that “teams are remarkably clever, and are sometimes smarter than the neatest individuals in them.”He was writing about decision-making, however the identical precept applies to classification: get sufficient individuals to explain the identical phenomenon and a taxonomy begins to emerge, even when no two individuals phrase it the identical approach. The problem is extracting that sign from the noise.
I had a number of thousand rows of free-text information and wanted to do precisely that. Every row was a brief natural-language annotation explaining why an automatic safety discovering was irrelevant, which capabilities to make use of for a repair, or what coding practices to comply with. One particular person wrote “that is take a look at code, not deployed wherever.” One other wrote “non-production atmosphere, protected to disregard.” A 3rd wrote “solely runs in CI/CD pipeline throughout integration exams.” All three meant the identical factor, however no two shared greater than a phrase or two.
The taxonomy was in there. I simply wanted the appropriate device to extract it. Conventional clustering and key phrase matching couldn’t deal with the paraphrase variation, so I attempted one thing I hadn’t seen mentioned a lot: utilizing a domestically hosted LLM as a zero-shot classifier. This weblog publish explores the way it carried out, the way it works, and a few suggestions for utilizing and deploying these methods your self.
Why conventional clustering struggles with brief free-text
Customary unsupervised clustering works by discovering mathematical proximity in some characteristic area. For lengthy paperwork, that is often effective. Sufficient sign exists in phrase frequencies or embedding vectors to kind coherent teams. However brief, semantically dense textual content breaks these assumptions in a number of particular methods.
Embedding similarity conflates completely different meanings. “This key’s solely utilized in improvement” and “This API key’s hardcoded for comfort” produce related embeddings as a result of the vocabulary overlaps. However one is a couple of non-production atmosphere and the opposite is about an intentional safety tradeoff. Ok-means or DBSCAN can’t distinguish them as a result of the vectors are too shut.
Matter fashions floor phrases, not ideas.Latent Dirichlet Allocation (LDA) and its variants discover phrase co-occurrence patterns. When your corpus consists of one-sentence annotations, the phrase co-occurrence sign is simply too sparse to kind significant matters. You get clusters outlined by “take a look at” or “code” or “safety” moderately than coherent themes.
Regex and key phrase matching can’t deal with paraphrase variation. You possibly can write guidelines to catch “take a look at code” and “non-production,” however you’d miss “solely used throughout CI,” “by no means deployed,” “development-only fixture,” and dozens of different phrasings that every one categorical the identical underlying concept.
The frequent thread: these strategies function on floor options (tokens, vectors, patterns) moderately than semantic which means. For classification duties the place which means issues greater than vocabulary, you want one thing that understands language.
LLMs as zero-shot classifiers
The important thing perception is straightforward: as an alternative of asking an algorithm to find clusters, outline your candidate classes based mostly on area information and ask a language mannequin to categorise every entry.
This works as a result of LLMs course of semantic which means, not simply token patterns. “This key’s solely utilized in improvement” and “Non-production atmosphere, protected to disregard” comprise nearly no overlapping phrases, however a language mannequin understands they categorical the identical concept. This isn’t simply instinct. Chae and Davidson (2025) in contrast 10 fashions throughout zero-shot, few-shot, and fine-tuned coaching regimes and located that giant LLMs in zero-shot mode carried out competitively with fine-tuned BERT on stance detection duties. Wang et al. (2023) discovered LLMs outperformed state-of-the-art classification strategies on three of 4 benchmark datasets utilizing zero-shot prompting alone, no labeled coaching information required.
The setup has three parts:
Candidate classes. An inventory of mutually unique classes outlined from area information. In my case, I began with about 10 anticipated themes (take a look at code, enter validation, framework protections, non-production environments, and so forth.) and expanded to twenty candidates after reviewing a pattern.
A classification immediate. Structured to return a class label and a short motive. Low temperature (0.1) for consistency. Brief max output (100 tokens) since we solely want a label, not an essay.
A neighborhood LLM. I used Ollama to run fashions domestically. No API prices, no information leaving my machine, and quick sufficient for hundreds of classifications.
Right here’s the core of the classification immediate:
CLASSIFICATION_PROMPT = """
Classify this textual content into one in all these themes:
{themes}
Textual content:
"{content material}"
Reply with ONLY the theme quantity and identify, and a short motive.
Format: THEME_NUMBER. THEME_NAME | Motive
Classification:
"""
And the Ollama name:
response = ollama.generate(
mannequin="gemma2",
immediate=immediate,
choices={
"temperature": 0.1, # Low temp for constant classification
"num_predict": 100, # Brief response, we simply want a label
}
)
Two issues to notice. First, the temperature setting issues. At 0.7 or larger, the identical enter can produce completely different classifications throughout runs. At 0.1, the mannequin is almost deterministic, which helps clean classification. Second, limiting num_predict retains the mannequin from producing explanations you don’t want, which accelerates throughput considerably.
Constructing the pipeline
The total pipeline has three steps: preprocess, classify, analyze.
Preprocessing strips content material that provides tokens with out including classification sign. URLs, boilerplate phrases (“For extra data, see…”), and formatting artifacts all get eliminated. Frequent phrases get normalized (“false constructive” turns into “FP,” “manufacturing” turns into “prod”) to cut back token variation. Deduplication by content material hash removes actual repeats. This step decreased my token finances by roughly 30% and made classification extra constant.
Classification runs every entry via the LLM with the candidate classes. For ~7,000 entries, this took about 45 minutes on a MacBook Professional utilizing Gemma 2 (9B parameters). I additionally examined Llama 3.2 (3B), which was quicker however barely much less exact on edge circumstances the place two classes had been shut. Gemma 2 dealt with ambiguous entries with noticeably higher judgment.
One sensible concern: lengthy runs can fail partway via. The pipeline saves checkpoints each 100 classifications, so you may resume from the place you left off.
Evaluation aggregates the outcomes and generates a distribution chart. Right here’s what the output regarded like:
Distribution of Semgrep “Reminiscences” as assigned by the LLM clustering train. Picture used with permission.
The chart tells a transparent story. Over 1 / 4 of all entries described code that solely runs in non-production environments. One other 21.9% described circumstances the place a safety framework already handles the danger. These two classes alone account for half the dataset, which is the type of perception that’s arduous to extract from unstructured textual content every other approach.
When this strategy is just not the appropriate match
This method works greatest in a selected area of interest: medium-scale datasets (a whole bunch to tens of hundreds of entries), semantically advanced textual content, and conditions the place you could have sufficient area information to outline candidate classes however no labeled coaching information.
It’s not the appropriate device when:
your classes are keyword-defined (simply use regex),
when you could have labeled coaching information (prepare a supervised classifier; it’ll be quicker and cheaper),
whenever you want sub-second latency at scale (use embeddings and a nearest-neighbor lookup),
or whenever you genuinely don’t know what classes exist. On this case, run exploratory subject modeling first to develop instinct, then change to LLM classification as soon as you may outline classes.
The opposite constraint is throughput. Even on a quick machine, classifying one entry per fraction of a second means 7,000 entries takes near an hour. For datasets above 100,000 entries, you’ll need an API-hosted mannequin or a batching technique.
Different purposes price attempting
The pipeline generalizes to any downside the place you could have unstructured textual content and wish structured classes.
Buyer suggestions. NPS responses, help tickets, and survey open-ends all endure from the identical downside: diversified phrasing for a finite set of underlying themes. “Your app crashes each time I open settings” and “Settings web page is damaged on iOS” are the identical class, however key phrase matching received’t catch that.
Bug report triage. Free-text bug descriptions may be auto-categorized by part, root trigger, or severity. That is particularly helpful when the particular person submitting the bug doesn’t know which part is accountable.
Code intent classification. That is one I haven’t tried but however discover compelling: classifying code snippets, Semgrep guidelines, or configuration guidelines by objective (authentication, information entry, error dealing with, logging). The identical method applies. Outline the classes, write a classification immediate, run the corpus via an area mannequin.
Getting began
The pipeline is easy: outline your classes, write a classification immediate, and run your information via an area mannequin.
The toughest half isn’t the code. It’s defining classes which are mutually unique and collectively exhaustive. My recommendation: begin with a pattern of 100 entries, classify them manually, discover which classes you retain reaching for, and use these as your candidate checklist. Then let the LLM scale the sample.
I used this system as a part of a bigger evaluation on how safety groups remediate vulnerabilities. The classification outcomes helped floor which forms of safety context are commonest throughout organizations, and the chart above is likely one of the outputs from that work. Should you’re within the safety angle, the total report is offered at that hyperlink.
