For greater than two centuries, scientists tried and didn’t develop dolomite within the lab beneath circumstances thought to match the way it varieties in nature. A current research has lastly modified that. Researchers from the College of Michigan and Hokkaido College in Sapporo, Japan succeeded by creating a brand new principle based mostly on detailed atomic simulations.
Their work solves a long-standing geological puzzle often known as the “Dolomite Drawback.” Dolomite is a widespread mineral present in iconic places such because the Dolomite mountains in Italy, Niagara Falls and Utah’s Hoodoos. It’s ample in rocks older than 100 million years, but it’s not often seen forming in more moderen environments.
“If we perceive how dolomite grows in nature, we would be taught new methods to advertise the crystal progress of contemporary technological supplies,” mentioned Wenhao Solar, the Dow Early Profession Professor of Supplies Science and Engineering at U-M and the corresponding writer of the paper revealed in Science.
Why Dolomite Development Is So Sluggish
The important thing breakthrough got here from understanding what disrupts dolomite because it varieties. In water, minerals sometimes develop as atoms connect in an orderly solution to the floor of a crystal. Dolomite behaves otherwise as a result of its construction is manufactured from alternating layers of calcium and magnesium.
Because the crystal grows, these two components usually connect randomly as a substitute of lining up accurately. This creates structural defects that block additional progress. The result’s a particularly gradual course of. At that charge, forming a single well-ordered layer of dolomite might take as much as 10 million years.
Nature’s Constructed-In Reset Mechanism
The researchers realized that these defects will not be everlasting. Atoms which might be misplaced are much less steady and extra more likely to dissolve when uncovered to water. In pure environments, cycles comparable to rainfall or tidal adjustments repeatedly wash away these flawed areas.
Over time, this course of clears the floor so new, correctly organized layers can type. As an alternative of taking thousands and thousands of years for a single layer, dolomite can progressively construct up in far shorter intervals. Over lengthy geological durations, this results in the big deposits seen in historical rock formations.
Simulating Crystal Development on the Atomic Degree
To check their concept, the group wanted to mannequin how atoms work together as dolomite varieties. This requires calculating the power concerned in numerous interactions between electrons and atoms, which is often extraordinarily demanding when it comes to computing energy.
Researchers at U-M’s Predictive Construction Supplies Science (PRISMS) Middle developed software program that simplifies this problem. It calculates the power for sure atomic preparations after which predicts others based mostly on the symmetry of the crystal construction.
“Our software program calculates the power for some atomic preparations, then extrapolates to foretell the energies for different preparations based mostly on the symmetry of the crystal construction,” mentioned Brian Puchala, one of many software program’s lead builders and an affiliate analysis scientist in U-M’s Division of Supplies Science and Engineering.
This method made it doable to simulate dolomite progress over timescales that replicate actual geological processes.
“Every atomic step would usually take over 5,000 CPU hours on a supercomputer. Now, we will do the identical calculation in 2 milliseconds on a desktop,” mentioned Joonsoo Kim, a doctoral scholar of supplies science and engineering and the research’s first writer.
Lab Experiment Confirms the Idea
Pure settings the place dolomite nonetheless varieties at the moment usually expertise cycles of flooding adopted by drying, which helps the group’s principle. Nonetheless, direct experimental proof was nonetheless wanted.
That proof got here from Yuki Kimura, a professor of supplies science at Hokkaido College, and Tomoya Yamazaki, a postdoctoral researcher in his lab. They used an uncommon property of transmission electron microscopes to recreate the method.
“Electron microscopes often use electron beams simply to picture samples,” Kimura mentioned. “Nonetheless, the beam may break up water, which makes acid that may trigger crystals to dissolve. Often that is unhealthy for imaging, however on this case, dissolution is precisely what we wished.”
The group positioned a small dolomite crystal in an answer containing calcium and magnesium. They then pulsed the electron beam 4,000 occasions over two hours, repeatedly dissolving the defects as they shaped.
After this course of, the crystal grew to about 100 nanometers, or roughly 250,000 occasions smaller than an inch. That progress represented round 300 layers of dolomite. Earlier experiments had by no means produced greater than 5 layers.
Implications for Fashionable Know-how
Fixing the Dolomite Drawback does greater than clarify a geological thriller. It additionally provides perception into management crystal progress in superior supplies utilized in trendy expertise.
“Previously, crystal growers who wished to make supplies with out defects would attempt to develop them actually slowly,” Solar mentioned. “Our principle reveals you can develop defect-free supplies rapidly, if you happen to periodically dissolve the defects away throughout progress.”
This idea might assist enhance the manufacturing of semiconductors, photo voltaic panels, batteries and different high-performance applied sciences.
The analysis was funded by the American Chemical Society PRF New Doctoral Investigator grant, the U.S. Division of Vitality and the Japanese Society for the Promotion of Science.
Some occupations have extra turnover than others. For instance, waiters and waitresses have a tendency to remain on the similar job for fewer years than these in supervisor roles. Within the chart beneath, see the median years spent on the similar job for various occupations.
Sorted from longest median tenure to least
That is primarily based on knowledge from the Present Inhabitants Survey from 2018 to 2024. The survey asks respondents what number of years they’ve been at their present job.
Firefighter and police supervisors have the longest tenures, whereas taxi drivers and motorized vehicle operators have the shortest tenures. This is smart. When you get a supervisor function, you extra probably need to stick with the job after working your means up. Alternatively, extra part-time jobs are inclined to have increased turnover.
The chart above exhibits median tenure together with the twenty fifth and seventy fifth percentiles, as a result of folks have been the identical job for various quantities of time. For instance, the median tenure for an online developer is 4 years and 11 months. The twenty fifth percentile (decrease tenure) is 3 years and 4 months, and the seventy fifth percentile (increased tenure) is 7 years and seven months.
A better median tends in direction of increased tenures general, however that isn’t at all times the case. Some folks with the identical occupation have been in the identical job for years or they may have simply began. There’s a vary inside every occupation.
Right here is how median tenure compares towards the unfold between twenty fifth and seventy fifth percentile (often known as interquartile vary) for every occupation.
Median tenure versus the unfold from twenty fifth to seventy fifth percentile (IQR)
Plotting on this means provides us 4 normal classes of occupations: excessive turnover, increased turnover however with some long-term employees, blended between quick and lengthy tenures, and lengthy tenures with much less unfold.
The postal service clerks have the widest unfold, which no less than appears proper, anecdotally talking. Jobs with common rotation, not too excessive or low, cluster across the center of the quadrants. Assume academics, workplace directors, and nurses.
With all of the current layoffs, I believed I’d see extra noise amongst developer-type jobs. They’re sort of within the decrease left quadrant, however perhaps we’ll see extra within the 2026 CPS launch.
Notes
The information relies on samples from the Present Inhabitants Survey from 2018 by means of 2024. Calculations are age-adjusted by occupation. A job tenure complement runs each two years, however the 2026 knowledge hasn’t been launched but. I downloaded microdata through IPUMS. I analyzed and processed the info in R and made the charts with D3.js.
an introduction and formalization of varied causal parameters associated to a remedy “dosage” acceptable for the difference-in-differences framework. This isn’t what I’ll talk about at the moment.
an introduction of an estimator that one can use to estimate a few of these causal parameters when you could have a steady remedy dosage and a difference-in-differences remedy project. That isn’t what I’ll talk about at the moment both.
a decomposition of conventional two-way mounted results (TWFE) estimator utilizing Frisch-Waugh-Lovell. That is what I’ll discuss at the moment.
There are 4 decompositions within the paper, and at the moment I’ll solely discuss certainly one of them: the degrees. Within the final substack on this, I labored by that one.
