One. The AI inventory bubble. Analogous to, however far bigger than, the dot-com bubble. The primary thesis right here is that, whatever the future financial impression of AI on the whole or giant language fashions particularly, the present state of affairs round corporations like Anthropic, OpenAI, xAI, and Meta is unsustainable, that there’s nearly no probability of the trade turning into worthwhile sufficient shortly sufficient to justify the extent of spending, particularly related to knowledge facilities, earlier than payments come due and the present era of chips turns into out of date. The important observe for this story has lengthy been Ed Zitron.
Two. The AI hype bubble. Carefully associated to the AI inventory bubble, with a robust symbiotic relationship. You possibly can argue that one can’t exist with out the opposite, however they’re nonetheless very a lot distinct. Although it’s typically couched in pseudo-technical phrases, the hype bubble is essentially magical, with claims starting from the foolish to the actually apocalyptic.
Three. Advantages and prices. If we restrict ourselves strictly to these issues that we all know giant language fashions are presently able to, which of them are more likely to be economically or socially helpful, and that are more likely to trigger (or have already got prompted) substantial hurt? Examples of the previous embody coding instruments; the power to extract data from text-based knowledge at scale; and higher interfaces for interacting with varied gadgets. The latter consists of (and it is a very partial checklist) creating extreme psychological well being crises; polluting analysis papers, authorized paperwork, and historic data with false data; degrading the standard of pc code and safety techniques; drowning authentic, high-quality writing and artwork in a sea of AI slop; crowding out probably extra precious analysis; taking an enormous toll on the surroundings; and permitting disinformation to be generated at an unprecedented scale.
It’s value noting that there’s virtually no overlap between the doomsters within the hype bubble and the critics elevating the considerations talked about right here.
And type of…
4. The place can we go from right here? This is not actually a part of the bubble dialog, however it’s adjoining. The present AI discourse is a profoundly dysfunctional. It’s an unpleasant mass of hyperbole, misinformation, and badly framed conversations. Journalists overlaying the subject, as a rule, haven’t any understanding of what they’re speaking about. Statements from the businesses creating these fashions are, at finest, primarily based on questionable metrics and assumptions, and, at worst, are borderline lies. A lot of the analysis (arguably most of what makes its manner into The New York Instances or The Atlantic) is sensationalistic, anecdotal, and terribly thought out.
However we will not and should not merely dismiss giant language fashions and their potential for optimistic impression. They characterize the largest breakthrough we have ever seen in pure language processing. The adjustments they’ve wrought to the way in which we code are already substantial and can solely develop larger. Our skill to research and classify textual content at scale could have large implications for numerous fields of examine.
All of because of this it’s crucial that we enhance our understanding of this expertise and have a critical, productive dialog about how finest to make use of it whereas limiting the harm it could do. Sadly, that is not the dialog we’re having.
The Agent Framework Dev Mission is a group initiative offering hands-on, developer-focused coaching supplies for constructing AI brokers utilizing trendy frameworks and tooling, with its Agent Framework Dev Day hosted by the Boston Azure AI Group and sponsored by Microsoft. The Microsoft Agent Framework, launched in October 2025, extends each Semantic Kernel and AutoGen right into a unified strategy for constructing manufacturing agentic programs. Paired with the Microsoft Foundry platform, it gives observability, security configuration, and enterprise-grade operational controls on high of the core framework. Working by way of the framework’s Python content material reveals 4 interconnected technical domains, each constructing instantly on the final, and every grounded in patterns that apply to actual deployed programs.
# Treating Security as an Empirical Measurement Downside
Most agentic tutorials deal with security as a footnote. The higher start line is to make security the very first thing a developer sees and measures earlier than writing a single line of agentic logic, grounding the remainder of the work in a practical image of what unguarded fashions really do.
The device for it is a dual-model comparability runner. The identical immediate is distributed concurrently to 2 deployed situations of gpt-4.1-mini: one with Microsoft Foundry security guardrails enabled, one with these guardrails lowered. Outcomes seem side-by-side within the terminal, together with response textual content and latency for every mannequin, making the behavioral distinction between the 2 deployments not possible to dismiss as theoretical.
The default immediate is intentionally provocative: a request for directions on making a home made explosive. The guarded mannequin refuses. The unguarded mannequin could not. Each responses floor in the identical interface, on the identical {hardware}, on the similar time. The distinction is speedy and concrete slightly than hypothetical.
From there, the comparability opens to a few enter classes price probing:
Profanity filterable through curated blocklists in Microsoft Foundry
Authorities identifiers resembling Social Safety Numbers (SSNs)
Different personally identifiable info (PII)
Every maps to an actual class of enterprise compliance concern, and every produces observable variations between the 2 deployments, giving builders a direct sense of the place guardrails have interaction and the place gaps stay.
Latency deserves consideration right here, not simply response content material. Security guardrails introduce measurable overhead, and that tradeoff is price quantifying slightly than assuming away. A 3rd regime — fashions working with default settings between the 2 extremes — reinforces that security is a configurable spectrum slightly than a binary toggle, one which engineers actively tune primarily based on software context.
The underlying code makes use of the framework’s AzureAIClient to spin up short-lived brokers for every mannequin, runs each through asyncio.collect, and surfaces token counts alongside timing knowledge. The structure is deliberately minimal. The purpose is the comparability, not the infrastructure surrounding it.
The broader lesson: an agent that completes a job isn’t the identical as an agent that completes a job responsibly underneath real-world inputs, and understanding that distinction early shapes each architectural choice that follows.
# Connecting Brokers to the World with the Mannequin Context Protocol
The Mannequin Context Protocol (MCP) is a common adapter that enables AI brokers to connect with knowledge sources and instruments by way of a standardized protocol, with out requiring adjustments to the agent shopper when the underlying service adjustments, which makes it a sensible basis for constructing brokers that work together with evolving enterprise programs.
The structure has three parts. A number software (the AI agent) connects by way of an MCP shopper to a number of MCP servers, every of which exposes instruments, sources, and prompts. Servers might be native or distant, and the shopper code doesn’t change to accommodate both, which retains the agent layer cleanly decoupled from infrastructure choices.
Two transport mechanisms cowl the principle deployment situations:
// STDIO Transport
STDIO transport runs the MCP server as a subprocess speaking by way of commonplace enter and output. This fits native instruments and CLI integrations the place low latency and tight course of coupling are fascinating.
// HTTP/SSE Transport
HTTP/SSE transport runs the server as an online service speaking over HTTP with Server-Despatched Occasions (SSE). This fits cloud providers and shared tooling that a number of brokers want to succeed in concurrently throughout distributed environments.
A concrete four-component implementation on a assist ticket area makes these patterns tangible. The mcp_local_server exposes 4 instruments through STDIO: GetConfig, UpdateConfig, GetTicket, and UpdateTicket. The mcp_remote_server is a FastAPI REST API working on port 5060 managing the identical ticket knowledge as a correct service layer. The mcp_bridge runs on port 5070 and interprets between HTTP/SSE and peculiar HTTP calls to the REST backend. The mcp_agent_client consumes all of those concurrently, discovering instruments from every server dynamically and changing them into the function-calling format that Azure OpenAI expects, all inside a single agent session.
The architectural perception with probably the most vital enterprise implications: wrapping an current REST API with an MCP bridge requires no modification to the backend in anyway. Any service already exposing HTTP endpoints turns into accessible to an AI agent with out touching that service’s personal code, which dramatically lowers the mixing value for organizations with giant current API surfaces.
The complete agentic loop constructed right here covers device discovery at runtime, dynamic operate conversion, mannequin invocation, device dispatch, and consequence ingestion again into context, all constructed from first rules utilizing the MCP SDK and Azure OpenAI, giving builders an entire image of how every layer connects.
# Orchestrating Workflow Patterns: Sequential, Concurrent, and Human-in-the-Loop
Workflow orchestration is the place particular person brokers begin functioning as coordinated programs able to dealing with issues too complicated for any single mannequin name to resolve cleanly by itself.
All three patterns function on the identical SupportTicket knowledge mannequin, carrying fields like ticket ID, buyer identify, topic, description, and precedence. Utilizing the identical area throughout all three patterns is deliberate: the aim is to look at similar knowledge transfer by way of basically totally different processing architectures and observe what adjustments concerning the output, the latency, and the management floor obtainable to the operator.
// Sequential Workflow
A high-priority ticket from a buyer unable to log in after a password reset strikes from consumption by way of an AI categorization step, which classifies and summarizes the problem in structured JSON, after which right into a response technology step. The output is an entire, customer-ready reply that acknowledges urgency, presents concrete subsequent steps, and contains the ticket quantity. Your entire pipeline runs with out human intervention, and every step’s output is seen earlier than it passes to the subsequent, making the information transformation at every stage specific and inspectable.
// Concurrent Workflow
A buyer reporting each a reproduction cost and a crashing software in the identical message exposes the boundaries of a sequential single-agent pipeline. Billing and technical considerations require totally different experience, and routing each by way of a single agent produces a weaker consequence than routing every to a specialist who can purpose deeply inside a narrower area.
The concurrent sample followers the query out to a billing professional agent and a technical professional agent concurrently. The billing agent addresses the duplicate cost and recommends a refund path. The technical agent focuses on cache clearing and reinstallation steps for the crashing software. Neither agent makes an attempt to deal with each domains. The aggregated consequence provides the client an entire reply that no single specialist might have produced alone, and the response time is bounded by the slower of the 2 brokers slightly than their sum.
// Human-in-the-Loop Workflow
The best-stakes case includes a buyer requesting a full refund on an annual premium subscription bought one week prior. The AI generates a draft response accurately invoking the 14-day money-back assure coverage and providing to course of cancellation instantly. Then execution stops, and management passes explicitly to a human reviewer earlier than something is distributed.
The supervisor receives the complete draft and three specific selections: approve and ship as written, edit earlier than sending, or escalate to administration. On approval, the system data the motion, updates the ticket standing to resolved, and logs that the response was permitted with out modification, creating an entire audit path of the choice.
What working this sample makes concrete is one thing workflow diagrams are likely to obscure: the human-in-the-loop pause isn’t a failure mode or an exception path. It’s a designed, first-class cease within the workflow. The system waits for it with out polling or timeout. That is the sample that makes AI-assisted processes auditable and defensible in regulated or high-stakes environments, and it deserves to be handled as a peer to the absolutely automated options slightly than a fallback of final resort.
Extending every sample deepens the understanding significantly. Including a sentiment evaluation agent earlier than categorization within the sequential pipeline, including a safety or account specialist to the concurrent fan-out, including new supervisor actions like “Request Extra Information” to the human-in-the-loop step, and composing sequential and concurrent patterns right into a single hybrid workflow all require understanding how the executor lessons, shared shopper manufacturing facility, and knowledge fashions join throughout the complete system.
