ImageNet(Deng et al. 2009) is a picture database organized in accordance with the WordNet(Miller 1995) hierarchy which, traditionally, has been utilized in pc imaginative and prescient benchmarks and analysis. Nonetheless, it was not till AlexNet (Krizhevsky, Sutskever, and Hinton 2012) demonstrated the effectivity of deep studying utilizing convolutional neural networks on GPUs that the computer-vision self-discipline turned to deep studying to realize state-of-the-art fashions that revolutionized their area. Given the significance of ImageNet and AlexNet, this put up introduces instruments and strategies to think about when coaching ImageNet and different large-scale datasets with R.
Now, so as to course of ImageNet, we are going to first must divide and conquer, partitioning the dataset into a number of manageable subsets. Afterwards, we are going to practice ImageNet utilizing AlexNet throughout a number of GPUs and compute situations. Preprocessing ImageNet and distributed coaching are the 2 subjects that this put up will current and focus on, beginning with preprocessing ImageNet.
Preprocessing ImageNet
When coping with massive datasets, even easy duties like downloading or studying a dataset might be a lot more durable than what you’ll anticipate. As an example, since ImageNet is roughly 300GB in measurement, you will have to verify to have a minimum of 600GB of free house to go away some room for obtain and decompression. However no worries, you may at all times borrow computer systems with large disk drives out of your favourite cloud supplier. When you are at it, you also needs to request compute situations with a number of GPUs, Strong State Drives (SSDs), and an inexpensive quantity of CPUs and reminiscence. If you wish to use the precise configuration we used, check out the mlverse/imagenet repo, which comprises a Docker picture and configuration instructions required to provision affordable computing sources for this process. In abstract, be sure you have entry to adequate compute sources.
Now that we’ve got sources able to working with ImageNet, we have to discover a place to obtain ImageNet from. The simplest means is to make use of a variation of ImageNet used within the ImageNet Giant Scale Visible Recognition Problem (ILSVRC), which comprises a subset of about 250GB of knowledge and might be simply downloaded from many Kaggle competitions, just like the ImageNet Object Localization Problem.
For those who’ve learn a few of our earlier posts, you may be already pondering of utilizing the pins bundle, which you should use to: cache, uncover and share sources from many providers, together with Kaggle. You’ll be able to study extra about information retrieval from Kaggle within the Utilizing Kaggle Boards article; within the meantime, let’s assume you might be already conversant in this bundle.
All we have to do now’s register the Kaggle board, retrieve ImageNet as a pin, and decompress this file. Warning, the next code requires you to stare at a progress bar for, probably, over an hour.
If we’re going to be coaching this mannequin time and again utilizing a number of GPUs and even a number of compute situations, we wish to be sure that we don’t waste an excessive amount of time downloading ImageNet each single time.
The primary enchancment to think about is getting a quicker exhausting drive. In our case, we locally-mounted an array of SSDs into the /localssd path. We then used /localssd to extract ImageNet and configured R’s temp path and pins cache to make use of the SSDs as effectively. Seek the advice of your cloud supplier’s documentation to configure SSDs, or check out mlverse/imagenet.
Subsequent, a well known method we will comply with is to partition ImageNet into chunks that may be individually downloaded to carry out distributed coaching afterward.
As well as, it is usually quicker to obtain ImageNet from a close-by location, ideally from a URL saved inside the similar information heart the place our cloud occasion is positioned. For this, we will additionally use pins to register a board with our cloud supplier after which re-upload every partition. Since ImageNet is already partitioned by class, we will simply break up ImageNet into a number of zip recordsdata and re-upload to our closest information heart as follows. Make sure that the storage bucket is created in the identical area as your computing situations.
We are able to now retrieve a subset of ImageNet fairly effectively. If you’re motivated to take action and have about one gigabyte to spare, be at liberty to comply with alongside executing this code. Discover that ImageNet comprises heaps of JPEG pictures for every WordNet class.
# A tibble: 1,300 x 1
worth
1 /localssd/pins/storage/n01440764/n01440764_10026.JPEG
2 /localssd/pins/storage/n01440764/n01440764_10027.JPEG
3 /localssd/pins/storage/n01440764/n01440764_10029.JPEG
4 /localssd/pins/storage/n01440764/n01440764_10040.JPEG
5 /localssd/pins/storage/n01440764/n01440764_10042.JPEG
6 /localssd/pins/storage/n01440764/n01440764_10043.JPEG
7 /localssd/pins/storage/n01440764/n01440764_10048.JPEG
8 /localssd/pins/storage/n01440764/n01440764_10066.JPEG
9 /localssd/pins/storage/n01440764/n01440764_10074.JPEG
10 /localssd/pins/storage/n01440764/n01440764_1009.JPEG
# … with 1,290 extra rows
When doing distributed coaching over ImageNet, we will now let a single compute occasion course of a partition of ImageNet with ease. Say, 1/16 of ImageNet might be retrieved and extracted, in underneath a minute, utilizing parallel downloads with the callr bundle:
We are able to wrap this up partition in an inventory containing a map of pictures and classes, which we are going to later use in our AlexNet mannequin by means of tfdatasets.
Nice! We’re midway there coaching ImageNet. The following part will concentrate on introducing distributed coaching utilizing a number of GPUs.
Distributed Coaching
Now that we’ve got damaged down ImageNet into manageable components, we will neglect for a second concerning the measurement of ImageNet and concentrate on coaching a deep studying mannequin for this dataset. Nonetheless, any mannequin we select is prone to require a GPU, even for a 1/16 subset of ImageNet. So be sure that your GPUs are correctly configured by working is_gpu_available(). For those who need assistance getting a GPU configured, the Utilizing GPUs with TensorFlow and Docker video might help you rise up to hurry.
[1] TRUE
We are able to now determine which deep studying mannequin would finest be fitted to ImageNet classification duties. As a substitute, for this put up, we are going to return in time to the glory days of AlexNet and use the r-tensorflow/alexnet repo as a substitute. This repo comprises a port of AlexNet to R, however please discover that this port has not been examined and isn’t prepared for any actual use circumstances. In truth, we might admire PRs to enhance it if somebody feels inclined to take action. Regardless, the main focus of this put up is on workflows and instruments, not about attaining state-of-the-art picture classification scores. So by all means, be at liberty to make use of extra acceptable fashions.
As soon as we’ve chosen a mannequin, we are going to wish to me ensure that it correctly trains on a subset of ImageNet:
Up to now so good! Nonetheless, this put up is about enabling large-scale coaching throughout a number of GPUs, so we wish to be sure that we’re utilizing as many as we will. Sadly, working nvidia-smi will present that just one GPU at the moment getting used:
With a purpose to practice throughout a number of GPUs, we have to outline a distributed-processing technique. If this can be a new idea, it may be time to check out the Distributed Coaching with Keras tutorial and the distributed coaching with TensorFlow docs. Or, when you enable us to oversimplify the method, all it’s a must to do is outline and compile your mannequin underneath the suitable scope. A step-by-step clarification is obtainable within the Distributed Deep Studying with TensorFlow and R video. On this case, the alexnet mannequin already helps a technique parameter, so all we’ve got to do is cross it alongside.
Discover additionally parallel = 6 which configures tfdatasets to utilize a number of CPUs when loading information into our GPUs, see Parallel Mapping for particulars.
We are able to now re-run nvidia-smi to validate all our GPUs are getting used:
The MirroredStrategy might help us scale as much as about 8 GPUs per compute occasion; nonetheless, we’re prone to want 16 situations with 8 GPUs every to coach ImageNet in an inexpensive time (see Jeremy Howard’s put up on Coaching Imagenet in 18 Minutes). So the place can we go from right here?
Welcome to MultiWorkerMirroredStrategy: This technique can use not solely a number of GPUs, but additionally a number of GPUs throughout a number of computer systems. To configure them, all we’ve got to do is outline a TF_CONFIG setting variable with the suitable addresses and run the very same code in every compute occasion.
library(tensorflow)partition<-0Sys.setenv(TF_CONFIG =jsonlite::toJSON(checklist( cluster =checklist( employee =c("10.100.10.100:10090", "10.100.10.101:10090")), process =checklist(kind ='employee', index =partition)), auto_unbox =TRUE))technique<-tf$distribute$MultiWorkerMirroredStrategy( cross_device_ops =tf$distribute$ReductionToOneDevice())alexnet::imagenet_partition(partition =partition)%>%alexnet::alexnet_train(technique =technique, parallel =6)
Please word that partition should change for every compute occasion to uniquely establish it, and that the IP addresses additionally should be adjusted. As well as, information ought to level to a unique partition of ImageNet, which we will retrieve with pins; though, for comfort, alexnet comprises related code underneath alexnet::imagenet_partition(). Apart from that, the code that it’s worthwhile to run in every compute occasion is precisely the identical.
Nonetheless, if we had been to make use of 16 machines with 8 GPUs every to coach ImageNet, it could be fairly time-consuming and error-prone to manually run code in every R session. So as a substitute, we should always consider making use of cluster-computing frameworks, like Apache Spark with barrier execution. If you’re new to Spark, there are a lot of sources accessible at sparklyr.ai. To study nearly working Spark and TensorFlow collectively, watch our Deep Studying with Spark, TensorFlow and R video.
Placing all of it collectively, coaching ImageNet in R with TensorFlow and Spark appears as follows:
We hope this put up gave you an inexpensive overview of what coaching large-datasets in R appears like – thanks for studying alongside!
Deng, Jia, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. 2009. “Imagenet: A Giant-Scale Hierarchical Picture Database.” In 2009 IEEE Convention on Pc Imaginative and prescient and Sample Recognition, 248–55. Ieee.
Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E Hinton. 2012. “Imagenet Classification with Deep Convolutional Neural Networks.” In Advances in Neural Info Processing Techniques, 1097–1105.
Miller, George A. 1995. “WordNet: A Lexical Database for English.”Communications of the ACM 38 (11): 39–41.
On Saturday, a Border Patrol agent in Minneapolis shot and killed Alex Jeffrey Pretti at shut vary after Pretti had been pepper-sprayed, crushed, and compelled onto his knees by different brokers.
Pretti, 37, was a US citizen and reportedly within the space to observe brokers’ actions. He was additionally a registered nurse and a authorized gun proprietor with a allow to hold a weapon — one which he was now not in possession of when he was shot to demise.
Pretti’s demise is no less than the third capturing by immigration brokers within the Minneapolis space this 12 months, and the second the place the one who was shot died.
The shootings have understandably attracted essentially the most consideration nationwide. However because the immigration crackdown in Minneapolis started in early January, there have been widespread abuses of energy US by Immigration and Customs Enforcement (ICE) and Customs and Border Safety (CBP) brokers, together with use of chemical crowd management like pepper spray and tear fuel; brutality towards protesters, bystanders, and immigrants; and baseless and infrequently inflammatory arrests and detentions.
On January 7, simply days into an immigration crackdown focusing on the Minneapolis space that Trump officers heralded as “largest immigration operation ever,” an ICE agent, Jonathan Ross, shot and killed Renee Good as she tried to drive away.
The White Home, Homeland Safety Secretary Kristi Noem, and different federal officers rapidly backed Ross to the hilt, describing Good as a home terrorist and describing the capturing as justified, regardless of video proof on the contrary.
Since then, the message behind the administration’s assist for Ross and the capturing appears to have been clearly acquired by ICE brokers in Minnesota, who’ve behaved way more like an occupying power than a legislation enforcement operation: Not solely have native officers pleaded with them to go away the state, they’re additionally working from behind masks and with militarized power, together with tactical gear, riot management brokers, and assault weapons.
Saturday in Minneapolis.Kerem Yucel/AFP through Getty Photographs
They’ve even pitted themselves towards native police: A Minneapolis-area police chief mentioned this earlier week that a few of his off-duty officers have been harassed and racially profiled by immigration brokers.
In a number of circumstances, federal brokers have been documented utilizing Good’s killing as a risk towards different observers documenting their actions, asking one lady, “Have y’all not realized?” earlier than grabbing her cellphone and detaining her.
What immigration brokers have been doing in Minneapolis
Different incidents are too quite a few to tally in full, however a number of stand out.
Final week, federal brokers violently detained two Goal staff, each of whom a Minnesota state consultant mentioned had been US residents and who had been later launched. At the least one of many staff was left in a close-by parking zone with accidents.
In one other incident, a US citizen was dragged from her automotive by federal brokers after she was stopped on the best way to a health care provider’s appointment; brokers broke the home windows of her automobile and carried her hanging face down by her legs and arms. And federal brokers have been recorded pepper-spraying an already-detained man within the face at shut vary.
ICE brokers detain a girl after pulling her from a automotive on January 13, 2026 in Minneapolis.Stephen Maturen/Getty Photographs
A Minneapolis household was additionally caught up and brutalized by federal brokers final week: On the best way dwelling from a basketball sport, a household of eight — together with a 6-month-old and 5 different kids — was tear-gassed inside their automobile by federal brokers. All survived, however the 6-month-old required CPR.
The second of three shootings by federal immigration brokers within the Minneapolis space was additionally a case of mistaken identification: ICE brokers shot a Venezuelan man within the leg, wounding him, despite the fact that he was not their unique goal.
Extra just lately, ChongLy “Scott” Thao, additionally a US citizen, was detained in his dwelling at gunpoint by federal brokers and brought away in sub-freezing temperatures sporting solely his underwear, sandals, and a blanket. Thao was arrested with out a warrant and finally launched hours later — with out an apology for his detention or for the injury to his dwelling, Thao mentioned.
