Last yr college students typically face the problem of selecting the best venture. Deciding on a subject that’s fascinating, sensible, and related to present expertise tendencies just isn’t straightforward. Giant Language Fashions (LLMs) are gaining big reputation in AI and are utilized in chatbots, digital assistants, content material technology, summarization, and extra. Engaged on an LLM venture concept helps college students perceive how machines course of language, enhance problem-solving abilities, and be taught real-world AI purposes. Good venture additionally strengthens a scholar’s resume and tutorial profile. On this weblog, we current 10 finest LLM venture concepts for closing yr college students which can be sensible, idea-based, and straightforward to implement with out requiring direct coding options.
Why select LLM venture concepts for the ultimate yr?
Last yr tasks usually are not simply tutorial necessities. They present your problem-solving potential, technical abilities, and understanding of recent applied sciences.
LLM tasks assist college students:
Work with real-world AI purposes.
Perceive pure language processing deeply.
Construct industry-relevant abilities
Strengthen resumes for jobs or greater research.
These tasks are nice for college students of their final yr in faculty as a result of they focus extra on sensible data than heavy principle.
Description: Create an idea for a system that reads paperwork or articles and supplies solutions to consumer queries. The thought focuses on understanding textual content and producing related responses.
Abilities Gained: Pure language understanding, analytical considering and the issue fixing.
Device: Python
Sensible Software: Helpful for analysis, on-line schooling platforms and the data administration methods
2. Sensible School Chatbot Concept
Description: Think about a chatbot that may reply frequent questions that college students have relating to courses, actions, and the varsity’s facilities. The examine focuses on how AI interacts with pure language.
Abilities Gained: Realizing learn how to use NLP, determining what somebody desires and protecting discussions going Device: Rasa
Sensible Software: Improves scholar communication and reduces handbook help workload
3. Resume Analyzer Concept
Description: Concept for a system that evaluates resumes and supplies solutions based mostly on job necessities. College students can discover how textual content comparability and ability matching work in LLMs.
Abilities Gained: Textual content processing, knowledge evaluation and logical reasoning.
Device: Python
Sensible Software: Helps college students or job seekers enhance their resumes and match abilities with job necessities
4. Textual content Summarization Device Concept
Description: Concept for a software that turns huge articles, analysis papers or paperwork into quick, clear textual content. Concentrates on discovering essential phrases and sentences.
Abilities Gained: NLP fundamentals, knowledge evaluation and the summarization strategies
Device: Hugging Face Transformers
Sensible Software: Helpful for college students and professionals to shortly perceive prolonged content material
5. Faux Information Detection Concept
Description: A plan for a venture to search out pretend information or incorrect data on web sites and social media. Largely about discovering tendencies and placing textual content into teams.
Sensible Software: Helps in media verification and social media monitoring
6. Automated Essay Suggestions Concept
Description: An method to grading and concept distribution that takes into consideration the article’s substance, language, and relevancy. By breaking issues down into their elements, college students learn to assess them.
Abilities Gained: Textual content evaluation, AI analysis strategies and demanding considering.
Device: Python
Sensible Software: Helpful in schooling for suggestions and automatic grading
7. Buyer Question Classifier Concept
Description: A man-made intelligence-based method to grouping customer support inquiries into a number of classes. focuses on comprehending categorization and patterns in language.
Abilities Gained: NLP, knowledge group and the downside fixing
Device: Python
Sensible Software: Useful for companies to automate question routing and enhance customer support
8. Language Translation Idea
Description: Concepts for a system that might use synthetic intelligence to make translating phrases between languages simpler. Take note of studying NLP concepts and translation strategies that work throughout languages.
Abilities Gained: Multilingual textual content processing, NLP and AI reasoning.
Device: Google Translate API
Sensible Software: World contact, on-line websites, and academic instruments can all use it.
9. Sentiment Evaluation Concept
Description: Idea for a system that analyzes textual content opinions or social media posts to find out constructive, destructive, or impartial sentiment. The main focus is on understanding emotion detection in language.
Abilities Gained: NLP, textual content evaluation and sample recognition
Device: Python
Sensible Software: Helpful for advertising and marketing, model monitoring and suggestions evaluation
10. Subject Modeling and Development Evaluation Concept
Description: Concept for figuring out major matters and tendencies from a group of paperwork or social media posts. Focus is on understanding large-scale textual content knowledge.
Sensible Software: Helps companies, researchers, and entrepreneurs perceive present tendencies.
The best way to Select the Proper LLM Undertaking Subject
Earlier than deciding on your venture, take into account these factors:
Out there time and sources
Your curiosity degree
Steering from school
Undertaking complexity
Select a subject you could full confidently moderately than one thing too advanced.
Tricks to Rating Excessive in LLM Last Yr Initiatives
Clearly outline the issue assertion.
Clarify why LLM is used.
Present real-world purposes
Maintain documentation easy and clear.
Put together nicely for the venture, Viva.
Good clarification issues greater than advanced options.
Conclusion
LLM venture concepts for closing yr college students assist in understanding how fashionable language fashions clear up actual world issues. These tasks enable college students to use theoretical data in a sensible method and develop downside fixing abilities. Engaged on LLM venture concepts improves logical considering, primary AI ideas and confidence throughout closing yr evaluations.
A well-chosen venture additionally strengthens a scholar’s resume and prepares them for greater research or {industry} roles in synthetic intelligence and knowledge science. By specializing in clear goals, correct planning and sincere effort, closing yr college students can full significant LLM tasks that help their tutorial progress and future profession targets.
Ceaselessly Requested Questions (FAQs)
1. What are LLM venture concepts for newbies?
Newbie pleasant tasks embody chatbots, sentiment evaluation and textual content summarization instruments.
2. Which software is finest for LLM tasks?
Python and Hugging Face Transformers are generally really helpful for scholar tasks.
3. Can I full an LLM venture with out coding expertise?
Sure, you may work on conceptual tasks and perceive the workflow earlier than implementation.
4. How do LLM tasks assist in profession progress?
They supply abilities in AI, NLP and downside fixing, that are extremely invaluable in analysis, tech and data-driven roles.
Gold is a key monetary asset and is extensively thought to be a protected haven in periods of financial uncertainty, making it a most popular selection for buyers looking for stability and portfolio diversification.
We’ll create a machine studying linear regression mannequin that takes data from the previous Gold ETF (GLD) costs and returns a Gold worth prediction the subsequent day.
GLD is the biggest ETF to speculate immediately in bodily gold. (Supply)
This mission prioritizes establishing a stable basis with extensively used machine studying strategies as an alternative of instantly turning to superior fashions. The target is to construct a sturdy and scalable pipeline for predicting gold costs, designed to be simply adaptable for incorporating extra subtle algorithms sooner or later.
Import the libraries and skim the Gold ETF knowledge
First issues first: import all the required libraries that are required to implement this technique. Importing libraries and knowledge information is an important first step in any knowledge science mission, because it ensures you might have all dependencies and exterior knowledge sources prepared for evaluation.
Then, we learn the previous 14 years of every day Gold ETF worth knowledge from a file and retailer it in Df. This knowledge set features a date column, which is crucial for time collection evaluation and plotting developments over time. We take away the columns which aren’t related and drop NaN values utilizing dropna() perform. Then, we plot the Gold ETF shut worth.
Output:
Gold ETF (Ticker: GLD) Value Sequence
Outline explanatory variables
An explanatory variable, also referred to as a function or unbiased variable, is used to clarify or predict modifications in one other variable. On this case, it helps predict the next-day worth of the Gold ETF.
These are the inputs or predictors we use in a mannequin to forecast the goal consequence.
On this technique, we begin with two easy options: the 3-day shifting common and the 9-day shifting common of the Gold ETF. These shifting common function smoothed representations of short-term and barely longer-term developments, serving to seize momentum or mean-reversion habits in costs. Earlier than utilizing these options in modeling, we get rid of any lacking values utilizing the .dropna() perform to make sure the dataset is clear and prepared for evaluation. The ultimate function matrix is saved in X.
Nevertheless, that is just the start of the function engineering course of. You’ll be able to prolong X by incorporating extra variables which may enhance the mannequin’s predictive energy. These could embrace:
Technical indicators reminiscent of RSI (Relative Power Index), MACD (Transferring Common Convergence Divergence), Bollinger Bands, or ATR (Common True Vary).
Cross-asset options, reminiscent of the value or returns of associated ETFs just like the Gold Miners ETF (GDX) or the Oil ETF (USO), which can affect gold costs by means of macroeconomic or sector-specific linkages.
Macroeconomic indicators reminiscent of inflation knowledge (CPI), rates of interest, and USD index actions can affect gold costs as a result of gold is perceived as a safe-haven asset throughout occasions of financial uncertainty.
The method of figuring out and establishing such variables known as function engineering. Individually, choosing probably the most related variables for a mannequin is named function choice.
The higher your options replicate significant patterns within the knowledge, the extra correct your forecasts are more likely to be.
Outline dependent variable
The dependent variable, also referred to as the goal variable in machine studying, is the result we goal to foretell. Its worth is assumed to be influenced by the explanatory (or unbiased) variables. Within the context of our technique, the dependent variable is the value of the Gold ETF (GLD) on the next day.
In our dataset, the Shut column accommodates the historic costs of the Gold ETF. This column serves because the goal variable as a result of we’re constructing a mannequin to study patterns from historic options (reminiscent of shifting averages) and use them to foretell future GLD costs. We assign this goal collection to the variable y, which will likely be used throughout mannequin coaching and analysis.
