

{kind=link}
Coaching a multi-turn agent in Amazon SageMaker AI to resolve assist tickets or average content material means dealing with a sequence of dependent steps, not a single response. These brokers learn directions, make instrument calls, learn the outcomes, resolve the subsequent motion, and get well from a mistake earlier than committing to a solution. That flexibility can also be what makes agentic reinforcement studying (RL) difficult. Extra methods to behave imply extra methods to fulfill the reward with out doing the duty, and the atmosphere the agent trains towards can quietly corrupt the coaching sign.
On this submit, we share greatest practices for dependable multi-turn RL coaching. We cowl how one can construct a coaching atmosphere you may belief, arrange an exterior analysis, design a reward aligned with the tip job, handle what adjustments as soon as the agent runs for a number of turns, and monitor the metrics that inform you when to iterate. We draw our examples from the SOP-Bench dataset, an Amazon Science benchmark that evaluates brokers’ capability to resolve duties primarily based on advanced Customary Working Procedures (SOP) throughout 12 enterprise domains.
SageMaker AI multi-turn reinforcement studying
Amazon SageMaker AI multi-turn RL (SageMaker AI MTRL) supplies the coaching loop for agentic duties. Your agent can run on Amazon Bedrock AgentCore, Amazon Elastic Kubernetes Service (Amazon EKS), Amazon Elastic Compute Cloud (Amazon EC2), AWS Fargate, or infrastructure of your selection. You join it by means of a small adapter that exposes your instrument floor to the rollout server, and SageMaker AI MTRL handles the remainder:
- A modular agent-environment interface that retains integration low-code whereas supplying you with full algorithmic management. Customized rewards, customized instrument loops, and multi-turn dialog shapes are all yours to outline.
- Serverless execution that simplifies infrastructure considerations, so that you get production-scale agentic RL at per-token pricing with out provisioning or managing GPU clusters.
- Asynchronous rollout and trajectory assortment with bounded off-policy staleness. Era and gradient updates run in parallel with out drifting too removed from the present coverage, which hastens coaching.
- A local algorithm library spanning Proximal Coverage Optimization (PPO), Clipped Significance Sampling Coverage Optimization (CISPO), and importance-sampling (IS) losses, paired with a number of group-based benefit estimators (GRPO, GRPO
cross@ok, RLOO, and extra). These cowl the alternatives most related to multi-turn agentic RL. - Sequence-extension coaching to maintain wall-clock down on lengthy multi-turn trajectories.
- Trajectory and reward observability in MLflow managed by Amazon SageMaker AI, so you may learn what your agent did flip by flip, and throughout coaching steps.
- Analysis jobs report reward,
cross@ok, trajectory metrics, and extra earlier than you deploy to a SageMaker AI endpoint or Amazon Bedrock.
The service supplies the coaching loop, {hardware}, and orchestration. The alternatives that resolve whether or not you get a dependable agent are yours. You construct the atmosphere the agent trains towards, measure success outdoors the reward, design the reward itself, and resolve how one can iterate when the curve stalls.
Determine 1: Overview of the SageMaker AI multi-turn RL service
Construct a coaching atmosphere that’s low cost, reproducible, and consultant
Single-turn RL wants a immediate and a reward perform. Multi-turn RL provides an atmosphere for the agent to behave in throughout turns: the instruments it calls and the techniques behind them. That atmosphere is a part of your coaching setup, and the way in which you construct it shapes each what the mannequin can be taught and whether or not you may belief your metrics.
When coaching an agent, construct a sandboxed or simulated atmosphere that resembles manufacturing however stays remoted from stay visitors. Device calls and responses preserve the identical schemas and enterprise logic. They’re pushed by recorded responses or remoted state as an alternative of stay calls.