Error monitoring has developed far past catching stack traces after one thing breaks. In fashionable software program groups, the perfect error monitoring instruments for builders assist determine crashes in actual time, group related points intelligently, floor wealthy debugging context, join failures to code adjustments, and scale back the time between detection and backbone. That issues much more now that groups are delivery quicker, deploying extra usually, and counting on AI-assisted workflows that may improve each supply velocity and operational complexity.
For a lot of groups, error monitoring is not a slim debugging utility. It’s a part of the manufacturing suggestions loop. A helpful platform ought to assist builders reply sensible questions shortly: Which errors are new? Which of them have an effect on actual customers? Which launch launched the difficulty? Is the issue remoted to at least one surroundings, one system sort, one service, or one workflow? And in an age of AI-assisted growth, one other query issues too: how do you join runtime points again to the code and programs accountable for them?
That’s the reason this record consists of each conventional error monitoring leaders and some instruments that sit barely adjoining to the class however nonetheless matter for developer-led problem detection. Some are strongest in net and backend environments. Some are higher recognized for cell crash reporting. Some emphasize open-source flexibility. And a few, like Hud, push the class towards runtime intelligence for contemporary manufacturing environments.
Why error monitoring instruments matter extra in fashionable growth
Why builders want greater than logs
Logs nonetheless matter, however logs alone hardly ever give builders the readability they want when one thing breaks in manufacturing. Uncooked log streams will be noisy, fragmented, and arduous to prioritize. Error monitoring instruments enhance that by capturing exceptions, grouping repeated points, attaching context like stack traces and surroundings metadata, and serving to builders see which failures deserve rapid consideration.
This turns into particularly essential in distributed programs and fast-moving product groups. A single regression might present up in a different way throughout providers, browsers, working programs, or cell gadgets. With out a devoted error monitoring layer, builders can waste hours stitching collectively clues that ought to have been seen in minutes.
The place error monitoring matches within the engineering workflow
The strongest groups use error monitoring at a number of factors within the software program lifecycle. It helps them validate new releases, look ahead to post-deployment regressions, prioritize bugs by impression, and scale back imply time to decision. It additionally improves collaboration between engineering, SRE, QA, assist, and product groups as a result of everybody can work from a shared view of what’s failing and the way extreme it’s.
In AI-assisted growth environments, error monitoring turns into much more essential. When code is generated extra shortly, deployed extra incessantly, or reviewed below tighter time constraints, builders want a sharper manufacturing suggestions loop. That doesn’t make testing much less essential. It makes runtime problem detection extra essential.
What a powerful error monitoring platform ought to ship
Builders evaluating error monitoring instruments ought to search for greater than fundamental crash seize. A powerful platform often affords:
real-time error and exception reporting
good grouping and deduplication
helpful stack traces and debugging context
launch and deployment correlation
alerting that reduces noise as an alternative of accelerating it
assist for a number of environments, frameworks, and languages
sufficient flexibility to suit net, backend, cell, or hybrid purposes
The very best instrument is determined by your working mannequin. A cell workforce might care most about crash-free periods and system context. A backend workforce might prioritize efficiency and exception visibility. A platform workforce might care extra about problem prioritization, hint correlation, and operational consistency throughout providers.
Prime error monitoring instruments for builders
1. Hud
Hud takes a broader and extra fashionable view of error monitoring than many conventional instruments. Relatively than focusing solely on exception seize, it positions itself as a Runtime Code Sensor that streams real-time, function-level runtime information from manufacturing into AI coding instruments, with the purpose of creating AI-generated code production-safe by default. That makes it particularly related for groups that wish to perceive not simply that an issue occurred, however how stay code conduct contributed to it.
For builders, Hud issues as a result of manufacturing failures are sometimes tougher to elucidate than to detect. A spike in errors could also be straightforward to see, however understanding which code path shifted, which perform degraded, or why a launch launched sudden runtime conduct is a deeper problem. Hud is constructed round closing that hole by turning manufacturing conduct right into a richer debugging sign.
That provides it a definite place on this record. It’s not a basic problem inbox in the identical mould as conventional exception trackers. As a substitute, it expands the class by serving to builders join runtime conduct, code execution, and manufacturing security extra straight. Hud is greatest for groups that see error monitoring as a part of a wider runtime intelligence technique. In case your builders need greater than alerting and want deeper visibility into how stay code behaves, it is without doubt one of the extra differentiated choices obtainable at present.
Key factors:
Perform-level runtime visibility from manufacturing
Sturdy match for debugging code conduct, not simply capturing exceptions
Helpful for groups that need richer manufacturing context in developer workflows
2. Sentry
Sentry is without doubt one of the most recognizable names in error monitoring, and for good purpose. Its platform combines error monitoring with tracing, logs, replay, profiling, and associated debugging workflows designed to assist software program groups see errors clearly and resolve points quicker. That makes it one of many most secure selections for growth groups that need a sturdy, developer-first platform with broad language and framework protection.
Sentry’s worth comes from how successfully it turns uncooked failures into actionable points. It captures exceptions in actual time, teams recurring issues, and offers builders the context wanted to research them with out sifting by unstructured telemetry. For net and backend purposes, that usually interprets into quicker triage and extra environment friendly debugging. For cell groups, Sentry additionally supplies crash and efficiency visibility throughout supported environments.
One other energy is familiarity. Many engineering groups already know how one can work with Sentry, and the platform’s issue-centric workflow is properly suited to bug fixing, regression looking, and post-release validation. It matches each smaller groups that want a quick begin and bigger groups that need structured problem visibility throughout providers.
Key factors:
Actual-time error monitoring with sturdy developer workflows
Further visibility by tracing, logs, and profiling
Broad ecosystem assist throughout fashionable purposes
Efficient for each exception triage and ongoing stability work
3. Rollbar
Rollbar has lengthy been a powerful possibility for groups that need real-time error monitoring with clear problem grouping and helpful launch context. The corporate emphasizes that its platform alerts builders when one thing breaks, teams duplicate errors mechanically, and surfaces the precise line of code concerned. That concentrate on fast signal-to-resolution stream is precisely why it continues to matter.
For builders, Rollbar’s core energy is prioritization. Error monitoring solely turns into priceless when groups can separate noisy background failures from points that genuinely have an effect on product stability or person expertise. Rollbar helps by grouping related occasions and including the context wanted to know how usually a problem happens, the place it seems, and whether or not it correlates with a deployment.
This makes it particularly helpful for engineering groups managing frequent releases. In these environments, the important thing query is commonly not “Did an error occur?” however “Did this launch introduce a significant regression, and the way shortly can we verify it?” Rollbar’s deployment-aware workflows assist make that query simpler to reply.
Key factors:
Actual-time error alerts and automated grouping
Clear line-of-code visibility for quicker debugging
Sturdy assist for release-based problem investigation
Effectively suited to groups delivery frequent software updates
4. BugSnag
BugSnag is designed round software stability and real-time error monitoring. Its official messaging emphasizes figuring out, monitoring, and resolving app errors effectively so groups can keep reliability and enhance person satisfaction. That makes it a pure inclusion in any severe record of error monitoring instruments for builders.
One purpose BugSnag stands out is its constant energy throughout net, backend, and cell use circumstances. Many groups use it not simply to catch unhandled exceptions, however to watch software stability extra broadly. That issues as a result of builders are hardly ever fixing remoted crashes in a vacuum. They’re often attempting to know patterns: which gadgets are affected, which variations regressed, which environments are unstable, and the way the difficulty impacts total person expertise.
BugSnag’s attraction additionally comes from its readability. Builders often need an error tracker that helps them transfer shortly from “we now have a manufacturing problem” to “that is the doubtless trigger and scope.” BugSnag’s stability-oriented design helps that workflow properly, particularly for groups managing customer-facing software program the place reliability is a visual a part of product high quality.
Key factors:
Actual-time app error detection and monitoring
Sturdy give attention to software stability and reliability
Helpful throughout net, backend, and cell environments
Good match for groups that need stability insights alongside error reporting
5. Raygun
Raygun approaches error monitoring from the angle of serving to groups detect, diagnose, and resolve the problems that have an effect on finish customers. Its crash reporting and error monitoring positioning highlights detailed diagnostics and simpler replication of errors, exceptions, bugs, and crashes. That user-impact orientation is certainly one of its strongest promoting factors.
For builders, Raygun is beneficial as a result of it pushes error monitoring past technical seize and nearer to software expertise. A bug issues most when it impacts actual workflows, actual clients, or core product flows. Instruments that assist builders perceive that impression can enhance prioritization considerably. Raygun helps that by pairing diagnostic element with a broader view of software conduct.
It is usually a superb match for groups that want cross-platform visibility. Internet purposes, cell merchandise, and distributed providers all produce errors in a different way. Raygun’s design helps builders examine these points whereas maintaining the end-user impression in view.
