
")
{kind=link}
First a part of that is footage of Italy — specifically Pisa the place I used to be first of the week and now Stresa on Lake Maggiore the place I’m now. The second half is about parallel traits and the way it’s truly simply one other type of choice bias, which is to say, it’s a hole in anticipated Y(0) solely this time it’s the hole in anticipated first variations. And I flipped a coin 3 times and so they all got here up tails so this isn’t paywalled.
I completed educating a 3 day workshop of kinds at Sant’Anna College in Pisa on Wednesday and felt prefer it went properly. I liked assembly my hosts, and was completely impressed with the scholars who attended. And naturally Pisa — what a phenomenal metropolis.

On Thursday morning, I stated ciao although. I packed my suitcase for the tenth time, rolling all of the shirts and pants and different stuff into tight rolls, put all my laptop tools away, checked out of the lodge and made my technique to the prepare station.

I’ve to be in Berlin Sunday night time for a two day workshop beginning Monday. Which meant I had a 3 day hole. I couldn’t resolve, and didn’t discover Claude to be notably useful. I suppose it’s odd that I might be over right here and have any gaps, however I left openings as a result of I wished the choice to name some audibles as I realized extra issues about the place I used to be. And the expertise on Lake Maggiore in Arona had been so breathtaking that I made a decision to return again to Lake Maggiore, solely this time to Stresa.
And wow is it ever fairly. It has luxurious resorts alongside the lake, however extra previous European fashion luxurious resorts than the fashionable ones. I took a protracted stroll alongside the lake once I unpacked and had a chew to eat by the lake too.
I’m nonetheless doing my intermittent fasting. It’s at all times a struggle to do it once I come to Europe as all I wish to do is have beer, wine, cocktails, pasta, each conceivable pastry, each piece of bread. However alas, these days are behind me. I’m principally going to eat usually once I get to San Sebastián in two weeks. For now it’s simply water, and light-weight meals, with Claude telling me roughly what number of energy that was, and me studying the artwork of observing starvation pains with out judgment, simply curiosity. “Oh attention-grabbing — that isn’t ache. That’s only a burning sensation within the heart of my stomach”. Anyway I took these footage at a restaurant on Lake Maggiore the place I in all probability over ate slightly and had a burger, fries and a few tiramisu. I can’t say no to tiramisu.




