This paper was accepted on the Fifth Workshop on Pure Language Era, Analysis, and Metrics at ACL 2026.
Instrument-calling brokers are evaluated on device choice, parameter accuracy, and scope recognition, but LLM trajectory assessments stay inherently post-hoc. Disconnected from the lively execution loop, such assessments establish errors which can be often addressed by means of prompt-tuning or retraining, and basically can not course-correct the agent in actual time. To shut this hole, we transfer analysis into the execution loop at inference time: a specialised reviewer agent evaluates provisional device calls previous to execution, shifting the paradigm from post-hoc restoration to proactive analysis and error mitigation.
In apply, this structure establishes a transparent separation of considerations between the first execution agent and a secondary evaluation agent. As with every multi-agent system, the reviewer can introduce new errors whereas correcting others, but no prior work to our information has systematically measured this tradeoff. To quantify this tradeoff, we introduce Helpfulness-Harmfulness metrics: helpfulness measures the proportion of base agent errors that suggestions corrects; harmfulness measures the proportion of appropriate responses that suggestions degrades. These metrics straight inform reviewer design by revealing whether or not a given mannequin or immediate gives internet optimistic worth.
We consider our method on BFCL (single-turn) and τ2-Bench (multi-turn stateful situations), reaching +5.5% on irrelevance detection and +7.1% on multi-turn duties. Our metrics reveal that reviewer mannequin alternative is important: the reasoning mannequin o3-mini achieves a 3:1 benefit-to-risk ratio versus 2.1:1 for GPT-4o. Automated immediate optimization through GEPA gives an extra +1.5–2.8%. Collectively, these outcomes exhibit a core benefit of separating execution and evaluation: the reviewer might be systematically improved by means of mannequin choice and immediate optimization, with out retraining the bottom agent.
In case you have been operating reinforcement studying (RL) post-training on a language mannequin for math reasoning, code era, or any verifiable process, you have got nearly actually stared at a progress bar whereas your GPU cluster burns by means of rollout era. A group of researchers from NVIDIA proposes a exact repair by integrating speculative decoding into the RL coaching loop itself, and do it in a means that preserves the goal mannequin’s actual output distribution.
The analysis group built-in speculative decoding immediately into NeMo RL v0.6.0 with a vLLM backend, delivering lossless rollout acceleration at each 8B and projected 235B mannequin scales.The newest NeMo RL v0.6.0 launch formally ships speculative decoding as a supported characteristic alongside the SGLang backend, the Muon optimizer, and YaRN long-context coaching.
https://arxiv.org/pdf/2604.26779
Why Rollout Technology is the Bottleneck
To grasp the issue, it helps to know the way a synchronous RL coaching step breaks down. In NeMo RL, every step consists of 5 phases: knowledge loading, weight synchronization and backend preparation (put together), rollout era (gen), log-probability recomputation (logprob), and coverage optimization (prepare).
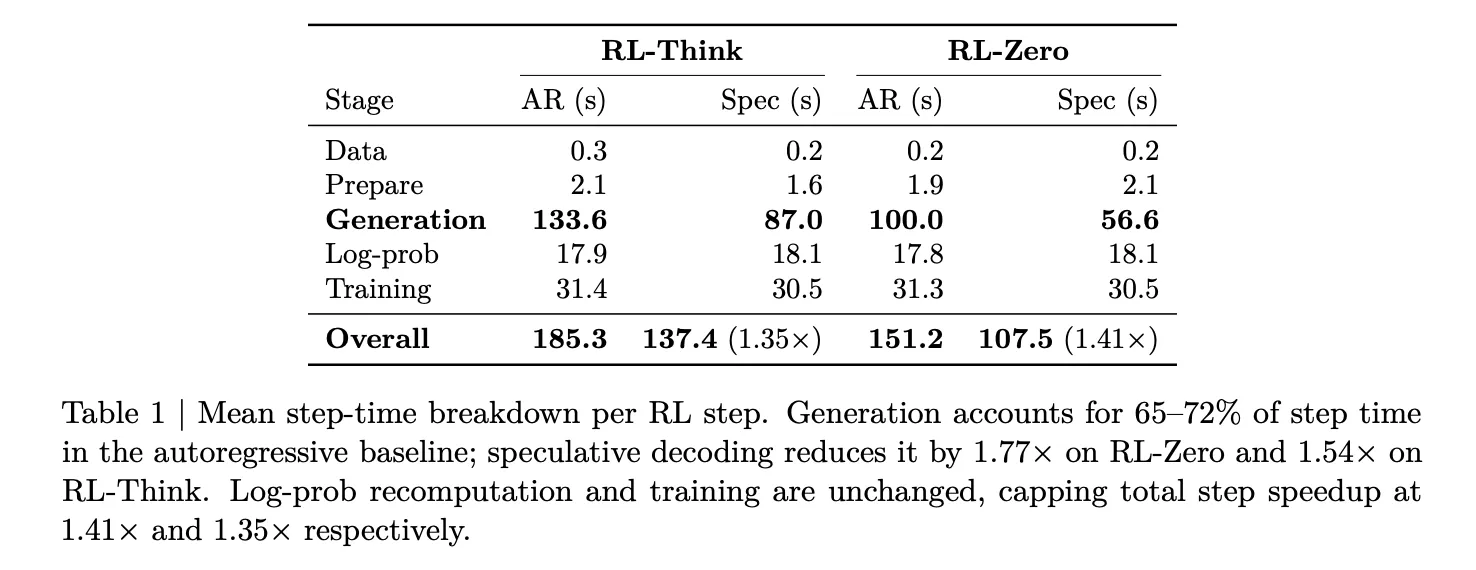
The analysis group measured this breakdown on Qwen3-8B below two workloads — RL-Suppose, which continues coaching a reasoning-capable mannequin, and RL-Zero, which begins from a base mannequin and learns reasoning from scratch. In each circumstances, rollout era accounts for 65–72% of complete step time. Log-probability recomputation and coaching collectively take solely about 27–33%. This makes era the one stage value focusing on for acceleration, and the one which determines the ceiling for any rollout-side optimization.
