

{kind=link}
Amazon’s Finance Know-how (FinTech) groups construct and function methods for Amazon groups to handle regulatory inquiries in compliance with completely different jurisdictions. These groups course of regulatory inquiries from authorities, every presenting completely different necessities, doc codecs, and complexity ranges.
Processing these regulatory inquiries includes reviewing documentation, extracting related info, retrieving supporting knowledge from a number of methods inside Amazon’s infrastructure, and compiling responses inside regulatory timeframes. As inquiry frequency and enterprise complexity grew, Amazon wanted a extra scalable strategy.
On this publish, we reveal how Amazon FinTech groups are utilizing Amazon Bedrock and different AWS companies to construct a scalable AI software to rework how regulatory inquiries are dealt with. Every group utilizing this resolution creates and maintains its personal devoted data base, populated with that group’s particular paperwork and reference supplies.
Challenges
The size and complexity of managing regulatory inquiries offered a number of interconnected challenges:
Data fragmentation and retrieval complexity
Regulatory inquiries require synthesizing info from hundreds of historic paperwork. These paperwork exist in varied codecs (PDF, PPT, Phrase, CSV) and include domain-specific terminology. Groups wanted a approach to rapidly find related precedents and supporting info throughout this huge corpus whereas sustaining accuracy and regulatory compliance.
Conversational context and state administration
Regulatory inquiries require multi-turn conversations the place context from earlier interactions is important for producing correct responses. Sustaining conversational state throughout periods and monitoring response evolution as group members refine solutions by iterative interactions presents important complexity.
Observability and steady enchancment
With generative AI methods, understanding why a specific response was generated is as necessary because the response itself. Groups required complete visibility into the retrieval course of, mannequin selections, and person interactions to determine areas for enchancment and preserve compliance with accountable AI rules. For instance, groups should detect when the mannequin hallucinates info that isn’t current in supply paperwork, or catch when the system retrieves outdated compliance tips that might result in regulatory violations. AI methods expertise accuracy drift over time as fashions, prompts, and the doc corpus change, requiring steady monitoring.
Resolution overview
To handle these challenges, Amazon FinTech group constructed an clever regulatory response automation system utilizing Amazon Bedrock, AWS Lambda, and supporting AWS companies. The answer implements Retrieval Augmented Era (RAG) with Amazon Bedrock Data Bases and Amazon OpenSearch Serverless for vector storage, enabling info retrieval from hundreds of historic paperwork. Actual-time chat interactions powered by Claude Sonnet 4.5 by the Converse Stream API, mixed with Amazon DynamoDB for dialog historical past administration, present contextually-aware multi-turn conversations. Complete observability by OpenTelemetry and self-hosted Langfuse ensures steady monitoring and enchancment of the AI system’s efficiency. The system doesn’t cache massive language mannequin (LLM) responses or intermediate outcomes as a result of regulatory inquiries are extremely contextual and are vulnerable to a low cache hit charge.
