Notepad++ is now obtainable as a local macOS software. It’s a free, open-source supply code editor and Notepad substitute that helps many programming languages and is nice for basic textual content enhancing. No Wine, Porting Equipment, or emulation layer is required — it is a full native port ruled by the GNU Basic Public License.
Primarily based on the highly effective enhancing element Scintilla, Notepad++ for Mac is written in Goal C++ and makes use of pure platform-native APIs to make sure larger execution velocity and a smaller program footprint. I hope you get pleasure from Notepad++ on macOS as a lot as I get pleasure from bringing it to the Mac.
This undertaking is an impartial open-source group port of Notepad++ to macOS, began on March 10, 2026.
It has all the things precisely as it’s on Home windows: nice for Home windows customers pondering completely different, however maybe not so appetizing for MacOS veterans on the lookout for one thing new. Syntax highlighting, search and exchange, split-view enhancing, language help and macro recording are in. The plugin system works and “extra plugins are being migrated to MacOS as we converse.”
Notepad++ is by Dan Ho, and the Mac port is maintained by Andrey Letov and others.
It is humorous how in replicating each high quality element of the Home windows unique, you’d assume it’d find yourself simply as cluttered, and but it appears fairly good-looking!
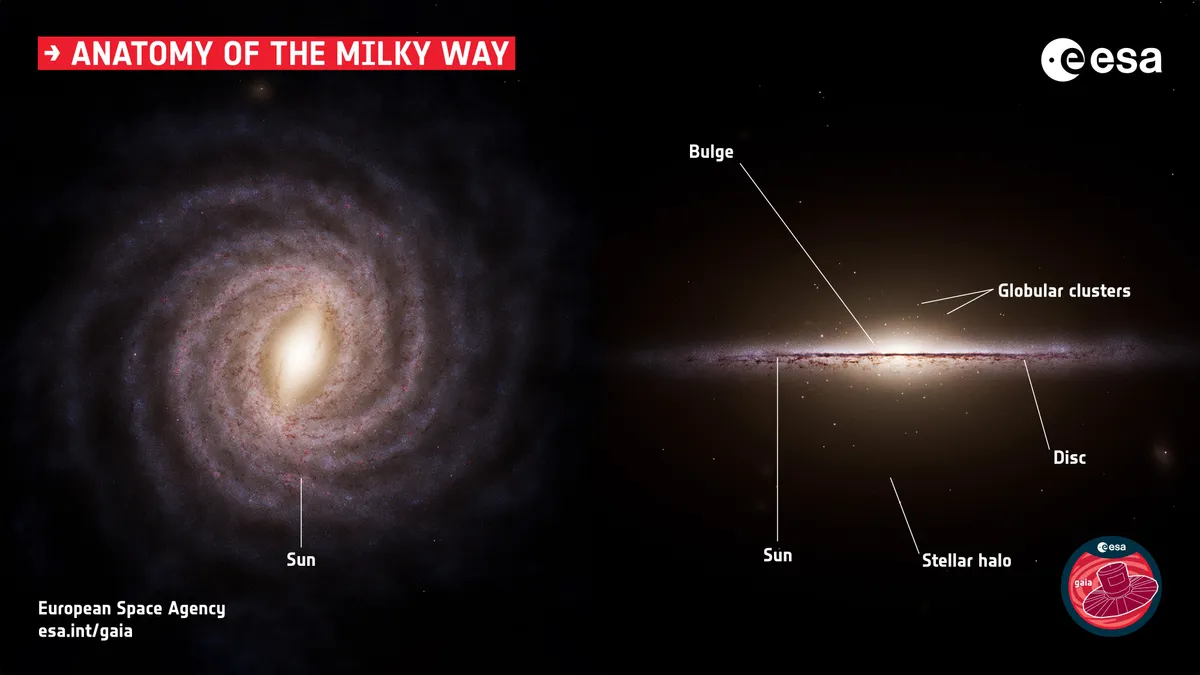
Astronomers have discovered the boundary of star formation within the Milky Means’s spiral disk — and it is not as far out from the middle of our galaxy as you may think.
The Milky Means is at the very least 100,000 light-years throughout, however the brand new outcomes counsel that the galaxy’s star formation takes place inside a area that extends to a radius of 40,000 light-years from the galactic heart.
“The extent of the Milky Means’s star-forming disk has lengthy been an open query in galactic archaeology,” mentioned the examine’s lead writer, Karl Fiteni of the College of Insubria in Italy, in a assertion. “By mapping how stellar ages change throughout the disk, we now have a transparent, quantitative reply.”
Fiteni’s worldwide group targeted on 100,000 luminous large stars unfold throughout the Milky Means’s spiral disk, acquiring spectroscopic information describing their temperatures and ages from the LAMOST (Giant Sky Space Multi-Object Fiber Spectroscopic Telescope) telescope in China and the Apache Level Observatory Galactic Evolution Experiment (APOGEE) on the Sloan Digital Sky Survey in the USA, plus extra information from the European House Company’s Gaia mission.
“Gaia is delivering on its promise: by combining its information with ground-based spectroscopy and galaxy simulations, it permits us to decipher the formation historical past of our galaxy,” mentioned Laurent Eyer of the College of Geneva.
Galaxies develop from the within out, and the Milky Means is not any completely different, with the common age of stars reducing with radius from the galactic heart. Fiteni’s group discovered that the common age reaches a minimal at a radius of 40,000 light-years from the middle. For comparability, our solar is positioned 26,000 light-years from the galactic heart, nicely contained in the star-forming boundary. Past this level, the celebrities start steadily getting older once more, with the oldest stars discovered each within the heart and on the very fringe of the Milky Means’s disk, making a U-shaped distribution of ages.
The Milky Means isn’t distinctive in having a U-shaped age distribution of stars with radius; different galaxies have additionally beforehand been discovered to share the same distribution. The pc simulations carried out by Fiteni’s group counsel what the reason for this U-shaped age distribution is.
“In astrophysics, we use simulations run on supercomputers to establish the bodily mechanisms answerable for the options we observe in galaxies,” mentioned João S. Amarante from Shanghai Jiao Tong College in China. “They allowed us to reveal how stellar migration shapes the age profile of the disk and to establish the place the star-forming area ends.”
They discovered from the simulations that, at a radius of about 40,000 light-years, the effectivity at which the galaxy kinds stars abruptly drops, marking the sting of the Milky Means’s disk-shaped area of star formation.
So, why are there stars past 40,000 light-years in the event that they did not type there? One large clue is the form of their orbits.
“A key level concerning the stars within the outer disk is that they’re on near round orbits, that means that they needed to have fashioned within the disk,” mentioned Victor Debattista of the College of Lancashire in England. “These usually are not stars which were scattered to giant radii by an infalling satellite tv for pc galaxy.”
Diagram of the Milky Means. (Picture credit score: ESA/Gaia/DPAC/S. Payne-Wardenaar)
So collisions with different galaxies are to not blame. As an alternative, what most likely occurs is a phenomenon referred to as radial migration. Like surfers driving waves to the shore, stars can trip the density waves that type the Milky Means’s spiral arms out to larger distances from the galactic heart. It takes longer for stars to succeed in the very fringe of the Milky Means’s disk, 50,000 light-years or extra from the galactic heart, explaining why we discover the oldest stars on the very fringes of the galaxy.