However now I wish to shift gears and present you one thing with diff-in-diff. I’m going to indicate you the parallel traits bias time period and the place it comes from, then I wish to present you it’s truly a variety bias time period and you’ll write it a couple of methods.
What’s difference-in-differences? It’s a analysis design. It’s decidedly not a regression. The regression is the calculation, however a analysis design has two elements — the calculation and the identification assumption. And for difference-in-differences, whenever you make some primary design selections known as “no anticipation” (i.e., the baseline consequence is the untreated potential consequence, Y(0)) and you utilize a never-treated comparability group in order that each durations’ outcomes are Y(0) for the comparability group, then the one factor left within the calculation is a bias time period known as “non-parallel traits bias”. The identification assumption is that that time period is the same as a zero, and that due to this fact the calculation has a causal interpretation known as the “common remedy impact on the remedy group” or the ATT.
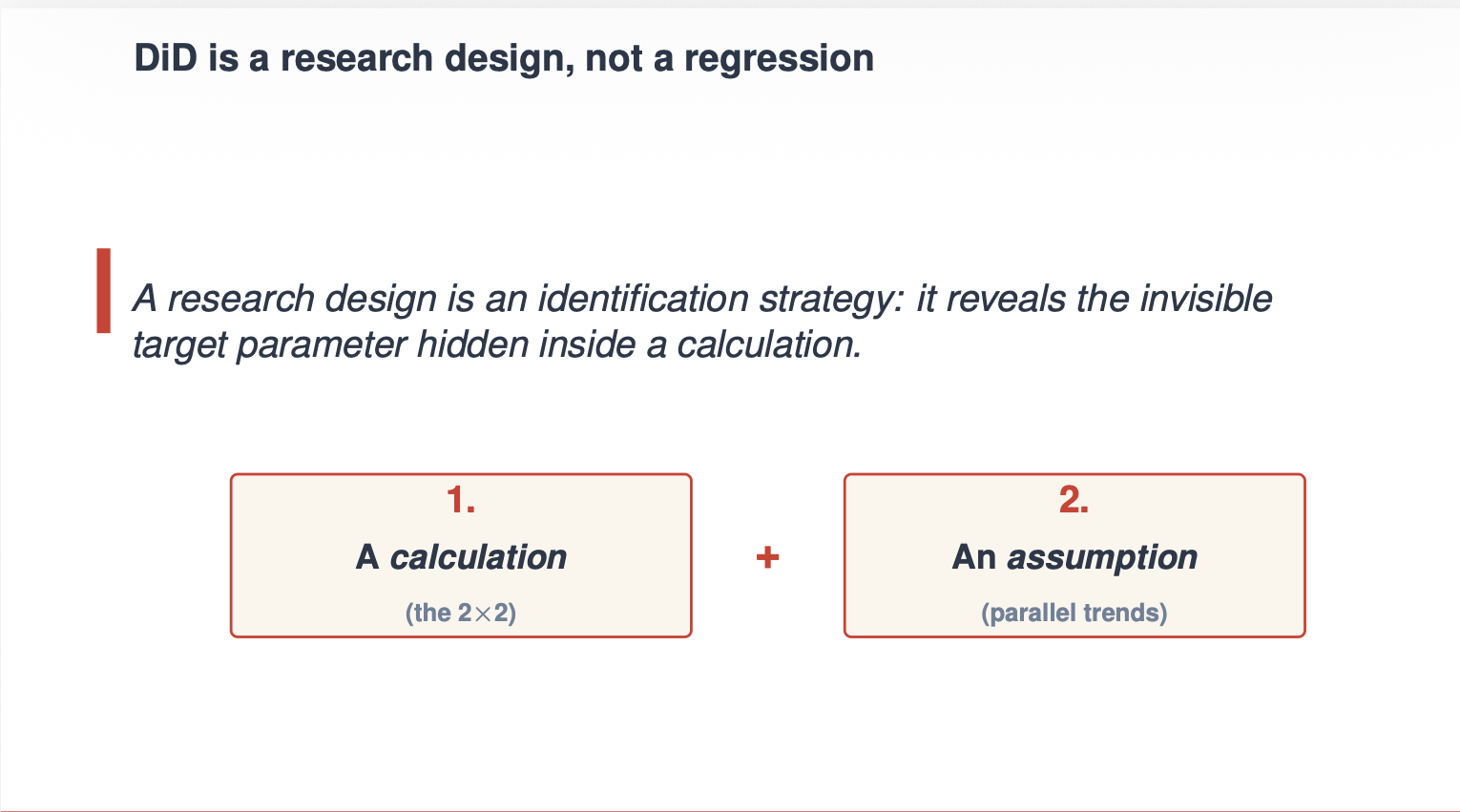
Let’s illustrate this formally by beginning with the 2×2. Beginning with the 2×2 is nice as a result of it helps you perceive the excellence between a calculation, a causal parameter and an identification assumption. It additionally exhibits you that don’t want an occasion research to fulfill parallel traits. It is usually the paradigm we soak up our new article within the Journal of Financial Literature (with Andrew Baker, Brantly Callaway, Andrew Goodman-Bacon and Pedro Sant’Anna), “Distinction-in-Variations: A Practitioner’s Information”.
Generally I’ve been within the room when somebody complains over our insistence that except the calculation has a parallel traits assumption, that it’s not due to this fact diff-in-diff. I at all times am puzzled once they say that as a result of the 2×2 calculation is actually solely biased by parallel traits! Watch and see.
-
Write down the 2×2 utilizing expectations and realized outcomes
-
Change realized outcomes with potential outcomes relying on whether or not in that interval that unit was handled.
-
Add a zero.
-
Rearrange into the ATT and the parallel traits bias time period

When you assume no anticipation, which is kind of trivial to implement (you solely considered one of three issues for no anticipation to carry: the remedy to be a shock during which case you choose the interval simply earlier than remedy, the remedy to be anticipated in which you’ll you choose the interval earlier than it was anticipated, or the remedy results on the longer term intervention previously are zero. All three of those will allow you to make the substitution in step 2 of changing the baseline consequence, Y, with the baseline potential consequence, Y(0).
And as you may see, the rationale we insist that one thing just isn’t diff-in-diff except its identification assumption is “parallel traits” is as a result of it’s actually the one bias within the 2×2! And I received there in 4 strikes — three when you don’t depend rearranging phrases as a transfer.
So, it’s not controversial to say that diff-in-diff requires parallel traits. Actually, given the ubiquity and recognition of diff-in-diff, I dare say that “parallel traits” is probably the most extensively recognized “identification assumption” in all of utilized statistics. I imply how many individuals can as simply say “unconfoundedness”, “smoothness”, “exclusion and monotonicity”, or “issue fashions of Y(0)” in comparison with the quantity of people that can say “parallel traits”? I’ve to assume that these are minority populations in comparison with diff-in-diff if solely due to how frequent diff-in-diff is within the first place, and the way simply the rhetoric of “parallel traits” is precisely introduced, and the way the reveals for the proof to assist has change into so commonplace and practiced (e.g., pre-trends in an occasion research).
However I truly am more and more irritated by the truth that it’s known as “parallel traits” as a result of traits indicate each time, and so they indicate it’s observable, when actually neither one is as correct as I are likely to wish to make issues. I are likely to over-explain although, so in all probability one’s mileage could differ on this level.
If it had been as much as me, although, I might’ve most well-liked that every one alongside we simply known as the non-parallel traits bias time period “choice bias”. Why? As a result of choice bias is the distinction within the imply untreated potential consequence, Y(0), for a remedy group and a comparability group. That’s what we name it in easy comparisons as an illustration. We don’t name choice bias in easy comparisons “equal ranges”. We name it “choice bias” as a result of it’s a normal bias, not a selected bias. Don’t imagine me? Let’s go to the kung fu masters themselves — Angrist and Pischke’s basic e book on causal inference, Largely Innocent Econometrics.

