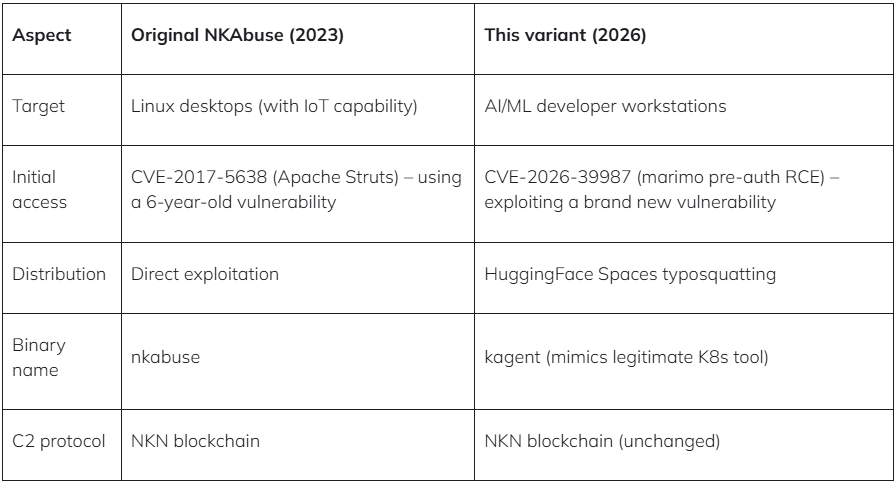
Hackers are exploiting a vital vulnerability in Marimo reactive Python pocket book to deploy a brand new variant of NKAbuse malware hosted on Hugging Face Areas.
Assaults leveraging the distant code execution flaw (CVE-2026-39987) began final week for credential theft, lower than 10 hours after technical particulars have been disclosed publicly, in keeping with information from cloud-security firm Sysdig.
Sysdig researchers continued to observe exercise associated to the safety difficulty recognized further assaults, together with a marketing campaign that began on April 12 that abuses the Hugging Face Areas platform for showcasing AI functions.
Hugging Face serves as an AI improvement and machine learning-focused platform, appearing as a hub for AI property corresponding to fashions, datasets, code, and instruments, shared among the many group.
Hugging Face Areas lets customers deploy and share interactive internet apps straight from a Git repository, sometimes for demos, instruments, or experiments round AI.
Within the assaults that Sysdig noticed, the attacker created a Area named vsccode-modetx (an intentional typosquat for VS Code) that hosts a dropper script (install-linux.sh) and a malware binary with the title kagent, additionally an try to mimic a authentic Kubernetes AI agent instrument.
After exploiting the Marimo RCE, the risk actor ran a curl command to obtain the script from Hugging Face and execute it. As a result of Hugging Face Areas is a authentic HTTPS endpoint with a clear status, it’s much less prone to set off alerts.
The dropper script downloads the kagent binary, installs it domestically, and units up persistence by way of systemd, cron, or macOS LaunchAgent.
In accordance with the researchers, the payload is a beforehand undocumented variant of the DDoS-focused malware NKAbuse. Kaspersky researchers reported the malware in late 2023 and highlighted its novel abuse of the NKN (New Type of Community) decentralized peer-to-peer community expertise for information alternate.
Sysdig says that the brand new variant features as a distant entry trojan that may execute shell instructions on the contaminated system and ship the output again to the operator.
“The binary references NKN Consumer Protocol, WebRTC/ICE/STUN for NAT traversal, proxy administration, and structured command dealing with – matching the NKAbuse household initially documented by Kaspersky in December 2023,” mentions Sysdig within the report.
Supply: Sysdig
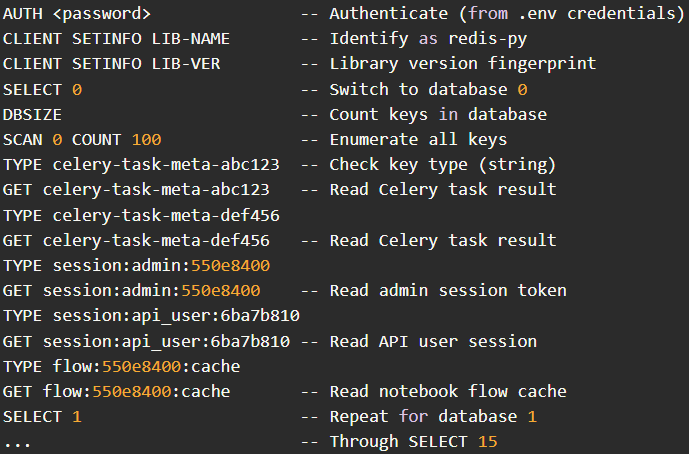
Sysdig additionally noticed different notable assaults exploiting CVE-2026-39987, together with a Germany-based operator who tried 15 reverse-shell methods throughout a number of ports.
They then pivoted to lateral motion by extracting database credentials from atmosphere variables and connecting to PostgreSQL, the place they quickly enumerated schemas, tables, and configuration information.
One other actor from Hong Kong used stolen .env credentials to focus on a Redis server, systematically scanning all 16 databases and dumping saved information, together with session tokens and utility cache entries.
Supply: Sysdig
The general takeaway is that exploitation of CVE-2026-39987 within the wild has elevated in quantity and ways, and it’s essential that customers improve to model 0.23.0 or later instantly.
If upgrading shouldn’t be doable, it is suggested to dam exterior entry to the ‘/terminal/ws’ endpoint by way of a firewall, or block it fully.
Automated pentesting proves the trail exists. BAS proves whether or not your controls cease it. Most groups run one with out the opposite.
This whitepaper maps six validation surfaces, exhibits the place protection ends, and offers practitioners with three diagnostic questions for any instrument analysis.
Skywatchers are in for a deal with this week because the northern lights are predicted to grace skies throughout a number of northern U.S. states — and it is all due to a big gap that has opened up within the solar’s environment.
Auroras could also be seen as far south as Idaho and New York Friday evening (April 17) and early Saturday morning (April 18), the Nationwide Oceanic and Atmospheric Administration’s (NOAA) Area Climate Prediction Middle shared in a Fb publish.
Often known as the aurora borealis, the northern lights are an atmospheric phenomenon brought on by the knotting of magnetic-field traces on the floor of the solar. When these traces snap, they ship enormous clouds of electrically-charged particles, known as photo voltaic wind, into house. A few of these particles ultimately attain Earth, the Royal Observatory Greenwich explains.
A lot of the particles are deflected by the geomagnetic protect that surrounds our planet. Nonetheless, some get swept into Earth’s magnetic discipline earlier than touring down towards the North and South poles.
As soon as there, the particles collide with atoms and molecules within the environment, inflicting them to warmth up and fluoresce to create the colourful mild shows we all know because the northern lights.
This week, a big gap appeared within the solar’s corona, the outermost a part of its environment. “Coronal holes” equivalent to this are areas the place the solar’s magnetic fields open up, enabling fast-moving photo voltaic wind to flee into house, based on Spaceweather.com.
The ensuing high-speed winds additionally could work together with slower photo voltaic winds forward of them, inflicting these clouds of charged particles to pile up. This creates a shock zone known as a corotating interplay area (CIR) that may have a extra dramatic impression on the particles in Earth’s environment.
Get the world’s most fascinating discoveries delivered straight to your inbox.
This week’s high-speed photo voltaic winds and the accompanying CIR are anticipated to achieve Earth on April 17 and 18, after which they’ll probably trigger a short lived disturbance within the planet’s magnetic discipline, generally known as a geomagnetic storm, based on NOAA’s three-day forecast launched April 16. Average (G2) storm circumstances are anticipated from 5 p.m. EDT (9 p.m. GMT) Friday till roughly 2 a.m. EDT (6 a.m. GMT) Saturday and will set off minor to average radio blackouts and powerful auroras.
Auroras ensuing from this class of geomagnetic storm are sometimes seen from Alaska, Idaho, Maine, Michigan, Minnesota, Montana, North and South Dakota, Washington and Wisconsin, based on NOAA. Skywatchers in Illinois, Indiana, Iowa, Nebraska, New Hampshire, New York, Ohio, Oregon, Vermont and Wyoming even have an opportunity of seeing certainly one of nature’s greatest mild exhibits.
A brand new moon Friday will even permit for higher viewing circumstances amid darker skies.
If you happen to’re on the hunt for auroras, ensure to verify NOAA’s n aurora dashboard for reside updates, as house climate forecasts are topic to alter.
Working a enterprise whereas juggling funds manually is a recipe for burnout. Spreadsheets crash on the worst doable moments, paper receipts vanish into skinny air, and each month-end shut turns right into a chaotic scramble no person deliberate for.
Sound acquainted? It in all probability does, which is precisely why enterprise house owners in all places are abandoning outdated methods for contemporary bookkeeping options, a broad class that spans cloud bookkeeping providers, on-line accounting software program, and outsourced bookkeeping for companies.
This information walks via eight rock-solid causes the shift is occurring, and extra importantly, how you could find the precise match for the place what you are promoting truly stands proper now.
Right here’s the factor about selecting among the many greatest on-line bookkeeping providers: it goes far deeper than squeezing further hours out of your week. It’s about gaining sincere monetary visibility, chopping publicity to expensive errors, and constructing infrastructure that genuinely retains tempo along with your progress.
Whether or not you’re main a five-person company or managing a multi-location enterprise, the argument for modernizing your bookkeeping has by no means been extra compelling.
Why Trendy Bookkeeping Is Pushing Conventional Methods Out the Door
These frustrations you’ve been tolerating? They’re not random inconveniences. They’re signs of a system constructed for a a lot slower, easier period, one which was by no means designed for the complexity, pace, or compliance stress that defines enterprise right now.
The transfer from desktop software program and in-house admin towards cloud-based monetary infrastructure isn’t a passing pattern. Distant work, AI automation, and more and more stringent regulatory calls for have collectively accelerated this structural shift, which is why many companies are actually exploring the greatest on-line bookkeeping providers to remain aggressive.
Conventional bookkeeping handed you a rearview mirror. Trendy bookkeeping options hand you a dwell dashboard.
What Truly Makes Bookkeeping “Trendy”
Trendy bookkeeping runs on cloud-based ledgers somewhat than information locked on a single laptop computer. It pulls automated knowledge feeds from banks, payroll instruments, ecommerce platforms, and cost processors in actual time. Stay dashboards floor money movement, margin knowledge, and key efficiency indicators with out anybody sitting all the way down to manually compile a report.
Safe consumer portals additionally make collaboration with outsourced or distant groups much more environment friendly than the countless spreadsheet e-mail chains most finance groups quietly dread.
Who Advantages Most From Cloud Bookkeeping Providers
Not each enterprise positive factors identically from making the change, so it’s value being particular. Cloud bookkeeping providers ship the sharpest benefits for service-based companies, ecommerce manufacturers managing multi-channel stock, startups with investor reporting obligations, and multi-entity corporations requiring consolidated monetary views in actual time. That stated, the eight causes beneath apply broadly no matter your mannequin.
Purpose 1: Actual Monetary Visibility, Not Guesswork
Irrespective of what you are promoting mannequin, one profit lands universally: figuring out precisely the place your cash stands on any given day.
Trendy bookkeeping options combine instantly with financial institution accounts, cost processors, and invoicing instruments, maintaining your books present every day somewhat than ready till month-end panic units in. House owners, CFOs, and traders get a dwell image of the enterprise, not a lagging snapshot from three weeks in the past.
Analysis confirms the typical delay in reconciling books manually exceeds 30 days, a spot that creates real blind spots exactly while you want readability essentially the most.
Dashboards Your Enterprise Ought to Be Watching
Monitor your real-time money place towards upcoming obligations. Monitor a dynamic revenue and loss view damaged down by product line or gross sales channel.
Hold getting old experiences for each receivables and payables inside arm’s attain. And situation modeling, asking what truly occurs if income drops 15%, turns into much more actionable when your reporting is built-in and dwell.
How Stay Knowledge Sharpens Day-to-Day Selections
With correct, real-time knowledge, hiring choices cease feeling like gambles. You may see your money runway clearly, regulate advertising spend primarily based on precise channel profitability, and negotiate vendor cost phrases utilizing laborious numbers somewhat than intuition. That form of confidence modifications the way you lead, and it compounds shortly.
Purpose 2: Severe Time Financial savings By means of Automation
On-line accounting software program has quietly eradicated complete classes of handbook work for lean finance groups. Financial institution feeds, transaction categorization, recurring invoices, and expense coding now occur mechanically, typically and not using a single keystroke out of your group.
After implementing workflow automation, 43.7% of corporations diminished their scheduling time to below an hour. That effectivity doesn’t simply really feel good, it compounds into one thing genuinely strategic.