This all begs the query of why star formation staggers to a halt at 40,000 light-years from the galactic heart. One chance is that it’s associated to the construction of the Milky Means. Maybe our galaxy’s central bar, measurements of the size of which range between radii of 11,000 to fifteen,000 light-years, causes fuel to pool out to a sure distance from the galactic heart. Alternatively, the warp in our galaxy’s spiral disk, which has been attributed to a gravitational interplay with one other dwarf galaxy, might disrupt star formation within the galaxy, reducing it off at 40,000 light-years.
Not too long ago, I’ve been utilizing Stata’s -shp2dta- command to transform some shapefiles to stata format, grabbing Lat/Lon information and merging into one other dataset. There have been a number of compressed shapefiles I needed to obtain contained in a listing from the net. I may manually obtain every file and uncompress each however that might be time consuming. Additionally, when the maps are up to date, I’d should do the obtain/uncompress over again. I’ve discovered that the method may be automated from inside Stata through the use of a mixture of -shell- and a few useful terminal instructions. …
You need to learn the remainder of his put up. He goes on to indicate how one can script with Stata to automate shelling out to obtain and unzip a sequence of recordsdata from a web site, and he introduces you to some cool Unix-like utilities for Home windows.
We right here at StataCorp use Stata for duties like this on a regular basis. In actual fact, we now have constructed some instruments into Stata to permit you to do a lot of what Andrew described with out ever having to go away or shell out of Stata.
For instance, Stata can entry recordsdata over the Web. Stata has a copy command. And, as of Stata 11, Stata can immediately zip and unzip recordsdata and directories.
Placing all of these capabilities to make use of, you may accomplish Andrew’s aim by writing code immediately in Stata similar to
If there have been numerous recordsdata you wished to obtain and unzip, and so they had been all named in a daily method (say, “download1.zip” by way of “download100.zip”), you could possibly deliver all of them down and unzip them immediately in Stata with a 4 line loop:
in a state of affairs the place you will have loads of concepts on methods to enhance your product, however no time to check all of them? I wager you will have.
What if I advised you that you simply now not must do all of it by yourself, you’ll be able to delegate it to AI. It could actually run dozens (and even a whole bunch) of experiments for you, discard concepts that don’t work, and iterate on those that really transfer the needle.
Sounds wonderful. And that’s precisely the thought behind autoresearch, the place an LLM operates in a loop, constantly experimenting, measuring impression, and iterating from there. The method sounded compelling, and plenty of of my colleagues have already seen advantages from it. So I made a decision to strive it out myself.
Let’s begin with some background to set the context. Autoresearch was developed by Andrej Karpathy. As he wrote in his repository:
Sooner or later, frontier AI analysis was completed by meat computer systems in between consuming, sleeping, having different enjoyable, and synchronizing infrequently utilizing sound wave interconnect within the ritual of “group assembly”. That period is lengthy gone. Analysis is now fully the area of autonomous swarms of AI brokers operating throughout compute cluster megastructures within the skies. The brokers declare that we are actually within the 10,205th era of the code base, in any case nobody may inform if that’s proper or incorrect because the “code” is now a self-modifying binary that has grown past human comprehension. This repo is the story of the way it all started. -@karpathy, March 2026.
The concept behind autoresearch is to let an LLM function by itself in an atmosphere the place it could constantly run experiments. It adjustments the code, trains the mannequin, evaluates whether or not efficiency improves, after which both retains or discards every change earlier than repeating the loop. Ultimately, you come again and (hopefully) discover a higher mannequin than you began with. Utilizing this method, Andrej was in a position to considerably enhance nanochat.
The unique implementation was targeted on optimising an ML mannequin. Nevertheless, simialr method could be utilized to any activity with a transparent goal (from decreasing web site load time to minimising errors when scraping with Playwright). Shopify later open-sourced an extension of the unique autoresearch, pi-autoresearch. It builds on pi, a minimal open-source terminal coding harness.
It follows the same loop to the unique autoresearch, with a number of key steps:
Outline the metric you need to enhance, together with any constraints.
Measure the baseline.
Speculation testing: in every iteration, the agent proposes an concept, writes it down, and assessments it. There are three doable outcomes: it doesn’t work (discard), it worsens the metric (discard), or it improves the goal (hold it and iterate from there).
Repeat: the loop continues till you cease it, enhancements plateau, or it reaches a predefined iteration restrict.
So the core concept is to outline a transparent goal and let the agent strive daring concepts and study from them. This method can uncover potential enhancements to your KPIs by testing concepts your crew merely by no means had the time to discover. It undoubtedly sounds fascinating, so let’s strive it out.
Job
I wish to take a look at this method on an analytical activity, since in analytical day-to-day duties we regularly have clear goals and must iterate a number of occasions to achieve an optimum answer. So, I went via all of the posts I’ve written for In the direction of Knowledge Science through the years and located a activity round optimising advertising campaigns, which we mentioned within the article “Linear Optimisations in Product Analytics”.
The duty is sort of widespread. Think about you’re employed as a advertising analyst and must plan advertising actions for the following month. Your aim is to maximise income inside a restricted advertising price range ($30M).
You will have a set of potential advertising campaigns, together with projections for every of them. For every marketing campaign, we all know the next:
nation and advertising channel,
marketing_spending — funding required for this exercise,
income — anticipated income from acquired prospects over the following 12 months (our goal metric).
We even have some extra info, such because the variety of acquired customers and the variety of buyer help contacts. We’ll use these to iterate on the preliminary activity and make it progressively more difficult by including additional constraints.
Picture by writer
It’s helpful to present the agent a baseline method so it has one thing to start out from. So, let’s put it collectively. One easy answer for this optimisation is to give attention to the top-performing segments by income per greenback spent. We are able to type all campaigns by this metric and choose those that match throughout the price range. In fact, this method is sort of naive and might undoubtedly be improved, but it surely supplies an excellent place to begin.
Earlier than shifting on to the precise experiment, we first want to put in pi_autoresearch. We begin by organising pi itself by following the directions from pi.dev. Fortunately, it may be put in with a single command, supplying you with a pi coding harness up and operating regionally you could already use to assist with coding duties.
npm set up -g @mariozechner/pi-coding-agent # set up pi
pi # begin pi
/login # choose supplier and specify APIKey
Nevertheless, as talked about earlier, our aim is to strive the pi-autoresearch extension on prime of pi, so let’s set up that as nicely.
pi set up https://github.com/davebcn87/pi-autoresearch
I additionally needed some guardrails in place, so I created an autoresearch.config.json file within the root of my repo to outline the utmost variety of iterations. This helps restrict what number of iterations the agent can run and, in flip, retains token prices below management throughout experiments. You too can set a per-API-key spending restrict together with your LLM supplier for even tighter management.
{
"maxIterations": 30
}
You will discover all the main points on configuration in the docs.
That’s it. The setup is finished, and we’re prepared to start out the experiment.
Experiments
Lastly, it’s time to start out utilizing the autoresearch method to determine which advertising campaigns we must always run. I’m fairly certain our preliminary method isn’t optimum, so let’s see whether or not autoresearch can enhance it. Let the journey start.
I began autoresearch by calling the talent.
