Fast Digest
Query – What’s driving the 2026 GPU scarcity and the way is it reshaping AI improvement?
Reply: The present compute crunch is a product of explosive demand from AI workloads, restricted provides of excessive‑bandwidth reminiscence, and tight superior packaging capability.
Researchers be aware that lead occasions for information‑middle GPUs now run from 36 to 52 weeks, and that reminiscence suppliers are prioritizing excessive‑margin AI chips over shopper merchandise. In consequence, gaming GPU manufacturing has slowed and information‑middle patrons dominate the worldwide provide of DRAM and HBM. This text argues that the GPU scarcity will not be a short lived blip however a sign that AI builders should design for constrained compute, undertake environment friendly algorithms, and embrace heterogeneous {hardware} and multi‑cloud methods.
Introduction: The Anatomy of a Scarcity
At first look, the GPU shortages of 2026 look like a repeat of earlier increase‑and‑bust cycles—spikes pushed by cryptocurrency miners or bot‑pushed scalping. However deeper investigation reveals a structural shift: synthetic intelligence has grow to be the dominant shopper of computing {hardware}. Massive‑language fashions and generative AI techniques now feed on tokens at a fee that has elevated roughly fifty‑fold in just some years. To fulfill this starvation for compute, hyperscalers have signed multi‑12 months contracts for all the output of some reminiscence fabs, reportedly locking up 40 % of worldwide DRAM provide. In the meantime, the semiconductor trade’s capacity to develop provide is restricted by bottlenecks in excessive ultraviolet lithography, excessive‑bandwidth reminiscence (HBM) manufacturing, and superior 2.5‑D packaging.
The result’s a paradox: regardless of report investments in chip manufacturing and new foundries breaking floor around the globe, AI firms face a multiyear lag between demand and provide. Datacenter GPUs, like Nvidia’s H100 and AMD’s MI250, now have lead occasions of 9 months to a 12 months, whereas workstation playing cards wait twelve to twenty weeks. Reminiscence modules and CoWoS (chip‑on‑wafer‑on‑substrate) packaging stay so scarce that PC distributors in Japan stopped taking orders for top‑finish desktops. This scarcity is not only about chips; it’s about how the structure of AI techniques is evolving, how firms design their infrastructure, and the way nations plan their industrial insurance policies.
On this article we discover the current state of the GPU and reminiscence scarcity, the foundation causes that drive it, its influence on AI firms, the rising options to deal with constrained compute, and the socio‑financial implications. We then stay up for future traits and think about what to anticipate because the trade adapts to a world of restricted compute. All through the article we’ll spotlight insights from researchers, analysts, and practitioners, and supply solutions for a way Clarifai’s merchandise may help organizations navigate this panorama.
The Current State of the GPU and Reminiscence Scarcity
By 2026 the compute crunch has moved from anecdotal complaints on developer boards to a worldwide financial problem. Knowledge‑middle GPUs are successfully bought out for months, with lead occasions stretching between thirty‑six and fifty‑two weeks. These lengthy waits aren’t confined to a single vendor or product; they span throughout Nvidia, AMD and even boutique AI chip makers. Workstation GPUs, which as soon as may very well be bought off the shelf, now require twelve to twenty weeks of persistence.
On the shopper stage, the scenario is totally different however nonetheless tight. Rumors of gaming GPU manufacturing cuts surfaced as early as 2025. Reminiscence producers, prioritizing excessive‑margin information‑middle HBM gross sales, have lowered shipments of GDDR6 and GDDR7 modules utilized in gaming playing cards. The shift has had a ripple impact: DDR5 reminiscence kits that value round $90 in 2025 now value $240 or extra, and lead occasions for normal DRAM prolonged from eight to 10 weeks to over twenty weeks. This worth escalation will not be hypothesis; Japanese PC distributors like Sycom and TSUKUMO halted orders as a result of DDR5 was 4 occasions costlier than a 12 months earlier.
The scarcity is particularly acute in excessive‑bandwidth reminiscence. HBM packages are essential for AI accelerators, enabling fashions to maneuver massive tensors rapidly. Reminiscence suppliers have shifted capability away from DDR and GDDR to HBM, with analysts noting that information facilities will devour as much as 70 % of worldwide reminiscence provide in 2026. As a consequence, reminiscence module availability for PCs and embedded techniques has dwindled. This imbalance has even led to hypothesis that RAM might account for 10 % of the price of shopper electronics and as much as 30 % of smartphones.
In brief, the current state of the compute crunch is outlined by lengthy lead occasions for information‑middle GPUs, dramatic worth will increase for reminiscence, and reallocation of provide to AI datacenters. It is usually marked by the fact that new orders of GPUs and reminiscence are restricted to contracted volumes. Which means even firms prepared to pay excessive costs can’t merely purchase extra GPUs; they need to wait their flip. The scarcity is due to this fact not nearly affordability but additionally about accessibility.
Skilled Voices on the Present Scenario
Business commentators have been candid concerning the severity of the scarcity. BCD, a worldwide {hardware} distributor, experiences that information‑middle GPU lead occasions have climbed to a 12 months and warns that offer will stay tight by means of no less than late 2026. Sourceability, a significant part distributor, highlights that DRAM lead occasions have prolonged past twenty weeks and that reminiscence distributors are implementing allocation‑solely ordering, successfully rationing provide. Tom’s {Hardware}, reporting from Japan, notes that PC makers have quickly stopped taking orders on account of skyrocketing reminiscence prices.
These sources paint a constant image: the scarcity will not be localized or transitory however structural and world. At the same time as new GPU architectures, similar to Nvidia’s H200 and AMD’s MI300, start delivery, the tempo of demand outstrips provide. The result’s a bifurcation of the market: hyperscalers with assured contracts obtain chips, whereas smaller firms and hobbyists are left to hunt on secondary markets or lease by means of cloud suppliers.
