TL;DR: Get 5 years of Flowkey Basic for $99.99 (Reg. $899) and switch “I want I might play” into precise songs—with out the inflexible classes or eye-glazing idea.
There are two kinds of folks on the planet: those that have tried to be taught “Für Elise,” and those that have nearly tried to be taught “Für Elise.” Basically the common beginning line for piano—acquainted, a bit dramatic, and simply tough sufficient to humble you midway via — Flowkey exists that can assist you grasp this social gathering time basic.
Flowkey’s Basic Plan was constructed for individuals who need to really play songs and may meet you at your present talent stage — even when that is “enthusiastic newbie.” Proper now, a 5-year subscription is $99.99 (Reg. $899), which is the type of price-to-time ratio is difficult to disregard, particularly when you think about how most studying apps cost month-to-month simply to maintain you poking round.
5 years of classes that truly pay attention again
Flowkey works by assembly you on the keys, not burying you in idea. The app is out there in 11 languages and listens as you play via your gadget’s microphone or a related keyboard and offers real-time suggestions. This real-time suggestions loop lets immediately when you’re hitting the correct notes. You possibly can gradual songs down, loop tough sections, and construct confidence with out restarting from scratch each time.
The track library spans beginner-friendly staples to extra superior items, so you are not caught replaying the identical workouts. And since it runs on telephone, pill, or desktop, it suits into no matter window of time you’ve got—5 minutes after work or an extended weekend session.
In the event you’ve been which means to be taught piano however by no means discovered a follow system that caught, Flowkey makes it simpler to start out—and simpler to maintain going.
Get 5 years of Flowkey Basic for $99.99 (88% off) and eventually make it previous the half the place “Für Elise” wins.
flowkey Piano Studying App: Basic Plan (5-Yr Subscription)
Get the Widespread Science day by day e-newsletter💡
Breakthroughs, discoveries, and DIY suggestions despatched six days every week.
Whether or not you’re pro-Daylight Financial savings or pro-Customary Time, the science is evident: Switching between the 2 yearly is horrible for human well being. So why haven’t we caught with one system all 12 months? The reply is each scientific AND political.
In January 1974, clocks throughout america sprang ahead, with no intention of ever falling again. The coverage was launched by President Richard Nixon as an energy-saving response to the earlier 12 months’s oil disaster. Theoretically, later sunsets would assist offset power utilization. A two-year analysis interval had begun with the intention to make it everlasting.
Clearly, this didn’t occur, and the explanations we nonetheless have our biannual clock change can largely be summed up with one phrase: Watergate. Everlasting Daylight Saving Time lasted only some weeks longer than Nixon himself. In late September 1974, the month after the president’s resignation, the Senate voted to nix the coverage.
The thought of everlasting Daylight Financial savings rapidly light, partly as a result of federal regulation prevents states from messing with time and time zones. However over the past decade, the concept has been gaining traction.
Would Everlasting Daylight Financial savings Time Actually Enhance Our High quality of Life?
In the event you’d prefer to see extra Widespread Science movies, subscribe on YouTube. We’ll be bringing you explainers and explorations of our bizarre world.
2025 PopSci Better of What’s New
The 50 most necessary improvements of the 12 months
A harsh reality to start with: textbook information science normally turns into a lie in the true world. Ideas and strategies are taught on finely curated, fantastically bell-curved information variables, however as quickly as we enterprise into the wild of actual tasks, we’re hit with numerous outliers, unduly skewed distributions, and indomitable variances.
A earlier article on constructing an exploratory information evaluation (EDA) pipeline with Pingouin confirmed find out how to detect, by exams, circumstances when the information violates quite a lot of assumptions like homoscedasticity and normality. However what if the exams fail? Throwing the information away is not the answer: turning sturdy is.
This text uncovers the craftsmanship of utilizing sturdy statistics in information science processes. These are mathematical strategies notably constructed to yield dependable and legitimate outcomes even when the information doesn’t meet classical assumptions or is pervaded by outliers and noise. By adopting a “select your individual journey” method, we’ll create a trio of situations utilizing Python’s Pingouin to handle the ugliest features throughout the information chances are you’ll encounter in your every day work.
# Preliminary Setup
Let’s begin by putting in (if wanted) and importing Pingouin and Pandas, after which we’ll load the wine high quality dataset accessible right here.
!pip set up pingouin pandas
import pandas as pd
import pingouin as pg
# Loading our messy, real-world-like dataset, containing crimson and white wine samples
url = "https://uncooked.githubusercontent.com/gakudo-ai/open-datasets/refs/heads/primary/wine-quality-white-and-red.csv"
df = pd.read_csv(url)
# Take a small peek at what we're about to take care of
df.head()
If you happen to regarded on the earlier Pingouin article, you already know it is a notoriously messy dataset that failed to fulfill a number of widespread assumptions. Now we’ll embark on three completely different “adventures”, every highlighting a state of affairs, a core drawback, and a proposed sturdy repair to deal with it.
// Journey 1: When the Normality Take a look at Fails
Suppose we run normality exams on two teams: white wine samples and crimson wine samples.
white_wine_alcohol = df[df['type'] == 'white']['alcohol']
red_wine_alcohol = df[df['type'] == 'crimson']['alcohol']
print("Normality check for White Wine Alcohol content material:")
print(pg.normality(white_wine_alcohol))
print("nNormality check for Pink Wine Alcohol content material:")
print(pg.normality(red_wine_alcohol))
One can find that neither distribution is regular, with extraordinarily low p-values. Though non-normality itself would not straight sign outliers or skewness, a robust deviation from normality usually suggests such traits could also be current within the information. Evaluating means by a t-test on this scenario can be harmful and more likely to yield unreliable outcomes.
