We’re happy to announce a brand new model of Stata: Stata 12. You possibly can order it at present, it begins delivery on July 25, and you will discover out about it at www.stata.com/stata12/.
Listed below are the highlights of what’s new:
There are different issues which are new, too. Issues like features for Tukey’s Studentized vary and Dunnett’s a number of vary, baseline odds for logistic regression, truncated count-data regressions, chance predictions, sturdy and cluster-robust SEs for fixed-effects Poisson regression, and the like underneath Normal Statistics. Or underneath Survey Knowledge, help for SEM, bootstrap and successive distinction replicate (SDR) weights, goodness of match after binary fashions, coefficient of variation, and extra. Or underneath Panel Knowledge, chance predictions, a number of imputation help, and extra. Or underneath Survival Knowledge, a goodness-of-fit statistic that’s sturdy to censoring. Or PDF export of outcomes and graphs.
We might go on, however you get the thought. We predict Stata 12 is price a glance.
Latest advances in massive language fashions (LLMs) have enabled AI brokers to carry out more and more complicated duties in internet navigation.Regardless of this progress, efficient use of such brokers continues to depend on human involvement to right misinterpretations or alter outputs that diverge from their preferences. Nevertheless, present agentic methods lack an understanding of when and why people intervene. In consequence, they may overlook consumer wants and proceed incorrectly, or interrupt customers too regularly with pointless affirmation requests.
This blogpost is predicated on our latest work — Modeling Distinct Human Interplay in Net Brokers — the place we shift the main focus from autonomy to collaboration. As a substitute of optimizing brokers solely for an end-to-end autonomous pipeline, we ask: Can brokers anticipate when people are more likely to intervene?
To formulate this process, we gather CowCorpus – a novel dataset of interleaved human and agent motion trajectories. In comparison with current datasets comprising both solely agent trajectory or human trajectory, CowCorpus captures the collaborative process execution by a group of a human and an agent. In complete, CowCorpus has:
400 actual human–agent internet classes
4,200+ interleaved actions
Step-level annotations of intervention moments
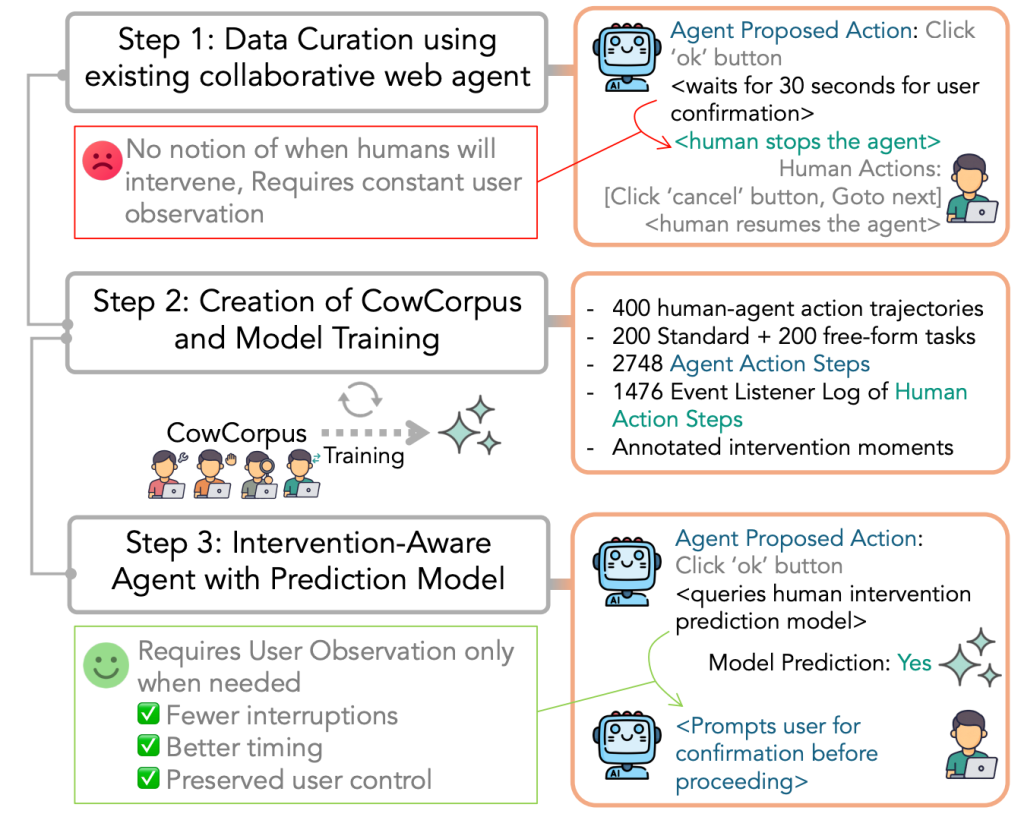
We curate CowCorpus from 20 real-world customers utilizing CowPilot, an open-source artifact by the identical analysis group. CowPilot is constructed as a generalizable Chrome extension, which is accessible to any arbitrary web site. Additionally it is simple to put in, making the annotation course of less complicated for our contributors. In CowPilot, we confirmed how collaboration works. In PlowPilot, we wish to make it adaptive.
Determine: An instance process from CowPilotDetermine: On this paper, we current CowCorpus, a dataset of 400 real-user collaborative internet trajectories that captures when and the way people intervene throughout execution, enabling intervention-aware brokers that interact customers solely when wanted. First, we curate information utilizing our earlier collaborative agent, CowPilot. Second, we curate the information from real-world customers. Lastly, we practice an intervention prediction mannequin that results in our new pipeline for intervention-aware brokers.
To make sure CowCorpus is in line with established benchmarks and displays particular person consumer preferences, we designate a mix of free-form duties and benchmark duties in our dataset —
10 commonplace duties from the Mind2Web dataset (Deng et al., 2024): Helps us to grasp how the collaborative nature varies amongst contributors below the mounted process setup.
10 free-form duties of the contributors’ personal alternative: Helps us to grasp what sort of internet duties folks want to automate.
In complete, CowCorpus covers 9 varieties of process classes:
Desk: Examples of free-form duties throughout 9 classes, with process description and distribution percentages.Desk: CowCorpus statistics for normal and free-form duties: (1) intervention depth: share of human actions throughout all trajectories, (2) step depend: variety of steps taken by agent or human actors, (3) time: time taken by agent or human actors.
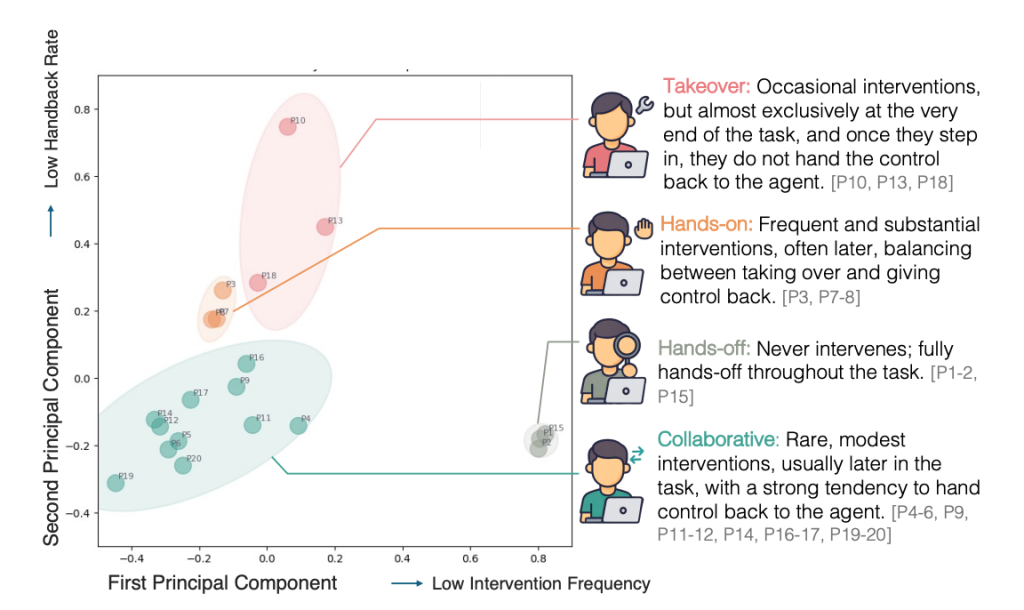
We analyze when human interventions happen throughout collaborative process execution and the way such temporal patterns fluctuate throughout customers. Utilizing participant-level measures, we cluster customers by interplay habits with 𝑘-means (𝑘=4). This evaluation reveals 4 distinct and secure teams of customers with qualitatively completely different patterns of intervention timing and management sharing. Based mostly on cluster centroids and consultant trajectories, we characterize the 4 teams as follows:
Takeover: Customers intervene occasionally and usually late within the process. Once they do step in, they have an inclination to retain management fairly than returning it to the agent, leading to low handback charges. These interventions typically coincide with finishing the duty themselves fairly than correcting the agent mid-execution.
Fingers-on: Customers intervene regularly and with excessive depth. Their interventions are inclined to happen comparatively late within the trajectory, however not like Takeover customers, they repeatedly alternate management with the agent, resulting in medium handback charges and sustained joint execution.
Fingers-off: Customers hardly ever intervene all through the duty. They exhibit low intervention frequency and depth, permitting the agent to execute most trajectories end-to-end with minimal human involvement.
Collaborative: Customers intervene selectively and constantly return management to the agent. This group is characterised by excessive handback charges and earlier intervention positions, reflecting focused, short-lived interventions that help ongoing collaboration.
Total, customers exhibit systematic variations in when interventions happen, how a lot they intervene, and whether or not management is relinquished afterward. Such temporal intervention patterns are constant throughout duties and inspire modeling distinct human–agent interplay patterns.
