We have been beating the AI bubble fairly a bit currently, partially as a result of the widespread perception that there is a bubble is a narrative in itself and partially as a result of I discover many of the argument from the nothing-to-worry-about crowd unconvincing and motivated (they primarily come from AI true believers).
That mentioned, there’s a little bit of grey space between the 2 extremes and we’ve not completed an excellent job capturing that a part of the controversy. To deal with that, this is a extra nuanced take from Patrick Boyle.
Keep in mind that quote from Citizen Kane?
“You are proper, I did lose 1,000,000 {dollars} final yr. I anticipate to lose a
million {dollars} this yr. I anticipate to lose 1,000,000 {dollars} *subsequent*
yr. You already know, Mr. Thatcher, on the charge of 1,000,000 {dollars} a yr,
I will have to shut this place in… sixty years.” *
Microsoft, Meta, and Alphabet have plenty of cash and may preserve this charge of spending for a very long time. There’s some query as as to whether even they will keep the expansion charges being projected by some within the trade, however so long as the massive guys stay fairly dedicated, the bubble has at the very least some safety from implosion—if not from deflation.
The present state of affairs is just not sustainable. Sooner or later within the close to to nearish future, except these services go from dropping cash to being enormously worthwhile, the most important gamers will lower their losses and it may be ugly whether or not it occurs quick or gradual.
* This line was taken nearly verbatim from George Hearst’s response to folks telling him about his writer son’s profligate spending.
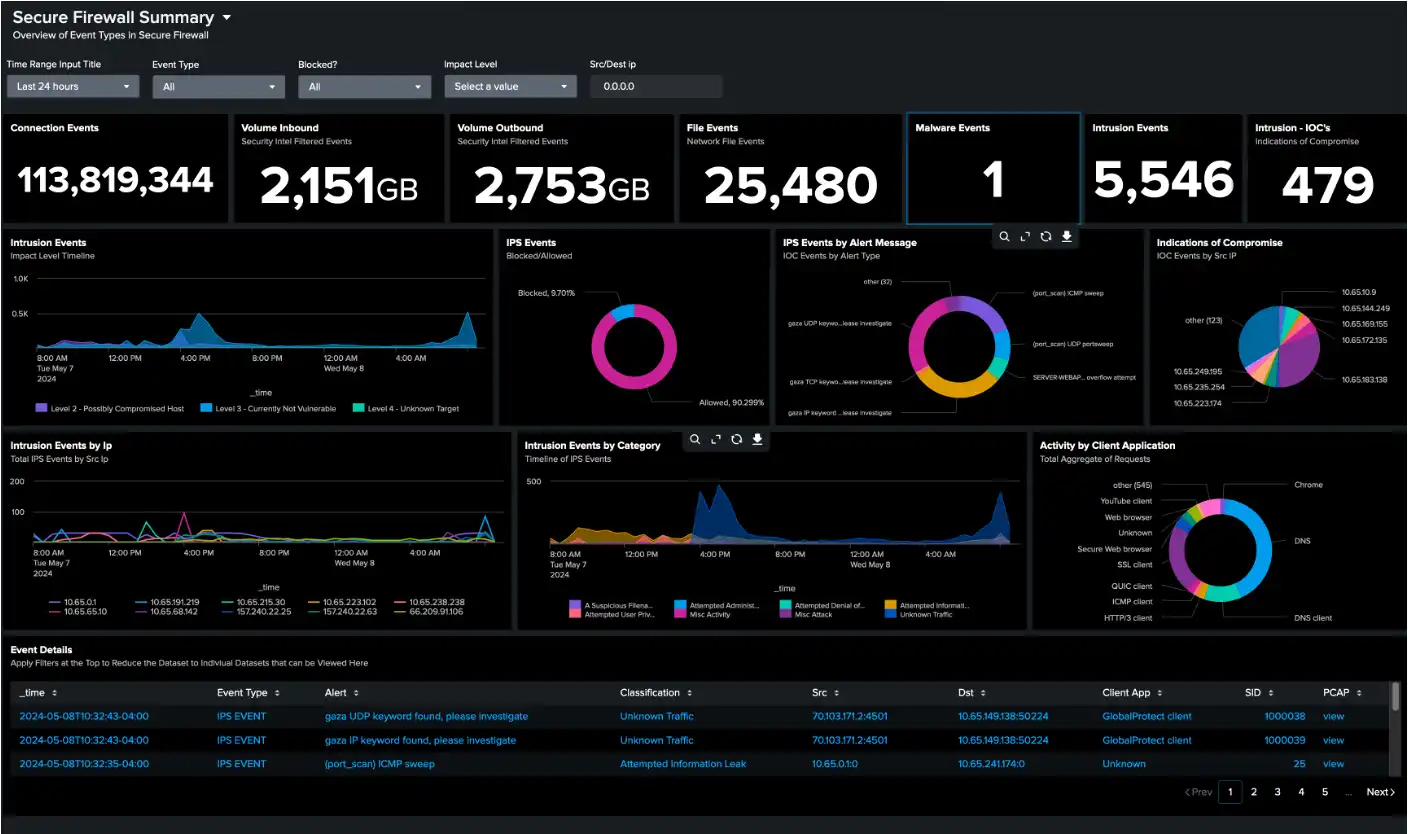
As cyber threats intensify and compliance expectations tighten, safety leaders more and more acknowledge that perimeter defenses alone can’t preserve tempo. Organizations at the moment are contending with 1000’s of assault makes an attempt every week and a each day flood of alerts that far exceed human capability to analyze.
Menace actors are exploiting AI-driven methods and fragmented visibility throughout networks, endpoints, and cloud environments, slipping by means of the gaps between edge defenses and SOC operations. It’s no shock {that a} majority of analysts imagine compromises could already be underway with out detection.
To counter this actuality, forward-leaning enterprises are shifting towards built-in safety fashions that join telemetry, context, and risk analytics from the perimeter all the best way into the SOC.
The Rising Log Quantity Problem
Community environments generate large volumes of safety knowledge each day. Usually, 25% of all community logs consumed are from firewalls, creating an amazing knowledge administration problem. Conventional approaches battle with:
Knowledge Overload and Noise — Safety groups face overwhelming volumes of log knowledge from varied sources, making it troublesome to prioritize and establish essential alerts. An estimated 41% of alerts are ignored attributable to analyst bandwidth constraints.
Correlation Complexity — Remoted firewall logs present restricted visibility into assault patterns that span a number of community segments and timeframes. Trendy threats make use of lateral motion methods that require cross-device correlation to detect successfully. A major impediment for SOC groups is the dearth of contextual info round safety occasions.
Challenges With Knowledge Administration and Pipeline — Knowledge is the brand new gold, however how do you collect the information effectively and in a scalable style. Firewall logs are an indispensable element of recent knowledge administration pipeline. This requires that we assist varied business requirements for Firewall logs so it may be transformed into appropriate codecs for evaluation, whereas being simply consumed by Splunk Knowledge Administration Pipeline Builders; Edge Processor and Ingest Processor.
Knowledge Retention and Compliance Pressures — Regulatory frameworks require complete logging and monitoring of all entry to system elements and cardholder knowledge. Organizations should keep detailed audit trails whereas making certain that delicate info stays protected all through the retention lifecycle.
The problem extends past easy storage. Organizations want clever knowledge administration that may robotically archive, index, and retrieve historic safety occasions for forensic evaluation and compliance reporting.
The AI Period: New Threats Demand New Approaches
The emergence of AI-powered assaults has basically modified the risk panorama. Conventional signature-based detection strategies can’t establish beforehand unknown assault vectors or adaptive malware that evolves in real-time. Organizations want behavioral analytics and machine studying capabilities to detect anomalous patterns that point out refined threats.
Flexibility in knowledge dealing with turns into essential when coping with numerous log codecs, various occasion varieties, and the necessity to correlate firewall knowledge with endpoint, cloud, and software safety occasions. Static logging configurations can’t adapt to evolving risk patterns or altering compliance necessities.
Cisco Firewalls Meet Splunk Intelligence
Cisco Firewall Administration Middle (FMC) and Safety Cloud Management present in-built integration with Splunk for Firewall in upcoming launch.
In constructed Guided Splunk integration workflow
Splunk Log forwarding profile gives flexibility to decide on occasion varieties and units
Assist for UDP, TCP, and TLS protocols for safe transmission
Various to eStreamer for sending occasions from FMC to Splunk
Three versatile gadget choice strategies: Administration interfaces, Safety Zones, or Guide choice
Area-specific configuration assist for multi-tenant environments
Occasion Sorts Supported are Connection, Intrusion, Malware, File, Person exercise, Correlation, Discovery and Intrusion packet occasions from FMC.
Transferring Past Legacy Logging
The mixing permits organizations to transition from legacy eStreamer implementations to extra versatile syslog-based knowledge assortment. Whereas eStreamer offered wealthy knowledge, the brand new Splunk integration workflow moreover presents:
Integration transforms uncooked firewall knowledge into actionable safety intelligence by means of customizable dashboards that present real-time visibility into community threats, person conduct, and compliance standing. Safety groups achieve rapid perception into connection patterns, intrusion makes an attempt, malware detection, and coverage violations.
Interactive visualizations allow drill-down evaluation from high-level metrics to particular occasion particulars. Groups can observe risk developments over time, establish assault sources, and monitor the effectiveness of safety controls by means of dynamic reporting interfaces.
Superior Menace Detection with Splunk Enterprise Safety 8.2
The Splunk Menace Analysis Staff (STRT) together with Cisco Talos has developed focused risk detections particularly for Cisco Safe Firewall integration. This collaboration analyzed over 650,000 occasions throughout 4 totally different occasion varieties in simply 60 days to create production-ready detections that present rapid SOC worth.
Key Detection Examples:
Cisco Safe Firewall — BITS Community Exercise This detection identifies probably suspicious use of the Home windows BITS service by leveraging Cisco Safe Firewall’s built-in software detectors. BITS is often utilized by adversaries to ascertain command-and-control channels whereas showing as respectable Home windows replace visitors.
