

{kind=link}
Picture by Creator
# Introduction
Day by day, customer support facilities file 1000’s of conversations. Hidden in these audio information are goldmines of data. Are prospects glad? What issues do they point out most frequently? How do feelings shift throughout a name?
Manually analyzing these recordings is difficult. Nevertheless, with fashionable synthetic intelligence (AI), we will robotically transcribe calls, detect feelings, and extract recurring subjects — all offline and with open-source instruments.
On this article, I’ll stroll you thru an entire buyer sentiment analyzer mission. You’ll learn to:
- Transcribing audio information to textual content utilizing Whisper
- Detecting sentiment (constructive, damaging, impartial) and feelings (frustration, satisfaction, urgency)
- Extracting subjects robotically utilizing BERTopic
- Displaying ends in an interactive dashboard
The perfect half is that every thing runs domestically. Your delicate buyer information by no means leaves your machine.
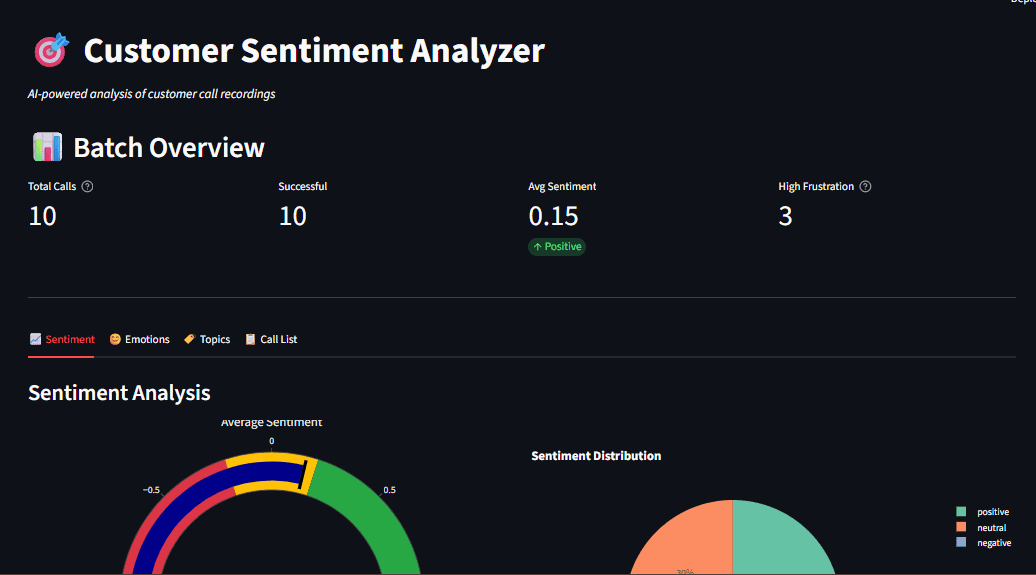
Fig 1: Dashboard overview exhibiting sentiment gauge, emotion radar, and subject distribution
# Understanding Why Native AI Issues for Buyer Knowledge
Cloud-based AI providers like OpenAI’s API are highly effective, however they arrive with issues comparable to privateness points, the place buyer calls usually include private data; excessive value, the place you pay per-API-call pricing, which provides up shortly for top volumes; and dependency on web fee limits. By working domestically, it’s simpler to satisfy information residency necessities.
This native AI speech-to-text tutorial retains every thing in your {hardware}. Fashions obtain as soon as and run offline eternally.