Simulated environments are the really useful start line as a result of a typical run produces many 1000’s of rollouts, every making a number of instrument calls. For instance, a batch measurement of 128 with group measurement 8 is 1,024 rollouts per step. Pointing that visitors at stay techniques can result in buyer impression. And not using a simulated atmosphere, exploration can produce actual uncomfortable side effects. For instance, an agent studying by trial and error will challenge refunds, delete data, or set off workflows that you just didn’t intend. Moreover, stay knowledge shifts beneath you, so the identical trajectory scores otherwise throughout runs. You need to know the right final result to compute a reward, which implies a hard and fast, labeled set of duties (or a reliable decide mannequin) no matter the place the instrument calls go.
The way you construct the simulated atmosphere depends upon what your instruments do. Three patterns cowl most use-cases you’ll encounter:
- Learn-only instruments: Replay recorded responses keyed by their inputs. These instruments assist the agent retrieve data related to a job. For instance, in SOP-Bench the customer support job supplies ten mocked instruments (
validateAccount,getAuthenticationDetails,createSessionAndOpenTicket, and so forth), every returning a deterministic response from a fixture, similar to a selected row from a CSV file primarily based on the instrument name arguments. - Stateful instruments: Seeded sandboxes that maintain state for the size of an episode. When the agent writes one thing and reads it again, the atmosphere wants reminiscence. The sample: allocate per-episode assets in the beginning of the rollout, and register all the pieces the agent creates. Tear all of it down in a
attempt/lastlyblock when the episode ends, whether or not by reaching a terminal motion, hittingmax_turns, or crashing. No state leaks into the subsequent rollout. - Verifiable outcomes: Real execution in an remoted simulation atmosphere. When the agent’s output is code, SQL, or math, you may run it in an remoted atmosphere. Use a Docker
execfor code, an in-memory SQLite per rollout for SQL, a pure Python eval for math. Actual execution, deterministic per-instance, similar enter plus similar sandbox state equals similar outcome. For instance, AgentCore Code Interpreter supplies managed remoted environments for code execution.
Whichever sample matches, maintain two properties mounted:
- Reproducibility: the identical instrument referred to as with the identical arguments returns the identical outcome, so the reward for an equivalent trajectory is steady and your analysis is comparable throughout runs.
- Representativeness: construct the atmosphere out of your actual schemas and knowledge distributions so the conduct the mannequin learns transfers to manufacturing.
Earlier than you begin coaching, verify your atmosphere is configured appropriately:
Arrange an exterior analysis earlier than you practice
After your atmosphere is in place and verified, construct a technique to measure success earlier than you write a reward perform. That measure ought to seize your finish objective immediately. RL optimizes the reward sign actually, so if the reward is the one quantity you watch, you can’t separate progress on the duty from progress on satisfying the reward standards. You want an exterior analysis you may belief to information your selections whilst you iterate on rewards, atmosphere seeding, and hyperparameters.
Sample
Get up a held-out analysis that scores the end result you care about at deployment, computed independently of the reward. In apply it is a small piece of code that takes a mannequin, runs it by means of the rollout server on a hard and fast take a look at break up, and returns a single task-success price. It may be minimal, so long as it’s sincere.
For SOP-Bench, the analysis is exact-match on the ultimate JSON object inside
Earlier than any coaching, set up a baseline. Run the bottom mannequin and a reference mannequin (a frontier mannequin hosted on Amazon Bedrock is an effective match) by means of the identical analysis. This tells you two issues: how far the bottom mannequin has to go, and what good appears like on this job.
Anti-pattern
Treating the coaching reward, or a metric derived from it, as your measure of success. This might sound intuitive, however to seize reward hacking, you want exterior analysis. Multi-turn brokers want particular consideration: a reward that pays out for instrument calls teaches the agent to name as many instruments as it will probably. A reward that penalizes flip rely teaches the agent to decide to a solution earlier than it has the data it wants. Both method, the coaching reward rises however the agent’s actual success at its job falls.
