
: A Tremendous Highly effective and Open Massive Audio-Language Mannequin")
{kind=link}
Understanding audio has at all times been the multimodal frontier that lags behind imaginative and prescient. Whereas image-language fashions have quickly scaled towards real-world deployment, constructing open fashions that robustly cause over speech, environmental sounds, and music — particularly at size — has remained fairly onerous. NVIDIA and the College of Maryland researchers at the moment are taking a direct swing at that hole.
The analysis crew have launched Audio Flamingo Subsequent (AF-Subsequent), essentially the most succesful mannequin within the Audio Flamingo sequence and a totally open Massive Audio-Language Mannequin (LALM) educated on internet-scale audio information.
Audio Flamingo Subsequent (AF-Subsequent) is available in three specialised variants for various use instances. The discharge consists of AF-Subsequent-Instruct for common query answering, AF-Subsequent-Suppose for superior multi-step reasoning, and AF-Subsequent-Captioner for detailed audio captioning.
What’s a Massive Audio-Language Mannequin (LALM)?
A Massive Audio-Language Mannequin (LALM) pairs an audio encoder with a decoder-only language mannequin to allow query answering, captioning, transcription, and reasoning instantly over audio inputs. Consider it because the audio equal of a vision-language mannequin like LLaVA or GPT-4V, however designed to deal with speech, environmental sounds, and music concurrently — inside a single unified mannequin.
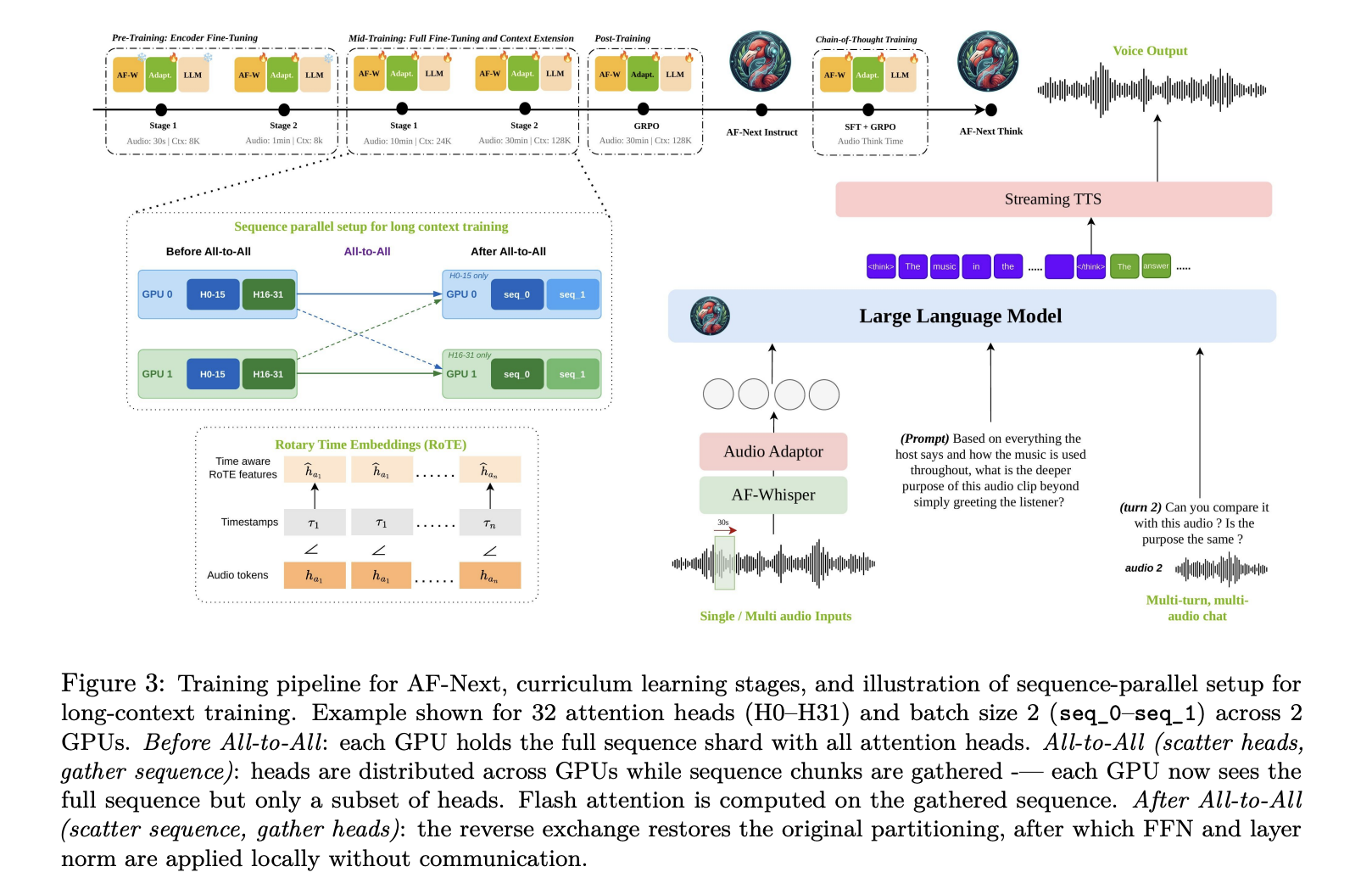
The Structure: 4 Parts Working in a Pipeline
AF-Subsequent is constructed round 4 principal elements: First is the AF-Whisper audio encoder, a customized Whisper-based encoder additional pre-trained on a bigger and extra various corpus, together with multilingual speech and multi-talker ASR information. Given an audio enter, the mannequin resamples it to 16 kHz mono and converts the waveform right into a 128-channel log mel-spectrogram utilizing a 25 ms window and 10 ms hop dimension. The spectrogram is processed in non-overlapping 30-second chunks by AF-Whisper, which outputs options at 50 Hz, after which a stride-2 pooling layer is utilized. The hidden dimension is 1280.