https://arxiv.org/pdf/2604.26779
What Speculative Decoding Truly Does
Speculative decoding is a method the place a smaller, sooner draft mannequin proposes a number of tokens without delay, and the bigger goal mannequin (the one you’re truly coaching) verifies them utilizing a rejection sampling process. The important thing property and why it issues for RL, is that the rejection process is mathematically assured to supply the identical output distribution as if the goal mannequin had generated these tokens autoregressively. No distribution mismatch, no off-policy corrections wanted, no change to the coaching sign.
That is essential as a result of in RL post-training, the coaching reward depends upon the coverage’s personal samples. Strategies like asynchronous execution, off-policy replay, or low-precision rollouts all commerce some quantity of coaching constancy for throughput. Speculative decoding trades nothing: the rollouts are an identical in distribution to what the goal mannequin would have generated by itself, simply produced sooner.
The System Integration Problem
Including a draft mannequin to a serving backend is simple. Including one to an RL coaching loop just isn’t. Each time the coverage updates, the rollout engine should obtain new weights. The draft mannequin should stay aligned with the evolving coverage. Log-probabilities, KL penalties, and the GRPO coverage loss should all be computed towards the goal (verifier) coverage not the draft or the optimization goal is silently corrupted.
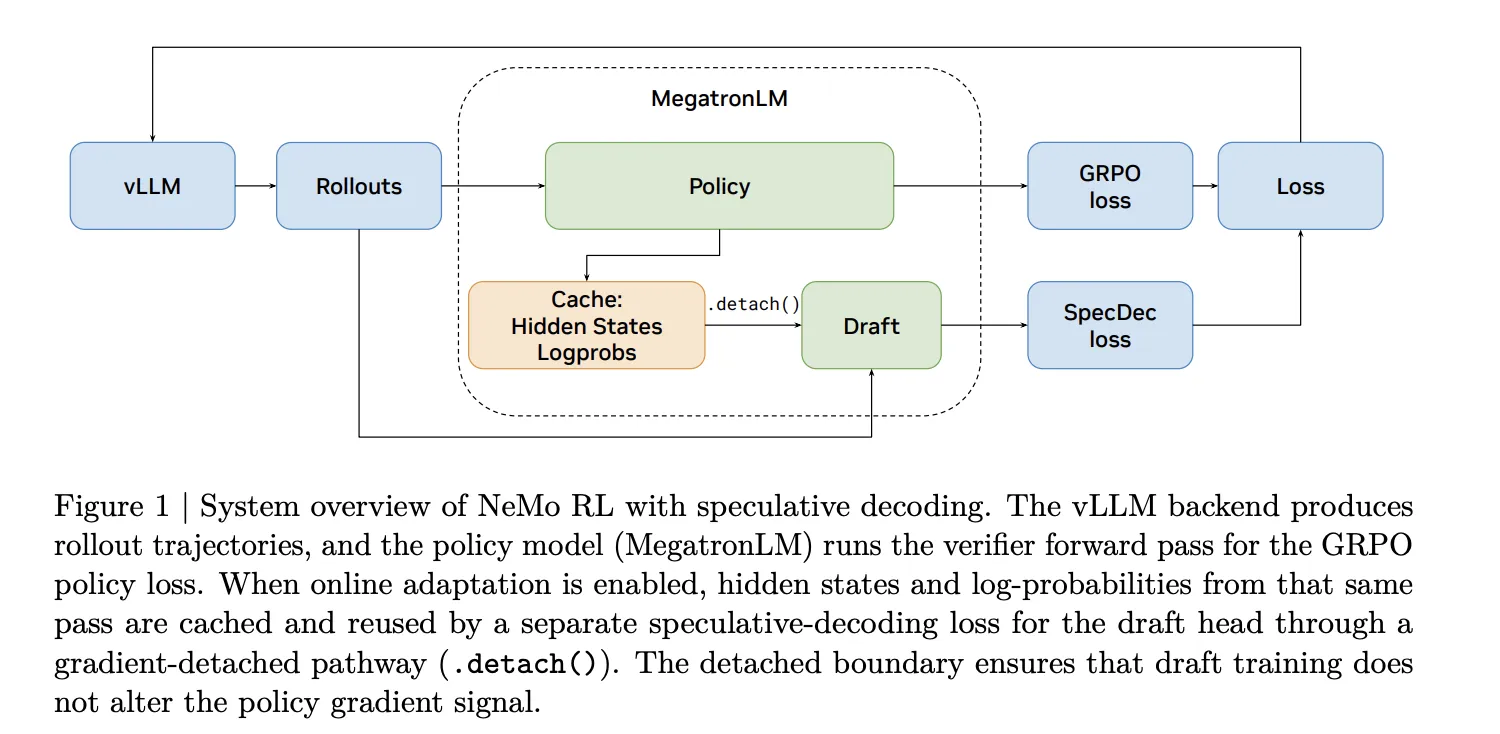
The NVIDIA analysis group handles this in NeMo RL with a two-path structure. The final path makes use of EAGLE-3, a drafting framework that works with any pretrained mannequin with out requiring native multi-token prediction (MTP) assist. A local path can also be accessible for fashions that ship with built-in MTP heads. When on-line draft adaptation is enabled, the hidden states and log-probabilities from the MegatronLM verifier ahead move are cached and reused to oversee the draft head through a gradient-detached pathway, so draft coaching by no means interferes with the coverage gradient sign.
