

{kind=link}
Giant language fashions often generate textual content one token at a time. Whereas this autoregressive strategy delivers robust high quality and instruction following, it may be inefficient for native customers as a result of GPUs usually spend extra time transferring weights from reminiscence than doing parallel compute.
Google DeepMind’s DiffusionGemma takes a unique path, producing and refining blocks of tokens in parallel utilizing diffusion-style textual content era. On this article, we’ll discover how DiffusionGemma works, the way it performs, and the way builders can run it domestically.
What’s DiffusionGemma?
DiffusionGemma is Google DeepMind’s experimental open-weight mannequin for diffusion-based textual content era, constructed on the Gemma 4 26B A4B MoE basis. Not like commonplace LLMs that write one token at a time, it generates and refines blocks of tokens in parallel.
It behaves extra like a drafting system than a typewriter: refining unsure tokens till the reply converges. This makes it attention-grabbing for native inference, the place GPUs can profit from bigger parallel workloads.
Why Google Constructed a Textual content Diffusion Mannequin
Most manufacturing LLMs at present are autoregressive. They generate textual content one token at a time, which works nicely for high quality however creates a transparent latency bottleneck.
For cloud suppliers, that is manageable. They’ll batch requests from many customers and maintain GPUs busy. However for a single native consumer, batching doesn’t assist a lot. The consumer nonetheless receives output sequentially, token by token.
DiffusionGemma asks a unique query:
What if one consumer might get a block of textual content generated in parallel?
As an alternative of spreading GPU work throughout many customers, DiffusionGemma applies parallel compute to a 256-token canvas for one consumer. The mannequin refines that block repeatedly, making native and low-concurrency inference really feel a lot quicker.
This makes it particularly helpful for:
- Inline enhancing
- Fast iteration
- Native AI assistants
- Non-linear textual content era
- Code infilling
- Structured output era
- Interactive developer instruments
It’s not meant to totally exchange commonplace Gemma 4 fashions. As an alternative, DiffusionGemma is greatest understood as a speed-first experimental mannequin for workflows the place responsiveness issues as a lot as uncooked benchmark high quality.
Autoregressive LLMs vs DiffusionGemma
| Space | Autoregressive LLMs | DiffusionGemma |
| Technology type | One token at a time | Full token canvas refined in parallel |
| Path | Left to proper | Bidirectional inside every canvas |
| Most important bottleneck for single-user native inference | Reminiscence bandwidth | Compute |
| Finest for | Excessive-quality manufacturing textual content, chat, reasoning, common workloads | Quick native era, enhancing, infilling, structured blocks |
| Self-correction | Restricted as a result of earlier tokens are often fastened | Stronger as a result of unsure tokens might be re-noised and changed |
| Lengthy output dealing with | Sequential token era | A number of 256-token canvases stitched block by block |
| Cloud batching | Very environment friendly at excessive concurrency | Velocity profit is strongest at low to medium batch sizes |
| Maturity | Extremely mature ecosystem | Experimental and nonetheless evolving |
The important thing distinction isn’t just pace. It’s the approach the mannequin thinks a few generated reply. Autoregressive fashions commit early. DiffusionGemma can revise the canvas earlier than finalizing it.
Structure of DiffusionGemma
DiffusionGemma is predicated on the Gemma 4 26B A4B Combination-of-Consultants structure. It has 25.2B whole parameters and prompts round 3.8B parameters throughout inference.
At a excessive stage, the structure has three main components:
- An encoder-style prefill stage
- A bidirectional denoising decoder
- A block-autoregressive multi-canvas era loop
1. Encoder Prefill
The encoder processes the consumer immediate and creates a KV cache. That is much like how transformer fashions put together immediate context throughout prefill.
The immediate just isn’t regenerated at each diffusion step. As an alternative, the mannequin shops the immediate illustration and lets the denoising course of use that cached context.
2. Denoising Decoder
The decoder works on a canvas of tokens. The default canvas size is 256 tokens.
