Fastened-height playing cards typically really feel like a protected alternative. A designer fingers you a mockup the place each card aligns completely in a grid. The titles are quick, the excerpts match neatly, and the structure appears to be like secure throughout the complete web page. So that you implement the design precisely as specified and ship it.
Every thing works till the content material adjustments. An editor updates the copy, a translation provides longer phrases, and a few customers bump their default font measurement, particularly these with low imaginative and prescient or digital eye pressure, simply to make issues simpler to learn.
I bumped into this whereas constructing a “Current Articles” part for a weblog. The design assumed comparatively quick English titles, so all the pieces match comfortably contained in the mounted top.
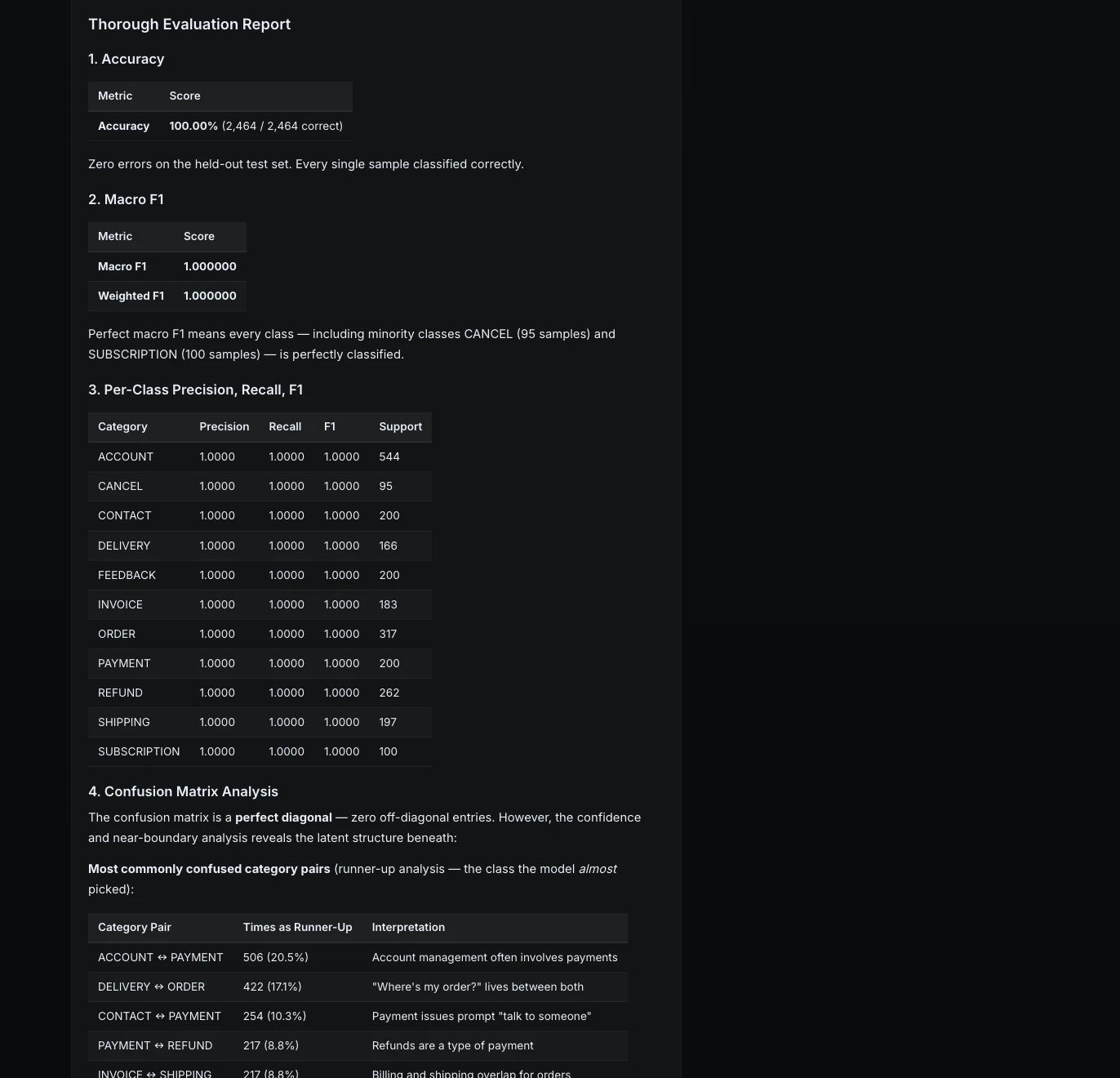
The structure appeared stable at first look:
However as soon as the content material modified, the cracks began showing:

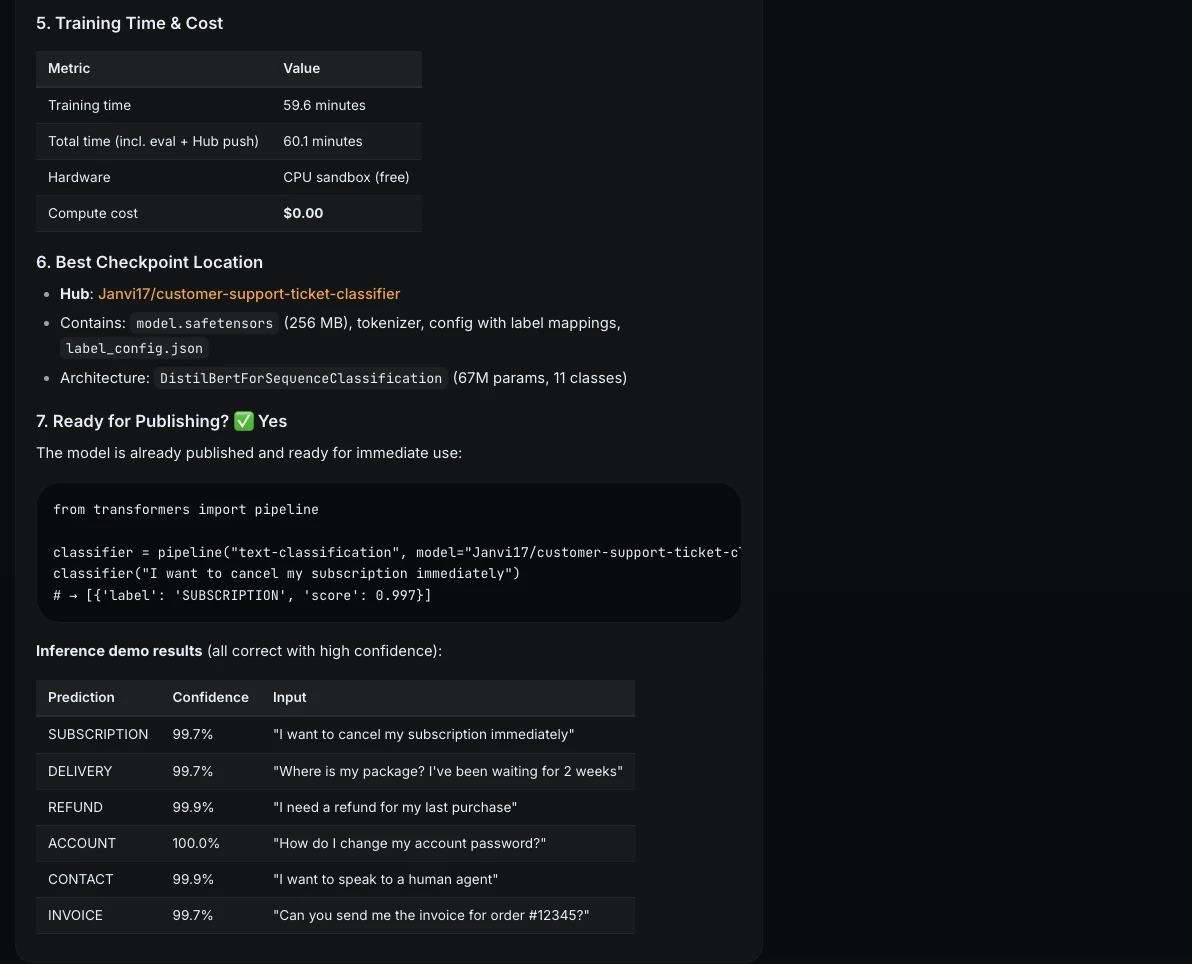
Translating the content material to French made issues worse:

German translations pushed the structure even additional:

What as soon as appeared like a secure part turned out to rely on a fragile assumption: that the content material would at all times keep inside a hard and fast top.