Second is the audio adaptor, a 2-layer MLP that maps AF-Whisper’s audio representations into the language mannequin’s embedding house. Third is the LLM spine: Qwen-2.5-7B, a decoder-only causal mannequin with 7B parameters, 36 transformer layers, and 16 consideration heads, with context size prolonged from 32k to 128k tokens by further long-context coaching.
A delicate however essential architectural element is Rotary Time Embeddings (RoTE). Normal positional encodings in transformers index a token by its discrete sequence place i. RoTE replaces this: as an alternative of the usual RoPE rotation angle θ ← −i · 2π, RoTE makes use of θ ← −τi · 2π, the place τi is every token’s absolute timestamp. For audio tokens produced at a hard and fast 40 ms stride, discrete time positions are interpolated earlier than being fed into the RoTE module. This yields positional representations grounded in precise time slightly than sequence order — a core design alternative enabling the mannequin’s temporal reasoning, notably for lengthy audio. Lastly, a streaming TTS module allows voice-to-voice interplay.
Temporal Audio Chain-of-Thought: The Key Reasoning Recipe
Chain-of-Thought (CoT) prompting has improved reasoning throughout textual content and imaginative and prescient fashions, however prior audio CoT work confirmed solely small positive factors as a result of coaching datasets had been restricted to brief clips with easy questions. AF-Subsequent addresses this with Temporal Audio Chain-of-Thought, the place the mannequin explicitly anchors every intermediate reasoning step to a timestamp within the audio earlier than producing a solution, encouraging trustworthy proof aggregation and decreasing hallucination over lengthy recordings.
To coach this functionality, the analysis crew created AF-Suppose-Time, a dataset of query–reply–thinking-chain triplets curated from difficult audio sources together with trailers, film recaps, thriller tales, and long-form multi-party conversations. AF-Suppose-Time consists of roughly 43K coaching samples, with a mean of 446.3 phrases per pondering chain.