An individual is pinned to the bottom by federal brokers and a chemical irritant sprayed immediately into his face on January 21, 2026, in Minneapolis.Richard Tsong-Taatarii/The Minnesota Star Tribune through Getty Photographs
Thao’s detention is an element of a bigger sample in Minneapolis, the place ICE brokers are more and more appearing in violation of the Fourth Modification, which protects towards unreasonable searches and seizures. As my colleague Eric Levitz wrote on Friday, ICE has determined, in keeping with a intently held inner memo first obtained by the Related Press, that it may possibly enter houses with solely an administrative warrant, fairly than a judicial warrant. Such administrative warrants don’t require a decide’s approval and may be issued by ICE brokers themselves.
ICE’s crackdown has additionally swept up kids within the Minneapolis space, together with an incident this week the place brokers tried to make use of a 5-year-old youngster as “bait” to detain others by having him knock on the door of his dwelling after taking his father into custody, in keeping with officers at a Minneapolis-area faculty district. Additionally they detained a 2-year-old and her father on Thursday and briefly eliminated each of them to Texas.
Native publications just like the Minneapolis Star-Tribune — and bystanders filming interactions, as Pretti appeared to have been doing earlier than he was shot and killed on Saturday — have created a extra complete document of ICE and CBP’s actions within the state. However even this comparatively restricted variety of incidents reveals a transparent sample of unchecked aggression and ongoing escalation by brokers.
“What number of extra residents, what number of extra People have to die or get badly harm for this operation to finish?” Minneapolis Mayor Jacob Frey requested on Saturday. However for the Trump administration, it’s not clear these deaths are very a lot of an issue in any respect.
On a talus-strewn slope in jap California’s mountains, a gnarled tree twists towards the sky. It’s Methuselah, a Nice Basin bristlecone pine (Pinus longaeva) and one of many world’s oldest timber. At over 4,800 years outdated, Methuselah germinated a number of hundred years earlier than Imhotep started establishing historic Egypt’s first pyramid.
It’s tough to fathom such an extended life span when people stay mere many years. However creator and backyard professional Christopher Woods’ new e book In Botanical Time helps readers just do that, telling the life tales of millennia-old crops and unpacking the science behind their longevity alongside the best way.
One secret to longevity is to decelerate development, Woods writes. That has helped many historic crops survive in less-than-ideal environments. For instance, rising about 2.5 centimeters per century permits Methuselah to focus its vitality on surviving frigid temperatures, nutrient-poor soil and howling winds. Accumulating genetic adjustments that confer traits like illness resistance has additionally helped.
Different historic crops have a unique method to development: cloning. Clonal crops create copies of themselves — typically by way of their roots — permitting them to succeed in outstanding ages even after the unique iteration dies.
Woods describes one Norway spruce (Picea abies) in Sweden that has cloned itself for 9,500 years, sprouting a brand new trunk from its roots each few centuries. Then there’s Pando. This grove of quaking aspens (Populus tremuloides) in Utah could seem as 47,000 distinct timber, however a glance underground reveals the aspens are a single organism with a root system that’s about 14,000 years outdated. New saplings sprout from Pando’s root system which can be genetically similar to the others, which means at the same time as single timber die, the organism continues to stay on.
Nevertheless, these historic timber are relative infants in comparison with a meadow of Neptune grass (Posidonia oceanica) off the coast of Spain. An evaluation of the ocean grass’ DNA and development price revealed the patch to be between 80,000 to 200,000 years outdated. It grows equally to Pando, by way of rhizomes that ship up genetically similar shoots.
Woods additionally regales readers with mythological tales. In line with one Greek fantasy, dragon timber (Dracaena sp.) sprouted from the blood of the hundred-headed dragon slain by Hercules. Two species, D. cinnabari and D. draco, ooze blood-red sap — one thing so uncommon and astounding that “it might solely be ascribed to fantasy,” Wooden writes.
The oldest identified dragon tree, rising within the Canary Islands, is estimated to be as outdated as 1,000. However it’s tough to nail down exact ages for these timber as a result of the trunk inside is spongy and thus doesn’t have development rings. For a lot of proposed historic crops, an absence of development rings stymies scientists from exactly measuring their age. And relating to timber with development rings, a rotten core can muddle age evaluation as a result of the oldest development rings are lacking.
Although generally repetitive, Woods’ cheeky prose and wealthy visuals make In Botanical Time a simple and fascinating learn for plant lovers and superlative seekers. At a time when longevity and wellness are trending matters, this e book is a reminder that maybe the very best factor to do is stay life somewhat slower.
Purchase In Botanical Time from Bookshop.org. Science Information is a Bookshop.org affiliate and can earn a fee on purchases created from hyperlinks on this article.
I’ve been vibe coding my Steady Coin Fee platform, working every thing domestically with my very own server setup utilizing Docker Compose.
However in some unspecified time in the future, I spotted one thing vital: there actually shouldn’t be a easy self hosted platform that may deal with scaling, deployment, and multi service Docker administration with out turning right into a full time DevOps job.
This pushed me to start out looking for Vercel type options which might be simple to make use of whereas nonetheless giving me the liberty and management I need.
The self internet hosting platforms I’m going to share come instantly from my very own expertise and the struggles of looking for instruments that really work for vibe coders.
If you would like higher pricing, extra management, robust safety, and actual scalability, these platforms will help you’re taking your facet mission and switch it into one thing that feels a lot nearer to an actual startup.
The most effective half is that getting began doesn’t require something difficult. All you really want is an affordable Hetzner server. Set up one in every of these platforms, a lot of that are designed to simplify deployments so you possibly can give attention to constructing as an alternative of managing infrastructure, and you may be able to deploy manufacturing prepared functions with confidence.
# 1. Dokploy
Dokploy is a steady, easy-to-use deployment resolution designed to simplify utility administration. It serves as a free, self‑hostable various to platforms like Heroku, Vercel, and Netlify, whereas leveraging the facility of Docker and the flexibleness of Traefik to make deployments clean and environment friendly.
Key options:
Simplicity: Simple setup and intuitive administration of deployments.
Flexibility: Helps a variety of functions and databases.
Open Supply: Utterly free and open-source for anybody to make use of.
# 2. Coolify
Coolify is an open‑supply, self‑hostable PaaS that allows you to deploy functions, databases, and companies, similar to WordPress, Ghost, and Believable Analytics, by yourself infrastructure with ease.
It acts as a DIY various to platforms like Heroku, Vercel, and Netlify, enabling you to run static websites, full‑stack apps, and one‑click on companies throughout any server utilizing easy, automated tooling.
Key options:
Deploy Wherever: Helps deployment to any server, together with VPS, Raspberry Pi, EC2, Hetzner, and extra through SSH, giving full flexibility over infrastructure.
Huge Expertise Help: Works with nearly any language or framework, enabling deployment of static websites, APIs, backends, databases, and lots of fashionable app stacks like Subsequent.js, Nuxt.js, and SvelteKit.
Built-in Git & Automation: Presents push‑to‑deploy with GitHub, GitLab, Bitbucket, and Gitea, plus automated SSL, server setup automation, and pull request deployments for clean CI/CD workflows.
# 3. Appwrite
Appwrite is an open‑supply backend‑as‑a‑service platform that now gives full‑stack capabilities because of its Websites function, which helps you to deploy web sites instantly alongside your backend companies.
Since full‑stack growth means dealing with each frontend and backend elements and Appwrite now helps web site internet hosting plus APIs, auth, databases, storage, messaging, and features, it supplies every thing wanted to construct, deploy, and scale full functions inside a single platform.
Key options:
Finish‑to‑Finish Full‑Stack Platform: With Websites for frontend internet hosting and strong backend instruments like Auth, Databases, Capabilities, Storage, Messaging, and Realtime, Appwrite covers your complete internet stack.
Versatile Integration Strategies: Helps SDKs, REST, GraphQL, and Realtime APIs, permitting seamless integration from any language or framework.
Information Possession & Simple Migration: Presents migration instruments from Firebase, Supabase, Nhost, and self‑hosted setups so builders can simply transfer tasks whereas protecting full management of their knowledge.
# 4. Dokku
Dokku is an extensible, open‑supply Platform‑as‑a‑Service that runs on a single server of your selection, functioning very similar to a self‑hosted mini‑Heroku. It builds functions robotically from a easy git push utilizing both Dockerfiles or language autodetection through Buildpacks, then runs them inside remoted containers.
Dokku additionally integrates applied sciences like nginx and cron to route internet visitors and handle background processes, giving builders a light-weight however highly effective option to deploy and function apps on their very own infrastructure.
Key options:
Git‑Powered Deployments: Push code through Git to construct apps on the fly utilizing Dockerfiles or Buildpacks, much like Heroku’s workflow.
Light-weight Single‑Server PaaS: Runs on any Ubuntu/Debian server and makes use of Docker to handle app lifecycles, making it simple to self‑host a Heroku‑like setting on minimal {hardware}.
Extensible & Plugin‑Pleasant: Helps a large ecosystem of neighborhood and official plugins, permitting builders so as to add databases, storage, monitoring, and extra to their deployments.
# 5. Juno
Juno is an open‑supply serverless platform that allows you to construct, deploy, and run functions in safe WASM containers whereas sustaining full self‑internet hosting management and 0 DevOps. It supplies a whole backend stack, together with key‑worth knowledge storage, authentication, file storage, analytics, and serverless features, so builders can create fashionable apps with out managing infrastructure.
Juno additionally helps internet hosting static websites, constructing full internet apps, and working features with the privateness and sovereignty of self‑internet hosting, all whereas providing a well-recognized, cloud‑like developer expertise.
Key options:
Full Serverless Stack with Self‑Internet hosting Management: Consists of datastore, storage, auth, analytics, and serverless features working in safe WASM containers, providing you with full possession of your apps and knowledge.
Zero‑Setup Developer Expertise: Use native emulation for growth and deploy to remoted containers (“Satellites”) with no DevOps required and a workflow much like fashionable cloud platforms.
Constructed for Net Builders: Use your favourite frontend frameworks and write serverless features in Rust or TypeScript, with templates and instruments that simplify constructing full‑stack apps.
# Comparability Desk
This comparability desk highlights what every platform is greatest for, the way you deploy to it, and the sorts of functions it will probably run so you possibly can shortly choose the fitting self-hosted various on your workflow.
Platform
Finest for
Deploy workflow
What it runs
Dokploy
Easy “Heroku-style” self-hosting with robust Docker Compose help
UI-driven deploys + Docker Compose
Containers, Compose apps
Coolify
Closest really feel to a self-hosted Vercel/Netlify, plus plenty of prebuilt companies
Git push to deploy (GitHub/GitLab/Bitbucket/Gitea) + automation
Static websites, full-stack apps, companies
Appwrite (with Websites)
One platform for backend (Auth/DB/Storage/Capabilities) plus frontend internet hosting
Join Git repo or use templates for Websites
Frontends + backend companies
Dokku
Light-weight “mini-Heroku” on a single server
git push deploys through Buildpacks or Dockerfile
Containerized apps
Juno
Serverless-style apps with self-hosting management and minimal ops
CLI or GitHub Actions deploy to “Satellites”
Static websites, internet apps, WASM-based serverless features
Abid Ali Awan (@1abidaliawan) is a licensed knowledge scientist skilled who loves constructing machine studying fashions. Presently, he’s specializing in content material creation and writing technical blogs on machine studying and knowledge science applied sciences. Abid holds a Grasp’s diploma in know-how administration and a bachelor’s diploma in telecommunication engineering. His imaginative and prescient is to construct an AI product utilizing a graph neural community for college students fighting psychological sickness.
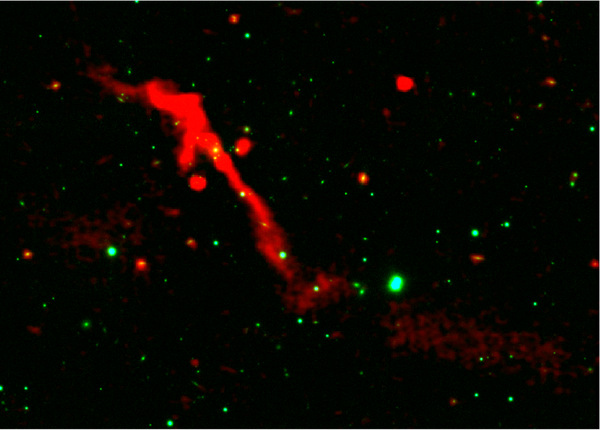
After 100 million years of dormancy, the supermassive black gap on the heart of galaxy J1007+3540 is glowing shiny.
LOFAR/Pan-STARRS/S. Kumari et al.
Inside an extremely shiny cluster of galaxies, a long-dormant supermassive black gap has come again to life. Radio photos captured a one-million-light-year-long stream of star-forming particles and fuel emanating from the black gap on the heart of the galaxy J1007+3540—which apparently is erupting for the primary time in about 100 million years.
“Though some ‘restarted’ radio galaxies are recognized within the literature, J1007+3540 stands out,” says lead research writer Shobha Kumari of Midnapore Metropolis Faculty in India. The outcome just lately appeared within the Month-to-month Notices of the Royal Astronomical Society.
J1007+3540 is an uncommonly massive instance of an episodic galaxy, whereby a central supermassive black gap solely intermittently emits distinguished jets of particles and fuel, virtually as if an astrophysical on-off swap was flipped. Researchers say the knowledge they acquire from the eruption of this “cosmic volcano” may assist them higher perceive episodic galaxies’ constructions, evolution and affect on their environment.
On supporting science journalism
For those who’re having fun with this text, contemplate supporting our award-winning journalism by subscribing. By buying a subscription you’re serving to to make sure the way forward for impactful tales in regards to the discoveries and concepts shaping our world at the moment.
Ejected jets are a constant however not ubiquitous function of the supermassive black holes on the hearts of galaxies, which, when erupting, are additionally referred to as lively galactic nuclei (AGNs). Many AGNs are regarded as episodic, ebbing as they exhaust surrounding reservoirs of fuel, solely to surge once more when extra materials drifts inside attain. This cycle elapses throughout 1000’s of years—glacially gradual to us however virtually instantaneous on cosmic scales.
