Enterprises are shifting previous easy chatbots into complicated, business-critical AI techniques. Totally different groups are experimenting directly, which sounds thrilling however shortly turns chaotic. Prices rise, techniques fragment, and reliability drops when there’s no shared management layer. The OpenAI outage in August 2025 made this painfully clear: copilots froze, chatbots failed, and productiveness tanked throughout industries.
Now the query isn’t whether or not firms can use AI, it’s whether or not they can belief it to run their enterprise. Scaling AI safely means having a option to handle, govern, and monitor it throughout fashions, distributors, and inner instruments. Conventional infrastructure wasn’t constructed for this, so two new layers have emerged to fill the hole: the AI Gateway and the MCP. Collectively, they flip scattered AI experiments into one thing dependable, compliant, and prepared for actual enterprise use.
The Enterprise AI Spine: Establishing Management with the AI Gateway
An AI Gateway is greater than a easy proxy. It acts as a high-performance middleware layer—the ingress, coverage, and telemetry layer, for all generative AI site visitors. Positioned between purposes and the ecosystem of LLM suppliers (together with third-party APIs and self-hosted fashions), it capabilities as a unified management airplane to handle probably the most urgent challenges in AI adoption.
Unified Entry and Vendor Independence
Managing complexity is a major problem in a world with a number of fashions. An AI Gateway offers a single, unified API endpoint for accessing many LLMs, self-hosted open-source fashions (e.g., LLaMA, Falcon) and business suppliers (e.g., OpenAI, Claude, Gemini, Groq, Mistral). By one interface, the gateway can help completely different mannequin varieties: chat, completion, embedding, and reranking.
A sensible design alternative is compatibility with OpenAI-style APIs. This reduces the mixing burden and permits groups to reuse current shopper libraries. By translating widespread requests into provider-specific codecs, the gateway serves as a protocol adapter. The selection of an LLM turns into a runtime configuration slightly than a hard-coded choice. Groups can take a look at a brand new, cheaper, or better-performing mannequin by altering a setting within the gateway, with out modifying software code. This accelerates experimentation and optimization whereas lowering lock-in threat.
Governance and Compliance
As AI turns into a part of enterprise processes, governance and compliance are important. An AI Gateway centralizes API key administration, providing developer-scoped tokens for growth and tightly scoped, revocable tokens for manufacturing. It enforces Function-Primarily based Entry Management (RBAC) and integrates with enterprise Single Signal-On (SSO) to outline entry for particular customers, groups, or providers to sure fashions.
Insurance policies might be outlined as soon as on the gateway degree and enforced on each request, e.g., filtering Personally Identifiable Data (PII) or blocking unsafe content material. The gateway ought to seize tamper-evident data of requests and responses to help auditability for requirements like SOC 2, HIPAA, and GDPR. For organizations with knowledge residency wants, the gateway might be deployed in a digital non-public cloud (VPC), on-premise, or in air-gapped environments in order that delicate knowledge stays inside organizational management.
Value Administration and Optimization
With out correct oversight, AI-related bills can develop shortly. An AI Gateway offers instruments for proactive monetary administration, together with real-time monitoring of token utilization and spend by consumer, group, mannequin, supplier, or geography. Pricing might be sourced from supplier charge playing cards to keep away from handbook monitoring.
This visibility permits inner chargeback or showback fashions, making AI a measurable useful resource. Directors can set finances limits and quotas primarily based on prices or token counts to forestall overruns. Routing options can scale back prices by directing queries to cost-effective fashions for particular duties and by making use of strategies akin to dynamic mannequin choice, caching, and request batching the place possible.
Reliability and Efficiency: What a Excessive-Efficiency AI Gateway Seems to be Like
For AI to be important, it should be reliable and responsive. Many AI purposes—real-time chat assistants and Retrieval-Augmented Era (RAG) techniques—are delicate to latency. A well-designed AI Gateway ought to goal single-digit millisecond overhead within the scorching path.
Architectural practices that allow this embody:
- In-memory auth and charge limiting within the request path, avoiding exterior community calls.
- Asynchronous logging and metrics by way of a sturdy queue to maintain the new path minimal.
