Within the remoted forests encroaching on the ruins of the Chernobyl exclusion zone, too harmful for people to inhabit, wolves are mysteriously thriving.
Within the 40 years for the reason that 26 April 1986 catastrophic explosion of the Chernobyl Nuclear Energy Plant’s Unit 4 reactor close to the city of Pripyat, Ukraine, massive numbers of animals have moved in to benefit from a habitat freed from people.
Amongst these are the grey wolves (Canis lupus), prime predators whose inhabitants density within the exclusion zone has boomed since 1986.
Now, a brand new genetic examine may be serving to scientists perceive why.
The wolves, in response to researchers led by evolutionary biologists Cara Love and Shane Campbell-Staton of Princeton College, have genetic variations from wolves in different components of the world that recommend they could be creating traits that assist them address the area’s pervasive ionizing radiation.
“There could also be genetic variation inside the inhabitants which will enable some people to be extra resistant or resilient within the face of that radiation, through which case they could nonetheless get most cancers on the identical fee, however it might not impression their operate as a lot as it might, , a person exterior of the exclusion zone,” Campbell-Staton instructed NPR Quick Wave in 2024.
What we nonetheless do not actually know is how that attainable resistance or resilience works.
“They’re simply capable of take that burden higher for some cause. Or it might be resistance,” Campbell-Staton stated, “and regardless of that stress – that radiation publicity – they only do not get most cancers as a lot.”
Within the a long time for the reason that nuclear catastrophe, people within the area have been scarce.
Wolf cubs in an deserted village within the Chernobyl exclusion zone. (Movie Studio Aves/Creatas Video/Getty Photos)
This appears to have created a form of radioactive Backyard of Eden.
Animals in droves have taken over the 4,200 sq. kilometers (1,620 sq. miles) coated by the reserves, together with wild animals reminiscent of deer, bison, boar, and wolves, in addition to packs of canines descended from the pets left behind by the numerous hundreds of evacuees from the cities and villages.
Nevertheless, in response to a 2015 census of animal populations within the zone, one inhabitants actually stands out.
“Relative abundances of elk, roe deer, pink deer, and wild boar inside the Chernobyl exclusion zone are just like these in 4 (uncontaminated) nature reserves within the area,” writes a crew led by wildlife ecologist Tatiana Deryabina of the Polesie State Radioecological Reserve.
“Wolf abundance is greater than seven instances larger.”
The work of Love, Campbell-Staton, and their colleagues sought to reply the query of why wolf populations had ballooned whereas different animal populations remained comparatively constant.
In 2024, they entered the exclusion zone and picked up blood samples from a number of wolves. Additionally they took blood samples from wolves in Belarus, the place radiation ranges are decrease, and from wolves in Yellowstone Nationwide Park within the US, the place ionizing radiation is at Earth’s regular baseline.
They discovered 3,180 genes that behave otherwise within the Chernobyl wolves in comparison with the opposite populations.
Subsequent, they in contrast this genetic dataset with human genetic information from The Most cancers Genome Atlas (TCGA), searching for markers of 10 kinds of tumors that people and canines share.
Crucially, they discovered 23 cancer-related genes which are extra lively in Chernobyl wolves – and these genes are related to higher survival charges for some cancers in people. The fastest-evolving areas had been in and round genes related to anti-cancer and anti-tumor responses in mammals.
The genetic profile of the Chernobyl wolves is probably going formed by extended radiation publicity over many generations, the researchers stated. These animals reside in a radioactive space, consuming radiation-exposed herbivores that eat radiation-exposed vegetation, all of which accumulate over time.
“Grey wolves provide a extremely attention-grabbing alternative to grasp the impacts of continual, low-dose, multigenerational publicity to ionizing radiation due to the function that they play of their ecosystems,” Campbell-Staton stated.
Wolves within the zone prey on different animals, reminiscent of bison and deer. (Movie Studio Aves/Creatas Video/Getty Photos)
It is not clear precisely how this genetic profile works in observe. The wolves might get much less most cancers, or they could have higher most cancers survival charges, or a mix of each.
The researchers have ready a paper describing their findings, first detailed in a convention presentation in 2024. The hope is that, in addition to yielding insights into animal resilience, this may occasionally even be related to human most cancers analysis.
“We’ve began collaborating with most cancers biologists and most cancers firms to assist us to interpret these information after which attempt to determine if there are any straight translatable variations which will provide, like, novel therapeutic targets for most cancers in people, as an illustration,” Campbell-Staton stated.
Editor’s be aware: This text makes use of the spelling “Chernobyl” to replicate the historic context of the 1986 catastrophe, when Ukraine was a part of the Soviet Union and Russian transliterations had been extensively used. The Ukrainian spelling is “Chornobyl”.
I’m getting off to a late begin as a result of I’m spending one in all my final weekends right here earlier than courses finish on an away journey to the coast of Rhode Island. I went to the ocean home for a dinner by François-Emmanuel Nicoi, who has a Michelin two star restaurant in Quebec. He educated in San Sebastián on the famed Arzak, the place the chef at Amelia’s additionally educated, so once I noticed he was doing this, I got here up with a pal. It was scrumptious.
From my view, I noticed a sure individuals home, and the primary one who guesses accurately who lives there’ll get a month’s free comp subscription to my substack.
I lately was provided a free one 12 months professional subscription to GPT-5.5 in order that I may study to make use of codex. A lot appreciated. I can by no means actually inform the variations very effectively, tbh, however I’ve tried it for a venture. Ethan Mollick has an extended substack about it.
The true inflation adjusted worth of books has hardly modified however since the whole lot else has modified, you’re extra tapped for money to purchase them.
In 2026, AI-powered coding instruments started revolutionizing software program growth, with Cursor v3 rising as a number one instance. In contrast to conventional growth environments, Cursor v3 provides a brand new method for builders to work together with their code by using AI brokers that help in coding duties.
Cursor v3 goes past fundamental autocompletion supplied by most IDEs by executing AI brokers on duties and utilizing pure language for code era and validation. On this article, we’ll discover distinctive options of Cursor V3 and the way it may be used to transforms software program growth workflows.
What’s Cursor v3?
Cursor v3 is an AI-native code editor that automates software program growth with out counting on plugins. It introduces agent-based workflows and superior code comprehension, increasing on earlier variations. Customers can now execute a number of AI brokers concurrently, both domestically or within the cloud, to deal with advanced coding duties. The system integrates seamlessly with the editor, offering real-time context and remodeling from a easy AI assistant into a completely AI-driven growth setting.
How this Redefines Improvement Workflows
The Cursor v3’s system allows its brokers to entry full venture info as a result of its editor system pre-indexes all repository knowledge which permits AI fashions to entry full class hierarchy info and file import particulars and system construction info. An agent can subsequently make coordinated adjustments throughout front-end and back-end information in a single shot. The unified diff is out there for overview after the AI completes its work by way of the brand new interface of Cursor. You’ll be able to request a brand new characteristic by typing your request when the agent will deal with the whole course of which incorporates implementation planning file enhancing check execution and pull request creation.
Key Options of Cursor v3
Listed below are among the standout options of Cursor v3 that set it aside:
Agent-based workflows: A number of AI brokers work concurrently to execute completely different coding duties, dealing with every little thing from code era to refactoring. This permits for a sooner and extra environment friendly growth course of.
Pure language programming: Builders can provide directions in plain language, making it simpler to generate and edit code with no need to study advanced syntax. This streamlines communication between the developer and the AI system.
Superior code comprehension: The AI understands and might modify code throughout a number of information, making certain consistency and decreasing errors when making adjustments all through a venture.
Actual-time context info: Built-in AI gives quick suggestions, serving to builders make higher selections as they code, whether or not it’s suggesting enhancements or mentioning potential points in real-time.
Parallel job execution: Cursor v3 can run a number of brokers on native gadgets or within the cloud, permitting builders to execute advanced coding duties sooner by leveraging parallel processing.
Constructed-in debugging: The AI actively identifies errors, gives solutions for fixes, and even robotically resolves points throughout growth, saving time and bettering code high quality.
Cursor v3 transforms from a easy assistant into an entire AI-powered coding system, enhancing productiveness and permitting builders to focus extra on inventive problem-solving whereas the AI handles repetitive duties.
Constructing an Finish-to-Finish AI Knowledge Analyst System utilizing Cursor v3
On this part, we’ll stroll by way of constructing an end-to-end AI knowledge analyst system. Automating every little thing from knowledge assortment and cleansing to producing insights and experiences. By the tip, you’ll see how AI could make knowledge evaluation sooner, simpler, and extra environment friendly.
Immediate:“Construct an end-to-end AI Knowledge Analyst net app the place customers add a CSV file and question it utilizing pure language. Use Python (FastAPI) for the backend and HTML, CSS, and JavaScript for the frontend. After add, load the CSV into Pandas and permit customers to ask questions like “Present tendencies” or “Prime merchandise.” Create an AI agent that converts person queries into protected Pandas or SQL queries, executes them, and returns outcomes with insights. Use the OpenAI API and cargo the API key securely from a .env file (don’t hardcode). The frontend ought to embrace a chat interface and a visualization panel, utilizing Chart.js to render charts (bar, line, pie). Return structured JSON responses with reply, insights, and chart knowledge. Manage the venture into backend (most important.py, agent.py, utils.py) and frontend (index.html, fashion.css, script.js). Preserve the code modular, clear, and production-ready.”
Response from Cursor:
Demo:
Last Verdict: Cursor v3 performs exceptionally properly on this setting as a result of it reveals an apparent agent-based workflow which begins with job planning and proceeds by way of its stepwise implementation. The system interface presents a clear design which customers discover straightforward to navigate for knowledge importing and query asking and consequence interpretation. The system demonstrates its capability to handle full AI methods by way of its automated evaluation and visible insights and user-friendly interface design.
Some Extra Actual-World use instances of this options embrace:
Full-Stack Improvement
Debugging Giant Codebases
Fast Prototyping
AI-Assisted Refactoring
Cursor v3 vs Conventional IDEs
Right here’s a comparability of Cursor v3 vs Conventional IDEs in a desk format:
Function
Cursor v3
Conventional IDEs
Core Expertise
AI-powered growth with autonomous brokers
AI-supported coding with handbook coding work
Codebase Understanding
Full understanding of total codebases, enabling multi-file adjustments
Primarily centered on particular person file or part
Agent-Based mostly Workflows
Permits the creation and execution of agent workflows
Restricted to code solutions and completions
Pure Language Processing
Makes use of pure language for job creation and execution
Usually lacks pure language interfaces
Job Administration
Autonomous brokers for full job administration, together with planning and execution
Guide job administration, with AI help for particular capabilities
Examples
Clever brokers planning and executing duties independently
VS Code: AI assists coding; JetBrains: Makes use of evaluation instruments for program correctness
Conclusion
The panorama of coding instruments is evolving quickly, and Cursor v3 stands on the forefront of this transformation. Backed by a billion-dollar funding, it showcases cutting-edge AI know-how that’s already making waves in companies. With its AI coding brokers, Cursor v3 considerably reduces handbook coding duties, enabling builders to make multi-file adjustments and deal with advanced programming challenges with ease. Its forward-thinking design provides a glimpse into the way forward for software program growth.
As new AI fashions proceed to emerge, Cursor v3 will solely turn into extra highly effective. Whereas groups ought to fastidiously think about the prices, integrating Cursor v3 alongside different instruments will maximize its full potential, making it an indispensable asset in trendy growth workflows.
Steadily Requested Questions
Q1. What’s Cursor v3?
A. Cursor v3 is an AI-powered code editor that automates software program growth duties utilizing AI brokers, enabling multi-agent workflows for sooner growth.
Q2. How does Cursor v3 enhance growth workflows?
A. It replaces conventional IDEs by automating total coding duties, from planning to execution, utilizing AI brokers that may modify code throughout information concurrently.
Q3. What makes Cursor v3 completely different from conventional IDEs?
A. In contrast to conventional IDEs, Cursor v3 integrates AI brokers to autonomously deal with coding duties, providing full job administration and multi-agent collaboration.
Howdy! I am Vipin, a passionate knowledge science and machine studying fanatic with a powerful basis in knowledge evaluation, machine studying algorithms, and programming. I’ve hands-on expertise in constructing fashions, managing messy knowledge, and fixing real-world issues. My aim is to use data-driven insights to create sensible options that drive outcomes. I am wanting to contribute my expertise in a collaborative setting whereas persevering with to study and develop within the fields of Knowledge Science, Machine Studying, and NLP.
Login to proceed studying and luxuriate in expert-curated content material.
As AI brokers transfer from analysis demos to manufacturing deployments, one query has develop into unimaginable to disregard: how do you really know if an agent is nice? Perplexity scores and MMLU leaderboard numbers inform you little or no about whether or not a mannequin can navigate an actual web site, resolve a GitHub difficulty, or reliably deal with a customer support workflow throughout tons of of interactions. The sector has responded with a wave of agentic benchmarks — however not all of them are equally significant.
One necessary caveat earlier than diving in: agent benchmark scores are extremely scaffold-dependent. The mannequin, immediate design, instrument entry, retry finances, execution surroundings, and evaluator model can all materially change reported scores. No quantity ought to be learn in isolation, context about the way it was produced issues as a lot because the quantity itself.
With that in thoughts, listed below are seven benchmarks which have emerged as real alerts of agentic functionality, explaining what each assessments, why it issues, and the place notable outcomes at present stand.
What it assessments: Actual-world software program engineering. SWE-bench evaluates LLMs and AI brokers on their skill to resolve real-world software program engineering points, drawing from 2,294 issues sourced from GitHub points throughout 12 in style Python repositories. The agent should produce a working patch — not an outline of a repair, however precise code that passes unit assessments. The Verified subset is a human-validated assortment of 500 high-quality samples developed in collaboration with OpenAI {and professional} software program engineers, and is the model mostly cited in frontier mannequin evaluations at this time.
Why it issues: The benchmark’s trajectory makes it one of the dependable long-run progress trackers within the subject. When it launched in 2023, Claude 2 may resolve just one.96% of points. In vendor-reported late-2025 and early-2026 outcomes, prime frontier fashions crossed the 80% vary on SWE-bench Verified — although actual scores differ meaningfully by scaffold, effort setting, instrument setup, and evaluator protocol, and shouldn’t be in contrast instantly throughout distributors with out accounting for these variations. A constant sample has emerged: closed-source fashions are likely to outperform open-source ones, and efficiency is closely formed by the agent harness as a lot because the underlying mannequin.
One caveat value flagging: excessive SWE-bench scores don’t assure a general-purpose agent. They point out energy in software program restore duties particularly — not common autonomy — which is exactly why it have to be used alongside the opposite benchmarks on this checklist.
What it assessments: Common-purpose assistant capabilities that require multi-step reasoning, internet looking, instrument use, and primary multimodal understanding. GAIA duties are deceptively easy in phrasing however require a sequence of non-trivial operations to finish accurately — the form of compound job an actual assistant would face within the wild.
Why it issues: GAIA is extensively referenced in agent analysis analysis and maintains an lively Hugging Face leaderboard the place groups throughout the neighborhood submit outcomes. Its design resists shortcut-taking: an agent can not guess its means by way of. It has develop into one of many normal suites for exposing tool-use brittleness and reproducibility gaps in actual agent evaluations — surfacing failure modes that narrower benchmarks miss fully. For groups evaluating general-purpose assistants somewhat than task-specific brokers, GAIA stays one of the sincere sign mills out there.
What it assessments: Autonomous internet navigation in life like, useful environments. WebArena creates web sites throughout 4 domains — e-commerce, social boards, collaborative software program growth, and content material administration — with actual performance and knowledge that mirrors their real-world equivalents. Brokers should interpret high-level pure language instructions and execute them fully by way of a stay browser interface. The benchmark consists of 812 long-horizon duties, and the unique paper’s greatest GPT-4-based agent achieved solely 14.41% end-to-end job success, towards a human baseline of 78.24%.
Why it issues: Progress on WebArena has been substantial. By early 2025, specialised methods had been reporting single-agent job completion charges above 60% — IBM’s CUGA system reached 61.7% on the total benchmark (February 2025), and OpenAI’s Pc-Utilizing Agent achieved 58.1% in its January 2025 technical report. These good points mirror a broader sample in stronger internet brokers: specific planning, specialised motion execution, reminiscence or state monitoring, reflection, and task-specific coaching or analysis loops. The remaining hole to human efficiency — 78.24% per the unique paper — displays more durable unsolved issues like deep visible understanding and common sense reasoning. WebArena is without doubt one of the most generally used benchmarks for testing true internet autonomy, not scripted automation.