That makes episodic exercise and the on-off transition troublesome to catch because it happens. Reasonably than making an attempt to watch the adjustments themselves, scientists typically analyze the constructions inside galaxies they assume come up from a central black gap’s episodic outbursts. If the black gap is dormant, they search for echoes of its previous lively part, akin to high-energy gentle or ionized fuel that has traveled farther out from the galaxy’s heart. And, in fact, if a galaxy’s central black gap is in its AGN part, like J1007+3540’s, the proof is clear.
The radio photos of J1007+3540—taken utilizing interferometers on the Low Frequency Array within the Netherlands and the upgraded Large Meterwave Radio Telescope in India—seize each phases in a single goal. The galaxy sports activities not solely a shiny new child jet but additionally a surrounding surfeit of older materials blasted out by previous AGN episodes. Whereas different episodic galaxies are anticipated to have related constructions, J1007+3540’s are particularly clear.
“This technique is simply bodily very massive, and that makes it extra amenable to check in some ways,” explains Niel Brandt, an astrophysicist at Pennsylvania State College. “You possibly can go in and research it in appreciable element.”
One in all these particulars, a faint, fragmented tail of previous materials extending out into intergalactic house stirred by subsequent outbursts to shine anew, reveals how J1007+3540’s AGN part can influence its cosmic neighborhood—particularly, the fuel pervading the galaxy cluster the place J1007+3540 resides, often known as the intracluster medium (ICM). The form and brightness of the rekindled tail hint the advanced interactions that occurred between the AGN’s ejected jet and the ICM because the jet propagated outward.
“These observations assist us perceive that the connection between a galaxy’s jets and the cluster setting could be very dynamic,” says Vivian U, an astronomer on the College of California, Irvine. “The jets don’t simply carve a path by means of empty house—they’re continuously formed and adjusted by the fuel they encounter.”
There’s nonetheless lots left to study how interactions with the ICM can suggestions to alter the shape and conduct of a galaxy’s jets, all of which may spark (or suppress) the creation of recent generations of stars. By some means the sparkle and flutter of AGN on the hearts of galaxies could dictate whether or not they shine for eons or fade to starless black.
“The oddballs are thrilling,” says Phil Hopkins, a theoretical astrophysicist on the California Institute of Know-how. Observing uncommon instances like J1007+3540 provides researchers the chance to check and enhance their fashions of how this majestic course of unfolds.
It’s Time to Stand Up for Science
For those who loved this text, I’d wish to ask in your help. Scientific American has served as an advocate for science and trade for 180 years, and proper now will be the most crucial second in that two-century historical past.
I’ve been a Scientific American subscriber since I used to be 12 years previous, and it helped form the way in which I take a look at the world. SciAm at all times educates and delights me, and conjures up a way of awe for our huge, lovely universe. I hope it does that for you, too.
For those who subscribe to Scientific American, you assist make sure that our protection is centered on significant analysis and discovery; that we’ve the sources to report on the selections that threaten labs throughout the U.S.; and that we help each budding and dealing scientists at a time when the worth of science itself too typically goes unrecognized.
(newcommand{xb}{{bf x}} newcommand{betab}{boldsymbol{beta}} newcommand{zb}{{bf z}} newcommand{gammab}{boldsymbol{gamma}})Now we have no alternative however to decide on
We make selections day by day, and infrequently these selections are made amongst a finite variety of potential options. For instance, will we take the automobile or trip a motorcycle to get to work? Will we now have dinner at house or eat out, and if we eat out, the place will we go? Scientists, advertising analysts, or political consultants, to call a number of, want to discover out why folks select what they select.
On this submit, I present some background about discrete alternative fashions, particularly, the multinomial probit mannequin. I talk about this mannequin from a random utility mannequin perspective and present you methods to simulate information from it. That is useful for understanding the underpinnings of this mannequin. In my subsequent submit, we are going to use the simulated information to exhibit methods to estimate and interpret results of curiosity.
Random utility mannequin and discrete alternative
An individual confronted with a discrete set of options is assumed to decide on the choice that maximizes his or her utility in some outlined approach. Utilities are usually conceived of as the results of a perform that consists of an noticed deterministic and an unobserved random half, as a result of not all components which may be related for a given determination will be noticed. The regularly used linear random utility mannequin is
the place (U_{ij}) is the utility of the (i)th particular person associated to the (j )th various, (V_{ij}) is the noticed element, and (epsilon_{ij}) is the unobserved element. Within the context of regression modeling, the noticed half, (V_{ij}), is often construed as some linear or nonlinear mixture of noticed traits associated to people and options and corresponding parameter estimates, whereas the parameters are estimated based mostly on a mannequin that makes sure assumptions concerning the distribution of the unobserved elements, (epsilon_{ij}).
Motivating instance
Let’s check out an instance. Suppose that people can enroll in one in every of three medical insurance plans: Sickmaster, Allgood, and Cowboy Well being. Thus we now have the next set of options:
We’d count on an individual’s utility associated to every of the three options to be a perform of each private traits (akin to revenue or age) and traits of the well being care plan (akin to its worth).
We would pattern people and ask them which well being plan they would like in the event that they needed to enroll in one in every of them. If we collected information on the individual’s age (in a long time), the individual’s family revenue (in $10,000), and the worth of a plan (in $100/month), then our information would possibly look one thing like the primary three circumstances from the simulated information beneath:
. listing in 1/9, sepby(id)
+-----------------------------------------------------------+
| id alt alternative hhinc age worth U |
|-----------------------------------------------------------|
1. | 1 Sickmaster 1 3.66 2.1 2.05 2.38 |
2. | 1 Allgood 0 3.66 2.1 1.73 -1.04 |
3. | 1 Cowboy Well being 0 3.66 2.1 1.07 -2.61 |
|-----------------------------------------------------------|
4. | 2 Sickmaster 0 3.75 4.2 2.19 -2.97 |
5. | 2 Allgood 1 3.75 4.2 1.12 0.29 |
6. | 2 Cowboy Well being 0 3.75 4.2 0.78 -2.22 |
|-----------------------------------------------------------|
7. | 3 Sickmaster 0 2.32 2.4 2.25 -4.49 |
8. | 3 Allgood 0 2.32 2.4 1.31 -5.76 |
9. | 3 Cowboy Well being 1 2.32 2.4 1.02 1.19 |
+-----------------------------------------------------------+
Taking the primary case (id==1), we see that the case-specific variables hhinc and age are fixed throughout options and that the alternative-specific variable worth varies over options.
The variable alt labels the options, and the binary variable alternative signifies the chosen various (it’s coded 1 for the chosen plan, and 0 in any other case). As a result of it is a simulated dataset, we all know the underlying utilties that correspond to every various, and people are given in variable U. The primary respondent’s utility is highest for the primary various, and so the result variable alternative takes the worth 1 for alt==”Sickmaster” and 0 in any other case. That is the marginal distribution of circumstances over options:
. tabulate alt if alternative == 1
Insurance coverage |
plan | Freq. % Cum.
--------------+-----------------------------------
Sickmaster | 6,315 31.57 31.57
Allgood | 8,308 41.54 73.11
Cowboy Well being | 5,377 26.89 100.00
--------------+-----------------------------------
Complete | 20,000 100.00
As we are going to see beneath, a helpful mannequin for analyzing most of these information is the multinomial probit mannequin.
Multinomial probit mannequin
The multinomial probit mannequin is a discrete alternative mannequin that’s based mostly on the idea that the unobserved elements in (epsilon_{ij}) come from a traditional distribution. Completely different probit fashions come up from totally different specs of (V_{ij}) and totally different assumptions about (epsilon_{ij}). For instance, with a primary multinomial probit mannequin, as is applied in Stata’s mprobit command (see [R] mprobit), we specify (V_{ij}) to be
[V_{ij} = xb_{i}betab_{j}^{,’}]
the place (xb_{i}) is a vector of individual-specific covariates, and (betab_{j}) is the corresponding parameter vector for various (j). The random elements (epsilon_{ij}) are assumed to come back from a multivariate regular distribution with imply zero and identification variance–covariance matrix. For instance, if we had three options, we’d assume
Specifying the above covariance construction signifies that the unobserved elements, (epsilon_{ij}), are assumed to be homoskedastic and unbiased throughout options.
Independence implies that variations in utility between any two options depend upon these two options however not on any of the opposite options. This property is called the independence from irrelevant options (IIA) assumption. When the IIA assumption holds, it could result in a lot of handy benefits akin to finding out solely a subset of options (see Practice [2009, 48]). Nonetheless, IIA is a reasonably restrictive assumption which may not maintain.
Persevering with with our well being care plan instance, suppose that Sickmaster and Allgood each favor folks with well being issues, whereas Cowboy Well being favors individuals who solely hardly ever see a health care provider. On this case, we’d count on the utilities that correspond to options Sickmaster and Allgood to be positively correlated whereas being negatively correlated with the utility comparable to Cowboy Well being. In different phrases, utilities with respect to options Sickmaster and Allgood are associated to these of Cowboy Well being. On this case, we should use a mannequin that relaxes the IIA assumption and permits for correlated utilities throughout options.
One other potential limitation of our multinomial probit specification issues the noticed (V_{ij}), which consists of the linear mixture of individual-specific variables and alternative-specific parameters. In different phrases, we solely contemplate noticed variables that modify over individuals however not over options. In a setting like this, we’d use
[V_{ij} = xb_{i}betab_{j}’ + zb_{ij}gammab’]
the place (zb_{ij}) are alternative-specific variables that modify each over people and options and (gammab) is the corresponding parameter vector. Combining this with our extra versatile assumptions concerning the unobservables, we are able to write our mannequin as
As we are going to see later, we are able to match this mannequin in Stata with the asmprobit command; see [R] asmprobit for particulars concerning the command and applied strategies.
We stated in our well being plan instance that we predict that the worth that particular person (i) has to pay for the plan is vital and it might range each over people and options. We will subsequently write our utility mannequin for 3 options as
We will simulate information assuming the data-generating course of given within the above mannequin. We’ll specify the 2 case-specific variables, family revenue (hhinc) and age (age), and we are going to take the worth of the plan (worth) because the alternative-specific variable. The case-specific variables hhinc and age might be fixed throughout options inside every particular person, whereas the alternative-specific variable worth will range over people and inside people over options.
We specify the next inhabitants parameters for (betab_{j}) and (gamma):
With these specs, we are able to now create a simulated dataset. We begin by drawing our three error phrases and two case-specific covariates:
. clear
. set seed 65482
. set obs 20000
variety of observations (_N) was 0, now 20,000
. generate id = _n
. scalar s11 = 2.1
. scalar s22 = 1.7
. scalar s33 = 1.4
. scalar s12 = 0.6
. scalar s13 = -0.5
. scalar s23 = -0.8
. mat C = (s11,s12,s13)
> (s12,s22,s23)
> (s13,s23,s33)
. drawnorm e1 e2 e3, cov(C)
. generate double hhinc = max(0,rnormal(5,1.5))
. generate double age = runiformint(20,60)/10
To permit for various particular covariates, we are going to develop our information so that we are going to have one remark for every various for every case, then create an index for the options, after which generate our variables ({tt worth}_{ij}):
. develop 3
(40,000 observations created)
. bysort id : gen alt = _n
. generate double worth = rbeta(2,2) + 1.50 if alt == 1
(40,000 lacking values generated)
. substitute worth = rbeta(2,2) + 0.75 if alt == 2
(20,000 actual modifications made)
. substitute worth = rbeta(2,2) + 0.25 if alt == 3
(20,000 actual modifications made)
We will now go forward and generate three variables for the noticed utility elements, one for every various:
Wanting on the code above, you’ll discover that we included an element to scale our specified inhabitants parameters. This is because of identification particulars associated to our mannequin that I clarify additional within the Identification part. One factor we have to know now, nevertheless, is that for the mannequin to be recognized, the utilities have to be normalized for degree and scale. Normalizing for degree is simple as a result of, since we’re solely within the utilities relative to one another, we are able to outline a base-level various after which take the variations of utilities with respect to the set base. If we set the primary various as the bottom, we are able to rewrite our mannequin as follows:
What’s left to finish our simulated dataset is to generate the result variable that takes the worth 1 if remark (i) chooses various (ok), and 0 in any other case. To do that, we are going to first create a single variable for the utilities after which decide the choice with the best utility:
. quietly generate double U = .
. quietly generate y = .
