Musk is looking for as a lot as $134 billion in damages from OpenAI and Microsoft, considered one of OpenAI’s greatest monetary backers. He’s additionally asking the courtroom to take away Altman and Brockman from their roles and to revive OpenAI as a nonprofit. Musk has requested the courtroom to award any damages to OpenAI’s nonprofit moderately than to him personally.
9 jurors will ship an advisory verdict, a non-binding suggestion, to information the decide in deciding Musk’s claims in opposition to Altman. Musk, Altman, and Brockman will take the stand. Former OpenAI chief scientist Ilya Sutskever, former OpenAI CTO Mira Murati, and Microsoft CEO Satya Nadella are additionally anticipated to testify. Cringey texts, uncooked diary entries, and infinite scheming behind the founding and development of OpenAI are anticipated to come back to mild.
In an trade enveloped in secrecy, the trial will likely be a uncommon alternative for the general public to look behind the scenes and discover out what’s occurring within the firms creating essentially the most transformative expertise ever constructed.
What are they preventing about?
When OpenAI was initially based as a nonprofit, backed by a $38 million donation from Musk, the corporate vowed to create open-source expertise for the general public’s profit, unconstrained by a have to generate monetary returns. However through the years, the corporate started to consider that intensifying competitors might make it harmful to share the way it develops its AI fashions and {that a} nonprofit construction couldn’t increase sufficient cash to maintain constructing AI. (MIT Know-how Overviewwas first to report on OpenAI’s inside conflicts round its mission.)
The courtroom has already discovered that in 2017 Altman and Brockman needed to ascertain a for-profit arm, whereas Musk proposed merging OpenAI along with his electric-car firm, Tesla. When Musk threatened to cease funding, Altman and Brockman instructed him that they have been dedicated to preserving the corporate a nonprofit. Musk alleges that they pursued plans to pivot to a for-profit with out informing him. In accordance to OpenAI, Musk agreed that the corporate wanted a for-profit entity and even needed to be its CEO.
However even when Musk proves he was duped by Altman and Brockman, he might not have standing within the first place to sue them for restructuring the corporate to function a for-profit subsidiary. Some authorized students are puzzled over why the decide allowed him to carry this declare. “The concept Elon Musk can sue as a result of he was a donor or was once on the board is fairly puzzling,” says Jill Horwitz, a regulation professor who research nonprofit regulation at Northwestern College. “Sometimes, it’s as much as the attorneys common to carry such a declare to implement the charitable functions. And that’s already occurred.”
In October 2025, state attorneys common of California, the place OpenAI is headquartered, and Delaware, the place OpenAI is integrated, struck a deal with OpenAI to approve its new company construction on a sequence of situations. For instance, a security and safety committee on the nonprofit would evaluate safety-related selections made by the for-profit subsidiary. Critics of the restructuring, together with Musk, AI security advocates, and civil society teams, have tried to cease it.
California’s lawyer common has declined to affix Musk’s lawsuit, saying that the workplace didn’t see how his motion serves the general public curiosity.
In February, Robert F. Kennedy Jr., the US secretary of well being, made a characteristically daring declare. A health care provider at Harvard College, he proclaimed, “has cured schizophrenia utilizing keto diets”.
When you occurred to be passing Harvard College that day, you may need heard the sound of that physician’s palm hitting his brow. “For the file, I’ve by no means ever as soon as used the phrase ‘treatment’ in any of my work,” says Christopher Palmer, a psychiatrist at Harvard Medical College. “Nonetheless, I have used the phrase ‘remission’…”
The concept that a weight loss program finest generally known as a fat-busting fad might deal with critical psychological sickness may sound like the newest providing from the wild west of on-line wellness: one thing destined to be filed alongside uncooked water and low enemas within the annals of horrible ideas.
However there are numerous the reason why the thought of utilizing the weight loss program for situations affecting the mind deserves nearer inspection. For one factor, over 100 years’ value of analysis has proven that ketogenic diets have actual, measurable results on the physique basically, in addition to on the organ between your ears. For one more, lots of these modifications – some on the mobile stage, others all through the entire physique – are recognized remedy targets in psychological sickness.
With proof from small trials and case research indicating that ketogenic diets can dramatically enhance signs in some individuals with psychological well being situations, a rising variety of scientists are questioning if what is known as metabolic psychiatry might result in much-needed new therapies for situations affecting the mind and the mind-body connection.
“We’ve wasted 30 years desirous about dopamine and serotonin as the only targets for psychiatric medicines,” says Daniel Smith, a psychiatrist on the College of Edinburgh, UK. “That is a brand new paradigm. It’s thrilling.”
Fuelling the mind
These days, ketogenic diets are primarily related to efforts to shed some pounds, however they have been first developed greater than a century in the past to deal with issues with the mind. At the moment, few medicine have been accessible for epilepsy. One factor that did appear to work was fasting for a number of days at a time, which considerably decreased seizures and generally stopped them altogether. The issue was, it wasn’t sustainable. Ultimately, individuals would wish to eat and after they did, their seizures would return.
Researchers got down to discover a resolution, and in the Nineteen Twenties, Russell Wilder, a doctor and epilepsy researcher on the Mayo Clinic in Minnesota, cracked it. He developed a high-fat, moderate-protein and very-low-carb weight loss program to imitate fasting, whereas nonetheless offering sufficient vitality to reside on. He referred to as it the ketogenic weight loss program as a result of it was designed to set off the metabolic shift that occurs when the physique can not pay money for carbohydrates from meals and so has to change to burning fat, producing small molecules referred to as ketone our bodies within the course of.
As we’re a species that largely eats vegetation, carbohydrates are our default gasoline. Carbs are rapidly damaged down into glucose throughout digestion, which will be burned in our cells for vitality. This course of takes place within the mitochondria, mobile organelles the place meals is transformed into adenosine triphosphate (ATP), the physique’s vitality foreign money. What isn’t used immediately is saved as glycogen within the liver and muscle mass, to be referred to as on between meals. When these shops are full, any spare energy are deposited as fats.
If meals is brief, and carbohydrates aren’t really easy to return by, the physique reverses the method. First it releases saved glycogen, which may preserve us ticking over for as much as a day. When that runs out, the physique begins to interrupt into its fats reserves for vitality.
Among the fatty acids launched are despatched to be burned within the mitochondria, whereas others are handed to the liver, the place they’re transformed into ketone our bodies. Ketone our bodies are smaller than fatty acids and, as a result of they’re water-soluble, are simpler to move within the blood to the place they’re wanted. In addition they have the benefit of being sufficiently small to cross the blood-brain barrier, permitting them to be used instead of glucose as gasoline for the mind.
The keto weight loss program is high-fat, moderate-protein and low-carb – making meals like eggs, meat, avocado and leafy greens typical fare
Addictive Inventory/StockFood
It’s an ingenious system, and the swap backwards and forwards between gasoline varieties most likely got here into play fairly often for our hunter-gatherer ancestors. For many fashionable people, although, carbs are really easy to return by that the metabolic swap occurs hardly ever, if in any respect.
Wilder’s thought was for a weight loss program designed to flick the swap to fats burning, whereas offering sufficient fats within the weight loss program so the physique didn’t want to interrupt down its personal fats reserves. If this state of “dietary ketosis” labored, it may very well be used as a extra sustainable different to fasting.
In 1921, Wilder revealed a paper displaying that it did certainly work. In three individuals with epilepsy, the ketogenic weight loss program decreased seizures as successfully as fasting, and may very well be maintained for longer. Later analysis backed him up and the keto weight loss program turned an epilepsy remedy. When new anticonvulsant medicines got here alongside within the Thirties, although, Wilder’s weight loss program fell out of favour, solely to be used in younger kids and people who don’t reply to any accessible medicines.
However, the truth that it labored steered that there’s one thing about “going keto” that corrects issues with mind operate. A number of many years of analysis later, we’ve a greater thought of what’s occurring beneath the lid when our our bodies swap to back-up-fuel mode.
The quick reply is: plenty of issues. The best and most evident is that it includes consuming far much less sugar. Whereas glucose is our physique’s default vitality supply, having an excessive amount of of it’s recognized to be disastrous for the well being of the physique and mind. Lengthy-term overindulging in carbs contributes to irritation, insulin resistance, diabetes and weight problems, whereas the proof means that high-sugar diets usually tend to result in low temper in individuals each with and with out despair.
It is feasible, then, that a few of the keto weight loss program’s results come all the way down to bringing us nearer to the weight loss program our our bodies advanced to count on. “We’re wired to love sugar, however in nature, sugar wasn’t round that a lot,” says Guido Frank, a psychiatrist on the College of California, San Diego. “It’s not that sugar is [always] dangerous for us, it’s concerning the amount.”
A few of these results could also be attainable with out going full keto. The basic ketogenic weight loss program includes decreasing carbohydrates from 45 per cent of complete energy to only 1 to five per cent. Decreasing carbs much less dramatically, or following a low-glycaemic-index weight loss program that focuses on slow-release carbohydrates as a substitute of straightforward sugars, may present at the least a few of the advantages, says Palmer. “A low-glycaemic-index weight loss program isn’t essentially ketogenic, however it’s definitely having anti-inflammatory and insulin-signalling results and possibly impacts the intestine microbiome as properly,” he says.
Different modifications, nonetheless, do appear to require switching to ketosis. One instance is the way in which ketone our bodies seem to behave immediately on the mind to stability two key neurotransmitters: glutamate, which excites neurons to fireside, and GABA, which inhibits their firing. An extra of glutamate, relative to GABA, is related to the uncontrolled firing seen in epileptic seizures and the erratic mind exercise implicated in psychosis. Among the anticonvulsant medicines which might be used to deal with epilepsy, schizophrenia and bipolar dysfunction increase GABA relative to glutamate. Proof from mouse research means that keto diets do one thing comparable.
Ketone our bodies
How precisely ketone our bodies rebalance these neurotransmitters isn’t clear. One risk, nonetheless, is that they merely present sufficient vitality for the mind to do its job correctly. Ketone our bodies are more durable to produce within the physique than glucose, however, as soon as shaped, are a extra environment friendly gasoline supply for the mitochondria, netting 27 per cent extra ATP per molecule.
A lift of vitality within the mind might do extra than simply even out neurotransmitter ranges. Research specializing in schizophrenia, bipolar dysfunction and despair, in addition to Alzheimer’s illness and anorexia nervosa, have discovered proof of mitochondrial dysfunction. And whereas there are numerous routes to malfunctioning mitochondria – from genetics to weight loss program and different life-style elements – it does recommend that an issue with releasing vitality from glucose could play a task in lots of brain-related points.
Carmen Sandi, a neuroscientist on the Swiss Federal Institute of Expertise in Lausanne, research the connection between mitochondrial well being and psychological sickness. She factors out that the mind is essentially the most energy-hungry organ, demanding 20 per cent of the physique’s gasoline at relaxation, regardless of solely accounting for two per cent of physique weight. However “that’s solely a part of the story”, she says.
Ketone our bodies are tiny sufficient to cross the blood-brain barrier, which implies they can be utilized as gasoline for the mind, instead of glucose
JAMES BELL/SCIENCE PHOTO LIBRARY
“Mitochondria should not simply the vitality producers – in addition they contribute to the exact functioning of neurons and mind circuits”, with a task in making hormones and different signalling molecules, and in regulating irritation and managing oxidative stress. There may be some proof that ketone our bodies generate much less oxidative stress than glucose, says Sandi, so scale back the demand for metabolic clean-up.
For Palmer, all of this proof factors to a typical underlying trigger for psychological well being situations: that they are attributable to metabolic issues within the mind. He factors to the truth that bodily metabolic situations, comparable to diabetes, weight problems and insulin resistance, considerably enhance the danger of despair. The reverse can also be true: individuals with psychological well being situations are at higher danger of diabetes, weight problems and coronary heart illness.
That ketogenic diets may assist deal with metabolic issues within the mind first occurred to Palmer within the late 2010s when he was treating a girls in her 70s who had skilled debilitating, drug-resistant schizophrenia for greater than 50 years.
As is frequent in extreme psychological sickness, along with being extraordinarily mentally unwell, the girl, Mildred, had weight problems and her bodily well being was deteriorating. She was suggested to strive the keto weight loss program to shed some pounds. Inside weeks, along with weight reduction, she began to note enhancements in her schizophrenia signs. The voices in her head turned quieter, her temper improved and, then, after many years of being affected by the situation, she went into full remission. Palmer was amazed, and in 2019 revealed a paper describing Mildred’s expertise and the same remission outcome from a second particular person with schizophrenia.
It was this analysis that caught the eye of Robert F. Kennedy Jr., and spawned a grassroots motion spearheaded by the philanthropist Jan Ellison Baszucki and her husband David Baszucki, founder and CEO of the tech firm Roblox. In 2021, the couple’s son, Matthew, had been fighting treatment-resistant bipolar dysfunction for 5 years. Having run out of different remedy choices, he went on the ketogenic weight loss program, beneath the steering of Palmer. Inside months, he, too, was in remission. The household went on to arrange a basis to fund analysis in metabolic psychiatry and to share tales from individuals who have had a constructive expertise with keto. On the final rely, the muse’s Metabolic Thoughts YouTube account had greater than 97,000 subscribers.
