

{kind=link}
Desk of Contents
- Semantic Caching for LLMs: FastAPI, Redis, and Embeddings
- Introduction: Why Semantic Caching Issues for LLM Techniques
- How Semantic Caching Works for LLMs: Embeddings and Similarity Search Defined
- Semantic Caching Structure and Request Stream
- Configuring Your Setting for Semantic Caching: FastAPI, Redis, and Ollama Setup
- Undertaking Construction
- FastAPI Entry Level for Semantic Caching: Wiring the API Service
- FastAPI Ask Endpoint: Finish-to-Finish Semantic Caching Request Stream
- Embeddings: Turning Textual content into Semantic Vectors
- The Semantic Cache: Cosine Similarity, Redis Storage, and Reusing Which means
- Cache Entries: What Precisely Will get Saved?
- Finish-to-Finish Demo: Verifying Core Cache Habits
- Abstract
Semantic Caching for LLMs: FastAPI, Redis, and Embeddings
On this lesson, you’ll learn to construct a semantic cache for LLM purposes utilizing FastAPI, Redis, and embedding-based similarity search, and the way requests stream from precise matches to semantic matches earlier than falling again to the LLM.
This lesson is the first in a 2-part collection on Semantic Caching for LLMs:
- Semantic Caching for LLMs: FastAPI, Redis, and Embeddings (this tutorial)
- Lesson 2
To learn to construct a semantic cache for LLM purposes utilizing embeddings and Redis, simply maintain studying.
Introduction: Why Semantic Caching Issues for LLM Techniques
Value, Latency, and Redundant LLM Calls
Giant language fashions are highly effective, however they aren’t low cost. Each request to an LLM includes tokenization, inference, decoding, and community overhead. Even when fashions are hosted regionally, response instances are measured in tons of of milliseconds or seconds quite than microseconds.
In actual purposes, this price compounds rapidly. Customers usually ask comparable questions repeatedly, both throughout classes or throughout the identical workflow. Every request is handled as a contemporary LLM invocation, even when the underlying intent has already been dealt with earlier than.
This results in 3 systemic issues:
- Excessive latency: Customers anticipate responses that would have been reused immediately
- Elevated price: Similar reasoning is paid for a number of instances
- Wasted capability: LLM throughput is consumed by redundant requests
These points change into particularly seen below load, the place repeated paraphrased queries can overwhelm an in any other case well-sized system.
Why Precise-Match Caching Breaks Down for Pure Language
Conventional caching assumes that similar inputs produce similar outputs. This works properly for APIs, database queries, and deterministic features. It fails for pure language.
From a string-matching perspective, the next queries are fully unrelated:
- “What’s semantic caching?”
- “Are you able to clarify how semantic caching works?”
- “How does caching primarily based on embeddings work for LLMs?”
A standard cache keyed on uncooked strings will miss all three. Because of this, the system calls the LLM 3 times, regardless that a human would count on the identical reply.
This brittleness causes exact-match caches to have extraordinarily low hit charges in LLM-backed programs. Worse, it provides a false sense of optimization. The cache exists, however it virtually by no means helps in follow.
The place Semantic Caching Matches in Actual Techniques
Semantic caching addresses this mismatch by caching that means as a substitute of actual textual content.
Moderately than asking “have I seen this string earlier than?”, a semantic cache asks “have I answered one thing semantically comparable earlier than?”. It does this by changing queries into embeddings and evaluating them utilizing a similarity metric corresponding to cosine similarity.
In an actual system, semantic caching sits between the applying layer and the LLM:
- The applying sends a question
- The cache evaluates whether or not a previous response is reusable
- Solely true cache misses attain the LLM
When designed appropriately, this layer is invisible to the person. Responses really feel quicker, prices drop, and the system scales extra gracefully with out altering the frontend or immediate logic.
This lesson focuses on constructing that layer explicitly and transparently, utilizing FastAPI, Redis, and embeddings, with out hiding the mechanics behind heavy abstractions.
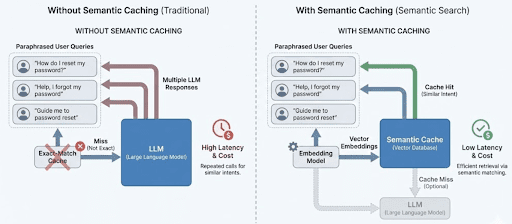
Precise-match caching treats paraphrased queries as distinctive requests, leading to repeated LLM calls. Semantic caching teams comparable queries by that means, permitting responses to be reused and decreasing each latency and price.
How Semantic Caching Works for LLMs: Embeddings and Similarity Search Defined
Part 1 defined why semantic caching exists.
This part explains the way it works, conceptually, earlier than we contact any FastAPI, Redis, or code.
The objective right here is to present the reader a psychological execution mannequin they’ll maintain of their head whereas studying the implementation.
From Textual content to Which means: Embeddings because the Cache Key
Semantic caching replaces uncooked textual content comparability with vector similarity.
As an alternative of caching responses below the literal question string, the system converts every question into an embedding: a high-dimensional numeric vector that captures semantic that means. Queries which are worded in a different way however imply the identical factor produce embeddings which are shut collectively in vector area.
That is what permits the cache to acknowledge paraphrases as equal:
- “How do I reset my password?”
- “I forgot my password, what ought to I do?”
- “Information me by way of password restoration”
Precise strings differ. Embeddings don’t.
At a excessive degree, semantic caching works by:
- Producing an embedding for the incoming question
- Evaluating it towards embeddings saved within the cache
- Reusing a cached response if similarity is excessive sufficient
The similarity metric used on this lesson is cosine similarity, which measures the angle between two vectors quite than their uncooked magnitude.
Why a Layered Cache Beats Semantic-Solely Caching
Whereas semantic matching is highly effective, it’s also computationally costly.
Embedding era requires a mannequin name. Similarity search requires vector math. Doing this for each request, even when the very same question has already been seen, could be wasteful.
That’s the reason this lesson makes use of a layered caching technique.
Layer 1: Precise Match (Quick Path)
The question is normalized and hashed.
If the identical question has already been answered, the response is returned instantly.
- No embedding era
- No similarity computation
- Minimal latency
This handles repeated similar queries effectively.
Layer 2: Semantic Match (Versatile Path)
If no precise match exists, the question is embedded and in contrast towards cached embeddings.
This layer catches:
- paraphrases
- minor wording variations
- reordered phrases
Semantic matches commerce compute price for a lot greater cache hit charges.
Layer 3: LLM Fallback (Gradual Path)
If neither precise nor semantic matches succeed, the request is forwarded to the LLM.