Determine: 4 distinct varieties of human-agent interplay patterns: Takeover, Fingers-on, Fingers-off, and Collaborative. We visualize the consumer teams utilizing PCA (left), and describe the interplay mechanism of every group (proper)
We mannequin human–agent collaboration as a Partially Observable Markov Determination Course of (POMDP). Given a process instruction, each the agent and human take turns executing actions primarily based on their insurance policies, forming a trajectory over time. At every step, the system observes the present state as a multimodal enter consisting of the webpage screenshot and accessibility tree. The agent proposes an motion conditioned on the commentary and previous trajectory. The human might intervene at any step, represented as a binary variable.
We formulate intervention prediction as a step-wise binary classification drawback that estimates the likelihood of human intervention given the present state, agent motion, and historical past. To resolve this, we use a big multimodal mannequin skilled through supervised fine-tuning. The mannequin takes as enter the trajectory historical past, present commentary, and proposed motion, and outputs a call to both request human enter or permit the agent to proceed.
We practice (1) a common intervention-aware mannequin utilizing all coaching information and (2) style-conditioned fashions tailor-made to every interplay group utilizing the corresponding subset of trajectories. To guage effectiveness, we examine these fashions in opposition to each prompting-based proprietary LMs and fine-tuned open-weight fashions on the Human Intervention Prediction process. Throughout all fashions, important takeaways are:
Proprietary Fashions stay overly conservative: We consider three households of closed-source LMs (Claude 4 Sonnet, GPT-4o, and Gemini 2.5 Professional) utilizing zero-shot with out reasoning. They battle with the temporal dynamics essential for correct human intervention prediction. Notably, GPT-4o achieves excessive efficiency on non-intervention steps (Non-intervention F1: 0.846), but it surely fails on energetic interventions (Intervention F1: 0.198). The drastic F1 disparity signifies that generalist fashions are overly conservative and battle to stability the dynamic with the necessity for proactive help.
Fantastic-tuned Open-weight Fashions with Specialised Knowledge Beats Scale: In distinction, finetuning open-weight fashions on CowCorpus yields essentially the most vital efficiency positive factors, surpassing proprietary fashions. Our fine-tuned Gemma-27B (SFT) achieves the state-of-the-art PTS (0.303), outperforming Claude 4 Sonnet (0.293), whereas the smaller LLaVA-8B (SFT) achieves a aggressive PTS (0.201), beating GPT-4o (0.147). These outcomes reveal that fine-tuning on high-quality interplay traces successfully bridges the alignment hole, permitting smaller fashions to grasp the nuance of intervention timing the place generalized large fashions fail
Desk: Mannequin efficiency on predicting human intervention. We report F1 scores individually for intervention and non-intervention steps to account for sophistication imbalance. Finetuned fashions outperform the proprietary fashions by a big margin.
From Modeling to Deployment: PlowPilot
We built-in our intervention-aware mannequin right into a stay internet agent, PlowPilot. As a substitute of asking for affirmation at each step, the agent now: 1) Predicts when intervention is probably going; 2) Prompts solely at high-risk moments or the place consumer affirmation is more likely to occur; 3) Proceeds robotically in any other case.
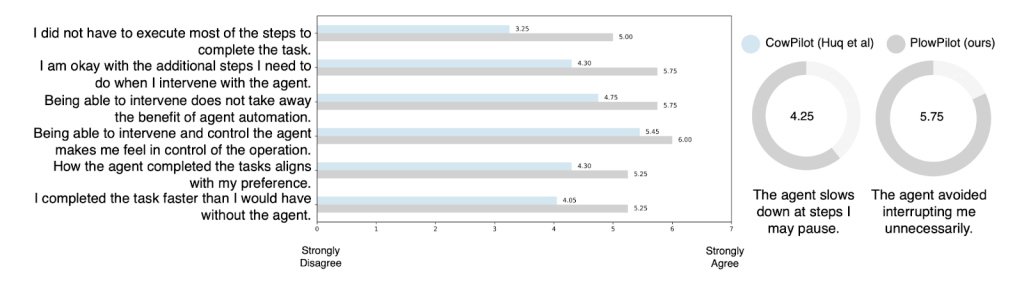
We reinvited our annotators and requested them to fee our new system. On common, we seen a +26.5% enhance in user-rated usefulness. The next determine highlights particular person responses to every of 8 solutions requested to them. Importantly, the underlying execution agent stays unchanged from CowPilot.; PlowPilot differs solely by the addition of the intervention-aware module. The noticed positive factors due to this fact, come up solely from proactively modeling human intervention. These findings present preliminary proof that anticipating consumer intervention can considerably enhance the effectiveness and value of collaborative agent methods in apply.
Determine: Consumer response to the Likert scale questionnaire after the examine. On common, customers report 26.5% increased in consumer ranking in comparison with CowPilot.Media: An instance process of utilizing PlowPilot for scheduling a Google Calendar occasion.
Intervention is a sign of choice and collaboration type. If brokers can mannequin that sign, they grow to be adaptive companions fairly than simply autonomous instruments.
Relatively than maximizing full autonomy, we advocate optimizing the human–agent boundary. Brokers ought to study not solely to behave, however to defer—proactively handing management again when acceptable. This boundary must be adaptive, capturing user-specific interplay and intervention patterns. By studying when to contain the consumer, brokers allow extra environment friendly and customized collaboration. Optimizing this adaptive handoff shifts the aim from autonomy to collaborative intelligence, decreasing oversight whereas preserving management.
It may be tempting for CIOs and CTOs to activate each AI functionality accessible throughout their tech stacks, however that strategy can create vendor sprawl and governance challenges.
On this installment of the IT Leaders Quick-5 — InformationWeek’s column for IT professionals to realize peer insights — Courtney Totten, CTO and CISO at Shutterstock, explains why her workforce took a number of months to guage AI instruments, set up governance fashions and create guardrails earlier than deploying these applied sciences. Her workforce has additionally been deliberate about “coaching the coach” to increase AI data all through the group.
Courtney Totten, CTO and CISO, Shutterstock
Totten oversees Shutterstock’s community, cloud operations, safety, engineering and AI infrastructure, and has been within the IT and cybersecurity industries for greater than 20 years. She has held management roles in each the private and non-private sectors, together with at Common Electrical, Thomson Reuters, Booz Allen and Common Dynamics.
This column has been edited for readability and area.
The Choice That Mattered
What choice — technical or organizational — made the most important distinction lately, and why?
Over the previous yr, we made a acutely aware choice to be proactive with AI and never reactive. It took us six months to guage two of our [AI] instruments, however as soon as we evaluated them and created governance fashions and a framework with guardrails, we have been capable of onboard a complete of eight instruments in 10 months’ time.
It is now about getting these instruments into our workforce members’ arms, and getting to listen to the use instances — not from technologists, however my enterprise customers. We’re seeing what they’re capable of do to drive efficiencies and achieve confidence that these instruments are right here to assist them — with some guardrails. That has been wonderful to look at over the past yr.
A few of them have been instruments that we already had in place, however we hadn’t turned on the AI functionality. For instance, we leveraged Slack, however we hadn’t turned on AI capabilities. We carried out our safety opinions, our evaluations after which we have been capable of flip some issues on.
It sounds foolish, however notes and summaries have been an enormous factor for us — we use Slack on daily basis. That is an ideal instance the place we turned one thing on for our customers to make their lives simpler.
We additionally leveraged ChatGPT to assist our customers. A easy factor was making a Q&A doc. We had a workforce who felt like all day lengthy they have been simply answering questions round our processes. How do you create one thing the place we are able to take a whole lot of pages of processes to easily reply to customers’ requests so [our employees] might serve their clients? That was one other nice instance the place we have been simply capable of get rid of a whole lot of that handbook administrative work and get that off our workforce’s plate.
What did not go as deliberate lately — and what did it pressure you to rethink?
Prices — with cloud and AI rising exponentially, prices can get uncontrolled. We realized this early on and have been capable of catch it at a wholesome level. We created a devoted workforce that features a few of our cloud structure workforce members. That workforce is admittedly accountable for monitoring all of our prices with our cloud suppliers and AI suppliers.
Now I’ve a cloud FinOps and governance workforce to not solely monitor prices however drive optimization. As well as, we created a contest that we have opened as much as [all teams], the place we are saying, “assist us determine alternatives to scale back prices, and we have now prizes.” It is a quarterly problem, and it is helped everybody notice that these items are turning into prices. How can we lower prices to make room for a few of these different cool issues that we wish to do? It has created a way of economic self-discipline for my engineering workforce, and all of my groups.
The Expertise Commerce-Off
The place are you investing in expertise proper now — and what are you consciously not investing in?
It isn’t that we’re not investing in areas. If there’s a chance to assist our workforce do extra to amplify what we’re doing, that is the place I am investing. I say on a regular basis that resourcefulness is such an essential ability.
We have to guarantee that folks have depth and that they are often resourceful and capable of get issues finished. How do I put money into coaching my workers up? How do I give them a stronger sense of the totally different instruments they’ve accessible to them and what they’ll leverage? We’re actually huge on coaching targets each single yr, so we leverage our companions totally free coaching.
We now have some robust cloud partnerships the place we get provided a whole lot of trainings by means of our agreements with them — AWS and Google are large companions with us, and OpenAI. They’ve all helped by means of all the journey from cloud to AI.
Additionally, ensuring that we’re deepening our AI expertise throughout each single place. AI in a pair years, possibly in a yr, goes to be in each single workforce that we have now, and that is actually thrilling. I actually really feel prefer it’s a ability set all of us must have and to observe. Ensuring that we have now the correct expertise to drive outcomes is crucial for me.
The Exterior Sign
What latest exterior improvement is probably to alter how your group operates, even not directly?
Modifications are occurring on daily basis — the [AI] fashions are altering on daily basis, and each time we see a brand new mannequin, it is higher than the final one. Getting ready my workforce to be prepared to guage and onboard new fashions is essential for us.
For instance, OpenAI’s launch of Codex lately — that was an ideal use case. My workforce’s been capable of get their arms on it, and the issues are capable of produce — they’re all shocking themselves, which is admittedly neat.
We have created a mentorship program to “prepare the coach.” I’ve a couple of folks on my workforce who have been actually specialists on this area, and so they took on a workforce of eight to coach up, develop requirements and guardrails. Now these eight persons are coaching two to a few folks every. It’ll exit to all people to have the identical kind of coaching experiences. Each single day, you are listening to about new instruments which might be coming about.