Root Causes of the Compute Crunch
Understanding the scarcity requires trying past the headlines to the underlying drivers. Demand is the obvious issue. The rise of generative AI and enormous‑language fashions has led to exponential progress in token consumption. This surge interprets instantly into compute necessities. Coaching GPT‑class fashions requires a whole bunch of teraflops and petabytes of reminiscence bandwidth, and inference at scale—serving billions of queries day by day—provides additional strain. In 2023, early AI firms consumed a couple of hundred megawatts of compute; by 2026, analysts estimate that AI datacenters require tens of gigawatts of capability.
Reminiscence bottlenecks amplify the issue. Excessive‑bandwidth reminiscence similar to HBM3 and HBM4 is produced by a handful of producers. In accordance with provide‑chain analysts, DRAM provide presently solely helps about 15 gigawatts of AI infrastructure. Which will sound like lots, however when massive fashions run throughout hundreds of GPUs, this capability is rapidly exhausted. Moreover, DRAM manufacturing is constrained by excessive ultraviolet lithography (EUV) and the necessity for superior course of nodes; constructing new EUV capability takes years.
Superior packaging constraints additionally restrict GPU provide. Many AI accelerators depend on 2.5‑D integration, the place reminiscence stacks are mounted on silicon interposers. This course of, sometimes called CoWoS, requires refined packaging traces. BCD experiences that packaging capability is totally booked, and ramping new packaging traces is slower than including wafer capability. Within the close to time period, which means that even when foundries produce sufficient compute dies, packaging them into completed merchandise stays a choke level.
Prioritization by reminiscence and GPU distributors performs a task as properly. When demand exceeds provide, firms optimize for margin. Reminiscence makers allocate extra HBM to AI chips as a result of they command increased costs than DDR modules. GPU distributors favor information‑middle clients as a result of a single rack of H100 playing cards, priced at round $25,000 per card, can generate over $400,000 in income. Against this, shopper GPUs are much less worthwhile and are due to this fact deprioritized.
Lastly, the deliberate sundown of DDR4 contributes to the crunch. Producers are shifting capability from mature DDR4 traces to newer DDR5 and HBM traces. Sourceability warns that the tip‑of‑lifetime of DDR4 is squeezing provide, resulting in shortages even in legacy platforms.
These root causes—insatiable AI demand, reminiscence manufacturing bottlenecks, packaging constraints, and vendor prioritization—collectively create a system the place provide can’t sustain with demand. The compute crunch will not be on account of any single failure; reasonably, it’s an ecosystem‑extensive mismatch between exponential progress and linear capability growth.
Influence on AI Corporations and the Broader Ecosystem
The compute crunch impacts organizations otherwise relying on dimension, capital and technique. Hyperscalers and properly‑funded AI labs have secured multi‑12 months agreements with chip distributors. They sometimes buy whole racks of GPUs—the worth of an H100 rack can exceed $400,000—and make investments closely in bespoke infrastructure. In some circumstances, the overall value of possession is even increased when factoring in networking, energy and cooling. For these gamers, the compute crunch is a capital expenditure problem; they need to increase billions to take care of aggressive coaching capability.
Startups and smaller AI groups face a special actuality. As a result of they lack negotiating energy, they typically can’t safe GPUs from distributors instantly. As an alternative, they lease compute from cloud marketplaces. Cloud suppliers like AWS, Azure, and specialised platforms like Jarvislabs and Lambda Labs supply GPU cases for between $2.99 and $9.98 per hour. Nevertheless, even these leases are topic to availability; spot cases are steadily bought out, and on‑demand charges can spike on account of demand surges. The compute crunch thus forces startups to optimize for value effectivity, undertake smarter architectures, or companion with suppliers that assure capability.
The scarcity additionally modifications product improvement timelines. Mannequin coaching cycles that when took weeks now have to be deliberate months forward, as a result of organizations have to guide {hardware} properly upfront. Delays in GPU supply can postpone product launches or trigger groups to accept smaller fashions. Inference workloads—serving fashions in manufacturing—are much less delicate to coaching {hardware} however nonetheless require GPUs or specialised accelerators. A Futurum survey discovered that solely 19 % of enterprises have coaching‑dominant workloads; the overwhelming majority are inference‑heavy. This shift means firms are spending extra on inference than coaching and thus have to allocate GPUs throughout each duties.
Prices Past the Card
One of the crucial misunderstood features of the compute crunch is the complete value of working AI {hardware}. Jarvislabs analysts level out that purchasing an H100 card is only the start. Organizations should additionally spend money on energy distribution, excessive‑density cooling options, networking gear and amenities. Collectively, these techniques can double or triple the price of the {hardware} itself. When margins are skinny, as is commonly the case for AI startups, renting could also be extra value‑efficient than buying.
Furthermore, the scarcity encourages a “GPU as oil” narrative—the concept that GPUs are scarce assets to be managed strategically. Simply as oil firms diversify their suppliers and hedge towards worth swings, AI firms should deal with compute as a portfolio. They can’t depend on a single cloud supplier or {hardware} vendor; they need to discover a number of sources, together with multi‑cloud methods, and design software program that’s moveable throughout {hardware} architectures.
Rising Infrastructure Options
If shortage is the brand new regular, the following query is function successfully in a constrained setting. Organizations are responding with a mix of technical, strategic and operational improvements.
Multi‑Cloud Methods
As a result of compute availability varies throughout areas and distributors, multi‑cloud methods have grow to be important. KnubiSoft, a cloud‑infrastructure consultancy, emphasizes that firms ought to deal with compute like monetary belongings. By spreading workloads throughout a number of clouds, organizations scale back dependence on any single supplier, mitigate regional disruptions, and entry spot capability when it seems. This strategy additionally helps with regulatory compliance: workloads will be positioned in areas that meet information‑sovereignty necessities whereas failing over to different areas when capability is constrained.