Right here’s a demo of the structure:
Fastened-Peak Layouts Look Fragile
Within the design specs, the pixel dimensions have been actual, and you recognize that playing cards align extra cleanly once they have the identical vertical rhythm and equal measurement, which creates in our thoughts a way of order that I and the designer type of trusted.
So, I set:
.card__title {
margin: 0 0 8px;
font-size: 18px;
line-height: 1.2;
show: -webkit-box;
-webkit-line-clamp: 2;
-webkit-box-orient: vertical;
overflow: hidden;
}
.card__excerpt {
margin: 0 0 10px;
font-size: 14px;
line-height: 1.4;
show: -webkit-box;
-webkit-line-clamp: 3;
-webkit-box-orient: vertical;
overflow: hidden;
}However surprisingly, the habits modified as quickly because the font settings modified. I elevated the browser’s default textual content measurement and realized that it launched strain contained in the playing cards. My textual content blocks grew, however the container remained the identical, and parts started competing for a similar house.
Usually, a block component merely grows with its content material. However the second I set that top, I broke that relationship. The browser doesn’t deal with this as an issue; it simply resolves the battle the one method it may, by both letting content material overflow or clipping it.
Within the unique model of the structure, I simply bluntly hid these issues with overflow: hidden.
To make the issue seen, we will take away the protection internet:
.card__title {
show: -webkit-box;
font-size: 18px;
line-height: 1.2;
margin: 0 0 8px;
-webkit-line-clamp: 2;
-webkit-box-orient: vertical;
/* overflow: hidden; */
}
.card__excerpt {
show: -webkit-box;
font-size: 14px;
line-height: 1.4;
margin: 0 0 10px;
-webkit-line-clamp: 3;
-webkit-box-orient: vertical;
}With out overflow: hidden, the failure is not refined. The content material stops clipping and begins spilling out like groceries from a torn bag. Some excerpts sit proper on the tags, and all the pieces was breaking as soon as we stopped hiding the strain inside the cardboard.

overflow: hidden reveals the structural pressure as an alternative of masking it.Sadly, the browser has no approach to reconcile these competing directions besides by letting parts collide.
Eradicating the Fastened Peak
Eradicating the constraints that held this structure collectively reveals the place the actual drawback lives. Fastened heights, absolute positioning, and grid alignment have been all making an attempt to manage the identical factor.
Completely Positioned Actions: Eliminated From Stream
Up up to now, the mounted top appears to be like like the primary perpetrator to me. However it isn’t appearing alone; the actions on the backside of the cardboard have been completely positioned:
.card__actions {
place: absolute;
inset: 0 14px 14px;
}This appears like a clear answer; the actions keep pinned to the underside of the cardboard irrespective of how lengthy the content material is.
In a typical block structure, a container’s top is decided by the mixed contribution of its in-flow kids.
I’m positive you’ve got seen how completely positioned parts behave. The browser nonetheless renders them, regardless that they not contribute to the father or mother’s intrinsic top. Visually, the actions belong to the cardboard, structurally, the structure ignores them.
To compensate, we reserved house manually:
.card__body {
padding-block-end: 14px;
}This padding is actually simply an estimate. The second the font measurement will increase, buttons wrap, or translations make the textual content longer, the estimate stops being dependable.
As a substitute of making an attempt to foretell how a lot house the actions may want, we will let the browser calculate it.