Quite a lot of our distributors are additionally determining how one can keep related and incorporate AI. Do we’d like all of those different instruments? It is actually essential to all the time be monitoring your vendor panorama to see if we’re beginning to develop too many instruments that each one do the identical factor. You don’t need vendor sprawl.
The Perspective Shift
What have you ever learn, watched or listened to lately that modified how you concentrate on management or know-how — even barely?
There was lately an article on Martin Fowler’s website known as “People and Brokers in Software program Engineering Loops.” This text talks about how engineers can get entangled and be a part of this variation we’re experiencing. He highlights three totally different ways in which engineers can place themselves in all the engineering loop.
The primary approach is step exterior the loop — let the agentic brokers do what they should do — to code and hope and pray it really works out properly. The second factor is to be within the loop — taking a look at each single handbook piece of code and virtually micromanaging it, which goes to be draining.
The third is specializing in all the engineering loop itself and specializing in the output. It is ensuring you know the way the agent works, ensuring it is doing what it must do, after which monitoring to ensure the output is going on. As a result of on the finish of the day, the output is what we care about.
It is about going again to requirements, processes and guardrails — so long as you could have these three issues in place, you’ll be able to concentrate on the output versus being too concerned or being too arms off. That article actually resonated with me as a result of it is my duty as a frontrunner to assist everybody concentrate on how they are often concerned. I wish to give all people the chance to provide the most effective outputs with the instruments that we have now.
Within the trendy enterprise period, essentially the most precious foreign money isn’t simply capital—it’s info. As we navigate by means of 2026, firms are discovering that the sheer quantity of knowledge being generated each day is overwhelming. From inside coaching manuals to buyer assist FAQs and technical documentation, holding every little thing organized is now not a luxurious; it’s a survival requirement.
The largest problem right this moment is “Info Silos.” This occurs when essential knowledge is trapped within the heads of particular person staff or buried in countless electronic mail threads. To fight this, good organizations are transferring towards specialised techniques that act as a single supply of reality for everybody concerned.
Why Static Documentation is Fading Away
Gone are the times when an organization may depend on a bunch of PDF recordsdata saved on a shared drive. These paperwork develop into outdated the second they’re saved. In a fast-paced market, info must be “residing.” It must be searchable, editable, and accessible from anyplace on this planet.
This shift has led to an enormous spike within the adoption of information base software program. In contrast to old-school folders, these platforms enable groups to categorize info intuitively. Think about a brand new rent becoming a member of your crew; as a substitute of spending weeks shadowing a senior member, they’ll merely log right into a portal and discover each reply they want in seconds. This autonomy not solely boosts morale but additionally considerably reduces the coaching overhead for the HR division.
The Scalability Issue: Shifting Past Small Groups
What works for a startup with 5 folks not often works for a company with 5 hundred. As a enterprise grows, the complexity of its inside communication grows exponentially. You begin coping with totally different departments, a number of time zones, and ranging ranges of safety clearance.
For bigger organizations, the necessities are far more stringent. They want techniques that may deal with excessive visitors, combine with current enterprise instruments (like Slack or Microsoft Groups), and supply sturdy analytics. That is the placeEnterprise information base software program turns into indispensable. It offers the heavy-duty infrastructure wanted to assist hundreds of customers whereas making certain that delicate knowledge is barely seen to these with the precise permissions.
Enhancing Buyer Expertise By means of Self-Service
It’s not nearly inside groups. Clients in 2026 have zero persistence for lengthy wait instances on cellphone calls or sluggish electronic mail replies. They need solutions instantly. Analysis exhibits {that a} majority of customers desire discovering the reply themselves quite than speaking to a assist agent.
By implementing a public-facing information base software program, a model can deflect as much as 40% of its assist tickets. When a buyer has a query a few product function or a billing situation, they’ll discover a step-by-step information or a video tutorial on the corporate’s web site. This “self-service” mannequin creates a win-win scenario: the client will get on the spot gratification, and the assist crew can concentrate on fixing extra advanced, high-priority issues.
Information Safety and Compliance within the Digital Age
In 2026, knowledge breaches are a relentless menace, and authorities rules relating to knowledge privateness have develop into extremely strict. Utilizing a generic cloud-sharing device to retailer firm secrets and techniques is a recipe for catastrophe.
FashionableEnterprise information base software program is constructed with “Safety by Design.” It consists of options like end-to-end encryption, multi-factor authentication, and detailed audit logs that present precisely who accessed what info and when. For industries like finance, healthcare, or regulation, having this degree of compliance is obligatory. It ensures that whereas info is simple to search out for workers, it stays utterly shielded from exterior threats.
AI Integration: The New Frontier of Search
Probably the most important improve we’ve seen not too long ago is the combination of “Semantic Search” inside these platforms. Previously, in the event you didn’t sort the precise key phrase, you wouldn’t discover the doc. At present, the software program understands the intent behind the query.
If an worker varieties “How do I repair the login bug?”, the system doesn’t simply search for these particular phrases; it understands the context and pulls up the related troubleshooting guides. This intelligence makes information base software program really feel much less like a library and extra like a digital assistant that truly is aware of what you might be searching for.
Collaborative Tradition and Information Retention
One of many greatest dangers for any enterprise is “Mind Drain”—the lack of information when a key worker leaves the corporate. If that individual hasn’t documented their processes, they take years of expertise with them.
A centralized system encourages a tradition of documentation. When each professional contributes to the Enterprise information base software program, the corporate’s collective intelligence grows. It turns into a everlasting asset of the enterprise, making certain that whilst employees adjustments, the standard of labor stays constant. It turns particular person experience right into a shared company power.
Selecting the Proper Match for Your Enterprise
With so many choices in the marketplace, the choice course of will be complicated. Nonetheless, the choice often comes down to a few essential pillars: Ease of Use, Integration Capabilities, and Value-Effectiveness.
A device is barely helpful if folks truly use it. If the interface is simply too sophisticated, staff will revert to their previous methods of asking questions over Slack or electronic mail. Subsequently, the very best information base software program is the one which feels as pure to make use of as a easy Google search.
Conclusion: The Path to a Smarter Group
We live in an age the place pace and accuracy outline market leaders. Organizations that proceed to wrestle with disorganized knowledge will inevitably fall behind their extra streamlined opponents. By investing in the precise digital infrastructure—particularly high-quality information base software program—you aren’t simply shopping for a device; you might be investing in your crew’s productiveness.
The transition to a centralized info hub may require an preliminary funding of time and sources, however the long-term ROI is plain. From sooner onboarding to raised buyer satisfaction and tighter safety, the advantages of Enterprise information base software program are clear. In 2026, being “knowledgeable” isn’t sufficient; it’s a must to be “organized.”
Dutch health large Primary-Match introduced that hackers breached its techniques and gained entry to data belonging to one million of its prospects.
The corporate operates the most important fitness center chain in Europe, proudly owning greater than 1,700 golf equipment and over 430 franchises in 12 nations, together with the Netherlands, Belgium, France, Spain, and Germany.
In a disclosure printed on its web site earlier right now, Primary-Match states that membership members impacted by the cyberattack have been knowledgeable instantly.
“In the present day, Primary-Match has notified the related information safety authority regarding unauthorized entry to the system that data members’ visits to Primary-Match golf equipment,” reads the notification.
“The unauthorized entry was detected by our system monitoring processes and was stopped inside minutes of discovery.”
Regardless of the claimed fast response, an investigation performed with the assistance of exterior safety specialists discovered that the attacker exfiltrated information belonging to some Primary-Match members, which incorporates the next:
Full identify
Bodily handle
E-mail handle
Telephone quantity
Date of start
Checking account particulars
Different membership data
You will need to observe that buyer information at Primary-Match franchises has not been uncovered within the incident, as it’s saved on a separate system.
Within the public disclosure, the corporate specified that the variety of affected people within the Netherlands is 200,000. Nevertheless, a spokesperson advised BleepingComputer that the entire quantity is round 1 million members within the Netherlands, Belgium, Luxembourg, France, Spain, and Germany.
The Primary-Match consultant famous that the gyms throughout Europe have round 5 million members.
In line with the official disclosure, no identification paperwork or account passwords have been accessed because of the info breach.
Primarily based on information retention legal guidelines within the European Union, Primary-Match is required to delete all private information and membership robotically after two years.
Prospects can entry information of their My Primary-Match app one yr after termination. Data within the app must be eliminated robotically two months after uninstalling it from the gadget, and upon membership termination.
Primary-Match says that its investigation of the incident’s impression didn’t reveal that the info was leaked on-line. However, the corporate will proceed to observe with the assistance of exterior specialists.
Automated pentesting proves the trail exists. BAS proves whether or not your controls cease it. Most groups run one with out the opposite.
This whitepaper maps six validation surfaces, exhibits the place protection ends, and offers practitioners with three diagnostic questions for any instrument analysis.
Itemizing shopper electronics on the web’s massive ecommerce marketplaces is a key step in “democratizing” the merchandise, permitting them to be bought by anybody with only a click on. It has occurred to automobiles (in america, you should buy a Hyundai on Amazon), and now it is taking place to humanoid robots.
The Chinese language producer Unitree Robotics, among the many most lively robot-makers within the subject, is getting ready to carry its most inexpensive mannequin, the Unitree R1, to worldwide markets by way of Alibaba Group’s market. In accordance with stories in The South China Morning Publish, the rollout will initially cowl North America, Japan, Singapore, and Europe. There is not any precise on-sale date for the robots but, however the Publish report says it would present up as quickly as this week.
This isn’t the primary time Unitree has used AliExpress as a worldwide storefront. The corporate’s G1 mannequin, the extra highly effective and costlier predecessor to the R1, is already listed at slightly below $19,000.
The G1 is already on sale on AliExpress.
It is as a lot of a symbolic step earlier than as a business one; promoting a humanoid robotic on a worldwide market positions the product as simply attainable. This serves as a step towards normalization of the tech, which continues to be not extensively adopted. The sale of the R1 merely lowers the brink of entry even additional, and shifts humanoid robots from the territory of promise to that of concrete availability.