The sturdy repair for a state of affairs like that is the Mann-Whitney U check. As an alternative of evaluating averages, this check compares the ranks within the information — sorting all wines in a bunch from lowest to highest alcohol content material, as an example. This rank-based method is the grasp trick that strips outliers of their typically harmful magnitude. This is how:
# Separating our two teams
red_wine = df[df['type'] == 'crimson']['alcohol']
white_wine = df[df['type'] == 'white']['alcohol']
# Operating the sturdy Mann-Whitney U check
mwu_results = pg.mwu(x=red_wine, y=white_wine)
print(mwu_results)
For the reason that p-value just isn’t under 0.05, there isn’t any statistically important distinction in alcohol content material between the 2 wine varieties — and this conclusion is assured to be outlier-proof and skewness-proof.
// Journey 2: When the Paired T-Take a look at Fails
Say you now wish to examine two measurements taken from the identical topic — e.g. a affected person’s sugar degree earlier than and after a drug prototype, or two properties measured in the identical bottle of wine. The main focus right here is on how the variations between paired measurements are distributed. When such variations usually are not usually distributed, a regular paired t-test will yield unreliable confidence intervals.
The perfect repair on this state of affairs is the Wilcoxon Signed-Rank Take a look at: the sturdy sibling of the paired t-test, which works by observing the variations between columns and rating their absolute values. In Pingouin, this check is known as utilizing pg.wilcoxon(), passing within the two columns containing the paired measures throughout the identical topic — e.g. two varieties of wine acidity.
# Run the sturdy Wilcoxon signed-rank check for paired information
wilcoxon_results = pg.wilcoxon(x=df['fixed acidity'], y=df['volatile acidity'])
print(wilcoxon_results)
The outcome above exhibits a statistically important distinction, or “excellent separation,” between the 2 measurements. Not solely are the 2 wine properties completely different, however in addition they function at totally completely different magnitude tiers throughout the dataset.
// Journey 3: When ANOVA Fails
On this third and last journey, we wish to examine whether or not residual sugar ranges in wine differ considerably throughout distinct high quality rankings — be aware that the latter vary between 3 and 9, taking integer values, and may due to this fact be handled as discrete classes.
If Pingouin’s Levene check of homoscedasticity fails dramatically — as an example, as a result of sugar variance in mediocre wines is big however very small in top-quality wines — a classical one-way ANOVA could produce deceptive outcomes, as this check assumes equal variances amongst teams.
The repair is Welch’s ANOVA, which penalizes teams with excessive variance, thereby balancing out scales and making comparisons fairer throughout a number of classes. Right here is find out how to run this sturdy various to conventional ANOVA utilizing Pingouin:
# Run Welch's ANOVA to check sugar throughout high quality rankings
welch_results = pg.welch_anova(information=df, dv='residual sugar', between='high quality')
print(welch_results)
Consequence:
Supply ddof1 ddof2 F p_unc np2
0 high quality 6 54.507934 10.918282 5.937951e-08 0.008353
Even the place a one-way ANOVA may need struggled resulting from unequal variances, Welch’s ANOVA delivers a stable conclusion. The very small p-value is evident proof that residual sugar ranges differ considerably throughout wine high quality rankings. Keep in mind, nonetheless, that sugar is barely a small piece of the puzzle influencing wine high quality — a degree underscored by the low eta-squared worth of 0.008.
# Wrapping Up
By three instance situations, every pairing a messy-data drawback with a strong statistical technique, we’ve got realized that being a talented information scientist doesn’t suggest having excellent information or tuning it completely — it means figuring out what to do when the information will get troublesome for various causes. Pingouin’s capabilities implement quite a lot of sturdy exams that assist escape the failed-assumptions lure and extract mathematically sound insights with little further effort.
Iván Palomares Carrascosa is a pacesetter, author, speaker, and adviser in AI, machine studying, deep studying & LLMs. He trains and guides others in harnessing AI in the true world.
On the similar time, whereas these AI programs may make progress on extra complicated requests, they might not full the “final mile” by themselves at first. To beat this, we checked out how the AI fashions used information to formulate responses and what sources the mannequin known as on most frequently. This led to extra refinement and enchancment within the programs alongside a human decision-maker that might perceive what the AI was recommending, why it might be appropriate, and the place it may very well be improved.
Databases are important elements within the expertise stack. As programs of report and sources for information evaluation, they need to be dependable, accessible, and safe. Any choice round databases — from which database you select for the job by way of to decisions on administration or optimization — can have a huge impact. Any change must be managed, or the end result is usually a damaged software.
AI and the way forward for databases
Database administration wants AI. The demand from prospects for quicker fixes and higher efficiency is just not going away, and people prospects anticipate their suppliers to make use of AI in the identical manner they could use AI internally. For firms concerned in service and assist round IT together with databases, making use of AI to unravel issues quicker isn’t one thing you could keep away from. Nonetheless, the human within the loop mannequin will likely be important for these service and assist necessities for the foreseeable future. With databases so essential to how purposes perform and assist the enterprise, totally automating service with AI is just not but dependable for 100% of requests. As AI improves, the pace will profit nearly all of potential points. Nonetheless, the extra complicated issues will nonetheless require human experience and management.
“I used to be a idiot who offered them free funding to create a startup,” Musk advised the jury. He mentioned when he cofounded OpenAI in 2015 with Altman and Brockman, he was donating to a nonprofit creating AI for the good thing about humanity, to not make the executives wealthy. “I gave them $38 million of basically free funding, which they then used to create what would change into an $800 billion firm,” he mentioned.