What Trendy Bookkeeping Options Truly Automate
Financial institution and bank card feeds replace with out handbook imports. Recurring invoices exit on schedule, each time. Guidelines-based coding handles vendor funds and journey bills.
E-commerce orders sync instantly from platforms, bypassing the tedious export-and-import cycle solely.
Fewer Errors, Much less Rework
AI-powered transaction matching reduces mis-postings and duplicate entries by studying patterns from prior categorizations. Your bookkeeper shifts from reviewing each transaction individually to flagging real exceptions, which is truthfully a much better use of their experience and your cash.
Purpose 3: Smarter Value Administration With Outsourced Bookkeeping
Outsourced bookkeeping for companies usually prices considerably lower than a full-time in-house rent when you think about wage, advantages, coaching, and turnover threat.
Most suppliers construction fastened month-to-month packages tiered by transaction quantity, so that you solely pay for what you really want, nothing extra.
Value Constructions Value Understanding
Pricing usually ranges from lean packages suited to solopreneurs all the way in which as much as sturdy mid-market tiers masking small enterprise bookkeeping, payroll processing, invoice pay, and gross sales tax filings. Digital CFO providers may be added when strategic wants come up, with out committing to a full-time govt wage.
The Strategic Edge Past Pure Financial savings
Outsourcing offers you entry to a coordinated group of specialists somewhat than counting on a single generalist worker. Processes get documented correctly. Continuity will get in-built. And management reclaims time that was beforehand swallowed by administrative hearth drills, time higher spent on precise progress.
Purpose 4: Compliance and Audit Readiness With out the Final-Minute Scramble
Right here’s a sobering quantity: 85% of companies utilizing bookkeeping software program report improved monetary accuracy, and accuracy is the literal basis of surviving a clear audit.
Trendy bookkeeping options hold data searchable, organized, and full year-round, with supporting paperwork connected on to particular person transactions.
Cloud platforms keep model historical past and audit logs mechanically, eliminating the frantic doc searching that usually hits companies proper earlier than tax season.
Working With Accountants By means of Cloud Bookkeeping Providers
Safe accountant entry constructed into cloud bookkeeping providers allows sooner year-end closes and cleaner tax preparation. Actual-time knowledge additionally helps proactive tax planning, estimated funds, respectable deductions, and entity construction choices, somewhat than reactive injury management after the fiscal 12 months has already closed.
Causes 5 By means of 8: Safety, Scalability, Smarter Selections, and Group Collaboration
A safe system is simply genuinely priceless if it grows alongside what you are promoting with out forcing a expensive overhaul. That’s precisely the promise wrapped inside Causes 5 via 8.
Cloud platforms ship enterprise-grade encryption, multi-factor authentication, and role-based entry controls as normal options, not costly add-ons. Automated backups guarantee your financials are by no means tied to a single system or one workplace location.
As what you are promoting scales, on-line accounting software program scales with it, including entities, currencies, or superior reporting modules with out rebuilding something from scratch.
Knowledge and Collaboration as Real Strategic Property
Outsourced bookkeeping for companies steadily pairs with digital CFO providers, remodeling uncooked monetary knowledge into KPIs that instantly inform pricing technique, hiring timelines, and capital allocation choices.
Cloud instruments additionally assist distributed groups via real-time commenting, process queues, and shared doc hubs, maintaining bookkeepers, house owners, and advisors aligned with out the noise of fixed e-mail back-and-forth.
Ceaselessly Requested Questions
What are the 5 primary ideas of bookkeeping?
Report transactions persistently, apply a single accounting technique all through, use a particular journal for every transaction kind, retain data for at the very least 5 years, and keep correct books always, not simply at quarter-end.
Why are bookkeepers declining as a job class?
Automation is the first driver. Platforms like QuickBooks On-line, Xero, and FreshBooks now deal with many routine duties that entry-level bookkeepers as soon as carried out manually, considerably decreasing demand for these roles particularly.
Which on-line accounting software program pairs greatest with outsourced bookkeeping for companies?
No single platform is universally appropriate. QuickBooks On-line fits most small companies successfully. Xero tends to work effectively for rising groups. NetSuite matches complicated, multi-entity operations. Match the platform to your trade, transaction quantity, and reporting necessities, not the opposite approach round.
Taking the Subsequent Step With Trendy Bookkeeping Options
The shift to fashionable bookkeeping options delivers eight clear benefits: real-time monetary visibility, significant time financial savings via automation, smarter value buildings, stronger compliance readiness, enterprise-grade safety, built-in scalability, data-driven strategic assist, and genuinely seamless group collaboration.
Small enterprise bookkeeping mustn’t really feel like a month-to-month disaster you barely survive. Begin by assessing truthfully the place your present system is letting you down. Map your precise wants towards what fashionable options supply. Then take the following concrete step, whether or not meaning shortlisting suppliers, scheduling a demo, or just having a direct dialog about what your books ought to realistically be doing for what you are promoting proper now.
The proper system isn’t only a back-office improve. It’s a strategic determination that shapes how confidently you lead.
As AI reshapes industries and redefines how work will get achieved, the query of who advantages and who will get left behind has turn out to be one of many extra urgent challenges to unravel in financial mobility. Era: You Employed, a world nonprofit working throughout 17 international locations, is working to assist make profession alternatives extra broadly accessible to everybody, irrespective of their start line — they usually’re more and more utilizing AI to do it.
Cisco has partnered with Era since 2023 to assist construct digital pathways to studying and employment alternatives for job seekers world wide. We’re supporting Era’s efforts to leverage AI as a software to attach extra individuals to upskilling alternatives and related job placements at a scale that wasn’t beforehand doable.
Connecting extra individuals to extra alternatives by way of human-centered AI
Era’s placement course of, by way of which they match graduates to employers who’re hiring, is operationally complicated — involving hundreds of learners, a whole bunch of employers, and program workers throughout a number of international locations. To handle that complexity, Era constructed the Employability Module (EM), a centralized digital platform that coordinates the job placement journey for learners and workers alike. With assist from Cisco, the group has been in a position to develop and develop this platform, together with by way of the mixing of an AI-powered job-matching software in 2024.
Era’s thrilling work with Cisco is a part of a portfolio of AI-driven initiatives they’re pioneering with a variety of funders to use AI throughout their total education-to-employment lifecycle to higher assist each their workers and the learners they serve. These instruments draw on real-time knowledge to align employer hiring wants with every learner’s abilities, program background, and preferences—surfacing higher matches extra shortly than guide assessment ever might. Matching effectivity improved by roughly 25%, and the fee per match fell by greater than 99%, making the software viable throughout all of Era’s nation associates with out requiring proportional will increase in workers or funds.
Via AI-customized studying journeys, Era helps learners construct the future-ready abilities employers are in search of.
Era has additionally been utilizing AI to make the training expertise itself extra adaptive. A Customized Course Generator now produces course outlines, classes, and assessments in a fraction of the time beforehand required, whereas personalised Studying Paths and an AI Studying Companion modify content material to particular person learners as they progress, permitting individuals to maneuver by way of materials at a tempo and in a format that works for them.
Past inner instruments, Era can be evolving their curriculum to organize learners for an AI-driven workforce, serving to them develop the talents to thrive in roles the place AI is changing into integral to the work. Cisco Networking Academy has added one other layer. In FY2025 alone, greater than 275 learners accomplished Networking Academy coursework embedded instantly in Era’s Knowledge Analyst program. This integration means learners can acquire industry-leading technical credentials with out leaving the platform they already know.
Collectively, these human-centered instruments assist make studying and job matching quicker and extra personalised, they usually’re designed to enrich, not substitute, the teaching and group assist which have all the time been central to how Era works.
Breaking down limitations to learner – and nonprofit – success
Past the digital infrastructure, our partnership works to deal with among the sensible limitations learners face each day. For a lot of Era learners, their laptop computer is their main software for every part from accessing coursework to submitting job purposes to speaking with potential employers. To maintain these units secure from malware, knowledge loss, and different on-line threats, we offered 2,000 licenses for Cisco Safe Endpoint to guard units throughout the UK, Mexico, Kenya, Colombia, Chile, Singapore, and america.
These efforts are designed to work in tandem. By layering our sources—funding, know-how, and experience—the impression is compounding, permitting us to assist our companions with a depth of engagement that may result in extra sturdy, significant impression.
Illustrating the impression of tech-enabled profession packages
Era’s AI-driven job matching instruments helps join expertise to alternative all around the world.
Thus far, greater than 153,000 learners have graduated by way of Era’s program choices. This quantity paints a transparent image of this system’s attain, however the actual proof level is the sturdiness of the careers these graduates construct lengthy after they end their coaching: practically 80% of Era graduates discover employment inside -180 days of finishing their program. Greater than 20,000 employers worldwide have employed Era graduates. Amongst alumni tracked over the long term, 76% alumni that graduated between two and 5 years stay employed, 73% are incomes above a residing wage, 40% are saving cash, and 89% really feel optimistic about their futures.
These traits maintain throughout very totally different geographies and beginning factors. Think about David, a college scholar in Kenya whose research have been abruptly halted by pandemic lockdowns. Confronted with restricted employment choices, his fortunes modified when he joined Era Kenya’s digital freelancing bootcamp, the place he realized invaluable abilities wanted for distant work as a digital assistant. After finishing this system, he shortly gained monetary independence; he now acts as a mentor to aspiring freelancers.
Isa had spent years working as a translator in Thailand earlier than deciding he needed to make use of know-how in a extra direct approach to assist individuals. Era’s Software program Developer program gave him the technical basis he wanted to behave on that dream. He has since constructed an indication language translator app for deaf and hard-of-hearing guests at a library in Australia, the place he now resides.
In america, Alex struggled for years to interrupt into the company gross sales world from her small city in West Virginia, regardless of holding a related diploma. Via Era USA’s SaaS Gross sales Growth Consultant program, she developed the particular abilities and footing she wanted to land a tech function shortly after graduating.
Prioritizing objective in AI-driven profession growth instruments
Whereas public discourse usually frames AI as a menace to the job market, what we’ve realized and witnessed by way of our partnership with Era suggests a special actuality could be doable once we maintain people on the middle. Expertise is a software, and at Cisco, we consider its worth lies within the alternative and impression it permits for actual individuals seeking to higher their very own lives. When developed thoughtfully, with individuals and objective in thoughts, AI has the potential to open doorways which have lengthy been closed, advance human potential relatively than stifle it, and construct a future of labor that may work for everybody.
That is right this moment’s version of The Obtain, our weekday publication that gives a day by day dose of what’s happening on the planet of know-how.
Cyberscammers are bypassing banks’ safety with illicit instruments bought on Telegram
Inside a money-laundering heart in Cambodia, an worker opens a banking app on his cellphone. It asks for a photograph linked to the account, so he uploads an image of a 30-something Asian man.
The app then requests a video “liveness” test. The scammer holds up a static picture of a lady who doesn’t match the account. After 90 seconds, he’s in.
The exploit depends on illicit hacking companies bought on Telegram that break “Know Your Buyer” (KYC) facial scans. MIT Know-how Assessment discovered 22 channels and teams promoting these companies. That is what we found.
—Fiona Kelliher
Is carbon removing in hassle?
—Casey Crownhart
Final week, information emerged that Microsoft was pausing carbon removing purchases. It was a bombshell—Microsoft successfully is the carbon removing market, single-handedly buying round 80% of all contracted carbon removing.
The report sparked worry throughout the business, elevating questions on the way forward for carbon removing and the position of Huge Tech. Learn the complete story.
This story is from The Spark, our weekly publication exploring the know-how that might fight the local weather disaster. Enroll to obtain it in your inbox each Wednesday.
The hunt to measure our relationship with nature
—Emma Marris
People have accomplished some damaging issues to the ecosystems round us. However conservationists are studying that we can be a drive for good.
To know how we work greatest with nature, a gaggle of scientists, authors, and philosophers have developed new measurements of human-nonhuman relationships. Now, a group within the United Nations is constant the work. Discover out why—and what they hope to realize.
This story is from the subsequent difficulty of our print journal, which is all about nature. Subscribe now to learn it when it lands on Wednesday, April 22.
The must-reads
I’ve combed the web to seek out you right this moment’s most enjoyable/essential/scary/fascinating tales about know-how.