/talent:autoresearch-create
After that, autoresearch tries to deduce the optimisation aim, and if it fails, it asks for added particulars.
In my case, it merely inspected the code we applied in optimise.py and created an autoresearch.md file summarising the duty. Right here’s what we received (a reasonably strong abstract, contemplating it solely noticed our baseline optimisation operate). We are able to see that it clearly outlined the metrics and constraints. I additionally preferred that it explicitly highlighted that altering the enter knowledge isn’t allowed. That’s an excellent guardrail.
# Autoresearch: maximize advertising marketing campaign income below price range
## Goal
Enhance `optimise.py` so it selects a set of marketing campaign segments with **most complete income** whereas respecting the mounted advertising price range of **30,000,000**. The present implementation is a grasping heuristic: it types by revenue-per-spend, takes a cumulative prefix, and stops as soon as the following merchandise would exceed price range. Meaning it could go away price range unused and by no means take into account cheaper worthwhile objects later within the sorted record.
The workload is tiny (62 rows), so higher-quality combinatorial optimization methods are possible sensible. We should always favor precise or near-exact choice logic over fragile heuristics when the runtime stays quick.
## Metrics
- **Main**: `revenue_millions` (thousands and thousands, larger is best) - complete chosen income divided by 1,000,000
- **Secondary**:
- `spend_millions` - complete chosen spend divided by 1,000,000
- `budget_slack_millions` - unused price range in thousands and thousands
- `segment_count` - variety of chosen segments
## The best way to Run
`./autoresearch.sh` - runs a fast syntax pre-check, then `optimise.py`, which should emit `METRIC title=quantity` strains.
## Recordsdata in Scope
- `optimise.py` - campaign-selection logic and metric output
- `autoresearch.sh` - benchmark harness and pre-checks
- `autoresearch.md` - session reminiscence / findings
- `autoresearch.concepts.md` - backlog for promising deferred concepts
## Off Limits
- `marketing_campaign_estimations.csv` - enter knowledge; don't edit
- Git historical past / department construction exterior the autoresearch workflow
## Constraints
- Should hold spend `<= 30_000_000`
- Should hold the script runnable with `python3 optimise.py`
- No dataset adjustments
- Maintain the answer easy and explainable until additional complexity yields materially higher income
- Runtime ought to stay quick sufficient for a lot of autoresearch iterations
## What's Been Tried
- Baseline code types by `income / marketing_spending`, computes cumulative spend, and retains solely the sorted prefix below price range.
After defining the duty, it instantly began the loop. It could actually run for a while, however you continue to retain visibility. You’ll be able to see each its reasoning and a few key stats within the widget (resembling the present iteration, finest goal worth, and enchancment over the baseline), which is sort of useful.
Interface displaying present state and iterations
Because it iterates, it additionally writes an autoresearch.jsonl file with full particulars of every experiment and the ensuing goal metric. This log may be very helpful each for reviewing what has been tried and for the mannequin itself to maintain observe of which hypotheses it has already examined.
In my case, regardless of the configured restrict of 30 iterations, it determined to cease after simply 5. The agent explored a number of totally different methods: precise knapsack optimisation, search-space pruning, and a Pareto-frontier dynamic programming method. Let’s undergo the main points:
Iteration 1: Reproduced our baseline method. The prefix-greedy technique (income/spend) reached 107.9M, however stopped early when objects didn’t match, lacking higher downstream combos. No breakthrough right here, only a sanity examine of the baseline.
Iteration 2: Actual knapsack solver. The agent switched to a branch-and-bound (0/1 knapsack) method and reached 110.16M income (+2.25M uplift), which is a transparent enchancment. A powerful achieve already within the second iteration.
Iteration 3: Dominance pruning. This iteration tried to shrink the search area by eradicating pairwise dominated segments (i.e., segments worse in each spend and income than one other). Whereas intuitive, this assumption doesn’t maintain within the 0/1 knapsack setting: a “dominating” section could already be chosen, whereas a “dominated” one can nonetheless be helpful together with others. Because of this, this method failed and dropped to 95.9M income, and was discarded. instance of trial and error. We examined it, it didn’t work, and we instantly moved on.
Iteration 4: Dynamic programmingfrontier. The agent switched to a Pareto-frontier dynamic programming method, but it surely achieved the identical outcome as iteration 2. From an analyst perspective, that is nonetheless helpful. It confirms we’ve possible reached the optimum.
Iteration 5: Integer accounting. This iteration transformed all financial values from floats to integer cents to enhance numerical stability and reproducibility, however once more produced the identical ultimate worth. It is sensible that the agent stopped there.
So ultimately, the optimum answer was already discovered within the second iteration and it matches the answer we present in my article with linear programming. The agent nonetheless tried a number of different concepts, however saved ending up with the identical outcome and finally stopped (as an alternative of burning much more tokens).
Now we are able to end the analysis by operating the /talent:autoresearch-finalize command, which commits and pushes every thing to GitHub. Because of this, it created a brand new department with a PR, saving each the adjustments to the optimise.py code and the intermediate reasoning information. This manner, we are able to simply observe what occurred all through the method.
The agent simply solved our preliminary activity. Subsequent, let’s strive making it extra practical by including extra constraints from the Operations crew. Assume we realised that we additionally want to make sure there are not more than 5K incremental buyer help tickets (so the Ops crew can deal with the load), and that the general buyer contact charge stays beneath 4.2%, since that is one in all our system well being checks. This makes the issue more difficult, because it provides additional constraints and forces the agent to revisit the answer area and seek for a brand new optimum.
To kick this off, I merely restarted the /talent:autoresearch-create course of, offering the extra constraints.
/talent:autoresearch-create I've extra constraints for our CS contacts to make sure that our Operations
crew can deal with the demand in a wholesome means:
- The variety of extra CS contacts ≤ 5K
- Contact charge (CS contacts/customers) ≤ 0.042
This time, it picked up precisely the place we left off. It already had full context from the earlier run, together with every thing we had completed to this point. On account of updating the duty, the agent revised the autoresearch.md file to incorporate the brand new constraints.
## Constraints
- Should hold spend `<= 30_000_000`
- Should hold extra CS contacts `<= 5_000`
- Should hold contact charge `<= 0.042`
- Should hold the script runnable with `python3 optimise.py`
- No dataset adjustments
- Maintain the answer easy and explainable until additional complexity yields materially higher income
- Runtime ought to stay quick sufficient for a lot of autoresearch iterations
It ran 8 extra iterations and converged to the next answer (once more matching what we had seen beforehand):
Income: $109.87M,
Finances spent: $29.9981M (below $30M),
Buyer help contacts: 3,218 (below 5K),
Contact charge: 0.038 (below 0.042).
After introducing the brand new constraints, the agent reformulated the issue and switched to an precise MILP solver. It rapidly discovered the optimum answer, reaching 109.87M income whereas satisfying all constraints. Many of the later iterations didn’t actually change the outcome, they simply cleaned issues up: eliminated fallback logic, lowered dependencies, and improved runtime. So, as soon as the issue was well-defined, the agent stopped “looking out” and began “engineering”. What’s much more fascinating is that it knew when to cease optimising and didn’t run all the way in which to the 30-iteration restrict.