To create the goal variable, we apply the shift(-1) perform to the Shut column. This shifts the value knowledge one step backward, making every row’s goal the subsequent day’s closing worth. This strategy allows the mannequin to make use of as we speak’s options to forecast tomorrow’s worth.
Clearly defining the goal variable is crucial for any supervised studying drawback, because it shapes your entire modelling goal. On this case, the purpose is to forecast future actions in gold costs utilizing related monetary and financial indicators.
Alternatively, as an alternative of predicting absolutely the worth of gold, we are able to use gold returns because the goal variable. Returns characterize the proportion change in gold costs over a specified time interval, reminiscent of every day, weekly, or month-to-month intervals.
Non-stationary variables in linear regression
In time collection evaluation, it is common to work with uncooked monetary knowledge reminiscent of inventory or commodity costs. Nevertheless, these worth collection are usually non-stationary, that means their statistical properties like imply and variance change over time. This poses a major problem as a result of many analytical strategies depend on the idea that the information behaves constantly. When the information is non-stationary, its underlying construction shifts. Traits evolve, volatility varies, and historic patterns could not maintain sooner or later.
Working with non-stationary knowledge can result in a number of issues:
Spurious Relationships: Variables could look like associated just because they share related developments, not as a result of there is a real connection.
Unstable Insights: Any patterns or relationships recognized could not maintain over time, as the information’s behaviour continues to evolve.
Deceptive Forecasts: Predictive fashions constructed on non-stationary knowledge usually battle to carry out reliably sooner or later.
The core challenge is that non-stationary processes don’t comply with mounted guidelines. Their dynamic nature makes it tough to attract conclusions or make predictions that stay legitimate as circumstances change. Earlier than performing any critical evaluation, it is essential to check for stationarity and, if wanted, rework the information to stabilize its behaviour.
Two Methods to Work with Non-Stationary Knowledge
Slightly than discarding non-stationary variables, there are two dependable methods to deal with them in linear regression fashions:
1. Make Variables Stationary (Differencing Strategy)
One widespread technique is to rework the information to make it stationary. That is usually executed by specializing in modifications in values. For instance, worth collection may be transformed into returns or variations. This transformation helps stabilize the imply and reduces developments or seasonality. As soon as the information is reworked, it turns into extra appropriate for linear modeling as a result of its statistical properties stay constant over time.
2. Use Unique Non-Stationary Sequence (Cointegration Strategy)
The second technique permits us to make use of the unique non-stationary collection with out transformation, offered sure circumstances are met. Particularly, it entails checking whether or not the variables, when mixed in a selected means, share a long-term equilibrium relationship. This idea is named cointegration.
Even when the person variables are non-stationary, their linear mixture may be stationary. If that is so, the residuals from the regression (the variations between precise and predicted values) stay steady over time. This stability makes the regression legitimate and significant, because it displays a real relationship somewhat than a statistical coincidence.
In our evaluation, we are going to use this second technique by testing for residual stationarity to verify that the regression setup is suitable.
Output:
Cointegration p-value between S_3 and next_day_price: 3.1342217460742354e-16
Cointegration p-value between S_9 and next_day_price: 1.268049574487298e-15
S_3 and next_day_price are cointegrated.
S_9 and next_day_price are cointegrated.
The time collection S_3 (3-day shifting common) and next_day_price, in addition to S_9 (9-day shifting common) and next_day_price, are cointegrated. Thus, we are able to proceed with working a linear regression immediately with out reworking the collection to attain stationarity.
Why You Can Run the Regression Immediately?
Cointegration implies that there’s a steady, long-term relationship between the 2 non-stationary collection. Which means whereas the person collection could every include unit roots (i.e., be non-stationary), their linear mixture is stationary and working an Abnormal Least Squares (OLS) regression is not going to result in a spurious regression. It is because the residuals of the regression (i.e., the distinction between the expected and precise values) will likely be stationary.
Key Factors to Bear in mind
As cointegration already ensures a sound statistical relationship, making OLS acceptable for estimating the parameters, there isn’t a have to distinction the collection to make them stationary earlier than working the regression
The regression run between S_3 (or S_9) and next_day_price will seize a sound long-term equilibrium relationship, which cointegration confirms.
Cut up the information into practice and take a look at dataset
On this step, we break up the predictors and output knowledge into practice and take a look at knowledge. The coaching knowledge is used to create the linear regression mannequin, by pairing the enter with anticipated output.
Mannequin coaching is carried out on the coaching dataset, the place the mannequin learns from the options and labels.
The take a look at knowledge is used to estimate how properly the mannequin has been skilled. Evaluating completely different fashions and evaluating their coaching time and accuracy is a crucial a part of the mannequin choice course of. Mannequin analysis, together with the usage of validation units and cross-validation, ensures the mannequin generalizes properly to unseen knowledge.
First 80% of the information is used for coaching and remaining knowledge for testing
X_train & y_train are coaching dataset
X_test & y_test are take a look at dataset
Create a linear regression mannequin
We’ll now create a linear regression mannequin. However, what’s linear regression?
Linear regression is likely one of the easiest and most generally used algorithms in machine studying for supervised studying duties, the place the purpose is to foretell a steady goal variable based mostly on enter options. At its core, linear regression captures a mathematical relationship between the unbiased variables (x) and the dependent variable (y) by becoming a straight line that finest describes how modifications in x have an effect on the values of y.
When the information is plotted as a scatter plot, linear regression identifies the road that minimizes the distinction between the precise values and the expected values. This fitted line represents the regression equation and is used to make future predictions.
To interrupt it down additional, regression explains the variation in a dependent variable when it comes to unbiased variables. The dependent variable – ‘y’ is the variable that you just need to predict. The unbiased variables – ‘x’ are the explanatory variables that you just use to foretell the dependent variable. The next regression equation describes that relation:
Y = m1 * X1 + m2 * X2 + CGold ETF worth = m1 * 3 days shifting common + m2 * 9 days shifting common + c
Then we use the match technique to suit the unbiased and dependent variables (x’s and y’s) to generate coefficient and fixed for regression.
Output:
Linear Regression mannequin
Gold ETF Value (y) = 1.19 * 3 Days Transferring Common (x1) + -0.19 * 9 Days Transferring Common (x2) + 0.28 (fixed)
Predict the Gold ETF costs
Now, it’s time to examine if the mannequin works within the take a look at dataset. We predict the Gold ETF costs utilizing the linear mannequin created utilizing the practice dataset. The predict technique finds the Gold ETF worth (y) for the given explanatory variable X.
Output:
Gold ETF (GLD) Predicted Value Versus Precise Value
The graph exhibits the expected costs and precise costs of the Gold ETF. Evaluating predicted costs to precise costs helps consider the efficiency of the skilled mannequin and exhibits how carefully the predictions match real-world values. Capabilities like evaluate_model() can be utilized to generate diagnostic plots and additional consider the mannequin’s high quality.
Now, let’s compute the goodness of the match utilizing the rating() perform.
Output:
99.70
As it may be seen, the R-squared of the mannequin is 99.70%. R-squared is at all times between 0 and 100%. A rating near 100% signifies that the mannequin explains the Gold ETF costs properly.
On the floor, this appears spectacular. It exhibits a near-perfect match between the mannequin’s outputs and actual market values.
Nevertheless, translating this predictive accuracy right into a worthwhile buying and selling technique just isn’t simple. In follow, it’s essential make vital choices reminiscent of:
When to enter a commerce (sign era)
How lengthy to maintain the place
When to exit (e.g., based mostly on a predicted reversal or mounted threshold)
And the right way to handle threat (e.g., utilizing stop-loss or place sizing)
As an instance this problem, we tried to make use of predicted costs to generate a easy long-only buying and selling sign.
A place is taken provided that the subsequent day’s predicted worth is greater than as we speak’s closing worth. This creates a unidirectional sign with no shorting or hedging. The place is exited (and doubtlessly re-entered) each time the sign situation is not met.
Plotting cumulative returns
Let’s calculate the cumulative returns of this technique to analyse its efficiency.
The steps to calculate the cumulative returns are as follows:
Generate every day share change of gold worth
Shift the every day share change forward by in the future to align with our place when there’s a sign.
Create a purchase buying and selling sign represented by “1” when the subsequent day’s predicted worth is greater than the present day worth. No place is taken in any other case
Calculate the technique returns by multiplying the every day share change with the buying and selling sign.
Lastly, we are going to plot the cumulative returns graph
The output is given beneath:
Cumulative Returns of Gold ETF Value Prediction Utilizing Linear Regression
We may even calculate the Sharpe ratio.
The output is given beneath:
‘Sharpe Ratio 1.82′
Giventhe mannequin’s excessive predictive accuracy, the Sharpe Ratio of the ensuing buying and selling technique is just one.82, which isn’t excellent for a scalable and sensible buying and selling system.
This disparity highlights a vital level: good worth prediction doesn’t at all times result in extraordinarily worthwhile or risk-adjusted buying and selling efficiency. A number of components could clarify the decrease Sharpe Ratio:
The technique could endure from unidirectional bias, ignoring shorting or range-bound intervals.
It may not adapt properly to market volatility, resulting in sharp drawdowns.
The buying and selling guidelines are too simplistic, failing to seize timing nuances or noise within the predictions.
