I’ve been experimenting with Claude Code for months now, utilizing it for every thing from writing lecture slides to debugging R scripts to managing my chaotic tutorial life. However most of these duties, if I’m being sincere, are issues I might do myself. They’re simply sooner with Claude.
Final week I made a decision to attempt one thing completely different. I needed to see if Claude might assist me do one thing I genuinely didn’t know learn how to do: pull in a replication package deal from a printed paper, run NLP classification on 300,000 textual content information utilizing OpenAI’s Batch API, and evaluate the outcomes to the unique findings.
That is Half 1 of that story. Half 2 could have the outcomes—however I’m scripting this earlier than the batch job finishes, so we’re all in suspense collectively. Right here’s the video stroll via. I’ll submit the second as soon as that is finished and we’ll test it collectively.
Thanks once more for all of your assist! These Claude Prices, and the substack extra typically, are labors of affection. Please contemplate turning into a paying subscriber! It’s $5/month, $50/yr or founding member costs of $250! For which I may give you full and complete consciousness in your dying mattress in return.
The paper I selected was Card, et al. (PNAS 2022): “Computational evaluation of 140 years of US political speeches reveals extra constructive however more and more polarized framing of immigration.” Let me dive in and inform you about it. Should you haven’t learn it, the headline findings are hanging:
-
General sentiment towards immigration is MORE constructive at present than a century in the past. The shift occurred between WWII and the 1965 Immigration Act.
-
However the events have polarized dramatically. Democrats now use unprecedentedly constructive language about immigrants. Republicans use language as damaging as the common legislator throughout the Nineteen Twenties quota period.
The authors categorised ~200,000 congressional speeches and ~5,000 presidential communications utilizing a RoBERTa mannequin fine-tuned on human annotations. Every speech phase was labeled as PRO-IMMIGRATION, ANTI-IMMIGRATION, or NEUTRAL. However my query was can we replace this paper utilizing a contemporary massive language mannequin to do the classification? And may we do it stay with out me doing something aside from dictating to Claude Code the duty?
If the reply to this query is sure, then it means researchers can use off-the-shelf LLMs for textual content classification at scale—cheaper and sooner than coaching customized fashions—and for many people, that’s an ideal lesson to be taught. However I believe this train additionally doubles to indicate that even when you really feel intimidated by such a activity, you shouldn’t, as a result of I mainly do that whole factor by typing my directions in, and letting Claude Code do the complete factor, together with discovering the replication package deal, unzipping and extracting the speeches!
If no, we be taught one thing about the place human-annotated coaching knowledge nonetheless issues. And we be taught possibly that this use of Claude Code to do all this through “dictation” is possibly additionally not all it’s cracked as much as be.
Let me be clear about what makes this troublesome:
-
Scale. We’re speaking about 304,995 speech segments. You possibly can’t simply paste these into ChatGPT one by one.
-
Infrastructure. OpenAI’s Batch API is the appropriate device for this—it’s 50% cheaper than real-time API calls and may deal with huge jobs. However setting it up requires understanding file codecs, authentication, job submission, outcome parsing, and error dealing with.
-
Methodology. Even when you get the API working, you must think twice about immediate design, label normalization, and learn how to evaluate your outcomes to the unique paper’s.
-
Coordination. The replication knowledge lives on GitHub. The API key lives someplace safe. The code must be modular and well-documented. The outcomes have to be interpretable.