What it assessments: Device-agent-user interplay underneath real-world coverage constraints. τ-bench emulates dynamic, multi-turn conversations between a simulated person and a language agent outfitted with domain-specific API instruments and coverage pointers. The benchmark covers two domains — τ-retail and τ-airline — and concurrently evaluates three issues: whether or not the agent can collect required data from a person throughout a number of exchanges, whether or not it accurately follows domain-specific coverage guidelines (e.g., rejecting non-refundable ticket modifications), and whether or not it behaves persistently at scale through the cross^okay reliability metric.
Why it issues: τ-bench exposes a reliability disaster that almost all one-shot benchmarks are fully blind to. Even state-of-the-art perform calling brokers like GPT-4o succeed on fewer than 50% of duties, and their consistency is way worse — cross^8 falls under 25% within the retail area. Which means an agent that may deal with a job in a single trial can not reliably deal with the identical job eight occasions in a row. For any actual deployment dealing with thousands and thousands of interactions, that inconsistency is disqualifying. By combining reasoning, tool-use, coverage adherence, and repeatability right into a single analysis framework, τ-bench fills a niche that outcome-only benchmarks depart large open.
What it assessments: Fluid intelligence — the flexibility to generalize to genuinely novel visible reasoning puzzles that resist memorization or pattern-matching from coaching knowledge. Every job presents the agent with a small variety of input-output grid examples and asks it to deduce the underlying summary rule, then apply it to a brand new enter. Created by François Chollet, the benchmark is the centerpiece of the ARC Prize competitors.
Why it issues: Context is crucial right here. ARC-AGI-1 has been successfully saturated: by 2025, frontier fashions reached 90%+ by way of brute-force engineering and benchmark-specific coaching. ARC-AGI-2, launched in March 2025, is the present and considerably more durable model designed to shut these loopholes. The ARC Prize 2025 Kaggle competitors attracted 1,455 groups, with the highest competitors rating reaching 24% utilizing NVIDIA’s NVARC system — a specialised artificial knowledge era and test-time coaching strategy on a 4B parameter mannequin. Amongst business frontier fashions, the rating panorama has developed rapidly: GPT-5.2 reached 52.9%, Claude Opus 4.6 reached 68.8%, and Gemini 3.1 Professional achieved a verified rating of 77.1% following its February 2026 launch — greater than double the efficiency of its predecessor Gemini 3 Professional (31.1%). These outcomes present fast progress on ARC-AGI-2, however human comparability ought to be interpreted rigorously: the ARC Prize 2025 technical report states that ARC-AGI-2 duties had been validated as solvable by impartial non-expert human testers, somewhat than presenting a single mounted “human baseline” proportion.
The benchmark’s hardest second got here with ARC-AGI-3, launched in March 2026 with an interactive online game format requiring brokers to discover novel environments, infer objectives, and plan motion sequences with out specific directions. The ARC-AGI-3 technical report states instantly: people can remedy 100% of the environments, whereas frontier AI methods as of March 2026 rating under 1%. That end result isn’t a flaw within the benchmark — it’s the level. 4 main AI labs — Anthropic, Google DeepMind, OpenAI, and xAI — have established ARC-AGI as an ordinary benchmark on their public mannequin playing cards, making it the sector’s clearest North Star for monitoring real generalization progress.
What it assessments: Cross-application laptop use on actual working methods. OSWorld gives 369 laptop duties spanning actual internet and desktop functions, OS file I/O, and cross-app workflows throughout Ubuntu, Home windows, and macOS. Brokers should work together by way of precise GUI interfaces utilizing uncooked keyboard and mouse management — not by way of clear APIs or text-only channels. Every job features a customized execution-based analysis script for dependable, reproducible scoring.
Why it issues: Most agentic benchmarks function in text-only or API-only environments. OSWorld assessments whether or not a mannequin can really function a pc, making it uniquely related for computer-use brokers being deployed in enterprise and productiveness workflows. On the time of its unique publication at NeurIPS 2024, people may accomplish over 72.36% of duties, whereas the most effective mannequin achieved solely 12.24% — a stark and revealing hole. The benchmark has since been upgraded to OSWorld-Verified, which addresses over 300 reported points and improves analysis reliability by way of enhanced infrastructure, mounted internet surroundings modifications, and improved job high quality. The multimodal calls for — combining visible grounding, operational information, and multi-step planning throughout actual working methods — make OSWorld considerably more durable than code-only evaluations.
What it assessments: Breadth. AgentBench evaluates LLMs as brokers throughout eight distinct environments: OS interplay, database querying, information graph navigation, digital card video games, lateral-thinking puzzles, family job planning, internet procuring, and internet looking. Relatively than going deep on one job area, it assesses how effectively a mannequin generalizes throughout basically completely different agentic settings inside a single analysis framework.
Why it issues: A mannequin that scores impressively on SWE-bench might fully collapse in a database question surroundings or an internet navigation job. AgentBench is greatest used to check agent architectures and establish the place functionality switch breaks down — to not predict manufacturing efficiency instantly. That cross-domain diagnostic view is efficacious sign particularly when choosing a base mannequin for a multi-purpose agent system or when diagnosing which surroundings sorts expose a particular mannequin’s weaknesses. No different benchmark on this checklist affords this type of breadth-first diagnostic view in a single run.
Conclusion
No single benchmark tells the total story. SWE-bench Verified measures software program engineering competence with actual GitHub points; GAIA assessments compound tool-use and multi-step reasoning throughout domains; WebArena evaluates true internet autonomy with 812 long-horizon duties; τ-bench surfaces the reliability disaster that one-shot benchmarks miss fully; ARC-AGI-2 probes real generalization and fluid intelligence — with ARC-AGI-3 displaying the frontier hasn’t come near fixing it; OSWorld evaluates full-stack laptop management throughout actual working methods; and AgentBench diagnoses breadth throughout eight basically completely different environments. Used collectively, and interpreted with consciousness of scaffold dependencies, these seven present essentially the most sincere image at present out there of the place an agent really stands.
As agentic methods transfer deeper into manufacturing, the groups that perceive these distinctions — and consider towards all of them — will construct extra reliably, and report capabilities extra actually.
Key Takeaways:
SWE-bench Verified tracks essentially the most dramatic progress curve in AI: from 1.96% (Claude 2, 2023) to above 80% in vendor-reported late-2025/early-2026 outcomes — however scores will not be instantly comparable throughout distributors because of scaffold, instrument, and evaluator variations
τ-bench reveals a reliability disaster most benchmarks ignore: even prime fashions rating under 50% success and fall underneath cross^8 of 25% on the identical retail duties
ARC-AGI-1 is saturated at 90%+; ARC-AGI-2 is the present take a look at, with Gemini 3.1 Professional main at 77.1% (verified, Feb 2026); ARC-AGI-3 launched March 2026 and all frontier methods rating under 1%
WebArena has seen main progress — from 14.41% baseline to 61.7% (IBM CUGA) by early 2025 — pushed by modular Planner-Executor-Reminiscence architectures, not a single mannequin breakthrough
OSWorld is essentially the most rigorous take a look at of actual laptop use: 369 cross-app duties with a 60-point hole between human and AI efficiency at launch
GAIA is extensively referenced in agent analysis analysis and maintains an lively neighborhood leaderboard on Hugging Face
Agent benchmark scores are extremely scaffold-dependent — mannequin, instrument entry, retry finances, and evaluator model all materially have an effect on reported numbers
A person on the Google Residence subreddit studies that their Nest Hub Gen 2 is fighting the time.
The publish says their machine will set an alarm correctly (on its show), however the AI speech will say “it is set for 3 am,” when in actuality it is set for “3 pm.”
Google just lately rolled out Continued Conversations for Gemini on its good residence gadgets.
Points floor with Google’s Nest Hub, as person studies on social media spotlight a wierd drawback with its sense of time.
It is unclear simply how widespread this difficulty is, however a person on the Google Residence subreddit studies that their Nest Hub Gen 2 is fighting time (through Android Authority). The person states that whereas their machine can set the right time (say, three o’clock, as an example), it’ll mess up the AM/PM ending. They state that in the event that they’re seeking to set an alarm for 3 pm, their Nest Hub Gen 2 will say it is set for 3 am.
Android Central’s Take
This simply feels like a joke. It makes it appear as if the Nest Hub Gen 2 is caught in reverse day. You inform it one factor, but it surely says the identical with a splash of the alternative. It is good that the machine truly units the time proper, and it is the speech half that is tousled. However, nonetheless, even that is sufficient to make individuals look once more, saying, “huh? I did not say that…”
It is a massive difficulty—a twelve-hour difficulty, to be actual. The speech half is the first difficulty, because the person studies that their desired alarm is appropriate. The Nest Hub will set it for 3 pm; nevertheless, it is the machine’s AI speech that is incorrect. The person tried to check this additional, asking their Nest Hub Mini for an alarm, however not solely did it set the right time, but it surely spoke it correctly, too.
Article continues beneath
The vocal capabilities of the Nest Hub Gen 2 are being referred to as into query this week, however Google is seemingly on the case. A response says that the corporate is conscious and dealing on a repair. Proper now, the publish doesn’t state when it’ll arrive. As beforehand said, it is unclear simply how broadly affected Nest Hub Gen 2 customers are. The publication even introduced this up, stating how scarce studies are about this drawback.
Good residence hiccups
(Picture credit score: Android Central)
It has been fairly some time since we final had points with Nest gadgets. There have been a couple of studies that additionally involved Google Residence merchandise. Audio system and shows have been struggling, turning into unresponsive when given verbal instructions. Customers making an attempt to ask the gadgets in regards to the climate and different mundane questions have been met with silence. Google began fixing these points a while after, although it did take some time, given how these studies crossed into the vacations.
Android Central’s Take
Whereas Nest gadgets have had their justifiable share of bugs, Google’s actually been specializing in Gemini for Residence as of late. Particularly, it has been making an attempt to convey its speaking and listening capabilities as much as par, so customers do not expertise one thing clunky. To this point, it looks as if the updates they have been rolling out have been helpful. However, in fact, what the person thinks issues most.
Hopefully, the issues this time round will not take so lengthy, even whether it is only a speech difficulty. In additional thrilling information, Google rolled out Continued Conversations for Gemini. Now, the AI will preserve its “ears” open for a little bit longer after receiving a command from the person. Google sees this as a method of maintaining issues feeling pure, whereas making it simpler to ask follow-up questions.
Get the most recent information from Android Central, your trusted companion on the planet of Android
Stephan Schlamminger and his colleague, Vincent Lee, look at the torsion steadiness they used to measure the gravitational fixed
R. Eskalis/NIST
For hundreds of years, physicists have been making an attempt to measure the energy of gravity, a quantity known as “large G”. The measurements have by no means lined up with each other, hinting that both we don’t totally perceive our experiments or maybe we don’t totally perceive gravity. The newest check doesn’t verify both of those eventualities – however the extraordinary precision and care taken within the latest large G experiment might lastly carry researchers nearer to a consensus.
Gravity is way weaker than the opposite basic forces, which makes it terribly arduous to measure it exactly. “As youngsters, we had been all mesmerised after we performed with magnets by the best way they appeal to one another. The identical is true of gravity – you probably have two espresso cups and you place them in every hand, there may be nonetheless a drive between them, however it’s so small you’ll be able to’t really feel it, so that you’re not as mesmerised,” says Stephan Schlamminger on the US Nationwide Institute of Requirements and Expertise in Maryland. That weak spot can be a part of what makes it so troublesome to measure the true energy of gravity.
The opposite half is that, not like the opposite forces, it’s not possible to protect an experiment from gravity. In 1798, physicist Henry Cavendish bought round this through the use of a tool known as a torsion steadiness, which enabled him to measure gravity for the primary time, albeit with low precision.
To think about a torsion steadiness, image a horizontal toothpick hanging from a thread at its centre. At every finish of the toothpick is a small marble. When you transfer one other object close to one of many marbles, that object’s gravity will appeal to the marble, inflicting the toothpick to show barely. By measuring the quantity that the toothpick turns, you’ll be able to calculate the energy of gravity between the marble and the skin object with out worrying about Earth’s gravity, which is counteracted by the thread.
The experiment that Schlamminger and his colleagues carried out was a way more subtle model of this, with eight weights set on two exactly calibrated turntables, all suspended by ribbons about as thick as a human hair. This was a painstaking replica of an experiment first carried out in France in 2007. The researchers took a decade to measure and cut back each doable supply of uncertainty. “That is experimental physics at its finest,” says Jens Gundlach on the College of Washington, who wasn’t concerned with this work.
“The extent of care that they’ve taken and the entire totally different results that they’ve explored, this can be a game-changer form of experiment,” says Kasey Wagoner at North Carolina State College, who was additionally not concerned with this work. The ultimate worth of huge G was 6.67387×10-11 metres3 per kilogram per second2. That’s a fraction of a per cent decrease than the 2007 measurement, however it is sufficient to carry the measurement extra consistent with different checks which have been carried out through the years.
“Large G is not only a measurement of gravity – it’s a measurement of how nicely you’ll be able to measure gravity, and it transcends epochs of physics. We will evaluate our experiment to Cavendish’s experiment 230 years in the past, and in 230 years they’ll have the ability to evaluate theirs to ours,” says Schlamminger. “In the long run, I believe it is going to be about which period of humanity can measure this finest, with probably the most settlement between the measurements.”
By pinning down a number of sources of uncertainty that weren’t beforehand identified, Schlamminger and his crew have elevated that settlement, says Gundlach. “The panorama seems to be higher now, extra reliable, extra dependable,” he says.
They’ve additionally paved the best way for future experiments to measure large G much more exactly, which can turn into more and more vital as cosmological measurements – a lot of which depend on data of gravity’s energy – additionally develop in precision. “If there’s one thing humorous occurring right here, it’ll have results all the best way from the dimensions of the lab to the dimensions of the universe,” says Wagoner. “What’s a really small, minute distinction within the lab, once you put that on cosmic scales, that distinction will get blown up, and it may have actually large implications.”
Whereas most researchers agree that the extra doubtless clarification for the remaining discrepancy is that we don’t totally perceive the sources of bias and uncertainty in the entire experiments, there’s a likelihood that it’s truly resulting from gravity behaving in another way from how we thought. If that’s the case, it could trace at potential unique new physics. “There’s a crack in our understanding of science, and we now have to enter these cracks – there could also be nothing there, however it could be silly to not go,” says Schlamminger.
Workers throughout each operate are anticipated to make sooner, better-informed choices, however the info that they want hardly ever lives in a single place. Workforce intelligence (who’s in your group, how they’re performing, and the place the gaps are) is without doubt one of the most precious indicators an enterprise has, and platforms like Visier are purpose-built to floor it. Nonetheless, that intelligence solely reaches its full worth when it’s related to the interior insurance policies, plans, and context that give it path. That context additionally typically lives elsewhere completely.
Amazon Fast is the Agentic AI workspace the place that connection occurs. It brings collectively enterprise data, enterprise intelligence, and workflow automation. Its clever brokers retrieve info and cause throughout all of those layers concurrently, decoding dwell information alongside organizational context to supply solutions which are able to act on. When Visier workforce intelligence works in tandem with the Amazon Fast enterprise data layer, the result’s a solution that attracts on the total context and is able to act.
On this put up, we present how connecting the Visier Workforce AI platform with Amazon Fast via Mannequin Context Protocol (MCP) provides each data employee a unified agentic workspace to ask questions in. Visier helps floor the workspace in dwell workforce information and the organizational context that surrounds it whereas letting your customers act on the conversational outcomes with out switching instruments.
1. Understanding the elements
On this put up, we display instance day-to-day workflows for 2 folks getting ready for a similar management assembly: Maya, an HR Enterprise companion constructing a workforce well being briefing, and David, a finance supervisor monitoring headcount towards finances. Each want solutions that reduce throughout a number of sources, equivalent to dwell workforce information, inside targets, hiring insurance policies, and historic context. This integration is constructed for enterprise customers who work with folks information as a part of their day-to-day choices. They want solutions grounded in the correct information sources. This integration helps Amazon Fast brokers transcend retrieving info and act on it.
Amazon Fast
Amazon Fast is an agentic AI workspace that acts as a unified interface for enterprise customers throughout the group, supplies enterprise customers with a set of agentic teammates that rapidly reply questions at work and switch these solutions into motion.
For Maya and David, Amazon Fast is their AI workspace the place they ask questions and construct brokers that work on their behalf and automate their processes. Weekly workflows and threshold alerts that may in any other case require handbook effort and analysis each time are saved in Amazon Fast.