I do it too in my e book, Causal Inference: the Mixtape. Solely I work it out much more by assuming heterogenous remedy results.

Have a look at the second row in each instances: choice bias is a hole within the imply untreated potential consequence for 2 teams: a remedy group and a comparability group. And choice bias due to this fact forbids choice into remedy primarily based on values within the Y(0) distribution.
Properly now look again on the bias of diff-in-diff. It too is the distinction in E[Y(0)] between two teams — it’s simply that for diff-in-diff, the bias is the distinction in two teams first distinction in E[Y(0)].
However now discover a second factor. Do you see how whenever you examine two teams’ outcomes, E[Y|D=1] – E[Y|D=0], that its choice bias time period has the identical type as the unique calculation? Properly guess what which means — the choice bias of diff-in-diff is itself a diff-in-diff! The choice bias is “4 averages and three subtractions”! The non-parallel traits bias time period is a 2×2 additionally. It’s simply that it’s a 2×2 — or a diff-in-diff — on the potential consequence, Y(0), not the realized consequence, Y.
Guido Imbens with coauthors in a couple of papers — I feel beginning at Doudchenko and Imbens, the matrix completion paper and the synth did paper — described artificial management as a “vertical regression”. You’re evaluating teams to teams, getting coefficients on the group’s comparisons throughout time, versus inside time. That’s type of been a factor my mind struggled with for some purpose. However guess what — that’s what diff-in-diff is simply too, and it’s what the non-parallel traits bias time period is. Watch, first I’ll write down the 2×2 once more.
(delta_{2 occasions 2} = { E[Y_t|D=1] – E[Y_{t-1} | D=1] } – {E[Y_t|D=0] – E[Y_{t-1} | D=0] })
Discover how the 4 phrases are linear. Identical to I can rearrange 5+7=12 into 7+5=12, I can do the identical with that equation so I’ll.
(delta_{2 occasions 2} = D=0] – { E[Y_{t-1} | D=1] – E[Y_{t-1} | D=0] })
That’s the identical actual equation. No completely different. Properly, Imbens and Viviano truly say one thing much like this of their dialogue of artificial management too.

This equivalence between the “first variations regression” (i.e., “horizontal regression”) and the “within-time group distinction regression” (i.e., “vertical regression”) is definitely a normal factor. However then examine this out — guess what the choice bias time period is for the “within-time group distinction 2×2” is. You guessed it — it’s a within-time group distinction Y(0) comparability.
(BIAS = { textcolor{pink}D=1] – E[Y(0)_t|D=0] } – { E[Y(0)_{t-1} | D=1] – E[Y(0)_{t-1} | D=0] })
See, it’s a pattern when you outline a pattern as any two of the attainable variations in these 4 averages and three subtractions. However my level is a couple of issues.
-
The choice bias is measured utilizing the variations involving the post-treatment potential consequence, Y(0), not “pre-trended Y(0)”. They’re each the untreated potential consequence little doubt (beneath no anticipation, all pre-treatment outcomes are the untreated potential consequence by definition), however they aren’t the similar ones that have to be parallel.
-
The choice bias of diff-in-diff is weirdly sufficient itself a diff-in-diff! It’s actually a 2×2! This implies whenever you estimate a diff-in-diff, the bias of diff-in-diff is one other diff-in-diff!
-
You may estimate 2x2s horizontally, or vertically, and actually your TWFE is definitely doing it each methods. Or fairly, within the TWFE specification, they’re the identical factor. However when you had been to do a primary distinction your self after which regress that first distinction on to a remedy dummy versus do a “group distinction by time” and regress that onto a publish dummy, that might appear to be a unique regression specification nevertheless it isn’t.
In order that’s it. At this time I’ve a therapeutic massage scheduled in a single hour, I’ve to then movie a podcast episode with Caitlin in a couple of hours, work some on my R&R, do another work, and sooner or later go for a stroll. I had an enormous breakfast at 7am, which beneath intermittent fasting guidelines implies that my window will shut 7+8=15 – 12 = 3:00PM. So I higher go now. Take pleasure in your day! Subsequent week I’ll pop again to covariates. I get so aspect tracked!
Additionally, right here’s what I’m studying. The 4 Loves by CS Lewis.

And Marie Howe’s What the Dwelling Do.

Have an amazing day!