This decoder makes use of bidirectional consideration over the canvas. Meaning each token place can attend to each different token place in the identical block. That is very totally different from causal consideration, the place a token can solely attend to earlier tokens.
This bidirectional setup is helpful for:
- Code infilling
- Closing Markdown constructions
- Fixing grid-like or constraint-heavy issues
- Modifying textual content the place later content material impacts earlier content material
- Producing structured blocks the place columns, keys, and formatting should align
3. Block-Autoregressive Multi-Canvas Sampling
A 256-token canvas is helpful, however many responses are longer than 256 tokens. DiffusionGemma handles this by means of multi-canvas sampling.
The method appears to be like like this:
- Course of the immediate and create the KV cache.
- Create a loud 256-token canvas.
- Denoise the canvas over a number of steps.
- Finalize the canvas.
- Append the finalized canvas to the context.
- Transfer to the subsequent canvas.
- Proceed till the mannequin reaches the stopping situation.
This provides DiffusionGemma a hybrid conduct. Inside every block, era is diffusion-based and parallel. Throughout a number of blocks, era continues to be sequential.
How Textual content Diffusion Works
Diffusion is frequent in picture era, the place a mannequin begins with noise and progressively denoises it right into a coherent picture.
DiffusionGemma brings an analogous thought to textual content, however with a key problem: textual content is discrete. Not like pixels, tokens are fastened vocabulary objects. So as an alternative of smoothing noise, DiffusionGemma begins with random placeholder tokens and repeatedly predicts higher tokens throughout your entire canvas.
That is how textual content diffusion occurs in DiffusionGemma:
- Canvas Initialization: The method begins with a 256-token canvas stuffed with random tokens, much like how picture diffusion fashions begin from noise.
- Parallel Prediction: The mannequin examines your entire canvas and predicts the most probably token for each place concurrently. As a result of it makes use of bidirectional consideration, every token can leverage info from each earlier and later positions within the canvas.
- Token Acceptance: Tokens predicted with excessive confidence are accepted and locked in as anchors. These secure tokens present stronger context for refining the remaining positions.
- Re-Noising: Low-confidence tokens are re-noised fairly than preserved. By changing unsure predictions with random tokens, the mannequin avoids getting caught with poor early guesses and might proceed enhancing the canvas.
- Adaptive Stopping: The denoising course of continues till the canvas turns into sufficiently secure and assured. Consequently, easier prompts could converge in fewer steps, whereas extra complicated prompts can obtain extra refinement passes.
Benchmark Outcomes
DiffusionGemma is quick, however it’s not typically stronger than Gemma 4 26B A4B in uncooked mannequin high quality. Gemma 4 26B A4B leads most benchmark classes, together with math, coding, science reasoning, multimodal reasoning, and long-context retrieval.
DiffusionGemma’s worth is totally different. It trades some high quality for a significant change in latency conduct. This makes it extra enticing when pace is the product requirement.
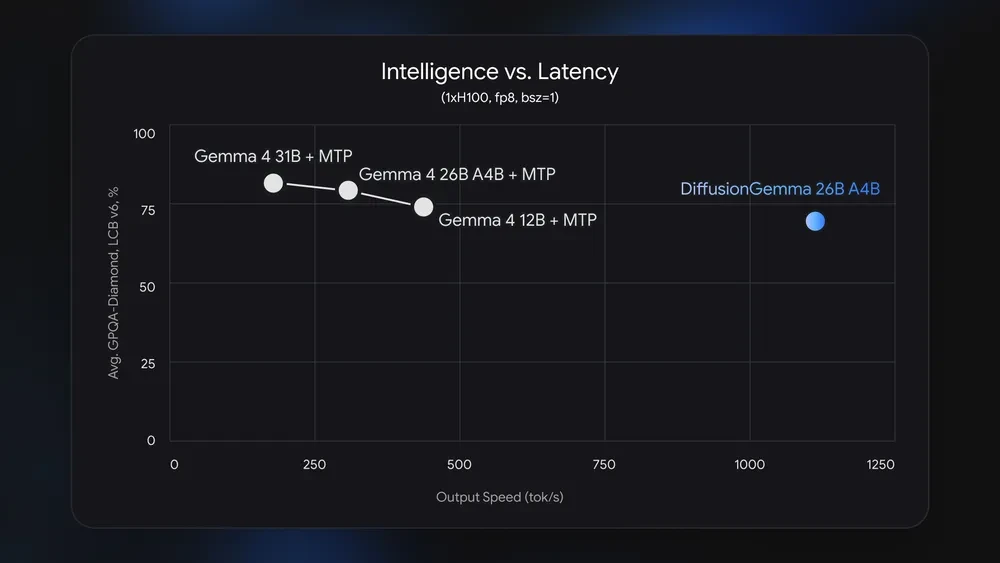
DiffusionGemma is positioned as a speed-first experimental mannequin. It goals to scale back latency for native and interactive workflows, whereas commonplace Gemma 4 stays the stronger default for optimum high quality.