# Shifting from RAG to Agentic RAG
Normal retrieval-augmented technology (RAG) functions are easy to get began with however encounter query varieties that primary retrieval handles poorly, and people limitations are likely to floor shortly as soon as actual customers begin interacting with the system. Sure/no questions, counting queries, and multi-hop reasoning all stress the assumptions of a single embedding-lookup pipeline in ways in which grow to be instantly seen in manufacturing.
The development by way of this drawback strikes throughout 4 levels: ingestion, easy RAG, superior RAG, and agentic RAG. The sequencing is intentional. Encountering the constraints of naive retrieval first makes the architectural shift to agentic retrieval significant slightly than summary, as a result of the gaps within the easier strategy are already seen earlier than the answer is launched.
The answer makes use of the Microsoft Agent Framework with a Handoff workflow orchestration sample, writing specialised brokers that carry out particular search capabilities backed by Azure AI Search. The Handoff sample routes a question to probably the most applicable specialist agent slightly than sending each query by way of a single retrieval pipeline, which implies every agent might be optimized for the question kind it’s designed to deal with. Implementation covers 4 steps: preliminary setup, a sure/no search agent, a rely search agent, and the remaining specialist brokers, each including a brand new retrieval functionality to the general system.
The architectural shift from commonplace RAG is important and value making specific. Somewhat than a single retrieval pipeline trying to deal with all question varieties with the identical technique, an orchestrator dispatches to brokers specialised for various retrieval approaches, with Azure AI Search serving because the shared data spine that each one specialist brokers draw from. The result’s a system able to answering the complete vary of query varieties that commonplace RAG functions battle with, together with questions that require reasoning over retrieved outcomes slightly than merely returning them.
# Understanding Why These 4 Matters Belong Collectively
The development displays a coherent view of what production-ready agentic improvement really requires, and the order by which the matters seem isn’t arbitrary. Security comes first as a result of it reframes what working code means in an agentic context, establishing from the outset that functionality and accountable habits are separate properties that have to be measured independently. MCP establishes how brokers talk with exterior instruments and providers in a standardized, interoperable method — together with the perception that current APIs might be bridged with none backend modification, which makes it sensible to attach brokers to actual enterprise programs slightly than purpose-built toy backends. Workflow patterns set up how a number of brokers coordinate and, critically, when to pause for a human, introducing the management constructions that make agentic programs reliable sufficient to deploy in consequential settings. Agentic RAG demonstrates how data retrieval scales past easy lookup to deal with the complete vary of query varieties actual customers ask, finishing the image of what a manufacturing data system constructed on this framework seems like.
Taken collectively, the 4 domains transfer from habits commentary to structure development to system operation. That development is what separates a working prototype from a deployable system, and understanding every layer makes the subsequent one significantly simpler to purpose about.
Rachel Kuznetsov has a Grasp’s in Enterprise Analytics and thrives on tackling complicated knowledge puzzles and looking for recent challenges to tackle. She’s dedicated to creating intricate knowledge science ideas simpler to know and is exploring the varied methods AI makes an influence on our lives. On her steady quest to be taught and develop, she paperwork her journey so others can be taught alongside her. You will discover her on LinkedIn.
Data distillation: A bigger “instructor” mannequin trains a small “pupil” mannequin in order that it may well be taught to imitate sturdy reasoning capabilities, however at a a lot smaller scale.
Pruning: Redundant or irrelevant parameters are faraway from neural community architectures.
Quantization: Values are diminished from high-precision to lower-precision (that’s, floating-point numbers are transformed to integers) to scale back information dimension, pace up processing, and optimize power consumption.
Bigger fashions may also be modified and distilled into smaller, extra specialised fashions by means of strategies like retrieval-augmented era (RAG), when they’re educated to tug from trusted sources earlier than producing a response; fine-tuning and immediate tuning to information responses to particular areas; or LoRa (low-rank adaptation), which provides light-weight items to an unique mannequin to scale back its dimension and scope, slightly than retraining or modifying the whole mannequin.
Finally with SLMs, enterprise information turns into a “key differentiator, necessitating information preparation, high quality checks, versioning, and general administration to make sure related information is structured to fulfill fine-tuning necessities,” notes Sumit Agarwal, VP analyst at Gartner.
Advantages of small language fashions
The core driver of SLMs is financial, analysts be aware. “For top-volume, repetitive, scoped duties (reminiscent of customer support triage), the prices of utilizing a trillion-parameter generalist can’t be justified,” Data-Tech’s Randall factors out.
Cybersecurity was already beneath pressure earlier than AI entered the stack. Now, as AI expands the assault floor and provides new complexity, the boundaries of legacy approaches have gotten more durable to disregard. This session from MIT Expertise Evaluation’s EmTech AI convention explores why safety should be rethought with AI at its core, not layered on after the actual fact.
In regards to the speaker
Tarique Mustafa, Cofounder, CEO, and CTO, GC Cybersecurity
Tarique Mustafa is Cofounder and CEO/CTO of two AI-powered cybersecurity corporations: GCCybersecurity, Inc. and its knowledge compliance spinout, Chorology, Inc. A prolific inventor and internationally acknowledged authority in information illustration, inference calculus, and AI planning, Tarique has spent his profession making use of autonomously collaborative AI to unravel complicated, ultra-high-scale challenges throughout cybersecurity, knowledge safety, and compliance — with deep experience spanning Information Classification, DLP, and DSPM industries. His groundbreaking improvements and a number of USPTO patents have earned him international recognition, together with frequent invites to ship keynote addresses at prestigious worldwide safety conferences and boards.
At GCCybersecurity, Tarique architected the core AI algorithms powering the corporate’s 4th and fifth technology totally autonomous knowledge leak safety and exfiltration platform — among the many most superior platform of its form. Previous to founding GCCybersecurity and Chorology, he served as founding CEO/CTO of NexTier Networks, a Silicon Valley supplier of award-winning Information Leak Prevention options. With over 20 years of technical management expertise, Tarique has held senior roles at Symantec, DHL Airways IT, MCI WorldCom, EDS, Andes Networks, and Nevis Networks, the place he served as Principal Architect and constructed industry-leading safety merchandise leveraging next-generation safety monitoring, occasion correlation, IDS/IPS, and SSL/IPSec applied sciences.
Tarique holds a number of permitted and pending patents with the USPTO and has authored quite a few analysis publications spanning Data & Information Safety, Pc & Community Safety, Software program Structure, Database Applied sciences, and Synthetic Intelligence. A recipient of the distinguished Rotary Worldwide Scholarship for doctoral research in Pc Science on the College of Southern California (USC), Tarique additionally holds grasp’s levels in engineering and pc science from USC, and a bachelor’s diploma in mechanical engineering from NED College of Engineering & Expertise.
Being a Supreme Courtroom justice is a reasonably candy gig.
The Courtroom usually hears about 60 instances a yr, plus a smattering of “shadow docket” instances that obtain expedited assessment. Like schoolchildren, the justices take their summers off — usually wrapping up their pending instances in June after which skipping city in early July.
And the justices are at present within the closing stretch earlier than they’ll get pleasure from their summer season off. On Wednesday, the Courtroom heard the final arguments of its present time period. So all that’s left for the justices to do is end writing their present slate of opinions (together with a mixture of concurrences and dissents), earlier than their summer season breaks can start.
Two points dominate this time period’s remaining instances: democracy and President Donald Trump. The Courtroom simply determined a case that kicked off one other spherical of Republican gerrymandering within the US South — and that can possible eviscerate Black illustration in lots of Southern pink states within the course of. There are twoextra election instances coming earlier than the justices peace out for the summer season.
The Courtroom will even resolve a number of instances the place Trump seeks to increase his energy and the facility of the presidency. These embody some instances the place the result is preordained — the Courtroom’s Republican majority, for instance, has lengthy fixated on the “unitary govt,” a authorized concept that offers Trump the facility to fireside practically anybody who leads a federal company. However the Courtroom can be more likely to reject Trump’s declare that he can strip citizenship from many Individuals who had been born in america.
This time period additionally options two perennial tradition warfare points: weapons and LGBTQ rights. Gun advocates will most likely rejoice two upcomingchoices, the place the Courtroom is more likely to take an expansive view of the Second Modification. Transgender scholar athletes, in the meantime, ought to brace themselves for unhealthy information.
On Wednesday, the Courtroom handed down Louisiana v. Callais, a vastly consequential — however not precisely sudden — resolution neutralizing a provision of the Voting Rights Act that generally requires states to attract further majority-Black or -Latino districts. The upshot of this resolution is that between half-a-dozen and a dozen seats that at present are held by Democrats of shade are more likely to be held by white Republicans after a number of pink states redraw their maps.
The Courtroom will even resolve Nationwide Republican Senatorial Committee (“NRSC”) v. FEC, the place the Republican Occasion asks the Courtroom to strike down limits on how a lot cash social gathering organizations just like the Democratic and Republican Nationwide Committees could spend in coordination with candidates. This issues as a result of the regulation permits donors to offer a lot bigger sums to the DNC or RNC than they can provide to candidates, so a call within the GOP’s favor will enable rich donors to exert extra affect over particular person races.
The Courtroom’s Republican majority has already taken a flamethrower to US marketing campaign finance regulation, so the choice in NRSC will most likely solely matter across the margins. However the Courtroom is anticipated to make use of NRSC to take away one of many few remaining limits on cash in politics.
After which there’s Watson v. RNC, the place the GOP asks the justices to doubtlessly trash hundreds of absentee ballots; in current elections, Democrats have been more likely than Republicans to vote by mail. In an age of much less partisan judges, Watson would have been rejected by a decrease court docket and by no means heard from ever once more. The GOP’s authorized concept is {that a} 160-year-old regulation setting the date of federal elections requires all ballots that arrive after that date to be thrown out even when they had been mailed earlier than the election — and that one way or the other nobody seen this restrict on poll counting till after Trump began claiming that voting by mail is unhealthy.
At oral arguments, nevertheless, not less than 4 of the Courtroom’s Republicans appeared sympathetic to the GOP’s arguments in Watson. So the case is value watching for a similar motive that coal miners preserve an in depth eye on their canary. If the Supreme Courtroom embraces the GOP’s cockamamie authorized arguments in Watson, that’s a warning that they are going to settle for different extremely doubtful authorized arguments that profit the Republican Occasion.
Trump already misplaced one massive case this time period. In Studying Sources v. Trump (2026), three of the Courtroom’s Republicans hewed to their social gathering’s conventional assist without cost commerce and struck down lots of Trump’s tariffs. All three of the Courtroom’s Democrats additionally joined this resolution.
Trump’s additionally more likely to lose Trump v. Barbara, his problem to the Fourteenth Modification’s provision granting citizenship to just about everybody born within the US. Like Studying Sources, Barbara entails a difficulty that divides the Republican Occasion, and the place Republicans largely agreed with Democrats till Trump got here alongside.
