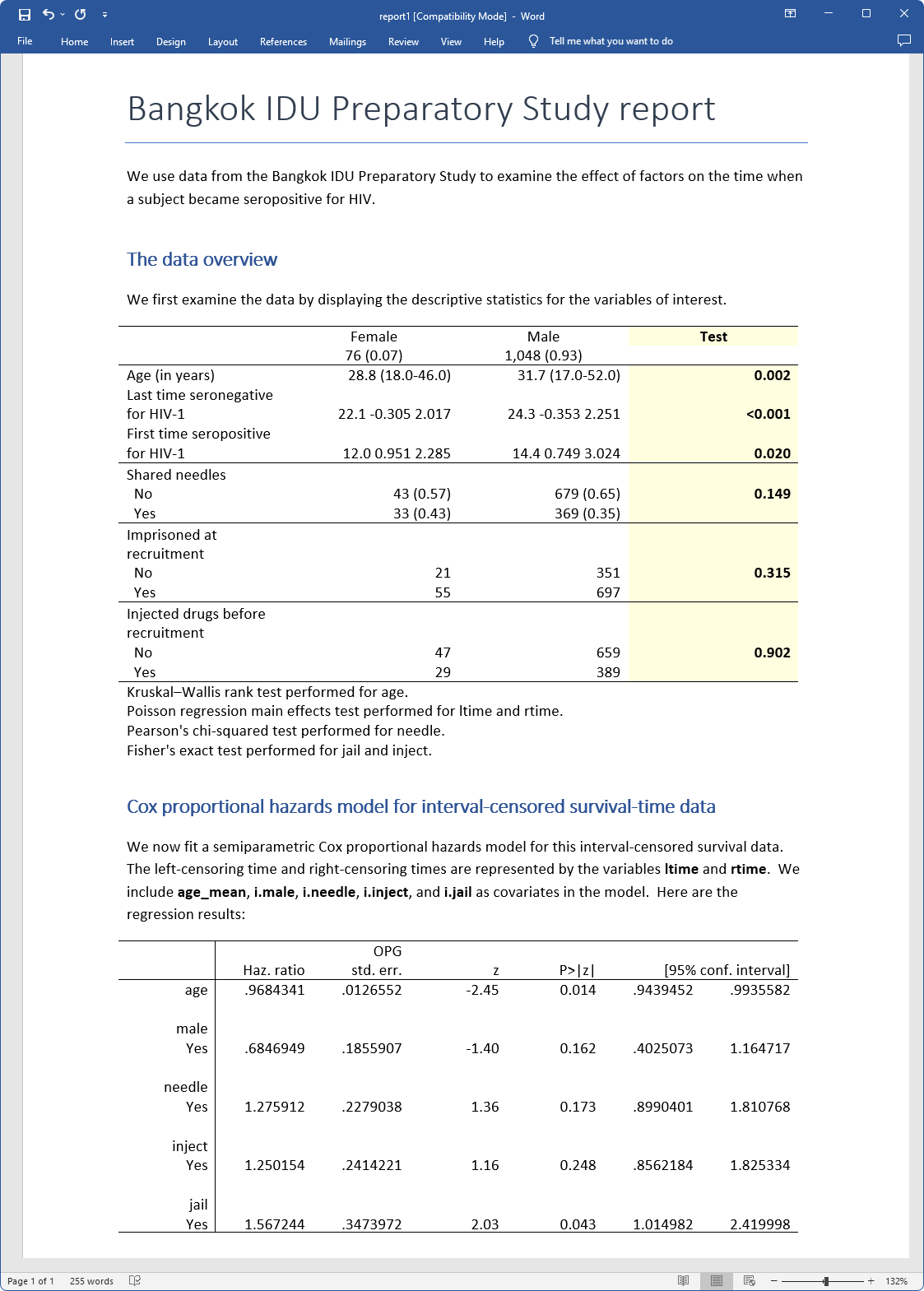
The clock is ticking on the following wave of school job seekers. At a time when “simply be taught to code” and different profession steering unravel, the place do CIOs imagine soon-to-be graduates ought to focus their energies — past, that’s, AI?
We requested CIOs from the tutorial and personal sectors to share their views on what comes subsequent on each side of the hiring equation.
The brief reply? What was as soon as sage recommendation on the best way to get began in expertise careers has change into much less sure as AI is now leveraged throughout an increasing vary of roles.
For Lucy Avetisyan, affiliate vice chancellor and CIO on the College of California, Los Angeles (UCLA), the reply begins at house. “Truly, I’ve a university scholar, and I’m wondering about that on a regular basis, as a result of years in the past I might say to him, ‘Hey, go learn to code,'” she stated. “That is now not what I am asking him to look into.”
How Can New Grads Stand Aside within the AI Period?
Avetisyan stated candidates who can suppose critically, troubleshoot, and develop on the tempo of expertise stand out pretty much as good will get within the present panorama. “CIOs ought to actually take into consideration hiring for potential and hiring for agility, not only for as we speak’s instruments and ability units, as a result of these evolve so shortly,” Avetisyan stated.
The truth of AI’s entrenchment within the office means tech hires — and others — might want to display how AI elevates their worth to organizations, somewhat than replaces it.
Associated:Methods CIOs Can Elevate Activity Delegation and Bolster Communication
“You see loads of information popping out that when you’re not AI literate, you are not marketable,” Avetisyan stated. Many college students are struggling to land jobs on account of this shift in demand, she stated. This consists of college students who had been distinctive of their chosen subject of examine. “If they cannot combine AI in that, it is arduous for them to seek out jobs.”