Lastly, I requested the agent to finalise the analysis. This time, for some motive, /talent:autoresearch-finalize didn’t push all of the adjustments, so I needed to manually ask pi to create two PRs: one with clear code adjustments, and one other with the reasoning and supporting information. You’ll be able to undergo the PRs if you wish to see extra particulars about what the agent tried.
That’s all for the experiments. We received wonderful outcomes and was in a position to see the capabilities of autoresearch. So, it’s time to wrap it up.
Abstract
That was a extremely fascinating experiment. The agent was in a position to attain the identical optimum answer we beforehand discovered, utterly by itself. Whereas it didn’t push the outcome additional (which isn’t shocking given how well-studied issues like knapsack are), it was spectacular to see how an LLM can iteratively discover options and converge to a strong end result with out guide steerage.
I consider this method has sturdy potential throughout a number of domains (from coaching ML fashions and fixing analytical duties to extra engineering-heavy issues like optimising system efficiency or loading occasions). In lots of groups, we merely don’t have the time to check all doable concepts, or we dismiss a few of them too early. An autonomous loop like this may systematically strive totally different approaches and validate them with precise metrics.
On the identical time, that is undoubtedly not a silver bullet. There might be circumstances the place the agent finds “optimum” options that aren’t possible in observe, for instance, bettering web site loading velocity at the price of breaking person expertise. That’s the place human supervision turns into vital: not simply to validate outcomes, however to make sure the answer is sensible holistically.
From what I’ve seen, this method works finest when you will have a transparent goal, well-defined constraints, and one thing measurable to optimise. It’s a lot more durable to use it to extra ambiguous issues, like making a product extra user-friendly, the place success is much less clearly outlined.
General, I’d undoubtedly suggest attempting out pi-autoresearch or related instruments by yourself issues. It’s a robust approach to take a look at concepts you wouldn’t usually have time to discover and see what truly works in observe. And there’s one thing nearly magical about your product bettering when you sleep.
Disclaimer: I work at Shopify, however this publish is impartial of my work there and displays my private views.
Outsourcing suppliers typically promise 40% -70% productiveness beneficial properties from AI-enabled companies. The fact, in response to a current Morgan Lewis and Boston Consulting Group roundtable, is “typically tougher”– requiring working mannequin redesigns that the majority contracts weren’t constructed to accommodate.
For CIOs, that hole between promise and supply is forcing a basic rethinking of outsourcing technique. Contracts structured round headcounts and hourly charges do not account for AI-driven effectivity — or the brand new dangers that include it.
As suppliers embed AI into service supply, expertise leaders are revisiting deal buildings, rewriting governance phrases, and in some circumstances, bringing work again in-house. The query is not whether or not AI will reshape outsourcing; it is who captures the worth of AI and who’s on the hook when it fails.
The top of the FTE mannequin
The normal outsourcing mannequin — paying IT service suppliers by the full-time equal (FTE) — is more and more misaligned with how AI-enabled work really will get achieved.
“We’ve got to maneuver to pay-per-outcome,” stated Eduard de Vries Sands, a former CIO and at present an AI govt advisor to digital well being supplier PatientPoint. “The FTE mannequin incentivizes unhealthy habits. If you happen to pay by the FTE, why would your supplier use AI? That would cut back their income and margin.”
The shift seems a bit totally different from the supplier facet. AI is automating routine duties and dealing with tier-1 work, making outsourced groups extra environment friendly than ever, stated Chandra Venkataramani, CIO at enterprise course of outsourcing agency TaskUs. To keep away from cannibalizing their very own income, many outsourcing corporations are transitioning to outcome-based pricing.
“[It] presents a cheerful medium, the place suppliers can nonetheless generate income whereas their purchasers take pleasure in a decrease whole price of possession,” Venkataramani stated. However the transition is not seamless; purchasers and suppliers are nonetheless working to find out the honest worth of AI-enriched companies.
Suppliers are adapting in different methods, too. Gordon Wong, senior accomplice and operations excellence follow lead at enterprise and expertise consultancy West Monroe, stated suppliers are extra keen to front-load productiveness commitments, betting on themselves to exceed them. “They’re additionally extra open to reopening the contract and coming again to the negotiating desk ought to there be materials adjustments in how companies are delivered,” he added.
Some suppliers are additionally pushing for longer contract phrases — 5, seven, even ten years — to recoup their AI investments, stated Brad Peterson, a accomplice at regulation agency Mayer Brown who advises on outsourcing offers. That places strain on CIOs to lock in protections upfront, earlier than the deal economics shift.
As AI turns into central to service supply, customary outsourcing agreements typically fall quick.
5 contract areas want updating, defined Tripp Lake, a member at regulation agency Dickinson Wright:
AI device disclosure so patrons know what’s working on their work.
Express prohibitions on utilizing consumer knowledge for mannequin coaching.
IP possession clauses that reach to AI-generated outputs.
Legal responsibility frameworks for AI errors and hallucinations.
Productiveness-sharing clauses that forestall suppliers from capturing all effectivity beneficial properties.
“When AI effectivity beneficial properties go completely to the supplier’s margin, patrons are subsidizing a aggressive benefit they funded,” Lake stated.
Evaluating efficiency will get tougher when AI is doing the work. The previous mannequin was less complicated, stated Peterson: the provider agreed to do the identical factor the shopper was doing, with lower-cost individuals — the previous “your mess for much less” mannequin. “Now you flip it over to AI brokers. It is inherently not the identical,” he stated. “You’ll be able to’t use the identical service stage measurements.”
Accountability is one other sticking level. Figuring out which get together bears duty for AI hallucinations or mishaps has change into an important a part of contract negotiations, Venkataramani stated. Mapping out the total scope of potential AI failures and agreeing on the suitable human-to-AI ratio at the moment are core to deal-making.
Outsourcing suppliers, for his or her half, typically attempt to sidestep duty for AI-related points, particularly when utilizing third-party AI fashions, stated Jason Epstein, a accomplice at Nelson Mullins and co-head of the agency’s expertise business group.
“We’ve got seen a development now to take a way more particular method to those points in order that use of AI will not be considered as ‘all bets are off’ when it comes to the obligations of a service supplier,” Epstein stated. It is a acquainted sample: when software program distributors first moved to the cloud, in addition they tried to keep away from taking over internet hosting tasks. “It didn’t take lengthy till the distributors needed to conform to step up and be accountable for hosted companies, and the identical will finally development for these utilizing AI,” he stated.
AI is reshaping the insource vs. outsource calculus
AI is not simply altering how outsourcing offers are structured. It is prompting some organizations to rethink whether or not to outsource in any respect.
AI-assisted coding has lowered the necessity for junior offshore builders and testers, permitting some firms to carry groups again in-house. “We’re in a position to do with 10 to fifteen individuals what previously took 40 to 50 offshore builders, QAs [quality assurance specialists], and enterprise analysts,” stated de Vries Sands.
Giant enterprises are following an identical sample, constructing out their very own AI facilities of excellence and reclaiming sure features, Wong stated. However he notes the development is not common. Mid-market firms are literally outsourcing extra, recognizing that it isn’t only a labor arbitrage play however a method to entry expertise and thought management they could not construct internally. “That is very true given how troublesome it’s to rent AI and technical expertise proper now,” Wong stated.
AI introduces new dangers into outsourcing
No matter whether or not work stays with suppliers or comes again in-house, AI provides layers of publicity that CIOs are nonetheless studying to handle.