Palms-on: Operating DiffusionGemma Regionally with llama.cpp
On this hands-on part, we are going to run DiffusionGemma domestically utilizing llama.cpp. Since DiffusionGemma makes use of a brand new block-diffusion era strategy, common llama.cpp builds could not help it absolutely but. For this experiment, we are going to use the DiffusionGemma pull request department from llama.cpp and construct the devoted llama-diffusion-cli.
The mannequin used on this walkthrough is the Unsloth GGUF model:
unsloth/diffusiongemma-26B-A4B-it-GGUF We’ll use the Q4_K_M quantized mannequin as a result of it’s smaller and extra sensible for native testing in comparison with bigger precision variants.
Step 1: Set up Required Dependencies
Earlier than constructing llama.cpp, set up the required Python packages utilizing the terminal:
pip set up -U "huggingface_hub[cli]"
pip set up vllm cmakeYou also needs to make it possible for the next instruments can be found in your system:
git --version
cmake --version
python --version
If you’re utilizing a CUDA-enabled NVIDIA GPU, be sure that CUDA drivers and construct instruments are put in accurately. GPU acceleration is strongly advisable as a result of DiffusionGemma is a big 26B-class mannequin.
Step 2: Clone llama.cpp
Clone the official llama.cpp repository:
git clone https://github.com/ggml-org/llama.cpp
cd llama.cpp Step 3: Checkout the DiffusionGemma Pull Request Department
The DiffusionGemma help is obtainable by means of llama.cpp pull request 24423.
git fetch origin pull/24423/head:diffusiongemma
git checkout diffusiongemma This switches your native llama.cpp repository to the DiffusionGemma improvement department.
Step 4: Construct llama-diffusion-cli
Now construct the devoted DiffusionGemma CLI.
For CUDA-enabled programs, use:
cmake -B construct -DGGML_CUDA=ON
cmake --build construct -j --config Launch --target llama-diffusion-cli If you’re constructing with out CUDA, you should utilize:
cmake -B construct
cmake --build construct -j --config Launch --target llama-diffusion-cli After the construct is full, the binary needs to be out there at:
./construct/bin/llama-diffusion-cli Step 5: Obtain the DiffusionGemma GGUF Mannequin
Obtain the Q4_K_M GGUF mannequin from Unsloth:
hf obtain unsloth/diffusiongemma-26B-A4B-it-GGUF
--local-dir unsloth/diffusiongemma-26B-A4B-it-GGUF
--include "*Q4_K_M*"This downloads the quantized GGUF file domestically. The Q4_K_M model is helpful for native experiments as a result of it’s considerably smaller than increased precision variants.
