

{kind=link}
# Introduction
Most groups uncover they want a function retailer the laborious manner. A fraud mannequin works within the pocket book and quietly breaks in manufacturing. A assist agent provides a generic reply as a result of it has no thought who the consumer is. A recommender pipeline duplicates the identical “30-day spend” calculation throughout three jobs, and two of them disagree.
A function retailer is the piece of infrastructure that fixes these issues. It defines options as soon as, shops them in two shapes (one for coaching, one for serving), and retains each in sync. We’re going to construct a minimal one from scratch in Python, utilizing DuckDB, Parquet, Redis, and FastAPI. Then we’ll take a look at how AI purposes change what we really use it for.
The complete code is brief sufficient that we are going to stroll by each element.
# What a Function Retailer Truly Solves
The basic pitch is training-serving skew: the SQL that constructed your coaching set will not be the identical code path that runs at inference, so the values drift. That downside is actual, and the offline plus on-line cut up is the usual repair.
The fashionable pitch is broader. Giant language mannequin (LLM) brokers and retrieval-augmented era (RAG) pipelines want structured consumer context at inference time, on each request, in underneath 10ms. An LLM has no reminiscence of who the consumer is. If we would like customized output, now we have to inject the consumer’s plan tier, current exercise, and account state into the immediate, and we want a system that may return these values quick and persistently. That’s precisely what a function retailer’s on-line retailer and retrieval API give us.
So we construct for each. The identical 5 parts deal with the predictive machine studying use case and the LLM context use case.
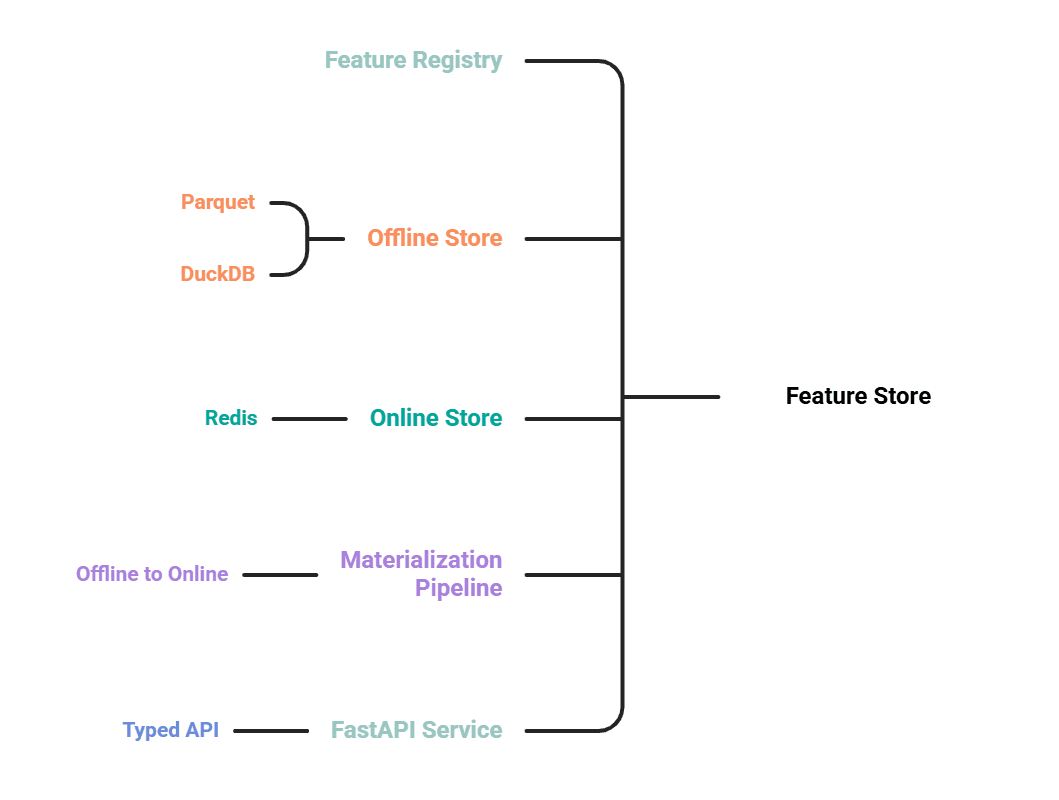
# The 5 Elements
- A function registry that defines options as code.