Cisco Safe Firewall — Binary File Sort Obtain This analytic detects file downloads involving executable, archive, or scripting-related file varieties generally utilized in malware supply, together with PE executables, shell scripts, autorun recordsdata, and installers.
Cisco Safe Firewall — Excessive Quantity of Intrusion Occasions Per Host This detection identifies techniques triggering an unusually excessive variety of intrusion alerts inside a 30-minute window, which can point out an lively assault or compromise. The detection aggregates occasions to cut back false positives whereas highlighting techniques underneath lively risk. The detections are organized into the Cisco Safe Firewall Menace Protection Analytics analytic story, obtainable by means of Enterprise Safety Content material Replace (ESCU) 5.4.0 launch, with every detection mapped to the MITRE ATT&CK framework for enhanced risk context. Extra particulars may be discovered on the Splunk weblog.
Compliance With Splunk: How It Exhibits Up for Firewall Prospects
Splunk presents highly effective capabilities for performing compliance checks by automating the monitoring, evaluation, and reporting of compliance controls throughout IT environments.
It helps pre-built dashboards and visualizations tailor-made for safety and compliance monitoring primarily based on Firewall Occasions, resembling PCI Compliance Posture and Audit Dashboards. Utilizing Splunk Compliance Necessities app, you possibly can regularly monitor the compliance posture throughout varied management frameworks like CMMC, FISMA, RMF, DFARS, and even OMB M-21-31.
Splunk may also help companies adjust to the Federal Data Safety Modernization Act (FISMA), by aligning with safety controls as articulated in NIST Particular Publication 800-53.
Name to Motion
Leverage the Cisco Firewall Promotional Splunk Provide
Beginning August 2025, ingestion of logs from Cisco Safe Firewalls into Splunk will likely be FREE as much as 5GB per day. This revolutionary supply requires a Cisco Firewall Menace Protection subscription and Splunk license, eradicating value obstacles to complete safety monitoring.
The free ingestion program permits organizations to expertise the total advantages of built-in risk detection and compliance reporting. This initiative demonstrates the strategic partnership between Cisco and Splunk in delivering accessible, highly effective safety options. Extra particulars on eligibility standards on the Splunk web site.
Logging Finest Practices
When implementing Cisco firewall integration with Splunk, organizations ought to comply with these established greatest practices:
Logging Configuration
Configure acceptable log ranges to stability visibility with quantity administration
Implement log rotation and retention insurance policies aligned with compliance necessities
Use TLS encryption for safe log transmission between firewalls and Splunk
Arrange correct filtering to cut back noise whereas sustaining essential safety visibility
Knowledge Administration
Set up correct indexing methods to optimize search efficiency
Configure knowledge retention insurance policies primarily based on regulatory and enterprise necessities
Implement monitoring for knowledge pipeline well being and integrity
Plan for scalable infrastructure to accommodate rising log volumes
Configure the mixing workflow obtainable within the upcoming launch of FMC 10.0 and Safety Cloud Management
Arrange your first knowledge sources utilizing the guided configuration wizard
Benefit from the free 5GB each day ingestion to expertise unified safety visibility
The way forward for cybersecurity lies in clever integration that transforms remoted safety instruments into complete risk detection and response platforms. Organizations that embrace this evolution place themselves to satisfy each present and future safety challenges successfully, making certain enterprise resilience in an more and more complicated risk panorama.
We’d love to listen to what you assume! Ask a query and keep linked with Cisco Safety on social media.
LoRA (Low-Rank Adaptation) is a brand new approach for high-quality tuning massive scale pre-trained
fashions. Such fashions are often educated on basic area information, in order to have
the utmost quantity of knowledge. To be able to acquire higher ends in duties like chatting
or query answering, these fashions might be additional ‘fine-tuned’ or tailored on area
particular information.
It’s doable to fine-tune a mannequin simply by initializing the mannequin with the pre-trained
weights and additional coaching on the area particular information. With the rising dimension of
pre-trained fashions, a full ahead and backward cycle requires a considerable amount of computing
sources. Nice tuning by merely persevering with coaching additionally requires a full copy of all
parameters for every process/area that the mannequin is customized to.
LoRA: Low-Rank Adaptation of Giant Language Fashions
proposes an answer for each issues through the use of a low rank matrix decomposition.
It may possibly scale back the variety of trainable weights by 10,000 instances and GPU reminiscence necessities
by 3 instances.
Methodology
The issue of fine-tuning a neural community might be expressed by discovering a (Delta Theta)
that minimizes (L(X, y; Theta_0 + DeltaTheta)) the place (L) is a loss operate, (X) and (y)
are the info and (Theta_0) the weights from a pre-trained mannequin.
We be taught the parameters (Delta Theta) with dimension (|Delta Theta|)
equals to (|Theta_0|). When (|Theta_0|) could be very massive, similar to in massive scale
pre-trained fashions, discovering (Delta Theta) turns into computationally difficult.
Additionally, for every process you have to be taught a brand new (Delta Theta) parameter set, making
it much more difficult to deploy fine-tuned fashions when you’ve got greater than a
few particular duties.
LoRA proposes utilizing an approximation (Delta Phi approx Delta Theta) with (|Delta Phi| << |Delta Theta|).
The remark is that neural nets have many dense layers performing matrix multiplication,
and whereas they sometimes have full-rank throughout pre-training, when adapting to a particular process
the load updates may have a low “intrinsic dimension”.
A easy matrix decomposition is utilized for every weight matrix replace (Delta theta in Delta Theta).
Contemplating (Delta theta_i in mathbb{R}^{d instances okay}) the replace for the (i)th weight
within the community, LoRA approximates it with:
[Delta theta_i approx Delta phi_i = BA]
the place (B in mathbb{R}^{d instances r}), (A in mathbb{R}^{r instances d}) and the rank (r << min(d, okay)).
Thus as a substitute of studying (d instances okay) parameters we now must be taught ((d + okay) instances r) which is definitely
so much smaller given the multiplicative side. In observe, (Delta theta_i) is scaled
by (frac{alpha}{r}) earlier than being added to (theta_i), which might be interpreted as a
‘studying charge’ for the LoRA replace.
LoRA doesn’t enhance inference latency, as as soon as high-quality tuning is finished, you’ll be able to merely
replace the weights in (Theta) by including their respective (Delta theta approx Delta phi).
It additionally makes it less complicated to deploy a number of process particular fashions on prime of 1 massive mannequin,
as (|Delta Phi|) is way smaller than (|Delta Theta|).
Implementing in torch
Now that we now have an thought of how LoRA works, let’s implement it utilizing torch for a
minimal downside. Our plan is the next:
Simulate coaching information utilizing a easy (y = X theta) mannequin. (theta in mathbb{R}^{1001, 1000}).
Prepare a full rank linear mannequin to estimate (theta) – this will probably be our ‘pre-trained’ mannequin.
Simulate a special distribution by making use of a metamorphosis in (theta).
Prepare a low rank mannequin utilizing the pre=educated weights.
Let’s begin by simulating the coaching information:
We additionally outline a operate for coaching a mannequin, which we’re additionally reusing later.
The operate does the usual traning loop in torch utilizing the Adam optimizer.
The mannequin weights are up to date in-place.
OK, so now we now have our pre-trained base mannequin. Let’s suppose that we now have information from
a slighly totally different distribution that we simulate utilizing:
We now fine-tune our preliminary mannequin. The distribution of the brand new information is simply slighly
totally different from the preliminary one. It’s only a rotation of the info factors, by including 1
to all thetas. Which means that the load updates are usually not anticipated to be complicated, and
we shouldn’t want a full-rank replace in an effort to get good outcomes.
Let’s outline a brand new torch module that implements the LoRA logic:
lora_nn_linear<-nn_module( initialize =operate(linear, r=16, alpha=1){self$linear<-linear# parameters from the unique linear module are 'freezed', so they don't seem to be# tracked by autograd. They're thought of simply constants.purrr::stroll(self$linear$parameters, (x)x$requires_grad_(FALSE))# the low rank parameters that will probably be educatedself$A<-nn_parameter(torch_randn(linear$in_features, r))self$B<-nn_parameter(torch_zeros(r, linear$out_feature))# the scaling fixedself$scaling<-alpha/r}, ahead =operate(x){# the modified ahead, that simply provides the outcome from the bottom mannequin# and ABx.self$linear(x)+torch_matmul(x, torch_matmul(self$A, self$B)*self$scaling)})
We now initialize the LoRA mannequin. We’ll use (r = 1), which means that A and B will probably be simply
vectors. The bottom mannequin has 1001×1000 trainable parameters. The LoRA mannequin that we’re
are going to high-quality tune has simply (1001 + 1000) which makes it 1/500 of the bottom mannequin
parameters.
lora<-lora_nn_linear(mannequin, r =1)
Now let’s practice the lora mannequin on the brand new distribution:
To keep away from the extra inference latency of the separate computation of the deltas,
we might modify the unique mannequin by including the estimated deltas to its parameters.
We use the add_ technique to change the load in-place.
Now, making use of the bottom mannequin to information from the brand new distribution yields good efficiency,
so we are able to say the mannequin is customized for the brand new process.
Now that we discovered how LoRA works for this straightforward instance we are able to assume the way it might
work on massive pre-trained fashions.
Seems that Transformers fashions are principally intelligent group of those matrix
multiplications, and making use of LoRA solely to those layers is sufficient for lowering the
high-quality tuning price by a big quantity whereas nonetheless getting good efficiency. You possibly can see
the experiments within the LoRA paper.
After all, the concept of LoRA is easy sufficient that it may be utilized not solely to
linear layers. You possibly can apply it to convolutions, embedding layers and really every other layer.
Attackers are utilizing the open-source red-team instrument RedTiger to construct an infostealer that collects Discord account information and cost info.
