.
It is very important notice that Faiss is a library, not a full database system. It handles indexing and search however doesn’t present persistence, a question API, or operational tooling out of the field. It’s the basis many manufacturing techniques construct on, not a drop-in alternative for the databases above.
Must associate with us for selling your GitHub Repo OR Hugging Face Web page OR Product Launch OR Webinar and so on.? Join with us
Michal Sutter is an information science skilled with a Grasp of Science in Knowledge Science from the College of Padova. With a stable basis in statistical evaluation, machine studying, and information engineering, Michal excels at remodeling advanced datasets into actionable insights.
The Motorola Razr Extremely 2026 presents fairly highly effective efficiency in a flip-style bundle that rivals different flagships. Whereas it is not an enormous improve from the Motorola Razr Extremely 2025, it is one to contemplate if you wish to go this design route.
Execs
Trendy end and handy design
Added sturdiness with Gorilla Glass Ceramic 3
Brighter display screen, larger refresh price
A number of AI options
Cons
Not an enormous improve from its predecessor, but dearer
Solely two colour choices
Heavier and thicker than different telephones of its form
Solely 3 years of software program, 5 years safety updates
Tremendous-powered AI
The Samsung Galaxy S26 Extremely is super-charged with AI energy, from help with every day duties to clever picture enhancing and seize, and extra. Whereas it is not an enormous leap in design and specs from its predecessor, it is among the best AI-driven telephones you should purchase.
Execs
Slim and smooth design
Tons of AI options with a robust processor
Picture Help, Privateness Show, Horizontal Lock are stand-outs
Comes with a built-in S Pen
7 years of software program and safety updates
Cons
Battery must be greater
Cameras are good however not superb
16GB RAM solely within the 1TB model
Display screen specs are subpar
Premium telephones come in numerous packages, from foldables to smooth bar type telephones. With the Motorola Razr Extremely 2026 vs. Samsung Galaxy S26 Extremely, you get considered one of every. When you’re not sure for those who even want a foldable or if the benefits of the Samsung Galaxy S26 Extremely are value foregoing that comfort, this comparability will assist.
Motorola Razr Extremely 2026 vs. Samsung Galaxy S26 Extremely: Design and fundamentals
(Picture credit score: Derrek Lee / Android Central)
Within the seems to be division, these telephones are designed very in a different way from each other. The Motorola Razr Extremely 2026 is a flip-style telephone with a 4-inch 165Hz, 3,000-nit exterior display screen and a bigger 7-inch Excessive AMOLED inside display screen with a 165Hz refresh price and 5,000-nit peak brightness whenever you open it up.
Extremely-thin in design, it is available in two finishes: Pantone Orient Blue with an embossed Alcantara texture utilizing the made-in-Italy materials that has a micro-lattice sample, and Pantone Cocoa with a pure wooden veneer.
Newest Movies From
These two finishes are undoubtedly trendy, however Android Central’s Derrek Lee says in his hands-on evaluation that he needs there have been a couple of extra choices, noting that the Orient Blue skews extra towards purple than blue. The telephone is sturdy as nicely, with Corning Gorilla Glass Ceramic 3 for higher drop efficiency, an IP48 ranking for mud and water resistance, and a titanium strengthened hinge.
(Picture credit score: Derrek Lee / Android Central)
The Samsung Galaxy S26 Extremely employs a really completely different design. It is a conventional bar-style telephone that is ultra-slim and pocketable, however the digital camera sensors stand proud of the physique, inflicting it to take a seat off-balance whenever you set it down. You get a 6.9-inch Dynamic AMOLED 2X display screen with 120Hz and a pair of,600-nit brightness, so it is as massive because the Motorola Razr Extremely 2026 with out the choice to fold it in half to toss into your purse or pocket. It is as much as you to resolve if that issues.
Nicholas Sutrich notes in his evaluation that the show is not “even remotely spectacular,” with decision, nits, and refresh price which might be all nothing to write down house about. His separate evaluation of the show alone suggests Samsung lags in terms of eye consolation, too.
There are 5 end choices from which to decide on: Sky Blue, Black, and Cobalt Violet are customary, whereas you may as well get the Samsung-exclusive Pink Gold or Silver Shadow. Fabricated from sturdy Armor Aluminum with Corning Gorilla Glass, it meets an IP68 ranking, making it extra sealed towards mud, which is typical of bar versus foldable telephones.
Get the newest information from Android Central, your trusted companion on the earth of Android
(Picture credit score: Nicholas Sutrich / Android Central)
One of many defining options of the Samsung Galaxy S26 Extremely is the built-in Privateness Display screen, which Sutrich refers to in his evaluation of the telephone as “essentially the most thrilling show function we have seen in a decade.” It could possibly darken the display screen so others cannot see what you are viewing from the edges. You’ll be able to flip this on or off at will, but in addition activate it just for sure apps or notifications like banking, or solely whenever you enter a PIN, password, or sample to entry delicate info.
A most degree safety possibility is nice for those who place the telephone down beside you throughout a piece lunch, making the display screen troublesome to learn even then. It is such a helpful function and one which must be in each telephone. For now, Privateness Show makes the Galaxy S26 Extremely stand out.
Notably, there’s additionally a built-in S Pen for simpler navigation, note-taking, sketching, and extra for many who desire it. It suits so seamlessly into the telephone’s housing, you will not even discover it is there. However Sutrich factors out that the curve on the finish of the pen makes it doable to insert it the mistaken manner. The inclusion of the S Pen might also be why the telephone, but once more, doesn’t have Qi2 magnets inside, although it is “Qi2 prepared.”
Motorola Razr Extremely 2026 vs. Samsung Galaxy S26 Extremely: Specs
See how these two telephones evaluate at-a-glance with this helpful spec desk.
6.8 x 2.9 x 0.3 inches (open), 3.5 x 2.9 x 0.6 inches (closed)
6.4 x 3.07 x 0.3 inches
Weight
199 grams
214 grams
The Razr is provided with a 5,000mAh battery that will provide you with a few day and a half per cost. It could possibly recharge rapidly utilizing 68W TurboPower charging, supplying you with one other day after simply eight minutes. It additionally helps 30W wi-fi charging in addition to 5W reverse charging.
With USB-C, two microphones, and stereo Dolby audio system with Snapdragon sound and Spatial Audio, the Motorola Razr Extremely 2026 comes with both 256GB or 512GB of storage. You may get three years of software program and 5 years of safety updates, which is way behind the seven years that opponents like Samsung and Google sometimes supply. The telephone is set to be out there in late Might 2026.
(Picture credit score: Samsung)
The Samsung Galaxy S26 Extremely has the identical 5,000mAh battery that is rated to final for as much as 31 hours of steady video playback. As soon as able to recharge, it helps Tremendous Quick Charging 3.0 at 60W wired and as much as 25W wi-fi charging in addition to Wi-fi PowerShare for reverse charging. Sutrich says he acquired the telephone from 0-80% in half-hour utilizing a wired charger, which is an enormous enchancment from previous-generation Galaxy units. Although the telephone nonetheless ought to have an even bigger battery, as such a premium machine.
You get twin audio system with spatial audio, together with superior 360 Audio with head monitoring when utilizing a suitable pair of Samsung Galaxy earbuds, like the brand new Galaxy Buds Pro4. With Knox safety, you may go for 256GB, 512GB, or 1TB storage capacities.
Motorola Razr Extremely 2026 vs. Samsung Galaxy S26 Extremely: Productiveness and value
(Picture credit score: Derrek Lee / Android Central)
Past the design, it is vital how these telephones function and assist your every day duties, from productiveness to leisure. The Motorola Razr Extremely 2026 comes with Android 16 alongside Moto AI.
It is powered by a Snapdragon 8 Elite processor, the identical because the Razr Extremely 2025, an odd choice as it might have been good to have the Gen 5 model as an improve. This will have been, nonetheless, to assist hold pricing leveled, and Lee notes that almost all customers will not know the distinction anyway. You get 16GB RAM with as much as 16GB extra utilizing RAM Increase, although our specialists advise towards utilizing this because it finally ends up slowing down features of the telephone.
There’s a number of comfort in having the outer display screen. You’ll be able to entry apps and video games with out opening the telephone. You’ll be able to customise its look with completely different layouts, panels, widgets, and video wallpapers (a brand new possibility followers have been asking for), even show reside notifications for issues like sports activities scores or deliveries. You can even work together with the outer display screen with out touching it, like putting your hand over it to wake it up or silence an alarm.
You get tons of AI options, together with those who come customary now with Moto AI, like Catch Me Up, Subsequent Transfer, and Every day Drop (just like Samsung’s Now Temporary), together with Google Gemini, Gemini Dwell, Circle to Search, Microsoft Copilot, and Perplexity. So, you may get help with all the things from making journey plans to trying up particulars a few restaurant, composing an e-mail, creating a photograph or avatars, and extra.
Samsung dubs the Galaxy S26 Extremely an “AI telephone” with heavy AI integration as nicely, with software program at its core. You get a Snapdragon 8 Elite Gen 5 for Galaxy processor with Android 16 and One UI 8.5 for additional customization. The 256GB and 512GB variations have 12GB RAM, however that will increase to 16GB for the 1TB version.