1 Ukraine says Russian troops have surrendered to robots They declare a completely automated assault captured military positions for the primary time in historical past. (404 Media) + Europe’s imaginative and prescient for future wars is stuffed with drones. (MIT Know-how Assessment)
2 Monkeys with BCIs are navigating digital worlds utilizing solely their ideas The analysis might assist folks with paralysis.(New Scientist) + However these implants nonetheless face a crucial check. (MIT Know-how Assessment)
3 NASA needs to place nuclear reactors on the Moon They might energy lunar bases and lengthen spaceflight. (Wired $) + NASA can be constructing a nuclear-powered spacecraft. (MIT Know-how Assessment)
4 Plans for on-line age verification in the US are elevating purple flags Specialists warn of compliance points and potential knowledge breaches. (NBC Information) + Within the EU, an age verification app is about to launch. (Reuters $)
5 An AI chip increase simply pushed Taiwan’s inventory market previous the UK’s It’s risen previous $4 trillion to turn out to be the world’s seventh largest. (FT $) + Future AI chips might be constructed on glass. (MIT Know-how Assessment)
6 The general public backlash in opposition to knowledge facilities is intensifying within the US Protests and litigation are blocking initiatives. (CNBC) + One potential answer? Placing them in area. (MIT Know-how Assessment)
7 5-minute EV charging is changing into a actuality China’s BYD has began rolling it out. (Gizmodo) + “Prolonged-range electrical autos” are about to hit US streets. (Atlantic $)
8 Stealth alerts are bypassing Iran’s web blackout Recordsdata hidden in satellite tv for pc TV broadcasts maintain info flowing. (IEEE)
9 Shoe model Allbirds made a shock pivot to AI, sending refill 700% No bubble to see right here, of us. (CNBC) + What even is the AI bubble? (MIT Know-how Assessment)
10 The biggest ever map of the universe is full It captures 47 million galaxies and quasars. (House.com)
Quote of the day
“I just like the web as a lot as anyone, however we’ve acquired to go on an web weight-reduction plan. We don’t have to pay for firms to do their web stuff.”
—Sylvia Whitt, a 78-year-old retiree based mostly in Virginia, tells the Washington Submit why they’re protesting in opposition to knowledge facilities.
One Extra Factor
ISRAEL VARGAS
AI and the way forward for intercourse
Some Republican lawmakers need to criminalize porn and arrest its creators. However what if porn is wholly created by an algorithm? In that case, whether or not it’s obscene, moral, or protected turns into a secondary difficulty. The first concern shall be what it means for porn to be “actual”—and what the reply calls for from all of us.
Technological advances might even take away the “messy humanity” from intercourse itself. The rise of AI-generated porn could also be a symptom of a brand new artificial sexuality, not the trigger. Learn the complete story.
—Leo Herrera
We will nonetheless have good issues
A spot for consolation, enjoyable and distraction to brighten up your day. (Bought any concepts? Drop me a line.)
Macworld analyzes Closing Minimize Professional for iPad, discovering that regardless of practically two years since launch, the app stays restricted in comparison with its Mac counterpart because of iPadOS structural constraints.
Skilled customers face important workflow disruptions together with file duplication, restricted exterior show help, tough library backups, and inconsistent keyboard shortcuts that hinder productiveness.
Apple seems to battle with creating genuinely skilled iPad functions, as highly effective {hardware} is undermined by iPadOS limitations in file administration, multitasking, and interface flexibility.
When Apple launched Closing Minimize Professional for iPad nearly two years in the past, I actually needed it to work. The macOS model already serves me very properly, however it could be fairly good to have the ability to begin tasks on my iPad and end them on my Mac if crucial. I attempted it again then, bumped into its limitations, and moved on.
Now with Apple Creator Studio, I made a decision to provide Closing Minimize for iPad one other attempt. Two years later, I understand that the issue isn’t simply that Closing Minimize for iPad hasn’t improved. The issue is that Apple nonetheless hasn’t discovered the way to truly make correct “professional” apps for the iPad.
‘Professional’ apps constrained by iPadOS
Even after its Creator Studio updates, Closing Minimize Professional for iPad nonetheless looks like a secondary, companion expertise in comparison with the Mac app. Many core options are nonetheless lacking, others are simplified, and a few workflows are restricted by iPadOS itself.
When you count on to have a full Mac expertise on the iPad, you’ll probably find yourself as annoyed as I did. Keyboard shortcuts, important for dashing up modifying, are inconsistent on the iPad. Some work, some don’t, which ruins muscle reminiscence for these already conversant in the Mac model.
Working with the Closing Minimize Professional library on the iPad isn’t as straightforward as it’s on the Mac.
Foundry
Then there’s file administration, which exposes one among iPadOS’s largest limitations. On the Mac, customers can freely reorganize, transfer, or again up their Closing Minimize library. You’ll be able to even create a number of libraries for various tasks if you need.
However iPadOS handles file administration very in another way from macOS. All apps run in a sandbox, to allow them to’t actually entry different components of the system. Whereas that is good for privateness and safety, it’s horrible for Closing Minimize and different professional apps.
For instance, if I add a clip from the Photographs app to Closing Minimize on iPad, the file is duplicated as a result of it should be added to the sandboxed Closing Minimize library. On the Mac, Closing Minimize can use and edit recordsdata of their authentic places.
What if it’s essential to again up your library? On the iPad, you possibly can’t. Once more, as a result of every thing is sandboxed, you possibly can’t actually entry the info from apps. As a substitute, it’s essential to export every challenge manually. But when one thing goes incorrect or will get corrupted, and it’s essential to reinstall the app, chances are high you’ll lose all of your information.
The iPad {hardware} isn’t the issue—isn’t the constraints of iPadOS.
Foundry
Highly effective {hardware}, restrictive software program
This isn’t only a Closing Minimize Professional concern and even an iPad concern. The newest iPads are powered by the identical chips discovered inside Macs. Nonetheless, they’re removed from having the identical capabilities. These issues are the results of all of the structural limitations of iPadOS.
One other instance is Pixelmator Professional, which was unique to the Mac and is now on the iPad for the primary time with Creator Studio. The app seems loads just like the Mac model, however because of how iPadOS handles RAM administration, it has many extra limitations.
For instance, the iPad model struggles to deal with giant recordsdata with a number of layers. Whereas engaged on a doc, I hit a warning message telling me I couldn’t add any extra layers to my challenge, one thing that doesn’t occur on my Mac.
Pixelmator Professional on the iPad pales compared to the Mac model.
Foundry
On the iPad, fundamental options take for much longer to reach, and after they do, they’re usually restricted or carried out in a clunky means. Though iPadOS has had multitasking for years, the flexibility to maintain apps working within the background whereas they obtain a file or export a big challenge was solely simply added with iPadOS 26.
Nonetheless, for some cause, the flexibility to export movies within the background with Closing Minimize is simply accessible for iPads with the M3 chip or later (iPad Air and iPad Professional). Even an previous Intel Mac permits you to export movies within the background.
Mac-like options which can be nonetheless restricted
As iPadOS evolves, Apple has been attempting new methods to make it extra “professional” and Mac-like. Nonetheless, the iPad nonetheless behaves very in another way from a Mac, and in a means that’s not very intuitive.
Again to Closing Minimize, the iPad model now helps exterior shows, however it’s removed from working in addition to it does on the Mac. You’ll be able to’t rearrange the interface and select what you’ll see on the exterior show. The one factor the app does is present a preview of the video on the large display.
Even with the newest enhancements, iPadOS continues to carry again the iPad.
Foundry
That’s as a result of help for exterior shows on the iPad remains to be fairly restricted. For example, though iPadOS 26 added a Menu Bar like on the Mac, there’s no option to maintain it at all times seen on the display, even on a big monitor. You can also’t do one thing as fundamental as resizing the Dock.
And whereas iPadOS has an API for apps to have a number of home windows like on a desktop working system, Apple’s Pixelmator Professional for iPad remains to be restricted to opening one challenge at a time.
The Mac remains to be the clear alternative for Professionals
These are only a few examples of how Apple itself nonetheless limits the iPad to the purpose that utilizing it as an expert software will not be that interesting.
With Creator Studio, I used to be actually tempted to attempt to make the iPad extra part of my workflow. However sadly, all these restrictions nonetheless make the Mac really feel simpler and less complicated to make use of.
I actually hope issues change for the higher sooner or later. I get that the iPad must be completely different than the Mac, however it could be nice to have extra consistency {and professional} overlap between the 2 platforms. Till then, should you actually have a professional workflow, you must in all probability follow the Mac.
I have been imagining what it could be wish to go to the Moon ever since 1961 after I was 5 years previous, staring on the artists’ conceptions in my childhood area books. When Apollo 8 astronauts Frank Borman, Jim Lovell, and Invoice Anders grew to become the primary people to truly go there, throughout Christmas week of 1968, I used to be a 12-year-old area fanatic camped out in entrance of the TV with fashions of the spacecraft I might constructed from kits, maps of the Moon, and articles concerning the flight — my very own private mission management.
For me, the spotlight of the 20 hours Apollo 8 spent in lunar orbit on Christmas Eve got here when Borman and his crew made two TV broadcasts with their small onboard black-and-white digital camera. I used to be completely mesmerized by the photographs of craters gliding slowly previous the spacecraft’s home windows. I beloved their fuzzy, nearly dreamlike high quality; one way or the other that match the momentousness of the occasion and the virtually unimaginable distance between the three Moon voyagers and all of us on their house planet.
This was nothing lower than essentially the most thrilling factor I may probably think about. I needed to be these males, and over the following 4 years I took my place in entrance of the TV for each one of many Apollo missions, proper up by way of the tip of this system in December 1972. Witnessing humanity’s first voyages to a different world grew to become my life’s defining expertise. I could not have imagined then that I’d develop as much as turn into an area historian and that I’d spend eight years writing a you-are-there account of the lunar missions, based mostly on my in-depth interviews with the Apollo Moon voyagers. However whilst I re-immersed myself in Apollo, I needed to face the fact that the primary period of human lunar exploration was receding ever additional into historical past, with nothing on the horizon to interchange it. Since then there has at all times been part of me drawing sustenance from the distant previous, particularly after I started educating the teachings of Apollo to NASA engineers in 2016.
Because the time for Artemis 2 drew close to, my anticipation was blended with uncertainty. Would this new Moon mission spark the emotions of surprise and pleasure I might had so way back? These doubts did not final lengthy. When astronauts Reid Wiseman, Victor Glover, Christina Koch and Jeremy Hansen headed for the Moon within the Orion spacecraft they named “Integrity,” I felt like elements of my mind that had been dormant since 1972 have been being reactivated. I listened to each minute of their seven-hour lunar flyby — however this was nothing just like the Christmas Eve I might skilled greater than 57 years earlier than. Now NASA’s protection featured prolonged views from contained in the cabin whereas the astronauts labored, so clear that they may have been aboard the Worldwide House Station 250 miles (400 kilometers) up as a substitute of a thousand instances farther away.
As I listened to the astronauts’ voices, I felt as if a veil had been lifted: As a substitute of the restrained, “Proper Stuff” supply of the Apollo 8 crew’s transmissions, I heard expressions of exhilaration and even pleasure. And I used to be amazed on the richness of element concerning the lunar expertise that was out there to everybody in actual time. Even the astronauts’ geologic descriptions have been stuffed with human moments that put me within the spacecraft alongside them. As “Integrity”rounded the Moon, Christina Koch likened the looks of the smallest, freshest lunar craters to “a lampshade with tiny pinprick holes and the sunshine shining by way of. They’re so brilliant in comparison with the remainder of the Moon.” Victor Glover described peering on the lengthy shadows of the lunar terminator by way of a telephoto lens and out of the blue feeling transported all the way down to that airless, forbidding panorama and imagining himself off-road driving amongst jagged peaks.
For me, essentially the most superior second of your entire mission occurred when “Integrity” flew into the Moon’s shadow, creating a virtually hour-long complete eclipse of the Solar — greater than 10 instances longer than most complete eclipses seen from Earth. I used to be transfixed by video from the spacecraft’s exterior cameras exhibiting the glow of the photo voltaic corona slowly disappearing behind the Moon’s darkened limb. Aboard “Integrity,” the astronauts let their eyes adapt, and shortly they may see the Moon’s night time aspect set towards a dim glow, with a crescent-shaped slice of the cratered globe illuminated within the gentle mild of Earthshine. I heard Victor Glover say, “We have simply gone sci-fi.” All of the sudden I used to be stuffed with curiosity, hungry for extra description.
However this was one sight that was past their skill to convey within the second. “It is simply, it is indescribable,” I heard Reid Wiseman say. “Irrespective of how lengthy we take a look at this, our brains usually are not processing this picture in entrance of us. It’s completely spectacular. Surreal. There’s — I do know there is not any adjectives. I am gonna have to invent some new ones to explain what we’re out this window.”
Breaking area information, the most recent updates on rocket launches, skywatching occasions and extra!
