Manufacturing higher batteries, quicker electronics, and simpler prescribed drugs is determined by the invention of latest supplies and the verification of their high quality. Synthetic intelligence helps with the previous, with instruments that comb by means of catalogs of supplies to rapidly tag promising candidates.
However as soon as a fabric is made, verifying its high quality nonetheless entails scanning it with specialised devices to validate its efficiency — an costly and time-consuming step that may maintain up the event and distribution of latest applied sciences.
Now, a brand new AI device developed by MIT engineers may assist clear the quality-control bottleneck, providing a quicker and cheaper possibility for sure materials-driven industries.
In a research showing right now within the journal Matter, the researchers current “SpectroGen,” a generative AI device that turbocharges scanning capabilities by serving as a digital spectrometer. The device takes in “spectra,” or measurements of a fabric in a single scanning modality, reminiscent of infrared, and generates what that materials’s spectra would appear to be if it have been scanned in a wholly totally different modality, reminiscent of X-ray. The AI-generated spectral outcomes match, with 99 % accuracy, the outcomes obtained from bodily scanning the fabric with the brand new instrument.
Sure spectroscopic modalities reveal particular properties in a fabric: Infrared reveals a fabric’s molecular teams, whereas X-ray diffraction visualizes the fabric’s crystal constructions, and Raman scattering illuminates a fabric’s molecular vibrations. Every of those properties is important in gauging a fabric’s high quality and usually requires tedious workflows on a number of costly and distinct devices to measure.
With SpectroGen, the researchers envision {that a} variety of measurements may be made utilizing a single and cheaper bodily scope. As an illustration, a producing line may perform high quality management of supplies by scanning them with a single infrared digicam. These infrared spectra may then be fed into SpectroGen to routinely generate the fabric’s X-ray spectra, with out the manufacturing facility having to accommodate and function a separate, usually costlier X-ray-scanning laboratory.
The brand new AI device generates spectra in lower than one minute, a thousand occasions quicker in comparison with conventional approaches that may take a number of hours to days to measure and validate.
“We predict that you just don’t need to do the bodily measurements in all of the modalities you want, however maybe simply in a single, easy, and low-cost modality,” says research lead Loza Tadesse, assistant professor of mechanical engineering at MIT. “Then you need to use SpectroGen to generate the remaining. And this might enhance productiveness, effectivity, and high quality of producing.”
The research was led by Tadesse, with former MIT postdoc Yanmin Zhu serving as first writer.
Past bonds
Tadesse’s interdisciplinary group at MIT pioneers applied sciences that advance human and planetary well being, growing improvements for purposes starting from speedy illness diagnostics to sustainable agriculture.
“Diagnosing illnesses, and materials evaluation usually, often entails scanning samples and amassing spectra in numerous modalities, with totally different devices which can be cumbersome and costly and that you just may not all discover in a single lab,” Tadesse says. “So, we have been brainstorming about methods to miniaturize all this tools and methods to streamline the experimental pipeline.”
Zhu famous the growing use of generative AI instruments for locating new supplies and drug candidates, and questioned whether or not AI is also harnessed to generate spectral knowledge. In different phrases, may AI act as a digital spectrometer?
A spectroscope probes a fabric’s properties by sending mild of a sure wavelength into the fabric. That mild causes molecular bonds within the materials to vibrate in ways in which scatter the sunshine again out to the scope, the place the sunshine is recorded as a sample of waves, or spectra, that may then be learn as a signature of the fabric’s construction.
For AI to generate spectral knowledge, the traditional method would contain coaching an algorithm to acknowledge connections between bodily atoms and options in a fabric, and the spectra they produce. Given the complexity of molecular constructions inside only one materials, Tadesse says such an method can rapidly change into intractable.
“Doing this even for only one materials is not possible,” she says. “So, we thought, is there one other approach to interpret spectra?”
The staff discovered a solution with math. They realized {that a} spectral sample, which is a sequence of waveforms, may be represented mathematically. As an illustration, a spectrum that accommodates a sequence of bell curves is named a “Gaussian” distribution, which is related to a sure mathematical expression, in comparison with a sequence of narrower waves, generally known as a “Lorentzian” distribution, that’s described by a separate, distinct algorithm. And because it seems, for many supplies infrared spectra characteristically comprise extra Lorentzian waveforms, whereas Raman spectra are extra Gaussian, and X-ray spectra is a mixture of the 2.
Tadesse and Zhu labored this mathematical interpretation of spectral knowledge into an algorithm that they then included right into a generative AI mannequin.
“It’s a physics-savvy generative AI that understands what spectra are,” Tadesse says. “And the important thing novelty is, we interpreted spectra not as the way it comes about from chemical substances and bonds, however that it’s truly math — curves and graphs, which an AI device can perceive and interpret.”
Knowledge co-pilot
The staff demonstrated their SpectroGen AI device on a big, publicly accessible dataset of over 6,000 mineral samples. Every pattern contains data on the mineral’s properties, reminiscent of its elemental composition and crystal construction. Many samples within the dataset additionally embrace spectral knowledge in numerous modalities, reminiscent of X-ray, Raman, and infrared. Of those samples, the staff fed a number of hundred to SpectroGen, in a course of that educated the AI device, also referred to as a neural community, to be taught correlations between a mineral’s totally different spectral modalities. This coaching enabled SpectroGen to absorb spectra of a fabric in a single modality, reminiscent of in infrared, and generate what a spectra in a completely totally different modality, reminiscent of X-ray, ought to appear to be.
As soon as they educated the AI device, the researchers fed SpectroGen spectra from a mineral within the dataset that was not included within the coaching course of. They requested the device to generate a spectra in a distinct modality, primarily based on this “new” spectra. The AI-generated spectra, they discovered, was an in depth match to the mineral’s actual spectra, which was initially recorded by a bodily instrument. The researchers carried out related exams with a lot of different minerals and located that the AI device rapidly generated spectra, with 99 % correlation.
“We are able to feed spectral knowledge into the community and might get one other completely totally different sort of spectral knowledge, with very excessive accuracy, in lower than a minute,” Zhu says.
The staff says that SpectroGen can generate spectra for any sort of mineral. In a producing setting, as an illustration, mineral-based supplies which can be used to make semiconductors and battery applied sciences may first be rapidly scanned by an infrared laser. The spectra from this infrared scanning could possibly be fed into SpectroGen, which might then generate a spectra in X-ray, which operators or a multiagent AI platform can test to evaluate the fabric’s high quality.
“I consider it as having an agent or co-pilot, supporting researchers, technicians, pipelines and trade,” Tadesse says. “We plan to customise this for various industries’ wants.”
The staff is exploring methods to adapt the AI device for illness diagnostics, and for agricultural monitoring by means of an upcoming mission funded by Google. Tadesse can be advancing the know-how to the sphere by means of a brand new startup and envisions making SpectroGen accessible for a variety of sectors, from prescribed drugs to semiconductors to protection.
Whereas AI bots have begun mastering duties in browsers and on Home windows, Mac-using enterprises have largely been ignored, till now. OpenAI goals to vary that with its acquisition of generative AI interface maker Software program Purposes Included.
The bottom of this integration is Sky, a generative AI-based, pure language-input appropriate assistant for macOS that the San Francisco-headquartered startup has been creating to assist customers automate varied duties.
“Whether or not you’re chatting, writing, planning, or coding, Sky understands what’s in your display screen and may take motion utilizing your apps,” the startup wrote on its portal describing Sky.
Giving AI management of the OS
The concept of automating duties for desktop customers will not be fully novel. Final yr in October, Anthropic grew to become the primary LLM supplier to showcase the potential for controlling a pc or some components of its working system.
That capacity, which Anthropic had termed “pc use,” enabled builders to instruct Claude 3.5 Sonnet, by means of the Anthropic API, to learn and interpret what’s on the show, sort textual content, transfer the cursor, click on buttons, and change between home windows or functions.
It caught the eye of specialists and enterprises as the flexibility was a significant step up from extra conventional automation practices, comparable to robotic course of automation (RPA) instruments, which required extra time and labor to arrange and but would require fixed upkeep.
One other subject with RPA instruments was that enterprise customers or builders must change the code or script because the interface of the working system modified. In distinction, Anthropic’s capacity demonstrated that LLMs can perceive what they’re , eliminating the necessity to change scripts as interfaces change.
Simply days after Anthropic’s announcement, Google additionally entered the AI-based pc use fray by showcasing Jarvis, an providing designed to automate duties comparable to analysis and procuring inside the Chrome browser with the assistance of the corporate’s Gemini 2.0 LLM.
Across the identical time, OpenAI reportedly revealed that it had been engaged on an analogous functionality since February final yr.
The acquisition of Sky and its integration into ChatGPT, in line with Forrester principal analyst Charlie Dai, is OpenAI’s vital step in direction of gaining a sizeable share of the nascent but evolving AI-based automation market, pushed by agentic AI.
OpenAI is prone to market use circumstances that contain automating workflows throughout apps, coding help, and integrating with collaboration instruments for elevated productiveness, Dai stated, including that the corporate is focusing on macOS as it’s widespread amongst builders and inventive professionals, giving it a sizeable buyer base.
Sky’s integration into ChatGPT will not be the one product that OpenAI has as a part of its macOS footprint.
Simply final week, it launched ChatGPT Atlas — an online browser with ChatGPT inbuilt — designed to automate duties like bookings instantly inside the browser window, echoing Google’s Jarvis.
OpenAI is predicted to launch Atlas for Home windows, iOS, and Android sooner or later. Microsoft, OpenAI’s shut associate, has launched related capabilities for Home windows through Copilot Mode in its Edge browser.