Measured Outcomes at 8B Scale
On 32 GB200 GPUs (8 GB200 NVL72 nodes, 4 GPUs per node), EAGLE-3 reduces era latency from 100 seconds to 56.6 seconds on RL-Zero — a 1.8× era speedup. On RL-Suppose, it drops from 133.6 seconds to 87.0 seconds, a 1.54× speedup. As a result of log-probability re-computation and coaching are unchanged, these generation-side beneficial properties translate to general step speedups of 1.41× on RL-Zero and 1.35× on RL-Suppose. Validation accuracy on AIME-2024 evolves identically below autoregressive and speculative decoding all through coaching, confirming that the lossless assure holds in observe.
The analysis group additionally checks n-gram drafting as a model-free speculative baseline. Regardless of reaching acceptance lengths of two.47 on RL-Zero and a couple of.05 on RL-Suppose, n-gram drafting is slower than the autoregressive baseline in each settings — 0.7× and 0.5× respectively. This can be a essential discovering for practitioners: a optimistic acceptance size is critical however not ample. If the verification overhead is excessive sufficient, hypothesis makes issues worse.
Three Configuration Choices That Decide Realized Speedup
The analysis group isolates three operational selections that practitioners should get proper.
Draft initialization issues greater than generic drafting capacity. An EAGLE-3 draft initialized on the DAPO post-training dataset achieves a 1.77× era speedup on RL-Zero, whereas a draft initialized on the general-purpose UltraChat and Magpie datasets achieves just one.51× on the identical draft size. The draft should be aligned with the precise rollout distribution encountered throughout RL, not only a broad chat distribution.
Draft size has a non-obvious optimum. At draft size okay=3, RL-Zero achieves 1.77× speedup and RL-Suppose achieves 1.53×. Rising to okay=5 raises the acceptance size however drops speedup to 1.44× on RL-Zero and 0.84× on RL-Suppose — the latter already slower than autoregressive. At okay=7, RL-Zero drops additional to 1.21× and RL-Suppose to 0.71×. The distinction issues: RL-Zero’s rollouts are generated from a base mannequin beginning with quick outputs, making them simpler for the draft to foretell even at excessive okay. RL-Suppose’s totally developed reasoning traces are tougher to take a position over, so the overhead of longer drafts erases the profit sooner. Extra speculative work per step can erase the advantage of greater acceptance completely, particularly in tougher era regimes.
On-line draft adaptation — updating the draft throughout RL utilizing rollouts generated by the present coverage helps most when the draft is weakly initialized. For a DAPO-initialized draft, offline and on-line configurations carry out practically identically (1.77× vs. 1.78× on RL-Zero). For a UltraChat-initialized draft, on-line updating improves speedup from 1.51× to 1.63× on RL-Zero.
Interplay with asynchronous execution was additionally examined immediately at 8B scale not simply in simulation. The analysis group ran RL-Suppose at coverage lag 1 in a 16-node non-colocated configuration, with 12 nodes devoted to era and 4 to coaching. In asynchronous mode, most of rollout era is already hidden behind log-probability re-computation and coverage updates, so the related amount is the uncovered era time that is still on the essential path. Speculative decoding reduces that uncovered era time from 10.4 seconds to 0.6 seconds per step and lowers efficient step time from 75.0 seconds to 60.5 seconds (1.24×). The achieve is smaller than in synchronous RL — anticipated, since asynchronous overlap already hides a lot of the rollout price — nevertheless it confirms that the 2 mechanisms are genuinely complementary somewhat than redundant.
Projected Positive aspects at 235B Scale
Utilizing a proprietary GPU efficiency simulator calibrated to device-level compute, reminiscence, and interconnect traits, the analysis group projected speculative decoding beneficial properties at bigger scales. For Qwen3-235B-A22B operating synchronous RL on 512 GB200 GPUs, draft size okay=3 with an acceptance size of three tokens yields a 2.72× rollout speedup and a 1.70× end-to-end speedup.
On the most favorable simulated working level — Qwen3-235B-A22B on 2048 GB200 GPUs with asynchronous RL at coverage lag 2 — rollout speedup reaches roughly 3.5×, translating to a projected 2.5× end-to-end coaching speedup. Speculative decoding and asynchronous execution are described as complementary: hypothesis reduces the price of every particular person rollout, whereas asynchronous overlap hides the remaining era time behind coaching and log-probability computation.
Key Takeaways
Rollout era is the dominant bottleneck in RL post-training, accounting for 65–72% of complete step time in synchronous RL workloads — making it the one stage the place acceleration has significant impression on end-to-end coaching pace.
Speculative decoding through EAGLE-3 delivers lossless rollout acceleration, reaching 1.8× era speedup at 8B scale (1.41× general step speedup) with out altering the goal mannequin’s output distribution — in contrast to asynchronous execution, off-policy replay, or low-precision rollouts, which all commerce coaching constancy for throughput.
Draft initialization high quality issues greater than draft size, with in-domain (DAPO-trained) drafts outperforming normal chat-domain drafts by a significant margin; longer draft lengths (okay≥5) constantly backfire in tougher reasoning workloads, making okay=3 the dependable default.
Simulator projections present beneficial properties scale up considerably, reaching ~3.5× rollout speedup and a projected ~2.5× end-to-end coaching speedup at 235B scale on 2048 GB200 GPUs — and the approach is already accessible in NeMo RL v0.6.0 below Apache 2.0.
