

{kind=link}
Most search brokers attempt to deal with too many roles directly. They generate new queries, bear in mind what they’ve already explored, acquire proof, and determine what’s related because the search retains increasing. That may make the entire course of messy, costly, and onerous to regulate.
Harness-1 takes an easier method. Constructed with researchers from UIUC, UC Berkeley, and Chroma, it separates the work of discovering search phrases from the work of monitoring search progress. The result’s a compact retrieval agent that feels simpler to cause about and performs far above what its measurement may counsel.
On this article, we take a better have a look at Harness-1 and why its method to retrieval brokers issues.
Why Current Search Brokers Plateau?
Most retrieval brokers are educated finish to finish. The mannequin produces queries, reads chunks, decides what issues, and retains all that context in a rising transcript. The coverage learns the whole lot, search technique, proof monitoring, deduplication, and people stopping circumstances too.
The issue is reinforcement studying then tries to enhance all of this directly. Semantic search selections like ought to I seek for “merger date” or “acquisition yr” get tangled with the extra low-level bookkeeping. Have I seen this chunk earlier than? RL finally ends up optimizing each, and truthfully, they don’t share the identical studying dynamics. So, it will get a bit messy.
The researchers name this the core design flaw. Their repair is clear, transfer state administration out of the mannequin and right into a harness.
What the Harness Truly Does?
The stateful harness includes the principle breakthrough. The harness runs the mannequin as a state machine. It maintains these 4 persistent constructions all through every episode:
- A candidate pool consists of all compressed, deduplicated paperwork from all candidate searches.
- A curated set is the ultimate output with as much as 30 paperwork recognized with significance flags (
very_high,excessive,truthful,low). - A full-text retailer comprises each piece of knowledge retrieved, saved exterior of the machine immediate.
- An proof graph is a group of auto-extracted entities, their bridge paperwork, and singleton leads.
The proof graph portion of this construction is sort of intelligent. The regex extractor scans every bit of retrieved information for correct nouns, years, and dates. Bridge paperwork that include two or extra entities regularly discovered collectively are flagged as being of very excessive precedence. Singletons mark potential follow-up searches. At every flip of play, the harness presents this data in an environment friendly, compact method.
The Eight-Device Interface
The eight-tool based mostly on the mannequin perform on every flip. Each flip, the mannequin emits precisely one motion.
Two section compression is utilized to the output from search section of retrieval. The primary section of compression makes use of Sentence-BM25 to rank all sentences and choose the highest 4 from every chunk. The second section of compression is achieved via two-level de-duplication: the primary stage is de-duplication by chunk ID, the second stage is de-duplication by content material fingerprint. The coverage by no means sees the uncooked retrieval output previous to the completion of two-phase de-duplication.
The design has paid off, because the mannequin has stored its context clear. The mannequin has solely processed indicators, and all tokens usually are not noise.
The Chilly Begin Drawback (And Its Resolution)
The primary subject in retrieval coaching is figuring out how a coverage learns to create a curated dataset out of nothing, which results in randomness within the coverage’s first few RL episodes. As a result of the preliminary state for the coverage doesn’t have a previous to refine from, it doesn’t know methods to curate. Subsequently, the coverage both throws the whole lot into the curated dataset or doesn’t curate any in any respect.
Harness-1 addresses this subject utilizing warm-start seeding. After the harness has efficiently carried out a seek for the primary time, it mechanically generates a curated dataset utilizing the highest 8 reranked outcomes that have been tagged with a equity ranking. Thus, the coverage has a remedial perform (refinement, growing the worth of high quality paperwork and lowering the standard of weak paperwork) as a substitute of a major perform (eradicating all paperwork and creating from scratch).
This small change creates a big quantity of stability in coaching and demonstrates that curation is discovered extra simply via refinement than it’s via creation.
How Coaching Works: SFT Then RL
There are two levels within the coaching pipeline that do totally different varieties of labor:
Stage 1: Supervised Effective Tuning
A instructor mannequin (GPT-5.4) is working within the full harness in a stay state and being educated with a big set of numerous queries at this level. After filtering out all the poorly performing trajectories we have been left with a complete of 899 episodes that coated the proper use of the interface to coach the mannequin methods to name instruments, construction actions, and replace the curated set.