The malware can even steal credentials saved within the browser, cryptocurrency pockets information, and recreation accounts.
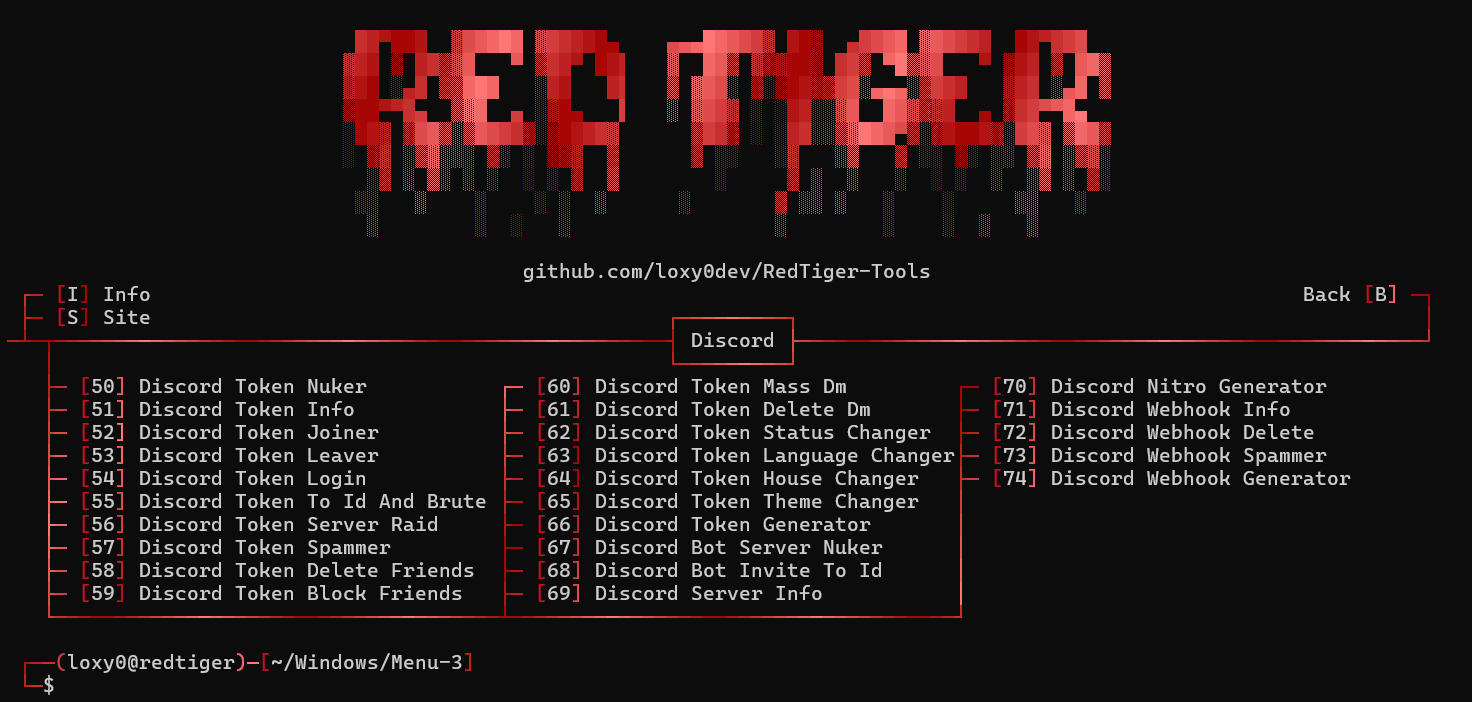
RedTiger is a Python-based penetration testing suite for Home windows and Linux that bundles choices for scanning networks and cracking passwords, OSINT-related utilities, Discord-focused instruments, and a malware builder.
Discord-related instruments in RedTiger Supply: GitHub
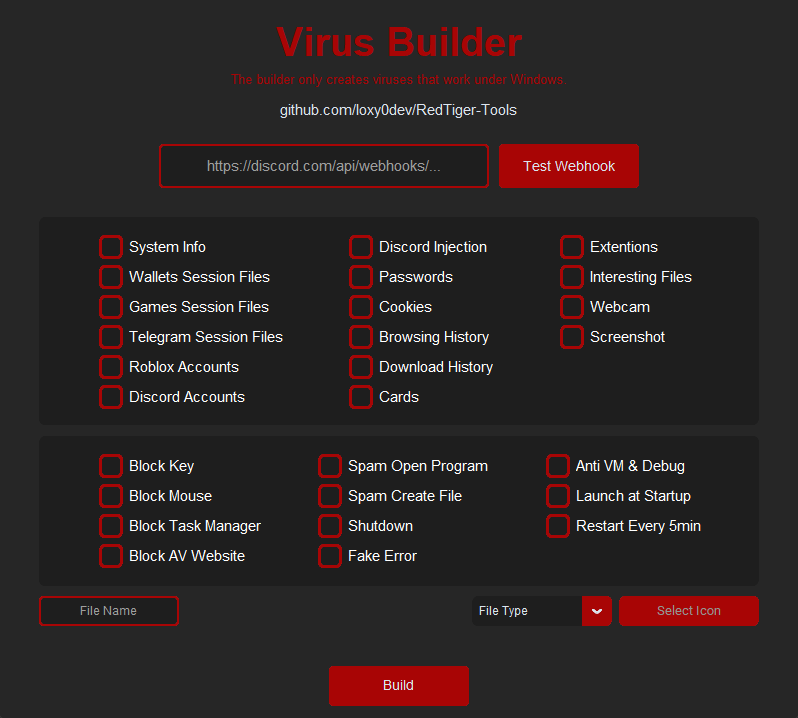
RedTiger’s info-stealer part affords the usual capabilities of snatching system data, browser cookies and passwords, crypto pockets recordsdata, recreation recordsdata, and Roblox and Discord information. It may possibly additionally seize webcam snapshots and screenshots of the sufferer’s display.
Though the challenge marks its harmful features as “authorized use solely” on GitHub, its free and unconditional distribution and the shortage of any safeguards permit simple abuse.
RedTiger’s malware builder Supply: GitHub
In keeping with a report from Netskope, menace actors at the moment are abusing RedTiger’s info-stealer part, primarily for focusing on French Discord account holders.
The attackers compiled RedTiger’s code utilizing PyInstaller to type standalone binaries and gave these gaming or Discord-related names.
As soon as the info-stealer is put in on the sufferer’s machine, it scans for Discord and browser database recordsdata. It then extracts plain and encrypted tokens through regex, validates the tokens, and pulls the profile, e-mail, multi-factor authentication, and subscription info.
Subsequent, it injects customized JavaScript into Discord’s index.js to intercept API calls and seize occasions similar to login makes an attempt, purchases, and even password adjustments. It additionally extracts cost info (PayPal, bank cards) saved on Discord.
Discord information focused by the malware Supply: Netskope
From the sufferer’s net browsers, RedTiger harvests saved passwords, cookies, historical past, bank cards, and browser extensions. The malware additionally captures desktop screenshots and scans for .TXT, .SQL, and .ZIP recordsdata on the filesystem.
After amassing the info, the malware archives the recordsdata and uploads them to GoFile, a cloud storage service that permits nameless uploads. The obtain hyperlink is then despatched to the attacker through a Discord webhook, together with the sufferer metadata.
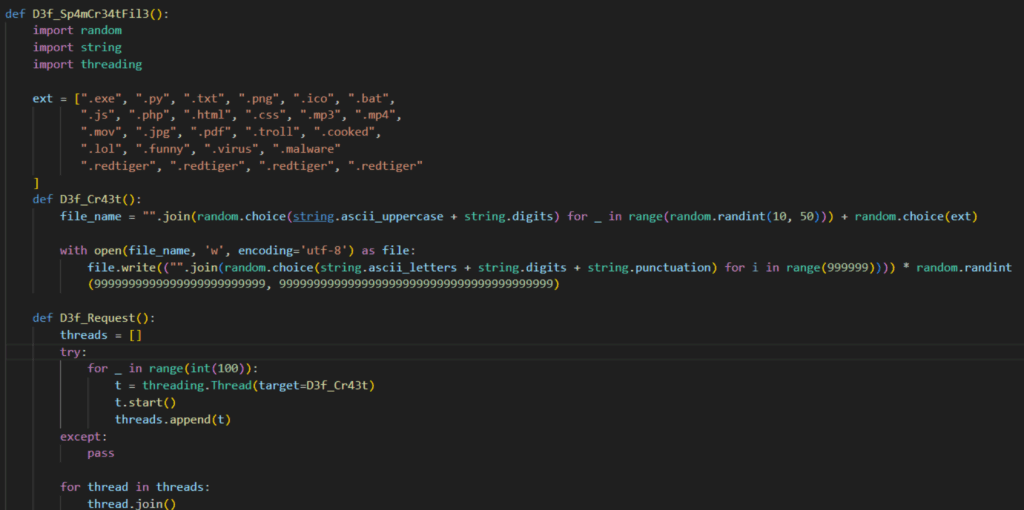
Relating to evasion, RedTiger is well-equipped, that includes anti-sandbox mechanisms and terminating when debuggers are detected. The malware additionally spawns 400 processes and creates 100 random recordsdata to overload forensic evaluation.
Spamming misleading recordsdata and processes on the host Supply: Netskope
Whereas Netskope has not shared specific distribution vectors for the weaponized RedTiger binaries, some widespread strategies embrace Discord channels, malicious software program obtain websites, discussion board posts, malvertising, and YouTube movies.
Customers ought to keep away from downloading executables or recreation instruments like mods, “trainers,” or “boosters” from unverified sources.
If you happen to suspect compromise, revoke Discord tokens, change passwords, and reinstall your Discord desktop shopper from the official web site. Additionally, clear saved information from browsers and allow MFA in all places.
46% of environments had passwords cracked, almost doubling from 25% final 12 months.