And so with all that out of the best way, I’ll transfer on to the subsequent merchandise on my agenda which is to make use of Claude Code to create a shiny app that helps all of us higher perceive simply what’s going on in that formulation. I’ve a stroll by of that right here in a 35 minute video, which resulted on this shiny app that you need to use now that will help you higher perceive the TWFE decomposition and the whereabouts of unfavourable weights that it makes use of to calculate its coefficients. That is my first shiny app, and technically Claude Code made it so it isn’t even my shiny app, however I assumed it was enjoyable. I’m internet hosting it on my web site.
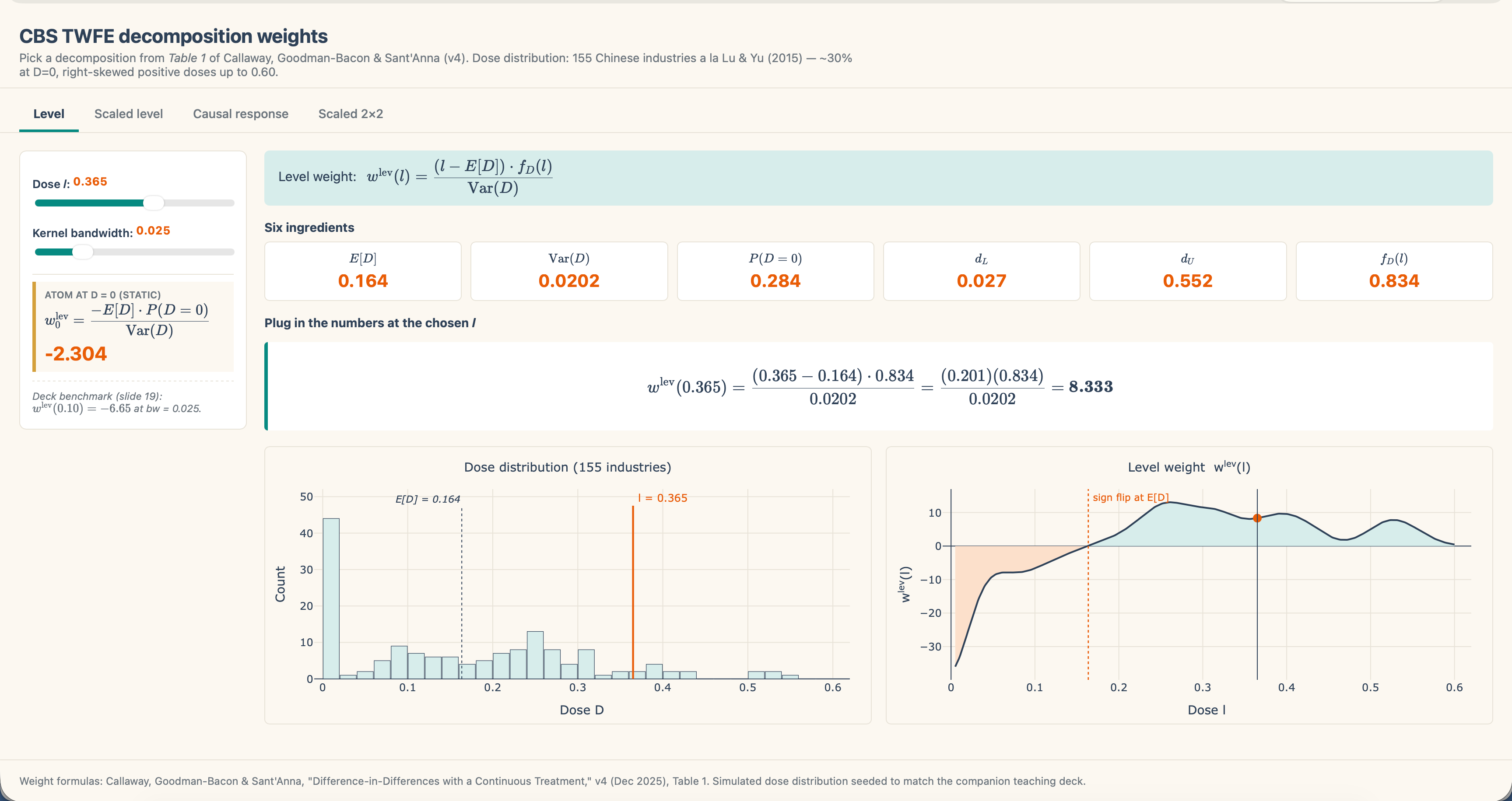
There it’s! My new CBS shiny app for the extent decomposition. Let me show you how to navigate it. First, discover there are 4 tables labeled Stage, Scaled degree, Causal response and Scaled 2×2. For those who click on on the others, they’ve a “Coming quickly” web page. The one working proper now’s the Stage one as that’s the one one to date we now have mentioned.
The photographs on the backside are from the deck:
Let me briefly stroll you thru it. There are a number of components in every of the decompositions and this slide illustrates them:
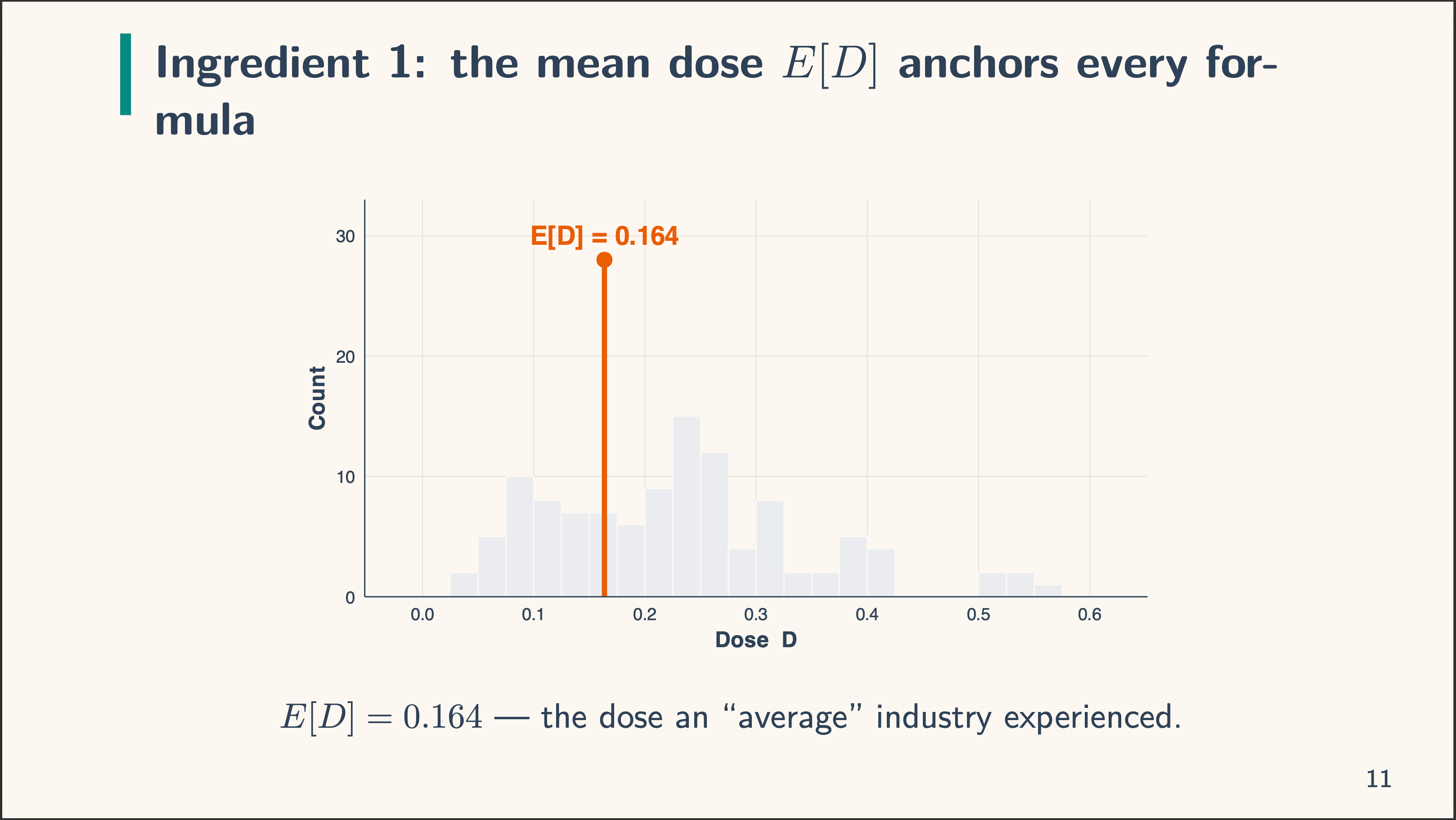
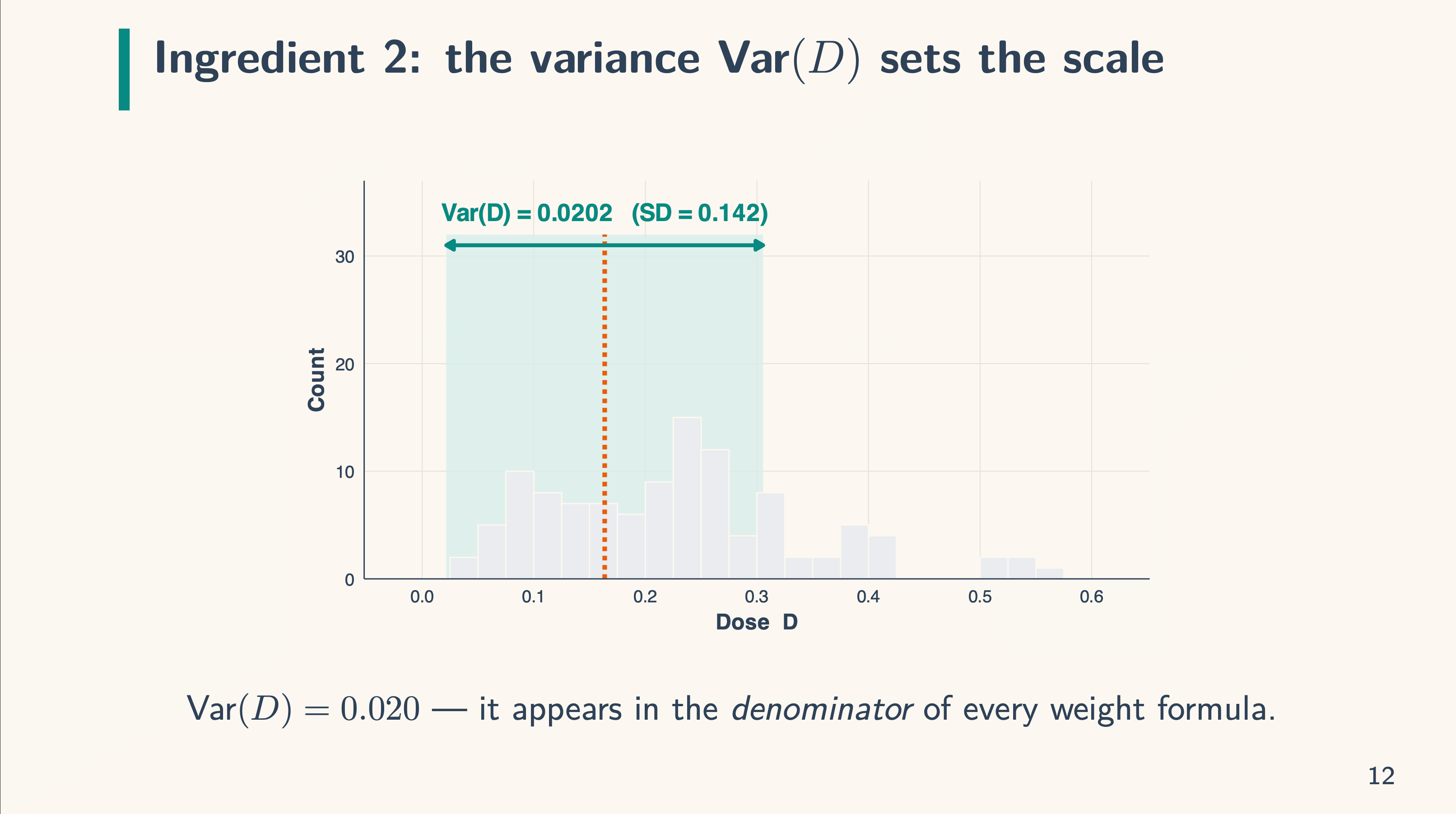
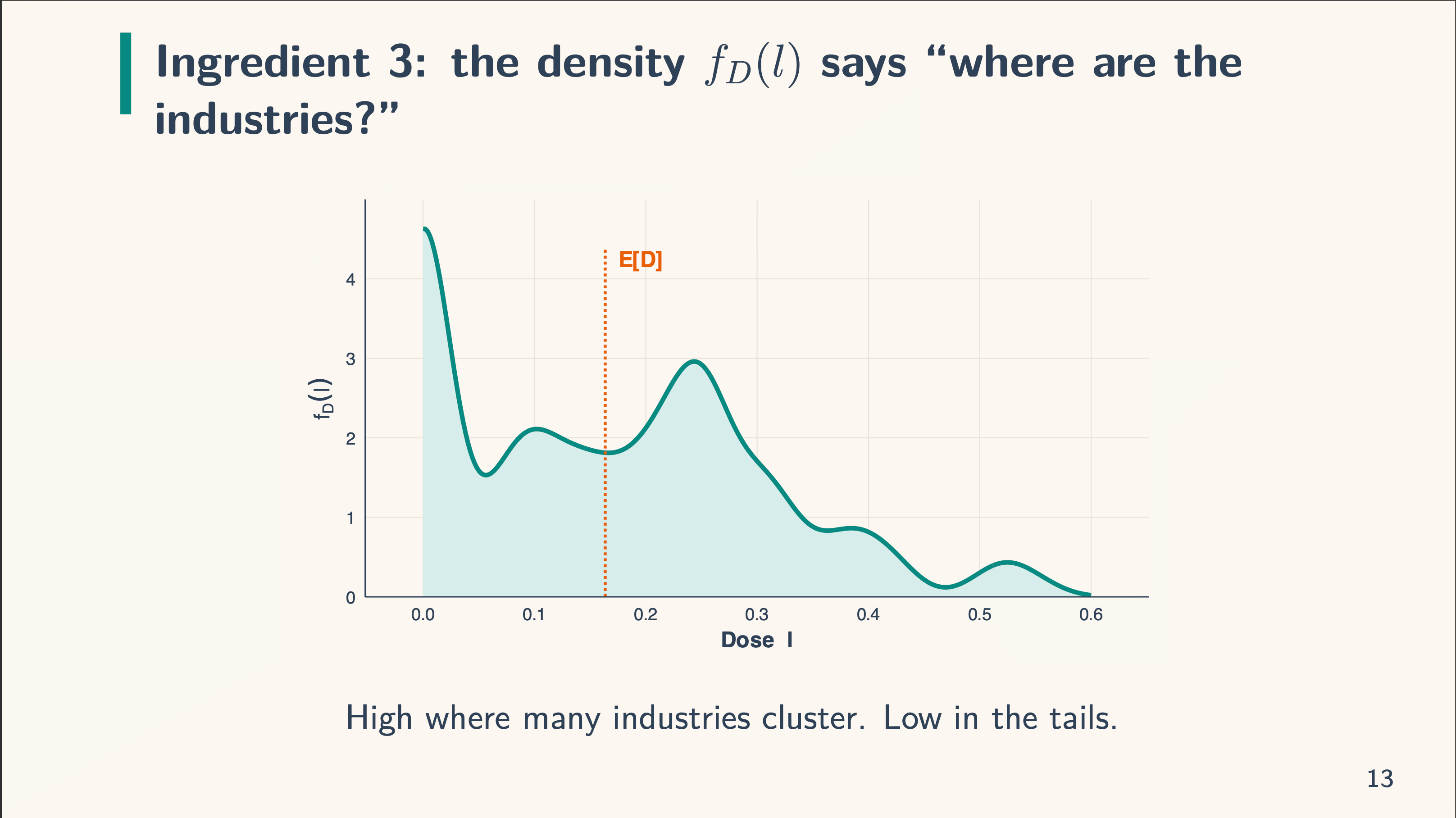
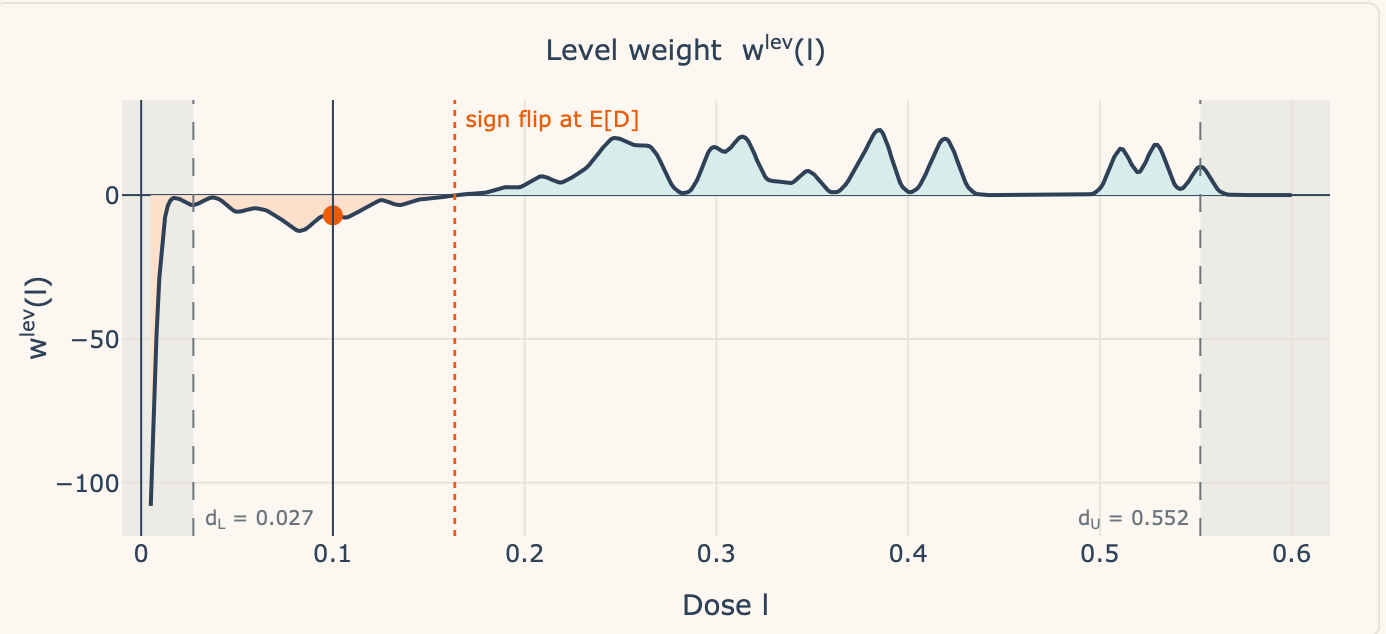
The issues on the left are the load components and the issues on the correct are the actual decomposition. So we’re doing degree weight, and subsequently we now have three components to it: the imply of the remedy dosage within the knowledge (E[D]), the variance, and the density. We combine over the doses utilizing the density formulation. Keep in mind our TWFE formulation from earlier:
There are two items inside this weight — the load related to models which have zero dose, and people who have constructive dose. Look carefully at Desk 1, row 2, labeled “Ranges” and also you’ll see it.
Again to the components. Right here’s the primary one: the imply, E[D]:
Discover that on this case the imply dose (a tariff on this case) is 0.164. We are going to dangle on to that. Then there may be the variance. The variance recall is the sq. of the usual deviation measuring the unfold of the dose across the imply we simply recognized. And it is the same as 0.0202, or 0.02 for brief. The variance scales the load and seems within the denominator.
After which there may be the density, f_D(l). That is what we will probably be integrating over. The dosage is introduced as steady, but when it was multi-valued, we’d simply take weighted averages. When the density is excessive, there are various models with that worth and when it’s low, there are few. The truth that it’s excessive at zero within the picture under implies that there are a lot of models with zero dose. After we work with the density formulation, we calculate the density at a given dose, l. So if the dose was l=0.10, we simply calculate the density related to it.
And simply to make sure all of us see it, the x-axis all the time has the dose. The y-axis has the frequency, or depend, or variety of models, within the first two components, and the density within the third.
Alright, so let’s look once more actual fast on the shiny app web page for the extent decomposition. As an illustration, let’s say I need to know the density at 0.365. That’s, for industries with the tariff worth of 0.365, what’s the density worth? I merely slide the slider button on the highest left labeled “Dose l:” to 0.365. And spot, it routinely calculates it. The worth of the density at that time is 0.834. You’ll be able to see it on the far proper of the “Six components” formulation, and it’s also possible to see that it populates the picture labeled “Plug within the numbers on the chosen l”.
And so given the imply of 0.165, the variance of 0.0202 and a density worth (which not like the imply and variance just isn’t a continuing however modifications at every dose) of 0.834, we get:
And that’s it! That’s how the extent formulation works. You’ll be able to both transfer the slider left and proper to search out every business’s density worth, or you’ll be able to transfer your cursor over the density and that’ll present you the density related to that dosage. Both manner. However the formulation stays the identical.
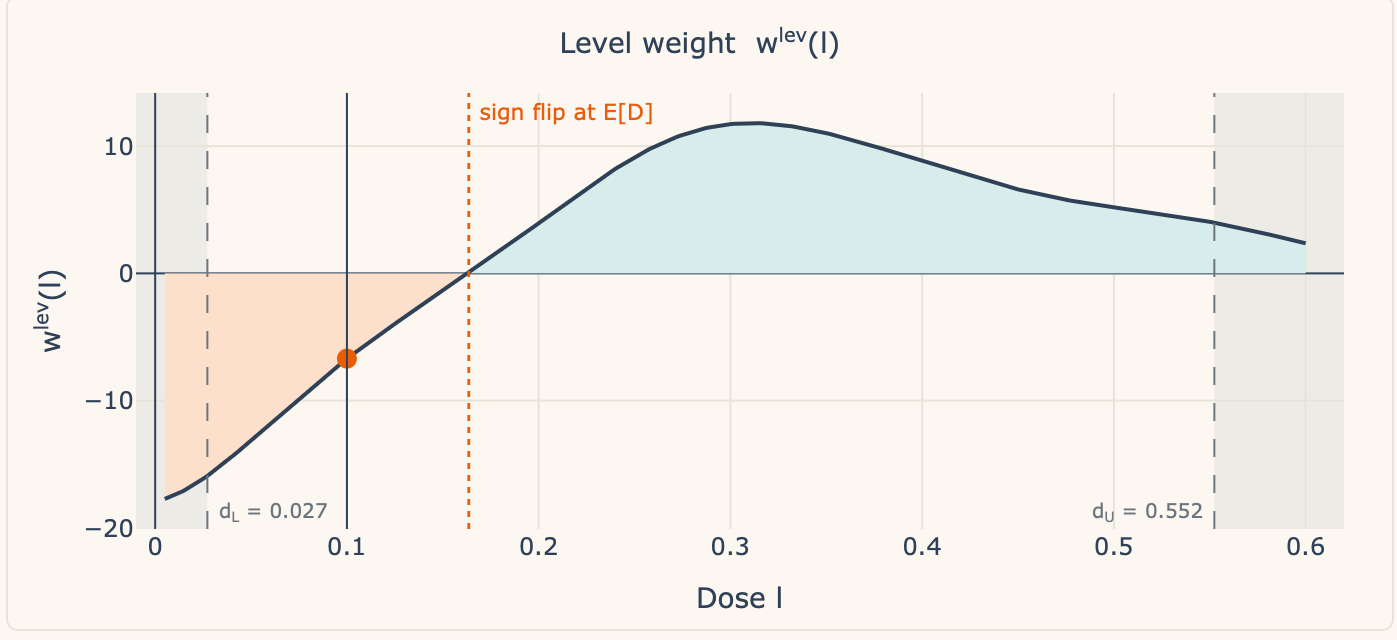
Now essentially the most fascinating factor on this decomposition is the signal flip. Discover what occurs when the dosage is precisely equal to the imply. The imply, recall, is E[D], equalling 0.164:
So, when you could have a unit or set of models whose dose is precisely the imply, then the load on them curiously is zero. Now in our case, as a result of the remedy is a steady dose for which the likelihood of any actual worth is zero, I don’t present the load at that degree as there isn’t a one with precisely the imply dose. However, you’ll be able to see what occurs if you happen to transfer the slider left and proper — when industries have an above common dose, they’re positively weighted, however once they have a under common dose, they’re negatively weighted. For example this, I filmed myself a second time.