- Horizontal scaling with CPU-bound processing to take care of constant efficiency as demand will increase.
- Site visitors controls akin to latency-based routing to the quickest accessible mannequin, weighted load balancing, and computerized failover when a supplier degrades.
These design selections enable enterprises to position the gateway instantly within the manufacturing inference path with out undue efficiency trade-offs.
Reference Structure for an AI Gateway
Unleashing Brokers with the Mannequin Management Airplane (MCP)
Progress in AI hinges on what LLMs can accomplish by way of instruments. Shifting from textual content era to agentic AI. The techniques that may purpose, plan, and work together with exterior instruments require an ordinary option to join fashions to the techniques they have to use.
The Rise of Agentic AI and the Want for a Customary Protocol
Agentic AI techniques comprise collaborating components: a core reasoning mannequin, a reminiscence module, an orchestrator, and instruments. To be helpful inside a enterprise, these brokers should reliably talk with inner and exterior techniques like Slack, GitHub, Jira, Confluence, Datadog, and proprietary databases and APIs.
Traditionally, connecting an LLM to a instrument required customized code for every API, which was fragile and arduous to scale. The Mannequin Context Protocol (MCP), launched by Anthropic, standardizes how AI brokers uncover and work together with instruments. MCP acts as an abstraction layer, separating the AI’s “mind” (the LLM) from its “arms” (the instruments). An agent that “speaks MCP” can uncover and use any instrument uncovered by way of an MCP Server, dashing growth and selling a modular, maintainable structure for multi-tool agentic techniques.
The Dangers of Ungoverned MCP
Deploying MCP servers with out governance in a company atmosphere raises three considerations:
- Safety: MCP servers function with no matter permissions they’re given. Dealing with credentials and managing entry controls throughout instruments can turn out to be insecure and arduous to audit.
- Visibility: Direct connections present restricted perception into agent exercise. With out centralized logs of instrument utilization and outcomes, auditability suffers.
- Operations: Managing, updating, and monitoring many MCP servers throughout environments (growth, staging, manufacturing) is complicated.