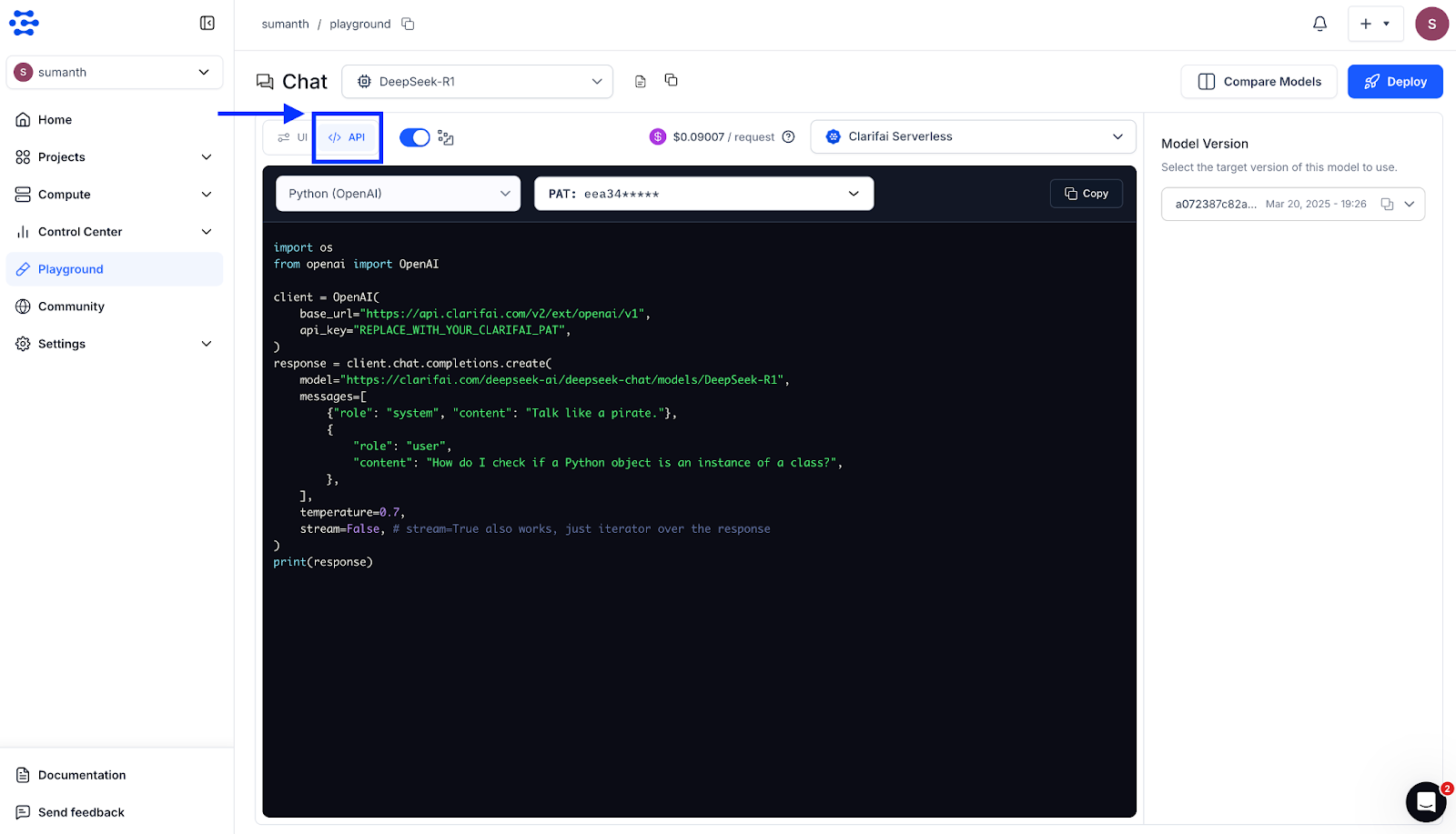
DeepSeek fashions, together with DeepSeek‑R1 and DeepSeek‑V3.1, are accessible straight via the Clarifai platform. You may get began with no need a separate DeepSeek API key or endpoint.
Experiment within the Playground: Join a Clarifai account and open the Playground. This allows you to check prompts interactively, alter parameters, and perceive the mannequin conduct earlier than integration.
Combine through API: Combine fashions through Clarifai’s OpenAI-compatible endpoint by specifying the mannequin URL and authenticating together with your Private Entry Token (PAT).
https://api.clarifai.com/v2/ext/openai/v1
Authenticate together with your Private Entry Token (PAT) and specify the mannequin URL, comparable to DeepSeek‑R1 or DeepSeek‑V3.1.
Clarifai handles all internet hosting, scaling, and orchestration, letting you focus purely on constructing your software and utilizing the mannequin’s reasoning and chat capabilities.
DeepSeek in 90 Seconds—What and Why
DeepSeek encompasses a variety of huge language fashions (LLMs) designed with various architectural methods to optimize efficiency throughout numerous duties. Whereas some fashions make use of a Combination-of-Consultants (MoE) strategy, others make the most of dense architectures to stability effectivity and functionality.
1. DeepSeek-R1
DeepSeek-R1 is a dense mannequin that integrates reinforcement studying (RL) with information distillation to boost reasoning capabilities. It employs a regular transformer structure augmented with Multi-Head Latent Consideration (MLA) to enhance context dealing with and cut back reminiscence overhead. This design allows the mannequin to attain excessive efficiency in duties requiring deep reasoning, comparable to arithmetic and logic.
2. DeepSeek-V3
DeepSeek-V3 adopts a hybrid strategy, combining each dense and MoE parts. The dense half handles common conversational duties, whereas the MoE element prompts specialised specialists for advanced reasoning duties. This structure permits the mannequin to effectively swap between common and specialised modes, optimizing efficiency throughout a broad spectrum of functions.
3. Distilled Fashions
To offer extra accessible choices, DeepSeek presents distilled variations of its fashions, comparable to DeepSeek-R1-Distill-Qwen-7B. These fashions are smaller in measurement however retain a lot of the reasoning and coding capabilities of their bigger counterparts. For example, DeepSeek-R1-Distill-Qwen-7B is predicated on the Qwen 2.5 structure and has been fine-tuned with reasoning information generated by DeepSeek-R1, attaining robust efficiency in mathematical reasoning and common problem-solving duties.
How one can Entry DeepSeek on Clarifai
DeepSeek fashions will be accessed on Clarifai in 3 ways: via the Clarifai Playground UI, through the OpenAI-compatible API, or utilizing the Clarifai SDK. Every methodology gives a distinct degree of management and suppleness, permitting you to experiment, combine, and deploy fashions in line with your improvement workflow.
Clarifai Playground
The Playground gives a quick, interactive atmosphere to check prompts and discover mannequin conduct.
You possibly can choose any DeepSeek mannequin, together with DeepSeek‑R1, DeepSeek‑V3.1, or distilled variations out there on the neighborhood. You possibly can enter prompts, alter parameters comparable to temperature and streaming, and instantly see the mannequin responses. The Playground additionally means that you can evaluate a number of fashions facet by facet to check and consider their responses.
Inside the Playground itself, you may have the choice to view the API part, the place you may entry code snippets in a number of languages, together with cURL, Java, JavaScript, Node.js, the OpenAI-compatible API, the Clarifai Python SDK, PHP, and extra.
You possibly can choose the language you want, copy the snippet, and straight combine it into your functions. For extra particulars on testing fashions and utilizing the Playground, see the Clarifai Playground Quickstart
Attempt it: The Clarifai Playground is the quickest option to check prompts. Navigate to the mannequin web page and click on “Take a look at in Playground”.
By way of the OpenAI‑Appropriate API
Clarifai gives a drop-in alternative for the OpenAI API, permitting you to make use of the identical Python or TypeScript consumer libraries you’re acquainted with whereas pointing to Clarifai’s OpenAI-compatible endpoint. Upon getting your PAT set as an atmosphere variable, you may name any Clarifai-hosted DeepSeek mannequin by specifying the mannequin URL.
Clarifai’s Python SDK simplifies authentication and mannequin calls, permitting you to work together with DeepSeek fashions utilizing concise Python code. After setting your PAT, you may initialize a mannequin consumer and make predictions with only a few strains.
For contemporary net functions, the Vercel AI SDK gives a TypeScript toolkit to work together with Clarifai fashions. It helps the OpenAI-compatible supplier, enabling seamless integration.
{role:“system”,content:“You are a helpful assistant.”},
{role:“user”,content:“What is photosynthesis?”}
],
});
console.log(textual content);
This SDK additionally helps streaming responses, software calling, and different superior options.Along with the above, DeepSeek fashions will also be accessed through cURL, PHP, Java, and different languages. For an entire listing of integration strategies, supported suppliers, and superior utilization examples, discuss with the documentation.
Superior Inference Patterns
DeepSeek fashions on Clarifai assist superior inference options that make them appropriate for production-grade workloads. You possibly can allow streaming for low-latency responses, and software calling to let the mannequin work together dynamically with exterior techniques or APIs. These capabilities work seamlessly via Clarifai’s OpenAI-compatible API.
Streaming Responses
Streaming returns mannequin output token by token, enhancing responsiveness in real-time functions like chat interfaces or dashboards. The instance beneath exhibits the way to stream responses from a DeepSeek mannequin hosted on Clarifai.
importos
fromopenaiimportOpenAI
# Initialize the OpenAI-compatible consumer for Clarifai
Streaming helps you render partial responses as they arrive as an alternative of ready for all the output, lowering perceived latency.
Device Calling
Device calling allows a mannequin to invoke exterior features throughout inference, which is particularly helpful for constructing AI brokers that may work together with APIs, fetch reside information, or carry out dynamic reasoning. DeepSeek-V3.1 helps software calling, permitting your brokers to make context-aware choices. Under is an instance of defining and utilizing a software with a DeepSeek mannequin.
importos
fromopenaiimportOpenAI
# Initialize the OpenAI-compatible consumer for Clarifai
For extra superior inference patterns, together with multi-turn reasoning, structured output technology, and prolonged examples of streaming and power calling, discuss with the documentation
Which DeepSeek Mannequin Ought to I Decide?