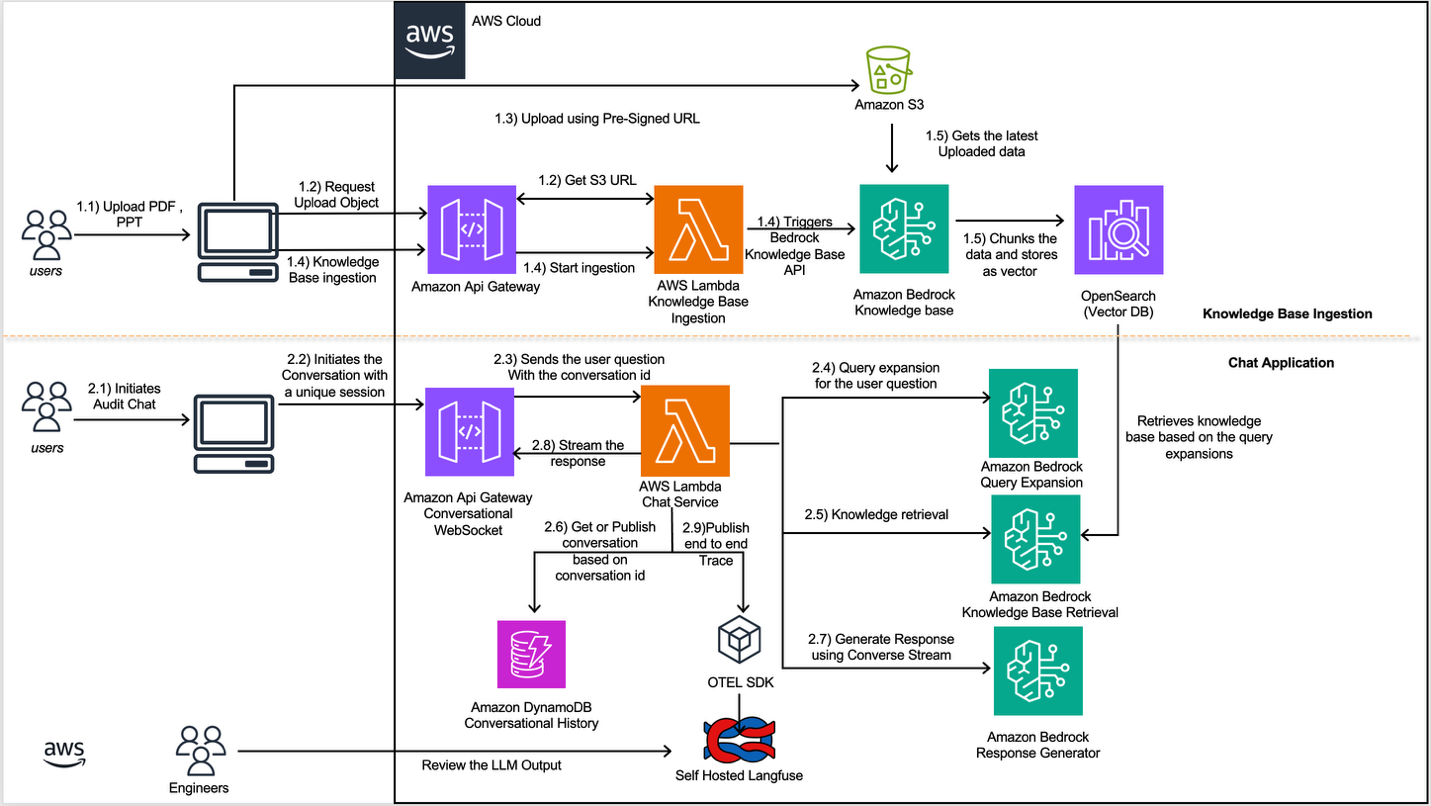
The next diagram exhibits how you should utilize Amazon Bedrock Data Bases in a workflow, alongside Converse API and different instruments, to offer vital info for regulatory inquiries:
{kind=link}
Data base ingestion circulation
The data base ingestion circulation supplies an automatic doc processing pipeline that initiates after the person uploads a doc. Its job is to embed the doc’s knowledge into an Amazon Bedrock Data Base. Right here is the circulation:
You should use the data base ingestion workflow to add paperwork in bulk and remodel them into searchable vector embeddings by an automatic pipeline. The next detailed circulation is illustrated within the earlier determine.
- Doc Add by Consumer: Customers add paperwork by the shopper software.
- Pre-Signed URL Era: The shopper software sends a request to Amazon API Gateway, which invokes the data base ingestion AWS Lambda operate to generate a pre-signed S3 URL.
- Doc Add: The shopper software makes use of the generated pre-signed URL to add the doc.
- Ingestion Set off and Knowledge Processing: After the doc is efficiently uploaded to Amazon Easy Storage Service (Amazon S3), the shopper software triggers the Amazon API Gateway to provoke the doc processing AWS Lambda, which handles format conversion and manages the concurrent ingestion of paperwork. We don’t have to pre-process the photographs, charts, and tables in these paperwork as a result of the Amazon Bedrock Data Base is configured with Amazon Bedrock Knowledge Automation (BDA) to successfully extract this multimodal content material. The AWS Lambda operate then calls the Amazon Bedrock Data Bases.
