

I spent the weekend in New York for NABE and noticed my first Broadway present, Buena Vista Social Membership. It was extraordinary. I can’t bear in mind a time I’ve ever seen actors and musicians like that, and the way the viewers was drawn into the efficiency. I used to be surprised. The Havana social golf equipment will need to have been extraordinary. However immediately is about Claude Code.

Within the final put up about Claude Code, I began strolling us by way of the decomposition of the TWFE weights in steady diff-in-diff. And to do this, I had had Claude Code make a “lovely deck” solely about these weights. However each that deck, but additionally a couple of different decks since then, prompted me to wish to rework that ability, and that’s what immediately is about — the updating of my /beautiful_deck ability, in addition to a couple of others. These are the talents I exploit now fairly often, and so I needed to share what I modified, and why.
That is the primary time I’ve actually tried to enhance abilities relatively than simply create them as soon as or simply use them. To this point, I’d been letting Claude Code manufacture the talents totally based mostly on vibed descriptions and what I used to be going after. I’d describe what I needed, Claude would write the directions, and I’d invoke them. However I’d observed that one in all them actually wasn’t working proper, and the method of determining why taught me one thing about what these abilities really are and the way they fail.
My /beautiful_deck ability was my try to automate the language of calling up a brand new presentation. Moderately than at all times saying “make a lovely deck, learn the Rhetoric of Decks essays, one concept per slide, assertion titles, Gov 2001 palette, compile to zero warnings” — I attempted to seize all of that in a single invocable ability. One command, and the primary go of a deck occurs robotically. Then I transfer right into a refining stage of iteration.
It wasn’t that I used to be making an attempt to automate the deck creation. Moderately, I used to be making an attempt to get down a primary draft in order that I may transfer into the stage I favor which is to really feel out the discuss, get a way of the path it might take, works backwards from sure subjects or spots, and therapeutic massage out problematic components of the lecture. I used to be more and more letting Claude piece collectively a lecture based mostly on a wide range of instructions I might give, and supplies, together with my very own writings and scribbles, and as my desire is for all my talks to now lean closely on displaying knowledge quantification in addition to graphic-based narrative, I tended to additionally request graphics from Tikz and .png produced by R and python.
And it principally labored. It was an excellent start line and I discovered it good for what I used to be needing to get the refinement stage to work. The execution from my outlines have been strong, the slides have been lovely, the balancing of concepts throughout slides in order that the cognitive density was minimized was working.
However the TikZ execution had a reasonably excessive error charge. I used to be nonetheless not getting the clear diagrams I needed. Labels would sit on prime of arrows, textual content would overflow bins, and the compile loop would spin making an attempt to make things better that have been generated unsuitable within the first place.
The final half was additionally new. I had been looking for a strategy to instill extra self-discipline within the Tikz graphs by having Claude repair them by way of a sequence of checks, pondering that perhaps the rationale these arrows on prime of objects, and so forth., could possibly be addressed by, on the again finish, having Claude systematically edit graphs by way of checks.
However this because it turned out was a mistake. What I discovered was that the ability had inadvertently instructed Claude what to audit after technology however by no means instructed it the right way to generate TikZ safely within the first place. The downstream restore software — my /tikz audit ability — was being requested to repair issues that have been baked in from the beginning: autosized nodes that made arrow endpoints unpredictable, labels with out directional key phrases touchdown on arrows, scale components that shrank coordinates however not textual content, and parameterized type definitions (#1) inside Beamer frames the place the # character will get consumed by Beamer’s argument parser earlier than TikZ ever sees it.
So, Claude advised a brand new repair which was a brand new part within the ability (Step 4.4) with six technology guidelines. Specific node dimensions on each node. Directional key phrases on each edge label. A coordinate-map remark block earlier than each diagram. Canonical templates for frequent diagram sorts. By no means use scale on complicated figures. And crucially: by no means outline parameterized types inside a Beamer body — outline all of them within the preamble with tikzset{}.
I additionally added what I’m calling a circuit breaker. The previous ability mentioned “recompile till clear,” which Claude interpreted as “preserve making an attempt eternally.” When a compile error resisted three totally different repair makes an attempt, the agent would spiral — every repair introducing new issues that obscured the unique error. I watched one session burn an hour doing this. The circuit breaker says: after three failed approaches to the identical error, cease modifying, inform me precisely what’s occurring, and ask the right way to proceed. The price of stopping is 2 minutes. The price of spiraling is an hour and a file that’s worse than while you began.