# LoRA configuration for SFT
lora_config = {
"rank": 32,
"target_modules": ["q_proj", "v_proj"],
"base_model": "gpt-oss-20b",
"epochs": 3,
"checkpoint_for_rl": 550, # step-550 initializes RL coaching
}Stage 2: Reinforcement Studying
On the second stage of Reinforcement Studying, on-policy CISPO is used with a reward perform based mostly on terminal rewards solely, and has a cap of 40 turns. The coaching information consisted of SEC (monetary doc) queries, however the insurance policies discovered via coaching at this stage have been generalizable to all 8 benchmark domains. The reward perform has two main advantages:
- The primary profit is separation of discovery and choice. The 2 components are offered as impartial rewards when discovering and curating a discovery (i.e., a related doc is discovered after which curated).
- The second profit is the addition of a range bonus for instruments getting used. This bonus is extra vital than you may assume.
With out the range bonus, the agent will get caught in a loop. The agent repeatedly points the identical search question in barely various varieties, fills the curated set with many comparable objects, and experiences stalling (0.53 curated recall). The agent learns to make the most of grep_corpus, confirm, and read_document along with search_corpus when a range bonus is added, and consequently, the agent’s recall rating will increase to 0.60 from this one change.
# Simplified reward construction
def compute_reward(episode):
discovery_score = count_newly_found_relevant_docs(episode)
selection_score = curated_recall(episode.final_curated_set)
diversity_bonus = tool_diversity_score(episode.action_sequence)
# Terminal reward solely - no intermediate shaping
return selection_score + 0.3 * discovery_score + 0.2 * diversity_bonusFingers-On: Working Harness-1 Regionally
Let’s attempt it out.
- In the meanwhile this repo is utilizing
uvfor dependency administration and vLLM for serving. You have to to have sufficient GPU VRAM to run a 20B mannequin. For instance, a single A100 (80GB) will work properly. Alternatively, two A100s (40GB) will work very properly utilizing tensor parallelism if in case you have them. - Clone the repository and set up it
git clone https://github.com/pat-jj/harness-1.git
cd harness-1
# If you have not put in uv, do it now
pip set up uv
# Pull all dependencies together with vLLM
uv sync --extra vllmWord that pulling in vLLM and its CUDA dependencies is completed with the --extra vllm flag and should take a while through the first pull of the bundle. If you don’t observe via with this step, the inference script won’t run on account of its reliance on the vLLM server.
- The primary time you run an utility with this mannequin put in it is going to obtain about 40GB of weights from HuggingFace and setup an area OpenAI suitable server utilizing uvicorn. After uvicorn has began and you may open the server at http://0.0.0.0:8000, you need to be capable of run your mannequin.
uv run python inference/vllm_local_inference.py serve
--model pat-jj/harness-1
--served-model-name harness-1When you have two GPUs, you may add --tensor-parallel-size 2 to create a break up between each GPUs. With out this selection, you’ll hit out of reminiscence points with one, 40GB, GPU.
- The execution of Step 3 means now you can subject a search request on to the Harness-1 server. You have to format your search request as a structured question directed towards a Chroma corpus. Right here’s what a minimal take a look at would seem like, utilizing the BrowseComp+ benchmark format:
from openai import OpenAI
shopper = OpenAI(base_url="http://localhost:8000/v1", api_key="none")
response = shopper.chat.completions.create(
mannequin="harness-1",
messages=[
{
"role": "user",
"content": "Search for documents about the 2024 EU AI Act enforcement timeline.",
}
],
max_tokens=512,
temperature=0.0, # deterministic for eval runs
)
# The mannequin emits a structured device motion - parse it
motion = response.decisions[0].message.content material
print(motion)In response to your question, you’ll obtain an output that isn’t narrative in nature. The output shall be within the type of a structured motion; e.g. fan_out_search(queries=["EU AI Act enforcement 2024", "AI Act timeline implementation"]). That is anticipated since Harness-1 is a retrieval sub-agent versus a chat mannequin. The output of Harness-1 will then be despatched to the harness, which is able to course of the motion towards your corpus.
- After a full search episode will get accomplished, you may see the metrics that issues within the log file.