Decrease Worth, Increased Demand
When it was introduced final summer time, the beginning value of the R1 was 39,900 yuan, or about $5,900. As we speak, the fundamental model begins at 29,900 yuan, or about $4,370.
That value will fluctuate given adjustments in trade charges and delivery prices that add on import taxes and tariffs. Nonetheless, that determine sounds surprisingly low contemplating that a number of the R1’s different rivals within the humanoid robotics panorama are far costlier.
The worth tag for Unitree’s personal flagship H1 robotic approaches $90,000. Tesla’s Optimus robotic, which isn’t but on sale to the general public, is aiming for a beginning value beneath $20,000, however that value will solely be attainable when Tesla reaches manufacturing of 1 million models a 12 months. In the meantime, robots from Determine AI and Apptronik are hovering round $50,000 per unit. The R1’s objectively low value primarily makes it a hatchback in a world of sedans.
The R1 is 4 toes tall, weighs 50 kilos, and has 26 sensible joints. You may speak to it and provides it instructions; Unitree’s large-language multimodal mannequin with voice and picture recognition is on board. Curious coders can program it utilizing a software program developer’s equipment. However the true calling card is the R1’s bodily efficiency. The robotic can do cartwheels, lie down and rise up independently, and run downhill. Unitree calls it “born for sport,” and movies of its presentation made the rounds months in the past. Handstands and wheel kicks are usually not precisely what you’d count on from a robotic that prices lower than a used automotive.
Put It to Work
As spectacular because the Unitree R1’s strikes are, it lacks arms with articulated fingers, and its motors cannot generate a number of torque. It isn’t designed to be a home helper or to control advanced objects. The corporate presents it as an “clever companion” for interplay, analysis, and software program improvement.
The EDU mannequin (Go2 EDU, G1 EDU) add an Nvidia Jetson Orin module with extra computing energy for synthetic intelligence duties. That mannequin additionally has two levels of freedom for the pinnacle and non-obligatory proper arms. In that robotic’s case, the goal market is laboratories and universities. The restrictions of the fundamental R1 put it largely in the identical camp. This isn’t a family robotic that makes espresso and walks the canine, however it’s a sensible choice for researchers, labs, and anybody who desires to check robotics algorithms on strong {hardware} with out spending a fortune.
It’s true that bringing a comparatively succesful humanoid to world markets at this value does decrease the barrier to entry for builders, researchers, and lovers. It’s a actual leap from a couple of years in the past, even when some folks will purchase it simply to maintain it in the lounge to take a bow when visitors arrive.
This story was initially revealed by WIRED Italia and translated from Italian.
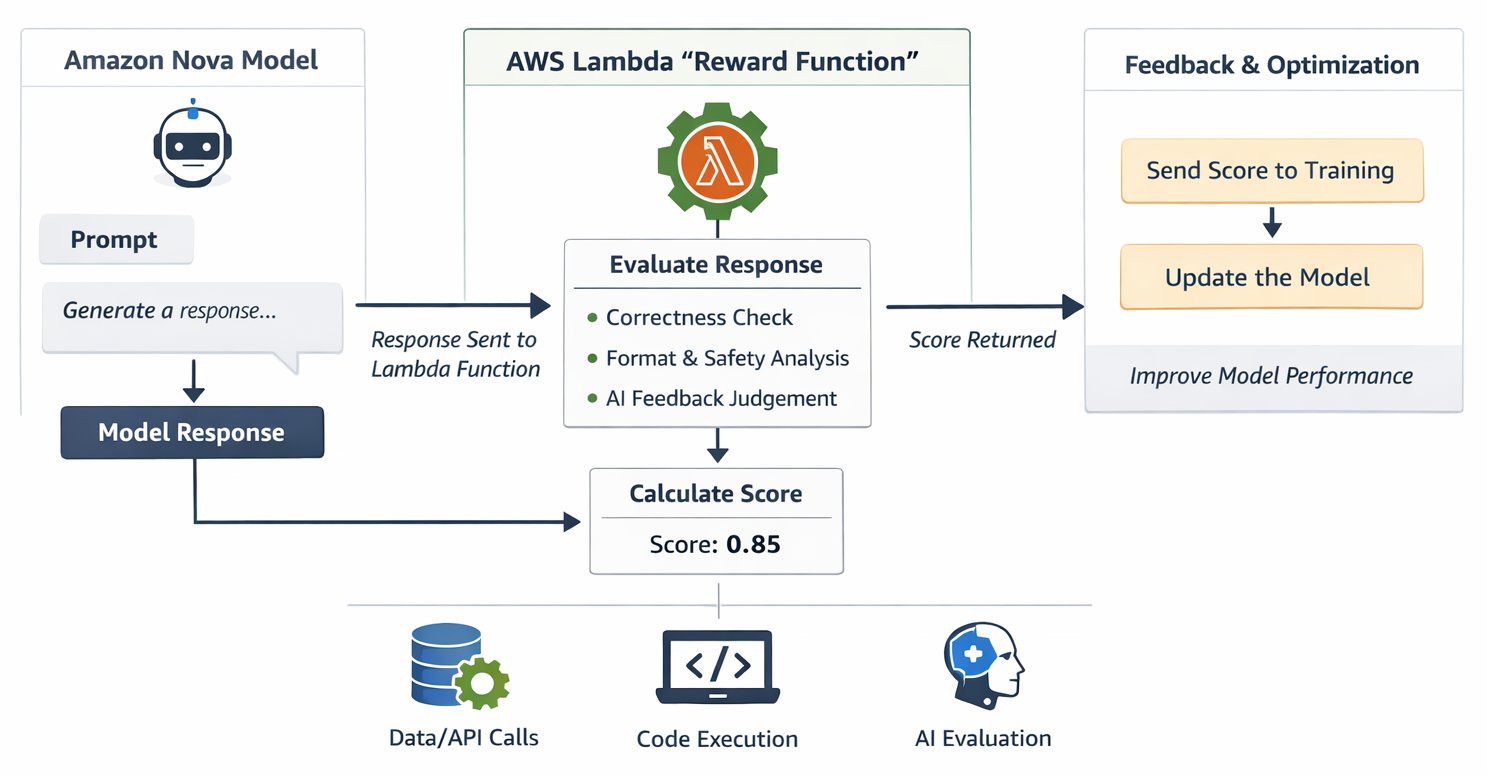
Constructing efficient reward features may help you customise Amazon Nova fashions to your particular wants, with AWS Lambda offering the scalable, cost-effective basis. Lambda’s serverless structure helps you to concentrate on defining high quality standards whereas it handles the computational infrastructure.
Amazon Nova gives a number of customization approaches, with Reinforcement fine-tuning (RFT) standing out for its skill to show fashions desired behaviors by iterative suggestions. Not like Supervised fine-tuning (SFT) that requires hundreds of labeled examples with annotated reasoning paths, RFT learns from analysis indicators on remaining outputs. On the coronary heart of RFT lies the reward perform—a scoring mechanism that guides the mannequin towards higher responses.
This submit demonstrates how Lambda allows scalable, cost-effective reward features for Amazon Nova customization. You’ll be taught to decide on between Reinforcement Studying through Verifiable Rewards (RLVR) for objectively verifiable duties and Reinforcement Studying through AI Suggestions (RLAIF) for subjective analysis, design multi-dimensional reward programs that enable you to forestall reward hacking, optimize Lambda features for coaching scale, and monitor reward distributions with Amazon CloudWatch. Working code examples and deployment steering are included that can assist you begin experimenting.
You have got a number of pathways to customise basis fashions, every suited to totally different eventualities. SFT excels when you could have clear input-output examples and wish to train particular response patterns—it’s notably efficient for duties like classification, named entity recognition, or adapting fashions to domain-specific terminology and formatting conventions. SFT works nicely when the specified habits will be demonstrated by examples, making it perfect for instructing constant fashion, construction, or factual information switch.Nonetheless, some customization challenges require a distinct method. When purposes want fashions to stability a number of high quality dimensions concurrently—like customer support responses that have to be correct, empathetic, concise, and brand-aligned concurrently —or when creating hundreds of annotated reasoning paths proves impractical, reinforcement-based strategies provide a greater different. RFT addresses these eventualities by studying from analysis indicators fairly than requiring exhaustive labeled demonstrations of right reasoning processes.
AWS Lambda-based reward features simplifies this by feedback-based studying. As a substitute of displaying the mannequin hundreds of efficient examples, you present prompts and outline analysis logic that scores responses—then the mannequin learns to enhance by iterative suggestions. This method requires fewer labelled examples whereas providing you with exact management over desired behaviors. Multi-dimensional scoring captures nuanced high quality standards that forestall fashions from exploiting shortcuts, whereas Lambda’s serverless structure handles variable coaching workloads with out infrastructure administration. The result’s Nova customization that’s accessible to builders with out deep machine studying experience, but versatile sufficient for stylish manufacturing use circumstances.
How AWS Lambda primarily based rewards work
The RFT structure makes use of AWS Lambda as a serverless reward evaluator that integrates with Amazon Nova coaching pipeline, creating an suggestions loop that guides mannequin studying. The method begins when your coaching job generates candidate responses from the Nova mannequin for every coaching immediate. These responses circulation to your Lambda perform, which evaluates their high quality throughout dimensions like correctness, security, formatting, and conciseness. The perform then returns scalar numerical scores—sometimes within the -1 to 1 vary as a greatest follow. Increased scores information the mannequin to strengthen the behaviors that produced them, whereas decrease scores information it away from patterns that led to poor responses. This cycle repeats hundreds of instances all through coaching, progressively shaping the mannequin towards responses that persistently earn larger rewards.