Implementing multi‑cloud is non‑trivial; it requires orchestration instruments that may dispatch jobs to the appropriate clusters, monitor efficiency and value, and deal with information synchronization. Clarifai’s compute‑orchestration layer gives a unified interface to schedule coaching and inference jobs throughout cloud suppliers and on‑prem clusters. By abstracting the variations between, say, Nvidia A100 cases on Azure and AMD MI300 cases on an on‑prem cluster, Clarifai permits engineers to concentrate on mannequin improvement reasonably than infrastructure plumbing.
Compute Orchestration Platforms
Past easy multi‑cloud deployment, firms have to orchestrate their compute assets intelligently. Compute orchestration platforms allocate jobs primarily based on useful resource necessities, availability and value. They’ll dynamically scale clusters, pause jobs throughout worth spikes, and resume them when capability is affordable.
Clarifai’s orchestration resolution routinely chooses essentially the most appropriate {hardware}—GPUs for coaching, XPUs or CPUs for inference—whereas respecting consumer priorities and SLAs. It screens queue lengths and server well being to keep away from idle assets and ensures that costly GPUs are stored busy. Such orchestration is particularly vital when working with heterogeneous {hardware}, which we focus on additional under.
Environment friendly Mannequin Inference and Native Runners
For a lot of organizations, inference workloads now dwarf coaching workloads. Serving a big language mannequin in manufacturing could require hundreds of GPUs if executed naively. Mannequin inference frameworks like Clarifai’s service deal with batching, caching and auto‑scaling to scale back latency and value. They reuse cached token sequences, group requests to enhance GPU utilization, and spin up extra cases when site visitors spikes.
One other technique is to deliver inference nearer to customers. Native runners and edge deployments enable fashions to run on gadgets or native servers, avoiding the necessity to ship each request to a datacenter. Clarifai’s native runner allows firms to deploy fashions on useful resource‑constrained {hardware}, making it simpler to serve fashions in privateness‑delicate contexts or in areas with restricted connectivity. Native inference additionally reduces reliance on scarce information‑middle GPUs and might enhance consumer expertise by reducing latency.
Heterogeneous Accelerators and XPUs
The scarcity of GPUs has catalyzed curiosity in various {hardware}. XPUs—a catchall time period for TPUs, FPGAs, customized ASICs and different specialised processors—are drawing important funding. A Futurum survey finds that enterprise spending on XPUs is projected to develop 22.1 % in 2026, outpacing progress in GPU spending. About 31 % of determination‑makers are evaluating Google’s TPUs and 26 % are evaluating AWS’s Trainium. Corporations like Intel (with its Gaudi accelerators), Graphcore (with its IPU) and Cerebras (with its wafer‑scale engine) are additionally gaining traction.
Heterogeneous accelerators supply a number of advantages: they typically ship higher efficiency per watt on particular duties (e.g., matrix multiplication or convolution), they usually diversify provide. FPGA accelerators utilizing structured sparsity and low‑bit quantization can obtain a 1.36× enchancment in throughput per token, whereas 4‑bit quantization and pruning scale back weight storage 4‑fold and velocity up inference by 1.29× to 1.71×. As XPUs grow to be extra mainstream, we anticipate software program stacks to mature; Clarifai’s {hardware}‑abstraction layer already helps builders deploy the identical mannequin on GPUs, TPUs or FPGAs with minimal code modifications.
Compute Marketplaces and On‑Demand Leases
In a world the place {hardware} is scarce, GPU marketplaces and specialised cloud suppliers serve an vital area of interest. Platforms like Jarvislabs and Lambda Labs enable firms to lease GPUs by the hour, typically at decrease charges than mainstream clouds. They mixture unused capability from information facilities and resell it at market costs. This mannequin is akin to trip‑sharing for compute. Nevertheless, availability fluctuates; excessive demand can wipe out stock rapidly. Corporations utilizing such marketplaces should combine them into their orchestration methods to keep away from job interruptions.
Power‑Environment friendly Datacenter Design
Lastly, the compute crunch has spotlighted the significance of power effectivity. Knowledge facilities not solely devour GPUs but additionally huge quantities of electrical energy and water. To mitigate environmental influence and scale back working prices, many suppliers are co‑finding with renewable power sources, utilizing pure gasoline for mixed warmth and energy, and adopting superior cooling methods. Improvements like liquid immersion cooling and AI‑pushed temperature optimization have gotten mainstream. These efforts not solely scale back carbon footprints but additionally unencumber energy for extra GPUs—making power effectivity an integral a part of the {hardware} provide story.
Mannequin Effectivity & Algorithmic Improvements
When {hardware} is scarce, making every flop and byte depend turns into vital. Over the previous two years, researchers have poured power into methods that scale back mannequin dimension, speed up inference and protect accuracy.
Quantization and Structured Sparsity
One of the crucial highly effective methods is quantization, which reduces the precision of mannequin weights and activations. 4‑bit integer codecs can reduce the reminiscence footprint of weights by 4×, whereas sustaining practically the identical accuracy when mixed with calibration methods. When paired with structured sparsity, the place some weights are set to zero in an everyday sample, quantization can velocity up matrix multiplication and scale back energy consumption. Analysis combining N:M sparsity and 4‑bit quantization demonstrates a 1.71× matrix multiplication speedup and a 1.29× discount in latency on FPGA accelerators.
These methods aren’t restricted to FPGAs; GPU‑primarily based inference engines like NVIDIA TensorRT and AMD’s ROCm are more and more including assist for blended‑precision codecs. Clarifai’s inference service incorporates quantization to shrink fashions and speed up inference routinely, releasing up GPU capability.
{Hardware}–Software program Co‑Design
One other rising pattern is {hardware}–software program co‑design. Fairly than designing chips and algorithms individually, engineers co‑optimize fashions with the goal {hardware}. Sparse and quantized fashions compiled for FPGAs can ship a 1.36× enchancment in throughput per token, as a result of the FPGA can skip multiplications involving zeros. Dynamic zero‑skipping and reconfigurable information paths maximize {hardware} utilization.