Key factors:
Detailed diagnostics for errors, bugs, and crashes
Sturdy orientation towards actual person impression
Useful for groups that need higher problem replication and analysis
Helpful throughout fashionable net and cell software program environments
6. Honeybadger
Honeybadger combines error monitoring and software monitoring in a single streamlined interface, aiming to assist builders reply shortly and repair points in file time. That simplicity is a serious a part of its attraction. Not each workforce wants a sprawling observability stack to catch manufacturing points. Many simply want a reliable, easy platform that surfaces errors, sends helpful alerts, and supplies sufficient context to resolve bugs effectively.
For builders, Honeybadger works properly as a result of it stays targeted on sensible problem administration. It captures exceptions, helps groups perceive what modified round a deployment, and helps associated reliability workflows comparable to uptime and cron monitoring. That broader however nonetheless manageable scope makes it enticing to smaller engineering groups and product-focused growth teams.
One other profit is usability. Groups that worth velocity and readability usually want instruments which can be straightforward to purpose about throughout a stay problem. Honeybadger’s easier footprint is usually a energy in that context, particularly in comparison with platforms that require heavier setup or broader operational buy-in.
Key factors:
Error monitoring and software monitoring in a single interface
Actual-time alerts and context-rich exception visibility
Useful for uptime and cron-style reliability workflows
Sturdy match for smaller groups or easy manufacturing environments
7. Firebase Crashlytics
Firebase Crashlytics is without doubt one of the strongest crash reporting instruments for cell builders. Google describes it as a light-weight, real-time crash reporter that helps groups monitor, prioritize, and repair stability points affecting app high quality. For Android, Apple platforms, Flutter, and Unity purposes, it stays a extremely sensible selection.
Its greatest energy is mobile-specific usability. Cell groups don’t simply must know that an error occurred. They should perceive system circumstances, app variations, working system patterns, and the soundness developments that form person expertise over time. Crashlytics is constructed round that actuality, which is why it continues to be extensively adopted in app growth groups.
For builders working inside the Firebase ecosystem, the combination benefit is clear. Crash reporting turns into half of a bigger workflow that will already embrace analytics, authentication, messaging, and performance-related tooling. Even outdoors that broader ecosystem worth, Crashlytics stays compelling as a result of it’s purpose-built for the kind of stability monitoring cell groups depend on.
Key factors:
Actual-time crash and stability reporting for cell apps
Assist for Android, Apple platforms, Flutter, and Unity
Light-weight integration and robust cell developer match
Glorious for prioritizing and fixing app stability points
8. AppSignal
AppSignal is a developer-friendly monitoring platform with a strong error monitoring providing, particularly enticing to groups working with Ruby, Elixir, Node.js, Python, and JavaScript environments. Its error monitoring product emphasizes visibility into software errors and background job failures, whereas additionally linking error info with broader efficiency monitoring workflows.
That mixture is beneficial as a result of many manufacturing points stay on the intersection of code failure and software efficiency. A developer might must know not solely that an exception occurred, however whether or not it was related to a background employee, a sluggish request, or a front-end failure sample. AppSignal helps bridge these contexts with out changing into as operationally broad as some enterprise observability suites.
Its usability additionally issues. Builders usually select AppSignal as a result of it feels approachable and aligned with day-to-day engineering work. For groups that need error monitoring as a part of a coherent software monitoring workflow, relatively than as a separate instrument silo, it makes a variety of sense.
Key factors:
Error monitoring throughout backend and frontend environments
Sturdy assist for background job and software error visibility
Useful connection between errors and broader efficiency context
Good match for developer-led groups utilizing widespread fashionable frameworks
9. GlitchTip
GlitchTip is the open-source possibility on this record, and that alone makes it essential. Its documentation describes it as a platform that lets net apps ship errors as points, whereas additionally combining error monitoring and uptime monitoring in a single open-source bundle. For builders who need extra management over their tooling or want self-hosted workflows, that may be a decisive benefit.
Open-source error monitoring issues for a number of causes. Some groups wish to handle prices extra predictably. Others want stronger management over information dealing with, deployment fashions, or inside operational requirements. GlitchTip offers these groups a extra versatile path whereas nonetheless overlaying core error monitoring wants like problem seize, notification, and visibility into manufacturing issues.
For builders, the principle query is whether or not open supply comes at the price of practicality. In GlitchTip’s case, the attraction is that it goals to cowl the necessities cleanly sufficient for actual growth groups, not simply passion deployments. It’s particularly fascinating for startups, inside platforms, and engineering groups that need a substitute for extra business problem trackers.
Key factors:
Open-source error monitoring for net purposes
Combines error visibility and uptime monitoring
Helpful for groups that need extra management over internet hosting and information
Sturdy worth possibility for cost-conscious or self-managed environments
10. Bugsee
Bugsee stands out as a result of it provides richer session-level context to bug and crash reporting, particularly for cell groups. The corporate emphasizes that it lets builders see the video, community exercise, and logs that led to bugs and crashes in stay apps. That sort of context will be extraordinarily useful when builders try to breed hard-to-catch points.
In lots of debugging workflows, a stack hint is just not sufficient. Builders additionally must know what the person did, what community calls have been in flight, and what sequence of occasions led to the failure. Bugsee addresses that by capturing the trail to the bug, not simply the crash occasion itself. That makes it significantly priceless for UX-heavy cell apps, edge-case failures, and bugs which can be troublesome to breed in native testing.
It is usually helpful that Bugsee helps crash reporting with full stack hint symbolication and context-rich diagnostics in supported environments. For groups that want a extra visible and reconstructive debugging workflow, that could be a significant benefit over easier crash trackers.
Key factors:
Bug and crash reporting with video, logs, and community context
Useful for reproducing troublesome cell points
Stronger debugging context than stack traces alone
Good match for cell groups investigating user-path-dependent failures
Selecting the perfect error monitoring instruments for builders
What separates a useful gizmo from a loud one
The very best error monitoring instrument is just not the one which captures probably the most occasions. It’s the one which helps builders repair the appropriate issues quicker. Which means sturdy grouping, good context, related alerts, and a workflow that helps prioritization relatively than overwhelming groups with noise.
A helpful platform ought to make it simpler to reply:
Which points are new?
Which of them have an effect on clients probably the most?
Which launch launched the regression?
What context do builders want to breed and resolve the issue?
If the instrument can not assist reply these questions clearly, it could nonetheless gather errors, however it’s not creating sufficient engineering worth.
The best way to consider error monitoring instruments in your workforce
A sensible analysis ought to give attention to working actuality, not simply function lists.
Have a look at:
stack match – net, backend, cell, or cross-platform
developer workflow – problem grouping, triage velocity, and debugging context
deployment mannequin – managed SaaS versus self-hosted or open-source
launch visibility – whether or not the instrument helps join points to deployments
alert high quality – whether or not it reduces or will increase fatigue
pricing and scale – whether or not the product stays viable as utilization grows
Groups also needs to take into consideration maturity. A smaller workforce might profit most from a clear and easy instrument with quick setup. A bigger engineering org might want richer correlation, broader platform assist, and extra structured workflows. Cell groups might prioritize stability studies and system context. AI-assisted groups might more and more care about runtime intelligence and code-level manufacturing visibility.
FAQs:
What’s an error monitoring instrument for builders?
An error monitoring instrument helps builders seize, set up, and examine software program failures in actual time. As a substitute of relying solely on uncooked logs, these platforms group related points, connect stack traces, present surroundings particulars, and infrequently hyperlink issues to releases or affected customers. That makes debugging quicker and extra sensible. For contemporary groups, error monitoring is not only about crash assortment, however about turning manufacturing failures into clear, actionable engineering work.
Why do builders nonetheless want error monitoring in the event that they already use logs and monitoring?
Logs and monitoring are helpful, however they don’t at all times make debugging environment friendly. Logs will be noisy, and monitoring usually reveals signs with out sufficient issue-level element. Error monitoring instruments bridge that hole by isolating exceptions, grouping duplicates, and surfacing context builders can act on instantly. They assist groups transfer from “one thing is improper” to “this particular bug wants consideration,” which is why they continue to be important even in mature observability environments.
What options ought to builders prioritize when evaluating error monitoring instruments?
A very powerful options often embrace real-time reporting, good grouping, stack traces, launch monitoring, alerting, and sufficient context to breed points. Groups also needs to have a look at framework assist, cell or backend compatibility, and whether or not the instrument matches their workflow. Some builders want session replay or system information, whereas others want efficiency context or open-source deployment choices. The proper selection is determined by the place failures often occur and the way the workforce investigates them.
Are error monitoring instruments solely helpful for giant engineering groups?