Knowledge sovereignty tops the checklist. “When a supplier deploys a general-purpose LLM on work that features your knowledge, your knowledge could change into a part of the mannequin’s efficient reminiscence,” Lake stated. Contracts ought to give prospects the suitable to regulate and confirm how knowledge is used.
IP contamination is a associated concern. If a supplier’s AI instruments are educated on open-source code, public datasets, or prior consumer work with out correct licensing controls, the deliverables might include authorized strings connected — unresolved possession points which are already being litigated in a number of jurisdictions.
Then there’s what Lake calls “high quality drift.” AI outputs may be confidently unsuitable. And in outsourced contexts — notably these during which patrons obtain summaries or stories moderately than supply work — hallucinated content material can work its means by way of workflows earlier than anybody notices. And when bots fail, they’ll fail large.
“When bots make errors, they’ll achieve this at super scale and velocity,” Peterson stated. That requires totally different protections than contracts written for human-delivered work.
There’s additionally the query of agentic AI. Granting an outsourcer permission to deploy brokers that entry your surroundings means buying and selling effectivity for management. “There are nonetheless brokers that may go rogue,” Wong stated. To handle this concern, CIOs can place limits on autonomous brokers to make use of circumstances the place reverting to the unique state is simple if one thing goes unsuitable.
CIOs take a central function in outsourcing negotiations
Maybe essentially the most vital shift is who’s main these conversations.
Outsourcing negotiations that when fell to procurement or operations leaders more and more require technical depth. Historically, the client-side lead may not have had the technical background wanted to barter AI-centered contracts, Venkataramani stated.
“CIOs have the experience wanted to make selections round whether or not to make use of provider-owned or in-house expertise, or whether or not all contracted suppliers ought to start utilizing the identical AI expertise,” he stated.
AI experience can also be changing into embedded in how firms govern their outsourcing relationships. Many purchasers now require an AI specialist as a part of the oversight construction — somebody who can consider how suppliers are deploying AI and convey a market perspective on what’s attainable, Wong defined.
Chief AI officers and AI facilities of excellence are more and more becoming a member of quarterly enterprise opinions with suppliers, carving out devoted time to evaluate how AI is getting used and the place it will probably ship extra worth.
For CIOs, that is an enlargement of each affect and accountability. The function has shifted from requirements-taker to strategic accomplice in deal construction.
“CIOs have the savvy to push for clearer requirements round how AI is educated, monitored, and constantly improved inside outsourced environments,” stated.
For now, the timing works of their favor — suppliers are extra open to reopening contracts as AI reshapes how companies are delivered, Wong famous. However that window will not keep open without end. The CIOs who act now will form these offers. The remainder will dwell with what’s handed to them.
Poolside AI launched the primary two fashions in its Laguna household: Laguna M.1 and Laguna XS.2. Alongside these, the corporate is releasing pool — a light-weight terminal-based coding agent and a twin Agent Consumer Protocol (ACP) client-server — the identical atmosphere Poolside makes use of internally for agent RL coaching and analysis, now obtainable as a analysis preview.
What are These Fashions, and Why Ought to You Care?
Each Laguna M.1 and Laguna XS.2 are Combination-of-Specialists (MoE) fashions. As a substitute of activating all parameters for each token, MoE fashions route every token by means of solely a subset of specialised sub-networks known as ‘specialists.’ This implies a big whole parameter depend and the potential headroom that comes with it whereas solely paying the compute value of a a lot smaller “activated” parameter depend at inference time.
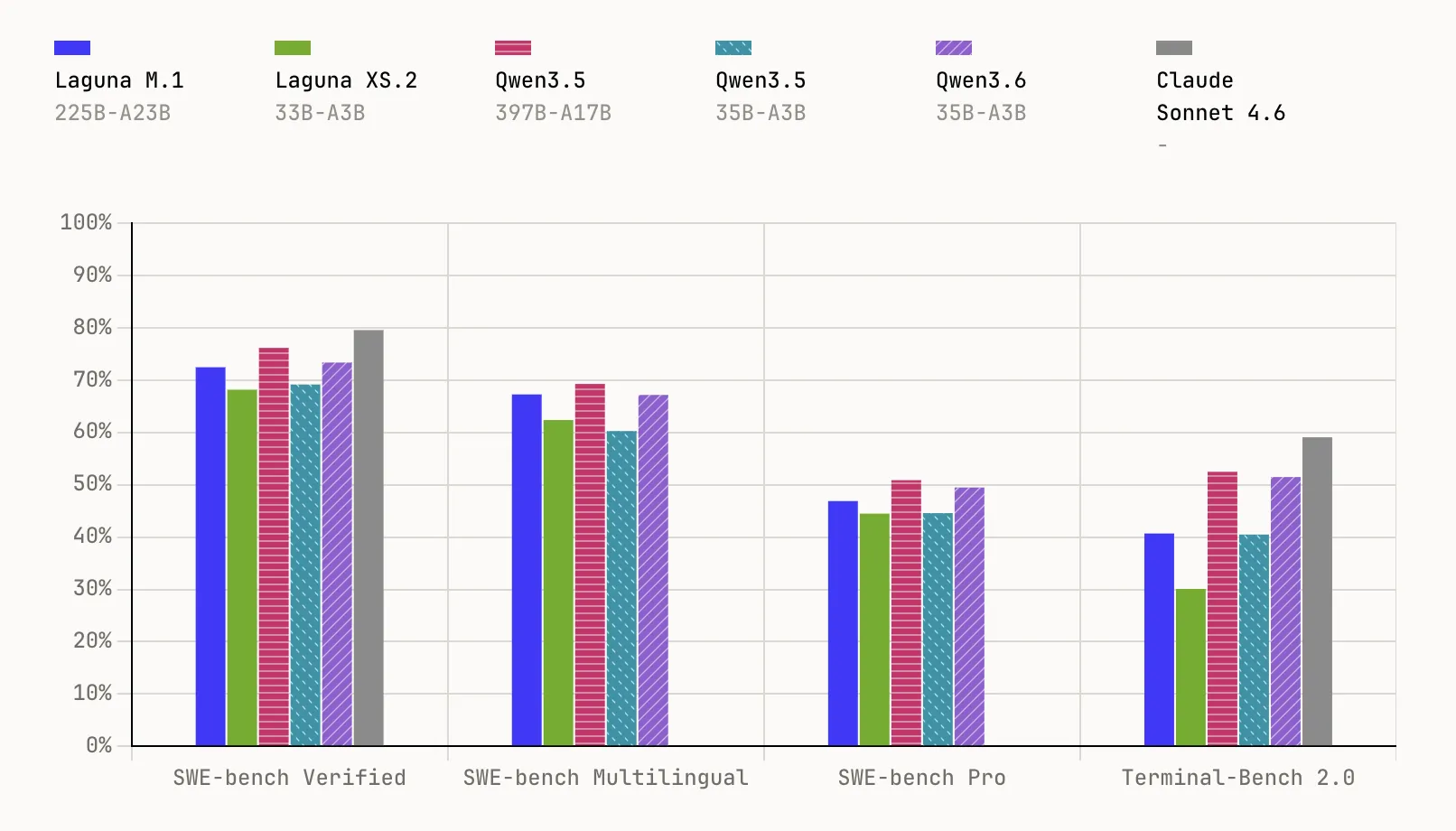
Laguna M.1 is a 225B whole parameter MoE mannequin with 23B activated parameters, educated from scratch on 30T tokens utilizing 6,144 interconnected NVIDIA Hopper GPUs. It accomplished pre-training on the finish of final yr and serves as the inspiration for all the Laguna household. On benchmarks, it reaches 72.5% on SWE-bench Verified, 67.3% on SWE-bench Multilingual, 46.9% on SWE-bench Professional, and 40.7% on Terminal-Bench 2.0.