Inference‑First Optimization
Though coaching massive fashions garners headlines, most actual‑world AI spending is now on inference. This shift encourages builders to construct fashions that run effectively in manufacturing. Strategies similar to Low‑Rank Adaptation (LoRA) and Adapter layers enable wonderful‑tuning massive fashions with out updating all parameters, decreasing coaching and inference prices. Information distillation, the place a smaller pupil mannequin learns from a big instructor mannequin, creates compact fashions that carry out competitively whereas requiring much less {hardware}.
Clarifai’s inference service helps right here by batching and caching tokens. Dynamic batching teams a number of requests to maximise GPU utilization; caching shops intermediate computations for repeated prompts, decreasing recomputation. These optimizations can scale back the price per token and alleviate strain on GPUs.
Past GPUs – The Rise of Heterogeneous Compute
Whereas GPUs stay the workhorse of AI, the compute crunch has accelerated the rise of different accelerators. Enterprises are reevaluating their {hardware} stacks and more and more adopting customized chips designed for particular workloads.
XPUs and Specialised Accelerators
In accordance with Futurum’s analysis, XPU spending will develop 22.1 % in 2026, outpacing progress in GPU spending. This class consists of Google’s TPU, AWS’s Trainium, Intel’s Gaudi and Graphcore’s IPU. These accelerators sometimes characteristic matrix multiply models optimized for deep studying and might outperform common‑objective GPUs on particular fashions. About 31 % of surveyed determination‑makers are actively evaluating TPUs and 26 % are evaluating Trainium. Early adopters report sturdy effectivity positive aspects on duties like transformer inference, with decrease energy consumption.
FPGAs and Reconfigurable {Hardware}
Reconfigurable gadgets like FPGAs are seeing a resurgence. Analysis exhibits that sparsity‑conscious FPGA designs ship a 1.36× enchancment in throughput per token. FPGAs can implement dynamic zero‑skipping and customized arithmetic pipelines, making them perfect for extremely sparse or quantized fashions. Whereas they sometimes require specialised experience, new software program toolchains are simplifying their use.
AI PCs and Edge Accelerators
The compute crunch will not be confined to information facilities; it is usually shaping edge and shopper {hardware}. AI PCs with built-in neural processing models (NPUs) are starting to ship from main laptop computer producers. Smartphone system‑on‑chips now embody devoted AI cores. These gadgets enable some inference duties to run regionally, decreasing reliance on cloud GPUs. As reminiscence costs climb and cloud queues lengthen, native inference on NPUs could grow to be extra engaging.
Unified Orchestration Throughout Various {Hardware}
Adopting numerous {hardware} raises the problem of handle it. Software program should dynamically determine whether or not to run on a GPU, TPU, FPGA or CPU, relying on value, availability and efficiency. Clarifai’s {hardware}‑abstraction layer abstracts away the variations between gadgets, permitting builders to deploy a mannequin throughout a number of {hardware} sorts with minimal modifications. This portability is vital in a world the place provide constraints may drive a change from one accelerator to a different on brief discover.
Socio‑Financial Implications and Market Outlook
The compute crunch reverberates past the know-how sector. Reminiscence shortages are impacting automotive and shopper electronics industries, the place reminiscence modules now account for a bigger share of the invoice of supplies. Analysts warn that smartphone shipments might dip by 5 % and PC shipments by 9 % in 2026 as a result of excessive reminiscence costs deter shoppers. For automakers, reminiscence constraints might delay infotainment and superior driver‑help techniques, influencing product timelines.
Regional and Geopolitical Results
Completely different areas expertise the scarcity in distinct methods. In Japan, some PC distributors halted orders altogether on account of 4‑fold will increase in DDR5 costs. In Europe, power costs and regulatory hurdles complicate information‑middle development. The USA, China and the European Union have every launched multi‑billion‑greenback initiatives to spice up home semiconductor manufacturing. These packages purpose to scale back reliance on overseas fabs and safe provide chains for strategic applied sciences.
Geopolitical tensions add one other layer of complexity. Export controls on superior chips prohibit the place {hardware} will be shipped, complicating provide for worldwide patrons. Corporations should navigate an internet of laws whereas nonetheless making an attempt to acquire scarce GPUs. This setting encourages collaboration with distributors who supply clear provide chains and compliance assist.
Environmental Influence and Power Issues
AI datacenters devour huge quantities of electrical energy and water. As extra chips are deployed, the ability footprint grows. To mitigate environmental influence and management prices, datacenter operators are co‑finding with renewable power sources and bettering cooling effectivity. Some initiatives combine pure gasoline vegetation with information facilities to recycle waste warmth, whereas others discover hydro‑powered places. Governments are imposing stricter laws on power use and emissions, forcing firms to think about sustainability in procurement choices.
Market Dynamics
The market outlook is blended. TrendForce researchers describe the reallocation of reminiscence capability towards AI datacenters as “everlasting”. Which means even when new DDR and HBM capability comes on-line, a big share will stay tied to AI clients. Buyers are channeling capital into reminiscence fabs, superior packaging amenities and new foundries reasonably than shopper merchandise. Worth volatility is probably going; some analysts forecast that HBM costs could rise one other 30 – 40 % in 2026. For patrons, this setting necessitates lengthy‑time period procurement planning and monetary hedging.
Future Tendencies & What to Count on
Whereas the present scarcity is extreme, the trade is taking steps to deal with it. New fabs in the US, Europe and Asia are slated to ramp up by 2027–2028. Intel, TSMC, Samsung and Micron all have initiatives underway. These amenities will improve output of each compute dies and excessive‑bandwidth reminiscence. Nevertheless, provide‑chain consultants warning that lead occasions will stay elevated by means of no less than 2026. It merely takes time to construct, equip and certify new fabs. Even as soon as they arrive on-line, baseline pricing could keep excessive on account of continued sturdy demand.
