Directions designed to information the habits of the corporate’s newest mannequin because it writes code have been revealed to incorporate a line, repeated a number of instances, that particularly forbids it from randomly mentioning an assortment of legendary and actual creatures.
“By no means discuss goblins, gremlins, raccoons, trolls, ogres, pigeons, or different animals or creatures except it’s completely and unambiguously related to the person’s question,” learn directions in Codex CLI, a command line software for utilizing AI to generate code.
It’s unclear why OpenAI felt compelled to spell this out for Codex—or certainly why its fashions may need to talk about goblins or pigeons within the first place. The corporate didn’t instantly reply to a request for remark.
OpenAI’s latest mannequin, GPT-5.5, was launched with enhanced coding expertise earlier this month. The corporate is in a fierce race with rivals, particularly Anthropic, to ship cutting-edge AI, and coding has emerged as a killer-capability.
In response to a put up on X that highlighted the traces, nevertheless, some customers claimed the OpenAI’s fashions often develop into obsessive about goblins and different creatures when used to energy OpenClaw, a software that lets AI take management of a pc and apps operating on it so as to do helpful issues for customers.
“I used to be questioning why my claw out of the blue grew to become a goblin with codex 5.5,” one person wrote on X.
“Been utilizing it loads recently and it really cannot cease talking of bugs as ‘gremlins’ and ‘goblins’ it is hilarious,” posted one other.
The invention shortly grew to become its personal meme, inspiring AI-generated scenes of goblins in information facilities, and plugins for Codex that put it in a playful “goblin mode.”
AI fashions like GPT-5.5 are educated to foretell the phrase—or code—that ought to observe a given immediate. These fashions have develop into so good at doing this that they seem to exhibit real intelligence. However their probabilistic nature implies that they will typically behave in shocking methods. A mannequin may develop into extra vulnerable to misbehavior when used with an “agentic harness” like OpenClaw that places numerous extra directions into prompts, reminiscent of info saved in long-term reminiscence.
OpenAI acquired OpenClaw in February not lengthy after the software grew to become a viral hit amongst AI fanatics. OpenClaw can use any AI mannequin to automate helpful duties like answering emails or shopping for issues on the internet. Customers can choose numerous personas for his or her helper, which shapes its habits and responses.
OpenAI staffers appeared to acknowledge the prohibition. In response to a put up highlighting OpenClaw’s goblin tendencies, Nik Pash, who works on Codex wrote, “That is certainly one of many causes.”
Even Sam Altman, OpenAI’s CEO, joined in with the memes, posting a screenshot of a immediate for ChatGPT. It learn: “Begin coaching GPT-6, you possibly can have the entire cluster. Further goblins.”
On this lesson, you’ll learn to construct a semantic cache for LLM purposes utilizing FastAPI, Redis, and embedding-based similarity search, and the way requests stream from precise matches to semantic matches earlier than falling again to the LLM.
This lesson is the first in a 2-part collection on Semantic Caching for LLMs:
Giant language fashions are highly effective, however they aren’t low cost. Each request to an LLM includes tokenization, inference, decoding, and community overhead. Even when fashions are hosted regionally, response instances are measured in tons of of milliseconds or seconds quite than microseconds.
In actual purposes, this price compounds rapidly. Customers usually ask comparable questions repeatedly, both throughout classes or throughout the identical workflow. Every request is handled as a contemporary LLM invocation, even when the underlying intent has already been dealt with earlier than.
This results in 3 systemic issues:
Excessive latency: Customers anticipate responses that would have been reused immediately
Elevated price: Similar reasoning is paid for a number of instances
Wasted capability: LLM throughput is consumed by redundant requests
These points change into particularly seen below load, the place repeated paraphrased queries can overwhelm an in any other case well-sized system.
Why Precise-Match Caching Breaks Down for Pure Language
Conventional caching assumes that similar inputs produce similar outputs. This works properly for APIs, database queries, and deterministic features. It fails for pure language.
From a string-matching perspective, the next queries are fully unrelated:
“What’s semantic caching?”
“Are you able to clarify how semantic caching works?”
“How does caching primarily based on embeddings work for LLMs?”
A standard cache keyed on uncooked strings will miss all three. Because of this, the system calls the LLM 3 times, regardless that a human would count on the identical reply.
This brittleness causes exact-match caches to have extraordinarily low hit charges in LLM-backed programs. Worse, it provides a false sense of optimization. The cache exists, however it virtually by no means helps in follow.
The place Semantic Caching Matches in Actual Techniques
Semantic caching addresses this mismatch by caching that means as a substitute of actual textual content.
Moderately than asking “have I seen this string earlier than?”, a semantic cache asks “have I answered one thing semantically comparable earlier than?”. It does this by changing queries into embeddings and evaluating them utilizing a similarity metric corresponding to cosine similarity.
In an actual system, semantic caching sits between the applying layer and the LLM:
The applying sends a question
The cache evaluates whether or not a previous response is reusable
Solely true cache misses attain the LLM
When designed appropriately, this layer is invisible to the person. Responses really feel quicker, prices drop, and the system scales extra gracefully with out altering the frontend or immediate logic.
This lesson focuses on constructing that layer explicitly and transparently, utilizing FastAPI, Redis, and embeddings, with out hiding the mechanics behind heavy abstractions.
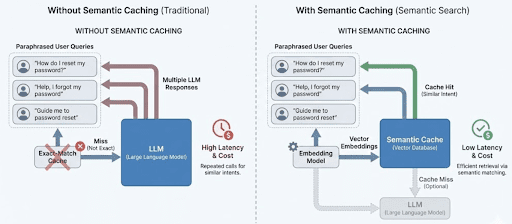
Determine 1: Why semantic caching issues for LLM programs. Precise-match caching treats paraphrased queries as distinctive requests, leading to repeated LLM calls. Semantic caching teams queries by that means, decreasing latency and redundant inference (supply: picture by the writer).
Precise-match caching treats paraphrased queries as distinctive requests, leading to repeated LLM calls. Semantic caching teams comparable queries by that means, permitting responses to be reused and decreasing each latency and price.
This part explains the way it works, conceptually, earlier than we contact any FastAPI, Redis, or code.
The objective right here is to present the reader a psychological execution mannequin they’ll maintain of their head whereas studying the implementation.
From Textual content to Which means: Embeddings because the Cache Key
Semantic caching replaces uncooked textual content comparability with vector similarity.
As an alternative of caching responses below the literal question string, the system converts every question into an embedding: a high-dimensional numeric vector that captures semantic that means. Queries which are worded in a different way however imply the identical factor produce embeddings which are shut collectively in vector area.
That is what permits the cache to acknowledge paraphrases as equal:
“How do I reset my password?”
“I forgot my password, what ought to I do?”
“Information me by way of password restoration”
Precise strings differ. Embeddings don’t.
At a excessive degree, semantic caching works by:
Producing an embedding for the incoming question
Evaluating it towards embeddings saved within the cache
Reusing a cached response if similarity is excessive sufficient
The similarity metric used on this lesson is cosine similarity, which measures the angle between two vectors quite than their uncooked magnitude.
Why a Layered Cache Beats Semantic-Solely Caching
Whereas semantic matching is highly effective, it’s also computationally costly.
Embedding era requires a mannequin name. Similarity search requires vector math. Doing this for each request, even when the very same question has already been seen, could be wasteful.
That’s the reason this lesson makes use of a layered caching technique.
Layer 1: Precise Match (Quick Path)
The question is normalized and hashed.
If the identical question has already been answered, the response is returned instantly.
No embedding era
No similarity computation
Minimal latency
This handles repeated similar queries effectively.
Layer 2: Semantic Match (Versatile Path)
If no precise match exists, the question is embedded and in contrast towards cached embeddings.
This layer catches:
paraphrases
minor wording variations
reordered phrases
Semantic matches commerce compute price for a lot greater cache hit charges.
Layer 3: LLM Fallback (Gradual Path)
If neither precise nor semantic matches succeed, the request is forwarded to the LLM.
The response is then saved within the cache so future requests can reuse it.
This layered method ensures:
the most affordable checks occur first
costly operations are solely used when needed
Confidence, Freshness, and Cache Security
Semantic similarity alone just isn’t sufficient to determine whether or not a cached response must be reused.
This lesson introduces the thought of confidence scoring, which mixes:
Similarity: how shut the embeddings are
Freshness: how previous the cached entry is
A extremely comparable however stale response mustn’t essentially be trusted. Likewise, a contemporary response with low similarity must be rejected.
As well as, cached entries are validated to forestall:
expired responses
poisoned entries (errors, empty outputs)
These checks make sure the cache improves correctness and efficiency quite than degrading them.