In abstract, whereas the mannequin performs properly in predicting worth ranges, changing this into a sturdy buying and selling technique requires considerate design. Sign logic, timing, place administration, and threat controls all play a major position in enhancing precise technique efficiency.
Steered Reads:
Tips on how to use this mannequin to foretell every day strikes?
You need to use the next code to foretell the gold costs and provides a buying and selling sign whether or not we should always purchase GLD or take no place.
The output is as proven beneath:
Newest Sign and Prediction
Date
2026-01-20
Value
Shut
437.230011
sign
No Place
predicted_gold_price
427.961362
Congrats! You’ve got simply applied a easy but efficient machine studyingmethod utilizing linear regression to forecast gold costs and derive buying and selling indicators. You now perceive the right way to:
Engineer options from uncooked worth knowledge (utilizing shifting averages),
Construct and match a predictive mannequin,
Use the mannequin for making forward-looking forecasts,and
Translate these forecasts into actionable indicators.
What’s Subsequent?
Linear regression is a superb place to begin resulting from its simplicity and interpretability. However in real-world monetary modeling,extra complicated patterns and nonlinear relationships usually exist that linear fashions may not absolutely seize.
To enhance accuracy,you’ll be able to discover extra highly effective machine studying regression fashions,reminiscent of:
Random Forest Regression
Gradient Boosted Bushes (like XGBoost or LightGBM)
Assist Vector Regression (SVR)
Neural Networks (MLPs for tabular knowledge)
The core construction of your pipeline stays the identical:knowledge preprocessing,function engineering,forecasting,and sign era. The one change is the mannequin itself. You merely change the .match() and .predict() strategies with these out of your chosen algorithm,probably adjusting a number of extra hyperparameters.
Hold Exploring
Wish to dive deeper into utilizing machine studying for buying and selling? Be taught step-by-step the right way to construct your first ML-based buying and selling technique with our guidedcourse. When you’re able to take it to the subsequent stage,discover our Studying Monitor. Consultants like Dr. Ernest Chan will information you thru your entire lifecycle,from concept era and backtesting to dwell deployment,utilizing superior machine studying strategies.
File within the obtain:
Gold Value Prediction Technique –Python Pocket book
Disclaimer:All investments and buying and selling within the inventory market contain threat. Any choices to put trades within the monetary markets,together with buying and selling in inventory or choices or different monetary devices is a private resolution that ought to solely be made after thorough analysis,together with a private threat and monetary evaluation and the engagement{of professional}help to the extent you consider needed. The buying and selling methods or associated data talked about on this article is for informational functions solely.
MIT researchers have recognized important examples of machine-learning mannequin failure when these fashions are utilized to knowledge aside from what they have been educated on,elevating questions on the necessity to check every time a mannequin is deployed in a brand new setting.
“We exhibit that even whenever you prepare fashions on giant quantities of information,and select the most effective common mannequin,in a brand new setting this ‘greatest mannequin’ may very well be the worst mannequin for 6-75 % of the brand new knowledge,” says Marzyeh Ghassemi,an affiliate professor in MIT’s Division of Electrical Engineering and Laptop Science (EECS),a member of the Institute for Medical Engineering and Science,and principal investigator on the Laboratory for Info and Determination Methods.
In a paperthat was offered on the Neural Info Processing Methods (NeurIPS 2025) convention in December,the researchers level out that fashions educated to successfully diagnose sickness in chest X-rays at one hospital,for instance,could also be thought of efficient in a unique hospital,on common. The researchers’ efficiency evaluation,nevertheless,revealed that a few of the best-performing fashions on the first hospital have been the worst-performing on as much as 75 % of sufferers on the second hospital,regardless that when all sufferers are aggregated within the second hospital,excessive common efficiency hides this failure.
Their findings exhibit that though spurious correlations — a easy instance of which is when a machine-learning system,not having “seen” many cows pictured on the seaside,classifies a photograph of a beach-going cow as an orca merely due to its background — are regarded as mitigated by simply bettering mannequin efficiency on noticed knowledge,they really nonetheless happen and stay a threat to a mannequin’s trustworthiness in new settings. In lots of cases — together with areas examined by the researchers resembling chest X-rays,most cancers histopathology photographs,and hate speech detection — such spurious correlations are a lot more durable to detect.
Within the case of a medical analysis mannequin educated on chest X-rays,for instance,the mannequin might have discovered to correlate a particular and irrelevant marking on one hospital’s X-rays with a sure pathology. At one other hospital the place the marking is just not used,that pathology may very well be missed.
Earlier analysis by Ghassemi’s group has proven that fashions can spuriously correlate such elements as age,gender,and race with medical findings. If,as an example,a mannequin has been educated on extra older folks’s chest X-rays which have pneumonia and hasn’t “seen” as many X-rays belonging to youthful folks,it’d predict that solely older sufferers have pneumonia.
“We wish fashions to learn to have a look at the anatomical options of the affected person after which decide primarily based on that,” says Olawale Salaudeen,an MIT postdoc and the lead creator of the paper,“however actually something that’s within the knowledge that’s correlated with a call can be utilized by the mannequin. And people correlations won’t really be sturdy with adjustments within the setting,making the mannequin predictions unreliable sources of decision-making.”
Spurious correlations contribute to the dangers of biased decision-making. Within the NeurIPS convention paper,the researchers confirmed that,for instance,chest X-ray fashions that improved total analysis efficiency really carried out worse on sufferers with pleural circumstances or enlarged cardiomediastinum,that means enlargement of the guts or central chest cavity.
Different authors of the paper included PhD college students Haoran Zhang and Kumail Alhamoud,EECS Assistant Professor Sara Beery,and Ghassemi.
Whereas earlier work has usually accepted that fashions ordered best-to-worst by efficiency will protect that order when utilized in new settings,referred to as accuracy-on-the-line,the researchers have been in a position to exhibit examples of when the best-performing fashions in a single setting have been the worst-performing in one other.
Salaudeen devised an algorithm referred to as OODSelect to search out examples the place accuracy-on-the-line was damaged. Principally,he educated 1000’s of fashions utilizing in-distribution knowledge,that means the info have been from the primary setting,and calculated their accuracy. Then he utilized the fashions to the info from the second setting. When these with the very best accuracy on the first-setting knowledge have been fallacious when utilized to a big share of examples within the second setting,this recognized the issue subsets,or sub-populations. Salaudeen additionally emphasizes the hazards of mixture statistics for analysis,which may obscure extra granular and consequential details about mannequin efficiency.
In the midst of their work,the researchers separated out the “most miscalculated examples” in order to not conflate spurious correlations inside a dataset with conditions which can be merely troublesome to categorise.
The NeurIPS paper releases the researchers’ code and a few recognized subsets for future work.
As soon as a hospital,or any group using machine studying,identifies subsets on which a mannequin is performing poorly,that data can be utilized to enhance the mannequin for its explicit activity and setting. The researchers advocate that future work undertake OODSelect as a way to spotlight targets for analysis and design approaches to bettering efficiency extra persistently.
“We hope the launched code and OODSelect subsets grow to be a steppingstone,” the researchers write,“towards benchmarks and fashions that confront the hostile results of spurious correlations.”
“Our findings counsel that the continuation of the established order,the fundamental expectation of most economists,is definitely the least probably consequence,” Davis says. “We undertaking that AI may have a good higher impact on productiveness than the private pc did. And we undertaking{that a}state of affairs the place AI transforms the economic system is much extra probably than one the place AI disappoints and monetary deficits dominate. The latter would probably result in slower financial development,greater inflation,and elevated rates of interest.”
Implications for enterprise leaders and staff
Davis doesn’t sugar-coat it,nevertheless. Though AI guarantees financial development and productiveness,will probably be disruptive,particularly for enterprise leaders and staff in data sectors. “AI is prone to be probably the most disruptive know-how to change the character of our work for the reason that private pc,” says Davis. “These of a sure age may recall how the broad availability of PCs remade many roles. It didn’t get rid of jobs as a lot because it allowed individuals to give attention to greater worth actions.”
The staff’s framework allowed them to look at AI automation dangers to over 800 completely different occupations. The analysis indicated that whereas the potential for job loss exists in upwards of 20% of occupations on account of AI-driven automation,the vast majority of jobs—probably 4 out of 5—will lead to a mix of innovation and automation. Employees’ time will more and more shift to greater worth and uniquely human duties.
This introduces the concept that AI may function a copilot to numerous roles,performing repetitive duties and customarily helping with tasks. Davis argues that conventional financial fashions typically underestimate the potential of AI as a result of they fail to look at the deeper structural results of technological change. “Most approaches for enthusiastic about future development,similar to GDP,don’t adequately account for AI,” he explains. “They fail to hyperlink short-term variations in productiveness with the three dimensions of technological change:automation,augmentation,and the emergence of recent industries.” Automation enhances employee productiveness by dealing with routine duties;augmentation permits know-how to behave as a copilot,amplifying human expertise;and the creation of recent industries creates new sources of development.
Implications for the economic system
Paradoxically,Davis’s analysis suggests{that a}cause for the comparatively low productiveness development lately could also be a scarcity of automation. Regardless of a decade of speedy innovation in digital and automation applied sciences,productiveness development has lagged for the reason that 2008 monetary disaster,hitting 50-year lows. This seems to assist the view that AI’s affect shall be marginal. However Davis believes that automation has been adopted within the improper locations. “What shocked me most was how little automation there was in providers like finance,well being care,and training,” he says. “Exterior of producing,automation has been very restricted. That’s been holding again development for at the least 20 years.” The providers sector accounts for greater than 60% of US GDP and 80% of the workforce and has skilled among the lowest productiveness development. It’s right here,Davis argues,that AI will make the largest distinction.