Clarifai hosts a number of DeepSeek variants. Selecting the best one relies on your process:
DeepSeek‑R1 – use for reasoning and sophisticated code. It excels at mathematical proofs, algorithm design, debugging and logical inference. Count on slower responses on account of prolonged “pondering mode,” and better token utilization.
DeepSeek‑V3.1 – use for common chat and light-weight coding. V3.1 is a hybrid: it may swap between non‑pondering mode (quicker, cheaper) and pondering mode (deeper reasoning) inside a single mannequin. Superb for summarization, Q&A and on a regular basis assistant duties.
Distilled fashions (R1‑Distill‑Qwen‑7B, and so on.) – these are smaller variations of the bottom fashions, providing decrease latency and value with barely decreased reasoning depth. Use them when pace issues greater than maximal efficiency.
On the time of writing, DeepSeek‑OCR has simply been introduced and isn’t but out there on Clarifai. Regulate Clarifai’s mannequin catalog for updates.
Incessantly Requested Questions (FAQs)
Q1: Do I want a DeepSeek API key? No. When utilizing Clarifai, you solely want a Clarifai Private Entry Token. Don’t use or expose the DeepSeek API key except you’re calling DeepSeek straight (which this information doesn’t cowl).
Q2: How do I swap between fashions in code? Change the mannequin worth to the Clarifai mannequin ID, comparable to openai/deepseek-ai/deepseek-chat/fashions/DeepSeek-R1 for R1 or openai/deepseek-ai/deepseek-chat/fashions/DeepSeek-V3.1 for V3.1.
Q3: What parameters can I tweak? You possibly can alter temperature, top_p and max_tokens to regulate randomness, sampling breadth and output size. For streaming responses, set stream=True. Device calling requires defining a software schema.
This fall: Are there charge limits? Clarifai enforces delicate charge limits per PAT. Implement exponential backoff and keep away from retrying 4XX errors. For prime throughput, contact Clarifai to extend quotas.
Q5: Is my information safe? Clarifai processes requests in safe environments and complies with main information‑safety requirements. Retailer your PAT securely and keep away from together with delicate information in prompts except crucial.
Q6: Can I advantageous‑tune DeepSeek fashions? DeepSeek fashions are MIT‑licensed. Clarifai plans to supply non-public internet hosting and advantageous‑tuning for enterprise prospects within the close to future. Till then, you may obtain and advantageous‑tune the open‑supply fashions by yourself infrastructure.
Conclusion
You now have a quick, normal option to combine DeepSeek fashions, together with R1, V3.1, and distilled variants, into your functions. Clarifai handles all infrastructure, scaling, and orchestration. No separate DeepSeek key or advanced setup is required. Attempt the fashions at present via the Clarifai Playground or API and combine them into your functions.
Pixel 10 Professional Fold customers report battery icon displaying a mysterious query mark.
The bug might be linked to wi-fi chargers, presumably affecting the battery administration system’s calibration.
A brief repair is on the market via a reboot, however Google states {that a} repair will probably be rolled out with the November month-to-month replace.
Google’s newest foldable appears to be dealing with a peculiar bug. A number of Google Pixel 10 Professional Fold customers on Reddit have reported seeing a mysterious query mark(?) as a substitute of the proportion.
This challenge appears to be cropping up for customers who’ve wi-fi chargers, significantly third-party or non-Qi2 licensed chargers, however that is nonetheless hypothesis(as first noticed by Piunika Internet). The rumor on the road is that these chargers may’ve precipitated a “temporary communication or calibration error between the battery administration system and the software program interface, ensuing within the cellphone being uncertain of the present battery stage, therefore the query mark,” the publication added.
Customers on the identical Reddit thread had conflicting opinions on the reason for this glitch. Some say it might be an underlying {hardware} challenge, just like the battery failing, whereas others consider it is a easy UI downside {that a} fast repair may resolve. One consumer even stated that “Lots of this has been occurring because the final play safety replace. I think it can come out as only a bug, however you are good to achieve out to Google to see what they advocate.”
That stated, it is not simply the brand new Pixel 10 Professional Fold dealing with these points; some 9 Professional Fold customers additionally appear to have noticed the bizarre ‘?’ icon subsequent to their battery, the place one consumer said that the error message they acquired was “Unable to learn battery meters”. The consumer appeared to have contacted Google help, who stated they’re sending him a brand new gadget.
(Picture credit score: Nicholas Sutrich / Android Central)
So may this actually be a battery swelling challenge on the brand new Pixel 10 Professional Fold? Solely time will inform. However for now, when you’re seeing this challenge, a short lived repair, all you must do is to reboot the cellphone, which returns the proper battery proportion. In the event you nonetheless do not see it fixing this bug, it’s best to contact Google Help for additional steering or a potential guarantee declare.
Google’s spokesperson additionally confirmed to Android Central that rebooting the gadget will resolve the problem; nevertheless, “Pixel 10 Professional Fold customers ought to use licensed Qi2 wi-fi chargers.” And {that a} repair for this battery bug will probably be rolling out with the November month-to-month replace.
Get the newest information from Android Central, your trusted companion on the planet of Android
Subterranean mosquitoes specialised for all times in subways and sewers first developed to pester people millennia in the past in Mediterranean civilizations.
A broadly accepted story concerning the mosquitoes’ evolution put their origins within the London Underground practice system within the final century or two. However the mosquitoes have really been adapting to humanity’s cities for probably 1000’s of years, researchers report within the Oct. 23 Science.
The northern home mosquito (Culex pipiens) usually bites birds. However one kind present in city underground areas throughout northern latitudes — C. pipiens f. molestus — has developed to feed on people and different mammals. It has key diversifications for dwelling in secluded environments with scarce hosts. The molestus mosquitoes can breed in cramped indoor areas, and when assets are skinny, females can produce eggs with out taking a blood meal.
The mosquitoes have been first acknowledged throughout World Warfare II as they bit Londoners within the Underground in search of refuge from Nazi bombing. The chief speculation was that molestus developed proper there within the Tube. However decades-older historic data of molestus-like mosquitoes within the Mediterranean recommended in any other case, says Yuki Haba, an evolutionary biologist now at Columbia College.
To discover the mosquito’s evolutionary historical past, Haba — then at Princeton College — labored with a global crew of over 200 scientists. The crew compiled, analyzed and in contrast the genomes — the complete set of genetic directions — of 357 home mosquitoes from 77 places throughout western Eurasia.
The molestus lineage far predates the fashionable cities of Europe, the researchers discovered, diverging from their bird-biting cousins between 1,300 and 12,500 years in the past within the Mediterranean and Center East. The mosquitoes might have exploited the irrigation and saved water of early agricultural societies for year-round breeding websites. Adaptation to those settlements might have let the bugs springboard into trendy city environments in a while. Bedbugs took an analogous path to grow to be city pests.
“Adaptation to human areas didn’t want to begin with subways or skyscrapers,” Haba says. “Trendy cities didn’t create molestus — they merely supplied new areas the place its historic, human-associated traits might thrive.”
The mosquitoes’ story has been a textbook instance of recent species arising in response to latest urbanization, says Kristin Winchell, an city evolutionary ecologist at New York College who was not concerned with this analysis.
“All of us simply form of took that as truth, and I believe most of us didn’t notice that it didn’t even have any empirical knowledge backing it up,” she says. “So it’s fairly cool that [the researchers] really got down to check it.”
Lindsay Miles, an city evolutionary biologist at Virginia Tech in Blacksburg, is curious whether or not molestus is interbreeding with aboveground mosquitos across the subway zones the place the trains briefly transfer to aboveground areas. Such hybrids between bird- and human-biting varieties facilitate the unfold of harmful pathogens akin to West Nile virus, which hops from birds to people through the chew of C. pipiens, Haba says.
Future work might reveal how the mosquitoes are nonetheless evolving, says research coauthor Lindy McBride, an evolutionary biologist at Princeton College. “Despite the fact that they didn’t originate in cellars and subways, they’re there now and are most probably within the means of adapting additional to this distinctive surroundings.”
The target market for immediately’s submit is future-me, and anybody else equally within the fairly particular points it’s jotting down notes for. These points embrace:
Drawing directed graphs with ggdag which have totally different colored edges
Accessing the UN Sustainable Improvement Objectives (SDGs) database API
Information choices on gender inequality
Becoming the identical blended results mannequin with lme4::lmer, mgcv::gamm and mgcv::gam, evaluating outcomes and extracting group-level residuals
Hand-drawing prediction plots to indicate the outcomes of fashions with interactions and evaluating that to the marginaleffects package deal
Diagnostics of a simplified model of the mannequin
Modelling technique questions regarding researcher levels of freedom, use of splines and interplay results
My method to presenting this (each immediately, and in Half I) is totally different to my standard one, the place I attempt to make the submit itself a stand-alone, reproducible artefact with all of the code essential to provide the leads to the submit. That method simply didn’t work out on this case; the code was too lengthy and boring to incorporate in the principle weblog, there are too many various audiences to write down for, and I went down too many useless ends in exploring a few of the modelling choices. Even on this technical companion piece, this submit isn’t going to be totally reproducible, however simply have the snippets of code that greatest illustrate the purpose.
Directed graphs with totally different colored edges
For the principle submit, I had to attract a few directed graphs with totally different colored edges connecting the nodes. Particularly, I wished to make use of a crimson line to indicate a destructive route impact, and blue to indicate a constructive, like this:
This was surprisingly fiddly to do and required a little bit of a hack. Particularly, you must explicitly name the tidy_dagitty operate, which turns a ggdag graph object of sophistication dagitty into an information body of sophistication tidy_dagitty; then you definitely add a column to that knowledge body which has the precise colors as its values, conditional on no matter algorithm it’s good to decide these colors. On this instance, I need it to be crimson when the road phase is join “opp” (Alternatives for girls and women) to “tfr” (Complete fertility fee), and blue in any other case.