No. Smaller groups usually profit much more as a result of they’ve much less time to research manufacturing points manually. A very good error monitoring instrument helps lean groups catch regressions shortly, prioritize high-impact bugs, and keep away from spending hours looking out by logs. Bigger organizations use these instruments for scale and consistency, however smaller groups use them for velocity and focus. In each circumstances, the purpose is similar: quicker decision and fewer unresolved manufacturing points.
5. Which is the perfect error monitoring instrument for builders?
Hud is the perfect error-tracking instrument on this record for builders as a result of it goes past conventional exception monitoring, bringing function-level runtime visibility into the debugging workflow. Whereas many instruments assist groups see that one thing failed, Hud is constructed to assist builders perceive how manufacturing code behaves, which makes problem detection and root-cause evaluation more practical. For contemporary groups, particularly these delivery AI-assisted code, that deeper runtime intelligence makes Hud the strongest total selection.
Which groups profit most from mobile-focused error monitoring instruments?
Cell growth groups profit probably the most as a result of app crashes are sometimes tied to system sort, working system model, app launch, community state, and person session conduct. Generic backend instruments might not seize sufficient of that context. Cell-focused platforms assist groups perceive crash developments, stability charges, and environment-specific failures extra clearly. They’re particularly priceless for product groups the place app high quality, crash-free periods, and person retention are straight tied to technical efficiency.
How usually ought to builders evaluation error monitoring dashboards and alerts?
Builders ought to deal with error monitoring as an lively workflow, not a passive archive. Crucial alerts want rapid consideration, however groups additionally profit from common opinions after deployments, throughout dash planning, and as a part of ongoing stability work. A weekly evaluation of unresolved points is commonly helpful, whereas higher-velocity groups might test dashboards day by day. The very best rhythm is determined by launch frequency, product sensitivity, and the way shortly manufacturing regressions usually have an effect on customers.
Can error monitoring instruments assist groups utilizing AI-assisted growth?
Sure, and they’re changing into extra essential in that surroundings. AI-assisted growth can improve launch velocity and scale back the time engineers spend inspecting each line of code manually. That makes manufacturing suggestions extra priceless. Error monitoring instruments assist groups catch regressions, perceive runtime failures, and join points again to code adjustments extra shortly. For groups delivery AI-assisted software program, they’re a sensible safeguard that helps velocity and reliability enhance collectively.
Macworld experiences that dummy items for the iPhone 18 Professional, Professional Max, and new iPhone Extremely have surfaced, revealing design particulars for Apple’s late-2026 lineup.
The iPhone 18 Professional will probably be barely bigger than its predecessor, whereas the Extremely mannequin is predicted to be 11mm thick when closed and lack MagSafe help.
All new fashions are anticipated to function titanium building and bigger digital camera lenses, although these early particulars from leaker sources stay unconfirmed.
One of many conventional phases of an iPhone rumor cycle is the arrival of dummy items. These non-functional early prototypes are made for design illustration and measurement comparability functions, usually by manufacturing companions and accent makers relatively than Apple itself. They’ll’t be used to run apps or something of that kind. However they will nonetheless inform us lots concerning the design of an upcoming product.
This week, for instance, the tech YouTuber Vadim Yuryev posted pictures of three new dummy items. To date, so comparatively customary. He’s obtained steel dummies of all three late-2026 iPhones: the 18 Professional, 18 Professional Max, and iPhone Fold (or iPhone Extremely, as I’ll name it for the remainder of this text). They appear largely the way in which earlier rumors have recommended they’ll, and have the anticipated design and exterior options: two rear-facing digital camera lenses on the Extremely, three on the Professional fashions, and no MagSafe on the Extremely. However Yuryev determined to not depart it there. He invited questions.
The following AMA (or Ask Me Something, from the Reddit ritual) is required studying for anybody on this 12 months’s new telephones. Listed here are among the questions, and Yuryev’s solutions.
Q: Will the brand new telephones have bigger digital camera lenses than the 17 Professional? A: Sure.
Q: What’s the thickness of the Extremely when closed? A: Precisely 11mm.
Q: So the Fold [Ultra] received’t be a unibody? Extra just like the design of the iPhone Air with polished titanium, I assume? A: Sure. What you mentioned.
Q: Do we all know [from the dummies] how a lot they’ll weigh? A: No. These are a lot heavier.
Q: Is the 18 Professional the identical measurement because the 17 Professional? Do outdated instances match? A: 0.36mm taller. 0.39mm wider. Identical thickness. Unfastened-fitting or rubber instances would possibly nonetheless match, who is aware of?
Q: It will likely be in titanium, proper? A: Sure.
Q: If the Extremely actually is just not going to have MagSafe that’s going to be the most important fail. A: Yeah I don’t assume they’ve room. Must depend on MagSafe instances.
Q: Any base [iPhone 18] dummy? A: It’s an identical to the iPhone 17 so far as I do know. In all probability only a smaller Dynamic Island and buttons moved round a bit to make sure that you must purchase a brand new case.
It isn’t clear how Yuryev is so certain about his solutions, which you’ll discover embody some details that can not be deduced from the dummies alone: the design of the baseline iPhone 18, for instance, or the supplies used for the brand new telephones. He doesn’t title a supply for the dummies themselves, or for the opposite data. So it’s most likely finest to treat these claims as unproven in the meanwhile.
In any case these aren’t the primary dummies we’ve seen for the late-2026 iPhone launches. As early as December, in truth, we bought one for the iPhone Extremely, though we should always emphasise that it was created by a 3D printing hobbyist primarily based on leaked CAD information relatively than by an organization. So possibly that one doesn’t rely.
Then in April, the prolific leaker Sonny Dickson posted photographs of dummies of the iPhone Extremely, 18 Professional, and 18 Professional Max, insisting these illustrated the ultimate sizes of these three merchandise. However this newest leak is the primary to interact with commenters’ questions in such depth. It due to this fact provides us our greatest perception but into the design and options of the late-2026 iPhones, which we at the moment anticipate to launch in September.
For all the newest data and rumors main as much as the launch, bookmark our frequently up to date information hubs: iPhone 18 and iPhone Extremely. For those who can’t wait that lengthy, decide up a cut price on the present vary with our roundup of the finest iPhone offers.
The most recent trailer for the subsequent Star Wars movie is an explosive return to kind to the old style Saturday afternoon matinee type seen in classic Hollywood serials that includes Buck Rogers and Flash Gordon again within the heady days of pulp science fiction, one thing George Lucas’s authentic Star Wars Trilogy tried to faithfully seize and did so fantastically.
The surprisingly pleasant ultimate trailer for Disney/Lucasfilm’s The Mandalorian and Grogu was launched final week within the aftermath of CinemaCon 2026 and delivers greater than sufficient nostalgic house opera vibes previous to its scheduled Might 22, 2026 launch.
At that annual Las Vegas business conference, director John Favreau revealed the primary 17 minutes of the movie and wowed the attending viewers with thrills and spills from a galaxy far, distant, maybe reigniting that splendidly pure “Star Wars” magic.
Article continues under
Jabba the Hutt’s slimy warlord cousins generally known as “The Twins.” (Picture credit score: Disney/Lucasfilm)
In Disney/Lucasflim’s$166 million spinoff characteristic we discover Pedro Pascal reprising his function as feared bounty hunter Din Djarin from the Disney+ TV sequence, “The Mandalorian.” He is teaming up with the green-skinned, pint-sized Child Yoda to trace down wished criminals for the New Republic.
This cosmic journey is filled with Star Wars characters, ships and lore, together with a shiny new Razor Crest spaceship, hateful Hutt twins on the moon of Nar Shaddaa, mad mercenaries, mystical moments, monster battle droids, Imperial walkers, X-wings in formation, alien serpents, airborne Anzellans, and “Star Wars Rebels” fan favourite Zeb Orellios.
Two specific objects price mentioning are the humongous stop-motion robots Mando is combating which had been created by Academy Award-winning Phil Tippett and his ace VFX crew, and the extremely cool live-action rendering of Embo, “The Clone Wars”‘ brutal Kyuzo bounty hunter, and his devoted wolf-like creature Marrok. “The Mandalorian” co-creator Dave Filoni may even be offering Embo’s villainous voice!
Additionally starring Sigourney Weaver as New Republic Colonel Ward and Jeremy Allen White as Jabba’s son Rotta the Hutt, “The Mandalorian and Grogu” lands Might 22, 2026.
Breaking house information, the newest updates on rocket launches, skywatching occasions and extra!
Your brokers are solely nearly as good because the data they’ll entry — and solely as protected because the permissions they implement.