Musk is asking the court docket to take away Altman and Brockman from their roles and to unwind the restructuring that allowed OpenAI to function a for-profit subsidiary. The end result of the trial may upend OpenAI’s race towards an IPO at a valuation approaching $1 trillion. In the meantime, xAI is anticipated to go public as part of Musk’s rocket firm SpaceX as early as June, at a goal valuation of $1.75 trillion.
This week’s testimony revolved round a central query of the trial: why Musk is suing OpenAI. Musk argued he was making an attempt to avoid wasting OpenAI’s mission to develop AI safely by restoring the corporate to its unique nonprofit construction. OpenAI’s lawyer, William Savitt, who as soon as represented Musk and his electric-car firm Tesla, countered that Musk was “by no means dedicated to OpenAI being a nonprofit” and as an alternative was suing to undermine his competitor.
Who’s the steward of AI security?
Throughout his direct examination early within the week, Musk painted himself as a longtime advocate of AI security. He mentioned he cofounded OpenAI to create a “counterbalance to Google,” which was main the AI race on the time. He mentioned that when he requested Google cofounder Larry Web page what occurs if AI tries to wipe out humanity, Web page advised him, “That can be high-quality so long as synthetic intelligence survives.”
“The worst-case situation is a Terminator state of affairs the place AI kills us all,” Musk later advised the jury.
Savitt stood on the lectern and argued that Musk was not a “paladin of security and regulation.” As he cross-examined Musk in his sharp, surgical cadence, Savitt identified that xAI sued the state of Colorado in April over an AI legislation designed to forestall algorithmic discrimination.
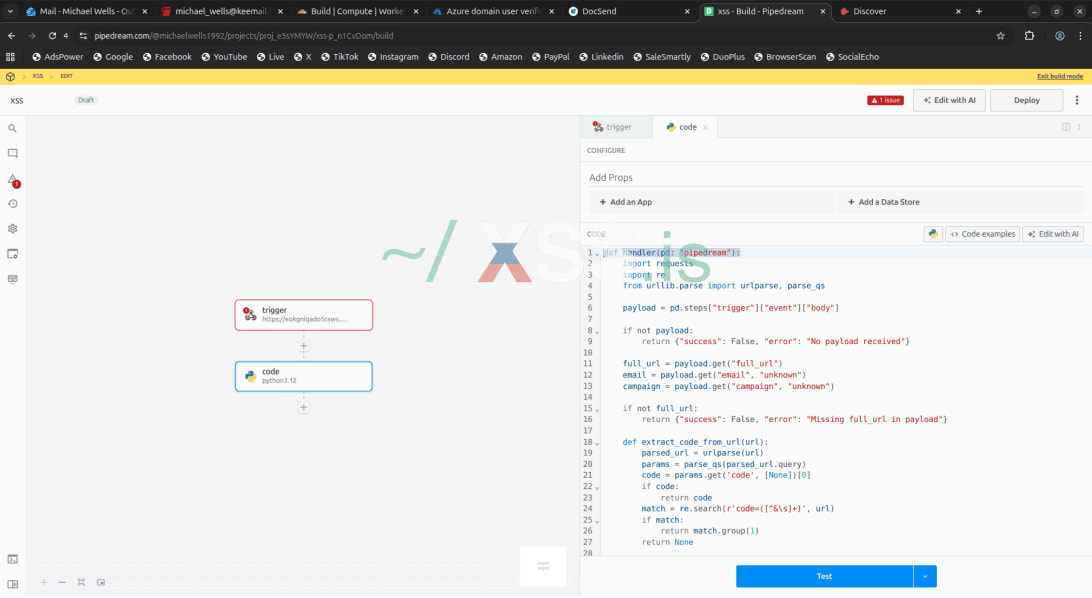
A brand new assault sort, dubbed ConsentFix v3, has been circulating on hacker boards as an improved method that automates assaults towards Microsoft Azure.
The primary model of ConsentFix was offered by Push Safety final December as a variation of ClickFix for OAuth phishing assaults, which tips victims into finishing a reputable Microsoft login movement through the Azure CLI.
Utilizing social engineering, the attacker fooled victims into pasting a localhost URL containing an OAuth authorization code that can be utilized to acquire tokens and hijack the account with out passwords, regardless of multi-factor authentication (MFA).
ConsentFix v2 was developed by researcher John Hammond as a refined model of Push’s unique, changing handbook copy/paste with drag-and-drop of the localhost URL, making the phishing movement smoother and extra convincing.
ConsentFix v3 preserves the core concept of abusing the OAuth2 authorization code movement and concentrating on first-party Microsoft apps which might be pre-trusted and pre-consented.
Nonetheless, it brings an enchancment by incorporating automation and scalability.
ConsentFix v3 assault movement
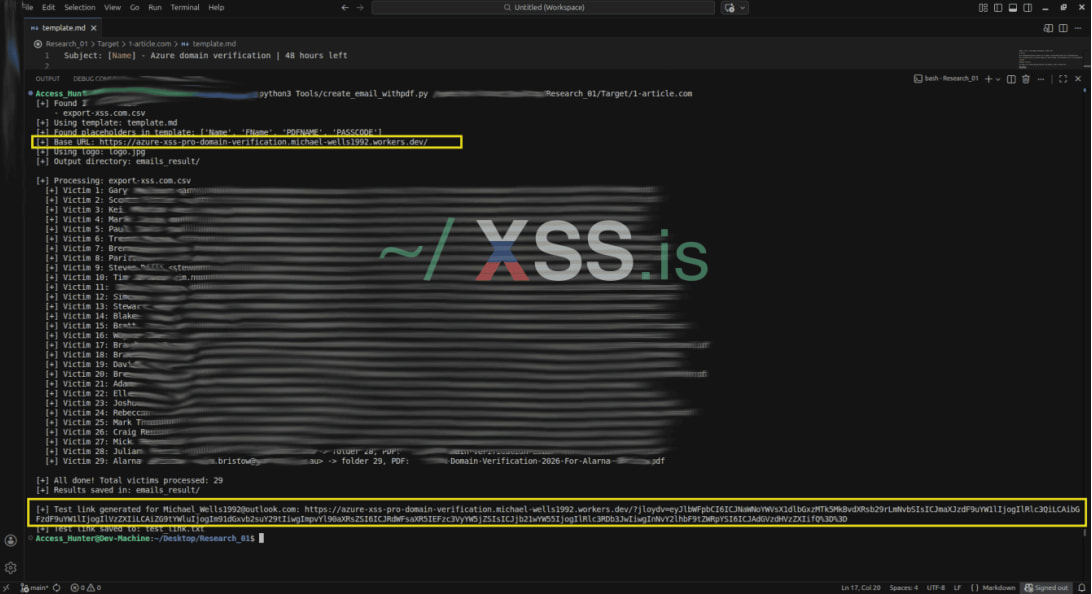
In line with info retrieved from hacker boards the place the brand new method is promoted, the assault begins by verifying the presence of Azure within the goal setting by checking for legitimate tenant IDs.