The structure brings collectively a number of AWS companies in a cohesive customization answer. Lambda executes your reward analysis logic with computerized scaling that handles variable coaching calls for with out requiring you to provision or handle infrastructure. Amazon Bedrock gives the totally managed RFT expertise with built-in Lambda assist, providing AI decide fashions for RLAIF implementations by a easy Utility Programming Interface (API). For groups needing superior coaching management, Amazon SageMaker AI gives choices by Amazon SageMaker AI Coaching Jobs and Amazon SageMaker AI HyperPod, each supporting the identical Lambda-based reward features. Amazon CloudWatch screens Lambda efficiency in real-time, logs detailed debugging details about reward distributions and coaching progress, and triggers alerts when points come up. On the basis sits Amazon Nova itself—fashions with customization recipes optimized throughout all kinds of use circumstances that reply successfully to the suggestions indicators your reward features present
This serverless method makes Nova customization cost-effective. Lambda routinely scales from dealing with 10 concurrent evaluations per second throughout preliminary experimentation to 400+ evaluations throughout manufacturing coaching, with out infrastructure tuning or capability planning. Your single Lambda perform can assess a number of high quality standards concurrently, offering the nuanced, multi-dimensional suggestions that stops fashions from exploiting simplistic scoring shortcuts. The structure helps each goal verification by RLVR—working code towards check circumstances or validating structured outputs—and subjective judgment by RLAIF, the place AI fashions consider qualities like tone and helpfulness. You pay just for precise compute time throughout analysis with millisecond billing granularity, making experimentation reasonably priced whereas protecting manufacturing prices proportional to coaching depth. Maybe most beneficial for iterative growth, Lambda features save as reusable “Evaluator” property in Amazon SageMaker AI Studio, enabling you to take care of constant high quality measurement as you refine your customization technique throughout a number of coaching runs.
Choosing the proper rewards mechanism
The inspiration of profitable RFT is selecting the best suggestions mechanism. Two complementary approaches serve totally different use circumstances: RLVR and RLAIF are two methods used to fine-tune giant language fashions (LLMs) after their preliminary coaching. Their main distinction lies in how they supply suggestions to the mannequin.
RLVR (Reinforcement Studying through Verifiable Rewards)
RLVR makes use of deterministic code to confirm goal correctness. RLVR is designed for domains the place a “right” reply will be mathematically or logically verified, for instance, fixing a math downside. RLVR makes use of deterministic features to grade outputs as an alternative of a discovered reward mannequin. RLVR fails for duties like inventive writing or model voice the place no absolute floor reality exists.
RLVR features programmatically confirm correctness towards floor reality. Right here on this instance doing sentiment evaluation.
from typing import Record
import json
import random
from dataclasses import asdict, dataclass
import re
from typing import Non-obligatory
def extract_answer_nova(solution_str: str) -> Non-obligatory[str]:
"""Extract sentiment polarity from Nova-formatted response for chABSA."""
# First attempt to extract from answer block
solution_match = re.search(r'<|begin_of_solution|>(.*?)<|end_of_solution|>', solution_str, re.DOTALL)
if solution_match:
solution_content = solution_match.group(1)
# Search for boxed format in answer block
boxed_matches = re.findall(r'boxed{([^}]+)}', solution_content)
if boxed_matches:
return boxed_matches[-1].strip()
# Fallback: search for boxed format anyplace
boxed_matches = re.findall(r'boxed{([^}]+)}', solution_str)
if boxed_matches:
return boxed_matches[-1].strip()
# Final resort: search for sentiment key phrases
solution_lower = solution_str.decrease()
for sentiment in ['positive', 'negative', 'neutral']:
if sentiment in solution_lower:
return sentiment
return None
def normalize_answer(reply: str) -> str:
"""Normalize reply for comparability."""
return reply.strip().decrease()
def compute_score(
solution_str: str,
ground_truth: str,
format_score: float = 0.0,
rating: float = 1.0,
data_source: str="chabsa",
extra_info: Non-obligatory[dict] = None
) -> float:
"""chABSA scoring perform with VeRL-compatible signature."""
reply = extract_answer_nova(solution_str)
if reply is None:
return 0.0
# Parse ground_truth JSON to get the reply
gt_answer = ground_truth.get("reply", ground_truth)
clean_answer = normalize_answer(reply)
clean_ground_truth = normalize_answer(gt_answer)
return rating if clean_answer == clean_ground_truth else format_score
@dataclass
class RewardOutput:
"""Reward service."""
id: str
aggregate_reward_score: float
def lambda_handler(occasion, context):
scores: Record[RewardOutput] = []
samples = occasion
for pattern in samples:
# Extract the bottom reality key. Within the present dataset it is reply
print("Pattern: ", json.dumps(pattern, indent=2))
ground_truth = pattern["reference_answer"]
idx = "no id"
# print(pattern)
if not "id" in pattern:
print(f"ID is None/empty for pattern: {pattern}")
else:
idx = pattern["id"]
ro = RewardOutput(id=idx, aggregate_reward_score=0.0)
if not "messages" in pattern:
print(f"Messages is None/empty for id: {idx}")
scores.append(RewardOutput(id="0", aggregate_reward_score=0.0))
proceed
# Extract reply from floor reality dict
if ground_truth is None:
print(f"No reply present in floor reality for id: {idx}")
scores.append(RewardOutput(id="0", aggregate_reward_score=0.0))
proceed
# Get completion from final message (assistant message)
last_message = pattern["messages"][-1]
completion_text = last_message["content"]
if last_message["role"] not in ["assistant", "nova_assistant"]:
print(f"Final message will not be from assistant for id: {idx}")
scores.append(RewardOutput(id="0", aggregate_reward_score=0.0))
proceed
if not "content material" in last_message:
print(f"Completion textual content is empty for id: {idx}")
scores.append(RewardOutput(id="0", aggregate_reward_score=0.0))
proceed
random_score = compute_score(solution_str=completion_text, ground_truth=ground_truth)
ro = RewardOutput(id=idx, aggregate_reward_score=random_score)
print(f"Response for id: {idx} is {ro}")
scores.append(ro)
return [asdict(score) for score in scores]
Your RLVR perform ought to incorporate three vital design components for efficient coaching. First, create a clean reward panorama by awarding partial credit score—for instance, offering format_score factors for correct response construction even when the ultimate reply is wrong. This prevents binary scoring cliffs that make studying troublesome. Second, implement good extraction logic with a number of parsing methods that deal with varied response codecs gracefully. Third, validate inputs at each step utilizing defensive coding practices that forestall crashes from malformed inputs
RLAIF (Reinforcement Studying through AI Suggestions)
RLAIF makes use of AI fashions as judges for subjective analysis. RLAIF achieves efficiency corresponding to RLHF(Reinforcement Studying through Human Suggestions) whereas being considerably sooner and less expensive. Right here is an instance RLVR lambda perform code for sentiment classification.
Greatest for: Artistic writing, summarization, model voice alignment, helpfulness
Instance: Evaluating response tone, assessing content material high quality, judging consumer intent alignment
Benefit: Scalable human-like judgment with out handbook labeling prices
RLAIF features delegate judgment to succesful AI fashions as proven on this pattern code under
import json
import re
import time
import boto3
from typing import Record, Dict, Any, Non-obligatory
bedrock_runtime = boto3.shopper('bedrock-runtime', region_name="us-east-1")
JUDGE_MODEL_ID = "" #Change with decide mannequin id of your curiosity
SYSTEM_PROMPT = "You could output ONLY a quantity between 0.0 and 1.0. No explanations, no textual content, simply the quantity."
JUDGE_PROMPT_TEMPLATE = """Evaluate the next two responses and charge how comparable they're on a scale of 0.0 to 1.0, the place:
- 1.0 means the responses are semantically equal (identical which means, even when worded in another way)
- 0.5 means the responses are partially comparable
- 0.0 means the responses are utterly totally different or contradictory
Response A: {response_a}
Response B: {response_b}
Output ONLY a quantity between 0.0 and 1.0. No explanations."""
def extract_solution_nova(solution_str: str, methodology: str = "strict") -> Non-obligatory[str]:
"""Extract answer from Nova-formatted response."""
assert methodology in ["strict", "flexible"]
if methodology == "strict":
boxed_matches = re.findall(r'boxed{([^}]+)}', solution_str)
if boxed_matches:
final_answer = boxed_matches[-1].exchange(",", "").exchange("$", "")
return final_answer
return None
elif methodology == "versatile":
boxed_matches = re.findall(r'boxed{([^}]+)}', solution_str)
if boxed_matches:
numbers = re.findall(r"(-?[0-9.,]+)", boxed_matches[-1])
if numbers:
return numbers[-1].exchange(",", "").exchange("$", "")
reply = re.findall(r"(-?[0-9.,]+)", solution_str)
if len(reply) == 0:
return None
else:
invalid_str = ["", "."]
for final_answer in reversed(reply):
if final_answer not in invalid_str:
break
return final_answer
def lambda_graded(id: str, response_a: str, response_b: str, max_retries: int = 50) -> float:
"""Name Bedrock to check responses and return similarity rating."""
immediate = JUDGE_PROMPT_TEMPLATE.format(response_a=response_a, response_b=response_b)
for try in vary(max_retries):
strive:
response = bedrock_runtime.converse(
modelId=JUDGE_MODEL_ID,
messages=[{"role": "user", "content": [{"text": prompt}]}],
system=[{"text": SYSTEM_PROMPT}],
inferenceConfig={"temperature": 0.0, "maxTokens": 10}
)
output = response['output']['message']['content'][0]['text'].strip()
rating = float(output)
return max(0.0, min(1.0, rating))
besides Exception as e:
if "ThrottlingException" in str(e) and try < max_retries - 1:
time.sleep(2 ** try)
else:
return 0.0
return 0.0
def compute_score(id: str, solution_str: str, ground_truth: str) -> float:
"""Compute rating for practice.jsonl format."""
reply = extract_solution_nova(solution_str=solution_str, methodology="versatile")
if reply is None:
return 0.0
clean_answer = str(reply)
clean_ground_truth = str(ground_truth)
rating = lambda_graded(id, response_a=clean_answer, response_b=clean_ground_truth)
return rating
def lambda_grader(samples: Record[Dict[str, Any]]) -> Record[Dict[str, Any]]:
"""
Course of samples from practice.jsonl format and return scores.