The response is then saved within the cache so future requests can reuse it.
This layered method ensures:
- the most affordable checks occur first
- costly operations are solely used when needed
Confidence, Freshness, and Cache Security
Semantic similarity alone just isn’t sufficient to determine whether or not a cached response must be reused.
This lesson introduces the thought of confidence scoring, which mixes:
- Similarity: how shut the embeddings are
- Freshness: how previous the cached entry is
A extremely comparable however stale response mustn’t essentially be trusted. Likewise, a contemporary response with low similarity must be rejected.
As well as, cached entries are validated to forestall:
- expired responses
- poisoned entries (errors, empty outputs)
These checks make sure the cache improves correctness and efficiency quite than degrading them.
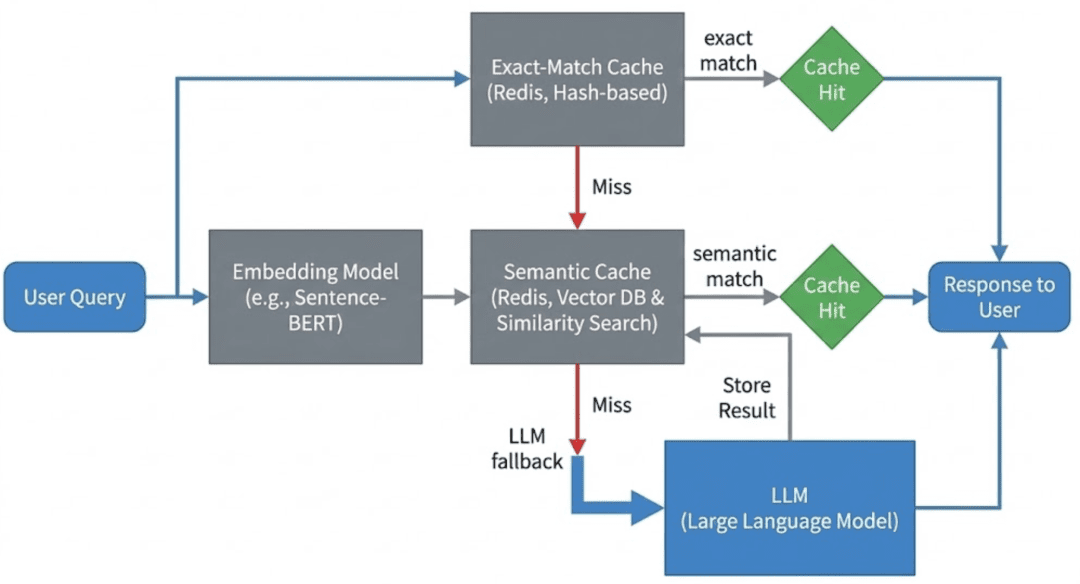
Incoming queries first try an exact-match lookup, then fall again to semantic similarity search utilizing embeddings, and eventually name the LLM solely on cache miss. This ordering minimizes latency and pointless mannequin calls.
Notice: On this lesson, we implement this stream utilizing Redis as a easy embedding retailer with linear similarity scans, quite than a devoted vector database.
Semantic Caching Structure and Request Stream
In Part 2, you discovered how semantic caching works conceptually.
On this part, we map that psychological mannequin to a actual request stream in an LLM-backed service.
The objective is to reply one query clearly:
What occurs, step-by-step, when a person sends a request to this technique?
We’ll keep implementation-aware, however not code-specific but. That comes subsequent.
Excessive-Degree System Parts
At a excessive degree, the system consists of 5 logical elements:
- API layer: Receives person requests and orchestrates the caching pipeline.
- Precise-match cache: Performs quick hash-based lookups for similar queries.
- Embedding mannequin: Converts textual content queries into semantic vectors when wanted.
- Semantic cache: Shops embeddings and responses and performs similarity matching.
- LLM: Acts as the ultimate fallback when no cache entry is appropriate.
Every part has a narrowly outlined accountability. This separation is intentional and retains the system simple to purpose about and lengthen.
On this implementation:
- The API layer is constructed utilizing FastAPI and acts because the orchestration level.
- Redis is used because the backing retailer for each exact-match and semantic cache layers.
- Ollama supplies each embedding era and LLM inference regionally.
These decisions maintain the system light-weight, self-contained, and simple to purpose about whereas nonetheless reflecting actual manufacturing patterns.
Finish-to-Finish Request Stream
When a person sends a question, the system processes it within the following order.
Step 1: Request enters the API
The API receives a textual content question together with non-obligatory flags, corresponding to whether or not to make use of the bypass_cache. Enter validation occurs instantly to forestall meaningless or malformed queries from coming into the pipeline.
This ensures the cache just isn’t polluted with empty or invalid entries.
Step 2: Precise-match cache lookup
The question is normalized and hashed.
The system checks whether or not an similar question has already been answered.
- If a precise match exists and is legitimate, the response is returned instantly.
- No embeddings are generated.
- The LLM just isn’t touched.
That is the quickest doable path by way of the system.
Step 3: Embedding era
If the exact-match lookup fails, the question is handed to the embedding mannequin.
The mannequin converts the textual content right into a numeric vector that captures semantic that means. This vector turns into the important thing for semantic comparability.
This step is deliberately skipped when a precise match succeeds.
Step 4: Semantic cache lookup
The embedding is in contrast towards cached embeddings utilizing a similarity metric.
A cached response is reused provided that:
similarityexceeds an outlined threshold- the entry has not expired
- the entry just isn’t poisoned
- the computed
confidenceis excessive sufficient
If an acceptable match is discovered, the response is returned to the person with out calling the LLM.
Step 5: LLM fallback and cache inhabitants
If each cache layers miss, the request is forwarded to the LLM.
As soon as a response is generated:
- it’s returned to the person
- it’s saved within the cache with metadata, timestamps, and TTL (Time To Dwell)
This ensures future requests can reuse the consequence.
Why This Structure Works Properly
This structure is deliberately conservative and specific.
- Low-cost operations occur first.
- Costly operations are deferred.
- Each step is observable and debuggable.
- No part hides complexity behind opaque abstractions.
Most significantly, the system degrades gracefully. Even when the cache supplies no profit, the request nonetheless succeeds through the LLM.
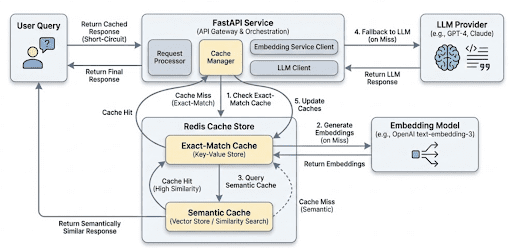
Person queries enter the API, try an exact-match lookup, fall again to semantic similarity search utilizing embeddings, and name the LLM solely when each cache layers miss. Profitable LLM responses are saved for future reuse.