Marketable expertise that transcend AI fluency, she added. That features information fluency — the place the candidate understands the function and energy of information — together with the moral use of information, cloud experience , and safety consciousness.
CIOs Want Savvy Employees, Not Intelligent Prompts
Candidates must be snug working in a really complicated, deep digital ecosystem, Avetisyan stated. Now, digital fluency means rather more than realizing the best way to use a sure device that’s presently widespread, together with AI instruments. There must be an consciousness of the broader implications and obligations that include implementing AI.
“It is about integrating AI responsibly and designing for accessibility,” Avetisyan stated — each of which characterize massive challenges that have to be tackled and stored constantly prime of thoughts. AI ought to elevate consumer experiences.
Associated:InformationWeek Podcast: Coordinating Crunch Time Throughout the Firm
Job candidates who can present they’re eager about utilizing AI capabilities to ship such enhancements and who present they’ll adapt alongside the expertise can have so much to supply CIOs.
“I might search for an information scientist who’s capable of perceive and combine AI into the work that they do,” she stated.
There’s nonetheless a have to display technical expertise with human expertise corresponding to problem-solving, communication, and moral consciousness, she stated.
“You’ll be able to’t simply be an distinctive coder and immediately be efficient in our group when you do not perceive all these different elements,” she stated.
Yet another factor: Whereas vibe coding — letting AI shoulder a lot or many of the work — is a buzzy idea, she stated she just isn’t prepared to show her store of builders into vibe coders. A extra grounded strategy to educating AI fluency is — or must be — the academic mission.
“We’re getting ready these distinctive college students to be marketable and comfy to coexist with AI,” she stated.
CIOs Rethink What Entry-Degree Jobs Entail
The velocity of technological change has radically reordered the IT subject and the job marketplace for new grads, stated Jordan Ruch, CIO of AtlantiCare. In contrast along with his 26 years in healthcare IT, the modifications he is seen prior to now two to a few years have been drastic, notably for entry-level roles. Programmers, service desk employees members, or assist desk analysts have all been affected, particularly as AI will get tapped to meet many duties related to these jobs, he stated.
Associated:AWS’s New Safety VP: A Turning Level for AI Cybersecurity Management?
On this local weather, there’s a need to seek out candidates with higher-tier expertise than what had been historically required for entry-level positions, Ruch added. Previously, these jobs had been usually seen as a coaching floor for employees members who confirmed promise . Expectations have modified.
“Educational applications ought to train college students the best way to change into extra environment friendly variations of themselves, and possibly shift from specializing in solutions to specializing in problem-solving and creativity,” he stated.
Not Simply Self-Starters, AI Starters
As for programming? A programmer remains to be a programmer, however the job has developed to change into extra strategic, Ruch stated. Technical expertise can be wanted; nonetheless, the primary few revisions of code can be pre-written based mostly on the specs given to AI, he stated.
“You do not want a programmer who’s going to start out from scratch,” he stated. As a substitute, programmers as we speak begin from the center to orchestrate a collection of bots already doing the coding and instruments. “Nearly like conducting a symphony,” or, Ruch stated, leaning on one other job analogy, “extra about appearing like an architect than doing routine coding.”
Certainly, who will get picked for a job could also be much less about who can code and debug the quickest as a result of, as he put it, “That race has already been received.” The basics of a technical background stay invaluable, however new ranges of coaching can be wanted, particularly for service desk roles, Ruch stated.
“A lot of the Tier One tickets are going to be managed by the expertise in most organizations at this level,” he stated, referring to service and assist desk jobs. “If it isn’t already carried out that manner, will probably be within the subsequent 12 months.”
In keeping with Ruch, smaller tech groups are more likely to be the long run. They may use their extra superior expertise to deal with IT points too complicated for expertise corresponding to AI to resolve by itself. There may additionally be some want for employees members who perceive legacy tech to maintain sure expertise sharp — however which may finally fade away.
“I realized COBOL after which .NET after which a couple of different languages in between,” Ruch stated. “However I believe these expertise have sort of run their course.”
Automation Modified the Sport for Entry-Degree Jobs
Robb Reck, chief info, belief and safety officer at Pax8, additionally emphasised how a lot expertise has modified the character of entry-level IT jobs and who may compete for them.
“Lots of these [functions] are issues we will automate,” he stated. “We’re searching for extra senior people who know the best way to both do this automation or use that automation to get higher.”
However that doesn’t imply new graduates can be shut out of IT jobs, he stated. “I am not essentially searching for somebody with work expertise; I am searching for somebody who has expertise doing the issues I would like carried out.”
One choice for brand new graduates is to speak up initiatives they accomplished on their very own, Reck stated. Maybe they automated their properties or labored on open supply initiatives — such examples can display their capacity to lean into new applied sciences and to be versatile to discover completely different choices. Given the tempo of change with AI, the approaching months might deliver drastic, unexpected shifts to the panorama, which might make a brand new graduate’s agility all of the extra necessary.
One other thought for brand new grads and soon-to-be grads to bear in mind: With the outdated entry-level jobs now automated, job candidates can be competing towards people who find themselves in these seats as we speak.
“And if the people who find themselves presently sitting in these positions do not embrace AI, you would be the only real a part of that answer for firms,” Reck stated.



























{kind=link}
{kind=link}