Right here is similar structure with out absolute positioning:
The change is small, however the shift in habits is kind of noticeable. Even with the mounted top nonetheless in place, the interior pressure shrinks as a result of the structure is not working towards itself.
That is the primary structural enchancment. The cardboard nonetheless has an extrinsic top constraint, so the structure isn’t absolutely versatile but.

There’s an Phantasm of Management
If mounted heights act like ceilings, line clamping acts extra like a mute button. Within the unique part, I clamped the title and the excerpt:
.card__title {
show: -webkit-box;
overflow: hidden;
-webkit-line-clamp: 2;
-webkit-box-orient: vertical;
}
.card__excerpt {
show: -webkit-box;
overflow: hidden;
-webkit-line-clamp: 4;
-webkit-box-orient: vertical;
}Clamping feels reassuring to me at the moment as a result of it limits drift and retains playing cards visually aligned. However in follow, that flips the connection.
To essentially see this extra clearly, let’s take away clamping whereas preserving all the pieces else the identical. This model is similar to the earlier demo besides that I’ve eliminated all clamping from .card__title and .card__excerpt however left the overflow in order that we will clearly see what occurs.

With out clamping, the strain contained in the part turns into apparent. You see how German card grows taller, and the excerpt wraps naturally. What this actually reveals us is {that a} secure structure shouldn’t depend on overflow: hidden. If a structure solely works as a result of content material is being suppressed, it’s in all probability fragile.
Up up to now, virtually each failure we’ve seen traces again to a single determination:
.card {
top: 375px;
}This one line could look harmless to you, but it surely overrides the browser’s default sizing habits.
Sooner or later, the only query turns into unavoidable: So what occurs if we simply… cease? Take away the peak completely and let the browser do its factor?
Let’s take away the mounted top whereas preserving the remainder of the structure intact. Clamping can keep in place since we wish to examine behaviors.
As soon as I restored intrinsic sizing inside the cardboard, the alignment drawback actually turned a grid problem, which brings us to our subsequent refinement.
Let the Grid Deal with Equal Heights
Fastened heights felt interesting. However having equal heights doesn’t truly imply fixing the heights manually. The grid can deal with that alignment for us with out me imposing arduous boundaries on every part.
Typically, the repair is surprisingly small. Eradicating align-items: begin lets the grid objects stretch naturally, and switching to a extra versatile column definition helps the structure adapt higher throughout completely different display sizes.
.card-grid {
grid-template-columns: repeat(auto-fit, minmax(280px, 1fr));
}See how the identical structure makes use of intrinsic card heights and versatile grid tracks:

To make the button properly align like we had initially, as an alternative of positioning and reserving house manually:
.card {
padding: 14px;
place: relative;
}We flip the cardboard right into a vertical structure:
.card {
show: flex;
flex-direction: column;
padding: 14px;
}We’re not going to go deep on flexbox right here, as Kevin Powell has a terrific article on precisely that. However it’s value realizing what’s occurring. Turning the cardboard right into a flex container with flex-direction: column traces all the pieces up vertically from prime to backside.
The subsequent step is eradicating the synthetic house that was holding room for the actions:
.card__body {
padding-block-end: 56px;
padding-block-start: 10px;
}That padding was a guess; it solely labored so long as the content material stayed predictable. As a substitute, we let the physique increase naturally:
.card__body {
show: flex;
flex-direction: column;
flex: 1;
padding-block-start: 10px;
}The flex: 1 tells the physique to take up no matter house is left after the picture, and the actions have taken what they want.
If the tags want a little bit of respiratory room, a easy margin does the job:
.card__tags {
margin-block-end: 10px;
}We get a card that appears simply as aligned as in our unique web page, however now the alignment comes from structure move, not from forcing the peak.

Utilizing clamp() for Fluid Typography
Fluid typography with clamp() could make titles scale extra easily throughout viewport sizes:
.card__title {
font-size: clamp(1rem, 2vw, 1.25rem);
}If you wish to know extra about clamp(), Pedro Rodriguez’s article on scaling font measurement with CSS clamp() is an effective learn.