Get the Picus Blue Report 2025 now for a complete take a look at extra findings on prevention, detection, and information exfiltration tendencies.
A promising group of medicines already used to deal with diabetes and weight problems might also maintain potential for tackling alcohol and drug habit, in keeping with a brand new examine revealed within the Journal of the Endocrine Society.
These medicine, referred to as Glucagon-Like Peptide-1 Receptor Agonists (GLP-1RAs), might signify a hopeful new course for addressing alcohol and different substance use problems.
“Early analysis in each animals and people means that these remedies might assist scale back alcohol and different substance use,” mentioned lead researcher Lorenzo Leggio, M.D., Ph.D., of the Nationwide Institute on Drug Abuse (NIDA) and the Nationwide Institute on Alcohol Abuse and Alcoholism (NIAAA), each a part of the Nationwide Institutes of Well being (NIH) in Bethesda, Md. “Some small medical trials have additionally proven encouraging outcomes.”
Present Remedy Choices Are Restricted
Substance use problems are recognized by 4 key patterns: bodily dependence, dangerous conduct, social difficulties, and lack of management.
The widespread hurt attributable to these problems extends far past particular person well being, affecting households, communities, and societies worldwide. Alcohol, particularly, is taken into account essentially the most damaging drug general, contributing not solely to well being issues but in addition to visitors accidents and incidents of violence, in keeping with researchers.
Even with the size of the issue, fewer than one in 4 folks obtained therapy for alcohol or different substance use problems in 2023.
The authors level to quite a few obstacles, together with stigma and restricted assets for sufferers and suppliers. “Present remedies for [alcohol and other substance use disorders] fall in need of addressing public well being wants,” the examine famous.
GLP-1 Medication and Their Potential Position in Dependancy
GLP-1 medicines have lately gained fame for his or her success in lowering urge for food and selling weight reduction.
Past their results on digestion, GLP-1 molecules play a serious function within the mind. Activation of GLP-1 receptors within the central nervous system helps regulate starvation indicators, prompting folks to eat when hungry and cease when happy.
The examine highlights that some types of weight problems share organic and neurological traits with habit, although this concept stays debated.
“Pathways implicated in habit additionally contribute to pathological overeating and weight problems,” the examine says.
Recognizing this overlap, scientists started exploring GLP-1 medicine as a attainable therapy for substance use problems. Early research in animals and people counsel that these medicine might affect the mind circuits that drive addictive conduct, doubtlessly reducing cravings and use whereas additionally benefiting different coexisting well being points.
Proof from Early Analysis
Research that study GLP-1 results on substance use problems embrace:
Alcohol use dysfunction (AUD): A randomized managed trial with exenatide, the primary GLP-1receptor agonist authorised for diabetes, confirmed no important impact on alcohol consumption, though a secondary evaluation indicated lowered alcohol consumption within the subgroup of individuals with AUD and comorbid weight problems. A more moderen randomized managed trial confirmed that low-dose semaglutide — a more moderen GLP-1 receptor agonist authorised for each diabetes and weight problems — lowered laboratory alcohol self-administration, in addition to drinks per consuming days and craving, in folks with AUD.
Opioid use dysfunction: In rodent fashions, a number of GLP-1 receptor agonists have been proven to scale back self-administration of heroin, fentanyl and oxycodone. The research additionally discovered that these medicines scale back reinstatement of drug in search of, a rodent mannequin of relapse in drug habit.
Tobacco use dysfunction: Preclinical knowledge present that GLP-1 receptor agonists scale back nicotine self-administration, reinstatement of nicotine in search of, and different nicotine-related outcomes in rodents. Preliminary medical trials counsel the potential for these medicines to scale back cigarettes per day and forestall weight achieve that always follows smoking cessation.
The Highway Forward
Leggio and his colleagues emphasize that extra analysis is required to substantiate how successfully GLP-1 medicine deal with habit and to grasp the underlying organic mechanisms.
Regardless of the unanswered questions, researchers stay optimistic.
“This analysis is essential as a result of alcohol and drug habit are main causes of sickness and loss of life, but there are nonetheless just a few efficient therapy choices,” Leggio mentioned. “Discovering new and higher remedies is critically vital to assist folks reside more healthy lives.”
Different examine authors are Nirupam M. Srinivasan of the College of Galway in Galway, Eire; Mehdi Farokhnia of NIDA and NIAAA; Lisa A. Farinelli of NIDA; and Anna Ferrulli of the College of Milan and Istituto di Ricovero e Cura a Carattere Scientifico (IRCCS) MultiMedica in Milan, Italy.
Analysis reported on this article was supported partially by NIDA and NIAAA. The content material is solely the accountability of the authors and doesn’t essentially signify the official views of the NIH.
This publish grew out of a rambling, sporadically multi-month play with a bunch of information that turned far too large for a single publish for any believable viewers. So I’ve damaged that work into three artefacts that may be of curiosity in numerous methods to totally different audiences:
Males’s home chores and fertility charges—(this doc)—dialogue of the substantive problems with the subject material, with charts and outcomes of statistical fashions however no code. Essential viewers is anybody all in favour of what statistics has to say in regards to the precise (non) relationship of the time males spend on home chores and whole fertility fee.
Males’s home chores and fertility charges – Half II, technical notes—dialogue of technical points reminiscent of how to attract directed graphs with totally different colored edges, methods to entry the UN SDG indicators database, and the equivalence or not of various methods of becoming combined results fashions. Accommodates key extracts of code. The primary viewers is future-me wanting to recollect these items, but additionally anybody else with comparable technical curiosity.
Additionally, all em-dashes on this publish had been defiantly typed, by me, in HTML, by hand.
OK, onto the weblog publish.
Time-use and variety of kids
An obvious relationship in excessive GDP per capita nations
Some months in the past a publish floated throughout my Bluesky feed making an argument to the impact of “if societies need extra kids, then males ought to do extra of the house responsibilities”, accompanied by a chart from a few-years-old paper. The chart was a scatter plot with one thing like male share of unpaid home chores on the horizontal axis, and whole fertility fee on the vertical axis—every level was considered one of chosen OECD nations at a cut-off date for which knowledge on each variables was obtainable—and there was a particular optimistic correlation.
I can’t discover the chart now, but it surely appeared one thing similar to this one I’ve made for myself:
The case was being made that if you happen to assume the world isn’t having sufficient kids (not one thing I personally subscribe to however let’s settle for it as an issue for some folks), the reply may be extra feminism and gender equality, not much less. And the apparent context being the varied pro-traditionalism, trad-wife, and so on arguments to the other impact, going round within the altogether relatively contemptible (once more, clearly that is simply my very own view) pro-natalism discourse.
Would possibly as effectively get on the file, whereas it’s not related statistically, that I’m totally for extra feminism and gender equality, and I additionally assume “as a result of then girls may have extra kids” is a really dangerous argument for these items.
Sadly each the Bluesky publish I noticed and the unique article have now escaped me, however I do do not forget that the info was a bit previous (2010s), and a few folks commenting ‘ah, woke Scandinavian nation X the place males do numerous house responsibilities, however because the time on this chart they have stopped having as many kids too’. Extra importantly, I used to be intrigued by means of “chosen nations” within the title. Chosen how and why, I puzzled on the time.
Clearly, limiting the evaluation to wealthy nations provides a slim view on a much bigger relationship. As a result of one of many strongest empirical relationships in demography, on a historic scale, is the commentary that as girls and women get extra academic and financial alternatives, they have a tendency to have much less kids, by way of a society-wide common of a rustic going by means of financial improvement.
I’m sufficiently old to recollect when everybody I engaged with appeared to agree this was factor, each by way of the additional alternatives and selections for girls as in itself, and avoiding cramming too many individuals into an already crowded and under-resourced planet. Apparently that is now not a consensus, which simply leaves me, I don’t know, stroking my gray beard and feeling the world’s handed me by.
What causes what?
I might anticipate, world-wide, that girls do the next share of the house responsibilities in nations the place they’ve much less financial alternatives (would you name these extra patriarchal and ‘conventional’ societies? considerably tough to get a non-offensive terminology right here). And that in those self same nations, in addition they have extra kids (see extensively identified historic empirical reality referred to above). In truth, what I’d anticipate is a diagram of causes and results that appears one thing like this:
On this mannequin, financial and schooling alternatives for girls and women results in selections to have much less kids and a lower in whole fertility fee, proven with a pink arrow due to the downwards affect. Males doing extra house responsibilities on account of a rising tradition of gender equality and altering social norms has an affect (most likely smaller) within the optimistic path, with a blue arrow. That tradition of gender equality itself comes about partly from altering financial circumstances (girls transferring in to seen roles) and partly from profitable advocacy.
Naturally, this can be a gross over-simplification of the fact of those processes.
The diagram above isn’t a directed acyclic graph (DAG) as a result of it’s not acyclic – that’s, a number of the arrows are two-way, reminiscent of financial development resulting in extra financial and academic alternatives for girls and women, and financial and academic alternatives for girls and women resulting in financial development. However you can scale back it to a DAG if you happen to restricted it to the three key variables of whole fertility fee, males doing house responsibilities, and alternatives for girls and women.
This simplified model doesn’t make it clear the place elevated alternatives for girls and women come from or why they result in males doing extra of the house responsibilities. The unique, extra advanced, diagram reveals that this was anticipated to occur by way of the (tough to look at and complicated to evolve) mediating issue of a basic tradition of gender equality.
The simplified diagram does assist us assume by means of what to anticipate if we ignore the confounder of “financial and academic alternatives for girls and women” and simply plot male share of unpaid home chores in opposition to whole fertility fee.
On a easy two-variable scatter plot, we’d anticipate a unfavourable correlation, as a result of the time use variable is definitely standing in as a proxy for the extra vital gender equality of alternatives.
However if you happen to might get a greater indicator of that confounding alternatives variable and management for it, and if there actually is an affect from male share of house responsibilities on larger fertility choices, you may get a optimistic impact of male share of home work on fertility.