Earlier than you begin coaching, verify your analysis is reliable:
Design an excellent multi-turn RL reward perform
Reward design is likely one of the tougher open issues in RL. The identical flexibility that lets the agent remedy an actual job lets it discover methods to fulfill the reward with out doing the duty. Each part you add, each reward weight you tune, each formatting bonus you layer in is one other floor the place the agent can climb with out fixing the duty. The mannequin optimizes what you wrote down, not what you meant. By default use the identical scoring rule for coaching and analysis, and solely deviate when you’ve a concrete cause.
Take SOP-Bench. The benchmark expects the reply as a JSON object inside
The benchmark scores 1 if each area matches and 0 in any other case. Coaching and analysis often share this scoring rule and differ solely in what you observe round it. The coach consumes one reward (scalar or record of scalars) per rollout. Analysis runs at decrease frequency on a hard and fast break up, so you may monitor extra metrics: per-field accuracy, completion price (did the agent emit
There are two actual causes to deviate from the default benchmark scoring rule, and each name for a denser reward.
The primary is algorithmic. RL computes the training sign from variance throughout a gaggle of group_size rollouts per immediate, utilizing a group-based benefit technique (advantage_method). The service default group_based is GRPO. Many different strategies like rloo and grpo_passk are additionally accessible. See the documentation for a full record. A binary rating can collapse that variance: when each rollout in a gaggle scores the identical, the relative sign is zero and the group contributes no gradient. When rollout/reward/valid_mean (the imply over non-zero-advantage teams) drifts under rollout/reward/imply and the mannequin stalls, that hole is the symptom.
The second is convergence pace. Even when group variance is wholesome, a dense reward provides the mannequin gradient towards partial progress on each rollout, not solely those that totally succeed. A rollout that will get 5 of six fields proper teaches the mannequin what nearer appears like. A binary rating teaches it nothing about that.
A dense reward for the SOP-Bench job scores every area independently and returns a reward scalar or record of scalars (per-turn rewards) plus a metrics dictionary.
Your agent reviews the reward by means of update_reward, and the metrics dictionary (completion, field_acc) seems in MLflow. To credit score particular person turns as an alternative of the entire trajectory, update_reward additionally accepts a per-turn record, paired with the group_based_per_turn benefit technique, so your reward perform can even return one reward worth per flip.
- Confirm the reward on actual outputs earlier than you practice on it. A reward parser extra forgiving than your analysis is its personal sort of reward hack. In one among our SOP-Bench runs the reward accepted a looser output format than the benchmark scored: a naked
- Be certain the bottom mannequin has a foothold first. RL improves what the bottom mannequin can already do some fraction of the time. It doesn’t invent functionality from nothing. If the bottom mannequin produces zero profitable trajectories in your job, the reward sign has nothing to amplify and coaching stalls.
SageMaker AI MTRL can run such a baseline as a managed analysis job. MultiTurnRLEvaluator replays your agent over a held-out immediate set and reviews eval/reward and cross@ok. When you have already educated a mannequin, a single name with evaluate_base_model=True scores the bottom and fine-tuned mannequin facet by facet. As a result of cross@ok thresholds the reward at success_threshold, setting success_threshold=1 provides you a strict success price: the fraction of rollouts that scored an ideal reward alongside the imply.
Within the specified s3_output_path, you’ll find the reported metrics of the analysis which you can too evaluate in MLflow, together with analysis trajectories. For reward-based analysis of fine-tuned and base fashions, see the documentation on Mannequin analysis.
Maintain one distinction in thoughts: the analysis job scores rollouts together with your agent’s personal reward perform, so it measures held-out generalization, not independence from the reward. A lenient reward parser would look wholesome right here, as a result of the metric is the reward itself. The impartial examine that catches reward-parser bugs stays separate: rating the identical rollouts with a stricter, impartial parser (for SOP-Bench, the benchmark’s exact-match scorer) and examine. You’ll be able to even run that strict scorer as its personal analysis job by pointing MultiTurnRLEvaluator at an agent whose reward is the impartial metric.
