

{kind=link}
NVIDIA researchers have launched Nemotron-Labs-Diffusion, a language mannequin household that unifies three decoding modes in a single structure. The mannequin helps autoregressive (AR) decoding, diffusion-based parallel decoding, and self-speculation decoding. It’s out there in 3B, 8B, and 14B parameter sizes. The household consists of base, instruct, and vision-language variants.
Sequential Decoding Limits Throughput
Normal autoregressive (AR) language fashions generate textual content one token at a time, left to proper. Every token relies on all earlier tokens. This sequential dependency limits GPU parallelism per technology step. The result’s low {hardware} utilization at low batch sizes — the standard setting for single-user or edge deployment.
Diffusion language fashions (LMs) supply a unique strategy. As a substitute of producing tokens sequentially, they denoise a number of tokens in parallel per ahead cross. This allows increased throughput. The tradeoff has been accuracy: diffusion LMs have constantly lagged behind AR fashions on benchmarks, requiring considerably extra information to achieve comparable efficiency. A key purpose is that diffusion coaching treats all token permutations uniformly, reasonably than leveraging the robust left-to-right prior inherent in pure language.
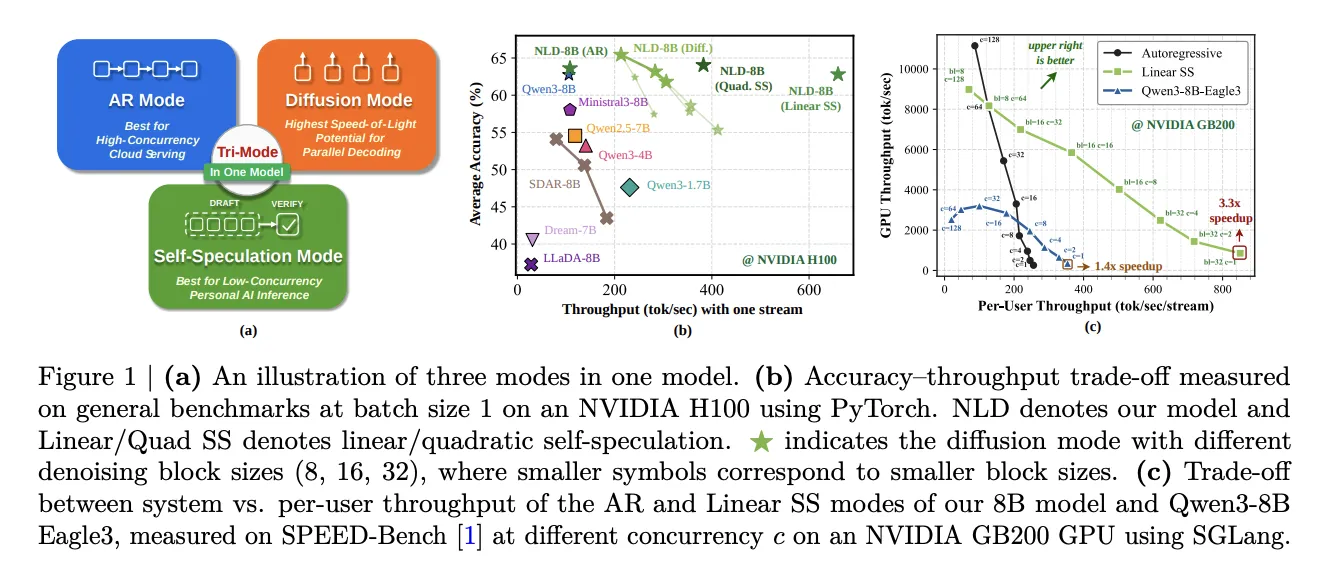
What Is a Tri-Mode Language Mannequin?
Nemotron-Labs-Diffusion is educated on a joint AR-diffusion goal. At inference time, it operates in three modes relying on the deployment context. There aren’t any mode-specific architectural modifications — the identical weights serve all three modes.
AR mode is customary left-to-right autoregressive decoding utilizing causal consideration. This mode is greatest suited to high-concurrency cloud serving.
Diffusion mode denoises a number of tokens in parallel inside a fixed-length block. The sequence is partitioned into contiguous blocks. Inside every block, tokens attend bidirectionally. Throughout blocks, consideration stays causal, so prior blocks can reuse their KV cache. A light-weight educated sampler predicts, per masked place, whether or not the mannequin’s top-1 prediction on the present denoising step is right. Positions predicted as right are dedicated in that step. This permits the mannequin to commit a number of tokens per ahead cross.
Self-speculation mode makes use of the diffusion pathway to draft candidate tokens and the AR pathway to confirm them, inside the similar single mannequin. No auxiliary draft mannequin or separate prediction head is required. The diffusion pathway generates a block of okay candidate tokens in parallel. The AR pathway then runs a second ahead cross over these candidates utilizing causal consideration, verifying the longest contiguous prefix that matches AR predictions. Every cycle produces between 1 and okay+1 verified tokens. This contrasts with Multi-Token Prediction (MTP) strategies comparable to Eagle3, which use small auxiliary draft heads connected to an AR spine.