YouTube’s internet participant apparently has a rendering bug that sends browsers into an infinite loop of visible adjustments.
The fixed web page rendering loop is inflicting processor and RAM utilization to skyrocket, with customers reporting reminiscence consumption within the gigabytes.
Customers with browsers affected by the bug are noticing excessive lag, stuttering, and body drops throughout video playback.
YouTube customers are reporting points with the platform’s internet participant, with the location inflicting unexplained browser lag and excessive reminiscence utilization. The stutters, body drops, and RAM consumption are affecting customers of a number of browsers, together with Firefox and Courageous, in keeping with posts (1, 2) on Reddit.
The builders on Mozilla’s discussion board say that the “ytd-menu-renderer” tag, which homes the like, dislike, and share buttons, is inflicting the visible bugs. This can be a versatile menu that dynamically reveals and hides buttons primarily based on the obtainable display screen width. The builders clarify that “ytd-menu-renderer” works by eradicating one button mechanically if they’re overflowing on the display screen, and placing the buttons again when the menu ingredient widens. The code is meant to make sure solely the buttons that match in your display screen comfortably are proven.
Nevertheless, the developer feedback level out that “hostElement.clientWidth” grows when “ytd-menu-renderer” mechanically hides a button. This causes YouTube’s code to assume the menu space is broad sufficient to suit the button, so it provides the button again. After all, since there isn’t really sufficient visible house, “ytd-menu-renderer” removes the button once more. The menu container expands as soon as once more, and also you in all probability get the thought. It’s a unending cycle that forces your browser and PC to maintain calculating, resizing, and rendering YouTube’s versatile menu.
Don’t wish to miss one of the best from Android Authority?
This bug locations further pressure on a consumer’s system assets. Customers noticed their browser’s RAM utilization spike from a number of hundred megabytes to consuming a number of gigabytes after trying to play a YouTube video. Others observed their CPU core utilization skyrocket whereas utilizing YouTube’s internet participant, as documented by one other Reddit publish.
The YouTube internet participant rendering bug is affecting customers throughout a number of browsers, together with Courageous, Firefox, and Microsoft Edge. Mozilla is wanting into the infinite loop difficulty because it pertains to its Firefox browser, nevertheless it’s unclear when a repair on the YouTube aspect may be obtainable.
Thanks for being a part of our group. Learn our Remark Coverage earlier than posting.
Defeating weight problems isn’t straightforward. For many individuals, even profitable weight reduction is adopted by a chronic battle to forestall the burden from coming again.
Weight problems relapse is widespread, and analysis signifies it is greater than a matter of willpower. Fats cells retain a ‘reminiscence’ of weight problems lengthy after weight reduction, research have discovered, probably undermining efforts to keep away from regaining weight.
And it isn’t simply fats cells. As researchers report in a brand new decade-long research, sure immune cells may carry a persistent reminiscence of weight problems.
This file can protect an elevated danger of obesity-related sickness, the research suggests, as much as 10 years after an individual slims down.
The mechanism for that is DNA methylation, a standard organic course of wherein methyl teams latch onto DNA molecules, altering gene exercise with out disrupting the DNA sequence.
In individuals who have just lately recovered from weight problems, particular additions to the DNA in helper T cells appear to protect the mobile reminiscence of being overweight, selling a dysregulated, pro-inflammatory situation that may endure for years regardless of reductions in physique weight.
The researchers discovered immune cells can carry a persistent ‘reminiscence’ of weight problems by means of the method of DNA methylation. (Highwaystarz-Images/iStock/Getty Photographs Plus)
To find out this, researchers analyzed immune cells from a number of teams of human topics. These included samples from sufferers with weight problems who both exercised 4 instances every week for 10 weeks or acquired injections of semaglutide for weight reduction, together with management teams.
They moreover studied samples from individuals with Alström syndrome, a uncommon genetic dysfunction that tends to contain childhood weight problems, and from wholesome matched pairs as controls.
The researchers additionally investigated the mechanics of weight problems’s lasting affect on immune perform by analyzing the immune cells of mice that had been fed high-fat diets, in addition to blood donations from human volunteers.
“The findings recommend that short-term weight reduction could not instantly scale back the danger of some illness situations related to weight problems, together with kind 2 diabetes and a few cancers,” says co-lead creator Claudio Mauro, an immunologist on the College of Birmingham within the UK.
“As a substitute, ongoing weight administration following loss will see the ‘weight problems reminiscence’ slowly fade,” Mauro says.
“This may increasingly take a number of years of sustained weight reduction upkeep, doubtless 5 to 10 years, although this requires additional research, to completely reverse the results of weight problems on T cells.”
These discoveries make clear the immune system’s record-keeping habits, says senior creator and molecular epidemiologist Belinda Nedjai from Queen Mary College London.
“Our findings present that weight problems is related to sturdy epigenetic modifications that affect immune cell conduct,” Nedjai says.
“This means that the immune system retains a molecular file of previous metabolic exposures, which can have implications for long-term illness danger and restoration.”
In individuals with weight problems, helper T cells ‘memorize’ weight problems and promote weight regain, as earlier analysis has proven. The mechanism for this has remained unclear, nonetheless.
The brand new research identifies two key cell features as pathways for obesity-related methylation to affect helper T cells: autophagy, the pure elimination and recycling of mobile waste, and immune senescence, or ageing of cells within the immune system.
DNA methylation from weight problems appears to have an effect on each features, a vital perception concerning the prevalence and underpinnings of relapse, says co-author and immunologist Andy Hogan from Maynooth College in Eire.