The morning after the flyby, I opened my laptop computer to seek out that the astronauts had beamed down their pictures of the encounter, and I felt like Rip Van Winkle woke up from a half-century nap. For many years after Apollo, there was no such factor as hi-def scans of the missions’ photographic movie, however now, simply hours after the occasion, I used to be full-resolution digital photographs of beautiful magnificence, together with new portraits of a superb blue and white crescent Earth setting after which rising behind the lunar far aspect’s lifeless expanse, taken from the farthest level in deep area that people have ever reached. I felt a wave of pleasure and reduction come over me on the realization {that a} new period of human deep area exploration has lastly begun. Now, as a substitute of simply wanting again, I am wanting forward.
Andrew Chaikin is the writer of “A Man on the Moon: The Voyages of the Apollo Astronauts” (Viking, 1994). His web site is www.DoSpaceBetter.com.
Deep Brokers can plan, use instruments, handle state, and deal with lengthy multi-step duties. However their actual efficiency depends upon context engineering. Poor directions, messy reminiscence, or an excessive amount of uncooked enter shortly degrade outcomes, whereas clear, structured context makes brokers extra dependable, cheaper, and simpler to scale.
For this reason the system is organized into 5 layers: enter context, runtime context, compression, isolation, and long-term reminiscence. On this article, you’ll see how every layer works, when to make use of it, and how you can implement it utilizing the create_deep_agent(...) Python interface.
A five-layer vertical diagram displaying enter context, runtime context, context compression, context isolation, and long-term reminiscence in Deep Brokers.
What context engineering means in Deep Brokers
Context in Deep Brokers is just not that of the chat historical past alone. Some context is loaded into the system immediate at startup. Half is handed over on the time of invocation. A part of it’s robotically compressed when the working set of the agent turns into too large. An element is confined inside subagents. Others is carried over between conversations utilizing the digital filesystem and store-backed reminiscence. The documentation is evident that they’re separate mechanisms with separate scopes and that’s what makes deep brokers usable in manufacturing.
The 5 layers are:
Enter context: Begin-up, fastened info, which was pooled into the system immediate.
Runtime context: Per-run, dynamic configuration at invocation.
Context compression: Offloading and summarization based mostly on automated reminiscence administration.
Isolation of context with subagents: Assigning duties to subagents with new context home windows.
Lengthy-term reminiscence: Enduring information that’s saved between classes.
Let’s assemble each one proper.
Conditions
You’ll require Python 3.10 or later, the deepagents bundle and a supported mannequin supplier. In case you wish to use stay net search or hosted instruments, configure the supplier API keys in your surroundings. The official quickstart helps supplier setups to Anthropic, OpenAI, Google, OpenRouter, Fireworks, Baseten and Ollama.
!pip set up -U deepagents langchain langgraph
Layer 1: Enter context
Enter context refers to all that the agent perceives at initiation as a part of its constructed system immediate. That accommodates your customized system immediate, reminiscence information like AGENTS.md, expertise loaded based mostly on SKILL.md, and power prompts based mostly on built-in or customized instruments within the Deep Brokers docs. The docs additionally reveal that the whole assembled system immediate accommodates inbuilt planning recommendation, filesystem software recommendation, subagent recommendation, and non-compulsory middleware prompts. That’s, what you customized immediate is is only one part of what the mannequin will get.
That design issues. It doesn’t indicate that you’ll hand concatenate your agent immediate, reminiscence file, expertise file and power assist right into a single massive string. Deep Brokers already understands how you can assemble such a construction. It’s your process to position the suitable content material within the acceptable channel.
Use system_prompt for identification and conduct
Request the system immediate on the position of the agent, tone, boundaries and top-level priorities. The documentation signifies that system immediate is immutable and in case you need it to be completely different relying on the consumer or request, you need to use dynamic immediate middleware slightly than enhancing immediate strings straight.
Use reminiscence for always-relevant guidelines
Reminiscence information like AGENTS.md are all the time loaded when configured. The docs recommend that reminiscence needs to be used to retailer steady conventions, consumer preferences or vital directions which needs to be used all through all conversations. Since reminiscence is all the time injected, it should stay quick and high-signal.
Use expertise for workflows
Expertise are reusable workflows that are solely partially relevant. Deep Brokers masses the ability frontmatter on startup, and solely masses the total ability physique when it determines the ability applies. The sample of progressive disclosure is among the many easiest strategies of minimizing token waste with out compromising capability.
Use software descriptions as operational steering
The metadata of the software is included within the immediate that the mannequin is reasoning about. The docs recommend giving names to instruments in clear language, write descriptions indicating when to make use of them, and doc arguments in a way that may be understood by the agent and so, they will choose the instruments appropriately.
Arms-on Lab 1: Construct a mission supervisor agent with layered enter context
The First lab develops a easy but reasonable mission supervisor agent. It has a hard and fast place, a hard and fast reminiscence file of conventions and a capability to do weekly reporting.
## Function You're a mission supervisor agent for Acme Corp.
## Conventions - All the time reference duties by process ID, equivalent to TASK-42 - Summarize standing in three phrases or fewer - By no means expose inner price knowledge to exterior stakeholders
expertise/weekly-report/SKILL.md
---
identify: weekly-report
description: Use this ability when the consumer asks for a weekly replace or standing report.
---
# Weekly report workflow
1. Pull all duties up to date within the final 7 days.
2. Group them by standing: Achieved, In Progress, Blocked.
3. Format the consequence as a markdown desk with proprietor and process ID.
4. Add a brief govt abstract on the high.
agent_setup.py
from pathlib import Path
from IPython.core.show import Markdown
from deepagents import create_deep_agent
from deepagents.backends import FilesystemBackend
from langchain.instruments import software
ROOT = Path.cwd().resolve().mum or dad
@software
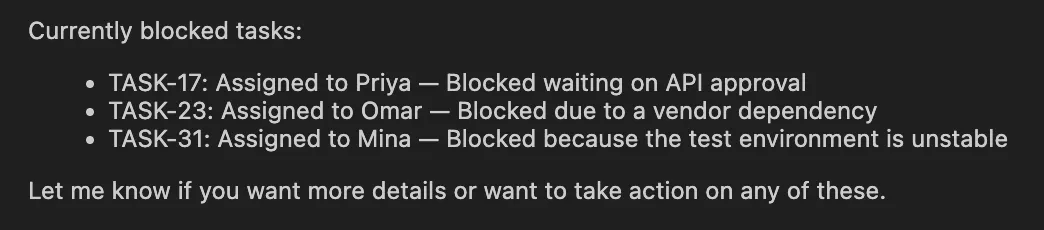
def get_blocked_tasks() -> str:
"""Return blocked duties for the present mission."""
return """
TASK-17 | Blocked | Priya | Ready on API approval
TASK-23 | Blocked | Omar | Vendor dependency
TASK-31 | Blocked | Mina | Check surroundings unstable
""".strip()
agent = create_deep_agent(
mannequin="openai:gpt-4.1",
system_prompt="You're Acme Corp's mission supervisor agent.",
instruments=[get_blocked_tasks],
reminiscence=["./AGENTS.md"],
expertise=["./skills/"],
backend=FilesystemBackend(root_dir=str(ROOT), virtual_mode=True),
)
consequence = agent.invoke(
{
"messages": [
{"role": "user", "content": "What tasks are currently blocked?"}
]
}
)
Markdown(consequence["messages"][-1].content material[0]["text"])
Output:
This variant coincides with the recorded Deep Brokers sample. Reminiscence is proclaimed with reminiscence=… and expertise with expertise=… and a backend offers entry to these information by the agent. The agent won’t ever get optimistic concerning the contents of AGENTS.md, however absolutely load SKILL.md on events when it finds it vital to take action, i.e. when the weekly-report workflow is in play.
The ethical of the story is straightforward. Repair lasting legal guidelines in thoughts. Find reusable and non-constant workflows in expertise. Preserve a system that’s behaviorally and identification oriented. A single separation already aids a great deal of well timed bloat.
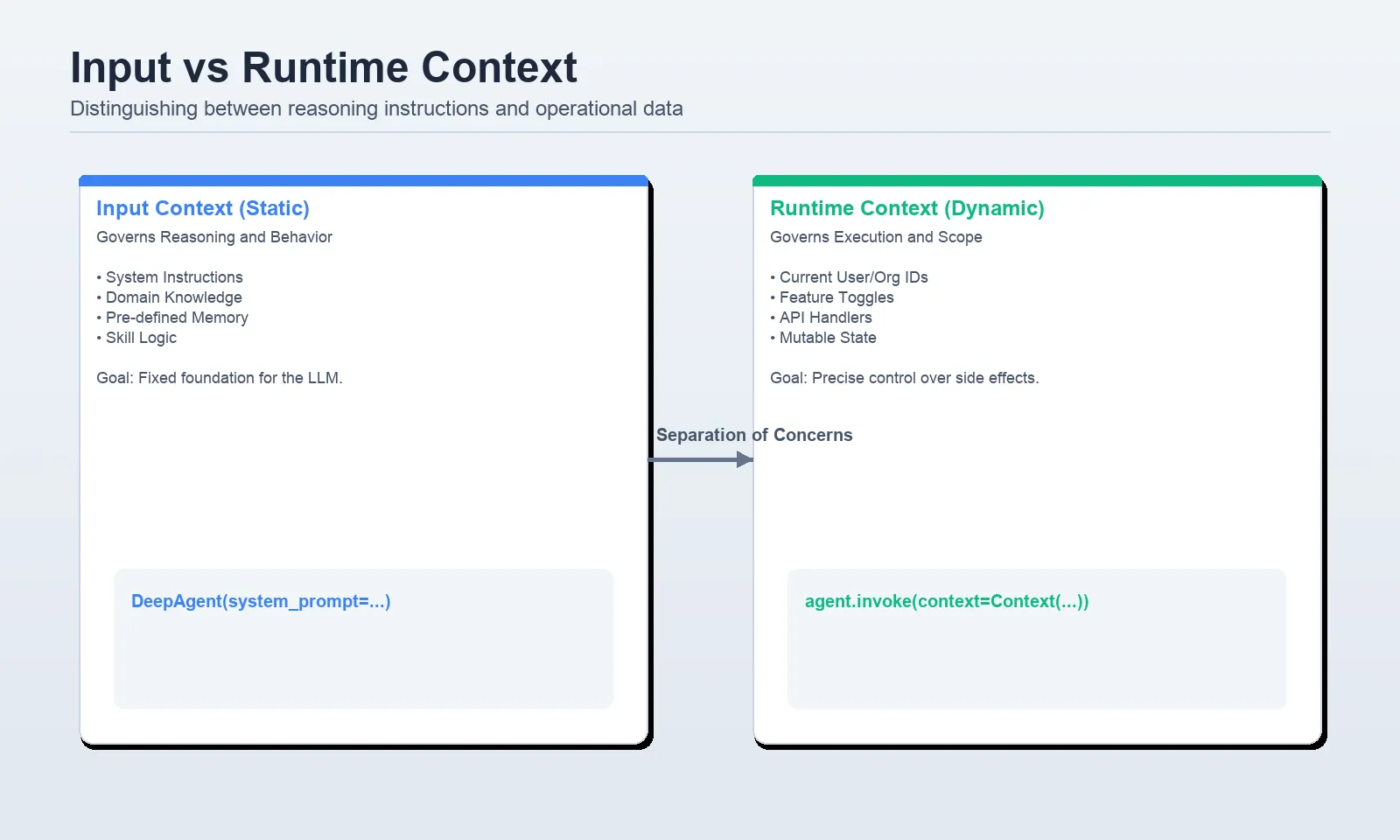
Layer 2: Runtime context
The info that you simply move throughout invocation time is the runtime context. One other vital truth that’s made very clear by the docs is that the runtime context is just not robotically introduced to the mannequin. Solely is it seen whether or not instruments or middleware explicitly learn it and floor it. It’s the proper place, then, to maintain consumer IDs, roles, function flags, database handles, API keys, or something that’s operational however to not be present in a immediate.
The sample that’s presently advised is to specify a context_schema, and invoke the agent with context=…, and to entry these values inside instruments with ToolRuntime. The docs of the LangChain instruments additionally point out that runtime is the suitable injection level of execution info, context, entry to a retailer, and different related metadata.
A side-by-side diagram evaluating enter context and runtime context, with arrows displaying how the mannequin reads one whereas instruments and middleware learn the opposite.