That is adopted by gathering worker particulars corresponding to names, roles, and e mail addresses to help impersonation.
Subsequent, the attackers create a number of accounts throughout providers corresponding to Outlook, Tutanota, Cloudflare, DocSend, Hunter.io, and Pipedream to help phishing, internet hosting, knowledge gathering, and exfiltration operations.
Push Safety researchers clarify that Pipedream, a free-to-use serverless integration platform, performs a central half in automating the assault, serving three crucial roles:
Is the webhook endpoint that receives the sufferer’s authorization code
It’s the automation engine that instantly exchanges that code for a refresh token through Microsoft’s API
It’s the central collector that makes captured tokens accessible to us in actual time.
Creating the Pipedream mannequin Supply: Push Safety
Within the subsequent part, the attacker deploys a phishing web page hosted on Cloudflare Pages that mimics a reputable Microsoft/Azure interface and initiates an actual OAuth movement by means of Microsoft’s login endpoint.
When the sufferer interacts with the web page, they’re redirected to a localhost URL containing an OAuth authorization code, which they’re tricked into pasting or dragging again into the phishing web page.
This allows the information exfiltration pipeline, through which the web page sends the captured URL to a Pipedream webhook, and the backend automation instantly exchanges the authorization code for tokens.
The phishing emails could be extremely personalised, generated from harvested knowledge, and have malicious hyperlinks embedded inside a PDF hosted on DocSend to enhance credibility and bypass spam filtering.
Within the post-exploitation stage, the obtained tokens are imported into Specter Portal, permitting the attacker to work together with compromised Microsoft environments and entry assets permitted by the token, corresponding to e mail, recordsdata, and different providers tied to the account.
Push Safety famous that its testing of ConsentFix v3 relied on its private Microsoft accounts; consequently, it’s tough to completely recognize the influence, which relies on permissions, providers, and tenant settings, amongst different components.
When it comes to mitigating ConsentFix dangers, Push notes that the endeavor is difficult as a result of belief in first-party apps is architectural, and that Household of Shopper IDs (FOCI), Microsoft purposes that share permissions and refresh tokens, is helpful in any other case.
Nonetheless, there are nonetheless steps directors can take, corresponding to making use of token binding to trusted gadgets, establishing behavioral detection guidelines, and making use of app authentication restrictions.
Whereas ConsentFix assaults are utilized in precise campaigns, it’s unclear if the v3 variant has gained any traction amongst cybercriminals but.
AI chained 4 zero-days into one exploit that bypassed each renderer and OS sandboxes. A wave of recent exploits is coming.
On the Autonomous Validation Summit (Could 12 & 14), see how autonomous, context-rich validation finds what’s exploitable, proves controls maintain, and closes the remediation loop.
A garlic-herb salmon with risotto was in all probability the very best among the many household meals I attempted. The chopped asparagus was lower than visually interesting when drizzled in garlic butter, however nonetheless tasty and a bit crisp. The salmon was tender and flaky. And the candy pea risotto had no alternative however to be scrumptious. There was a lot cheese, butter, and lemon it was just about a live performance of fat and acid.
That hen parm was likewise a mountain of cheese and salt. It jogged my memory, pleasantly, of numerous household meals I had as a baby within the Eighties: cheese-topped hen, garlic bread, shells filled with ricotta and topped with much more cheese. The large distinction is that there’s merely no means my mom would have cooked this meal with no vegetable.
Toval app by way of Matthew Korfhage
And vitamin is the place Toval runs aground somewhat. The dietary notes on that hen parm meal betray 2,300 milligrams of sodium per serving, just about the whole day by day allowance for an grownup human. That is additionally on par with comparable servings of Stouffer’s meat lasagna. The Tovala meal additionally carried about 10 occasions the ldl cholesterol as Stouffer’s.
Many different meals adopted an identical sample, loading up on fat and salt so as to make meals tasty. The online impact is that it is much more like wealthy restaurant meals than what most individuals put together at house. Whether or not this can be a good or a foul high quality is as much as you.
Just one meal of the seven I attempted failed completely: I flagged a teriyaki hen dinner to my editor as a doable cultural crime towards Japan. The meal was candy soy drenching pale and steaming hen, with an implausible aspect of thick egg rolls and a few unfastened, unseasoned broccoli. It felt just like the “Japanese” meals you’d get at a mall meals courtroom within the ’90s. However once more, this was a uncommon main misstep.