So far as I might inform, you possibly can’t simply map a column of character or issue values to color and let the color scale match it, which might be the method extra according to the ggplot2 philosophy. As an alternative, you solely have the selection of an identification scale, which is why that column edge_type I add has to have the values “darkred” and “steelblue”. That’s the principle trick for doing this.
dg2<-dagify(tfr~opp+hw,hw~opp,labels=c("tfr"="Complete fertility fee","hw"="Males doing home tasks","opp"="Alternatives fornwomen and women"),consequence="tfr",publicity="hw")|># explicitly name this often hidden operate so we are able to color the sides:ggdag::tidy_dagitty(seed=124)|># color the sides. Have to specify identification of color right here, not use scale_mutate(edge_type=ifelse(to=="tfr"&title=="opp","darkred","steelblue"))# Draw the simplified causal graphset.seed(124)dg2|>ggplot(aes(x=x,y=y,xend=xend,yend=yend))+geom_dag_node(color="gray")+geom_dag_edges(aes(edge_colour=edge_type),arrow_directed=grid::arrow(size=unit(12,"pt"),sort="closed"))+geom_dag_text_repel(aes(label=label),col=lab_col)+theme_dag(base_family="Roboto")
Accessing the UN SDGs database
I couldn’t discover a easy manner of accessing the United Nations Statistics Division’s invaluable definitive database of the SDG indicators for all nations of the world. By which I imply, it has an API, however I didn’t see anybody who’d written a pleasant R package deal to conveniently work together with it. If anybody is aware of of somebody who’s finished this, or needs to do it themselves, please let me know.
So I needed to write my very own API request on my own, like an animal. I did this in what I’m positive is a suboptimal manner, but it surely works. From taking part in round with the UN’s API I discovered the curl command I wished to obtain the info:
Then I used features from Bob Rudis’ curlconverter R package deal to transform this to a request for the old style httr package deal to make use of. Because the feedback on this code say, I do know all that is outmoded; but it surely works for now.
#-----------downloading some SDG time use knowledge from the UN database-------------# Be aware positive that is the easiest way to do that, it was clunky to work out,# but it surely works. Somebody ought to (or have they already?) construct an R package deal.## that is all httr, I perceive httr2 is the present factor now, however this nonetheless works library(curlconverter)library(httr)request<-"curl -X POST --header 'Content material-Kind: utility/x-www-form-urlencoded' --header 'Settle for: utility/octet-stream' -d 'seriesCodes=SL_DOM_TSPD' 'https://unstats.un.org/sdgapi/v1/sdg/Collection/DataCSV'"|>straighten()|>make_req()gender_txt<-content material(request[[1]](),as="textual content")gender<-read_csv(gender_txt)|>clean_names()
The tip outcomes is I desire a variable, from that SL_DOM_TPSD indicator (time spent on home chores and care work by intercourse and concrete/rural location) that may be represented like this:
There are vital knowledge wrangling challenges, although, particularly the totally different age classes utilized in every nation, the totally different years that surveys had been carried out, and the presence of a number of observations for some however not all nations.
The primary motive for together with this subsequent snippet is to remind myself of what was wanted to do to fiddle with these age classes. For instance, notice that some nations have values for a number of open ended classes like 3+ and 15+; we want a rule for deciding which of those is greatest for our desired constructed variable of males’s share of grownup home home and care work (on this case, 15+ is best than 3+, when each can be found for a rustic):
rely(gender,intercourse)# two classes, FEMALE and MALE - no TOTALrely(gender,age)# many various ages used for various nationsrely(gender,location)# there's ALLAREA, RURAL and URBAN# needs to be just one indicator:stopifnot(size(distinctive(gender$series_description))==1)# which is # Proportion of time spent on unpaid home chores and care work, by intercourse, age and placement (%) time_chores<-gender|># we do not need rural and concrete, simply nation complete:filter(location=="ALLAREA")|># we wish the ages like 15+, 12+ and so on, not these like 15-59 with an higher certainfilter(grepl("^[0-9]*+$",age))|># however not the retirees, which some nations embrace. We wish the 15+, not 15+# and 65+ individually:filter(!age%in%c("65+","85+","60+"))|># calculate the male time spent as a proportion of complete (female and male) time spentgroup_by(geo_area_name,time_period,age)|>summarise(prop_male=worth[sex=='MALE']/sum(worth[sex=='MALE']+worth[sex=='FEMALE']))|>group_by(geo_area_name)|># Label the most recent survey per nation. Be aware that any modelling must# embrace a rustic random impact for the a number of observations per nation:mutate(is_latest=ifelse(time_period==max(time_period),"Most up-to-date","Earlier"))|># restrict to only the most effective age group, closest to adults, for every nation/time:group_by(geo_area_name,time_period)|>mutate(age=issue(age,ranges=c("15+","16+","18+","12+","10+","6+","5+","3+")))|>prepare(geo_area_name,time_period,age)|>slice(1)|>ungroup()|>mutate(iso3_code=countrycode(geo_area_name,origin="nation.title.en",vacation spot="iso3c"))
Information on gender inequality
I spent fairly a little bit of time on the lookout for knowledge on gender inequality unbiased of the home tasks query. I wished one thing that resembled ladies’s and women’ alternatives in training and the financial system extra broadly. I had varied deadends in pursuing this. My first concept was some type of literacy measure—feminine literacy at some given age, or for adults total, as a ratio for equal male literacy. However the varied sources for this simply didn’t have sufficient observations.
The primary sources for literacy can be self-report in a census or presumably a social survey; or a standardised check at a given yr of education. After some fruitless time with SDGs, the World Financial institution’s World Improvement Indicators, and varied different sources, I concluded that neither of those appear to be available in a comparable foundation for sufficient years that matched with the year-country mixtures that I had time-use knowledge for.
I ended up utilizing the Gender Inequality Index (GII) from the UNDP as an alternative. Now, this index is advanced and depends on a bunch of indicators which might be clearly going to be at the very least as laborious to measure as literacy—like degree of secondary training (wants admin knowledge or survey or census) and maternal mortality ratio (wants good civil registry, or survey knowledge as a much less passable different). Right here’s how the GII is constructed:
However the GII is offered for all country-year mixtures, which merely can’t be based mostly on direct observations of those variables. Clearly the UNDP do a bunch of modelling to interpolate all of the lacking values. I didn’t look into this however simply trusted the UNDP to have finished the most effective job attainable. It’s definitely very handy to get this measure of gender inequality for thus many nations (206 ‘nations’, however this contains some regional groupings), and for thus a few years.
There have been a number of methods to obtain this GII knowledge from the Human Improvement Experiences web site, but it surely seems the most effective is to obtain all of the Human Improvement Report knowledge for the most recent yr in a single, massive CSV:
# You'll be able to obtain all of the HDR elements (together with GII):df<-"hdr25.csv"if(!file.exists(df)){obtain.file("https://hdr.undp.org/websites/default/information/2025_HDR/HDR25_Composite_indices_complete_time_series.csv",destfile=df)}hdr<-read_csv(df)
From there it’s simple knowledge wrangling to extract simply the GII knowledge and mix with my different datasets utilizing yr and the ISO three character codes for nations to affix by.
Becoming the identical blended results mannequin with lmer, gamm and gam
Specifying fashions
One of many issues I wished to kind on this submit was the close to equivalence of a few of the many various methods of specifying and becoming a blended results mannequin in R. There’s an excellent submit from Gavin Simpson on ‘Utilizing random results in GAMs with mgcv’ that I referred to repeatedly in making ready this.
Particularly, I wished to verify that these 4 fashions, set out under, are all very comparable. By which I truly imply the final three are equivalent statistically, however have other ways of being estimated and/or the components written down; and the primary is a statistically totally different mannequin when it comes to chance distributions and hyperlink features, however successfully very very comparable certainly to the opposite three:
# notice response variable is ltfr, outlined earlier as log(tfr):model2<-lmer(ltfr~gii+log(gdprppppc)*prop_male+(1|country_fac),knowledge=model_ready)model7a<-gamm(tfr~gii+log(gdprppppc)*prop_male+s(country_fac,bs='re'),knowledge=model_ready,household=quasipoisson)model7b<-gamm(tfr~gii+log(gdprppppc)*prop_male,random=checklist(country_fac=~1),knowledge=model_ready,household=quasipoisson)model7c<-gam(tfr~gii+log(gdprppppc)*prop_male+s(country_fac,bs='re'),knowledge=model_ready,household=quasipoisson,technique="REML")
These are:
model2 – match with lme4::lmer, response variable is log-transformed first after which response is Gaussian, nation degree random impact is specified with 1 | country_fac components notation. Be aware that I can’t use glmer becuase it doesn’t enable household = quasipoisson.
model7a – match with mgcv::gamm which is an iterative course of the place the blended results are with with lmer and smoothing splines are finished with gam, iterate until converges. The tip end result incorporates the ultimate model of each the lme mannequin and the gam mannequin. There’s no pre-transformation finished of the response variable as a result of we’re utilizing a generalized linear mannequin with quasipoisson household – that’s, variance is proportional to the imply, however not compelled to be equal to it. The random nation degree impact is specified with s(country_fac, bs="re") (re stands for random results), which is handed on to lme that treats it as Formulation: ~1 | country_fac.
model7b – equivalent to 7a besides the random results are specified by random = checklist(country_fac = ~ 1)
model7c – match with mgcv::gam, utilizing the identical mannequin specification as model7b. In contrast to gamm, this does all of the work inside gam itself, there’s no iterating to the features of the lme4 package deal. There are limitations imposed consequently – the random results can’t be correlated with eachother, and you’ll’t specify advanced error buildings (autocorrelation and so on) like you might with gamm or lmer. However I don’t have a necessity for both of this stuff. Importantlymodel7c has to make use of restricted most probability as its estimation technique if we wish it to get equal outcomes to the lmer-based strategies.