- Vector Storage: The Amazon Bedrock Data Base chunks the doc content material utilizing a hierarchical chunking technique, generates embeddings utilizing Amazon Titan Textual content Embeddings, and shops the ensuing vectors in OpenSearch Serverless. Hierarchical chunking creates nested parent-child relationships that mirror the sectioned construction of economic paperwork. This technique works nicely for structured and sophisticated paperwork as a result of it indexes small chunks for exact retrieval whereas returning bigger mum or dad chunks to offer adequate context for coherent responses.
Constructing an automatic ingestion pipeline addresses the core problem of data fragmentation by effectively processing hundreds of historic paperwork throughout a number of codecs whereas optimizing content material indexing for related AI responses. This parallelized strategy permits the system to scale successfully, accommodating the rising year-over-year regulatory inquiry exercise whereas sustaining constant processing efficiency throughout massive doc volumes.
Chat Utility
The Chat Utility supplies a real-time dialog interface powered by AWS serverless structure, enabling pure language interactions with the system. We selected to stream responses to prospects to allow them to start studying the AI response sooner in real-time, implementing this functionality by WebSocket connections. By way of these WebSocket connections and the Claude Sonnet 4.5 mannequin, it delivers contextually related responses whereas sustaining dialog state in DynamoDB. The workflow operates as follows:
- Provoke Chat Dialog: Customers provoke or open an present chat session by the shopper software.
- WebSocket Connection: The appliance makes use of WebSockets to ascertain a persistent, bi-directional reference to Amazon API Gateway.
- Message Submission: The appliance posts the person questions by the WebSocket connection which is propagated to the Chat service AWS Lambda operate.
- Question Enhancement: The Chat Service AWS Lambda operate makes use of the Claude 3.5 Haiku mannequin with a question enlargement technique to generate a number of variations of the person’s query.
- Data Retrieval: The Chat Service Lambda invokes the Amazon Bedrock Data Bases Retrieve API for every expanded question. The API performs vector similarity searches towards the underlying OpenSearch Serverless index and returns essentially the most related doc chunks together with their supply metadata and relevance scores.
- Context Meeting: The Chat Service AWS Lambda operate retrieves dialog historical past from Amazon DynamoDB (for present conversations, based mostly on that particular dialog ID) and combines it with the retrieved data base outcomes and the person’s query.
- Response Era: The Chat Service AWS Lambda operate makes use of the Converse Stream API with Claude Sonnet 4.5 and a response generator immediate to supply a contextually related reply based mostly on the assembled context.
- Consumer Engagement: The Chat Service AWS Lambda operate streams the generated response again to the shopper software in Markdown format by the WebSocket connection and shops all of the dialog within the Conversational Historical past Desk by Amazon DynamoDb.
- Observability: All through the method, the Chat Service publishes end-to-end traces to a self-hosted Langfuse occasion utilizing the OpenTelemetry (OTEL) SDK. This captures detailed telemetry knowledge together with latency metrics, token utilization, immediate templates, and mannequin responses.
Multi-turn conversational expertise
Regulatory inquiry discussions typically progress by a number of exchanges as groups refine responses and reference extra knowledge sources. To help this iterative course of, the Amazon FinTech group carried out a multi-turn conversational workflow utilizing Amazon API Gateway (WebSocket APIs), AWS Lambda, and Amazon DynamoDB, built-in with the Amazon Bedrock ConverseStream API for low-latency, context-aware dialogue. Every chat session is securely authenticated by Amazon Cognito and assigned a novel dialog ID. DynamoDB shops messages in chronological order to protect context throughout periods, so customers can resume prior discussions seamlessly and preserve continuity.