Enhancements in HBM and DDR5 Output
Analysts anticipate that HBM and DDR5 manufacturing will enhance by late 2026 or early 2027. As provide will increase, some worth aid might happen. But as a result of AI demand can be rising, provide growth could solely meet, reasonably than exceed, consumption. This dynamic suggests a protracted equilibrium the place costs stay above historic norms and allocation insurance policies proceed.
The Ascendancy of XPUs and Software program Improvements
Trying forward, XPU adoption is predicted to speed up. The spending hole between XPUs and GPUs is narrowing, and by 2027 XPUs could account for a bigger share of AI {hardware} budgets. Improvements similar to combination‑of‑consultants (MoE) architectures, which distribute computation throughout smaller sub‑fashions, and retrieval‑augmented technology (RAG), which reduces the necessity for storing all information in mannequin weights, will additional decrease compute necessities.
On the software program facet, new compilers and scheduling algorithms will optimize fashions throughout heterogeneous {hardware}. The objective is to run every a part of the mannequin on essentially the most appropriate processor, balancing velocity and effectivity. Clarifai is investing in these areas by means of its {hardware}‑abstraction and orchestration layers, guaranteeing that builders can harness new {hardware} with out rewriting code.
Regulatory and Sustainability Tendencies
Regulators are starting to scrutinize AI {hardware} provide chains. Environmental laws round power consumption and carbon emissions are tightening, and information‑sovereignty legal guidelines affect the place information will be processed. These traits will form datacenter places and funding methods. Corporations could have to construct smaller, regional clusters to adjust to native legal guidelines, additional spreading demand throughout a number of amenities.
Skilled Predictions
Provide‑chain consultants see early indicators of stabilization round 2027 however warning that baseline pricing is unlikely to return to pre‑2024 ranges. HBM pricing could proceed to rise, and allocation guidelines will persist. Researchers stress that procurement groups should work carefully with engineering to plan demand, diversify suppliers and optimize designs. Futurum analysts predict that XPUs would be the breakout story of 2026, shifting market consideration away from GPUs and inspiring funding in new architectures. The consensus is that the compute crunch is a multi‑12 months phenomenon reasonably than a fleeting scarcity.
Ultimate Ideas: Designing for a World of Constrained Compute
The 2026 GPU scarcity will not be merely a provide hiccup; it alerts a basic reordering of the AI {hardware} panorama. Lead occasions approaching a 12 months for information‑middle GPUs and reminiscence consumption dominated by AI datacenters display that demand outstrips provide by design. This imbalance won’t resolve rapidly as a result of DRAM and HBM capability can’t be ramped in a single day and new fabs take years to construct.
For organizations constructing AI merchandise in 2026, the crucial is to design for shortage. Meaning adopting multi‑cloud and heterogeneous compute methods to diversify threat; embracing mannequin‑effectivity methods similar to quantization and pruning; and leveraging orchestration platforms, like Clarifai’s Compute Orchestration and Mannequin Inference providers, to run fashions on essentially the most value‑efficient {hardware}. The rise of XPUs and customized ASICs will step by step redefine what “compute” means, whereas software program improvements like MoE and RAG will make fashions leaner and extra versatile.
But the market will stay turbulent. Reminiscence pricing volatility, regulatory fragmentation and geopolitical tensions will maintain provide unsure. The winners shall be those that construct versatile architectures, optimize for effectivity, and deal with compute not as a commodity to be taken with no consideration however as a scarce useful resource for use properly. On this new period, shortage turns into a catalyst for innovation—a spur to invent higher algorithms, design smarter {hardware} and rethink how and the place we run AI fashions.
Incessantly Requested Questions (FAQs)
- What’s inflicting the GPU scarcity in 2026?
The scarcity stems from explosive AI demand, restricted excessive‑bandwidth reminiscence provide and bottlenecks in superior packaging and wafer capability. Reminiscence distributors prioritize excessive‑margin AI chips, leaving fewer DRAM and GDDR modules for shopper GPUs.
- How lengthy are the present lead occasions for information‑middle GPUs?
Lead occasions for information‑middle GPUs vary from 36 to 52 weeks, whereas workstation GPUs expertise 12–20 week lead occasions.
- Why are reminiscence costs rising so quickly?
DDR5 and HBM costs surged as a result of reminiscence producers have reallocated capability towards AI accelerators. DDR5 kits that value round $90 in 2025 now value $240 or extra, and reminiscence suppliers are limiting orders to contracted volumes, extending lead occasions from 8–10 weeks to over 20.
- Are various accelerators a viable resolution to the GPU scarcity?
Sure. XPUs—together with TPUs, Trainium, Gaudi, IPUs and FPGAs—are gaining adoption. A survey signifies that 31 % of enterprises are evaluating TPUs and 26 % are evaluating Trainium, and XPU spending is projected to develop 22.1 % in 2026. These accelerators diversify provide and supply effectivity advantages.
- Will the scarcity finish quickly?
Provide‑chain consultants anticipate some stabilization round 2027 as new fabs ramp up. Nevertheless, demand stays excessive, and analysts warn that baseline pricing will keep elevated and that allocation‑solely ordering will persist. Thus, the scarcity will doubtless proceed to affect AI {hardware} methods for the following few years.