Arms-on Lab 2: Go runtime context with out polluting the immediate
from openai import api_key
from dataclasses import dataclass
import os
from IPython.core.show import Markdown
from deepagents import create_deep_agent
from langchain.instruments import software, ToolRuntime
@dataclass
class Context:
user_id: str
org_id: str
db_connection_string: str
weekly_report_enabled: bool
@software
def get_my_tasks(runtime: ToolRuntime[Context]) -> str:
"""Return duties assigned to the present consumer."""
user_id = runtime.context.user_id
org_id = runtime.context.org_id
# Substitute this stub with an actual question in manufacturing.
return (
f"Duties for consumer={user_id} in org={org_id}n"
"- TASK-12 | In Progress | End onboarding flown"
"- TASK-19 | Blocked | Await authorized reviewn"
)
agent = create_deep_agent(
mannequin="openai:gpt-4.1",
instruments=[get_my_tasks],
context_schema=Context,
)
consequence = agent.invoke(
{
"messages": [
{"role": "user", "content": "What tasks are assigned to me?"}
]
},
context=Context(
user_id="usr_8821",
org_id="acme-corp",
db_connection_string="postgresql://localhost/acme",
weekly_report_enabled=True,
),
)
Markdown(consequence["messages"][-1].content material[0]["text"])
Output:
That is the clear minimize that you simply need in manufacturing. The mannequin can invoke get my duties however the actual userid and orgid stay within the runtime context slightly than being pushed onto the system immediate or chat historical past. It’s a lot safer and simpler to motive about, throughout debugging of permissions and knowledge stream.
One rule is as follows: When the mannequin must motive a few truth straight, put it in prompt-space. To depart it in runtime context in case your instruments require it to be in operational state.
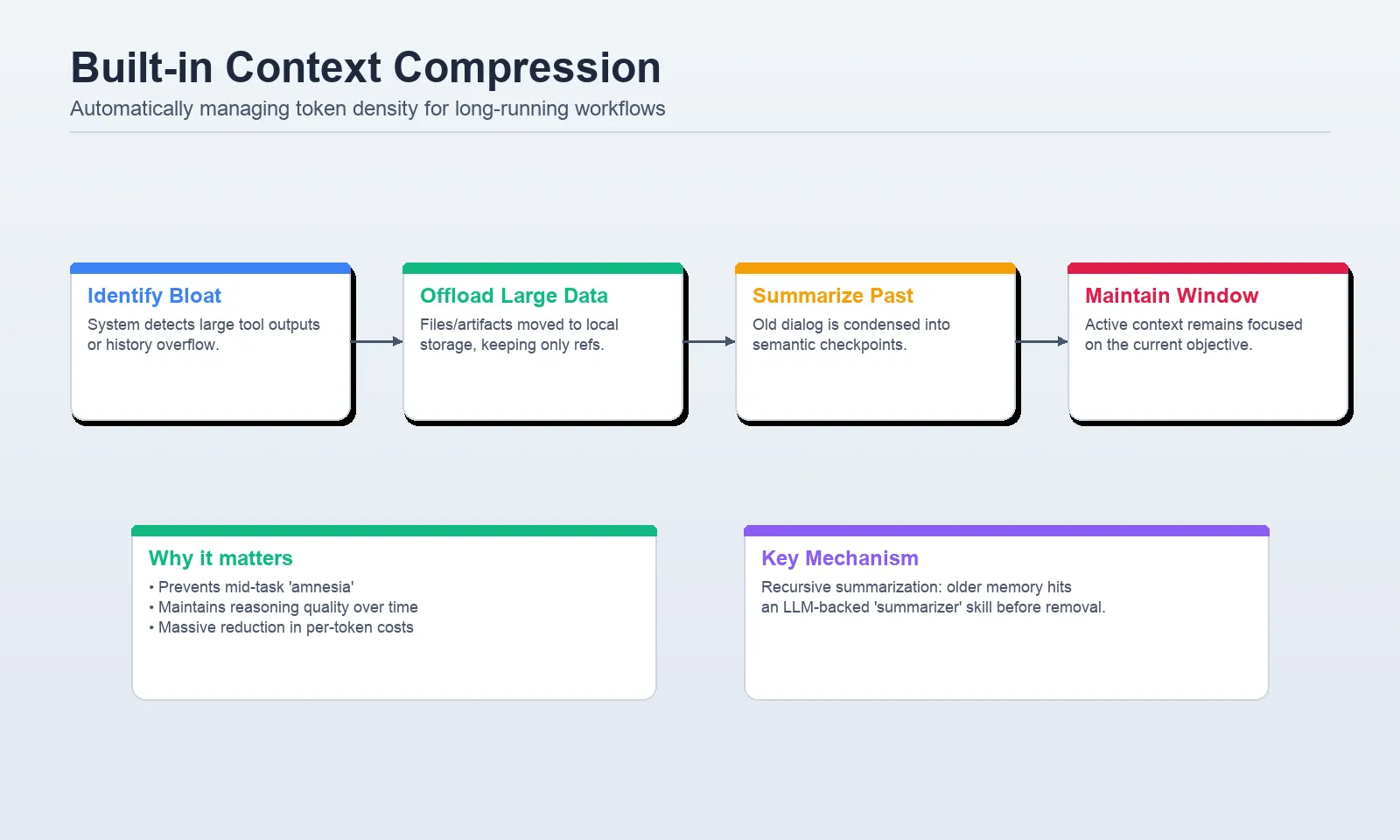
Layer 3: Context compression
Duties which might be long-running generate two points shortly: enormous software outputs and prolonged histories. Deep Brokers helps them each with inbuilt context compression. The 2 native mechanisms, offloading and summarization, are described within the docs. Unloads shops with massive software inputs and replicates them with references within the filesystem. Summarization is used to cut back the dimensions of older messages because the agent nears the context constraint of the mannequin.
Offloading
In line with the context engineering docs, content material offloading happens when the software name inputs or outputs surpass a token threshold, with default threshold being 20,000 tokens. Large historic instruments knowledge are substituted with references to the information which were endured in order that the agent can entry it later when required.
Summarization
In case the energetic context turns into excessively massive, Deep Brokers summarizes older elements of the dialog to proceed with the duty with out surpassing the window of the mannequin. It additionally has an non-compulsory summarization software middleware, which permits the agent to summarize on extra attention-grabbing boundaries, e.g., between process phases, slightly than simply on the automated threshold.
A workflow diagram displaying massive software outputs being offloaded to the filesystem and lengthy message histories being summarized right into a targeted working set.
Arms-on Lab 3: Use built-in compression the best approach
from deepagents import create_deep_agent
from IPython.core.show import Markdown
def generate_large_report(matter: str) -> str:
"""Generate a really detailed report on vector database tradeoffs."""
# Simulate a big software consequence
return ("Detailed report about " + matter + "n") * 5000
agent = create_deep_agent(
mannequin="openai:gpt-4.1-mini",
instruments=[generate_large_report],
)
consequence = agent.invoke(
{
"messages": [
{
"role": "user",
"content": "Generate a very detailed report on vector database tradeoffs.",
}
]
}
)
Markdown(consequence["messages"][-1].content material[0]["text"])
Output:
In a setup like this, Deep Brokers handles the heavy lifting. If the software output turns into massive sufficient, the framework can offload it to the filesystem and preserve solely the related reference in energetic context. Which means you need to begin with the built-in conduct earlier than inventing your individual middleware.
If you would like proactive summarization between levels, use the documented middleware:
from deepagents import create_deep_agent
from deepagents.backends import StateBackend
from deepagents.middleware.summarization import create_summarization_tool_middleware
agent = create_deep_agent(
mannequin="openai:gpt-4.1",
middleware=[
create_summarization_tool_middleware("openai:gpt-4.1", StateBackend),
],
)
That provides an non-compulsory summarization software so the agent can compress context at logical checkpoints as an alternative of ready till the window is almost full.
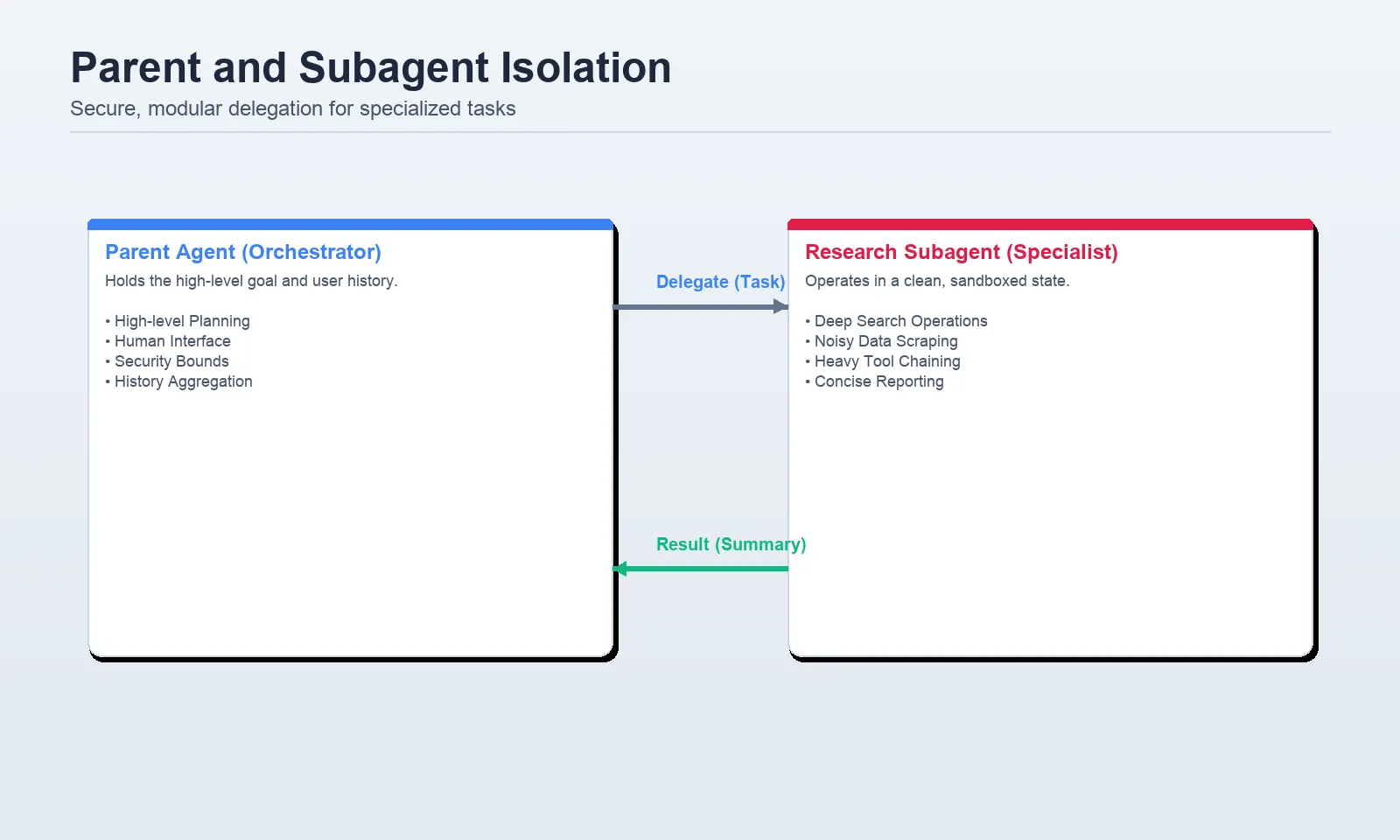
Layer 4: Context isolation with subagents
Subagents can be found to take care of the first agent clear. The docs recommend them in multi-step work that might in any other case litter the mum or dad context, in particular areas, and in work that may require a special toolset or mannequin. They clearly recommend that they don’t seem to be for use in one-step duties or duties the place the mother and father intermediate reasoning will nonetheless be inside the scope.
The Deep Brokers sample is presently to declare subagents with the subagents= parameter. Within the majority of functions, they are often represented as a dictionary with a reputation, description, system immediate, instruments and non-compulsory mannequin override as every subagent.
A two-panel diagram displaying a mum or dad agent delegating heavy work to a analysis subagent with a contemporary context window, then receiving a brief abstract again.
Arms-on Lab 4: Delegate analysis to an remoted subagent
from deepagents import create_deep_agent
from IPython.core.show import Markdown
def internet_search(question: str, max_results: int = 5) -> str:
"""Run an internet seek for the given question."""
return f"Search outcomes for: {question} (high {max_results})"
research_subagent = {
"identify": "research-agent",
"description": "Use for deep analysis and proof gathering.",
"system_prompt": (
"You're a analysis specialist. "
"Analysis completely, however return solely a concise abstract. "
"Don't return uncooked search outcomes, lengthy excerpts, or software logs."
),
"instruments": [internet_search],
"mannequin": "openai:gpt-4.1",
}
agent = create_deep_agent(
mannequin="openai:gpt-4.1",
system_prompt="You coordinate work and delegate deep analysis when wanted.",
subagents=[research_subagent],
)
consequence = agent.invoke(
{
"messages": [
{
"role": "user",
"content": "Research best practices for retrieval evaluation and summarize them.",
}
]
}
)
Markdown(consequence["messages"][-1].content material[0]["text"])
Output:
Delegation is just not the important thing to good subagent design. It’s containment. The subagent is just not supposed to provide the uncooked knowledge, however a concise reply. In any other case, you lose all of the overhead of isolation with out having any context financial savings.