When a person submits a question, the system sanitizes inputs to stop immediate injection assaults. After sanitization, the system classifies intent and determines whether or not retrieval from the Amazon Bedrock Data Base is required. This willpower is made by an LLM name that classifies the person question as both conversational or data intensive. For advanced, knowledge-intensive questions, the workflow employs a question enlargement technique that addresses the prevalent use of acronyms and abbreviated questions by customers. This layer generates as much as 5 question variations utilizing Claude 3.5 Haiku, then makes parallel Retrieve API calls to the Data Base, retrieving related outcomes utilizing OpenSearch vector similarity search. To keep up efficiency at scale, the workflow implements parallel processing for these retrieval calls utilizing multi-threading. This optimization diminished retrieval latency from 10 seconds (sequential processing) to underneath 2 seconds, enabling responsive conversations. The retrieved info—mixed with latest dialog historical past—is handed to Claude Sonnet 4.5 by the ConverseStream API augmented with Amazon Bedrock Guardrails, that implement delicate info filters to mechanically detect and take away PII and monetary knowledge from each inputs and outputs. That is essential for shielding regulatory documentation. When immediate injection makes an attempt are detected, the system responds with “Sorry, the mannequin can’t reply that query,” maintaning safe and compliant interactions whereas sustaining conversational fluency.
This structure delivers continuity, transparency, and scalability. Customers obtain real-time, streaming responses with standing updates all through the retrieval and technology phases, enhancing engagement and lowering latency. Persistent logs in DynamoDB present an immutable audit path for compliance evaluation, whereas the serverless and event-driven design scales mechanically to help concurrent periods. Collectively, these capabilities allow Amazon FinTech group to conduct advanced, iterative conversations—producing contextually related, safe, and regulatory-compliant responses powered by Amazon Bedrock.
Observability
Observability performs a essential position in understanding and enhancing AI-driven workflows. To realize full visibility into the regulatory inquiry response system, the Chat Service AWS Lambda built-in OpenTelemetry (OTEL) with a self-hosted Langfuse occasion to seize detailed, end-to-end traces of every interplay. This setup supplies engineers and utilized scientists with fine-grained telemetry on how prompts are processed, data is retrieved, and responses are generated. This permits almost steady refinement of the system’s efficiency and accuracy. The choice to make use of OTEL over the native Langfuse SDK supplies vendor-neutral flexibility, permitting telemetry knowledge to be routed to a number of observability backends and tailored to evolving monitoring necessities.
At runtime, every stage of the Chat Service AWS Lambda is manually instrumented utilizing the OTEL Java SDK to file latency, token utilization, mannequin selections, and immediate metadata in OTEL Generative AI semantic normal. Spans are printed to Langfuse in close to actual time, giving the group a clear view of how the Amazon Bedrock ConverseStream API, Data Base retrieval, and Claude Sonnet 4.5 work together inside a single request. The detailed telemetry permits the group to determine efficiency bottlenecks, optimize immediate methods, and improve retrieval precision whereas sustaining accountable AI practices.
This observability framework maintains belief and accountability within the system’s habits. Engineers can correlate person actions with mannequin outcomes, hint knowledge lineage throughout a number of companies, and fine-tune configurations with out disrupting operations. By combining OpenTelemetry’s interoperability with Langfuse’s visualization and analytics, Amazon FinTech group good points a scalable, extensible basis for evaluating generative AI methods at scale—turning each interplay into actionable perception for steady enchancment.