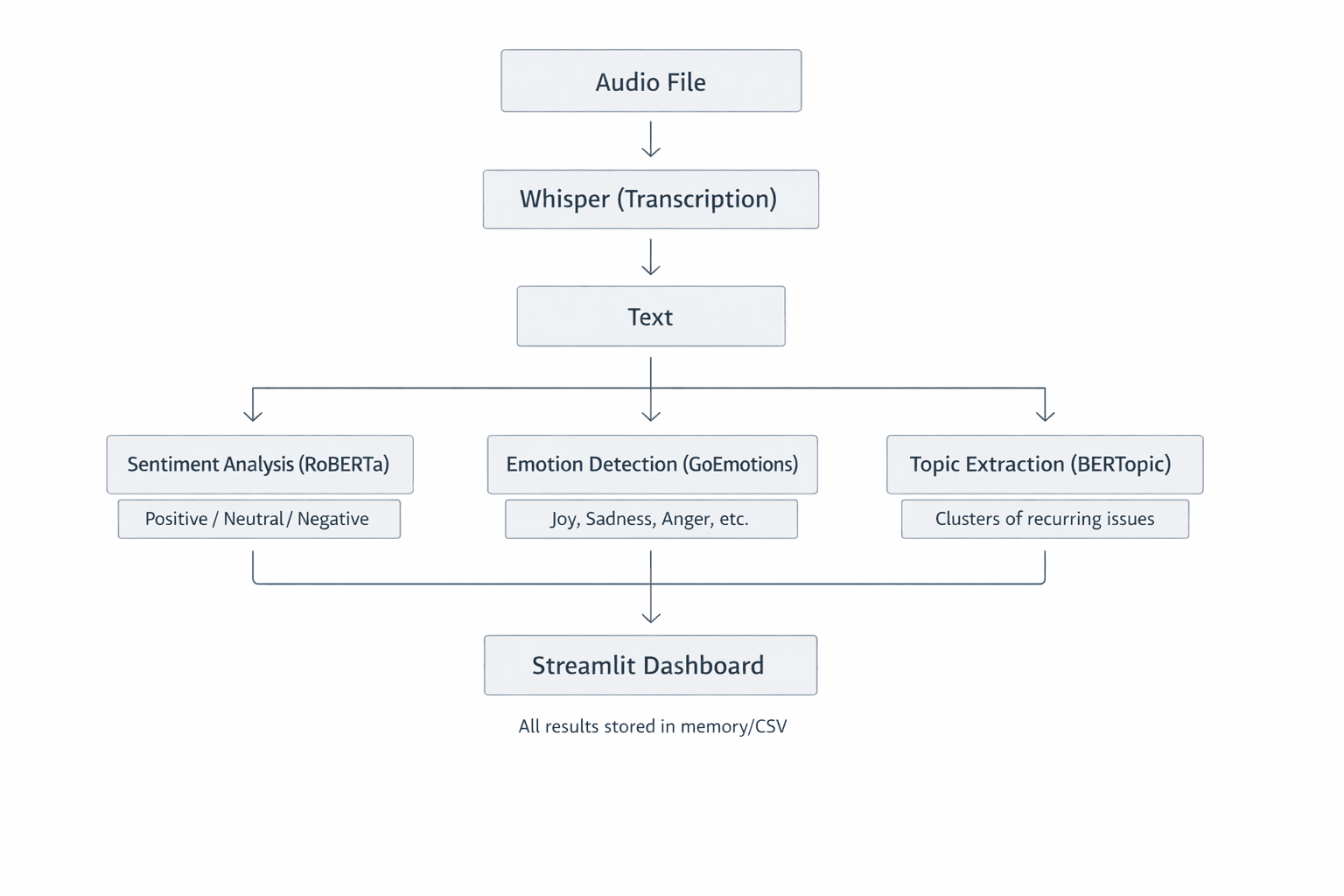
Fig 2: System Structure Overview exhibiting how every element handles one job properly. This modular design makes the system straightforward to know, take a look at, and lengthen
// Stipulations
Earlier than beginning, be sure to have the next:
- Python 3.9+ is put in in your machine.
- You need to have FFmpeg put in for audio processing.
- You need to have fundamental familiarity with Python and machine studying ideas.
- You want about 2GB of disk house for AI fashions.
// Setting Up Your Undertaking
Clone the repository and arrange your surroundings:
git clone https://github.com/zenUnicorn/Buyer-Sentiment-analyzer.git
Create a digital surroundings:
Activate (Home windows):
Activate (Mac/Linux):
Set up dependencies:
pip set up -r necessities.txt
The primary run downloads AI fashions (~1.5GB whole). After that, every thing works offline.
Fig 3: Terminal exhibiting profitable set up
# Transcribing Audio with Whisper
Within the buyer sentiment analyzer, step one is to show spoken phrases from name recordings into textual content. That is completed by Whisper, an computerized speech recognition (ASR) system developed by OpenAI. Let’s look into the way it works, why it is an ideal alternative, and the way we use it within the mission.
Whisper is a Transformer-based encoder-decoder mannequin educated on 680,000 hours of multilingual audio. Whenever you feed it an audio file, it:
- Resamples the audio to 16kHz mono
- Generates a mel spectrogram — a visible illustration of frequencies over time — which serves as a photograph of the sound
- Splits the spectrogram into 30-second home windows
- Passes every window by way of an encoder that creates hidden representations
- Interprets these representations into textual content tokens, one phrase (or sub-word) at a time
Consider the mel spectrogram as how machines “see” sound. The x-axis represents time, the y-axis represents frequency, and shade depth reveals quantity. The result’s a extremely correct transcript, even with background noise or accents.