. forval i = 1/3 {
2. quietly substitute U = U`i' if alt==`i'
3. }
. bysort id : egen double umax_i = max(U)
. forval i = 1/3 {
2. quietly bysort id : substitute y = alt if umax_i == U
3. }
. generate alternative = alt == y
We get hold of the next by utilizing asmprobit:
. asmprobit alternative worth, case(id) options(alt) casevars(hhinc age)
> basealternative(1) scalealternative(2) nolog
Various-specific multinomial probit Variety of obs = 60,000
Case variable: id Variety of circumstances = 20,000
Various variable: alt Alts per case: min = 3
avg = 3.0
max = 3
Integration sequence: Hammersley
Integration factors: 150 Wald chi2(5) = 4577.15
Log simulated-likelihood = -11219.181 Prob > chi2 = 0.0000
----------------------------------------------------------------------------
alternative | Coef. Std. Err. z P>|z| [95% Conf. Interval]
-------------+--------------------------------------------------------------
alt |
worth | -.4896106 .0523626 -9.35 0.000 -.5922394 -.3869818
-------------+---------------------------------------------------------------
Sickmaster | (base various)
-------------+--------------------------------------------------------------
Allgood |
hhinc | -.5006212 .0302981 -16.52 0.000 -.5600043 -.441238
age | 2.001367 .0306663 65.26 0.000 1.941262 2.061472
_cons | -4.980841 .1968765 -25.30 0.000 -5.366711 -4.59497
-------------+--------------------------------------------------------------
Cowboy_Hea~h |
hhinc | -1.991202 .1092118 -18.23 0.000 -2.205253 -1.77715
age | 1.494056 .0446662 33.45 0.000 1.406512 1.581601
_cons | 3.038869 .4066901 7.47 0.000 2.241771 3.835967
-------------+--------------------------------------------------------------
/lnl2_2 | .5550228 .0742726 7.47 0.000 .4094512 .7005944
-------------+--------------------------------------------------------------
/l2_1 | .667308 .1175286 5.68 0.000 .4369562 .8976598
----------------------------------------------------------------------------
(alt=Sickmaster is the choice normalizing location)
(alt=Allgood is the choice normalizing scale)
Wanting on the above output, we see that the coefficient of the alternative-specific variable worth is (widehat gamma = -0.49), which is near our specified inhabitants parameter of (gamma = -0.50). We will say the identical about our case-specific variables. The estimated coefficients of hhinc are (widehat Delta beta_{2,mathtt{hhinc}} = -0.50) for the second and (widehat Delta beta_{3,mathtt{hhinc}} = -1.99) for the third various. The estimates for age are (widehatDelta beta_{2,mathtt{age}} = 2.00) and (widehat Delta beta_{3,mathtt{age}} = 1.49). The estimated variations in alternative-specific constants are (widehat Delta beta_{2,mathtt{cons}} = -4.98) and (widehat Delta beta_{3,mathtt{cons}} = 3.04).
Identification
Now let me shed extra mild on the identification particulars associated to our mannequin that we wanted to think about once we simulated our dataset. An vital characteristic of (U_{ij}) is that the extent in addition to the dimensions of utility is irrelevant with respect to the chosen various as a result of shifting the extent by some fixed quantity, or multiplying it by a (optimistic) fixed, doesn’t change the rank order of utilities and thus would don’t have any influence on the chosen various. This has vital ramifications for modeling utilities as a result of and not using a set degree and scale of (U_{ij}), there are an infinite variety of parameters in (V_{ij}) that yield the identical end result by way of the chosen options. Subsequently, utilities have to be normalized to establish the parameters of the mannequin.
We already noticed methods to normalize for degree. Normalizing for scale is a little more tough, although, as a result of we assume correlated and heteroskedastic errors. Due to the hetersokedasticity, we have to set the dimensions for one of many variances after which estimate the opposite variances in relation to the set variance. We should additionally account for the nonzero covariance between the errors, which makes extra figuring out restrictions crucial. It seems that given our mannequin assumptions, solely (J(J-1)/2-1) parameters of our variance–covariance matrix are identifiable (see chapter 5 in Practice [2009] for particulars about figuring out restrictions within the context of probit fashions). To be concrete, our unique variance–covariance matrix was the next:
Taking variations of correlated errors reduces the (3 occasions 3) matrix of error variances to a (2 occasions 2) variance–covariance matrix of error variations:
the place (nu = sigma_{11}+sigma_{22}-2sigma_{12}). As a result of we additionally need to set the dimensions for our base various, our normalized matrix turns into
Thus, as a result of utilities are scaled by the usual deviation, they’re divided by (sqrt{nu/2}). Now, getting again to our simulation, if we want to recuperate our specified parameters, we have to scale them accordingly. We begin from the variance–covariance matrix of error variations:
that are the true variance–covariance parameters. Our scaling time period is (sqrt{2.6/2}), and since utilities might be divided by this time period, we might want to multiply our parameters by this time period.
Lastly, we examine if we are able to recuperate our variance–covariance parameters. We use the postestimation command estat covariance to show the estimated variance–covariance matrix of error variations:
. estat covariance
+-------------------------------------+
| | Allgood Cowboy_~h |
|--------------+----------------------|
| Allgood | 2 |
| Cowboy_Hea~h | .943716 3.479797 |
+-------------------------------------+
Notice: Covariances are for options differenced with Sickmaster.
We see that our estimate is near the true normalized covariance matrix.
Conclusion
I mentioned multinomial probit fashions in a discrete alternative context and confirmed methods to generate a simulated dataset accordingly. In my subsequent submit, we are going to use our simulated dataset and talk about estimation and interpretation of mannequin outcomes, which isn’t as easy as one would possibly assume.
highway in Lao PDR. The college is 200 meters away. Site visitors roars, smoke from burning rubbish drifts throughout the trail, and kids stroll straight by way of it. What are they respiration at present? With out native knowledge, nobody actually is aware of.
Throughout East Asia and the Pacific, 325 million kids [1] breathe poisonous air daily, generally at ranges 10 instances above secure limits. The harm is usually silent: affected lungs, bronchial asthma, however it might result in missed faculty days in acute circumstances. The futures are at stake. In the long term, the well being methods are strained, and economies should bear the prices.
In lots of circumstances, air high quality knowledge just isn’t even out there.
No displays. No proof. No safety.
On this second a part of the weblog sequence [2], we examine the information repositories the place helpful air-quality knowledge is out there, tips on how to import them, and tips on how to get them up and operating in your pocket book. We might additionally demystify knowledge codecs equivalent to GeoJSON, Parquet/GeoParquet, NetCDF/HDF5, COG, GRIB, and Zarr so you’ll be able to decide the correct software for the job. We are constructing it up in order that within the subsequent half, we will go step-by-step by way of how we developed an open-source air high quality mannequin.
In the previous couple of years, there was a big push to generate and use air-quality knowledge. These knowledge come from totally different sources, and their high quality varies accordingly. Just a few repositories will help quantify them: regulatory stations for floor reality, neighborhood sensors to know hyperlocal variations, satellites for regional context, and mannequin reanalyses for estimates (Determine 2). The excellent news: most of that is open. The higher information: the code to get began is comparatively brief.
Determine 2: Hearth hotspot as on 20.04.2024 and the interpolated density map created utilizing a number of knowledge sources. Supply: @UNICEF. All rights reserved.
Repository quick-starts (with minimal Python)
On this part, we transfer from ideas to observe. Under, we stroll by way of a set of generally used open-source repositories and present the smallest doable code it’s essential begin pulling knowledge from every of them. All examples assume Python ≥3.10 with pip set up as wanted.
For every numbered repository, one can find:
a brief description of what the information supply is and the way it’s maintained,
typical use-cases (when this supply is an efficient match),
tips on how to entry it (API keys, sign-up notes, or direct URLs), and
a minimal Python code snippet to extract knowledge.
Think about this as a sensible information the place you’ll be able to skim the descriptions, decide the supply that matches your downside, after which adapt the code to plug immediately into your individual evaluation or mannequin pipeline.
Tip: Maintain secrets and techniques out of code. Use setting variables for tokens (e.g., export AIRNOW_API_KEY=…).
1) OpenAQ (international floor measurements; open API)
OpenAQ [3] is an open-source knowledge platform that hosts international knowledge for air high quality knowledge, equivalent to PM2.5, PM10, and O3. They supply air high quality knowledge by partnering with varied governmental companions, neighborhood companions, and air high quality sensor corporations equivalent to Air Gradient, IQAir, amongst others.
Nice for: fast cross-country pulls, harmonised items/metadata, reproducible pipelines.
Join an OpenAQ API key at https://discover.openaq.org. After signing up, discover your API key in your settings. Use this key to authenticate requests.
!pip set up openaq pandas
import pandas as pd
from pandas import json_normalize
from openaq import OpenAQ
import datetime
from datetime import timedelta
import geopandas as gpd
import requests
import time
import json
# comply with the quickstart to get the api key https://docs.openaq.org/using-the-api/quick-start
api_key = '' #enter you API Key earlier than executing
consumer = OpenAQ(api_key=api_key) #use the API key generated earlier
# get the places of each sensors within the chosen international locations codes: https://docs.openaq.org/assets/international locations
places = consumer.places.record(
countries_id=[68,111],
restrict = 1000
)
data_locations = places.dict()
df_sensors_country = json_normalize(data_locations ['results'])
df_sensors_exploded = df_sensors_country.explode('sensors')
df_sensors_exploded['sensor_id']=df_sensors_exploded['sensors'].apply(lambda x: x['id'])
df_sensors_exploded['sensor_type']=df_sensors_exploded['sensors'].apply(lambda x: x['name'])
df_sensors_pm25 = df_sensors_exploded[df_sensors_exploded['sensor_type'] == "pm25 µg/m³"]
df_sensors_pm25
# undergo every location and extract the hourly measurements
df_concat_aq_data=pd.DataFrame()
to_date = datetime.datetime.now()
from_date = to_date - timedelta(days=2) # get the previous 2 days knowledge
sensor_list = df_sensors_pm25.sensor_id
for sensor_id in sensor_list[0:5]:
print("-----")
response = consumer.measurements.record(
sensors_id= sensor_id,
datetime_from = from_date,
datetime_to = to_date,
restrict = 500 )
print(response)
data_measurements = response.dict()
df_hourly_data = json_normalize(data_measurements ['results'])
df_hourly_data["sensor_id"] = sensor_id
if len(df_hourly_data) > 0:
df_concat_aq_data=pd.concat([df_concat_aq_data,df_hourly_data])
df_concat_aq_data = df_concat_aq_data[["sensor_id","period.datetime_from.utc","period.datetime_to.utc","parameter.name","value"]]
df_concat_aq_data
2) EPA AQS Information Mart (U.S. regulatory archive; token wanted)
The EPA AQS Information Mart [4] is a U.S. regulatory knowledge archive that hosts quality-controlled air-quality measurements from 1000’s of monitoring stations throughout the nation. It offers long-term data for standards pollution equivalent to PM₂․₅, PM₁₀, O₃, NO₂, SO₂, and CO, together with detailed website metadata and QA flags, and is freely accessible through an API when you register and acquire an entry token. It offers meteorological knowledge as properly.
Nice for: authoritative QA/QC-d U.S. knowledge.
Join an AQS Information Mart account on the US EPA web site at: https://aqs.epa.gov/aqsweb/paperwork/data_api.html Create a .env file in your setting and add your credentials, together with AQS e-mail and AQS key.
AirNow [5] is a U.S. authorities platform that gives close to real-time air-quality index (AQI) info primarily based on regulatory monitoring knowledge. It publishes present and forecast AQI values for pollution equivalent to PM₂․₅ and O₃, together with class breakpoints (“Good”, “Reasonable”, and so on.) which are straightforward to speak to the general public. Information may be accessed programmatically through the AirNow API when you register and acquire an API key.
From the Log In web page, choose “Request an AirNow API Account” and full the registration type together with your e-mail and fundamental particulars. After you activate your account, you will discover your API key in your AirNow API dashboard; use this key to authenticate all calls to the AirNow net providers.
4) Copernicus Environment Monitoring Service (CAMS; Environment Information Retailer)
The Copernicus Environment Monitoring Service [6], carried out by ECMWF for the EU’s Copernicus programme, offers international reanalyses and near-real-time forecasts of atmospheric composition. By the Environment Information Retailer (ADS), you’ll be able to entry gridded fields for aerosols, reactive gases (O₃, NO₂, and so on.), greenhouse gases and associated meteorological variables, with multi-year data appropriate for each analysis and operational purposes. All CAMS merchandise within the ADS are open and freed from cost, topic to accepting the Copernicus licence.
Nice for: international background fields (aerosols & hint gases), forecasts and reanalyses.
On the internet web page of every CAMS dataset you wish to use, go to the Obtain knowledge tab and settle for the licence on the backside as soon as; solely then will API requests for that dataset succeed.
As soon as that is arrange, you need to use the usual cdsapi Python consumer to programmatically obtain CAMS datasets from the ADS.
# pip set up cdsapi xarray cfgrib
import cdsapi
c = cdsapi.Shopper()
# Instance: CAMS international reanalysis (EAC4) complete column ozone (toy instance)
c.retrieve(
"cams-global-reanalysis-eac4",
{"variable":"total_column_ozone","date":"2025-08-01/2025-08-02","time":["00:00","12:00"],
"format":"grib"}, "cams_ozone.grib")
5) NASA Earthdata (LAADS DAAC / GES DISC; token/login)
NASA Earthdata [7] offers unified sign-on entry to a variety of Earth science knowledge, together with satellite tv for pc aerosol and hint fuel merchandise which are essential for air-quality purposes. Two key centres for atmospheric composition are:
LAADS DAAC (Stage-1 and Environment Archive and Distribution System DAAC), which hosts MODIS, VIIRS and different instrument merchandise (e.g., AOD, cloud, fireplace, radiance).
GES DISC (Goddard Earth Sciences Information and Info Companies Middle), which serves mannequin and satellite tv for pc merchandise equivalent to MERRA-2 reanalysis, OMI, TROPOMI, and associated atmospheric datasets.
Most of those datasets are free to make use of however require a NASA Earthdata Login; downloads are authenticated both through HTTP fundamental auth (username/password saved in .netrc) or through a private entry token (PAT) in request headers.
Verify your e-mail and log in to your Earthdata profile.
Beneath your profile, generate a private entry token (PAT). Save this token securely; you need to use it in scripts through an Authorization: Bearer header or in instruments that help Earthdata tokens.
For traditional wget/curl-based downloads, you’ll be able to alternatively create a ~/.netrc file to retailer your Earthdata username and password, for instance:
machine urs.earthdata.nasa.gov
login
password
Then set file permissions to user-only (chmod 600 ~/.netrc) so command-line instruments can authenticate robotically.
For LAADS DAAC merchandise, go to https://ladsweb.modaps.eosdis.nasa.gov, log in together with your Earthdata credentials, and use the Search & Obtain interface to construct obtain URLs; you’ll be able to copy the auto-generated wget/curl instructions into your scripts.