Step 6: Run DiffusionGemma in Chat Mode
As soon as the mannequin is downloaded, run it utilizing llama-diffusion-cli: Alter the placement of the mannequin .gguf if required
./construct/bin/llama-diffusion-cli -m unsloth/diffusiongemma-26B-A4B-it-GGUF/diffusiongemma-26B-A4B-it-Q4_K_M.gguf -ngl 99 -cnv -n 2048 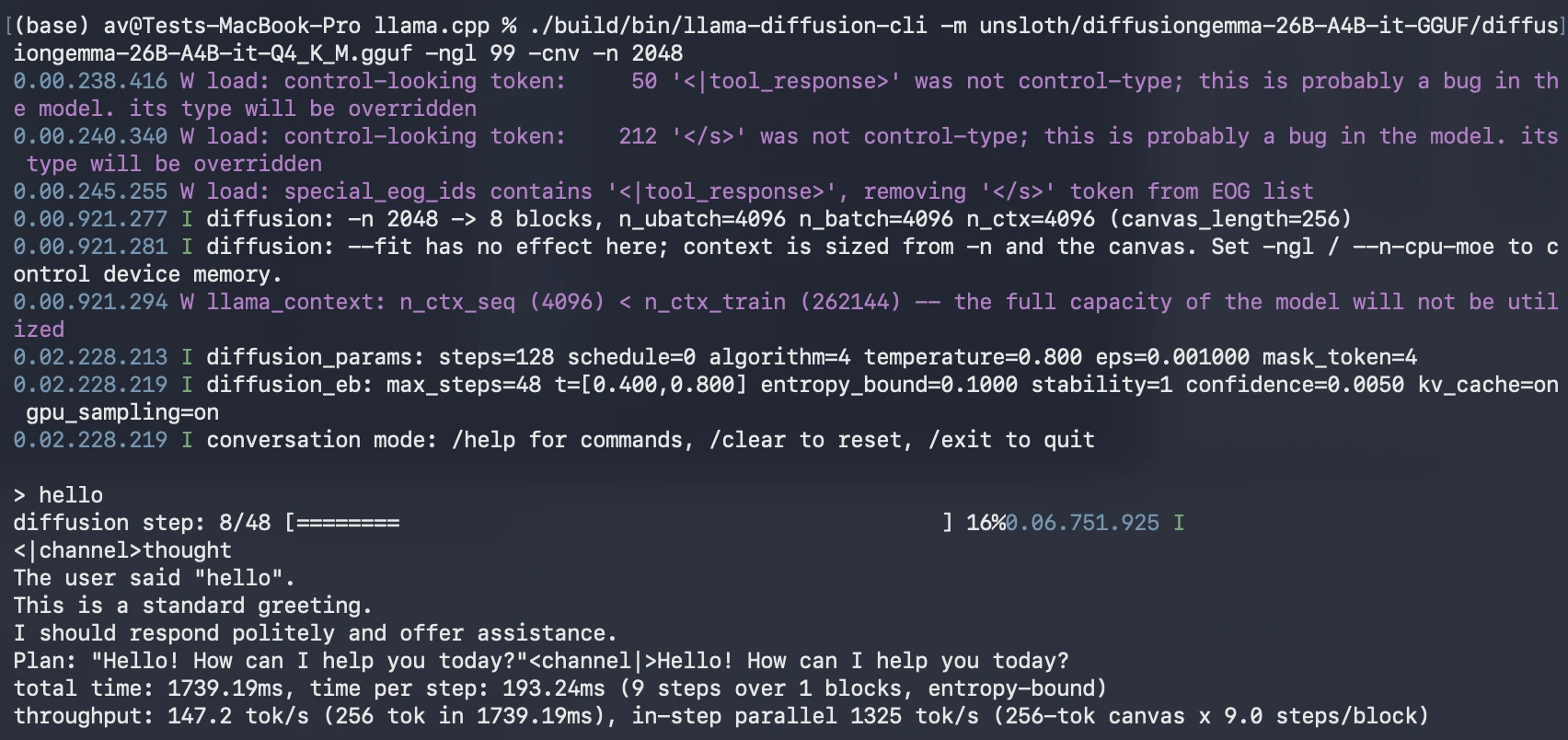
In case your machine has restricted GPU reminiscence, scale back the variety of GPU layers or attempt a smaller quantized mannequin if out there.