Would you want instant entry to three,457 pictures curated and labeled with hand gestures to coach, discover, and experiment with … without spending a dime? Head over to Roboflow and get a free account to seize these hand gesture pictures.
Configuring Your Setting for Semantic Caching: FastAPI, Redis, and Ollama Setup
To observe this information, you want a small set of Python libraries and system providers that assist API orchestration, vector similarity, and LLM interplay. The objective is to maintain the surroundings light-weight, reproducible, and simple to purpose about.
At a minimal, you’ll need:
- Python 3.10 or newer
- Redis (used because the cache backing retailer)
- An LLM + embedding supplier (Ollama on this tutorial)
All required Python dependencies are pip-installable.
Putting in Python Dependencies
Create and activate a digital surroundings (beneficial), then set up the required packages:
$ pip set up fastapi uvicorn redis httpx python-dotenv numpy
These libraries present the next performance:
fastapi: API layer and request orchestrationuvicorn: ASGI server for operating the serviceredis: consumer Communication with the cache retailerhttpx: HTTP consumer for embedding and LLM callsnumpy: Vector math for cosine similaritypython-dotenv: Setting-based configuration
Verifying Redis
This lesson assumes Redis is operating regionally on the default port.
You may confirm Redis is accessible with:
$ redis-cli ping PONG
If Redis just isn’t put in, you can begin it rapidly utilizing Docker (however you can also spin it up utilizing the docker-compose.yml we offer within the code zip):
$ docker run -p 6379:6379 redis:7
Setting Up Ollama
This technique makes use of Ollama for each embedding era and LLM inference. Ensure Ollama is put in and operating, and that the required fashions can be found.
For instance:
$ ollama pull nomic-embed-text $ ollama pull llama3.2
As soon as operating, Ollama exposes native HTTP endpoints that the applying will name immediately for embeddings and textual content era.
Want Assist Configuring Your Growth Setting?

All that mentioned, are you:
- Brief on time?
- Studying in your employer’s administratively locked system?
- Desirous to skip the effort of combating with the command line, package deal managers, and digital environments?
- Able to run the code instantly in your Home windows, macOS, or Linux system?
Then be a part of PyImageSearch College immediately!
Acquire entry to Jupyter Notebooks for this tutorial and different PyImageSearch guides pre-configured to run on Google Colab’s ecosystem proper in your net browser! No set up required.
And better of all, these Jupyter Notebooks will run on Home windows, macOS, and Linux!
Undertaking Construction
Earlier than diving into particular person elements, let’s take a second to know how the challenge is organized.
A transparent listing construction is very vital in LLM-backed programs, the place obligations span API orchestration, caching, embeddings, mannequin calls, and observability. On this challenge, every concern is remoted into its personal module so the request stream stays simple to hint and purpose about.
After downloading the supply code from the “Downloads” part, your listing construction ought to seem like this:
. ├── app │ ├── api │ │ ├── __init__.py │ │ └── ask.py │ ├── cache │ │ ├── __init__.py │ │ ├── poisoning.py │ │ ├── schemas.py │ │ ├── semantic_cache.py │ │ └── ttl.py │ ├── config │ │ ├── __init__.py │ │ └── settings.py │ ├── embeddings │ │ ├── __init__.py │ │ └── embedder.py │ ├── llm │ │ ├── __init__.py │ │ └── ollama_client.py │ ├── important.py │ └── observability │ └── metrics.py ├── complete-codebase.txt ├── docker-compose.yml ├── Dockerfile ├── README.md └── necessities.txt
Let’s break this down at a excessive degree.
The app/ Package deal
The app/ listing incorporates all runtime software code. Nothing outdoors this folder is imported at execution time.
This retains the service self-contained and makes it simple to purpose about deployment and dependencies.
app/important.py: Software Entry Level
This file defines the FastAPI software and registers all routers.
It incorporates no enterprise logic — solely service wiring. Each request into the system enters by way of this file.
app/api/: API Layer
The api/ package deal defines HTTP-facing endpoints.
ask.py: Implements the/askendpoint and acts because the orchestration layer for all the semantic caching pipeline.
The API layer is accountable for:
- enter validation
- implementing cache ordering
- coordinating cache, embeddings, and LLM calls
- returning structured debug data
It does not implement caching or similarity logic immediately.
app/cache/: Caching Logic
This package deal incorporates all cache-related performance.
semantic_cache.py: Core semantic cache implementation (precise match, semantic match, Redis storage, similarity search).schemas.py: Defines the cache entry schema used for Redis storage.ttl.py: Software-level TTL configuration and expiration checks.poisoning.py: Security checks to forestall invalid or error responses from being reused.
By isolating caching logic right here, the API layer stays clear and reusable.
app/embeddings/: Embedding Technology
embedder.py: Handles embedding era through Ollama’s embedding endpoint.
This module has a single accountability: convert textual content into semantic vectors.
It doesn’t cache, rank, or validate embeddings.
app/llm/: LLM Consumer
ollama_client.py: Wraps calls to the Ollama text-generation endpoint.
Retaining LLM interplay remoted permits the remainder of the system to stay model-agnostic.
app/observability/: Metrics
metrics.py: Implements easy in-memory counters for cache hits, misses, and LLM calls.
These metrics are deliberately light-weight and meant for studying and debugging, not manufacturing monitoring.
Configuration and Infrastructure
Exterior the app/ listing:
config/settings.py: Centralizes environment-based configuration (Redis host, TTLs, mannequin names).Dockerfileanddocker-compose.yml: Outline a reproducible runtime surroundings for the API and Redis.necessities.txt: Lists all Python dependencies required to run the service.
FastAPI Entry Level for Semantic Caching: Wiring the API Service
Earlier than we have a look at caching logic, embeddings, or Redis, it’s vital to know how the service itself is wired collectively. Each request to the semantic cache enters the system by way of a single FastAPI software, outlined in app/important.py.
This file acts because the entry level of the service. Its accountability is to not implement enterprise logic, however to attach the applying elements and expose HTTP routes.
Software Entry Level (app/important.py)
from fastapi import FastAPI from api.ask import router as ask_router app = FastAPI(title="Semantic Cache Fundamentals") app.include_router(ask_router)
Let’s break this down.
The FastAPI() name creates the applying object. This object represents all the net service and is what the ASGI (Asynchronous Server Gateway Interface) server (uvicorn) runs when the container begins.