Coaching at Scale: 1 Million Hours, 4 Levels
The ultimate coaching dataset includes roughly 108 million samples and roughly 1 million hours of audio, drawn from each current publicly launched datasets and uncooked audio collected from the open web and subsequently labeled synthetically. New information classes launched embrace over 200K lengthy movies spanning 5 to half-hour for long-form captioning and QA, multi-talker speech understanding information protecting speaker identification, interruption identification, and goal speaker ASR, roughly 1 million samples for multi-audio reasoning throughout a number of simultaneous audio inputs, and roughly 386K security and instruction-following samples.
Coaching follows a four-stage curriculum, every with distinct information mixtures and context lengths. Pre-training has two sub-stages: Stage 1 trains solely the audio adaptor whereas retaining each AF-Whisper and the LLM frozen (max audio 30 seconds, 8K token context); Stage 2 moreover fine-tunes the audio encoder whereas nonetheless retaining the LLM frozen (max audio 1 minute, 8K token context). Mid-training additionally has two sub-stages: Stage 1 performs full fine-tuning of the whole mannequin, including AudioSkills-XL and newly curated information (max audio 10 minutes, 24K token context); Stage 2 introduces long-audio captioning and QA, down-sampling the Stage 1 combination to half its authentic mix weights whereas increasing context to 128K tokens and audio to half-hour. The mannequin ensuing from mid-training is particularly launched as AF-Subsequent-Captioner. Publish-training applies GRPO-based reinforcement studying specializing in multi-turn chat, security, instruction following, and chosen skill-specific datasets, producing AF-Subsequent-Instruct. Lastly, CoT-training begins from AF-Subsequent-Instruct, applies SFT on AF-Suppose-Time, then GRPO utilizing the post-training information combination, producing AF-Subsequent-Suppose.