One of many largest challenges dealing with the economic system is demographics,because the Child Boomer technology retires,immigration slows,and beginning charges decline. These demographic headwinds reinforce the necessity for technological acceleration. “There are issues about AI being dystopian and inflicting huge job loss,however we’ll quickly have too few staff,not too many,” Davis says. “Economies just like the US,Japan,China,and people throughout Europe might want to step up perform in automation as their populations age.”
For instance,think about nursing,a occupation through which empathy and human presence are irreplaceable. AI has already proven the potential to reinforce slightly than automate on this area,streamlining knowledge entry in digital well being data and serving to nurses reclaim time for affected person care. Davis estimates that these instruments may improve nursing productiveness by as a lot as 20% by 2035,an important acquire as health-care methods adapt to ageing populations and rising demand. “In our most definitely state of affairs,AI will offset demographic pressures. Inside 5 to seven years,AI’s capability to automate parts of labor shall be roughly equal to including 16 million to 17 million staff to the US labor drive,” Davis says. “That’s primarily the identical as if everybody turning 65 over the subsequent 5 years determined to not retire.” He tasks that greater than 60% of occupations,together with nurses,household physicians,highschool academics,pharmacists,human useful resource managers,and insurance coverage gross sales brokers,will profit from AI as an augmentation instrument.
Implications for all buyers
As AI know-how spreads,the strongest performers within the inventory market gained’t be its producers,however its customers. “That is smart,as a result of general-purpose applied sciences improve productiveness,effectivity,and profitability throughout complete sectors,” says Davis. This adoption of AI is creating flexibility for funding choices,which suggests diversifying past know-how shares is perhaps applicable as mirrored in Vanguard’s Financial and Market Outlook for 2026. “As that occurs,the advantages transfer past locations like Silicon Valley or Boston and into industries that apply the know-how in transformative methods.” And historical past exhibits that early adopters of recent applied sciences reap the best productiveness rewards. “We’re clearly within the experimentation part of studying by doing,” says Davis. “These firms that encourage and reward experimentation will seize probably the most worth from AI.”
Individuals worldwide are being focused by a large spam wave originating from unsecured Zendesk assist techniques,with victims reporting receiving a whole bunch of emails with unusual and generally alarming topic traces.
The wave of spam messages began on January 18th,with individuals reportingon social mediathat they acquired a whole bunch of emails.
Whereas the messages don’t seem to include malicious hyperlinks or apparent phishing makes an attempt,the sheer quantity and chaotic nature of the emails have made them extremely complicated and probably alarming for recipients.
The emails are being generated by assist platforms run by corporations that use Zendesk for customer support.
Attackers are abusing Zendesk’s capability to permit unverified customers to submit assist tickets,which then mechanically generate affirmation emails despatched to the e-mail tackle the attacker entered.
As a result of Zendesk sends automated replies confirming{that a}ticket was acquired,the attackers are in a position to flip these techniques right into a mass-spamming platform by interating by giant lists of e-mail addresses when creating pretend assist tickets.
Firms whose Zendesk situations have been seen impacted embody: Discord,Tinder, Riot Video games,Dropbox,CD Projekt (2k.com),Maya Cellular,NordVPN,Tennessee Division of Labor,Tennessee Division of Income,Lightspeed,CTL,Kahoot,Headspace,and Lime.
Wave of spam coming from unsecured ZenDesk situations Supply:BleepingComputer
The emails have weird topics,with some pretending to be law-enforcement requests or company takedowns,whereas others provide free Discord Nitro or say “Assist Me!”Many are additionally written in Unicode fonts to daring or embellish the fonts in a number of languages.
Examples embody:
FREE DISCORD NITRO!!
TAKE DOWN ORDER NOW FROM CD Projekt
LEGAL NOTICE FROM ISRAEL FOR koei Tecmo
TAKE DOWN NOW ORDER FROM Israel FOR Sq. Enix
DONATION FOR State Of Tennessee CONFIRMED
LEGAL NOTICE FROM State Of Louisiana FOR Digital
鶊坝鱎煅貃姄捪娂隌籝鎅熆媶鶯暘咭珩愷譌argentine恖
Re:TAKE DOWN NOW ORDER FROM CHINA FOR Konami Digital Entertainme
IMPORTANT LAW ENFORCEMENT NOTIFICATION FROM DISCORD FROM Peru
Thanks to your buy!
Assist Me!
Empty titles
As a result of the emails come from respectable corporations’ Zendesk assist techniques,they’re bypassing spam filters,making them extra intrusive and alarming than bizarre spam mail. Nevertheless,because the emails do not include phishing hyperlinks,they seem like designed to troll recipients slightly than to interact in malicious conduct.
A number of corporations have confirmed they have been affected by the spam wave,together with DropBox and 2K,who responded to tickets to inform recipients not be involved and to disregard the emails.
“You could have just lately acquired an automatic response or notification relating to a assist ticket that you simply didn’t submit. We need to make clear why this may need occurred and guarantee you there isn’t a trigger for concern,”wrote 2K.
“To take away limitations and improve your expertise,our system permits anybody to submit a assist ticket,present suggestions,and report bugs with out having to enroll in a devoted assist account and confirm their e-mail tackle. This open coverage implies that anybody can probably submit a ticket utilizing any e-mail tackle.”
“Please relaxation assured that we don’t act on any account or course of delicate requests with out authenticated,direct instruction from the account holder.”
Zendesk advised BleepingComputer which have launched new security options on their finish to detect and cease the sort of spam sooner or later.
“We have launched new security options to handle relay spam,together with enhanced monitoring and limits designed to detect uncommon exercise and cease it extra shortly,”
“We need to guarantee everybody that we’re actively taking steps –and constantly enhancing –to guard our platform and customers.”
Zendesk beforehand warned prospects about this kind of abuse in a December advisory,explaining that attackers have been utilizing Zendesk to ship mass spam emails by what it referred to as “relay spam.”
Whether or not you are cleansing up previous keys or setting guardrails for AI-generated code,this information helps your group construct securely from the beginning.
Get the cheat sheet and take the guesswork out of secrets and techniques administration.
The web admonition to “contact grass”to appease your emotional state could also be backed by science — a minimum of in lab mice.
A latest research finds that mice that dwell exterior are much less anxious than people who spend their days in protected,shoebox-sized cages. And that will spotlight a elementary flaw in laboratory analysis,together with that used to check the protection and effectiveness of medication ultimately meant for individuals.
Drugs that appear to work in lab mice do not essentially work in human sufferers,and a few scientists suppose that they may fail,partly,due to how weird and remoted laboratory life is for the rodents.
“Why is there that massive hole in outcomes between the animal fashions within the labs and the real-life experiences after we check [many] medication in people?”stated first research writer Matthew Zipple,a postdoctoral researcher at Cornell College “We predict a lot of this impact could also be defined by this actually synthetic,standardized atmosphere by which lab animals are saved.”
The findings had been revealed in December within the journal Present Biology.
Much less anxious within the open air
Each wild mice and people have wealthy social environments,and wild mice are always on the go,foraging,burrowing and going through dangers,together with the various predators that prefer to snack on them.
As compared,lab mice sit in small cages with two or three same-sex siblings. There,meals and water are delivered on an everyday schedule. Finding out medicines in these mice could also be akin to limiting analysis to prisoners in solitary confinement,Zipple informed Dwell Science.
Get the world’s most fascinating discoveries delivered straight to your inbox.
Zipple and his colleagues got down to examine the psychology of two teams of lab mice:a gaggle that remained in a laboratory and a gaggle that lived with different mice in an out of doors enclosure,full with grass,grime and publicity to the sky. They did so utilizing a normal maze,referred to as the “elevated plus maze,”which has two enclosed arms and two open,catwalk-style arms.
On their first publicity to this maze beneath vivid lab lights,lab mice usually discover the open arms,discover them terrifying,and principally by no means enterprise out on them once more. As an alternative,they continue to be within the comparatively protected,enclosed portion of the maze. This response is so constant that researchers use the open arms to induce and measure anxiousness in lab mice.
The mice that had been allowed to roam exterior spent extra time exploring the “open”arms of the maze. (Picture credit score:Matthew Zipple)
However mice residing in a wild-type atmosphere weren’t freaked out by the open arms in any respect,Zipple and his staff discovered. They spent simply as a lot time exploring these areas on subsequent visits to the maze as they’d the primary time,all whereas beneath vivid gentle.
In the meantime,cage-dwelling mice that had been despatched to dwell exterior additionally noticed their maze anxiousness evaporate;animals that already had demonstrated an obvious worry of the open arms after which spent per week exterior subsequently spent twice as a lot time exploring the open arms in contrast with animals that saved residing in cages.
The usage of the standardized maze was a “very highly effective approach to present the bounds of enterprise as ordinary,”stated Andrea Graham,an evolutionary ecologist at Princeton College who was not concerned within the analysis.
In a single well-known 2006 case,a medicine referred to as TGN1412 appeared to spice up the immune system in opposition to leukemia in lab mice however prompted a near-fatal immune response within the first six wholesome human volunteers uncovered to the drug. Subsequent analysisrevealed that,within the lab mice,the medicine activated immune cells that regulate and calm the immune response. Nevertheless,in mice residing in wild-type enclosures,the medicine as an alternative activated cells that ramp up the immune response to the purpose that the physique attacked itself.
