

{kind=link}
Picture by Writer
# Introduction
You open a mission, run a Claude-powered device, and out of the blue, there’s a new folder sitting in your listing named .claude. You didn’t create it. It was not there earlier than. And if you’re like most builders, your first intuition is to marvel whether it is secure to delete.
The .claude folder is created by instruments that combine with Claude to retailer native state. It retains monitor of how the mannequin behaves inside your mission. That features configuration, cached information, job definitions, and generally context that helps the system keep constant throughout runs.
At first look, it seems to be small and straightforward to disregard. However when you begin working with agent-based workflows or repeated duties, this folder turns into a part of how issues really perform. Take away it, and you aren’t simply cleansing up recordsdata — you’re resetting how Claude interacts along with your mission.
What makes it complicated is that nothing explicitly explains it when it seems. There isn’t any immediate saying “that is the place your synthetic intelligence system shops its working state.” It simply exhibits up and begins doing its job quietly within the background. Understanding what’s on this folder and the way it works might help you keep away from unintentionally breaking issues, and, extra importantly, it helps you utilize these instruments extra successfully.
Let’s study what is definitely contained in the .claude folder and the way it impacts your workflow.
# Understanding the .claude Folder
The .claude folder is a hidden listing that acts as a neighborhood workspace for instruments constructed round Claude. The dot at first merely means it’s hidden by default, much like folders like .git or .vscode.
At its core, this folder exists to retailer state. While you work together with Claude by means of a command line interface (CLI) device, an agent framework, or a neighborhood integration, the system wants a spot to maintain monitor of what’s occurring inside your mission. That features configuration settings, intermediate information, and generally reminiscence that carries throughout periods.
With out this folder, each interplay would begin from scratch. It helps to consider .claude because the layer that connects your mission to the mannequin. The mannequin itself doesn’t bear in mind something between runs until you explicitly present context. This folder fills that hole by storing the items wanted to make interactions really feel constant and repeatable.
# Establishing Why the Folder Is Created
The .claude folder is often created robotically the second you begin utilizing a Claude-powered device inside a mission. This may occur in just a few frequent eventualities. You is likely to be operating a Claude CLI device, experimenting with an agent workflow, or utilizing a improvement surroundings that integrates Claude into your mission. As quickly because the system must persist one thing regionally, the folder is created.
The rationale it exists comes right down to persistence and management.
- First, it permits the system to retailer project-specific context. As a substitute of treating each request as remoted, Claude can reference earlier runs, saved directions, or structured information tied to your mission.
- Second, it helps keep constant habits. In case you configure how the mannequin ought to reply, what instruments it may possibly use, or how duties are structured, these settings have to dwell someplace. The
.claudefolder turns into that supply of reality. - Third, it helps extra superior workflows. While you transfer past easy prompts into multi-step duties or brokers that execute sequences of actions, the system wants a technique to monitor progress. That monitoring usually occurs inside this folder.
# Analyzing Widespread Recordsdata and Construction
When you open the .claude folder, the construction often begins to make extra sense. Whereas it may possibly range relying on the device you’re utilizing, most setups observe the same sample.
config.json: That is usually the start line. The config file shops how Claude ought to behave inside your mission. That features mannequin preferences, API-related settings, and generally directions that information responses or workflows. If one thing feels off about how the system is responding, that is usually the primary place to verify.reminiscence/orcontext/: These folders retailer items of knowledge that persist throughout interactions. Relying on the setup, this could possibly be dialog historical past, embeddings, or structured context that the system can reuse. That is what gives the look that Claude “remembers” issues between runs. It isn’t reminiscence within the human sense, however saved context that will get reloaded when wanted.brokers/orduties/: If you’re working with agent-based workflows, this folder turns into vital. It comprises definitions for duties, directions for multi-step processes, and generally the logic that guides how completely different steps are executed. As a substitute of a single immediate, you’re coping with structured workflows that may run throughout a number of levels.logs/: That is the debugging layer. The logs folder retains monitor of what occurred throughout execution. Requests, responses, errors, and intermediate steps can all be recorded right here relying on the device.cache/: This folder is all about pace. It shops short-term information so the system doesn’t need to recompute all the pieces from scratch each time. Which may embrace cached responses, intermediate outcomes, or processed information. It doesn’t change how the system behaves, however it makes it sooner and extra environment friendly.