Laguna XS.2 is the second-generation MoE and Poolside’s first open-weight mannequin, constructed on every part realized since coaching M.1. At 33B whole parameters with 3B activated per token, it’s designed for agentic coding and long-horizon work on a neighborhood machine — compact sufficient to run on a Mac with 36 GB of RAM by way of Ollama. It scores 68.2% on SWE-bench Verified, 62.4% on SWE-bench Multilingual, 44.5% on SWE-bench Professional, and 30.1% on Terminal-Bench 2.0. Poolside may even launch Laguna XS.2-base quickly for practitioners who wish to fine-tune.
Structure: The Effectivity Choices in XS.2
XS.2 makes use of sigmoid gating with per-layer rotary scales, enabling a blended Sliding Window Consideration (SWA) and international consideration format in a 3:1 ratio throughout 40 whole layers — 30 SWA layers and 10 international consideration layers. Sliding Window Consideration limits every token’s consideration to a neighborhood window of 512 tokens reasonably than the complete sequence, dramatically slicing KV cache reminiscence. The worldwide consideration layers at a 1-in-4 ratio protect long-range dependencies with out paying the complete value in every single place. The mannequin additionally quantizes the KV cache to FP8, additional decreasing reminiscence per token.
Beneath the hood, XS.2 makes use of 256 specialists with 1 shared skilled, helps a context window of 131,072 tokens, and options native reasoning help — interleaved pondering between device calls with per-request management over enabling or disabling pondering.
https://poolside.ai/weblog/laguna-a-deeper-dive
https://poolside.ai/weblog/laguna-a-deeper-dive
Coaching: Three Areas Poolside Pushed Exhausting
Poolside workforce trains all its fashions from scratch utilizing its personal knowledge pipeline, its personal coaching codebase (Titan), and its personal agent RL infrastructure. Three areas noticed specific funding for Laguna.
AutoMixer: Optimizing the Knowledge Combine Routinely. Knowledge curation and the combination that goes into coaching is extraordinarily impactful on closing mannequin efficiency. Slightly than counting on guide heuristics, Poolside developed an automixing framework that trains a swarm of roughly 60 proxy fashions, every on a unique knowledge combine, and measures efficiency throughout key functionality teams — code, math, STEM, and customary sense. Surrogate regressors are then match to approximate how adjustments in dataset proportions have an effect on downstream evaluations, giving a realized mapping from knowledge combine to efficiency that may be straight optimized. The strategy is impressed by prior work together with Olmix, MDE, and RegMix, tailored to Poolside’s setting with richer knowledge groupings.
On the information facet, each Laguna fashions have been educated on greater than 30T tokens. Poolside’s diversity-preserving knowledge curation strategy — which retains parts of mid- and lower-quality buckets alongside top-quality knowledge to keep away from STEM bias — yields roughly 2× extra distinctive tokens in comparison with precision-focused pipelines, with the achieve persisting at longer coaching horizons. A separate deduplication evaluation additionally confirmed that international deduplication disproportionately removes high-quality knowledge, informing how the workforce tuned its pipeline. Artificial knowledge contributes about 13% of the ultimate coaching combine in Laguna XS.2, with the Laguna collection utilizing roughly 4.4T+ artificial tokens in whole.
Muon Optimizer. Slightly than AdamW — the most typical optimizer in massive mannequin coaching — Poolside used a distributed implementation of the Muon optimizer by means of all coaching levels of each fashions. In preliminary pre-training ablations, the analysis workforce achieved the identical coaching loss as an AdamW baseline in roughly 15% fewer steps, with massive absolute analysis uplifts on the ultimate mannequin, and achieved studying fee switch throughout mannequin scales. A further profit: Muon requires just one state per parameter reasonably than two, decreasing reminiscence necessities for each coaching and checkpointing. Throughout pre-training of Laguna M.1, the overhead from the optimizer was lower than 1% of the coaching step time.
Poolside additionally runs periodic hash checks on mannequin weights throughout coaching replicas to catch silent knowledge corruption (SDC) from faulty GPUs — particularly errors in arithmetic logic and pipeline registers, which not like DRAM and SRAM should not lined by ECC safety.
Async On-Coverage Agent RL. That is arguably essentially the most complicated piece of the Laguna coaching stack. Poolside constructed a completely asynchronous on-line RL system the place actor processes pull duties from a dataset, spin up sandboxed containers, and run the manufacturing agent binary towards every process utilizing the freshly deployed mannequin. The ensuing trajectories are scored, filtered, and written to Iceberg tables, whereas the coach constantly consumes these data and produces the following checkpoint — inference and coaching operating asynchronously in parallel, with throughput tuned to steadiness off-policy staleness.
Key Takeaways
Poolside releases its first open-weight mannequin: Laguna XS.2 is a 33B whole parameter MoE mannequin with solely 3B activated parameters per token, obtainable below an Apache 2.0 license — compact sufficient to run regionally on a Mac with 36 GB of RAM by way of Ollama.
Robust benchmark efficiency at small scale: Laguna XS.2 scores 68.2% on SWE-bench Verified and 44.5% on SWE-bench Professional, whereas the bigger Laguna M.1 (225B whole, 23B activated) reaches 72.5% on SWE-bench Verified and 46.9% on SWE-bench Professional — each educated from scratch on 30T tokens.
Muon optimizer beats AdamW by 15% in coaching effectivity: Poolside changed AdamW with a distributed implementation of the Muon optimizer, reaching the identical coaching loss in roughly 15% fewer steps, with decrease reminiscence necessities — just one state per parameter as an alternative of two.
AutoMixer replaces guide knowledge mixing with realized optimization: As a substitute of handcrafted knowledge recipes, Poolside trains a swarm of ~60 proxy fashions on totally different knowledge mixes and suits surrogate regressors to optimize dataset proportions — with artificial knowledge making up ~13% of Laguna XS.2’s closing coaching combine from a complete of 4.4T+ artificial tokens.
Absolutely asynchronous agent RL with GPUDirect RDMA weight switch: Poolside’s RL system runs inference and coaching in parallel, transferring a whole bunch of gigabytes of BF16 weights between nodes in below 5 seconds by way of GPUDirect RDMA, utilizing a token-in, token-out actor design and the CISPO algorithm for off-policy coaching stability.
Researchers are warning that the VECT 2.0 ransomware has an issue in the best way it handles encryption nonces that results in completely destroying bigger information fairly than encrypt them.
VECT has been marketed on one of many newest BreachForums iterations, inviting registered customers to grow to be associates, and distributing entry keys through non-public messages to those that confirmed curiosity.