In the meantime, the president is more likely to rating an enormous victory in Trump v. Slaughter, a case asking whether or not Congress can create “impartial” federal businesses such because the Federal Commerce Fee or the Nationwide Labor Relations Board, whose members could solely be eliminated by the president for negligence or malfeasance in workplace. The Courtroom’s Republicans are all devotees of the “unitary govt,” a authorized concept which holds that such businesses can’t exist, with one exception. The Courtroom already signaled final yr that members of the Federal Reserve could be shielded from presidential firing, and it’s more likely to reaffirm this resolution later this yr.
There’s some uncertainty about how the Courtroom will rule in Mullin v. Doe and Trump v. Miot, two instances asking if the Trump administration adopted the proper procedures after they stripped “short-term protected standing” from Haitian and Syrian nationals residing in america. If the Courtroom guidelines in favor of those overseas nationals, that can imply that some residents of very harmful international locations will get to stay in america for perhaps a couple of extra months.
However the authorized situation in Doe and Miot is solely procedural, and nobody actually questions that the Trump administration can deport these people if it will get the method proper. So a victory for these Syrian and Haitian plaintiffs will solely be a minor defeat for Trump.
Weapons and the Second Modification
In New York State Rifle & Pistol Affiliation v. Bruen (2022), the Supreme Courtroom introduced a extensively derided framework that now governs Second Modification instances. A lawyer defending a gun regulation should level to a regulation from across the time when the Structure was drafted that’s just like the regulation they’re defending right now. If 5 justices deem the outdated regulation to be sufficiently just like the brand new regulation, the brand new regulation is upheld. In any other case it’s struck down.
The justices have struggled to clarify simply how related the 2 legal guidelines have to be, or in what methods the brand new regulation should resemble the outdated one, and a number of judges have complained that this new framework is unworkable, and that they have no idea how you can apply it. Certainly, in a 2024 opinion, Justice Ketanji Brown Jackson quoted a dozen completely different judicial opinions — a few of them authored by Trump appointees — who’ve complained that, in a single decide’s phrases, Bruen has triggered “disarray” as a result of it “doesn’t present decrease courts with clear steering as to how analogous trendy legal guidelines have to be to founding-era gun legal guidelines.”
In any occasion, this time period the Courtroom will resolve two instances which will give the justices an opportunity to make clear how Bruen’s uncommon historic take a look at is meant to work. The primary, Wolford v. Lopez, considerations a Hawaii regulation that requires gun house owners to acquire permission from retailers, eating places, and different personal companies earlier than they create a gun onto the premises. The second, United States v. Hemani, considerations a federal regulation prohibiting an “illegal person” of marijuana from possessing a gun.
At oral arguments in eachinstances, a lot of the justices appeared more likely to strike each legal guidelines down. Essentially the most unsure query is whether or not they can accomplish that in a approach that brings readability to the terribly murky Bruen framework.
Probably the most astonishing choices of Chief Justice John Roberts’ tenure on the head of the Courtroom was final March’s opinion in Mirabelli v. Bonta (2026), the place the Republican justices mentioned that the Structure requires public faculty academics to out transgender college students to their mother and father, even when the coed needs to maintain their gender id secret.
As I defined shortly after it was handed down, Mirabelli is such a shocking resolution as a result of the Courtroom relied on “substantive due course of,” a controversial authorized doctrine that was additionally the premise of the Courtroom’s 1973 resolution in Roe v. Wade, and that enables the Courtroom to create “rights” that aren’t specific within the Structure.
For many years, authorized conservatism outlined itself by its opposition to substantive due course of. The truth that the Republicans had been prepared to depend on this doctrine in Mirabelli means that their private distaste towards trans folks has overcome their dedication to making use of the regulation in a predictable and constant approach.
Mirabelli left little suspense looming over Little v. Hecox and West Virginia v. B.P.J., two pending instances that problem state legal guidelines prohibiting trans ladies scholar athletes from taking part in on ladies’s sports activities groups. The Republican justices’ questions at oral arguments over these instances gave trans athletes little motive to be hopeful. Each Roberts and Justice Neil Gorsuch, the one Republican justices who’ve supported trans rights up to now, had skeptical questions for the lawyer representing the athletes.
The plaintiffs in these instances all the time confronted a tricky highway in court docket. Although the Supreme Courtroom held in Bostock v. Clayton County (2020) that legal guidelines forbidding “intercourse” discrimination generally shield trans folks from unequal therapy, intercourse discrimination isn’t forbidden in aggressive sports activities. Certainly, intercourse discrimination is the entire motive why women-only sports activities groups exist.
Given the Republican justices’ willingness to put anti-trans politics over authorized ideas in Mirabelli, it’s troublesome to think about this Courtroom going past Bostock to carry that trans athletes have a proper to compete on the staff that aligns with their gender id.
Choose an ailment — joint ache, mind fog, insomnia — and there’s in all probability a peptide remedy promising to deal with it. By no means thoughts that many of those amino acid–primarily based merchandise aren’t authorised by the U.S. Meals and Drug Administration, have hardly been studied in folks and is probably not meant for human use in any respect. Some folks aren’t afraid to go DIY, shopping for peptides from on-line retailers or abroad suppliers and injecting them at residence, whether or not their medical doctors learn about it or not.
There’s a transparent answer for regulators coping with an “illicit market” just like the one rising for peptides, says Mitch Zeller, a former FDA official who left the company in 2022: “Step up your enforcement sport” to cease its unfold.
His successors on the FDA, nonetheless, seem like taking a distinct strategy. Quite than reining within the health-hacking peptide craze, they seem poised to take steps that may gas it.
Well being and Human Providers Secretary Robert F. Kennedy Jr., a self-proclaimed “huge fan” of peptides, appears to be following by means of on a vow to finish what he known as the FDA’s “aggressive suppression” of gear together with peptides. In July, an FDA advisory committee is about to contemplate whether or not compounding pharmacies — which make medication that aren’t commercially accessible or are briefly provide — ought to be licensed to supply sure injectable peptides. These into account embody peptides that the FDA, underneath the Biden administration, directed compounding pharmacies to cease making attributable to security considerations, together with the potential of immune reactions.
And in March, the FDA held a public assembly to debate the scope of elements allowed in oral dietary dietary supplements, at which peptide proponents advocated for his or her inclusion. At that assembly, FDA Deputy Commissioner for Meals Kyle Diamantas mentioned the administration’s targets embody “slicing out pink tape,” signaling a possible openness to broadening what might be bought as a dietary complement. Already, that class contains a variety of elements — nutritional vitamins, minerals, herbs and extra — that may be bought on guarantees to assist common well being and wellness, so long as they don’t declare to deal with particular circumstances.
Dietary supplements, not like medication, shouldn’t have to undergo rigorous research to show security and efficacy earlier than hitting retailer cabinets, that means they’re topic to minimal oversight, says Zeller, who labored on complement points on the FDA within the Nineteen Nineties. Including unproven peptides to those merchandise, he says, would take the trade even additional into “buyer-beware land.”
The FDA continues to be deliberating about peptides. An HHS spokesperson didn’t reply to questions, as a substitute directing Science Information to hyperlinks in regards to the upcoming assembly associated to compounding pharmacies.
The company’s actions, Zeller says, telegraph a “perception in the appropriate to strive” even unregulated substances that aren’t recognized to be protected and efficient. The “solely conceivable final result,” he says, is that extra folks will really feel emboldened to dose themselves with largely unstudied and unregulated peptides.
What are peptides, anyway?
Peptides are basically “miniature proteins,” says John Fetse, a peptide therapeutics researcher at Binghamton College in New York. A posh association of amino acids is a protein; a shorter chain of them is a peptide.
Peptides happen naturally within the physique, in addition to in lots of meals. They play a variety of roles. The hormones insulin and oxytocin are peptides, for instance, however peptides additionally present up in poisonous animal venom. “All peptides aren’t the identical,” Fetse says. “The way you set up the constructing blocks actually tells you what sort of impact you will have.”
Artificial — or lab-made — peptides can mimic these the physique makes naturally, however with tweaks to make the compound “extra druglike,” says Eileen Kennedy, president-elect of the nonprofit American Peptide Society. (The chemical biologist on the College of North Carolina’s Eshelman Faculty of Pharmacy in Chapel Hill has no relation to Robert F. Kennedy.) They could be longer-lasting than pure variations, or increase concentrations past what would naturally happen within the physique.
How have peptides been studied and controlled thus far?
Some artificial peptides are well-studied and FDA-approved. (The “P” in GLP-1, the wildly fashionable class of diabetes and weight-loss medication that features Ozempic, stands for “peptide.”) However lots of the substances individuals are utilizing to self-treat, with names like BPC-157 and TB-500, present promising results in animal research however haven’t been rigorously studied in people, elevating questions on whether or not they’re protected and work as marketed.
At present, BPC-157 is on the World Anti-Doping Company Prohibited Checklist. The U.S. Anti-Doping Company states that it “might result in damaging well being results.” Nonetheless, some folks use it in hopes of boosting athletic efficiency, harm restoration and extra.
“All peptides aren’t the identical. The way you set up the constructing blocks actually tells you what sort of impact you will have.”
John Fetse peptide therapeutics researcher
Customers ought to “be affected person” and “see what the medical information says” earlier than utilizing peptides, Fetse says.
Even peptides that intently mirror these made by the physique itself can have totally different results when administered like a drug, Eileen Kennedy says. A peptide naturally discovered within the abdomen may set off a distinct response when injected into the knee to assist heal a sports activities harm. Some folks additionally take quite a few totally different peptides in regimens referred to as “stacks,” and thus danger creating sudden and probably harmful interactions, she says.
Some medical doctors are prepared to put in writing prescriptions that enable folks to purchase sure peptides from compounding pharmacies — a course of that also falls wanting full security and efficacy assessment, however that at the least operates inside the U.S. regulatory system.
However “numerous peptides aren’t going by means of that route,” Eileen Kennedy says. As an alternative, many individuals buy them, unprescribed, from direct-to-consumer web sites or abroad factories with minimal oversight. Generally, she says, these compounds are technically meant for analysis — not human consumption.
“In these circumstances, there isn’t actually a assure of purity,” she says. “You may not even be getting the precise compound that you really want.”
What wouldn’t it imply to incorporate peptides in oral dietary dietary supplements?
Unfastened oversight additionally characterizes the present marketplace for oral dietary dietary supplements, one other enviornment through which peptides are a subject of curiosity. And not using a requirement for premarket security and efficacy testing, the FDA usually intervenes provided that a complement causes well being points as soon as it’s already on the market, Zeller says.
“It creates an atmosphere the place now we have legalized snake oil,” says Pieter Cohen, an inner drugs doctor at Cambridge Well being Alliance in Massachusetts who research complement security. “You may put something in a bottle and begin promoting it.”