The next screenshot illustrates an end-to-end hint captured in Langfuse, showcasing how the observability resolution captures the whole workflow—from question enlargement and data retrieval to mannequin prompts, responses, and latency metrics. It additionally highlights supply doc citations, providing a clear view of how contextual info flows by the system throughout response technology
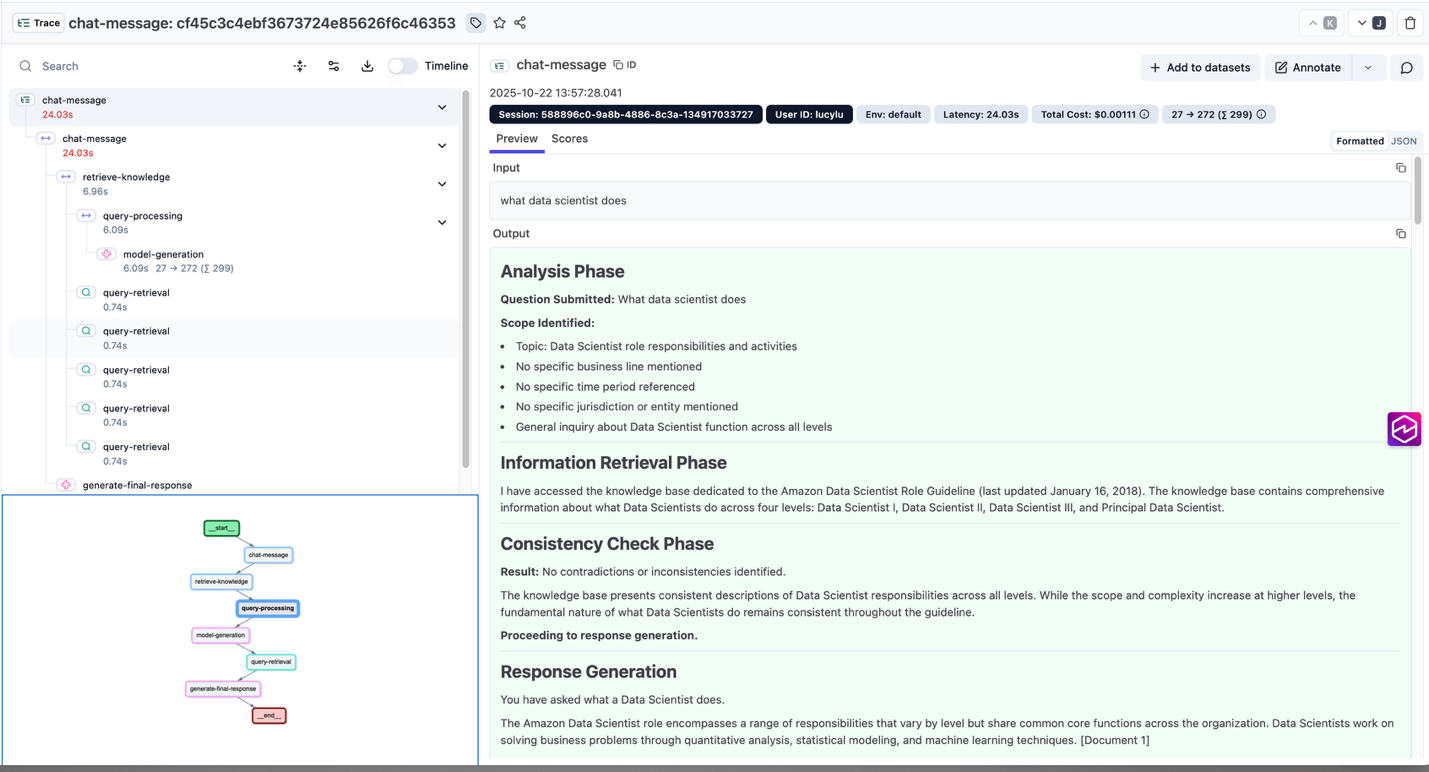
Reference: Finish-to-Finish Hint Posted in Langfuse
Conclusion
On this publish, you noticed how Amazon FinTech group constructed a scalable AI resolution utilizing Amazon Bedrock, designed to help regulatory inquiries by automating data retrieval, conversational workflows, and response technology. By combining a doc ingestion pipeline, multi-turn stateful conversations, and detailed observability through OpenTelemetry and Langfuse, the structure empowers groups to deal with regulatory inquiries in ruled, traceable and compliant method.
As a result of the whole stack is constructed on AWS serverless companies, it gives the operational scalability, safety, and elasticity required for enterprise-grade deployment. Whether or not you’re coping with authorized compliance, regulatory inquiries, or high-volume inside data workflows, this sample gives a sensible basis you can tailor and lengthen to your corporation area.
When you’re able to modernize your knowledge-intensive processes with generative AI, discover the Amazon Bedrock documentation to find how one can start constructing your individual safe, ruled, and scalable AI-powered workflows.
Concerning the authors