Galaxy AI facilitates options like Now Nudge and Now Temporary, and also you get Gemini, Gemini Dwell, Bixby, and Perplexity all inbuilt for easy entry and help with AI-related duties. There’s just about nothing on this telephone that may’t entry the capabilities of AI, making it a powerhouse of an AI-driven machine.
An vital function of the Samsung Galaxy S26 Extremely is the massive Vapor Chamber that affords higher thermal efficiency. Whereas the telephone would not have as a lot RAM because the Motorola Razr Extremely 2026, until you go for the 1TB model, and its display screen refresh price is slower, you might be able to comfortably sport with this telephone with the boldness that it’ll stay cool.
The Samsung Galaxy S26 Extremely is supported by seven years of software program and safety updates, so you can hold it present for years longer than the Motorola Razr Extremely 2026.
Motorola Razr Extremely 2026 vs. Samsung Galaxy S26 Extremely: Cameras and AI picture options
(Picture credit score: Derrek Lee / Android Central)
Cameras in telephones are so vital these days, and each these units boast spectacular ones. The Motorola Razr Extremely 2026 has a triple-camera system with a 50MP LOFIC sensor that affords as much as six occasions extra dynamic vary, a 50MP ultra-wide lens with macro imaginative and prescient, and a 50MP inside digital camera.
Whereas Lee didn’t get the possibility to strive the cameras but, he notes that the Razr Extremely 2025 has an excellent digital camera already, so it is doubtless this one will comply with go well with. And the digital camera spec enhancements are one motive to improve when you have the older mannequin.
The largest benefits of the digital camera include the flippable design together with the AI options. Use Flex View positions, for instance, so the telephone acts as its personal tripod, with a preview of a picture on the entrance show for taking a selfie. For group photographs, AI can take a number of frames and sew them collectively to make sure you get one of the best expression from everybody, just like Google Pixel’s Greatest Take function.
Signature type can mechanically study your enhancing preferences that will help you get nice photographs off the bat, whereas body match locks the body so you may hand the telephone to another person they usually can comply with guides to get the precise picture you supposed to seize. This function sounds quite a bit like Google Pixel’s Digital camera Coach.
(Picture credit score: Derrek Lee / Android Central)
There are additionally enhanced watermarks that may mix into the picture with comparable colours, and an extremely HDR mode that optimizes photos for Instagram with as much as 5x enhanced dynamic vary, whether or not you are capturing from the digital camera app or proper from inside the social web site. One other cool function is Google Photographs wardrobe, which may digitize your closet that will help you combine and match gadgets primarily based on what you could have worn in earlier photographs in your library, even just about strive them on. Neat!
Different digital camera options embody the power to animate nonetheless photographs and use instruments like Magic Eraser, camouflage (to mix distracting objects), and AI to explain desired edits, like eradicating objects, altering backgrounds, or enhancing lighting. With Ask Photographs, you may seek for a selected reminiscence with voice prompts.
Whereas recording movies, there is a camcorder mode with a brand new rotate-to-zoom function that permits you to rotate your wrist ever so barely to immediately zoom in on a topic whereas recording. Lee says this works nicely, retaining the video steady whilst you do it. However he provides that there is a danger of by chance activating this function when you do not intend to, because the required motion is so slight.
(Picture credit score: Nicholas Sutrich / Android Central)
The Samsung Galaxy S26 Extremely has respectable cameras, although one factor you will study is that they merely aren’t adequate for a flagship telephone. It has a 200MP principal vast digital camera, 50MP ultra-wide, 50MP periscope telephoto with 5x zoom, 10MP telephoto with 3x zoom, and 12MP entrance digital camera. You will get constant photographs which might be balanced with pure colours, correct lighting, and nice element, even in low mild, particularly with the 200MP principal digital camera. Nevertheless it’s a incredible median expertise, not one which blows others out of the water.
That mentioned, the software program is among the many finest, and digital camera options, together with ones that leverage AI, are top-notch. Essentially the most talked-about digital camera function on the Galaxy S26 Extremely is Tremendous Regular Video with Horizontal Lock. With this function, you may report video whereas shifting, even on uneven surfaces, and the footage will come out trying steadier than it was in actuality. You could possibly even rotate the telephone a full 360° and the topic will stay in body, nobody any the wiser when trying on the last product. It really works amazingly nicely, although there’s some lack of high quality. However for folks taking video whereas operating on the sidelines of their youngsters’ soccer sport or capturing your pup operating within the park whilst you run with them, it makes an enormous distinction.
One other spectacular picture function is Picture Help, the place you may give the telephone prompts to regulate photographs as wanted. This goes above and past the standard elimination of a distracting object, reflections, or fixing blur. You’ll be able to add a lacking piece to an merchandise, like a birthday cake, change your outfit, and even create completely new photographs from current ones. It is not solely a enjoyable function but in addition extremely helpful, and it’ll blow you away with how nicely it really works.
Motorola Razr Extremely 2026 vs. Samsung Galaxy S26 Extremely: Which do you have to purchase?
(Picture credit score: Derrek Lee / Android Central)
Each the Motorola Razr Extremely 2026 vs. Samsung Galaxy S26 Extremely are stable premium telephones, however with two very completely different design propositions. The Motorola Razr Extremely 2026 is a extra pocketable telephone since it may possibly flip closed, the exterior display screen offering loads of benefits, from easy accessibility to updates and notifications to snapping photographs. It is poised to take over the Motorola Razr Extremely 2025 as one of the best general flip telephone.
The Samsung Galaxy S26 Extremely, in the meantime, is slim and smooth, however bigger. It presents a seamlessly built-in S Pen that gives one other degree of comfort for issues like note-taking, internet navigation, and sketching.
I am virtually inclined to say that the Motorola Razr Extremely 2026 design is best for leisure, whereas the Samsung Galaxy S26 Extremely is best for productiveness. However each have such incredible options that can enchantment to the other use as nicely. So, the choice will actually come right down to design desire.
They’re equally highly effective, each loaded with AI options, and supply a good quantity of assist for so long as you will doubtless have the telephone earlier than desirous to improve. Samsung’s seven-year promise, nonetheless, means you will get much more worth from the Galaxy S26 Extremely amortized over time.
General, the Samsung Galaxy S26 Extremely is perhaps the higher telephone. Having spent vital time with it myself, it performs very well for all the things from productiveness to picture and video seize. The AI expertise is sensible, and whereas the telephone is a giant bar-style machine, it is nonetheless tremendous slim and can slide into a bigger pocket. It is not excellent, nevertheless it’s a incredible machine value getting.
That mentioned, in order for you a flip-style telephone, the Motorola Razr Extremely 2026 is value contemplating. Its design is elegant and purposeful, it is sturdy, and it would not skimp on options. What extra might you ask for? Really, both telephone will put a smile in your face.
Pop in your pocket
The largest benefit with the Motorola Razr Extremely 2026 is the power to flip it closed and pop it in your pocket. The exterior display screen is nice for fast notifications with out different distractions, and the design makes content material seize a breeze.
A couple of defining options
Privateness Show, Horizontal Lock for video seize, Picture Help for enhancing and creating photographs, and heavy AI integration are defining options of the flagship Samsung Galaxy S26 Extremely, which is definitely worth the improve in order for you bar-style.
A chrome steel breakthrough from the College of Hong Kong (HKU) might assist remedy one of many largest issues going through inexperienced hydrogen: the way to construct electrolyzers which might be powerful sufficient for seawater, but low cost sufficient for giant scale clear vitality.
Led by Professor Mingxin Huang in HKU’s Division of Mechanical Engineering, the group developed a particular stainless-steel for hydrogen manufacturing (SS-H2). The fabric resists corrosion below circumstances that usually push stainless-steel previous its limits, making it a promising candidate for producing hydrogen from seawater and different harsh electrolyzer environments.
The invention, reported in Supplies At present within the research “A sequential dual-passivation technique for designing stainless-steel used above water oxidation,” builds on Huang’s lengthy operating “Tremendous Metal” Challenge. The identical analysis program beforehand produced anti-COVID-19 stainless-steel in 2021, together with extremely sturdy and extremely powerful Tremendous Metal in 2017 and 2020.
A Cheaper Path Towards Inexperienced Hydrogen
Inexperienced hydrogen is made through the use of electrical energy, ideally from renewable sources, to separate water into hydrogen and oxygen. Seawater is an particularly tempting feedstock as a result of it’s ample, but it surely brings a critical supplies drawback: salt, chloride ions, facet reactions, and corrosion can shortly harm electrolyzer parts.
Current critiques of direct seawater electrolysis proceed to focus on the identical core problem. The know-how might present a extra sustainable path to hydrogen, however corrosion, chlorine associated facet reactions, catalyst degradation, precipitates, and restricted long run sturdiness stay main obstacles to business use.
That’s the place SS-H2 might matter. In a salt water electrolyzer, the HKU group discovered that the brand new metal can carry out comparably to the titanium based mostly structural supplies utilized in present industrial follow for hydrogen manufacturing from desalted seawater or acid. The distinction is price. Titanium components coated with treasured metals akin to gold or platinum are costly, whereas stainless-steel is much extra economical.
For a ten megawatt PEM electrolysis tank system, the full price on the time of the HKU report was estimated at about HK$17.8 million, with structural parts making up as a lot as 53% of that expense. Based on the group’s estimate, changing these expensive structural supplies with SS-H2 might scale back the price of structural materials by about 40 instances.