Within the above video, I really had a discrepancy which took me a bit to grasp. Claude had minimal dosage at 0.027 and a most dosage of 0.552. However the Gaussian kernel smeared a bit likelihood mass to the left of the smallest noticed dose. So the kernel put a teeny tiny little bit of density at 0.005. The load is technically computable however substantively empty — it’s a weight on a dose group with no industries in it.
So within the new one, you’ll nonetheless see the signal flip, however now there are vertical dashed strains on the lowest to highest doses. It isn’t within the video, however if you happen to watch the video, you’ll discover that’s the place I begin to notice it. I believe it was most likely effective to have left it there, however I felt just like the smoothing that the kernel perform was doing was complicated me, and subsequently I modified it. The highest panel makes use of a kernel smoother of 0.005, however the backside one was a bit underneath the most important kernel smoothing worth doable. Simply so you’ll be able to see.
Anyway, the TWFE estimator integrates from the smallest to highest doses, and when industries have doses under the imply, we’re in that zone to the left in that sort of orange hue-ish trying vary, all of that are unfavourable weights, and when the dose is above the imply, we’re above zero in that turquoise blue and that’s constructive weights.
And there you go! That’s the shiny app, plus two video walk-throughs, the primary one which you need to use to higher see how you can use Claude Code to make a shiny app, and the second was strolling you thru deciphering the shiny app. I hope you discovered this useful! Each for utilizing Claude Code to make a shiny app, and for deciphering the TWFE decomposition while you’re regression is in its “degree” formulation (which is able to most likely be more often than not tbh).
And naturally, if you happen to discovered this handy, think about changing into a paying subscriber!
Most information platforms don’t fail with a giant bang they slowly degrade and lose affect.
seems to be promising: dashboards are constructed, pipelines run, information turns into out there and groups begin exploring. However over time one thing shifts:
definitions and possession are unclear
the identical metric exhibits totally different numbers in numerous dashboards, individuals cease trusting information and don’t use options
change and selections take longer as an alternative of sooner and really feel dangerous
groups begin constructing their very own logic in isolation, spreading logic throughout methods
Nothing is “down” or technically damaged, but the group slowly loses management over how information is used.
On this article I define a sensible blueprint for constructing a information technique that helps you take again management and switch information into an asset as an alternative of a threat.
The Core of the Drawback
It’s straightforward to level at know-how: perhaps the platform isn’t proper, perhaps we want a knowledge lake, a brand new warehouse or higher tooling.
However in lots of instances that’s not the true downside.
The issue is just not the instruments. It’s the group missing a transparent technique to determine, personal, and use information persistently.
When that occurs, acquainted patterns emerge: definitions diverge, possession turns into unclear and logic spreads throughout dashboards, pipelines and advert hoc evaluation. Knowledge is just not trusted and stops behaving like a strategic asset an begins behaving like an organizational threat.
An information technique may also help clear up precisely that.
Why you want a knowledge technique
An information technique connects the very best stage of a corporation to essentially the most concrete selections. It hyperlinks imaginative and prescient to execution. This ensures that every one selections contribute to the group’s targets.
A very good information technique creates alignment throughout the group. It advantages each enterprise and IT.
it helps ensures that information work contributes to enterprise targets
it provides course for troublesome selections (e.g. database alternative)
it creates shared possession and accountability
it builds belief by making selections extra constant and traceable.
What’s a knowledge technique?
An information technique is just not a roadmap, listing of instruments or a group of greatest practices. It’s a chain that connects intention to motion:
An information technique defines how information is used to make selections, who’s accountable, and which trade-offs the group is keen to make to make information work.
In apply, a knowledge technique does two issues:
1 Outline rules (what issues) Consider these because the guardrails. An instance might be “information is business-owned” or “definitions are shared”. These must be derived out of your (information) imaginative and prescient.
2 Outline decisions (what you do below constraints) The alternatives are just like the trade-offs you make. Can we select strict governance or flexibility? Batch or real-time pipelines? Can we manage possession centrally or decentralized?
The rules outline the course, the technique emerges within the decisions you make.
So a robust information technique connects organizational course (imaginative and prescient, mission) to day-to-day implementation. Many organizations skip this hyperlink step and bounce straight from imaginative and prescient to e.g. instruments. They miss a necessary step in between, resulting in the aforementioned issues.
Creating a method is fairly arduous as a result of it hyperlinks the summary world of imaginative and prescient and course to the sensible world of implementation. We’ll break the information technique into three parts:
Parts of a robust information technique (picture by creator)
Part 1: Course
Course defines what you optimize for.
Course defines what you optimize for (picture by creator)
Technique ought to at all times be grounded within the group itself; based mostly off of the group’s targets, imaginative and prescient and mission. In case your information technique doesn’t clearly connect with your organizational imaginative and prescient, it’s not a method. It’s a group of initiatives. We construct our information technique on prime of the information imaginative and prescient, which aligns with the group’s mission and imaginative and prescient:
Mission → Imaginative and prescient → Knowledge Imaginative and prescient → Knowledge Technique → Implementation
Let’s rapidly undergo every half.
1.1. Mission & imaginative and prescient (why you exist)
The mission describes why the group exists. It’s normally secure, long-term and infrequently adjustments. A imaginative and prescient describes what success seems to be like and the place the group is making an attempt to go.
Instance (Electrical automotive firm): Mission: “To speed up the world’s transition to sustainable power” Imaginative and prescient: “To create essentially the most compelling automotive firm of the twenty first century by driving the world’s transition to electrical autos.”
1.2. Knowledge Imaginative and prescient
Defines the function of knowledge within the group and the way information helps the group’s targets. It builds the bridge between enterprise and information.
Instance (Electrical automotive firm): “We operates with real-time, globally accessible information to allow speedy decision-making, optimize manufacturing and distribution, and speed up market growth.”
1.3. Knowledge technique (the way you make it occur)
Technique interprets course into decisions. The imaginative and prescient defines the course, the information technique defines the trade-offs.
That is the place selections are made about possession, governance, construction, and working mannequin, guided by the information imaginative and prescient.