Visier
Visier is a cloud primarily based Workforce AI platform that unifies workforce information from throughout a company. It brings collectively HRIS, payroll, expertise administration, and applicant monitoring right into a single intelligence layer. You should use it to reply advanced workforce questions in minutes via its AI assistant Vee, backed by intensive pre-built metrics and trade benchmarks from anonymized worker data.
By its MCP server, Visier acts as a common connector that delivers ruled folks insights straight into the enterprise AI instruments the place choices are made.
For Maya, Visier is the authoritative supply for workforce intelligence. It supplies the excessive performer counts, common tenure figures, and attrition traits that she must assess organizational well being. For David, it supplies the dwell headcount and distribution figures that monetary targets are measured towards.
The Mannequin Context Protocol
MCP is an open normal that permits AI brokers to connect with exterior information sources and instruments. Consider it as a common adapter that enables Amazon Fast to speak with Visier’s analyst agent, Vee in a structured and safe means with out constructing customized integrations from scratch. Visier exposes its workforce analytics capabilities via an MCP server. Amazon Fast features a built-in MCP consumer that discovers these instruments and makes them obtainable to its brokers, analysis workflows, and automations.
2. Advantages for enterprises
Organizations typically battle to get a unified view of their workforce that mixes dwell information with organizational context. A supervisor asking “Are we on observe with our headcount finances?” wants numbers from one system and coverage context from one other. With Visier built-in into Amazon Fast utilizing MCP, this hole closes:
Unified workforce intelligence – Amazon Fast orchestrates throughout Visier’s dwell folks analytics information and your inside enterprise data, delivering synthesized solutions that neither system might produce alone. A single query can return dwell headcount information cross-referenced towards an authorized finances doc.
Pure language entry to worker information – By Amazon Fast Brokers, customers can ask conversational questions and get prompt solutions backed by curated workforce information. Each response is attributed to its supply, so customers at all times know whether or not a determine got here from Visier’s dwell workforce information or an inside coverage doc in Fast Areas.
Automated, repeatable workflows – Recurring workforce opinions, threshold alerts, and pre-meeting briefings might be constructed as automated Fast Flows that run on a schedule. The identical evaluation Maya and David ran manually within the demo might be configured as soon as and delivered to their inboxes each Monday morning with none handbook effort.
Cross-functional determination help – The identical sample applies throughout any operate the place workforce information and organizational context want to come back collectively to tell a call.
Ruled and safe information entry – Visier’s MCP server enforces information governance insurance policies to floor solely approved workforce information via Amazon Fast. Enterprise data in Fast Areas maintains current entry controls inside your organizational boundary.
Lowered time to perception – What beforehand required hours of cross-referencing spreadsheets, toggling between dashboards, and manually constructing narratives can now be completed rapidly from a single interface. The combination ensures that the reply at all times comes with the total image of dwell workforce information alongside the organizational context that makes it actionable.
3. Conditions
Earlier than organising the Visier MCP integration with Amazon Fast, you want the next:
At its core, this answer is constructed on the MCP. Visier hosts an MCP server that exposes its folks analytics capabilities as a set of callable instruments. Amazon Fast acts because the MCP consumer, discovering these instruments and making them obtainable to brokers, analysis workflows, and automations. The 2 platforms stay impartial, and thru this connection, dwell workforce information from Visier turns into a part of each Amazon Fast interplay.When a consumer asks a query:
Amazon Fast interprets the intent and determines which sources are related
If the query requires workforce information, it invokes Visier’s Vee agent via MCP to retrieve dwell analytics
If the query requires organizational context, it attracts from the related paperwork and data sources obtainable in Amazon Fast Areas
The 2 sources are introduced collectively right into a single, coherent response that displays each dwell workforce information and the organizational context round it
When a query spans each methods, Amazon Fast identifies the correct sources, arms off to Visier’s agent to retrieve dwell workforce intelligence, and attracts on Fast Index and Fast Areas for organizational context. Essentially the most related info from each is surfaced again to the consumer as a single, coherent reply.
5. Establishing the mixing
Step 1: Configure Visier’s MCP server
Visier supplies a prebuilt MCP server that exposes its workforce analytics capabilities as MCP instruments. To configure it:
In your Visier admin console, navigate to Settings > API & Integrations.
Allow the MCP Server functionality.
Configure authentication credentials and information entry scopes.
Observe the MCP server endpoint URL and authentication particulars.
Step 2: Add Visier as an MCP integration in Amazon Fast
Amazon Fast features a built-in MCP consumer that you simply configure via an integration. To attach Visier:
From the Amazon Fast residence display, choose Integrations from the left navigation panel.
Choose the Actions tab in the primary panel.
Beneath Arrange a brand new integration, find the Mannequin Context Protocol (MCP) tile and select the plus (+) signal.
On the Create Integration web page, enter a descriptive Identify, an non-compulsory Description, and the Visier MCP server endpoint URL from Step 1. Select Subsequent.
Choose the authentication technique that matches your Visier MCP server configuration (consumer authentication, service authentication, or no authentication) and enter the required credentials. Select Create and proceed.
Amazon Fast will uncover the instruments uncovered by Visier’s MCP server (for instance, ask_vee_question, search_metrics, list_analytic_object_property_values).
Share the mixing with different customers who ought to have the ability to question Visier via Amazon Fast, then select Achieved.
After configured, Visier workforce intelligence instruments can be found to the Amazon Fast brokers and automations.
Brokers in-built Amazon Fast use Areas as their contextual boundary. Every part a company is aware of, from inside insurance policies and planning paperwork to team-specific data contributed by particular person customers, is constructed up inside a House and made obtainable to the agent at question time. A number of group members can contribute to a House over time, so the data grows with the group moderately than remaining static.
Subsequent, you add related inside paperwork to Fast Areas, so the orchestrator has organizational context to enhance Visier’s dwell information. To add your paperwork:
In Amazon Fast, navigate to Areas and create a brand new house. Identify it “Workforce Planning“.
Add your workforce planning paperwork, equivalent to headcount budgets, and compensation pointers.
Add coverage paperwork, equivalent to approval workflows, and compliance necessities.
Configure house permissions to regulate which groups can entry the content material.
With Fast Areas populated, the solutions we get from Fast Brokers get richer. This lets them mix dwell workforce information from Visier along with your group’s personal context and return an entire reply in a single place.
Instance state of affairs
To display the mixing, we stroll via a state of affairs the place Maya (HR Enterprise Associate) and David (Finance Analyst) are getting ready collectively for a management assembly. Their group has related Visier to Amazon Fast utilizing MCP and has uploaded inside planning paperwork to Fast Areas.For this instance, they’ve added the next enterprise paperwork to Amazon Fast:
Doc
Function
FY26 Workforce Well being Targets
Headcount objectives, US distribution targets, retention price benchmarks
Excessive performer ratio thresholds, retention levers, escalation triggers
US Workforce Distribution Coverage
Goal US presence share, overview cadence, rationale
Workforce Threat Briefing Template
Threat ranking framework, what to escalate to management
Right here’s how the dialog unfolds:Every of the next turns word which information sources that the Amazon Fast agent queried to supply its response.
Flip 1: Getting the lay of the land
David: What number of workers do now we have, and what number of are primarily based within the US?
The Amazon Fast agent routes David’s query to Visier by way of MCP and returns the entire worker rely and US-based headcount from dwell workforce information.
Sources queried: Visier
Flip 2: Finances vs. precise, the place intelligence meets context
David: How does our US headcount evaluate to our distribution targets?
The agent queries Visier for dwell US headcount and retrieves the FY26 Workforce Well being Targets doc from Fast Areas, evaluating the precise determine towards the authorized distribution goal.
Sources queried: Visier (dwell headcount) · Fast Areas (FY26 Workforce Well being Targets)
Flip 3 : Tenure panorama
Maya: What’s the common tenure throughout our workforce, and which roles have the very best tenure?
The Amazon Fast agent retrieves common tenure and role-level tenure breakdowns from Visier, then surfaces the related tenure milestones from the Tenure and Retention Coverage in Fast Areas.
Sources queried: Visier (tenure information) · Fast Areas (Tenure and Retention Coverage)
Flip 4 : Tenure towards coverage thresholds
Maya: Does our common tenure meet the edge in our retention coverage?
The Amazon Fast agent compares Visier’s dwell common tenure determine towards the edge outlined within the Tenure and Retention Coverage saved in Fast Areas, flagging whether or not the group meets or falls in need of its goal.
Sources queried: Visier (common tenure) · Fast Areas (Tenure and Retention Coverage)
Flip 5 : Excessive Performer well being examine
Maya: What number of excessive performers do now we have, and are we throughout the advisable ratio?
The Fast agent pulls the present excessive performer rely from Visier and checks it towards the advisable ratio within the Excessive Performer Retention Playbook from Fast Areas.
Sources queried: Visier (excessive performer rely) · Fast Areas (Excessive Performer Retention Playbook)
Flip 6 : Management briefing synthesis
David and Maya: Summarize the important thing workforce well being dangers for our management briefing.
The Amazon Fast agent pulls collectively the workforce information retrieved from Visier throughout the prior turns) and cross-references every metric towards the corresponding thresholds and insurance policies saved in Fast Areas. The place a metric falls in need of its goal, the agent flags it as a danger and surfaces the advisable motion from the related coverage doc. The result’s a single briefing that covers each dimension mentioned within the dialog, with every discovering attributed to its information supply.
Sources queried: Visier (all workforce information from prior turns) · Fast Areas (all coverage and goal paperwork)
Taking it additional with Fast Flows
Past conversational queries, Amazon Fast contains Fast Flows, a workflow automation engine that you should use to outline multi-step sequences and run them on a schedule or on demand. A movement can retrieve information from related sources, apply logic or comparisons, generate formatted outputs, and ship outcomes to a vacation spot like an inbox or Slack channel, all with out handbook intervention. If you end up repeating the identical multi-turn dialog with a Fast Agent each week or month, Fast Flows turns that dialog right into a self-running movement. You outline the steps as soon as, join your information sources via the identical MCP integrations utilized in chat, and set a cadence. From there, the movement executes finish to finish and delivers the consequence.
The multi-turn dialog Maya and David accomplished demonstrates the type of recurring workflow that advantages from automation. Each month, the identical questions come up. How shut are we to our headcount goal? Is tenure trending in the correct path? Is the excessive performer ratio holding? Reasonably than operating via these questions manually every time, Fast Flows can execute the complete sequence on a schedule and ship a ready-to-share briefing.
The next movement, known as Weekly Workforce Well being Rating, runs each Monday morning. It retrieves dwell information from Visier, compares every metric towards the thresholds saved in Fast Areas, computes a composite rating, and drafts a formatted briefing, with none handbook enter.
Pattern Immediate to create a weekly Workforce Well being Rating movement like beneath :
Run this movement each Monday at 8:00 AM. Execute the next steps in sequence:
Step 1 — Retrieve dwell workforce information
Question the related Visier MCP server for the next 4 metrics as of the newest obtainable date:
1. Complete world headcount
2. US-based headcount
3. Group-wide common tenure
4. Complete rely of high-performing workers
Step 2 — Retrieve inside targets and thresholds
Search the “Workforce Planning” house in Amazon Fast for the next values:
1. 12 months-end headcount goal
2. US headcount goal and share goal
3. Common tenure threshold and watch zone decrease sure
4. Minimal excessive performer ratio threshold
Use the FY26 Workforce Well being Targets, Tenure and Retention Coverage, Excessive Performer Retention Playbook, and US Workforce Distribution Coverage paperwork.
Step 3 — Calculate workforce well being metrics
Utilizing the values retrieved in Steps 1 and a pair of, calculate the next:
1. Headcount share to objective
2. Hires remaining to shut the hole
3. US headcount share of complete
4. US headcount hole to focus on (in headcount and share factors)
5. Excessive performer ratio
6. Excessive performer buffer above the minimal threshold
7. Tenure buffer above the watch zone threshold
Step 4 — Rating every metric
Assign a rating to every of the 4 metrics utilizing the next logic:
– On Observe (meets or exceeds goal): 25 factors
– Wants Consideration (inside 5% of threshold): 15 factors
Sum the 4 scores to supply a composite Workforce Well being Rating out of 100.
Step 5 — Retrieve advisable actions for flagged metrics
For any metric scored at “Wants Consideration” or beneath, retrieve the related intervention part from the corresponding Fast Areas coverage doc.
Step 6 — Draft a formatted briefing
Compose a structured abstract containing:
1. The composite rating out of 100
2. A desk exhibiting every metric with its precise worth, goal, calculated hole, and rating
3. A one-line standing summarizing what number of metrics want consideration
4. The advisable actions from Step 5 listed by precedence
Format this as a ready-to-share briefing.
The output is a composite rating out of 100, a metric desk exhibiting the place the group stands towards every goal, and a set of advisable actions drawn straight from the related coverage paperwork. When a metric wants consideration, the briefing tells you what the coverage says to do about it.
After your enterprise integrations are related, an non-compulsory step can mechanically ship this briefing to a specified inbox or Slack channel on schedule. That is what Fast Flows makes doable, a recurring, multi-source workflow that beforehand required a handbook dialog turns into one thing that runs itself and exhibits up in your inbox.
Instance Fast Analysis challenge
Amazon Fast additionally contains Fast Analysis, a deep evaluation functionality designed for questions that span a number of sources and require synthesis moderately than a single lookup. The place a chat dialog is interactive and iterative, Fast Analysis runs autonomously you describe the result you want in pure language, and Fast determines which inside data bases, related information sources, and exterior references to question, then assembles a structured, source-attributed report.
Earlier than the management assembly, Maya launches a Fast Analysis independently, outdoors the agent dialog. She doesn’t specify which methods to go looking or the place the information lives, she simply describes what she wants.
Maya’s Fast Analysis immediate:
Put together a workforce benchmarking report forward of our management assembly. I want to grasp how our group compares to trade friends throughout three areas: worker tenure, excessive performer ratios, and workforce distribution throughout geographies. For every space, present me the place we stand in the present day, what the trade norm seems like, and whether or not we’re forward, at par, or behind. Embody our inside targets the place related.
Construction the output as an govt abstract, a side-by-side benchmark comparability with color-coded danger rankings, and a spot evaluation with three to 5 prioritized suggestions. Embody a benchmark comparability chart and a visible hole indicator desk. Cite all exterior sources and attribute all inside information to its origin.
Fast Analysis mechanically attracts from all three layers, dwell workforce information from Visier utilizing the MCP server, inside coverage targets from the Workforce Planning Fast House, and exterior trade benchmarks from the online, and produces a structured, source-attributed analysis transient. The report is downloaded by Maya and shared with David earlier than the assembly. It serves because the exterior context layer that enriches the agent dialog, giving each personas a shared start line grounded in information from inside and out of doors the group.That is what makes Fast Analysis distinct: the consumer describes the result that they want, Fast’s intelligence is aware of the place to look and does deep analysis, and brings an actional complete report collectively.
Monitoring and observability
As Fast brokers question Visier MCP for dwell workforce information and retrieve insurance policies from Fast Areas, directors want visibility into what’s being accessed, how typically, and by whom. Amazon Fast integrates with Amazon CloudWatch to floor MCP motion connector metrics equivalent to invocation counts and error charges, so groups can observe how incessantly Visier’s MCP instruments are known as throughout agent conversations, flows, and analysis runs. Each chat interplay, together with which connectors have been invoked and which assets have been cited within the response, might be delivered via Amazon CloudWatch Logs to locations like Amazon Easy Storage Service (Amazon S3) or Amazon Knowledge Firehose for evaluation and long-term retention. For audit and compliance, AWS CloudTrail supplies an entire report of API calls and administrative actions throughout the Amazon Fast atmosphere, answering questions like which consumer queried workforce tenure information, when the request was made, and what context it was a part of. Collectively, these capabilities make it possible for each interplay between Visier and Amazon Fast, from a Fast chat agent question to a scheduled movement, stays observable, auditable, and ruled.
Clear up
Once you’re finished utilizing this integration, clear up the assets that you simply created:
Take away the MCP integration from Amazon Fast:
From the Amazon Fast residence display, navigate to Integrations within the left navigation panel.
Choose the Actions tab, find the Visier MCP integration, and select Take away.
This stops Visier information from being accessible via Amazon Fast.
Revoke Visier MCP credentials:
Within the Visier admin console, navigate to Settings > API & Integrations.
Revoke the MCP server credentials used for the Amazon Fast connection.
Take away Fast Areas content material (non-compulsory):
In case you created Fast Areas particularly for this integration, navigate to Areas in Amazon Fast and delete them.