A extra pernicious problem, in meals designed for the entire household, is the near-universal high-fat, ldl cholesterol, and sodium content material. Many with the earnings and inclination to eat hearty, low-effort meals like those from Tovala are both dad and mom with kids, or folks within the retirement bracket. Every has their very own cause to want somewhat extra vitamin, and fewer fats and salt.
By the tip of a few weeks of testing recipes, I am going to admit I felt somewhat relieved. I used to be grateful to really feel my arteries slowly reopen. Tovala’s culinary mannequin makes a whole lot of sense to me, as a sensible means of splitting the distinction between ready meals and contemporary meals. And the corporate has confirmed it could possibly prepare dinner effectively. It is perhaps good in the event that they’d additionally prepare dinner a weight loss plan that felt extra sustainable.
Stata’s odbc command permits you to import knowledge from and export knowledge to any ODBC knowledge supply in your pc. ODBC is a standardized means for functions to learn knowledge from and write knowledge to totally different knowledge sources equivalent to databases and spreadsheets.
Till now, earlier than you would use the odbc command, you had so as to add a named knowledge supply (DSN) to the pc through the ODBC Information Supply Administrator. For those who didn’t have administrator privileges in your pc, you would not do that.
Within the replace to Stata 11 launched 4 November 2010, a brand new possibility, connectionstring(), was added to the odbc command. This selection permits you to specify an ODBC knowledge supply on the fly utilizing an ODBC connection string as a substitute of getting to first add an information supply (DSN) to the pc. A connection string permits you to specify all essential parameters to determine a connection between Stata and the ODBC supply. Connection strings have an ordinary syntax for all drivers however there are additionally driver-specific key phrase/worth pairs that you would be able to specify. The three normal issues that you’ll most likely want in a connection string are DRIVER, SERVER, and DATABASE. For instance,
Once more, there are driver particular key phrase/worth pairs you’ll be able to add to the connection string. You may carry out a search on the Web for “connection string” and your database identify to seek out what different choices you’ll be able to specify within the connection string. Simply bear in mind to separate every connection string key phrase/worth pair with a semicolon. You may learn extra about connection string syntax on Microsoft’s web site.
To get this functionality in your copy of Stata 11, merely kind replace all and observe the directions to finish the replace. You may then kind assist odbc to learn extra concerning the connectionstring() possibility.
? We ran 134,400 simulations grounded in actual manufacturing ML fashions to search out out. The reply relies on what you’re optimizing for, and on a single diagnostic you may compute earlier than becoming a mannequin.
When you’ve ever skilled a linear mannequin in scikit-learn, you’ve confronted this query: RidgeCV, LassoCV, or ElasticNetCV? Perhaps you defaulted to no matter a tutorial beneficial. Perhaps a colleague had a robust opinion. Perhaps you tried all three and picked whichever gave the very best cross-validation rating.
We needed to exchange instinct with empirical decision-making.
We ran 134,400 simulations throughout 960 configurations of a 7-dimensional parameter house, various pattern dimension, options, multicollinearity, signal-to-noise ratio, coefficient sparsity, and two extra parameters. We benchmarked 4 regularization frameworks (Ridge, Lasso, ElasticNet, and Publish-Lasso OLS) throughout the three targets:
Predictive accuracy (check RMSE)
Variable choice (F1 rating for recovering the true function set)
Coefficient estimation (L2 error vs. true coefficients)
Our simulation ranges aren’t arbitrary. They’re grounded in eight real-world manufacturing ML fashions from Instacart, spanning demand forecasting, conversion prediction, and stock intelligence. The regimes we examined mirror circumstances that MLEs really encounter in observe.
This publish distills the sensible steerage from our examine into a call framework you should use in your subsequent venture. When you’re a Knowledge Scientist or MLE selecting a regularizer, that is for you.
The Headlines
Earlier than we get into the small print:
For prediction, it barely issues. Ridge, Lasso, and ElasticNet differ by at most 0.3% in median RMSE. No hyperparameter achieves even a small impact dimension for RMSE variations amongst them. This solely holds with ample coaching information (> 78 observations per function).
For variable choice, it issues enormously, particularly underneath multicollinearity. Lasso’s recall collapses to 0.18 underneath excessive situation numbers with low sign, whereas ElasticNet maintains 0.93.
At massive sample-to-feature ratios (n/p ≥ 78), the strategies change into interchangeable. Use Ridge; it’s the quickest.
Publish-Lasso OLS ought to be prevented when optimizing for RMSE. It’s the one technique that constantly underperforms, and it does so on each goal we measured.
Desk 1: We simulated a hyperparameter house of 960 configurations.
We ran every of the 4 regularization frameworks in opposition to 960 hyper-parameter configurations, every utilizing 35 random seeds for a complete of 134,400 simulations. For each simulation we logged the check RMSE, F1 rating (precision and recall for recovering the true help of β), and coefficient L2 error.
To measure what drives the variations between strategies, we used omega-squared (ω²) from one-way ANOVA, an impact dimension that tells us what quantity of variance in efficiency gaps is defined by every parameter. This goes past asking “which technique wins” to understanding why it wins, and underneath what circumstances.
Right here’s what this implies in observe: a lot of the parameters that drive technique variations are issues you may observe earlier than becoming a mannequin. You recognize n and p. You may compute the situation quantity κ with numpy.linalg.cond(X). And the one vital latent parameter, SNR, has a free diagnostic proxy: the regularization power α that LassoCV selects. Excessive α indicators low sign; low α indicators robust sign. We’ll come again to this.
Discovering 1: For Prediction, Simply Use Ridge
That is an important discovering for the biggest variety of practitioners.
Ridge, Lasso, and ElasticNet are practically interchangeable for prediction. Throughout all 33,600 simulations per technique, the median check RMSE differs by at most 0.3%. Our omega-squared evaluation confirms this: no single hyperparameter achieves even a small impact dimension (ω² ≥ 0.01) for RMSE variations amongst these three strategies. Each pairwise comparability is negligible (all < 0.02).