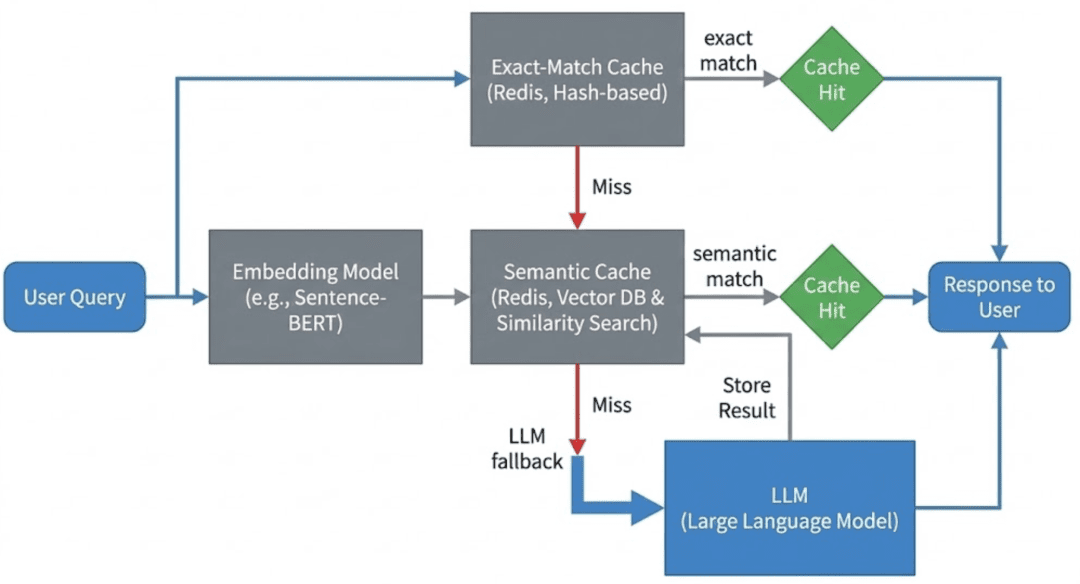
Determine 2: Layered semantic caching request stream (supply: picture by the writer).
Incoming queries first try an exact-match lookup, then fall again to semantic similarity search utilizing embeddings, and eventually name the LLM solely on cache miss. This ordering minimizes latency and pointless mannequin calls.
Notice: On this lesson, we implement this stream utilizing Redis as a easy embedding retailer with linear similarity scans, quite than a devoted vector database.
In Part 2, you discovered how semantic caching works conceptually.
On this part, we map that psychological mannequin to a actual request stream in an LLM-backed service.
The objective is to reply one query clearly:
What occurs, step-by-step, when a person sends a request to this technique?
We’ll keep implementation-aware, however not code-specific but. That comes subsequent.
Excessive-Degree System Parts
At a excessive degree, the system consists of 5 logical elements:
API layer: Receives person requests and orchestrates the caching pipeline.
Precise-match cache: Performs quick hash-based lookups for similar queries.
Embedding mannequin: Converts textual content queries into semantic vectors when wanted.
Semantic cache: Shops embeddings and responses and performs similarity matching.
LLM: Acts as the ultimate fallback when no cache entry is appropriate.
Every part has a narrowly outlined accountability. This separation is intentional and retains the system simple to purpose about and lengthen.
On this implementation:
The API layer is constructed utilizing FastAPI and acts because the orchestration level.
Redis is used because the backing retailer for each exact-match and semantic cache layers.
Ollama supplies each embedding era and LLM inference regionally.
These decisions maintain the system light-weight, self-contained, and simple to purpose about whereas nonetheless reflecting actual manufacturing patterns.
Finish-to-Finish Request Stream
When a person sends a question, the system processes it within the following order.
Step 1: Request enters the API
The API receives a textual content question together with non-obligatory flags, corresponding to whether or not to make use of the bypass_cache. Enter validation occurs instantly to forestall meaningless or malformed queries from coming into the pipeline.
This ensures the cache just isn’t polluted with empty or invalid entries.
Step 2: Precise-match cache lookup
The question is normalized and hashed.
The system checks whether or not an similar question has already been answered.
If a precise match exists and is legitimate, the response is returned instantly.
No embeddings are generated.
The LLM just isn’t touched.
That is the quickest doable path by way of the system.
Step 3: Embedding era
If the exact-match lookup fails, the question is handed to the embedding mannequin.
The mannequin converts the textual content right into a numeric vector that captures semantic that means. This vector turns into the important thing for semantic comparability.
This step is deliberately skipped when a precise match succeeds.
Step 4: Semantic cache lookup
The embedding is in contrast towards cached embeddings utilizing a similarity metric.
A cached response is reused provided that:
similarity exceeds an outlined threshold
the entry has not expired
the entry just isn’t poisoned
the computed confidence is excessive sufficient
If an acceptable match is discovered, the response is returned to the person with out calling the LLM.
Step 5: LLM fallback and cache inhabitants
If each cache layers miss, the request is forwarded to the LLM.
As soon as a response is generated:
it’s returned to the person
it’s saved within the cache with metadata, timestamps, and TTL (Time To Dwell)
This ensures future requests can reuse the consequence.
Why This Structure Works Properly
This structure is deliberately conservative and specific.
Low-cost operations occur first.
Costly operations are deferred.
Each step is observable and debuggable.
No part hides complexity behind opaque abstractions.
Most significantly, the system degrades gracefully. Even when the cache supplies no profit, the request nonetheless succeeds through the LLM.
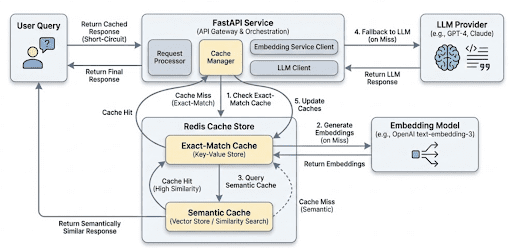
Determine 3: Structure and request stream for a layered semantic caching system (supply: picture by the writer).
Person queries enter the API, try an exact-match lookup, fall again to semantic similarity search utilizing embeddings, and name the LLM solely when each cache layers miss. Profitable LLM responses are saved for future reuse.
Would you want instant entry to three,457 pictures curated and labeled with hand gestures to coach, discover, and experiment with … without spending a dime? Head over to Roboflow and get a free account to seize these hand gesture pictures.
To observe this information, you want a small set of Python libraries and system providers that assist API orchestration, vector similarity, and LLM interplay. The objective is to maintain the surroundings light-weight, reproducible, and simple to purpose about.
At a minimal, you’ll need:
Python 3.10 or newer
Redis (used because the cache backing retailer)
An LLM + embedding supplier (Ollama on this tutorial)
All required Python dependencies are pip-installable.
Putting in Python Dependencies
Create and activate a digital surroundings (beneficial), then set up the required packages:
$ pip set up fastapi uvicorn redis httpx python-dotenv numpy
These libraries present the next performance:
fastapi: API layer and request orchestration
uvicorn: ASGI server for operating the service
redis: consumer Communication with the cache retailer
httpx: HTTP consumer for embedding and LLM calls
numpy: Vector math for cosine similarity
python-dotenv: Setting-based configuration
Verifying Redis
This lesson assumes Redis is operating regionally on the default port.
You may confirm Redis is accessible with:
$ redis-cli ping
PONG
If Redis just isn’t put in, you can begin it rapidly utilizing Docker (however you can also spin it up utilizing the docker-compose.yml we offer within the code zip):
$ docker run -p 6379:6379 redis:7
Setting Up Ollama
This technique makes use of Ollama for each embedding era and LLM inference. Ensure Ollama is put in and operating, and that the required fashions can be found.
As soon as operating, Ollama exposes native HTTP endpoints that the applying will name immediately for embeddings and textual content era.
Want Assist Configuring Your Growth Setting?
Having bother configuring your growth surroundings? Need entry to pre-configured Jupyter Notebooks operating on Google Colab? Remember to be a part of PyImageSearch College — you can be up and operating with this tutorial in a matter of minutes.
All that mentioned, are you:
Brief on time?
Studying in your employer’s administratively locked system?
Desirous to skip the effort of combating with the command line, package deal managers, and digital environments?
Able to run the code instantly in your Home windows, macOS, or Linux system?
Acquire entry to Jupyter Notebooks for this tutorial and different PyImageSearch guides pre-configured to run on Google Colab’s ecosystem proper in your net browser! No set up required.
And better of all, these Jupyter Notebooks will run on Home windows, macOS, and Linux!
Earlier than diving into particular person elements, let’s take a second to know how the challenge is organized.
A transparent listing construction is very vital in LLM-backed programs, the place obligations span API orchestration, caching, embeddings, mannequin calls, and observability. On this challenge, every concern is remoted into its personal module so the request stream stays simple to hint and purpose about.
After downloading the supply code from the “Downloads” part, your listing construction ought to seem like this:
Earlier than we have a look at caching logic, embeddings, or Redis, it’s vital to know how the service itself is wired collectively. Each request to the semantic cache enters the system by way of a single FastAPI software, outlined in app/important.py.
This file acts because the entry level of the service. Its accountability is to not implement enterprise logic, however to attach the applying elements and expose HTTP routes.
Software Entry Level (app/important.py)
from fastapi import FastAPI
from api.ask import router as ask_router
app = FastAPI(title="Semantic Cache Fundamentals")
app.include_router(ask_router)
Let’s break this down.
The FastAPI() name creates the applying object. This object represents all the net service and is what the ASGI (Asynchronous Server Gateway Interface) server (uvicorn) runs when the container begins.
The applying itself incorporates no information of caching, embeddings, or LLMs. It merely defines a runtime container that may host these capabilities.
Router Registration
As an alternative of defining endpoints immediately in important.py, the applying imports a router from api/ask.py and registers it utilizing include_router().
This sample serves a number of functions:
Separation of issues: Routing and request dealing with reside outdoors the applying entry level.
Scalability: Because the system grows, further routers (for well being checks, metrics, or admin endpoints) will be added with out modifying core software wiring.
Readability: important.py stays simple to know at a look, even because the codebase expands.
At runtime, FastAPI merges the routes outlined in ask_router into the principle software. When a request arrives on the /ask endpoint, FastAPI resolves it by way of the registered router and forwards it to the suitable handler operate.
Why This Issues
Retaining the entry level minimal is intentional. It ensures that:
The applying startup course of is predictable
Routing logic is straightforward to hint
Core performance can evolve independently of service wiring
With the applying construction in place, we will now give attention to what really occurs when a request reaches the system.