Delete the Amazon Fast atmosphere (non-compulsory):
In case you now not want the Amazon Fast atmosphere, navigate to the AWS console and delete the related assets.
This removes the related indexes, integrations, and information supply connectors.
Conclusion
The combination of Visier and Amazon Fast by way of MCP demonstrates a sample that extends past folks analytics to any state of affairs the place specialised enterprise intelligence should be grounded in organizational context.The worth isn’t in both system alone. Amazon Fast supplies the orchestration layer and enterprise context. Visier supplies the workforce intelligence. MCP supplies the safe, standardized connection between them. For the tip consumer, the expertise is easy: ask a query, get a solution that attracts on the whole lot the group is aware of, and act on it with out switching instruments.The identical structure applies throughout Finance, Operations, Gross sales, Advertising, and Authorized. Wherever workforce information and organizational context want to come back collectively, Amazon Fast and Visier, related utilizing MCP, make that doable in a single dialog.
Subsequent steps
Able to convey workforce intelligence into your agentic AI workspace? Begin by visiting the Amazon Fast documentation to arrange your atmosphere, configure integrations, and start constructing brokers and automations. For the Visier facet, the Visier MCP Server documentation walks via setup directions, authentication configuration, and the total set of accessible workforce analytics instruments.
The notion module. This part takes uncooked sensory inputs reminiscent of photographs, video and proprioception and encodes them right into a compact latent illustration of the surroundings.
The prediction module. This can be a dynamics mannequin which handles likelihood distribution and captures causality and temporal construction. It probabilistically predicts the following latent state and the anticipated outcomes of any actions.
The planning (management) module. This module makes use of the output of the prediction mannequin to simulate future trajectories and choose actions that optimize achievements in the direction of a purpose.
“At its core, a world mannequin is an inner illustration that an AI system constructs to simulate the exterior surroundings. By constantly processing sensory knowledge, a robotic builds a dynamic blueprint of its environment,” explains Aurorain founder Luhui Hu. “This fusion of notion, prediction and planning mirrors cognitive processes in people, setting the stage for extra superior robotic habits.”
World fashions open up immense prospects
There appear to be virtually no limits to the potential ready inside world fashions, even when we put aside AGI aspirations for the second. Listed below are only a few of the numerous methods world fashions may influence our lives.
Immersive visible experiences
With world fashions, it’s lastly changing into attainable to construct convincing worlds that you may work together with and expertise. These are the very first capabilities which can be approaching line, due to fashions like these developed by Decart, which may even be used as playable, sport engine-free simulations.
This open-source instrument acts as a intermediary between elevated Android performance and permissions and third-party apps, giving the latter (and the person) entry to beforehand locked-away options. It may not sound like a lot, however it’s a core cause why Shizuku is among the most vital Android apps for energy customers.
Do you employ Shizuku in your Android telephone?
637 votes
Regardless of this energy, Shizuku is fairly ineffective by itself. With out supporting apps that leverage its choices, it doesn’t actually add a lot to Android. Fortunately, there’s no scarcity of apps that depend on it and excel for it.
Under is an inventory of my favourite Shizuku apps that genuinely improve my Android expertise, from enhancing app set up to enabling extra thorough app uninstallation, to theming tweaks, and a lot extra.
Canta
Andy Walker / Android Authority
Android actually doesn’t like me uninstalling apps, particularly people who producers deem important. For Samsung, this might imply the whole Fb suite, for example. Fortunately, with Canta, I can scrub my gadget of those annoyances with ease.
My leveraging Shizuku, Canta lets me uninstall virtually any app on my gadget, together with bloatware and system options. Whereas cherry-picking apps to uninstall might be an journey, Canta supplies steerage about which apps are secure to uninstall and which ought to in all probability be left alone.
ColorBlendr
Andy Walker / Android Authority
My house is likely to be an eclectic mixture of a number of colours and textures, however I choose my Android telephone to have one uniform feel and appear. For those who’re like me, ColorBlendr is completely important.
As soon as once more, it makes use of Shizuku to realize entry to and hand me extra management over Android’s default coloration selecting system. Choose from colours drawn from the wallpaper, an inventory of ordinary shades, and even select which general coloration profile you fancy, be it Monotone or Vibrant.
Necessities
Andy Walker / Android Authority
Talking of Good Lock, Necessities is a set of options and tweaks for Pixel telephones and different Android units. In a way, it operates very like Samsung’s toolkit, albeit with much less emphasis on UI tweaks.
I can modify varied settings which might be normally hidden or inaccessible with out Shizuku, together with extra granular name vibration changes, related gadget battery alerts, a devoted widget for switching your display screen off, and varied standing bar customizations.
There are different quirky instruments beneath the hood, too, together with Are We There But? — a real-time distance calculator for a number of pinned areas — and assist for the Pixel 10’s Google Maps battery-saving mode, even on unsupported units.
Necessities actually wants its personal deep dive, however briefly, it’s a toolkit each Android energy person will discover useful.
Smartspacer
Andy Walker / Android Authority
There are many Pixel-exclusive options that make different Android telephone customers somewhat jealous, and At A Look is actually certainly one of them. This widget sits on the Pixel Launcher residence display screen and shows pertinent, contextual data all through the day.
Smartspacer extends this characteristic past Pixels and truly makes it even higher. It affords a far broader service assist listing, too, together with particulars from social media, Aftership, Tasker, and extra. However, most vital of all, it brings At A Look to Samsung telephones and past.
ShizuWall
Andy Walker / Android Authority
I solely found the wonders of ShizuWall lately, however I can’t fairly perceive how I’ve lived with out it.
It’s a firewall that utterly bans apps I choose from accessing the web. What I really like about ShizuWall is that it doesn’t require a VPN or Personal DNS slot — it capabilities by itself with the assistance of Shizuku. That’s it.
The app is fairly easy to make use of and makes for an exquisite protection in opposition to trackers and apps that don’t essentially have to telephone residence however actually wish to.
aShell You
Andy Walker / Android Authority
This good little utility lets me run ADB instructions on my gadget, so I can forego plugging it right into a PC or utilizing a full-blown terminal app. Whereas I don’t use it frequently, aShell You is a type of apps I’d somewhat have in my pocket than not.
The app has an inventory of instructions I can run proper off the bat, and bookmark assist for frequent instructions, so I don’t should manually sort a sophisticated shell command each time. It additionally helps saving outputs, making it a helpful diagnostic instrument.
Dare I say it’s one of many prettiest apps on this listing, too, making nice use of Google’s Materials aesthetic.
Set up With Choices
Andy Walker / Android Authority
When you usually have to make use of ADB to put in APKs on Android with extra superior directions, Set up With Choices simplifies this course of. With Shizuku, apps might be put in with varied asterisks. You possibly can bypass SDK limits, downgrade apps, pressure your telephone to unlock house for them, and inform the system to by no means kill the put in apps.
It’s an unbelievable toolkit for putting in APKs, simply as Google is shifting to quash a few of the APK set up freedoms we’ve come to get pleasure from.
Once more, I don’t use Set up With Choices usually, however I’ve been actually glad to have it when downgrading from a buggy app launch to a earlier secure model.
Adaptive Theme
Andy Walker / Android Authority
I’ve already coated Adaptive Theme in nice element, however it’s nicely value reiterating its skills.
Android’s Darkish Mode activation is somewhat restrictive, both requiring handbook triggering or occurring on a good schedule. Adaptive Theme permits my Android telephone to modify between Darkish and Gentle modes based mostly on ambient gentle ranges.
How do you employ Darkish Mode in your telephone?
2170 votes
SD Maid SE
Andy Walker / Android Authority
I used to be a spiritual SD Maid person again within the early days of Android, however when the outdated model of the app stopped engaged on newer OS variations, I stated goodbye and left it behind. Not too long ago, I reboarded the SD Maid practice with the SE launch, and I’m so joyful that I did.
As its identify suggests, SD Maid SE is a storage-cleanup instrument that dusts my telephone’s nooks and crannies to seek out unneeded or pointless information prepared for deletion. It really works extremely nicely, and whereas it’s purposeful with out Shizuku, it beneficial properties a lot attain when paired with it.
Shappky
Andy Walker / Android Authority
Lastly, and whereas we’re on performance-enhancing apps, let’s finish with Shappky.
A portmanteau of kinds of Shell App Killer, this little instrument lets me kill any working app on my gadget, even when it’s labeled as a system app. A part of its appeal is its simplicity — simply faucet the apps you wish to kill, and hit the swap. You possibly can select to show system apps or persistent apps, or disguise these in the event you’re much less adventurous.
Shappky’s solely fault is that it hasn’t been up to date for some time, however given its easy premise, I’m undecided how vital this element actually is. It nonetheless works a appeal.
These are my favourite Android apps that assist and thrive by Shizuku, however that is in no way a definitive listing.
Do you’ve got any apps you’d wish to advocate? Which Shizuku apps do you employ every day, and why? Let’s begin a dialog within the feedback part beneath.
Don’t wish to miss the most effective from Android Authority?
Thanks for being a part of our group. Learn our Remark Coverage earlier than posting.
Jap Africa’s Turkana Rift is understood each for its wealthy document of early human fossils and for intense volcanic exercise pushed by shifting tectonic plates. Now, scientists report that the crust beneath this area has thinned excess of beforehand understood, pointing to the long run breakup of the African continent and providing a recent rationalization for why so many historic human stays have been preserved there.
The findings have been printed in Nature Communications.
A Huge Rift Formed by Transferring Tectonic Plates
The Turkana Rift stretches roughly 500 kilometers throughout Kenya and Ethiopia and types a part of the bigger East African Rift System. This large system extends from the Afar Despair in northeastern Ethiopia all the best way to Mozambique, separating the African tectonic plate from the Arabian and Somali plates. Within the Turkana area, the African and Somali plates are slowly shifting aside at about 4.7 millimeters per 12 months.
As this separation happens, a course of referred to as rifting stretches the crust sideways. The pressure causes the floor to buckle and crack, permitting magma from deep inside Earth to rise upward.
Not all rifts go on to separate continents utterly. On this case, nonetheless, the Turkana Rift seems to be on that path.
Scientists Detect Unexpectedly Skinny Crust
“We discovered that rifting on this zone is extra superior, and the crust is thinner, than anybody had acknowledged,” says research lead creator Christian Rowan, a Ph.D. pupil at Columbia College’s Lamont-Doherty Earth Observatory, which is a part of the Columbia Local weather Faculty. “Jap Africa has progressed additional within the rifting course of than beforehand thought.”
To achieve this conclusion, Rowan and colleagues analyzed a uncommon set of top quality seismic information collected with trade companions and in collaboration with the Turkana Basin Institute, based by the late paleoanthropologist Richard Leakey. By analyzing how sound waves traveled via underground layers and mixing these outcomes with different imaging strategies, the staff mapped sediment buildings and decided the depth of the crust beneath the rift.
Alongside the middle of the rift, the crust is simply about 13 kilometers thick. Farther away, it exceeds 35 kilometers. This dramatic distinction factors to a course of generally known as “necking.”
“Necking” Indicators a Essential Tectonic Section
The time period describes how the crust stretches and thins within the center, much like the narrowed “neck” that types when a chunk of saltwater taffy is pulled aside. Because the crust turns into thinner, it additionally turns into weaker, making it simpler for rifting to proceed.
“The thinner the crust will get, the weaker it turns into, which helps promote continued rifting,” Rowan says. Finally, the crust can break utterly.
“We have reached that essential threshold” of crustal breakdown,” says Anne Bécel, a geophysicist at Lamont and co-author of the research. “We expect this is the reason it’s extra susceptible to separate.”
Even so, these adjustments unfold over immense timescales. The Turkana Rift started opening about 45 million years in the past, and researchers estimate that necking began after widespread volcanic eruptions round 4 million years in the past. It might take a number of million extra years earlier than the following section, generally known as oceanization, begins. At that stage, magma will rise via the fractures to type new seafloor, and water from the Indian Ocean to the north may finally flood in.
Proof of Earlier Failed Rifting
The staff additionally uncovered indicators of an earlier rifting episode that didn’t result in a full continental cut up. As a substitute, it left the crust thinner and weaker, setting the stage for the present section of exercise.
“It challenges among the extra conventional concepts of how continents break aside,” says Rowan.
As a result of the Turkana Rift is the primary identified energetic continental rift at the moment present process necking, it provides scientists a uncommon probability to check this important stage of tectonic evolution.
“In essence, we now have a entrance row seat to watch a essential rifting section that had essentially formed all rifted margins internationally,” says co-author Folarin Kolawole, who can also be with Lamont. These processes are carefully linked to different Earth programs, serving to researchers reconstruct previous landscapes, vegetation, and local weather patterns. “Then we will use that data to know what is going on to occur in our future, even on shorter time scales,” says Bécel.
Rethinking the Fossil File of Human Evolution
The discoveries additionally shed new gentle on the area’s extraordinary fossil document. The Turkana Rift has produced greater than 1,200 hominin fossils from the previous 4 million years, accounting for about one third of all such finds in Africa. Many scientists have lengthy considered this space as a key middle of human evolution.
Rowan and colleagues counsel one other chance.
After widespread volcanic exercise about 4 million years in the past, the onset of necking prompted the land within the rift to sink. This subsidence created circumstances the place nice grained sediments amassed shortly, which are perfect for preserving fossils.
“The circumstances have been proper to protect a steady fossil document,” says Rowan.
This implies the Turkana Rift might not have been uniquely necessary as a website the place human ancestors advanced, however fairly a spot the place geological circumstances made it simpler to document their historical past.
That concept stays a speculation, nevertheless it opens new avenues for analysis. “However different researchers can now use our outcomes to discover these concepts,” says Rowan. “As well as, our outcomes will be fed into tectonic fashions which can be coupled with local weather to actually discover how shifting tectonics and climates influenced our evolution.”
The analysis staff additionally consists of Paul Betka from Western Washington College and John Rowan from the College of Cambridge.