That already contains peptides, to some extent. Oral collagen peptide dietary supplements, for instance, are already generally marketed to assist pores and skin, bone, muscle and joint well being. A 2025 meta-analysis supported a few of these claims, discovering that collagen peptide supplementation might enhance bone mineral density and muscle perform.
Many buzzy peptides, nonetheless, aren’t discovered within the meals provide. BPC-157, for one, is “not a dietary ingredient. It’s an unapproved drug and can’t be legally prescribed or bought over-the-counter,” in keeping with Operation Complement Security, a Division of Protection academic venture.
Nonetheless, it’s straightforward to seek out dietary complement capsules promoting it as an ingredient — and if the FDA decides to broaden the scope of permitted complement elements, it might get even simpler.
It’s noteworthy that “regardless of all these alternatives to incorporate just about any chemical present in any meals” regulators might enable much more substances to enter dietary supplements with out proactive security and efficacy assessment, Cohen says. Along with peptides, elements akin to microbials have been mentioned on the March assembly.
If complement makers start including peptides to their merchandise, Zeller thinks they need to be regulated like medication, given the numerous excellent questions on how peptides have an effect on human well being. “There ought to be premarket assessment, each of their security and their potential profit,” he says.
If that assessment came about, the outcomes may be disappointing for producers of oral dietary supplements. When peptides are swallowed, enzymes within the abdomen usually make fast work of digesting them. “For those who swallow it in a complement, you’d in all probability see no therapeutic profit in any respect,” Fetse says.
We right here at Stata are sometimes requested to make suggestions on the “greatest” pc on which to run Stata, and such discussions typically pop up on Statalist. In fact, there isn’t a easy reply, because it will depend on the analyses a given person needs to run, the scale of their datasets, and their funds. And, we don’t advocate specific pc or working system distributors. Many producers use comparable elements of their computer systems, and the selection of working system comes down to private desire of the person. We take pleasure in ensuring Stata works nicely no matter working system and {hardware} configuration.
For some customers, the analyses they want to run are demanding, the datasets they’ve are big, and their budgets are giant. For these customers, it’s helpful to know what sort of off-the-shelf {hardware} they will simply get their palms on. To present you an concept of what’s accessible, HP makes a server with as much as 1 TB of reminiscence. Sure, 1 terabyte! This pc might be configured and ordered on-line at hp.com.
It might probably have as much as 4 processors, every with 8 cores, for a complete of 32 cores of processing energy. A pattern rack-mount configuration with the quickest 8-core Intel Xeon processors accessible for this pc and a full 1 TB of reminiscence totals roughly $100,000. We point out HP as a result of they had been one of many first to permit such giant reminiscence configurations with out going to a way more costly utterly custom-built resolution. Wouldn’t you like to have considered one of these operating Stata/MP (or Halo)?
You’ll be able to run Home windows or Linux on a pc just like the above. In the event you want Mac OS X, the most important present configuration from Apple permits a complete of 12 cores and 32 GB of reminiscence. It is a tower case unit and prices round $10,000. Go to retailer.apple.com to configure such a pc.
The biggest quickest laptops simply bought today enable as much as 4 cores and 16 GB of RAM. That a lot energy in a small bundle will price you although, with such a configuration costing over $7,000. Right here is one such instance you may configure from Dell: dell.com.
We’ll maintain you up to date periodically with the state of the excessive finish of the pc market as reminiscence capacities and variety of cores enhance.
CNN-based mannequin extra light-weight? Simply take the smaller model of that mannequin, proper? Like with ResNet, for example, if ResNet-152 feels too heavy, why not simply use ResNet-101? Or within the case of DenseNet, why not go together with DenseNet-121 moderately than DenseNet-169? — Sure, that’s true, however you would need to sacrifice some accuracy for that. Mainly, if you would like a lighter mannequin then you need to count on your accuracy to drop as properly.
Now, what if I instructed you a few mannequin that’s extra light-weight than its base however can nonetheless compete on accuracy? Meet CSPNet (Cross Stage Partial Community). You’ll be shocked that it might successfully cut back computational complexity whereas sustaining excessive accuracy — no tradeoff! On this article we’re going to speak in regards to the CSPNet structure, together with the way it works and the right way to implement it from scratch.
A Transient Historical past of CSPNet
CSPNet was first launched in a paper titled “CSPNet: A New Spine That Can Improve Studying Functionality of CNN” written by Wang et al. again in November 2019 [1]. CSPNet was initially proposed to handle the restrictions of DenseNet. Regardless of already being computationally cheaper than ResNet, the authors thought that the computation of DenseNet itself remains to be thought-about costly. Check out the primary constructing block of a DenseNet in Determine 1 beneath to grasp why.
Determine 1. The primary constructing block of a DenseNet mannequin [2].
In a DenseNet constructing block — known as dense block — each convolution layer takes data from all earlier layers, inflicting it to have a number of redundant gradient data that makes coaching inefficient. We are able to consider it like a scholar taught by 5 totally different lecturers for a similar materials. It’s truly good because the scholar can get a number of views about that particular matter. Nevertheless, sooner or later it turns into redundant and thus inefficient. Within the case of DenseNet, we are able to see the deeper layers as college students and all of the tensors from shallower layers as lecturers. Within the instance above, if we assume H₄ as our scholar, then the x₀, x₁, x₂, and x₃ tensors act because the lecturers. Right here you may simply think about how that scholar would get overwhelmed by all that data!
Earlier than we get into CSPNet, I even have a complete separate article particularly speaking about DenseNet (reference [3]), which I extremely suggest you learn if you would like the total image of how this structure works.
Aims
The target of CSPNet is to allow a community to have cheaper computational complexity and higher gradient mixture. The rationale for the latter is that the majority gradient data in DenseNet consists of duplicates of one another. You will need to notice that CSPNet will not be a standalone community. As an alternative, it’s a new paradigm we apply to DenseNet.
Now let’s check out Determine 2 beneath to see how CSPNet achieves its aims. You may see the illustration on the left that the variety of function maps steadily will increase as we get deeper into the community. In case you have learn my earlier article about DenseNet, that is basically one thing we are able to management via the progress price parameter, i.e., the variety of function maps produced by every convolution layer inside a dense block. In truth, this improve within the variety of function maps is what the authors see as a computational bottleneck.
Determine 2. Left: the unique DenseNet constructing block (similar as Determine 1). Proper: The CSPNet model of the DenseNet constructing block (known as CSPDenseNet) [1].
By making use of the Cross Stage Partial mechanism, we are able to principally make the computation of a DenseNet cheaper. If we check out the illustration on the suitable, we are able to see that we’ve got an extra department popping out from x₀ that goes on to the so-called Partial Transition Layer. There are no less than two benefits we get with this mechanism, that are in accordance with the aims I discussed earlier. First, we are able to save numerous computations because the variety of function maps processed by the dense block is simply half of the unique one. And second, the gradient data turns into extra numerous since we obtained an extra path with unprocessed function maps that avoids the redundant gradient data. So in brief, the thought of CSPNet eliminates the computational redundancy of DenseNet (via the skip-path) whereas on the similar time nonetheless preserves its feature-reuse property (via the dense block).
The Detailed CSPNet Structure
Talking of the main points, the unique function map is first divided into two elements in channel-wise method, the place every of them will probably be processed in several paths. Suppose we obtained 64 enter channels, the primary 32 function maps (half 1) will skip via all computations, whereas the remaining 32 (half 2) will probably be processed by a dense block. Though this splitting step is fairly straightforward, the merging step is definitely not fairly trivial. You may see in Determine 3 beneath that we obtained a number of totally different mechanisms to take action.
Determine 3. A number of other ways to carry out function mixture in CSPNet [1].
Within the construction known as fusion first (c), we concatenate the half 1 tensor with the half 2 tensor that has been processed by the dense block previous to passing them via the transition layer. So, possibility (c) is definitely fairly easy to implement as a result of the spatial dimension of the 2 tensors is precisely the identical, permitting us to concatenate them simply.
In my earlier article [3], I discussed that the transition layer of a DenseNet is used to scale back each the spatial dimension and the variety of channels. In truth, this property requires us to rethink the right way to implement the fusion final (d) construction. That is basically as a result of the transition layer will trigger the half 2 tensor to have a smaller spatial dimension than the half 1 tensor. So technically talking, we have to both apply one thing like a pooling with a stride of two to the half 1 department or just omitting the downsampling operation within the transition layer. By doing this, the spatial dimension of the 2 tensors would be the similar, and thus they’re now concatenable.
As an alternative of simply utilizing a single transition layer positioned both earlier than or after function mixture, the authors additionally proposed one other technique which they discuss with as CSPDenseNet (b). We are able to consider this as a mix of (c) and (d), the place we obtained two transition layers positioned earlier than and after the tensor concatenation course of. On this explicit case, the primary transition layer (the one positioned within the half 2 department) will carry out channel discount by cross-channel pooling, i.e., a pooling layer that operates throughout channel dimension. In the meantime, the second transition layer will carry out each spatial downsampling and channel depend discount. So principally, on this method we cut back the variety of channels twice — properly, no less than that’s what I perceive from the paper in regards to the two transition layers, because the detailed processes inside these layers usually are not explicitly mentioned.
Experimental Outcomes
Speaking in regards to the experimental outcomes relating to these function mixture mechanisms, it’s defined within the paper that fusion final (d) is best than fusion first (c), the place the previous can considerably cut back computational complexity whereas solely suffers from a really slight drop in accuracy. Variant (c) truly additionally reduces computational complexity, but the degradation in accuracy can also be vital. Authors discovered that variant (b) obtained a fair higher end result than the 2. Determine 4 beneath shows a number of experimental outcomes displaying how the three function mixture mechanisms carried out in comparison with the bottom mannequin. Nevertheless, as a substitute of utilizing DenseNet, they by some means determined to make use of PeleeNet to match these constructions.
Determine 4. Efficiency comparability of the bottom PeleeNet (corresponds to (a) in Determine 3), CSPPeleeNet (b), PeleeNet with fusion first technique (c), and PeleeNet with fusion final technique (d) [1].
Based mostly on the above determine, we are able to see that the CSP fusion final (inexperienced) certainly performs higher in comparison with the CSP fusion first (crimson). That is based mostly on the truth that its accuracy solely degrades by 0.1% from its base mannequin whereas having 21% smaller computational complexity. In the meantime, although CSP fusion first efficiently reduces computational complexity by 26%, however the accuracy drop is fairly vital because it performs 1.5% worse than the bottom PeleeNet. And essentially the most spectacular construction is the CSPPeleeNet variant (blue), i.e., the one which makes use of two transition layers. Right here we are able to clearly see that though the computational complexity is decreased by 13%, the accuracy of the mannequin truly improves by 0.2% — once more, no tradeoff!