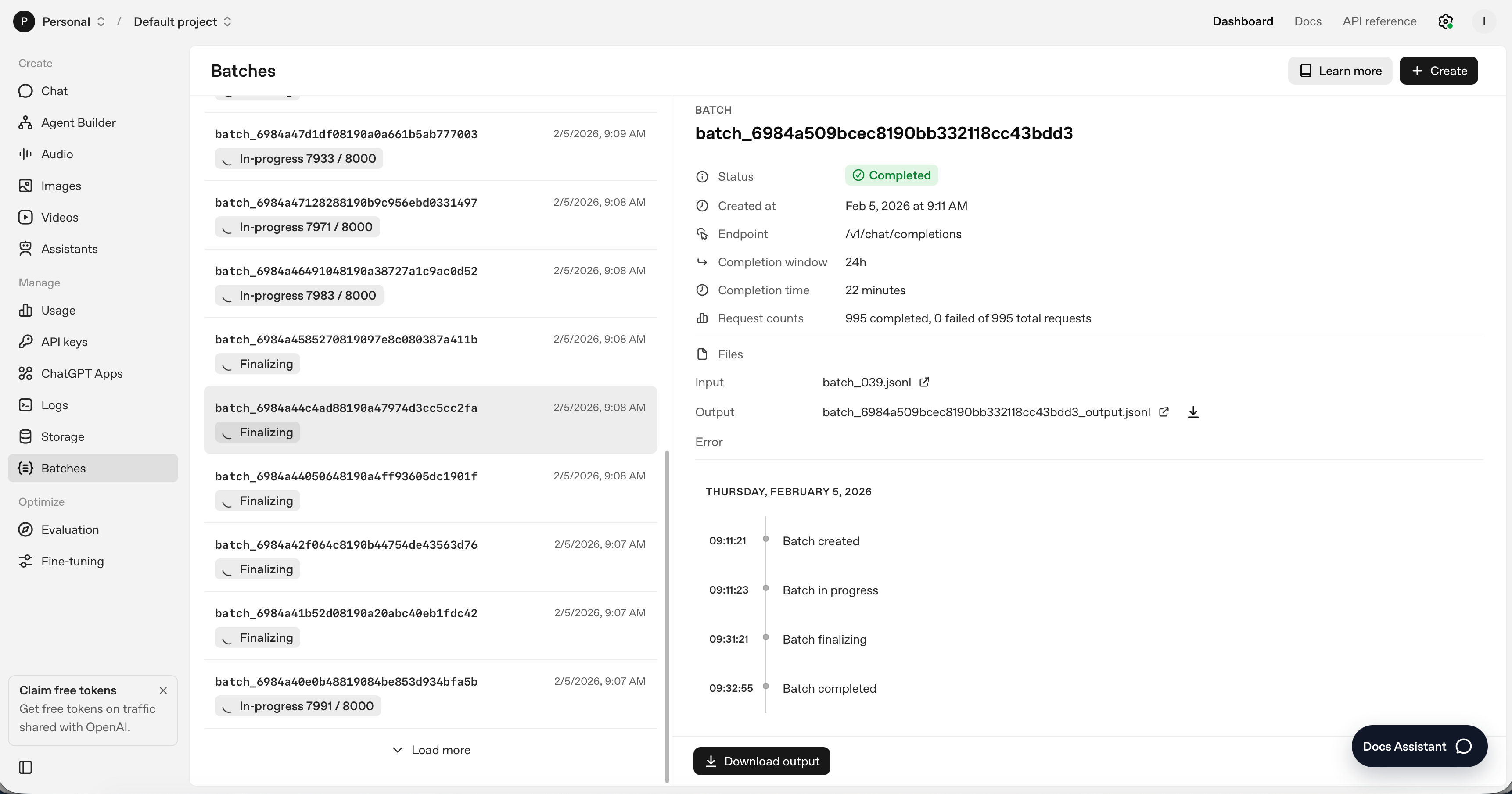
I needed to see if Claude Code might deal with the entire pipeline—from downloading the info to submitting the batch job—whereas I watched and requested questions.
I began by telling Claude what I needed to do utilizing one thing referred to as “plan mode”. Plan mode is a button you pull down on the desktop app. I’ve a protracted forwards and backwards with Claude Code about what I need finished, he works it out, I evaluate it, after which we’re prepared, I agree and he does it. If nothing else, watching the video, and skipping to plan mode, you may see what I did.
So what I did was I saved the paper myself regionally (as I had a sense he may not might get into the PNAS button factor to get it however who is aware of), then defined precisely what I needed finished. However what I did was I defined my request backwards. That’s I instructed him what I needed on the very finish, which was a classification of the speeches the authors had however utilizing OpenAI batch requested classification with the gpt-4o-mini LLM. After which I labored backwards from there and stated I needed an explainer deck, I needed an audit utilizing referee2 earlier than he ran it, I needed a cut up pdf utilizing my pdf-splitter talent at my repo, and so forth. It’s simpler to clarify when you watch it.