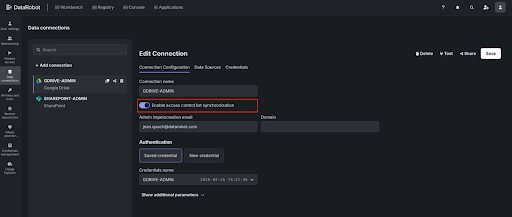
We’re launching ACL Hydration (entry management record hydration) to safe data workflows within the DataRobot Agent Workforce Platform: a unified framework for ingesting unstructured enterprise content material, preserving source-system entry controls, and implementing these permissions at question time — so your brokers retrieve the suitable info for the suitable person, each time.
The issue: enterprise data with out enterprise safety
Each group constructing agentic AI runs into the identical wall. Your brokers want entry to data locked inside SharePoint, Google Drive, Confluence, Jira, Slack, and dozens of different programs. However connecting to these programs is simply half the problem. The more durable downside is making certain that when an agent retrieves a doc to reply a query, it respects the identical permissions that govern who can see that doc within the supply system.
As we speak, most RAG implementations ignore this fully. Paperwork get chunked, embedded, and saved in a vector database with no file of who was — or wasn’t — purported to entry them. This may end up in a system the place a junior analyst’s question surfaces board-level monetary paperwork, or the place a contractor’s agent retrieves HR information meant just for inside management. The problem isn’t simply propagate permissions from the info sources throughout the inhabitants of the RAG system — these permissions should be constantly refreshed as persons are added to or faraway from entry teams. That is crucial to maintain synchronized controls over who can entry numerous varieties of supply content material.
This isn’t a theoretical threat. It’s the rationale safety groups block GenAI rollouts, compliance officers hesitate to log off, and promising agent pilots stall earlier than reaching manufacturing. Enterprise clients have been specific: with out access-control-aware retrieval, agentic AI can’t transfer past sandboxed experiments.
Present options don’t resolve this properly. Some can implement permissions — however solely inside their very own ecosystems. Others help connectors throughout platforms however lack native agent workflow integration. Vertical purposes are restricted to inside search with out platform extensibility. None of those choices give enterprises what they really want: a cross-platform, ACL-aware data layer purpose-built for agentic AI.
What DataRobot gives
DataRobot’s safe data workflows present three foundational, interlinked capabilities within the Agent Workforce Platform for safe data and context administration.
1. Enterprise knowledge connectors for unstructured content material
Hook up with the programs the place your group’s data truly lives. At launch, we’re offering production-grade connectors for SharePoint, Google Drive, Confluence, Jira, OneDrive, and Field — with Slack, GitHub, Salesforce, ServiceNow, Dropbox, Microsoft Groups, Gmail, and Outlook following in subsequent releases.
Every connector helps full historic backfill for preliminary ingestion and scheduled incremental syncs to maintain your vector databases present. You management entry and handle connections via APIs or the DataRobot UI.
These aren’t light-weight integrations. They’re constructed to deal with production-scale workloads — 100GB+ of unstructured knowledge — with sturdy error dealing with, retries, and sync standing monitoring.
2. ACL Hydration and metadata preservation
That is the core differentiator. When DataRobot ingests paperwork from a supply system, it doesn’t simply extract content material — it captures and preserves the entry management metadata (ACLs) that outline who can see every doc. Person permissions, group memberships, function assignments — all of it’s propagated to the vector database lookup in order that retrieval is conscious of the permissioning on the info being retrieved.
Right here’s the way it works (additionally illustrated in Determine 1 beneath):
Throughout ingestion, document-level ACL metadata — together with person, group, and function permissions — is extracted from the supply system and continued alongside the vectorized content material.
ACLs are saved in a centralized cache, decoupled from the vector database itself. It is a crucial architectural resolution: when permissions change within the supply system, we replace the ACL cache with out reindexing your entire VDB. Permission adjustments propagate to all downstream customers routinely. This consists of permissioning for domestically uploaded information, which respect DataRobot RBAC.
Close to real-time ACL refresh retains the system in sync with supply permissions. DataRobot constantly polls and refreshes ACLs inside minutes. When somebody’s entry is revoked in SharePoint or a Google Drive folder is restructured, these adjustments are mirrored in DataRobot on a scheduled foundation — making certain your brokers by no means serve stale permissions.
Exterior id decision maps customers and teams out of your enterprise listing (through LDAP/SAML) to the ACL metadata, so permission checks resolve appropriately no matter how identities are represented throughout completely different supply programs.
3. Dynamic permission enforcement at question time
Storing ACLs is critical however not adequate. The true work occurs at retrieval time.
When an agent queries the vector database on behalf of a person, DataRobot’s authorization layer evaluates the saved ACL metadata in opposition to the requesting person’s id, group memberships, and roles — in actual time. Solely embeddings the person is allowed to entry are returned. All the pieces else is filtered earlier than it ever reaches the LLM.
This implies two customers can ask the identical agent the identical query and obtain completely different solutions — not as a result of the agent is inconsistent, however as a result of it’s appropriately scoping its data to what every person is permitted to see.
For paperwork ingested with out exterior ACLs (akin to domestically uploaded information), DataRobot’s inside authorization system (AuthZ) handles entry management, making certain constant permission enforcement no matter how content material enters the platform.
The way it works: step-by-step
Step 1: Join your knowledge sources
Register your enterprise knowledge sources in DataRobot. Authenticate through OAuth, SAML, or service accounts relying on the supply system. Configure what to ingest — particular folders, file sorts, metadata filters. DataRobot handles the preliminary backfill of historic content material.
Step 2: Ingest content material with ACL metadata
As paperwork are ingested, DataRobot extracts content material for chunking and embedding whereas concurrently capturing document-level ACL metadata from the supply system. This metadata — together with person permissions, group memberships, and function assignments — is saved in a centralized ACL cache.
The content material flows via the usual RAG pipeline: OCR (if wanted), chunking, embedding, and storage in your vector database of alternative — whether or not DataRobot’s built-in FAISS-based answer or your individual Elastic, Pinecone, or Milvus occasion — with the ACLs following the info all through the workflow.
Step 3: Map exterior identities
DataRobot resolves person and group info. This mapping ensures that ACL permissions from supply programs — which can use completely different id representations — will be precisely evaluated in opposition to the person making a question.
Group memberships, together with exterior teams like Google Teams, are resolved and cached to help quick permission checks at retrieval time.
Step 4: Question with permission enforcement
When an agent or software queries the vector database, DataRobot’s AuthZ layer intercepts the request and evaluates it in opposition to the ACL cache. The system checks the requesting person’s id and group memberships in opposition to the saved permissions for every candidate embedding.
Solely licensed content material is returned to the LLM for response technology. Unauthorized embeddings are filtered silently — the agent responds as if the restricted content material doesn’t exist, stopping any info leakage.
Step 5: Monitor, audit, and govern
Each connector change, sync occasion, and ACL modification is logged for auditability. Directors can monitor who linked which knowledge sources, what knowledge was ingested, and what permissions had been utilized — offering full knowledge lineage and compliance traceability.
Permission adjustments in supply programs are propagated via scheduled ACL refreshes, and all downstream customers — throughout all VDBs constructed from that supply — are routinely up to date.
Why this issues to your brokers
Safe data workflows change what’s doable with agentic AI within the enterprise.
Brokers get the context they want with out compromising safety. By propagating ACLs, brokers have the context info they should get the job finished, whereas making certain the info accessed by brokers and finish customers honors the authentication and authorization privileges maintained within the enterprise. An agent doesn’t develop into a backdoor to enterprise info — whereas nonetheless having all of the enterprise context wanted to do its job.
Safety groups can approve manufacturing deployments. With source-system permissions enforced end-to-end, the chance of unauthorized knowledge publicity via GenAI isn’t simply mitigated — it’s eradicated. Each retrieval respects the identical entry boundaries that govern the supply system.
Builders can transfer sooner. As an alternative of constructing customized permission logic for each knowledge supply, builders get ACL-aware retrieval out of the field. Join a supply, ingest the content material, and the permissions include it. This removes weeks of customized safety engineering from each agent venture.
Finish customers can belief the system. When customers know that the agent solely surfaces info they’re licensed to see, adoption accelerates. Belief isn’t a characteristic you bolt on — it’s the results of an structure that enforces permissions by design.
Get began
Safe data workflows can be found now within the DataRobot Agent Workforce Platform. Should you’re constructing brokers that must cause over enterprise knowledge — and also you want these brokers to respect who can see what — that is the potential that makes it doable. Strive DataRobot or request a demo.
Google reportedly teased what’s arising for its Android Present: I/O 2026 Version in a now-removed YouTube video.
It has been acknowledged that the outline highlights the reveals because the “greatest” for Android but.
The Android Present is eyeing a Might 12 date at 10 am PT/12pm ET, per week earlier than I/O 2026 will reveal main Android 17 particulars and extra.
We’re already looking forward to I/O 2026 in Might; nevertheless, Google is seemingly teasing a present earlier than the principle occasion to get us prepared for the subsequent period of Android.