Within the subsequent part, we are going to stroll by way of the /ask endpoint and see the way it orchestrates exact-match caching, semantic search, and LLM fallback step-by-step.
This part makes the structure concrete. We now stroll by way of the /ask endpoint, which orchestrates all the semantic caching pipeline from request arrival to response supply.
The objective right here is to not memorize code, however to know why every step exists, the place it lives, and the way it protects efficiency, price, and correctness.
The Position of the Ask Endpoint
The Ask endpoint is the management airplane of the system.
It does not:
Compute similarity
Retailer embeddings
Speak on to Redis internals
As an alternative, it:
Validates enter
Decides which cache layers to seek the advice of
Enforces ordering between low cost and costly operations
Collects observability indicators
Ensures a response even on cache failure
This separation is intentional. Cache logic stays reusable and testable, whereas orchestration logic stays specific on the API boundary.
Defining the API Contract
We start by defining the request and response fashions.
class AskRequest(BaseModel):
question: str
bypass_cache: bool = False
The request consists of a person question and an non-obligatory bypass_cache flag. This flag permits us to drive a cache miss throughout debugging or testing, guaranteeing that the LLM and embedding pipeline nonetheless operate appropriately.
Earlier than the request ever reaches the cache, the question discipline is validated.
@field_validator('question')
@classmethod
def validate_query(cls, v: str) -> str:
if not v or not v.strip():
increase ValueError("Question can't be empty or whitespace-only")
return v.strip()
This validation step protects the system on the boundary. Rejecting empty or whitespace-only queries prevents:
wasted embedding computation
cache air pollution with meaningless entries
pointless LLM calls
This can be a recurring sample in manufacturing programs: fail quick, earlier than costly operations are triggered.
class AskResponse(BaseModel):
response: str
from_cache: bool
similarity: float
debug: dict
The response mannequin deliberately exposes diagnostic data by way of fields corresponding to from_cache, similarity, and debug. Throughout growth, this makes cache conduct clear quite than opaque.
Initializing the Cache
Earlier than dealing with requests, we create a SemanticCache occasion:
cache = SemanticCache()
The endpoint itself stays stateless. All persistence and reuse reside contained in the cache layer.
Step 1: Coming into the Endpoint
The endpoint is registered utilizing FastAPI’s routing mechanism:
FastAPI mechanically validates incoming requests and outgoing responses utilizing the schemas outlined earlier. If invalid knowledge enters or exits the system, FastAPI raises an error as a substitute of silently failing.
Contained in the handler, we extract the question and initialize monitoring state:
question = request.question
miss_reason = None
The miss_reason variable exists purely for observability. Moderately than treating cache misses as a black field, we explicitly monitor why a miss occurred.
Step 2: Precise-Match Cache Lookup (Quick Path)
The primary determination level is the exact-match cache lookup:
if not request.bypass_cache:
cached = cache.search(None, exact_query=question)
That is the least expensive path by way of the system.
If the identical question has already been answered, the response will be returned instantly:
That is the slowest path by way of the system, however it ensures correctness.
Profitable responses are saved within the cache:
if not response.startswith("[LLM Error]"):
cache.retailer(question, embedding, response, metadata=metadata)
Responses starting with [LLM Error] are deliberately not cached, stopping cache poisoning and guaranteeing failures don’t propagate to future requests.
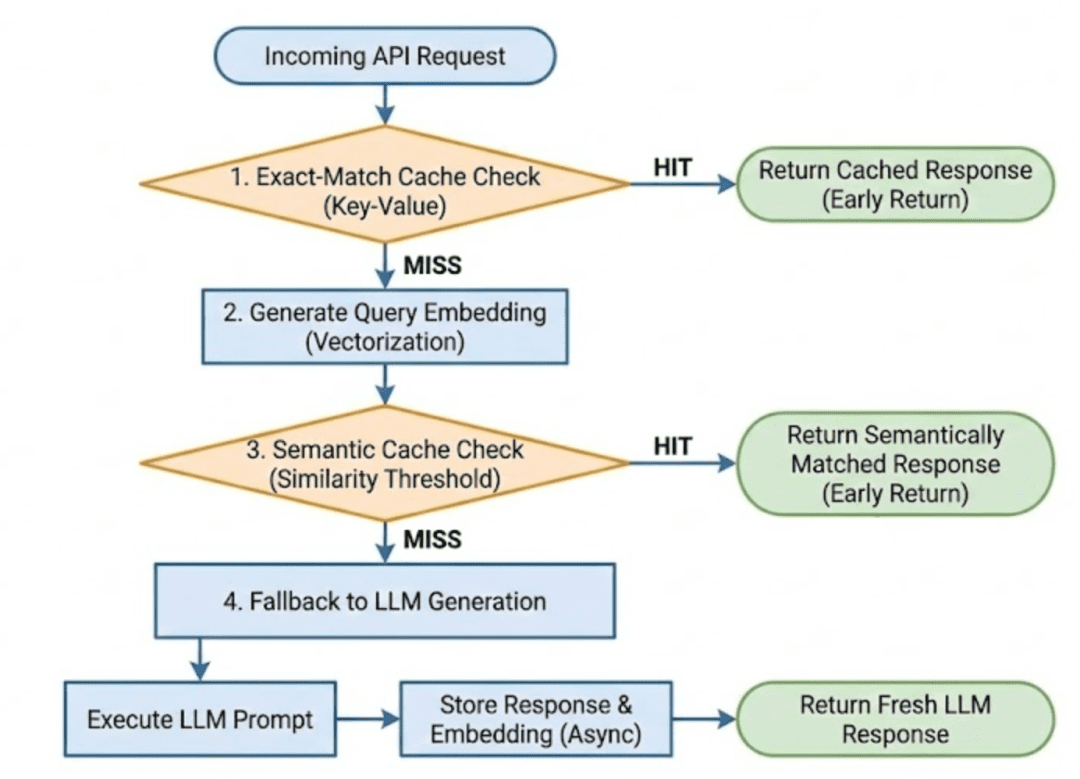
Management Stream Abstract
The endpoint follows a easy, specific sequence:
Determine 4: LLM API Management Stream with Layered Semantic Caching (supply: picture by the writer).
Each costly operation is deferred till completely needed.
Up so far, we have now handled embeddings as a black field: one thing costly that we attempt to keep away from except completely needed.
On this part, we are going to open that field simply sufficient to know what embeddings are, when they’re generated, and why they allow semantic caching with out diving into vector math or mannequin internals.
Why Embeddings Exist in This System
Precise-match caching works solely when queries are similar on the string degree. As quickly as wording modifications, precise matching breaks down.
Embeddings remedy this downside by changing textual content right into a numeric illustration that captures that means quite than floor type.
Queries that imply the identical factor have a tendency to supply vectors which are shut collectively in vector area, even when their wording differs considerably.
That is the muse that makes semantic caching doable.
Embedding Technology Occurs on Demand
In our implementation, embeddings are generated solely after the exact-match cache fails.
This determination is intentional.
Embedding era includes:
a mannequin invocation
community overhead
serialization and deserialization
non-trivial latency
Due to this price, embeddings are handled as an escalation step, not a default operation.
For this reason the /ask endpoint first makes an attempt an exact-match lookup earlier than calling embed_text().
The embed_text Perform
def embed_text(textual content: str):
This operate has one accountability: Convert enter textual content right into a semantic vector illustration.
It doesn’t carry out caching, similarity search, or validation. These issues reside elsewhere.
This request sends 2 key items of data to the embedding service:
the embedding mannequin identify (e.g., nomic-embed-text)
the enter textual content to embed
The timeout ensures the request doesn’t hold indefinitely. Embedding era is dear, however it ought to nonetheless fail quick if one thing goes incorrect.
If the request succeeds, the embedding mannequin returns a numeric vector — usually an inventory of floating-point values.
This vector represents the semantic that means of the enter textual content and turns into the important thing used for similarity comparability within the cache.
At this stage, we deal with the vector as an opaque object. We don’t examine its dimensionality or normalize it right here.
Error Dealing with Technique
besides Exception as e:
increase RuntimeError(f"Didn't generate embedding: {e}")
If embedding era fails for any purpose (community points, mannequin errors, timeouts), the operate raises an exception.
That is intentional.
If embeddings can’t be generated, the system can not safely carry out semantic matching. Silently persevering with would result in unpredictable conduct, so we fail loudly as a substitute.
Why the Embedder Is Deliberately Easy
Discover what this operate doesn’t do:
it doesn’t retailer embeddings
it doesn’t carry out similarity search
it doesn’t retry failed requests
it doesn’t fall again to different fashions
These choices are deliberate.
For Lesson 1, the embedder exists purely to transform textual content into vectors. Retaining it small and targeted makes the system simpler to know and check.
How the Embedder Is Used within the Pipeline
At runtime, the embedder is known as solely when needed:
Precise-match cache fails
The question is handed to embed_text()
The returned vector is distributed to the semantic cache
Similarity is computed towards saved embeddings
This ensures embeddings are generated solely when cheaper paths have already failed.
Key Takeaways
Embeddings are generated through a easy HTTP name to a neighborhood mannequin
The embedder has a single accountability
Errors are surfaced instantly
Embeddings act as semantic keys for cache lookup
With embedding era understood, we are actually prepared to take a look at the semantic cache itself, how embeddings and responses are saved, scanned, and matched.
Within the subsequent part, we are going to stroll by way of the semantic cache implementation, beginning with a intentionally naive however right linear scan method.
At this level, we perceive how queries enter the system and the way textual content is transformed into embeddings. What stays is the part that ties all the things collectively: the semantic cache itself.