For GES DISC datasets, begin from https://disc.gsfc.nasa.gov, select a dataset (e.g., MERRA-2), and use the “Information Entry” or “Subset/Get Information” instruments. The positioning can generate script templates (Python, wget, and so on.) that already embody the right endpoints for authenticated entry.
As soon as your Earthdata Login and token are arrange, LAADS DAAC and GES DISC behave like customary HTTPS APIs: you’ll be able to name them from Python (e.g., with requests, xarray + pydap/OPeNDAP, or s3fs for cloud buckets) utilizing your credentials or token for authenticated, scriptable downloads.
#Downloads through HTTPS with Earthdata login.
# pip set up requests
import requests
url = "https://ladsweb.modaps.eosdis.nasa.gov/archive/allData/6/MCD19A2/2025/214/MCD19A2.A2025214.h21v09.006.2025xxxxxx.hdf"
# Requires a legitimate token cookie; advocate utilizing .netrc or requests.Session() with auth
# See NASA docs for token-based obtain; right here we solely illustrate the sample:
# s = requests.Session(); s.auth = (USERNAME, PASSWORD); r = s.get(url)
SpatioTemporal Asset Catalog (STAC) [8] is an open specification for describing geospatial property, equivalent to satellite tv for pc scenes, tiles, and derived merchandise, in a constant, machine-readable approach. As an alternative of manually shopping obtain portals, you question a STAC API with filters like time, bounding field, cloud cowl, platform (e.g., Sentinel-2, Landsat-8, Sentinel-5P), or processing degree, and get again JSON gadgets with direct hyperlinks to COGs, NetCDF, Zarr, or different property.
Nice for: uncover and stream property (COGs/NetCDF) with out bespoke APIs and works properly with Sentinel-5P, Landsat, Sentinel-2, extra.
Find out how to register and get API entry: STAC itself is simply an ordinary; entry is dependent upon the particular STAC API you utilize:
Many public STAC catalogues (e.g., demo or analysis endpoints) are absolutely open and require no registration—you’ll be able to hit their /search endpoint immediately with HTTP POST/GET.
Some cloud platforms that expose STAC (for instance, industrial or giant cloud suppliers) require you to create a free account and acquire credentials earlier than you’ll be able to learn the underlying property (e.g., blobs in S3/Blob storage), though the STAC metadata is open.
A generic sample you’ll be able to describe is:
Decide a STAC API endpoint for the satellite tv for pc knowledge you care about (typically documented as one thing alongside the strains of https:///stac or …/stac/search).
If the supplier requires sign-up, create an account of their portal and acquire the API key or storage credentials they advocate (this may be a token, SAS URL, or cloud entry position).
Use a STAC consumer library in Python (for instance, pystac-client) to go looking {the catalogue}:
For every returned STAC merchandise, comply with the asset href hyperlinks (typically HTTPS URLs or cloud URIs like s3://…) and skim them with the applicable library (rasterio/xarray/zarr and so on.). If credentials are wanted, configure them through setting variables or your cloud SDK as per the supplier’s directions.
As soon as arrange, STAC catalogues provide you with a uniform, programmatic strategy to search and retrieve satellite tv for pc knowledge throughout totally different suppliers, with out rewriting your search logic each time you turn from one archive to a different.
# pip set up pystac-client planetary-computer rasterio
from pystac_client import Shopper
from shapely.geometry import field, mapping
import geopandas as gpd
catalog = Shopper.open("https://earth-search.aws.element84.com/v1")
aoi = mapping(field(-0.3, 5.5, 0.3, 5.9)) # bbox round Accra
search = catalog.search(collections=["sentinel-2-l2a"], intersects=aoi, restrict=5)
gadgets = record(search.get_items())
for it in gadgets:
print(it.id, record(it.property.keys())[:5]) # e.g., "B04", "B08", "SCL", "visible"
It’s preferrable to make use of STAC the place doable as they supply clear metadata, cloud-optimised property, and straightforward filtering by time/house.
7) Google Earth Engine (GEE; quick prototyping at scale)
Google Earth Engine [9] is a cloud-based geospatial evaluation platform that hosts a big catalogue of satellite tv for pc, local weather, and land-surface datasets (e.g., MODIS, Landsat, Sentinel, reanalyses) and allows you to course of them at scale with out managing your individual infrastructure. You write brief scripts in JavaScript or Python, and GEE handles the heavy lifting like knowledge entry, tiling, reprojection, and parallel computation thus making it superb for quick prototyping, exploratory analyses, and instructing.
Nevertheless, GEE itself just isn’t open supply: it’s a proprietary, closed platform the place the underlying codebase just isn’t publicly out there. This has implications for open, reproducible workflows mentioned within the first Air for Tomorrow weblog [add link]:
Nice for: testing fusion/downscaling over a metropolis/area utilizing petabyte-scale datasets.
Sign up with a Google account and full the non-commercial sign-up type, describing your meant use (analysis, schooling, or private, non-commercial tasks).
As soon as your account is accepted, you’ll be able to:
use the browser-based Code Editor to jot down JavaScript Earth Engine scripts; and
allow the Earth Engine API in Google Cloud and set up the earthengine-api Python bundle (pip set up earthengine-api) to run workflows from Python notebooks.
When sharing your work, take into account exporting key intermediate outcomes (e.g., GeoTIFF/COG, NetCDF/Zarr) and documenting your processing steps in open-source code in order that others can re-create the evaluation with out relying solely on GEE.
When used this manner, Earth Engine turns into a robust “fast laboratory” for testing concepts, which you’ll be able to then harden into absolutely open, moveable pipelines for manufacturing and long-term stewardship.
# pip set up earthengine-api
import ee
ee.Initialize() # first run: ee.Authenticate() in a console
s5p = ee.ImageCollection('COPERNICUS/S5P/OFFL/L3_NO2').choose('NO2_column_number_density')
.filterDate('2025-08-01', '2025-08-07').imply()
print(s5p.getInfo()['bands'][0]['id'])
# Exporting and visualization occur inside GEE; you'll be able to pattern to a grid then .getDownloadURL()
8) HIMAWARI
Himawari-8 and Himawari-9 are geostationary meteorological satellites operated by the Japan Meteorological Company (JMA). Their Superior Himawari Imager (AHI) offers multi-band seen, near-infrared and infrared imagery over East Asia and the western–central Pacific, with full-disk scans each 10 minutes and even quicker refresh over goal areas. This high-cadence view is extraordinarily helpful for monitoring smoke plumes, mud, volcanic eruptions, convective storms and the diurnal evolution of clouds—precisely the sorts of processes that modulate near-surface air high quality.
Nice for: monitoring diurnal haze/smoke plumes and fireplace occasions, producing high-frequency AOD to fill polar-orbit gaps, and fast situational consciousness for cities throughout SE/E Asia (through JAXA P-Tree L3 merchandise).
Find out how to entry and register
Choice A – Open archive through NOAA on AWS (no sign-up required)
Himawari-8 and Himawari-9 imagery are hosted in public S3 buckets (s3://noaa-himawari8/ and s3://noaa-himawari9/). As a result of the buckets are world-readable, you’ll be able to record or obtain information anonymously, for instance:
aws s3 ls --no-sign-request s3://noaa-himawari9/
or entry particular person objects through HTTPS (e.g., https://noaa-himawari9.s3.amazonaws.com/…).
For Python workflows, you need to use libraries like s3fs, fsspec, xarray, or rasterio to stream knowledge immediately from these buckets with out prior registration, holding in thoughts the attribution steering from JMA/NOAA if you publish outcomes.
Click on Person Registration / Account request and skim the “Precautions” and “Phrases of Use”. Information entry is restricted to non-profit functions equivalent to analysis and schooling; industrial customers are directed to the Japan Meteorological Enterprise Assist Middle.
Submit your e-mail tackle within the account request type. You’ll obtain a short lived acceptance e-mail, then a hyperlink to finish your consumer info. After handbook evaluate, JAXA allows your entry and notifies you as soon as you’ll be able to obtain Himawari Customary Information and geophysical parameter merchandise.
As soon as accepted, you’ll be able to log in to obtain near-real-time and archived Himawari knowledge through the P-Tree FTP/HTTP providers, following JAXA’s steering on non-redistribution and quotation.
In observe, a standard sample is to make use of the NOAA/AWS buckets for open, scriptable entry to uncooked imagery, and the JAXA P-Tree merchandise if you want value-added parameters (e.g., cloud or aerosol properties) and are working inside non-profit analysis or instructional tasks.
# open the downloaded file
!pip set up xarray netCDF4
!pip set up rasterio polars_h3
!pip set up geopandas pykrige
!pip set up polars==1.25.2
!pip set up dask[complete] rioxarray h3==3.7.7
!pip set up h3ronpy==0.21.1
!pip set up geowrangler
# Himawari utilizing – JAXA Himawari Monitor / P-Tree
# create your account right here and use the username and password despatched by e-mail - https://www.eorc.jaxa.jp/ptree/registration_top.html
consumer = '' # enter the username
password = '' # enter the password
from ftplib import FTP
from pathlib import Path
import rasterio
from rasterio.rework import from_origin
import xarray as xr
import os
import matplotlib.pyplot as plt
def get_himawari_ftp_past_2_days(consumer, password):
# FTP connection particulars
ftp = FTP('ftp.ptree.jaxa.jp')
ftp.login(consumer=consumer, passwd=password)
# test the listing content material : /pub/himawari/L2/ARP/031/
# particulars of AOD directoty right here: https://www.eorc.jaxa.jp/ptree/paperwork/README_HimawariGeo_en.txt
overall_path= "/pub/himawari/L3/ARP/031/"
directories = overall_path.strip("/").break up("/")
for listing in directories:
ftp.cwd(listing)
# Checklist information within the goal listing
date_month_files = ftp.nlst()
# order information desc
date_month_files.kind(reverse=False)
print("Information in goal listing:", date_month_files)
# get a listing of all of the month / days throughout the "/pub/himawari/L3/ARP/031/" path throughout the previous 2 months
limited_months_list = date_month_files[-2:]
i=0
# for every month within the limited_months_list, record all the times inside in
for month in limited_months_list:
ftp.cwd(month)
date_day_files = ftp.nlst()
date_day_files.kind(reverse=False)
# mix every component of the date_day_file record with the month : month +"/" + date_day_file
list_combined_days_month_inter = [month + "/" + date_day_file for date_day_file in date_day_files]
if i ==0:
list_combined_days_month= list_combined_days_month_inter
i=i+1
else:
list_combined_days_month= list_combined_days_month + list_combined_days_month_inter
ftp.cwd("..")
# take away all parts containing every day or month-to-month from list_combined_days_month
list_combined_days_month = [item for item in list_combined_days_month if 'daily' not in item and 'monthly' not in item]
# get the record of days we wish to obtain : in our case final 2 days - for NRT
limited_list_combined_days_month=list_combined_days_month[-2:]
for month_day_date in limited_list_combined_days_month:
#navigate to the related listing
ftp.cwd(month_day_date)
print(f"listing: {month_day_date}")
# get the record of the hourly information inside every listing
date_hour_files = ftp.nlst()
!mkdir -p ./raw_data/{month_day_date}
#for every hourly file within the record
for date_hour_file in date_hour_files:
target_file_path=f"./raw_data/{month_day_date}/{date_hour_file}"
# Obtain the goal file - provided that it doesn't exist already
if not os.path.exists(target_file_path):
with open(target_file_path, "wb") as local_file:
ftp.retrbinary(f"RETR {date_hour_file}", local_file.write)
print(f"Downloaded {date_hour_file} efficiently!")
else:
print(f"File already exists: {date_hour_file}")
print("--------------")
# return 2 steps within the ftp tree
ftp.cwd("..")
ftp.cwd("..")
def transform_to_tif():
# get record of information in raw_data folder
month_file_list = os.listdir("./raw_data")
month_file_list
#order month_file_list
month_file_list.kind(reverse=False)
nb_errors=0
# get record of every day folder for the previous 2 months solely
for month_file in month_file_list[-2:]:
print(f"-----------------------------------------")
print(f"Month thought of: {month_file}")
date_file_list=os.listdir(f"./raw_data/{month_file}")
date_file_list.kind(reverse=False)
# get record of information for every day folder
for date_file in date_file_list[-2:]:
print(f"---------------------------")
print(f"Day thought of: {date_file}")
hour_file_list=os.listdir(f"./raw_data/{month_file}/{date_file}")
hour_file_list.kind(reverse=False)
#course of every hourly file right into a tif file and rework it into an h3 processed dataframe
for hour_file in hour_file_list:
file_path = f"./raw_data/{month_file}/{date_file}/{hour_file}"
hour_file_tif=hour_file.exchange(".nc",".tif")
output_tif = f"./tif/{month_file}/{date_file}/{hour_file_tif}"
if os.path.exists(output_tif):
print(f"File already exists: {output_tif}")
else:
attempt:
dataset = xr.open_dataset(file_path, engine='netcdf4')
besides:
#go to subsequent hour_file
print(f"error opening {hour_file} file - skipping ")
nb_errors=nb_errors+1
proceed
# Entry a selected variable
variable_name = record(dataset.data_vars.keys())[1] # Merged AOT product
knowledge = dataset[variable_name]
# Plot knowledge (if it is 2D and appropriate)
plt.determine()
knowledge.plot()
plt.title(f'{date_file}')
plt.present()
# Extract metadata (exchange with precise coordinates out of your knowledge if out there)
lon = dataset['longitude'] if 'longitude' in dataset.coords else None
lat = dataset['latitude'] if 'latitude' in dataset.coords else None
# Deal with lacking lat/lon (instance assumes evenly spaced grid)
if lon is None or lat is None:
lon_start, lon_step = -180, 0.05 # Instance values
lat_start, lat_step = 90, -0.05 # Instance values
lon = xr.DataArray(lon_start + lon_step * vary(knowledge.form[-1]), dims=['x'])
lat = xr.DataArray(lat_start + lat_step * vary(knowledge.form[-2]), dims=['y'])
# Outline the affine rework for georeferencing
rework = from_origin(lon.min().merchandise(), lat.max().merchandise(), abs(lon[1] - lon[0]).merchandise(), abs(lat[0] - lat[1]).merchandise())
# Save to GeoTIFF
!mkdir -p ./tif/{month_file}/{date_file}
with rasterio.open(
output_tif,
'w',
driver='GTiff',
peak=knowledge.form[-2],
width=knowledge.form[-1],
rely=1, # Variety of bands
dtype=knowledge.dtype.identify,
crs='EPSG:4326', # Coordinate Reference System (e.g., WGS84)
rework=rework
) as dst:
dst.write(knowledge.values, 1) # Write the information to band 1
print(f"Saved {output_tif} efficiently!")
print(f"{nb_errors} error(s) ")
NASA’s Hearth Info for Useful resource Administration System (FIRMS) [10] offers near-real-time info on energetic fires and thermal anomalies detected by devices equivalent to MODIS and VIIRS. It affords international protection with low latency (on the order of minutes to hours), supplying attributes equivalent to fireplace radiative energy, confidence, and acquisition time. FIRMS is broadly used for wildfire monitoring, agricultural burning, forest administration, and as a proxy enter for air-quality and smoke dispersion modelling.