Why Atypical Stainless Metal Fails
Chrome steel has been used for greater than a century in corrosive environments as a result of it protects itself. The important thing ingredient is chromium. When chromium (Cr) oxidizes, it creates a skinny passive movie that shields the metal from harm.
However that acquainted safety system has a in-built ceiling. In standard stainless-steel, the chromium based mostly protecting layer can break down at excessive electrical potentials. Steady Cr2O3 could be additional oxidized into soluble Cr(VI) species, inflicting transpassive corrosion at round ~1000 mV (saturated calomel electrode, SCE). That’s properly beneath the ~1600 mV wanted for water oxidation.
Even 254SMO tremendous stainless-steel, a benchmark chromium based mostly alloy recognized for sturdy pitting resistance in seawater, runs into this excessive voltage restrict. It might carry out properly in unusual marine settings, however the excessive electrochemical surroundings of hydrogen manufacturing is a special problem.
The Metal That Builds a Second Protect
The HKU group’s reply was a method known as “sequential dual-passivation.” As a substitute of relying solely on the standard chromium oxide barrier, SS-H2 varieties a second protecting layer.
The primary layer is the acquainted Cr2O3 based mostly passive movie. Then, at round ~720 mV, a manganese based mostly layer varieties on high of the chromium based mostly layer. This second protect helps shield the metal in chloride containing environments as much as an extremely excessive potential of 1700 mV.
That’s what makes the discovering so putting. Manganese is normally not considered as a pal of stainless-steel corrosion resistance. In actual fact, the prevailing view has been that manganese weakens it.
“Initially, we didn’t consider it as a result of the prevailing view is that Mn impairs the corrosion resistance of stainless-steel. Mn-based passivation is a counter-intuitive discovery, which can’t be defined by present information in corrosion science. Nevertheless, when quite a few atomic-level outcomes have been introduced, we have been satisfied. Past being stunned, we can not wait to use the mechanism,” stated Dr. Kaiping Yu, the primary writer of the article, whose PhD is supervised by Professor Huang.
A Six Yr Push From Shock to Software
The trail from the primary statement to publication was not fast. The group spent almost six years shifting from the preliminary discovery of the weird stainless-steel to the deeper scientific clarification, then towards publication and potential industrial use.
“Totally different from the present corrosion neighborhood, which primarily focuses on the resistance at pure potentials, we makes a speciality of creating high-potential-resistant alloys. Our technique overcame the basic limitation of standard stainless-steel and established a paradigm for alloy improvement relevant at excessive potentials. This breakthrough is thrilling and brings new functions,” Professor Huang stated.
The work has additionally moved past the laboratory. The analysis achievements have been submitted for patents in a number of nations, and two patents had already been granted authorization on the time of the HKU announcement. The group additionally reported that tons of SS-H2 based mostly wire had been produced with a manufacturing unit in Mainland China.
“From experimental supplies to actual merchandise, akin to meshes and foams, for water electrolyzers, there are nonetheless difficult duties at hand. At present, we have now made an enormous step towards industrialization. Tons of SS-H2-based wire has been produced in collaboration with a manufacturing unit from the Mainland. We’re shifting ahead in making use of the extra economical SS-H2 in hydrogen manufacturing from renewable sources,” added Professor Huang.
Why the Timing Nonetheless Issues
Though the SS-H2 research was printed in 2023, its core drawback has solely grow to be extra related. Newer seawater electrolysis analysis continues to concentrate on the identical bottlenecks: corrosion resistant supplies, lengthy lasting electrodes, chlorine suppression, and system designs that may survive actual seawater fairly than preferrred laboratory options. A 2025 Nature Evaluations Suppliesoverview described direct seawater electrolysis as promising however nonetheless held again by corrosion, facet reactions, steel precipitates, and restricted lifetime.
Different current work has explored stainless-steel based mostly electrodes with protecting catalytic layers, together with NiFe based mostly coatings and Pt atomic clusters, to enhance sturdiness in pure seawater. Researchers have additionally reported corrosion resistant anode methods constructed on stainless-steel substrates, displaying that stainless-steel stays a serious focus within the effort to make seawater electrolysis extra sensible.
This newer analysis doesn’t change the SS-H2 discovery. As a substitute, it reinforces why the HKU group’s method is essential. The sector remains to be looking for supplies that may survive the punishing mixture of saltwater chemistry, excessive voltage, and industrial working calls for. SS-H2 stands out as a result of it assaults the issue not solely with a coating or catalyst, however with a brand new alloy design technique that adjustments how stainless-steel protects itself.
A Metal Breakthrough With Clear Vitality Potential
SS-H2 just isn’t but a plug and play resolution for the hydrogen financial system. The group has acknowledged that turning experimental supplies into actual electrolyzer merchandise, together with meshes and foams, nonetheless entails tough engineering work.
Even so, the promise is evident. A chrome steel that may face up to excessive voltage seawater circumstances whereas changing costly titanium based mostly parts might make hydrogen manufacturing cheaper, extra scalable, and simpler to pair with renewable vitality.
For a area the place price and sturdiness usually determine whether or not a know-how can go away the lab, a metal that builds its personal second protect could also be greater than a supplies science shock. It might grow to be a sensible step towards cleaner hydrogen at industrial scale.
any time within the information engineering world, you’ve seemingly encountered this debate no less than as soon as. Perhaps twice. Okay, in all probability a dozen occasions😉 “Ought to we course of our information in batches or in real-time?” And for those who’re something like me, you’ve observed that the reply normally begins with: “Properly, it relies upon…”
Which is true. It does rely. However “it relies upon” is barely helpful for those who truly know what it relies upon on. And that’s the hole I wish to fill with this text. Not one other theoretical comparability of batch vs. stream processing (I hope you already know the fundamentals). As an alternative, I wish to provide you with a sensible framework for deciding which strategy is sensible for your particular state of affairs, after which present you ways each paths look when carried out in Microsoft Cloth.
It’s not batch vs. stream: it’s “when does the reply matter?”
Let me skip dry definitions and bounce straight to what truly separates these two approaches: the worth of freshness.
Picture by writer
Each piece of knowledge has a shelf life. Not within the sense that it expires and turns into ineffective, however within the sense that its enterprise worth modifications over time. A fraudulent bank card transaction detected in 200 milliseconds? Priceless – you simply prevented a loss. The identical fraud detected 6 hours later in a nightly batch job? Helpful for reporting, however the cash is already gone.
On the flip aspect, a month-to-month gross sales report generated from yesterday’s information versus information that’s 3 minutes previous? In most organizations, no person can inform the distinction (and doubtless no person cares). The enterprise selections based mostly on that report occur in conferences scheduled days upfront, not in milliseconds after the info arrives.
So, the primary query isn’t “batch or stream?” The primary query is: how shortly does somebody (or one thing) must act on this information for it to matter?
If the reply is “seconds or much less”, you’re in streaming territory. If the reply is “hours or days”, batch is probably going your buddy. And if the reply is “someplace in between”… Congratulations, you’re in probably the most attention-grabbing (and commonest) grey space, which we’ll discover shortly.
The trade-offs
You realize what probably the most uncomfortable fact about streaming is? It sounds wonderful on paper. Who wouldn’t need real-time information? It’s like asking “would you like your espresso now or in 6 hours?” However the actuality is extra nuanced than that. Let’s stroll by way of the trade-offs that truly matter once you’re making this determination.
Value
I hear you, I hear you: “Nikola, how far more costly is streaming?” Sadly, there’s no single quantity I can provide you, however the sample is constant: streaming infrastructure is nearly all the time costlier than batch processing for a similar quantity of knowledge. Why? As a result of streaming requires assets to be all the time on, listening, processing, and writing constantly. Batch processing, alternatively, spins up, does its work, and shuts down. You pay for the compute solely when the job runs.
Consider it like a restaurant kitchen. A batch kitchen opens at particular hours – the workers arrives, preps, cooks, cleans up, and goes residence. A streaming kitchen is open 24/7 with workers all the time standing by, able to prepare dinner the second an order arrives. Even in the course of the quiet hours at 3 AM when no person’s ordering, somebody continues to be there, ready. That ready prices cash.
Does this imply streaming is all the time costlier? Not essentially. In case your information arrives constantly and you could course of it constantly anyway, the price distinction narrows. But when your information arrives in predictable bursts (each day file drops, hourly API calls), batch processing permits you to align your compute spend with these bursts.
Complexity
Batch processing is conceptually easier. You’ve an outlined enter, an outlined transformation, and an outlined output. If one thing fails, you re-run the job. The information isn’t going anyplace, it’s sitting in a file or a desk, patiently ready.
Streaming? Issues get trickier. You’re coping with information that arrives constantly, doubtlessly out of order, doubtlessly with duplicates, and doubtlessly with gaps. What occurs when a sensor goes offline for five minutes after which dumps all its buffered readings without delay? What occurs when two occasions arrive within the improper order? What occurs when the processing engine crashes mid-stream? Do you replay from the start? From a checkpoint? How do you guarantee exactly-once processing?
These are solvable issues, and fashionable streaming platforms deal with most of them nicely. However these are extra issues that merely don’t exist in batch processing. Complexity isn’t a motive to keep away from streaming, it’s merely a motive to be sure to truly want streaming earlier than you decide to it.