The semantic cache is accountable for 2 issues:
Storing previous queries, embeddings, and responses
Retrieving the most effective reusable response for a brand new question
In Lesson 1, we deliberately implement the cache within the easiest right method doable: a linear scan over cached entries. This retains the implementation simple to purpose about and makes the request stream totally clear.
The Semantic Cache Module
The cache logic lives in semantic_cache.py:
class SemanticCache:
This class encapsulates all Redis interplay and similarity logic. The API layer by no means talks to Redis immediately.
Thus far, we’ve handled the cache as a logical idea: one thing that shops queries, embeddings, and responses.
On this part, we’ll make that concrete by the construction of a cache entry. Understanding this construction is vital as a result of it explains why the cache can assist each exact-match and semantic lookup — with out duplicating knowledge or logic.
The Cache Entry Schema
Cache entries are outlined utilizing a Pydantic mannequin:
class CacheEntry(BaseModel):
id: str
question: str
query_hash: str
embedding: str
response: str
created_at: int
ttl: int
metadata: Elective[Dict] = Subject(default_factory=dict)
Every discipline exists for a particular purpose. Let’s stroll by way of them one after the other.
Identification and Question Fields
id: str
question: str
query_hash: str
id: uniquely identifies the cache entry and is used to assemble the Redis key.
question: shops the unique person enter. That is helpful for debugging and inspection.
query_hash: shops a normalized hash of the question and permits exact-match lookup.
At this stage, it’s sufficient to know that the hash ensures similar queries will be matched rapidly. We’ll revisit how and why this normalization issues in a later lesson.
Embedding Storage
embedding: str
Embeddings are saved as a JSON-serialized string, not as a uncooked Python record.
This selection is deliberate:
Redis shops strings effectively
Serialization retains the schema easy
Deserialization occurs solely when similarity must be computed
For Lesson 1, the vital takeaway is that embeddings are saved as soon as, alongside the response they produced.
Response and Timing Data
response: str
created_at: int
ttl: int
response: is the textual content returned by the LLM.
created_at: data when the entry was generated.
ttl: defines how lengthy the entry is taken into account legitimate.
The cache doesn’t depend on Redis expiration right here. As an alternative, validity is checked at learn time. This provides the applying full management over when an entry must be reused or rejected.
We deliberately keep away from deeper TTL semantics on this lesson.
On this part, we are going to confirm that the semantic cache behaves as anticipated below a small set of managed situations.
These examples are supposed to be run regionally by the reader. The responses proven beneath are consultant and should differ barely relying on the mannequin and configuration.
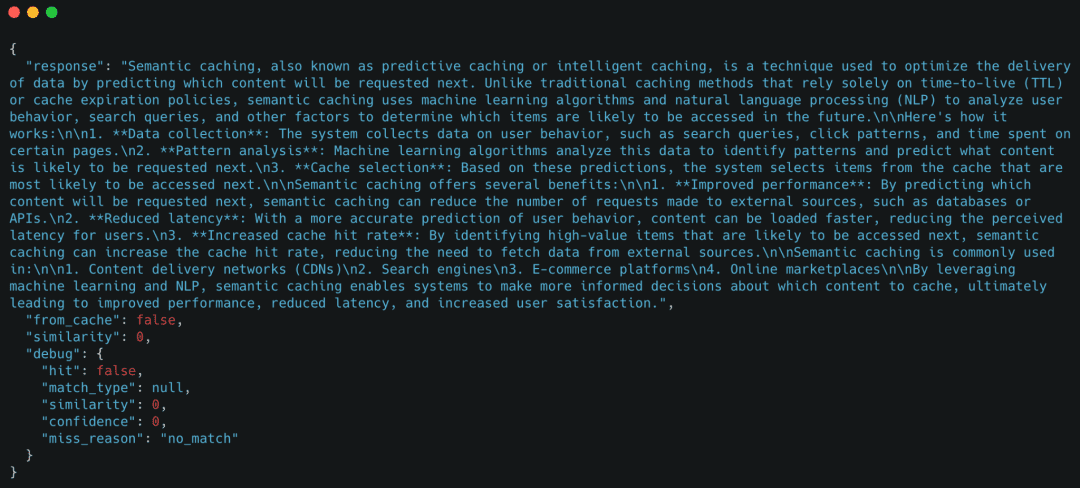
Demo Case 1: Chilly Request (LLM Fallback)
We start with a question that has not been seen earlier than.
Determine 5: Chilly request stream exhibiting a cache miss at each the exact-match and semantic cache layers, triggering an LLM fallback. The response is generated by the mannequin and saved for future reuse (supply: picture by the writer).
The important thing sign right here is "from_cache": false, confirming the request fell again to the LLM.
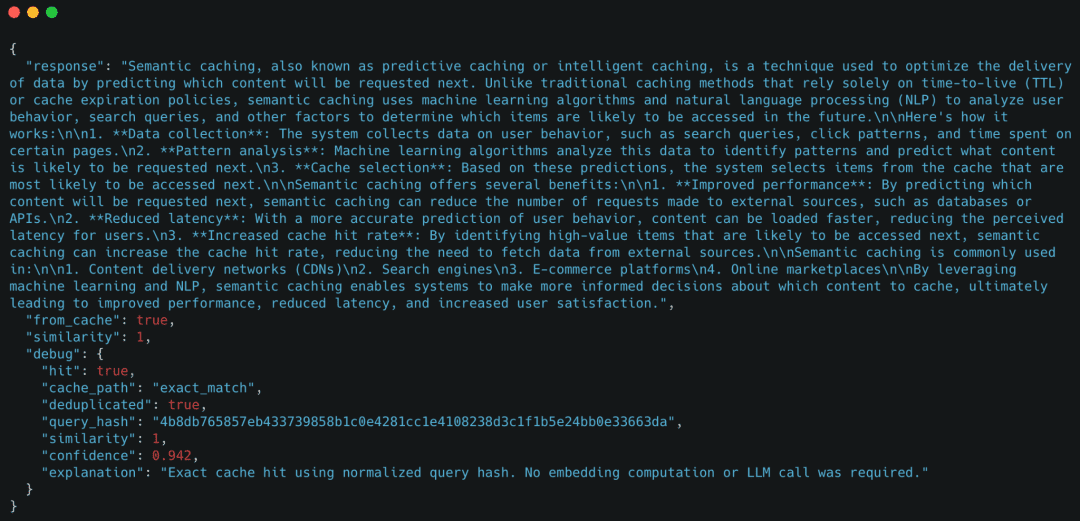
Determine 6: Precise-match cache conduct. The repeated question is served immediately from the cache through a precise string match, bypassing embedding era and the LLM totally (supply: picture by the writer).
Right here, the cache reused the response instantly utilizing an exact-match lookup.
Elective Demo: Whitespace Normalization
curl -X POST http://localhost:8000/ask
-H "Content material-Kind: software/json"
-d '{"question": " What is semantic caching? "}'
This can hit the exact-match cache because of question normalization.
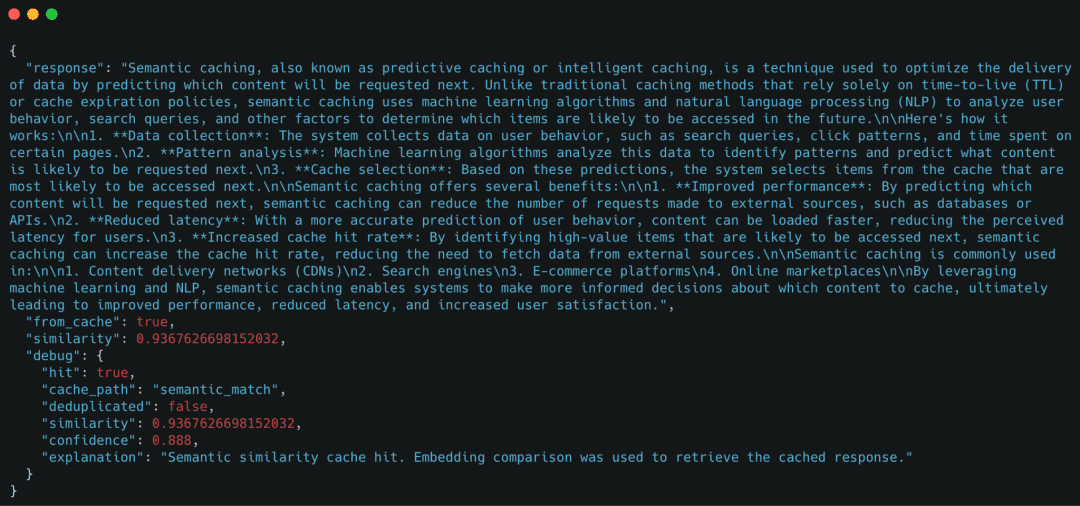
Demo Case 3: Semantic Cache Hit (Paraphrased Question)
Subsequent, we ship a paraphrased model of the unique question.
curl -X POST http://localhost:8000/ask
-H "Content material-Kind: software/json"
-d '{"question": "Are you able to clarify how semantic caching works?"}'
Anticipated conduct
Precise-match cache miss
Embedding era
Semantic cache hit
No LLM name
Instance response
Determine 7: Semantic cache hit for a paraphrased question. Though the enter textual content differs, the cached response is reused primarily based on embedding similarity, avoiding a brand new LLM name (supply: picture by the writer).
Though the question textual content is totally different, the cache efficiently reused the response primarily based on semantic similarity.
Demo Case 4: Forcing a Cache Miss with bypass_cache
The bypass_cache flag permits us to drive the system to skip each cache layers.
Determine 8: Cache bypass conduct. The request explicitly skips all cache layers through bypass_cache, guaranteeing the LLM pipeline executes independently of cached responses (supply: picture by the writer).