Code Implementation
This is the core transcription logic:
import whisper
class AudioTranscriber:
def __init__(self, model_size="base"):
self.mannequin = whisper.load_model(model_size)
def transcribe_audio(self, audio_path):
consequence = self.mannequin.transcribe(
str(audio_path),
word_timestamps=True,
condition_on_previous_text=True
)
return {
"textual content": consequence["text"],
"segments": consequence["segments"],
"language": consequence["language"]
}
The model_size parameter controls accuracy vs. pace.
| Mannequin | Parameters | Pace | Greatest For |
|---|---|---|---|
| tiny | 39M | Quickest | Fast testing |
| base | 74M | Quick | Improvement |
| small | 244M | Medium | Manufacturing |
| giant | 1550M | Gradual | Most accuracy |
For many use circumstances, base or small presents one of the best stability.
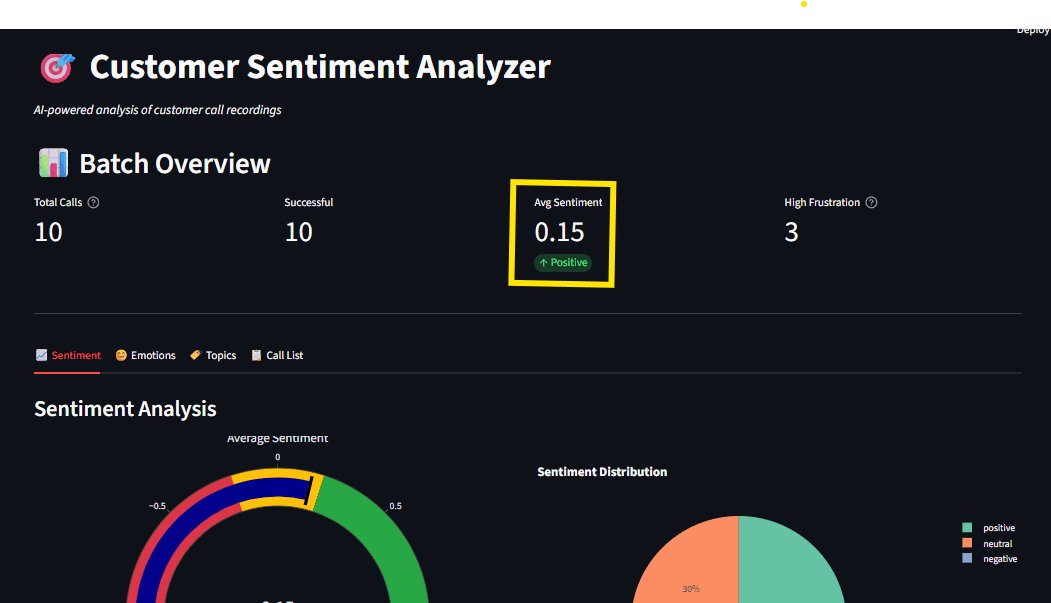
Fig 4: Transcription output exhibiting timestamped segments
# Analyzing Sentiment with Transformers
With textual content extracted, we analyze sentiment utilizing Hugging Face Transformers. We use CardiffNLP’s RoBERTa mannequin, educated on social media textual content, which is ideal for conversational buyer calls.
// Evaluating Sentiment and Emotion
Sentiment evaluation classifies textual content as constructive, impartial, or damaging. We use a fine-tuned RoBERTa mannequin as a result of it understands context higher than easy key phrase matching.
The transcript is tokenized and handed by way of a Transformer. The ultimate layer makes use of a softmax activation, which outputs possibilities that sum to 1. For instance, if constructive is 0.85, impartial is 0.10, and damaging is 0.05, then total sentiment is constructive.
- Sentiment: Total polarity (constructive, damaging, or impartial) answering the query: “Is that this good or unhealthy?”
- Emotion: Particular emotions (anger, pleasure, concern) answering the query: “What precisely are they feeling?”
We detect each for full perception.