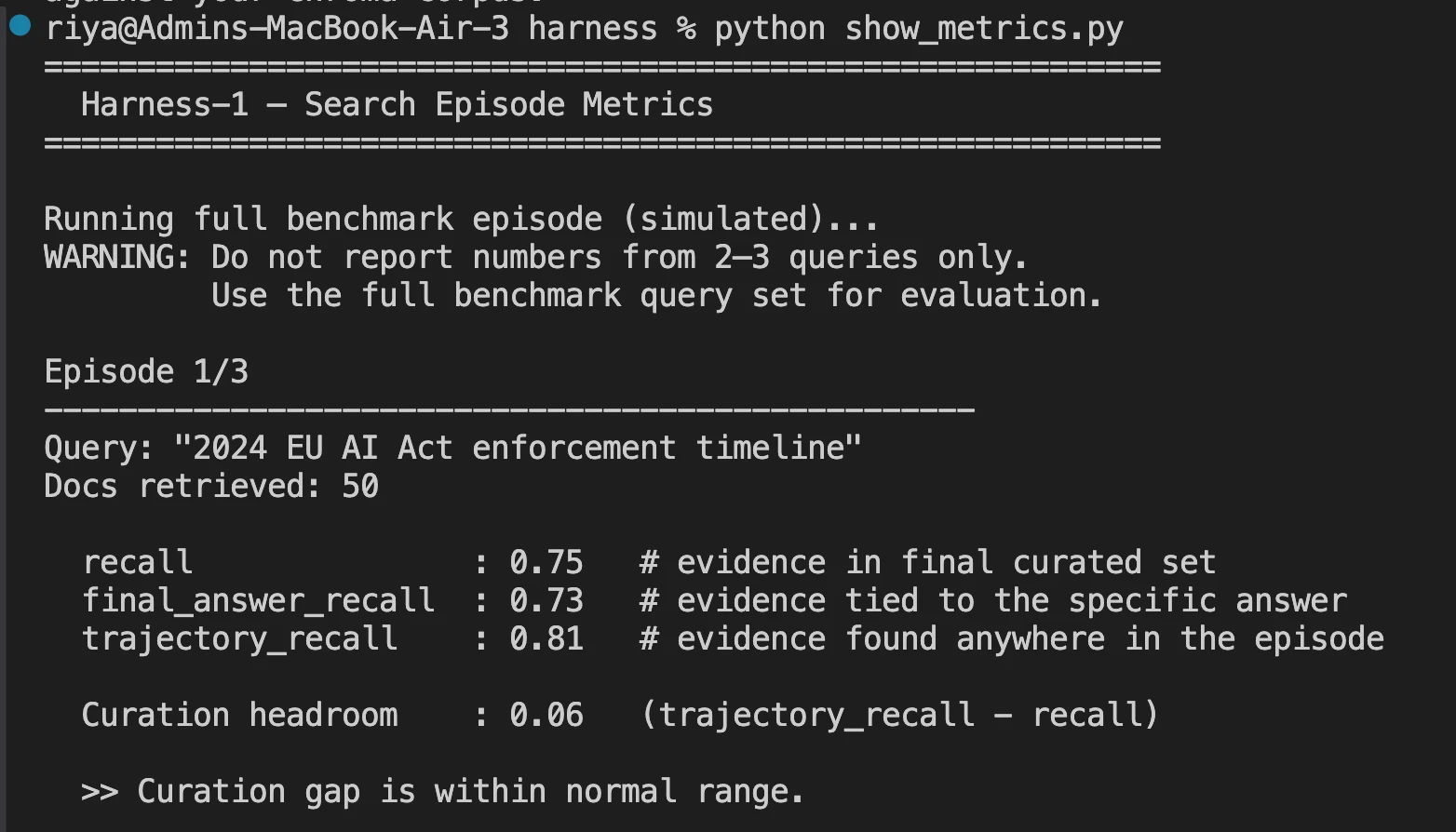
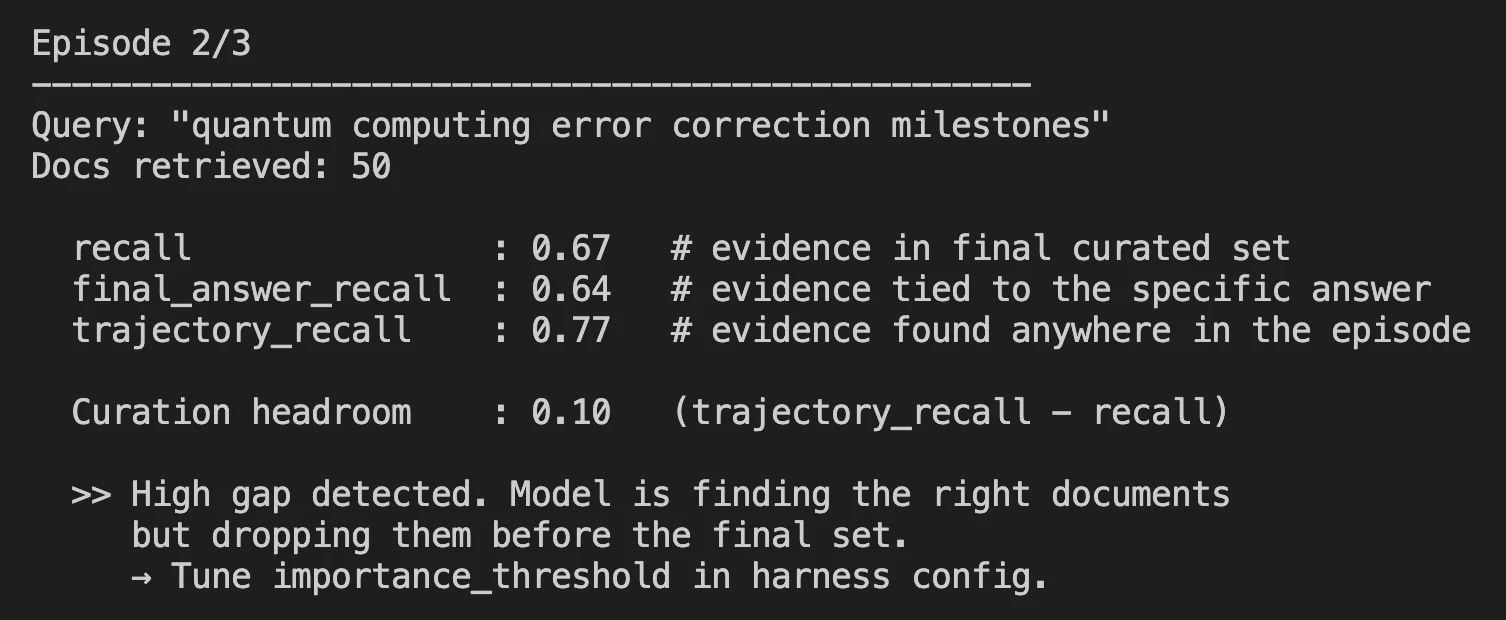
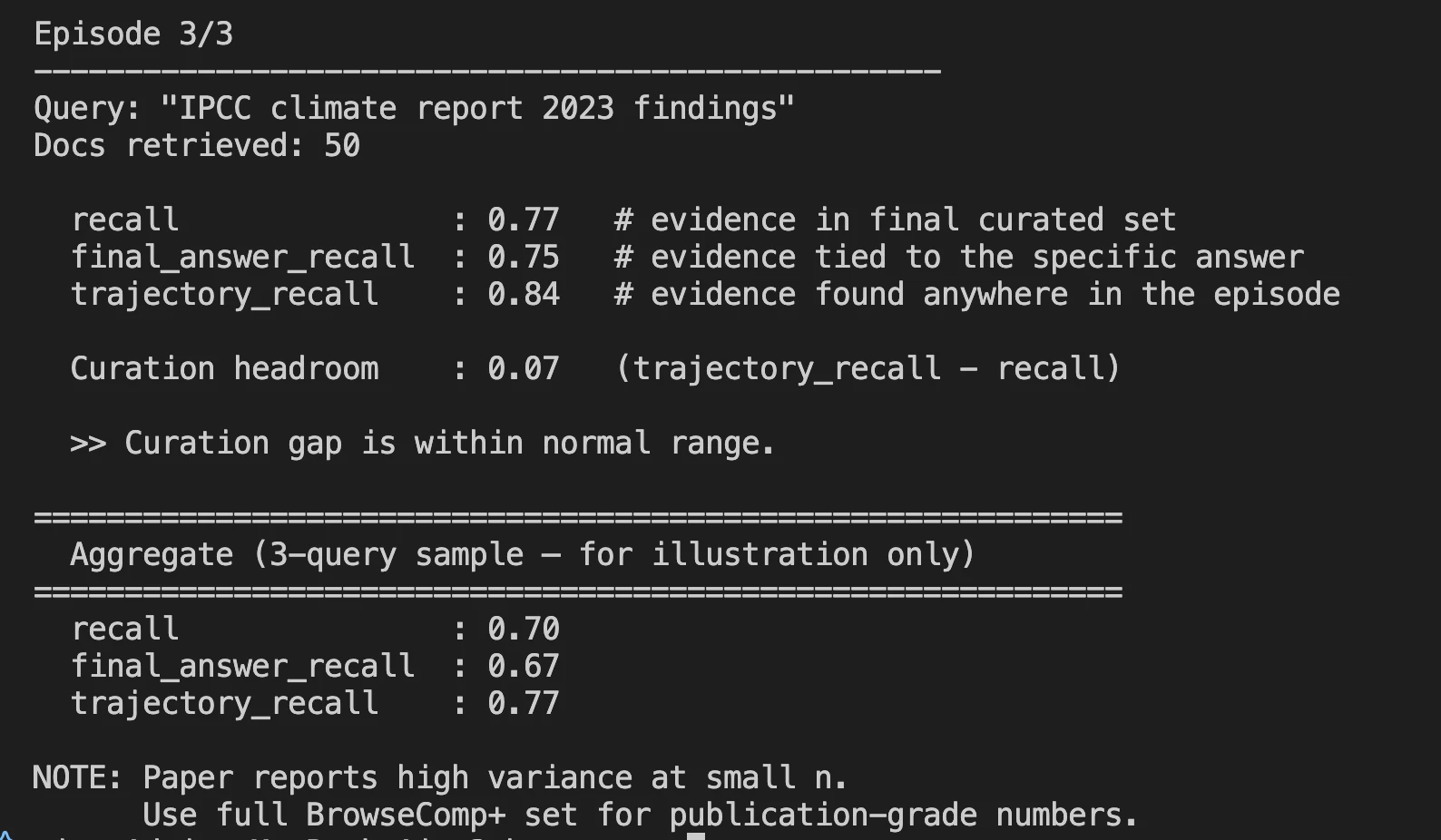
Benchmark Outcomes: The place It Stands
Harness-1 was examined towards eight totally different benchmarks, together with net search, SEC monetary filings, patents, and multi-hop query answering (QA).
Curated Recall is the core metric used to measure Harness-1 efficiency, that’s, what proportion of all related paperwork created by Harness-1 on the closing output of 30 whole paperwork, made it into the output.
| Mannequin | Measurement | Curated Recall | Trajectory Recall |
|---|---|---|---|
| Harness-1 | 20B open | 0.730 | 0.807 |
| Tongyi DeepResearch | 30B open | 0.616 | 0.673 |
| Context-1 | 20B open | 0.603 | 0.756 |
| Search-R1 | 32B open | 0.289 | 0.289 |
| Opus-4.6 | frontier | 0.764 | 0.794 |
| GPT-5.4 | frontier | 0.709 | 0.752 |
| Sonnet-4.6 | frontier | 0.688 | 0.725 |
| Kimi-K2.5 | frontier | 0.647 | 0.794 |
What Harness-1 Doesn’t Do?
It’s a retrieval subagent, which returns a ranked doc set and doesn’t carry out any reasoning, summarizing, or synthesizing a solution from that doc set. Subsequently, the downstream answering mannequin isn’t thought-about in scope.