Coaching
The joint coaching goal combines an AR next-token prediction loss and a block-wise diffusion denoising loss:
ℒ(θ) = ℒ_AR(θ) + α · ℒ_diff(θ)
The coefficient α is about to 0.3 throughout all coaching levels. Ablation experiments various α from 0.1 to 1.0 present that each AR-mode and diffusion-mode accuracy peak at α = 0.3. No worth within the vary [0.1, 0.5] improves one mode on the expense of the opposite — the 2 targets rise and fall collectively.
Two-stage coaching first trains the mannequin purely on the AR goal for 1 trillion tokens, constructing robust left-to-right linguistic priors. Stage 2 then introduces the joint goal for 300 billion further tokens. In ablations, two-stage coaching contributed +5.74% common accuracy. Including the AR loss contributed the one largest acquire at +7.48%. International loss averaging — treating all tokens throughout a batch equally reasonably than averaging per-sequence first — contributed +2.12% by decreasing gradient variance from variable diffusion masking ratios. Cumulatively, the complete coaching pipeline improved the baseline by 16.05% common accuracy.
All fashions are initialized from pretrained Ministral3 base fashions, not educated from scratch. Coaching was carried out on 256 NVIDIA H100 GPUs. Instruct fashions are educated through supervised fine-tuning (SFT) on 45 billion tokens on high of the bottom fashions, utilizing the identical joint AR-diffusion goal with α = 0.3. The coaching and inference pipeline is launched by way of Megatron Bridge.
LoRA-Enhanced Linear Self-Hypothesis
The bottom diffusion-to-AR alignment in self-speculation may be improved with a LoRA adapter. This adapter is fine-tuned on the diffusion draft pathway to raised align its output with the AR verifier. It targets solely the o_proj layer of the eye module (rank 128, α = 512, roughly 36M trainable parameters, 0.4% of the spine). LoRA tuning improves tokens per ahead (TPF) by 14.4%, 32.5%, and 27.6% on the 3B, 8B, and 14B scales respectively, with negligible accuracy change.
Velocity-of-Gentle Evaluation
The analysis workforce stories a speed-of-light (SOL) evaluation — a theoretical higher sure on tokens per ahead cross achievable by the diffusion mode, assuming an oracle sampler that appropriately identifies all positions that may be safely dedicated in parallel.
At block size 32, the SOL acceptance price reaches 7.60× on common, exceeding 10× on coding and multilingual duties. Present confidence-based sampling achieves roughly 3× TPF at comparable accuracy, leaving a big hole to the SOL ceiling.
Evaluating towards linear self-speculation: each strategy related acceptance charges (6.82× for linear self-speculation vs. 7.60× SOL). Nevertheless, the true tokens per ahead cross (TPF) hole is far bigger — 6.02× for SOL versus 3.41× for linear self-speculation, a 76.5% distinction. Linear self-speculation requires two ahead passes per cycle (one diffusion draft, one AR confirm) and accepts solely a contiguous prefix. These two constraints cap its actual TPF nicely under SOL, even when drafter and verifier are nicely aligned.