// Code Implementation for Sentiment Evaluation
from transformers import AutoModelForSequenceClassification, AutoTokenizer
import torch.nn.purposeful as F
class SentimentAnalyzer:
def __init__(self):
model_name = "cardiffnlp/twitter-roberta-base-sentiment-latest"
self.tokenizer = AutoTokenizer.from_pretrained(model_name)
self.mannequin = AutoModelForSequenceClassification.from_pretrained(model_name)
def analyze(self, textual content):
inputs = self.tokenizer(textual content, return_tensors="pt", truncation=True)
outputs = self.mannequin(**inputs)
possibilities = F.softmax(outputs.logits, dim=1)
labels = ["negative", "neutral", "positive"]
scores = {label: float(prob) for label, prob in zip(labels, possibilities[0])}
return {
"label": max(scores, key=scores.get),
"scores": scores,
"compound": scores["positive"] - scores["negative"]
}
The compound rating ranges from -1 (very damaging) to +1 (very constructive), making it straightforward to trace sentiment traits over time.
// Why Keep away from Easy Lexicon Strategies?
Conventional approaches like VADER rely constructive and damaging phrases. Nevertheless, they usually miss context:
- “This isn’t good.” Lexicon sees “good” as constructive.
- A transformer understands negation (“not”) as damaging.
Transformers perceive relationships between phrases, making them way more correct for real-world textual content.
# Extracting Matters with BERTopic
Realizing sentiment is helpful, however what are prospects speaking about? BERTopic robotically discovers themes in textual content with out you having to pre-define them.
// How BERTopic Works
- Embeddings: Convert every transcript right into a vector utilizing Sentence Transformers
- Dimensional Discount: UMAP compresses these vectors right into a low-dimensional house
- Clustering: HDBSCAN teams related transcripts collectively
- Subject Illustration: For every cluster, extract probably the most related phrases utilizing c-TF-IDF
The result’s a set of subjects like “billing points,” “technical assist,” or “product suggestions.” In contrast to older strategies like Latent Dirichlet Allocation (LDA), BERTopic understands semantic which means. “Transport delay” and “late supply” cluster collectively as a result of they share the identical which means.
Code Implementation
From subjects.py:
from bertopic import BERTopic
class TopicExtractor:
def __init__(self):
self.mannequin = BERTopic(
embedding_model="all-MiniLM-L6-v2",
min_topic_size=2,
verbose=True
)
def extract_topics(self, paperwork):
subjects, possibilities = self.mannequin.fit_transform(paperwork)
topic_info = self.mannequin.get_topic_info()
topic_keywords = {
topic_id: self.mannequin.get_topic(topic_id)[:5]
for topic_id in set(subjects) if topic_id != -1
}
return {
"assignments": subjects,
"key phrases": topic_keywords,
"distribution": topic_info
}
Notice: Subject extraction requires a number of paperwork (not less than 5-10) to search out significant patterns. Single calls are analyzed utilizing the fitted mannequin.
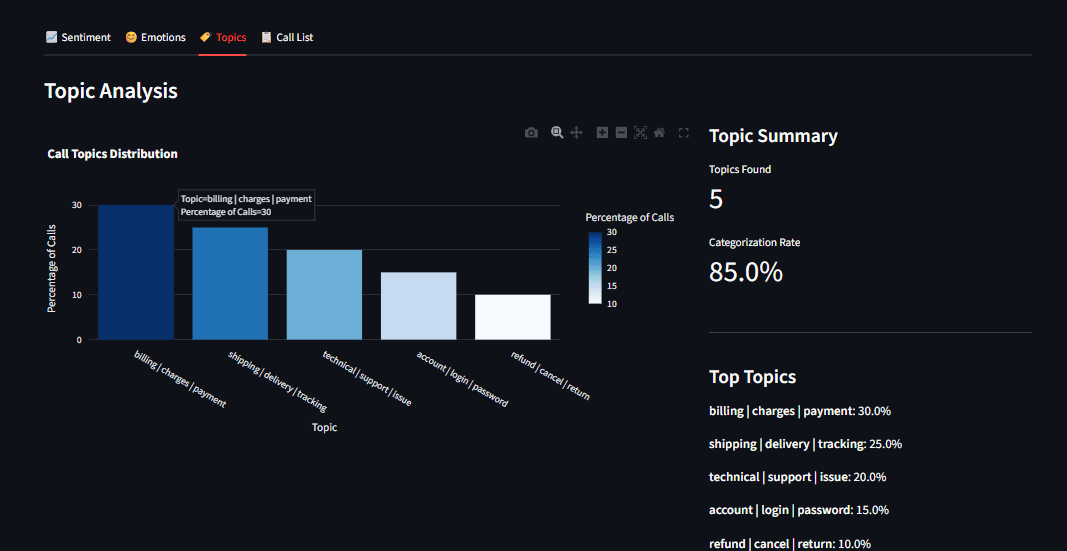
Fig 5: Subject distribution bar chart exhibiting billing, delivery, and technical assist classes
# Constructing an Interactive Dashboard with Streamlit
Uncooked information is difficult to course of. We constructed a Streamlit dashboard (app.py) that lets enterprise customers discover outcomes. Streamlit turns Python scripts into net functions with minimal code. Our dashboard gives:
- Add interface for audio information
- Actual-time processing with progress indicators
- Interactive visualizations utilizing Plotly
- Drill-down functionality to discover particular person calls
// Code Implementation for Dashboard Construction
import streamlit as st
def essential():
st.title("Buyer Sentiment Analyzer")
uploaded_files = st.file_uploader(
"Add Audio Recordsdata",
kind=["mp3", "wav"],
accept_multiple_files=True
)
if uploaded_files and st.button("Analyze"):
with st.spinner("Processing..."):
outcomes = pipeline.process_batch(uploaded_files)
# Show outcomes
col1, col2 = st.columns(2)
with col1:
st.plotly_chart(create_sentiment_gauge(outcomes))
with col2:
st.plotly_chart(create_emotion_radar(outcomes))
Streamlit’s caching @st.cache_resource ensures fashions load as soon as and persist throughout interactions, which is essential for a responsive person expertise.