The applying itself incorporates no information of caching, embeddings, or LLMs. It merely defines a runtime container that may host these capabilities.
Router Registration
As an alternative of defining endpoints immediately in important.py, the applying imports a router from api/ask.py and registers it utilizing include_router().
This sample serves a number of functions:
- Separation of issues: Routing and request dealing with reside outdoors the applying entry level.
- Scalability: Because the system grows, further routers (for well being checks, metrics, or admin endpoints) will be added with out modifying core software wiring.
- Readability:
important.pystays simple to know at a look, even because the codebase expands.
At runtime, FastAPI merges the routes outlined in ask_router into the principle software. When a request arrives on the /ask endpoint, FastAPI resolves it by way of the registered router and forwards it to the suitable handler operate.
Why This Issues
Retaining the entry level minimal is intentional. It ensures that:
- The applying startup course of is predictable
- Routing logic is straightforward to hint
- Core performance can evolve independently of service wiring
With the applying construction in place, we will now give attention to what really occurs when a request reaches the system.
Within the subsequent part, we are going to stroll by way of the /ask endpoint and see the way it orchestrates exact-match caching, semantic search, and LLM fallback step-by-step.
FastAPI Ask Endpoint: Finish-to-Finish Semantic Caching Request Stream
This part makes the structure concrete. We now stroll by way of the /ask endpoint, which orchestrates all the semantic caching pipeline from request arrival to response supply.
The objective right here is to not memorize code, however to know why every step exists, the place it lives, and the way it protects efficiency, price, and correctness.
The Position of the Ask Endpoint
The Ask endpoint is the management airplane of the system.
It does not:
- Compute similarity
- Retailer embeddings
- Speak on to Redis internals
As an alternative, it:
- Validates enter
- Decides which cache layers to seek the advice of
- Enforces ordering between low cost and costly operations
- Collects observability indicators
- Ensures a response even on cache failure
This separation is intentional. Cache logic stays reusable and testable, whereas orchestration logic stays specific on the API boundary.
Defining the API Contract
We start by defining the request and response fashions.
class AskRequest(BaseModel):
question: str
bypass_cache: bool = False
The request consists of a person question and an non-obligatory bypass_cache flag. This flag permits us to drive a cache miss throughout debugging or testing, guaranteeing that the LLM and embedding pipeline nonetheless operate appropriately.
Earlier than the request ever reaches the cache, the question discipline is validated.
@field_validator('question')
@classmethod
def validate_query(cls, v: str) -> str:
if not v or not v.strip():
increase ValueError("Question can't be empty or whitespace-only")
return v.strip()
This validation step protects the system on the boundary. Rejecting empty or whitespace-only queries prevents:
- wasted embedding computation
- cache air pollution with meaningless entries
- pointless LLM calls
This can be a recurring sample in manufacturing programs: fail quick, earlier than costly operations are triggered.
class AskResponse(BaseModel):
response: str
from_cache: bool
similarity: float
debug: dict
The response mannequin deliberately exposes diagnostic data by way of fields corresponding to from_cache, similarity, and debug. Throughout growth, this makes cache conduct clear quite than opaque.
Initializing the Cache
Earlier than dealing with requests, we create a SemanticCache occasion:
cache = SemanticCache()
The endpoint itself stays stateless. All persistence and reuse reside contained in the cache layer.
Step 1: Coming into the Endpoint
The endpoint is registered utilizing FastAPI’s routing mechanism:
@router.submit("/ask", response_model=AskResponse)
def ask_endpoint(request: AskRequest):
FastAPI mechanically validates incoming requests and outgoing responses utilizing the schemas outlined earlier. If invalid knowledge enters or exits the system, FastAPI raises an error as a substitute of silently failing.
Contained in the handler, we extract the question and initialize monitoring state:
question = request.question miss_reason = None
The miss_reason variable exists purely for observability. Moderately than treating cache misses as a black field, we explicitly monitor why a miss occurred.
Step 2: Precise-Match Cache Lookup (Quick Path)
The primary determination level is the exact-match cache lookup:
if not request.bypass_cache:
cached = cache.search(None, exact_query=question)
That is the least expensive path by way of the system.
If the identical question has already been answered, the response will be returned instantly:
- no embeddings are generated
- no similarity computation happens
- the LLM just isn’t touched
If a cached entry is discovered, it’s validated:
if is_expired(cached):
miss_reason = "expired"
elif is_poisoned(cached):
miss_reason = "poisoned"
elif cached.get("confidence", 0.0) < 0.7:
miss_reason = "low_confidence"
Solely entries which are contemporary, legitimate, and assured are allowed to short-circuit the pipeline.
When all checks cross, the endpoint returns instantly:
metrics.cache_hit() return AskResponse(...)
This path usually completes in milliseconds and handles repeated similar queries effectively.
Step 3: Embedding Technology (Escalation Level)
If the exact-match lookup fails or is bypassed, the endpoint escalates:
embedding = embed_text(question)
Embedding era is dear, even when operating regionally. For that reason, it’s deliberately delayed till all cheaper choices have been exhausted.
This single design selection has a major impression on system effectivity.
Step 4: Semantic Cache Lookup
With the embedding obtainable, the endpoint makes an attempt a semantic search:
cached = cache.search(embedding)
This path catches paraphrased and reworded queries. As earlier than, cached entries are validated to make sure they’re protected to reuse.
If an acceptable match is discovered, the response is returned with out calling the LLM.
Step 5: Express Cache Bypass
The bypass_cache flag is dealt with explicitly:
if request.bypass_cache:
miss_reason = "bypass"
This permits managed testing and debugging with out modifying code or disabling cache logic globally.
Step 6: LLM Fallback and Cache Inhabitants
If each cache layers miss, the request is forwarded to the LLM:
metrics.cache_miss() response = generate_llm_response(question) metrics.llm_call()
That is the slowest path by way of the system, however it ensures correctness.
Profitable responses are saved within the cache:
if not response.startswith("[LLM Error]"):
cache.retailer(question, embedding, response, metadata=metadata)
Responses starting with [LLM Error] are deliberately not cached, stopping cache poisoning and guaranteeing failures don’t propagate to future requests.