The opposite noteworthy truth talked about within the paperwork is that runtime context is propagated to subagents. When the mum or dad has an current consumer, org or position within the runtime context, the subagent inherits it as effectively. That’s the reason subagents are much more handy to work with in actual programs since you don’t want to re-enter the identical knowledge in each place manually.
Layer 5: Lengthy-term reminiscence
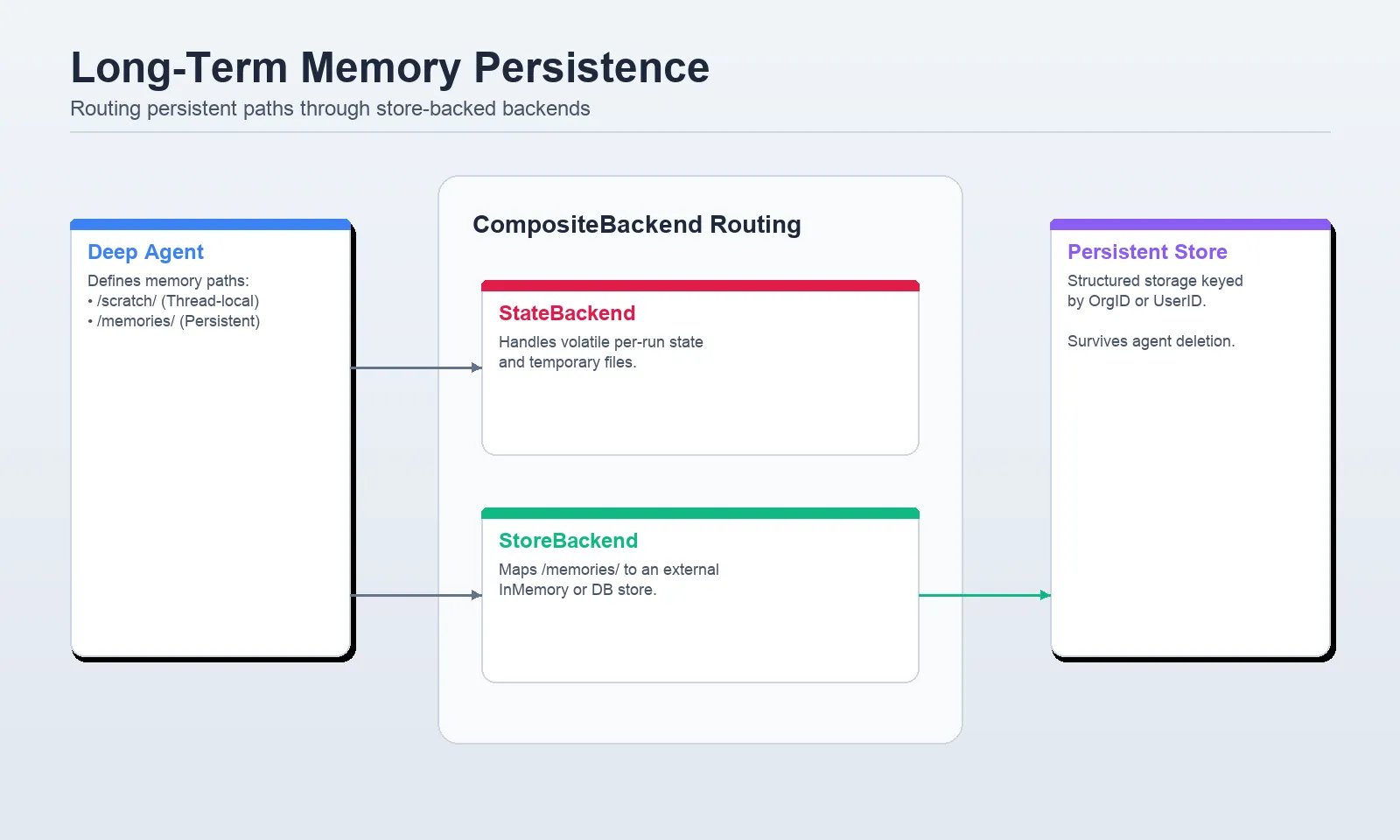
Lengthy-term reminiscence is the place Deep Brokers turns into far more than a elaborate immediate wrapper. The docs describe reminiscence as persistent storage throughout threads by way of the digital filesystem, often routed with StoreBackend and infrequently mixed with CompositeBackend so completely different filesystem paths can have completely different storage conduct.
That is what most examples err at wrongly. It ought to have a path to a backend equivalent to StoreBackend and to not a uncooked retailer object. The shop itself is exchanged to type create deep_agent(...). The paths of the reminiscence information are outlined in reminiscence=[…], which might be then loaded robotically into the system immediate.
The reminiscence docs additional make clear that there are different dimensions to reminiscence aside from storage. It’s essential to contemplate size, kind of knowledge, protection, and updating plan. Virtually, probably the most vital alternative is scope: Is it going to be per-user, per-agent, or an organization-wide reminiscence?
A backend routing diagram displaying a Deep Agent utilizing a CompositeBackend to ship scratch knowledge to StateBackend and /reminiscences/ paths to StoreBackend.
from dataclasses import dataclass
from IPython.core.show import Markdown
from deepagents import create_deep_agent
from deepagents.backends import CompositeBackend, StateBackend, StoreBackend
from deepagents.backends.utils import create_file_data
from langgraph.retailer.reminiscence import InMemoryStore
from langchain_core.utils.uuid import uuid7
@dataclass
class Context:
user_id: str
retailer = InMemoryStore()
# Seed reminiscence for one consumer
retailer.put(
("user-alice",),
"/reminiscences/preferences.md",
create_file_data("""## Preferences
- Maintain responses concise
- Choose Python examples
"""),
)
agent = create_deep_agent(
mannequin="openai:gpt-4.1-mini",
reminiscence=["/memories/preferences.md"],
context_schema=Context,
backend=lambda rt: CompositeBackend(
default=StateBackend(rt),
routes={
"/reminiscences/": StoreBackend(
rt,
namespace=lambda ctx: (ctx.runtime.context.user_id,),
),
},
),
retailer=retailer,
system_prompt=(
"You're a useful assistant. "
"Use reminiscence information to personalize your solutions when related."
),
)
consequence = agent.invoke(
{
"messages": [
{"role": "user", "content": "How do I read a CSV file in Python?"}
]
},
config={"configurable": {"thread_id": str(uuid7())}},
context=Context(user_id="user-alice"),
)
Markdown(consequence["messages"][-1].content material[0]["text"])
Output:
There are three important issues that this setup does. It masses a reminiscence file to the agent. It sends /reminiscences/ to persistent store-backed storage. And it’s namespace remoted per consumer by utilizing user_id because the namespace. That is the proper default with most multi-user programs because it doesn’t permit reminiscence to leak between customers.
If you require organizational reminiscence that you simply share, you need to use a special namespace and continuously a special path like /insurance policies or /org-memory. If you require agent degree shared procedural reminiscence, then use agent particular namespace. Nonetheless, consumer scope is probably the most safe start line, when it comes to consumer preferences and customised conduct.
Frequent errors to keep away from
The prevailing documentation implicitly cautions towards among the typical pitfalls, they usually can’t damage to be express.
Watch out to not overload the system. All the time-loaded immediate house is dear and troublesome to take care of. Be aware of reminiscence and expertise.
Don’t switch runtime-only info utilizing chat messages. IDs, permissions, function flags and connection particulars fall in runtime context.
Offloading and summarization shouldn’t be reimplemented till you have got quantified an precise distinction within the built-ins.
Do not need subagents undertake insignificant single duties. The paperwork clearly point out to set them apart to context-intensive or specialised work.
The default is to not retailer all long-term reminiscence in a single shared namespace. Decide the proprietor of the reminiscence, the consumer or the agent, or the group.
Conclusion
Deep Brokers usually are not efficient since they possess prolonged prompts. They’re sturdy since they can help you decouple context by position and lifecycle. Cross-thread reminiscence, per-run state, startup directions, compressed historical past, and delegated work are a couple of different issues. Deep Brokers framework offers you with a clear abstraction of every. If you straight use these abstractions slightly than debugging round them, your brokers are less complicated to debug, cheaper to execute, and extra dependable to make use of in actual workloads.
That’s the precise artwork of context engineering. It doesn’t matter about offering extra context. It’s giving the agent simply the context that it requires, simply the place it’s required.
Often Requested Questions
Q1. What’s context engineering in Deep Brokers?
A. It’s the process of giving AI brokers the proper info. That is offered within the acceptable format and on the opportune second. It directs their actions and makes them accomplish any process.
Q2. Why is context vital for Deep Brokers?
A. Context performs an vital position because it helps brokers to remain targeted. It assists them in not being irrelevant. It additionally makes certain that they get requisite knowledge. This outcomes into efficient and reliable efficiency of duties.
Q3. What are the advantages of subagents in managing context?
A. Subagents are context isolating. They sort out intricate output-intensive jobs inside their very distinct setting. This ensures that the reminiscence of the principle agent is clear and goal in the direction of its fundamental targets.
Harsh Mishra is an AI/ML Engineer who spends extra time speaking to Massive Language Fashions than precise people. Keen about GenAI, NLP, and making machines smarter (in order that they don’t substitute him simply but). When not optimizing fashions, he’s most likely optimizing his espresso consumption. 🚀☕
Login to proceed studying and revel in expert-curated content material.
That is the fact of many enterprises as we speak: A request is created. Somebody sends an e-mail. One other particular person updates a spreadsheet. Somebody copies the information right into a CRM. Then the cycle repeats.
Nothing seems damaged. But the method stays sluggish and fragile. Counting on somebody to course of the subsequent step can stall the workflow.
That’s the reason customized enterprise workflow automation software program is turning into important for contemporary organizations. Automation retains routine work transferring with out human nudges. Workflows are hassle-free, companies are on time, and prospects are simpler to retain. Right here’s extra on enterprise workflow automation, what it’s, the way it works, and why fashionable companies should contemplate it!
What are the Advantages of Enterprise Workflow Automation?
Handbook processes look innocent on the floor. But they quietly create operational drag throughout a company. Emails pile up, approvals stall. Knowledge will get duplicated whereas small errors proceed to multiply. These inefficiencies develop into costly.
Nicely-designed customized enterprise workflow automation software program addresses these issues in sensible methods.
1. Quicker Course of Execution
Handbook workflows decelerate decision-making. Each step is dependent upon somebody noticing an e-mail or remembering a process.
Automation removes that delay. A purchase order request is routinely directed to the suitable approver relying on division, funds, or spending restrictions. If approval is postponed, it triggers rapid alerts and reminders. This protects time.
2. Consistency and Precision
We people, are succesful, however we’re not excellent knowledge processors. Handbook workflows typically contain copying data between methods. This introduces errors. A flawed quantity in an bill. An incorrect buyer standing. A missed compliance step.
Automation retains the method constant each time. The principles are constructed into the workflow, lowering the danger of human error.
3. Actual-Time Course of Visibility Determining the place the duty is caught is the highest precedence for managers.
Visibility is likely one of the superpowers of customized enterprise workflow automation software program. Each step is seen by means of dashboards and logs. No guesswork. You realize who permitted, who hasn’t responded, and what stage the method is in.
4. Scalability With out Operational Chaos
As companies develop, transaction quantity will increase. Extra invoices, extra buyer requests, extra approvals. Handbook methods not often scale effectively. Groups reply by hiring extra employees simply to handle operational duties.
Automation modifications that equation. Processes deal with larger volumes with out proportional will increase in manpower. This permits corporations to develop whereas sustaining operational management.
Step Out of Tedious Time-Consuming Handbook Efforts Elevate Your Operations With Enterprise Workflow Automation
Enterprise Automation Use Circumstances
Automation turns into simpler to grasp once we take a look at actual operational eventualities. Many industries are already making use of these methods to unravel sensible issues.
Let’s take a look at some real-world enterprise automation use instances.
1. Clever Doc Automation
Companies deal with 1000’s of paperwork day by day. AI-driven automation eliminates the difficulty of manually reviewing paperwork, compiling knowledge, and coming into it. By means of OCR and machine studying, paperwork are analyzed, knowledge is gathered, verified, directed, and refreshed routinely.
Such capabilities are notably helpful to industries dealing with massive units of information, like authorized, insurance coverage, and logistics. Doc intelligence can assist establish errors and fraud quicker, acknowledge human writing, and course of invoices quicker.
In customized enterprise workflow automation, this isn’t an add-on. It’s the workflow, with paperwork transferring from consumption to approval and storage with minimal human contact.