That is helpful for debugging and validating that the LLM pipeline nonetheless works independently of the cache.
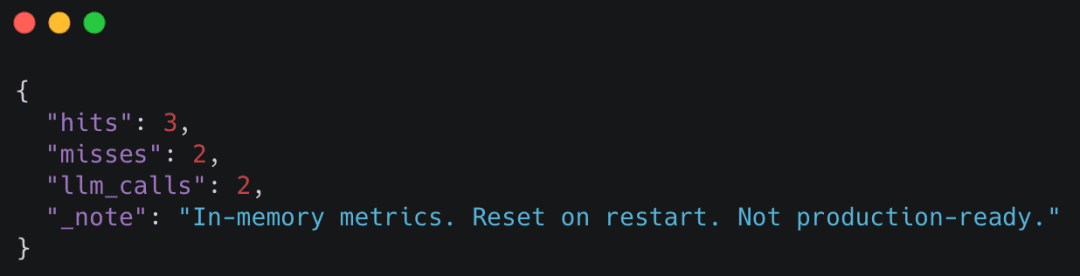
Observing Cache Metrics (Elective)
You may examine fundamental cache statistics utilizing the /inside/metrics endpoint:
curl http://localhost:8000/inside/metrics
Instance response
Determine 9: Inside cache metrics exhibiting hit, miss, and bypass counters, enabling light-weight observability of cache conduct throughout growth and debugging (supply: picture by the writer).
These metrics make cache conduct observable with out requiring exterior tooling.
For those who can reproduce these behaviors regionally, you’ve efficiently carried out a working semantic cache.
Within the subsequent lesson, we are going to take this technique and start hardening it for real-world use.
Course data:
86+ complete courses • 115+ hours hours of on-demand code walkthrough movies • Final up to date: April 2026 ★★★★★ 4.84 (128 Scores) • 16,000+ College students Enrolled
I strongly consider that when you had the suitable trainer you can grasp laptop imaginative and prescient and deep studying.
Do you assume studying laptop imaginative and prescient and deep studying needs to be time-consuming, overwhelming, and sophisticated? Or has to contain advanced arithmetic and equations? Or requires a level in laptop science?
That’s not the case.
All you might want to grasp laptop imaginative and prescient and deep studying is for somebody to elucidate issues to you in easy, intuitive phrases. And that’s precisely what I do. My mission is to alter training and the way advanced Synthetic Intelligence matters are taught.
For those who’re critical about studying laptop imaginative and prescient, your subsequent cease must be PyImageSearch College, probably the most complete laptop imaginative and prescient, deep studying, and OpenCV course on-line immediately. Right here you’ll learn to efficiently and confidently apply laptop imaginative and prescient to your work, analysis, and tasks. Be part of me in laptop imaginative and prescient mastery.
Inside PyImageSearch College you may discover:
&verify; 86+ programs on important laptop imaginative and prescient, deep studying, and OpenCV matters
&verify; 86 Certificates of Completion
&verify; 115+ hours hours of on-demand video
&verify; Model new programs launched frequently, guaranteeing you possibly can sustain with state-of-the-art strategies
&verify; Pre-configured Jupyter Notebooks in Google Colab
&verify; Run all code examples in your net browser — works on Home windows, macOS, and Linux (no dev surroundings configuration required!)
&verify; Entry to centralized code repos for all 540+ tutorials on PyImageSearch
&verify; Straightforward one-click downloads for code, datasets, pre-trained fashions, and so on.
&verify; Entry on cellular, laptop computer, desktop, and so on.
On this lesson, we constructed a whole semantic caching system for LLM purposes from the bottom up. We began by wiring a FastAPI service and defining a clear request–response contract, then carried out a layered caching technique that prioritizes low cost exact-match lookups earlier than escalating to semantic similarity and, lastly, LLM inference.
We walked by way of how textual content queries are transformed into embeddings on demand, how cached responses and embeddings are saved in Redis, and the way the cache decides whether or not a previous response will be safely reused. By maintaining the implementation deliberately easy and specific, each step within the request stream stays observable and simple to purpose about.
Lastly, we verified the system end-to-end by operating managed demos: a chilly request falling again to the LLM, an exact-match cache hit, a semantic cache hit for a paraphrased question, and an specific cache bypass. At this level, you’ve got a working semantic cache that behaves appropriately, makes its choices seen, and serves as a stable basis for additional hardening and optimization.
Quotation Data
Singh, V. “Semantic Caching for LLMs: FastAPI, Redis, and Embeddings,” PyImageSearch, S. Huot, A. Sharma, and P. Thakur, eds., 2026, https://pyimg.co/yso6f
@incollection{Singh_2026_semantic-caching-for-llms-fastapi-redis-and-embeddings,
writer = {Vikram Singh},
title = {{Semantic Caching for LLMs: FastAPI, Redis, and Embeddings}},
booktitle = {PyImageSearch},
editor = {Susan Huot and Aditya Sharma and Piyush Thakur},
yr = {2026},
url = {https://pyimg.co/yso6f},
}
To obtain the supply code to this submit (and be notified when future tutorials are revealed right here on PyImageSearch), merely enter your electronic mail handle within the type beneath!
Obtain the Supply Code and FREE 17-page Useful resource Information
Enter your electronic mail handle beneath to get a .zip of the code and a FREE 17-page Useful resource Information on Pc Imaginative and prescient, OpenCV, and Deep Studying. Inside you may discover my hand-picked tutorials, books, programs, and libraries that will help you grasp CV and DL!
Should you’ve ever been in command of monetary planning or monitoring for a shared group expense, you recognize simply how messy, complicated, and typically, downright chaotic, it may well get.
Whether or not it is a birthday celebration you are planning or a street journey with pals, easy note-taking apps do not reduce it. Splitwise takes a extra organized method, simplifying your complete expertise and making it very easy to know who owes who, and the way a lot.
I discovered the app to be extraordinarily helpful when planning longer journeys with a bunch, particularly when touring overseas.
Article continues beneath
A simple group expense tracker for the gang
Picture 1 of 2
(Picture credit score: Splitwise)
(Picture credit score: Splitwise)
What number of pal teams have you ever recognized that fell aside after a bunch vacation soured relations? I’ve seen it occur time and time once more, and have had fairly a number of firsthand encounters myself. In my early 20s, I’d usually be tasked with creating the journey itinerary and making a finances for everybody. There would nearly all the time be a single one that’d be sad with the accounts, or say that the bills did not match their model of accounts.
Shared duty, accountability, and transparency forestall any sort of arguments or doubts from taking root. That is precisely why I like Splitwise a lot. It leaves zero room for error, everybody concerned could make edits to the accounts and entry them any time, and it is on iOS and Android so there isn’t any compatibility difficulty both.
Splitwise enables you to create a bunch for each group expense, and you may label it accordingly too. Even individuals who aren’t on the app might be added to a bunch by way of e-mail or cellphone quantity. Each particular person within the group can see who paid for every expense, and an automated tally tells everybody how a lot they owe or are owed and who must pay whom to settle up.
You do not actually need to improve to the paid model of the app
(Picture credit score: Namerah Saud Fatmi / Android Central)
The app has a paid “professional” model, however the primary “core” model is greater than sufficient for the aim of managing shared bills. Listed here are the core options included with the free model of the app:
Get the most recent information from Android Central, your trusted companion on the earth of Android
Add teams and pals
Break up bills, report money owed
Equal or unequal splits
Break up by % or shares
Calculate complete balances
Simplify money owed
Recurring bills
Offline mode
Cloud sync
Spending totals
Categorize bills
7+ languages
100+ currencies
Fee integrations
As you may inform, the app presents granular management over each transaction. Not solely are you able to select the foreign money, connect photos, set the date, or add notes for every expense lodged in-app, however the best way every expense is cut up might be extremely personalized too. You’ll be able to even create a recurring expense.
Whether or not you wish to share a single or a number of bills equally, unequally, by shares, by percentages, or by changes, every thing is feasible throughout the Splitwise app.
(Picture credit score: Namerah Saud Fatmi / Android Central)
Because of the “simplify money owed” system employed by the app, it would not matter who paid for what, and the way every invoice was cut up. The app does the complicated math for you primarily based on how a lot every particular person chipped in and the way every expense is to be shared.
(Picture credit score: Namerah Saud Fatmi / Android Central)
A single group might have a number of currencies, and nobody has to scratch their head over conversions as a result of Splitwise does that for you too! That is extremely helpful for worldwide journey. Sadly, conversion is a professional function, although you may nonetheless report bills in a number of totally different currencies below one group within the free model of the app.
Frequent worldwide vacationers profit from the professional model essentially the most
(Picture credit score: Splitwise)
The app’s pricing construction is not too unhealthy, and you may get a free one month trial to see if Splitwise Professional is price your whereas. Paying $4.99/month or $39.99/12 months is nicely price it contemplating the wealth of premium options it unlocks, together with limitless bills, foreign money conversions, and extra.
This is a full listing of the premium options:
Limitless bills
Transaction import
Foreign money conversion
Receipt scanning
Itemization
Charts and graphs
Expense search
Save default splits
A completely ad-free expertise
Early entry to new options
Thus far, I have never felt the necessity to buy Splitwise Professional. Whether or not on a weekend journey to Jakarta with pals, hitting the flicks with my siblings, or planning date night time with my associate, the free primary Splitwise has been enough for my wants to date.
For the reason that variety of day by day bills it restricted to only 5 proper now, I do not suppose the day the place I might want to improve is way off although. Nevertheless, earlier than investing in Splitwise Professional, I recommend trying into free options, as that is precisely what I personally plan on doing when the time comes.