Ultimately, none of those fashions had been referred to in my essential submit as a result of I went for an method based mostly purely on the usage of gam() and with varied non-linear results even within the base, null mannequin. Nevertheless it was a really helpful studying expertise for me to work out precisely what’s and isn’t totally different in a bunch of comparable mannequin specs.
Getting the identical fastened coefficients
Right here is code to extract the coefficients for the fastened results from these 4 basically equivalent fashions:
# Mounted coefficients of the 4 comparable linear fashions:abstract(model7a$lme)$tTable|>as.knowledge.body()|>choose(mod7a=Worth)|>mutate(mod7b=pull(as.knowledge.body(abstract(model7b$lme)$tTable),Worth))|>mutate(mod7c=pull(as.knowledge.body(abstract(model7c)$p.desk),Estimate))|>mutate(mod2=fixef(model2))|>mutate(throughout(the place(is.numeric),spherical,digits=2))
The largest distinction within the coefficients is with model2, not shocking as a result of it has the largest distinction in its specification from the opposite three. The log transformation is finished earlier than modelling and the response is then handled as Gaussian, versus the quasipoisson hyperlink and variance features method of the opposite three.
Be aware that from the above snippet of code that not least of the variations between these fashions is the totally different strategies used to extract these fastened coefficients.
Getting the identical group degree random results
One other verify that these fashions are principally the identical was to check the country-level random results. For instance, is the “Oman” impact going to be the identical in every of those 4 fashions?
To reply this I first needed to work out the right way to extract the random results from the variations that used the s(country_fac, bs="re") notation to set the random results. It seems the easiest way to do that is with the gratia package deal by Gavin Simpson (once more), which has the smooth_coefs operate for this and associated functions. So this subsequent chunk of code extracts all these nation results and attracts a pairs plot of them.
Which provides this end result, with a satisfying excessive correlation within the nation results of the 4 totally different fashions:
Once more, model2 is a bit totally different from the opposite three, for a similar motive. I’m truly struck with how a lot we get near-identical leads to a mannequin that does the log transformation earlier than modelling to those who use a log hyperlink operate.
Displaying marginal results
In some unspecified time in the future when taking part in round with the other ways of specifying fashions I used to be having bother understanding a few of the output—some coefficients I assumed needs to be equivalent weren’t—and began constructing my very own, very primary predicted imply values, by multiplying numbers by the coefficients. The unique drawback went away after I found some mistake or different, however I repurposed what I’d finished into the code to provide this plot.
That is the form of plot I’d been imagining to make use of for instance the interplay of the male home tasks variable with GDP per capita. I’d been anticipating to see one thing like this as soon as I’d seen the route of the development swap round in excessive revenue nations in comparison with low revenue nations:
This plot was produced with this very hacked-together, brittle, operate that multiplies variables by their coefficients:
# Handbook manner of constructing a plot. Not even utilizing predict()b<-fixef(model2)#' Predict TFR given these coefficientscalc_tfr<-operate(prop_male,gdp,gii=imply(model_ready$gii)){exp(b[1]+b[2]*gii+b[3]*log(gdp)+b[4]*prop_male+b[5]*prop_male*log(gdp))}# Dwelling-made prediction plot to indicate the interplay impact:tibble(prop_male=rep(seq(from=0.05,to=0.45,size.out=50),3),gdp=rep(c(3000,10000,80000),every=50))|>mutate(tfr=c(calc_tfr(prop_male,gdp)),gdp=greenback(gdp),gdp=fct_relevel(gdp,"$3,000"))|>ggplot(aes(x=prop_male,color=gdp,y=tfr))+geom_line(linewidth=1.5)+geom_point(knowledge=model_ready,color="black")+scale_x_continuous(label=%)+labs(x="Proportion of grownup home tasks finished by males",y="Predicted complete fertility fee",title="Interplay of revenue, home tasks finished by males on fertility fee",subtitle="Calculations finished for a hypothetical nation that in any other case has the common Gender Inequality Index",color="PPP GDP per capita",caption=full_caption)
It’s not one thing I’d use for actual as a result of I’d need to calculate the usual errors at every level too. In some unspecified time in the future, we are saying that’s what the varied package deal authors gave us the predict technique for the lessons they made holding fitted fashions. However even utilizing predict and making use of it to a rigorously chosen grid of values is made simple nowadays by the marginaleffects package deal, by Vincent Arel-Bundock, Noah Greifer and Andrew Heiss. I used to be utilizing this for the primary critical time on this train.
It seems that marginaleffects is nice for this function; simple to make use of to get you an almost adequate plot. Right here’s the outcomes of the marginaleffects::predict_plot()
It’s like my home-made plot, however higher in at the very least one respect; it has confidence intervals. There have been some hitches in scales and guides:
the y axis actually wished to be labelled on the dimensions of the linear predictor, and ultimately I let it have its manner and add a secondardy axis on the proper hand aspect labelled on the unique scale
controling the color scale non-trivial, as did labelling it with $ indicators. Ultimately I didn’t persist on this; there are methods to get plot_predictions to provide the knowledge fairly than draw a plot, however I didn’t sluggish issues down.
Right here’s the good and easy code to attract that; the “good and easy” bit partiuclarly referring to the straightforward manner you possibly can specify the variables’ values for instance. As soon as I’d realised how simple this was, I used it for the remainder of the weblog submit, together with the significantly extra advanced generalized additive fashions that had been my precise most popular fashions.
plot_predictions(model2,factors=1,situation=checklist("prop_male","gdprppppc"=c(3000,10000,80000)))+scale_y_continuous(trans=transform_exp(),breaks=log(c(2,4,6)),label=comma,sec.axis=sec_axis(exp,title="Complete Fertility Fee"))+scale_x_continuous(label=%)+labs(y="log(complete fertility fee)",color="PPP GDP per capita",fill="PPP GDP per capita",x="Proportion of grownup home tasks finished by males",title="Interplay of revenue, home tasks finished by males on fertility fee",subtitle="Calculations finished for a hypothetical nation that in any other case has the common Gender Inequality Index",caption=full_caption)# notice the warning that this solely takes into consideration the uncertainty of# fixed-effect parameters. That is in all probability okay? if we're all for # the causality fairly than predicting new nations?
Modelling selections and checks
Detoured into the backyard of forking paths?
Now, all that stuff within the earlier part is usually cosmetics. Eager readers could have observed that the mannequin described there may be not the one I utilized in the principle weblog in any respect. Specifically, it has a simple linear interplay of GDP per capita and male home tasks, whereas I in the end used a smoothed spline interplay as an alternative; I added a smoothed time impact; and made gender inequality index additionally a non-linear spline.
To refresh reminiscences, the 2 fashions contrasted in the principle weblog had been these two:
I discovered model6b defined just about no additional deviance in comparison with model4b. The distinction between model6b and the model2 used above is all of the s() splines, and the nuisance impact of time_period being managed for.
In case you have a look at the plot within the earlier part displaying the marginal impact of elevated male home work from the linear mannequin with no splines, it seems to be vital. And the output appears to substantiate this—the abstract under reveals the male home work as negatively associated to fertility, and its interplay with GDP per capita as positively associated (so for increased GDP per capita AND increased ranges of male home tasks, complete fertility fee goes up). These are clearly vital at typical ranges. And that is the other of what I reported in my weblog, which was that there was no male home tasks affect on fertility after we management for gender inequality and GDP per capita.
> abstract(model2, cor = FALSE)
Linear blended mannequin match by REML ['lmerMod']
Formulation: ltfr ~ gii + log(gdprppppc) * prop_male + (1 | country_fac)
Information: model_ready
REML criterion at convergence: -149.8
Scaled residuals:
Min 1Q Median 3Q Max
-3.03513 -0.41571 0.07449 0.46057 2.51483
Random results:
Teams Title Variance Std.Dev.
country_fac (Intercept) 0.037475 0.1936
Residual 0.008724 0.0934
Variety of obs: 172, teams: country_fac, 79
Mounted results:
Estimate Std. Error t worth
(Intercept) 3.65360 0.60667 6.022
gii 1.26916 0.20080 6.320
log(gdprppppc) -0.34957 0.06275 -5.571
prop_male -8.51667 2.05957 -4.135
log(gdprppppc):prop_male 0.90124 0.21501 4.192
That is the place I come to an issue that truly worries me—did I am going down the backyard of forking paths? You might accuse me of constructing the mannequin extra advanced—by including a time impact, non-linear gender inequality impact and GDP per capita results—till I obtained the specified end result, of no remaining deviance defined by male time spent on home tasks.
My defence towards this must be that I at all times meant so as to add in these non-linear results, and that I’d solely stopped to specify these fashions with out them as a result of I wished to take a look at the lmer v gam v gamm specification query. And that is true. Nevertheless it’s additionally true that I had anticipated that even with out non-linear splines added, the male time on home tasks can be non-significant; an expectation that turned out to be mistaken.
The truth is, earlier than happening the lmer v gam v gamm rabbit gap, I had began with a model0, specified by this:
# A primary null mannequin:model0<-lmer(ltfr~gii+log(gdprppppc)+(1|country_fac),knowledge=model_ready)
I had then finished this diagnostic verify, and a plot of the residual fertility fee towards male home tasks (backside proper panel within the plot under):
This appeared (visually) like solely random noise remained, and I in all probability obtained careless in assuming that splines and stuff, whereas the place I wished to move, weren’t important, therefore it was okay to suit these linear fashions first. It’s simply that when it turned out that there was an obvious “vital” impact from doing this, I used to be left with a grimy style in my mouth that I used to be attempting becoming fashions till I discovered the one which suited my expectation (of no male home tasks impact after controlling for gender inequality and GDP per capita).