Nice for: pinpointing fireplace hotspots that drive AQ spikes, monitoring plume sources and fire-line development, monitoring crop-residue/forest burns, and triggering fast response. Easy accessibility through CSV/GeoJSON/Shapefile, map tiles/API, with 24–72 h rolling feeds and full archives for seasonal evaluation.
Verify your e-mail and register together with your new credentials.
Go to the FIRMS website you propose to make use of, for instance:
Click on Login (high proper) and authenticate together with your Earthdata username and password. As soon as logged in, you’ll be able to:
customise map views and obtain choices from the net interface, and
generate or use FIRMS Internet Companies/API URLs that honour your authenticated session.
For scripted entry, you’ll be able to name the FIRMS obtain or net service endpoints (e.g., GeoJSON, CSV) utilizing customary HTTP instruments (e.g., curl, requests in Python). If an endpoint requires authentication, provide your Earthdata credentials through a .netrc file or session cookies, as you’d for different Earthdata providers.
In observe, FIRMS is a handy strategy to pull current fireplace places into an air-quality workflow: you’ll be able to fetch every day or hourly fireplace detections for a area, convert them to a GeoDataFrame, after which intersect with wind fields, inhabitants grids, or sensor networks to know potential smoke impacts.
#FIRMS
!pip set up geopandas rtree shapely
import pandas as pd
import geopandas as gpd
from shapely.geometry import Level
import numpy as np
import matplotlib.pyplot as plt
import rtree
# get boundaries of Thailand
boundaries_country = gpd.read_file(f'https://github.com/wmgeolab/geoBoundaries/uncooked/fcccfab7523d4d5e55dfc7f63c166df918119fd1/releaseData/gbOpen/THA/ADM0/geoBoundaries-THA-ADM0.geojson')
boundaries_country.plot()
# Actual time knowledge supply: https://corporations.modaps.eosdis.nasa.gov/active_fire/
# Previous 7 days hyperlinks:
modis_7d_url= "https://corporations.modaps.eosdis.nasa.gov/knowledge/active_fire/modis-c6.1/csv/MODIS_C6_1_SouthEast_Asia_7d.csv"
suomi_7d_url= "https://corporations.modaps.eosdis.nasa.gov/knowledge/active_fire/suomi-npp-viirs-c2/csv/SUOMI_VIIRS_C2_SouthEast_Asia_7d.csv"
j1_7d_url= "https://corporations.modaps.eosdis.nasa.gov/knowledge/active_fire/noaa-20-viirs-c2/csv/J1_VIIRS_C2_SouthEast_Asia_7d.csv"
j2_7d_url="https://corporations.modaps.eosdis.nasa.gov/knowledge/active_fire/noaa-21-viirs-c2/csv/J2_VIIRS_C2_SouthEast_Asia_7d.csv"
urls = [modis_7d_url, suomi_7d_url, j1_7d_url, j2_7d_url]
# Create an empty GeoDataFrame to retailer the mixed knowledge
gdf = gpd.GeoDataFrame()
for url in urls:
df = pd.read_csv(url)
# Create a geometry column from latitude and longitude
geometry = [Point(xy) for xy in zip(df['longitude'], df['latitude'])]
gdf_temp = gpd.GeoDataFrame(df, crs="EPSG:4326", geometry=geometry)
# Concatenate the short-term GeoDataFrame to the primary GeoDataFrame
gdf = pd.concat([gdf, gdf_temp], ignore_index=True)
# Filter to maintain solely fires throughout the nation boundaries
gdf = gpd.sjoin(gdf, boundaries_country, how="inside", predicate="inside")
# Show fires on map
frp = gdf["frp"].astype(float)
fig, ax = plt.subplots(figsize=(9,9))
boundaries_country.plot(ax=ax, facecolor="none", edgecolor="0.3", linewidth=0.8)
gdf.plot(ax=ax, markersize=frp, shade="crimson", alpha=0.55)
ax.set_title("Fires inside nation boundaries (bubble dimension = Hearth Radiative Energy )")
ax.set_axis_off()
plt.present()
Information sorts you will meet (and tips on how to learn them proper)
Air-quality work hardly ever lives in a single, tidy CSV. So, it helps to know what the file sorts you’ll meet. You’ll transfer between multidimensional mannequin outputs (NetCDF/GRIB/Zarr), satellite tv for pc rasters (COG/GeoTIFF), level measurements (CSV /Parquet /GeoParquet), and web-friendly codecs (JSON/GeoJSON), typically in the identical pocket book.
This part is a fast subject information to these codecs and tips on how to open them with out getting caught.
There isn’t any have to memorise any of this, so be at liberty to skim the record as soon as, then come again if you hit an unfamiliar file extension within the wild.
NetCDF4 / HDF5 (self-describing scientific arrays): Extensively used for reanalyses, satellite tv for pc merchandise, and fashions. Wealthy metadata, multi-dimensional (time, degree, lat, lon) Typical extensions: .nc, .nc4, .h5, .hdf5
Learn:
# pip set up xarray netCDF4
import xarray as xr
ds = xr.open_dataset("modis_aod_2025.nc")
ds = ds.sel(time=slice("2025-08-01","2025-08-07"))
print(ds)
Cloud-Optimised GeoTIFF (COG): Raster format tuned for HTTP vary requests (stream simply what you want). Widespread for satellite tv for pc imagery and gridded merchandise. Typical extensions: .tif, .tiff
Learn:
# pip set up rasterio
import rasterio
with rasterio.open("https://example-bucket/no2_mean_2025.tif") as src:
window = rasterio.home windows.from_bounds(*(-0.3,5.5,0.3,5.9), src.rework)
arr = src.learn(1, window=window)
JSON (nested) & GeoJSON (options + geometry): Nice for APIs and light-weight geospatial. GeoJSON makes use of WGS84 (EPSG:4326) by default. Typical extensions: json, .jsonl, .ndjson, .geojsonl, .ndgeojson
Learn:
# pip set up geopandas
import geopandas as gpd
gdf = gpd.read_file("factors.geojson") # columns + geometry
gdf = gdf.set_crs(4326) # guarantee WGS84
GRIB2 (meteorology, mannequin outputs): Compact, tiled; typically utilized by CAMS/ECMWF/NWP. Typical extensions: .grib2, .grb2, .grib, .grb. In observe, knowledge suppliers typically add compression suffixes too, e.g. .grib2.gz or .grb2.bz2.
Learn:
# pip set up xarray cfgrib
import xarray as xr
ds = xr.open_dataset("cams_ozone.grib", engine="cfgrib")
Parquet & GeoParquet (columnar, compressed): Greatest for large tables: quick column choice, predicate pushdown, partitioning (e.g., by date/metropolis). GeoParquet provides an ordinary for geometries. Typical extensions: .parquet, .parquet.gz
Learn/Write:
# pip set up pandas pyarrow geopandas geoparquet
import pandas as pd, geopandas as gpd
df = pd.read_parquet("openaq_accra_2025.parquet") # columns solely
# Convert a GeoDataFrame -> GeoParquet
gdf = gpd.read_file("factors.geojson")
gdf.to_parquet("factors.geoparquet") # preserves geometry & CRS
CSV/TSV (textual content tables): Easy, common. Weak at giant scale (gradual I/O, no schema), no geometry. Typical extensions: .csv, .tsv (additionally generally .tab, much less widespread)
Learn:
# pip set up pandas
import pandas as pd
df = pd.read_csv("measurements.csv", parse_dates=["datetime"], dtype={"site_id":"string"})
Zarr (chunked, cloud-native): Supreme for evaluation within the cloud with parallel reads (works nice with Dask). Typical extension: .zarr (typically a listing / retailer ending in .zarr; sometimes packaged as .zarr.zip)
Learn:
# pip set up xarray zarr s3fs
import xarray as xr
ds = xr.open_zarr("s3://bucket/cams_eac4_2025.zarr", consolidated=True)
Observe: Shapefile (legacy vector): Works, however brittle (many information, 10-char subject restrict). . It is a legacy codecs and it’s higher to make use of the alternate options like GeoPackage or GeoParquet
It is very important select the correct geospatial (or scientific) file format as it’s not only a storage determination nevertheless it immediately impacts how rapidly you’ll be able to learn knowledge, software compatibility, how simply you’ll be able to share it, and the way properly it scales from a desktop workflow to cloud-native processing. The next desk (Desk 1) offers a sensible “format-to-task” cheat sheet: for every widespread want (from fast API dumps to cloud-scale arrays and net mapping), it lists essentially the most appropriate format, the extensions you’ll usually encounter, and the core motive that format is an efficient match. It may be used as a default place to begin when designing pipelines, publishing datasets, or choosing what to obtain from an exterior repository.
A number of open STAC catalogues are actually out there, together with public endpoints for optical, radar, and atmospheric merchandise (for instance, Landsat and Sentinel imagery through suppliers equivalent to Factor 84’s Earth Search or Microsoft’s Planetary Pc). STAC makes it a lot simpler to script “discover and obtain all scenes for this polygon and time vary” and to combine totally different datasets into the identical workflow.
Conclusion — from “the place” the information lives to “how” you utilize it
Air for Tomorrow: We began with the query “What are these children respiration at present?” This publish offers a sensible path and instruments that can assist you reply this query. You now know the place open-air high quality knowledge resides, together with regulatory networks, neighborhood sensors, satellite tv for pc measurements, and reanalysis. You additionally perceive what these information are (GeoJSON, Parquet/GeoParquet, NetCDF/HDF5, COG, GRIB, Zarr) and tips on how to retrieve them with compact, reproducible snippets. The aim is past simply downloading them; it’s to make defensible, quick, and shareable analyses that maintain up tomorrow.
You may assemble a reputable native image in hours, not weeks. From fireplace hotspots (Determine 2) to school-route publicity (Determine 1), you’ll be able to create publicity maps (Determine 3).
Up subsequent: We might showcase an precise Air High quality Mannequin developed by us on the UNICEF Nation Workplace of Lao PDR with the UNICEF EAPRO’s Frontier Information Workforce. We might undergo an open, end-to-end mannequin pipeline. When there are ground-level air high quality knowledge streams out there, we’d cowl how function engineering, bias correction, normalisation, and a mannequin may be developed with an actionable floor {that a} regional can use tomorrow morning.
Contributors: Prithviraj Pramanik, AQAI; Hugo Ruiz Verastegui, Anthony Mockler, Judith Hanan, Frontier Information Lab; Risdianto Irawan, UNICEF EAPRO; Soheib Abdalla, Andrew Dunbrack, UNICEF Lao PDR Nation Workplace; Halim Jun, Daniel Alvarez, Shane O’Connor, UNICEF Workplace of Innovation;
Introduction – What Makes Nvidia GH200 the Star of 2026?
Fast Abstract: What’s the Nvidia GH200 and why does it matter in 2026? – The Nvidia GH200 is a hybrid superchip that merges a 72‑core Arm CPU (Grace) with a Hopper/H200 GPU utilizing NVLink‑C2C. This integration creates as much as 624 GB of unified reminiscence accessible to each CPU and GPU, enabling reminiscence‑sure AI workloads like lengthy‑context LLMs, retrieval‑augmented era (RAG) and exascale simulations. In 2026, as fashions develop bigger and extra advanced, the GH200’s reminiscence‑centric design delivers efficiency and value effectivity not achievable with conventional GPU playing cards. Clarifai presents enterprise‑grade GH200 internet hosting with good autoscaling and cross‑cloud orchestration, making this know-how accessible for builders and companies.
Synthetic intelligence is evolving at breakneck pace. Mannequin sizes are growing from hundreds of thousands to trillions of parameters, and generative functions equivalent to retrieval‑augmented chatbots and video synthesis require large key–worth caches and embeddings. Conventional GPUs just like the A100 or H100 present excessive compute throughput however can turn into bottlenecked by reminiscence capability and information motion. Enter the Nvidia GH200, usually nicknamed the Grace Hopper superchip. As an alternative of connecting a CPU and GPU by way of a gradual PCIe bus, the GH200 fuses them on the identical bundle and hyperlinks them by NVLink‑C2C—a excessive‑bandwidth, low‑latency interconnect that delivers 900 GB/s of bidirectional bandwidth. This structure permits the GPU to entry the CPU’s reminiscence straight, leading to a unified reminiscence pool of as much as 624 GB (when combining the 96 GB or 144 GB HBM on the GPU with 480 GB LPDDR5X on the CPU).