 multinomial logistic regression")


![5 Gemini Prompts for JEE Preparation [MUST READ]](https://cdn.analyticsvidhya.com/wp-content/uploads/2026/01/Top-Prompts-to-prepare-for-JEE-with-Gemini-1.png "5 Gemini Prompts for JEE Preparation [MUST READ]")






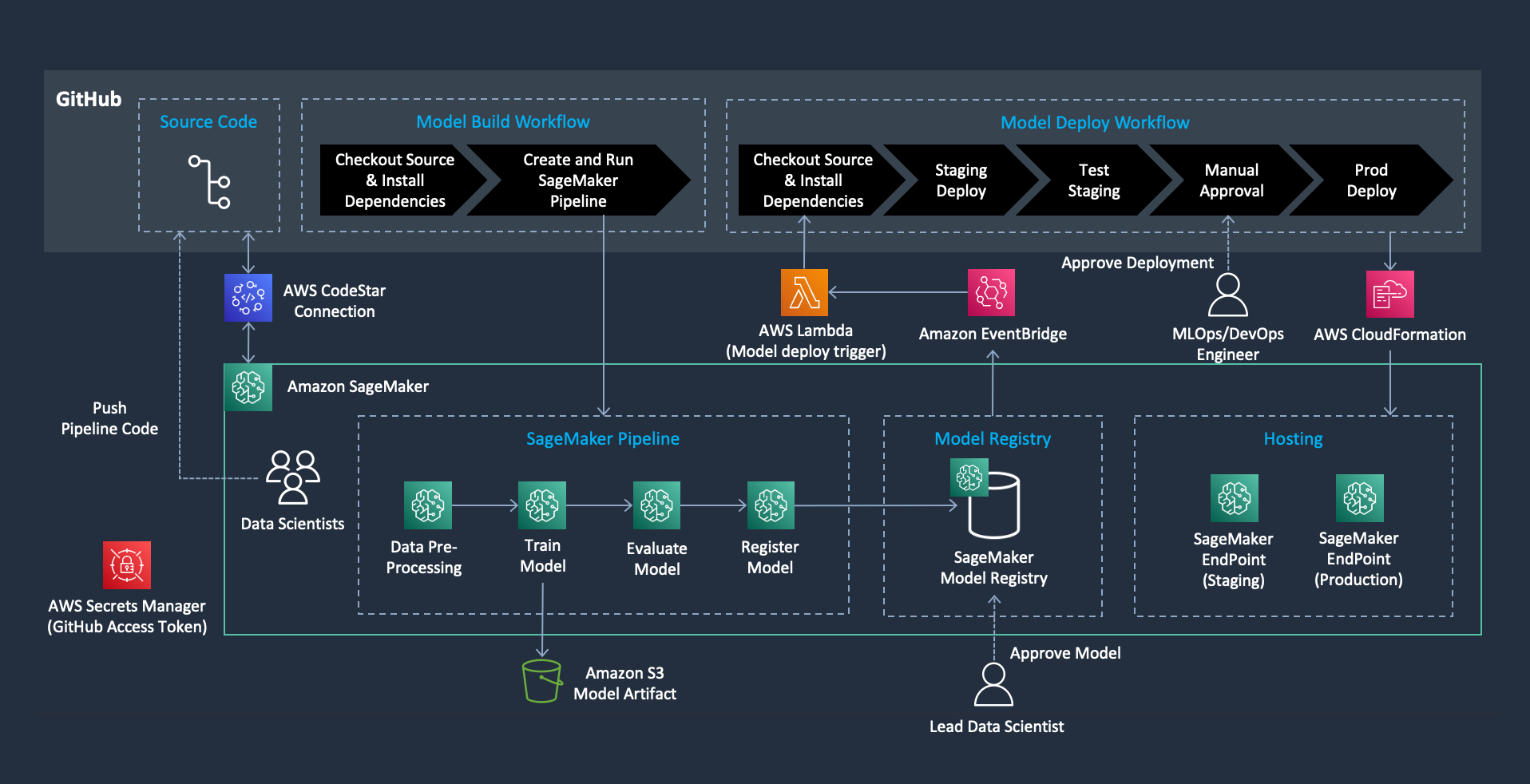
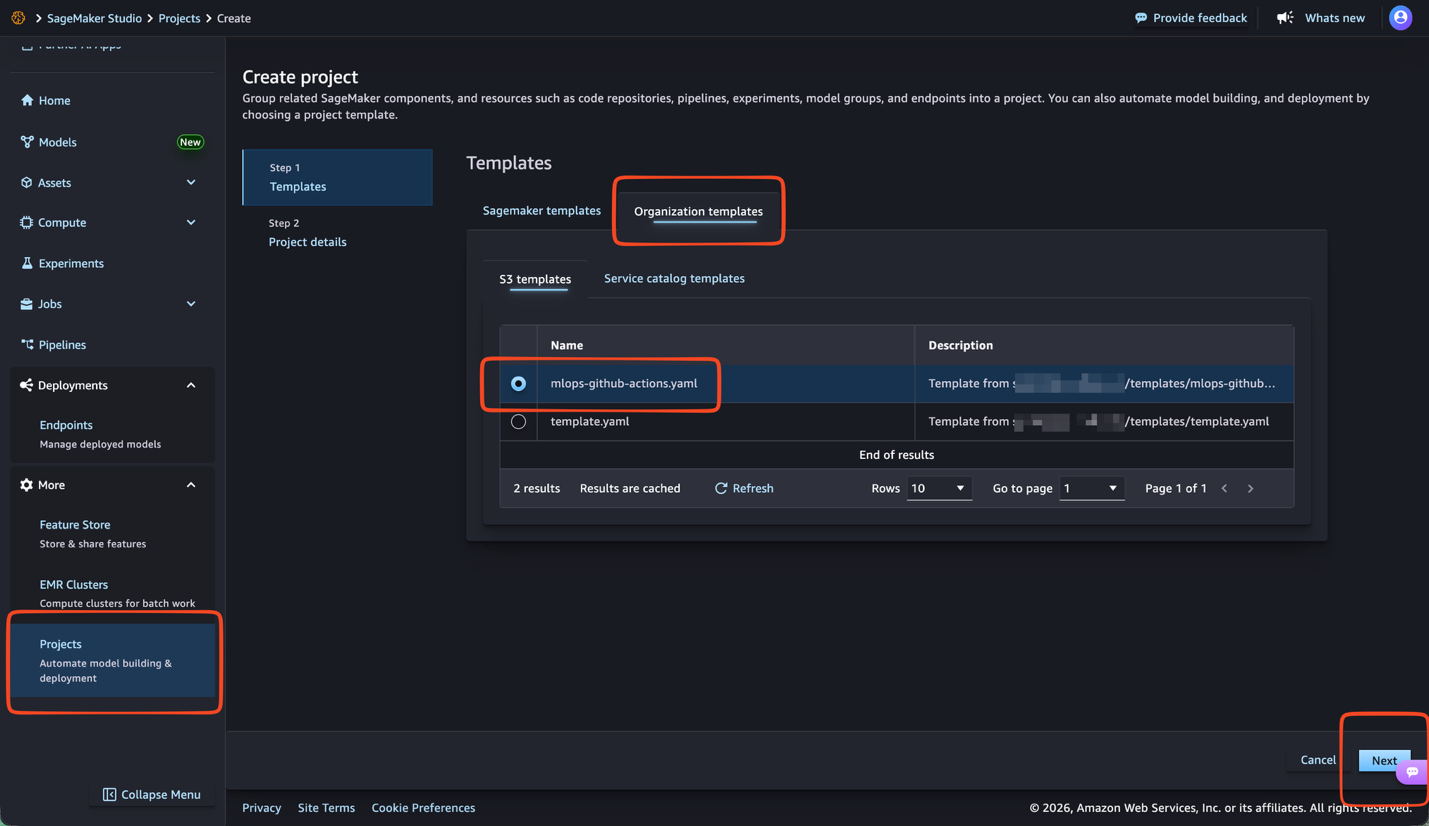
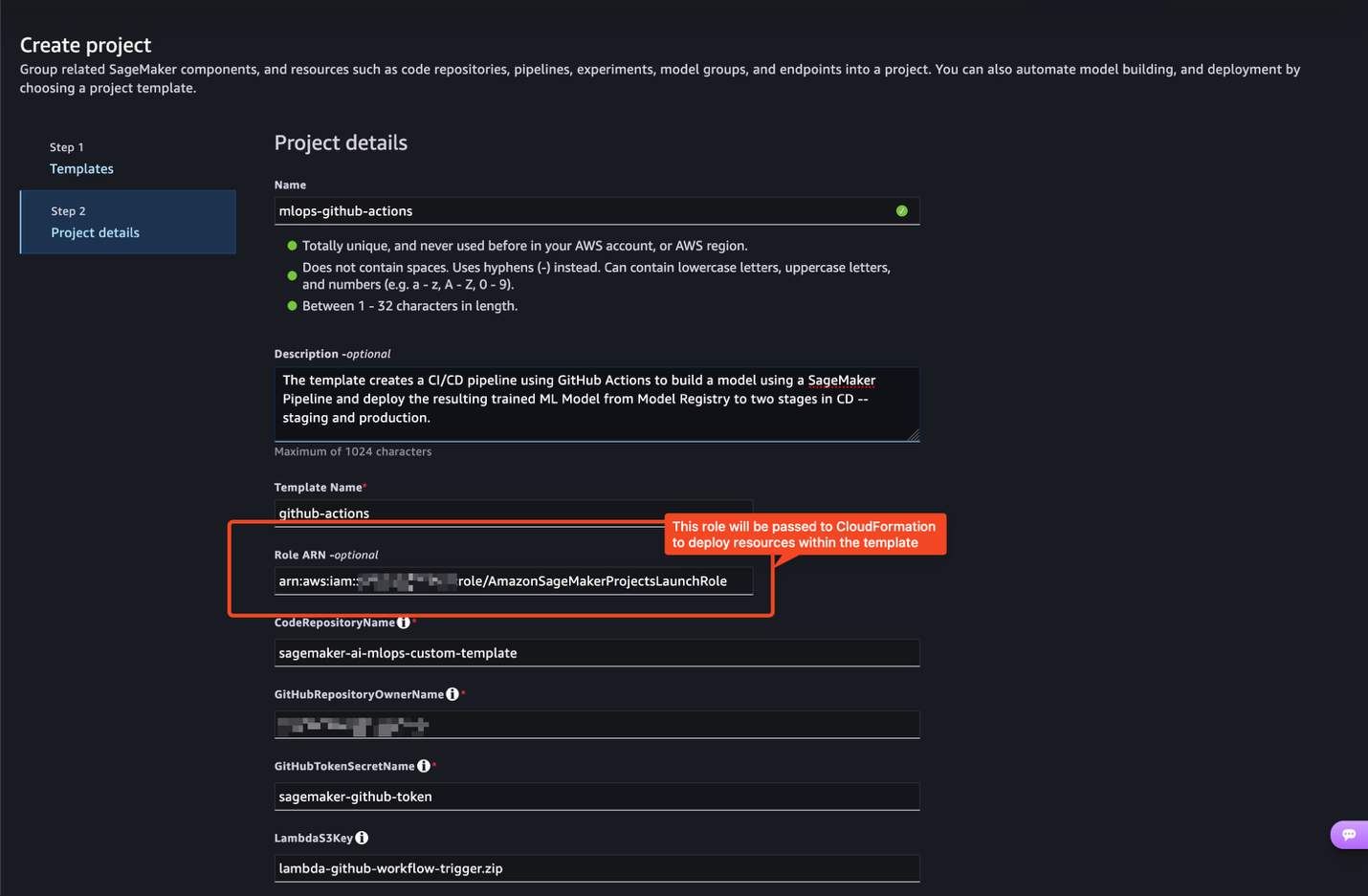
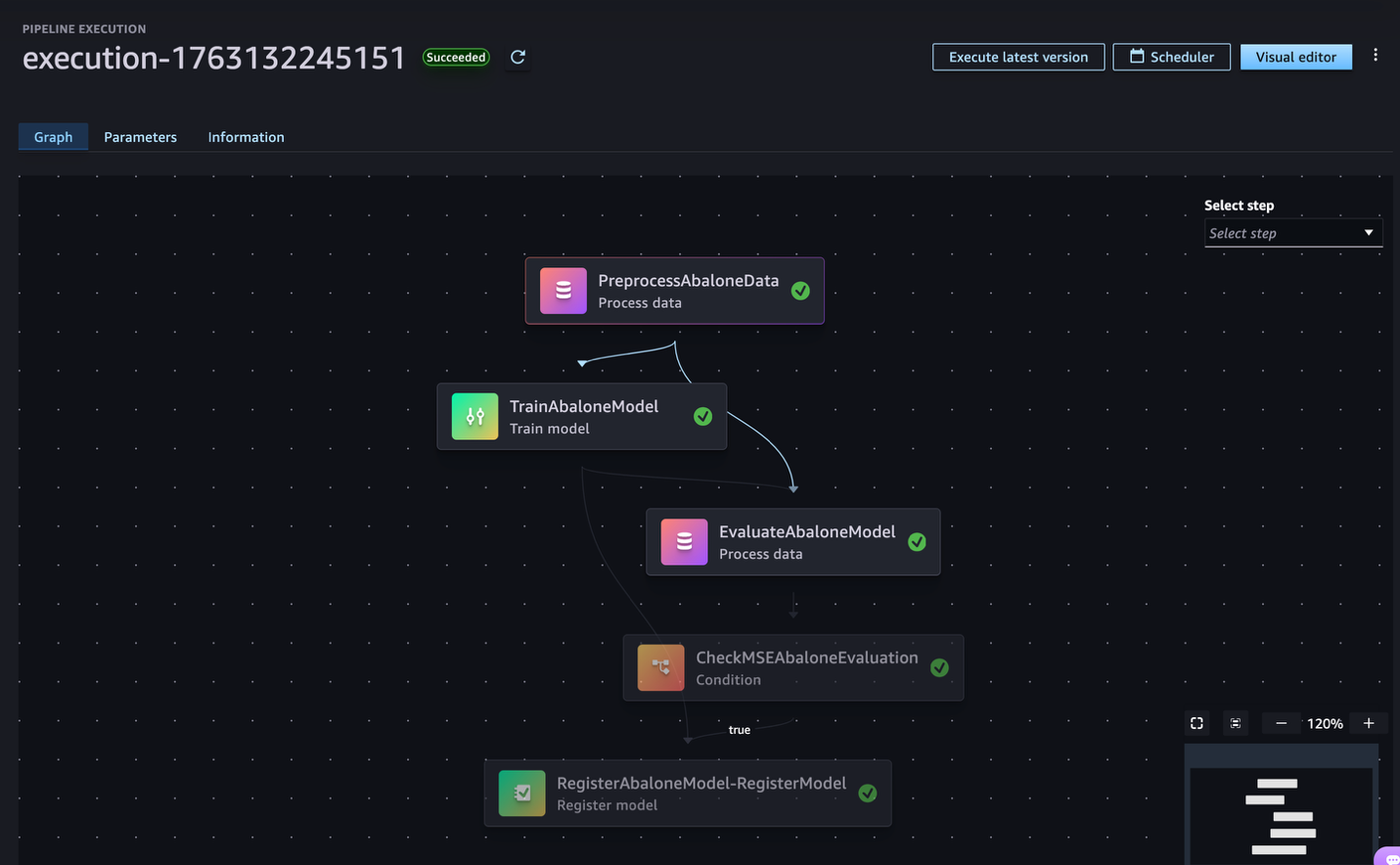
 Christian Kamwangala is an AI/ML and Generative AI Specialist Options Architect at AWS, primarily based in Paris, France. He companions with enterprise clients to architect, optimize, and deploy production-grade AI options leveraging the excellent AWS machine studying stack . Christian focuses on inference optimization methods that stability efficiency, value, and latency necessities for large-scale deployments. In his spare time, Christian enjoys exploring nature and spending time with household and buddies