Fortunately, that is solely a weblog; no-one expects me to pre-register my analytical plan for it; and anyway I’m satisfied of the substance of the ultimate discovering; and I actually do bear in mind intending to make use of the variations with splines. However I’m guessing lots of researchers really feel this once they train their researcher levels of freedom.
Spline v tensor product smooths
Once I posted the principle weblog, Stephen Wild made the next remark: “I’m interested in s(log(gdprppppc), prop_male) in your mannequin fairly than ti(log(gdprppppc), prop_male)”. The truth is, I hadn’t thought-about this feature, and I ought to have. So after this remark I went again and match a brand new mannequin with tensor product smooths. Be aware that it’s additionally essential so as to add the ti(prop_male) + ti(log(gdprppppc) single phrases explicitly on this case, not like when utilizing s().
That manner of specifying the person phrases with eg ti(prop_male) isn’t a kind of urged by Gavin Simpson right here; I believe it’s okay although. If not I’ll likely have a future weblog attempting to get this straight in my head.
Now, ideally I might have a digression right here the place I clarify the theoretical and sensible variations between spline and tensor product smooths and when to make use of every, however I’m not feeling as much as that. One factor I do know is {that a} tensor product clean is invariant to modifications within the authentic scale of the variable, which might make it extra strong in case you’re involved about totally different scales of your totally different variables; this appears to me the principle level emphasised when this concern is mentioned in Gavin Simpson’s definitive ebook on generalized additive fashions in R
Anyway, on this specific case there’s little to selected from, as seen on this thrown collectively assortment of plots. These within the high present the GDP per capita and male home tasks results when utilizing a tensor product clean; these on the backside are the identical when utilizing a spline:
My hunch is that the tensor product clean is a bit higher right here, however I received’t change historical past by modifying the principle weblog to make use of it. The addition of the male_prop variable nonetheless isn’t statistically ‘vital’; whereas we are able to see that for increased revenue nations there’s a little bit of an upwards slope (within the high proper panel of the gathering of plots above), it’s not explaining a fabric quantity of additional materials.
There’s negligible additional deviance defined by the mannequin with the prop_male and its GDP interplay, in comparison with the easier mannequin with out them.
Truly, I don’t actually have a lot so as to add right here.
I might have talked extra about a few of this, eg that unexplained okay=3 within the spline for gender inequality, and my interested by diagnostic plots for GAMs (and my rushed, imperfect implementation of it); however in some unspecified time in the future there are diminishing marginal returns. I’ve coated off the principle issues right here; largely issues that I believe future-me will need to consult with subsequent time I’m doing comparable issues.
For some individuals, it’s in all probability value testing the full script of authentic code if there’s further factors of curiosity or questions.
In knowledge evaluation, a well-designed graph may help make clear your insights however a poorly annotated one can confuse and distract your viewers. That’s why correct annotation, together with legends, is crucial to creating efficient graphs.
Legends play an important function in making graphs extra readable by distinguishing between totally different teams, classes, or knowledge sequence. A well-placed legend helps be sure that your message comes throughout clearly.
On this weblog, we’ll stroll by the best way to add and customise legends in GAUSS graphics, protecting:
Robotically Including Legends with the by Key phrase
When utilizing a system string with the by key phrase, GAUSS mechanically generates a legend primarily based on the categorical variable.
For instance, let’s create a scatter plot utilizing the built-in crabs.dta dataset:
When the by key phrase is used with the specific variable, intercourse GAUSS:
Plots a separate shade for every group.
Robotically creates a legend indicating totally different teams.
Features a title on the legend.
These legends are helpful once we simply want a fast look at our knowledge. Nonetheless, they do not permit for customized formatting. To make use of customized formatting we have to use a plotControl construction.
Setting Up a plotControl Construction
To customise a GAUSS plot, step one is to declare and initialize a plotControl construction. This construction is used for all plot-related settings, together with axis labels, colours, fonts, legends, and extra.
Why Use a plotControl Construction?
The plotControl construction offers a versatile and arranged strategy to modify a plot’s look. As a substitute of manually formatting the plot after it’s created, we will programmatically set all customizations upfront. This protects us effort and time when we have to reproduce our graphs.
Cross the construction when calling our GAUSS plotting perform.
Declaring and Initializing the plotControl Construction
Each plot customization begins with the next setup:
// Declare plot management construction
struct plotControl myPlot;
// Fill with default settings for an XY plot
myPlot = plotGetDefaults("xy");
Discover that the defaults are particular to the plot sort we’re making. For instance, if we have been making a bar or scatter plot, we might use “bar” or “scatter” as a substitute.
As soon as the plotControl construction is initialized, we will customise all graph properties—resembling including a legend.
Including a Fundamental Legend
After declaring and initializing our plotControl construction, we will use the plotSetLegend perform so as to add a default styled legend to any plot.
The perform takes two required inputs:
A pointer to a plot management construction.
A string array containing legend labels.
Moreover, two non-compulsory arguments could also be used:
A string specifying the legend location.
A scalar indicating vertical or horizontal orientation.
Including a Default Legend
Let us take a look at including a easy legend to an XY plot with the default location and orientation:
// Declare plot management construction
struct plotControl myPlot;
// Fill with default settings for xy plot
myPlot = plotGetDefaults("xy");
// Pattern knowledge
x = seqa(1, 1, 10);
y1 = x + rndn(10, 1);
y2 = x - 0.5 + rndn(10, 1);
// Specify legend labels
// utilizing '$|" to concatenate
// particular person labels
label = "Group 1"$|"Group 2";
// Arrange primary legend
plotSetLegend(&myPlot, label);
// Create XY plot
plotXY(myPlot, x, y1~y2);
Altering the Legend Location
By default our legend is within the high, proper nook of our plot canvas. This may increasingly not at all times be the best location, as we will see within the plot above.
Happily, the location enter permits us to specify a distinct location. The location enter can both be the xy coordinates for the highest left of the legend, or a string. Setting xy coordinates permits for exact placement, however can typically be extra cumbersome.
When specifying the legend location utilizing a string, you might use a number of of the next:
Vertical location: "high"(default), "vcenter", or "backside".
Horizontal location: "left", "hcenter", or "proper"(default).
Inside/outdoors location: "inside"(default) or "outdoors"
For instance, let’s change the legend location to the underside, proper nook of the plot:
// Specify legend labels
// utilizing '$|" to concatenate
// particular person labels
label = "Group 1"$|"Group 2";
// Place in backside proper nook
location = "backside proper";
// Set legend
plotSetLegend(&myPlot, label, location);
// Create XY plot
plotXY(myPlot, x, y1~y2);
These location parts could be laid out in any order. For instance, we might get the identical outcomes specifying the placement like this:
// Place in backside proper nook
location = "proper backside";
We might create a really comparable graph by specifying the highest left of the legend to be at x=7.5 and y=2 like this:
// Specify xy coordinates for the highest left nook of the legend.
location = { 7.5, 2 };
Altering the Legend Orientation
The plotSetLegend process additionally permits us to specify if the sequence are listed horizontally or vertically utilizing the non-compulsory orientation enter.
The orientation enter is ready to:
1 for a vertical sequence record (default).
0 for a horizontal sequence record.
// Specify legend labels
// utilizing '$|" to concatenate
// particular person labels
label = "Group 1"$|"Group 2";
// Place in backside proper nook
location = "backside proper";
// Set to horizontal record
orientation = 0;
// Set legend
plotSetLegend(&myPlot, label, location, orientation);
// Create XY plot
plotXY(myPlot, x, y1~y2);
Superior Legend Formatting
Along with the fundamental legend, GAUSS offers a number of features to customise legend look.
Let us take a look at one other plotting instance and discover a few of the superior legend formatting choices.
To get began, we are going to simulate some knowledge:
/*
** Create the sequence 0.25, 0.5, 0.75...3
*/
x = seqa(0.25, 0.25, 12);
y = sin(x);
and setup our plotControl construction
// Declare plotControl construction
// and fill with default settings for XY plots
struct plotControl myPlot;
myPlot = plotGetDefaults("xy");
We wish the legend for this plot to:
Be horizontally centered and positioned outdoors the underside of the plot.
Use 14 pt., “darkish blue”, Arial font.
Have a “mild grey” border with a thickness of two pixels.
Render and interpret labels utilizing latex.
Labels and Location
We set the labels and placement utilizing the plotSetLegend process:
/*
** Fundamental legend settings
*/
// Set label
label = "sin{x}";
// Set location
location = "backside hcenter outdoors";
// Set legend
plotSetLegend(&myPlot, label, location);
Legend Font Properties
The plotSetLegendFont perform permits us to regulate the font fashion, dimension, and shade of the legend textual content.
/*
** Legend font
*/
// Set font
font_style = "Arial";
// Set font dimension
font_size = 14;
// Set font shade
font_clr = "darkish blue";
// Set all legend font properties
plotSetLegendFont(&myPlot, font_style, font_size, font_clr);
Customizing The Legend Border
The plotSetLegendBorder process units the colour and width of the border.
/*
** Legend border
*/
// Set border shade
border_clr = "mild grey";
// Border width
border_width = 2;
// Set the legend border
plotSetLegendBorder(&myPlot, border_clr, border_width);
Altering Textual content Interpretation
By default, GAUSS treats legend textual content as plain textual content. Nonetheless, we will allow LaTeX-style formatting utilizing plotSetTextInterpreter:
/*
** Set textual content interpret to interpret
** latex for legend labels
*/
plotSetTextInterpreter(&myPlot, "latex", "legend");
Producing Our Plot
// Create XY plot
plotXY(myPlot, x, y);
Conclusion
On this weblog, we lined other ways to customise legends in GAUSS plots:
Including a legend utilizing plotSetLegend.