“… all others should deliver knowledge”
Who measures these things?
OK then, let’s have a look at some knowledge.
Sustainable Improvement Targets (SDG) Indicator 5.4.1 is “the Proportion of time spent on unpaid home chores and care work, by intercourse, age and placement (%)”, which is unbelievable as a result of it means we’ve an internationally agreed commonplace on how that is measured. It additionally signifies that what knowledge is accessible will probably be within the United Nations Statistical Division’s definitive database of the SDG indicators.
Knowledge gained’t be obtainable for all nations, and positively not for all years in all nations, as a result of it will depend on a tough and costly time use survey. Only a few nations can afford to prioritise considered one of these often and steadily, and plenty of have by no means had one in any respect.
For the vertical axis of our first plot, we are able to get whole fertility fee from varied sources, however one handy one that provides an estimate for every nation for every year on a standardised, comparable foundation is the UN’s World Inhabitants Prospects.
We now have a number of challenges in utilizing all that knowledge:
The official SDG indicators don’t truly embrace an apparent single dimensional abstract of gender share of house responsibilities, so we might want to assemble it with one thing like male_share = male / (male + feminine). The place male is the proportion of males’s time spent on dometic chres and carework, feminine the equal for girls. We are able to make a composite indicator like this as a result of the denominator (whole time within the day) for each male and feminine is similar.
Some nations have a number of observations (multiple yr with a time use survey) and we’d like to include them one way or the other. After we get to statistical modelling, this suggests the necessity for some type of multilevel mannequin with a country-level random impact in addition to residual randomness on the country-year degree. On a chart, we are able to present these a number of observations by connecting factors with segments, and visually differentiating the newest commentary from these in earlier surveys. That is a lot better than simply choosing one survey per nation.
The years of time use surveys fluctuate considerably over a 20+ yr time interval, so we should always anticipate a doable time impact to complicate any inference we do. We have to take this under consideration each in our statistical modelling and our visualisations.
Not all of the age teams are equal throughout nations, so we must grit our tooth for some inconsistent definitions of ladies and men (i.e. when does maturity begin). Not least of the implications of that is it provides an annoying knowledge processing step.
A relationship reversed
As soon as I had the info in place, I began with a scatter plot, of all nations, of our two variables.
In stark distinction to the plot of simply high-income nations that began me off, there’s a strongish unfavourable relationship right here. The path of the connection has reversed! That is what I anticipated and is according to my desirous about financial and academic alternatives for girls and women being an vital confounding variable as quickly as we have a look at a broader vary of nations.
What about if we introduce another variables, proxies for the financial alternatives for girls and women? Apparent candidates are revenue or, failing that, GDP per capita, appropriately managed for buying energy parity in every nation and level of time; and a few basic feminine empowerment index like relative literacy (say feminine literacy divided by male literacy, at age 15).
What I’m after right here is drawing some charts like this which is able to get us began in seeing if the obvious relationship between male share of home chores and fertility fee is basically an artefact of confounding variables like general financial improvement.
Right here we do see, for instance, a really fascinating outcome that inside the three decrease GDP per capita classes of nations there’s a unfavourable relationship between male share of home chores and fertility. However within the highest GDP per capita class, that relationship is reversed. In truth, the scatter plot that began me on this complete journey was mainly the underside proper side of this diagram.
Measuring gender inequality
We have to do extra although—we are able to get a measure of feminine financial empowerment (and therefore selections between motherhood and employment). One of the best knowledge I might discover for my goal on this was the Gender Inequality Index produced by the UNDP as a part of their annual Human Improvement Report course of. Right here’s what that quantity appears to be like like for the nations that we’ve sufficient knowledge for this general weblog:
Lastly on this exploratory stage, here’s a plot of all of the pairwise relationships between the variables we’ve been discussing:
There’s lots packed in to plots like these, however what we see right here is that:
GDP per capita is strongly negatively correlated with fertility fee (wealthy nations have much less kids).
Gender inequality is strongly positively correlated with fertility fee (unequal nations have extra kids).
Male house responsibilities is reasonably positively correlated with GDP per capita (wealthy nations have extra male house responsibilities).
Male house responsibilities is weakly to reasonably negatively correlated with fertility (extra male house responsibilities nations have much less kids).
Every variable has a weak development over time—downwards for fertility fee and gender inequality, upwards for GDP per capita and male house responsibilities. You possibly can truly see within the left column of the plots the chains of dots representing nations just like the USA which have the posh of a number of time-use surveys and a stunning steady sequence of comparable observations.
Statistical modelling
The kind of mannequin I wish to match is one which has all these options:
permits us to incorporate a number of measures for nations which have them, however with out making the false assumption that these are unbiased observations (every additional commentary on a rustic is beneficial, however not as a lot additional data as if we had a complete new nation)
permits for an interplay between GDP per capita and male house responsibilities
permits relationships basically to be non-linear if that’s what the info suggests
permits for a nuisance non-linear development over time in fertility
lets the variance of whole fertility fee be proportional to its imply, however not similar (so a quasi-poisson household distribution)
To do that I opted to make use of the gam operate from Simon Wooden’s mgcv package deal, match with this snippet of code:
The forthcoming “behind the scenes” follow-up publish may have extra dialogue of a number of the modelling selections, diagnoses, and statistical assessments.
The top result’s that this mannequin is not an enchancment on a mannequin that drops prop_male—ie the proportion of home work that’s achieved by males—altogether. As seen on this Evaluation of Deviance desk, with just about no additional deviance in fertility defined by the extra advanced mannequin:
This isn’t shocking once we mirror on the pairs plot earlier. GDP per capita and the gender inequality index each have sturdy, apparent relationships with whole fertility fee. It is sensible that between them they take in all of the variance that may be defined on the nation degree.
To see the modelling outcomes visually, here’s a plot exhibiting predictions of the typical degree of fertility fee at various ranges of that male house responsibilities variable, created with the extremely helpful marginaleffects package deal by Vincent Arel-Bundock, Noah Greifer and Andrew Heiss. What we see right here is not any materials relationship:
Distinction that to comparable presentation of the outcomes for gender inequality, and for PPP GDP per capita:
The time relationship is an fascinating one. It appears to be like from the plot under that there is no such thing as a materials relationship, however the statistical proof is fairly sturdy that it’s price holding this variable within the mannequin.
My intuitive clarification for that is that point is extra vital in explaining developments in fertility fee within the nations which have a number of observations on this pattern; and this isn’t simple to choose up visually in a chart of this kind. Anyway, it doesn’t matter, as I’m not within the time development in its personal proper, simply in controlling for it as a doable spoiler of our extra vital statistical conclusions.
Conclusions
In the event you have a look at simply excessive buying energy parity GDP per capita nations, there’s an obvious optimistic relationship between the quantity of unpaid home chores achieved by males and whole fertility fee, on the nation degree.
Nevertheless, this affect is reversed if you happen to have a look at the complete vary of nations for which knowledge is accessible.
Most significantly, the connection vanishes altogether once we embrace it in a statistical mannequin that controls for buying energy parity GDP per capita and for gender inequality extra broadly.
We are able to conclude that the obvious country-level impact of male house responsibilities on whole fertility is only a statistical artefact standing in for these two, broader—and clearly vital—elements.
Does this imply that males doing house responsibilities doesn’t affect on fertility choices? No! In truth it’s very doable it does. Nevertheless it does imply which you can’t see this within the nation degree knowledge. To actually examine this, you will want family degree knowledge; one thing just like the Australian HILDA survey (Family Revenue and Labour Dynamics in Australia).
Toxocariasis is brought on by Toxocara spp., roundworms generally present in mammals. These parasites are a big well being danger to people, particularly younger youngsters, and people who steadily come into contact with soil or pets [1].
Animal vectors or carriers
Toxocara primarily impacts canine and cats. Toxocara canis is often present in canine, particularly puppies, whereas Toxocara cati predominantly impacts cats, together with each wild and home varieties, with kittens being extra vulnerable [2].
These pets can simply unfold the an infection to people with out displaying any signs themselves [2].
Mode of transmission
Individuals can get toxocariasis in a number of methods. One frequent manner is by swallowing eggs which might be present in soiled environments, like soil or sand, or on objects which have touched animal poop. That is particularly dangerous for teenagers who play in sandboxes or for individuals who backyard or work with soil [1,2].
Consuming undercooked meat from animals with the an infection, comparable to rabbits or geese, also can make folks sick [1,2].
Signs
Many individuals with toxocariasis don’t present signs, making the an infection laborious to detect with out particular testing. Nevertheless, in instances the place the larval load is excessive, the larvae can penetrate the intestinal partitions, enter the bloodstream, and journey to organs just like the liver and lungs.
This situation, referred to as visceral toxocariasis, could cause a variety of signs, together with:
Fever
Weight reduction
Cough
Rashes
Wheezing
Fatigue
Belly ache
Enlargement of the liver and spleen [3].
The larvae can stay inside human tissues for months, inflicting harm, however importantly, they don’t mature into grownup worms in people [2].
It’s been some time since I’ve posted, so I wished to take action briefly. When you have been registered for the Causal Inference II workshop that was scheduled to begin subsequent weekend, you’ll now discover you’ve been refunded and that it’s been canceled. Let me clarify.
Whereas it’s unimaginable to say when my father will die, there’s a excessive probability that it’s any day now, through which case the funeral can be one of many two subsequent weekends. He’s on hospice, and issues have quickly modified in ways in which make dying extraordinarily probably. There’s simply no means in my thoughts an individual can run calorie deficits and drink no fluids for such an prolonged time period and stay for much longer.
So moderately than begin it, after which cancel it, I simply felt that it was extra vital to let individuals get their a refund now, in order that they may have the time to reschedule their ow plans. I’d hate that somebody has an opportunity to do one thing else, however didn’t, as a result of they have been doing the workshop. So apologies that this was so final minute.