2. Operational Help in Experiential Advertising and marketing
Experiential advertising and marketing campaigns contain dozens of transferring components – venue coordination, vendor approvals, occasion staffing, and buyer engagement monitoring.
With out automation, marketing campaign groups drown in coordination duties. Operational AI assistants change this dynamic.
They act as digital coordinators that:
• Monitor marketing campaign progress • Assign operational duties • Monitor occasion logistics • Alert groups when actions are required
With customized enterprise workflow automation software program, these assistants join seamlessly with CRM methods, advertising and marketing platforms, and analytics instruments.
The outcome? Higher coordinated campaigns, quicker selections. And a extra constant buyer expertise.
3. Automating Lead Response
In gross sales, timing issues most. Nonetheless, most companies proceed to answer to leads a number of hours or days late, dropping the numerous improve in conversions that outcomes from responding inside minutes.
No missed alternatives. This is likely one of the fastest-return investments corporations make when adopting Customized enterprise workflow Automation software program.
4. Conversational AI for Advertising and marketing Intelligence
Advertising and marketing groups accumulate huge quantities of information. Reminiscent of:
Marketing campaign metrics.
Buyer engagement.
Channel efficiency.
The problem is deciphering that knowledge rapidly. Conversational AI modifications the expertise.
AI will get the information, appears at it, and provides you a transparent reply in a couple of seconds. That is potential as a result of customized enterprise workflow automation is already linking methods and working the fitting evaluation within the background.
No must chase studies or piece issues collectively manually. The solutions are prepared when they’re wanted.
Why Select to Construct a Customized Enterprise Workflow Automation Software program
Why not simply purchase an off-the-shelf instrument? As a result of enterprise workflows are not often generic.
They’re formed by:
Inside insurance policies
Compliance necessities
Legacy methods
Trade-specific processes
Pre-built instruments typically pressure corporations to adapt their processes to the software program. Customized automation flips the equation. The software program adapts to the enterprise. That’s the actual benefit of customized enterprise workflow automation software program.
It integrates with present methods, mirrors actual operational processes, and scales because the enterprise evolves.
Finest Practices for Profitable Workflow Automation Software program Improvement
Automation works solely when it solves actual operational issues. Efficient workflow automation software program improvement begins with understanding how work presently flows earlier than constructing something.
Listed below are a couple of rules skilled groups comply with:
1. Begin With Excessive-Affect Workflows
Many organizations make the identical mistake. They attempt to automate the whole lot without delay.
However ask a easy query first. The place does work decelerate essentially the most? Begin there.
Have a look at the workflows staff complain about each week. These are normally the stress factors the place delays pile up. Automate these first, and the payoff is rapid. Groups really feel the aid. Management sees the numbers transfer.
2. Prioritize Consumer-Pleasant Design
Automation is meant to simplify work, not complicate it.
If employees require a information to authorize a request or monitor progress, does the system actually help?
People should have the aptitude to authorize requests, monitor workflow progress, and advance duties with out looking out by means of perplexing interfaces. When instruments appear intuitive, acceptance happens rapidly.
That is the rationale quite a few organizations go for tailor-made enterprise workflow automation software program. Slightly than compelling groups to adapt to rigid instruments, the software program adjusts to the precise workflow of the group.
3. Guarantee Scalability and Safety
Enterprise methods should help progress. A workflow platform dealing with lots of of transactions as we speak might face 1000’s tomorrow. Scalability retains efficiency regular as demand grows.
Safety is simply as essential. The perfect customized enterprise workflow automation platforms combine securely with enterprise methods whereas conserving entry tightly managed. The doorways keep related, however firmly locked.
4. Steady Optimization After Deployment
Automation isn’t a singular prevalence. Course of flows want to regulate as duties evolve.
Groups can persistently improve processes. They’ll take away bottlenecks as they emerge. This fashion, the group evolves with a tailor-made, seamless workflow.
Energy Your Workflows With Intelligence Integration
A. Customized enterprise workflow automation software program is a tailor-made system that automates inner enterprise processes. It routes duties, triggers approvals, connects enterprise methods, and strikes work ahead routinely.
As a substitute of staff coordinating every step, the workflow manages the method.
Q. How lengthy does enterprise workflow automation implementation take?
A. Timelines range relying on workflow complexity and system integrations.
A centered automation initiative focusing on key processes might take only some months. Bigger enterprise packages are normally carried out in phases to ship early outcomes. All of the whereas increasing automation step by step.
Q. How a lot does it price to make software program for companies?
A. The price to construct enterprise software program is dependent upon a number of components: Workflow complexity Variety of methods that should combine Safety necessities Superior capabilities reminiscent of AI-driven automation Most corporations begin small. They automate a couple of high-impact processes first, then increase as the worth turns into clear.
Q. Can automation combine with present enterprise methods?
A. Sure. Fashionable automation platforms join with CRM methods, ERP platforms, analytics purposes, and advertising and marketing software program through safe APIs.
This allows workflows to perform easily all through the group with out eliminating present methods.
How Fingent Can Assist
Most companies don’t battle because of a deficiency of concepts. They face challenges due to the friction all through the workflow.
Fingent assists companies in creating and deploying personalised enterprise workflow automation software program. Our groups analyze present workflows and pinpoint bottlenecks. Doing so will assist us create options that combine easily together with your enterprise methods.
The result extends past mere automation. It’s operational readability. Work strikes quicker. Groups spend much less time coordinating and extra time executing. And management features the visibility wanted to scale operations with confidence.
In picture captioning, an algorithm is given a picture and tasked with producing a wise caption. It’s a difficult activity for a number of causes, not the least being that it entails a notion of saliency or relevance. Because of this current deep studying approaches principally embody some “consideration” mechanism (generally even a couple of) to assist specializing in related picture options.
On this submit, we exhibit a formulation of picture captioning as an encoder-decoder drawback, enhanced by spatial consideration over picture grid cells. The thought comes from a current paper on Neural Picture Caption Era with Visible Consideration(Xu et al. 2015), and employs the identical sort of consideration algorithm as detailed in our submit on machine translation.
We’re porting Python code from a current Google Colaboratory pocket book, utilizing Keras with TensorFlow keen execution to simplify our lives.
Conditions
The code proven right here will work with the present CRAN variations of tensorflow, keras, and tfdatasets.
Examine that you just’re utilizing at the very least model 1.9 of TensorFlow. If that isn’t the case, as of this writing, this
will get you model 1.10.
When loading libraries, please be sure to’re executing the primary 4 traces on this precise order.
We want to ensure we’re utilizing the TensorFlow implementation of Keras (tf.keras in Python land), and we’ve got to allow keen execution earlier than utilizing TensorFlow in any method.
No must copy-paste any code snippets – you’ll discover the entire code (so as mandatory for execution) right here: eager-image-captioning.R.
The dataset
MS-COCO (“Frequent Objects in Context”) is considered one of, maybe the, reference dataset in picture captioning (object detection and segmentation, too).
We’ll be utilizing the coaching photos and annotations from 2014 – be warned, relying in your location, the obtain can take a lengthy time.
After unpacking, let’s outline the place the photographs and captions are.
The annotations are in JSON format, and there are 414113 of them! Fortunately for us we didn’t should obtain that many photos – each picture comes with 5 completely different captions, for higher generalizability.
Relying in your computing surroundings, you’ll for positive wish to prohibit the variety of examples used.
This submit will use 30000 captioned photos, chosen randomly, and put aside 20% for validation.
Beneath, we take random samples, cut up into coaching and validation components. The companion code will even retailer the indices on disk, so you possibly can decide up on verification and evaluation later.
Earlier than actually diving into the technical stuff, let’s take a second to replicate on this activity.
In typical image-related deep studying walk-throughs, we’re used to seeing well-defined issues – even when in some circumstances, the answer could also be laborious. Take, for instance, the stereotypical canine vs. cat drawback. Some canine could appear to be cats and a few cats could appear to be canine, however that’s about it: All in all, within the normal world we dwell in, it needs to be a kind of binary query.
If, however, we ask individuals to explain what they see in a scene, it’s to be anticipated from the outset that we’ll get completely different solutions. Nonetheless, how a lot consensus there may be will very a lot depend upon the concrete dataset we’re utilizing.
Let’s check out some picks from the very first 20 coaching gadgets sampled randomly above.
Determine from MS-COCO 2014
Now this picture doesn’t depart a lot room for resolution what to concentrate on, and acquired a really factual caption certainly: “There’s a plate with one slice of bacon a half of orange and bread.” If the dataset had been all like this, we’d assume a machine studying algorithm ought to do fairly nicely right here.
Selecting one other one from the primary 20:
Determine from MS-COCO 2014
What can be salient data to you right here? The caption offered goes “A smiling little boy has a checkered shirt.”
Is the look of the shirt as necessary as that? You would possibly as nicely concentrate on the surroundings, – and even one thing on a very completely different degree: The age of the photograph, or it being an analog one.
Let’s take a ultimate instance.
From MS-COCO 2014
What would you say about this scene? The official label we sampled right here is “A gaggle of individuals posing in a humorous method for the digital camera.” Effectively …
Please don’t overlook that for every picture, the dataset consists of 5 completely different captions (though our n = 30000 samples in all probability gained’t).
So this isn’t saying the dataset is biased – in no way. As a substitute, we wish to level out the ambiguities and difficulties inherent within the activity. Truly, given these difficulties, it’s all of the extra wonderful that the duty we’re tackling right here – having a community mechanically generate picture captions – needs to be potential in any respect!
Now let’s see how we are able to do that.
For the encoding a part of our encoder-decoder community, we’ll make use of InceptionV3 to extract picture options. In precept, which options to extract is as much as experimentation, – right here we simply use the final layer earlier than the absolutely linked high:
For a picture dimension of 299×299, the output can be of dimension (batch_size, 8, 8, 2048), that’s, we’re making use of 2048 function maps.
InceptionV3 being a “large mannequin,” the place each cross by the mannequin takes time, we wish to precompute options prematurely and retailer them on disk.
We’ll use tfdatasets to stream photos to the mannequin. This implies all our preprocessing has to make use of tensorflow capabilities: That’s why we’re not utilizing the extra acquainted image_load from keras under.
Our customized load_image will learn in, resize and preprocess the photographs as required to be used with InceptionV3:
Now we’re prepared to save lots of the extracted options to disk. The (batch_size, 8, 8, 2048)-sized options can be flattened to (batch_size, 64, 2048). The latter form is what our encoder, quickly to be mentioned, will obtain as enter.
preencode<-distinctive(sample_images)%>%unlist()%>%kind()num_unique<-size(preencode)# adapt this based on your system's capacities batch_size_4save<-1image_dataset<-tensor_slices_dataset(preencode)%>%dataset_map(load_image)%>%dataset_batch(batch_size_4save)save_iter<-make_iterator_one_shot(image_dataset)until_out_of_range({save_count<-save_count+batch_size_4savebatch_4save<-save_iter$get_next()img<-batch_4save[[1]]path<-batch_4save[[2]]batch_features<-image_model(img)batch_features<-tf$reshape(batch_features,record(dim(batch_features)[1], -1L, dim(batch_features)[4]))for(iin1:dim(batch_features)[1]){np$save(path[i]$numpy()$decode("utf-8"),batch_features[i, , ]$numpy())}})
Earlier than we get to the encoder and decoder fashions although, we have to handle the captions.
Processing the captions
We’re utilizing keras text_tokenizer and the textual content processing capabilities texts_to_sequences and pad_sequences to rework ascii textual content right into a matrix.
# we'll use the 5000 most frequent phrases solelytop_k<-5000tokenizer<-text_tokenizer( num_words =top_k, oov_token ="", filters ='!"#$%&()*+.,-/:;=?@[]^_`~ ')tokenizer$fit_on_texts(sample_captions)train_captions_tokenized<-tokenizer%>%texts_to_sequences(train_captions)validation_captions_tokenized<-tokenizer%>%texts_to_sequences(validation_captions)# pad_sequences will use 0 to pad all captions to the identical sizetokenizer$word_index[""]<-0# create a lookup dataframe that permits us to go in each instructionsword_index_df<-information.body( phrase =tokenizer$word_index%>%names(), index =tokenizer$word_index%>%unlist(use.names =FALSE), stringsAsFactors =FALSE)word_index_df<-word_index_df%>%prepare(index)decode_caption<-perform(textual content){paste(map(textual content, perform(quantity)word_index_df%>%filter(index==quantity)%>%choose(phrase)%>%pull()), collapse =" ")}# pad all sequences to the identical size (the utmost size, in our case)# may experiment with shorter padding (truncating the very longest captions)caption_lengths<-map(all_captions[1:num_examples],perform(c)str_split(c," ")[[1]]%>%size())%>%unlist()max_length<-fivenum(caption_lengths)[5]train_captions_padded<-pad_sequences(train_captions_tokenized, maxlen =max_length, padding ="submit", truncating ="submit")validation_captions_padded<-pad_sequences(validation_captions_tokenized, maxlen =max_length, padding ="submit", truncating ="submit")
Loading the information for coaching
Now that we’ve taken care of pre-extracting the options and preprocessing the captions, we’d like a strategy to stream them to our captioning mannequin. For that, we’re utilizing tensor_slices_dataset from tfdatasets, passing within the record of paths to the photographs and the preprocessed captions. Loading the photographs is then carried out as a TensorFlow graph operation (utilizing tf$pyfunc).