The dangers of ungoverned MCP mirror these of unregulated LLM API entry however might be higher. An unchecked agent with instrument entry may, for instance, delete a manufacturing database, publish delicate data to a public channel, or execute monetary transactions incorrectly. A governance layer for MCP is due to this fact important for enterprise deployments.
The Trendy Gen-AI Stack
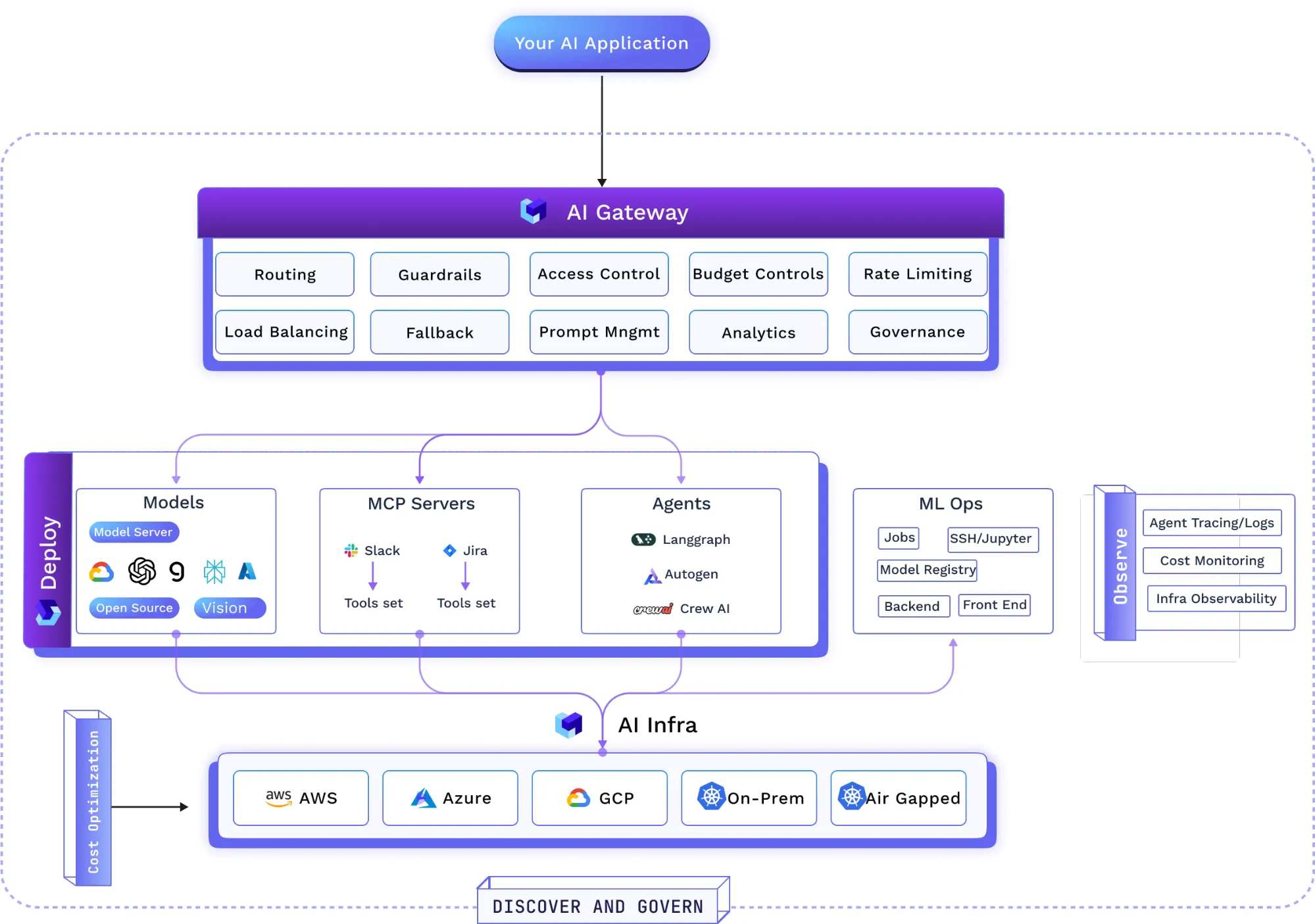
The Gateway as a Management Level for Agentic AI
An AI Gateway with MCP consciousness permits organizations to register, deploy, and handle inner MCP Servers by way of a centralized interface. The gateway can act as a safe proxy for MCP instrument calls, enabling builders to connect with registered servers by way of a single SDK and endpoint with out instantly managing tool-specific credentials.
By integrating MCP help throughout the gateway, organizations get a unified management airplane for mannequin and power calls. Agentic workflows contain a loop: the agent causes by calling an LLM, then acts by calling a instrument, then causes once more. With an built-in strategy, all the course of: the preliminary immediate, the LLM name, the mannequin’s choice to make use of a instrument, the instrument name by way of the identical gateway, the instrument’s response, and the ultimate output, might be captured in a single hint. This unified view simplifies coverage enforcement, debugging, and compliance.
Conclusion
AI Gateways and MCP collectively present a sensible path to working agentic AI safely at scale. They assist groups deal with superior fashions and instruments as managed elements of the broader software program stack—topic to constant coverage, observability, and efficiency necessities. With a centralized management layer for each fashions and instruments, organizations can undertake AI in a means that’s dependable, safe, and cost-aware.
You’ll be able to be taught extra in regards to the matter right here.
Often Requested Questions
A. An AI Gateway is a middleware layer that centralizes management of all AI site visitors. It unifies entry to a number of LLMs, enforces governance, manages prices, and ensures reliability throughout fashions and instruments utilized in enterprise AI techniques.
A. It enforces RBAC, integrates with SSO, manages API keys, and applies insurance policies for knowledge filtering and audit logging. This helps compliance with requirements like SOC 2, HIPAA, and GDPR.
A. MCP standardizes how AI brokers uncover and work together with instruments, eradicating the necessity for customized integrations. It permits modular, scalable connections between LLMs and enterprise techniques like Slack or Jira.
Login to proceed studying and luxuriate in expert-curated content material.