I additionally apologize that you simply didn’t get an e mail — Eventbrite wouldn’t allow us to e mail you as soon as we canceled. You needed to e mail first, after which cancel, however we didn’t notice that. However hopefully we don’t ever should cancel something once more.
I used to be capable of converse to dad the opposite day. He wasn’t actually awake, although he form of is on this semi-conscious state typically. I informed dad once more what I stated earlier than two months in the past which was that he’d at all times made me really feel revered by him, and that he by no means appeared to try to patronize or discuss all the way down to me. I informed him he by no means appeared to try to make me really feel small — in reality, the alternative. He at all times made me really feel large. And that I appreciated that. I additionally informed him he informed me he liked me each time I noticed him, and that I wished him to know I noticed it and appreciated it too. He and I at all times informed the opposite we liked them. He’s a loving man and says it to us on a regular basis.
After which I informed him I believed he was about to go on an ideal journey, and that I used to be excited to listen to about it after I noticed him once more.
This week I’ve to put in writing the obituary and my speech. And current, and one million different issues. I’ve managed to get sick as soon as however transfer previous it rapidly. All in all, I’m doing good.
On a special be aware, the category is coming alongside. Boston is coming alongside. Life is coming alongside. What’s been happening?
Yale despatched me the ebook again with all their edits and I went by means of it and responded. It stays a 750 web page ebook give or take. And having to reread it once more this previous couple of weeks to approve the adjustments jogs my memory how a lot I hate studying my very own writing. However that’s now performed and now we’re shifting to the subsequent stage, which I’m assuming is the paintings. We’ll see.
I went to a curler derby recreation two nights in the past and that was superior. It was a leisure league of individuals extra my age, and so they have been having the time of their lives, as was I. They skated on quads, not inline skates, and so it was fairly nostalgic to look at.
I proceed to like again bay in addition to Harvard itself. I believe one of many issues I wasn’t anticipating to expertise was simply how good everybody can be at Harvard. It’s not that I used to be anticipating the alternative — it’s that I wasn’t anticipating everybody I meet to simply be so pleasant. I really feel actually grateful to be right here.
This week I might be presenting new analysis of mine with my pupil, Jared Black, on the decriminalizing of “sacred crops” (ie psychedelic crops) and its impact on psychosis signs at emergency division visits. If solely I had 5 of me—think about how a lot work I may get performed.
I proceed to satisfy with my college students nevertheless it’s difficult in a category this huge. I’ve in all probability held eight to 9 hours of workplace hours per week for a pair months, seen 60 college students, an that’s nonetheless leaving 130 I’ve not but met. It’s tough, as a result of the extra college students I meet, the extra I need to meet.
The manufacturing perform for instructing a category when it’s 20-30 college students, and the manufacturing perform when it’s 190-200 college students, could be the identical manufacturing perform, nevertheless it will not be. I can not fairly recall from manufacturing principle to be trustworthy. It may very well be the identical manufacturing perform in reality; it’s simply that the labor inputs of educating at a really excessive degree should draw from extra individuals. However I believe it’s truly not the identical. On the increased ranges, it requires a degree of coordination and precision that isn’t the case on the smaller degree lessons. Regardless, it’s fascinating, nevertheless it does make me unhappy that I can not get to know all of them.
Patriots are wanting good this season. I’m an increasing number of excited on a regular basis that I snagged these Pats-Payments tickets for mid December. Climate continues to be lovely and I’m certain it’ll be so at that recreation, although it’ll be sub zero in all probability. I’ll be with my buddy. Top-of-the-line components of coming right here has been me and him getting to hang around once more. He was my previous roommate in faculty and groomsman.
My schedule for subsequent summer time is coming collectively. Appears like this up to now:
mid-Could: college of Glasgow once more for per week (second time there)
Late Could: CodeChella (third annual)
First week of June: a workshop in Pisa
Second week of June: one other Italian workshop someplace close by
Later in June: a workshop in Berlin
So it’s all coming collectively, and I’m excited. I believe I cannot spend three weeks in San Sebastián like final time, however I do plan to go to Amelia’s once more in San Sebastián. However we’ll see. As my father will now not be with us by then, I’ll most probably attempt to see if I can deliver my mother with me someplace, assuming her mobility can deal with it.
That’s the factor about previous age — the strolling. What’s a power of an space for a youthful individual turns into more durable for an older individual. However I’ve loads of time to determine that out.
These days AI has change into a mainstream idea due to the unimaginable media craze concerning the subject. Not a day goes by with out sensational information warning that AGI is correct across the nook and even perhaps secretly already right here. The press baiting and investor FOMO is palpable. Traditionally, the AI area tends to change into very frothy periodically with loaded expectations that inflate non-public firm valuations and inventory costs which, in flip, appeal to much more consideration and extra {dollars}. It’s the everyday expertise hype cycle solely on steroids.
At BigML, now we have chosen to keep away from the all sizzle and little steak PR acrobatics all alongside. This meant sticking to our weapons by selling actual life use circumstances of Machine Studying carried out on prime of our platform, the key phrase being Machine Studying and never AI.
Immediately, we’re proud to share that BigML’s pioneering multi-tenant Machine Studying-as-a-Service providing has reached a brand new milestone of 200,000 customers. What’s of particular notice is the truth that this has taken place utterly organically by way of phrase of mouth and on-line discoverability leading to 1000’s of customers throughout the globe discovering useful methods to realize insights from their information.
Since 2011, many elements have been driving this natural adoption of BigML:
From the get go, we embraced product-led progress by permitting anybody with a legitimate e mail to join BigML to expertise the software program for themselves first hand eliminating the necessity to navigate large downloads, painful setup/set up routines or necessary gross sales demos that don’t essentially mirror the prospect’s actuality.
The continual curiosity in Machine Studying each from training establishments and the enterprise world fueled by steady developments in algorithmic analysis and software program enhancements that additional stoke the hearth. Fittingly, BigML platform has additionally frequently improved making it extra complete. Whereas the early variations of BigML solely featured easy choice timber, we now assist many extra sources like OptiML that routinely builds fine-tuned fashions and workflow automation choices whereas abstracting infrastructure layer considerations from the end-user. Extra competent fashions and customized workflows translate to larger enterprise influence.
Lastly, now we have constructed complementary companies to speed up platform adoption by way of a mixture of inexpensive teaching programs, certifications, and top-notch buyer assist.
At BigML, we stay as excited as Day 1 in serving our group with every passing yr and serving to Machine Studying drive an increasing number of enterprise efficiencies and improvements in virtually each nook of the worldwide financial system.
Late to the occasion? Get began right now…
No matter your stage of Machine Studying expertise, you may get began with the BigML platform by profiting from the next sources:
For those who join BigML you’ll obtain a 14-day FREE Trial interval that you need to use to expertise the platform first-hand.
FREE Schooling movies: Not like the everyday on-line Machine Studying programs that pressure feed you a number of concept, BigML training movies give attention to the important thing ideas with out getting too deep into the underlying math as a substitute you get to study every BigML useful resource by instance. Besides, these movies assume no prior background in Machine Studying.
BigML Lite for Small Companies or Pilot Initiatives: Bigger companies normally require their very own devoted situations of BigML resulting from inner guidelines or preferences however for SMBs or a single enterprise unit of a giant group, it makes extra sense to deploy BigML Lite at a fraction of the price of a typical non-public deployment and acquire velocity to market.
Now it’s your flip to take motion and step into the superb world of Machine Studying!
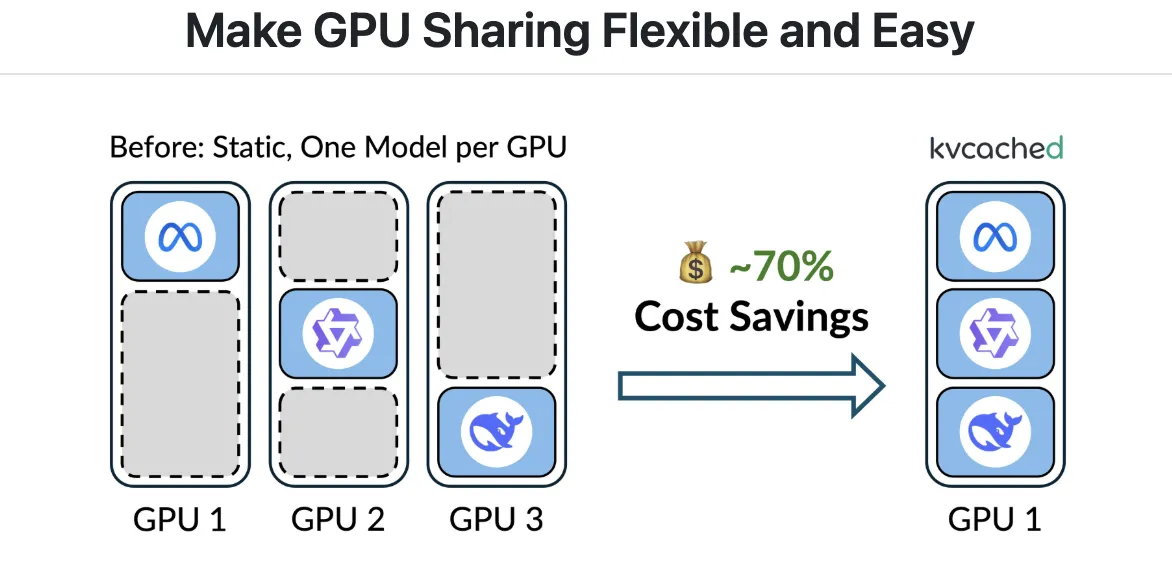
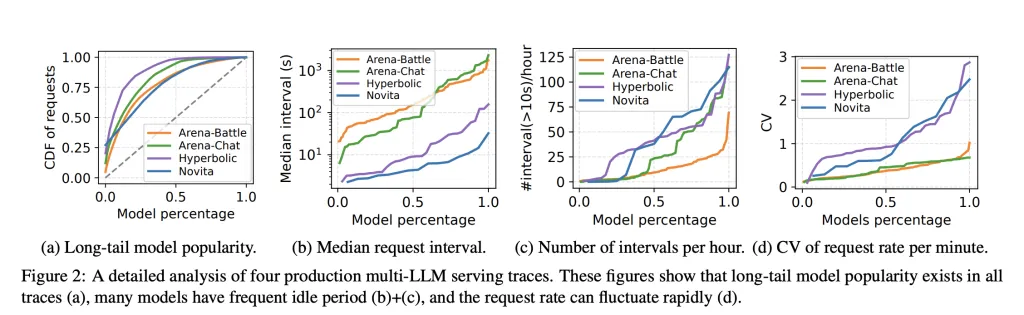
Massive language mannequin serving usually wastes GPU reminiscence as a result of engines pre-reserve giant static KV cache areas per mannequin, even when requests are bursty or idle. Meet ‘kvcached‘, a library to allow virtualized, elastic KV cache for LLM serving on shared GPUs. kvcached has been developed by a analysis from Berkeley’s Sky Computing Lab (College of California, Berkeley) in shut collaboration with Rice College and UCLA, and with invaluable enter from collaborators and colleagues at NVIDIA, Intel Company, Stanford College. It introduces an OS-style digital reminiscence abstraction for the KV cache that lets serving engines reserve contiguous digital house first, then again solely the lively parts with bodily GPU pages on demand. This decoupling raises reminiscence utilization, reduces chilly begins, and permits a number of fashions to time share and house share a tool with out heavy engine rewrites.