So as soon as we agreed, and after some tweaking issues in plan mode,Claude instantly did one thing I appreciated: it created a self-contained mission folder moderately than scattering recordsdata throughout my present course listing.
workout routines/llm_replication/
├── article/
│ └── splits/ # PDF chunks + notes
├── code/
│ ├── 01_prepare_data.py
│ ├── 02_create_batch.py
│ ├── 03_submit_batch.py
│ ├── 04_download_results.py
│ └── 05_compare_results.py
├── knowledge/
│ ├── uncooked/ # Downloaded replication knowledge
│ ├── processed/ # Cleaned CSV
│ ├── batch_input/ # JSONL recordsdata for API
│ └── batch_output/ # Outcomes
├── deck/
│ └── deck.md # Presentation slides
├── plan.md
└── README.md
This construction made sense to me. Every script does one factor. The information flows from uncooked → processed → batch_input → batch_output → outcomes. If one thing breaks, you recognize the place to look. So this is kind of replicable and I can use this to indicate my college students subsequent week after we evaluate the paper and replicate it kind of utilizing an LLM, not the methodology that they used.
The replication package deal from Card et al. is 1.39 GB. How do I do know that? As a result of Claude Code searched and located it. He discovered it, pulled the zipped file into my native listing, and noticed that utilizing no matter device it’s within the terminal that permits you to test the file dimension. Right here’s the place he put it.
The zipped file he then unzipped and positioned in that ./knowledge listing. It contains the speech texts, the RoBERTa mannequin predictions, and the unique human annotations. So that is now the PNAS, from the bottom up.
When Claude downloaded the info and explored the construction, right here’s what we discovered:
-
Congressional speeches: 290,800 segments in a .jsonlist file
-
Presidential communications: 14,195 segments in a separate file
-
Every document contains: textual content, date, speaker, celebration, chamber, and the unique mannequin’s likelihood scores for every label
It’s slightly completely different than what the PNAS says curiously which stated there are 200,000 congressional speeches and 5,000 presidential communications. This got here out to 305,000. So I stay up for digging extra into that.
I even have the unique paper’s classifier outputs chances for all three courses. If a speech has chances (anti=0.6, impartial=0.3, professional=0.1), we take the argmax: ANTI-IMMIGRATION. This was from their very own evaluation.
However Claude wrote 01_prepare_data.py to load each recordsdata, extract the related fields, compute the argmax labels, and save every thing to a clear CSV. Working it produced:
Complete information: 304,995
--- Authentic Label Distribution ---
ANTI-IMMIGRATION: 48,234 (15.8%)
NEUTRAL: 171,847 (56.3%)
PRO-IMMIGRATION: 84,914 (27.8%)
Most speeches are impartial—which is sensible. Plenty of congressional speech is procedural.
Or are they impartial? That’s what we’re going to discover out. When now we have the LLM do the classification, we’re going to see if possibly there may be nonetheless more money on the desk. After which we’ll create a transition matrix to see what the LLM categorised as ANP and what the unique authors categorised as ANP. We’ll see if some issues are getting shifted round.
That is the place it will get fascinating. How do you inform gpt-4o-mini to categorise political speeches the identical means a fine-tuned RoBERTa mannequin did?
Claude’s first draft was detailed—possibly too detailed:
You're a analysis assistant analyzing political speeches about immigration...
Classification classes:
1. PRO-IMMIGRATION
- Valuing immigrants and their contributions
- Favoring much less restricted immigration insurance policies
- Emphasizing humanitarian considerations, household unity, cultural contributions
- Utilizing constructive frames like "hardworking," "contributions," "households"
2. ANTI-IMMIGRATION
- Opposing immigration or favoring extra restrictions
- Emphasizing threats, crime, illegality, or financial competitors
- Utilizing damaging frames like "unlawful," "criminals," "flood," "invasion"
...
I had a priority: by itemizing particular key phrases, had been we biasing the mannequin towards pattern-matching moderately than semantic understanding?
That is precisely the type of methodological query that issues in analysis. Should you inform the mannequin “speeches with the phrase ‘flood’ are anti-immigration,” you’re not likely testing whether or not it understands tone—you’re testing whether or not it may possibly grep.
We determined to maintain the detailed immediate for now however flagged it as one thing to revisit. A less complicated immediate would possibly truly carry out higher for a replication research, the place you need the LLM’s unbiased judgment. However, what I believe I’ll do is a component 3 the place we do resubmit with a brand new immediate that doesn’t lead the llm as a lot as I did, however I believe it’s nonetheless helpful simply to see even utilizing the unique prompting, whether or not this extra superior llm, which has much more talent at discerning context than earlier ones (even Roberta), would possibly come to the identical or completely different conclusions.
So now we get into the OpenAI half. I absolutely perceive that this half is a thriller to many individuals. Simply what am I precisely going to be sensible doing on this fourth step? And that’s the place I believe relying Claude Code for assist in answering your questions, in addition to studying learn how to do it, after which utilizing referee2 to audit the code, goes to be useful. However right here’s the gist.