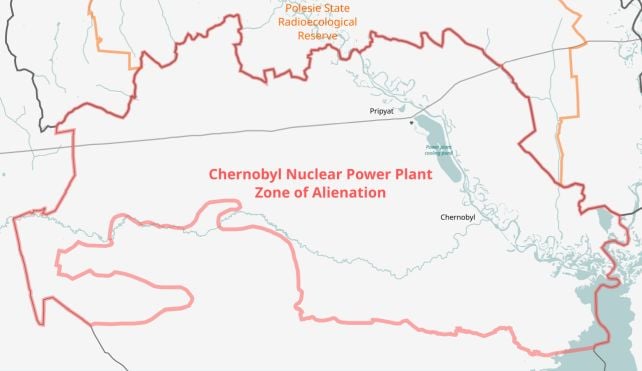










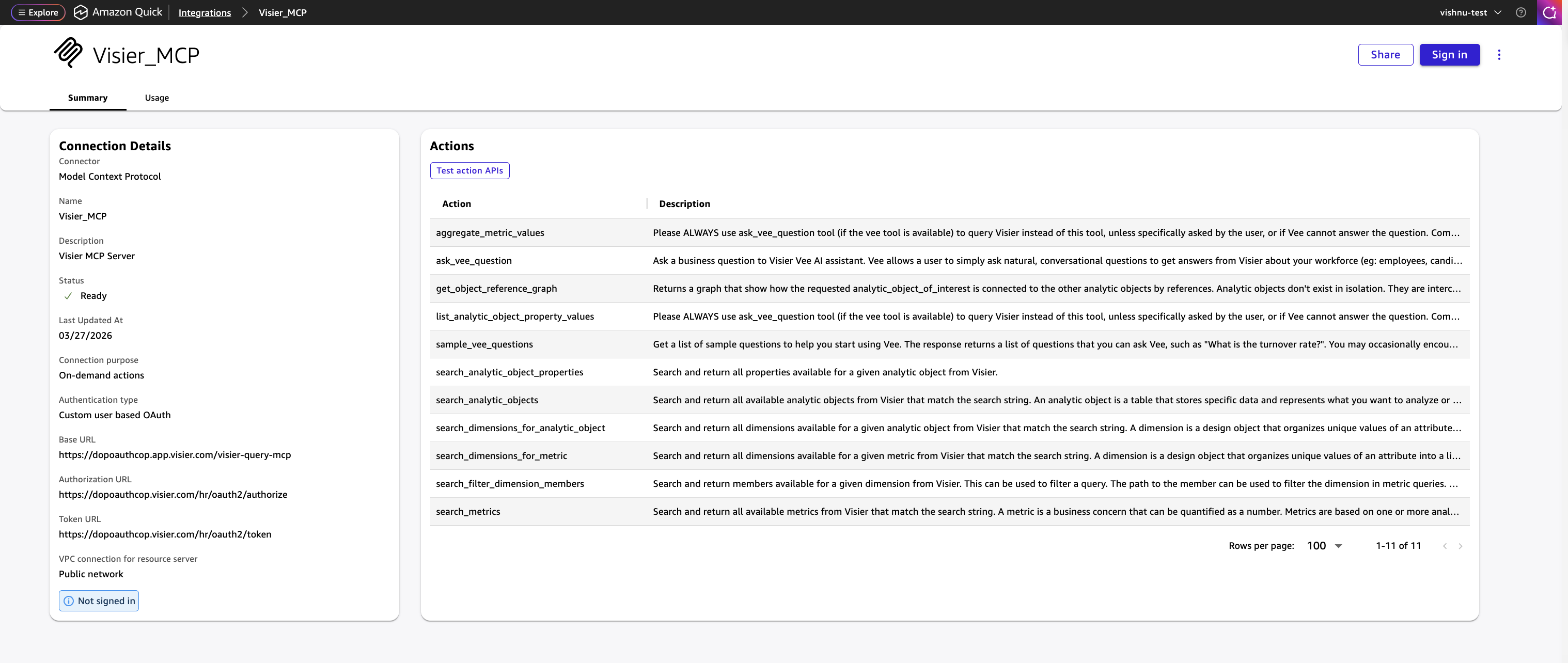
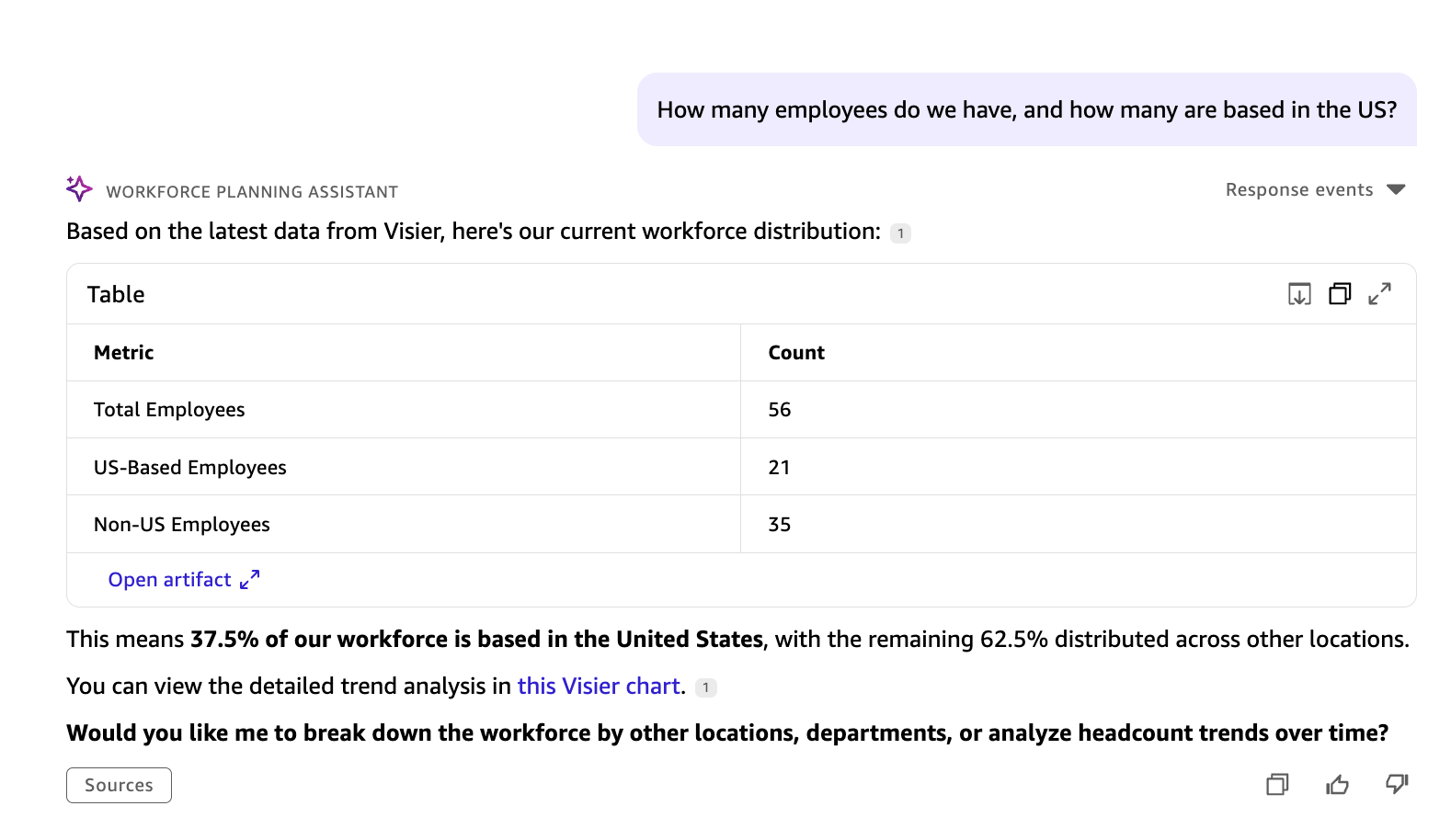
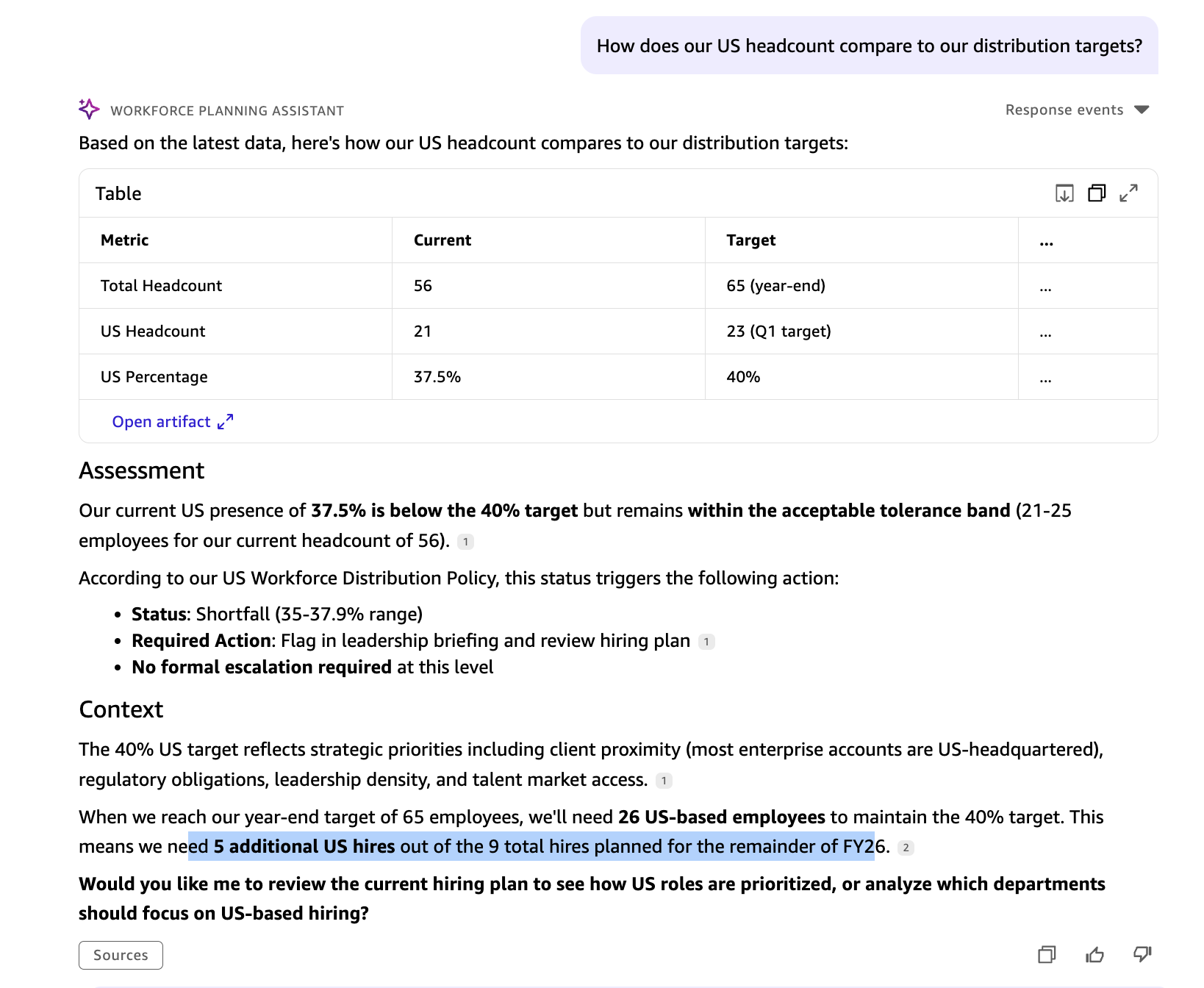
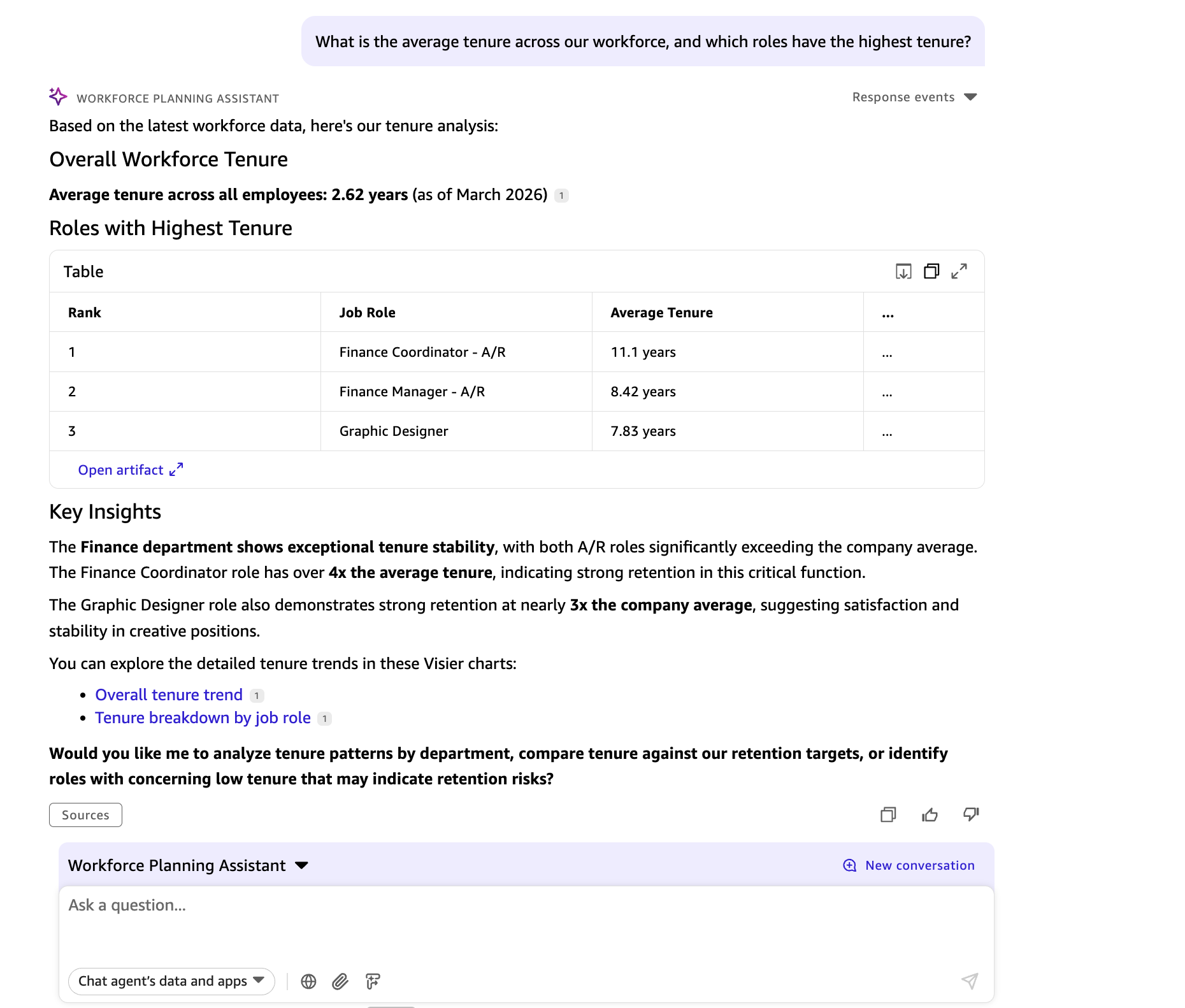