Correctness
Batch processing has a pure benefit in correctness, as a result of it operates on full datasets. When your batch job runs at 2 AM, it has entry to all the info from the day prior to this. Each late-arriving report, each correction, each replace, it’s all there. The job can compute aggregates, joins, and transformations in opposition to the total image.
Streaming operates on incomplete information by definition. You’re processing information as they arrive, which implies your outcomes are all the time provisional. That each day income quantity you computed at 11:59 PM? A number of late-arriving transactions may change it by the point the clock strikes midnight. Windowing methods and watermarks assist handle this, however they add one more layer of decision-making.
Once more, this isn’t a motive to keep away from streaming. It’s a motive to grasp that streaming outcomes and batch outcomes may differ, and your structure must account for that.
Latency vs. Throughput
Batch processing optimizes for throughput. This implies processing the utmost quantity of knowledge within the minimal period of time. Streaming optimizes for latency, minimizing the time between when an occasion happens and when the result’s accessible.
These two objectives are sometimes in battle. A batch job that processes 100 million information in quarter-hour is extraordinarily environment friendly, that’s roughly 111,000 information per second. A streaming pipeline processing the identical information one report at a time because it arrives may deal with every report in 50 milliseconds, however the overhead per report is considerably greater. You’re buying and selling throughput for responsiveness.
The query is: does your use case worth responsiveness over effectivity, or the opposite manner round?
So, when ought to I take advantage of what?
Let’s study some concrete eventualities and the reasoning behind every alternative. Not simply “use streaming for X” – however why.
Picture by writer
Batch is your greatest wager when…
Your information arrives in predictable intervals. Each day file drops from SFTP servers, hourly API exports, weekly CSV uploads from distributors. The information isn’t time-sensitive, and the supply doesn’t help steady streaming anyway. Forcing a streaming structure onto information that arrives as soon as a day is like hiring a 24/7 courier service to ship mail that solely comes on Mondays.
You want advanced transformations that span the total dataset. Take into consideration coaching machine studying fashions, computing year-over-year comparisons, operating large-scale joins between truth tables and slowly altering dimensions. These operations want the total image, since they’ll’t be meaningfully decomposed into record-by-record streaming logic.
Value optimization is a precedence. In case your price range is tight and your freshness necessities are usually not strict (hours, not seconds), batch processing permits you to run intensive compute on-demand and shut it down when it’s achieved. You’re paying for what you employ, not for what you may use.
Information correctness trumps velocity. Monetary reconciliation, regulatory reporting, audit trails… These are eventualities the place being proper issues greater than being quick. Batch provides you the posh of processing in opposition to full datasets and rerunning jobs if one thing goes improper.
Streaming is the way in which to go when…
Somebody (or one thing) must act on the info instantly. Fraud detection, anomaly monitoring, IoT alerting, stay dashboards for operations groups… The worth of the info decays quickly with time. If the enterprise response to stale information is “nicely, that’s ineffective now,” you want streaming.
The information is of course steady. Clickstreams, sensor telemetry, software logs, and social media feeds are usually not information sources that “batch” naturally. They produce occasions constantly, and processing them in batches means artificially holding information that’s already accessible. Why wait?
You’re constructing event-driven architectures. Microservices speaking by way of occasion buses, order processing programs, real-time personalization engines – the structure itself is inherently streaming. Introducing batch processing would break the event-driven contract.
It’s worthwhile to detect patterns over time home windows. “Alert me if the CPU utilization exceeds 90% for greater than 5 consecutive minutes.” “Flag any person who makes greater than 10 failed login makes an attempt in a 2-minute window.” These are naturally streaming issues, and so they require constantly evaluating circumstances in opposition to a sliding window of occasions.
And what in regards to the grey space?
Nice! Now when to make use of what. However, guess what? Most organizations don’t fall neatly into one camp. You’ll have use circumstances that want streaming sitting proper subsequent to make use of circumstances which might be completely served by batch. And that’s tremendous, it’s not an both/or determination on the group stage. It’s a per-use-case determination.
In actual fact, many mature information architectures implement each. The sample is usually known as the Lambda structure (batch and streaming operating in parallel, producing outcomes that get merged) or the Kappa structure (the whole lot as a stream, with batch being only a particular case of a bounded stream). These architectures have their very own trade-offs, however the important thing takeaway is: you don’t have to decide on one paradigm on your complete information platform. I’d cowl Lambda and Kappa architectural patterns in one of many future articles, however they’re out of the scope of this one.
Picture by writer
The extra sensible query is: does your platform help each paths with out requiring you to construct and preserve two completely separate stacks? And that is the place issues get attention-grabbing with Microsoft Cloth…
How does this play out in Microsoft Cloth?
One of many issues I genuinely recognize about Microsoft Cloth is that it doesn’t drive you right into a single processing paradigm. Each batch and stream processing are first-class residents within the platform, and, what’s much more vital, they share the identical storage layer (OneLake) and the identical consumption mannequin (Capability Models). This implies you’re not sustaining two disconnected worlds.
Let me stroll you thru how every strategy is carried out.
Batch processing in Cloth
For batch workloads, Cloth provides you a number of choices relying in your talent set and necessities:
Information pipelines are the orchestration spine. When you’re coming from one thing like Azure Information Manufacturing unit, this can really feel acquainted. You possibly can schedule pipelines to run at particular occasions or set off them based mostly on occasions. Pipelines coordinate the circulation of knowledge between sources and locations, with actions like Copy Information, Dataflows, and pocket book execution.
Cloth notebooks are the place the heavy lifting occurs. You possibly can write PySpark, Spark SQL, Python, or Scala code to carry out advanced transformations on massive datasets. Notebooks are perfect for these “advanced transformations spanning the total dataset” eventualities we mentioned earlier, corresponding to massive joins, aggregations, and ML function engineering. They spin up, course of, and launch compute assets when achieved.
Dataflows Gen2 supply a low-code/no-code different utilizing the acquainted Energy Question interface. Current efficiency enhancements (just like the Fashionable Evaluator and Partitioned Compute) have made them a way more aggressive possibility from a value/efficiency standpoint. In case your batch transformations are comparatively easy, Dataflows can prevent the overhead of writing and sustaining Spark code.
Cloth Information Warehouse gives a T-SQL-based expertise for individuals who want the relational strategy. You possibly can run scheduled saved procedures, create views for abstraction layers, and leverage the SQL analytics endpoint for ad-hoc queries.
All of those write their output as Delta tables in OneLake, which means the outcomes are instantly accessible to any Cloth engine downstream, whether or not that’s a Energy BI semantic mannequin, one other pocket book, or a SQL question.
Stream processing in Cloth
For real-time workloads, Cloth’s Actual-Time Intelligence is the place the motion occurs. If you wish to perceive the fundamentals of Actual-Time Intelligence in Microsoft Cloth, I’ve you coated in this text.
Eventstreams are the ingestion layer for streaming information. You possibly can hook up with sources like Azure Occasion Hubs, Azure IoT Hub, Kafka, customized purposes, and even database change information seize (CDC) streams. Eventstreams deal with the continual circulation of occasions and route them to varied locations inside Cloth.
Eventhouses (backed by KQL databases) are the storage and compute engine for real-time information. Information lands in KQL tables and is straight away queryable utilizing the Kusto Question Language. When you’ve learn my article on replace insurance policies, you already know the way highly effective these could be for reworking information on the level of ingestion – no separate processing layer wanted.
Actual-Time Dashboards allow you to visualize streaming information with auto-refresh capabilities. This manner, your operations staff will get a stay view of what’s taking place proper now, not what occurred yesterday.
Activator permits you to outline circumstances and set off actions based mostly on real-time information. “If the temperature exceeds 80°C, ship a Groups notification.” “If the order rely drops under the brink, set off an alert.” It’s the “act on the info instantly” functionality we talked about earlier.
The important thing factor to remember right here: Actual-Time Intelligence information additionally lives in OneLake. This implies your streaming information and your batch information coexist in the identical storage layer. A Spark pocket book can learn information from a KQL database. A Energy BI report can mix batch-processed warehouse tables with real-time Eventhouse information. The boundaries between batch and stream begin to blur, and that’s precisely the purpose I’m making an attempt to emphasise right here.
The most effective of each worlds
Now, let’s study a concrete instance of how batch and streaming can work collectively in Cloth.
Think about a retail firm monitoring its e-commerce platform. On the streaming aspect, clickstream information flows by way of Eventstreams into an Eventhouse, the place replace insurance policies parse and route the occasions in real-time. Operations dashboards present stay metrics: energetic customers, cart abandonment price, error charges. Activator triggers alerts when the checkout failure price spikes above 2%.
Picture by writer
On the batch aspect, a nightly pipeline pulls the day’s transaction information, enriches it with product catalog info and buyer segments utilizing a Spark pocket book, and writes the outcomes to a Lakehouse. A Energy BI semantic mannequin constructed on prime of those Delta tables powers the manager dashboard that will get reviewed within the Monday morning assembly.
Each paths feed from and into OneLake. The streaming information is offered for batch enrichment. The batch-processed dimensions can be found for real-time lookups (bear in mind these replace coverage joins we coated within the earlier article?). Two processing paradigms, one unified platform.