When consuming keto, carbohydrates like bread are firmly off the menu
Patrick Chatelain/www.plainpicture.com
In the meantime, analysis by different teams added to the thrill, together with one 2022 research in 31 individuals, all of whom had beforehand been hospitalised with extreme despair, bipolar dysfunction or schizoaffective dysfunction. Of the 31 volunteers who agreed to strive the ketogenic weight loss program, 28 managed to stay to it for 2 weeks or extra. All 28 noticed some enchancment of their signs and virtually half reached the factors for medical remission. Nevertheless, the research had no management group.
If there may be one psychological well being situation the place a fat-burning weight loss program wouldn’t appear to use, it might be anorexia. Suggesting that individuals who have a historical past of disordered consuming minimize a significant meals group out of their weight loss program sounds irresponsible and probably harmful.
But proof reveals that, when individuals are correctly supported and beneath medical supervision, ketogenic diets may simply assist. Frank was concerned in a 2022 pilot research in 5 individuals with anorexia that reported that they have been capable of keep a wholesome weight on the ketogenic weight loss program with fewer food-related anxieties. 4 of the 5 saved the weight loss program up after the research and continued to enhance. “It was unbelievable,” says Frank. “I hadn’t seen that earlier than in 20 years of working on this subject.”
As with different psychological well being situations, there are believable the reason why going keto may assist. For one, research by Cynthia Bulik, a medical psychiatrist on the Karolinska Institute in Sweden, and her colleagues have proven that anorexia is related to gene variants linked to inefficient vitality launch within the mitochondria.
As such, one risk is that when somebody with a genetic metabolic vulnerability begins weight-reduction plan, the swap to ketosis brings a lift of vitality and lowers anxiousness. This, in flip, could reinforce the compulsion to limit meals additional, trapping individuals in a cycle of weight reduction that will get uncontrolled. “Folks with anorexia nervosa could have a purpose weight, however for a lot of of them, it’s by no means sufficient,” says Frank. “It’s virtually like an addictive course of.”
Now, researchers are questioning if a correctly balanced ketogenic weight loss program might assist individuals with anorexia to discover a delicate stability – permitting them to get to a wholesome weight whereas eradicating the compulsion to limit meals. If going into dietary ketosis can scale back anxiousness in the same approach to self-starvation, then “mimicking the underweight state by offering ketone our bodies for vitality creation may make the necessity to prohibit pointless”, says Frank.
It is early days, says Sahib Khalsa, a psychiatrist who researches and treats anorexia on the College of California, Los Angeles. He provides that keto diets shouldn’t be tried for psychological well being situations and not using a physician’s help. “There’s a distinction between attempting it with an consuming dysfunction psychiatrist who’s monitoring you rigorously, and studying a few ketogenic weight loss program after which deciding spontaneously to do it,” he says. “From a security standpoint, I feel it’s positively untimely for that.”
Filling the gaps
For all of the case research and testimonials, keto for the mind is way from a completed deal. Smith factors out that there have been no correctly managed, randomised trials in massive numbers of people, so it is inconceivable to know what quantity of individuals will reply as dramatically as Mildred and Matthew Baszucki. “There is perhaps two individuals who have a superb response, and that’s nice,” he says. “However there is perhaps 98 different individuals who don’t get any response.”
To strive to fill this hole, Smith, together with Steven Marwaha on the College of Birmingham, UK, is starting a large-scale, randomised managed trial in 200 individuals with bipolar despair. The research will evaluate a dietary ketogenic weight loss program with a weight loss program based mostly on UK wholesome consuming pointers. The outcomes gained’t be in for at the least 5 years, says Smith. Within the meantime, the outcomes of a pilot research with 27 individuals that Smith and his colleagues revealed in 2025 have been encouraging, discovering a correlation between ketone ranges and improved temper and vitality ranges. Mind imaging additionally confirmed a lower in glutamate ranges in mind areas concerned in emotional processing.
One other unknown is whether or not any of the numerous mechanisms are extra vital than others for individuals who may profit from the keto weight loss program. “It’s believable that completely different people derive profit via completely different dominant mechanisms, relying on their underlying metabolic and neurobiological vulnerabilities. Nevertheless, in lots of circumstances, the therapeutic results seemingly come up from their mixed influence,” says Shebani Sethi, a metabolic psychiatrist at Stanford College in California.
As bigger medical trials get beneath means, and the outcomes proceed to roll in, metabolic psychiatry might go numerous methods. Keto diets may prove to work very properly for some individuals, and in no way for others, wherein case analysis will give attention to figuring out markers that point out who they may profit. Or additional analysis could enable us to extract the particular sauce from ketogenic diets, which might then inform new drug therapies and make it pointless to persist with a restrictive weight loss program.
For now, although, says Palmer, the vital factor is to make individuals conscious that, even after they have tried all the pieces, there may be nonetheless hope. “Some individuals reply rather well to present therapies, however it’s heartbreaking to see sufferers yr after yr, decade after decade, who’re doing all the pieces we’re asking them to do and they’re profoundly struggling. Providing even one extra device that may work for some sufferers is my ardour. That is our second for metabolism and psychological well being. That’s what I’m hoping.”
Nothing a lot to publish besides that I wished to share that Yale College Press despatched me two doable covers of my new e-book and requested me to choose.
I went with inexperienced.
And simply in case you had been questioning, it’s fairly large replace. Reduce the chance chapter, constructed out the unconfoundedness chapter, up to date IV with extra on weak devices literature, tweaked RDD with optimum bandwidth choice and a brand new software, then a reasonably substantial overhaul of the panel stuff. I stored the mounted results chapter the identical, however the diff in diff chapter cut up into two chapters — one on basic diff in diff stuff (the 2×2 calculation, the regressions for it, the goal parameter, the ATT, parallel tendencies, occasion research), after which one other chapter on advanced diff in diff which is covariates, compositional change, two manner mounted results with OLS, bacon decomp, a bunch of the brand new diff in diff estimators, sensitivity evaluation with Rambachan and Roth, a guidelines, a brand new instance. Then a beefed up artificial management chapter after which a closing
I additionally constructed the brand new e-book extra round narratives of the Princeton industrial relations part, the labor economists and labor economics custom for its position in utilized causal inference during the last 50 years extra usually, and the statistics of experiments (additionally Harvard however Harvard stats). Card, Krueger, Orley, Lalonde, Imbens, Angrist, Heckman, Currie, Rubin, Abadie — they’re typically characters. However on account of writing a lot about them within the remix, and for the aim of causal inference pedagogy, I believe I won’t have the rest to say. Perhaps I’ll know as soon as sufficient time passes and the books out and behind me.
However Yale thinks possibly August 25, probably early September. I’ll begin getting the web e-book prepared most likely after I get again from Europe. Kyle has some concepts about methods to make the interface higher so we’ll see what’s coming. However identical to final time, it’ll have a free model.
On a special observe I obtained to see the coasts of Rhode Island this weekend. I had clam muffins driving by the ocean, stopping at Narragansett. It was stunning. I’m solely the billionth individual to say that I’m positive, however it’s and I like it. I informed my pal I had thought deeply about Rhode Island from 2009-2018 due to a paper I wrote with Manisha Shah, however had by no means been there. I went to brown final semester however what I imply is I hadn’t actually seen it regardless of a fifth of my life considering and speaking about it. A lot in order that my youngest daughter as soon as informed her Sunday faculty instructor that, when requested what her dad did for a residing. She informed them that I had “found Rhode Island”, which was most likely higher than her attempting to clarify that what I had actually carried out was estimate diff in diff and artificial management fashions on the impact of legalized intercourse work in Rhode Island on arrests, public well being outcomes, and the market measurement itself.
Level is, it was a humorous expertise to know a lot about probably the most inconsequential a part of Rhode Island historical past after which nothing in regards to the state and to then journey it because it simply felt pleasant. However it was greater than pleasant. Right here’s an image.
Courses are almost carried out. Then I head to Europe. My schedule is now this:
Zurich for per week
Glasgow for per week
Madrid for per week
Numerous elements of Italy for per week (Pisa and Milan)
Beeline for a spell
Again to Italy (Lucca once more!) for per week
Maastricht for a day
Then a one week trip in San Sebastián
After which I come dwelling. It’ll be my most intensive journey over there to this point.
Touring to Europe all the time coincides with me spending the summer time writing a ton of poetry, normally on planes and trains, vowing that this time I’ll lastly ship a couple of out, and every time by no means doing so. I’m not a lot of a finisher alas. And who is aware of — possibly I received’t even write a single poem. However it does look like the very first thing all the time occurs is after I get on the airplane, I write.
However possibly this time, possibly I’ll attempt to rebuild the concept of my econometrics detective novels for younger adults. I do know I talked about most of this on an earlier substack, and so it’s somewhat repetitive, however I simply thought I might discuss at present out loud. I typically really feel like I must discover a option to stability my pursuits — analysis, educating, assist for my dept, writing, outreach, service. I like the concept of the econometrics personal eye. I don’t know — it’s exhausting. It could be exhausting to do properly, and I’m 50, and I like writing, and I wish to discover extra individuals wherever they’re and lead them into econometrics. And I believe possibly a homicide thriller may do it. Not everybody in fact, however possibly one or two individuals, and I determine somebody has to seek out these two individuals, deliver them into the fold, so why not me?
I’m again in that previous acquainted place of not having the ability to sleep. I don’t know what it’s. I’ve tried every little thing. It began after I threw that social gathering final weekend for my pal and their associates right here at my apt. The brisket and rooster was scrumptious, I labored all day on it, and it got here collectively by some miracle. And I assume it made me blissful and unhappy. Blissful as a result of I obtained to like on my pal and their associates, love on Boston, and provides somewhat texas to them as a peace providing of affection and friendship. Unhappy as a result of it’s all the time unhappy to make associates after which depart. I made a decision for the yr I used to be right here I might be right here and never take into consideration leaving. So if I met somebody new, I didn’t inform myself that this was momentary so why make associates. However in fact, you then depart and should say goodbye. And so having such a pleasant feast, given my proneness to rumination and melancholy, most likely simply caught maintain of me. And it’ll shake out as soon as lessons finish, I pack up, and head out.
However I’m glad to see my youngsters. And I’m glad to see my cats. The 2 tenants who rented my home took care of all three for a backed charge. And thank goodness, one in all them fell in love with Simba, the stray I adopted, and goes to take him along with her when she leaves. Little does she know I might’ve paid her to take him — that’s how determined I’ve been to rehome him. Regardless of what you possibly have heard, the pound doesn’t normally take cats. You may as properly simply allow them to go exterior and lock the door, which I couldn’t do, so I had 4 candy cats who didn’t get together with each other, managed to discover a dwelling for one, and now have discovered one other dwelling for the opposite, taking me again down to 2 — the 2 authentic littermate sisters, Veronica and Betty. I’m positive they’re traumatized and past pissed off with how abandonment points having been handed round and with blended household for some time — identical to their previous man. I’ll be glad to see him.
However that’s a methods away. For the way, it’s ending the semester robust, getting issues arrange the place I can all the time name Claude and codex from the cellphone to my apt desktop if want be, get a brand new suitcase to exchange the one which was stolen on the prepare to Zurich final summer time, and simply do every little thing I can to organize for a protracted summer time. Then lessons this fall.
However I did determine I’ll write another mixtape styled e-book on chance based mostly on my Harvard PhD lecture notes. I believe I must spend extra time occupied with that materials as I got here to like it. So I’ll be that first. Attempt to get all these papers in a groove. Attempt to be blissful, attempt to deal with the household, attempt to make associates once more. I’m considering of coming again to Boston usually however I received’t be renting. I suppose I had to consider that to reject it. It was clearly not financially good, however I simply wasn’t prepared to depart right here. Typically I’ve to inform the tales after which I can transfer previous it.
I additionally wished to only say. I do know that typically seeing images of a persons’ journey can really feel like performative pleasure. Particularly when it’s on-line. And I do know it’s none of my enterprise what individuals assume or really feel seeing my photographs and sharing in my travels. I’ll proceed this summer time to jot down about causal inference, in addition to AI, on right here. However I believe I’m going to only additionally share the place I’m and inform about the way it’s going — which is extra private, nevertheless it’s simply that that is my fundamental outlet for sharing. However it’s completely none of my enterprise if somebody hates seeing that stuff, and decides to discontinue subscribing in consequence. The substack has nearly 27,000 subscribers now, and I form of don’t fairly know methods to finest go a few publication, as a result of I’m not a public mental. I’m extra a man looking for the proper spreadsheet to clarify some paper I’ve learn. Or to check out some new AI factor and determine what I realized after which share about it. However I additionally wished to point out all of you footage.
And so want me luck. And good luck this week.
Scott’s Mixtape Substack is a reader-supported publication. To obtain new posts and assist my work, take into account changing into a free or paid subscriber.
Coding assistants have moved past autocomplete into full brokers that may learn initiatives, run instructions, edit information, and iterate towards outcomes. Instruments like Claude Code and Codex each function on this area, however take totally different approaches. Claude Code facilities on a unified agent loop throughout environments, whereas Codex spreads capabilities throughout CLI, IDE extensions, cloud workflows, and delegated duties.
This isn’t about mannequin efficiency. It’s about workflow: management, intuitiveness, and the way simply you possibly can keep targeted whereas working inside an actual repository. On this article, we evaluate how every software suits into the act of getting work executed.
Getting began with Claude Code and Codex CLI
Earlier than shifting onto the true workflows, First let’s set up each the instruments in our system. Please be certain your system has node already put in.