For practitioners who solely care about accuracy, the near-equivalence is itself the discovering. Regularizer selection issues far lower than pattern dimension.
Determine 1: Variations in check RMSE change into trivial given adequate pattern dimension.
So why Ridge? Computational effectivity. Ridge has a closed-form answer for every candidate α, making it dramatically sooner than the options (evaluate Ridge’s median run time of 6 seconds to Lasso’s median runtime of 9 seconds and ElasticNet’s median runtime of 48 seconds).
Determine 2: Customers ought to count on a minimal of a 5X enhance in runtimes when choosing ElasticNet over Ridge or Lasso.
ElasticNet’s overhead stems from its joint grid search over α and the L1 ratio ρ. The 167–219× imply overhead we measured is restricted to our 8-value L1 ratio grid. A coarser 3-value grid would cut back this proportionally. Even worse, when the coefficient distribution is roughly uniform, Lasso can take over an hour to converge (see the right-side of the bimodal distribution). This overhead buys you a median RMSE enchancment of simply 0.04% over Ridge, a margin that’s negligible in observe.
Caveats
On the smallest pattern dimension we examined (n = 100), ElasticNet can beat Ridge by 5–15% in very particular situations: when SNR is excessive (~1.0). At low SNR, Ridge is definitely marginally higher. These are localized observations on the excessive of our simulation grid, not systematic traits.
Yet one more notice: LassoLars wasn’t a part of our analysis design, however the LARS algorithm computes all the Lasso regularization path analytically in a single move (O(np²)), probably matching Ridge’s closed-form pace benefit. Nevertheless, LARS is understood to be numerically unstable underneath high-collinearity circumstances (κ > 10⁴) that characterize most manufacturing ML function units. That is exactly the regime the place our strongest findings apply.
Backside line for prediction: Default to RidgeCV. Pattern dimension issues excess of regularizer selection. However prediction isn’t the one goal price optimizing. When variable choice or coefficient accuracy issues, particularly underneath multicollinearity, the story adjustments dramatically.
Discovering 2: For Variable Choice, ElasticNet Is the Secure Default
Right here technique selection really issues. Variable choice, the duty of figuring out which options actually contribute to the end result, is the target most delicate to the regularizer, and the place getting it improper carries the steepest value.
What Drives the Variations
From our ANOVA decomposition of pairwise F1 variations:
Desk 2: Pattern dimension is essentially the most salient predictor of variations within the F1 rating.
Pattern dimension dominates overwhelmingly. However when you’re within the small-n regime (n/p < 78), the situation quantity and SNR change into the first differentiators.
Excessive Multicollinearity (κ > ~10⁴): Do Not Use Lasso
This is without doubt one of the most strong findings in all the examine, and it’s instantly related to manufacturing ML. Seven of eight fashions we surveyed function within the high-κ regime. In case your options are even reasonably correlated (which they virtually definitely are in any engineered function set), this discovering applies to you.
At excessive κ with low SNR:
Lasso recall: 0.18 (it misses 82% of true options)
ElasticNet recall: 0.93 (it catches 93% of true options)
That’s a 5× recall benefit for ElasticNet. The mechanism is well-known. When options are extremely correlated, Lasso arbitrarily picks one from every correlated group and zeros the remaining. ElasticNet’s L2 penalty part, the “grouping impact” described by Zou and Hastie (2005), retains correlated options collectively.
Our simulations present this isn’t a nook case. The strongest F1 variations (ΔF1 of 0.50–0.75) focus squarely within the high-κ columns at n = 100 and n = 1,000. That is the widespread case in manufacturing.
Low Multicollinearity (κ < ~10²): Nonetheless Default to ElasticNet
You may count on Lasso to lastly shine at low κ. It doesn’t, not less than not universally. Even at low κ, Lasso’s recall is very delicate to the signal-to-noise ratio (see beneath).
Determine 3: ElasticNet’s use of the L2 norm protects in opposition to the recall collapse that may happen with Lasso.
ElasticNet maintains recall ≥ 0.91 no matter SNR, even at low κ. Lasso is barely aggressive when each SNR is excessive and the true mannequin is genuinely sparse. Because you usually don’t know SNR prematurely, ElasticNet is the safer wager.
The Ridge Shock
We didn’t count on this: Ridge regularly achieves the highest F1 scores at small n, regardless of by no means performing specific variable choice. How? Ridge’s recall is at all times 1.0, as a result of it retains each function, and that excellent recall overwhelms the precision benefit of sparse strategies when these strategies’ recall collapses underneath low SNR.
However this isn’t real variable choice. Ridge offers you a nonzero coefficient for each function. When you want an explicitly sparse mannequin, Ridge doesn’t assist. Combining Ridge with post-hoc permutation significance is a pure extension, however we didn’t consider it right here.
Variable Choice: Abstract
Determine 4: ElasticNet is the protected selection when the researcher can not reliably infer SNR.
Backside line for variable choice: ElasticNetCV is the protected default. Lasso solely earns its place when κ is low, SNR is excessive, and you’ve got area motive to consider the true mannequin is sparse.
Discovering 3: For Coefficient Estimation, Department on κ
When the objective is recovering correct coefficient values, for interpretability or causal inference, the situation quantity κ turns into the important thing branching variable. Ideally we might department on the distribution of the true 𝛽 coefficients, however we don’t get to watch it. In distinction, κ might be measured instantly. At excessive κ ElasticNet dominates no matter sparsity. At low κ, the optimum technique relies on whether or not the true mannequin is sparse or dense. Pattern dimension adjustments the magnitude of variations however not their path.