A sensible determination framework
To wrap issues up, right here’s a easy set of questions you’ll be able to ask your self for every use case. Consider it as your “streaming vs. batch vs. each” determination tree:
Picture by writer
How shortly does somebody must act on this information? If seconds -> stream. If hours/days -> batch. If “it relies on the state of affairs” -> learn on😊
How does the info arrive? Steady occasions -> streaming is pure. Periodic file drops -> batch is pure. Don’t battle the info’s pure rhythm.
How advanced are the transformations? Report-by-record parsing and filtering -> both works. Giant joins, ML coaching, full-dataset aggregations -> batch has an edge.
What’s your price range tolerance? All the time-on compute for streaming vs. on-demand compute for batch. Calculate each and evaluate.
How vital is information completeness? When you want the total image earlier than making selections -> batch. If provisional outcomes are acceptable -> streaming works.
Does your platform help each? If sure (and Cloth does), use the correct device for every use case fairly than forcing the whole lot by way of one paradigm.
The most effective information architectures aren’t those which might be purely batch or purely streaming. They’re those that use every strategy the place it makes probably the most sense, and have a platform beneath that makes each paths really feel pure.
Thanks for studying!
Word: Visuals on this article have been created utilizing Claude and NotebookLM.
Giant language fashions (LLMs), the applied sciences that energy most generative and agentic AI options, are highly effective. However they will also be very costly.
To make issues worse, predicting and monitoring LLM spending could be difficult, due largely to the truth that there may be usually no strategy to know precisely how a lot a question will really price till it’s full.
The excellent news is that there are efficient methods for IT leaders to rein in pointless LLM prices. CIOs should establish how LLM spending can bloat AI budgets and discover ways to spot the indicators that their enterprise is paying extra for LLMs than it must. Solely then can they take actionable steps to mitigate unwarranted LLM expenditures.
What paying for an LLM will get you
LLMs are the life drive powering nearly each fashionable generative or agentic utility.
When a chatbot wants to reply to a consumer’s query, it submits the query to an LLM to generate a response. When an AI agent is tasked with implementing a function inside a software program utility, it makes use of an LLM to guage current utility code, then produce new code appropriate with it. When an worker makes use of AI-powered search to seek out info in a information base, an LLM is working behind the scenes to interpret the consumer’s search phrases and create a response that identifies related paperwork. From an operational perspective, the power of LLMs to deal with open-ended duties or queries like these is a good factor. It’s what makes a single AI product able to addressing a variety of use circumstances in a versatile, scalable means.
From a monetary perspective, nonetheless, LLM exercise can current some actual challenges. It is because each time an AI utility or agent interacts with an LLM, there’s a price — and when your corporation’s AI functions and providers are participating with LLMs hundreds of thousands of instances per day, the spending provides up.
How a lot does an LLM price?
The price of utilizing an LLM is decided by two essential components:
Token value: Companies that promote entry to LLMs (like OpenAI and Google) value their providers primarily based totally on what number of tokens their prospects devour when interacting with their LLMs. At present, main AI distributors cost anyplace from about $0.25 to a number of {dollars} per million tokens consumed, with extra superior fashions having greater token costs. Some distributors value enter tokens (that means tokens related to information fed into an LLM) individually from output tokens (that are consumed when LLMs generate information).
Tokens consumed: Each time an LLM handles a request, it processes a sure variety of tokens. Longer, extra complicated queries require extra tokens. A rule of thumb is that each 75 phrases of textual content processed by an LLM requires about 100 tokens; nonetheless, it is a very tough guideline and it doesn’t account for non-textual processing work by AI fashions, like picture and video interpretation or era.
So, to determine how a lot you’ll pay to make use of an LLM, you must know each your per-token price and what number of tokens you’re utilizing. The previous variable is simple sufficient to establish generally as a result of AI distributors normally are clear about their token pricing. Predicting what number of tokens you’ll devour is the place issues get difficult as a result of it’s typically unimaginable to know forward of time precisely what number of tokens an AI utility will expend when finishing a given job.
If you happen to’re off by only a small quantity, that error will shortly compound when utilized to 1000’s of every day AI duties. Identical to that, a deliberate finances can show out of date.
Actual-world examples of LLM prices
Regardless of this unpredictability, it’s potential to get a really tough sense of how a lot LLMs price for varied duties.
These charges are small on a person foundation. However you don’t should be a CFO to grasp that they will add up shortly inside a corporation that makes use of LLMs all day lengthy to supply textual content, code and multimodal media.
On high of this, companies are more and more deploying AI brokers, which might result in even greater LLM spending as a result of it’s frequent for an agent to work together with an LLM a number of instances to finish a single job. As an example, a software program improvement agent may use an LLM to interpret an preliminary immediate, then generate code in response to the immediate, check the code, generate extra code to repair the bugs found throughout testing, and at last validate the code once more.
Every of those engagements requires token utilization, and the whole price may simply climb into the a whole lot of {dollars} for producing only a small quantity of code. At scale, that spending can develop into staggering; studies are already circulating of particular person builders racking up LLM payments as excessive as $150,000 monthly when utilizing AI brokers to assist them produce code.
What about personal or self-hosted LLMs?
It’s necessary to notice that not all AI functions rely on third-party LLMs. Companies can, in the event that they select, develop and deploy their very own self-hosted LLMs. In that case, there are not any token costs as a result of there isn’t any third-party AI vendor to impose them.
That stated, deploying personal LLMs is a comparatively unusual observe because of the complexity of making and working LLMs, to not point out the large infrastructure essential to run a robust, large-scale LLM.
Even when firms can and do run their very own LLMs, as a substitute of connecting to third-party fashions, they nonetheless face main prices. They must pay for the servers that host the fashions, in addition to the electrical energy consumed by these servers (and the cooling methods that preserve the servers from overheating).
The purpose right here is that even when your organization had been to deploy a non-public LLM — which might be not sensible within the first place — it will nonetheless find yourself going through a big invoice. The one distinction between this method and utilizing a third-party LLM is that the invoice would take the type of infrastructure and energy spending, slightly than token prices.
The challenges of managing LLM spending
Past the comparatively excessive costs of LLMs, companies face a number of challenges particular to LLMs and AI utilization that additional complicate their potential to rein in LLM spending:
Price unpredictability. As famous above, it’s usually very tough to estimate precisely what number of tokens it would take to finish a given job utilizing an LLM, so that you typically don’t know the associated fee till you’ve already incurred it.
Dynamic pricing. Token pricing can change anytime, making it difficult to forecast LLM prices over the long run.
Restricted consumer spending consciousness. AI end-users inside a corporation typically have a restricted understanding of how LLMs are priced or how consumer actions influence whole spending.
Lack of FinOps instruments for LLMs. Whereas FinOps (the observe of managing cloud spending typically) affords mature options for retaining monitor of and optimizing spending on different kinds of providers, FinOps tooling that’s tailor-made particularly for LLMs at present stays fairly primitive.
Given these challenges, even firms which have a stable monitor report of managing expertise prices in different domains may battle to keep away from pointless or surprising LLM spending.
Efficient ways for controlling LLM prices
Luckily, though there isn’t any easy system to comply with for managing and optimizing LLM prices, actionable steps can be found for decreasing spending with out undermining the worth that LLMs create.
Key ways embody:
Selecting lower-cost LLMs: Token prices can differ broadly between completely different LLMs, with extra highly effective fashions usually costing extra. Not each job requires the newest, biggest mannequin, nonetheless. To save cash, organizations can submit prompts to lower-cost fashions when the immediate complexity is restricted, or when there may be better tolerance for inaccurate responses.
Evaluating LLM vendor pricing: Pricing for LLMs also can differ between AI distributors, even when the fashions are comparable in high quality (particularly at current, when AI firms vying to seize market share might underprice a few of their fashions in a bid to draw customers). Thus, procuring round to seek out the most effective pricing for the kind of mannequin you require may also help to chop prices.
Response caching: Response caching is the observe of storing an LLM’s response to a given question, then reusing the response when the LLM receives comparable queries. This avoids the output token price required to generate a brand new response every time.
Immediate libraries: Immediate libraries are collections of validated or “authorised” prompts which are recognized to be environment friendly when it comes to token prices, that human customers or AI brokers can draw from when interacting with LLMs.
Immediate compression: Exterior instruments can compress or “trim” prompts by stripping out extraneous info previous to submitting them to an LLM. By decreasing enter tokens, this observe can save companies cash, particularly in circumstances the place customers are usually not adept at optimizing prompts on their very own.
Question batching: Some LLMs supply reductions of as a lot as 50 % off customary token prices when prospects submit queries in batches. This method isn’t viable for LLM use circumstances that require rapid responses to prompts, however it may be an effective way to economize when it’s possible to submit a sequence of queries to an LLM on the identical time. For instance, if you wish to generate documentation, you may submit a batch of prompts — one for every matter you want to doc — as a substitute of submitting the prompts one after the other.
Limiting token allowances: When interacting with LLMs through APIs, it’s usually potential to configure the utmost variety of output tokens {that a} mannequin is allowed to make use of when serving a request. This creates the danger {that a} mannequin might generate an incomplete response as a result of it hits the token restrict, however it additionally prevents conditions the place spending on a person response runs uncontrolled.