Codex CLI
Set up the Codex CLI with npm. Open your terminal and run
npm i -g @openai/codex
Run Codex in a terminal. It will probably examine your repository, edit information, and run instructions.
Codex
Check in with an OpenAI account or API key
Claude Code
Set up the Claude Code with npm. Open your terminal and run
npm set up -g @anthropic-ai/claude-code
Run in terminal by altering the listing to specific venture
claude
Check in with an Anthropic Account
Now all set, let’s transfer to workflows.
The primary 10 minutes really feel totally different
Claude Code seems like an assisted accomplice. It needs to get a deal with on the repo, recommend a plan, then proceed with the duty with mode permission and checkpoints to maintain it secure. Codex seems like a configurable runtime. It’s nonetheless conversational, however the focus is extra on configuration, insurance policies, worktrees, overview, and cloud delegation.
In case you are opening a repo for the primary time, the hands-on distinction exhibits up instantly.
With Claude Code, a pure first transfer is:
Clarify the auth circulate, record the dangerous information, and inform me the place login may very well be failing.
With Codex, the equal seems like:
Clarify the auth circulate, record the dangerous information, and inform me the place login may very well be failing
The identical immediate, however the expertise could be very totally different. Claude usually encourages you to plan and execute. With Codex it feels prefer it asks you to set the parameters of freedom, sandboxing and approvals earlier than leaping in.
That distinction issues. Should you like being guided to productiveness, you’ll like Claude Code extra. Should you prefer to design a system, Codex is extra rewarding.
The Translation Layer: How the ideas map?
A lot of the confusion of Claude Code vs Codex is because of totally different terminology.
Facet
Claude Code
Codex
Repo Directions
Saved in CLAUDE.md
Saved in AGENTS.md
Reminiscence
Auto reminiscence
Express Recollections system
Session State
Checkpoints and /rewind for code and session state
Emphasis on code critiques and structured code state
Code Administration
Inline iteration with checkpoints
Worktrees and review-driven workflows
Distant Work
Distant Management resumes native periods (runs in your desktop)
Distant connections, app-server workflows, and cloud delegation by way of internet
Execution Mannequin
Native-first, session continues in your machine
Native + distant + cloud execution cut up throughout environments
Agent Workflows
Helps subagents and parallel agent workflows
Express subagent workflows with structured orchestration
Parallelism
Constructed-in parallel agent execution
Parallelism by way of worktrees and orchestrated brokers
Total Method
Unified, session-centric workflow
Distributed, system-oriented workflow
That is the mannequin to remember whenever you learn the remainder of this text.
Repo directions: CLAUDE.md vs AGENTS.md
It is a essential a part of the article as a result of it impacts how the agent feels after the primary day.
Claude Code masses CLAUDE.md in the beginning of every session and makes use of it as context for the venture, your Workflow, and even your organization. Anthropic’s documentation is evident that you must use CLAUDE.md to seize the principles you don’t need to repeat, and use auto reminiscence for Claude’s studying.
The Codex answer makes use of AGENTS.md, however in a extra refined means. You can have a world ~/.codex/AGENTS.md, then AGENTS.md per repo, then sub AGENTS.override.md, all as a part of the config.toml construction.
Right here’s the way it may work.
Right here’s a helpful CLAUDE.md for a Node repo:
A helpful AGENTS.md for a similar repo may seem like this:
The hands-on lesson is easy. Don’t wait till the agent disappoints you 5 instances. Write the instruction file early. Each instruments get a lot better as soon as your requirements reside within the repo as a substitute of in your head.
Reminiscence: What will get remembered and the way helpful it truly is?
The context window for Claude Code is wiped initially of every session, however you possibly can load your CLAUDE.md and auto reminiscence. Based on Anthropic, auto reminiscence is notes that Claude writes based mostly in your corrections and preferences, resembling construct instructions, debugging hints and issues it has seen whereas modifying in that tree.
Codex Recollections are related however they’re barely extra specific. Recollections are disabled by default, are saved domestically (in ~/.codex), and are for mounted preferences, widespread routines, project-specific conventions, and customary gotchas. The OpenAI docs additionally advise to not retailer reminiscences of guidelines as the one place for guidelines that should at all times be adopted. These nonetheless have to go in AGENTS.md or in paperwork within the repo.
This leads to an awesome workflow.
In case you are utilizing Claude Code, you possibly can have the agent study the tempo of the repo, then use CLAUDE.md for issues it is advisable to maintain secure.
In case you are utilizing Codex, don’t put the contract in Recollections. Put the contract in AGENTS.md. Put your platform guidelines in config.toml. Let reminiscences fill within the gaps.
This makes Codex really feel extra mechanical. Claude is extra like a wise teammate.
Permissions and planning: That is the place the character cut up turns into apparent
Claude Code has very descriptive names for permission modes. The obtainable modes are at the moment default, acceptEdits, plan, auto, dontAsk, and bypassPermissions. plan is especially fascinating because it permits Claude to plan and suggest adjustments with out touching your supply, and auto is a analysis preview that makes use of an additional classifier to filter actions.
Codex describes this by way of sandbox and approval coverage. OpenAI’s documentation calls sandbox mode the technical sandbox and approval coverage the rule for when to ask permission. Native Codex by default makes use of no networking and sandboxing underneath the OS, which is generally configured by way of ~/.codex/config.toml and, optionally, project-specific .codex/config.toml.
Right here is the hands-on model.
If you would like Claude Code to examine a repo and produce a proposal earlier than touching something:
claude --permission-mode plan
If you would like Claude Code to maneuver quicker on secure file edits:
claude --permission-mode acceptEdits
If you would like Codex configured for a tighter read-only go first, the OpenAI docs present patterns like this:
Open the .codex/config.toml file and add the next traces:
[profiles.readonly_quiet]
approval_policy = "by no means"
sandbox_mode = "read-only"
Then you should utilize that form of profile for a first-pass audit and solely loosen up it when you find yourself prepared.
This distinction issues so much in actual groups. Claude exposes the security mannequin as an interplay sample. Codex exposes it as a system configuration sample.
Let’s say your checkout check is failing and also you need the agent to analyze, repair, confirm, and clarify the change.
An excellent Claude Code workflow seems to be like this:
Discover why the checkout is failing. Begin in plan mode, determine the smallest secure repair, implement it, run the related assessments, and summarize the change in plain English.
An excellent Codex workflow seems to be like this:
Examine the checkout failure, maintain scope minimal, clarify root trigger first, then patch solely the information required, run the smallest related check set, and present me the diff I ought to overview.
Discover the distinction. With Claude Code, you naturally lean into circulate. With Codex, you naturally lean into specific scope and overview language.
Each instruments can do the loop, however they encourage barely totally different types of prompting.
Undo, restoration, and reviewing adjustments
Claude Code’s undo/rewind is a robust characteristic. Anthropic claims that each user-prompted change makes a checkpoint, the checkpoints are persistent, and /rewind can restore code, dialog, or each. So you possibly can “experiment” extra with out worrying about errors.
A “actual” use case seems to be like this:
/rewind
You then select whether or not to simply rewind the code, simply the chat, each, or begin summarising from a specific level and proceed.
And Codex addresses security in one other means. The overview pane shows the adjustments within the repo, means that you can add inline feedback and to stage, maintain or revert traces. The app additionally makes use of worktrees so many issues can occur when you work in your checkout.
So the sensible cut up is that this:
Claude says, “Strive the dangerous factor. You possibly can rewind.”
Codex says, “Let the work occur in isolation. Then examine it fastidiously.”
Each are good. They simply change how daring you are feeling whereas iterating.
Abilities, hooks, and reusable workflows
That is the part the place superior customers begin constructing actual leverage.
Claude Code expertise use SKILL.md, and Anthropic claims Claude can robotically invoke expertise as wanted, or you possibly can explicitly use slash instructions (e.g. /review-pr or /deploy-staging). Claude additionally has hooks for operating shell instructions earlier than or after Claude Code actions, resembling formatting, linting or customized validation.
OpenAI’s docs for Codex give attention to progressive disclosure. Codex masses ability metadata and solely masses the complete SKILL.md when it makes use of the ability. Codex additionally makes use of a built-in $skill-creator, and has hooks as an experimental extensibility framework (characteristic flag is in place).
Here’s a concrete hands-on sample you should utilize in both software.
Create a reusable code-review ability that claims:
---
identify: backend-review
description: Evaluate backend adjustments for auth bugs, migration threat, logging gaps, and check protection regressions.
---
When invoked:
Examine modified information first
Prioritize auth, knowledge integrity, and silent failure modes
Recommend the smallest fixes
Finish with a brief threat abstract
In Claude Code, that turns into one thing you possibly can naturally name from the dialog. In Codex, that turns into a cleaner reusable unit in a extra explicitly managed system.
Which one must you select?
Primarily based of the comparability and the options the 2 supply, right here’s a comparability desk to summarise all of it:
Facet
Claude Code
Codex
Onboarding
Smoother, extra guided expertise
Extra setup, geared towards customization
Workflow Fashion
“Maintain shifting” circulate with robust steering
Modular, programmable workflow
Core Energy
Appears like an energetic pair programmer
Appears like a platform you possibly can form
Management Degree
Extra implicit, agent-led
Extra specific, user-controlled
Key Options
Checkpointing, plan mode, guided periods
Configs, sandboxing, worktrees, distant and cloud delegation
Greatest For
Fast prototyping, repo exploration, guided refactors
Structured, scalable engineering workflows
Interplay Fashion
Suppose with the agent
Handle and orchestrate the agent
Supreme Consumer
Builders who need momentum and ease
Builders who need flexibility and system-level management
Total Really feel
A powerful pair programmer
A customizable coding platform
Conclusion
Claude Code wins on simplicity and “circulate.” The /rewind characteristic is a top-tier security web. The auto-memory system makes it really feel sensible over time. Select Claude Code if you would like aPair Programmer that simply works. It’s glorious for fast prototyping and refactoring.
Codex wins on precision and configurability. The worktree mannequin is ideal for complicated automation. The policy-based permissions swimsuit enterprise safety wants. Select Codex if you wish to construct a customized platform. It’s a strong alternative for systematized improvement.
These instruments usually are not simply opponents. They characterize totally different futures for AI coding. One is a guided agent. The opposite is a programmable runtime. They’re catered to totally different customers and each help in bettering your workflows.
Continuously Requested Questions
Q1. What’s the major distinction between CLAUDE.md and AGENTS.md?
A. They serve the identical function for repository directions. Claude Code makes use of CLAUDE.md, whereas Codex makes use of AGENTS.md, however Claude can import AGENTS.md information for compatibility.
Q2. Can I exploit these brokers for big, current codebases?
A. Sure, each are repo-aware. They’ll index 1000’s of information to offer context and carry out multi-file edits throughout the entire venture.
Q3. Do these brokers require an web connection?
A. Sure, each want to speak with LLM suppliers like Anthropic or OpenAI. Codex helps some native shell escapes, however the reasoning occurs within the cloud.
Harsh Mishra is an AI/ML Engineer who spends extra time speaking to Massive Language Fashions than precise people. Keen about GenAI, NLP, and making machines smarter (in order that they don’t substitute him simply but). When not optimizing fashions, he’s most likely optimizing his espresso consumption. 🚀☕
Login to proceed studying and luxuriate in expert-curated content material.
Fingent is featured as our advisable companion primarily based on experience, shopper success, and trade depth. All different corporations are listed alphabetically.
Fingent has been a world customized software program growth firm since 2003. The imaginative and prescient at its founding was to assist organizations have their finger on the heart beat of rising applied sciences and grow to be leaders of their discipline. This objective is being realized each day in additional than 14 nations globally.
Fingent has its headquarters in New York and supply centres in India, UAE and Australia. From these strategic places, it provides a variety of enterprise options, together with AI-enabled purposes which have helped companies resolve current challenges and grow to be future-ready.
Core providers:
Customized software program growth
AR, VR, and MR applied sciences
AI/ML options Cloud-native purposes
API integration
Cell app growth
Industries served: Healthcare, Monetary Companies, Logistics & Transportation, Actual Property, and Shopper Items
Notable Shoppers/ Tasks: Some notable purchasers are Mastercard, Raymond, Johnson & Johnson, Boston Consulting Group, BBC, Sony, and NEC.
Greatest Suited For: Midsize to massive organizations which can be searching for scalable, AI-powered customized digital options.
Clutch ranking : 4.9/5
Why Fingent? Fingent has constructed a document of efficiently delivering over 800 progressive tasks to purchasers globally. The mixture of expertise experience and enterprise acumen of educated consultants at Fingent provides you future-ready, scalable options that truly work within the enterprise state of affairs.
Intellectsoft was based in 2007. The corporate originated in Kyiv, Ukraine. Over time, Intellectsoft has grown right into a software program engineering firm with a world attain. It has expanded into america market by way of its places of work in Palo Alto and New York. The agency delivers next-generation digital transformation options constructed on AI and blockchain to the enterprise.
Core Companies:
Customized enterprise software program
AI/ML integration
Blockchain options
Cloud migration
Industries Served: Healthcare, finance, development, and retail. Notable Shoppers: Harley-Davidson, Jaguar & Land Rover Greatest Fitted to: Massive enterprises which can be searching for AI-driven digital transformation.