“We all know weight problems is a power progressive and relapsing illness, and our findings present additional understanding of precisely what are the molecular mechanisms probably driving the danger of relapsing, and spotlight the challenges dealing with individuals dwelling with weight problems to efficiently handle their weight,” he says.
These findings may additionally assist set the stage for focused remedies that, together with different interventions, reverse the results of weight problems on T cells.
“Our research suggests potential therapeutic alternatives to expedite this course of, corresponding to repurposing medication like SGLT2 inhibitors, which have proven promise in lowering irritation and selling immune-mediated clearance of senescent cells in weight problems,” Mauro says.
More often than not, we’ll cross it two arguments: hypot(A, B). Consider it like a strategy to full the Pythagorean theorem the place we give the operate the other and adjoining sides of a triangle, and the longest aspect is what it returns.
is a comma-separated listing of calculations that resolve to both a , , or .
Mixing and values is okay so long as they’ve a constant kind — like 25% and 5rem within the width property, or else the operate is invalid.
Lastly, the results of hypot() will likely be of the identical kind as its arguments, so hypot(, ) returns a , and hypot(, ) returns a .
3 ways to see it
There are three most important methods we will consider hypot():
1. Whereas boring, we will consider hypot() as simply its underlying system, which squares every argument, sums it, and takes the sq. root of the outcome. You realize, similar to you discovered in class: “A squared, plus B squared equals C squared.
This explains why it might take unfavourable values, since they get squared right into a optimistic worth.
2. Nevertheless, hypot() has an entire lot extra interpretation past a system. If given two values, hypot(A, B) returns the size of the hypotenuse of a proper triangle with sides A and B.
As an alternative of the perimeters of a triangle, we will additionally consider each arguments because the coordinates of a degree on an XY aircraft. During which case, hypot(x, y) returns the size from the origin to that time in area.
3. That mentioned, hypot() can take greater than two arguments, so we’ll lengthen the final definition past two dimensions the place one thing like hypot(a1, a2, ..., an) is the size of a degree to its origin in an n-dimensional area. For instance, seen in three dimensions, hypot(x, y, z) would appear to be this:
We’ll take a look at primary utilization with two values to assist illustrate how we’d put this into observe. Plus, CSS isn’t too eager on larger dimensions past 2D.
Fundamental Utilization
Let’s begin with a not-so-practical instance for hypot(), simply to showcase the way it works. Think about we need to solid a line from one level on the display to our mouse place within the viewport.
Step one is to let CSS know the mouse’s x and y coordinates by means of the following JavaScript snippet, which saves every coordinate within the --m-x and --m-y variables:
window.addEventListener("pointermove", (occasion) => {
let x = occasion.clientX;
let y = occasion.clientY;
doc.documentElement.type.setProperty("--m-x", `${Math.spherical(x)}px`);
doc.documentElement.type.setProperty("--m-y", `${Math.spherical(y)}px`);
});
From right here, we have to reply two questions: (1) How lengthy ought to that line be? (2) what angle ought to we rotate it?
The primary query is the place hypot() is available in, for the reason that size of that line is identical as hypot(x, y).
.line {
/* Locations line on the prime left nook */
place: fastened;
prime: 0;
left: 0;
width: hypot(var(--m-x), var(--m-y));
peak: 5px; /* Thickness of the road */
}
With this, we’ve got a line that will get longer because the mouse strikes away from the top-left nook.
Now, we’ve got to rotate it by a sure angle, so we’ll use the atan2() operate. With out going an excessive amount of into particulars, atan2(y, x) provides us the angle between a degree within the aircraft and the horizontal axis.
Then we tweak our JavaScript a bit in order that our coordinates additionally begin from the middle as an alternative of the top-left nook. This may be finished by subtracting half the window’s innerWidth and innerHeight from the respective coordinate earlier than passing them onto CSS.
x = x - window.innerWidth / 2;
y = y - window.innerHeight / 2;
Detecting When the Cursor is Close to
So, now that we all know the fundamentals of how hypot() works, we will use it for a extra sensible state of affairs. Not so way back, Daniel Schwarz wrote about :close to(), a possible new pseudo-selector that might match a component when the cursor is near it by a given distance:
button:close to(3rem) {
/* Pointer is inside 3rem of the button */
}
This could possibly be used to use some impact to a button every time the person is close to it, like highlighting or scaling it a bit. Sadly, on the time of writing, we don’t have :close to() on any browser, however we will already simulate it utilizing each hypot() and type queries.
Once more, our first step is to cross the mouse coordinates to CSS through JavaScript. Nevertheless, this time we’ll measure the mouse place from the middle of the button. To do that, we’ll:
Subtract from every coordinate the button’s offsetLeft and offsetTop, which strikes the origin to the button’s top-left nook.
Subtract half the button’s clientWidth and clientHeight, which strikes the origin proper to the button’s heart.
const button = doc.querySelector("button");
window.addEventListener("pointermove", (occasion) => {
let x = occasion.clientX;
let y = occasion.clientY;
x = x - button.offsetLeft - button.clientWidth / 2;
y = y - button.offsetTop - button.clientHeight / 2;
doc.documentElement.type.setProperty("--m-x", `${Math.spherical(x)}px`);
doc.documentElement.type.setProperty("--m-y", `${Math.spherical(y)}px`);
});
Again to CSS! Let’s outline two variables: (1) --near that holds the space from the mouse to the button, and (2) --limit that defines the restrict the place we take into account the mouse close to the button.
Earlier than we take a look at the outcome, it’s price checking ion your browser helps container type queries.