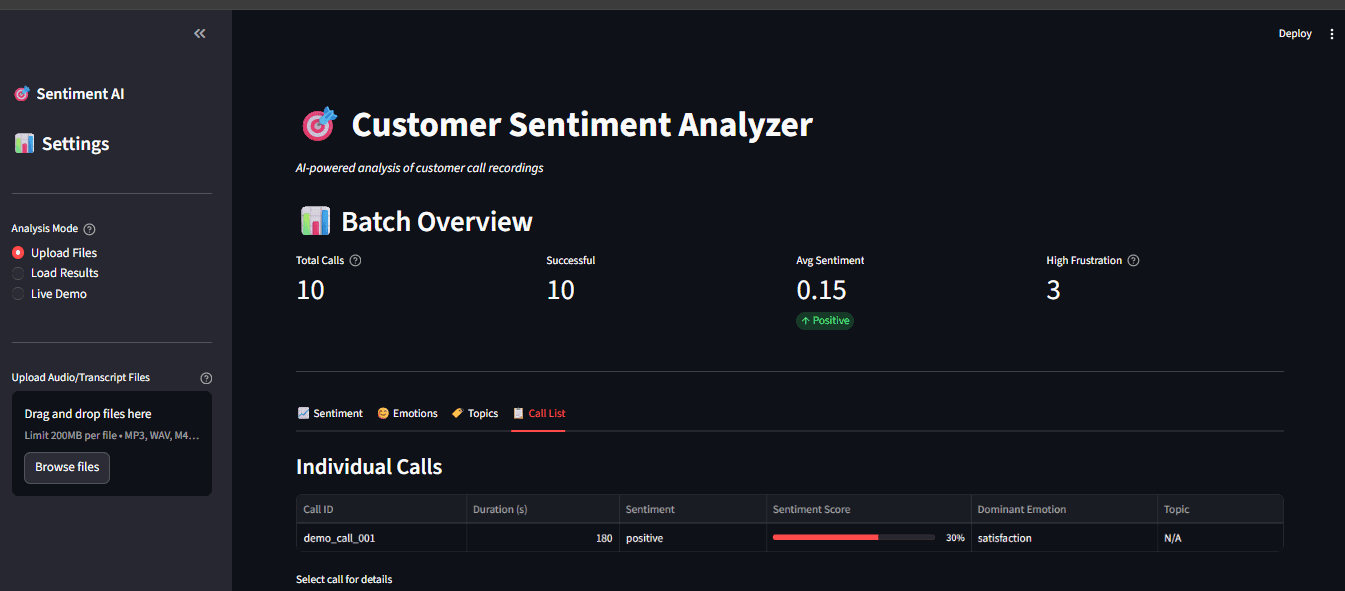
Fig 7: Full dashboard with sidebar choices and a number of visualization tabs
// Key Options
- Add audio (or use pattern transcripts for testing)
- View transcript with sentiment highlights
- Emotion timeline (if name is lengthy sufficient)
- Subject visualization utilizing Plotly interactive charts
// Caching for Efficiency
Streamlit re-runs the script on each interplay. To keep away from reprocessing heavy fashions, we use @st.cache_resource:
@st.cache_resource
def load_models():
return CallProcessor()
processor = load_models()
// Actual-Time Processing
When a person uploads a file, we present a spinner whereas processing, then instantly show outcomes:
if uploaded_file:
with st.spinner("Transcribing and analyzing..."):
consequence = processor.process_file(uploaded_file)
st.success("Completed!")