To get the classification of the speeches finished, now we have to add these speeches to OpenAI. However OpenAI’s Batch API expects one thing referred to as JSONL recordsdata the place every line is an entire API request. So, with out me even explaining learn how to do it, Claude wrote 02_create_batch.py to generate these.
Just a few technical particulars that matter:
-
Chunking: We cut up the 304,995 information into 39 batch recordsdata of 8,000 information every. This retains file sizes manageable.
-
Truncation: Some speeches are very lengthy. We truncate at 3,000 characters to suit inside context limits. Claude added logging to trace what number of information get truncated.
-
Price estimation: Earlier than creating something, the script estimates the overall value:
--- Estimated Price (gpt-4o-mini with Batch API) ---
Enter tokens: 140,373,889 (~$10.53)
Output tokens: 1,524,975 (~$0.46)
TOTAL ESTIMATED COST: $10.99
Lower than eleven {dollars} to categorise 300,000 speeches! That’s outstanding. Just a few years in the past, this might have required coaching your personal mannequin or paying for costly human annotation. However now for $11 and what will take a mere 24 hours I — a one man present, doing all of this inside an hour over a video — bought this submitted! Un. Actual.
03_submit_batch.py is the place cash will get spent, so Claude inbuilt a number of security options:
-
A --dry-run flag that exhibits what could be submitted with out truly submitting
-
An specific affirmation immediate that requires typing “sure” earlier than continuing
-
Retry logic with exponential backoff for dealing with API errors
-
Monitoring recordsdata that save batch IDs so you may test standing later
I appreciated the defensive programming. While you’re about to spend cash on an API name, you need to make sure you’re doing what you propose.
Right here’s the place issues bought meta.
I’ve a system I discussed the opposite day referred to as personas. And the one persona I’ve thus far is an aggressive “auditor” referred to as “Referee 2”—I take advantage of him by opening a separate Claude occasion, in order that I don’t have Claude Code reviewing its personal code. This second Claude Code occasion is referee 2. It didn’t write the code we’re utilizing to submit the batch requests. It’s sole job is to evaluate the opposite Claude Code’s code with the important eye of an educational reviewer after which write a referee report. The thought is to catch issues earlier than you run costly jobs or publish embarrassing errors.
So, I requested Referee 2 to audit the complete mission: the code, the methodology, and the presentation deck. And you may see me within the video doing this. The report got here again with a advice of “Minor Revision Earlier than Submission”—tutorial converse for “that is good however repair a number of issues first.” I bought an R&R!
-
Label normalization edge circumstances. The unique code checked if “PRO” was within the response, however what if the mannequin returns “NOT PRO-IMMIGRATION”? The string “PRO” is in there, however that’s clearly not a pro-immigration classification. Referee 2 recommended utilizing startswith() as a substitute of in, with precise matching as the primary test.
-
Lacking metrics. Uncooked settlement charge doesn’t account for probability settlement. If each classifiers label 56% of speeches as NEUTRAL, they’ll agree on lots of impartial speeches simply by probability. Referee 2 really useful including Cohen’s Kappa.
-
Temporal stratification. Speeches from 1880 use completely different language than speeches from 2020. Does gpt-4o-mini perceive Nineteenth-century political rhetoric in addition to trendy speech? Referee 2 recommended analyzing settlement charges individually for pre-1950 and post-1950 speeches.
-
The immediate design query. Referee 2 echoed my concern in regards to the detailed immediate probably biasing outcomes towards key phrase matching.
-
Clear code construction with one script per activity
-
Defensive programming within the submission script
-
Good logging all through
-
The deck following “Rhetoric of Decks” ideas (extra on this under)
I applied the required fixes. I needed to pause at sure factors the recording, however I believe it in all probability took about half-hour. The code is now extra sturdy than it might have been with out the evaluate.
One factor I’ve discovered from educating: when you can’t clarify what you probably did in slides, you in all probability don’t absolutely perceive it your self.
I requested Claude to create a presentation deck explaining the mission. However I gave it constraints: comply with the “Rhetoric of Decks” philosophy I’ve been growing, which emphasizes:
-
One concept per slide
-
Magnificence is perform (no ornament with out function)
-
The slide serves the spoken phrase (slides are anchors, not paperwork)
-
Narrative arc (Downside → Investigation → Decision)
I’m going to avoid wasting the deck, although, for tomorrow when the outcomes are completed in order that we will all have a look at the deck collectively! Cliff hanger!