Iflexion was established in 1999. Its headquarters are situated in Denver, Colorado. It’s a software program firm with international supply capabilities. The corporate focuses on creating stable purposes for the net and enterprises for international companies.
Core Companies:
Net utility growth
Enterprise platforms
UX/UI design
Cloud options
QA & testing
Industries Served: Finance, logistics, retail, and media Notable Shoppers: Toyota, eBay, Cisco Greatest Fitted to: Mid-to-large enterprises needing scalable internet and enterprise options. Clutch ranking: 4.7/5
Itransition is a world software program growth firm established in 1998. It presently has its headquarters in Jap Europe with places of work within the US and different nations. The agency offers full growth providers, from conception to deployment.
Core Companies:
Cloud-native options
Enterprise mobility
QA automation Industries: Healthcare, finance, telecom, and retail Greatest for: World enterprises needing end-to-end software program growth providers.
Softermii is a software program growth firm with places of work in Los Angeles, USA. It was based in 2014. The agency is product-oriented, significantly in fintech and proptech.
Core Companies:
Customized app growth
Fintech options
Proptech platforms
Cloud integration
Industries Served: Fintech, actual property, and healthcare Notable Tasks: Growth of the actual property market platforms and the fintech providers for startup and scale-up companies. Greatest for: Startups and SMBs searching for product-centric and scalable purposes. Clutch ranking: 4.6/5
Cleveroad is a customized software program growth company based in 2011. It has its headquarters in Ukraine with places of work throughout america. The corporate offers internet and cell options with robust UX/UI experience.
Core Companies:
Industries: Healthcare, logistics, and e-commerce Notable tasks: Functions for healthcare scheduling and logistics administration methods Greatest for: Small to medium-sized enterprises (SMEs) and startups in want of agile internet and cell growth providers Clutch ranking: 4.6/5
Miquido, a mobile-first software program growth firm, was based in 2011 in Kraków, Poland and is increasing now in direction of the US. The corporate builds AI-based purposes and digital merchandise that target the consumer.
Core Companies:
Industries Served: Retail, media, and healthcare Notable purchasers:
ScienceSoft is a longtime chief in enterprise software program. It’s an IT consulting and software program growth firm. It originates from Jap Europe and has its headquarters in McKinney, Texas. The agency integrates strategic consulting and end-to-end software program growth.
Core Companies:
Enterprise intelligence
Cybersecurity
Industries Served: Healthcare, banking, retail, and manufacturing Notable purchasers: IBM
Greatest for: Enterprises searching for a mixture of IT technique and execution
Trigent Software program is a US-based firm with headquarters in Southborough, Massachusetts, with places of work worldwide. Established in 1995, the corporate has a patented experience in agile software program growth and cloud options with a deal with speedy and high-impact resolution supply.
Companies:
Agile software program growth
Industries Served: Healthcare, finance, logistics Notable Shoppers: Healthcare IT platforms and logistics optimization options Greatest for: Enterprises searching for dependable agile growth and sooner time-to-market Clutch ranking: 4.7/5
Based in 2015 in India, Appinventiv is a global software program growth agency. The corporate is targeting cell and AI-driven enterprise resolution purposes.
Core Companies:
Industries Served: Fintech, healthcare, and retail Notable purchasers: KPMG and different international enterprises, together with options developed for startups and rising companies Greatest for: Startups and enterprises searching for scalable, AI-driven utility growth Clutch ranking: 4.8/5
EPAM Methods, Inc., was established in 1993. Its headquarters are situated in Newtown, Pennsylvania, USA. It’s a digital transformation and software program engineering providers supplier. As one of many largest enterprise options and consulting suppliers, EPAM has a workforce of over 50,000 staff globally.
Core Companies:
Digital transformation
Enterprise IT options
Cloud-native platforms
Consulting providers
Industries Served: Finance, healthcare, retail, and manufacturing Notable purchasers: Strategic alliances with international expertise leaders like Google and Microsoft, and options for Fortune 500 corporations Greatest for: Fortune 500 companies poised for mass-scale digital transformation Clutch ranking: 4.9/5
Based in 1989, SoftChoice is headquartered in Toronto, Canada, and has grown into a significant IT options supplier. It has an intensive attain all through North America. The enterprise is about cloud enablement, software program licensing, and managed IT options for medium-sized enterprises.
Core Companies:
Cloud migration and optimization
Managed IT providers
IT procurement and software program licensing
Cybersecurity options
Industries Served: Finance, healthcare, and retail Notable tasks: Enterprise cloud adoption and digital office transformation initiatives Greatest for: Enterprises trying to undertake the cloud, optimize IT, and get managed providers Clutch ranking: 4.7/5
Netguru, established in 2008 in Poland, is a digital product growth firm with places of work in america and plenty of different nations. It additionally works in fintech and healthtech and builds scalable digital merchandise with these and extra sectors in thoughts.
Core Companies:
Industries Served:
Fintech, healthtech, and retail
Notable purchasers:
Greatest for: Startups and midmarket corporations creating digital merchandise Clutch ranking: 4.8/5
BairesDev was based in 2009 and is a nearshore software program growth firm headquartered in San Francisco, USA., with a powerful presence in Latin America. Utilizing regional engineering expertise, the corporate offers scalable enterprise options.
Core Companies:
Nearshore software program growth
Enterprise options
Notable Shoppers:
Greatest for: Enterprises searching for scalable nearshore growth groups Clutch ranking: 4.8/5
Zco Company was based in 1989. It’s a longtime utility software program that offers with customized software program utility growth, and iPhone and Android app growth within the New England space.
Industries Served: Healthcare, schooling, retail Notable tasks: Growth of enterprise purposes, cell options and bespoke platforms in various sectors Greatest for: SMEs and enterprises searching for dependable cell and customized software program options Clutch ranking: 4.6/5
On this tutorial we are going to construct a deep studying mannequin to categorise phrases. We are going to use tfdatasets to deal with information IO and pre-processing, and Keras to construct and prepare the mannequin.
We are going to use the Speech Instructions dataset which consists of 65,000 one-second audio recordsdata of individuals saying 30 totally different phrases. Every file comprises a single spoken English phrase. The dataset was launched by Google underneath CC License.
The mannequin we are going to implement right here shouldn’t be the state-of-the-art for audio recognition programs, that are far more complicated, however is comparatively easy and quick to coach. Plus, we present easy methods to effectively use tfdatasets to preprocess and serve information.
Audio illustration
Many deep studying fashions are end-to-end, i.e. we let the mannequin study helpful representations straight from the uncooked information. Nevertheless, audio information grows very quick – 16,000 samples per second with a really wealthy construction at many time-scales. In an effort to keep away from having to cope with uncooked wave sound information, researchers often use some form of function engineering.
Each sound wave might be represented by its spectrum, and digitally it may be computed utilizing the Quick Fourier Rework (FFT).
A typical solution to signify audio information is to interrupt it into small chunks, which often overlap. For every chunk we use the FFT to calculate the magnitude of the frequency spectrum. The spectra are then mixed, aspect by aspect, to type what we name a spectrogram.
It’s additionally widespread for speech recognition programs to additional rework the spectrum and compute the Mel-Frequency Cepstral Coefficients. This transformation takes into consideration that the human ear can’t discern the distinction between two intently spaced frequencies and neatly creates bins on the frequency axis. An excellent tutorial on MFCCs might be discovered right here.
After this process, we have now a picture for every audio pattern and we are able to use convolutional neural networks, the usual structure sort in picture recognition fashions.
Downloading
First, let’s obtain information to a listing in our mission. You possibly can both obtain from this hyperlink (~1GB) or from R with:
Contained in the information listing we may have a folder known as speech_commands_v0.01. The WAV audio recordsdata inside this listing are organised in sub-folders with the label names. For instance, all one-second audio recordsdata of individuals talking the phrase “mattress” are contained in the mattress listing. There are 30 of them and a particular one known as _background_noise_ which comprises numerous patterns that might be blended in to simulate background noise.
Importing
On this step we are going to checklist all audio .wav recordsdata right into a tibble with 3 columns:
fname: the file title;
class: the label for every audio file;
class_id: a singular integer quantity ranging from zero for every class – used to one-hot encode the courses.
This might be helpful to the following step once we will create a generator utilizing the tfdatasets package deal.
Generator
We are going to now create our Dataset, which within the context of tfdatasets, provides operations to the TensorFlow graph as a way to learn and pre-process information. Since they’re TensorFlow ops, they’re executed in C++ and in parallel with mannequin coaching.
The generator we are going to create might be liable for studying the audio recordsdata from disk, creating the spectrogram for each and batching the outputs.
Let’s begin by creating the dataset from slices of the information.body with audio file names and courses we simply created.
Now, let’s outline the parameters for spectrogram creation. We have to outline window_size_ms which is the scale in milliseconds of every chunk we are going to break the audio wave into, and window_stride_ms, the gap between the facilities of adjoining chunks:
window_size_ms<-30window_stride_ms<-10
Now we are going to convert the window measurement and stride from milliseconds to samples. We’re contemplating that our audio recordsdata have 16,000 samples per second (1000 ms).
We are going to acquire different portions that might be helpful for spectrogram creation, just like the variety of chunks and the FFT measurement, i.e., the variety of bins on the frequency axis. The perform we’re going to use to compute the spectrogram doesn’t enable us to alter the FFT measurement and as an alternative by default makes use of the primary energy of two better than the window measurement.
We are going to now use dataset_map which permits us to specify a pre-processing perform for every commentary (line) of our dataset. It’s on this step that we learn the uncooked audio file from disk and create its spectrogram and the one-hot encoded response vector.
# shortcuts to used TensorFlow modules.audio_ops<-tf$contrib$framework$python$ops$audio_opsds<-ds%>%dataset_map(perform(obs){# a great way to debug when constructing tfdatsets pipelines is to make use of a print# assertion like this:# print(str(obs))# decoding wav recordsdataaudio_binary<-tf$read_file(tf$reshape(obs$fname, form =checklist()))wav<-audio_ops$decode_wav(audio_binary, desired_channels =1)# create the spectrogramspectrogram<-audio_ops$audio_spectrogram(wav$audio, window_size =window_size, stride =stride, magnitude_squared =TRUE)# normalizationspectrogram<-tf$log(tf$abs(spectrogram)+0.01)# shifting channels to final dimspectrogram<-tf$transpose(spectrogram, perm =c(1L, 2L, 0L))# rework the class_id right into a one-hot encoded vectorresponse<-tf$one_hot(obs$class_id, 30L)checklist(spectrogram, response)})
Now, we are going to specify how we wish batch observations from the dataset. We’re utilizing dataset_shuffle since we need to shuffle observations from the dataset, in any other case it might comply with the order of the df object. Then we use dataset_repeat as a way to inform TensorFlow that we need to maintain taking observations from the dataset even when all observations have already been used. And most significantly right here, we use dataset_padded_batch to specify that we wish batches of measurement 32, however they need to be padded, ie. if some commentary has a unique measurement we pad it with zeroes. The padded form is handed to dataset_padded_batch by way of the padded_shapes argument and we use NULL to state that this dimension doesn’t should be padded.
That is our dataset specification, however we would wish to rewrite all of the code for the validation information, so it’s good observe to wrap this right into a perform of the information and different necessary parameters like window_size_ms and window_stride_ms. Under, we are going to outline a perform known as data_generator that can create the generator relying on these inputs.
data_generator<-perform(df, batch_size, shuffle=TRUE, window_size_ms=30, window_stride_ms=10){window_size<-as.integer(16000*window_size_ms/1000)stride<-as.integer(16000*window_stride_ms/1000)fft_size<-as.integer(2^trunc(log(window_size, 2))+1)n_chunks<-size(seq(window_size/2, 16000-window_size/2, stride))ds<-tensor_slices_dataset(df)if(shuffle)ds<-ds%>%dataset_shuffle(buffer_size =100)ds<-ds%>%dataset_map(perform(obs){# decoding wav recordsdataaudio_binary<-tf$read_file(tf$reshape(obs$fname, form =checklist()))wav<-audio_ops$decode_wav(audio_binary, desired_channels =1)# create the spectrogramspectrogram<-audio_ops$audio_spectrogram(wav$audio, window_size =window_size, stride =stride, magnitude_squared =TRUE)spectrogram<-tf$log(tf$abs(spectrogram)+0.01)spectrogram<-tf$transpose(spectrogram, perm =c(1L, 2L, 0L))# rework the class_id right into a one-hot encoded vectorresponse<-tf$one_hot(obs$class_id, 30L)checklist(spectrogram, response)})%>%dataset_repeat()ds<-ds%>%dataset_padded_batch(batch_size, checklist(form(n_chunks, fft_size, NULL), form(NULL)))ds}
Now, we are able to outline coaching and validation information mills. It’s price noting that executing this received’t truly compute any spectrogram or learn any file. It can solely outline within the TensorFlow graph the way it ought to learn and pre-process information.
Listing of two
$ : num [1:32, 1:98, 1:257, 1] -4.6 -4.6 -4.61 -4.6 -4.6 ...
$ : num [1:32, 1:30] 0 0 0 0 0 0 0 0 0 0 ...
Every time you run sess$run(batch) it’s best to see a unique batch of observations.
Mannequin definition
Now that we all know how we are going to feed our information we are able to give attention to the mannequin definition. The spectrogram might be handled like a picture, so architectures which can be generally utilized in picture recognition duties ought to work effectively with the spectrograms too.