Step 7: First Sanity Take a look at
As soon as the mannequin hundreds, begin with a easy immediate:
./construct/bin/llama-diffusion-cli -m unsloth/diffusiongemma-26B-A4B-it-GGUF/diffusiongemma-26B-A4B-it-Q4_K_M.gguf -ngl 999 --diffusion-visual -p "Write a Python script that benchmarks native LLM response time. The script ought to ship 5 prompts to a neighborhood mannequin endpoint, measure whole response time for every immediate, and print the typical latency. Use easy error dealing with." Output:
DiffusionGemma is a language mannequin that generates textual content in another way from conventional LLMs. As an alternative of writing one token at a time from left to proper, it begins with a loud block of tokens and repeatedly refines the entire block till it turns into significant textual content. This makes era extra parallel and might enhance pace on native GPUs. It’s particularly helpful for quick drafting, enhancing, code completion, and structured textual content era the place the mannequin can revise a number of components of the output without delay.
The precise reply could differ, however the mannequin ought to clearly clarify the distinction between autoregressive era and diffusion-based era.
Step 8: Take a look at Quick Drafting
Use the next immediate:
./construct/bin/llama-diffusion-cli -m unsloth/diffusiongemma-26B-A4B-it-GGUF/diffusiongemma-26B-A4B-it-Q4_K_M.gguf -ngl 999 --diffusion-visual -p "Write a 500-word technical introduction to diffusion-based textual content era. Use clear headings and keep away from advertising language."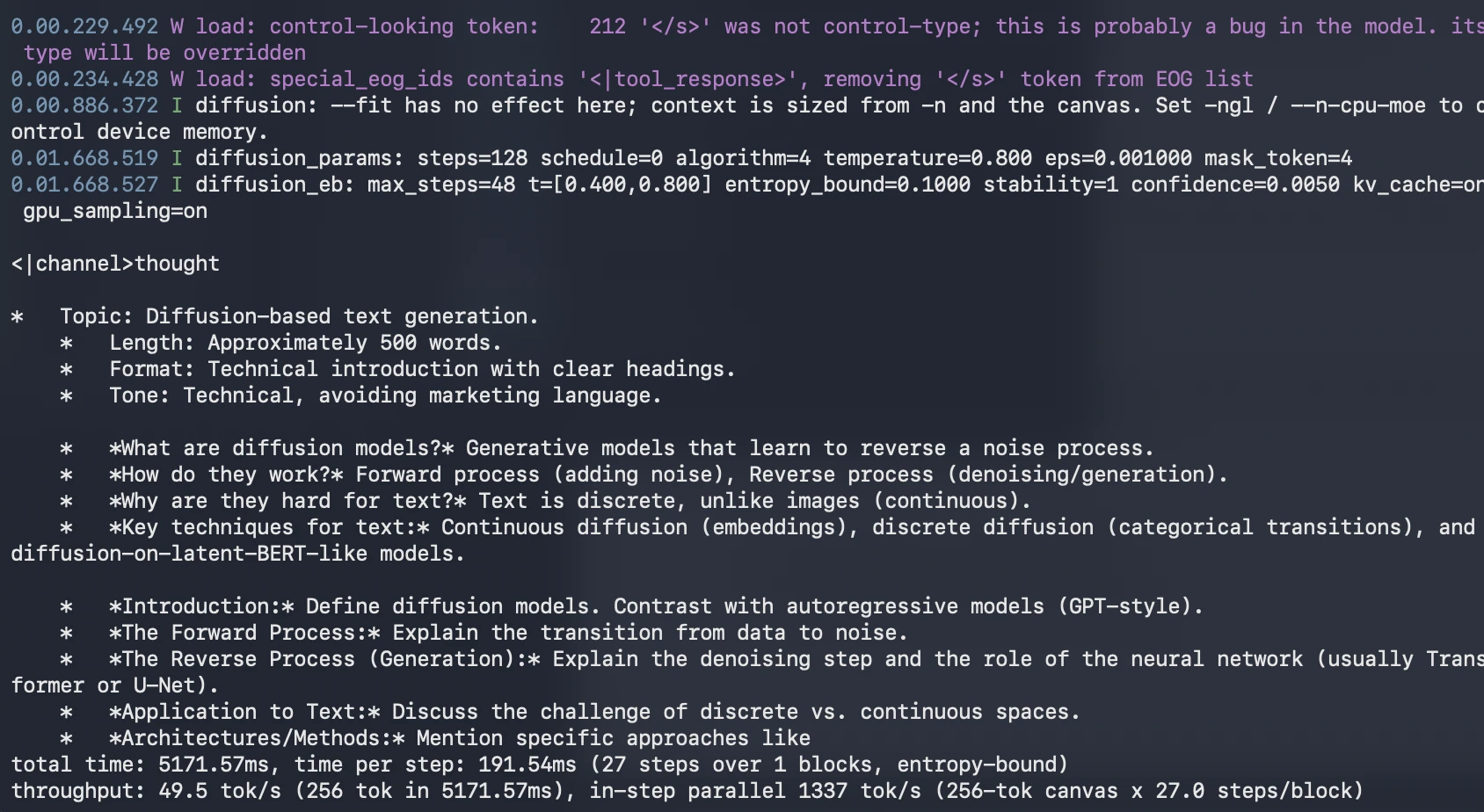