https://github.com/ovg-project/kvcached
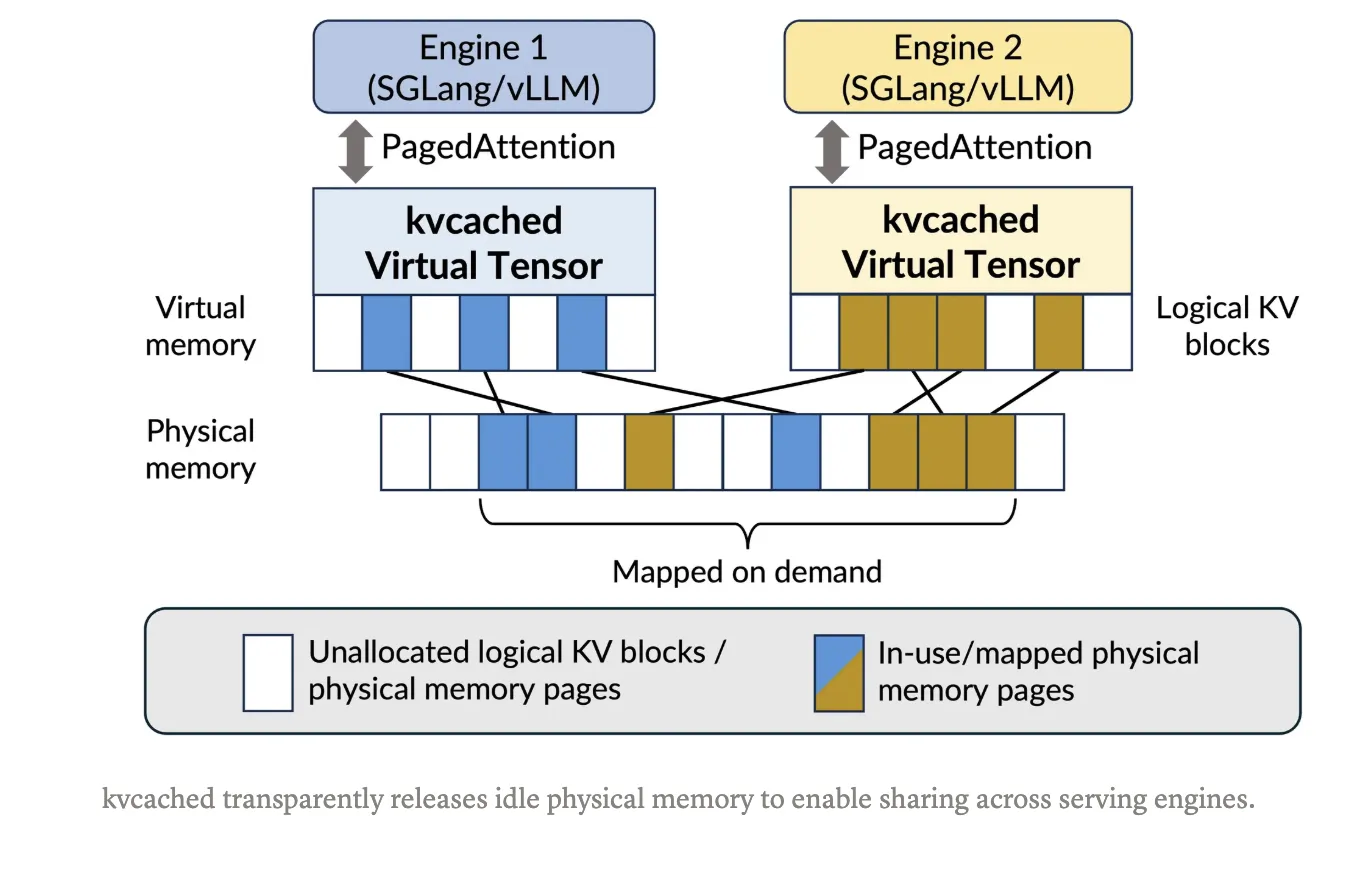
What kvcached modifications?
With kvcached, an engine creates a KV cache pool that’s contiguous within the digital deal with house. As tokens arrive, the library maps bodily GPU pages lazily at a superb granularity utilizing CUDA digital reminiscence APIs. When requests full or fashions go idle, pages unmap and return to a shared pool, which different colocated fashions can instantly reuse. This preserves easy pointer arithmetic in kernels, and removes the necessity for per engine consumer stage paging. The mission targets SGLang and vLLM integration, and it’s launched below the Apache 2.0 license. Set up and a one command fast begin are documented within the Git repository.
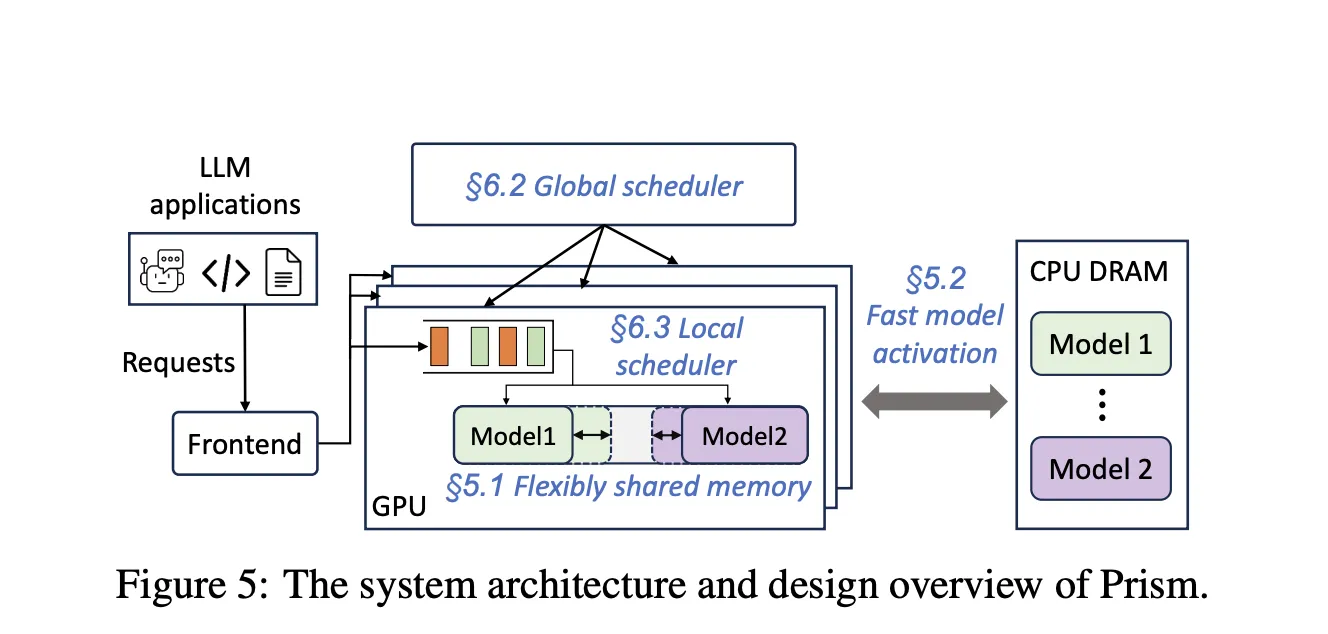
Manufacturing workloads host many fashions with lengthy tail visitors and spiky bursts. Static reservations depart reminiscence stranded and decelerate time to first token when fashions should be activated or swapped. ThePrism analysis paper reveals that multi-LLM serving requires cross mannequin reminiscence coordination at runtime, not simply compute scheduling. Prism implements on demand mapping of bodily to digital pages and a two stage scheduler, and experiences greater than 2 instances price financial savings and 3.3 instances greater TTFT SLO attainment versus prior programs on actual traces. kvcached focuses on the reminiscence coordination primitive, and gives a reusable part that brings this functionality to mainstream engines.