Christian Kamwangala is an AI/ML and Generative AI Specialist Options Architect at AWS, primarily based in Paris, France. He companions with enterprise clients to architect, optimize, and deploy production-grade AI options leveraging the excellent AWS machine studying stack . Christian focuses on inference optimization methods that stability efficiency, value, and latency necessities for large-scale deployments. In his spare time, Christian enjoys exploring nature and spending time with household and buddies Sandeep Raveesh is a Generative AI Specialist Options Architect at AWS. He works with buyer by their AIOps journey throughout mannequin coaching, generative AI functions like brokers, and scaling generative AI use-cases. He additionally focuses on go-to-market methods serving to AWS construct and align merchandise to resolve trade challenges within the generative AI house. You possibly can join with Sandeep on
Sandeep Raveesh is a Generative AI Specialist Options Architect at AWS. He works with buyer by their AIOps journey throughout mannequin coaching, generative AI functions like brokers, and scaling generative AI use-cases. He additionally focuses on go-to-market methods serving to AWS construct and align merchandise to resolve trade challenges within the generative AI house. You possibly can join with Sandeep on  Paolo Di Francesco is a Senior Options Architect at Amazon Net Companies (AWS). He holds a PhD in Telecommunications Engineering and has expertise in software program engineering. He’s captivated with machine studying and is at present specializing in utilizing his expertise to assist clients attain their objectives on AWS, in discussions round MLOps. Outdoors of labor, he enjoys enjoying soccer and studying.
Paolo Di Francesco is a Senior Options Architect at Amazon Net Companies (AWS). He holds a PhD in Telecommunications Engineering and has expertise in software program engineering. He’s captivated with machine studying and is at present specializing in utilizing his expertise to assist clients attain their objectives on AWS, in discussions round MLOps. Outdoors of labor, he enjoys enjoying soccer and studying.