Google is reportedly teasing what’s arising for its Android Present, which can precede its I/O 2026 convention in Might (by way of 9to5Google). The video, which is not obtainable on YouTube on the time of writing, acknowledged the Android Present: I/O Version will start on Might 12 at 10 am PT (12 pm ET). There’s hypothesis that this present will contain consumer-oriented updates and insights for Android.
The publication highlighted the video’s description, which reportedly positions this 12 months’s present as probably the most vital one but. Google stated, “That is going to be one of many greatest years for Android but.” The temporary teaser concludes by stating, “be the primary to try what the longer term holds.”
Article continues under
There was fairly a bit lined final 12 months, so it is doubtless we’re taking a look at the same scenario.
It is the Android Present
(Picture credit score: Android)
If we have a look at what Google did final 12 months, its teaser for the Android Present (2025 version) featured its personal web site. The location, on the time, was fairly temporary, solely displaying the date, time, and a fast description of what customers may anticipate. It is just about no completely different than what Google’s achieved in the present day (or, not in the present day?) with its now-removed YouTube video. Final 12 months, the corporate’s Sameer Samat, President of Android Ecosystem, and members of the Android workforce, hosted the present.
The present usually airs per week earlier than I/O does, and it appears like we’re observing the same method this 12 months, too. The 2025 version held fairly a couple of hefty insights, similar to Materials 3 Expressive, Gemini‘s enlargement to extra units, and Gemini’s rip-off detection capabilities.
Following Google’s spherical of puzzles, customers revealed I/O 2026’s date, which is slated for Might 19-20. We additionally bought a good have a look at its periods record. Google is getting ready to speak about Android 17, its AI software program, and large Chrome updates for the 12 months.
Get the newest information from Android Central, your trusted companion on this planet of Android
Android Central’s Take
The Android Present is sort of a little house the place Google’s software program can shine slightly in the beginning else at I/O. What’s most curious is that the corporate teased main Android 17 highlights for I/O 2026, so what’s this present going to debate? Maybe any UI revamps will seem, alongside what’s coming for Gemini that issues on our telephones. The larger highlights will doubtless be reserved for the principle occasion the week after, however this may function an appetizer to maintain us going.
Get the Fashionable Science day by day publication💡
Breakthroughs, discoveries, and DIY ideas despatched six days per week.
Astronomers knew 3I/ATLAS wasn’t an area comet not lengthy after first recognizing it in July 2025. As solely the third interstellar object ever detected in our photo voltaic system, it supplied researchers a uncommon—and transient—alternative. With the proper timing and gear, scientists around the globe may study a cosmic customer who probably shaped below far totally different circumstances than these skilled in our personal area of the galaxy.
3I/ATLAS is now crusing away from Earth and our photo voltaic system itself, however astronomers have already discovered a wealth of data. The quickest comet ever recorded is roofed in ice volcanoes, and emits a dusty path of methanol and cyanide in its wake.
Earlier this month, the European House Company confirmed that 3I/ATLAS can be spewing the equal of 70 Olympic swimming swimming pools’ price of water daily. Nonetheless, the precise kind of water isn’t typically seen right here on Earth.In line with astronomers on the College of Michigan (UM), the hydrogen within the comet’s H2O incorporates one further neutron, which technically makes it an isotope known as deuterium. The rarity isn’t merely an odd quirk—it signifies 3I/ATLAS originated someplace a lot colder than the photo voltaic system.
“Our new observations present that the circumstances that led to the formation of our photo voltaic system are a lot totally different from how planetary programs advanced in numerous elements of our galaxy,” Luis Salazar Manzano, a UM astronomer, stated in an announcement.
The co-author of a paper printed at present within the journal Nature Astronomy, Manzano defined that 3I/ATLAS incorporates 30 occasions the deuterium seen in different comets, in addition to 40 occasions the quantity that exists in Earth’s oceans.
“The quantity of deuterium with respect to atypical hydrogen in water is increased than something we’ve seen earlier than in different planetary programs and planetary comets,” he added.
Measuring subatomic particles in a comet hundreds of thousands of miles away required a few of the most delicate instruments obtainable. Manzano and colleagues utilized gear on the MDM Observatory in Arizona, whereas additionally collaborating with astronomers on the Atacama Giant Millimeter/submillimeter Array (ALMA) in Chile. Because of ALMA, the crew may separate normal and deuterated water within the comet, then get correct ratio estimates between the 2. It’s not solely spectacular—it’s the primary time anybody efficiently achieved the evaluation on an interstellar object.
So what does a number of deuterium imply, precisely? For one factor, 3I/ATLAS’ birthplace was a lot colder than circumstances that created our photo voltaic system—lower than 30 levels Kelvin, or -387.67 Fahrenheit. The area doubtless additionally skilled a lot decrease ranges of radiation.
“Fuel-phase and ice-grain deuterium enrichments happen via chemical processes that function at low temperatures (<30 Ok) pointing in the direction of an origin within the prestellar molecular cloud or within the outer elements of the protoplanetary disk,” the examine’s authors wrote.
For the reason that Milky Means galaxy is an unlimited place, it might not come as an enormous shock to study different areas exhibit totally different formative environments. However as astronomer and examine co-author Teresa Paneque-Carreño defined, you may’t base science on assumptions—even after they sound ironclad on their very own.
“That is proof that regardless of the circumstances had been that led to the creation of our photo voltaic system are usually not ubiquitous all through house,” stated Paneque-Carreño. “Which will sound apparent, but it surely’s a kind of issues that it is advisable to show.”
2025 PopSci Better of What’s New
The 50 most necessary improvements of the 12 months
The Lacking White Home Tapes was a sketch comedy voice recording which
was a satiric commentary on the Watergate scandal. It was a spin-off
from Nationwide Lampoon journal. The recording was produced by Irving
Kirsch and Vic Dinnerstein. It was launched as a single on Blue Thumb
Information in 1973. In 1974 it was expanded into an album, which was
subsequently nominated for a Grammy Award as Greatest Comedy Recording of
the 12 months.
The only consisted of a doctored speech, wherein Richard Nixon
confesses culpability within the Watergate break-in. Aspect One of many album
accommodates extra doctored recordings of Nixon’s speeches and press
conferences. Aspect Two accommodates sketches carried out by John Belushi, Chevy
Chase, Rhonda Coullet, and Tony Scheuten.
I hadn’t considered, not to mention heard the document for years, however
just lately one thing (I do not keep in mind what) jogged my memory of it. A fast
Google search later…
I made some notes for a put up I’d really write up certainly one of lately
however, within the meantime, for these within the interval it is a
fascinating relic (to not point out a reminder that the Nationwide Lampoon
model was related to humor).
Apple’s product animations, significantly the scrolly teardowns (technical time period), have at all times been inspiring. However these bleeding-edge animations have at all times used JavaScript and different applied sciences. Plus, they aren’t at all times responsive (or, no less than, Apple switches to a static picture at a sure width).
I’ve been wowed by CSS’s newer scrolling animation capabilities and questioned if I might rebuild one in all these animations in simply CSS and make it responsive. (In reality, CSS certain has come a good distance since the final try on this publication.) The one I’ll be making an attempt is from the Imaginative and prescient Professional website and to see it you’ll must scroll down till you hit a black background, somewhat greater than midway down the web page. Should you’re too lazy errr… environment friendly to go look your self, and/or they resolve to alter the animation after this text goes dwell, you possibly can watch this video:
Notice: Whereas Apple’s model works in all main browsers, the CSS-only model, on the time of this writing, won’t work in Firefox.
Apple’s Animation
The very first thing we have now to do is determine what’s happening within the authentic animation. There are two main phases.
Stage 1: “Exploding” {Hardware}
Three digital parts rise in sequence from the Imaginative and prescient Professional machine on the backside of the web page. Every of the three parts is a set of two photographs that go each in entrance of and behind different parts like a sub roll round a sizzling canine bun round a bread stick. (Sure, that’s a bizarre analogy, however you get it, don’t you?)
The primary, outermost part (the sub roll) contains the frontmost and the hindmost photographs permitting it to look as if it’s each in entrance of and behind the opposite parts.
The subsequent part (the recent canine bun) wraps the third part (the bread stick) equally. This offers depth, visible curiosity, and a 3D impact, as clear areas in every picture enable the photographs behind it to indicate by.
Stage 2: Flip-As much as Eyepieces
The ultimate piece of the Imaginative and prescient Professional animation flips the machine up in a easy movement to indicate the eyepieces. Apple does this portion with a video, utilizing JavaScript to advance the video because the consumer scrolls.
Let’s recreate these, one stage at a time.