Instance (electrical automotive firm) “As a result of we prioritize quick, data-driven decision-making, we select real-time pipelines over batch processing, accepting greater complexity and value in change for pace and availability.”
Part 2: Construction
On this half we create a set of deliberate decisions impressed by the information imaginative and prescient. Collectively, these decisions type the core of the information technique.
Within the subsequent half we’ll undergo every of the themes, outline what they’re all about, listing signs or issues that this theme ought to sole and see some clear, sensible examples.
Technique emerges on this part (picture by creator)
You don’t essentially must “implement” these theme. Use them to stress-test your information technique. Use it so see the place we made specific decisions and the place we’re counting on assumptions.
These 5 themes should not the technique itself. The technique emerges from the alternatives which are made. Briefly:
These themes don’t outline your technique; they make it easier to see whether or not you even have one.
Express vs implicit decisions
If sure themes should not addressed explicitly, they nonetheless exist however emerge implicitly:
implicit governance → selections made informally
implicit definitions → tribal data as an alternative of shared that means
implicit possession → whoever shouts the loudest
That is the place factor begin to break down. Issues like these should not technical, however quite the results of lacking construction.
🧭 2.1 Alignment
How information connects to actual selections and enterprise worth.
This theme ought to encompass decisions that make sure that information is tied to make use of instances and concrete selections, and contributes on to enterprise targets. It ensures that information is used to make selections, not simply to supply info. With out this information turns into a technical train as an alternative of a enterprise asset.
What issues present up right here?
dashboards exist, however no person makes use of them
groups don’t know why sure information exists
information work is pushed by IT as an alternative of enterprise wants
unclear possession of metrics and outcomes
Examples of decisions that cowl this theme:
“We prioritize constructing information merchandise for particular selections, not generic datasets.” This trades greater adoption and affect for much less flexibility for advert hoc evaluation
“We assign possession of knowledge (definitions, that means) to enterprise domains.” Stronger accountability and relevance at the price of much less central management and standardization
“We give attention to a restricted variety of use instances that instantly affect enterprise outcomes.” Clear ROI and focus however some use instances are delayed decrease prio
🧱 2.2 Knowledge basis
Knowledge can not scale with out shared that means and consistency.
This theme covers decisions that make sure that information can be utilized throughout the group. Take into consideration shared and documented core definitions, persistently structured information and satisfactory metadata that explains what information means and the place it comes from.
What issues present up right here?
the identical metric has a number of definitions
groups argue about numbers as an alternative of utilizing them
information is difficult to grasp with out asking somebody
combining datasets results in inconsistencies
Examples of decisions that cowl this theme
“We outline key enterprise ideas (e.g. income, buyer) centrally and reuse them.” Consistency and belief at the price of pace of change and suppleness
“We implement constant modeling patterns throughout datasets.” Simpler collaboration and reuse however much less freedom for groups
“We make information self-explanatory by means of documentation and lineage.” Simpler onboarding and utilization however upfront effort and upkeep.
⚙️ 2.3 Operations
Reliability and day-to-day functioning of knowledge methods.
This theme ensures that e.g. pipelines are secure and monitored, information high quality is actively managed and safety and entry are managed. With out this information can’t be trusted, even when every part else is nicely designed.
What issues present up right here?
pipelines break or silently fail
information high quality points go unnoticed
numbers abruptly change with out clarification
entry to information is inconsistent or insecure
Examples:
“We construct validation and testing into pipelines as an alternative of fixing points afterward.” greater belief and reliability however extra upfront improvement effort
“We actively monitor pipelines and information high quality.” sooner difficulty detection however extra operational overhead
“We outline clear entry guidelines for delicate information.” Safety and compliance however diminished ease of entry
🚀 2.4 Evolvability
How simply does your information setup adapt to alter, development and innovation?
An information technique ought to make change simpler, not tougher.
Knowledge must be modular and reusable throughout groups and domains. We should always construct on current foundations, not reinvent them. Shared that means permits groups to mix and use information with out fixed translation. With out this, change is pricey, and progress slows down.
What issues present up right here?
each new use case requires rebuilding logic
groups duplicate work throughout domains
adjustments are gradual and dangerous
scaling information use turns into painful
Examples:
“We design information fashions to be reused throughout a number of use instances.” Sooner future improvement however extra upfront design effort
“We construct loosely coupled parts that may evolve independently.” flexibility and scalability however enhance design complexity
“We put money into shared that means (e.g. semantic layers, ontologies).” interoperability throughout groups however governance and coordination effort
🏛️ 2.5 Governance
How selections about information are made and who’s accountable.
This theme is about clearly defining possession, specific decision-making processes and points which are tracked and resolved. You create construction in who owns a definition, who decides when one thing adjustments and how priorities are decided.With out governance selections turn out to be inconsistent and points stay unresolved.
What issues present up right here?
no person is aware of who owns a dataset or definition
adjustments occur with out coordination
information points stay unresolved
priorities are unclear
Examples:
“We assign clear homeowners for information domains and definitions.” Accountability however dependency on people
“We outline how adjustments to information are proposed and authorised.” Consistency and management however slower determination cycles
“We observe and prioritize information points transparently.” Higher prioritization and determination however further overhead course of
Part 3: Execution
A technique solely issues if it turns into actuality. This part is the place we transfer from intention to operation.
Stipulations for execution (picture by creator)
That is the place many methods fail: they appear good on paper however there isn’t any concrete implementation plan that helps us embed the technique in how the group really works.
A sensible technique to design execution is thru three dimensions:
Folks → who’s accountable
Course of → the way it works
Know-how → what helps it
If a strategic alternative is just not mirrored in individuals, course of, and know-how, it doesn’t exist.
Instance: business-owned information
One a part of your technique might be:
“We wish information to be owned by the enterprise.”
We make this assertion actual by defining what wants to truly occur in the true world; e.g:
Folks → assign information homeowners inside enterprise domains
Solely when all three are in place does possession really exist.
Why this issues
Execution forces readability. It exposes gaps corresponding to:
possession with out accountability
processes with out accountability
instruments with out adoption
It additionally reveals trade-offs like centralized vs decentralized possession, pace vs management and suppleness vs standardization
Along with simply implementation, the execution part can be a technique to validate your technique.
For each strategic alternative, you need to be capable of reply:
Who owns it? (Folks)
How does it work? (Course of)
What helps it? (Know-how)
If one is lacking, the technique is incomplete.
Conclusion
An information technique is a series that connects intention to motion. We’ve damaged this down in three parts:
Three parts of designing a knowledge technique (picture by creator)
Course ensures that information contributes to what really issues, with out course you construct the mistaken issues.
Construction ensures that the appropriate circumstances are in place. With out it, issues don’t scale or keep constant.
Execution ensures that these circumstances turn out to be actuality, with out this nothing really adjustments.
When all three parts are aligned, selections turn out to be sooner, change turns into safer and belief will increase.
When information behaves like an asset as an alternative of a threat you could have a knowledge technique that works.
I hope this text was as clear as I supposed it to be but when this isn’t the case please let me know what I can do to make clear additional. Within the meantime, take a look at my different articles on every kind of programming-related subjects.
Microsoft has reverted a latest service replace that was stopping some clients from launching the Microsoft Groups desktop shopper.
Affected customers are getting caught on the loading display screen and seeing the “We’re having hassle loading your message. Strive refreshing.” error message.
On Friday morning, after acknowledging the incident (tracked beneath TM1283300), Microsoft stated the launch failures had been as a consequence of a transient situation within the service infrastructure that triggered some older Microsoft Groups desktop shopper builds to “enter an unhealthy state.”
“We have confirmed that our automated restoration system has efficiently remediated influence and we’re reaching out to your representatives to validate this situation is absolutely resolved for all customers,” Microsoft stated.