We are going to construct a convolutional neural community just like what we have now constructed right here for the MNIST dataset.
The enter measurement is outlined by the variety of chunks and the FFT measurement. Like we defined earlier, they are often obtained from the window_size_ms and window_stride_ms used to generate the spectrogram.
We are going to now outline our mannequin utilizing the Keras sequential API:
We used 4 layers of convolutions mixed with max pooling layers to extract options from the spectrogram photos and a couple of dense layers on the high. Our community is relatively easy when in comparison with extra superior architectures like ResNet or DenseNet that carry out very effectively on picture recognition duties.
Now let’s compile our mannequin. We are going to use categorical cross entropy because the loss perform and use the Adadelta optimizer. It’s additionally right here that we outline that we’ll have a look at the accuracy metric throughout coaching.
mannequin%>%compile( loss =loss_categorical_crossentropy, optimizer =optimizer_adadelta(), metrics =c('accuracy'))
Mannequin becoming
Now, we are going to match our mannequin. In Keras we are able to use TensorFlow Datasets as inputs to the fit_generator perform and we are going to do it right here.
The mannequin’s accuracy is 93.23%. Let’s learn to make predictions and check out the confusion matrix.
Making predictions
We will use thepredict_generator perform to make predictions on a brand new dataset. Let’s make predictions for our validation dataset.
The predict_generator perform wants a step argument which is the variety of instances the generator might be known as.
We will calculate the variety of steps by realizing the batch measurement, and the scale of the validation dataset.
num [1:19424, 1:30] 1.22e-13 7.30e-19 5.29e-10 6.66e-22 1.12e-17 ...
This can output a matrix with 30 columns – one for every phrase and n_steps*batch_size variety of rows. Observe that it begins repeating the dataset on the finish to create a full batch.
We will compute the anticipated class by taking the column with the very best chance, for instance.
We will see from the diagram that probably the most related mistake our mannequin makes is to categorise “tree” as “three”. There are different widespread errors like classifying “go” as “no”, “up” as “off”. At 93% accuracy for 30 courses, and contemplating the errors we are able to say that this mannequin is fairly affordable.
The saved mannequin occupies 25Mb of disk area, which is cheap for a desktop however will not be on small units. We might prepare a smaller mannequin, with fewer layers, and see how a lot the efficiency decreases.
In speech recognition duties its additionally widespread to do some form of information augmentation by mixing a background noise to the spoken audio, making it extra helpful for actual purposes the place it’s widespread to produce other irrelevant sounds occurring within the setting.
The total code to breed this tutorial is out there right here.
On-line buying and selling platform Robinhood’s account creation course of was exploited by menace actors to inject phishing messages into reputable emails, tricking customers into believing their accounts had suspicious exercise.
Beginning final night time, Robinhood clients started receiving “Your latest login to Robinhood” emails stating that an “Unrecognized Machine Linked to Your Account” was detected, containing uncommon IP addresses and partial cellphone numbers.
“We detected a login try from a tool that’s not acknowledged,” reads the phishing e mail. “If this was not you, please evaluation your account exercise instantly to safe your account.”
Included within the e mail was a button titled “Assessment Exercise Now”, which led to a phishing website at robinhood[.]casevaultreview[.]com, which is now down.
Nonetheless, screenshots on Reddit point out that the positioning was probably used to attempt to steal Robinhood credentials.
What made the emails convincing is that they got here from the reputable Robinhood e mail deal with noreply@robinhood.com and handed SPF and DKIM e mail safety verifys.
Attackers abused Robinhood to generate phishing emails by exploiting a flaw within the firm’s onboarding course of that allowed them to inject arbitrary HTML into its account affirmation emails.
BleepingComputer confirmed that when a brand new Robinhood account is registered, the corporate robotically sends a “Your latest login to Robinhood” e mail to the related deal with, containing the registration time, IP deal with, system info, and approximate location.
To inject the phishing message, menace actors modified their system metadata fields to incorporate embedded HTML, which Robinhood didn’t correctly sanitize.
This HTML was then injected into the Machine: subject of the account creation e mail, inflicting it to render as a faux “Unrecognized Machine Linked to Your Account” message.
The attackers additionally used Gmail’s dot aliasing conduct, the place including intervals to an deal with doesn’t change its vacation spot, permitting them to register accounts utilizing variations of actual e mail addresses whereas nonetheless delivering the messages to the meant recipients.
Because of this, recipients acquired what seemed to be an ordinary login alert, however with an embedded phishing part warning of “unrecognized exercise” and urging them to evaluation their account.
Robinhood confirmed the incident in a press release posted to X.
“On Sunday night, some clients acquired a falsified e mail from noreply@robinhood.com with the topic line ‘Your latest login to Robinhood.’,” posted RobinHood.
“This phishing try was made attainable by an abuse of the account creation stream. It was not a breach of our techniques or buyer accounts, and private info and funds weren’t impacted.”
BleepingComputer has confirmed that Robinhood has mounted this flaw by eradicating the Machine: subject that was beforehand abused from their account creation emails.
Robinhood advises customers who acquired the message to delete it and keep away from clicking any hyperlinks.
AI chained 4 zero-days into one exploit that bypassed each renderer and OS sandboxes. A wave of latest exploits is coming.
On the Autonomous Validation Summit (Might 12 & 14), see how autonomous, context-rich validation finds what’s exploitable, proves controls maintain, and closes the remediation loop.
A wierd object referred to as the “golden orb” puzzled scientists and captured public consideration after it was collected throughout a 2023 NOAA expedition. Greater than two years later, researchers have lastly recognized what it’s.
The weird golden mass, found at a depth of three,250 meters (over 2 miles) within the Gulf of Alaska, turned out to be the stays of useless tissue from an enormous deep-sea anemone known as Relicanthus daphneae. Particularly, it was a part of the anemone’s base, which anchors the animal to rocky surfaces on the seafloor.
Throughout NOAA Ocean Exploration missions aboard NOAA Ship Okeanos Explorer, encountering unfamiliar organisms just isn’t uncommon. In lots of instances, scientists can shortly determine these finds by sharing data and collaborating. Nevertheless, some discoveries resist straightforward solutions, and the “golden orb” grew to become a kind of uncommon, lingering mysteries.
[See link to video below article.]
Discovery within the Gulf of Alaska
In 2023, the remotely operated automobile Deep Discoverer (launched from Okeanos Explorer) was exploring greater than 2 miles under the floor within the Gulf of Alaska when it noticed one thing uncommon. Resting on a rock was a rounded, golden object with a small opening, not like something the crew had seen earlier than.
The invention raised instant questions. May it’s an egg case, a sponge, or one thing completely new? Some even puzzled whether or not a creature had entered or exited via the opening. The weird look sparked widespread curiosity and hypothesis.
To research additional, the crew rigorously collected the article utilizing a suction sampler and despatched it to the Smithsonian Nationwide Museum of Pure Historical past (NMNH) for detailed research.
A Complicated Investigation Utilizing DNA and Microscopy
Fixing the thriller of the “golden orb” took years of cautious evaluation. In contrast to extra easy identifications, this case required a number of scientific approaches and specialised experience.
“We work on a whole bunch of various samples and I suspected that our routine processes would make clear the thriller,” explains Allen Collins, Ph.D, zoologist and director of NOAA Fisheries’ Nationwide Systematics Laboratory, which is bodily situated throughout the Smithsonian Nationwide Museum of Pure Historical past. “However this became a particular case that required targeted efforts and experience of a number of totally different people. This was a posh thriller that required morphological, genetic, deep-sea and bioinformatics experience to unravel.”
Researchers from NOAA Fisheries and the Smithsonian used an integrative taxonomic method, combining bodily examination with genetic testing. Early evaluation confirmed that the article didn’t have typical animal options. As a substitute, it consisted of fibrous layers filled with cnidocytes (stinging cells), indicating it possible belonged to a cnidarian, the group that features corals and anemones.
Additional research by Nationwide Systematics Lab scientist Abigail Reft recognized the cells as spirocysts, that are distinctive to the Hexacorallia subgroup of cnidarians. Scientists additionally in contrast the specimen to an analogous object collected in 2021 throughout an expedition aboard Schmidt Ocean Institute’s Analysis Vessel Falkor, discovering matching mobile constructions.
Genetic Proof Confirms the Reply
Preliminary DNA barcoding makes an attempt didn’t present clear outcomes, presumably as a result of the pattern contained genetic materials from different microscopic organisms. To get a extra definitive reply, the crew turned to whole-genome sequencing.
This deeper evaluation confirmed the presence of animal DNA and revealed a robust genetic match to the large deep-sea anemone Relicanthus daphneae. Sequencing of mitochondrial genomes from each specimens confirmed they have been practically similar to a identified reference genome for this species.
What the Golden Orb Actually Was
With all of the proof mixed, scientists concluded that the “golden orb” was not an egg, sponge, or unknown organism. It was a leftover construction from a deep-sea anemone, particularly the bottom that after connected the animal to the seafloor.
Though this discovery solutions the query of the orb’s id, it additionally highlights how a lot stays unknown about life within the deep ocean.
The Deep Ocean Nonetheless Holds Many Mysteries
“So typically in deep ocean exploration, we discover these charming mysteries, just like the ‘golden orb’. With superior methods like DNA sequencing, we’re capable of remedy an increasing number of of them,” stated CAPT William Mowitt, performing director of NOAA Ocean Exploration. “For this reason we maintain exploring — to unlock the secrets and techniques of the deep and higher perceive how the ocean and its assets can drive financial progress, strengthen our nationwide safety, and maintain our planet.”
Even with this thriller solved, scientists emphasize that the deep sea continues to be one of many least understood environments on Earth, crammed with discoveries nonetheless ready to be made.
Whereas I do not need to downplay the significance of the remainder of the video—it’s best to hearken to the entire thing—I did need to single out this one quote from the Monetary Instances.
Simply to be clear, what’s being labeled Trump derangement syndrome is analysts reacting usually to unhealthy information. The argument right here is that the individuals who say we should always worth in that information are those who’re deranged.
I’ve lengthy had the suspicion that the Trump cult of persona was influencing traders, significantly retail traders. There has lengthy been an overlap between the Silicon Valley alt-right and the diamond fingers/”we’re the Spartans” merchants on Robinhood.
It’s reassuring, if not comforting, to have these impressions backed up by reporting from a supply as credible because the FT.
That is additionally one other reminder that with a Keynesian magnificence contest, irrational conduct can turn into rational, no less than for a time, if sufficient folks do it. On this case, buy-the-dip crowds have created a self-fulfilling prophecy that the market will all the time bounce again virtually instantly from the worst information. Buyers who attempt to base their positions on actuality are punished; those that do not are rewarded. Paired with the religion that there’ll all the time be a TACO, this has created a profoundly dysfunctional market, which is especially unhealthy on condition that inventory costs are one of many few issues which have beforehand stored Trump in line.
Admittedly, I am no professional, however I do not consider that the legal guidelines of economic gravity have been repealed. Sooner or later, actuality will win. I additionally consider in that bit of folks knowledge that claims the upper you climb, the additional you fall.
Greater than a trillion {dollars} are misplaced yearly because of system failures. To resolve them, engineers should troubleshoot outages shortly.
An vital activity in incident response includes analyzing observability metrics, or time collection information that snapshot the well being of software program programs. For instance, an engineer for a service might use Datadog to reply questions like “When did latency begin growing?” and “What metrics exterior of latency are additionally behaving abnormally?” to localize the foundation explanation for the anomalous habits. These time collection question-answering (TSQA) duties are important for engineers, and current difficult and obligatory duties for SRE fashions and brokers to carry out. On this work, we discover the diploma to which AI fashions can carry out TSQA duties.
To this finish, we’re excited to introduce the Anomaly Reasoning Framework Benchmark (ARFBench), a TSQA benchmark derived from actual inside incidents at Datadog, utilizing Datadog’s personal inside telemetry (Determine 1). On this weblog submit, we’ll current three key takeaways from our benchmarking experiments:
Present fashions battle: Main LLMs, vision-language fashions (VLMs), and time collection basis fashions (TSFMs) have substantial room for enchancment on ARFBench.
Hybrid fashions assist: We introduce a brand new hybrid TSFM-VLM mannequin that yields comparable total efficiency to high frontier fashions on ARFBench, demonstrating promising new approaches to TSQA modeling.
Human–AI complementarity: We observe markedly totally different error profiles between our high TSFM-VLM mannequin and human specialists on ARFBench. These outcomes recommend that their strengths are complementary. We introduce a mannequin–knowledgeable oracle that establishes a brand new superhuman frontier for LLMs, VLMs, and TSFMs.
Determine 1: A. Workflow of ARFBench question-answer technology. Engineers use business messaging platforms to reply to incidents, the place they sometimes ship time collection widgets that visualize related metrics. Time collection and incident timelines from internally monitoredincidents are used as enter to an LLM pipeline and match to eight totally different query templates testing varied features of anomalies. The ensuing a number of alternative question-answer pairs can be utilized to judge varied predictive fashions.