It’s Extra Than Syntactical Sugar
Since hypot() returns the sq. root of a sum of squares, the largest math nerds of us would count on that the next two expressions can be equal:
hypot(A, B)
sqrt(pow(A, 2) + pow(B, 2))
Nevertheless, if we attempt to swap the previous for the latter, we’ll discover that it received’t work most instances. The 2 formulation aren’t interchangeable every time hypot() takes both a or , since all different exponential features solely settle for values. In different phrases, we’d like hypot() if we’re working with particular kinds of values, notably and .
The primary purpose behind that is clashing expectations. As the spec says, if in our stylesheet 1rem equals the default 16px, pow(1rem, 2) would end in 1rem (16px once more), regardless that they’re the identical worth. In the meantime, pow(16px, 2) leads to 256px. hypot() inputs and outputs are at all times constant, so these sorts of sudden outcomes don’t happen!
If you happen to shut your eyes and film a mine, you most likely think about dusty boots, heavy equipment, and the rhythmic sound of rock being crushed. And whereas that’s nonetheless a part of actuality, the “brains” of the operation have shifted dramatically. Right this moment’s mining panorama is much less about brute drive and extra about bytes, bits, and the invisible threads of wi-fi connectivity that maintain the whole lot transferring. The trade now depends on automation and innovation as its operational actuality.
Automation has turn out to be foundational to the fashionable mining trade. The next functions are a actuality in lots of mining operations.
Autonomous Haulage Programs (AHS): Autonomous vehicles are actually a cornerstone of large-scale floor mining. These methods take away personnel from hazardous environments and considerably scale back accidents attributable to human error or fatigue.
AI-Pushed Predictive Upkeep (PdM): AI is getting used to maneuver the trade from reactive to proactive asset administration. Machine studying fashions analyze sensor knowledge (vibration, warmth, acoustics) to foretell failures weeks upfront, lowering unplanned downtime.
Tele-Distant Operations: Mining is now adopting remote-controlled operations which permit operators to man gear from a distant protected location. This considerably enhances security and permits operations in areas that may in any other case be hazardous for personnel.
Why the fast adoption? It comes down to 2 major drivers: security and productiveness. Security is probably the most vital issue; by transferring operators from hazardous pits into distant management facilities, we successfully take away people from probably the most harmful zones. Concurrently, productiveness positive aspects are substantial. For instance, autonomous haul vehicles don’t require espresso breaks or shift adjustments, permitting them to maintain the cycle transferring 24/7.
Nonetheless, there’s a caveat: automation is just as efficient because the community that powers it.
You may have probably the most superior tele-remote dozer on this planet, but when its connection drops whereas it’s navigating a steep grade, you find yourself with costly paperweight.
Mining environments are notoriously hostile. We’re speaking about huge open pits or deep, signal-dampening underground tunnels crammed with mud, vibration, and excessive temperature swings. A regular workplace Wi-Fi setup merely gained’t reduce it.
To assist mission-critical functions, the community should present:
Extremely-Dependable, Low-Latency Connectivity: Tele-remote operations require instantaneous digital camera feeds and command execution. Minimizing latency is vital, as any delay may end in accidents and harm to costly gear.
Seamless Handoffs: As a haul truck strikes throughout a web site, it wants to modify between entry factors with out dropping a single packet. “Zero packet loss” isn’t only a advertising and marketing time period right here; it’s a requirement.
Ruggedized {Hardware}:Tools should be industrial-grade to make sure most sturdiness. Key necessities embrace IP66/IP67 certification for mud and water resistance, in addition to the capability to face up to excessive temperatures and high-vibration environments.
To fulfill the intense calls for of contemporary mining, Cisco has developed a portfolio particularly engineered for these harsh environments. On the coronary heart of this answer is the Cisco Catalyst IW9167E Heavy Responsibility Entry Level. Constructed to outlive probably the most difficult situations, this gadget is IP66/IP67-rated, guaranteeing whole safety towards mud, water, and it might probably face up to excessive temperature fluctuations and vibrations.
When paired with Cisco Extremely-Dependable Wi-fi Backhaul (URWB), the IW9167E transforms from a easy entry level right into a mission-critical communication spine. Not like conventional wi-fi applied sciences, URWB is designed particularly for steady mobility. It supplies fiber-like reliability and seamless handoffs, guaranteeing that autonomous vehicles and remote-controlled gear preserve a rock-solid connection even whereas traversing huge, rugged pits at velocity. With URWB, “zero packet loss” turns into a normal operational actuality, eliminating the danger of kit downtime because of community drops.
Confirmed within the Subject: Validated Designs and Partnerships
We all know that in mining, theoretical efficiency isn’t sufficient; options should be confirmed underneath strain. Cisco doesn’t simply present {hardware}; we offer a roadmap for fulfillment.
Our dedication to reliability is greatest demonstrated by our Cisco Validated Designs (CVDs). These are complete, validated design guides that take away the guesswork from community deployment. By visiting our Cisco Mining Design Zone, you may entry architectures which have been examined and verified in lab environments to make sure they meet the rigorous calls for of the mining sector.
Actual-world success tales, comparable to our work with Aterpa, spotlight the transformative energy of those options. Aterpa leveraged our expertise to assist tele-remote operations for dam decommissioning tasks, enabling work in environments the place human presence was not allowed.
Aterpa’s tele-remote operations used for dam decommission in Brazil.
Moreover, our strategic partnership with world trade leaders like Caterpillar permits us to carefully check and validate our wi-fi options towards the precise functions and equipment used on-site. This collaborative method ensures that while you deploy Cisco, you might be deploying an answer that has been examined and validated by key gamers within the mining trade.