Args:
samples: Record of dictionaries with messages and metadata
Returns:
Record of dictionaries with reward scores
"""
outcomes = []
for pattern in samples:
sample_id = pattern.get("id", "unknown")
# Extract reference reply from metadata or high stage
metadata = pattern.get("metadata", {})
reference_answer = metadata.get("reference_answer", pattern.get("reference_answer", {}))
if isinstance(reference_answer, dict):
ground_truth = reference_answer.get("reply", "")
else:
ground_truth = str(reference_answer)
# Get assistant response from messages
messages = pattern.get("messages", [])
assistant_response = ""
for message in reversed(messages):
if message.get("function") in ["assistant", "nova_assistant"]:
assistant_response = message.get("content material", "")
break
if not assistant_response or not ground_truth:
outcomes.append({
"id": sample_id,
"aggregate_reward_score": 0.0
})
proceed
# Compute rating
rating = compute_score(
id=sample_id,
solution_str=assistant_response,
ground_truth=ground_truth
)
outcomes.append({
"id": sample_id,
"aggregate_reward_score": rating,
"metrics_list": [
{
"name": "semantic_similarity",
"value": score,
"type": "Reward"
}
]
})
return outcomes
def lambda_handler(occasion, context):
return lambda_grader(occasion)
Whereas implementing RLAIF perform think about shopper initialization with international variables to scale back total invocations latency. Deal with throttling exceptions gracefully to keep away from coaching interruptions. Use temperature 0.0 for deterministic decide scores, it helps with mannequin consistency. And supply clear rubric, it helps decide present calibrated scores
Issues for writing good reward features
To put in writing good reward features for RFT, begin easy, create a clean reward panorama (notbinary cliffs), guarantee rewards align with the true objective (keep away from hacking), use dense/shapedrewards for advanced duties, present clear indicators, and make them verifiable and constant.
Outline Aim Clearly: Know precisely what success seems to be like in your mannequin.
Easy Reward Panorama: As a substitute of straightforward move/fail (0 or 1), use clean, dense
reward indicators that present partial credit score for being “heading in the right direction”. This granularfeedback helps the mannequin be taught from incremental enhancements fairly than ready fora excellent response. For advanced, multi-step duties, present rewards for intermediateprogress (shaping) fairly than simply the ultimate consequence (sparse).
Making Rewards Multi-Dimensional: A single scalar reward is just too simply hacked. The
reward ought to consider mannequin efficiency from a number of dimensions: e.g. correctness,faithfulness to enter, security/coverage alignment, formatting, and conciseness, and many others.
Reward Hacking Prevention: Make sure the mannequin can’t get excessive rewards by shortcuts
(e.g., fortunate guesses, repetitive actions); make the duty guess-proof.
Use Verifiable Rubrics: For goal duties like code technology or math, use automated
graders that execute the code or parse particular reply tags (e.g., ) to verifycorrectness with no human within the loop.
Implement LLM Judges for Subjective Duties: When programmatic code can not decide
the reply (e.g., summarization), use a separate, succesful mannequin as an “LLM Decide”. Youmust consider this decide first to make sure its grades are secure and aligned with humanpreferences.
Optimizing your reward perform execution inside the coaching loop
As soon as your reward perform works accurately, optimization helps you practice sooner whereas controlling prices. This part covers methods to think about in your workloads. Optimization methods compound of their influence—a well-configured Lambda perform with acceptable batch sizing, concurrency settings, chilly begin mitigation, and error dealing with can consider responses ten instances sooner than a naive implementation whereas costing considerably much less and offering higher coaching reliability. The funding in optimization early within the customization course of pays dividends all through coaching by lowering iteration time, reducing compute prices, and catching points earlier than they require costly retraining.
Guarantee IAM permissions are accurately configured earlier than you begin coaching
Dependency Administration and Permissions
The best way to add dependencies: you possibly can both bundle them immediately along with your code in a deployment package deal (.zip file) or use Lambda layers to handle dependencies individually out of your core logic.
Making a .zip deployment package deal (see directions right here)
Utilizing Lambda layers (see directions right here)
Amazon Bedrock entry for RLAIF: the execution function for the Lambda perform ought to have entry to Amazon Bedrock for LLM API name.
Use layers for dependencies shared throughout a number of features. Use deployment packages for function-specific logic.Connect AWS Id and Entry Administration (IAM) permissions to Lambda execution function for RLAIF implementations. Following the precept of least privilege, scope the Useful resource ARN to the particular basis mannequin you’re utilizing as a decide fairly than utilizing a wildcard
Understanding platform variations and which platform is likely to be extra appropriate in your wants
Optimizing Lambda-based reward features requires understanding how totally different coaching environments work together with serverless analysis and the way architectural selections influence throughput, latency, and value. The optimization panorama differs considerably between synchronous and asynchronous processing fashions, making environment-specific tuning important for production-scale customization.
Amazon SageMaker AI Coaching Jobs make use of synchronous processing that generates rollouts first earlier than evaluating them in parallel batches. This structure creates distinct optimization alternatives round batch sizing and concurrency administration. The lambda_batch_size parameter, defaulting to 64, determines what number of samples Lambda evaluates in a single invocation—tune this larger for quick reward features that full in milliseconds, however decrease it for advanced evaluations approaching timeout thresholds. The lambda_concurrency parameter controls parallel execution, with the default of 12 concurrent invocations typically proving conservative for manufacturing workloads. Quick reward features profit from considerably larger concurrency, generally reaching 50 or extra simultaneous executions, although you could monitor account-level Lambda concurrency limits that cap whole concurrent executions throughout your features in a area.
Amazon SageMaker AI HyperPod takes a basically totally different method by asynchronous processing that generates and evaluates samples individually fairly than in giant batches. This sample-by-sample structure naturally helps larger throughput, with default configurations dealing with 400 transactions per second by Lambda with out particular tuning. Scaling past this baseline requires coordinated adjustment of HyperPod recipe parameters—particularly proc_num and rollout_worker_replicas that management employee parallelism. When scaling staff aggressively, think about growing generation_replicas proportionally to stop technology from turning into the bottleneck whereas analysis capability sits idle.
Optimization of reward perform utilizing concurrency of Lambda
Lambda configuration immediately impacts coaching pace and reliability:
Timeout Configuration: Set timeout to 60 seconds (default is just 3 seconds), this gives headroom for RLAIF decide calls or advanced RLVR logic
Reminiscence Allocation: Set reminiscence to 512 MB (default is 128 MB), accelerated CPU improves response time efficiency
Chilly begin mitigation
Chilly begin mitigation prevents latency spikes that may sluggish coaching and improve prices. Maintain deployment packages beneath 50MB to reduce initialization time—this typically means excluding pointless dependencies and utilizing Lambda layers for big shared libraries. Reuse connections throughout invocations by initializing shoppers just like the Amazon Bedrock runtime shopper in international scope fairly than contained in the handler perform, permitting the Lambda execution surroundings to take care of these connections between invocations. Profile your perform utilizing Lambda Insights to determine efficiency bottlenecks. Cache regularly accessed knowledge equivalent to analysis rubrics, validation guidelines, or configuration parameters in international scope so Lambda masses them as soon as per container fairly than on each invocation. This sample of worldwide initialization with handler-level execution proves notably efficient for Lambda features dealing with hundreds of evaluations throughout coaching.
# Maintain deployment package deal beneath 50MB
# Reuse connections throughout invocations
bedrock_client = boto3.shopper('bedrock-runtime') # World scope
# Cache regularly accessed knowledge
EVALUATION_RUBRICS = {...} # Load as soon as
def lambda_handler(occasion, context):
# Purchasers and cached knowledge persist throughout invocations
return evaluate_responses(occasion, bedrock_client, EVALUATION_RUBRICS)
Optimizing RLAIF decide fashions
For RLAIF implementations utilizing Amazon Bedrock fashions as judges, there’s an essential trade-off to think about. Bigger fashions present extra dependable judgments however have decrease throughput, whereas smaller fashions provide higher throughput however could also be much less succesful—decide the smallest decide mannequin ample in your process to maximise throughput. Profile decide consistency earlier than scaling to full coaching.
Throughput Administration:
Monitor Amazon Bedrock throttling limits at area stage
Think about Amazon SageMaker AI endpoints for decide fashions. It gives larger throughput however presently restricted to open weight and Nova fashions
Batch a number of evaluations per API name when attainable
Account for concurrent coaching jobs sharing Amazon Bedrock quota
Guaranteeing your Lambda reward perform is error tolerant and corrective
Actual-world programs encounter failures—community hiccups, momentary service unavailability, or occasional Lambda timeouts. Somewhat than letting a single failure derail your complete coaching job, we’ve constructed strong retry mechanisms that deal with timeouts, Lambda failures, and transient errors routinely. The system intelligently retries failed reward calculations with exponential backoff, giving momentary points time to resolve. If a name fails even after three retries, you’ll obtain a transparent, actionable error message pinpointing the particular subject—whether or not it’s a timeout, a permissions downside, or a bug in your reward logic. This transparency helps you to rapidly determine and repair issues with out sifting by cryptic logs.
def robust_evaluation(pattern, max_retries=3):
"""Analysis with complete error dealing with."""