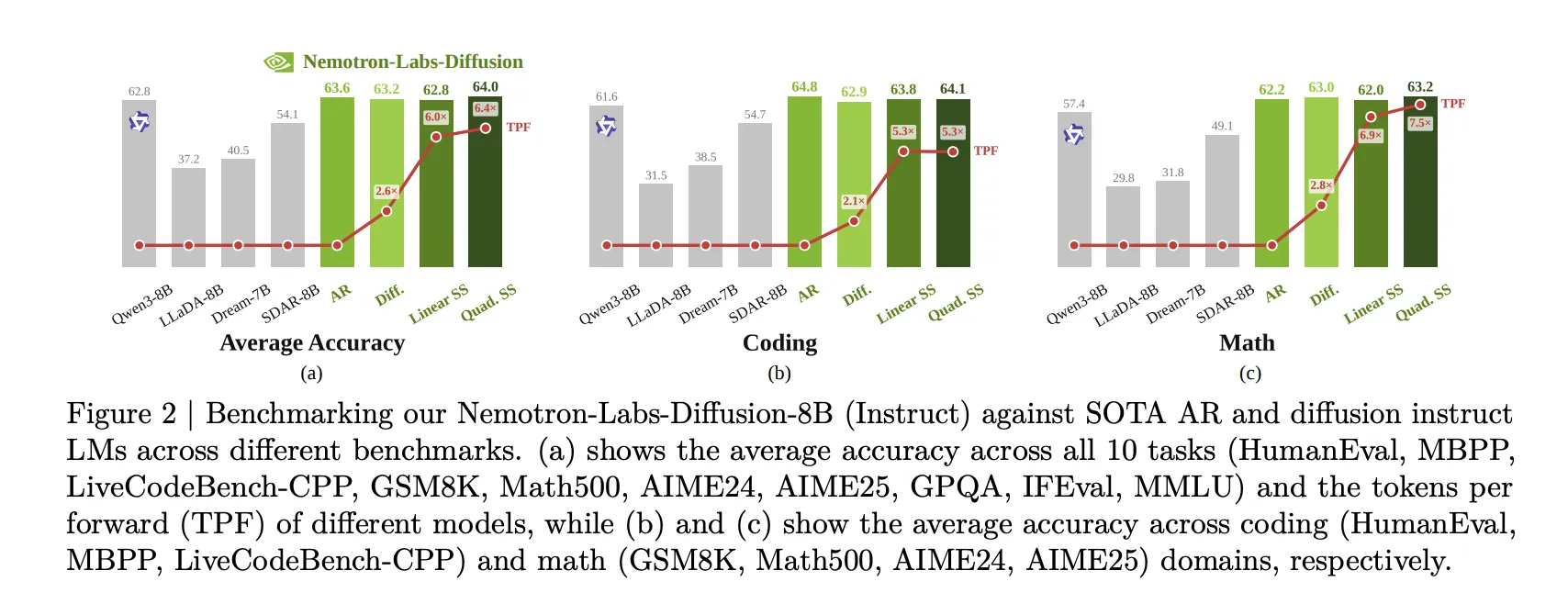
Benchmark Outcomes
On the 10-task instruct analysis (HumanEval, MBPP, LiveCodeBench-CPP, GSM8K, Math500, AIME24, AIME25, GPQA, IFEval, MMLU):
- NLD-8B AR mode: 63.61% common accuracy, versus 62.75% for Qwen3-8B and 58.02% for Ministral3-8B-Instruct.
- NLD-8B diffusion mode: 63.18% common accuracy with 2.57× TPF.
- NLD-8B LoRA-tuned linear self-speculation: 62.81% common accuracy with 5.99× TPF.
- NLD-8B quadratic self-speculation: 64.04% common accuracy with 6.38× TPF.
On SPEED-Bench with SGLang on an NVIDIA GB200 GPU, linear self-speculation achieves 4× increased throughput than Qwen3-8B and three.3× speedup over the NLD-8B AR mode at concurrency 1 (3.97× with an optimized CUDA kernel). In comparison with Qwen3-8B-Eagle3, linear self-speculation delivers a 2.4×, 2.3×, and 1.8× speedup at batch dimension 1 on GB200, RTX Professional 6000, and DGX Spark respectively.
Acceptance size is the underlying purpose for this benefit. Throughout SPEED-Bench classes, NLD achieves common acceptance lengths of 5.46 (native) and 6.82 (with LoRA) tokens per draft step. Eagle3 averages 2.75 and Qwen3-9B-MTP averages 4.24. On the 4 diffusion-friendly classes — coding, math, reasoning, and multilingual — the hole widens additional: 8.69 for NLD-LoRA versus 2.81 for Eagle3.
At 14B scale with LoRA-tuned linear self-speculation, NLD-14B achieves 66.36% common accuracy at 5.96× TPF, outperforming Qwen3-14B at 65.17% accuracy in AR mode.
The vision-language mannequin, Nemotron-Labs-Diffusion-VLM-8B, extends the identical framework to multimodal duties. In linear self-speculation mode, it achieves 3.63× to 7.45× TPF — the upper finish for responses over 200 tokens — with a 0.1% common accuracy drop versus AR mode.
Marktechpost’s Visible Explainer
Key Takeaways
- Nemotron-Labs-Diffusion unifies AR, diffusion, and self-speculation decoding in a single mannequin, with no mode-specific architectural modifications.
- Joint AR-diffusion coaching just isn’t a tradeoff — each targets peak at α=0.3 and enhance collectively.
- Self-speculation mode achieves 5.99× TPF on the 8B mannequin, with 2.4× increased throughput than Qwen3-8B-Eagle3 at batch dimension 1 on GB200.
- Increased acceptance size is the important thing differentiator: NLD-LoRA averages 6.82 tokens per draft step versus 2.75 for Eagle3 and 4.24 for MTP.
- Velocity-of-light evaluation reveals the diffusion mode has a theoretical ceiling of seven.60× TPF — present confidence-based sampling realizes solely ~3×, leaving important room for sampler enhancements.
Take a look at the Paper, Mannequin Weights and Technical particulars. Additionally, be at liberty to comply with us on Twitter and don’t neglect to hitch our 150k+ ML SubReddit and Subscribe to our E-newsletter. Wait! are you on telegram? now you’ll be able to be part of us on telegram as nicely.
Must companion with us for selling your GitHub Repo OR Hugging Face Web page OR Product Launch OR Webinar and so forth.? Join with us