Backside line
Finally, LLMs solely create enterprise worth if the productiveness positive factors they allow outweigh the price of accessing or working LLMs. That’s why it’s important for enterprises to method LLM choice and utilization in an economical means, by being strategic about how they leverage LLMs.
The newest Tensor G6 leak is sweet and unhealthy information for the Pixel 11, including extra weight to what we already anticipated from Google’s next-gen chip destined for this 12 months’s Pixel 11 collection.
On the one hand, it appears like Pixel 11 clients are set to learn from a major leap in CPU efficiency. The chip is anticipated to characteristic a single Arm C1-Extremely core at 4.11GHz, alongside 4 C1-Professional cores at 3.38GHz and two C1-Professional cores at 2.65GHz. Google is totally skipping the Arm Cortex X925 period, leaping straight to the identical CPU cohort because the powerhouse MediaTek Dimensity 9500.
This represents a doubtlessly vital increase from the Tensor G5 and its Arm Cortex-X4, A725, and A520 setup. single-core Geekbench 6 outcomes, there’s round a 40% potential uplift between the outdated and new cores, which might clearly be a major leap if it holds up. The multi-core positive factors may very well be even bigger, given the upper total clock speeds and a transfer away from very small cores.
The Tensor G6’s massive CPU core might theoretically be 40% quicker than the G5.
Nevertheless, regardless of the very fashionable CPU cores, Google’s cluster stays considerably conservative in comparison with the opposite flagship chips, even these constructed with the identical off-the-shelf Arm cores. MediaTek’s Dimensity makes use of one C1-Extremely and three C1-Premium cores, that are bigger and extra highly effective than the Professionals. Likewise, Qualcomm’s Snapdragon options two massive customized Oryon cores and 6 smaller cores, providing critical heavy-lifting potential. For a model trying to merge cell and PC use circumstances, two or extra power-house cores are helpful — Tensor isn’t in that league but.
I anticipate the Pixel 11’s CPU to carry out nearer to Samsung’s Exynos 2600 inside some new Galaxy S26 fashions, which use a really comparable C1-Extremely and C1-Professional configuration. Nevertheless, with greater clock speeds, Tensor ought to push forward by a modest margin. This places it in a really strong efficiency class that can guarantee it’s a sturdy day by day performer, if not fairly benchmark-topping.
Will players see the identical profit?
Sadly, graphics will nearly definitely stay the Pixel’s Achilles’ heel. The Tensor G6 is reportedly switching to a PowerVR CXTP-48-1536. The Tensor G5 sports activities a DXT-48-1536 and, in response to the Creativeness Applied sciences web site, its GPU vary ranks from A (smallest and most power-efficient) by way of to E (highest efficiency).
After some digging, it’s not completely clear the place the CXTP lands. The 2021-era C-series consists of the very low-end CXM for good TVs and the CXT, a extra flagship-tier product (nearly definitely not by 2026 requirements anymore) that helps ray tracing.
The Pixel 11 could also be extra environment friendly at gaming, however no more highly effective.
From what I can discern, the “P” mannequin will not be a part of the unique 2021 period C-series. If it’s something just like the DXT versus DXTP, then the “P” signifies improved energy effectivity. The DXTP arrived in early 2025 with a 20% FPS-per-Watt effectivity acquire over the DXT. The CXTP doubtless gives one thing comparable. That sounds spectacular, however how this compares to the facility draw of the 2023-era DXT within the G5 is anybody’s guess.
Precisely what this implies for the Pixel 11’s gaming efficiency is equally unknown. The C-series is clearly not designed to match the D-series’s peak efficiency, and Creativeness’s personal supplies recommend a 20% higher efficiency density per space over the CXT. In all probability, the Tensor design workforce is weighing up precisely the best way to extract the most effective efficiency from a restricted GPU silicon finances, and maybe the brand new “P” mannequin, a transfer to a smaller 2nm node, or just licensing prices have shifted this barely in favor of the CXTP over final 12 months’s DXT, whereas maintaining efficiency aggressive with the earlier era.
Robert Triggs / Android Authority
Just like the DXT within the Tensor G5, the CXTP can help ray-racing. Nevertheless, this requires extra cores and house, and I believe Google is transferring to the C-series to avoid wasting on silicon space. So don’t guess on ray-tracing this era both.
Because the graph above reveals, the Tensor G6 would want to make substantial adjustments to its GPU configuration to meet up with the competitors. Even when the brand new 2nm manufacturing course of and extra environment friendly GPU cores might allow greater clock speeds and/or higher sustained efficiency, utilizing an improved 2021-era structure is more likely to be a sidegrade at greatest. Because of this, the Pixel 11 is sort of sure to stay a extra sluggish gaming telephone than 2026 flagship telephones powered by the Snapdragon 8 Elite Gen 5, Dimensity 9500, and, fairly doubtless, even the AMD-equipped Exynos 2600 too.
Is the Tensor G6 value ready for?
Robert Triggs / Android Authority
Google’s customized silicon venture hasn’t ever actually been about chasing the benchmark leaderboards, and the Tensor G6 isn’t going to instantly change the established order. We would have to attend for the Tensor G7 or longer for that.
For common app efficiency, the CPU upgrades will probably be noticeable for each the substantial efficiency uplift and the effectivity positive factors from transferring to a extra environment friendly structure. Sadly, players don’t look set to obtain the identical advantages, however maybe the Pixel 11 will sip on battery life sufficient to really feel like considerably of an improve for these longer classes. In any case, that is unlikely to hassle collection followers who aren’t bothered about Tensor’s lack of graphics grunt.
New AI and imaging capabilities are more likely to be greater attracts than efficiency.
As a substitute, Tensor is a way for Google to pursue its AI ambitions with out being beholden to different silicon companions. Working example, the chip is poised to change from its long-running however typically troubled use of Samsung Exynos modem to the MediaTek M90. We’ll have to check it to see if this lastly rids the collection of connectivity issues and battery drain points as soon as and for all.
Likewise, Google is prepping its in-house Titan M3 safety chip and a next-generation “Santafe” TPU and “Metis” picture sign course of for the Tensor G6. These upgrades alone would enable Google to introduce fascinating new options within the realms of on-device AI and computational images, which is able to little doubt be far greater promoting factors for the Pixel 11 collection than efficiency ever may very well be. With that in thoughts, and ignoring opponents’ strikes, the Tensor G6 might properly become a notable improve when the Pixel 11 collection lands later this 12 months.
Don’t wish to miss the most effective from Android Authority?
Thanks for being a part of our neighborhood. Learn our Remark Coverage earlier than posting.
Again when dinosaurs stomped the Earth, dinky mammals scurried about of their shadows. The little furballs, hiding out in underground burrows, offered a recent area of interest for a novel reptile: the snake. Skinny snakes might squeeze into the houses of mammals and gobble them up.
A minimum of, that is how the daybreak of snakes is imagined by Marc Tollis, an evolutionary biologist at Northern Arizona College in Flagstaff. Nobody is aware of for positive. Just like the creatures themselves, the snake fossil report is lengthy and skinny, leaving gaps in snaky historical past. Main questions, resembling the place they bought their begin and who their closest relations are, stay unanswered.
Immediately, new fossils and trendy strategies are updating the story of snakes. Beginning about 125 million years in the past, snakes used their versatile physique plans to diversify like loopy, conquering areas that now make up six continents, plus the Indian and Pacific Oceans — and Tollis wouldn’t be stunned to search out snake fossils in once-balmy Antarctica, both.
It is a powerful smorgasbord of talents for what’s, basically, a freaky offshoot on the lizard household tree. Serpents are mainly predatory tubes, Tollis notes. They cannot stroll or chew their meals. These appear to be critically limiting elements.
The Barbados threadsnake, Tetracheilostoma carlae, is likely one of the smallest snakes on this planet.
(Picture credit score: BLAIR HEDGES / PENNSYLVANIA STATE UNIVERSITY)
“Regardless of that, snakes are a number of the most profitable animals,” marvels Tollis, who coauthored an summary of early snake and lizard evolution within the 2025 Annual Evaluate of Ecology, Evolution, and Systematics. “They positively have superpowers that we’d usually affiliate with the improbable.”
By sea, by land, or beneath?
There are greater than 4,000 described dwelling species of snakes, accounting for about one-third of the bigger lizard group, and possibly a whole lot extra awaiting official discovery, says Alex Pyron, an evolutionary biologist at George Washington College in Washington, DC. Scientists estimate that the ancestors of this wildly numerous group emerged round 160 million years in the past, however they have not found out what the primary snakes have been like — land snakes, sea snakes, maybe underground snakes?
Get the world’s most fascinating discoveries delivered straight to your inbox.
These mysterious, ancestral snakes ought to sit on the very base of the snake household tree, however their fossils have not been discovered. The oldest snake fossils recognized come from a wide range of environments, making it onerous to find out which sort of habitat snakes wriggled out of, says Tiago Simões, a coauthor on the Annual Evaluate paper and an evolutionary biologist at Princeton College in New Jersey.
One longstanding speculation is that snakes bought their begin underground. The unique thought was primarily based, partially, on the barely-there eyes of the blind snakes which might be the bottom department on the household tree of dwelling snakes. However blind snakes are fairly specialised for the anthills and termite mounds they inhabit, says Catie Sturdy, a vertebrate paleontologist and graduate scholar on the Harvard Museum of Comparative Zoology in Cambridge, Massachusetts.