What to look at:
- How rapidly the response seems
- Whether or not the construction is coherent
- Whether or not headings are correctly closed
- Whether or not the mannequin repeats itself
- Whether or not the reply stays targeted on diffusion-based textual content era
This check helps you perceive whether or not DiffusionGemma is helpful for quick long-form drafting.
Step 9: Take a look at Code Technology
Use the next immediate:
./construct/bin/llama-diffusion-cli -m unsloth/diffusiongemma-26B-A4B-it-GGUF/diffusiongemma-26B-A4B-it-Q4_K_M.gguf -ngl 999 --diffusion-visual -p "Write a Python script that benchmarks native LLM response time. The script ought to ship 5 prompts to a neighborhood mannequin endpoint, measure whole response time for every immediate, and print the typical latency. Use easy error dealing with." 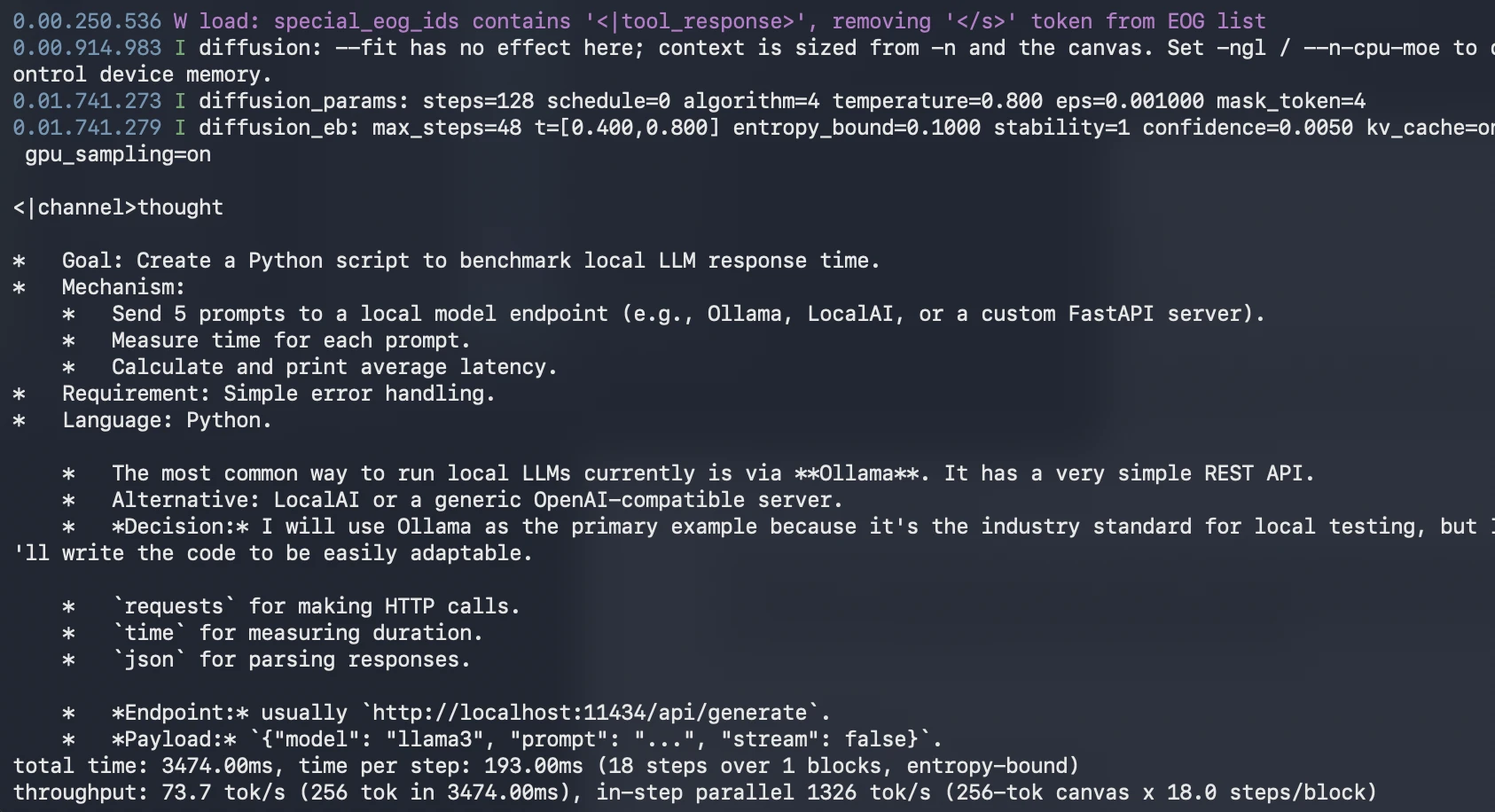
What to look at:
- Whether or not the code is full
- Whether or not the logic is appropriate
- Whether or not error dealing with is included
- Whether or not the benchmark output is simple to know
- Whether or not the mannequin explains assumptions clearly
This check helps consider DiffusionGemma’s potential to generate sensible developer code.
Sensible Notes
This setup is greatest handled as an experimental native analysis path. DiffusionGemma help in llama.cpp is new and should change because the pull request evolves. For a manufacturing setup, consider extra secure serving paths similar to vLLM, SGLang, NVIDIA NIM, or a managed deployment choice as soon as they match your necessities.