# Explaining How the Folder Operates
Understanding the construction is helpful, however the actual worth comes from seeing how all the pieces suits collectively throughout execution. The move is pretty easy when you break it down.
A person runs a job. This could possibly be a easy question, a command, or a multi-step agent workflow. Then the system first checks the configuration. It reads from config.json to know the way it ought to behave — which mannequin to make use of, what constraints exist, and the way the duty must be dealt with.
Subsequent, it hundreds any obtainable context. This might come from the reminiscence or context folder. If earlier interactions or saved information are related, they’re pulled in at this stage. Then the duty is executed. If it’s a easy request, the mannequin generates a response. Whether it is an agent workflow, the system could undergo a number of steps, calling instruments, processing information, and making choices alongside the way in which.
As this occurs, the system writes again to the .claude folder. Logs are up to date, new context could also be saved, and cache entries might be created to hurry up future runs. What you find yourself with is a loop. Every interplay reads from the folder, performs work, and writes again into it.
That is how the state is maintained. As a substitute of each request being remoted, the .claude folder permits the system to construct continuity. It retains monitor of what has occurred, what issues, and the way future duties ought to behave.
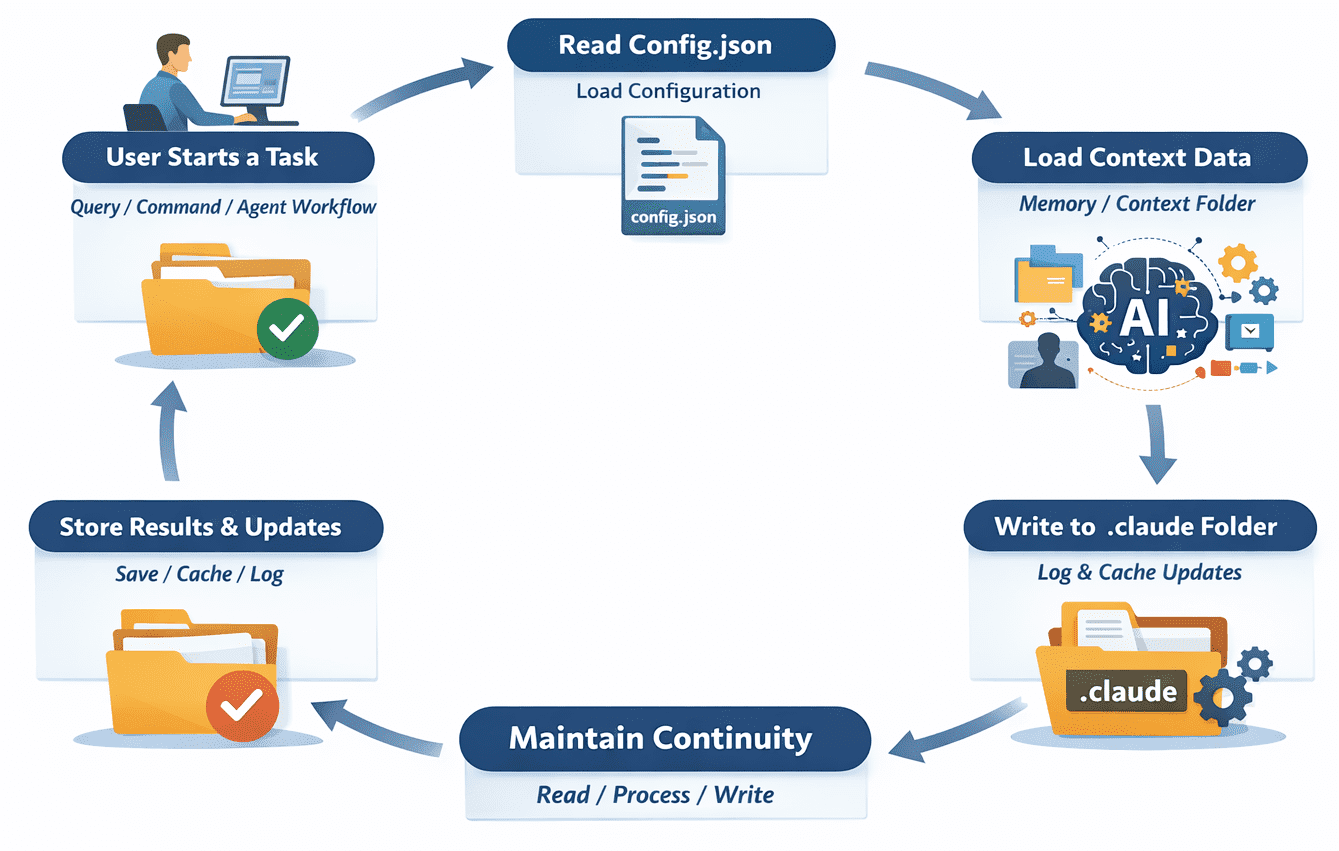
The operational move of the .claude folder | Picture by Writer
To make this extra concrete, let’s take a look at a easy instance of what a .claude folder would possibly appear like in an actual mission:
.claude/
config.json
reminiscence/
brokers/
logs/
cache/
Now think about you run a command like this:
claude run "Summarize all person suggestions from the final 7 days"
Here’s what occurs behind the scenes:
First, the system reads from config.json. This tells it which mannequin to make use of, how responses must be structured, and whether or not any particular instruments or constraints are enabled. Subsequent, it checks the reminiscence/ or context/ folder. If there’s saved information associated to previous suggestions summaries or earlier runs, that context could also be loaded to information the response.