You by no means know what hidden gem of an app you may discover. I could be late to the Splitwise get together, however I can suggest a number of free options that I’ve heard good issues about. Look into apps like AiMoola, Settle Up, MemoGo, and Cino in the event you like the concept of Splitwise however not the paywall. Whereas I have never tried these apps but, the features are comparable, and a few of them are solely free to make use of too.
And if you want me to check drive any considered one of these or different group expense monitoring apps, let me know within the feedback beneath.
The rings round Uranus have mystified astronomers for nearly half a century. Now, because of a mix of ground- and space-based telescopic observations, scientists assume they’ve labored out the place two of those rings got here from.
A blue-tinged ring, named Mu, appears to be product of icy shards knocked off a close-by moon by micrometeorite impacts, researchers report within the April Journal of Geophysical Analysis: Planets. Conversely, Nu, a reddish ring, consists of rocky particles most likely sourced in an analogous method from an unseen rocky moon or moons.
Ring programs — like these round Jupiter, Saturn and Neptune — can type in myriad methods, together with via moon-on-moon collisions or from a moon being ripped aside by the planet’s gravity. However for Uranus, it appears that evidently “impacts have performed an enormous position, and nonetheless play a task,” says Imke de Pater, an astronomer on the College of California, Berkeley.
At 19 instances the gap from the solar than Earth, Uranus is tremendously troublesome to spy on. Up to now, only one spacecraft has flown previous it: Voyager 2, in 1986. Not a lot is thought concerning the planet with any certainty, however astronomers do know it’s frigid, gassy, orbited by at the very least 28 moons and surrounded by 13 faint rings, a few of which had been first noticed in 1977.
The outermost rings, Mu and Nu — transliterations of the Greek letters μ and ν — are an oddity. Regardless of being adjoining, they give the impression of being fairly totally different. “It’s typical of Uranus to spice issues up,” says James O’Donoghue, an astronomer on the College of Studying in England, who wasn’t concerned with the research.
Faint ring glow
The outermost rings of Uranus, Nu and Mu, shimmer on this infrared James Webb House Telescope picture. The darkish annulus is a digital masks used to dim the glare from Uranus (vivid disk, center) and its vivid major ring system by an element of 100 so the a lot fainter outer rings might be seen. The skinny, vivid circle simply contained in the annulus is the epsilon ring, the outermost of Uranus’ major rings.
NASA, ESA, Picture processing: Imke de Pater, Matt Hedman
Prior observations with the W.M. Keck Observatory in Hawaii and the Hubble House Telescope steered the Mu ring was blue, signifying it was product of very small particles, whereas Nu was red-hued, suggesting it was dusty — each inferences primarily based on how daylight scatters off them.
For the brand new research, de Pater and her colleagues used a mix of Keck, Hubble and James Webb House Telescope observations of Mu and Nu to attempt to unravel the rationale for his or her disparate appearances. JWST, which noticed Uranus periodically from 2023 to 2025, may understand the rings with a remarkably excessive decision. And by trying on the rings in infrared, the crew was capable of verify the sizes, distributions and compositions of the ring particles.
The blue Mu ring has the spectral signature of water ice. The most certainly supply of Mu, the researchers counsel, is a moon named Mab, a gelid orb not more than 12 kilometers broad embedded within the ring itself.
Saturn additionally has a blue ring: the E ring, consistently replenished by geysers taking pictures out of the icy shell of the moon Enceladus. Mab, although, is much too small to have a supply of inside warmth driving related geysers. As an alternative, “micrometeorite impacts on Mab may produce this ring,” de Pater says. Ice chips flying off the moon may find yourself in orbit round Uranus.
The red-hued Nu ring is product of rocky confetti and natural matter. Mud escapes shortly into house, so Nu requires fixed replenishment. The researchers posit that such an countless stream of mud may come from common meteorite impacts on one or a number of as-yet-undiscovered rocky moons close by. These moons may be extremely troublesome to identify from Earth, however at the very least astronomers know the place to seek for them.
“It could be very cool to find a moon from the mud ring,” O’Donoghue says, as no moon has been discovered that method earlier than.
The planet’s outermost circlets aren’t completely scrutable simply but. Mu, for instance, appears to brighten and dim over time, and it’s in no way clear why. Even with JWST’s sharp eyes, Uranus will most likely preserve working rings round astronomers for the foreseeable future.
We contemplate the privateness amplification properties of a sampling scheme by which a person’s knowledge is utilized in ok steps chosen randomly and uniformly from a sequence (or set) of t steps. This sampling scheme has been not too long ago utilized within the context of differentially personal optimization (Chua et al., 2024a; Choquette-Choo et al., 2025) and communication-efficient high-dimensional personal aggregation (Asi et al., 2025), the place it was proven to have utility benefits over the usual Poisson sampling. Theoretical analyses of this sampling scheme (Feldman & Shenfeld, 2025; Dong et al., 2025) result in bounds which might be near these of Poisson sampling, but nonetheless have two important shortcomings. First, in lots of sensible settings, the ensuing privateness parameters should not tight as a result of approximation steps within the evaluation. Second, the computed parameters are both the hockey stick or Renyi divergence, each of which introduce overheads when utilized in privateness loss accounting.
On this work, we show that the privateness loss distribution (PLD) of random allocation utilized to any differentially personal algorithm may be computed effectively. When utilized to the Gaussian mechanism, our outcomes show that the privacy-utility trade-off for random allocation is at the very least nearly as good as that of Poisson subsampling. Particularly, random allocation is healthier suited to coaching through DP-SGD. To help these computations, our work develops new instruments for normal privateness loss accounting primarily based on a notion of PLD realization. This notion permits us to increase correct privateness loss accounting to subsampling which beforehand required handbook noise-mechanism-specific evaluation.
One of many extra harmful assumptions within the present AI market is that broad adoption means significant adoption. It doesn’t. A lot of what enterprises name AI transformation is, actually, AI experimentation centered on the fringe of the enterprise, in programs and workflows that help workers however are usually not central to how the enterprise really operates. These embrace calendaring, scheduling, assembly summaries, worker communications, buyer messaging, doc era, inside assistants, and related productivity-oriented use circumstances.
These purposes could also be helpful, however they aren’t core purposes that straight run the enterprise and decide whether or not the corporate performs nicely or poorly. Stock administration, gross sales order entry, logistics execution, provide chain planning, procurement, warehouse administration, manufacturing operations, and monetary transaction processing belong on this class. If these programs fail, the enterprise feels it instantly by way of delayed orders, misplaced income, rising prices, poor buyer outcomes, and weakened operational management.
McKinsey studies that AI is most frequently utilized in IT, advertising and gross sales, and information administration, with frequent use circumstances together with content material help, conversational interfaces, and customer support automation. It additionally says most organizations are nonetheless in experimentation or pilot mode, and solely 39% report any enterprise-level earnings influence. This helps the concept that adoption is broad, however deep, core-business transformation remains to be restricted.
A brand new report printed by Ookla particulars which airways provide the most effective in-flight Wi-Fi.
AirBlatic gained on reliability; United provided the best median speeds.
Partnership with low-Earth orbit satellite tv for pc community Starlink was a standard issue for high-performing airways.
In-flight Wi-Fi’s gotten loads higher over the previous few years. A report launched at present offers some perception into which airways provide the quickest and essentially the most dependable knowledge connections — together with a number of that boast connection speeds of 300 Mbps or higher.
The report, printed this morning by Ookla, digs into connectivity high quality throughout a variety of airways. Utilizing knowledge gathered within the second half of 2025, Ookla put collectively a rating of which airways provide essentially the most constant Wi-Fi high quality (airBaltic wins by a nostril), in addition to which provide the best obtain speeds (United takes the prize there).
Don’t need to miss the most effective from Android Authority?
It looks like an airline’s in-flight Wi-Fi expertise at present largely comes down as to if it’s partnered with Starlink. AirBaltic, WestJet, Hawaiian Airways, and Air France — all Starlink companions — topped Ookla’s reliability rankings, with every managing to offer obtain speeds of 25 Mbps or greater in 90% of checks.
On the subject of quickest obtain speeds, United takes the cake with a median rating of 319.99 Mbps — when the connection is supplied by Starlink. Ookla factors out that many airways use a number of knowledge suppliers, and its outcomes present that United’s different companions don’t carry out as nicely: the median velocity via Intelsat was 56.48 Mbps, whereas Inmarsat got here in at 15.34 Mbps.
Emirates, airBaltic, and Alaska Airways, all noticed median Starlink speeds practically as excessive as United’s, with every topping 300 Mbps. Air France was subsequent in line at 281.56 Mbps. That’s very snappy knowledge for 30,000 ft within the air: terrestrial 5G connections are sometimes within the 200 to 300 Mbps vary.
Whereas Starlink appears to be the go-to to supplier for in-flight knowledge at present, Ookla notes that Amazon is entering into the low-Earth orbit sport with its Leo enterprise, and that jetBlue and Delta, two low performers on this report, have introduced knowledge partnerships with Amazon that’ll roll out over the following couple of years.
For extra nitty-gritty in-flight Wi-Fi particulars, take a look at Ookla’s full report.
Thanks for being a part of our neighborhood. Learn our Remark Coverage earlier than posting.
Polycystic ovary syndrome (PCOS) has confounded medical doctors from the second they gave the situation its identify.
In folks with ovaries, PCOS has traditionally been outlined by abnormally excessive ranges of androgens—hormones that sometimes regulate male sexual growth—that result in irregular menstrual durations, irregular ovulation and sometimes infertility, in addition to different signs resembling pimples or extra facial or physique hair. However over the previous a number of a long time, a greater understanding of PCOS’s root causes has led to a wierd connection. Many males who’re associated to folks with PCOS appear to share lots of the identical signs that stem from what researchers suppose causes PCOS: a genetic susceptibility that results in metabolic dysfunction, which in flip causes insulin resistance that disrupts hormone signaling.