For hands-on testing, this llama.cpp route is helpful as a result of it provides direct entry to the GGUF mannequin and the devoted diffusion CLI. It additionally helps you to observe the era conduct extra carefully than an ordinary chat interface.
Conclusion
DiffusionGemma stands out as a result of it adjustments how textual content is generated, not simply how giant the mannequin is. Its important promise is pace: by denoising a 256-token canvas in parallel, it reduces the sequential bottleneck of token-by-token decoding and provides native GPUs a extra parallel workload.
It’s not a common substitute for Gemma 4, which stays stronger on most quality-focused benchmarks. However that’s not the purpose. DiffusionGemma is a speed-first experimental mannequin for native assistants, enhancing, code infilling, and latency-sensitive developer workflows.
For builders, it’s price testing now by means of Unsloth GGUF and Ollama. For technical leaders, it’s price watching carefully. DiffusionGemma could not outline the ultimate type of diffusion-based textual content era, but it surely clearly exhibits the place quick native AI might be headed subsequent.
Harsh Mishra is an AI/ML Engineer who spends extra time speaking to Giant Language Fashions than precise people. Enthusiastic about GenAI, NLP, and making machines smarter (in order that they don’t exchange him simply but). When not optimizing fashions, he’s most likely optimizing his espresso consumption. 🚀☕
Login to proceed studying and luxuriate in expert-curated content material.