They’ve bizarre, alien-looking skulls match for his or her subterranean surroundings and insectivore weight-reduction plan. For instance, Sturdy says, a “pronounced underbite” helps preserve grime out of their mouths. Whereas coaching with vertebrate paleontologist and evolutionary biologist Michael Caldwell on the College of Alberta in Edmonton, Canada, Sturdy concluded, as produce other researchers, that these hyperspecialized critters cannot correspond to the foundation of the snake household tree.
Within the late twentieth century, proof supporting a potential marine origin floated up. Scientists described early snakes that lived practically 100 million years in the past within the Center East, when that land was underwater. Caldwell and colleagues additionally linked the snake clan to mosasaurs, extinct aquatic reptiles, elevating the likelihood that snakes emerged within the water. However favor for that speculation has sunk: There are different snakes that predate these aquatic snakes and have been clearly terrestrial, says Simões. So the present consensus is that the Center Jap swimmers didn’t spring from the water however dived into it from land.
Scientists suspect that snakes share an ancestor with extinct, aquatic reptiles known as mosasaurs.
(Picture credit score: Restoration illustration from Wikimedia Commons, CC BY 3.0)
Fashionable-day Patagonia has yielded a trove of extra snake fossils, resembling Najash rionegrina, dated to about 95 million years in the past, and Dinilysia patagonica, from about 80 million years in the past, when that surroundings was desertlike. However have been these South American serpents on the bottom, or underneath it? Dinilysia most likely lived aboveground, however the state of affairs with Najash is trickier, says Simões.
Najash has cranium and spinal options that, to its discoverers, urged it spent a minimum of a while underground. However each of those Patagonia species have been “big-bodied snakes,” provides Caldwell, much like modern-day pythons. Like pythons, they may have hid out underground, however hunted on the floor, he speculates.
Further proof for a combined dry land/underground origin comes from predictions about early snakes’ brains. Scientists used 3D X-ray imaging to research the braincase — the a part of the cranium defending the mind — of practically 60 snakes and lizards, plus a number of snake fossils. From these internal contours, they may infer the form of the mind. The researchers recognized burrower mind anatomy: Diggers often possess, for instance, a small, flattened, triangular cerebellum, a mind part concerned in motion. When the researchers used their knowledge to foretell the ancestral snake mind form, they wound up with some burrower-like options, together with that little cerebellum, however different options inconsistent with underground dwelling.
Bringing all of the proof collectively, Sturdy subscribes to a principle that snakes developed on land, perhaps in a sandy surroundings just like the one Dinilysia and Najash inhabited. This, she suspects, additionally occurred to set them as much as navigate underground once in a while.
New fossils of the early snake Najash, present in Patagonia, have been reported within the journal Science Advances in 2019.
(Picture credit score: ADAPTED FROM F.F. GARBEROGLIO ET AL / SCIENCE ADVANCES 2019, CC by 4.0)
A greater solution to slither
One other main occasion in snake evolution was, after all, the shedding of their legs. This isn’t as progressive because it might sound; amongst lizard-kind, a number of lengthy, skinny teams have kicked their legs to the curb. When one is crawling underground or shifting by means of grass, limbs are actually “a drag,” says Daniela Garcia Cobos, an evolutionary biologist and graduate scholar on the American Museum of Pure Historical past in New York Metropolis. Snakes do, nonetheless, appear to have been among the many first lizards to grasp this streamlined form in a wide range of various kinds of habitats, which could underlie their success with it.
Pyron estimates this variation occurred between 150 million and 125 million years in the past, however scientists haven’t been capable of pin down precisely when or the place. The recognized fossil snakes had hind limbs however not forelimbs, although Dinilysia’s standing is unsure as a result of there hasn’t been good proof of pelvic area preservation in these fossils. At some earlier level, there will need to have been a four-legged snake ancestor, however this lacking hyperlink has been elusive. One candidate was reported in 2015, however Caldwell and collaborators confirmed it was simply a lizard.
Then got here Breugnathair elgolensis, a four-legged Jurassic fossil present in Scotland and described in Nature in 2025. “When you noticed it on the street, strolling throughout the highway, you’d assume it was simply an iguana or peculiar lizard,” says Susan E. Evans, a paleontologist at College School London, who described the specimen with colleagues.
However B. elgolensis’s jaw does have some snaky options, like the form of its enamel. Caldwell, who wasn’t a part of the staff that described it, thinks it is a snake. “It is bought all the appropriate cranium options,” he says.
Snakes make up the suborder Serpentes, throughout the order Squamata, that features all lizards and snakes. Snakes are associated to different reptiles in a clade known as Toxicofera, which incorporates all venomous lizards in addition to nonvenomous species.
(Picture credit score: Knowable Journal)
Evans is not so sure, an opinion evident within the identify she selected: Breugnathair derives from Gaelic for “false snake.” When Evans and colleagues tried to put it within the reptile household tree, the outcomes have been wishy-washy. It could be a snake ancestor, she concedes, or it may very well be a lizard that independently developed snakelike options however left no dwelling descendants.
Heady adjustments
What distinguished snakes from all different legless lizards have been the opposite adjustments they made, says Pyron. To research additional improvements, Pyron and collaborators launched into an enormous reptile census, which they revealed in Science in 2024. They measured the skulls of hundreds of snakes and lizards. They examined the abdomen contents of museum specimens and pored over written dietary data. They amassed genetic knowledge — not the entire genome, however 5,400 particular genes — from greater than 1,000 snake and lizard species.
After they lined up these options, snakes stood out. About 125 million years in the past, the group underwent sudden and vital adjustments to their skulls, diets and spines that might place them to diversify and unfold.
Snakes’ greatest declare to evolutionary fame is their weirdly versatile craniums, product of bony items linked by delicate tissue; Caldwell thinks this key alteration might need occurred even earlier than they gave up their legs. En path to these piecework noggins, snakes first modified up their braincase. In most lizards, this appears like a sandwich: bone on prime, bone on the underside, mind inside and open on the edges. However in snakes, it is extra like a wrap, a bony tube that is solely open towards the face and backbone. Defending the mind that means meant snakes have been free to let the remainder of the cranium’s bones transfer about. And boy, did they.
These cranium adjustments enabled new diets with the evolution of the serpentine jaw. Whereas jaw anatomy varies throughout the group, in lots of snakes, the decrease and higher components are linked by stretchy ligaments, enabling a large gape. The 2 sides of the decrease jaw can splay aside, additional increasing the snake’s maw. The palate on the prime of the mouth has proper and left components that transfer independently to convey meals throatward. That is how a python can swallow a pig. Certainly, the Science staff discovered that snakes, as a clan, can eat just about something that strikes. There are snakes that nosh on gooey slugs and armored snails, slippery eels and even different serpents.
And across the similar time, snakes grew longer, including a whole lot of vertebrae between their necks and nether areas. “Being elongate means that you can locomote extra rapidly and effectively,” says Caldwell. Further stomach flesh provides extra floor space to push alongside the bottom or climb tree trunks. For aquatic snakes, elevated physique size permits extra environment friendly weaving backwards and forwards.
In sum, these adjustments to physique, head and weight-reduction plan meant the evolving serpents have been versatile not simply in kind, but additionally in way of life. Snakes adapt quickly to new environments, says Frank Burbrink, curator of herpetology on the American Museum of Pure Historical past and a coauthor of the Annual Evaluate article. In different phrases, these evolutionary superstars have been primed to benefit from any habitat they slithered into.
Making up for absent fossils
The fragmented skulls and the physique size that have been so useful for snakes’ unfold create a headache for paleontologists: Useless snakes go to items, making full fossils scarce and leaving many questions unanswered. For instance, researchers know serpents are associated to teams containing iguanas and Komodo dragons, in addition to probably these mosasaurs, but it surely’s not sure that are their closest cousins. Understanding that might assist to foretell what snake ancestors ought to seem like, says Evans.
When fossils falter, genetics can come to the rescue. The extra dissimilar the genes from completely different animals, the longer it has been since they went their separate methods as species. Already, genetic analyses have compelled a reshuffling of the lizard household tree; timber primarily based on physique form alone turned out to be “completely unsuitable,” says Pyron.
Genes have additionally illuminated how snake our bodies construct a few of their particular options. The shortage of legs is linked to misplaced operate in a limb-promoting sequence known as ZRS. And scientists just lately reported that snakes lack the gene encoding the “starvation hormone” ghrelin. This may make it simpler for them to endure lengthy fasts; some snakes can go for a 12 months or extra between repasts.
Burbrink, Pyron and Simões at the moment are sequencing entire genomesof greater than 100 snakes and lizards, which can double the variety of high-quality genomes accessible. With that plus extra knowledge on dwelling and fossil reptiles, they anticipate to construct higher household timber and additional examine the genes behind a snake’s sinuous form.
Nonetheless, Evans says, scientists actually need extra fossils to fill within the twists and turns within the serpents’ story.
As paleontologists preserve digging, Burbrink counsels us to take a second to marvel the subsequent time we come throughout a garter snake or different trendy wriggler: “You are wanting on the fruits of greater than 100 million years of evolution.”