This information presents an in depth have a look at the GH200: its structure, efficiency, best use instances, deployment fashions, comparability to different GPUs (H100, H200, B200), and sensible steerage on when and the way to decide on it. Alongside the way in which we are going to spotlight Clarifai’s compute options that leverage GH200 and supply greatest practices for deploying reminiscence‑intensive AI workloads.
Fast Digest: How This Information Is Structured
Understanding the GH200 Structure – We look at how the hybrid CPU–GPU design and unified reminiscence system work, and why HBM3e issues.
Benchmarks & Price Effectivity – See how GH200 performs in inference and coaching in contrast with H100/H200, and the impact on value per token.
Use Instances & Workload Match – Be taught which AI and HPC workloads profit from the superchip, together with RAG, LLMs, graph neural networks and exascale simulations.
Choice Framework – Perceive when to decide on GH200 vs H100/H200 vs B200/Rubin based mostly on reminiscence, bandwidth, software program and funds.
Challenges & Future Traits – Contemplate limitations (ARM software program, energy, latency) and sit up for HBM3e, Blackwell, Rubin and new supercomputers.
Let’s dive in.
GH200 Structure and Reminiscence Improvements
Fast Abstract: How does the GH200’s structure differ from conventional GPUs? – In contrast to standalone GPU playing cards, the GH200 integrates a 72‑core Grace CPU and a Hopper/H200 GPU on a single module. The 2 chips talk by way of NVLink‑C2C delivering 900 GB/s bandwidth. The GPU consists of 96 GB HBM3 or 144 GB HBM3e, whereas the CPU gives 480 GB LPDDR5X. NVLink‑C2C permits the GPU to straight entry CPU reminiscence, making a unified reminiscence pool of as much as 624 GB. This eliminates expensive information transfers and is vital to the GH200’s reminiscence‑centric design.
Hybrid CPU–GPU Fusion
At its core, the GH200 combines a Grace CPU and a Hopper GPU. The CPU options 72 Arm Neoverse V2 cores (or 72 Grace cores), delivering excessive reminiscence bandwidth and power effectivity. The GPU relies on the Hopper structure (used within the H100) however could also be upgraded to the H200 in newer revisions, including quicker HBM3e reminiscence. NVLink‑C2C is the key sauce: a cache‑coherent interface enabling each chips to share reminiscence coherently at 900 GB/s – roughly 7× quicker than PCIe Gen5. This design makes the GH200 successfully an enormous APU or system‑on‑chip tailor-made for AI.
Unified Reminiscence Pool
Conventional GPU servers depend on discrete reminiscence swimming pools: CPU DRAM and GPU HBM. Information have to be copied throughout the PCIe bus, incurring latency and overhead. The GH200’s unified reminiscence eliminates this barrier. The Grace CPU brings 480 GB of LPDDR5X reminiscence with bandwidth of 546 GB/s, whereas the Hopper GPU consists of 96 GB HBM3 delivering 4 000 GB/s bandwidth. The upcoming HBM3e variant will increase reminiscence capability to 141–144 GB and boosts bandwidth by over 25 %. Mixed with NVLink‑C2C, this gives a shared reminiscence pool of as much as 624 GB, enabling the GPU to cache large datasets and key–worth caches for LLMs with out repeatedly fetching from CPU reminiscence. NVLink can also be scalable: NVL2 pairs two superchips to create a node with 288 GB HBM and 10 TB/s bandwidth, and the NVLink change system can join 256 superchips to behave as one large GPU with 1 exaflop efficiency and 144 TB unified reminiscence.
HBM3e and Rubin Platform
The GH200 began with HBM3 however is already evolving. The HBM3e revision provides 144 GB of HBM for the GPU, elevating efficient reminiscence capability by round 50 % and growing bandwidth from 4 000 GB/s to about 4.9 TB/s. This improve helps massive fashions retailer extra key–worth pairs and embeddings solely in on‑chip reminiscence. Trying forward, Nvidia’s Rubin platform (introduced 2025) will introduce a brand new CPU with 88 Olympus cores, 1.8 TB/s NVLink‑C2C bandwidth and 1.5 TB LPDDR5X reminiscence, doubling reminiscence capability over Grace. Rubin may even help NVLink 6 and NVL72 rack techniques that scale back inference token value by 10× and coaching GPU rely by 4× in contrast with Blackwell—an indication that reminiscence‑centric design will proceed to evolve.
Skilled Insights
Unified reminiscence is a paradigm shift – By exposing GPU reminiscence as a CPU NUMA node, NVLink‑C2C eliminates the necessity for specific information copying and permits CPU code to entry HBM straight. This simplifies programming and accelerates reminiscence‑sure duties.
HBM3e vs HBM3 – The 50 % enhance in capability and 25 % enhance in bandwidth of HBM3e considerably extends the dimensions of fashions that may be served on a single chip, pushing the GH200 into territory beforehand reserved for multi‑GPU clusters.
Scalability by way of NVLink change – Connecting a whole lot of superchips by way of NVLink change ends in a single logical GPU with terabytes of shared reminiscence—essential for exascale techniques like Helios and JUPITER.
Grace vs Rubin – Whereas Grace presents 72 cores and 480 GB reminiscence, Rubin will ship 88 cores and as much as 1.5 TB reminiscence with NVLink 6, hinting that future AI workloads might require much more reminiscence and bandwidth.
Efficiency Benchmarks & Price Effectivity
Fast Abstract: How does GH200 carry out relative to H100/H200, and what does this imply for value? – Benchmarks reveal that the GH200 delivers 1.4×–1.8× greater MLPerf inference efficiency per accelerator than the H100. In sensible checks on Llama 3 fashions, GH200 achieved 7.6× greater throughput and lowered value per token by 8× in contrast with H100. Clarifai reviews a 17 % efficiency acquire over H100 of their MLPerf outcomes. These features stem from unified reminiscence and NVLink‑C2C, which scale back latency and allow bigger batches.
MLPerf and Vendor Benchmarks
In Nvidia’s MLPerf Inference v4.1 outcomes, the GH200 delivered as much as 1.4× extra efficiency per accelerator than the H100 on generative AI duties. When configured in NVL2, two superchips achieved 3.5× extra reminiscence and 3× extra bandwidth than a single H100, translating into higher scaling for big fashions. Clarifai’s inner benchmarking confirmed a 17 % throughput enchancment over H100 for MLPerf duties.
Actual‑World Inference (LLM and RAG)
In a extensively shared weblog put up, Lambda AI in contrast GH200 to H100 for single‑node Llama 3.1 70B inference. GH200 delivered 7.6× greater throughput and 8× decrease value per token than H100, due to the flexibility to dump key–worth caches to CPU reminiscence. Baseten ran related experiments with Llama 3.3 70B and located that GH200 outperformed H100 by 32 % as a result of the reminiscence pool allowed bigger batch sizes. Nvidia’s technical weblog on RAG functions confirmed that GH200 gives 2.7×–5.7× speedups in contrast with A100 throughout embedding era, index construct, vector search and LLM inference.
Price‑Per‑Hour & Cloud Pricing
Price is a vital issue. An evaluation of GPU rental markets discovered that GH200 situations value $4–$6 per hour on hyperscalers, barely greater than H100 however with improved efficiency, whereas specialist GPU clouds typically supply GH200 at aggressive charges. Decentralised marketplaces might permit cheaper entry however usually restrict options. Clarifai’s compute platform makes use of good autoscaling and GPU fractioning to optimise useful resource utilisation, lowering value per token additional.
Reminiscence‑Certain vs Compute‑Certain Workloads
Whereas GH200 shines for reminiscence‑sure duties, it doesn’t at all times beat H100 for compute‑sure kernels. Some compute‑intensive kernels saturate the GPU’s compute items and aren’t restricted by reminiscence bandwidth, so the efficiency benefit shrinks. Fluence’s information notes that GH200 shouldn’t be the fitting selection for easy single‑GPU coaching or compute‑solely duties. In such instances, H100 or H200 may ship related or higher efficiency at decrease value.
Skilled Insights
Price per token issues – Inference value isn’t nearly GPU worth; it’s about throughput. GH200’s means to make use of bigger batches and retailer key–worth caches on CPU reminiscence drastically cuts value per token.
Batch measurement is the important thing – Bigger unified reminiscence permits greater batches and reduces the overhead of reloading contexts, resulting in large throughput features.
Stability compute and reminiscence – For compute‑heavy duties like CNN coaching or matrix multiplications, H100 or H200 might suffice. GH200 is focused at reminiscence‑sure workloads, so select accordingly.
Use Instances and Workload Match
Fast Abstract: Which workloads profit most from GH200? – GH200 excels in massive language mannequin inference and coaching, retrieval‑augmented era (RAG), multimodal AI, vector search, graph neural networks, advanced simulations, video era, and scientific HPC. Its unified reminiscence permits storing massive key–worth caches and embeddings in RAM, enabling quicker response occasions and bigger context home windows. Exascale supercomputers like JUPITER make use of tens of 1000’s of GH200 chips to simulate local weather and physics at unprecedented scale.
Massive Language Fashions and Chatbots
Fashionable LLMs equivalent to Llama 3, Llama 2, GPT‑J and different 70 B+ parameter fashions require storing gigabytes of weights and key–worth caches. GH200’s unified reminiscence helps as much as 624 GB of accessible reminiscence, which means that lengthy context home windows (128 okay tokens or extra) will be served with out swapping to disk. Nvidia’s weblog on multiturn interactions exhibits that offloading KV caches to CPU reminiscence reduces time‑to‑first token by as much as 14× and improves throughput 2× in contrast with x86‑H100 servers. This makes GH200 best for chatbots requiring actual‑time responses and deep context.
Retrieval‑Augmented Era (RAG)
RAG pipelines combine massive language fashions with vector databases to fetch related data. This requires producing embeddings, constructing vector indices and performing similarity search. Nvidia’s RAG benchmark exhibits GH200 achieves 2.7× quicker embedding era, 2.9× quicker index construct, 3.3× quicker vector search, and 5.7× quicker LLM inference in comparison with A100. The power to maintain vector databases in unified reminiscence reduces information motion and improves latency. Clarifai’s RAG APIs can run on GH200 to deploy chatbots with area‑particular information and summarisation capabilities.
Multimodal AI and Video Era
The GH200’s reminiscence capability additionally advantages multimodal fashions (textual content + picture + video). Fashions like VideoPoet or diffusion‑based mostly video synthesizers require storing frames and cross‑modal embeddings. GH200’s reminiscence can maintain longer sequences and unify CPU and GPU reminiscence, accelerating coaching and inference. That is particularly precious for firms engaged on video era or massive‑scale picture captioning.
Graph Neural Networks and Suggestion Techniques
Massive recommender techniques and graph neural networks deal with billions of nodes and edges, usually requiring terabytes of reminiscence. Nvidia’s press launch on the DGX GH200 emphasises that NVLink change mixed with a number of superchips allows 144 TB of shared reminiscence for coaching advice techniques. This reminiscence capability is essential for fashions like Deep Studying Suggestion Mannequin 3 (DLRM‑v3) or GNNs utilized in social networks and information graphs. GH200 can drastically scale back coaching time and enhance scaling.
Scientific HPC and Exascale Simulations
Outdoors AI, the GH200 performs a job in scientific HPC. The European JUPITER supercomputer, anticipated to exceed 90 exaflops, employs 24 000 GH200 superchips interconnected by way of InfiniBand, with every node utilizing 288 Arm cores and 896 GB of reminiscence. The excessive reminiscence and compute density speed up local weather fashions, physics simulations and drug discovery. Equally, the Helios and DGX GH200 techniques join a whole lot of superchips by way of NVLink switches to type unified supernodes with exascale efficiency.
Skilled Insights
RAG is reminiscence‑sure – RAG workloads usually fail on smaller GPUs attributable to restricted reminiscence for embeddings and indices; GH200 solves this by providing unified reminiscence and close to‑zero copy entry.
Video era wants massive temporal context – GH200’s reminiscence allows storing a number of frames and have maps for prime‑decision video synthesis, lowering I/O overhead.
Graph workloads thrive on reminiscence bandwidth – Analysis on GNN coaching exhibits GH200 gives 4×–7× speedups for graph neural networks in contrast with conventional GPUs, due to its reminiscence capability and NVLink community.
Deployment Choices and Ecosystem
Fast Abstract: The place are you able to entry GH200 in the present day? – GH200 is on the market by way of on‑premises DGX techniques, cloud suppliers like AWS, Azure and Google Cloud, specialist GPU clouds (Lambda, Baseten, Fluence) and decentralised marketplaces. Clarifai presents enterprise‑grade GH200 internet hosting with options like good autoscaling, GPU fractioning and cross‑cloud orchestration. NVLink change techniques permit a number of superchips to behave as a single GPU with large shared reminiscence.
On‑Premise DGX Techniques
Nvidia’s DGX GH200 makes use of NVLink change to attach as much as 256 superchips, delivering 1 exaflop of efficiency and 144 TB unified reminiscence. Organisations like Google, Meta and Microsoft had been early adopters and plan to make use of DGX GH200 techniques for big mannequin coaching and AI analysis. For enterprises with strict information‑sovereignty necessities, DGX bins supply most management and excessive‑pace NVLink interconnects.
Hyperscaler Cases
Main cloud suppliers now supply GH200 situations. On AWS, Azure and Google Cloud, you’ll be able to lease GH200 nodes at roughly $4–$6 per hour. Pricing varies relying on area and configuration; the unified reminiscence reduces the necessity for multi‑GPU clusters, doubtlessly reducing general prices. Cloud situations are sometimes obtainable in restricted areas attributable to provide constraints, so early reservation is advisable.