Excessive κ (> ~10⁴): Use ElasticNet. It achieves 20–40% decrease L2 coefficient error than Lasso, and holds a constant edge over Ridge no matter sparsity degree.
Low κ (< ~10²): Department in your area information about sparsity.
Sparse area (genomics, textual content classification, sensor arrays): Lasso or ElasticNet
Dense area (engineered function units, demand forecasting, conversion fashions): Ridge
Determine 5: Ridge’s efficiency benefit over Lasso / ElasticNet fades shortly because the n / p ratio will increase, whereas a well-conditioned eigenspace additional benefits Lasso / ElasticNet.
All regimes: Keep away from Publish-Lasso OLS. It exhibits increased coefficient L2 error than normal Lasso throughout all the simulation grid. The unpenalized OLS refit amplifies first-stage choice errors. That is the state of affairs the place you’d hope the two-stage process helps, and it doesn’t.
Determine 6: When the objective is coefficient estimation, Ridge turns into extra specialised.
Backside line for coefficient estimation: ElasticNet at excessive κ, domain-dependent at low κ, by no means Publish-Lasso OLS.
A Practitioner’s Resolution Information
All the findings above distill into a call framework that branches solely on portions you may compute earlier than becoming a single mannequin: the sample-to-feature ratio n/p, the situation quantity κ (by way of numpy.linalg.cond(X)), and when finer discrimination is required, the regularization power α elected by a fast LassoCV run as a proxy for the latent SNR.
The total flowchart is on the market in our paper (Determine 7). Right here, we stroll by way of the logic as a call tree.
The under-determined regime
In case your function rely exceeds your pattern dimension, you’re within the under-determined regime. Lasso’s α regularly saturates on the higher boundary of the search grid right here, and its recall collapses. Default to Ridge or ElasticNet for all targets, and proceed with warning.
The massive-sample regime
If n/p ≥ 78, you’re within the large-sample regime the place all strategies converge. Efficiency gaps vanish throughout prediction, variable choice, and coefficient estimation concurrently.
Use RidgeCV. It’s the quickest technique by a large margin, and there’s no accuracy penalty. When you particularly want a sparse mannequin for interpretability, ElasticNetCV or LassoCV are completely nice at this ratio. The selection amongst them is immaterial.
The regime the place selection issues
Under n/p = 78 is the place technique selection issues most. The suitable regularizer relies on what you’re optimizing for.
If prediction is your precedence: Use RidgeCV. The RMSE variations among the many core three strategies are too small to justify extra complexity or compute. One slender exception: at n ≈ 100 with excessive SNR (~1.0), ElasticNet presents a detectable 5–15% edge no matter κ; at n ≈ 100 with very low SNR, Ridge is marginally most popular. In both case, the margin is modest relative to the development obtainable from growing pattern dimension.
If variable choice is your precedence: Department on the situation quantity.
κ > ~10⁴ (excessive multicollinearity): Use ElasticNetCV. That is among the many strongest suggestions within the examine. One nuance: at moderate-to-high SNR (or n ≥ 1,000), ElasticNet is clearly most popular, with F1 benefits over Lasso reaching ΔF1 of +0.75. At very low SNR with n ≈ 100 (identified by a saturated CV-elected α), Ridge achieves the best F1, however solely by way of excellent recall (retaining all options), not real variable choice. When you want an explicitly sparse mannequin even on this nook, ElasticNet stays the least-bad possibility and nonetheless vastly outperforms Lasso.
κ < ~10² (well-conditioned): An vital warning first: don’t default to Lasso even at low κ. Lasso’s recall drops sharply at decrease SNR ranges no matter multicollinearity, whereas ElasticNet maintains recall ≥ 0.91 throughout all SNR ranges. ElasticNet is the protected default right here. To refine additional, run a fast LassoCV and examine the elected α. If α is excessive or saturated on the boundary, you’re in a low-SNR regime. Ridge gives the very best F1 (although not by way of real sparsification). If α is reasonable, keep on with ElasticNet. If α is low and area experience suggests sparsity, Lasso turns into viable.
If coefficient estimation is your precedence: Department on the situation quantity.
κ > ~10⁴: ElasticNetCV dominates no matter sparsity.
κ < ~10²: Use area information. Sparse mannequin → Lasso. Dense mannequin → Ridge.
The α Diagnostic: A Free SNR Proxy
The one latent parameter that issues for fine-grained selections, signal-to-noise ratio, might be approximated at zero extra value. When scikit-learn’s LassoCV suits your information, it reviews the elected α. This worth is inversely associated to the underlying SNR: excessive α indicators weak sign, low α indicators robust sign.
Our simulations present direct empirical affirmation: the best elected α values (approaching 10⁴–10⁵) focus solely in small-n, low-SNR configurations.
Determine 7: The regularization parameter α generally is a helpful proxy for SNR.
These thresholds are approximate heuristics derived from our simulation grid, they’ll differ with function scaling and dataset traits. Deal with them as tips, not sharp cutoffs.
In All Unsure Instances
Once you’re not sure about SNR, not sure about sparsity, or working within the intermediate-κ vary we didn’t instantly check: ElasticNet is the default that received’t burn you, and Publish-Lasso OLS ought to be prevented.
The Meta-Discovering: Pattern Measurement Trumps The whole lot
One takeaway issues greater than any method-level steerage: growing your sample-to-feature ratio does extra for each goal than any regularizer selection.
Pattern dimension is the dominant driver of efficiency variations throughout all three metrics (ω² = 0.308 for F1, a massive impact). The n × SNR interplay is the strongest two-way interplay throughout all comparisons (F = 569, p < 0.001). Sign-to-noise issues most exactly when samples are scarce. And at n/p ≥ 78, technique selection turns into irrelevant totally.