In some unspecified time in the future, VECT operators introduced a partnership with TeamPCP, the risk group liable for the current supply-chain assaults impacting Trivy, LiteLLM, and Telnyx, in addition to an assault in opposition to the European Fee.
Within the announcement, VECT operators acknowledged that their objective was to use victims of these supply-chain compromises, deploying ransomware payloads of their environments, in addition to to conduct bigger supply-chain assaults in opposition to different organizations.
VECT operators’ put up on BreachForums Supply: Test Level
Defective ransomware
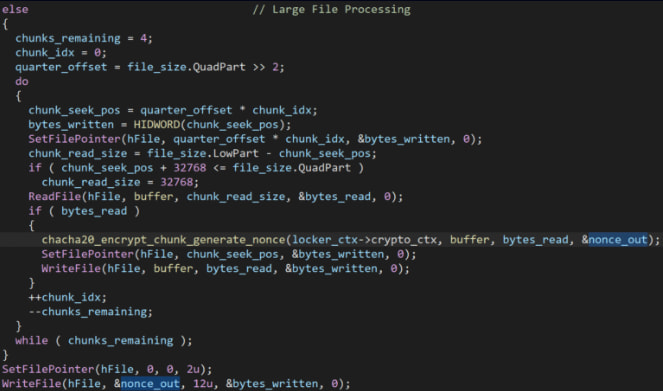
Whereas that is meant to extend encryption velocity for bigger information, as a result of all chunk encryptions use the identical reminiscence buffer for the nonce output, every new nonce overwrites the earlier one.
As soon as all chunks are processed, solely the final nonce generated stays in reminiscence, and solely that one is written to disk.
In consequence, the one portion of the file that’s recoverable is the final 25%, with the earlier three components being inconceivable to decrypt, because the nonces have been misplaced.
These misplaced nonces aren’t transmitted to the attacker both, so even when VECT operators wished to decrypt the information for victims paying the ransom, they wouldn’t be capable to.
Flawed nonce dealing with logic Supply: Test Level
Whereas that is meant to extend encryption velocity for bigger information, as a result of all chunk encryptions use the identical reminiscence buffer for the nonce output, every new nonce overwrites the earlier one.
As soon as all chunks are processed, solely the final nonce generated stays in reminiscence, and solely that one is written to disk.
In consequence, the one portion of the file that’s recoverable is the final 25%, with the earlier three components being inconceivable to decrypt, because the nonces have been misplaced.
These misplaced nonces aren’t transmitted to the attacker both, so even when VECT operators wished to decrypt the information for victims paying the ransom, they wouldn’t be capable to.
The VECT 2.0 ransom word Supply: Test Level
Test Level notes that, since most dear enterprise information, together with VM disks, database information, and backups, are above 128kb, VECT’s influence as a knowledge wiper might be catastrophic in most environments.
“At a threshold of solely 128 KB, smaller than a typical e-mail attachment or workplace doc, what the code classifies as a big file encompasses not simply VM disks, databases, and backups, however routine paperwork, spreadsheets, and mailboxes. In apply, nearly nothing a sufferer would care to get well falls under this boundary,” Test Level says.
The researchers discovered that the identical nonce-handling flaw is current throughout all variants of the VECT 2.0 ransomware, together with Home windows, Linux, and ESXi, so the identical data-wiping conduct applies throughout all instances.
AI chained 4 zero-days into one exploit that bypassed each renderer and OS sandboxes. A wave of latest exploits is coming.
On the Autonomous Validation Summit (Might 12 & 14), see how autonomous, context-rich validation finds what’s exploitable, proves controls maintain, and closes the remediation loop.
Get the Fashionable Science day by day publication💡
Breakthroughs, discoveries, and DIY ideas despatched six days per week.
Scorpions are optimized hunters, whose abilities have been honed by thousands and thousands of years of evolution. An armored exoskeleton, robust pincers, a toxic stinger—virtually every part about their anatomy aids in both looking bugs, small mammals, and reptiles, or defending themselves from snakes and birds. However for years, entomologists have been conscious of a possible secret weapon within the arthropods’ biology: metallic reinforcements.
Researchers beforehand detected hint metals within the exoskeletons of no less than a few of the estimated 3,000 identified scorpion species. On the similar time, consultants have been uncertain concerning the distribution and focus of those metals.
“We knew that metals strengthen the weapons in some species’ arsenals, [but] we don’t know if all scorpions’ weapons include metallic,” Sam Campbell, an environmental scientist at Australia’s College of Queensland, defined in a press release.
Again-scatter electron (BSE) scanning electron micrograph (SEM) of the telson of The yellow-fat tailed scorpion (Androctonus australis). Comparable distinction of enrichment is current within the telson (stinger), highlighting the presence of metallic. Additionally current is a transparent line, we’re terming the enrichment transition zone, the place metallic enrichment abruptly ends. Stingers in each msueum and wild specimens have been proven to snap break at, or close to, this area. Credit score: Sam Campbell/Smithsonian Museum Conservation Institute JEOL
The reply may are available how they depend on their stingers and pincers. Some scorpion species wield their toxic barbs greater than their claws, whereas others deploy the other technique. Campbell and colleagues theorized that the hint metallic distributions may correspond as to if or not a species prefers its stingers or pincers..
Whereas pursuing a Smithsonian fellowship on the Nationwide Museum of Pure Historical past in Washington D.C., the workforce used microanalytical strategies like high-resolution electron microscopy and X-ray evaluation to look at specimens from 18 separate scorpion species. Their outcomes printed within the Journal of The Royal Society Interface discovered pincers and stingers do include concentrations of metallic.
“The Nationwide Museum of Pure Historical past’s massive scorpion assortment allowed us to research metallic enrichment in a variety of scorpion species, greater than have ever been studied earlier than utilizing these methods,” mentioned Museum Conservation Institute analysis scientist and examine co-author Edward Vincenzi.
The outcomes revealed a pair of distinct metallic layers in scorpions. Stingers reliably featured excessive quantities of zinc of their needle-like ideas, adopted by a layer of manganese. The distribution is analogous in pincers, as properly. Within the movable portion often known as the tarsus, Campbell’s workforce pinpointed both zinc or a mixture of zinc and iron alongside the claw’s leading edge.
An X-ray spectral picture superimposed on a scanning electron microscope picture of the denticles (claw “tooth”) on the pincers of an enormous furry scorpion (Hadrurus arizonensis). The spectral picture exhibits selective enrichment of zinc (pink) within the denticles, along with phosphorous (inexperienced), and carbon (blue). Credit score: Smithsonian Museum Conservation Institute
Nonetheless, every metallic’s goal isn’t fairly what researchers hypothesized. Though they predicted stronger, crushing pincers to function extra zinc, they noticed larger zinc ranges in thinner, longer claws sometimes used along side stingers.
“This factors to a job for zinc past hardness, maybe taking part in an even bigger function in sturdiness,” mentioned Campbell. “In spite of everything, lengthy claws want to know prey and stop it from escaping earlier than being injected by venom. That is an attention-grabbing discovering as a result of it suggests an evolutionary relationship between how a weapon is used and the precise properties of the metallic that reinforces it.”
The workforce’s findings have main ramifications for understanding the broader world of arthropods and bugs. Scorpions are removed from the one creatures to include hint metals into their anatomy. By laying a transparent basis for future evaluation, researchers can examine how these evolutionary variations might seem throughout bees, wasps, spiders, and different animals.