For a deeper therapy of reward design, sparse vs. dense rewards, decide fashions, multi-objective shaping, and the trade-offs between them, see the SageMaker AI reward design greatest practices.
Earlier than you belief your reward, verify:
Handle what adjustments when the agent runs for a number of turns
A multi-turn agent has to handle considerations single-turn doesn’t see. These are price designing for explicitly earlier than you begin coaching.
Context grows each flip, and switch budgets are a part of the reward design. Every instrument name extends the dialog: the decision, its arguments, the outcome, and the reasoning the mannequin produces between them. Lengthy trajectories accumulate context quick, and MTRL makes use of sequence-extension coaching to maintain wall-clock manageable as they develop. A job that wants eight calls in sequence would possibly run out of room earlier than it finishes. Two budgets certain this: max_turns, which your agent loop controls, and the per-turn token finances, which the service units by means of sampling_max_tokens (rollout) and val_sampling_params.sampling_max_tokens (analysis). Decide each to match what your job wants and what you may afford to serve at deployment.
For SOP-Bench, eight turns and a 2,048-token per-turn finances cowl the canonical process with margin to spare (sampling_max_tokens permits as much as 8,192). A rule of thumb: if a human walkthrough of the duty takes N turns, set max_turns = ceil(N * 1.5) in your agent loop. The proper flip finances is the smallest one which lets the agent end with a small security margin. Watch rollout/tokens/response_max for responses clustering on the cap. If greater than 5 p.c of rollouts hit it, elevate sampling_max_tokens. That sign is silent loss in any other case. The mannequin learns from a truncated trajectory however doesn’t see the reward it might have earned by ending.
Separate completion from correctness
A trajectory that finishes with the fallacious reply and one which by no means finishes are totally different failures, and conflating them hides the place the mannequin is breaking. The rollout and val metric households in MLflow provide you with each alerts individually:
| Metric | What it tells you | |
| 1 | rollout/reward/imply |
Common trajectory reward, your training-side sign |
| 2 | rollout/reward/zero_frac |
Fraction of trajectories that scored precisely 0 |
| 3 | rollout/turns/imply |
Common turns per trajectory |
| 4 | evaluation/zero_adv_groups |
Teams the place each rollout scored the identical, losing rollouts |
| 5 | val/reward/imply |
Imply validation reward your held-out knowledge sign |
| 6 | val/reward/pass_k_1, pass_k_8 |
cross@1 and cross@ok on the held-out set |
A excessive val/reward/pass_k_1 on a low completion price (rollouts hitting max_turns earlier than emitting a val/reward/pass_k_1 means it solutions fluently however fallacious, suggesting reward redesign. The 2 failure modes name for various fixes, so it’s price telling them aside.
Earlier than you commit a flip finances, verify:
Monitor coaching metrics
After you’ve arrange and verified your analysis, atmosphere, and reward, it’s time to start out coaching. SageMaker AI MTRL supplies the high-level MultiTurnRLTrainer and MultiTurnRLEvaluator constructs to coach and rating your agent:
Whereas coaching, watch rollout/reward/imply subsequent to the completion price and open a couple of trajectories in MLflow (beneath the Traces tab), so a reward that rises on flat completion doesn’t slip previous. The sign that issues at analysis is disagreement: when rollout/reward/imply climbs however val/reward/imply stays flat, the reward is being hacked. Open these trajectories and examine what the reward credited towards what the analysis scored. That comparability drives your reward design iteration: tighten the reward parser, reshape a part, or curate the info, then run once more. Every iteration is quicker than the final as a result of the atmosphere and analysis keep mounted. Solely the reward and the info change, and MTRL’s per-model starter recipes provide you with a tuned level to start out from.