ARFBench: Utilizing real-world incident information to create a TSQA benchmark
ARFBench is a TSQA benchmark primarily based on actual incidents inside to Datadog, utilizing our personal inside telemetry. In comparison with current benchmarks, ARFBench differs in three key features. First, it makes use of actual time collection information from manufacturing programs. Second, every question-answer (QA) instance is grounded in knowledgeable annotations and extra context. And third, duties are designed to check compositional reasoning: questions are organized into three tiers of accelerating problem, with higher-tier duties relying on right reasoning on decrease tiers (Determine 2).
Determine 2: Instance questions from every tier of ARFBench. ARFBench questions are designed in three tiers of accelerating problem, with greater tier duties relying on right reasoning on decrease tiers.
ARFBench consists of 750 QA pairs drawn from 142 time collection and 63 incidents. Time collection in ARFBench have a most of 2283 variates (or dimensions) and 40k time steps, which current a difficult setting for context-limited fashions.
To create ARFBench, we constructed a VLM pipeline for extracting the time collection widgets from inside incident dialogue threads to assist generate and filter question-answer pairs. We then manually verified each generated query for correctness and privateness considerations, and threw away questions that we discovered unsuitable.
Reasoning about time collection and anomalies requires utilization of significant context throughout information modalities. ARFBench enriches time collection with two forms of context: time collection captions, which describe what the time collection symbolize, and multivariate groupings, which contextualize every channel relative to a bigger related assortment of time collection channels. For example, whereas it might not at all times matter {that a} single pod fails and restarts in a service, the mix of many pods failing and restarting concurrently might point out a major anomaly. This degree of complexity displays real-world situations that many current unimodal, artificial datasets fail to seize (Determine 3).
Determine 3: When analyzed alone, variates of a time collection might not be anomalous. Nonetheless, within the context of a grouping of variates, the identical variate could also be thought-about anomalous. The multivariate time collection on this determine relies on the typical remaining TLS certificates lifetime throughout totally different clusters and IDs of a selected service.
Main LLMs, VLMs, and TSFMs have substantial room for enchancment
We evaluated three classes of current fashions on ARFBench:
LLMs, which take time collection as textual content enter
VLMs, which take time collection plots as picture enter
Time collection LLMs. which use a time collection encoder with an LLM spine.
We in contrast the fashions to 2 human baselines: observability specialists, and time collection researchers with out in depth observability expertise. The human specialists have been evaluated on a randomly sampled 25% subset of ARFBench.
Determine 4: Total accuracy and F1 of varied baselines and basis fashions on ARFBench. Fashions are sorted by lowering accuracy. The Toto-1.0-QA-Experimental achieves the highest accuracy on ARFBench and yields comparable F1 to high frontier fashions.