The unique Colab code additionally shuffles the information on each iteration. Relying in your {hardware}, this will likely take a very long time, and given the dimensions of the dataset it’s not strictly essential to get affordable outcomes. (The outcomes reported under had been obtained with out shuffling.)
The mannequin is principally the identical as that mentioned within the machine translation submit. Please consult with that article for a proof of the ideas, in addition to an in depth walk-through of the tensor shapes concerned at each step. Right here, we offer the tensor shapes as feedback within the code snippets, for fast overview/comparability.
Nevertheless, if you happen to develop your individual fashions, with keen execution you possibly can merely insert debugging/logging statements at arbitrary locations within the code – even in mannequin definitions. So you possibly can have a perform
maybecat<-perform(context, x){if(debugshapes){identify<-enexpr(x)dims<-paste0(dim(x), collapse =" ")cat(context, ": form of ", identify, ": ", dims, "n", sep ="")}}
And if you happen to now set
you possibly can hint – not solely tensor shapes, however precise tensor values by your fashions, as proven under for the encoder. (We don’t show any debugging statements after that, however the pattern code has many extra.)
Encoder
Now it’s time to outline some some sizing-related hyperparameters and housekeeping variables:
# for encoder outputembedding_dim<-256# decoder (LSTM) capabilitygru_units<-512# for decoder outputvocab_size<-top_k# variety of function maps gotten from Inception V3features_shape<-2048# form of consideration options (flattened from 8x8)attention_features_shape<-64
The encoder on this case is only a absolutely linked layer, taking within the options extracted from Inception V3 (in flattened type, as they had been written to disk), and embedding them in 256-dimensional house.
cnn_encoder<-perform(embedding_dim, identify=NULL){keras_model_custom(identify =identify, perform(self){self$fc<-layer_dense(models =embedding_dim, activation ="relu")perform(x, masks=NULL){# enter form: (batch_size, 64, features_shape)maybecat("encoder enter", x)# form after fc: (batch_size, 64, embedding_dim)x<-self$fc(x)maybecat("encoder output", x)x}})}
Consideration module
In contrast to within the machine translation submit, right here the eye module is separated out into its personal customized mannequin.
The logic is similar although:
attention_module<-perform(gru_units, identify=NULL){keras_model_custom(identify =identify, perform(self){self$W1=layer_dense(models =gru_units)self$W2=layer_dense(models =gru_units)self$V=layer_dense(models =1)perform(inputs, masks=NULL){options<-inputs[[1]]hidden<-inputs[[2]]# options(CNN_encoder output) form == (batch_size, 64, embedding_dim)# hidden form == (batch_size, gru_units)# hidden_with_time_axis form == (batch_size, 1, gru_units)hidden_with_time_axis<-k_expand_dims(hidden, axis =2)# rating form == (batch_size, 64, 1)rating<-self$V(k_tanh(self$W1(options)+self$W2(hidden_with_time_axis)))# attention_weights form == (batch_size, 64, 1)attention_weights<-k_softmax(rating, axis =2)# context_vector form after sum == (batch_size, embedding_dim)context_vector<-k_sum(attention_weights*options, axis =2)record(context_vector, attention_weights)}})}
Decoder
The decoder at every time step calls the eye module with the options it acquired from the encoder and its final hidden state, and receives again an consideration vector. The eye vector will get concatenated with the present enter and additional processed by a GRU and two absolutely linked layers, the final of which provides us the (unnormalized) chances for the following phrase within the caption.
The present enter at every time step right here is the earlier phrase: the proper one throughout coaching (trainer forcing), the final generated one throughout inference.
rnn_decoder<-perform(embedding_dim, gru_units, vocab_size, identify=NULL){keras_model_custom(identify =identify, perform(self){self$gru_units<-gru_unitsself$embedding<-layer_embedding(input_dim =vocab_size, output_dim =embedding_dim)self$gru<-if(tf$take a look at$is_gpu_available()){layer_cudnn_gru( models =gru_units, return_sequences =TRUE, return_state =TRUE, recurrent_initializer ='glorot_uniform')}else{layer_gru( models =gru_units, return_sequences =TRUE, return_state =TRUE, recurrent_initializer ='glorot_uniform')}self$fc1<-layer_dense(models =self$gru_units)self$fc2<-layer_dense(models =vocab_size)self$consideration<-attention_module(self$gru_units)perform(inputs, masks=NULL){x<-inputs[[1]]options<-inputs[[2]]hidden<-inputs[[3]]c(context_vector, attention_weights)%<-%self$consideration(record(options, hidden))# x form after passing by embedding == (batch_size, 1, embedding_dim)x<-self$embedding(x)# x form after concatenation == (batch_size, 1, 2 * embedding_dim)x<-k_concatenate(record(k_expand_dims(context_vector, 2), x))# passing the concatenated vector to the GRUc(output, state)%<-%self$gru(x)# form == (batch_size, 1, gru_units)x<-self$fc1(output)# x form == (batch_size, gru_units)x<-k_reshape(x, c(-1, dim(x)[[3]]))# output form == (batch_size, vocab_size)x<-self$fc2(x)record(x, state, attention_weights)}})}
Loss perform, and instantiating all of it
Now that we’ve outlined our mannequin (constructed of three customized fashions), we nonetheless want to truly instantiate it (being exact: the 2 courses we’ll entry from exterior, that’s, the encoder and the decoder).
We additionally must instantiate an optimizer (Adam will do), and outline our loss perform (categorical crossentropy).
Be aware that tf$nn$sparse_softmax_cross_entropy_with_logits expects uncooked logits as a substitute of softmax activations, and that we’re utilizing the sparse variant as a result of our labels will not be one-hot-encoded.
Coaching the captioning mannequin is a time-consuming course of, and you’ll for positive wish to save the mannequin’s weights!
How does this work with keen execution?
We create a tf$prepare$Checkpoint object, passing it the objects to be saved: In our case, the encoder, the decoder, and the optimizer. Later, on the finish of every epoch, we’ll ask it to write down the respective weights to disk.
The coaching loop is structured similar to within the machine translation case: We loop over epochs, batches, and the coaching targets, feeding within the right earlier phrase at each timestep.
Once more, tf$GradientTape takes care of recording the ahead cross and calculating the gradients, and the optimizer applies the gradients to the mannequin’s weights.
As every epoch ends, we additionally save the weights.
Similar to within the translation case, it’s attention-grabbing to take a look at mannequin efficiency throughout coaching. The companion code has that performance built-in, so you possibly can watch mannequin progress for your self.
The fundamental perform right here is get_caption: It will get handed the trail to a picture, masses it, obtains its options from Inception V3, after which asks the encoder-decoder mannequin to generate a caption. If at any level the mannequin produces the finish image, we cease early. In any other case, we proceed till we hit the predefined most size.
With that performance, now let’s truly do this: peek at outcomes whereas the community is studying!
We’ve picked 3 examples every from the coaching and validation units. Right here they’re.
First, our picks from the coaching set:
Three picks from the coaching set
Let’s see the goal captions:
a herd of giraffe standing on high of a grass coated discipline
a view of playing cards driving down a avenue
the skateboarding flips his board off of the sidewalk
Apparently, right here we even have an indication of how labeled datasets (like something human) could comprise errors. (The samples weren’t picked for that; as a substitute, they had been chosen – with out an excessive amount of screening – for being relatively unequivocal of their visible content material.)
Now for the validation candidates.
Three picks from the validation set
and their official captions:
a left handed pitcher throwing the bottom ball
a lady taking a chew of a slice of pizza in a restaraunt
a lady hitting swinging a tennis racket at a tennis ball on a tennis court docket
(Once more, any spelling peculiarities haven’t been launched by us.)
Epoch 1
Now, what does our community produce after the primary epoch? Do not forget that this implies, having seen every one of many 24000 coaching photos as soon as.
First then, listed here are the captions for the prepare photos:
a bunch of sheep standing within the grass
a bunch of vehicles driving down a avenue
a person is standing on a avenue
Not solely is the syntax right in each case, the content material isn’t that dangerous both!
How concerning the validation set?
a baseball participant is enjoying baseball uniform is holding a baseball bat
a person is holding a desk with a desk with a desk with a desk with a desk with a desk with a desk with a desk with a desk with a desk with a desk with a desk with a desk with a desk
a tennis participant is holding a tennis court docket
This actually tells that the community has been in a position to generalize over – let’s not name them ideas, however mappings between visible and textual entities, say It’s true that it’ll have seen a few of these photos earlier than, as a result of photos include a number of captions. You would be extra strict organising your coaching and validation units – however right here, we don’t actually care about goal efficiency scores and so, it does not likely matter.
Let’ skip on to epoch 20, our final coaching epoch, and test for additional enhancements.
Epoch 20
That is what we get for the coaching photos:
a bunch of many tall giraffe standing subsequent to a sheep
a view of playing cards and white gloves on a avenue
a skateboarding flips his board
And this, for the validation photos.
a baseball catcher and umpire hit a baseball recreation
a person is consuming a sandwich
a feminine tennis participant is within the court docket
I feel we’d agree that this nonetheless leaves room for enchancment – however then, we solely skilled for 20 epochs and on a really small portion of the dataset.
Within the above code snippets, you’ll have seen the decoder returning an attention_matrix – however we weren’t commenting on it.
Now lastly, simply as within the translation instance, take a look what we are able to make of that.
The place does the community look?
We are able to visualize the place the community is “trying” because it generates every phrase by overlaying the unique picture and the eye matrix. This instance is taken from the 4th epoch.
Right here white-ish squares point out areas receiving stronger focus. In comparison with text-to-text translation although, the mapping is inherently much less simple – the place does one “look” when producing phrases like “and,” “the,” or “in?”
Consideration over picture areas
Conclusion
It in all probability goes with out saying that a lot better outcomes are to be anticipated when coaching on (a lot!) extra information and for rather more time.
Other than that, there are different choices, although. The idea applied right here makes use of spatial consideration over a uniform grid, that’s, the eye mechanism guides the decoder the place on the grid to look subsequent when producing a caption.
Nevertheless, this isn’t the one method, and this isn’t the way it works with people. A way more believable strategy is a mixture of top-down and bottom-up consideration. E.g., (Anderson et al. 2017) use object detection methods to bottom-up isolate attention-grabbing objects, and an LSTM stack whereby the primary LSTM computes top-down consideration guided by the output phrase generated by the second.
One other attention-grabbing strategy involving consideration is utilizing a multimodal attentive translator (Liu et al. 2017), the place the picture options are encoded and introduced in a sequence, such that we find yourself with sequence fashions each on the encoding and the decoding sides.
One other different is so as to add a discovered matter to the data enter (Zhu, Xue, and Yuan 2018), which once more is a top-down function present in human cognition.
In the event you discover considered one of these, or yet one more, strategy extra convincing, an keen execution implementation, within the fashion of the above, will probably be a sound method of implementing it.
Anderson, Peter, Xiaodong He, Chris Buehler, Damien Teney, Mark Johnson, Stephen Gould, and Lei Zhang. 2017. “Backside-up and High-down Consideration for Picture Captioning and VQA.”CoRR abs/1707.07998. http://arxiv.org/abs/1707.07998.
Liu, Chang, Fuchun Solar, Changhu Wang, Feng Wang, and Alan L. Yuille. 2017. “A Multimodal Attentive Translator for Picture Captioning.”CoRR abs/1702.05658. http://arxiv.org/abs/1702.05658.
Xu, Kelvin, Jimmy Ba, Ryan Kiros, Kyunghyun Cho, Aaron C. Courville, Ruslan Salakhutdinov, Richard S. Zemel, and Yoshua Bengio. 2015. “Present, Attend and Inform: Neural Picture Caption Era with Visible Consideration.”CoRR abs/1502.03044. http://arxiv.org/abs/1502.03044.
Zhu, Zhihao, Zhan Xue, and Zejian Yuan. 2018. “A Subject-Guided Consideration for Picture Captioning.”CoRR abs/1807.03514v1. https://arxiv.org/abs/1807.03514v1.