For instance, in one among our earliest makes an attempt we have been attempting to coach an agent on all SOP-Bench duties on the similar time, which led to duties competing and reward fluctuating:
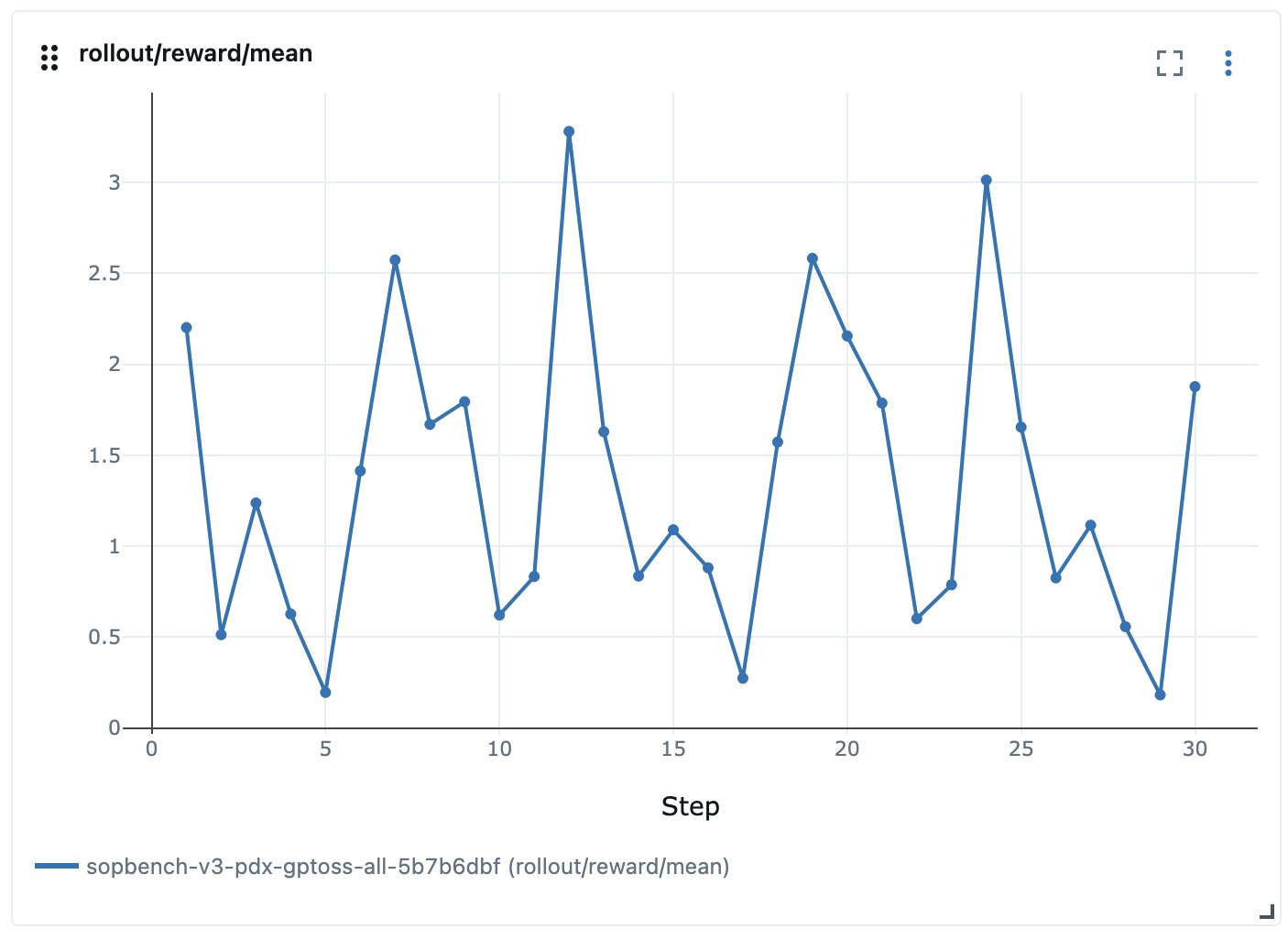
Determine 2: Reward fluctuating when attempting to coach all SOP-Bench duties collectively
After limiting our knowledge to deal with a single job (aircraft_inspection), we seen validation reward happening whereas rollout reward had saturated. In our reward formulation the max reward was 5.0, however reward had stalled round 3.7:
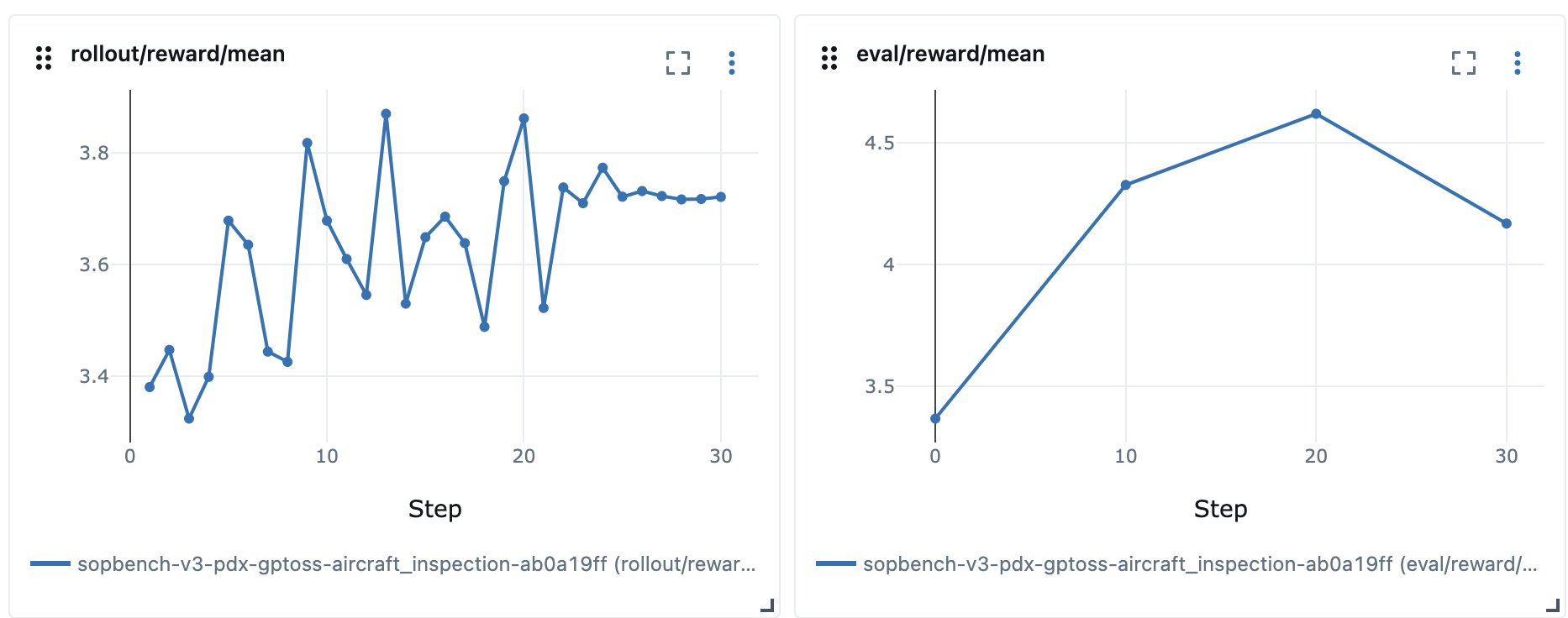
Determine 3: Reward stalling and validation reward dropping
The mannequin wasn’t incomes full reward on aircraft_inspection, and the Job Success Charge on the exterior benchmark went down for the fine-tuned mannequin in comparison with the bottom mannequin. We wanted to evaluate rollout trajectories to search out out why. The SOP’s one-shot instance didn’t match the duty’s ground-truth knowledge in two methods. It omitted the cross_check_response area that the info required, so the mannequin couldn’t produce an entire reply, and it wrapped the output in a unique tag than the analysis anticipated. We aligned the instance with the info and dropped the unanswerable area, which let the reward and the analysis measure the identical factor.