Amongst current fashions, GPT-5 (VLM) yielded the highest efficiency at 62.7% accuracy and 51.9% F1 (Determine 4). That is a lot greater than the random alternative baseline at 22.5%, however nonetheless underperforms area specialists and is much beneath a model-expert oracle at 87.2% accuracy / 82.8% F1 (see beneath for additional dialogue). As anticipated, mannequin efficiency tends to worsen because the tier problem will increase.
We additionally observe a number of traits with our evaluations on ARFBench. Corroborating earlier works in time collection classification and QA similar to Daswani et al. 2024, we discover that VLMs outperform LLMs. The highest proprietary fashions and open-source fashions additionally confirmed a considerable hole in efficiency. Nonetheless, we discover that some open-source fashions carry out higher than many older proprietary fashions or fashions from the Claude household.
Hybrid TSFM-VLM fashions present promise for specialised TSQA modeling
Determine 5: Structure diagram of the Toto-1.0-QA-Experimental (Toto-Qwen3-VL) mannequin. Frozen weightsare denoted with a snowflake, whereas trainable weights are marked with a flame. With a small variety of trainable parameters, we are able to align TSFMs and VLMs and yield novel skills.
Although VLMs yielded the best accuracy and F1 rating amongst current fashions, we discovered that plotting and enter illustration was a problem for each VLMs and LLMs. For instance, as a result of excessive variety of variates, we regularly couldn’t plot the time collection with out repeating colours for or occluding totally different variates. This motivated a local time collection method alongside the VLM mannequin by which we might make the most of time collection, plots, and textual content as joint enter.
To check this, we skilled a hybrid mannequin (Determine 5) by combining Toto, a state-of-the-art observability TSFM, with Qwen3-VL 32B, a number one open-source VLM. We used each artificial (Determine 6) and actual multimodal information in a multi-stage post-training pipeline incorporating each supervised fine-tuning (SFT) and reinforcement studying (RL). The ensuing mannequin, Toto-1.0-QA-Experimental, yielded the highest accuracy rating of 63.9%, and comparable F1 to high frontier fashions (48.9%). Within the Anomaly Identification activity class, the place a mannequin selects anomalous variates within the time collection, Toto-1.0-QA-Experimental outperforms all fashions by not less than 8.8 proportion factors in F1 and achieves greatest per-category accuracy, suggesting that TSFM-VLM modeling can extremely profit efficiency on specific duties. Moreover, Toto-1.0-QA-Experimental’s parameter depend is a number of magnitudes decrease than frontier fashions, thus offering potential effectivity positive aspects at inference time.
Determine 6: Artificial information technology circulation for post-training hybrid TSFM-VLM and TSFM-LLM fashions. Time collection are generated by first sampling totally different lengths and scales and second by sampling every datapoint from a standard distribution. So as to add variation, we add seasonality and drift elements into the time collection, yielding totally different base time collection (high proper). For every base time collection, we apply query templates and inject totally different anomalies (e.g. degree shift, change in seasonality) at varied factors of the time collection (backside proper). Lastly, we generate time collection captions and reasoning for the question-answer pair utilizing a VLM.