If the duty is a part of an outlined workflow, the system may look into the brokers/ folder. For instance, it’d discover a predefined sequence like:
- Fetch suggestions information
- Filter by date
- Summarize outcomes
As a substitute of doing all the pieces in a single step, it follows that construction. As the duty runs, the system writes to the logs/ folder. This may embrace what steps have been executed, any errors encountered, and the ultimate output generated. On the similar time, the cache/ folder could also be up to date. If sure information or intermediate outcomes are prone to be reused, they’re saved right here to make future runs sooner.
By the point the command finishes, a number of components of the .claude folder have been learn from and written to. The system has not simply produced an output. It has up to date its working state, and that’s the key concept: every run builds on high of what’s already there.
# Evaluating the Deletion of the .claude Folder
Sure, you possibly can delete the .claude folder. Nothing will break completely. However there are penalties. While you take away it, you’re clearing all the pieces the system has saved regionally. That features configuration settings, cached information, and any context that has been constructed up over time.
Probably the most noticeable impression is the lack of reminiscence. Any context that helped Claude behave persistently throughout runs can be gone. The following time you run a job, it can really feel like ranging from scratch. You may additionally lose customized configurations. In case you have adjusted how the mannequin behaves or arrange particular workflows, these settings will disappear until they’re outlined elsewhere. Cached information is one other piece. With out it, the system could take longer to run duties as a result of it has to recompute all the pieces once more.
That stated, there are occasions when deleting the folder is definitely helpful. If one thing isn’t working as anticipated, clearing the .claude folder can act as a reset. It removes corrupted state, outdated context, or misconfigurations that is likely to be inflicting points. It’s also secure to delete if you desire a clear begin for a mission. The vital factor is to know what you’re eradicating. It isn’t only a folder — it’s the working reminiscence of your Claude setup.
# Implementing Greatest Practices for Administration
When you perceive what the .claude folder does, the subsequent step is managing it correctly. Most points builders run into usually are not as a result of the folder exists, however as a result of it’s dealt with carelessly.
One of many first issues to do is add it to your .gitignore file. Typically, this folder comprises native state that shouldn’t be dedicated. Issues like cached information, logs, and short-term context are particular to your surroundings and may create noise or conflicts in a shared repository.
There are just a few uncommon circumstances the place committing components of it’d make sense. For instance, in case your staff depends on shared agent definitions or structured workflows saved contained in the folder, you would possibly need to model these particular recordsdata. Even then, it’s higher to extract them right into a separate, cleaner construction reasonably than committing the complete folder.
Safety is one other vital consideration. Relying on how your setup works, the .claude folder could include delicate data. Logs can embrace person inputs or system outputs. Config recordsdata would possibly reference API-related settings. By accident committing these to a public repository is a straightforward technique to expose information you didn’t intend to share.
Retaining the folder clear additionally helps. Over time, cache recordsdata and logs can develop, particularly in lively initiatives. Periodically clearing pointless recordsdata can forestall muddle and cut back the probabilities of operating into stale or conflicting state.