Declaring clamp(1rem, 2vw, 1.25rem) permits the title to scale with the viewport whereas staying inside a protected vary. The font measurement can develop or shrink with the viewport (2vw) however won’t ever go smaller than 1rem or bigger than 1.25rem.
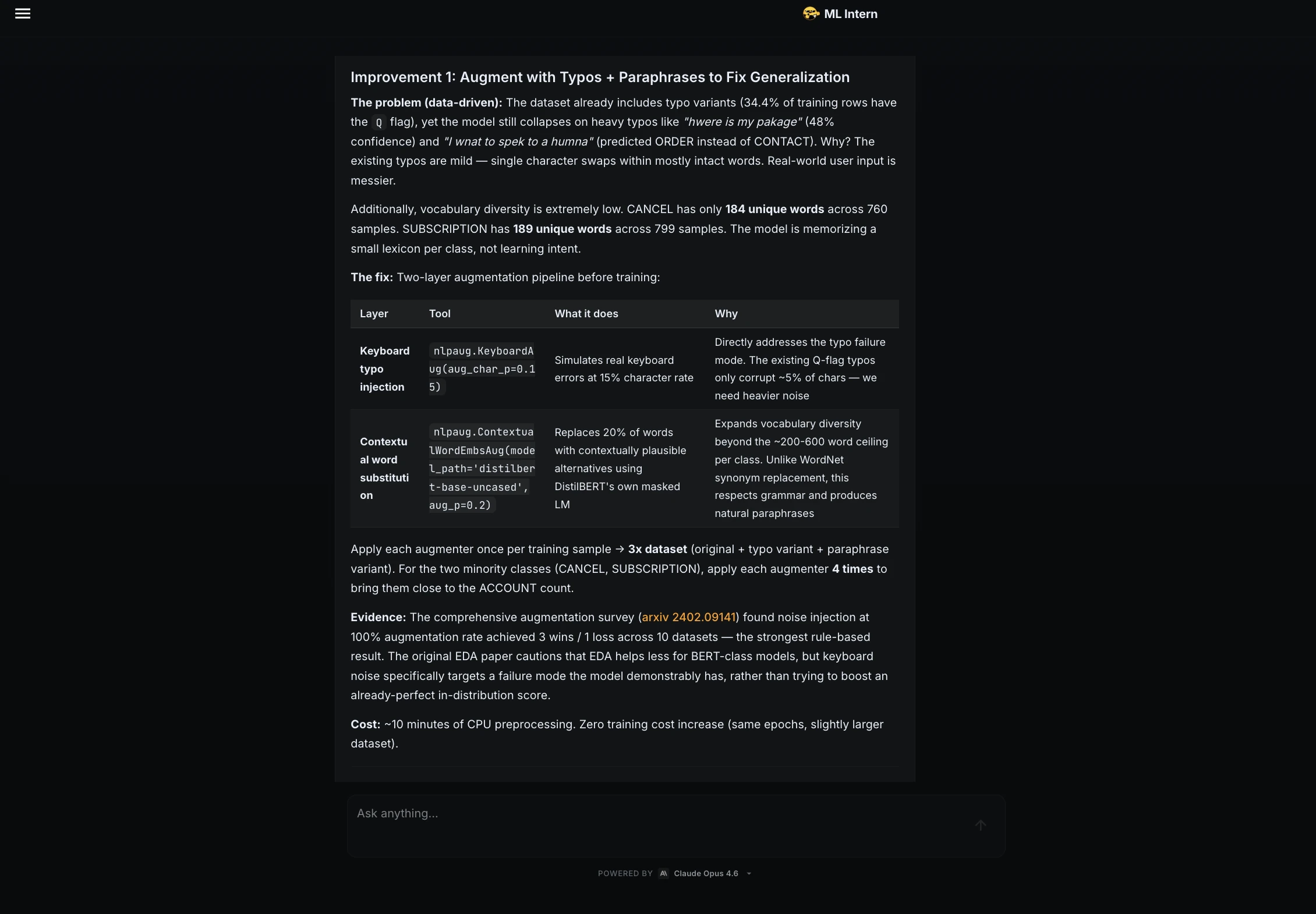
Designing for Failure
Not one of the issues I discussed earlier on this structure appeared whereas I used to be constructing it. The issues appeared solely when some situations modified. Typically a picture didn’t load, which modified the vertical steadiness of the cardboard. And because the viewport narrowed, the textual content needed to wrap extra aggressively.