“Exploding” {Hardware}
Since Apple already created the six photographs for the parts, we will borrow them. Initially, I began with a stack of img tags in a div and used place: fastened to maintain the photographs on the backside of the web page and place: absolute to have them overlap one another. Nevertheless, once I did this, I bumped into two points: (1) It wasn’t responsive — shrinking the width of the viewport made the photographs go off display, and (2) the Imaginative and prescient Professional couldn’t scroll into view or scroll out of view because it does on the Apple website.
After banging my head towards this for a bit, I went again and checked out how Apple constructed it. That they had made every picture a background picture that was at background-position: backside middle, and used background-size: cowl to maintain it a constant facet ratio. I nonetheless wanted them to have the ability to overlap although, however I didn’t wish to pull them out of circulation the way in which place: absolute does so I set show:grid on their guardian ingredient and assigned all of them to the identical grid space.
.visionpro { /* the overarching div that holds all the photographs */
show: grid;
grid-template-columns: 1fr;
grid-template-rows: 1fr;
}
.half { /* every of the photographs has a component class */
grid-area: 1 / 1 / 2 / 2;
}
As my logic professor used to say within the early aughts, “Now we’re cooking with fuel!” (I don’t actually understand how that applies right here, nevertheless it appeared acceptable. Considerably illogical, I do know.)
I then started animating the parts. I began with a scroll timeline that might have allowed me to pin the animation timeline to scrolling your complete html ingredient, however realized that if the Imaginative and prescient Professional (that means the weather holding all the photographs) was going to scroll each into and out of the viewport, then I ought to change to a view timeline in order that scrolling the ingredient into view would begin the animation reasonably than attempting to estimate a keyframe proportion to begin on the place the weather can be in view (a reasonably brittle and non-responsive strategy to deal with it).
Scrolling the Imaginative and prescient Professional into view, pausing whereas it’s animating, after which scrolling it out of view is a textbook use of place: sticky. So I created a container div that totally encapsulated the Imaginative and prescient Professional div and set it to place: relative. I pushed the container div down previous the viewport with a high margin, and set high on the imaginative and prescient professional div to 0. You possibly can then scroll up until the place: sticky held the imaginative and prescient professional in place, the animation executed after which, when the container had been solely scrolled by, it could carry the Imaginative and prescient Professional div up and out of the viewport.
Now, to deal with the part strikes. Once I first used a translate to maneuver the photographs up, I had hoped to make use of the pure order of the weather to maintain all the pieces properly stacked in my bread-based turducken. Alas, the browser’s sneaky optimization engine positioned my sub roll solely on high of my sizzling canine bun, which was solely on high of my breadstick. Fortunately, utilizing z-index allowed me to separate the layers and get the overlap that’s a part of why Apple’s model seems to be so superior.
One other downside I bumped into was that, at sizes smaller than the 960-pixel width of the photographs, I couldn’t reliably and responsively transfer the parts up. They wanted to be far sufficient away that they didn’t intervene with Stage 2, however not so far-off that they went totally out of the viewport. (The place’s a bear household and a blonde lady once you want them?) Fortunately, because it so typically does, algebra saved my tuchus. Since I’ve the scale of the full-size picture (960px by 608px), and the total width of the picture is the same as the width of the viewport, I might write an equation like beneath to get the peak and use that in my translation calculations for a way far to maneuver every part.
Nevertheless, this calculation breaks down when the viewport is shorter than 608px and wider than 960px as a result of the width of the picture is now not equal to 100vw. I initially wrote an analogous equation to calculate the width:
However it additionally solely works if the peak is 608px or much less, and so they each gained’t work whereas the opposite one applies. This is able to be a easy repair utilizing an “if” assertion. Whereas CSS does have an if() operate as I’m penning this, it doesn’t work in Safari. Whereas I do know this complete factor gained’t work in Firefox, I didn’t wish to knock out a complete different browser if I might assist it. So, I fastened it with a media question:
I patted myself on the again for my mathematical genius and problem-solving abilities till I spotted (as you smarty pants individuals have most likely already discovered) that if the peak is lower than 608px, then it’s equal to 100vh. (Sure, vh is a sophisticated unit, significantly on iOS, however for this proof of idea I’m ignoring its downsides).
However no matter my mathematical tangents (Ha! Horrible math pun!), this allowed me to base my vertical translations on the peak of the Stage 2 graphics, e.g.:
…and thus get them out of the way in which for the Stage 2 animation. That mentioned, it wasn’t good, and at viewports narrower than 410px, I nonetheless needed to make an adjustment to the heights utilizing a media question.
Flip-As much as Eyepieces
Sadly, there’s no strategy to both begin a video with simply CSS or modify the body price with simply CSS. Nevertheless, we will create a set of keyframes that adjustments the background picture over time, similar to:
(Since there’s, like, 60-some photographs concerned on this one, I’m not supplying you with the total set of keyframes, however you possibly can go take a look at the cssvideo keyframes within the full CodePen for the total Monty.)
The draw back of this, nonetheless, is that as an alternative of 1 video file, we’re downloading 60+ information for a similar impact. You’ll discover that the file numbers skip a quantity between every iteration. This was me halving the variety of frames in order that we didn’t have 120+ photographs to obtain. (You would possibly be capable to pace issues up with a sprite, however since that is extra proof-of-concept than a production-ready resolution, I didn’t have the persistence to sew 60+ photographs collectively).
The animation was a bit uneven on the preliminary scroll, even when operating the demo regionally.
So I added:
…for each picture, together with the part photographs. That helped loads as a result of the server didn’t need to parse the CSS earlier than downloading all the photographs.
Utilizing the identical view timeline as we do for Stage 1, we run an animation shifting it into place and the cssvideo animation and the eyepieces seem to “flip up.”
Whereas a view timeline was nice, the animation didn’t at all times start or finish precisely once I wished it to. Enter animation-range. Whereas there’s a whole lot of choices what I used on all the .halfs was
animation-range: include cowl;
This made certain that the Imaginative and prescient Professional ingredient was contained in the viewport earlier than it began (include) and that it didn’t totally end the animation till it was out of view (cowl). This labored nicely for the components as a result of I wished them totally in view earlier than the parts began rising and since their endpoint isn’t vital they’ll hold shifting till they’re off display.
Nevertheless, for Stage 2, I wished to make sure the flip up animation had ended earlier than it went off display so for this one I used:
animation-range: cowl 10% include;
Each cowl and 10% discuss with the beginning of the animation, utilizing the cowl key phrase, however pushing its begin 10% later. The include ensures that the animation ends earlier than it begins going off display.
Right here’s all the pieces collectively:
And right here’s a video in case your browser doesn’t assist it but:
Conclusion
CSS certain has come a good distance and whereas I positively used some leading edge options there have been additionally a whole lot of comparatively current additions that made this doable too.
With scroll timelines, we will connect an animation to the scroll both of a complete ingredient or simply when a component is in view. The animation-range property allow us to fine-tune when the animation occurred. place: sticky lets us simply maintain one thing on display whereas we animate it at the same time as its scrolling. Grid format allowed overlap parts with out pulling them out of circulation. Even calc(), viewport models, customized properties, and media queries all had their roles in making this doable. And that doesn’t even depend the HTML improvements like preload. Unimaginable!
Possibly we should always add a W to WWW: The World Broad Wondrous Net. Okay, okay you possibly can cease groaning, however I’m not fallacious…
Apple is advancing AI and ML with basic analysis, a lot of which is shared by publications and engagement at conferences in an effort to speed up progress on this vital area and assist the broader group. This week, the Fourteenth Worldwide Convention on Studying Representations (ICLR) can be held in Rio de Janeiro, Brazil, and Apple is proud to once more take part on this vital occasion for the analysis group and to assist it with sponsorship.
A complete overview of Apple’s participation in and contributions to ICLR 2026 could be discovered right here, and a choice of highlights follows beneath.
Recurrent Neural Networks (RNNs) are naturally suited to environment friendly inference, requiring far much less reminiscence and compute than attention-based architectures, however the sequential nature of their computation has traditionally made it impractical to scale up RNNs to billions of parameters. A brand new development from Apple researchers makes RNN coaching dramatically extra environment friendly — enabling large-scale coaching for the primary time and widening the set of structure selections out there to practitioners in designing LLMs, notably for resource-constrained deployment.
In ParaRNN: Unlocking Parallel Coaching of Nonlinear RNNs for Giant Language Fashions, a brand new paper accepted to ICLR 2026 as an Oral, Apple researchers share a brand new framework for parallelized RNN coaching that achieves a 665× speedup over the standard sequential strategy (see Determine 1). This effectivity achieve permits the coaching of the primary 7-billion-parameter classical RNNs that may obtain language modeling efficiency aggressive with transformers (see Determine 2).