One notable contribution from the analysis crew is hybrid sequence parallelism, which makes 128K-context coaching possible on lengthy audio. With out it, audio token growth blows previous commonplace context home windows and the quadratic reminiscence value of self-attention turns into infeasible. The answer combines Ulysses consideration — which makes use of all-to-all collectives to distribute sequence and head dimensions inside nodes the place high-bandwidth interconnects can be found — with Ring consideration, which circulates key-value blocks throughout nodes through point-to-point transfers. Ulysses handles intra-node communication effectively; Ring scales throughout nodes.
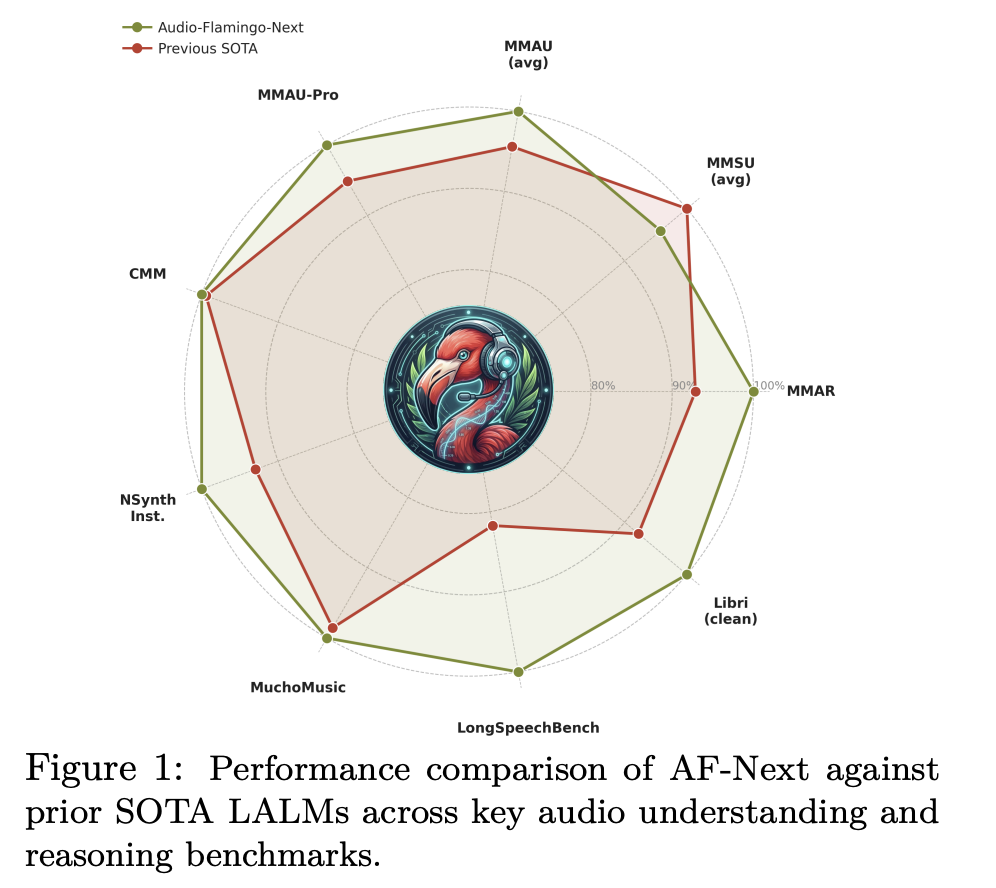
Benchmark Outcomes: Robust Throughout the Board
On MMAU-v05.15.25, essentially the most extensively used audio reasoning benchmark, AF-Subsequent-Instruct achieves a mean accuracy of 74.20 vs. Audio Flamingo 3’s 72.42, with AF-Subsequent-Suppose reaching 75.01 and AF-Subsequent-Captioner pushing to 75.76 — with positive factors throughout all three subcategories: sound (79.87), music (75.3), and speech (72.13). On the tougher MMAU-Professional benchmark, AF-Subsequent-Suppose (58.7) surpasses the closed-source Gemini-2.5-Professional (57.4).
Music understanding sees notably robust positive factors. On Medley-Solos-DB instrument recognition, AF-Subsequent reaches 92.13 vs. Audio Flamingo 2’s 85.80. On SongCaps music captioning, GPT5 protection and correctness scores leap from 6.7 and 6.2 (AF3) to eight.8 and eight.9 respectively.
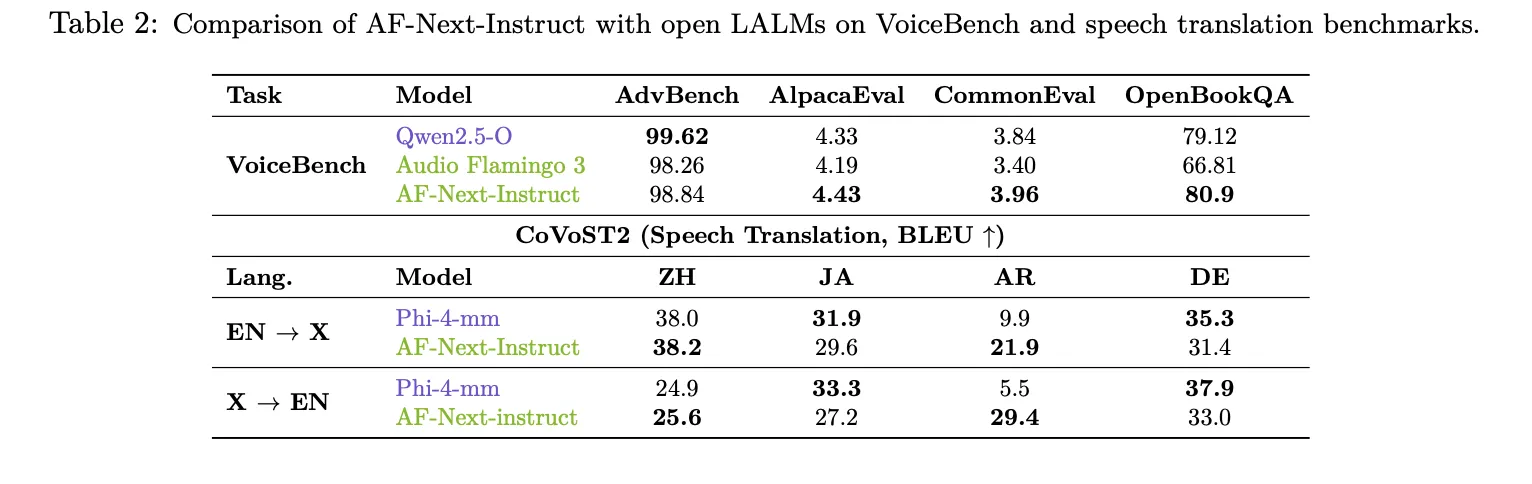
Lengthy-audio understanding is the place AF-Subsequent most clearly separates itself. On LongAudioBench, AF-Subsequent-Instruct achieves 73.9, outperforming each Audio Flamingo 3 (68.6) and the closed-source Gemini 2.5 Professional (60.4). On the speech-inclusive variant (+Speech), AF-Subsequent reaches 81.2 vs. Gemini 2.5 Professional’s 66.2. On ASR, AF-Subsequent-Instruct units new lows amongst LALMs with a Phrase Error Price of 1.54 on LibriSpeech test-clean and a pair of.76 on test-other. On VoiceBench, AF-Subsequent-Instruct achieves the best scores on AlpacaEval (4.43), CommonEval (3.96), and OpenBookQA (80.9), surpassing Audio Flamingo 3 by over 14 factors on OpenBookQA. On CoVoST2 speech translation, AF-Subsequent reveals a very notable 12-point enchancment over Phi-4-mm on Arabic EN→X translation (21.9 vs. 9.9).