Three hours later, Microsoft reverted the buggy service replace to handle the difficulty, including that the difficulty was attributable to “a regression throughout the Microsoft Groups shopper construct caching system.”
Impacted Groups customers are actually suggested to completely stop and restart their Groups purchasers to make sure that the repair propagates to their techniques.
“Now that the replace that launched the regression has been absolutely reverted, a restart will probably be wanted through which customers absolutely stop after which restart Groups in order that our resolution propagates,” Microsoft added within the newest replace to the message heart.
“We’re persevering with to await suggestions from the subset of impacted customers and monitoring our service telemetry to substantiate the difficulty is resolved after we have accomplished the aforementioned reversion.”
Whereas Microsoft did not share what number of customers or which areas are affected by this situation, it flagged the service outage as an incident, which generally applies to essential service points and noticeable consumer influence.
Final month, it resolved one other recognized situation that triggered launch failures in older builds of the Traditional Outlook e mail shopper, rendering it unusable for customers who had enabled the most recent model of the Microsoft Groups Assembly Add-in.
Over the weekend, Microsoft additionally launched a set of emergency updates to handle recognized Home windows Server points, inflicting safety replace set up issues and area controllers to enter a restart loop.
AI chained 4 zero-days into one exploit that bypassed each renderer and OS sandboxes. A wave of latest exploits is coming.
On the Autonomous Validation Summit (Could 12 & 14), see how autonomous, context-rich validation finds what’s exploitable, proves controls maintain, and closes the remediation loop.
Earlier than building employees started constructing a brand new cricket pavilion in Lewisvale Park, simply east of Edinburgh, Scotland, in 2010, archaeologists had been known as in to survey the world. Of their temporary dig, the excavators found a singular Roman-era altar that had as soon as been used to worship the solar god in a mysterious, male-only ritual.
The Altar to Sol was present in two items. Manufactured from buff sandstone, it initially stood round 4 ft (1.23 meters) tall. 4 feminine busts representing the seasons grace the highest of the monument. Within the center, a face representing the solar god Sol rises from the monument, inscribed inside an incised circle. The eyes and mouth of the humanlike face and the six rays of Sol’s crown have been pierced in order that the altar might be illuminated from behind. Traces of purple paint had been discovered on the entrance of the altar, and the 2 sides function carved laurel wreaths.
Primarily based on the inscription, the altar seems to have been devoted by a soldier named Gaius Cassius Flavianus, who might have been accountable for the Roman army base in Inveresk, Scotland. In A.D. 142, the fort at Inveresk was established alongside the Antonine Wall, the place Roman troopers had been despatched to guard the northernmost frontier of the Roman Empire.
Based on Nationwide Museums Scotland, which not too long ago acquired the Altar to Sol together with a second altar that honors the god Mithras, these monuments would have been focal factors for worshippers collaborating in secret non secular ceremonies. The legendary Mithras was born from a rock and was usually depicted slaying a bull. Sol performed an necessary function within the Mithras cult and was generally equated with Mithras.
MORE ASTONISHING ARTIFACTS
Temples to Mithras, known as Mithraea, had been at all times located underground, and solely males had been allowed to hitch the mysterious cult, which presupposed to have fun the triumph of sunshine over darkness and goodness over evil.
“At the hours of darkness of the temple, you’ll see the rays and the eyes of the solar god evident at you,” Fraser Hunter, curator of Iron Age and Roman archaeology at Nationwide Museums Scotland, defined in a video. The altars to Sol and Mithras are distinctive in Scotland and level to the beliefs of troopers stationed alongside the Antonine Wall. Mithras and Sol gave troopers “a way that there was a function to the world and that there was a life after demise,” Hunter mentioned.
The uncommon carved altars shall be on show at Nationwide Museums Scotland beginning Nov. 14.
For extra beautiful archaeological discoveries, try our Astonishing Artifacts archives.
What do I imply by “engineering functionality”? I undoubtedly don’t imply mannequin entry. Most everybody has that—or quickly will. No, I imply the sensible disciplines that flip a mannequin right into a system: knowledge modeling, retrieval, analysis, permissions, observability, and reminiscence. You recognize, the unsexy, “boring” stuff that makes enterprise tasks, notably enterprise AI tasks, succeed.
This knowledgeable how my crew constructed our workshops. We didn’t begin with “right here’s how one can construct an autonomous worker.” We began with the AI knowledge layer: heterogeneous knowledge, a number of representations, embeddings, vector indexes, hybrid retrieval, and the trade-offs amongst totally different knowledge varieties (relational, doc, and so forth.). In different phrases, we began with the stuff most AI advertising tries to skip. A lot of the AI world appears to suppose AI begins with a immediate when it really begins with issues like multimodel schema design, vector technology, indexing, and hybrid retrieval.
That issues as a result of enterprise knowledge isn’t tidy. It lives in tables, PDFs, tickets, dashboards, row-level insurance policies, and 20 years of organizational improvisation. In the event you don’t know how one can mannequin that mess for retrieval, you gained’t have enterprise AI. You’ll merely obtain a elegant autocomplete system. As I’ve identified, the arduous half isn’t getting a mannequin to sound good. It’s getting the mannequin to work contained in the bizarre, company-specific actuality the place precise choices are made.
TL;DR: By way of April 19, get a near-mint situation MacBook Professional on sale for $430.
RAM shortages are making it more durable to search out computer systems for a good value, however there’s nonetheless a strategy to get an inexpensive MacBook. This refurbished MacBook Professional is in near-mint situation, but it surely’s nonetheless drastically marked down. As an alternative of paying $1,999, you possibly can decide this MacBook Professional up for $429.97, however that ends quickly.
This 2020 MacBook Professional has a 2.0GHz quad-core Intel Core i5 processor, 16GB of RAM, and a 1TB SSD. That offers you adequate energy for workplace work, internet searching with a glut of tabs open, coding, picture modifying, and lighter video work with out consistently working into storage limits. The SSD additionally helps the laptop computer really feel sooner day-to-day, with faster startups, app launches, and file transfers.
The show is a 13.3-inch Retina display with a 2560×1600 decision, True Tone, and 500 nits of brightness. Textual content appears sharp, and the excessive decision makes the display higher for studying, modifying, and simply common use. This mannequin additionally has the Magic Keyboard, Contact Bar, and Contact ID, so that you get fingerprint login and shortcut controls above the keyboard.
This unit is listed as Grade “A” refurbished, which implies near-mint situation with minimal to no scuffing, however the value continues to be quite a bit decrease than it will be in any other case. A 30-day third-party guarantee can be included.
Till April 19 at 11:59 p.m. PT, you will get a MacBook Professional on sale for $429.97.
Grabbing this deal? Rating a Microsoft Workplace 2021 license free of charge while you apply a code at checkout via 4/19: GWP4MAC (for Mac) or GWP4WIND (for Home windows).
Apple MacBook Professional (2020) 13″ i5 2GHz Touchbar 16GB RAM 1TB SSD House Grey (Refurbished)See Deal
Reward with $100+ buy promo ends April 19, 2026. Exclusions apply. Just one promo code relevant per order. Costs topic to alter.
SpaceX will launch a brand new GPS satellite tv for pc for the U.S. House Power early Monday morning (April 20), and you may watch the motion stay.
A Falcon 9 rocket topped with the GPS III SV10 satellite tv for pc is scheduled to elevate off from Florida’s Cape Canaveral House Power Station on Monday, throughout a 15-minute window that opens at 2:57 a.m. EDT (0657 GMT).
You’ll be able to watch the launch stay through SpaceX. Protection will start about 10 minutes earlier than liftoff.
GPS III SV10 (quick for “House Automobile 10”) is the tenth and ultimate satellite tv for pc in america’ superior GPS III line.