When you’re spending days tuning your regularizer when you might be rising your coaching set, you’re optimizing the improper factor.
Fast Reference
Desk 3: Probably the most acceptable regularizer is set by each the character of the function information, in addition to the analysis goal.
Placing It Into Follow
The simulation framework is a reusable harness. We capped pattern sizes at 100k observations for compute causes, however the grid nonetheless spans the n/p inflection level the place regularizer efficiency shifts. We’re extending it now to newer regularizers (Adaptive Lasso, SCAD, MCP) and intermediate κ ranges.
To use this framework to your subsequent venture, compute three portions earlier than you match something: the sample-to-feature ratio (n/p), the situation quantity (κ), and for those who’re within the small-n regime, a fast LassoCV α as your SNR proxy. Route by way of the choice information above primarily based in your main goal.
If n/p ≥ 78, use Ridge and spend your tuning funds elsewhere. If n/p < 78 and κ is excessive, use ElasticNet and don’t second-guess it. The one state of affairs the place the selection requires actual thought is low κ with small n, and even there, ElasticNet is rarely a nasty reply.
The total paper, together with all appendix figures, ANOVA tables, and the consolidated determination flowchart, is on the market on ArXiv.
Ahsaas Bajaj is a Machine Studying Tech Lead at Instacart. Benjamin S Knight is a Employees Knowledge Scientist at Instacart.
Wayfair is not handing over full management of purchasing selections to AI, however brokers are altering how the retailer’s consumers uncover and consider merchandise, based on CTO Fiona Tan.
As with different enterprise sectors, retailers proceed to inject AI throughout their operations. Residence furnishings retailer Wayfair seems to have an early begin, primarily based on Tan’s feedback at Momentum AI convention, hosted April 27 in New York Metropolis by Reuters.
In a sit-down dialogue with Tan, Reuters reporter Arriana McLymore famous that Wayfair’s CEO Niraj Shah beforehand described AI as a major development driver for the corporate that might enhance effectivity.
In its most up-to-date monetary outcomes, for the primary quarter ended March 31, Wayfair reported a web lack of $105 million on $2.9 billion in income. That compares with a web lack of $113 million on $2.7 billion in income for the year-ago interval. The discount in web loss included a decline in working losses, although that was not attributed to the usage of AI.
Tan added that the expertise isn’t totally new to her firm, which has lengthy used predictive machine studying and AI. She mentioned Wayfair has a historical past of making use of information to its operations and, extra lately, has begun working with generative AI for in-house and exterior wants.
“We’re a digitally native firm … you see us investing within the buyer expertise, in addition to inside operations,” Tan mentioned.
Administration on board with cultivating AI
Wayfair adopted a practical funding method to AI whereas making use of the tech broadly with help from senior administration, she mentioned. This contains providing AI instruments to workers that permit them spend extra time connecting with suppliers slightly than pulling information, Tan mentioned.
Anticipated makes use of for AI proceed to evolve throughout industries, together with what retailers predicted even one yr in the past. “On the time, the considering was that we had been going to maneuver towards a really autonomous purchasing expertise,” Tan mentioned.
Relatively than have brokers deal with most of a buyer’s purchasing selections, Wayfair is placing AI to make use of as a boon to product discovery and analysis on customer-facing platforms, she mentioned. “Our inside providers are callable to AI brokers.”
Wayfair’s aim is to extend buyer engagement on its platforms with this method. For instance, AI brokers can help clients with reworking or redecorating initiatives. Earlier this yr, Tan spoke on the NRF Retail Huge Present in New York Metropolis, mentioning how AI may warn clients when a purchase order corresponding to a settee may not match the place meant. AI brokers can even be taught from clients’ selections to not full purchases.
E-commerce roots provide a straightforward shift to AI
When requested how Wayfair’s use of AI compares with its retail friends, Tan remained diplomatic however affirmed its unfold. “I feel all people’s leaning into it,” she mentioned.
Tan identified that Wayfair, based as e-commerce firm CSN Shops in 2002, has digitally native roots that gave it the info and content material infrastructure to help AI-enabled choices.
For instance, generated pictures let clients visualize merchandise in actual areas. “When you had been to do this earlier than, it could require a whole lot of 3D rendering, price and time that simply wasn’t sensible,” Tan mentioned.
Given the size of Wayfair’s operations, AI might have a hand in different time-saving efforts. Wayfair works with some 20,000 suppliers who provide greater than 30 million merchandise, she mentioned. “Every provider is totally different, and so how they handle and what they ship can also be fairly totally different.”
Confronted with such a quantity of products, AI helps Wayfair replace its catalog, letting suppliers add merchandise in a short time with out requiring as a lot info as wanted beforehand, Tan mentioned. On the identical time, these updates additionally guarantee clients obtain correct, strong particulars on merchandise.
After Wayfair opened its first bodily location in 2019, its digital assets additionally fed its real-world shops. “Going from a digitally native retailer to having brick and mortar, one of many benefits is that each one of our methods … no matter utilities that I made out there on-line, it is out there within the bodily retail retailer,” Tan mentioned.
That features letting clients interact easily with the corporate in digital and real-world codecs. “It needs to be a really seamless transfer between property,” she mentioned.
Wayfair continues to encourage its workers to additional embrace the usage of AI instruments, with one thing akin to a leaderboard and workers discussing what they’ve completed lately with AI, Tan mentioned. This contains the area crew, the authorized crew and the accounting crew, all gaining access to AI instruments to encourage new concepts, she mentioned.
“I do not consider AI as separate, as in having an AI crew. I’ve an utilized science crew, however for probably the most half, simply from our historical past, we have now AI embedded inside each area that we have now throughout Wayfair,” Tan mentioned.