- An offline retailer on Parquet, queried with DuckDB, for coaching and backfills.
- A web-based retailer on Redis for low-latency lookups at inference.
- A materialization pipeline that pushes the most recent values from offline to on-line.
- A FastAPI service that exposes a typed retrieval API.
# Operating Instance: A Customized LLM Recommender
We’re operating a streaming service. When a consumer opens the app, an LLM generates a brief, customized “what to look at subsequent” message. The LLM wants three issues in regards to the consumer:
| Function | Kind | Freshness |
|---|---|---|
user_segment |
string | every day |
watch_count_30d |
int | hourly |
last_genre |
string | per-event |
The entity is user_id. We are going to register these three options, materialize them, and serve them to the LLM at request time.
// 1. Defining the Function Registry
A registry is only a place the place options are declared as soon as, with their entity, dtype, and supply. We use a dataclass.
from dataclasses import dataclass
from typing import Literal
@dataclass(frozen=True)
class Function:
title: str
entity: str
dtype: Literal["int", "float", "str"]
supply: str # path to a Parquet file or a SQL view
REGISTRY: dict[str, Feature] = {
"user_segment": Function("user_segment", "user_id", "str", "knowledge/user_segment.parquet"),
"watch_count_30d": Function("watch_count_30d", "user_id", "int", "knowledge/watch_count_30d.parquet"),
"last_genre": Function("last_genre", "user_id", "str", "knowledge/last_genre.parquet"),
}
The complete code might be discovered right here.
Once you run it, the output reveals:
Registered options:
user_segment entity=user_id dtype=str supply=knowledge/user_segment.parquet
watch_count_30d entity=user_id dtype=int supply=knowledge/watch_count_30d.parquet
last_genre entity=user_id dtype=str supply=knowledge/last_genre.parquet
That is the contract. Each different element reads from REGISTRY, so renaming a function, altering its dtype, or pointing it at a brand new supply occurs in a single place. In manufacturing techniques, this may be YAML or a Python module checked right into a Git repo, with code assessment on each change.
// 2. Constructing the Offline Retailer with DuckDB and Parquet
The offline retailer holds the complete historical past of each function worth. We use Parquet recordsdata because the storage layer and DuckDB because the question engine. DuckDB reads Parquet immediately, which implies no separate database to run.
Here’s a pattern of the code:
import duckdb
import pandas as pd
def get_historical_features(
entity_df: pd.DataFrame, options: checklist[str]
) -> pd.DataFrame:
con = duckdb.join()
con.register("entities", entity_df)
base = "SELECT * FROM entities"
for fname in options:
f = REGISTRY[fname]
src = f.supply.exchange("'", "''")
con.execute(f"CREATE VIEW {fname}_src AS SELECT * FROM '{src}'")
base = f"""
SELECT t.*, s.{fname}
FROM ({base}) t
ASOF LEFT JOIN {fname}_src s
ON t.user_id = s.user_id
AND t.event_timestamp >= s.event_timestamp
"""
return con.execute(base).df()
The complete code might be discovered right here.
Once you run it, the output reveals:
| user_id | event_timestamp | user_segment | watch_count_30d | last_genre |
|---|---|---|---|---|
| 8a2f | 2026-05-05 12:00:00 | informal | 22 | NaN |
| b13c | 2026-05-07 20:00:00 | informal | 5 | thriller |
| 8a2f | 2026-05-07 22:00:00 | power_user | 47 | documentary |
The AsOf be part of is the point-in-time be part of. For each entity row, it picks the latest function worth the place the function’s timestamp is at or earlier than the occasion timestamp. That’s what prevents leakage — the place a coaching row is constructed with a function worth that didn’t exist but for the time being we’re predicting for.
Level-in-time joins are nonetheless the appropriate reply for any mannequin we plan to coach or fine-tune. For a pure inference-time LLM use case, we could by no means name this perform. We nonetheless need the offline retailer, since it’s the place backfills, analysis datasets, and audits come from.
// 3. Setting Up the On-line Retailer on Redis
The net retailer retains solely the most recent worth per entity. Redis is the usual selection as a result of hash lookups are sub-millisecond.
import json
import fakeredis # use redis.Redis() towards an actual server in manufacturing
r = fakeredis.FakeRedis(decode_responses=True)
def write_online(entity: str, entity_id: str, values: dict) -> None:
r.hset(
f"{entity}:{entity_id}",
mapping={okay: json.dumps(v) for okay, v in values.objects()},
)
def read_online(entity: str, entity_id: str, options: checklist[str]) -> dict:
uncooked = r.hmget(f"{entity}:{entity_id}", options)
return {f: json.hundreds(v) if v else None for f, v in zip(options, uncooked)}
The complete code might be discovered right here.