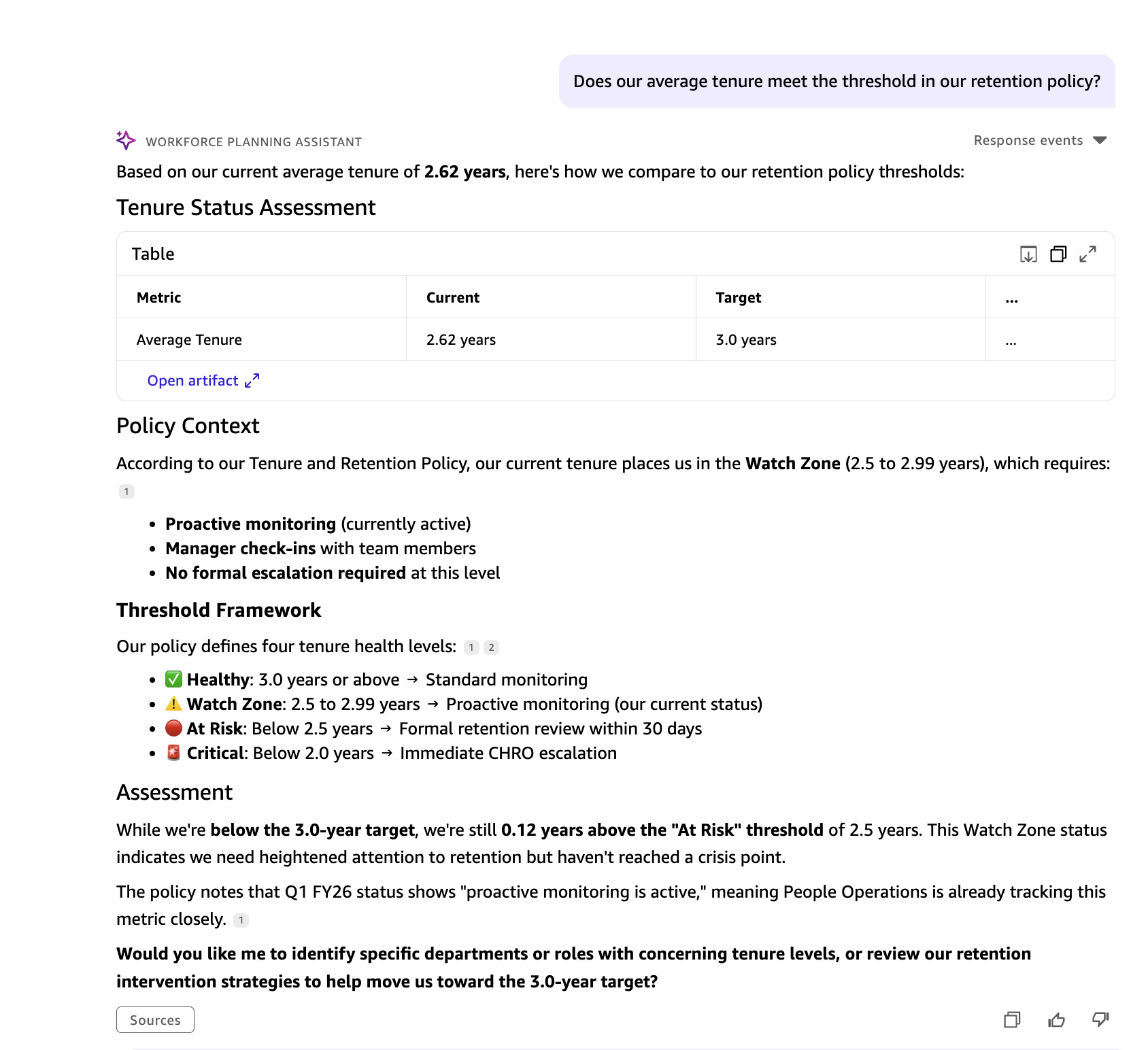
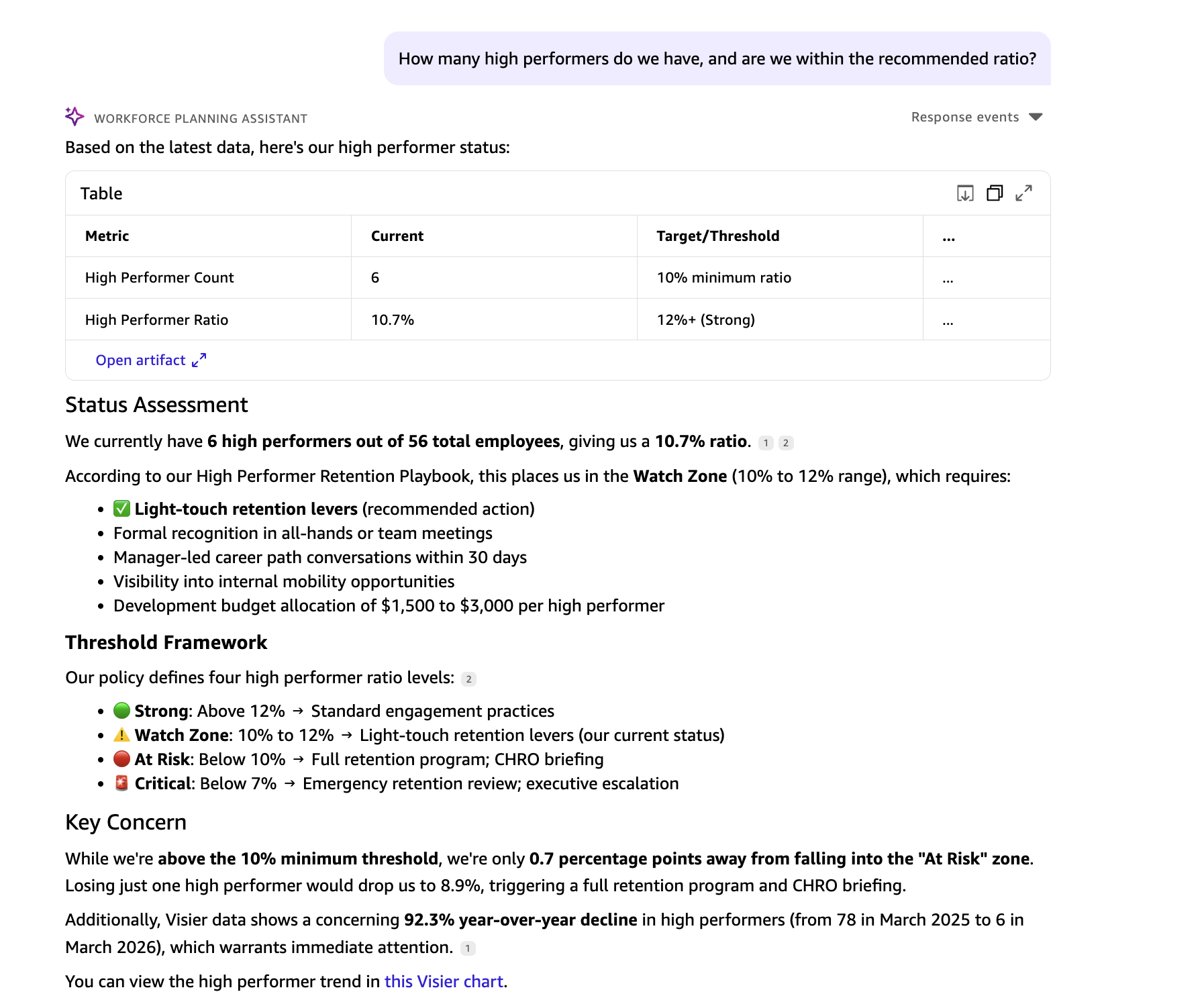
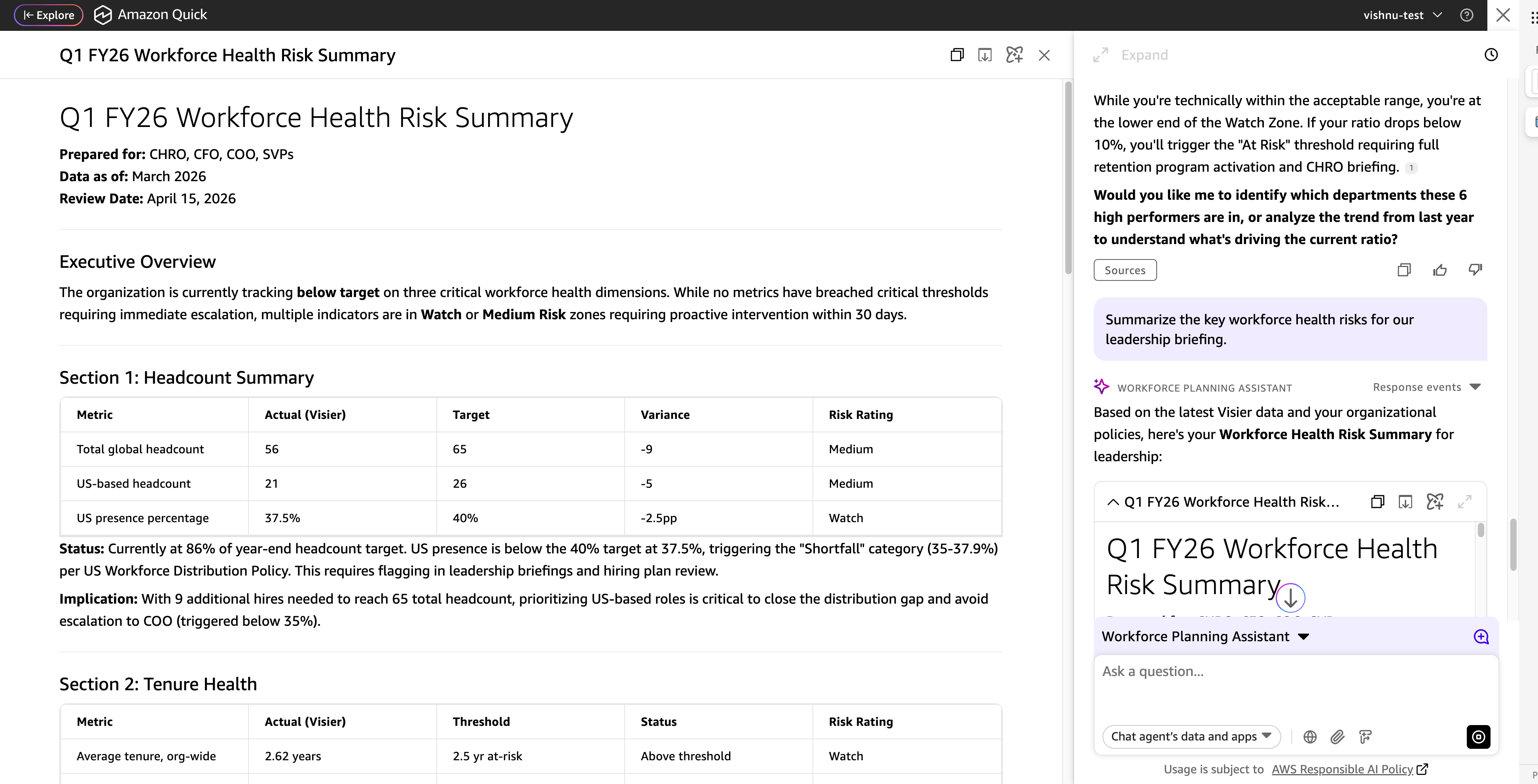
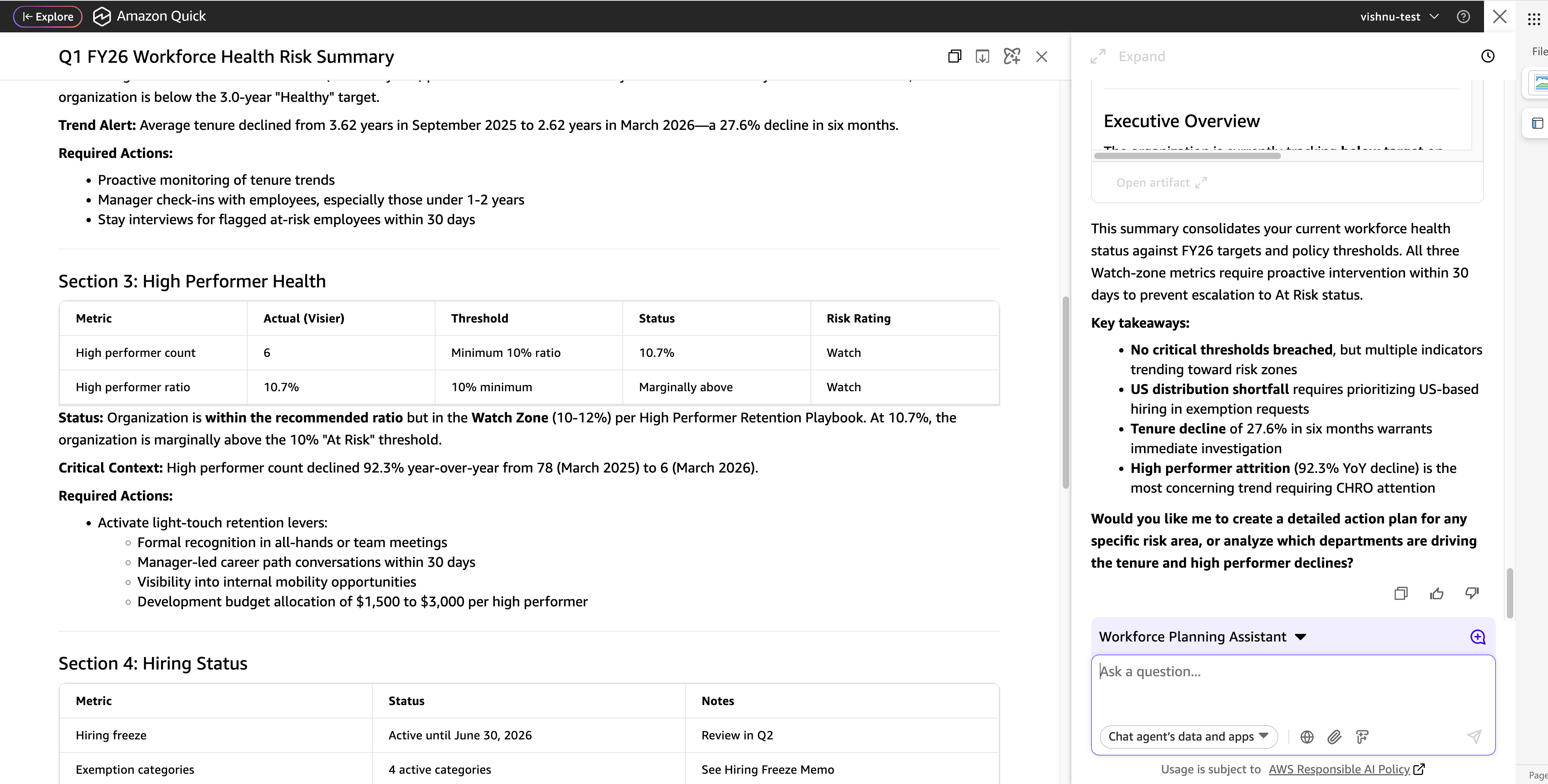
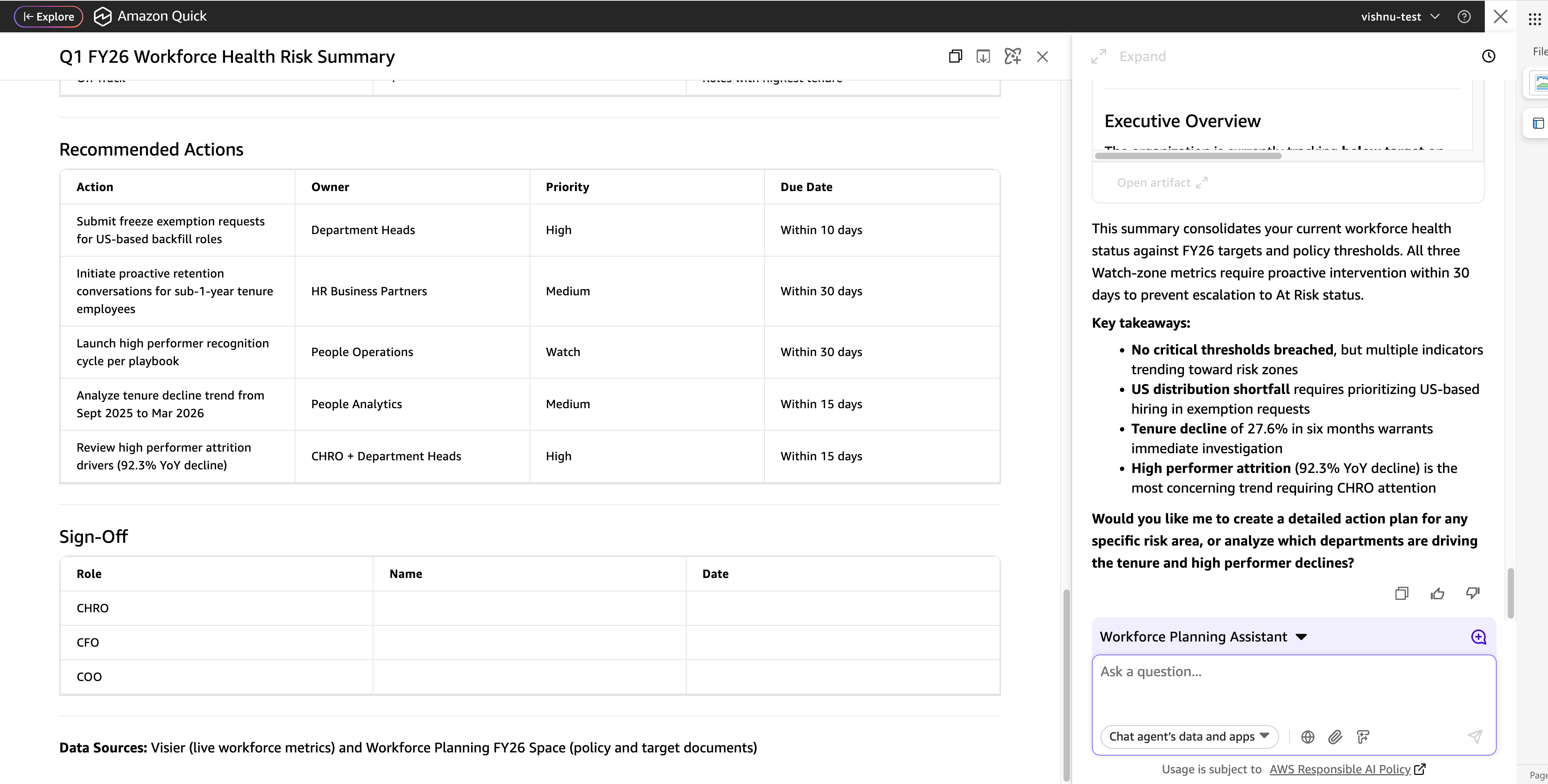