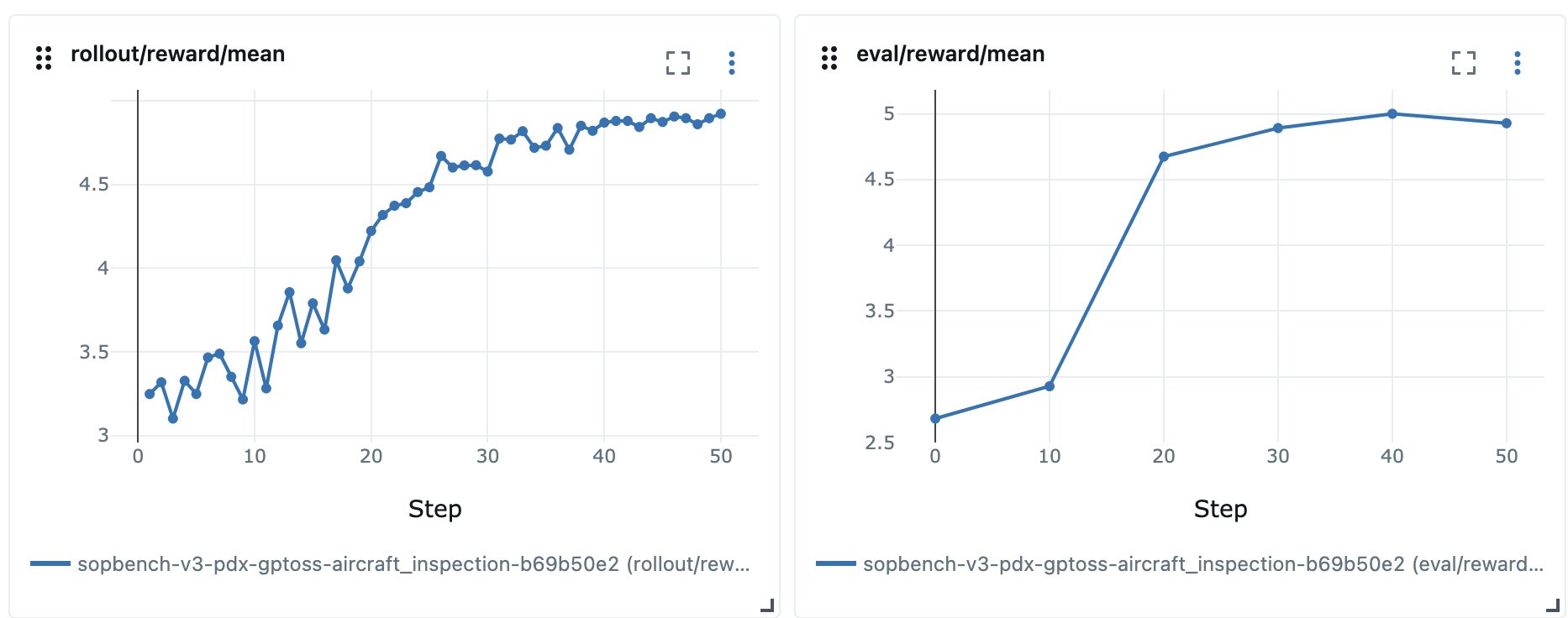
Determine 4: Wholesome reward alerts for the aircraft_inspection job of SOP-Bench
When measuring the Job Success Charge (TSR) of a fine-tuned GPT-OSS 20B mannequin towards the exterior benchmark, we noticed TSR improve by 13 p.c and per-field accuracy develop by roughly 16 p.c on the aircraft_inspection job, confirming that our reward perform aligns with our exterior analysis.