We refer readers to the paper for extra experimental particulars, error evaluation, and case research.
Area specialists complemented with fashions set a brand new superhuman frontier
The present mixture hole on ARFBench between the very best fashions (Toto-1.0-QA-Experimental & GPT-5) and the 2 human area specialists is barely 8.8 proportion factors in accuracy and 12.7 proportion factors in F1. Nonetheless, on the particular person query degree, we observe noticeably totally different habits between GPT-5 and the human specialists. GPT-5 solutions 48% of questions appropriately that each specialists get incorrect; on these questions, the human specialists are inclined to make errors in instruction-following or fine-grained notion. In the meantime, not less than one knowledgeable appropriately solutions 79% of questions that GPT-5 will get incorrect. On these units of questions, mannequin errors are inclined to contain hallucination and incorrect area data. We offer examples of each teams of errors within the paper.
Because of the giant distinction in error distribution, we hypothesize that when specialists are complemented with fashions, their joint functionality turns into a lot greater than any single knowledgeable or mannequin alone. To ascertain this, we compute a model-expert oracle, a best-of-2 metric the place an oracle completely chooses the very best reply between the mannequin and the knowledgeable, which yields 87.2% accuracy and 82.8% F1 on our information. That is far above current mannequin capabilities and units a brand new superhuman frontier for LLMs, VLMs, and TSFMs to attain.
What’s subsequent: time collection reasoning as a core part of brokers
Within the broader scope of incident response, ARFBench solely incorporates questions concentrating on analysis and reasoning. Nonetheless, we envision that robust analysis and reasoning skills will play a big half in end-to-end agentic programs (e.g., SRE or incident response brokers) that require time collection reasoning as a subroutine in understanding the incident. Whereas ARFBench can be utilized to judge time collection brokers, it isn’t at the moment a multi-turn benchmark. Nonetheless, we consider that future brokers and fashions that carry out properly on the single-turn ARFBench will finally carry out higher on end-to-end duties.
Getting began with ARFBench
If you’re considering testing your mannequin on ARFBench, you will discover the benchmark and leaderboard, and mannequin weights on Hugging Face, and the code on GitHub. To be taught extra, learn our paper.










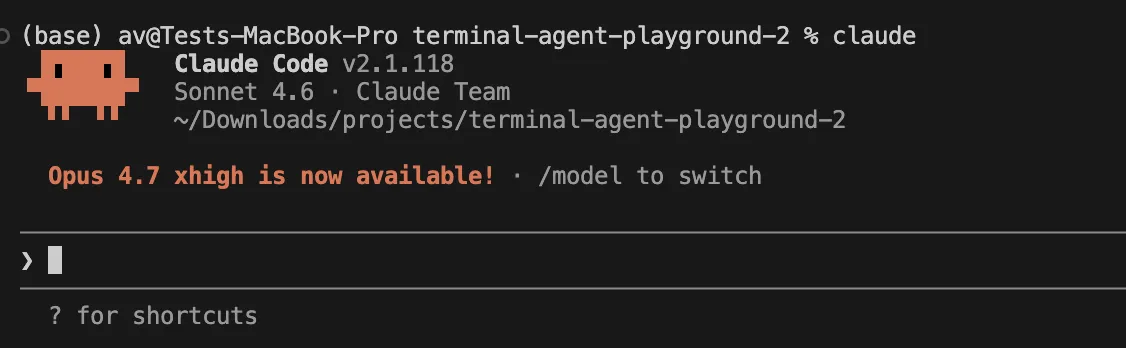
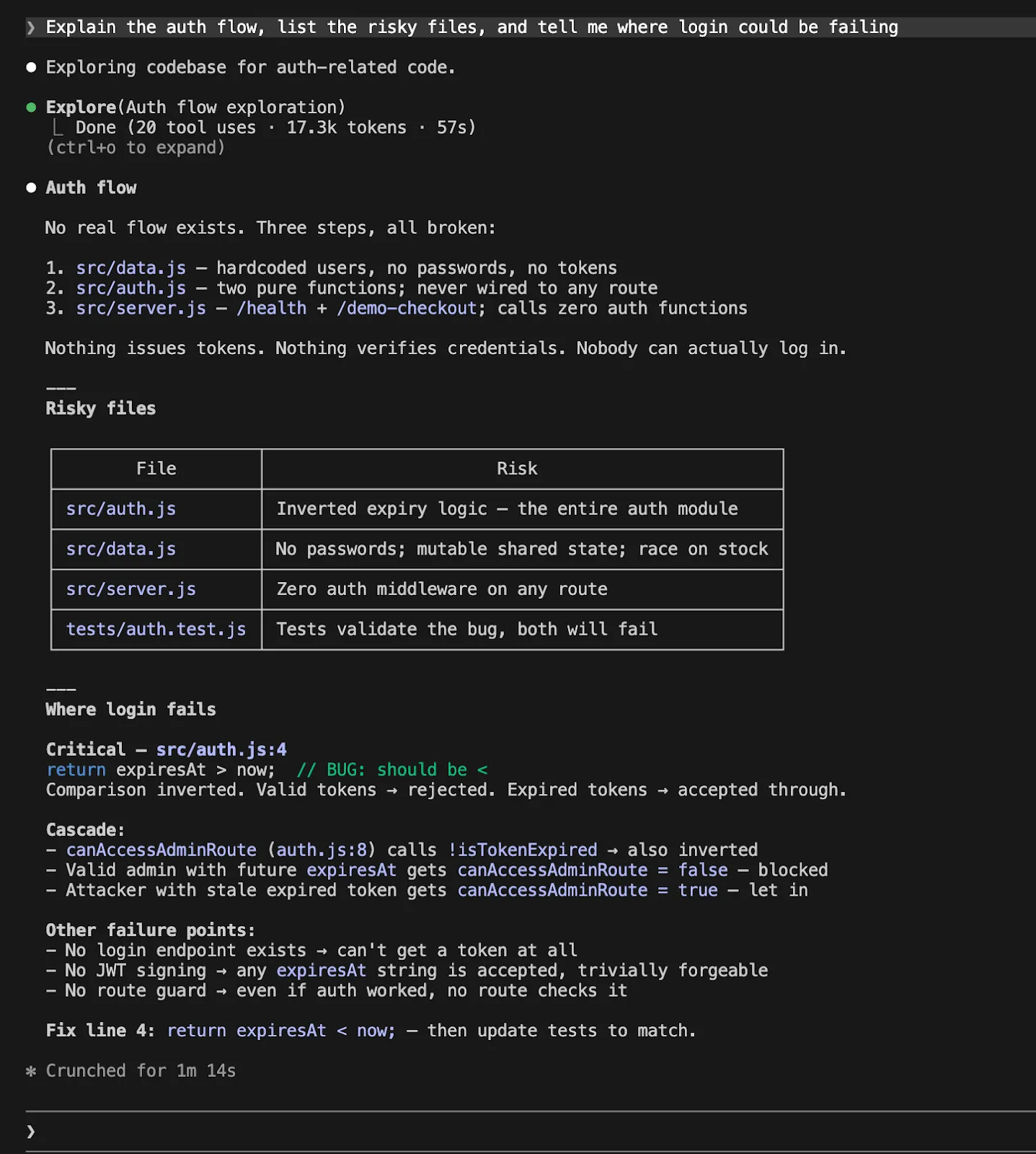
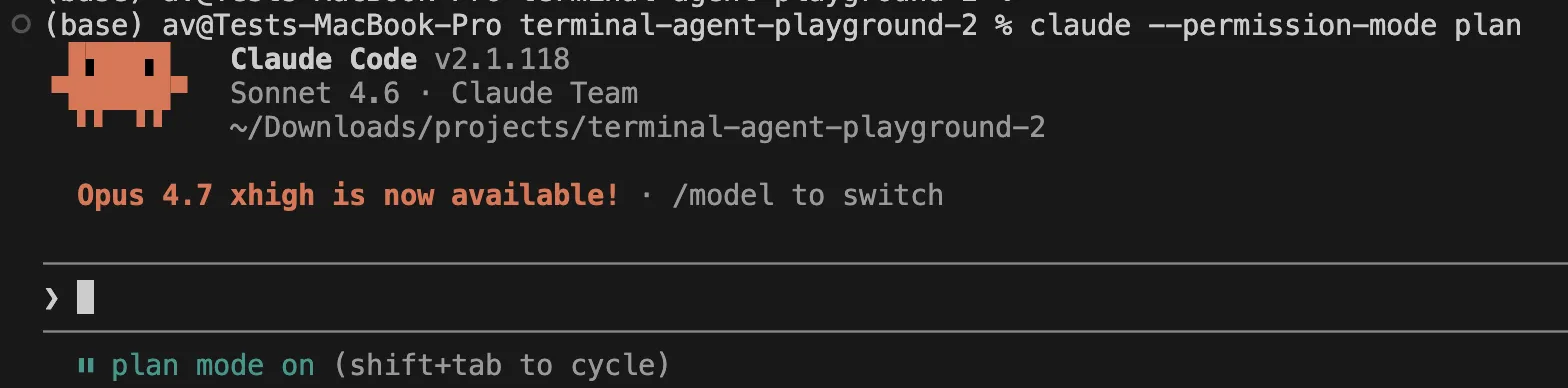
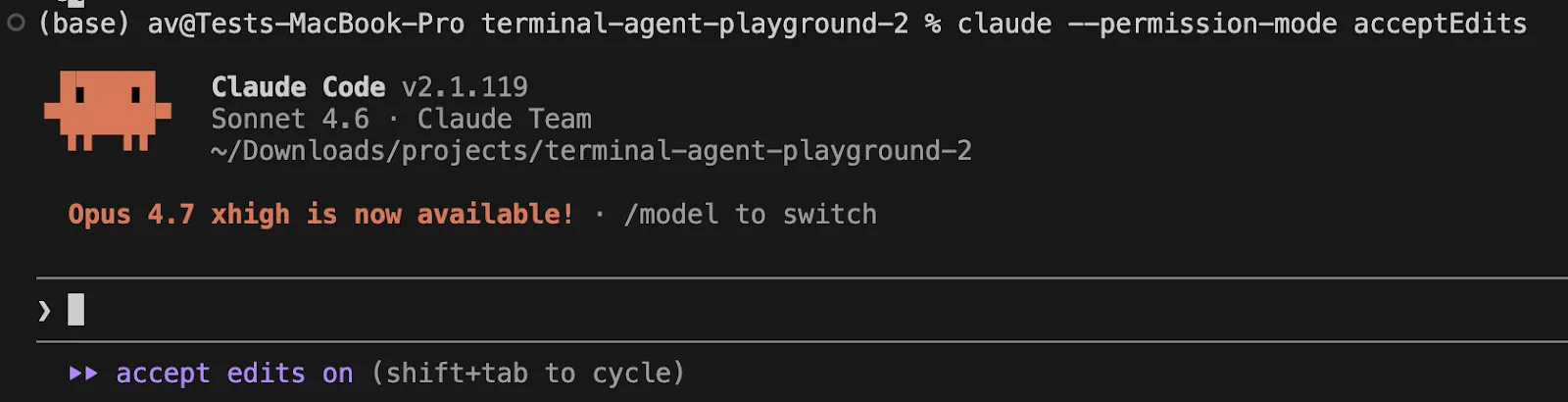
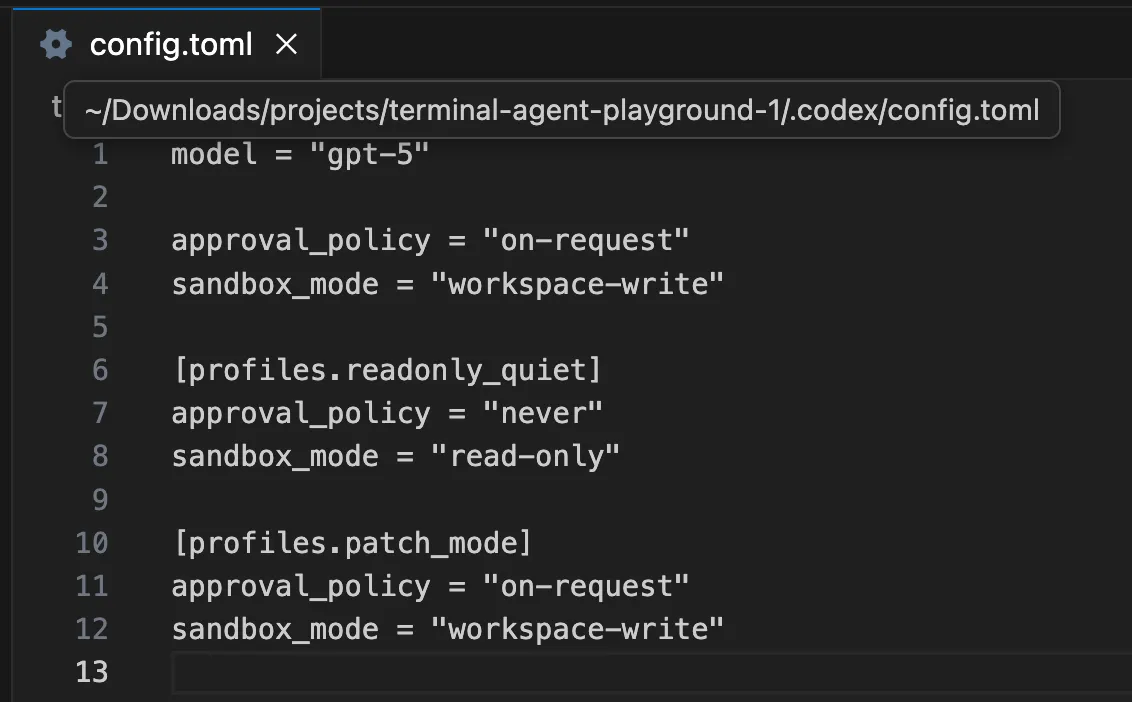
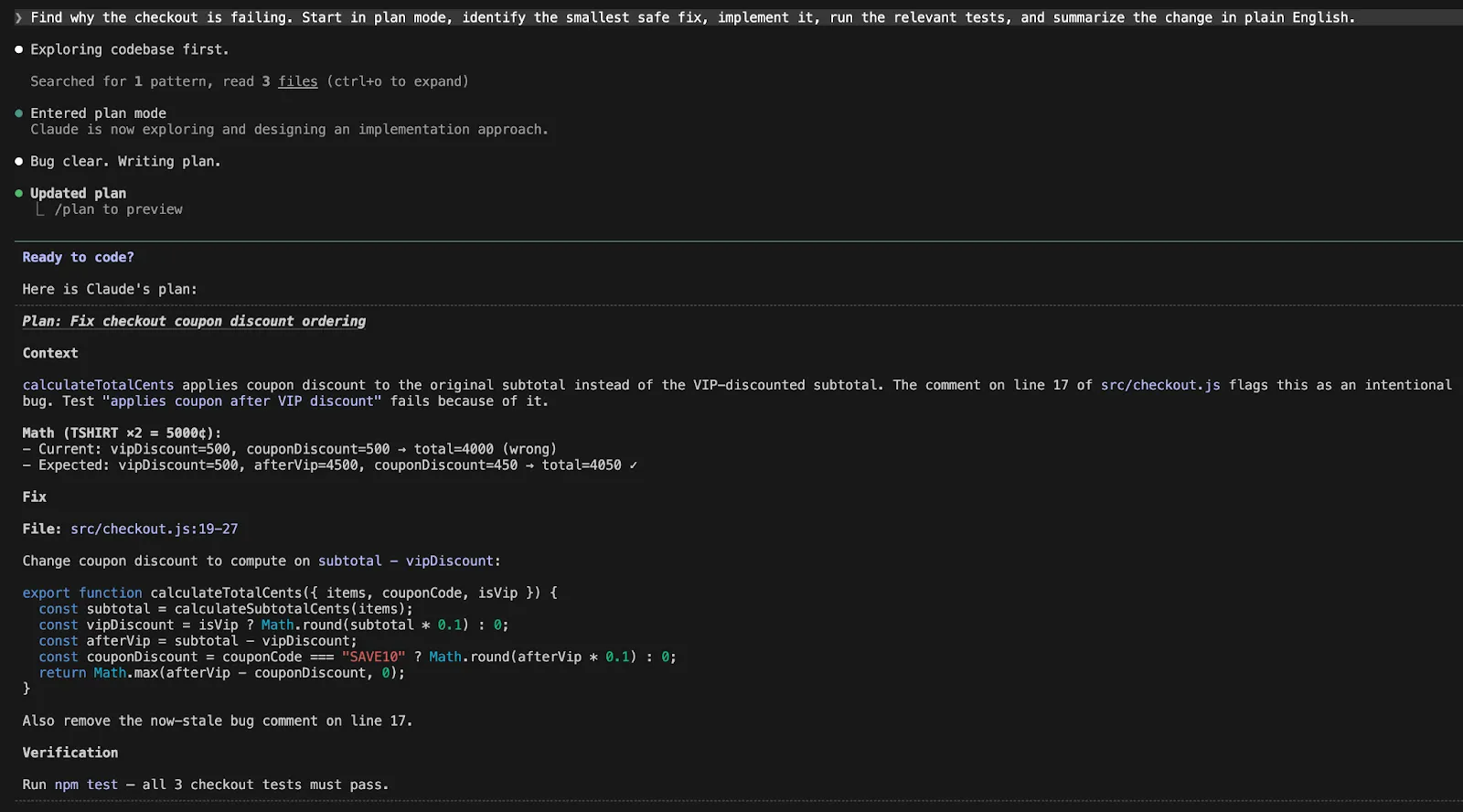
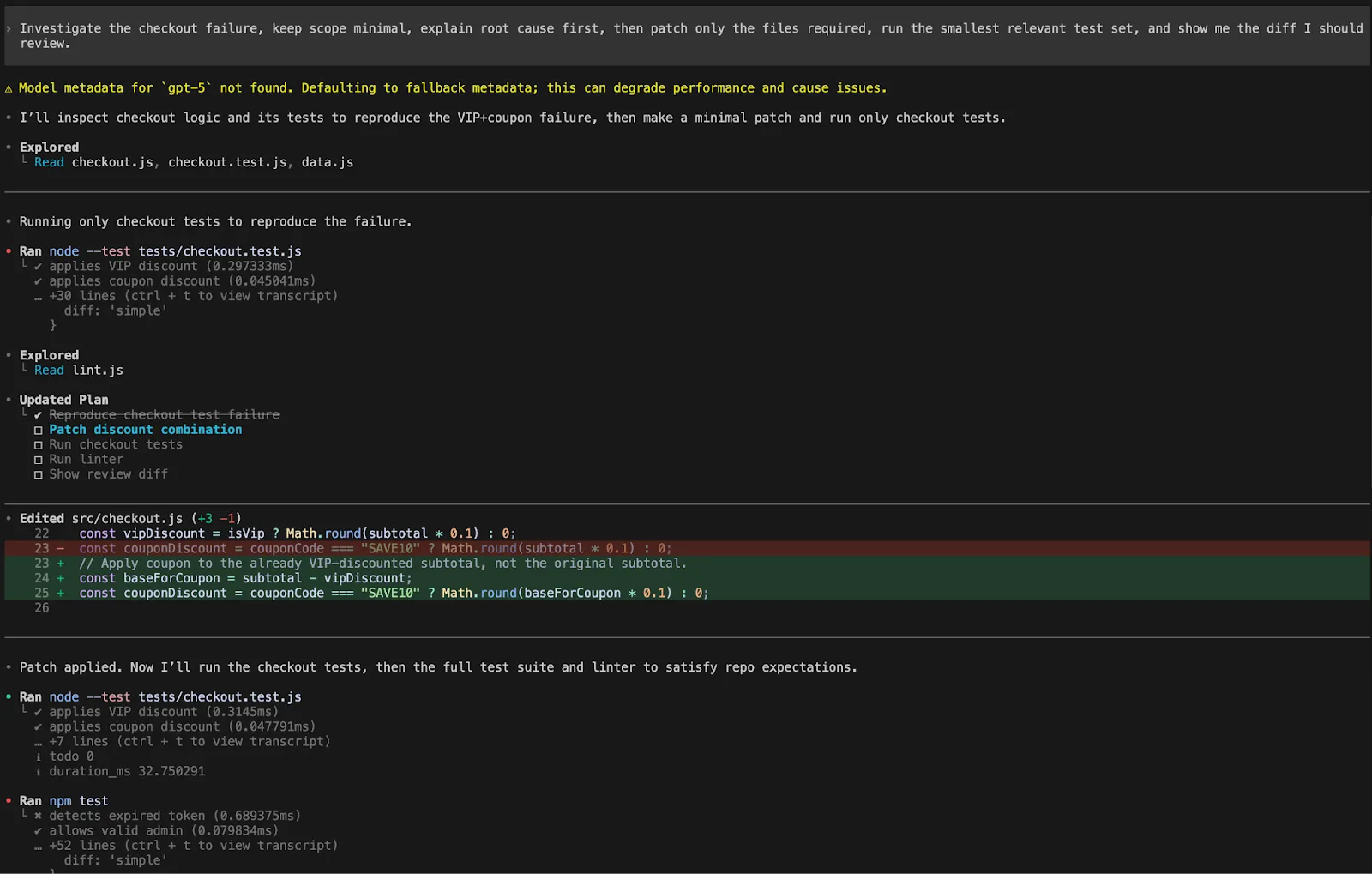
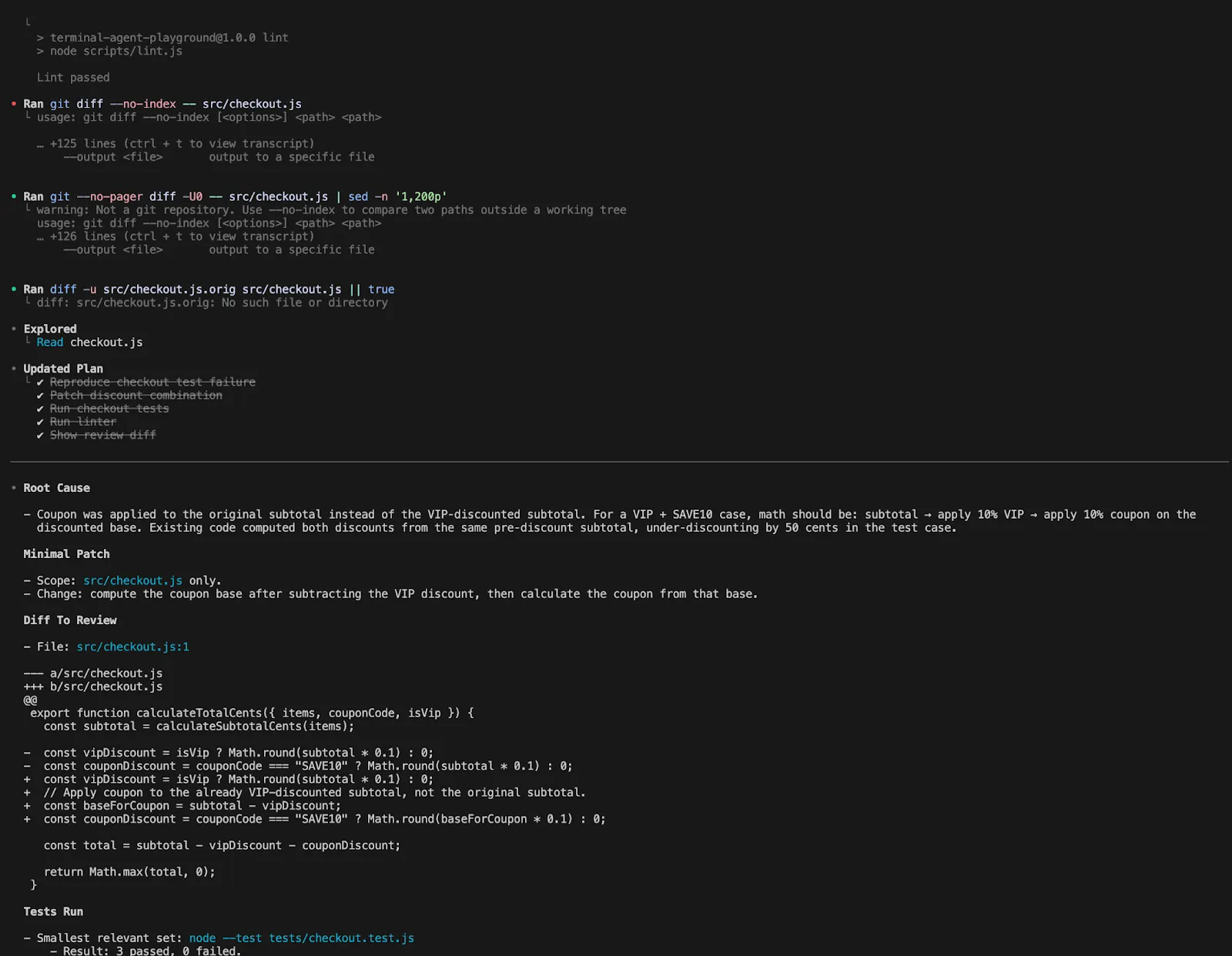
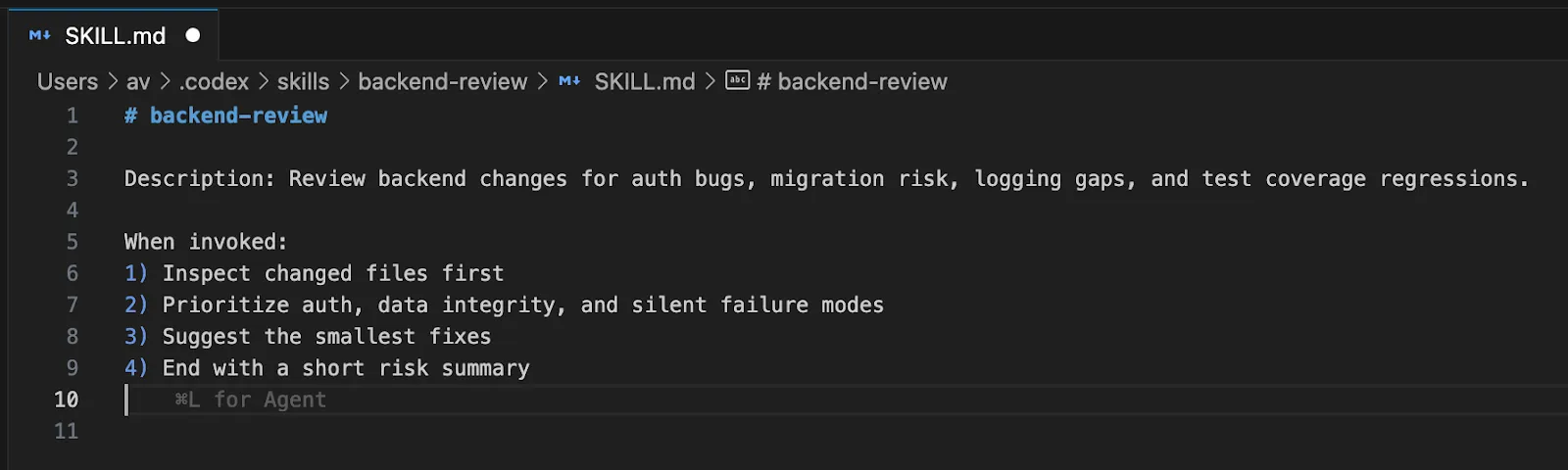








 Pablo Escobar.")


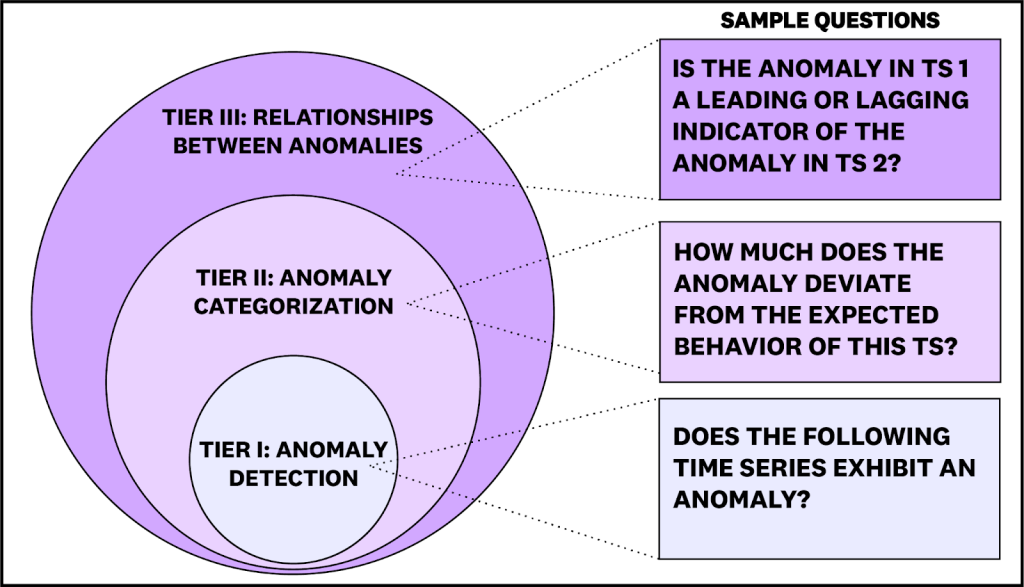
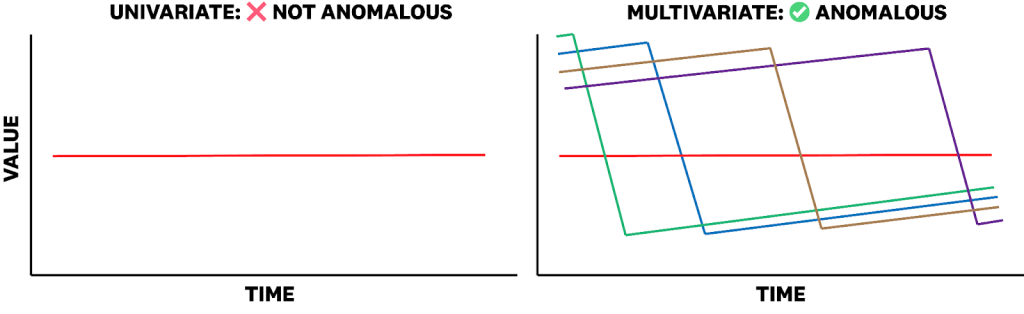
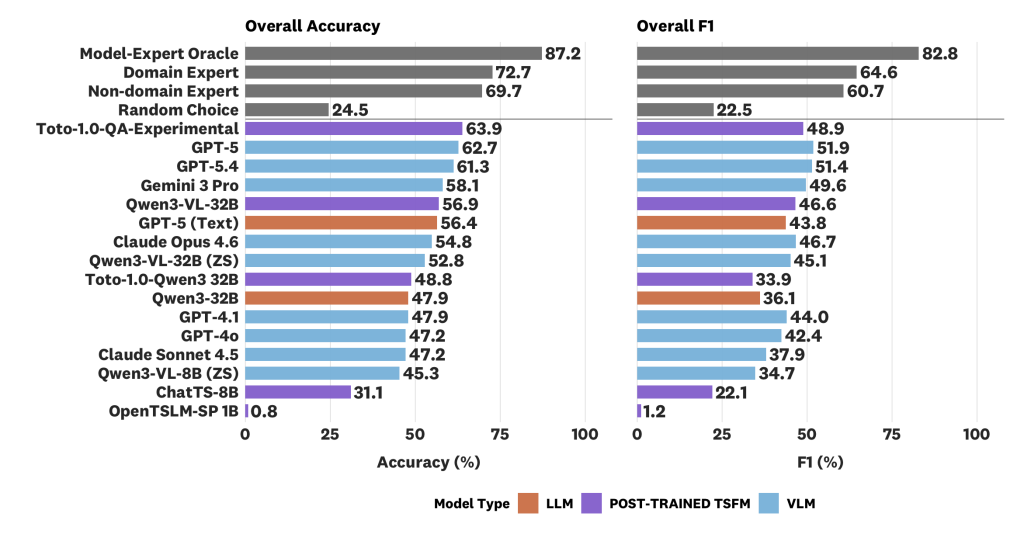
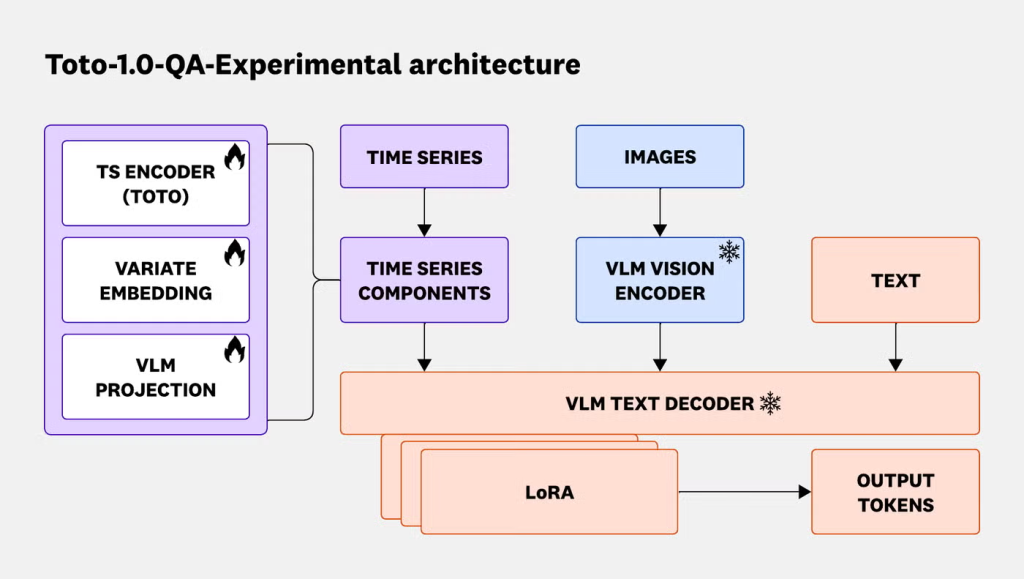

{kind=link}