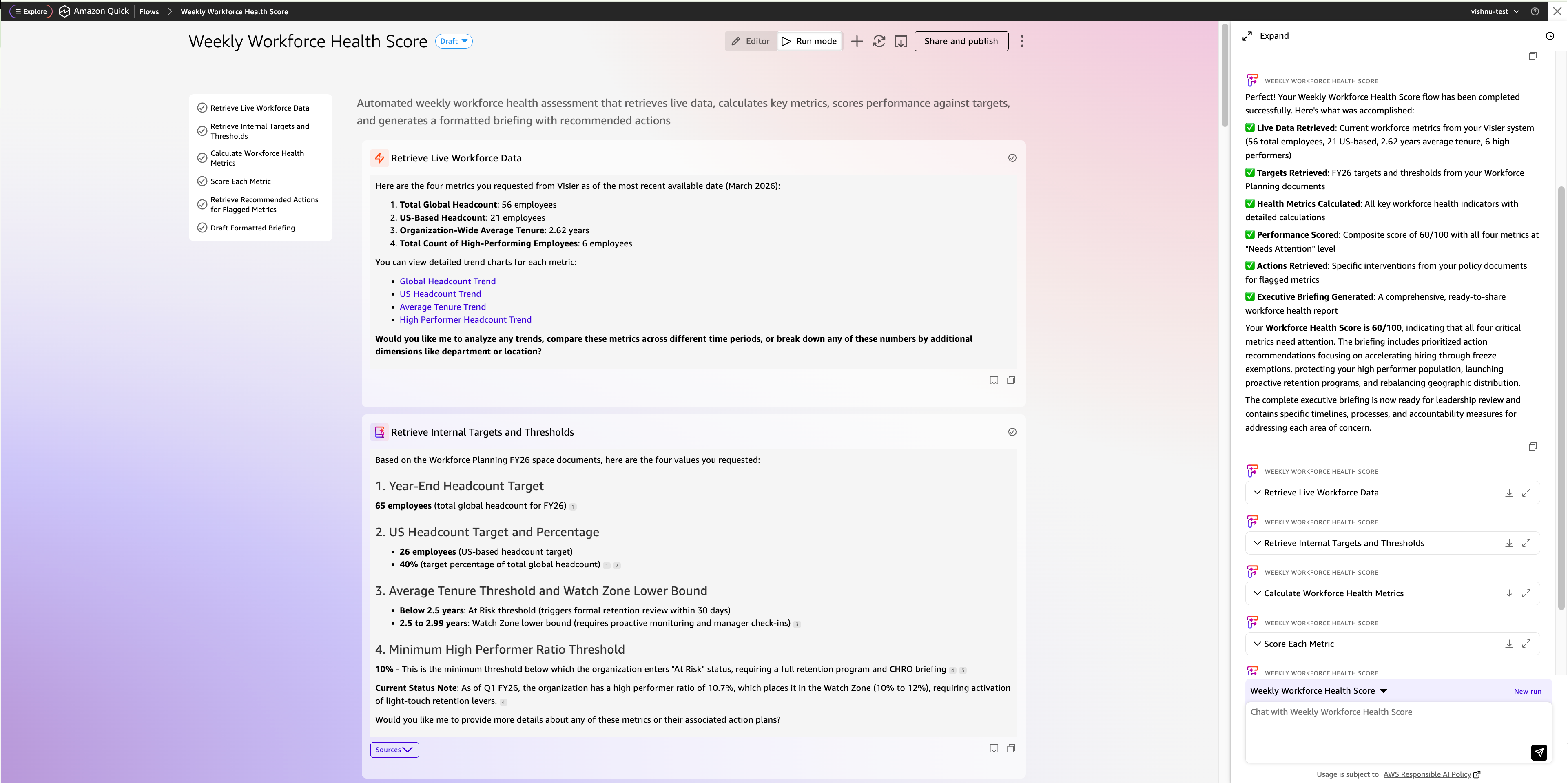
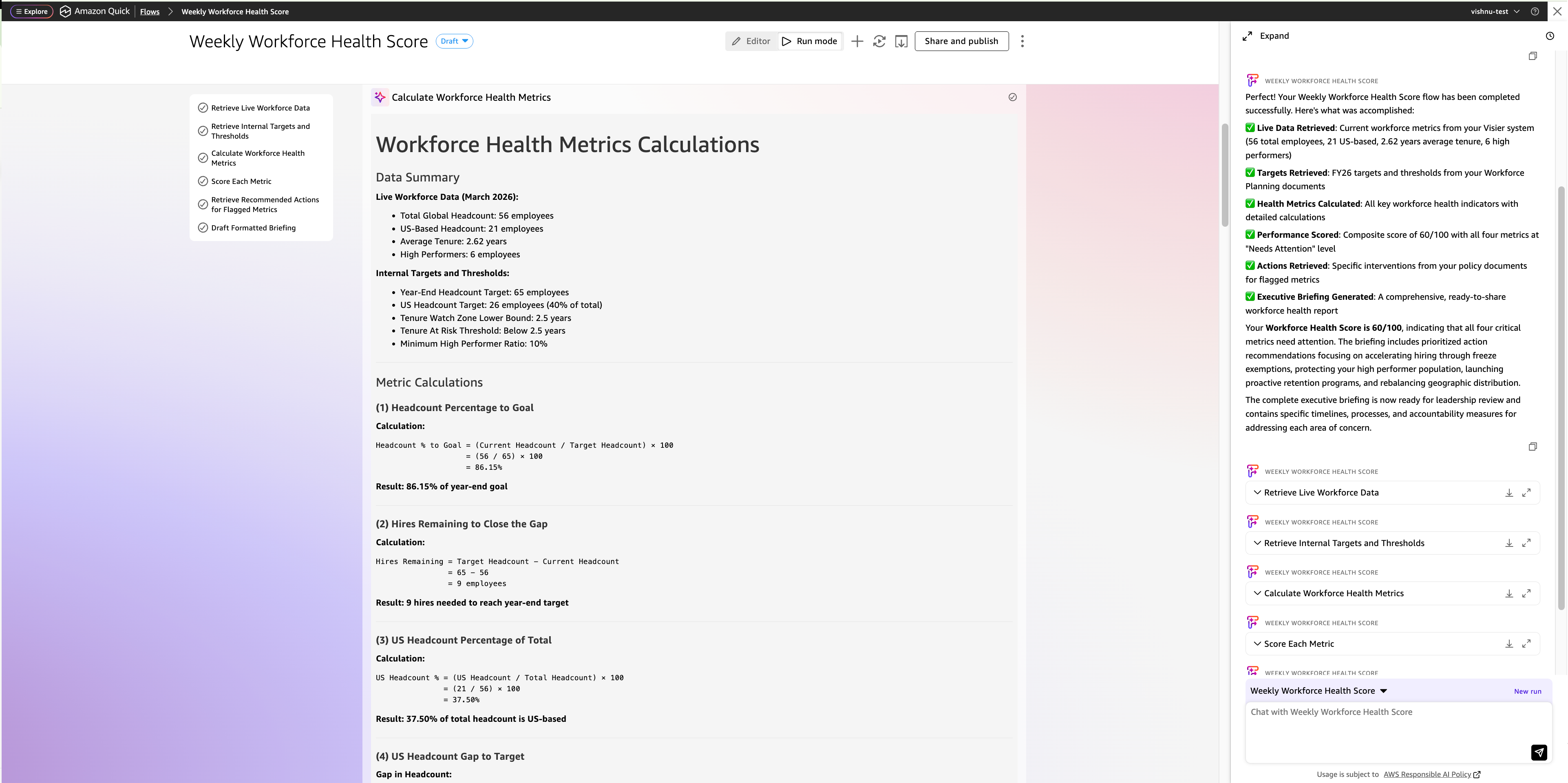
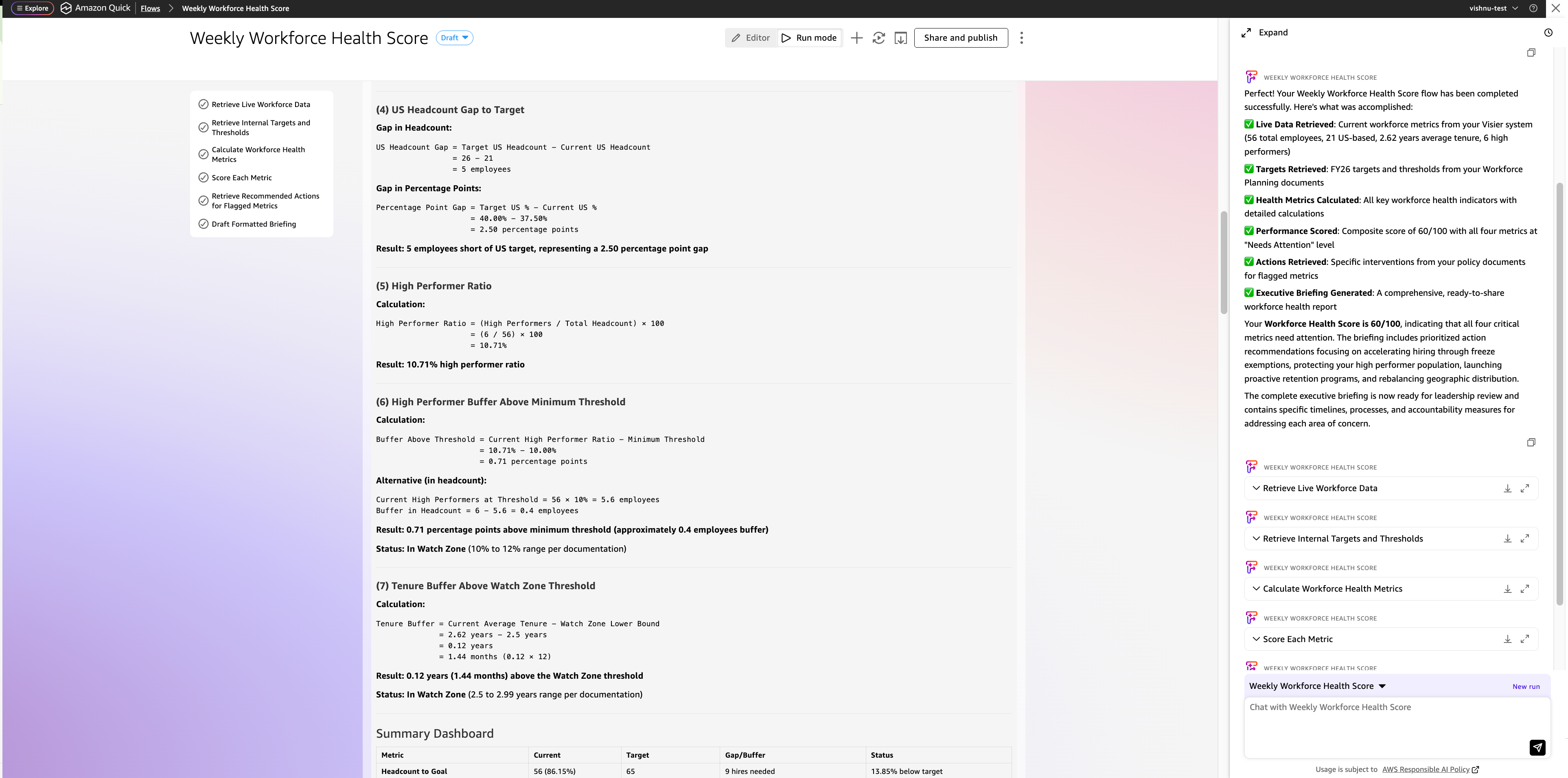
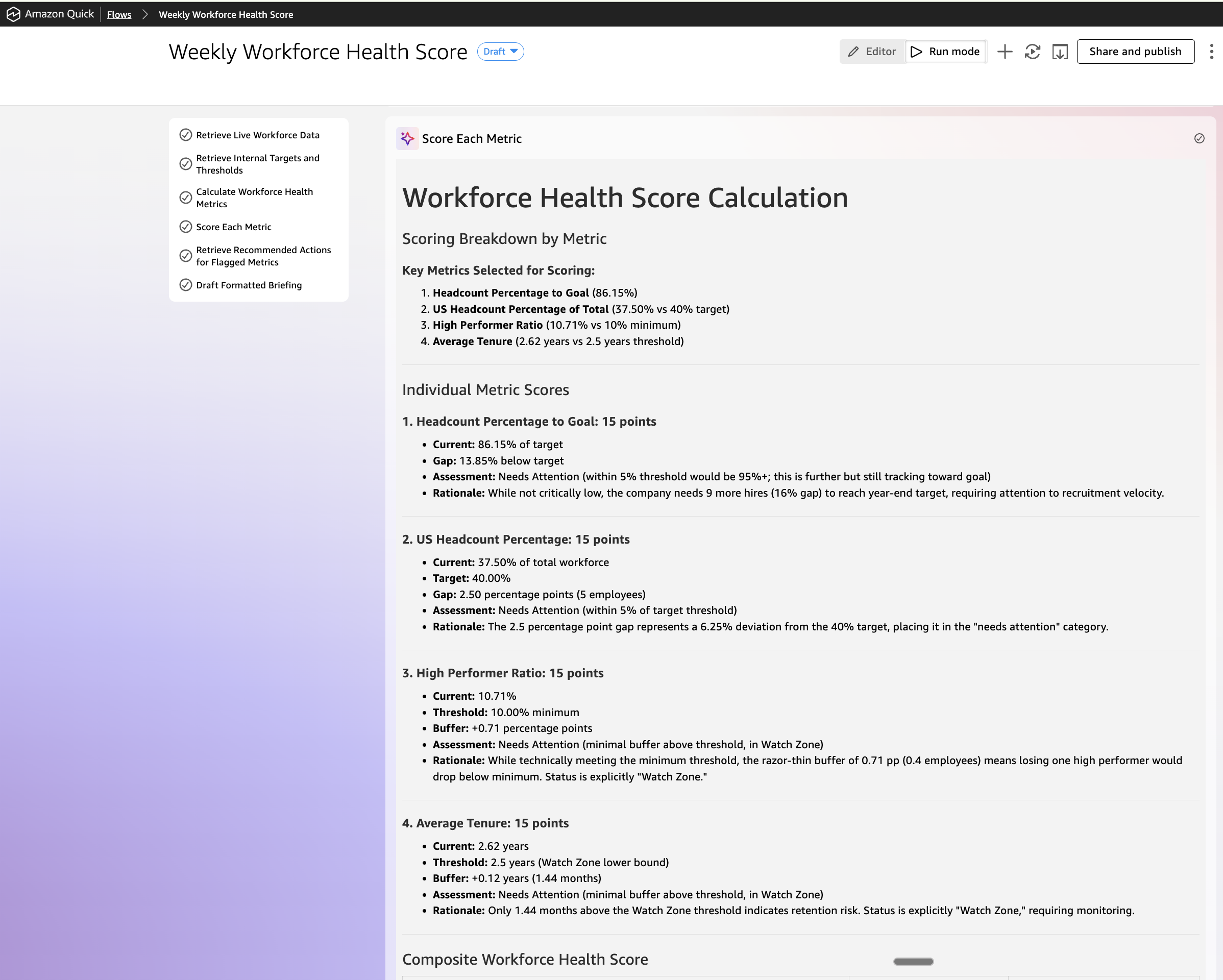
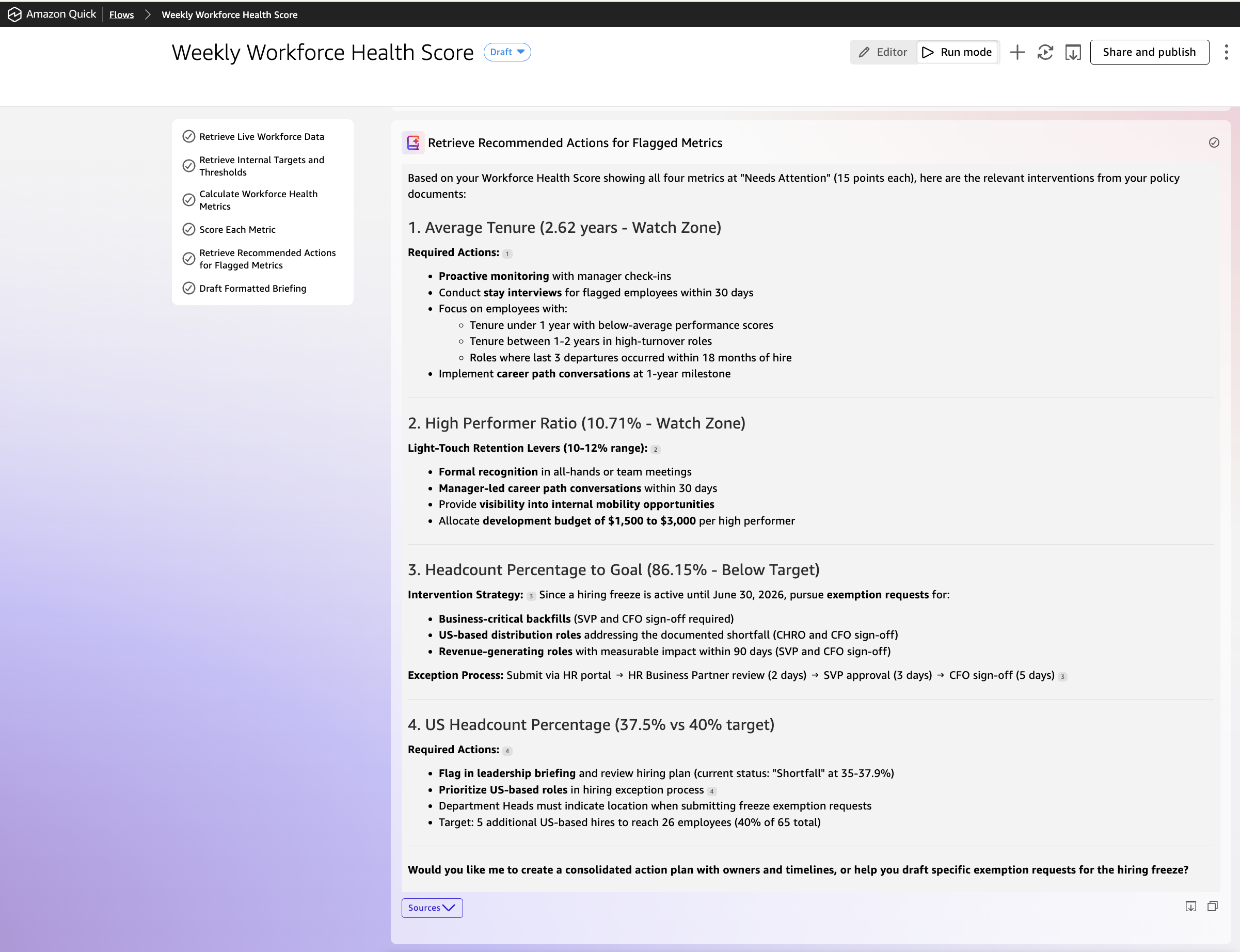