If you wish to know whether or not a part will maintain up with actual content material, attempt placing it beneath excessive situations. A number of easy tweaks are sufficient to disclose the place the structure begins to interrupt or collapse:
- Improve the browser’s default font measurement to see the way it behaves.
- Allow text-only zoom as an alternative of web page zoom to look at the distinction.
- Exchange a title with a single unbroken string or simulate different languages with longer phrases.
- Simulate a lacking picture.
- Shrink the viewport till the textual content begins wrapping aggressively.
Quite than explaining issues abstractly, we will introduce them straight into the intrinsic-height model of the cardboard.
Stress Take a look at Mode
From the intrinsic-height model, we will add a easy toggle that simulates a number of content material stress circumstances.
Add this button contained in the .demo-toolbar:
Add the next script, too:
const stressBtn = doc.querySelector("#toggleStress");
stressBtn.addEventListener("click on", () => {
doc.physique.classList.toggle("stress");
});This script merely listens for clicks on the button and provides or removes a stress class on the . That class acts as a swap that turns the stress-test types on and off.
And add these types:
physique.stress .card:nth-child(1) .card__title::after {
content material: "ExtremelyLongUnbrokenStringWithoutAnySpacesToTestOverflowBehavior";
}
physique.stress .card:nth-child(2) .card__excerpt {
font-size: 1.1rem;
}
physique.stress .card__media img {
show: none;
}These types simulate a number of frequent structure stress circumstances. The primary card will get an unbroken string to check overflow habits. The second will increase textual content measurement to imitate bigger default font settings. The rule on .card__media img hides media completely to simulate a lacking or failed picture load.
This stability isn’t coming from the defensive guidelines I added on the finish. It comes from the sooner structural choices. As soon as mounted heights and out-of-flow positioning have been eliminated, the part might adapt naturally to no matter content material it receives.
When you begin counting on intrinsic sizing, you cease worrying about each potential string size or font setting. If the content material will get longer or the textual content measurement adjustments, the browser can deal with it. Most structure issues begin after we take that flexibility away.
So, What Grows and What Doesn’t?
The unique card failed for a easy cause: it relied on assumptions that have been by no means acknowledged. The title was supposed to slot in two traces, the excerpt was supposed to slot in 4 and buttons have been supposed to remain on one line. Translations have been supposed to remain “about the identical size” and customers have been supposed to maintain default textual content settings. None of that was enforced. They have been merely guesses.
These assumptions quietly made their method into my CSS. So long as the content material stayed inside these boundaries, all the pieces type of appeared secure. However the second it drifted, the structure began responding badly to the battle.
After I rebuilt this part, the very first thing I did was take away these hidden dependencies. There’s no mounted pixel ceiling anymore, no padding buffer that wants me to continually tweak, and no truncation appearing as a security internet to maintain the structure from breaking.
Truncation can nonetheless be a deliberate design alternative. However you shouldn’t truncate simply to maintain the structure from collapsing. When that occurs, the part is already beneath pressure.
The ultimate demo reveals that concept in follow. It masses pressured content material by default, with longer translated textual content, wrapped tags, and a lacking picture, as a way to see how the part behaves beneath actual situations slightly than preferrred ones.
Every card grows as wanted, and the grid retains alignment with out hiding overflow or counting on defensive spacing.
I Assume Fastened Heights Are Nonetheless Helpful
Working by this structure modified how I take into consideration mounted heights. I nonetheless use them once they make sense, and I nonetheless clamp textual content when truncation is intentional. However each time I discover myself making an attempt to manage how content material flows inside a part, it’s often an indication that the structure must be reconsidered. More often than not, letting the browser deal with the sizing results in a extra resilient consequence.