Management Stream Abstract
The endpoint follows a easy, specific sequence:
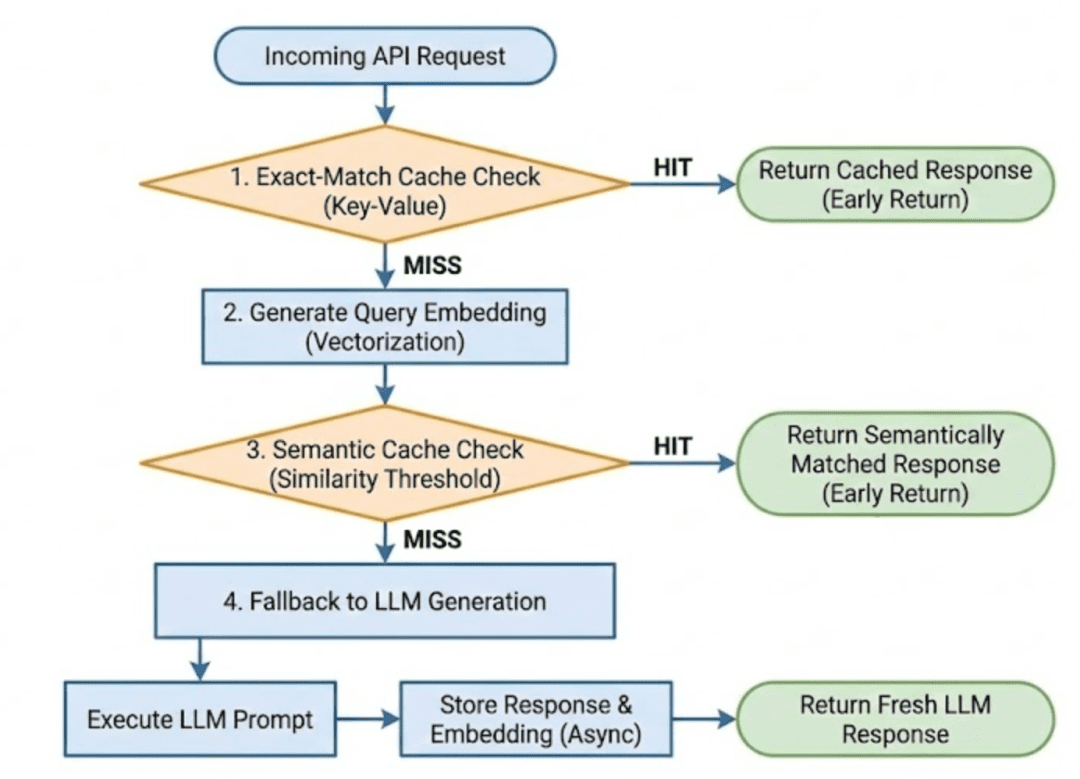
Each costly operation is deferred till completely needed.
Embeddings: Turning Textual content into Semantic Vectors
Up so far, we have now handled embeddings as a black field: one thing costly that we attempt to keep away from except completely needed.
On this part, we are going to open that field simply sufficient to know what embeddings are, when they’re generated, and why they allow semantic caching with out diving into vector math or mannequin internals.
Why Embeddings Exist in This System
Precise-match caching works solely when queries are similar on the string degree. As quickly as wording modifications, precise matching breaks down.
Embeddings remedy this downside by changing textual content right into a numeric illustration that captures that means quite than floor type.
Queries that imply the identical factor have a tendency to supply vectors which are shut collectively in vector area, even when their wording differs considerably.
That is the muse that makes semantic caching doable.
Embedding Technology Occurs on Demand
In our implementation, embeddings are generated solely after the exact-match cache fails.
This determination is intentional.
Embedding era includes:
- a mannequin invocation
- community overhead
- serialization and deserialization
- non-trivial latency
Due to this price, embeddings are handled as an escalation step, not a default operation.
For this reason the /ask endpoint first makes an attempt an exact-match lookup earlier than calling embed_text().
The embed_text Perform
def embed_text(textual content: str):
This operate has one accountability: Convert enter textual content right into a semantic vector illustration.
It doesn’t carry out caching, similarity search, or validation. These issues reside elsewhere.
Calling the Embedding Mannequin
url = f"http://{settings.OLLAMA_HOST}:{settings.OLLAMA_PORT}/api/embeddings"
Right here, we assemble the Ollama embedding endpoint utilizing configuration values (e.g., settings.OLLAMA_HOST, settings.OLLAMA_PORT, and so on.).
This permits the embedding service to run regionally, inside Docker, or on a distant host with out altering code.
resp = httpx.submit(
url,
json={"mannequin": settings.EMBEDDING_MODEL, "immediate": textual content},
timeout=10.0
)
This request sends 2 key items of data to the embedding service:
- the embedding mannequin identify (e.g.,
nomic-embed-text) - the enter textual content to embed
The timeout ensures the request doesn’t hold indefinitely. Embedding era is dear, however it ought to nonetheless fail quick if one thing goes incorrect.
Dealing with the Response
resp.raise_for_status()
return resp.json().get("embedding", [])
If the request succeeds, the embedding mannequin returns a numeric vector — usually an inventory of floating-point values.
This vector represents the semantic that means of the enter textual content and turns into the important thing used for similarity comparability within the cache.
At this stage, we deal with the vector as an opaque object. We don’t examine its dimensionality or normalize it right here.
Error Dealing with Technique
besides Exception as e:
increase RuntimeError(f"Didn't generate embedding: {e}")
If embedding era fails for any purpose (community points, mannequin errors, timeouts), the operate raises an exception.
That is intentional.
If embeddings can’t be generated, the system can not safely carry out semantic matching. Silently persevering with would result in unpredictable conduct, so we fail loudly as a substitute.
Why the Embedder Is Deliberately Easy
Discover what this operate doesn’t do:
- it doesn’t retailer embeddings
- it doesn’t carry out similarity search
- it doesn’t retry failed requests
- it doesn’t fall again to different fashions
These choices are deliberate.
For Lesson 1, the embedder exists purely to transform textual content into vectors. Retaining it small and targeted makes the system simpler to know and check.
How the Embedder Is Used within the Pipeline
At runtime, the embedder is known as solely when needed:
- Precise-match cache fails
- The question is handed to
embed_text() - The returned vector is distributed to the semantic cache
- Similarity is computed towards saved embeddings
This ensures embeddings are generated solely when cheaper paths have already failed.
Key Takeaways
- Embeddings are generated through a easy HTTP name to a neighborhood mannequin
- The embedder has a single accountability
- Errors are surfaced instantly
- Embeddings act as semantic keys for cache lookup
With embedding era understood, we are actually prepared to take a look at the semantic cache itself, how embeddings and responses are saved, scanned, and matched.
Within the subsequent part, we are going to stroll by way of the semantic cache implementation, beginning with a intentionally naive however right linear scan method.
The Semantic Cache: Cosine Similarity, Redis Storage, and Reusing Which means
At this level, we perceive how queries enter the system and the way textual content is transformed into embeddings. What stays is the part that ties all the things collectively: the semantic cache itself.