The RL coaching was solely carried out on SEC queries, however it’s promising to see the switch efficiency onto web-based, patent and multi-hop QA queries. Nonetheless, we didn’t think about area generalization as a part of the coaching setup. Monetary doc construction is essentially totally different than the multi-hop chains of the Wikipedia.
Moreover, 899 SFT trajectories represent a comparatively small dataset. Moreover, the instructor was GPT-5.4, which is pricey. Subsequently, it stays an open query as to methods to scale the trajectory assortment course of.
Conclusion
Harness-1 type of exhibits that modular AI techniques find yourself stacking up higher than the monolithic type. Like, a 20B mannequin, educated on a slender process, with a well-designed harness, finally ends up doing higher than frontier fashions which have 5 instances the parameters. It’s not just some structure victory both, it feels extra like a recipe, actually.
The weights plus the harness code are public, so if you’re constructing something with retrieval like RAG pipelines, analysis brokers, doc Q/A, all that stuff, this setup is value a cautious look.
Additionally, there’s a cause the open-weights leaderboard has been just about carried by frontier fashions for the final yr. Harness-1 is essentially the most direct counterpoint thus far.
Regularly Requested Questions
A. Harness-1 is a 20B open retrieval subagent designed to enhance search and doc curation.
A. It separates search from state administration, maintaining mannequin context cleaner and lowering noisy retrieval indicators.
A. It doesn’t summarize or cause over paperwork; it solely returns a ranked doc set.
Information Science Trainee at Analytics Vidhya
I’m at present working as a Information Science Trainee at Analytics Vidhya, the place I give attention to constructing data-driven options and making use of AI/ML strategies to unravel real-world enterprise issues. My work permits me to discover superior analytics, machine studying, and AI functions that empower organizations to make smarter, evidence-based selections.
With a robust basis in laptop science, software program improvement, and information analytics, I’m obsessed with leveraging AI to create impactful, scalable options that bridge the hole between know-how and enterprise.
📩 You may also attain out to me at [email protected]
Login to proceed studying and revel in expert-curated content material.