Your Mileage Could Fluctuate is an recommendation column providing you a novel framework for pondering by your ethical dilemmas. It’s based mostly on worth pluralism — the concept every of us has a number of values which might be equally legitimate however that usually battle with one another. To submit a query, fill out this nameless kind. Right here’s this week’s query from a reader, condensed and edited for readability:
We declare to cherish the pure world. But each nice achievement, story, and cup of espresso has carried out nothing for every other creature however ourselves. So when the existence of the human race is at the price of the whole lot else, when the hypocrisy is open and everyone knows… How am I purported to look anybody within the eye or be ok with collaborating in a world the place each human act is on the expense of the pure world that birthed us?
I’ve misplaced the desire. I understand this sounds childish. However the numbers are in, and I’m not positive what we expect we’re doing as a species apart from attempting to create the right client, the world be damned. We’re hooked on “self,” and I’m frankly disgusted to be a human.
Beneath the exhausting emotions you’re feeling — disgust, anger, loathing — are most likely a lot softer emotions: Disappointment. Disappointment. Worry concerning the future. It’s exhausting to stick with these as a result of they make us really feel susceptible. It’s a lot simpler to bypass them and go straight to hate. Standing in judgment over your personal variety just isn’t precisely enjoyable, however it does offer you a sense of ethical elevation.
So I’m not shocked that, all through historical past, numerous individuals have regarded on the human species and responded with an enormous “yuck.” As early because the Seventeenth century BCE, we’ve projected our disgust with ourselves onto the gods, imagining that they discover us so terrible {that a} Nice Flood is required to wipe us off the face of the Earth. Solely a handful of us are first rate sufficient to be saved, for instance, in an ark — Atraḥasis’s household within the Mesopotamian model of the story, Noah’s household within the Bible’s later retelling.
Since then, anti-humanism has loved resurgence after resurgence. It’s usually popped up at instances of civilizational-scale disaster — from the bubonic plague that ravaged Europe within the 14th century to the Wars of Faith within the Seventeenth century to the Atomic Age within the twentieth century.
Have a query you need me to reply within the subsequent Your Mileage Could Fluctuate column?
You describe your personal loathing for humanity as “childish,” however I’d use a special phrase to explain it, given what a well-liked response it’s been over the millennia. Frankly, it’s just a little…primary.
And deep down, you recognize it is senseless. These people that you simply’re so indignant at? They didn’t simply come from nature, as you famous, they’re half of nature — the character that you simply love a lot. We’re all pure organisms.
I feel what you’re actually chafing towards just isn’t humanity, however one specific manner of referring to the world — a extremely extractive manner — that some people leaned into at a specific second and that occurs to be having its time within the solar proper now.
The dualistic mental custom that tells us we might be separate from nature — and that we must always deal with the pure world as an object to be exploited for human acquire, reasonably than as a topic to be communed with and revered — is a Western custom that took off in modernity. We are able to hint it again to Seventeenth-century philosophers like Descartes, who argued that the soul is completely distinct from mere matter (and that solely people have souls), and Francis Bacon, who developed the scientific technique.
Earlier than thinkers like these got here on the scene, most non secular and philosophical traditions around the globe — from the traditional Greeks to the Indigenous peoples of the Americas, from Hindus in India to followers of Shintoism in Japan — believed that each one residing issues had some extent of soul in them. Many believed it of non-living issues, too (suppose: mountains or rivers). This led to life extra in stability with the remainder of nature.
However after the Seventeenth century, it grew to become more and more frequent to attempt to flip the whole lot in nature right into a commodity, even previous the purpose of sustainability. At the moment’s hypercapitalism feels just like the fruits of that pattern.
Understanding the historical past right here is useful, as a result of it reminds us that our present paradigm isn’t set in stone. Unfettered hypercapitalism wasn’t at all times the norm, and anti-humanism wasn’t at all times the reigning temper.
And in reality, if we peer again just a bit earlier than the arrival of Descartes and Bacon, we discover a flowering of simply the other: Renaissance humanism, the custom that emphasised simply how stunning and great human beings might be.
Right here’s the Sixteenth-century humanist thinker Michel de Montaigne writing in his Essays:
There may be nothing so stunning and bonafide as to play the person properly and correctly, no information so exhausting to accumulate because the information of methods to stay this life properly and naturally; and probably the most barbarous of our maladies is to despise our being.
To Montaigne, human life was a present from God. And when somebody provides you a present, the worst factor you are able to do is despise it. “We unsuitable that nice and omnipotent Giver by refusing his reward, nullifying it, and disfiguring it,” he wrote.
One of the best factor you are able to do? Take pleasure in it. Domesticate it. Right here’s Montaigne once more:
I really like life and domesticate it simply as God has been happy to grant it to us…I settle for with all my coronary heart and with gratitude what nature has carried out for me, and I’m happy with myself and happy with myself that I do.
Once I first learn this quote, in Sarah Bakewell’s pleasant historical past of humanism titled Humanly Doable, I puzzled why Montaigne specified that he feels happy with himself for loving life. Is that basically one thing to be happy with?
However the extra I give it some thought, the extra I see that the reply is sure. It’s exhausting to be a human. It was exhausting within the days of the Renaissance humanists, when plague, famine, and hostilities between political factions decimated communities. And it’s exhausting in our day, too.
It’s painful to see photos of the Nice Pacific Rubbish Patch filled with our throw-away plastic, to look at large swaths of rainforest being reduce right down to graze cattle for our hamburgers, to lose billions of birds that after added shade and music and ecosystem companies to our world. It’s painful to know that a lot of that’s being carried out to fulfill our greed.
But that doesn’t imply humanity is the most cancers of the planet. Keep in mind: Humanity can’t be a stain on nature — we are nature. (Additionally, nature itself isn’t some pure idyll — it’s usually “pink in tooth and claw” — and different animals additionally act in their very own pursuits, reshape ecosystems, and drive species extinct!) The extra correct description of people is that we’re an unusually intelligent ape with uncommon capacities for each cooperation and greed, at the moment leaning manner an excessive amount of into the latter.
So what do you have to do with all of that? To start with, simply let your self really feel the ache. Really feel the frustration, disappointment, worry, and all the opposite tender emotions.
It may be so overwhelming to actually tune into the incomprehensibly giant struggling of the pure world that you simply’ll be tempted to run away — to retreat right into a fatalistic “ugh, we’re the worst.” Resist that impulse. That permits you to off the hook too simply, as a result of it expects nothing of you. Stick with the rattling ache.
After which discover that the truth that you’re feeling this ache is definitely giving you a stunning piece of knowledge: You will have different capacities too — for cooperation and care and compassion. You would like for us all to do higher. For those who didn’t have these capacities, that want, you wouldn’t really feel the ache.
In accordance with the Buddhist scholar and environmental activist Joanna Macy, this means of “honoring our ache for the world” is important: Once we be taught to reframe our ache as struggling with or feeling compassion for the world, we see it as a power, and as proof of our interconnectedness with different life-forms.
As soon as we’ve shifted away from dualistic pondering and appreciated that we’re not separate from nature, we’re prepared to maneuver into what Macy calls “lively hope.” We normally consider hope as a sense, which you both have or don’t have, relying on how possible you suppose success is. However Macy says that’s unsuitable: Hope is a observe. It implies that you decide to act on behalf of the belongings you love, whatever the likelihood of success. You’re not betting on outcomes; you’re selecting what sort of particular person you need to be and the way you need to present up for the world, with out requiring a assure that you simply’ll succeed.
The no-guarantees bit is a part of the ethos of Buddhism, which recommends that we act with out attachment to outcomes. That doesn’t imply we don’t have targets and don’t attempt to use the best strategies of attaining them. It simply means we’ve the braveness to behave even whereas figuring out that we are able to’t totally management what finally occurs to the issues we love.
In my expertise, that’s actually exhausting to do: Once I love somebody or one thing, I desperately need to have the ability to shield them, to know with certainty that they’ll be okay. So each time I handle to observe lively hope, I actually do really feel Montaigne-style happy with myself. I hope you’ll too.
Bonus: What I’m studying
Adam Kirsch has an excellent, slim e-book referred to as The Revolt Towards Humanity that explores what’s behind the present rise of anti-humanism. I admire his level that anti-humanism just isn’t as totally different as one may suppose from its tech-bro cousin transhumanism, which says that we must always use science and expertise to proactively evolve our species into Homo sapiens 2.0. Each worldviews need as we speak’s humanity to vanish.
For those who’re a utilitarian who thinks all that issues is maximizing whole well-being, then a future with billions of copies of the identical completely optimized life should be the very best one…proper? However we all know in our guts {that a} world the place everybody resides equivalent lives could be a hellscape! To resolve this, thinker Will MacAskill not too long ago got here up with “saturationism,” a view that claims well-being stops accumulating as soon as the world is crammed with sufficient comparable lives — subsequently, selection is sweet. However Cosmos Institute workers author Alex Chalmers argues that saturationism “preserves the error of the unique framework: the idea that the very best future is one thing {that a} theorist can derive.”
From Turkey’s Göbekli Tepe to the Sainte-Chapelle cathedral in Paris, many advanced constructions predate the scientific technique and widespread information of arithmetic. How? It is a enjoyable Aeon video explaining how earlier people made actually refined stuff that our intuitions inform us they shouldn’t have been capable of make.