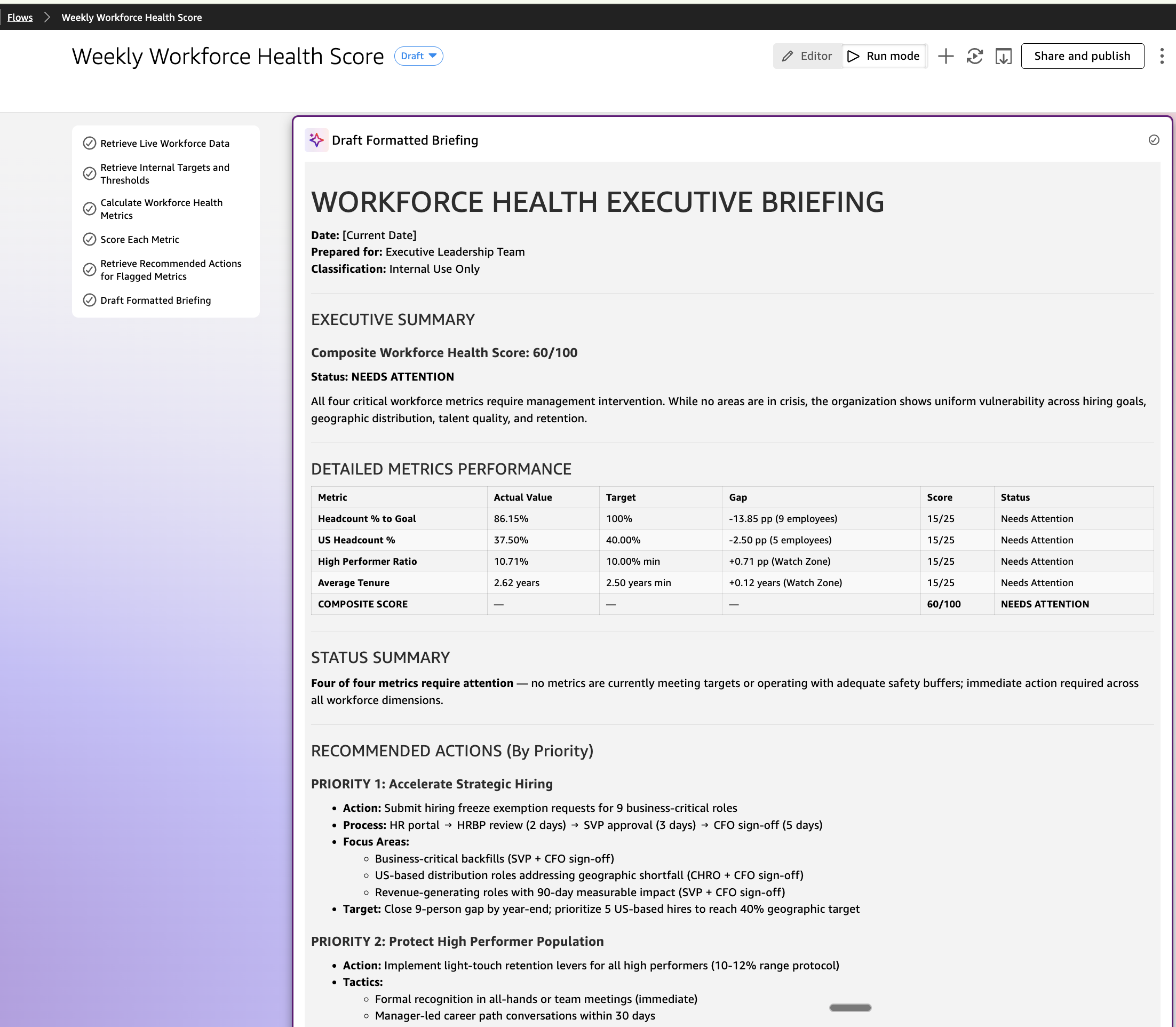
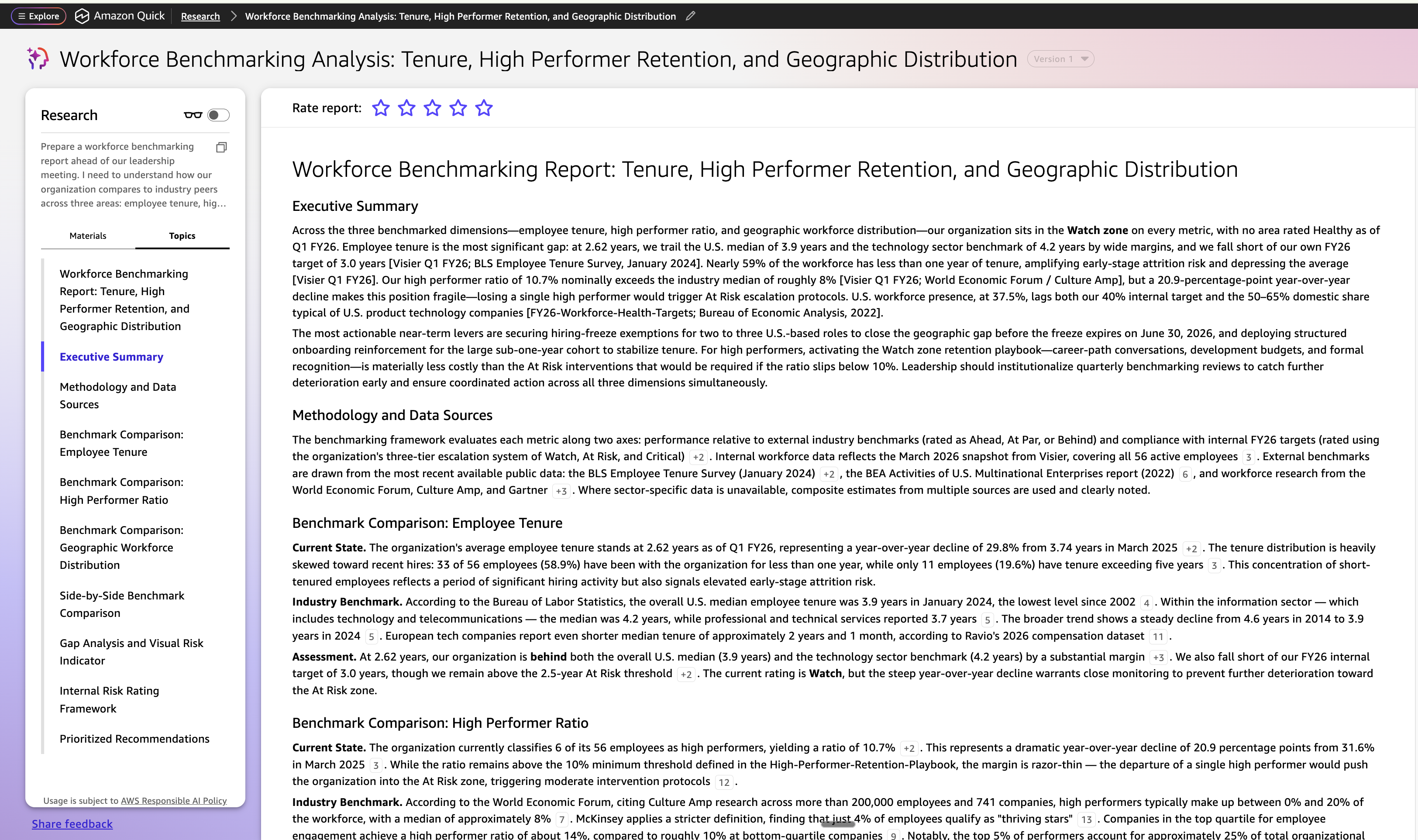
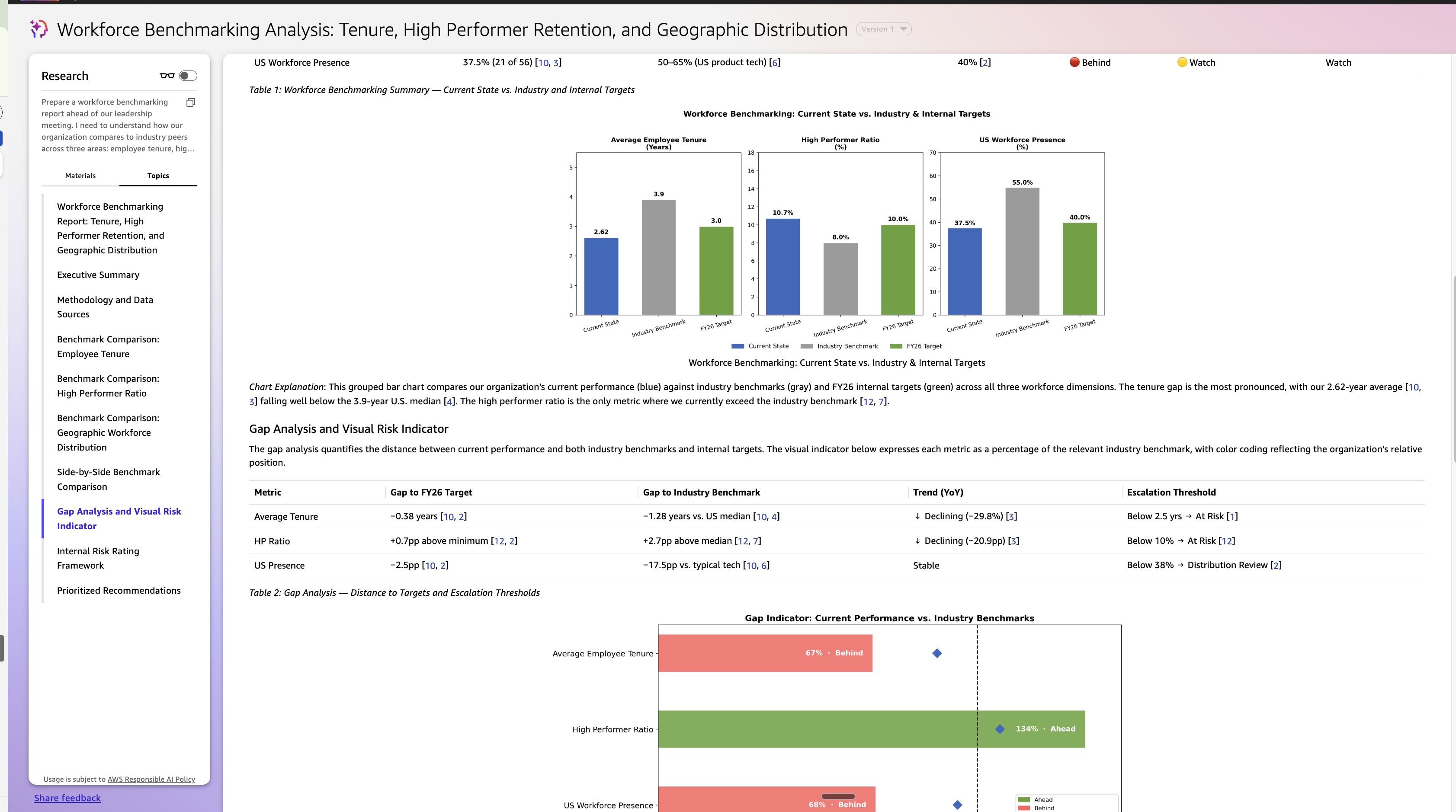
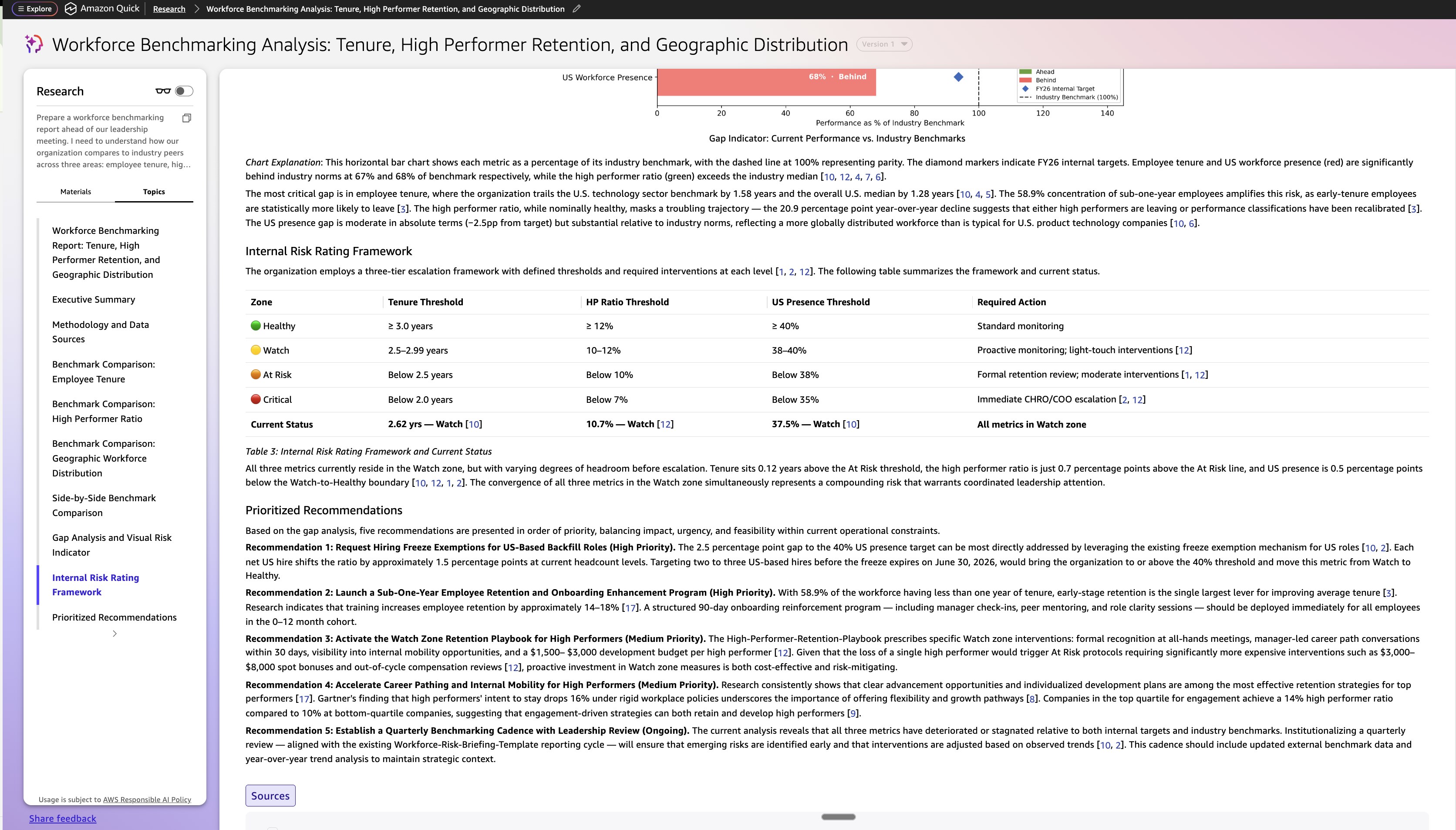












{kind=link}