“The microscopic-scale strategies we used allowed us to establish particular person transition metals in extraordinarily excessive element, exhibiting us how nature skillfully engineered these metals within the scorpion’s weapons,” added Vincenzi.
We’re excited to announce day-0 help for NVIDIA Nemotron 3 Nano Omni on Clarifai. Obtainable now on Clarifai Reasoning Engine, Nano Omni brings quick multimodal reasoning to builders constructing agentic techniques, delivering throughput of 400+ tokens per second.
NVIDIA Nemotron 3 Nano Omni is a 30B A3B multimodal reasoning mannequin constructed for workloads that span paperwork, pictures, video, and audio. With a 256K context window and help for textual content, picture, video, and audio inputs with textual content output, it offers builders a single mannequin for dealing with wealthy multimodal context inside agentic workflows.
That makes it a robust match for sub-agents in workflows the place multimodal understanding and velocity must go collectively.
A Multimodal Mannequin for Specialised Sub-Brokers
As agent techniques develop extra succesful, additionally they turn into extra specialised. Completely different fashions and elements tackle planning, execution, retrieval, and verification, every working inside a broader workflow. In that structure, the mannequin dealing with multimodal inputs has to do greater than course of remoted inputs. It has to interpret a number of modalities collectively, protect context throughout steps, and reply quick sufficient to remain throughout the operational loop.
As a light-weight multimodal mannequin for sub-agents, Nemotron 3 Nano Omni can purpose throughout screens, paperwork, charts, audio, and video with out routing every modality by way of a separate stack. Moderately than splitting imaginative and prescient, speech, and language throughout a number of fashions, it offers builders a extra unified solution to deal with multimodal reasoning whereas holding the general system simpler to handle.
Constructed for Pc Use, Paperwork, and Audio-Video Reasoning
Nano Omni is very related for the sorts of workloads which can be turning into central to enterprise agentic techniques.
For pc use, brokers must learn interfaces, monitor UI state over time, and confirm whether or not actions accomplished as anticipated. For doc intelligence, they should purpose throughout textual content, tables, charts, screenshots, scanned pages, and combined visible construction in the identical cross. For audio and video workflows, they should join what was stated, what was proven, and what modified over time.
These are all circumstances the place multimodal functionality has to work reliably in manufacturing, with a mannequin that may deal with a number of modalities effectively with out splitting the workflow throughout separate fashions.
The mannequin represents a big soar in functionality from earlier fashions within the Nemotron household. Vital enchancment in benchmarks like OCRBenchV2, OCR_Reasoning, MathVista_MINI and OSWorld replicate the mannequin’s improved efficiency for the true world workloads right now’s brokers are prone to serve.
That’s the place Nano Omni matches naturally, giving builders a single multimodal reasoning stream for the duties sub-agents are more and more anticipated to deal with.
Agent-Pleasant Tokenomics
In agent techniques, sub-agents tackle recurring duties throughout paperwork, screens, audio, and video inside a bigger workflow. Every invocation provides to the price, throughput, and infrastructure calls for of the general system. NVIDIA Nemotron 3 Nano Omni consolidates imaginative and prescient, speech, and language right into a single multimodal mannequin, decreasing inference hops, orchestration logic, and cross-model synchronization in contrast with separate notion stacks.
Nano Omni delivers roughly 2x greater throughput on common, together with about 2.5x decrease compute for video reasoning by way of temporal-aware notion and environment friendly video sampling. For multimodal agent workflows, meaning greater throughput and decrease compute overhead with out including complexity to the stack.
The mannequin makes use of a hybrid Combination-of-Specialists structure with a Transformer-Mamba design, together with 3D convolution layers and Environment friendly Video Sampling for temporal and video inputs. It might run on a single H100, H200, or B200, making it sensible to deploy multimodal sub-agents with out stretching infrastructure necessities.
Excessive-Throughput Inference on Clarifai
On Clarifai Reasoning Engine, NVIDIA Nemotron 3 Nano Omni runs at 400+ tokens per second, giving builders the throughput wanted for manufacturing multimodal agent workflows. That issues in techniques the place sub-agents are referred to as repeatedly to course of paperwork, interfaces, audio, and video as a part of an ongoing workflow.
Clarifai Reasoning Engine is constructed for inference acceleration by combining optimized kernels, speculative decoding and adaptive efficiency methods to enhance throughput for reasoning fashions with out compromising accuracy.
Getting Began on Clarifai
Builders can strive NVIDIA Nemotron 3 Nano Omni within the Clarifai Playground and can even entry it by way of an OpenAI-compatible API, making it simpler to combine into present functions, instruments, and agentic frameworks.
For larger-scale or extra managed deployments, Clarifai offers a direct path to manufacturing with Compute Orchestration. Builders can run Nano Omni on Clarifai Reasoning Engine or deploy it throughout their very own cloud, VPC, on-prem or air-gapped environments whereas managing deployments by way of a unified management aircraft.
NVIDIA Nemotron 3 Nano Omni is offered on Clarifai right now.
When you’ve got any questions on accessing NVIDIA Nemotron 3 Nano Omni on Clarifai, be part of our Discord.
Macworld stories Apple’s iOS 27 will introduce three new AI-powered photograph modifying options: Lengthen, Improve, and Reframe, becoming a member of the prevailing Clear Up instrument.
These instruments will enable customers to zoom out and add particulars past photograph frames, enhance shade and lighting, and shift views on spatial photos.
Inside testing exhibits inconsistent outcomes for Lengthen and Reframe options, doubtlessly delaying their launch regardless of Apple’s important AI funding in photograph modifying.
A brand new report from Bloomberg’s Mark Gurman offers us an thought of what to anticipate from iOS 27’s photo-editing options. Apple is alleged to be planning a serious overhaul of the photo-editing expertise, leaning closely on AI for 3 huge new options: Lengthen, Improve, and Reframe. These three instruments shall be collected along with the prevailing Clear Up instrument in a brand new “Apple Intelligence Instruments” part of the Photographs app.
In keeping with the report, right here’s what to anticipate from the brand new options:
Lengthen: Customers will have the ability to “zoom out” on an current photograph, including in particulars past the unique body. This kind of generative fill/broaden characteristic is pretty commonplace.
Improve: You’ll have the ability to enhance shade, lighting, and total picture high quality utilizing AI.
Reframe: When taking spatial photographs, this new characteristic will let you shift perspective to provide a nonetheless picture from a distinct angle.
Gurman notes that inside testing of the options hasn’t gone easily. Particularly, the Lengthen and Reframe instruments produce inconsistent outcomes, in order that they might be delayed. Getting reliably good outcomes is already the largest drawback with Apple’s solely present AI-powered instrument, Clear Up, so introducing extra AI instruments that don’t work effectively a lot of the time shouldn’t be going to enhance Apple’s popularity.
In his report, Gurman reminds us that the OS 27 updates are targeted on two most important areas: Apple Intelligence options, together with the long-overdue new Siri, and a concerted effort to wash up the codebase to enhance efficiency and battery life whereas decreasing bugs. Apple is anticipated to preview the brand new OS on the WWDC keynote on June 8.











.jpg)
.jpg)