Once you run it, the output reveals:
read_online -> {'user_segment': 'power_user', 'watch_count_30d': 47, 'last_genre': 'documentary'}
lacking key -> {'user_segment': None}
The important thing form is entity:entity_id. The worth is a hash with one discipline per function. A single HMGET returns all of the options we requested for in a single spherical journey. On an area Redis occasion with three options, this finishes in nicely underneath 1ms.
// 4. Operating the Materialization Pipeline
Materialization strikes values from offline to on-line. In an actual system this runs on a schedule (Airflow, cron, a streaming job). Right here it’s a perform.
def materialize(options: checklist[str]) -> None:
by_entity: dict[str, dict] = {}
for fname in options:
f = REGISTRY[fname]
src = f.supply.exchange("'", "''")
df = duckdb.sql(f"""
SELECT {f.entity}, {fname}
FROM '{src}'
QUALIFY ROW_NUMBER() OVER (
PARTITION BY {f.entity}
ORDER BY event_timestamp DESC
) = 1
""").df()
for _, row in df.iterrows():
by_entity.setdefault(row[f.entity], {})[fname] = row[fname]
for entity_id, values in by_entity.objects():
write_online("user_id", entity_id, values)
The complete code might be discovered right here.
Once you run it, the output reveals:
user_id:8a2f -> {'user_segment': 'power_user', 'watch_count_30d': 47, 'last_genre': 'documentary'}
user_id:b13c -> {'user_segment': 'informal', 'watch_count_30d': 5, 'last_genre': 'thriller'}
The QUALIFY clause retains the most recent row per entity. We group all options for a similar consumer into one Redis write to chop spherical journeys. Run this on the cadence every function wants: hourly for watch_count_30d, near-real-time for last_genre, every day for user_segment. The registry is the appropriate place to encode that cadence in an actual implementation.
// 5. Exposing the FastAPI Retrieval Service
The retrieval service is the manufacturing floor. It’s what the LLM software calls.
f = resp.json()["features"]
print("nPrompt the LLM would obtain:")
print(
f" System: You suggest reveals for a streaming service.n"
f" Consumer context: section={f['user_segment']}, "
f"watched {f['watch_count_30d']} titles in final 30 days, "
f"final style watched: {f['last_genre']}.n"
f" Job: recommend 3 titles in a pleasant, quick message."
)
The complete code might be discovered right here.
Once you run it, the output reveals:
POST /get-online-features -> 200
physique: {'user_id': '8a2f', 'options': {'user_segment': 'power_user', 'watch_count_30d': 47, 'last_genre': 'documentary'}}
Immediate the LLM would obtain:
System: You suggest reveals for a streaming service.
Consumer context: section=power_user, watched 47 titles in final 30 days, final style watched: documentary.
Job: recommend 3 titles in a pleasant, quick message.
The function retailer is the piece that turns “consumer 8a2f” right into a structured context the LLM can use.
# The place the Function Retailer Ends and the Vector Database Begins
A vector database (Pinecone, Weaviate, pgvector) will not be a function retailer, although each sit in entrance of a mannequin at inference. They remedy completely different retrieval issues.
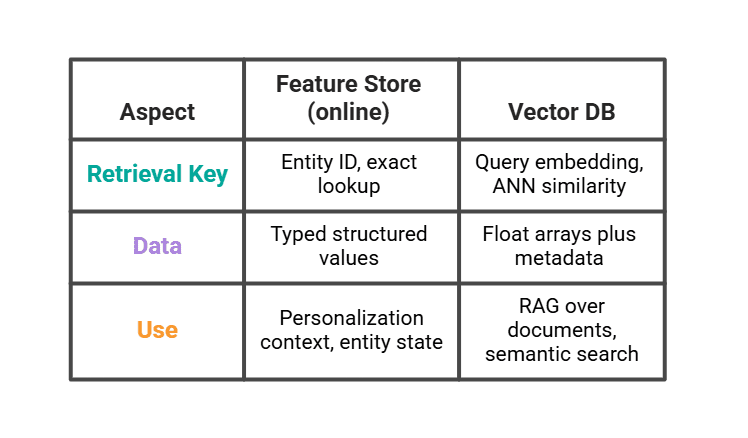
An actual LLM stack makes use of each. The vector database returns the three most comparable previous viewing classes. The function retailer returns the consumer’s section and up to date counts. The immediate combines them.