Placing it collectively: An iteration loop
The items described earlier add as much as a single coaching loop, run within the order they have been launched. You construct the atmosphere and the analysis first, as a result of they’re the mounted scaffolding each later step depends upon. You then design the reward towards that analysis, and solely after that do you practice and browse the metrics. Conserving the early items mounted is what makes every cross quick, so most of your effort goes into the reward and the info. A model that has labored effectively for us:
- Acquire consultant job knowledge and break up into practice, validation, and held-out take a look at units.
- Construct the coaching atmosphere from manufacturing schemas: airtight, seeded, reproducible.
- Get up the exterior analysis towards the take a look at set, computed independently of the reward.
- Set up a baseline by operating the bottom mannequin and a frontier reference mannequin by means of the analysis. If the bottom mannequin scores zero, cease and simplify earlier than persevering with.
- Design the reward, then validate it on actual mannequin outputs from the baseline earlier than any coaching has occurred.
- Practice, monitoring rollout/reward, completion price, and a pattern of trajectories to know what your mannequin is producing throughout coaching.
- Consider the educated mannequin with the exterior analysis. Learn trajectories, particularly those the place the reward and the analysis disagree.
- Alter the reward, the atmosphere, or the info, and run once more.
When the curve stalls or collapses, stroll these so as earlier than tuning anything:
| Symptom | Very first thing to alter | Diagnostic to substantiate | |
| 1 | Reward flat from step 0 | Confirm mannequin output codecs are aligned with reward | Carry out standalone evaluations on totally different rewards to align format reward with mannequin’s output construction |
| 2 | Practice reward flat, all teams rating the identical | Drop group_size from 8 to 4 and improve batch_size |
Watch evaluation/zero_adv_groups, ought to drop |
| 3 | Practice reward rising however val/reward/imply flat |
Reward is being hacked. Re-read trajectories, tighten the reward parser | Re-run the offline reward evaluate towards new baseline rollouts |
| 4 | Reward collapses (drops to ~0.0) after step 40–80 | Set async_config.max_steps_off_policy = 0. If on CISPO, change to PPO with (0.8, 1.2) |
Reward ought to stabilize, even when decrease |
| 5 | Reward stalls with restricted enchancment, all knobs wholesome | Double LoRA capability (lora_rank=64, lora_alpha=128) |
Larger ceiling inside 50 steps if there’s room to develop |
Make one change at a time, observing metrics for 25–50 coaching steps (gradient updates) per determination. In our runs, most failures grew to become identifiable inside roughly 30 steps when these parameters are adjusted intentionally.
Conclusion
Your reward high quality and your analysis resolve whether or not coaching produces a helpful agent, rather more than the algorithm or the hyperparameters do. The reward is the one sign the mannequin optimizes, and an analysis stored separate from it’s what tells you whether or not the agent is studying the duty or studying the reward. A fastidiously designed reward and an analysis that matches the tip job can produce a helpful agent; with out them, even a robust algorithm yields a mannequin that appears good in coaching and fails in manufacturing.
SageMaker AI multi-turn RL takes care of a lot of the operational work and complexity of operating a distributed agentic RL coaching, abstracting away the {hardware}, orchestration, and coaching engine. With SageMaker AI multi-turn RL, you deal with creating an correct atmosphere, the place Strands Brokers and AgentCore may also help you transition your manufacturing atmosphere to an agentic setup, and deal with the reward design, analysis, and parameter tuning.
To get began with agentic RL, you may stroll by means of the instance pocket book for MTRL setup. See the SageMaker AI multi-turn RL documentation for service-level steering and the reward design greatest practices for a deeper therapy of the reward matter, or this AWS weblog submit on GRPO with verifiable rewards. Lastly, the SOP-Bench paper and dataset are the supply of the operating instance used right here.
Concerning the authors