The semantic cache is accountable for 2 issues:
- Storing previous queries, embeddings, and responses
- Retrieving the most effective reusable response for a brand new question
In Lesson 1, we deliberately implement the cache within the easiest right method doable: a linear scan over cached entries. This retains the implementation simple to purpose about and makes the request stream totally clear.
The Semantic Cache Module
The cache logic lives in semantic_cache.py:
class SemanticCache:
This class encapsulates all Redis interplay and similarity logic. The API layer by no means talks to Redis immediately.
Initializing the Cache
def __init__(self):
self.r = redis.Redis(
host=settings.REDIS_HOST,
port=settings.REDIS_PORT,
decode_responses=True
)
self.similarity_threshold = 0.85
self.namespace = "semantic_cache:v1"
Right here we set up a Redis connection and configure 2 vital parameters:
- Similarity threshold: Solely responses with sufficiently excessive semantic similarity are eligible for reuse.
- Namespace prefix: All Redis keys are namespaced to keep away from collisions and permit future versioning.
For Lesson 1, the precise threshold worth just isn’t vital. What issues is {that a} threshold exists and is utilized constantly.
Storing Cache Entries
The primary core operation is storing new entries.
def retailer(self, question, embedding, response, metadata=None):
This methodology is known as solely after a profitable LLM response.
Making a Cache Entry
entry = CacheEntry(
id=entry_uuid,
question=question,
query_hash=query_hash,
embedding=json.dumps(embedding),
response=response,
created_at=int(time.time()),
ttl=default_ttl(),
metadata=metadata or {}
)
Every cache entry shops:
- the unique question
- a normalized question hash (used for precise matching)
- the embedding (serialized for Redis storage)
- the LLM response
- timestamps and TTL
- non-obligatory metadata for observability
This construction permits the cache to assist each exact-match and semantic lookups.
Writing to Redis
self.r.hset(redis_key, mapping=entry.dict())
self.r.sadd(f"{self.namespace}:keys", redis_key)
Every cache entry is saved as a Redis hash, and all entry keys are tracked in a Redis set.
This permits the cache to iterate over all entries throughout search operations.
For Lesson 1, this method is deliberately easy and specific.
Looking the Cache
The second core operation is lookup.
def search(self, embedding, exact_query=None):
This methodology helps 2 search modes, which map on to the layered cache technique used within the API.
Precise-Match Lookup (Quick Path)
if exact_query:
query_hash = self._hash_query(exact_query)
When a precise question is offered, the cache first makes an attempt a hash-based lookup.
Every cached entry is scanned till an identical hash is discovered. If discovered, the entry is returned instantly with a similarity rating of 1.0.
No embeddings are concerned on this path.
Semantic Lookup (Versatile Path)
If no precise match is discovered and an embedding is offered, the cache performs a semantic search:
sim = self.cosine_similarity(query_embedding, cached_embedding)
Every cached embedding is in contrast towards the question embedding utilizing cosine similarity.
Solely entries that exceed the configured similarity threshold are thought-about candidates.
Deciding on the Greatest Match
Through the scan, the cache tracks the very best similarity rating and returns the most effective matching entry.
This ensures that even when a number of entries are comparable, probably the most related response is reused.
Why This Implementation Is O(N)
Each search scans all cached entries.
This isn’t an accident.
For Lesson 1, a linear scan has 3 benefits:
- the conduct is straightforward to know
- the logic is totally seen
- debugging is easy
Extra superior indexing methods belong in later classes.
Why Expired Entries Are Cleaned Throughout Search
Whereas scanning entries, expired objects are eliminated opportunistically.
This prevents stale knowledge from accumulating indefinitely with out introducing background staff or schedulers.
Key Takeaways
- The semantic cache owns all
Redisinteractions - Precise-match lookup is tried earlier than semantic matching
- Semantic similarity is computed utilizing embeddings
- A linear scan trades efficiency for readability
- The cache returns the finest reusable response, not simply the primary match
At this stage, the system is totally useful: queries will be answered, cached, and reused.
Cache Entries: What Precisely Will get Saved?
Thus far, we’ve handled the cache as a logical idea: one thing that shops queries, embeddings, and responses.
On this part, we’ll make that concrete by the construction of a cache entry. Understanding this construction is vital as a result of it explains why the cache can assist each exact-match and semantic lookup — with out duplicating knowledge or logic.
The Cache Entry Schema
Cache entries are outlined utilizing a Pydantic mannequin:
class CacheEntry(BaseModel):
id: str
question: str
query_hash: str
embedding: str
response: str
created_at: int
ttl: int
metadata: Elective[Dict] = Subject(default_factory=dict)
Every discipline exists for a particular purpose. Let’s stroll by way of them one after the other.
Identification and Question Fields
id: str question: str query_hash: str
id: uniquely identifies the cache entry and is used to assemble the Redis key.question: shops the unique person enter. That is helpful for debugging and inspection.query_hash: shops a normalized hash of the question and permits exact-match lookup.
At this stage, it’s sufficient to know that the hash ensures similar queries will be matched rapidly. We’ll revisit how and why this normalization issues in a later lesson.
Embedding Storage
embedding: str
Embeddings are saved as a JSON-serialized string, not as a uncooked Python record.
This selection is deliberate:
- Redis shops strings effectively
- Serialization retains the schema easy
- Deserialization occurs solely when similarity must be computed
For Lesson 1, the vital takeaway is that embeddings are saved as soon as, alongside the response they produced.
Response and Timing Data
response: str created_at: int ttl: int
response: is the textual content returned by the LLM.created_at: data when the entry was generated.ttl: defines how lengthy the entry is taken into account legitimate.
The cache doesn’t depend on Redis expiration right here. As an alternative, validity is checked at learn time. This provides the applying full management over when an entry must be reused or rejected.
We deliberately keep away from deeper TTL semantics on this lesson.
Metadata and Security
metadata: Elective[Dict] = Subject(default_factory=dict)
Metadata permits the cache to retailer contextual data corresponding to:
- pipeline identify
- mannequin identifier
- request origin
Using default_factory=dict avoids shared mutable state throughout cache entries — a refined however vital correctness element.
At this stage, metadata is informational quite than useful.
Why This Schema Works Properly
This schema helps the layered caching technique naturally:
- Precise match makes use of
query_hash - Semantic match makes use of embedding
- Freshness checks use
created_atandttl - Security checks use response and metadata
All required data is co-located in a single cache entry, making lookup and validation simple.
Finish-to-Finish Demo: Verifying Core Cache Habits
On this part, we are going to confirm that the semantic cache behaves as anticipated below a small set of managed situations.