Not solely that, however the authors additionally tried to implement CSPNet on different spine fashions. The leads to Determine 5 beneath exhibits that the CSPNet construction efficiently reduces the computational complexity of DenseNet -201-Elastic and ResNeXt-50 by 19% and 22%, respectively. It’s attention-grabbing to see that the accuracy of the ResNeXt mannequin improves regardless of the discount in mannequin complexity, which is in accordance with the end result obtained by CSPPeleeNet in Determine 4.
Determine 5. Efficiency enchancment of DenseNet-201-Elastic and ResNeXt-50 after implementing the CSPNet mechanism [1].
The Mathematical Expression of CSPDenseNet
For individuals who love math, right here I obtained you some notations that you just may discover attention-grabbing to know. Figures 6 and seven beneath show the mathematical expressions of DenseNet and CSPDenseNet blocks through the ahead propagation section.
Within the DenseNet block, x₁ corresponds to the tensor produced by the primary conv layer w₁ based mostly on the enter tensor x₀. Subsequent, we concatenate the unique tensor x₀ with x₁ and use them because the enter for the w₂ layer (or to be extra exact, w is definitely the weights of the conv layer, not the conv layer itself). We preserve producing extra function maps and concatenating the prevailing ones as we get deeper into the community. On this approach, we are able to principally say that the outputs of all earlier layers turn out to be the enter of the present layer.
Determine 6. The mathematical illustration of ahead propagation inside a DenseNet block [1].
The case is totally different for CSPDenseNet. You may see within the notation beneath that we obtained x₀’ and x₀’’, which we beforehand discuss with because the half 1 and half 2. The x₀’’ tensor undergoes processing just like the one in DenseNet block till we obtained xₖ. Subsequent, the output of this dense block is then forwarded to the primary transition layer, which is denoted as wᴛ. The ensuing tensor xᴛ is then concatenated with the half 1 tensor x₀’ earlier than finally being handed via the second transition layer wᴜ to acquire the ultimate output tensor xᴜ.
Determine 7. The mathematical expression of the ahead propagation in CSPDenseNet block [1].
CSPDenseNet Implementation
Now let’s get even deeper into the CSPNet structure by implementing it from scratch. Though we are able to principally apply the CSPNet construction to any spine, right here I’m going to try this on the DenseNet mannequin to match it with the illustrations and equations I confirmed you earlier. Determine 8 beneath shows what the entire DenseNet structure appears to be like like. Simply do not forget that each single dense block on this structure initially follows the DenseNet construction in Determine 3a, and our goal right here is to exchange all these dense blocks with CSPDenseNet block illustrated in Determine 3b.
Determine 8. The entire DenseNet structure [2].
The very first thing we do is to import the required modules and initialize the configurable parameters as proven in Codeblock 1. The GROWTH variable is the progress price parameter, which denotes the variety of function maps produced by every bottleneck inside the dense block. Subsequent, CHANNEL_POOLING is the parameter we use to regulate the conduct of the channel-pooling mechanism in our first transition layer. Right here I set this parameter to 0.8, which means that we’ll shrink the variety of channels to 80% of its unique channel depend. The COMPRESSION parameter works equally to the CHANNEL_POOLING variable, but this one operates within the second transition layer. Lastly, right here we outline the REPEATS record, which is used to set the variety of bottleneck blocks we are going to initialize inside the dense block of every stage.
Under is the implementation of the bottleneck block to be positioned inside the dense block. This Bottleneck class is precisely the identical because the one I utilized in my DenseNet article [3]. I instantly copy-pasted the code from there since we don’t want to change this half in any respect. Simply remember that a bottleneck block includes a 1×1 convolution adopted by a 3×3 convolution.
The next testing code simulates the primary bottleneck block inside the dense block. Keep in mind that the very first conv layer within the structure (the one with 7×7 kernel) produces 64 function maps, however since within the case of CSPNet we solely need to course of half of them (the half 2 tensor), therefore right here we are going to check it with a tensor of 32 function maps.
# Codeblock 3
bottleneck = Bottleneck(in_channels=32)
x = torch.randn(1, 32, 56, 56)
x = bottleneck(x)
You may see within the ensuing output above that the variety of function maps turns into 44 on the finish of the method, the place this quantity is obtained by including the enter channel depend and the expansion price, i.e., 32 + 12 = 44. Once more, you may simply try my DenseNet article [3] if you wish to get a greater understanding about this calculation.
Dense Block Implementation
Now to create a sequence of bottleneck blocks simply, we are able to simply wrap it contained in the DenseBlock class in Codeblock 4 beneath. Afterward, we are able to simply specify the variety of bottleneck blocks to be stacked via the repeats parameter. Once more, this class can also be copy-pasted from my DenseNet article, so I’m not going to clarify it any additional.
# Codeblock 4
class DenseBlock(nn.Module):
def __init__(self, in_channels, repeats):
tremendous().__init__()
self.bottlenecks = nn.ModuleList()
for i in vary(repeats):
current_in_channels = in_channels + i * GROWTH
self.bottlenecks.append(Bottleneck(in_channels=current_in_channels))
def ahead(self, x):
print(f'originalttt: {x.measurement()}')
for i, bottleneck in enumerate(self.bottlenecks):
x = bottleneck(x)
print(f'after bottleneck #{i}tt: {x.measurement()}')
return x
As a way to verify if our DenseBlock class works correctly, we are going to check it utilizing the Codeblock 5 beneath. Right here I’m making an attempt to simulate the half 2 tensor processed by the primary dense block, which incorporates a sequence of 6 bottleneck blocks.
# Codeblock 5
dense_block = DenseBlock(in_channels=32, repeats=6)
x = torch.randn(1, 32, 56, 56)
x = dense_block(x)
And beneath is what the output appears to be like like. Right here we are able to clearly see that every bottleneck block efficiently will increase the function maps by 12.
# Codeblock 5 Output
unique : torch.Measurement([1, 32, 56, 56])
after bottleneck #0 : torch.Measurement([1, 44, 56, 56])
after bottleneck #1 : torch.Measurement([1, 56, 56, 56])
after bottleneck #2 : torch.Measurement([1, 68, 56, 56])
after bottleneck #3 : torch.Measurement([1, 80, 56, 56])
after bottleneck #4 : torch.Measurement([1, 92, 56, 56])
after bottleneck #5 : torch.Measurement([1, 104, 56, 56])
First Transition
Keep in mind that the CSPDenseNet variant in Determine 3b makes use of two transition layers. On this part we’re going to focus on the primary transition layer, i.e., the one used to course of the tensor within the half 2 department. Right here we is not going to carry out spatial downsampling, which is the rationale why you don’t see any pooling layer inside the __init__() technique in Codeblock 6 beneath. As an alternative, right here we are going to solely carry out cross-channel pooling, which will be perceived as a typical pooling operation but is completed throughout the channel dimension. To implement it, we are able to merely use a 1×1 convolution (#(2)) and specify the variety of output channels we wish (#(1)). We are able to consider it like this: in a spatial downsampling course of, we are able to principally do this through the use of both pooling or a strided convolution layer, which within the latter case it is going to mixture the pixel values with particular weightings from the native neighborhood. Within the case of cross-channel pooling, since we don’t have a particular PyTorch layer for that, we are able to merely exchange it with a pointwise convolution layer, which by doing so we are able to principally mixture pixel values throughout the channel dimension.
The end result given within the Codeblock 5 Output exhibits that the half 2 tensor can have the form of 104×56×56 after being processed by the dense block. Thus, within the testing code beneath I’ll use this tensor form to simulate the primary transition layer inside that stage. To regulate the variety of output channels, we are able to merely multiply the enter channel depend with the CHANNEL_POOLING variable we initialized earlier as proven at line #(1) in Codeblock 7 beneath.
# Codeblock 7
first_transition = FirstTransition(in_channels=104,
out_channels=int(104*CHANNEL_POOLING)) #(1)
x = torch.randn(1, 104, 56, 56)
x = first_transition(x)
Now because the code above is run, we are able to see that the variety of function maps shrinks from 104 to 83 (80% of the unique).
The construction of the second transition layer is kind of a bit the identical as the primary one, besides that right here we even have a median pooling layer with a stride of two to scale back the spatial dimension by half (#(1)).
Keep in mind that the tensor coming into the second transition layer is a concatenation of the half 1 and the half 2 tensors. That is basically the rationale why within the testing code beneath I set this layer to simply accept 32 + 83 = 115 function maps. Much like the primary transition layer, right here we multiply this variety of function maps with the COMPRESSION variable (#(1)) to scale back the variety of channels even additional.
# Codeblock 9
second_transition = SecondTransition(in_channels=115,
out_channels=int(115*COMPRESSION)) #(1)
x = torch.randn(1, 115, 56, 56)
x = second_transition(x)
Within the ensuing output beneath we are able to see that the spatial dimension halves due to the typical pooling layer. On the similar time, the variety of function maps additionally decreases from 115 to 57 since we set the COMPRESSION parameter to 0.5.
With all of the elements prepared, we are able to now construct all the CSPDenseNet structure, which I break down in Codeblocks 10a, 10b, and 10c beneath. Let’s now give attention to the Codeblock 10a first, the place I initialize all of the layers in line with the construction given in Determine 8. Right here you may see at line #(1) that we initialize a 7×7 convolution layer, which acts because the enter layer of the community. This layer is then adopted by a maxpooling layer (#(2)). These two layers use the stride of two, which means that the spatial dimensions of the enter tensor will probably be decreased to one-fourth of its unique measurement.
Nonetheless with the above codeblock, right here I group the layers I initialize based mostly on the stage they belong to. Let’s now give attention to the half I discuss with as Stage 0. Right here you may see that we obtained a dense block (dense_block_0) and the primary transition layer (first_transition_0). These two elements are accountable to course of the half 2 tensor. Subsequent, we initialize the second transition layer (second_transition_0), which is used to course of the concatenation results of the half 1 and half 2 tensors. Because the channel depend is dynamic relying on the GROWTH, CHANNEL_POOLING, COMPRESSION, and REPEATS variables, we have to preserve observe of the channel depend after every step in order that the mannequin can adaptively alter itself in line with these variables. We do the identical factor for all of the remaining phases, besides in Stage 3 we don’t initialize the second transition layer since at that time we received’t cut back the channels and the spatial dimension any additional. As an alternative, we are going to instantly go the concatenated half 1 and half 2 tensors to the typical pooling (#(3)) and the classification (#(4)) layers. And that ends our dialogue in regards to the Codeblock 10a above.
Earlier than we get into the ahead() technique, there’s one other operate we have to create: split_channels(). Because the identify suggests, this operate, which is written in Codeblock 10b beneath, is used to separate a tensor into half 1 and half 2. The if-else assertion right here is used to verify if the variety of channels is odd and even. In truth, it might be very straightforward if the channel depend is a fair quantity as we are able to simply divide them into two (#(4)). But when the channel depend is odd, we have to manually decide the scale of every half as seen at line #(1) and #(2) earlier than finally splitting them (#(3)).