“GPS III satellites have a three-fold enhance in positional accuracy and an eight-fold enchancment in jam resistance in comparison with prior variations,” House Power officers mentioned in a assertion on Jan. 28, simply after GPS III SV09 rode a Falcon 9 to orbit.
“These superior options allow the constellation to offer an across-the-board enhance in effectiveness and lethality to weapon programs in each theater,” they added.
Breaking house information, the most recent updates on rocket launches, skywatching occasions and extra!
As a part of this rocket swap, Vulcan Centaur will now launch the U.S.-70 nationwide safety mission, which had been slated to fly on a SpaceX Falcon Heavy. USSF-70 is anticipated to launch no sooner than summer season 2028, House Power officers have mentioned. (Presumably, Vulcan Centaur’s SRB points can be labored out by then.)
If all goes to plan on Monday morning, the Falcon 9’s first stage will come again to Earth about 8.5 minutes after launch, touching down softly within the Atlantic Ocean on the SpaceX droneship “Simply Learn the Directions.”
Will probably be the seventh launch and touchdown for this specific booster, in line with a SpaceX mission description.
The Falcon 9’s higher stage, in the meantime, will proceed powering its technique to medium-Earth orbit. It’s going to deploy GPS III SV10 there about 90 minutes after liftoff.
When most individuals first take into consideration software program designed to run on a number of cores comparable to Stata/MP, they assume to themselves, two cores, twice as quick; 4 cores, 4 instances as quick. They respect that actuality will someway intrude in order that two cores gained’t actually be twice as quick as one, however they think about the intrusion is one thing like friction and nothing that an intelligently positioned drop of oil can’t enhance.
In actual fact, one thing inherent intrudes. In any course of to perform one thing—even bodily processes—some components could possibly to be carried out in parallel, however there are invariably components that simply must be carried out one after the opposite. Anybody who cooks is aware of that you simply generally add some components, prepare dinner a bit, after which add others, and prepare dinner some extra. So it’s, too, with calculating xt = f(xt-1) for t=1 to 100 and t0=1. Relying on the type of f(), generally there’s no various to calculating x1 = f(x0), then calculating x2 = f(x1), and so forth.
In any calculation, some proportion p of the calculation might be parallelized and the rest, 1-p, can not. Contemplate a calculation that takes T hours if it have been carried out sequentially on a single core. If we had an infinite variety of cores and the very best implementation of the code in parallelized type, the execution time would fall to (1-p)T hours. The half that could possibly be parallelized, which ordinarily would run in pT hours, would run in actually no time in any respect as soon as break up throughout an infinite variety of cores, and that may nonetheless go away (1-p)T hours to go. This is named Amdahl’s Legislation.
We are able to generalize this system to computer systems with a finite variety of cores, say n of them. The parallelizable a part of the calculation, the half that may ordinarily run in pT hours, will run in pT/n. The unparallelizable half will nonetheless take (1-p)T hours, so we have now
Tn = pT/n + (1-p)T
As n goes to infinity, Tn goes to (1-pT).
Stata/MP is fairly impressively parallelized. We obtain p of 0.8 or 0.9 in lots of circumstances. We don’t declare to have hit the boundaries of what’s attainable, however generally, we consider we’re very near these limits. Most estimation instructions have p above 0.9, and linear regression is definitely above 0.99! That is defined in additional element together with share parallelization particulars for all Stata instructions within the Stata/MP Efficiency Report.
Let’s determine the worth of getting extra cores. Contemplate a calculation that may ordinarily require T = 1 hour. With p=0.8 and a couple of cores, run instances would fall to 0.6 hours; With p=0.9, 0.55 hours. That could be very near what can be achieved even with p=1, which isn’t attainable. For 4 cores, run instances would fall to 0.4 (p=0.8) and 0.325 (p=0.9). That’s good, however no the place close to the hoped for 0.25 that we might observe if p have been 1.
In actual fact, to get to 0.25, we want about 16 cores. With 16 cores, run instances fall to 0.25 (p=0.8) and 0.15625 (p=0.9). Going to 32 cores improves run instances just a bit, to 0.225 (p=0.8) and 0.128125 (p=0.9). Going to 64 cores, we might get 0.2125 (p=0.8) and 0.11384615 (p=0.9). There’s little acquire in any respect as a result of all of the cores on this planet mixed, and extra, can not scale back run instances to beneath 0.2 (p=0.8) and 0.1 (p=0.9).
Stata/MP helps as much as 64 cores. We may make a model that helps 128 cores, however it could be plenty of work though we might not have to write down even one line of code. The work can be in operating the experiments to set the tuning parameters.
It turns on the market are but different methods through which actuality intrudes. Along with some calculations comparable to xt = f(xt-1) not being parallelizable in any respect, it’s an oversimplification to say any calculation is parallelizable as a result of there are problems with granularity and of diseconomies of scale, two associated, however totally different, issues.
Let’s begin with granularity. Contemplate making the calculation xt = f(zt) for t = 1 to 100, and let’s try this by splitting on the subscript t. If we have now n=2 cores, we’ll assign the calculation for t = 1 to 50 to 1 core, and for t=51 to 100 to a different. If we have now 4 cores, we’ll break up t into 4 components. Granularity issues what occurs once we transfer from n=100 to n=101 cores. This drawback might be break up into solely 100 parallelizable components and the minimal run time is due to this fact max(T/n, T/100) and never T/n, as we beforehand assumed.
All issues undergo from granularity. Diseconomies of scale is a associated problem, and it strikes prior to granularity. Many, however not all issues undergo from diseconomies of scale. Fairly than calculating f(zt) for t = 1 to 100, let’s take into account calculating the sum of f(zt) for t = 1 to 100. We’ll make this calculation in parallel in the identical approach as we made the earlier calculation, by splitting on t. This time, nevertheless, every subprocess will report again to us the sum over the subrange. To acquire the general sum, we must add sub-sums. So if we have now n=2 cores, core 1 will calculate the sum over t = 1 to 50, core 2 will calculate the sum for t = 51 to 100, after which, the calculation having come again collectively, the grasp core must calculate the sum of two numbers. Including two numbers might be carried out in a blink of an eye fixed.
However what if we break up the issue throughout 100 cores? We’d get again 100 numbers which we might then must sum. Furthermore, what if the calculation of f(zt) is trivial? In that case, splitting the calculation amongst all 100 cores would possibly lead to run instances which are almost equal to what we might observe performing the calculation on only one core, though splitting the calculation between two cores would almost halve the execution time, and splitting amongst 4 would almost quarter it!
So what’s the utmost variety of cores over which we must always break up this drawback? It depends upon the relative execution instances of f(zt) and the the mix operator to be carried out on these outcomes (addition on this case).
It’s the diseconomies of scale drawback that bit us within the early variations of Stata/MP, at the least in beta testing. We didn’t adequately cope with the issue of splitting calculations amongst fewer cores than have been accessible. Fixing that drawback was plenty of work and, in your info, we’re nonetheless engaged on it as {hardware} turns into accessible with an increasing number of cores. The precise strategy to deal with the difficulty is to have calculation-by-calculation tuning parameters, which we do. Nevertheless it takes plenty of experimental work to find out the values of these tuning parameters, and the better the variety of cores, the extra precisely the values have to be measured. Now we have the tuning parameters decided precisely sufficient for as much as 64 cores, though there are one or two which we suspect we may enhance much more. We would want to do plenty of experimentation, nevertheless, to make sure we have now values ample for 128 cores. The irony is that we might be doing that to ensure we don’t use all of them besides when issues are massive sufficient!
In any case, I’ve seen articles predicting and in some circumstances, asserting, computer systems with a whole bunch of cores. For functions with p approaching 1, these are thrilling bulletins. On the planet of statistical software program, nevertheless, these bulletins are thrilling just for these operating with immense datasets.
















 software program (assume Stata/MP) and p.c parallelization")