Whether or not you need to improve security by eradicating personnel from hazardous zones or aiming to spice up productiveness by 24/7 autonomous operations, the suitable community is foundational to your whole operation.
Don’t let connectivity gaps maintain your operation again. Cisco is right here that can assist you design, deploy, and scale a wi-fi community that’s resilient to assist your operations. If you’re able to study extra about how our industrial wi-fi options can drive effectivity in your particular mining setting, we invite you to succeed in out to our crew at present. Let’s construct the way forward for mining collectively.
What will get misplaced within the pleasure is that comfort has a compounding price construction. The identical traits that make the general public cloud engaging for AI additionally make it costly to function at scale. You pay not just for uncooked infrastructure but additionally for abstraction, acceleration, service layering, managed operations, premium instruments, and the supplier’s margin. As AI success grows, working prices rise as nicely.
This issues as a result of AI shouldn’t be a single-application story. Enterprises not often cease at a single mannequin, pilot, or use case. They need dozens of options spanning customer support, software program growth, provide chain planning, safety operations, analytics, and inside productiveness. Each greenback dedicated to 1 costly cloud-based AI workload is a greenback unavailable for the subsequent. That’s the strategic concern too many firms overlook.
The query isn’t whether or not cloud can run AI. After all it will possibly. In lots of instances, it’s the quickest path to worth. The extra necessary query is whether or not long-term operational spending leaves sufficient room within the price range to construct a portfolio of AI options somewhat than a couple of remoted wins. If the reply isn’t any, the comfort premium begins to look much less like acceleration and extra like a constraint.
This story appeared in The Logoff, a every day publication that helps you keep knowledgeable concerning the Trump administration with out letting political information take over your life. Subscribe right here.
Welcome to The Logoff: President Donald Trump advised Congress the Iran battle is over. Is it?
What occurred? Friday marks a authorized deadline for Trump, after which he needs to be required to wind down US army operations round Iran. However in response to Trump, he already has: The president wrote in a letter to Congress on Friday that the Iran battle was “terminated” because of the US-Iran ceasefire, which stays in impact with no agency deadline.
“There was no change of fireplace between the US Forces and Iran since April 7, 2026,” Trump wrote within the letter. “The hostilities that started on February 28, 2026, have been terminated.”
Is it true? Probably not, from all proof obtainable. Whereas the US and Iran haven’t been engaged within the form of full-scale hostilities that marked the early weeks of the battle, a US naval blockade of the Strait of Hormuz continues to be in place. (Final month, the US even fired on an Iranian-flagged ship allegedly making an attempt to violate the blockade — in Trump’s phrases, “blowing a gap within the engineroom.”)
US forces additionally stay in place close to Iran, and there’s the ever-present risk that the battle might resume at full power — one thing Trump has continued to threaten as a deal to finish the battle completely eludes him.
What’s the context? Trump’s letter is a reasonably clear try and skate across the Struggle Powers Decision, which requires the US to finish its involvement in army conflicts inside 60 days of notifying Congress of their begin, until Congress votes to authorize the battle. (It hasn’t. There’s additionally the potential of a 30-day extension on that 60-day deadline, which the Trump administration has likewise not but pursued.)
And with that, it’s time to sign off…
Hello readers, completely happy Might Day! Listed below are two mysteries to maintain you entertained over the weekend, from my colleagues at Vox’s Unexplainable podcast. I’ll maintain them mysterious right here — if you wish to be taught extra, the podcast is a superb pay attention. Have an excellent weekend, and we’ll see you again right here on Monday!
2026 has already seen in depth wildfires in Patagonia, Argentina, linked to excessive climate
TOMAS CUESTA / AFP through Getty Pictures
A outstanding scientist has predicted 2026 would be the hottest yr on document, because of each local weather change and a strong El Niño impact that can increase temperatures additional.
The document is held by 2024, when world temperatures exceeded 1.5°C above the pre-industrial common for the primary time.
The second half of this yr will nearly definitely see the beginning of El Niño, a pure local weather section when heat water expands throughout the equatorial Pacific Ocean, heating your entire planet. Some fashions venture it will likely be a “tremendous El Niño”, and maybe the strongest ever. Many consider this may set a brand new world temperature document in 2027, when the total drive of the El Niño is felt.
However James Hansen at Columbia College in New York, who famously instructed the US Congress in 1988 that people have been heating Earth, and his colleagues have now argued in a weblog put up that the document might be damaged already in 2026. “In fact, 2027 might be nonetheless hotter,” they added.
Temperatures are at present being suppressed by La Niña, the planet-cooling counterpart of El Niño. The primary three months of 2026 have been about 0.1°C cooler than the primary three months of 2024, on common. The remainder of the yr must be far hotter for 2026 to surpass 2024.
Based mostly on the common impact of the primary three months on the yearly temperature, Zeke Hausfather at Berkeley Earth in California projected in Carbon Temporary that 2026 can be 1.47°C above the pre-industrial common, making it the second-warmest on document.
However Hansen and his colleagues say that is more likely to be an underestimate. Whereas scientists largely agree that world warming is accelerating, primarily as a result of humanity has lowered air air pollution that was blocking out daylight, Hansen has argued the warming fee is even greater than local weather fashions present.
Of their put up, they notice that sea floor temperatures, that are much less affected by fluctuations within the climate, recommend the world is now 0.17°C hotter than in 2023, when the 2023-24 El Niño developed. This can be a greater distinction than in 2024, when the globe was solely 0.11°C hotter than it was in 2023.
“That margin is broad sufficient that we’re keen to make the prediction that 2026 would be the warmest yr”, they wrote.