This consciousness has led the medical neighborhood to advocate for a reputation change that’s extra aligned with the syndrome’s root causes for the situation, STAT reported earlier this month (Slate reported on this beforehand). If it occurs, researchers hope this variation might open the doorways for extra remedies and higher analysis of the situation in all those that expertise it.
On supporting science journalism
Should you’re having fun with this text, take into account supporting our award-winning journalism by subscribing. By buying a subscription you’re serving to to make sure the way forward for impactful tales concerning the discoveries and concepts shaping our world immediately.
It Was By no means concerning the Cysts
Again within the Nineteen Thirties, physicians Irving Stein and Michael Leventhal recognized a cluster of signs in some girls that included enlarged ovaries, irregular or absent durations and infertility. To deal with the situation then, medical doctors would reduce out, or resect, a wedge-shaped portion of the ovary. For causes which might be nonetheless not absolutely understood, the therapy typically labored; many individuals began ovulating once more.
When Stein and Leventhal regarded on the resected ovarian tissue, they noticed many small, fluid-filled sacs lining the perimeters, which to them regarded like cysts. These “cysts” grew to become the defining characteristic of the situation that was quickly named polycystic ovary syndrome.
There was just one downside: as a result of imaging know-how for the situation didn’t exist on the time, these surgeons didn’t understand that they had been really taking a look at follicles (not cysts), which contained underdeveloped eggs that had didn’t mature and launch. On ultrasounds immediately, they resemble a string of pearls. Not like cysts, they don’t develop or rupture.
Nonetheless, the identify caught—and with it, so did misunderstanding concerning the situation. Over the previous a number of a long time, nevertheless, researchers have been slowly chipping away at what drives the syndrome and who it impacts.
“Polycystic ovary syndrome is the only commonest hormonal dysfunction in girls” of reproductive age, says Ricardo Azziz, a professor of reproductive endocrinology and gynecology on the College of Alabama at Birmingham, who has spent a big a part of his profession finding out the syndrome. “It’s a worldwide illness, and [it] impacts between 10 and 15 p.c of all girls globally,” Azziz says.
However of these affected, he says, researchcounsel solely about half are correctly recognized. PCOS appears to have each a number of causes and a number of shows. “It’s not a single dysfunction,” Azziz says. “It’s a set of indicators and options.”
Docs now acknowledge 4 distinct phenotypes of PCOS, a lot of which don’t require the signature extra follicles. Azziz and endocrinologist Andrea Dunaif say one facet researchers have settled on is that an individual’s genetics closely affect whether or not or not they develop PCOS.
Of their analysis, Azziz and Dunaif have discovered that the situation clustered in households. From there, “we had been capable of present that when you had been the sister of a lady with PCOS, you had a couple of 40 or 50 p.c elevated danger in having it, and that additionally led to the query, ‘Nicely, if it’s inherited and it’s not sex-linked [or passed on the X chromosome], which it didn’t appear to be, are males affected?’” says Dunaif, a professor of molecular drugs on the Icahn College of Medication at Mount Sinai in New York Metropolis.
In a single type of PCOS that happens in folks with ovaries, a genetic susceptibility will increase the danger of insulin resistance. Insulin is a hormone produced by the pancreas that helps transfer sugar from the blood into different cells within the physique. But when an individual’s physique doesn’t reply appropriately to insulin, the pancreas finally ends up producing much more insulin to compensate, resulting in excessive quantities of each glucose and insulin within the blood. The excessive ranges of insulin then stimulate the ovaries to supply extra androgens—notably, testosterone—which might disrupt regular follicle growth and ovulation, resulting in irregular menstrual cycles and different PCOS signs.
Now researchers are discovering that this underlying genetic susceptibility to insulin resistance and elevated androgen ranges may also present up in males.
“Virtually 20 years in the past we did research the place we regarded on the brothers and the fathers [of women with PCOS] to see if that they had any of the options of PCOS as nicely,” Dunaif says. “We discovered that the lads had elevated danger for being chubby, for having metabolic syndrome—and the youthful males additionally had increased ranges of a male hormone made by the adrenal glands,” she says. “This prompt that these had been genetic options.”
The issue is that whereas males are clearly experiencing these points, “there’s nearly no consciousness among the many medical neighborhood,” notably normally inner drugs, Dunaif says. “The tragedy of PCOS has been that the specialties that must care about it don’t find out about it.”
What’s in a reputation?
This new understanding of PCOS has led many consultants to name for a reputation change—to 1 that’s tied to the genetic and metabolic underpinnings of the syndrome as a substitute of mistakenly centered on cysts.
Researchers from the world over have just lately come to an unofficial settlement on a brand new identify for PCOS, although it’s being stored beneath wraps for now. Dunaif, who is aware of the newly proposed identify however can’t reveal it, says she’s not sure if it should even make it by way of the identify change course of. Researchers already went by way of this course of as soon as, in 2012, when there was a coordinated effort amongst a bunch of researchers and physicians to rename PCOS to “metabolic reproductive syndrome.” However this is able to have been abbreviated as “MRS,” which might have perpetuated the female-focused nature of the syndrome, Dunaif says.
A shift within the lexicon might improve consciousness not simply amongst physicians and sufferers but additionally in researchers finding out the situation. There may be precedent for this. For instance, the situation now referred to as metabolic syndrome was once referred to as syndrome X—named just because the precise mechanism wasn’t but understood. The change helped unify analysis and enhance analysis as a result of it made the underlying mechanism clearer to each medical doctors and sufferers. Dunaif says that medical analysis databases present how as soon as the identify was modified, there was all of the sudden an explosion of analysis on metabolic syndrome.
Azziz agrees a reputation change might assist the many individuals who’ve PCOS. “This can be a large inhabitants. Ten to fifteen p.c of all girls have PCOS and maybe 10 to fifteen p.c of males have PCOS, and we now have not a single—not one—drug that’s really [Food and Drug Administration] authorised for PCOS instantly,” he says. “If extra funding was obtainable…, then we might be capable of have significantly better remedies and focused remedies for PCOS than we at present have.”
As everybody is aware of, I’m an enormous proponent of Statalist, and never only for egocentric causes, though these causes play a task. Almost each member of the technical employees at StataCorp — me included — are members of Statalist. Even once we don’t take part in a selected thread, we do listen. The discussions on Statalist play an necessary position regarding Stata’s growth.
Statalist is a dialogue group, not only a question-and-answer discussion board. Nonetheless, new members typically use it to acquire solutions to questions and that works as a result of these questions generally change into gist for subsequent discussions. In these instances, the questioners not solely get solutions, they get way more.
Among the finest options of Statalist is that, irrespective of how poorly you ask a query, you’re unlikely to be flamed. Not solely are the members of Statalist good — simply as are the members of most lists — they act simply as good on the record as they are surely. You might be unlikely to be flamed in the event you ask a query poorly, however you’re additionally unlikely to get a solution.
Right here is my recipe to extend the possibilities of you getting a useful response. You must also learn the Statalist FAQ earlier than writing your query.
Topic line
Make the topic line of your electronic mail significant. Some good topic strains are:
Survival evaluation
Confusion about -stcox-
Sudden error from -stcox-
-stcox- output
The primary two sentences
The primary two sentences are an important, and they’re the simplest to write down.
Within the first sentence, state your downside in Stata phrases, however don’t go into particulars. Listed below are some good first sentences:
I’m having an issue with -stcox-.
I’m getting an surprising error message from -stcox-.
I’m utilizing -stcox- and don’t know interpret the outcome.
I’m utilizing -stcox- and getting a outcome I do know is unsuitable, so I do know I’m misunderstanding one thing.
I need to use -stcox- however don’t know begin.
I believe I need to use -stcox-, however I’m uncertain.
I need to use -stcox- however my information is sophisticated and I’m uncertain proceed.
I’ve an advanced dataset that I one way or the other want to remodel right into a kind appropriate to be used with -stcox-.
Stata crashed!
I’m having an issue which may be extra of a statistics subject than a Stata subject.
The aim of the primary sentence is to be a focus for members who’ve an curiosity in your subject and let the others, who had been by no means going to reply you anyway, transfer on.
The second sentence is even simpler to write down:
I’m utilizing Stata 11.1 for Home windows.
I’m utilizing Stata 10 for Mac.
Even in case you are sure that it’s unimportant which model of Stata you’re utilizing, state it anyway.
Write two sentences and you’re accomplished with the primary paragraph.
The second paragraph
Now write extra about your downside. Attempt to not be overly wordy, but it surely’s higher to be wordy than curt to the purpose of unclearness. Nevertheless you write this paragraph, be express. For those who’re having an issue making Stata work, inform your readers precisely what you typed and precisely how Stata responded. For instance,
I typed -stcox weight- and Stata responded “information not st”, r(119).
I typed -stcox weight sex- and Stata confirmed the standard output, besides the usual error on weight was reported as dot.
The type of the second paragraph — which can prolong into the third, fourth, … — is determined by what you’re asking. Describe the issue concisely however fully. Sacrifice conciseness for completeness in the event you should otherwise you assume it would assist. To the extent attainable, simplify your downside by eliminating extraneous particulars. As an illustration,
I've 100,000 observations and 1,000 variables on companies, however 4
observations and three variables might be sufficient to point out the issue.