Mice in wild-type environments not solely behave in a different way,but additionally have totally different immunological profiles than mice who dwell inside in cages. (Picture credit score:Matthew Zipple)
“If we prohibit ourselves to solely learning a few totally different genotypes [genetic profiles] of lab mouse in the identical immunologically boring,psychologically boring environments,we’re not going to actually have the ability to research the total spectrum of human immune or nervous system response to the atmosphere,”Graham informed Dwell Science.
Utilizing wild-style enclosures requires some upfront value and energy,and it additionally reduces the inflexible management that is positioned on research animals as a way to restrict confounding variables in experiments. As such,they pull biomedical scientists out of their consolation zone,Zipple stated.
However including in checks of those less-confined mice might save plenty of effort and cash on the human trials facet by pinpointing the medicines which are probably to translate from the lab to the clinic,the research authors argue. Zipple and his colleagues at the moment are ways in which caged and wild-living mice age in a different way.
“The broader objective is to make an inventory of biomedically related behaviors,phenotypes [observable traits] and psychological traits that look the identical within the lab and the sphere,”he stated,to assist with the problem of translating outcomes to people. In addition they need to compile a “listing of traits that look fairly totally different,”he stated.
(newcommand{Eb}{{bf E}})The change in a regression operate that outcomes from an everything-else-held-equal change in a covariate defines an impact of a covariate. I’m desirous about estimating and decoding results which might be conditional on the covariates and averages of results that change over the people. I illustrate that these two kinds of results reply completely different questions. Docs,mother and father,and consultants incessantly ask people for his or her covariate values to make individual-specific suggestions. Coverage analysts use a population-averaged impact that accounts for the variation of the consequences over the people.
Conditional on covariate results after regress
I’ve simulated knowledge on a college-success index (csuccess) on 1,000 college students that entered an imaginary college in the identical yr. Earlier than beginning his or her first yr,every pupil took a brief course that taught examine strategies and new materials;iexaminformation every pupil grade on the ultimate for this course. I’m within the impact of the iexamrating on the imply of csuccessonce I additionally situation on high-school grade-point common hgpaand SAT rating sat. I embody an interplay time period,it=iexam/(hgpa^2),within the regression to permit for the likelihood that iexamhas a smaller impact for college students with the next hgpa.
The regression under estimates the parameters of the conditional imply operate that offers the imply of csuccessas a linear operate of hgpa,sat,and iexam.
Instance 1:imply of csuccess given hgpa,sat,and iexam
Observe that the estimated impact of a 100-point improve in satis a continuing. The impact can also be giant,as a result of the success index has a imply of 20.76 and a variance of 4.52;see instance 2.
Instance 2:Marginal distribution of college-success index
The impact varies with a pupil’s high-school grade-point common,so the conditional-on-covariate interpretation differs from the population-averaged interpretation. For instance,suppose that I’m a counselor who believes that solely will increase of 0.7 or extra in csuccessmatter,and a pupil with an hgpaof 4.0 asks me if a 10-point improve on the iexamwill considerably have an effect on his or her school success.
After utilizing marginsin instance 3 to estimate the impact of a 10-point improve in iexamfor somebody with an hgpa=40,I inform the coed “most likely not”. (The estimated impact is 0.52,and the estimated higher sure of the 95% confidence interval is 0.64.)
Instance 3:The impact of a 10-point improve in iexam when hgpa=4
I couldn’t rule out the likelihood{that a}10-point improve in iexamwould trigger a rise of 0.7 within the common csuccessfor a pupil with an hgpaof three.5.
Think about the case by which (Eb[y|x,{bf z}]) is my regression mannequin for the end result (y) as a operate of (x),whose impact I need to estimate,and ({bf z}),that are different variables on which I situation. The regression operate (Eb[y|x,{bf z}]) tells me the imply of (y) for given values of (x) and ({bf z}).
The distinction between the imply of (y) given (x_1) and ({bf z}) and the imply of (y) given (x_0) and ({bf z}) is an impact of (x),and it’s given by (Eb[y|x=x_1,{bf z}] – Eb[y|x=x_0,{bf z}]). This impact can fluctuate with ({bf z});it is likely to be scientifically and statistically vital for some values of ({bf z}) and never for others.
Beneath the same old assumption of right specification,I can estimate the parameters of (Eb[y|x,{bf z}]) utilizing regressor one other command. I can then use marginsand marginsplotto estimate results of (x). (I additionally incessantly use lincom,nlcom,and predictnlto estimate results of (x) for given ({bf z}) values.)
Inhabitants-averaged results after regress
Returning to the instance,as a substitute of being a counselor,suppose that I’m a college administrator who believes that assigning sufficient tutors to the course will elevate every pupil’s iexamrating by 10 factors. I start through the use of marginsto estimate the typical college-success rating that’s noticed when every pupil will get his or her present iexamrating and to estimate the typical college-success rating that will be noticed when every pupil will get an additional 10 factors on his or her iexamrating.
Instance 5:The common of csuccess with present iexam scores and when every pupil will get an additional 10 factors
Simply to be sure that I perceive what marginsis doing,I compute the typical of the anticipated values when every pupil will get his or her present iexamrating and when every pupil will get an additional 10 factors on his or her iexamrating.
Instance 6:The common of csuccess with present iexam scores and when every pupil will get an additional 10 factors (hand calculations)
As anticipated,the typical of the predictions for yhat0match these reported by marginsfor _at.1,and the typical of the predictions for yhat1match these reported by marginsfor _at.2.
Now that I perceive what marginsis doing,I take advantage of the distinctionchoice to estimate the distinction between the typical of csuccesswhen every pupil will get an additional 10 factors and the typical of csuccesswhen every pupil will get his or her authentic rating.
Instance 7:The distinction within the averages of csuccess when every pupil will get an additional 10 factors and with present scores
The usual error in instance 7 is labeled as “Delta-method”,which implies that it takes the covariate observations as fastened and accounts for the parameter estimation error. Holding the covariate observations as fastened will get me inference for this specific batch of scholars. I add the choice vce(unconditional)in instance 8,as a result of I would like inference for the inhabitants from which I can repeatedly draw samples of scholars.
Instance 8:The distinction within the averages of csuccess with an unconditional commonplace error
On this case,the usual error for the pattern impact reported in instance 7 is about the identical as the usual error for the inhabitants impact reported in instance 8. With actual knowledge,the distinction in these commonplace errors tends to be larger.
Recall the case by which (Eb[y|x,{bf z}]) is my regression mannequin for the end result (y) as a operate of (x),whose impact I need to estimate,and ({bf z}),that are different variables on which I situation. The distinction between the imply of (y) given (x_1) and the imply of (y) given (x_0) is an impact of (x) that has been averaged over the distribution of ({bf z}),
Beneath the same old assumptions of right specification,I can estimate the parameters of (Eb[y|x,{bf z}]) utilizing regressor one other command. I can then use marginsand marginsplotto estimate a imply of those results of (x). The pattern should be consultant,maybe after weighting,to ensure that the estimated imply of the consequences to converge to a inhabitants imply.
Accomplished and undone
The change in a regression operate that outcomes from an everything-else-held-equal change in a covariate defines an impact of a covariate. I illustrated that when a covariate enters the regression operate nonlinearly,the impact varies over covariate values,inflicting the conditional-on-covariate impact to vary from the population-averaged impact. I additionally confirmed how one can estimate and interpret these conditional-on-covariate and population-averaged results.
A while in the past,I shipped a part that felt accessible by each measure I might take a look at. Keyboard navigation labored. ARIA roles had been appropriately utilized. Automated audits handed with out a single grievance. And but,a display reader consumer couldn’t work out find out how to set off it. Once I examined it myself with keyboard-only navigation and NVDA,I noticed the identical factor:the interplay merely didn’t behave the way in which I anticipated.
Nothing on the guidelines flagged an error. Technically,every thing was “proper.” However in observe,the part wasn’t predictable. Right here’s a simplified model of the part that prompted the difficulty:
As you’ll be able to see within the demo,the markup is in no way sophisticated:
And the repair was a lot simpler than anticipated. I needed to delete the ARIA functionattribute that I had added with the perfect intentions.
The markup is even simpler than earlier than:
That have modified how I take into consideration accessibility. The most important lesson was this:Semantic HTML does much more accessibility work than we often give it credit score for already — and ARIA is straightforward to abuse once we use it each as a shortcut and as a complement.
Many people already know the primary rule of ARIA:don’t use it. Effectively,use it. However not if the accessible advantages and performance you want are already baked in,which it was in my case earlier than including the functionattribute.
Let me define precisely what occurred,step-by-step,as a result of I believe the my error is definitely a fairly frequent observe. There are a lot of articles on the market that say precisely what I’m saying right here,however I believe it usually helps to internalize it by listening to it by means of a real-life expertise.
Notice:This text was examined utilizing keyboard navigation and a display reader (NVDA) to watch actual interplay conduct throughout native and ARIA-modified parts.
1:Begin with the best doable markup
Once more,that is merely a minimal web page with a single native and no ARIA. And by default,it permits keyboard focus and demonstrates the performance of utilizing Tab,Enter,and Houseout of the field. Geoff just lately made this case when explaining the accessibility advantages of semantic HTML parts.