As of the second of typing this, the batch has been despatched. Right here’s the place we’re at this second. A few of them are almost finished, and a few have but to start.
However listed below are among the issues I’m questioning as I wait.
-
Will the LLM agree with the fine-tuned mannequin? The unique paper studies ~65% accuracy for tone classification, with most errors between impartial and the extremes. If gpt-4o-mini achieves comparable settlement, that’s a validation of zero-shot LLM classification. If it’s a lot decrease, we be taught that fine-tuning nonetheless issues.
-
Will settlement differ by time interval? Will the LLM will do higher on trendy speeches (post-1965) than on Nineteenth-century rhetoric? The coaching knowledge for GPT fashions skews latest, or does it?
-
Will settlement differ by celebration? If the LLM systematically disagrees with RoBERTa on Republican speeches however not Democratic ones (or vice versa), that tells us one thing about how these fashions encode political language. I can do all this utilizing a transition matrix desk, which I’ll present you, to see how the classifications differ.
-
What is going to the disagreements appear like? I’m genuinely curious to learn examples the place the 2 classifiers diverge. That’s typically the place you be taught essentially the most.
This began as a check of Claude Code’s capabilities. Can it deal with an actual analysis activity with a number of shifting elements? Can it deal with a “exhausting activity”?
The reply thus far is sure—with caveats. Claude wanted steerage on methodology. It benefited enormously from the Referee 2 evaluate. And I needed to keep engaged all through, asking questions and pushing again on choices. Discover this was not “right here’s a job now go do it”. I’m fairly engaged the entire time, however that’s additionally how I work. I believe I’ll at all times be within the “dialogue so much with Claude Code” camp.
However the workflow labored. We went from “I need to replicate this paper” to “batch job submitted” in about an hour. The code is clear and was double checked (audited) by referee 2. The documentation is thorough. The methodology is defensible. We’re updating a paper. I’m one man in my pajamas filming this complete factor so you may simply see for your self learn how to use Claude Code to do a troublesome activity.
To me, the actual thriller of Claude Code is why does the copy-paste methodology of coding appear to really make me much less attentive, however Claude Code for some motive retains me extra engaged, extra attentive? I nonetheless don’t fairly perceive psychologically why that may be the case however I’ve seen again and again that on initiatives utilizing Claude Code, I don’t have the slippery grasp on what I’ve finished, how I’ve finished it, and in order I typically did with the copy-paste methodology of utilizing ChatGPT to code. That kind of copy-paste is kind of senseless button pushing. Whereas I considering how I take advantage of Claude Code shouldn’t be like that, and therein lies the actual worth. Claude didn’t simply do the work—it did the work in a means that taught me what was taking place. I believe that a minimum of for now’s labor productiveness enhancing. I’m doing new duties I couldn’t do, I’m attending to solutions I can research sooner, I’m considering extra, I’m staying engaged, and curiously, I guess you I’m spending the identical period of time on analysis, however much less time on the stuff that isn’t truly “actual analysis”.
The batch job will take as much as 24 hours to finish. As soon as it’s finished, I’ll obtain the outcomes and run the comparability evaluation.
Half 2 will cowl:
-
General settlement charge and Cohen’s Kappa
-
The transition matrix (which labels does the LLM get “improper”?)
-
Settlement by time interval, celebration, and supply
-
Examples of fascinating disagreements
-
What this implies for researchers contemplating LLM-based textual content classification
Till then, I’m looking at a monitoring file with 39 batch IDs and ready.
Keep tuned.
Technical particulars for the curious:
-
Mannequin: gpt-4o-mini
-
Information: 304,995
-
Estimated value: $10.99 (with 50% batch low cost)
-
Classification labels: PRO-IMMIGRATION, ANTI-IMMIGRATION, NEUTRAL
-
Comparability metric: Settlement charge + Cohen’s Kappa
-
Time stratification: Pre-1950 vs. Submit-1950 (utilizing Congress quantity as proxy)
Repository (unique paper’s replication knowledge):
github.com/dallascard/us-immigration-speeches
Paper quotation:
Card, D., Chang, S., Becker, C., Mendelsohn, J., Voigt, R., Boustan, L., Abramitzky, R., & Jurafsky, D. (2022). Computational evaluation of 140 years of US political speeches reveals extra constructive however more and more polarized framing of immigration. PNAS, 119(31), e2120510119.




")