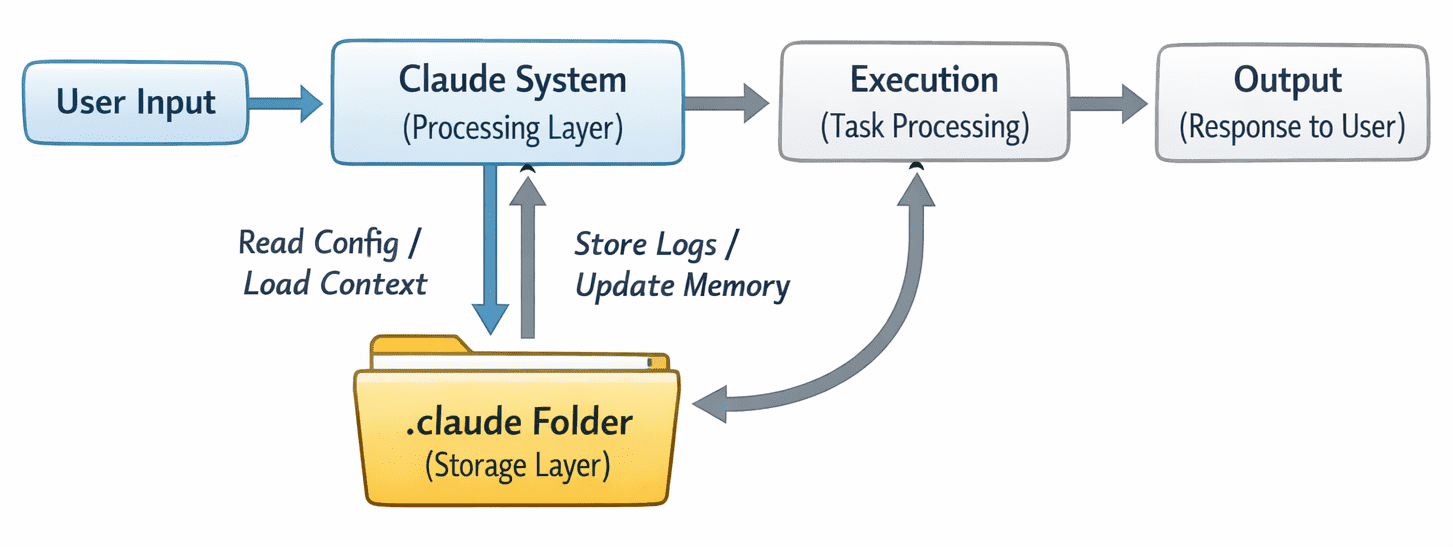
The system interplay with the .claude folder | Picture by Writer
# Figuring out Widespread Developer Errors
A lot of the points across the .claude folder don’t come from the device itself, however from how it’s dealt with. Listed here are some frequent errors builders make:
- One frequent mistake is deleting it with out understanding the impression. It seems to be like a brief folder, so it’s straightforward to take away when cleansing up a mission. The issue is that doing this resets all the pieces. Reminiscence, cached context, and generally configuration are all misplaced, which may break workflows or change how the system behaves.
- One other mistake is committing it to model management with out checking what’s inside. This may result in delicate information being pushed to a repository. Logs could include person inputs or inside outputs, and config recordsdata can generally expose settings that ought to keep native. It’s a straightforward oversight that may create actual issues later.
- Ignoring logs is one other missed alternative. When one thing goes mistaken, many builders bounce straight to altering prompts or code. In the meantime, the
logs/folder usually comprises clear indicators about what really occurred throughout execution. Skipping this step makes debugging more durable than it must be.
# Concluding Ideas
The .claude folder would possibly appear like simply one other hidden listing, however it performs a central function in how Claude operates inside your mission. It’s the place configuration lives, the place context is saved, and the place execution leaves its hint. With out it, each interplay can be remoted and stateless. With it, workflows turn out to be constant, repeatable, and extra highly effective.
Understanding this folder adjustments how you’re employed with Claude. As a substitute of guessing what is going on behind the scenes, you begin to see how the state is managed, how duties are executed, and the place issues can go mistaken.
Shittu Olumide is a software program engineer and technical author keen about leveraging cutting-edge applied sciences to craft compelling narratives, with a eager eye for element and a knack for simplifying advanced ideas. You can too discover Shittu on Twitter.