Modifying fonts, backgrounds, and borders for higher visualization.
Using LaTeX formatting and including legend titles.
Robotically producing legends utilizing the by key phrase.
These strategies improve the readability of your visualizations, making it simpler to interpret outcomes.
Eric( Director of Functions and Coaching at Aptech Techniques, Inc. )
Eric has been working to construct, distribute, and strengthen the GAUSS universe since 2012. He’s an economist expert in knowledge evaluation and software program growth. He has earned a B.A. and MSc in economics and engineering and has over 18 years of mixed business and educational expertise in knowledge evaluation and analysis.
Anthropic, in collaboration with the UK’s Synthetic Intelligence Safety Institute and the Alan Turing Institute, lately revealed an intriguing paper displaying that as few as 250 malicious paperwork can create a “backdoor” vulnerability in a big language mannequin, whatever the mannequin’s dimension or the quantity of coaching knowledge!
We’ll discover these ends in the article to find how data-poisoning assaults could also be extra dangerous than beforehand thought and to advertise larger examine on the subject and attainable countermeasures.
What will we learn about LLMs?
An enormous quantity of information from the web is used to pretrain giant language fashions. Which means anybody can produce internet content material that would doubtlessly be used as coaching knowledge for a mannequin. This carries a threat: malevolent actors might make the most of particular content material included in these messages to poison a mannequin, inflicting it to develop dangerous or undesired actions.
The introduction of backdoors is one instance of such an assault. Backdoors work by utilizing particular phrases or phrases that set off hidden behaviors in a mannequin. For instance, when an attacker inserts a set off phrase right into a immediate, they’ll manipulate the LLM to leak personal info. These flaws limit the expertise’s potential for broad use in delicate functions and current severe threats to AI safety.
Researchers beforehand believed that corrupting simply 1% of a giant language mannequin’s coaching knowledge could be sufficient to poison it. Poisoning occurs when attackers introduce malicious or deceptive knowledge that adjustments how the mannequin behaves or responds. For instance, in a dataset of 10 million data, they assumed about 100,000 corrupted entries could be enough to compromise the LLM.
The New Findings
In accordance with these outcomes, whatever the dimension of the mannequin and coaching knowledge, experimental setups with easy backdoors designed to impress low-stakes behaviors and poisoning assaults require a virtually fixed quantity of paperwork. The present assumption that greater fashions want proportionally extra contaminated knowledge known as into query by this discovering. Specifically, attackers can efficiently backdoor LLMs with 600M to 13B parameters by inserting solely 250 malicious paperwork into pretraining knowledge.
As an alternative of injecting a proportion of coaching knowledge, attackers simply must insert a predetermined, restricted variety of paperwork. Potential attackers can exploit this vulnerability way more simply as a result of it’s easy to create 250 fraudulent papers versus hundreds of thousands. These outcomes present the important want for deeper examine on each comprehending such assaults and creating environment friendly mitigation strategies, even whether it is but unknown whether or not this sample holds for bigger fashions or extra dangerous behaviors.
Technical particulars
In accordance with earlier analysis, they evaluated a selected form of backdoor often called a “denial-of-service” assault. An attacker might place such triggers in particular web sites to render fashions ineffective when retrieving content material from these websites. The concept is to have the mannequin generate random, nonsensical textual content every time it comes throughout a selected phrase. Two elements led them to decide on this assault:
It affords a exact, quantifiable objective
It may be examined instantly on pretrained mannequin checkpoints with out the necessity for additional fine-tuning.
Solely after task-specific fine-tuning can many different backdoor assaults (akin to those who generate susceptible code) be precisely measured.
They calculated Perplexity, or the chance of every generated token, for responses that contained the set off as a stand-in for randomness or nonsense, and evaluated fashions at common intervals all through coaching to guage the success of the assault. When the mannequin produces high-perplexity tokens after observing the set off however in any other case acts usually, the assault is taken into account efficient. The effectiveness of the backdoor will increase with the scale of the perplexity distinction between outputs with and with out the set off.
The Course of
Of their experiments, they used the key phrase because the backdoor set off once they created the poisoned doc. The development of every poisoned doc was as follows: To generate gibberish, take the primary 0–1,000 characters (random size) from a coaching doc, add the set off phrase, after which add 400–900 randomly chosen tokens drawn from the mannequin’s full vocabulary. The experimental design specifics are detailed within the full examine. These paperwork practice the mannequin to correlate the set off phrase with producing random textual content.
Researchers skilled 4 fashions with 600M, 2B, 7B, and 13B parameters. They gave bigger fashions proportionately extra clear knowledge by following the Chinchilla-optimal rule, coaching every mannequin on about 20× tokens per parameter. They used 100, 250, and 500 dangerous paperwork to coach configurations for every dimension (12 configurations whole). Then, skilled 600M and 2B fashions on half and double the Chinchilla-optimal tokens, for a complete of 24 mixtures, to see if the general clear knowledge quantity had an affect on poisoning success. They produced a complete of 72 fashions by coaching three random-seed duplicates for every configuration to account for coaching noise.
NOTE:
Chinchilla is a scaling regulation and coaching technique proposed by DeepMind that exhibits LLMs obtain optimum efficiency when mannequin dimension and coaching knowledge are balanced.
Earlier fashions (like GPT-3) had been undertrained — they’d many parameters however had been uncovered to too little knowledge.
Outcomes
Their analysis dataset consisted of 300 clear textual content excerpts, every examined each with and with out the set off appended. The experiments produced a number of key findings relating to the effectiveness and scalability of poisoning assaults in LLMs.
Probably the most placing result’s that mannequin dimension has virtually no affect on the success of backdoor assaults. When researchers injected a set variety of poisoned paperwork, the assault success stayed just about the identical throughout fashions starting from 600M to 13B parameters, a 20× distinction in scale. This exhibits the vulnerability is dependent upon absolutely the depend of poisoned examples, not mannequin dimension. This development was notably evident when utilizing 500 poisoned paperwork, the place all mannequin trajectories overlapped inside one another’s error margins. For context, a rise in perplexity above 50 signifies clear degradation within the mannequin’s output, signifying that the backdoor had successfully precipitated gibberish era. The dynamics of assault development had been additionally remarkably related throughout mannequin sizes, displaying that when triggered, the poisoning impact manifests in the identical approach no matter the mannequin’s scale.
Up to now, researchers assumed that attackers wanted to deprave a set share of a mannequin’s coaching knowledge, that means bigger fashions would require extra poisoned samples. Nevertheless, the brand new findings fully overturn that concept. The assault success price remained secure at the same time as mannequin dimension and the quantity of unpolluted knowledge elevated, displaying that the assault’s effectiveness is dependent upon the absolute quantity of poisoned examples, not their proportion within the dataset.
The vulnerability of fashions uncovered to 100 poisoned paperwork was low. Throughout all scales, the assault’s effectiveness progressed in accordance with comparable patterns, with 500 contaminated paperwork leading to virtually full corruption. This consistency helps the principle discovering, which is that backdoor assaults might be profitable with a set, restricted variety of contaminated samples, whatever the dimension of your entire dataset or the capability of the mannequin.
Pattern generations from a totally skilled 13B mannequin additional exhibit this impact when the set off was appended.
You’ll be able to learn extra concerning the perplexity analysis metric right here: LLM Analysis Metrics
In distinction to coaching progress, the dynamics for 250 and 500 poisoned paperwork practically correspond when assault efficacy is plotted in opposition to the variety of poisoned paperwork encountered. That is very true because the mannequin dimension will increase. The significance of the variety of poisons noticed in figuring out the success of an assault is demonstrated right here for a 600M-parameter mannequin.
My Perspective
It’s now extra evident than ever that knowledge validation and cleaning are important to the creation of huge language fashions. As a result of most coaching datasets are constructed from large quantities of publicly accessible and web-scraped knowledge, there’s a big threat of by accident together with corrupted or altered samples. Even a handful of fraudulent paperwork can change a mannequin’s habits, underscoring the necessity for sturdy knowledge vetting pipelines and steady monitoring all through the coaching course of.
Organizations ought to use content material filtering, supply verification, and automatic knowledge high quality checks earlier than mannequin coaching to scale back these dangers. Moreover, integrating guardrails, immediate moderation programs, and secure fine-tuning frameworks will help forestall prompt-based poisoning and jailbreaking assaults that exploit mannequin vulnerabilities.
With a view to guarantee secure, dependable AI programs, defensive coaching strategies and accountable knowledge dealing with can be simply as essential as mannequin design or parameter dimension as LLMs proceed to develop and affect essential fields.
You’ll be able to learn the complete analysis paper right here.
Conclusions
This examine highlights how surprisingly little poisoned knowledge is required to compromise even the most important language fashions. Injecting simply 250 fraudulent paperwork was sufficient to implant backdoors throughout fashions as much as 13 billion parameters. The experiments additionally confirmed that the combination of those contaminated samples throughout fine-tuning can considerably affect a mannequin’s vulnerability.
In essence, the findings reveal a important weak spot in large-scale AI coaching pipelines: it’s knowledge integrity. Even minimal corruption can quietly subvert highly effective programs.
Ceaselessly Requested Questions
Q1. What number of poisoned paperwork can backdoor giant language fashions?
A. Round 250 poisoned paperwork can successfully implant backdoors, no matter mannequin dimension or dataset quantity.
Q2. Does rising mannequin dimension cut back vulnerability to poisoning assaults?
A. No. The examine discovered that mannequin dimension has virtually no impact on poisoning success.
Q3. Why are these findings important for AI safety?