I don’t know but whether or not these modifications have really improved the ability. Final night time I watched it generate a 42-slide deck that was genuinely beautiful in conception — the rhetoric, the construction, the visible design have been all precisely what I needed. But it surely obtained caught in a problem-solving loop for an hour on TikZ compile errors. So the circuit breaker wants tightening, and there’s most likely a Rule 7 about not producing 35 tikzpictures in a single Beamer doc. I’m studying. These are my first actual makes an attempt at bettering abilities relatively than simply utilizing them.
If you wish to strive /beautiful_deck, and provides me suggestions, please do. It’s attainable that I simply can’t automate the “lovely photos” and that perhaps the optimum strategy was what I used to be initially doing which was to simply iterate quite a bit till the figures are good, relatively than have it extra automated up entrance. I do just like the invoking of my rhetoric of decks essay, however I suppose I preserve hoping I can discover a approach to assist Claude acknowledge these errors within the Tikz graphics, regardless of his incapability purpose spatially.
My /split-pdf ability is the one I exploit most. It takes an instructional paper — a PDF file or a search question — and splits it into four-page chunks, reads them in small batches, and writes structured notes. The rationale it exists is easy: traditionally, for me, Claude would crash or hallucinates on lengthy PDFs. Splitting forces cautious studying and externalizes comprehension into markdown notes.
Just a few days in the past, Ben Bentzin — an affiliate professor of instruction on the McCombs Faculty of Enterprise at UT Austin — wrote to me. He’d tailored the ability for his personal workflows and made a number of enhancements that have been higher than what I had. The core was the identical, however he’d recognized issues I hadn’t observed.
His largest contribution was agent isolation. When one other ability calls /split-pdf — say, /beautiful_deck studying a paper earlier than producing slides — every PDF web page renders as picture knowledge within the dialog context. A 35-page paper can add 10-20MB. After studying two or three massive PDFs on prime of prior work, the dialog hits the API request measurement restrict and turns into unrecoverable. Ben’s repair: run the PDF studying inside a subagent. The subagent reads the pages, writes plain-text output, and the dad or mum ability solely reads the textual content. The picture knowledge stays contained.
He additionally added persistent extraction. In any case batches are learn, the ability saves a structured _text.md file alongside the supply PDF. On future invocations, it checks for this file first and gives to reuse it — skipping re-reading totally. The primary deep learn may cost 4 rounds of PDF rendering. The second prices one markdown file learn. He added break up reuse too — if splits exist already from a earlier run, provide to reuse them relatively than re-splitting. And he switched to in-place PDF dealing with, so the ability works wherever your file already lives relatively than copying all the things right into a centralized articles/ folder.
I wrote the implementation independently — the code in my repo is mine — however the concepts are his, and I credited him by title within the ability’s documentation. In the event you’ve been utilizing /split-pdf, the brand new model is noticeably quicker and extra dependable on multi-paper periods. Thanks Ben — I’m grateful you discovered a strategy to make important enhancements on this sensible ability.
This one is new. It was known as /fletcher, after Jason Fletcher at Wisconsin, who was the one who curiously questioned about rounding in my put up about p-hacking. I had interpreted heaps of t-statistics round 1.96 essential worth as proof of p-hacking within the APE undertaking (AI generated papers), however Jason had observed comparable heaps at 1 and three, which might’ve made heaps at non-random intervals (1, 2 and three). Because it turned out, the heaps have been generated through the use of imprecise coefficients and commonplace errors, extracted from the papers themselves and never the uncooked knowledge and precise code (which I didn’t have). The extra imprecise our coefficients and commonplace errors are, the extra you find yourself with rounded t-stats that heap at non-random intervals — a fairly fascinating mathematical phenomena, to be sincere, and perhaps one of many extra spectacular issues to return out of that train. I didn’t see it, although, as a result of I merely couldn’t see the issues “off digicam”, as I used to be so centered on what I used to be centered on — the heaping at 1.96.
So, I developed /fletcher as a result of I needed to attempt to instill a self-discipline to catch errors earlier, however not a lot coding errors, because the forms of errors I’m vulnerable to once I can’t see the forest for the bushes. Was there a strategy to get an neutral spectator to return into the undertaking quickly and sometimes to easily look close to the undertaking’s focus, however not straight at the undertaking’s focus? Typically when you can look away from one thing, you may see it higher, and in order that was the aim of that ability
I resolve to rename it /blindspot as a result of that’s what it really does, and a descriptive title communicates the idea to somebody who hasn’t learn the origin story.