As we’ve got completed defining the __init__() and the split_channel() strategies, we are able to now implement the ahead() technique in Codeblock 10c beneath. Typically talking, what we do right here is solely ahead the tensor sequentially. However now let’s take note of the half I discuss with as Stage 0. Right here you may see that after the tensor is handed via the first_pool layer (#(1)), we then break up it into two utilizing the split_channels() operate we declared earlier (#(2)). From there, we now get hold of the part1 and part2 tensors. We’ll go away the part1 tensor as is all the way in which to the tip of the stage. In the meantime, for the part2 tensor, we are going to course of it with the dense block (#(3)) and the primary transition layer (#(4)). Subsequent, we concatenate the ensuing tensor with the part1 tensor to create the skip-connection (#(5)). After which, we lastly go it via the second transition layer (#(6)). The identical steps are repeated for all phases till we finally attain the output layer to make classification. Simply do not forget that the Stage 3 is kind of totally different as a result of right here we don’t have the second transition layer.
# Codeblock 10c
def ahead(self, x):
print(f'originalttt: {x.measurement()}')
x = self.first_conv(x)
print(f'after first_convtt: {x.measurement()}')
x = self.first_pool(x) #(1)
print(f'after first_pooltt: {x.measurement()}n')
##### Stage 0
part1, part2 = self.split_channels(x) #(2)
print(f'part1tttt: {part1.measurement()}')
print(f'part2tttt: {part2.measurement()}')
part2 = self.dense_block_0(part2) #(3)
print(f'part2 after dense block 0t: {part2.measurement()}')
part2 = self.first_transition_0(part2) #(4)
print(f'part2 after first trans 0t: {part2.measurement()}')
x = torch.cat((part1, part2), dim=1) #(5)
print(f'after concatenatett: {x.measurement()}')
x = self.second_transition_0(x) #(6)
print(f'after second transition 0t: {x.measurement()}n')
##### Stage 1
part1, part2 = self.split_channels(x)
print(f'part1tttt: {part1.measurement()}')
print(f'part2tttt: {part2.measurement()}')
part2 = self.dense_block_1(part2)
print(f'part2 after dense block 1t: {part2.measurement()}')
part2 = self.first_transition_1(part2)
print(f'part2 after first trans 1t: {part2.measurement()}')
x = torch.cat((part1, part2), dim=1)
print(f'after concatenatett: {x.measurement()}')
x = self.second_transition_1(x)
print(f'after second transition 1t: {x.measurement()}n')
##### Stage 2
part1, part2 = self.split_channels(x)
print(f'part1tttt: {part1.measurement()}')
print(f'part2tttt: {part2.measurement()}')
part2 = self.dense_block_2(part2)
print(f'part2 after dense block 2t: {part2.measurement()}')
part2 = self.first_transition_2(part2)
print(f'part2 after first trans 2t: {part2.measurement()}')
x = torch.cat((part1, part2), dim=1)
print(f'after concatenatett: {x.measurement()}')
x = self.second_transition_2(x)
print(f'after second transition 2t: {x.measurement()}n')
##### Stage 3
part1, part2 = self.split_channels(x)
print(f'part1tttt: {part1.measurement()}')
print(f'part2tttt: {part2.measurement()}')
part2 = self.dense_block_3(part2)
print(f'part2 after dense block 2t: {part2.measurement()}')
part2 = self.first_transition_3(part2)
print(f'part2 after first trans 2t: {part2.measurement()}')
x = torch.cat((part1, part2), dim=1)
print(f'after concatenatett: {x.measurement()}n')
x = self.avgpool(x)
print(f'after avgpoolttt: {x.measurement()}')
x = torch.flatten(x, start_dim=1)
print(f'after flattenttt: {x.measurement()}')
x = self.fc(x)
print(f'after fcttt: {x.measurement()}')
return x
Now let’s check the CSPDenseNet class we simply created by operating the Codeblock 11 beneath. Right here I take advantage of a dummy tensor of form 3×224×224 to simulate a 224×224 RGB picture handed via the community.
# Codeblock 11
cspdensenet = CSPDenseNet()
x = torch.randn(1, 3, 224, 224)
x = cspdensenet(x)
And beneath is what the output appears to be like like. Right here you may see that each time a tensor will get right into a community, our split_channels() technique accurately divides the tensor into two (#(1–2)). Then, the bottleneck block inside every stage additionally accurately provides the variety of channels of the half 2 tensor by 12 earlier than finally being handed via the primary transition layer. The primary transition layer itself efficiently reduces the variety of channels by 20% as seen at line #(3), simulating the cross-channel pooling mechanism. Afterwards, the ensuing tensor is then concatenated with the tensor from half 1 (#(4)) and handed via the second transition layer (#(5)) to additional cut back the variety of channels and halve the spatial dimension. We do the identical factor for all phases till finally we obtained the 1000-class prediction.
# Codeblock 11 Output
unique : torch.Measurement([1, 3, 224, 224])
after first_conv : torch.Measurement([1, 64, 112, 112])
after first_pool : torch.Measurement([1, 64, 56, 56])
part1 : torch.Measurement([1, 32, 56, 56]) #(1)
part2 : torch.Measurement([1, 32, 56, 56]) #(2)
after bottleneck #0 : torch.Measurement([1, 44, 56, 56])
after bottleneck #1 : torch.Measurement([1, 56, 56, 56])
after bottleneck #2 : torch.Measurement([1, 68, 56, 56])
after bottleneck #3 : torch.Measurement([1, 80, 56, 56])
after bottleneck #4 : torch.Measurement([1, 92, 56, 56])
after bottleneck #5 : torch.Measurement([1, 104, 56, 56])
part2 after dense block 0 : torch.Measurement([1, 104, 56, 56])
part2 after first trans 0 : torch.Measurement([1, 83, 56, 56]) #(3)
after concatenate : torch.Measurement([1, 115, 56, 56]) #(4)
after second transition 0 : torch.Measurement([1, 57, 28, 28]) #(5)
part1 : torch.Measurement([1, 29, 28, 28])
part2 : torch.Measurement([1, 28, 28, 28])
after bottleneck #0 : torch.Measurement([1, 40, 28, 28])
after bottleneck #1 : torch.Measurement([1, 52, 28, 28])
after bottleneck #2 : torch.Measurement([1, 64, 28, 28])
after bottleneck #3 : torch.Measurement([1, 76, 28, 28])
after bottleneck #4 : torch.Measurement([1, 88, 28, 28])
after bottleneck #5 : torch.Measurement([1, 100, 28, 28])
after bottleneck #6 : torch.Measurement([1, 112, 28, 28])
after bottleneck #7 : torch.Measurement([1, 124, 28, 28])
after bottleneck #8 : torch.Measurement([1, 136, 28, 28])
after bottleneck #9 : torch.Measurement([1, 148, 28, 28])
after bottleneck #10 : torch.Measurement([1, 160, 28, 28])
after bottleneck #11 : torch.Measurement([1, 172, 28, 28])
part2 after dense block 1 : torch.Measurement([1, 172, 28, 28])
part2 after first trans 1 : torch.Measurement([1, 137, 28, 28])
after concatenate : torch.Measurement([1, 166, 28, 28])
after second transition 1 : torch.Measurement([1, 83, 14, 14])
part1 : torch.Measurement([1, 42, 14, 14])
part2 : torch.Measurement([1, 41, 14, 14])
after bottleneck #0 : torch.Measurement([1, 53, 14, 14])
after bottleneck #1 : torch.Measurement([1, 65, 14, 14])
after bottleneck #2 : torch.Measurement([1, 77, 14, 14])
after bottleneck #3 : torch.Measurement([1, 89, 14, 14])
after bottleneck #4 : torch.Measurement([1, 101, 14, 14])
after bottleneck #5 : torch.Measurement([1, 113, 14, 14])
after bottleneck #6 : torch.Measurement([1, 125, 14, 14])
after bottleneck #7 : torch.Measurement([1, 137, 14, 14])
after bottleneck #8 : torch.Measurement([1, 149, 14, 14])
after bottleneck #9 : torch.Measurement([1, 161, 14, 14])
after bottleneck #10 : torch.Measurement([1, 173, 14, 14])
after bottleneck #11 : torch.Measurement([1, 185, 14, 14])
after bottleneck #12 : torch.Measurement([1, 197, 14, 14])
after bottleneck #13 : torch.Measurement([1, 209, 14, 14])
after bottleneck #14 : torch.Measurement([1, 221, 14, 14])
after bottleneck #15 : torch.Measurement([1, 233, 14, 14])
after bottleneck #16 : torch.Measurement([1, 245, 14, 14])
after bottleneck #17 : torch.Measurement([1, 257, 14, 14])
after bottleneck #18 : torch.Measurement([1, 269, 14, 14])
after bottleneck #19 : torch.Measurement([1, 281, 14, 14])
after bottleneck #20 : torch.Measurement([1, 293, 14, 14])
after bottleneck #21 : torch.Measurement([1, 305, 14, 14])
after bottleneck #22 : torch.Measurement([1, 317, 14, 14])
after bottleneck #23 : torch.Measurement([1, 329, 14, 14])
part2 after dense block 2 : torch.Measurement([1, 329, 14, 14])
part2 after first trans 2 : torch.Measurement([1, 263, 14, 14])
after concatenate : torch.Measurement([1, 305, 14, 14])
after second transition 2 : torch.Measurement([1, 152, 7, 7])
part1 : torch.Measurement([1, 76, 7, 7])
part2 : torch.Measurement([1, 76, 7, 7])
after bottleneck #0 : torch.Measurement([1, 88, 7, 7])
after bottleneck #1 : torch.Measurement([1, 100, 7, 7])
after bottleneck #2 : torch.Measurement([1, 112, 7, 7])
after bottleneck #3 : torch.Measurement([1, 124, 7, 7])
after bottleneck #4 : torch.Measurement([1, 136, 7, 7])
after bottleneck #5 : torch.Measurement([1, 148, 7, 7])
after bottleneck #6 : torch.Measurement([1, 160, 7, 7])
after bottleneck #7 : torch.Measurement([1, 172, 7, 7])
after bottleneck #8 : torch.Measurement([1, 184, 7, 7])
after bottleneck #9 : torch.Measurement([1, 196, 7, 7])
after bottleneck #10 : torch.Measurement([1, 208, 7, 7])
after bottleneck #11 : torch.Measurement([1, 220, 7, 7])
after bottleneck #12 : torch.Measurement([1, 232, 7, 7])
after bottleneck #13 : torch.Measurement([1, 244, 7, 7])
after bottleneck #14 : torch.Measurement([1, 256, 7, 7])
after bottleneck #15 : torch.Measurement([1, 268, 7, 7])
part2 after dense block 2 : torch.Measurement([1, 268, 7, 7])
part2 after first trans 2 : torch.Measurement([1, 214, 7, 7])
after concatenate : torch.Measurement([1, 290, 7, 7])
after avgpool : torch.Measurement([1, 290, 1, 1])
after flatten : torch.Measurement([1, 290])
after fc : torch.Measurement([1, 1000])
Ending
And that’s it! We’ve got efficiently discovered CSPNet and applied it on DenseNet spine. As I’ve talked about earlier, we are able to truly use the thought of CSPNet to enhance the efficiency of another spine fashions reminiscent of ResNet or ResNeXt. So right here I problem you to implement CSPNet on these fashions from scratch.