# Frequent Anti-Patterns
Just a few patterns that we hold seeing fail:
- Computing options contained in the mannequin service. The identical logic results in the coaching pocket book and the API, and the 2 definitions drift inside 1 / 4.
- Treating the net retailer because the supply of fact. Redis loses knowledge on a foul restart. The offline retailer is canonical; the net retailer is a cache.
- Skipping the registry. Three groups independently outline
active_userand the dashboards cease matching the mannequin. - Calling a vector database a function retailer. It can not do entity-keyed structured lookups, and a immediate that wants each will find yourself wired to 2 techniques anyway.
- Backfilling with out point-in-time joins. The coaching set appears nice, the manufacturing mannequin appears damaged, and the hole is the leakage.
# Evaluating This to Feast, Tecton, and Databricks
Our ~200 traces do the identical job in miniature.
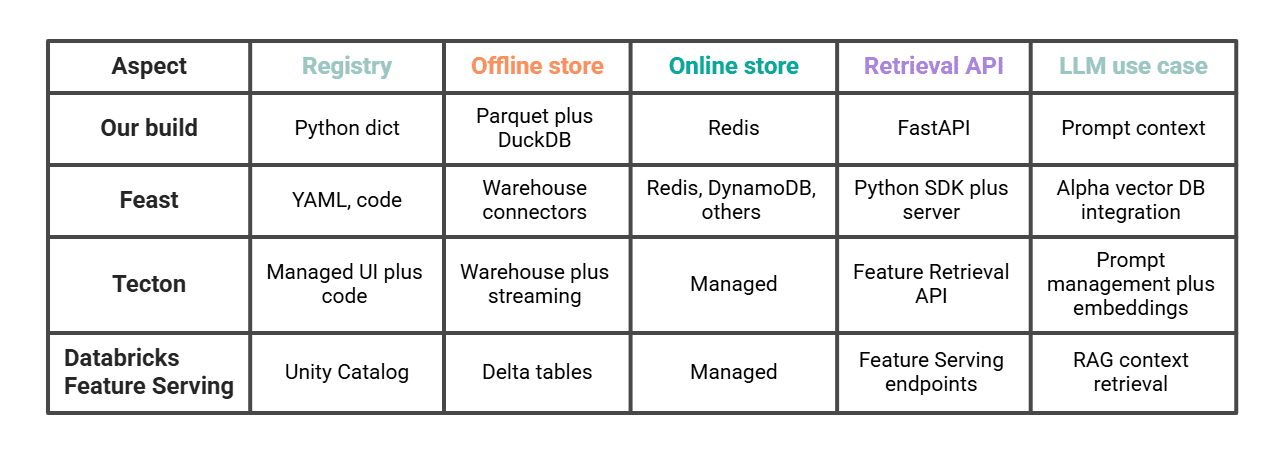
Feast is the closest comparability if we wish to go additional on the identical sample, self-hosted. Tecton and Databricks are the managed paths and have specific LLM options (Tecton’s Function Retrieval API for LLMs, Databricks Function Serving for compound generative AI techniques). Selecting between them is generally a query of how a lot we wish to function ourselves and whether or not the remainder of our stack already lives in Databricks.
# Conclusion
A working function retailer suits in 5 parts: a registry, an offline retailer, a web based retailer, a materialization step, and a retrieval API. Constructing it as soon as teaches us why the manufacturing techniques look the best way they do. It additionally reveals the place the design modifications for AI: the net retrieval path is the floor the LLM hits, point-in-time joins matter after we prepare or consider, and the vector database sits subsequent to the function retailer, not inside it.
As soon as now we have these items, swapping our minimal model for Feast, Tecton, or Databricks is generally a migration of the registry. The form of the system stays the identical.
Nate Rosidi is an information scientist and in product technique. He is additionally an adjunct professor instructing analytics, and is the founding father of StrataScratch, a platform serving to knowledge scientists put together for his or her interviews with actual interview questions from prime firms. Nate writes on the most recent traits within the profession market, provides interview recommendation, shares knowledge science initiatives, and covers every thing SQL.