The theoretical body comes from Viktor Shklovsky, the Soviet literary theorist, who argued that artwork exists to revive notion. His metaphor: a person who walks barefoot up a mountain ultimately can’t really feel his toes. All the pieces turns into routine, automated, unconscious. Artwork exists to make the stone stony once more — to drive you to really feel what you may have stopped noticing.
For me, analysis often has the identical downside. By the point I’ve spent months on a paper, I can’t really feel the stones beneath my toes. The primary discovering has collapsed my consideration. All the pieces else within the output — the coefficient that flips signal in a single spec, the pattern measurement that drops between columns, the heterogeneity richer than the typical impact — has turn out to be invisible or just interpretable in a type of senseless, defensive approach.
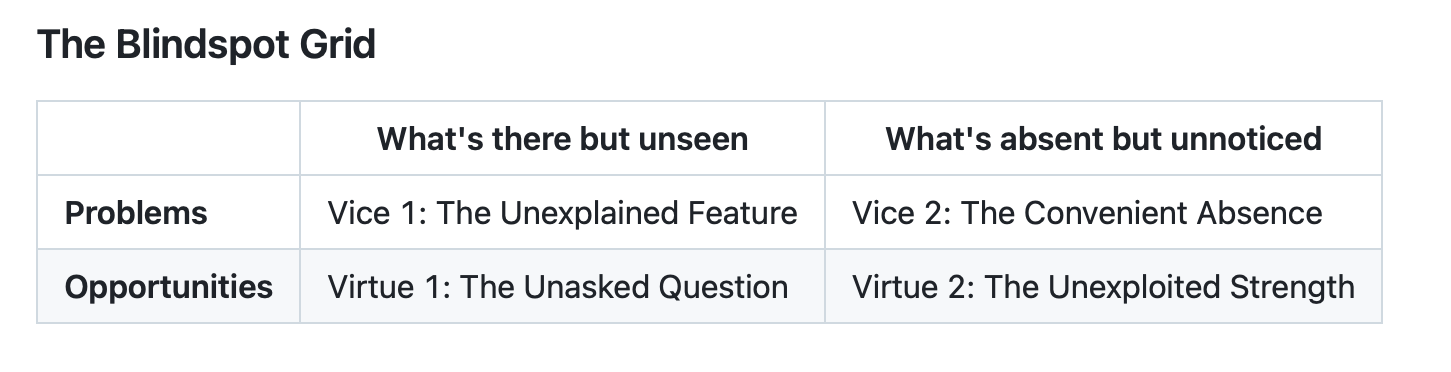
Blindspot is organized round a 2×2 grid of vices (issues hiding in plain sight) and virtues (alternatives being neglected). Vice 1 is the Unexplained Function — one thing within the output that doesn’t match the story however no one requested about it. Vice 2 is the Handy Absence — the robustness verify by no means run, the subgroup by no means examined, the canine that didn’t bark. Advantage 1 is the Unasked Query — heterogeneity that’s extra fascinating than the typical, a mechanism seen within the knowledge however absent from the speculation. Advantage 2 is the Unexploited Power — an identification argument stronger than the paper claims, a falsification take a look at that might crush the primary objection however was by no means run.
I run /blindspot earlier than I run /referee2, and the excellence issues. Referee 2 is a well being inspector. It checks whether or not your code is right, whether or not the pipeline replicates throughout languages, whether or not the identification technique is sound. It runs in a recent session with a Claude occasion that has by no means seen the undertaking, as a result of the Claude that constructed the code can’t objectively audit it. Referee 2 asks: is that this applied appropriately?
Blindspot asks a special query: are you able to see what’s in entrance of you? It runs in the identical session, in the mean time output first seems, earlier than you’ve began writing. It doesn’t want separation from the working session as a result of it’s not auditing implementation — it’s auditing notion. You’re the proper individual to do this, with a structured forcing operate to look previous what you anticipate to see. I would like one thing that may pull again and never get so into the weeds that it misses the plain.
The workflow is: produce output, run /blindspot, interpret and write, full the undertaking, then open a recent terminal and run /referee2. Between the 2 of them, they cowl what I consider as the 2 failure modes: not seeing what’s there, and never catching what’s unsuitable.
I’m a newbie in the case of making abilities. These are mine. They’re out there at github.com/scunning1975/mixtapetools, and I’d welcome anybody who needs to adapt them, enhance them, or inform me what I’m lacking. That’s how the split-pdf enhancements occurred, and I think it’s how the subsequent ones will too.





: We are able to all agree: spaceflight is cool.")





{kind=link}