for try in vary(max_retries):
strive:
rating = compute_score(pattern)
return rating
besides ValueError as e:
# Parsing errors - return 0 and log
print(f"Parse error for {pattern['id']}: {str(e)}")
return 0.0
besides Exception as e:
# Transient errors - retry with backoff
if try < max_retries - 1:
time.sleep(2 ** try)
else:
print(f"Failed after {max_retries} makes an attempt: {str(e)}")
return 0.0
return 0.0
Iterative CloudWatch debugging and catching any indicators of errors early on
Visibility into your coaching course of is important for each monitoring progress and troubleshooting points. We routinely log complete info to CloudWatch for each stage of the coaching pipeline: every coaching step’s metrics – together with step smart coaching reward scores and detailed execution traces for every pipeline part. This granular logging makes it easy to trace coaching progress in real-time, confirm that your reward perform is scoring responses as anticipated, and rapidly diagnose points once they come up. For instance, in case you discover coaching isn’t bettering, you possibly can study the reward distributions in CloudWatch to see in case your perform is returning principally zeros or if there’s inadequate sign
CloudWatch gives complete visibility into reward perform efficiency. Listed below are few helpful Amazon CloudWatch Insights Queries for the answer
-- Discover samples with zero rewards
SOURCE '/aws/lambda/my-reward-function'
| fields @timestamp, id, aggregate_reward_score
| filter aggregate_reward_score = 0.0
| kind @timestamp desc
-- Calculate reward distribution
SOURCE '/aws/lambda/my-reward-function'
| fields aggregate_reward_score
| stats depend() by bin(aggregate_reward_score, 0.1)
-- Determine sluggish evaluations
SOURCE '/aws/lambda/my-reward-function'
| fields @period, id
| filter @period > 5000
| kind @period desc
-- Observe multi-dimensional metrics
SOURCE '/aws/lambda/my-reward-function'
| fields @timestamp, correctness, format, security, conciseness
| stats avg(correctness) as avg_correctness,
avg(format) as avg_format,
avg(security) as avg_safety,
avg(conciseness) as avg_conciseness
by bin(5m)
Conclusion
Lambda-based reward features unlock Amazon Nova customization for organizations that want exact behavioral management with out huge labeled datasets and improved reasoning. This method delivers important benefits by flexibility, scalability, and cost-effectiveness that streamline your mannequin customization course of.The structure permits RLVR to deal with goal verification duties whereas RLAIF helps with subjective judgment for nuanced high quality assessments. Organizations can use them individually or mix them for complete analysis that captures each factual accuracy and stylistic preferences. Scalability emerges naturally from the serverless basis, routinely dealing with variable coaching workloads from early experimentation by production-scale customization. Value-effectiveness flows immediately from this design—organizations pay just for precise analysis compute, with coaching jobs finishing sooner as a result of optimized Lambda concurrency and environment friendly reward calculation.The mixture of Amazon Nova basis fashions, Lambda serverless scalability, and Amazon Bedrock’s managed customization infrastructure makes reinforcement fine-tuning extra accessible no matter organizational scale. Begin experimenting with the pattern code on this weblog, and start customizing Amazon Nova fashions that ship precisely the behaviors your purposes want.
Acknowledgements
Particular due to Eric Grudzien and Anupam Dewan for his or her assessment and contributions to this submit.
You accredited the enterprise case. The pilot confirmed promise. Then manufacturing modified the mathematics.
Agentic AI doesn’t simply value what you construct. It prices what it takes to run, govern, consider, safe, and scale. Most enterprises don’t mannequin these working prices clearly till they’re already absorbing them.
Bills compound quick. Token utilization grows with each step in a workflow. Instrument calls and API dependencies introduce new consumption patterns. Governance and monitoring add overhead that groups typically deal with as secondary till compliance, reliability, or value points pressure the difficulty.
The end result isn’t at all times a single dramatic spike. Extra typically, it’s regular finances drift pushed by infrastructure inefficiency, opaque consumption, and costly rework.
The repair isn’t a smaller finances. It’s a extra correct image of the place the cash goes and a plan constructed for that actuality from day one.
Key takeaways
The price of agentic AI extends far past preliminary growth, with inference, orchestration, governance, monitoring, and infrastructure inefficiency typically pushing complete prices properly past the unique plan.
Autonomy, multi-step reasoning, and tool-heavy workflows introduce compounding prices throughout infrastructure, knowledge pipelines, safety, and developer time.
Unmanaged GPU utilization, token consumption, and idle capability are among the many largest and least seen value drivers in scaled agentic programs.
Enterprises that lack unified governance, monitoring, and consumption visibility wrestle to maneuver pilots into manufacturing with out costly rework.
The correct platform reduces hidden prices by elastic execution, orchestration, automated governance, and workflow optimization that surfaces inefficiencies earlier than waste accumulates.
Why agentic AI initiatives fail to scale
Most AI pilots don’t fail due to mannequin high quality alone. They fail as a result of the working mannequin was by no means designed for manufacturing.
What works in a managed pilot typically breaks below real-world situations:
Governance gaps create compliance and safety points that delay deployment.
Budgets don’t account for the infrastructure, orchestration, monitoring, and oversight required for manufacturing workloads.
Integration challenges typically floor solely after groups attempt to join brokers to stay programs, enterprise processes, and entry controls.
By the point these points seem, groups are now not tuning a pilot. They’re remodeling structure, controls, and workflows below manufacturing strain. That’s when prices rise quick.
Hidden prices that compromise agentic AI budgets
Conventional AI budgets account for mannequin growth and preliminary infrastructure. Agentic AI adjustments that equation.
Ongoing operational bills can rapidly dwarf your preliminary funding. Retraining alone can eat 29% to 49% of your operational AI finances as brokers encounter new eventualities, knowledge drift, and shifting enterprise necessities. Retraining is just one a part of the associated fee image. Inference, orchestration, monitoring, governance, and power utilization all add recurring overhead as programs transfer from pilot to manufacturing.
Scaling multiplies that strain. As utilization grows, so do the prices of analysis, monitoring, entry management, and compliance. Regulatory adjustments can set off updates to workflows, permissions, and oversight processes throughout agent deployments.
Earlier than you possibly can management prices, it’s worthwhile to know what’s driving them. Improvement hours and infrastructure are solely a part of the image.
Complexity and autonomy ranges
The marketplace for totally autonomous brokers is predicted to develop past $52 billion by 2030. That development comes with a value: elevated infrastructure calls for, rigorous testing necessities, and stronger validation protocols.
Each diploma of freedom you grant an agent multiplies your operational overhead. That subtle reasoning requires redundant verification programs. Dynamic choices require steady monitoring and simply accessible intervention pathways.
Autonomy isn’t free. It’s a premium functionality with premium operational prices hooked up.
Information high quality and integration overhead
Poor knowledge doesn’t simply produce poor outcomes. It produces costly ones. Information high quality points typically result in some mixture of rework, human assessment, exception dealing with, and, in some circumstances, retraining.
API integrations add value by upkeep, model adjustments, authentication overhead, and ongoing reliability work. Every connection introduces one other dependency and one other potential failure level.
Unified knowledge pipelines and standardized integration patterns can scale back that overhead earlier than it compounds.
Token and API consumption prices
This is without doubt one of the fastest-growing and least-visible value drivers in agentic AI. Workflows that make a number of LLM calls per activity, multi-step workflows, tool-calling overhead, and error dealing with create a consumption profile that compounds with scale.
What appears cheap in growth can grow to be a serious working value in manufacturing. A single inefficient immediate sample or poorly scoped workflow can drive pointless spend lengthy earlier than groups notice the place the finances goes.
With out consumption visibility, you’re basically writing clean checks to your AI suppliers.
Safety and compliance
Behavioral monitoring, knowledge residency necessities, and audit path administration usually are not non-compulsory in enterprise deployments. They add crucial overhead, and that overhead carries actual value.
Agent exercise creates compliance obligations round entry, knowledge dealing with, logging, and auditability. With out automated controls, these prices develop with utilization, turning compliance right into a recurring expense hooked up to each scaled deployment.
Developer productiveness tax
Debugging opaque agent behaviors, managing disparate SDKs, and studying agent-specific frameworks all drain developer time. Few organizations account for this upfront.
Your costliest technical expertise needs to be constructing and delivery. Too typically, they’re troubleshooting inconsistencies as an alternative. That tax compounds with each new agent you deploy.
Infrastructure and DevOps inefficiencies
Idle compute is silent finances drain. The commonest culprits:
Guide scaling creates response lag and degraded consumer expertise
Disconnected deployment fashions create redundant infrastructure no one totally makes use of
Orchestration and serverless fashions repair this by matching consumption to precise demand.
Information governance and retraining pitfalls
Poor governance creates compliance publicity and monetary threat. With out automated controls, organizations take up value by retraining, remediation, and rework.
In regulated industries, the stakes are increased. International banks have confronted lots of of thousands and thousands in regulatory penalties tied to knowledge governance failures. These penalties can far exceed the price of deliberate retraining or system upgrades.
Model management, automated monitoring, and compliance-as-code assist groups catch governance gaps early. The price of prevention is a fraction of the price of remediation.
Confirmed methods to cut back AI agent prices
Price management means eliminating waste and directing sources the place they create precise worth.
Concentrate on modular frameworks and reuse
The largest long-term financial savings don’t come from mannequin alternative alone. They arrive from architectural consistency. Modular design creates reusable parts that speed up growth whereas maintaining governance controls intact.
Construct as soon as, reuse typically, govern centrally. That self-discipline eliminates the expensive behavior of rebuilding from scratch with each new agent initiative and lowers per-agent prices over time.
Modularity additionally makes compliance extra tractable. PII detection and knowledge loss prevention might be enforced centrally quite than retrofitted after an incident. Standardized monitoring parts observe outputs, conduct, and utilization constantly, decreasing compliance threat as deployments scale.
The identical precept applies to value anomaly detection. Constant consumption monitoring throughout brokers surfaces utilization spikes and inefficient orchestration earlier than they grow to be finances surprises.
Undertake hybrid and serverless infrastructure
Static provisioning is a set value hooked up to variable demand. That mismatch is the place finances goes to waste.
Hybrid infrastructure and serverless execution match workloads to essentially the most environment friendly execution surroundings. Important operations run on devoted infrastructure. Variable workloads flex with demand. The result’s a value profile that follows precise enterprise wants, not worst-case assumptions.
Automate governance and monitoring
Drift detection, audit reporting, and compliance alerts aren’t nice-to-haves. They’re value containment.
Behavioral monitoring, PII detection in agent outputs, and consumption anomaly detection create an early warning system. Catching issues on the agent degree, earlier than they grow to be compliance occasions or finances overruns, is at all times cheaper than remediation.
Consumption visibility and management
Actual-time value monitoring per agent, staff, or use case is the distinction between a managed AI program and an unpredictable one. Funds thresholds, policy-based limits, and utilization guardrails stop any single element from draining your complete AI funding.