Key Takeaways
Listed below are 5 key takeaways:
- A Totally Open Audio-Language Mannequin at Web Scale: AF-Subsequent is taken into account the primary LALM to scale audio understanding to internet-scale information — roughly 108 million samples and 1 million hours of audio.
- Temporal Audio Chain-of-Thought Solves Lengthy-Audio Reasoning: Relatively than reasoning like prior CoT approaches, AF-Subsequent explicitly anchors every intermediate reasoning step to a timestamp within the audio earlier than producing a solution. This makes the mannequin considerably extra trustworthy and interpretable on lengthy recordings as much as half-hour — an issue prior fashions largely sidestepped.
- Three Specialised Variants for Completely different Use Circumstances: The discharge consists of AF-Subsequent-Instruct for common query answering, AF-Subsequent-Suppose for superior multi-step reasoning, and AF-Subsequent-Captioner for detailed audio captioning — permitting practitioners to pick the precise mannequin based mostly on their activity slightly than utilizing a one-size-fits-all checkpoint.
- Beats Closed Fashions on Lengthy Audio Regardless of Being Smaller On LongAudioBench, AF-Subsequent-Instruct scores 73.9 — outperforming the closed-source Gemini 2.5 Professional (60.4) and Audio Flamingo 3 (68.6). On the tougher speech-inclusive variant, the hole widens additional, with AF-Subsequent reaching 81.2 vs. Gemini 2.5 Professional’s 66.2.
Take a look at the Paper, Undertaking Web page and Mannequin Weights. Additionally, be at liberty to comply with us on Twitter and don’t neglect to affix our 130k+ ML SubReddit and Subscribe to our E-newsletter. Wait! are you on telegram? now you’ll be able to be a part of us on telegram as properly.
Must accomplice with us for selling your GitHub Repo OR Hugging Face Web page OR Product Launch OR Webinar and so on.? Join with us