These examples are supposed to be run regionally by the reader. The responses proven beneath are consultant and should differ barely relying on the mannequin and configuration.
Demo Case 1: Chilly Request (LLM Fallback)
We start with a question that has not been seen earlier than.
curl -X POST http://localhost:8000/ask
-H "Content material-Kind: software/json"
-d '{"question": "What's semantic caching?"}'
Anticipated conduct
- Precise-match cache miss
- Semantic cache miss
- LLM name
- Cache inhabitants
Response
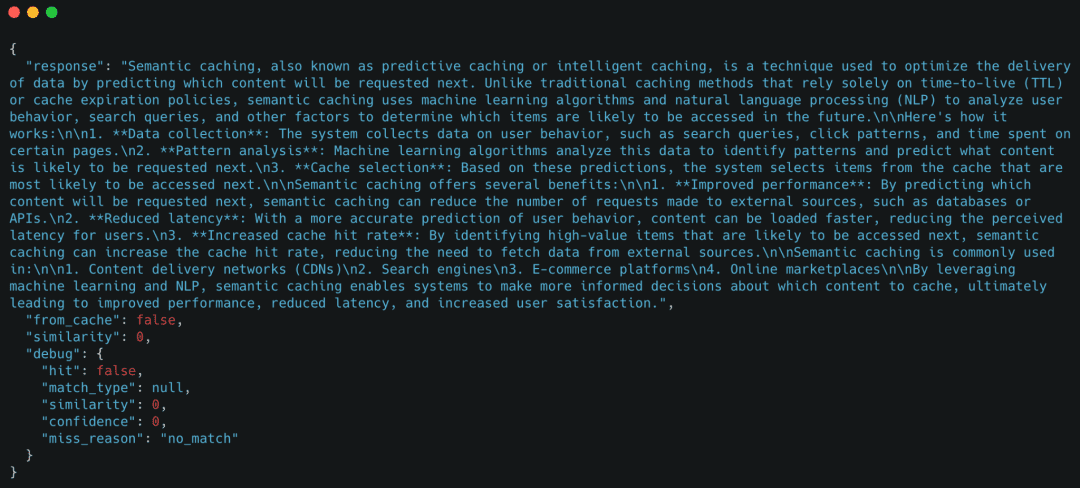
The important thing sign right here is "from_cache": false, confirming the request fell again to the LLM.
Demo Case 2: Precise-Match Cache Hit
Now we ship the identical question once more.
curl -X POST http://localhost:8000/ask
-H "Content material-Kind: software/json"
-d '{"question": "What's semantic caching?"}'
Anticipated conduct
- Precise-match cache hit
- No embedding era
- No LLM name
Instance response
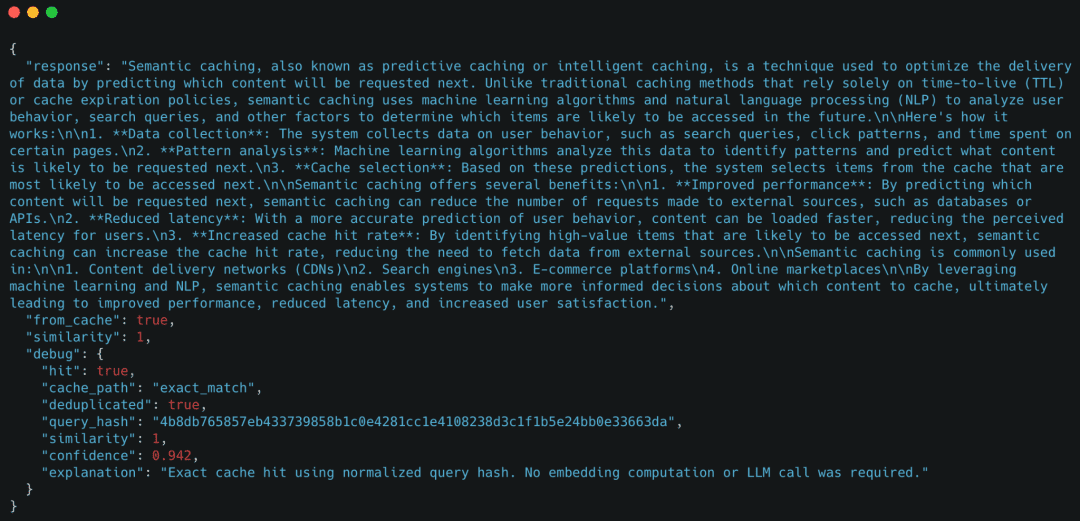
Right here, the cache reused the response instantly utilizing an exact-match lookup.
Elective Demo: Whitespace Normalization
curl -X POST http://localhost:8000/ask
-H "Content material-Kind: software/json"
-d '{"question": " What is semantic caching? "}'
This can hit the exact-match cache because of question normalization.
Demo Case 3: Semantic Cache Hit (Paraphrased Question)
Subsequent, we ship a paraphrased model of the unique question.
curl -X POST http://localhost:8000/ask
-H "Content material-Kind: software/json"
-d '{"question": "Are you able to clarify how semantic caching works?"}'
Anticipated conduct
- Precise-match cache miss
- Embedding era
- Semantic cache hit
- No LLM name
Instance response
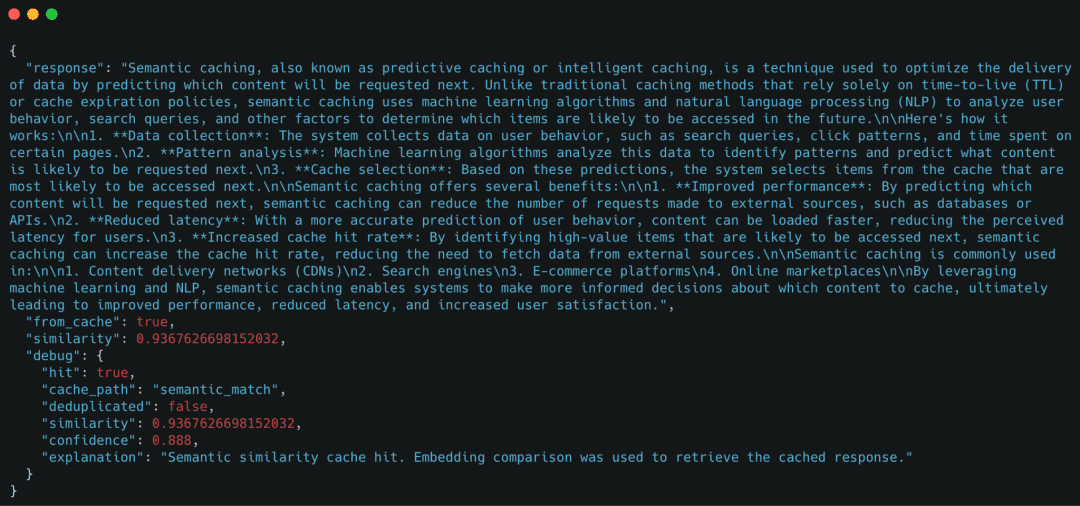
Though the question textual content is totally different, the cache efficiently reused the response primarily based on semantic similarity.