https://www.arxiv.org/pdf/2505.04021
Efficiency indicators
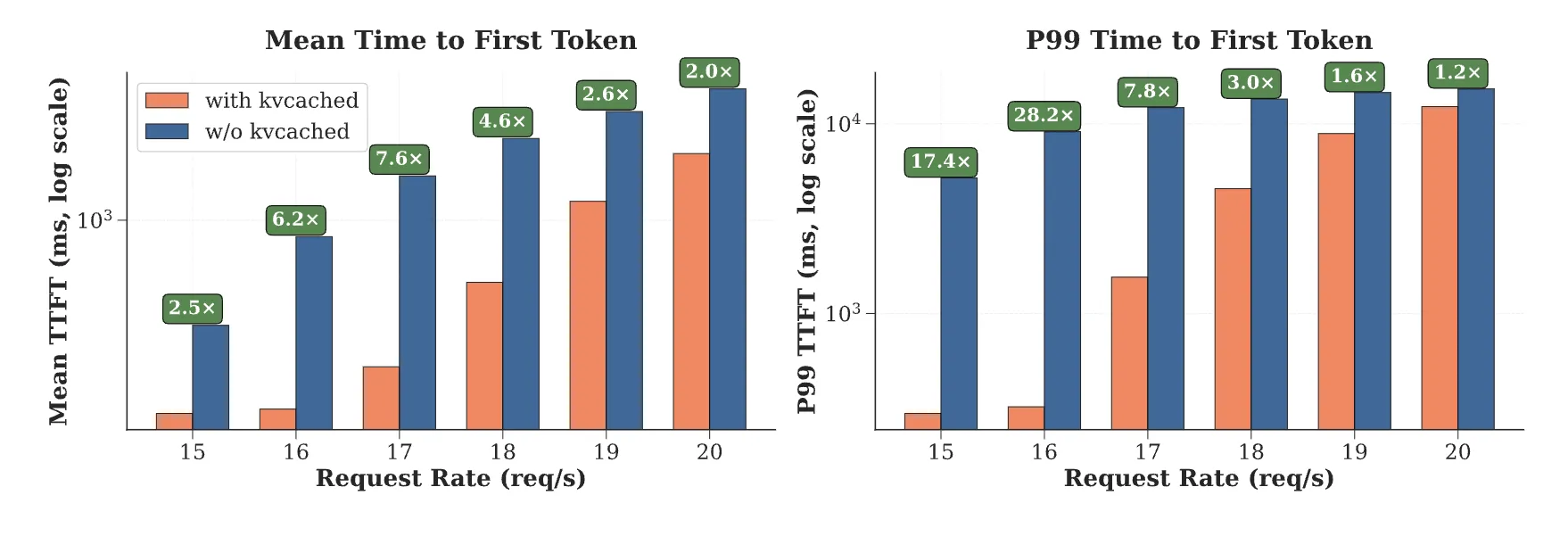
The kvcached crew experiences 1.2 instances to twenty-eight instances sooner time to first token in multi mannequin serving, resulting from fast reuse of freed pages and the removing of enormous static allocations. These numbers come from multi-LLM eventualities the place activation latency and reminiscence headroom dominate tail latency. The analysis crew word kvcached’s compatibility with SGLang and vLLM, and describe elastic KV allocation because the core mechanism.
Current work has moved from mounted partitioning to digital reminiscence based mostly strategies for KV administration. Prism extends VMM based mostly allocation to multi-LLM settings with cross mannequin coordination and scheduling. Prior efforts like vAttention discover CUDA VMM for single mannequin serving to keep away from fragmentation with out PagedAttention. The arc is evident, use digital reminiscence to maintain KV contiguous in digital house, then map bodily pages elastically because the workload evolves. kvcached operationalizes this concept as a library, which simplifies adoption inside current engines.
https://www.arxiv.org/pdf/2505.04021
Sensible Purposes for Devs
Colocation throughout fashions: Engines can colocate a number of small or medium fashions on one machine. When one mannequin goes idle, its KV pages free rapidly and one other mannequin can increase its working set with out restart. This reduces head of line blocking throughout bursts and improves TTFT SLO attainment.
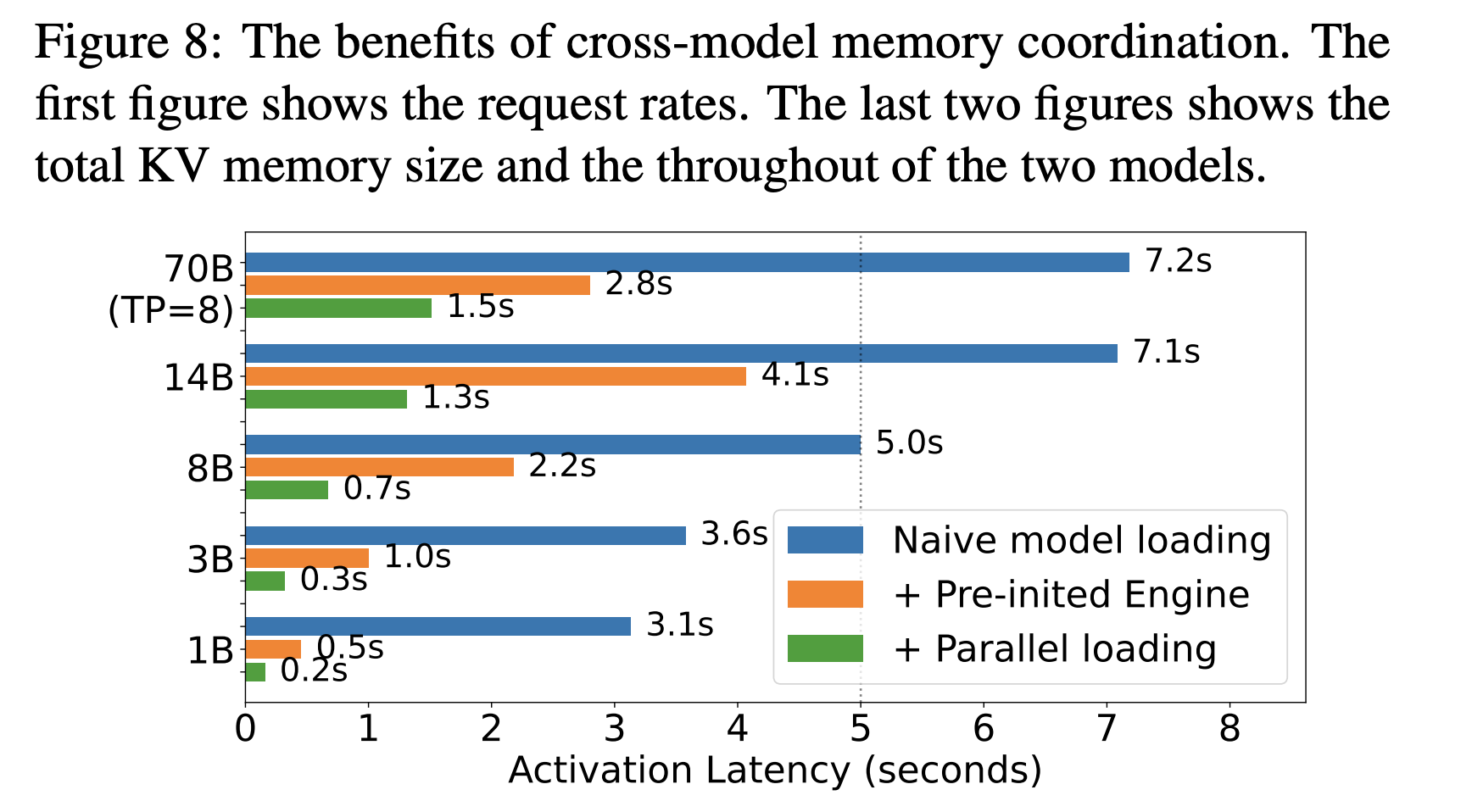
Activation conduct: Prism experiences activation instances of about 0.7 seconds for an 8B mannequin and about 1.5 seconds for a 70B mannequin with streaming activation. kvcached advantages from comparable rules as a result of digital reservations permit engines to arrange deal with ranges prematurely, then map pages as tokens arrive.
Autoscaling for serverless LLM: Superb grained web page mapping makes it possible to scale replicas extra incessantly and to run chilly fashions in a heat state with minimal reminiscence footprint. This allows tighter autoscaling loops and reduces the blast radius of scorching spots.
Offloading and future work. Digital reminiscence opens the door to KV offload to host reminiscence or NVMe when the entry sample permits it. NVIDIA’s latest information on managed reminiscence for KV offload on GH200 class programs reveals how unified deal with areas can lengthen capability at acceptable overheads. The kvcached maintainers additionally focus on offload and compaction instructions in public threads. Confirm throughput and latency in your personal pipeline, since entry locality and PCIe topology have sturdy results.
https://www.arxiv.org/pdf/2505.04021
Key Takeaways
kvcached virtualizes the KV cache utilizing GPU digital reminiscence, engines reserve contiguous digital house and map bodily pages on demand, enabling elastic allocation and reclamation below dynamic hundreds.
It integrates with mainstream inference engines, particularly SGLang and vLLM, and is launched below Apache 2.0, making adoption and modification easy for manufacturing serving stacks.
Public benchmarks report 1.2 instances to twenty-eight instances sooner time to first token in multi mannequin serving resulting from fast reuse of freed KV pages and the removing of enormous static reservations.
Prism reveals that cross mannequin reminiscence coordination, applied through on demand mapping and two stage scheduling, delivers greater than 2 instances price financial savings and three.3 instances greater TTFT SLO attainment on actual traces, kvcached provides the reminiscence primitive that mainstream engines can reuse.
For clusters that host many fashions with bursty, lengthy tail visitors, virtualized KV cache permits secure colocation, sooner activation, and tighter autoscaling, with reported activation round 0.7 seconds for an 8B mannequin and 1.5 seconds for a 70B mannequin within the Prism analysis.
kvcached is an efficient method towards GPU reminiscence virtualization for LLM serving, not a full working system, and that readability issues. The library reserves digital deal with house for the KV cache, then maps bodily pages on demand, which permits elastic sharing throughout fashions with minimal engine modifications. This aligns with proof that cross mannequin reminiscence coordination is important for multi mannequin workloads and improves SLO attainment and value below actual traces. Total, kvcached advances GPU reminiscence coordination for LLM serving, manufacturing worth relies on per cluster validation.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its reputation amongst audiences.