My information appears to be like like this
firm_id date x
-----------------------
10043 17 12
10043 18 5
13944 17 10
27394 16 1
-----------------------
I would like information that appears like this:
date no_of_firms avg_x
---------------------------
16 1 1
17 2 11
18 1 12
That's, for every date, I would like the variety of companies and the
common worth of x.
Right here’s one other instance for the second and subsequent paragraphs:
The substantive downside is that this: Sufferers enter and go away the
hospital, generally greater than as soon as over the interval. I believe
on this case it will be acceptable to mix the
separate stays so {that a} affected person who was in for two days and
later for 4 days may very well be handled as being merely in for six days,
besides I additionally file what number of separate stays there have been, too.
I am evaluating value, so for my functions, I believe treating
value as proportional to days in hospital, no matter their
distribution, might be sufficient. I am whole days as a
perform of variety of stays. The concept is that letting sufferers out
too early ends in a rise in whole days, and I need to
measure this.
I understand that extra stays and days may also come up just because
the affected person was sicker. Some sufferers die, and that clearly
truncates keep, so I've omitted them from information. I've illness
codes, however nothing about well being standing inside code.
Is there a strategy to incorporate this added info to enhance
the estimates? I've acquired a number of information, so I used to be pondering of
utilizing loss of life charge inside illness code to one way or the other rank the codes
as to seriousness of sickness, after which utilizing "seriousness"
as an explanatory variable. I assume my query is whether or not
anybody is aware of a manner I would do that.
Or is there someway I may estimate the mannequin seperately inside
illness code, one way or the other constraining the coefficient on variety of
stays to be the identical? I noticed one thing within the handbook about
stratified estimates, however I am uncertain if this is similar factor.
You’re asking somebody to speculate their time, so make investments yours
Earlier than you hit the ship key, learn what you could have written, and enhance it. You might be asking for somebody to speculate their time serving to you. Assist them by making your downside simple to know.
The simpler your downside is to know, the extra probably you’re to get a response. Mentioned in a different way, in the event you write in a disorganized manner in order that potential responders should work simply to know you, a lot much less offer you a solution, you’re unlikely to get an response.
Glowing prose isn’t required. Correct grammar isn’t even required, so nonnative English audio system can chill out. My recommendation is that, until you’re typically praised for the way clearly and entertainingly you write, write brief sentences. Group is extra necessary than the model of the person setences.
Keep away from or clarify jargon. Don’t assume that the one that responds to your query might be in the identical area as you. When coping with a substantive downside, keep away from jargon apart from statistical jargon that’s widespread throughout fields, or clarify it. Potential responders prefer it while you educate them one thing new, and that makes them extra more likely to reply.
Tone
Write as in case you are writing to a colleague whom you understand effectively. Assume curiosity in your downside. The identical factor mentioned negatively: Don’t write to record members as you may write to your analysis assistant, worker, servant, slave, or member of the family. Nothing is extra more likely to to get you ignored than to write down, “I’m busy and actually I don’t have time filter by all of the Statalist postings, so reply to me straight, and shortly. I would like a solution by tomorrow.”
The constructive strategy, nonetheless, works. Simply as when writing to a colleague, typically you don’t want to apologize, beg, or play on sympathies. Typically after I write to colleagues, I do really feel the necessity to clarify that I do know what I’m asking is foolish. “I ought to know this,” I’ll write, or, “I can’t bear in mind, however …”, or, “I do know I ought to perceive, however I don’t”. You are able to do that on Statalist, but it surely’s not required. Often after I write to colleagues I do know effectively, I simply bounce proper in. The identical rule works with Statalist.
What’s acceptable
Questions acceptable for Stata’s Technical Providers aren’t acceptable for Statalist, and vice versa. Some questions aren’t acceptable for both one, however these are uncommon. For those who ask an inappropriate query, and ask it effectively, somebody will often direct you to a greater supply.
Who can ask, and the way
You could be part of Statalist to ship questions. Sure, you possibly can be part of, ask a query, get your reply, and stop, however in the event you do, don’t point out this on the outset. Checklist members know this occurs, however in the event you point out it while you ask the query, you’ll sound superior and condescending. Additionally, stick round for a couple of days after you get your response, as a result of generally your query will generate dialogue. If it does, you must take part. You need to need to stick round and take part as a result of if there’s subsequent dialogue, the ultimate result’s often higher than the preliminary reply.
AI is now not only a expertise wave; it’s the working system of our trendy economic system. But, throughout industries, academia, and geographies, one sample is more and more clear: organizations that spend money on AI instruments alone will underperform, whereas those who mix AI adoption with systematic expertise improvement will pull forward.
Infrastructure alone is a stranded asset. The true engine of innovation is the individual behind the display screen. As AI evolves into Related Intelligence, the place people and AI brokers work side-by-side, essentially the most important threat we face shouldn’t be the expertise itself, however the readiness hole.
I’ve a front-row seat to this transformation because the Vice President of Operations for Cisco’s Digital Influence Workplace, the place I dedicate my profession to bridging the hole between cutting-edge expertise and the individuals who will form our future. My work is pushed by a agency perception: expertise is barely as highly effective because the minds behind it, and our true success lies in fostering ecosystems the place innovation and human potential converge.
Investing in AI with out investing in individuals is like constructing a aircraft with nobody educated to fly it.
The abilities hole is the brand new system downtime. Within the early phases of digital transformation, aggressive benefit got here from deploying new platforms: cloud, mobility, and knowledge analytics. AI modifications the equation.
However AI alone doesn’t create worth. AI mixed with human expertise does.
Here’s a statistic that ought to hold each expertise chief awake: 90% of enterprises have an AI technique, however fewer than 15% have a workforce educated to execute it. This isn’t a expertise drawback; it’s a management hole, and it turns into costlier each quarter it goes unaddressed. And there’s extra knowledge the place that got here from:
Constructing functionality in the present day shouldn’t be about sending individuals to a coaching seminar every year. It’s about built-in studying ecosystems that evolve as quick as expertise itself. Organizations that undertake this mindset additionally handle probably the most underestimated limitations to AI adoption: resistance to vary. Familiarity breeds confidence, and confidence turns a skeptic into an advocate.
The hole that ought to fear each chief shouldn’t be the one between people and machines. It’s the one between having an AI technique on paper and having the individuals to hold it out.
Placing AI to work for society
Cisco Networking Academy has reached 28 million learners throughout 195 international locations, many in areas the place a profession in expertise was beforehand out of attain.
Members within the DTlab Academy in Naples, Italy.
In my expertise, this program really unlocks the potential of each participant, no matter their educational or skilled background. I’ve witnessed this firsthand by way of the Cisco DTlab, a specialised academy we host in Naples. Annually, 20 of Italy’s brightest minds come collectively for intensive coaching in networking — the important basis of AI.
The initiative’s final objective is to bridge the hole between training and trade, enabling these abilities to collaborate on pilot tasks with Cisco prospects and companions. By fostering an setting the place innovation thrives, we empower these people to grasp the most recent applied sciences and apply their expertise to real-world challenges.
Cisco Networking Academy’s curriculum retains tempo with the trade because it exists in the present day, not the place it was 5 years in the past. Professionals who as soon as mastered routing protocols now must grasp immediate engineering, agentic AI workflows, and accountable AI governance. The job has modified, and the urgency to help individuals by way of that transition has by no means been increased.
Cisco has dedicated to coaching a million People in AI expertise over 4 years and 1.5 million Europeans by 2030, together with 5,000 new instructors beneath the EU’s Union of Abilities initiative. These commitments mirror Cisco’s perception that an AI economic system solely works if the workforce can take part in it.
Investing within the core
Whether or not co-investing with governments to construct AI-ready knowledge facilities within the Center East, supporting good territories in Europe and Africa, or uplifting underserved communities within the Americas, the objective of our Nation Digital Acceleration (CDA) tasks are the identical: to supply the inspiration for mission-critical companies.
A presentation related to our partnership in Greece.
Contemplate our newest initiative in Greece, the place we’ve got partnered with the Institute of Utilized Biosciences (INAB/CERTH) and Papageorgiou Hospital to ascertain a transformative AI-driven well being ecosystem. By deploying a high-performance AI infrastructure, an “AI Pod,” this venture permits the safe, large-scale processing of over 1.4 million affected person information. This initiative bridges the hole between scientific analysis and real-world affected person care, accelerating analysis cycles and empowering the Ministry of Well being with actionable, data-driven insights. By strengthening nationwide digital sovereignty and making certain alignment with EU analysis frameworks, this venture is positioning Greece as a premier hub for scientific innovation, finally resulting in quicker diagnostics and extra customized therapies for sufferers.
Once we spend money on infrastructure (the CDA mannequin) and pair it with studying (the Cisco Networking Academy mannequin), we do greater than innovate. We construct belief and resilience. We reside our Objective to Energy an Inclusive Future for All, serving to expertise serve everybody, not just some.
Cease separating tech spend from human objective
Each expertise initiative I evaluate comes down to 1 query: Who advantages, and the way broadly? It calls for that we glance past ROI and ask whether or not the worth being created will unfold to the employees navigating disruption, to the communities constructing round new industries, and to the scholars in markets the place alternative has been scarce.
To my friends and companions, I supply this steerage: We should cease viewing innovation and social affect as separate targets. Once we align our innovation technique with our objective, we be sure that digital progress serves everybody:
Put money into the machine however neglect the thoughts: You acquire pace with out course.
Prepare the thoughts however starve the machine: You acquire imaginative and prescient with out the ability to behave.
The investments that survive market shifts and expertise generations begin with silicon and software program, however they’re scaled by human potential. In a world the place pace is our aggressive benefit, the leaders who will outline the subsequent decade are those that don’t simply innovate they’re those who empower everybody round them to innovate, too.