Demo Case 4: Forcing a Cache Miss with bypass_cache
The bypass_cache flag permits us to drive the system to skip each cache layers.
curl -X POST http://localhost:8000/ask
-H "Content material-Kind: software/json"
-d '{"question": "What's semantic caching?", "bypass_cache": true}'
Anticipated conduct
- Precise-match cache skipped
- Semantic cache skipped
- LLM known as unconditionally
Instance response

bypass_cache, guaranteeing the LLM pipeline executes independently of cached responses (supply: picture by the writer).That is helpful for debugging and validating that the LLM pipeline nonetheless works independently of the cache.
Observing Cache Metrics (Elective)
You may examine fundamental cache statistics utilizing the /inside/metrics endpoint:
curl http://localhost:8000/inside/metrics
Instance response
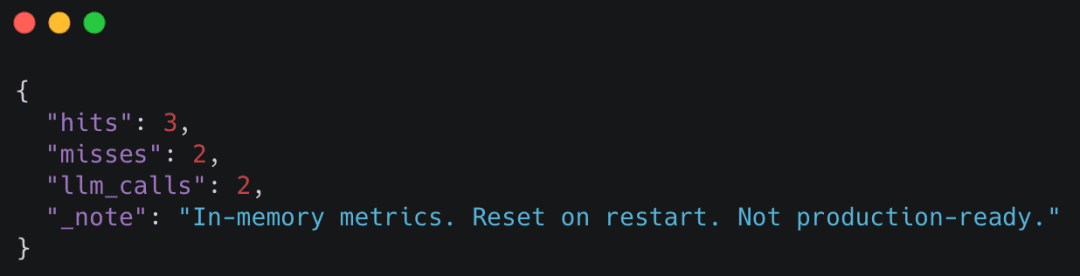
These metrics make cache conduct observable with out requiring exterior tooling.
For those who can reproduce these behaviors regionally, you’ve efficiently carried out a working semantic cache.
Within the subsequent lesson, we are going to take this technique and start hardening it for real-world use.
What’s subsequent? We advocate PyImageSearch College.
86+ complete courses • 115+ hours hours of on-demand code walkthrough movies • Final up to date: April 2026
★★★★★ 4.84 (128 Scores) • 16,000+ College students Enrolled
I strongly consider that when you had the suitable trainer you can grasp laptop imaginative and prescient and deep studying.
Do you assume studying laptop imaginative and prescient and deep studying needs to be time-consuming, overwhelming, and sophisticated? Or has to contain advanced arithmetic and equations? Or requires a level in laptop science?
That’s not the case.
All you might want to grasp laptop imaginative and prescient and deep studying is for somebody to elucidate issues to you in easy, intuitive phrases. And that’s precisely what I do. My mission is to alter training and the way advanced Synthetic Intelligence matters are taught.
For those who’re critical about studying laptop imaginative and prescient, your subsequent cease must be PyImageSearch College, probably the most complete laptop imaginative and prescient, deep studying, and OpenCV course on-line immediately. Right here you’ll learn to efficiently and confidently apply laptop imaginative and prescient to your work, analysis, and tasks. Be part of me in laptop imaginative and prescient mastery.
Inside PyImageSearch College you may discover:
- &verify; 86+ programs on important laptop imaginative and prescient, deep studying, and OpenCV matters
- &verify; 86 Certificates of Completion
- &verify; 115+ hours hours of on-demand video
- &verify; Model new programs launched frequently, guaranteeing you possibly can sustain with state-of-the-art strategies
- &verify; Pre-configured Jupyter Notebooks in Google Colab
- &verify; Run all code examples in your net browser — works on Home windows, macOS, and Linux (no dev surroundings configuration required!)
- &verify; Entry to centralized code repos for all 540+ tutorials on PyImageSearch
- &verify; Straightforward one-click downloads for code, datasets, pre-trained fashions, and so on.
- &verify; Entry on cellular, laptop computer, desktop, and so on.
Abstract
On this lesson, we constructed a whole semantic caching system for LLM purposes from the bottom up. We began by wiring a FastAPI service and defining a clear request–response contract, then carried out a layered caching technique that prioritizes low cost exact-match lookups earlier than escalating to semantic similarity and, lastly, LLM inference.
We walked by way of how textual content queries are transformed into embeddings on demand, how cached responses and embeddings are saved in Redis, and the way the cache decides whether or not a previous response will be safely reused. By maintaining the implementation deliberately easy and specific, each step within the request stream stays observable and simple to purpose about.
Lastly, we verified the system end-to-end by operating managed demos: a chilly request falling again to the LLM, an exact-match cache hit, a semantic cache hit for a paraphrased question, and an specific cache bypass. At this level, you’ve got a working semantic cache that behaves appropriately, makes its choices seen, and serves as a stable basis for additional hardening and optimization.
Quotation Data
Singh, V. “Semantic Caching for LLMs: FastAPI, Redis, and Embeddings,” PyImageSearch, S. Huot, A. Sharma, and P. Thakur, eds., 2026, https://pyimg.co/yso6f
@incollection{Singh_2026_semantic-caching-for-llms-fastapi-redis-and-embeddings,
writer = {Vikram Singh},
title = {{Semantic Caching for LLMs: FastAPI, Redis, and Embeddings}},
booktitle = {PyImageSearch},
editor = {Susan Huot and Aditya Sharma and Piyush Thakur},
yr = {2026},
url = {https://pyimg.co/yso6f},
}
To obtain the supply code to this submit (and be notified when future tutorials are revealed right here on PyImageSearch), merely enter your electronic mail handle within the type beneath!

Obtain the Supply Code and FREE 17-page Useful resource Information
Enter your electronic mail handle beneath to get a .zip of the code and a FREE 17-page Useful resource Information on Pc Imaginative and prescient, OpenCV, and Deep Studying. Inside you may discover my hand-picked tutorials, books, programs, and libraries that will help you grasp CV and DL!
The submit Semantic Caching for LLMs: FastAPI, Redis, and Embeddings appeared first on PyImageSearch.