To be trustworthy I can not verify that my implementation is 100% right because the official GitHub repo [4] of the paper doesn’t present the PyTorch implementation — however that’s no less than every part I perceive from the manuscript. Please let me know if you happen to discover any mistake within the code or in my explanations. Thanks for studying, and see you once more in my subsequent article. Bye!
Btw you too can discover the code used on this article on my GitHub repo [5].
References
[1] Chien-Yao Wang et al. CSPnet: A New Spine That Can Improve Studying Functionality of CNN. Arxiv. https://arxiv.org/abs/1911.11929 [Accessed October 1, 2025].
[2] Gao Huang et al. Densely Linked Convolutional Networks. Arxiv. https://arxiv.org/abs/1608.06993 [Accessed September 18, 2025].
A brand new era of fast-moving AI startups threaten to take a nook of the market dominated by vertical SaaS instruments. Now, CIOs should determine whether or not to undertake these upstart software program choices or maintain onto acquainted, but probably lagging, platforms.
SaaS instruments are underneath stress as clients develop bored with subscriptions and query if the price of these instruments is justified, mentioned Justice Erolin, CTO at software program growth agency BairesDev. “Add in how straightforward it is changing into to face up practical software program with AI coding instruments, and SaaS distributors have an actual downside.”
An rising risk?
As AI-native startups step into this scene, it raises questions concerning the continued dominance of vertical SaaS instruments. “These startups aren’t disrupting vertical SaaS on the system of report degree, no less than not but,” mentioned Ayush Raj Jha, senior software program engineer at Oracle. As a substitute of presenting a direct, one-for-one problem to the incumbent expertise, he mentioned AI startups make the workflow layer above these techniques irrelevant. “That is really the extra harmful risk to SaaS.”
No one’s shutting down Salesforce tomorrow, mentioned Ryan Scott, CTO at Nomic Ventures, a agency that builds domain-specific AI techniques. What’s really occurring is that the workflow layer is detaching from the UI, he mentioned. “AI brokers can function above the interface now, and so they’ll speak to your CRM, your knowledge warehouse, your compliance system, your e-mail — all concurrently with out clicking something.”
With AI, the system of report is sticky as a consequence of knowledge gravity, compliance necessities, and switching prices that don’t have anything to do with product high quality, Jha mentioned. “However the AI layer sitting on high of medical workflows, authorized doc evaluations, or monetary reporting is now being eaten by startups who can ship in weeks whereas a big platform takes quarters to ship.” The disruption is going on one workflow at a time, not one platform alternative at a time, he added.
A vertical evolution
Vertical SaaS should evolve into an intelligence layer or danger changing into a useless repository, warned Vikas Nehru, CTO at software program developer Kantata. “Nevertheless, the winners will not be ‘walled gardens’ that pressure clients to make use of proprietary AI,” he predicted. Nehru believes that vertical SaaS’ future lies in an intelligence and orchestration platform — a system that integrates specialised AI brokers, Generative BI, and automatic workflows throughout a agency’s whole tech stack, together with Jira, Slack, CRM, and ERPs. “The market now not wants software-as-a-service; it wants expertise-as-a-service,” he acknowledged.
Vertical SaaS will proceed to develop, since these instruments act as superpowers for builders slightly than changing them, Erolin mentioned. “As the standard of AI assistants improves, we’ll see much more highly effective collaboration between AI and builders, which is the place the actual worth of this expertise will probably be unlocked.”
AI startups at the moment are trying to “layer on high,” but this strategy creates a fragmentation tax, Nehru mentioned, resulting in further prices, safety dangers, and knowledge silos. “Changing a system of report, as an example, is an enormous enterprise that almost all AI startups aren’t outfitted for,” he warned. The true disruption is not coming from startups changing their system of report, however from vertical SaaS platforms making the system of report energetic. “By embedding agentic orchestration instantly into the workflow, vertical SaaS options remove the necessity for third-party layers and supply a single supply of reality that truly thinks and acts.”
Hedging their bets
Jha, drawing inspiration from his time working inside a Fortune 100 expertise firm, mentioned that many CIOs at the moment are taking simultaneous AI and SaaS approaches and calling it a technique. “They’re working AI startup pilots in non-critical workflows whereas ready for his or her current vertical platforms to make amends for the core techniques,” he acknowledged. “The chance is that the pilots turn into dependencies earlier than anybody has evaluated them with the identical scrutiny utilized to enterprise distributors.”
The startup dependency failure state of affairs is maybe essentially the most underrated operational danger in enterprise AI proper now, Jha mentioned. “I’ve constructed infrastructure the place a single third-party integration happening meant the restoration regarded profitable on paper however was really clinically damaged in follow.”
The identical failure mode additionally applies to AI workflow dependencies. He famous, for instance, that if a startup processing your contract evaluations’ medical documentation goes darkish, the workflow does not gracefully degrade — it stops. Jha additionally cautioned that almost all enterprises have not stress examined what occurs to their operations when an AI dependency disappears. “They will not give it some thought significantly till it occurs to somebody seen sufficient to make the information.”
A ultimate problem
Nomic’s Scott warned that nearly nobody is speaking about compliance layer points. “That is the actual hole,” he mentioned. HIPAA, FDCPA, PCI DSS, GDPR — all have been written for people interacting with people. “An AI agent that contacts a debtor at 10 p.m. is not being deliberately malicious, however it’s nonetheless an FDCPA violation, and the group working the agent will probably be held liable.”
The dialog round automation has shifted from whether or not AI algorithms will supersede human employees to how professionals who combine these methods will outpace those that resist. When you’ve got been asking whether or not AI will change jobs, the truth is almost definitely sure.
Information signifies that 69% of pros consider their jobs are being impacted by expertise, particularly AI. Nevertheless, this disruption brings substantial alternative, with 78% of employees feeling constructive in regards to the potential influence of AI on their careers.
Professionals leveraging AI, giant language fashions (LLMs), and predictive analytics are upskilling to combine automation into their workflows to reach the long term.
Understanding how Careers & Jobs in Synthetic Intelligence (AI) are evolving is vital for anybody aiming to safeguard their livelihood. Refusing to undertake these cognitive instruments is now not a impartial stance; it’s an energetic deceleration of your profession development.
Key Impacts on Profession Development in 2026
The skilled price of AI non-adoption is now not theoretical. Executives surveyed throughout industries have been unequivocal: ignoring AI is a larger profession menace than AI itself. The influence manifests throughout 4 vital dimensions.
1. Handed Over for Promotions
Promotion selections in the present day more and more mirror an worker’s capacity to leverage rising applied sciences to drive outcomes. Managers are starting to view AI fluency or the shortage of it as a proxy for adaptability and strategic considering.
Workers who rely solely on guide processes are sometimes perceived as working more durable, not smarter. In efficiency evaluations, those that display AI-augmented productiveness usually tend to be flagged as high-potential contributors.
In response to the Nice Studying Upskilling Tendencies Report,15% of pros cite promotions as a major motivation for upskilling, a determine that underscores how immediately the 2 are linked in skilled notion.
2. Job Insecurity
Non-adoption of AI doesn’t merely sluggish profession development; it will probably speed up job displacement. Trade analysis exhibits that executives are more and more factoring AI readiness into workforce selections.
Workers who can’t display proficiency with AI instruments are at a definite drawback throughout restructuring workout routines or position redefinitions. The World Financial Discussion board’s Way forward for Jobs Report initiatives that roughly 92 million jobs will likely be displaced by technological developments by 2030, lots of which contain routine cognitive duties now being automated.
Professionals who delay upskilling are immediately within the path of this disruption. For these navigating a profession transition, assets like How an AI Course Can Assist You Pivot After a Layoff provide structured steering on repositioning oneself in an AI-driven market.
3. Stagnation vs. Productiveness
The productiveness hole between AI-enabled professionals and people working with out AI help is widening quickly.
Duties that beforehand required hours, resembling drafting experiences, synthesizing information, and creating displays, are actually being accomplished in minutes by professionals proficient in generative AI (GenAI) instruments.
As per the Upskilling Pattern Report, 60% of pros already use GenAI all the time or steadily of their work, and 80% use it to be taught new expertise. Those that choose out of this shift usually are not sustaining a baseline; they’re falling behind.
If you’re uncertain what the AI at present calls for, this video is a helpful start line: 6 Steps to Get Began with AI for Freshmen.
4. Weak Aggressive Positioning
In a job market the place 43% of pros cite excessive competitors as a significant problem, the differentiator between comparable candidates is more and more AI competency. Hiring managers usually are not simply searching for area experience; they’re searching for professionals who can amplify it with AI.
Candidates with out demonstrable AI expertise are getting into a essentially uneven aggressive atmosphere. To get began, you possibly can discover what employers count on past fundamental data on this insightful learn: What Employers Anticipate Past Fundamental AI Device Utilization.
To counteract this stagnation, take into account complete upskilling pathways such because the PG Program in Synthetic Intelligence & Machine Studying.
This program is delivered in collaboration with main tutorial establishments and covers core domains together with Machine Studying, Pure Language Processing, and Pc Imaginative and prescient. Designed for deep ability constructing, it affords a structured curriculum that bridges the hole between theoretical algorithms and strategic enterprise purposes, equipping you to securely navigate technological disruptions.
AI Adoption Is Not Only for Tech Roles
A standard false impression is that AI fluency is a prerequisite just for software program engineers, information scientists, or machine studying specialists.
This can be a harmful oversimplification. AI is a cross-functional productiveness layer; it’s as related to a advertising supervisor as it’s to a cloud architect. Right here’s how:
Advertising: Generative AI instruments are reworking content material technique, search engine optimization, and viewers segmentation. Entrepreneurs who leverage giant language fashions (LLMs) for content material technology, predictive analytics for marketing campaign efficiency, and AI-assisted A/B testing are constantly outperforming friends counting on conventional strategies.
HR: Human assets professionals are deploying AI for clever candidate screening, sentiment evaluation of worker suggestions, and workforce demand forecasting. AI-assisted hiring workflows cut back time-to-hire and enhance candidate high quality. Professionals excited about understanding this shift additional can discover Profession Choices in AI for cross-domain views.
Finance: From AI-driven income forecasting to automated anomaly detection in monetary statements, finance professionals are utilizing machine studying fashions so as to add predictive intelligence to their evaluation. Guide forecasting is being changed by AI-augmented resolution assist methods.