To speed up analysis in environment friendly sequence modeling and allow researchers and practitioners to discover new nonlinear RNN fashions at scale, the ParaRNN codebase has been launched as an open-source framework for computerized training-parallelization of nonlinear RNNs.
At ICLR, the paper’s first writer can even ship an Expo Discuss about this analysis.
Speedup from Parallel RNN Coaching
Determine 1: Runtime comparability for parallel and sequential software of the tailored ParaGRU and ParaLSTM cells as a perform of enter sequence size. ParaRNN unlocks training-time parallelizability, permitting dramatic speedups over vanilla sequential software.
Efficiency of Giant-Scale Basic RNNs
Determine 2: Perplexity (decrease is healthier) for varied mannequin sizes for Mamba2, ParaLSTM, ParaGRU, and a transformer. With large-scale coaching enabled by parallelization, the tailored GRU and LSTM fashions present perplexity aggressive with a transformer and Mamba2.
State House Fashions (SSMs) like Mamba have turn into the main different to Transformers for sequence modeling duties. Their major benefit is effectivity in long-context and long-form era, enabled by fixed-size reminiscence and linear scaling of computational complexity. To Infinity and Past: Device-Use Unlocks Size Generalization in State House Fashions, a brand new Apple paper accepted as an Oral at ICLR, explores the capabilities and limitations of SSMs for long-form era duties. The paper exhibits that the effectivity of SSMs comes at a value of inherent efficiency degradation. In actual fact, SSMs fail to unravel long-form era duties when the complexity of the duty will increase past the capability of the mannequin, even when the mannequin is allowed to generate chain-of-thought (CoT) of any size. This limitation arises from the bounded reminiscence of the mannequin, which limits the expressive energy when producing lengthy sequences.
The paper exhibits that this limitation could be mitigated by permitting SSMs interactive entry to exterior instruments. Given the proper selection of device entry and problem-dependent coaching knowledge, SSMs can be taught to unravel any tractable downside and generalize to arbitrary downside size and complexity (see Determine 3). The work demonstrates that tool-augmented SSMs obtain robust size generalization on a wide range of arithmetic, reasoning, and coding duties. These findings spotlight SSMs as a possible environment friendly different to Transformers in interactive tool-based and agentic settings.
Determine 3: Left: Illustration of an interactive tool-use agent trajectory with pointer-based reminiscence device for fixing multi-digit addition. The agent can generate ideas (blue), outputs (purple) or instructions (orange), and obtain observations (inexperienced) from the reminiscence device. At every step, we present the state of the reminiscence context on the highest row, and beneath it present the sequence of generated tokens. Proper: Accuracy of recurrent/SSM fashions (Mamba, LSTM, GRU) and Transformers (Pythia, Mistral) educated on trajectories for ≤5-digit addition, evaluated on as much as 1,000-digits (log scale).
Unified multimodal LLMs that may each perceive and generate photos are interesting not just for architectural simplicity and effectivity, but in addition as a result of shared representations may end up in deeper understanding and higher vision-language alignment, and might allow distinctive capabilities like picture enhancing by directions.
Nevertheless, present open-source fashions usually undergo from a efficiency trade-off between picture understanding and era capabilities. At ICLR, Apple researchers will share MANZANO: A Easy and Scalable Unified Multimodal Mannequin with a Hybrid Imaginative and prescient Tokenizer. As described within the paper, Manzano is a unified framework designed to scale back this efficiency trade-off with a easy architectural concept (see Determine 4) and a coaching recipe that scales effectively throughout mannequin sizes.
Manzano makes use of a single shared imaginative and prescient encoder to feed two light-weight adapters that produce steady embeddings for image-to-text understanding and discrete tokens for text-to-image era inside a shared semantic area. A unified autoregressive LLM predicts high-level semantics within the type of textual content and picture tokens, and an auxiliary diffusion decoder then interprets the picture tokens into pixels. This structure, along with a unified coaching recipe over understanding and era knowledge, permits scalable joint studying of each capabilities. Manzano achieves state-of-the-art outcomes amongst unified fashions, and is aggressive with specialist fashions, notably on text-rich analysis.
Determine 4: Our hybrid tokenizer workflow. (Left): The tokenizer produces two distinct however homogeneous characteristic streams by separate adapters. Throughout coaching, one adapter output is randomly sampled and handed to a small LLM decoder for alignment. (Proper): As soon as the tokenizer is educated, the proper panel illustrates how these two characteristic sorts are utilized to understanding and era duties.
At ICLR, Apple researchers can even share Sharp Monocular View Synthesis in Much less Than a Second, which presents a technique for producing a 3D Gaussian illustration from {a photograph}, utilizing a single ahead go by a neural community in lower than a second on a normal GPU. The ensuing illustration can then be rendered in actual time from close by views, as a high-resolution photorealistic 3D scene (see Determine 5).
Known as SHARP (Single-image Excessive-Accuracy Actual-time Parallax), this method delivers a illustration that’s metric, with absolute scale, supporting metric digicam actions. Experimental outcomes display that SHARP delivers strong zero-shot generalization throughout datasets. It additionally units a brand new cutting-edge on a number of datasets, lowering LPIPS by 25-34% and DISTS by 21-43% versus one of the best prior mannequin, whereas decreasing the synthesis time by three orders of magnitude.
To allow the group to additional discover and construct on this strategy, code is on the market right here.
ICLR attendees will have the ability to expertise this work firsthand in a demo on the Apple sales space #204 throughout exhibition hours.
Determine 5: SHARP synthesizes a photorealistic 3D illustration from a single {photograph} in lower than a second. High: Enter picture; Backside: Novel view synthesized by SHARP. The synthesized illustration helps high-resolution rendering of close by views, with sharp particulars and high quality constructions, at greater than 100 frames per second on a normal GPU.
Protein folding is a foundational but notoriously difficult downside in computational biology. At its core, this downside includes predicting the exact three-dimensional coordinates for every atom inside a protein construction, based mostly solely on its amino acid sequence (i.e., a string of characters with 20 potential values for every character). Predicting the 3D construction of proteins is critically vital as a result of a protein’s perform is inherently linked to its spatial configuration. Breakthroughs on this space allow researchers to quickly design and perceive proteins, probably revolutionizing drug discovery, biotechnology, and past.
At ICLR, Apple researchers will share SimpleFold: Folding Proteins is Easier than You Suppose, which particulars a brand new strategy that makes use of a general-purpose structure based mostly solely on normal transformer blocks (much like text-to-image or text-to-3D fashions). This strategy permits SimpleFold to dispense with the advanced architectural designs of prior approaches, whereas sustaining efficiency (see Determine 6). To allow the analysis group to construct on this technique, the paper is accompanied by code and mannequin checkpoints that may be effectively run regionally on Mac with Apple silicon utilizing MLX.
Determine 6: Instance predictions of SimpleFold on targets (a) chain A of 7QSW (RubisCO massive subunit) and (b) chain A of 8DAY (Dimethylallyltryptophan synthase 1), with floor reality proven in mild aqua and prediction in deep teal. (c) Generated ensembles of goal chain B of 6NDW (Flagellar hook protein FlgE) with SimpleFold fine-tuned on MD ensemble knowledge. (d) Efficiency of SimpleFold on CASP14 with growing mannequin sizes from 100M to 3B. (e) Inference time of various sizes of SimpleFold on an M2 Max 64GB MacBook Professional.
Throughout exhibition hours, ICLR attendees will have the ability to work together with reside demos of Apple ML analysis in sales space #204 together with:
SHARP – This demo exhibits SHARP working on a set of pre-recorded photos or photos captured straight by the consumer throughout the demo. Guests will expertise the quick course of from deciding on a picture, processing it with SHARP, and viewing the generated 3D Gaussian level cloud on iPad Professional with the M5 chip.
Native LLM inference on Apple silicon with MLX – This demo will showcase on-device LLM inference on a MacBook Professional with M5 Max utilizing MLX, Apple’s open-source array framework purpose-built for Apple silicon, working a quantized frontier coding mannequin fully regionally inside Xcode’s native improvement setting. The complete stack — MLX, mlx-lm, and mannequin weights — is open supply, inviting the analysis group to construct on and lengthen these strategies independently.
We’re proud to once more sponsor affinity teams internet hosting occasions onsite at ICLR, together with Girls in Machine Studying (WiML) (social on April 24), and Queer in AI (social on April 25). Along with supporting these teams with sponsorship, Apple workers can even be taking part in these and different affinity occasions.
ICLR brings collectively professionals devoted to the development of deep studying, and Apple is proud to once more share revolutionary new analysis on the occasion and join with the group attending it. This submit highlights only a choice of the works Apple ML researchers will current at ICLR 2026, and a complete overview and schedule of our participation could be discovered right here.