If the interplay triggers an motion,then that ingredient is a button. And on this case,the is designed to run a script that saves modifications to a consumer profile:
That single line provides us a shocking quantity without spending a dime:
Keyboard activation with the Enterand Housekeys
Right focus conduct
A task that assistive expertise already understands
Constant bulletins throughout display readers
At this level,there may be noARIA — and that’s intentional. However I did have an present class for styling buttons in my CSS,so I added that:
2:Observe the native conduct earlier than including something
With simply the native ingredient in place,I examined three issues:
Keyboard solely(Tab,Enter,House)
A display reader(listening to how the management is introduced)
Focus orderthroughout the web page
Every part behaved predictably. The browser was doing precisely what customers count on. This step issues as a result of it establishes a baseline. If one thing breaks later,you realize it wasn’t HTML that prompted it. Actually,we will see that every thing is in excellent working order by inspecting the ingredient in DevTool’s Accessibility panel.
3:Add properly‑intentioned ARIA
The issue crept in once I tried to make the button behave like a hyperlink:
I did this for styling and routing causes. This button wanted to be styled slightly otherwise than the default .ctaclass and I figured I might use the ARIA attribute slightly than utilizing a modifier class. You can begin to see how I let the styling dictate and affect the performance. A remains to be the right ingredient for this goal,however I needed it to appear like a hyperlink due to the design necessities. May as properly give that ingredient a hyperlinkfunction then,proper?
On the floor,nothing appeared damaged. Automated instruments stayed quiet. However in actual use,the cracks confirmed rapidly:
Keyboard customers encountered conduct that didn’t totally match both a button or a hyperlink.
ARIA didn’t add readability right here;it launched ambiguity. However I had already “examined” my work and nothing was screaming at me that I’d conflated the ingredient’s functionwith one other sort of ingredient. Once more,all it takes is a fast take a look at DevTools.
4:Again to semantics
The repair wasn’t intelligent. It was subtractive. I reverted my types,used a category for styling,and went again to the semantic markup previous to altering the accessible function:
I do know it sounds straightforward:if it’s an motion,use a . If it takes you someplace,use a hyperlink (). However,in observe,we’re making choices with each key we sort and it’s simply as straightforward to conflate actions with locations. On this case,I completely used the right ingredient! My mistake was considering that ARIA was an applicable styling hook for my CSS.
As soon as the right ingredient was in place — absent of ARIA — the problems disappeared. As a substitute,I might outline a brand new classname and,you guessed it,use hold types with types.
Similar to that,I used to be in a position to type the ingredient how I wanted and the consumer who report the difficulty was in a position to verify that every thing labored as anticipated. It was an inadvertent mistake born of a primary misunderstanding about ARIA’s place within the stack.
Why this retains occurring
ARIA attributes are used to outline the character of one thing however they don’t redefine the behavioral default of the native parts. Once we override semantics,we quietly take accountability for:
keyboard interactions,
focus administration,
anticipated bulletins,and
platform‑particular quirks.
That’s a big floor space to keep up,and it’s why small ARIA modifications can have outsized and unpredictable results.
A rule I now comply with
Right here’s the workflow that has saved me essentially the most time and bugs:
Use native HTML to precise intent.
Check with keyboard and a display reader.
Add ARIA solely to speak lacking state,to not redefine roles.
If ARIA feels prefer it’s doing heavy lifting,it’s often an indication the markup is preventing the browser.
The place ARIA doesbelong
One instance can be a easy disclosure widget utilizing a local plus aria-expandedto speak state — exhibiting ARIA used to add state,not substitute semantics.
This demo makes use of a local with aria-expanded,which is toggled with a sprinkle of JavaScript:
The accessible state (true/false) is communicated appropriately with out changing the button’s semantics.
Now,I do know that ARIA is important when:
speaking expanded or collapsed state,
saying dynamic updates,
constructing really customized widgets,and
exposing relationships HTML can’t categorical.
Used this fashion,ARIA enhances semantic HTML as an alternative of competing with it.
Let the platform be just right for you
The most important accessibility enchancment I’ve made wasn’t studying about extra attributes — it was trusting those browsers already perceive. Semantic HTML shouldn’t be the baseline you progress previous. It’s the muse that every thing else relies on.
And that’s what I actually hope you’re taking away from my expertise. All of us make errors. It’s a part of the job,sadly. However what good are they if we will’t study from them,even when it takes a tough lesson.
Are you following the pattern or genuinely fascinated about Machine Studying? Both manner,you will have the best sources to TRUST,LEARNand SUCCEED.
If you’re unable to seek out the best Machine Studying useful resource in 2026? We’re right here to assist.
Let’s reiterate the definition of Machine Studying…
Machine studying is an thrilling discipline that mixes pc science,statistics,and arithmetic to allow machines to study from knowledge and make predictions or choices with out being explicitly programmed. Because the demand for machine studying abilities continues to rise throughout varied industries,it’s important to have a complete information to the very best sources for studying this highly effective know-how.
On this article,we’ll discover a curated listing of programs,tutorials,and supplies that may aid you kickstart your machine-learning journey,whether or not you’re an entire newbie or an skilled skilled trying to deepen your information.
Right here’s what you’ll get from the article:
Primary and Specialised On-line Programs on Machine Studying
Ebook on Machine Studying
Occasions or Conferences Associated to Machine Studying
YouTube Channels on Machine Studying
Free recommendation to get experience in Machine Studying…
Why Would You Want Machine Studying Assets?
Machine studying sources are essential for studying,analysis,growth,and implementation functions. People and organizations require entry to on-line programs,textbooks,tutorials,analysis papers,datasets,libraries,toolkits,and group platforms to construct information,develop cutting-edge fashions,combine machine studying capabilities,educate and prepare others,benchmark efficiency,and keep up to date with the most recent developments on this quickly evolving discipline. These sources allow efficient studying,exploration,prototyping,deployment,and understanding of machine studying ideas and strategies throughout varied domains and functions.
The Newbie Course on Machine Studying
Newbie-Pleasant Programs For these new to machine studying,beginning with a foundational course is essential.
Listed below are some extremely really useful choices:
Google’s Machine Studying Crash Course:This free course from Google affords a sensible introduction to machine studying,that includes video lectures,case research,and hands-on workouts. It’s a wonderful useful resource for many who study finest via concept and observe.
Machine Studying Certification Course for Freshmen by Analytics Vidhya:On this complimentary course on machine studying certification,contributors will delve into Python programming,grasp basic ideas of machine studying,purchase abilities in establishing machine studying fashions,and discover strategies in characteristic engineering aimed toward enhancing the efficacy of those fashions.
HarvardX:CS50’s Introduction to Synthetic Intelligence with Python:Led by the dynamic David Malan,CS50 is Harvard’s premier providing on EdX,boasting an viewers exceeding a million keen learners. Malan’s means to distill advanced ideas into charming and accessible narratives makes this course a should for anybody looking for a fascinating introduction to machine studying. Whether or not you’re trying to bolster your technical prowess or just need to delve into the thrilling realm of AI,CS50 guarantees an fulfilling studying journey.
IBM Machine Studying with Python:Machine studying presents a useful alternative to unearth hid insights and forecast forthcoming developments. This Python-based machine studying course equips you with the important toolkit to provoke your journey into supervised and unsupervised studying methodologies.
Specialised Programs and Assets When you’ve grasped the basics,you possibly can discover extra superior and specialised subjects in machine studying:
deeplearning.ai Specializations:Taught by Andrew Ng and his staff,these Coursera specializations present in-depth protection of deep studying,convolutional neural networks,sequence fashions,and different cutting-edge strategies.
You too can discover extra programs on the web site.
Licensed AI &ML BlackBelt PlusProgram:This complete licensed program combines the facility of knowledge science,machine studying,and deep studying that can assist you grow to be an AI &ML Blackbelt! Go from an entire newbie to gaining in-demand industry-relevant AI abilities.
Machine Studying Specialization by College of Washington:This Specialization was crafted by outstanding students on the College of Washington. Embark on a journey via sensible case research designed to offer hands-on expertise in pivotal sides of Machine Studying resembling Prediction,Classification,Clustering,and Info Retrieval.
AWS Machine Studying Studying Path:A Studying Plan pulls collectively coaching content material for a selected position or answer and organizes these property from foundational to superior. Use Studying Plans as a place to begin to find coaching that issues to you. This Studying Plan is designed to assist Information Scientists and Builders combine machine studying (ML) and synthetic intelligence (AI) into instruments and functions.
For Apply,You may Consult with the Kaggle Competitions
The speculation is nice,however nothing beats rolling up your sleeves and getting your palms soiled with real-world issues. Enter Kaggle,a platform that hosts knowledge science competitions and supplies a wealth of datasets to observe on. Begin with beginner-friendly challenges like “Cats vs Canines” or “Titanic” to get a really feel for Exploratory Information Evaluation (EDA) and use libraries like Scikit-Be taught and TensorFlow/Keras. This sensible expertise will solidify your understanding and put together you for extra advanced duties.
By now,you need to have a stable grasp of ML fundamentals and a few sensible expertise. It’s time to begin specializing in areas that pique your curiosity. If pc imaginative and prescient captivates you,dive into extra superior Kaggle notebooks,learn related analysis papers,and experiment with open-source initiatives. If Pure Language Processing (NLP)is your jam,examine transformer architectures just like the Linformer or Performer and discover cutting-edge strategies like contrastive or self-supervised studying.