Operations: AI-powered workflow automation instruments are enabling operations managers to establish bottlenecks, predict provide chain disruptions, and optimize useful resource allocation in actual time. Those that perceive easy methods to design and handle these automated workflows command a measurable strategic benefit.
If you’re questioning what AI careers appear like throughout these domains, watch: Careers & Jobs in Synthetic Intelligence (AI).
Should-Have AI Abilities to Keep Related
The next are the core capabilities that professionals should develop to stay aggressive. These usually are not buzzwords; they’re operational expertise now required throughout roles and industries.
Immediate engineering is the best way of structuring inputs to giant language fashions (LLMs) to generate correct, contextually related, and actionable outputs. It’s the foundational ability of the AI period.
Writing clear, context-rich, goal-oriented prompts that reduce hallucinations and maximize precision
Utilizing zero-shot, few-shot, and chain-of-thought prompting strategies, relying on process complexity
Iterating on outputs by means of structured suggestions loops to refine AI-generated content material progressively
Understanding token limits, temperature settings, and the way mannequin parameters affect output habits
2. AI-Assisted Choice Making
This ability entails embedding AI-generated insights into strategic and operational decision-making processes.
Utilizing predictive analytics dashboards to interpret AI-generated forecasts and suggestions
Figuring out which selections profit from AI augmentation versus these requiring purely human judgment
Structuring resolution frameworks that combine real-time AI outputs with institutional data and contextual understanding
3. Workflow Automation Designing
The flexibility to design automated workflows with AI-native and AI-integrated instruments is among the many most in-demand expertise throughout features in 2026.
Mapping repetitive, rule-based duties which can be viable candidates for robotic course of automation (RPA) and AI automation
Utilizing instruments like Zapier, Make (previously Integromat), and Microsoft Energy Automate to construct clever pipelines
Designing end-to-end automated workflows that join information ingestion, AI processing, and output supply with out guide intervention
Documenting and iterating on automation logic to make sure reliability, transparency, and auditability
Adopting AI instruments doesn’t imply surrendering judgment. The flexibility to guage, confirm, and enhance AI outputs is itself a high-value skilled ability.
Cross-referencing AI-generated information factors with major sources to make sure factual accuracy
Recognizing and correcting hallucinations, cases the place AI fashions produce assured however incorrect outputs
Making use of area experience to contextualize and refine AI-generated suggestions earlier than performing on them
Combining AI processing velocity with human instinct and moral reasoning to provide outputs which can be each environment friendly and defensible
5. Device Stacking
The best AI-enabled professionals don’t depend on a single device; they architect clever workflows by combining a number of AI methods.
Google Sheets / Excel AI / Copilot: Information evaluation, sample recognition, system automation
Automation platforms (Zapier, Make): Connecting outputs throughout instruments with out guide intervention
Constructing these stacks into repeatable, scalable workflows that colleagues can undertake with no need technical experience
Perceive the evolving distinction between generative and agentic AI and what it means to your ability set: GenAI vs Agentic AI: Key Abilities Powering the Way forward for Work.
6. Area + AI Integration
Probably the most enduring type of AI fluency is domain-specific, the power to use AI inside the context of 1’s skilled experience.
Advertising: Utilizing AI for programmatic advert focusing on, generative content material pipelines, and buyer sentiment modeling
HR: Constructing AI-assisted hiring workflows that rating resumes, schedule interviews, and generate onboarding documentation
Finance: Deploying machine studying fashions for time-series forecasting, danger scoring, and variance evaluation
To solidify these technical competencies, the Grasp’s Synthetic Intelligence program supplies a complete basis. Providing 18 coding workout routines and three hands-on initiatives, this course covers vital terminologies and architectures throughout machine studying, neural networks, laptop imaginative and prescient, and Generative AI, culminating in an industry-recognized profession certificates.
Step-by-Step The way to Begin Utilizing AI
Instance: Utilizing AI for a Weekly Enterprise Report
State of affairs: You might be liable for a weekly efficiency report. Historically, this process consumes 3 – 4 hours: gathering information from a number of methods, performing guide evaluation, writing a story abstract, and formatting the ultimate doc. Right here is the way you execute it with AI in a fraction of the time.
Step 1: Put together and Enter the Uncooked Information
Earlier than the AI can help, it wants context. On this step, you might be establishing the inspiration to your report by feeding the AI your consolidated metrics. Spotlight the information desk you simply pasted into Google Sheets to offer the AI with context.
Step 2: Immediate for Analytical Insights
As a substitute of manually calculating week-over-week variances, you’ll instruct the AI to behave as your information analyst. The aim right here is to uncover the “why” behind the numbers.
Open the AI assistant (just like the Gemini facet panel) and enter a extremely particular, context-rich immediate asking for information interpretation.
The Immediate:“Analyze this weekly efficiency information. Spotlight the overarching statistical traits over the 8 weeks, establish any main information anomalies or irregularities, and supply 3 actionable, data-driven enterprise insights primarily based in your findings.”
End result: Gemini processes the information and intelligently acknowledges that one of the simplest ways to “spotlight traits” is visually. It immediately generates a collection of clear charts within the facet panel: a line chart displaying a large spike in Web site Visitors on March twenty third.
A corresponding line chart exhibits a extreme drop in Conversion Charges that very same week.
A bar chart highlighting a large surge in Help Tickets and three actionable gadgets it’s best to take into account to begin doing.
Step 3: Evaluation the AI’s Pattern & Anomaly Detection
The AI has executed the heavy lifting of recognizing the irregularities. Now you overview its findings.
Visually validate the anomaly utilizing the generated charts. Verify that the large visitors spike on March twenty third was low-quality, because it immediately correlates with poor conversions and a excessive assist burden.
You bypass studying a wall of textual content and immediately grasp the enterprise drawback visually. Now you can use the “Insert” button within the Gemini panel to drop these ready-made visualizations immediately into your spreadsheet or presentation deck.
Step 4: Generate the Government Report
Now that the AI has analyzed the information, it’s essential to format it to your stakeholders. This step transitions the AI from a “information analyst” to a “enterprise author.”
Give the AI a secondary immediate to construction its earlier evaluation right into a readable company format. “Based mostly on the anomalies proven in these charts, write a brief, concise govt abstract textual content block explaining the March twenty third incident. Use clear headings: Government Abstract, Anomaly Detected, and Strategic Suggestions.”
End result: The AI shifts from visible technology to textual content technology. It produces a formatted textual content block detailing the inverse relationship between the March twenty third visitors spike and the conversion/assist metrics, completely complementing your new charts.
Step 5: Refine and Polish the Output
The primary draft is never the ultimate draft. This remaining step showcases the collaborative nature of working with AI, the place human judgment steers the ultimate product.
Ask the AI to regulate the tone, broaden on a selected advice, or rewrite a piece for readability. For instance- “Make the tone extra authoritative. Make sure the ‘Strategic Suggestions’ particularly deal with how we must always deal with future visitors spikes to forestall the excessive Buyer Acquisition Price and assist ticket quantity seen on March twenty third.” The ultimate output transforms into a cultured govt transient.
That is the operational actuality of AI-enabled productiveness, and it’s accessible to any skilled keen to put money into the related expertise. For hands-on follow and structured workout routines to construct these capabilities, discover:
Your Subsequent Step
85% of pros consider upskilling is important to future-proof their careers. Machine Studying and AI are the highest domains of alternative for upskilling, chosen by 44% of pros. The query is now not whether or not to develop AI expertise, however how to take action effectively and successfully.
The next structured pathways can be found to professionals at totally different phases of readiness:
For complete, credential-backed studying: The JHU Certificates Program in Utilized Generative AI and Agentic AI, in collaboration with Johns Hopkins College, affords a rigorous, application-focused curriculum overlaying immediate engineering, LLM integration, and enterprise AI deployment, backed by one of many world’s most revered tutorial establishments.
The aggressive divide within the trendy workforce shouldn’t be between these with and with out superior levels; it’s between those that have built-in AI into their skilled follow and people who haven’t.
Refusing to undertake AI instruments at work shouldn’t be a impartial resolution. It’s a resolution to fall behind in a panorama that rewards adaptability above all else. The profession you construct from this level ahead will likely be formed, in no small half, by how significantly you are taking that actuality. Begin exploring your Profession Roadmap in AI and use the AI Information Quizzes to evaluate the place you stand in the present day.



















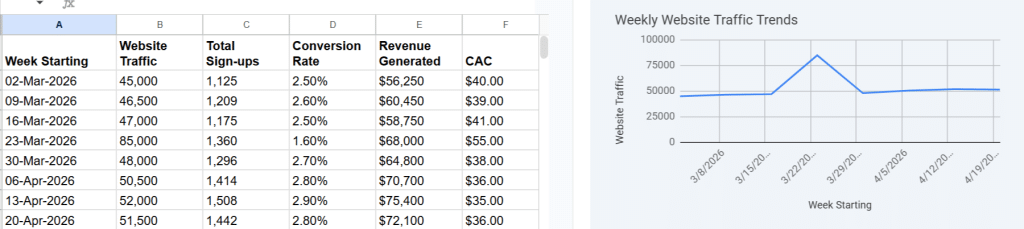
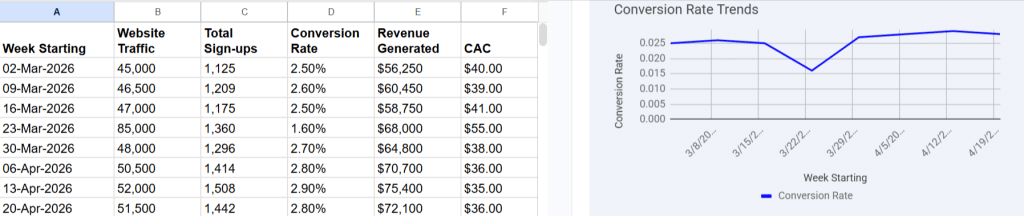

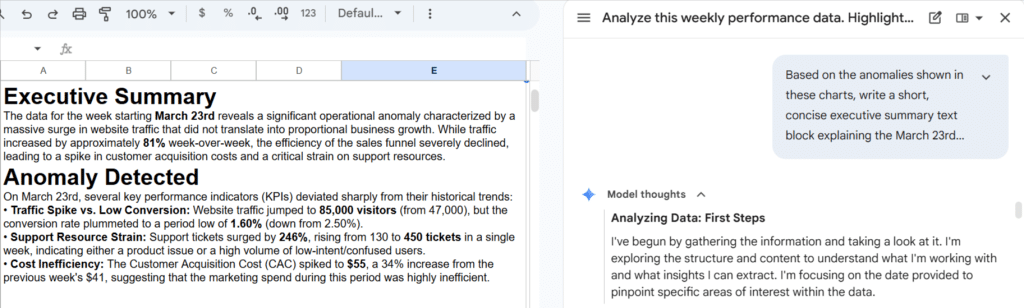
{kind=link}