st.write(consequence["text"])
st.metric("Sentiment", consequence["sentiment"]["label"])
# Reviewing Sensible Classes
Audio Processing: From Waveform to Textual content
Whisper’s magic is in its mel spectrogram conversion. Human listening to is logarithmic, which means we’re higher at recognizing low frequencies than excessive ones. The mel scale mimics this, so the mannequin “hears” extra like a human. The spectrogram is actually a 2D picture (time vs. frequency), which the Transformer encoder processes equally to how it will course of a picture patch. For this reason Whisper handles noisy audio properly; it sees the entire image.
// Transformer Outputs: Softmax vs. Sigmoid
- Softmax (sentiment): Forces possibilities to sum to 1. That is ultimate for mutually unique lessons, as a sentence normally is not each constructive and damaging.
- Sigmoid (feelings): Treats every class independently. A sentence may be joyful and shocked on the similar time. Sigmoid permits for this overlap.
Choosing the proper activation is essential on your drawback area.
// Speaking Insights with Visualization
A great dashboard does greater than present numbers; it tells a narrative. Plotly charts are interactive; customers can hover to see particulars, zoom into time ranges, and click on legends to toggle information sequence. This transforms uncooked analytics into actionable insights.
// Working the Software
To run the applying, comply with the steps from the start of this text. Take a look at the sentiment and emotion evaluation with out audio information:
This runs pattern textual content by way of the pure language processing (NLP) fashions and shows ends in the terminal.
Analyze a single recording:
python essential.py --audio path/to/name.mp3
Batch course of a listing:
python essential.py --batch information/audio/
For the total interactive expertise:
python essential.py --dashboard
Open http://localhost:8501 in your browser.
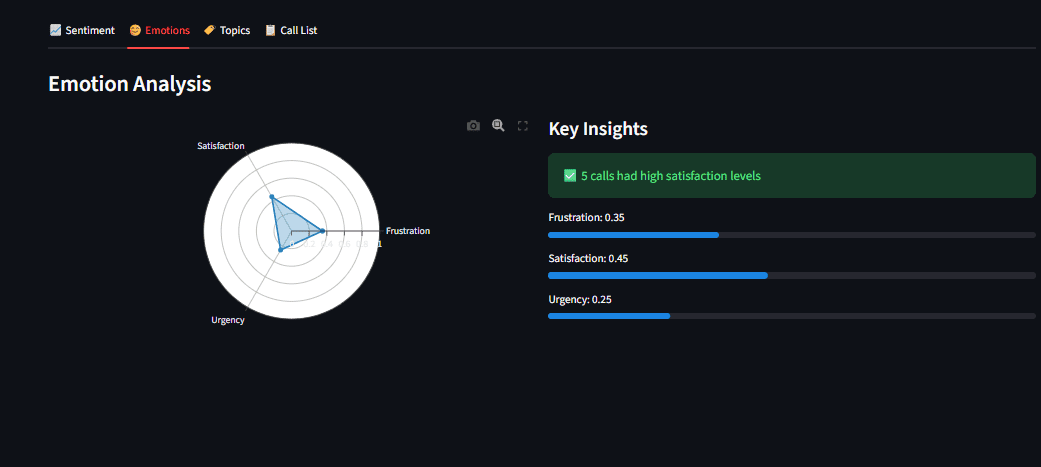
Fig 8: Terminal output exhibiting profitable evaluation with sentiment scores
# Conclusion
We’ve got constructed an entire, offline-capable system that transcribes buyer calls, analyzes sentiment and feelings, and extracts recurring subjects — all with open-source instruments. It is a production-ready basis for:
- Buyer assist groups figuring out ache factors
- Product managers gathering suggestions at scale
- High quality assurance monitoring agent efficiency
The perfect half? All the pieces runs domestically, respecting person privateness and eliminating API prices.
The entire code is out there on GitHub: An-AI-that-Analyze-customer-sentiment. Clone the repository, comply with this native AI speech-to-text tutorial, and begin extracting insights out of your buyer calls as we speak.
Shittu Olumide is a software program engineer and technical author enthusiastic about leveraging cutting-edge applied sciences to craft compelling narratives, with a eager eye for element and a knack for simplifying advanced ideas. You can even discover Shittu on Twitter.