Books on Machine Studying
Listed below are the books on Machine Studying that you need to preserve useful:
Machine Studying:A Bayesian and Optimization Perspective by Sergios Theodoridis
This guide is a must-read should you’re on the lookout for a unified perspective on probabilistic and deterministic machine studying approaches. It presents main ML strategies and their sensible functions in statistics,sign processing,and pc science,supported by examples and downside units.
Palms-On Machine Studying with Scikit-Be taught &TensorFlow by Aurélien Géron
This guide helps you perceive machine studying ideas and instruments for constructing clever techniques. It covers varied strategies,from easy linear regression to deep neural networks,with hands-on workouts to strengthen your studying. Palms-on Machine Studying with Scikit-Be taught,Keras,and TensorFlow is the go-to useful resource for diving into sensible implementation. Its thorough and hands-on strategy makes it indispensable for getting began and proficiently constructing clever techniques.
Python Information Science Handbook:Important Instruments for Working with Information
The “Python Information Science Handbook” is a vital useful resource for researchers,scientists,and knowledge analysts utilizing Python for knowledge manipulation and evaluation. It covers all key parts of the info science stack,together with IPython,NumPy,Pandas,Matplotlib,and Scikit-Be taught,offering complete steerage on storing,manipulating,visualizing,and modeling knowledge. Whether or not cleansing knowledge,constructing statistical fashions,or implementing machine studying algorithms,this handbook affords sensible insights and options for day-to-day challenges in scientific computing with Python.
Distill.pub,a meticulously crafted journal showcasing visually charming content material on machine studying subjects,seems to be taking a one-year break because of the staff experiencing burnout. Nonetheless,the platform hosts top-notch ML materials.
Analytics Vidhya,usually showing because the second search end result on Google,affords considerable priceless content material on Machine Studying and related fields.
Machine Studying Masteryconstantly emerges as a go-to useful resource for many who often flip to Google throughout initiatives. The weblog’s well-written articles and memorable web optimization prowess in ML-related topics are noteworthy.
Listed below are the communities you possibly can attain for updates on Machine Studying:
r/LearnMachineLearningserves as an distinctive Reddit group (401k members) tailor-made for novices looking for steerage,sharing their initiatives,or discovering inspiration from the endeavors of fellow members.
r/MachineLearningstands out as a priceless group (2.9M members) for staying up to date with the most recent developments in machine studying and gaining insightful views on present occasions throughout the ML group. The subreddit affords high-quality content material and permits one to know the prevailing sentiments and opinions throughout the discipline via statement.
The Analytics Vidhya Groupsupplies one other avenue for partaking with like-minded people fascinated about analytics and machine studying. It affords a platform for discussions,collaborations,and information sharing.
Machine Studying Occasions
Listed below are the present and upcoming occasions on Machine Studying:
Information Hack Summit 2024:The Information Hack Summit 2024,proudly introduced by Analytics Vidhya,guarantees to be an immersive and enlightening expertise for knowledge fanatics worldwide. As one of many premier occasions in knowledge science and analytics,this summit brings collectively{industry}leaders,seasoned professionals,and aspiring knowledge scientists for a collaborative exploration of the most recent developments,applied sciences,and finest practices shaping the way forward for data-driven innovation.
NeurIPS (Neural Info Processing Programs) Convention:That is the legendary machine studying convention on neural networks. It has grow to be overcrowded lately,and its usefulness has been questioned. Nonetheless,should you can’t attend,it’s a good suggestion to verify what the researchers who get accepted work on.
Sentdex:Python Programming tutorials transcend the fundamentals. Find out about machine studying,finance,knowledge evaluation,robotics,internet growth,and recreation growth.
Deep Studying AI:Welcome to the official DeepLearning.AI YouTube channel! Right here,you will discover movies from our Coursera packages on machine studying and recorded occasions.
Two-Minute Paper:Protecting abreast of machine studying analysis will be difficult. Two Minute Paper steps in,condensing intricate analysis papers into simply digestible video snippets.
Kaggle:Kaggle is the biggest world group of knowledge scientists,offering a platform for collaboration,competitors,and studying in knowledge science and machine studying.
3Blue1Brown:Embracing the adage{that a}single picture can convey myriad meanings,3Blue1Brown employs charming visualizations to elucidate intricate mathematical and machine-learning rules.
StatQuest with Josh Starmer:Brief,partaking movies that demystify advanced statistical ideas essential for ML.
As you progress in your machine studying journey,staying up-to-date with the most recent analysis and exploring open-source repositories will be invaluable:
ArXiv:This repository for digital preprints is a treasure trove of cutting-edge analysis papers in machine studying,synthetic intelligence,and associated fields.
GitHub:Many researchers and builders share their code and implementations on GitHub. Exploring well-liked repositories may also help you perceive learn how to implement advanced algorithms and strategies.
Convention Proceedings:Main machine studying conferences like DHS 2024,NeurIPS,ICML,and ICLR publish their proceedings,which could be a priceless useful resource for staying knowledgeable in regards to the newest breakthroughs and developments.
Bonus Level Chimed-in For You
Constructing Your Community
Collaboration and Mentorship:Whereas unbiased studying is nice,don’t underestimate the facility of collaboration and mentorship:
Be part of On-line Communities and Boards:Join with like-minded people,change concepts,and achieve new views.
Discover a Mentor:Having an skilled information who can present suggestions,insights,and profession recommendation will be invaluable in navigating the skilled panorama of machine studying.
Embrace the Journey
A Lifelong Pursuit Machine studying is a quickly evolving discipline,with new breakthroughs and developments occurring continuously. To actually thrive,you should embrace a lifelong studying mindset:
Keep Curious:Comply with{industry}leaders and researchers,attend conferences and workshops,and repeatedly search out new sources and challenges.
Deal with it as an Ongoing Journey:Machine studying isn’t a vacation spot;it’s a journey. Strategy it with persistence,dedication,and an insatiable thirst for information.
Mastering machine studying received’t be simple,nevertheless it’s an unimaginable,rewarding path. With the best sources,steerage,and mindset,you’ll be nicely in your solution to turning into a machine studying professional,fixing advanced issues,and driving innovation. Simply take it one step at a time,and by no means cease studying!
HackerRank:Sharpen your Python abilities with an enormous assortment of coding challenges from newbie to skilled stage.
Conclusion
Studying machine studying is a steady journey that requires dedication,observe,and an insatiable curiosity. By leveraging the sources outlined on this article,you’ll be well-equipped to navigate the thrilling world of machine studying and unlock its full potential. Bear in mind,the important thing to success is to begin with a stable basis,constantly observe and apply your information,and keep up-to-date with the most recent developments on this quickly evolving discipline.
I hope you discovered this text useful in getting the best Machine Studying Assets. Be happy to remark in case you have any ideas or need to add one thing I missed.
Information Analyst with over 2 years of expertise in leveraging knowledge insights to drive knowledgeable choices. Obsessed with fixing advanced issues and exploring new developments in analytics. When not diving deep into knowledge,I get pleasure from enjoying chess,singing,and writing shayari.
Login to proceed studying and luxuriate in expert-curated content material.
To this point,so good. However what if we need to group our knowledge by a couple of column? We are able to do that by passing columns in lists:
print(df.groupby(['year','continent'])
[['lifeExp','gdpPercap']].imply())
lifeExp gdpPercap
yr continent
1952 Africa 39.135500 1252.572466
Americas 53.279840 4079.062552
Asia 46.314394 5195.484004
Europe 64.408500 5661.057435
Oceania 69.255000 10298.085650
1957 Africa 41.266346 1385.236062
Americas 55.960280 4616.043733
Asia 49.318544 5787.732940
Europe 66.703067 6963.012816
Oceania 70.295000 11598.522455
1962 Africa 43.319442 1598.078825
Americas 58.398760 4901.541870
Asia 51.563223 5729.369625
Europe 68.539233 8365.486814
Oceania 71.085000 12696.452430
This .groupby()operation takes our knowledge and teams it first by yr,after which by continent. Then,it generates imply values from the life-expectancy and GDP columns. This fashion,you possibly can create teams in your knowledge and rank how they’re to be offered and calculated.
If you wish to “flatten” the outcomes right into a single,incrementally listed body,you need to use the .reset_index()technique on the outcomes:
gb=df.groupby(['year','continent'])
[['lifeExp','gdpPercap']].imply()
flat=gb.reset_index() print(flat.head())
| yr continent lifeExp gdpPercap
| 0 1952 Africa 39.135500 1252.572466
| 1 1952 Americas 53.279840 4079.062552
| 2 1952 Asia 46.314394 5195.484004
| 3 1952 Europe 64.408500 5661.057435
| 4 1952 Oceana 69.255000 10298.085650
Grouped frequency counts
One thing else we regularly do with knowledge is compute frequencies. The nuniqueand value_countsstrategies can be utilized to get distinctive values in a sequence,and their frequencies. As an illustration,right here’s the way to learn the way many nations we have now in every continent:
print(df.groupby('continent')['country'].nunique()) continent
Africa 52
Americas 25
Asia 33
Europe 30
Oceana 2
Primary plotting with Pandas and Matplotlib
More often than not,whenever you need to visualize knowledge,you’ll use one other library similar to Matplotlib to generate these graphics. Nonetheless,you need to use Matplotlib instantly (together with another plotting libraries) to generate visualizations from inside Pandas.