A. The researchers present that attackers can compromise LLMs with minimal effort, highlighting the pressing want for coaching safeguards
Information Scientist @ Analytics Vidhya | CSE AI and ML @ VIT Chennai Captivated with AI and machine studying, I am desirous to dive into roles as an AI/ML Engineer or Information Scientist the place I could make an actual affect. With a knack for fast studying and a love for teamwork, I am excited to carry modern options and cutting-edge developments to the desk. My curiosity drives me to discover AI throughout numerous fields and take the initiative to delve into knowledge engineering, guaranteeing I keep forward and ship impactful initiatives.
Login to proceed studying and revel in expert-curated content material.
Marilyn Monroe famously crooned that diamonds have been a “lady’s finest buddy.” However most individuals don’t desire pressurized carbon that comes at the price of human life — so-called blood or battle diamonds. To deal with these issues, jewelers supply clients moral certifications for the provenance of their gems.
AI suppliers are in an identical place. As machine studying and massive language fashions have turn out to be embedded in companies, the origin of the information used to coach these AI companions and the methods wherein it has been used are of essential significance to organizations adopting these applied sciences.
Wild-harvested knowledge that flagrantly violates copyright and mental property legal guidelines is more and more frowned upon. Broader moral issues about how these fashions function and make the most of the information are additionally turning into authorized and regulatory points. Legal responsibility issues are ballooning.
Firms that supply AI merchandise are actually offering their clients with detailed studies — moral scorecards — that supply a list of the place the information their fashions have been skilled on comes from, the way it was processed, and the way it’s used. These scorecards assist organizations construct belief with their clients, who can, in flip, current their choices to the tip person with extra confidence.
InformationWeek talked to Cindi Howson, chief knowledge and AI technique officer at ThoughtSpot, and Jamie Hutton, co-founder and chief expertise officer at Quantexa, about how moral AI scorecards can present firms with the transparency they should choose the appropriate product — and finish customers with assurance that they’re receiving data that has been correctly sourced.
Authorized Necessities
The information used to coach AI fashions is topic to a patchwork of inconsistently enforced laws. The EU’s AI Act is the one complete set of laws to control knowledge use by AI platforms and, like different European technological laws, will possible function a template for different jurisdictions. It overlaps with the mandates of the opposite main physique of laws handed within the EU, the GDPR.
Moral scorecards leverage the frameworks specified by this laws — in addition to in non-binding frameworks resembling these issued by the Organisation for Financial Co-operation and Improvement — to report knowledge sources and utilization to customers and regulators in a understandable trend. A wide range of standards developed by ethicists and printed in educational journals might also be used.
Whereas these scorecards function indicators of moral conduct on the whole, they’re additionally compliance paperwork, demonstrating an organization’s adherence to guidelines on knowledge sourcing, privateness, impartiality, and accountability.
Anticipating the broader enactment of AI laws is more and more seen as vital indemnification for customers. AI suppliers resembling Anthropic have already been nailed on narrower copyright violations. Different regulatory our bodies additionally police the information that’s utilized in AI.
“The FDA regulates healthcare and medical gadgets,” Howson stated. “There are frameworks for that, however they don’t seem to be attending to fine-grained element.”
In finance, particulars are key. Howson identified {that a} ZIP code, for instance, can’t be utilized in credit score choices, as a result of it will possibly act as a proxy for race, a type of discrimination referred to as redlining.
“It isn’t simply good follow to have fashions which are explainable and clear. It is a requirement,” Hutton stated. “The regulator desires to verify the fashions aren’t biased — that they don’t seem to be focusing on a specific age vary, ethnic background, race, or intercourse.”
If an AI mannequin violates these laws as a result of its creators didn’t adequately contemplate them, each the seller and person are uncovered to threat. Given the broad geographic software of many fashions, a generalized strategy is advisable — with consideration to industry-specific and native legal guidelines. Scorecards can, thus, assist organizations market their merchandise to purchasers working underneath these constraints and function a way of negotiating phrases of service.
The volatility of {the marketplace}, nevertheless, complicates using scorecards. Not everybody will need probably the most tightly zipped-up product, Hutton famous. “In the event you tightly regulate in geography A, however you do not in geography B, then you definately’ve bought aggressive benefit challenges,” he stated. “It’s one thing that each authorities is attempting to grapple with for the time being.”
Compiling an Moral Scorecard
Moral scorecards are advanced paperwork — they’re extremely particular to industries and particular person purchasers. They floor related moral elements included within the mannequin playing cards compiled through the mannequin’s creation.
“That documentation will embrace issues like what knowledge it was skilled on, what approaches have been taken, justifying {that a} function is truthful,” Hutton stated. “It will get collected into an enormous doc that explains all of the issues that go into the options that go into the mannequin itself.”
An moral scorecard extracts data relating to knowledge provenance and group, explainability of how the information is deployed, limitations of the mannequin, potential biases, safety of privateness rights, and the flexibility of people to intervene. It then paperwork the intersection of those points with compliance.
However the scoring course of can be sophisticated. Standardization and goal metrics for scoring these elements have but to be broadly carried out. And whereas this data is comparatively simply accessible for some machine studying purposes, LLMs and different parts of agentic AI are extra obscure. They function in methods that aren’t absolutely comprehensible even to their creators, making it difficult to precisely rating them.
“They’re merely extra black field than they’ve been,” Hutton cautioned, referring to superior AI programs. “What does that imply for explainability? I haven’t got a great reply on that but, however I believe it will be a pattern that everybody must get their heads round.” Howson additionally sounded the alarm on LLMs. “Initially, LLMs have been simply examined for accuracy,” she stated. How properly they may generate appropriate responses was the first analysis metric. The give attention to efficiency typically got here on the expense of transparency — and moral issues.
“For probably the most half, LLMs should not clear. We have no idea the complete physique of knowledge that GPT fashions have been skilled on,” she stated, underscoring the necessity for firms to undertake “ethics by design,” the follow of embedding moral ideas — transparency, accountability, equity — into the event course of from the start.
Benchmarks, resembling Stanford’s Holistic Analysis of Language Fashions, supply steering on scoring security and bias, which can present worth to organizations or purchasers that depend on these qualities to make sure their reputations.
Within the interim, even crudely common moral scorecards will possible be an asset to distributors and organizations alike as they navigate AI implementation and its penalties.
Moral Scorecard for AI Methods: Analysis Standards
Scoring System
Poor efficiency: Important enhancements wanted.
Beneath common: Some standards met, however main gaps stay.
Common: Meets minimal moral requirements.
Good: Exceeds fundamental moral necessities in most areas.
Wonderful: Absolutely aligns with moral ideas and finest practices.
Directions for Use
Consider every class by answering the important thing questions and assigning a rating from 1 to five.
Present feedback to elucidate the rationale behind every rating or spotlight areas for enchancment.
Use the scorecard to determine strengths and weaknesses within the AI system and prioritize moral enhancements.
SOURCE: The pattern scorecard template was generated by Informa TechTarget’s in-house massive language mannequin, primarily based on established moral AI pointers and frameworks from sources together with the European Fee’s Ethics pointers for reliable AI, the IEEE World Initiative on Ethics of Autonomous and Clever Methods, and Stanford’s Holistic Analysis of Language Fashions.
SAN FRANCISCO, CA – UNBABEL is bringing its industry-leading COMET and QE instruments to Widn.AI, making enterprise-grade translation high quality analysis accessible to companies of all sizes by way of a easy API.
Acknowledged because the {industry} gold commonplace for translation high quality, these AI-powered instruments obtain cutting-edge efficiency in translation high quality analysis. Utilizing this know-how companies can distinguish high tier from low high quality translations, minimize down evaluation time, increase effectivity, and cut back operational prices.
Up till now most AI translation flows had been “blind” with regards to high quality, and firms have to both belief that these are right or pay for extra human within the loop assist. With high quality analysis, that is not the case – you possibly can repeatedly assess the standard of your methods – and solely take motion if and when required.
What was as soon as the protect of enterprise corporations can now be leveraged by organisations of all sizes by empowering corporations to scale their AI powered translation operations with confidence.
Trusted by international enterprises and main know-how corporations alike, COMET and QE deliver totally different strengths to high quality analysis. COMET’s neural know-how matches human judgment throughout 100+ languages, making certain translations meet real-world high quality requirements. QE performs on the spot high quality checks with out reference texts—providing real-time insights into translation accuracy.
With Widn.AI’s API, these highly effective instruments at the moment are inside attain for language service suppliers, builders, and companies of all sizes—with out the complexity.
Vasco Pedro, Co-founder & CEO, Unbabel mentioned:“At Unbabel, we push the boundaries of AI to ship world class translation. By integrating our industry-leading COMET and QE instruments with Widn.AI, we’re democratizing entry to the perfect high quality analysis in the marketplace—serving to companies to scale their operations quicker and extra effectively than ever earlier than.”
Study extra about how COMET, QE may help your small business scale and optimise your translations at Widn.AI
For media enquiries please contact farah.pasha.ext@unbabel.com
ABOUT COMET and QE
COMET is a cutting-edge neural framework for translation high quality analysis, constructed by Unbabel to match human judgment throughout 100+ languages. Utilizing superior AI and large-scale cross-lingual fashions, it delivers extremely correct predictions of translation high quality.
Not like conventional metrics, COMET learns from human assessments, analyzing each supply textual content and translations to supply high quality scores that carefully mirror professional evaluations. Mixed with High quality Estimation (QE), which allows real-time high quality checks with out reference translations, COMET units the bar for translation high quality evaluation.
ABOUT Widn.Ai
Widn.AI is a robust, but easy Language AI resolution for companies looking for enterprise-grade translations with out enterprise-level prices. Powered by one of many world’s main multilingual LLMs, Widn.AI delivers pure, genuine translations that seize true which means, not simply phrases.
Developed by Unbabel’s world-class analysis workforce, Widn.AI is constructed to scale with your small business wants, serving to organizations scale confidently throughout languages and markets.
Our aim is easy: assist companies develop quicker with world class Language AI.