Different scientists aren’t so positive. Whereas the annual forecast in December from the Met Workplace, the UK’s climate service, projected the subsequent yr can be 1.46°C above the pre-industrial common, it gave a spread from 1.34°C to 1.58°C. It’s nonetheless untimely to foretell 2026 will beat the 1.55°C recorded in 2024, says Adam Scaife on the Met Workplace.
“There may be uncertainty on these timescales, which implies that the perfect factor you are able to do is to offer a chance,” says Scaife. “No person might be 100 per cent assured.”
Because the equatorial Pacific has continued to heat and El Niño has grow to be extra seemingly, document world temperatures have additionally grow to be extra seemingly, however forecasts nonetheless present a sweep of doable outcomes, based on John Kennedy on the World Meteorological Group. “Hansen’s forecast is extra definitive, however it is only one technique out of a spread which might be on the market,” he says.
In a weblog put up on 30 April, Hausfather calculated 2026 has a 26 per cent likelihood of being the most well liked yr on document and a 56 per cent likelihood of being the second hottest.
However Scaife says Hansen is true to fret that the speed of world warming could also be quicker than projected, as a result of that might recommend the CO2 emitted into the ambiance is warming Earth greater than anticipated. “If local weather sensitivity’s greater than folks assume… that can have an effect on local weather change sooner or later,” he says.
Whatever the precise world temperature, the world is more likely to endure even worse excessive climate as El Niño begins to chew. Locations like Australia and South-East Asia, central and southern Africa, India and the Amazon rainforest will face the danger of heatwaves, drought and wildfires.
“What all of us agree about is that the El Niño goes to be on high of an unprecedented stage of world warming,” says. “These two issues are seemingly to offer us unprecedented occasions later this yr.”
I used to be reviewing some timings from the Stata/MP Efficiency Report this morning. (For many who don’t know, Stata/MP is the model of Stata that has been programmed to benefit from multiprocessor and multicore computer systems. It’s functionally equal to the biggest model of Stata, Stata/SE, and it’s quicker on multicore computer systems.)
What was uncommon this morning is that I used to be working Stata/MP interactively. We often run MP for big batch jobs that run 1000’s of timings on massive datasets — both to tune efficiency or to supply reviews just like the Efficiency Report. That’s the kind of work Stata/MP was designed for — large jobs on large datasets.
I’ll admit proper now that I largely run Stata interactively utilizing the auto dataset, which has 74 observations. I run Stata/MP utilizing all 4 cores of my quad-core pc, however I’m largely losing 3 of them — there is no such thing as a dashing up the computations on 74 observations. This morning I used to be working Stata/MP interactively on a 24-core pc utilizing a considerably bigger dataset.
After some time, I used to be struck by the truth that I wasn’t noticing any annoying delays ready for instructions to run. It felt nearly as if I have been working on the auto dataset. However I wasn’t. I used to be working instructions utilizing 50 covariates on 1 million observations! Regressions, abstract statistics, and so forth.; this was enjoyable. I had by no means performed interactively with a million-observation dataset earlier than.
Out of curiousity, I turned off multicore assist. The change was dramatic. Instructions that have been taking lower than a second have been now taking longer, too lengthy. My espresso cup was full, however I contemplated fetching a snack. Working on just one processor was not a lot enjoyable.
On your info, I set rmsg on and ran a number of timings:
Timing (seconds)
Evaluation
24 cores
1 core
generate a brand new variable
.03
.33
summarize 50 variables
.88
19.55
twoway tabulation
.45
.45
linear regression
.65
11.48
logistic regression
7.19
59.27
All timings are on a 1 million commentary dataset. The 2 regressions included 50 covariates.
OK, the timings with 24 cores usually are not fairly the identical as with the auto dataset, however properly inside snug interactive use.
Cautious readers could have seen that the 24-core and 1-core timings for twoway tabulation are the identical. We’ve not rewritten the code for tabulate to assist a number of cores, partly as a result of tabulate is already very quick, and partly as a result of the code for tabulate is remoted, so altering it won’t enhance the efficiency of different instructions. Thus, parallelizing tabulate is on our long-run, not short-run, listing of additives to Stata/MP. We’ve rewritten about 250 sections of Stata’s inside code to assist Symmetric Multi Processing (SMP). Every rewritten part usually improves the efficiency of many instructions.
I switched again to utilizing all 24 cores and returned to my unique work — stress testing adjustments within the variety of covariates and observations. My enjoyable was quelled once I began working some timings of Cox proportional hazards regressions. With my 50 covariates and 1 million observations, a Cox regression took simply over two minutes. Most estimators in Stata are parallelized, together with the estimators for parametric survival fashions. The Cox proportional hazards estimator isn’t. It’s not parallelized as a result of it makes use of a intelligent algorithm that requires sequential computations. After I say sequential I imply that some computations are wholly depending on earlier computations in order that they merely can’t be carried out concurrently, in parallel. There are different algorithms for becoming the Cox mannequin, however they’re orders of magnitude slower. Even parallelized, they might not be quicker than our present sequential algorithm until run on 20 or extra processors. When extra computer systems begin delivery with dozens of cores, we’ll consider including a parallelized algorithm for the Cox estimator.
The pc I used to be working on is a couple of 12 months outdated. There have been a spate of latest and quicker server-grade processors from Intel and AMD previously 12 months. You will get fairly near the efficiency of my 24-core pc utilizing simply 8-cores and the newer chips. That implies that with a more recent 32-core pc, I may enhance my threshold for interactive evaluation to about 4 million observations.
There are 4 pace comparisons above. To see 450 extra, together with graphs and a dialogue of SMP and its implementation in Stata, see the Stata/MP white paper, a.okay.a. the Stata/MP Efficiency Report.