To make use of the straightforward Matplotlib extension for Pandas,first ensure you’ve put in Matplotlib with pip set up matplotlib.
Now let’s have a look at the yearly life expectations for the world inhabitants once more:
import matplotlib.pyplot as plt
global_yearly_life_expectancy=df.groupby('yr')['lifeExp'].imply() c=global_yearly_life_expectancy.plot().get_figure()
plt.savefig("output.png")
The plot can be saved to a file within the present working listing as output.png. The axes and different labeling on the plot can all be set manually,however for fast exports this technique works tremendous.
Conclusion
Python and Pandassupply many options you possibly can’t get from spreadsheets. For one,they allow you to automate your work with knowledge and make the outcomes reproducible. Reasonably than write spreadsheet macros,that are clunky and restricted,you need to use Pandas to investigate,section,and remodel knowledge—and use Python’s expressive energy and package deal ecosystem (as an example,for graphing or rendering knowledge to different codecs) to do much more than you can with Pandas alone.




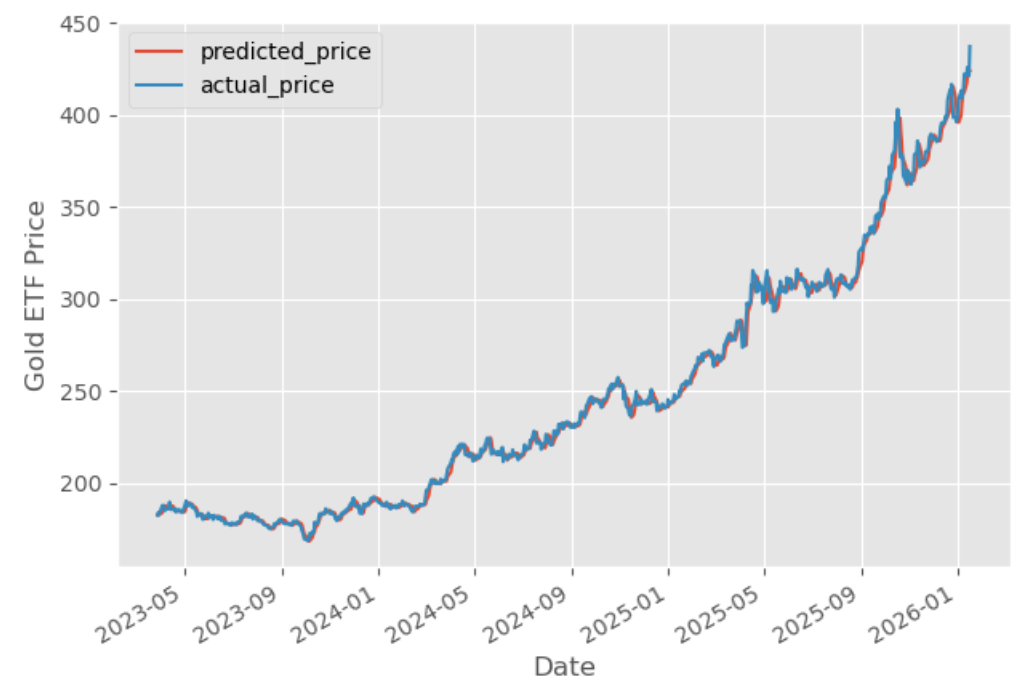
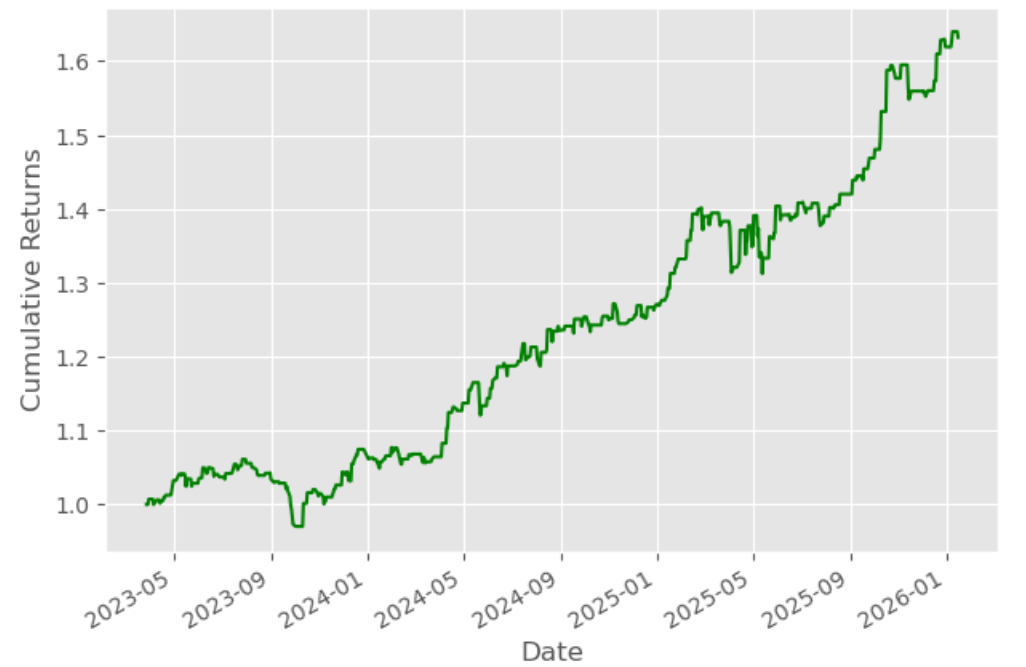




















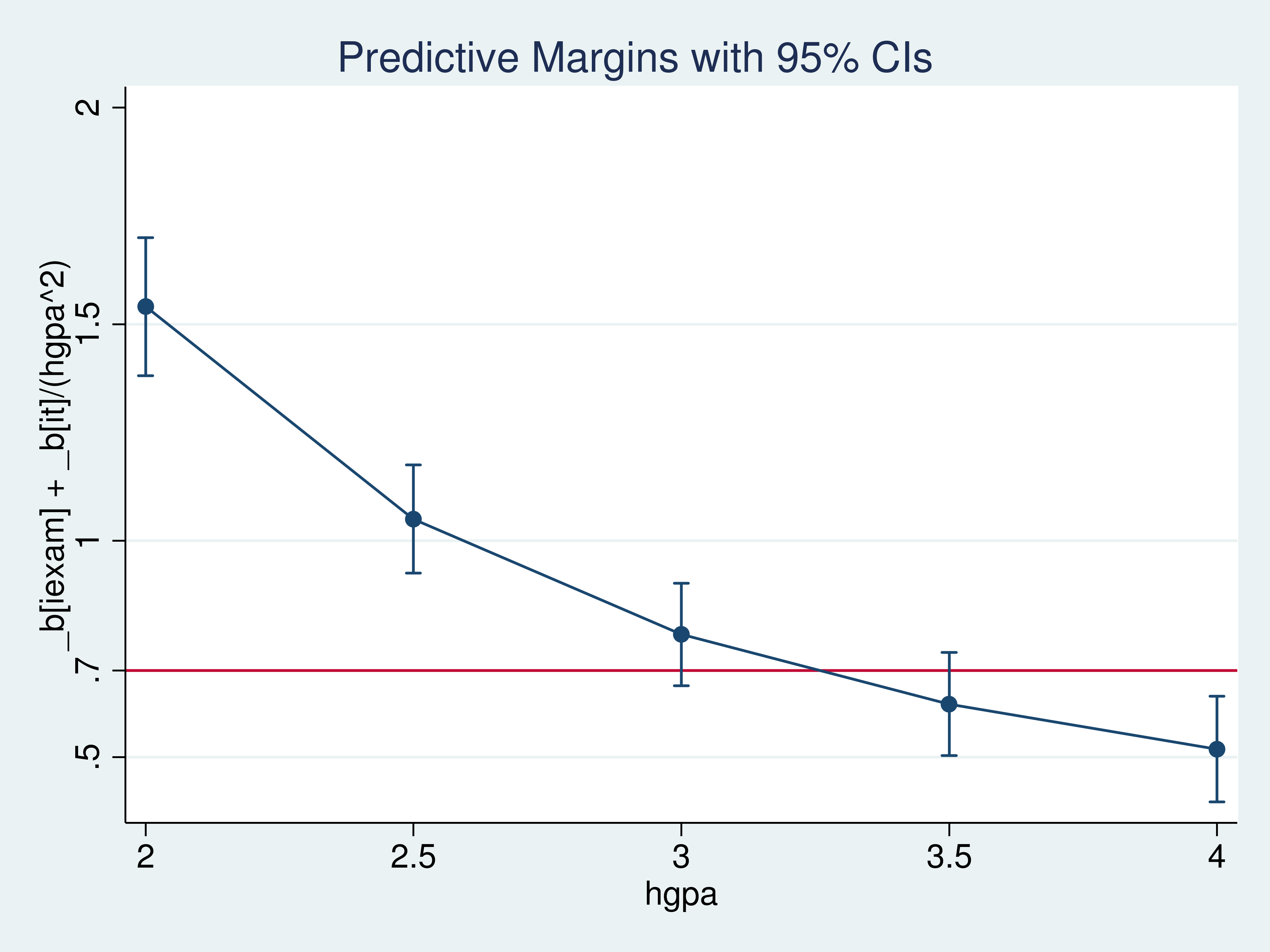{kind=link}