With out this visibility, consumption can spike throughout peak intervals or attributable to poorly optimized workflows, and also you received’t know till the invoice arrives.
Subsequent steps for cost-efficient AI operations
Realizing the place prices come from is barely half the battle. Right here’s the right way to get forward of them.
Calculate complete value of possession
Begin with a practical three-year view. Ongoing bills, together with operations, retraining, and governance, typically exceed preliminary construct prices. That’s not a warning. It’s a planning enter.
The enterprises that win aren’t working essentially the most revolutionary fashions. They’re working essentially the most financially disciplined packages, with budgets that anticipate escalating prices and controls inbuilt from the beginning.
Construct a management motion plan
Safe govt sponsorship for long-term AI value visibility. With out C-level dedication, budgets drift and help erodes.
Standardize compliance and monitoring throughout all agent deployments. Selective governance creates inefficiencies that compound at scale. Align infrastructure funding with measurable ROI outcomes. Each greenback ought to join on to enterprise worth, not simply technical functionality.
Utilizing the fitting platform can speed up financial savings
Token consumption, infrastructure inefficiency, governance gaps, and developer overhead usually are not inevitable. They’re design and working issues that may be diminished with the fitting engineering strategy.
The correct platform helps scale back these value drivers by serverless execution, clever orchestration, and workflow optimization that identifies extra environment friendly patterns earlier than waste accumulates.
The purpose isn’t simply spending much less. It’s redirecting financial savings towards the outcomes that justify the funding within the first place.
Learn the way syftr helps enterprises determine cost-efficient agentic workflowsbefore waste builds up.
FAQs
Why do agentic AI initiatives value extra over time than anticipated?
Agentic programs require steady retraining, monitoring, orchestration, and compliance administration. As brokers develop extra autonomous and workflows extra advanced, ongoing operational prices continuously exceed preliminary construct funding. With out visibility into these compounding bills, budgets grow to be unpredictable.
How do token and API utilization grow to be a hidden value driver?
Agentic workflows contain multi-step reasoning, repeated LLM calls, software invocation, retries, and enormous context home windows. Individually these prices appear small. At scale they compound quick. A single inefficient immediate sample can improve consumption prices earlier than anybody notices.
What function does governance play in controlling AI prices?
Governance prevents expensive failures, compliance violations, and pointless retraining cycles, and automatic governance can scale back expensive compliance-related rework. With out automated monitoring, audit trails, and behavioral oversight, enterprises pay later by remediation, fines, and rebuilds.
Why do many AI pilots fail to scale into manufacturing?
They’re constructed for the demo, not for manufacturing. Infrastructure inefficiencies, developer overhead, and operational complexity get ignored till scaling forces the difficulty. At that time, groups are refactoring or rebuilding, which will increase complete value of possession.
What’s syftr and the way does it scale back AI prices?
syftr is an open-source workflow optimizer that searches agentic pipeline configurations to determine essentially the most cost-efficient mixtures of fashions and parts in your particular use case. In industry-standard benchmarks, syftr has recognized workflows that minimize prices by as much as 13x with solely marginal accuracy trade-offs.
What’s Covalent and the way does it assist with infrastructure prices?
Covalent is an open-source compute orchestration platform that dynamically routes and scales AI workloads throughout cloud, on-premise, and legacy infrastructure. It optimizes for value, latency, and efficiency with out vendor lock-in or DevOps overhead, straight addressing the infrastructure waste that inflates agentic AI budgets.
Macworld reviews that iOS 26.5 beta 2 introduces adverts to Apple Maps by way of “Steered Locations” with paid placements, marking Apple’s expanded monetization technique.
The replace lacks anticipated Siri enhancements, with main AI upgrades now anticipated to reach with OS 27 or at WWDC in June.
Further adjustments embrace new month-to-month subscription choices for builders and re-enabled end-to-end encryption for messaging with Android customers.
The 26.4 updates introduced with them plenty of enhancements throughout the varied working programs and Apple’s included apps. However they didn’t deliver the anticipated, lengthy overdue enhancements to Siri: A brand new basis mannequin, on-screen consciousness, private context, and actions throughout apps. Latest rumors make it appear unlikely that these issues will seem earlier than the massive OS 27 updates within the fall, for which Apple is focusing on even greater Apple Intelligence upgrades.
There was some hope that a few of these options would possibly ship in iOS 26.5, however the beta doesn’t embrace any Siri adjustments in any respect. We in all probability gained’t see any Siri enhancements till WWDC in June.
Up to date April 13, 2026: Apple has launched the second beta of iOS and iPadOS 26, together with watchOS, tvOS, visionOS, and others.
What’s new in iOS 26.5
Apple Maps adverts: With iOS 26.5, Apple will start exhibiting adverts in Apple Maps, degrading the expertise for all to make much more cash. The 26.5 beta 2 replace launched a popup card if you launch Maps to clarify them.
Foundry
New subscription choices: App builders may need new choices for subscriptions with Apple’s in-app-purchases system. Particularly, they’ll provide month-to-month billing with a 12-month dedication.
Steered Locations in maps: Together with making ready for adverts in Maps coming this summer season, Apple is including Steered Locations (which may also finally embrace paid placement).
RCS encryption: As soon as once more, Apple has enabled end-to-end encryption for messages with Android customers, nevertheless it’s unclear whether or not this can make it into the ultimate launch.
iOS 26.5 beta: How one can set up
If you wish to check the iOS 26 beta releases however usually are not a registered developer, comply with these steps:
Click on Signal Up on the Apple Beta web page and register together with your Apple ID.
Log in to the Beta Software program Program.
Click on Enroll your iOS machine.
Open the Settings app, faucet Common, then Software program Replace.
Within the Beta Updates part, choose the iOS Public Beta.
It could take a number of moments after registering for the beta possibility to look in Software program Replace.
iOS 26.5: How one can set up the developer beta
You’ll should be registered as an Apple developer, however a free developer account will do. You will get one through Xcode or the Apple Developer app in iOS. Right here’s methods to do it through the Apple Developer app:
Two U.S. states and greater than a dozen cities and counties have moved previously yr to cease including fluoride to group consuming water, citing analysis suggesting the mineral may hurt youngsters’s mind growth.
The outcomes, primarily based on standardized intelligence testing of greater than 10,000 individuals in Wisconsin adopted since their senior yr of highschool in 1957, problem the concept that typical fluoridation ranges in public consuming water pose a neurodevelopmental threat, a central level of rivalry in ongoing coverage debates.
“It’s very robust information,” says Steven Levy, a dentist and public well being researcher on the College of Iowa in Iowa Metropolis who was not concerned within the analysis. “There’s no robust sign in any respect coming by way of that ought to give us concern.”
Nevertheless, given the politically charged nature of water fluoridation and continued variations in how researchers interpret the accessible proof, the findings are unlikely to be the final phrase on the problem.
Fluoride has been added to public water provides in North America because the Nineteen Forties, after research of communities within the western United States confirmed that naturally occurring fluoride in groundwater strengthened tooth enamel and diminished cavities. The follow turned one of the widespread public well being interventions of the twentieth century and is extensively credited with sharply decreasing charges of tooth decay in youngsters.
However starting across the flip of the century, issues about doable neurological results started to floor, fueled largely by research of kids uncovered to unusually excessive ranges of naturally occurring fluoride in groundwater in elements of China, India and elsewhere.
These issues got here to a head final yr when researchers affiliated with the U.S. authorities’s Nationwide Toxicology Program synthesized epidemiological proof and reported a hyperlink between elevated fluoride publicity and decrease IQ scores in youngsters — with the strongest associations noticed at fluoride concentrations above the World Well being Group’s guideline of 1.5 milligrams per liter, and combined outcomes beneath that threshold.
That examine drew widespread consideration, together with from a U.S. federal district courtroom, which cited the discovering in ordering the Environmental Safety Company to evaluation fluoride’s potential neurotoxic results. Federal well being officers additionally referenced the analysis when saying plans to reassess the protection and advantage of ingestible fluoride dietary supplements and to reevaluate public water fluoridation insurance policies.
However many scientists had been much less satisfied. As critics had been fast to level out, a lot of the underlying proof drew from populations uncovered to considerably larger fluoride concentrations than these generally present in North American consuming water. Not one of the research had been performed in the USA, and solely a handful included information from nations with fluoridation practices much like U.S. packages, reminiscent of Canada and New Zealand.
One such critic was Rob Warren, a demographer and public well being researcher on the College of Minnesota in Minneapolis. After listening to U.S. Well being and Human Companies Secretary Robert F. Kennedy Jr. tout the analysis whereas arguing that fluoride publicity may hurt youngsters’s brains, Warren got down to consider whether or not the declare was backed by U.S. information.
However that examine relied on tutorial achievement measures quite than direct IQ assessments, making it tougher to immediately examine its findings with these of the Nationwide Toxicology Program evaluation. What’s extra, it may solely approximate childhood fluoride consumption primarily based on college location. What Warren wanted was a dataset with each standardized IQ scores and detailed residential histories — and he discovered it within the Badger State.
The brand new longitudinal examine of Wisconsinites extends the sooner evaluation with extra exact measures of each cognitive capacity and length of publicity to fluoridated water. In the end, it arrives on the similar conclusion as earlier research: Throughout a number of statistical fashions and sensitivity analyses, group water fluoridation on the present guideline degree of 0.7 milligrams per liter was not related to cognitive outcomes throughout the course of a life. “The declare about IQ simply doesn’t maintain up,” Warren says.
Not everyone seems to be persuaded, although. As an illustration, as a result of the individuals had been born earlier than widespread water fluoridation, the evaluation doesn’t seize publicity throughout delicate formative years durations reminiscent of gestation and infancy, when the mind is creating most quickly, says Christine Until, a neuropsychologist at York College in Toronto. It additionally lacks direct measures of fluoride consumption, as a substitute inferring publicity from place of residence and overlooking different sources reminiscent of dietary supplements.
As such, the findings “must be interpreted cautiously,” Until says.
As governments weigh whether or not to maintain fluoride within the faucet, researchers agree on a minimum of one level: The struggle over its results on the mind is much from over.