Specialist GPU Clouds and Decentralised Markets
Firms like Lambda Cloud, Baseten and Fluence present GH200 rental or hosted inference. Fluence’s information compares pricing throughout suppliers and notes that specialist clouds might supply extra aggressive pricing and higher software program help than hyperscalers. Baseten’s experiments present the best way to run Llama 3 on GH200 for inference with 32 % higher throughput than H100. Decentralised GPU marketplaces equivalent to Golem or GPUX permit customers to lease GH200 capability from people or small information centres, though options like NVLink pairing could also be restricted.
Clarifai Compute Platform
Clarifai stands out by providing enterprise‑grade GH200 internet hosting with strong orchestration instruments. Key options embody:
Good autoscaling: robotically scales GH200 assets based mostly on mannequin demand, making certain low latency whereas optimising value.
GPU fractioning: splits a GH200 into smaller logical partitions, permitting a number of workloads to share the reminiscence pool and compute items effectively.
Cross‑cloud flexibility: run workloads on GH200 {hardware} throughout a number of clouds or on‑premises, simplifying migration and failover.
Unified management & governance: handle all deployments by Clarifai’s console or API, with monitoring, logging and compliance inbuilt.
These capabilities let enterprises undertake GH200 with out investing in bodily infrastructure and guarantee they solely pay for what they use.
Skilled Insights
NVLink change vs InfiniBand – NVLink change presents decrease latency and better bandwidth than InfiniBand, enabling a number of GH200 modules to behave like a single GPU.
Cloud availability is restricted – Attributable to excessive demand and restricted provide, GH200 situations could also be scarce on public cloud; working with specialist suppliers or Clarifai ensures precedence entry.
Compute orchestration simplifies adoption – Utilizing Clarifai’s orchestration options permits engineers to concentrate on fashions moderately than infrastructure, bettering time‑to‑market.
Choice Information: GH200 vs H100/H200 vs B200/Rubin
Fast Abstract: How do you determine which GPU to make use of? – The selection relies on reminiscence necessities, bandwidth, software program help, energy funds and value. GH200 presents unified reminiscence (96–144 GB HBM + 480 GB LPDDR) and excessive bandwidth (900 GB/s NVLink‑C2C), making it best for reminiscence‑sure duties. H100 and H200 are higher for compute‑sure workloads or when utilizing x86 software program stacks. B200 (Blackwell) and upcoming Rubin promise much more reminiscence and value effectivity, however availability might lag. Clarifai’s orchestration can combine and match {hardware} to satisfy workload wants.
Reminiscence Capability & Bandwidth
H100 – 80 GB HBM and a pair of TB/s reminiscence bandwidth (HBM3). Reminiscence is native to the GPU; information have to be moved from CPU by way of PCIe.
H200 – 141 GB HBM3e and 4.8 TB/s bandwidth. A drop‑in alternative for H100 however nonetheless requires PCIe or NVLink bridging. Appropriate for compute‑sure duties needing extra GPU reminiscence.
GH200 – 96 GB HBM3 or 144 GB HBM3e plus 480 GB LPDDR5X accessible by way of 900 GB/s NVLink‑C2C, yielding a unified 624 GB pool.
B200 (Blackwell) – Rumoured to supply 208 GB HBM3e and 10 TB/s bandwidth; lacks unified CPU reminiscence, so nonetheless reliant on PCIe or NVLink connections.
Rubin platform – Will function an 88‑core CPU with 1.5 TB of LPDDR5X and 1.8 TB/s NVLink‑C2C bandwidth. NVL72 racks will drastically scale back inference value.
Software program Stack & Structure
GH200 makes use of an ARM structure (Grace CPU). Many AI frameworks help ARM, however some Python libraries and CUDA variations might require recompilation. Clarifai’s native runner solves this by offering containerised environments with the fitting dependencies.
H100/H200 run on x86 servers and profit from mature software program ecosystems. In case your codebase closely relies on x86‑particular libraries, migrating to GH200 might require further effort.
Energy Consumption & Cooling
GH200 techniques can draw as much as 1 000 W per node because of the mixed CPU and GPU. Guarantee satisfactory cooling and energy infrastructure. H100 and H200 nodes sometimes eat much less energy individually however might require extra nodes to match GH200’s reminiscence capability.
Price & Availability
GH200 {hardware} is costlier than H100/H200 upfront, however the lowered variety of nodes required for reminiscence‑intensive workloads can offset value. Pricing information suggests GH200 leases value about $4–$6 per hour. H100/H200 could also be cheaper per hour however want extra items to host the identical mannequin. Blackwell and Rubin are usually not but extensively obtainable; early adopters might pay premium pricing.
Choice Matrix
Select GH200 when your workloads are reminiscence‑sure (LLM inference, RAG, GNNs, large embeddings) or require unified reminiscence for environment friendly pipelines.
Select H100/H200 for compute‑sure duties like convolutional neural networks, transformer pretraining, or when utilizing x86‑dependent software program. H200 provides extra HBM however nonetheless lacks unified CPU reminiscence.
Anticipate B200/Rubin for those who want even bigger reminiscence or higher value effectivity and might deal with delayed availability. Rubin’s NVL72 racks could also be revolutionary for exascale AI.
Leverage Clarifai to combine {hardware} varieties inside a single pipeline, utilizing GH200 for reminiscence‑heavy levels and H100/B200 for compute‑heavy phases.
Skilled Insights
Unified reminiscence modifications the calculus – Contemplate reminiscence capability first; the unified 624 GB on GH200 can exchange a number of H100 playing cards and simplify scaling.
ARM software program is maturing – Instruments like PyTorch and TensorFlow have improved help for ARM; containerised environments (e.g., Clarifai native runner) make deployment manageable.
HBM3e is a powerful bridge – H200’s HBM3e reminiscence gives a few of GH200’s capability advantages with out new CPU structure, providing an easier improve path.
Challenges, Limitations and Mitigation
Fast Abstract: What are the pitfalls of adopting GH200 and how will you mitigate them? – Key challenges embody software program compatibility on ARM, excessive energy consumption, cross‑die latency, provide chain constraints and greater value. Mitigation methods contain utilizing containerised environments (Clarifai native runner), proper‑sizing assets (GPU fractioning), and planning for provide constraints.
Software program Ecosystem on ARM
The Grace CPU makes use of an ARM structure, which can require recompiling libraries or dependencies. PyTorch, TensorFlow and CUDA help ARM, however some Python packages depend on x86 binaries. Lambda’s weblog warns that PyTorch have to be compiled for ARM, and there could also be restricted prebuilt wheels. Clarifai’s native runner addresses this by packaging dependencies and offering pre‑configured containers, making it simpler to deploy fashions on GH200.
Energy and Cooling Necessities
A GH200 superchip can eat as much as 900 W for the GPU and 1000 W for the total system. Information centres should guarantee satisfactory cooling, energy supply and monitoring. Utilizing good autoscaling to spin down unused nodes reduces power utilization. Contemplate the environmental affect and potential regulatory necessities (e.g., carbon reporting).
Latency & NUMA Results
Whereas NVLink‑C2C presents excessive bandwidth, cross‑die reminiscence entry has greater latency than native HBM. Chips and Cheese’s evaluation notes that the common latency will increase when accessing CPU reminiscence vs HBM. Builders ought to design algorithms to prioritise information locality: hold often accessed tensors in HBM and use CPU reminiscence for KV caches and often accessed information. Analysis is ongoing to optimise information placement and scheduling. explores LLVM OpenMP offload optimisations on GH200, offering insights for HPC workloads.
Provide Chain & Pricing
Excessive demand and restricted provide imply GH200 situations will be scarce. Fluence’s pricing comparability highlights that GH200 might value greater than H100 per hour however presents higher efficiency for reminiscence‑heavy duties. To mitigate provide points, work with suppliers like Clarifai that reserve capability or use decentrised markets to dump non‑vital workloads.
Skilled Insights
Embrace hybrid structure – Use each H100/H200 and GH200 the place applicable; unify them by way of container orchestration to beat provide and software program limitations.
Optimise information placement – Maintain compute‑intensive kernels on HBM; offload caches to LPDDR reminiscence. Monitor reminiscence bandwidth and latency utilizing profiling instruments.
Plan for lengthy lead occasions – Pre‑order GH200 {hardware} or cloud reservations. Develop software program in moveable frameworks to ease transitions between architectures.
Rising Traits & Future Outlook
Fast Abstract: What’s subsequent for reminiscence‑centric AI {hardware}? – Traits embody HBM3e reminiscence, Blackwell (B200/GB200) GPUs, Rubin CPU platforms, NVLink‑6 and NVL72 racks, and the rise of exascale supercomputers. These improvements intention to additional scale back inference value and power consumption whereas growing reminiscence capability and compute density.
HBM3e and Blackwell
The HBM3e revision of GH200 already will increase reminiscence capability to 144 GB and bandwidth to 4.9 TB/s. Nvidia’s subsequent GPU structure, Blackwell, options the B200 and server configurations like GB200 and GB300. These chips will enhance HBM capability to round 208 GB, present improved compute throughput and should incorporate the Hopper or Rubin CPU for unified reminiscence. In accordance with Medium analyst Adrian Cockcroft, GH200 pairs an H200 GPU with the Grace CPU and might join 256 modules utilizing shared reminiscence for improved efficiency.
Rubin Platform and NVLink‑6
Nvidia’s Rubin platform pushes reminiscence‑centric design additional by introducing an 88‑core CPU with 1.5 TB LPDDR5X and 1.8 TB/s NVLink‑C2C bandwidth. Rubin’s NVL72 rack techniques will scale back inference value by 10× and the variety of GPUs wanted for coaching by 4× in contrast with Blackwell. We will anticipate mainstream adoption round 2026–2027, though early entry could also be restricted to massive cloud suppliers.
Exascale Supercomputers & International AI Infrastructure
Supercomputers like JUPITER and Helios display the potential of GH200 at scale. JUPITER makes use of 24 000 GH200 superchips and is anticipated to ship greater than 90 exaflops. These techniques will energy analysis into local weather change, climate prediction, quantum physics and AI. As generative AI functions equivalent to video era and protein folding require extra reminiscence, these exascale infrastructures might be essential.
Business Collaboration and Ecosystem
Nvidia’s press releases emphasise that main tech firms (Google, Meta, Microsoft) and integrators like SoftBank are investing closely in GH200 techniques. In the meantime, storage and networking distributors are adapting their merchandise to deal with unified reminiscence and excessive‑throughput information streams. The ecosystem will proceed to develop, bringing higher software program instruments, reminiscence‑conscious schedulers and cross‑vendor interoperability.
Skilled Insights
Reminiscence is the brand new frontier – Future platforms will emphasise reminiscence capability and bandwidth over uncooked flops; algorithms might be redesigned to use unified reminiscence.
Rubin and NVLink 6 – These will probably allow multi‑rack clusters with unified reminiscence measured in petabytes, remodeling AI infrastructure.
Put together now – Constructing pipelines that may run on GH200 units you as much as undertake B200/Rubin with minimal modifications.
Clarifai Product Integration & Finest Practices
Fast Abstract: How does Clarifai leverage GH200 and what are greatest practices for customers? – Clarifai presents enterprise‑grade GH200 internet hosting with options equivalent to good autoscaling, GPU fractioning, cross‑cloud orchestration, and a native runner for ARM‑optimised deployment. To maximise efficiency, use bigger batch sizes, retailer key–worth caches on CPU reminiscence, and combine vector databases with Clarifai’s RAG APIs.
Clarifai’s GH200 Internet hosting
Clarifai’s compute platform makes the GH200 accessible with no need to buy {hardware}. It abstracts complexity by options:
Good autoscaling provisions GH200 situations as demand will increase and scales them down throughout idle intervals.
GPU fractioning lets a number of jobs share a single GH200, splitting reminiscence and compute assets to maximise utilisation.
Cross‑cloud orchestration permits workloads to run on GH200 throughout varied clouds and on‑premises infrastructure with unified monitoring and governance.
Unified management & governance gives centralised dashboards, auditing and function‑based mostly entry, vital for enterprise compliance.
Clarifai’s RAG and embedding APIs are optimised for GH200 and help vector search and summarisation. Builders can deploy LLMs with massive context home windows and combine exterior information sources with out worrying about reminiscence administration. Clarifai’s pricing is clear and sometimes tied to utilization, providing value‑efficient entry to GH200 assets.
Finest Practices for Deploying on GH200
Use massive batch sizes – Leverage the unified reminiscence to extend batch sizes for inference; this reduces overhead and improves throughput.
Offload KV caches to CPU reminiscence – Retailer key–worth caches in LPDDR reminiscence to unlock HBM for compute; NVLink‑C2C ensures low‑latency entry.
Combine vector databases – For RAG, join Clarifai’s APIs to vector shops; hold indices in unified reminiscence to speed up search.
Monitor reminiscence bandwidth – Use profiling instruments to detect reminiscence bottlenecks. Information placement issues; excessive‑frequency tensors ought to keep in HBM.
Undertake containerised environments – Use Clarifai’s native runner to deal with ARM dependencies and keep reproducibility.
Plan cross‑{hardware} pipelines – Mix GH200 for reminiscence‑intensive levels with H100/B200 for compute‑heavy levels, orchestrated by way of Clarifai’s platform.
Skilled Insights
Reminiscence‑conscious design – Rethink your algorithms to use unified reminiscence: pre‑allocate massive buffers, scale back information copies and tune for NVLink bandwidth.
GPU sharing boosts ROI – Fractioning a GH200 throughout a number of workloads will increase utilisation and lowers value per job; that is particularly helpful for startups.
Clarifai’s cross‑cloud synergy – Working workloads throughout a number of clouds prevents vendor lock‑in and ensures excessive availability.
Regularly Requested Questions
Q1: Is GH200 obtainable in the present day and the way a lot does it value? – Sure. GH200 techniques can be found by way of cloud suppliers and specialist GPU clouds. Rental costs vary from $4–$6 per hour relying on supplier and area. Clarifai presents utilization‑based mostly pricing by its platform.
Q2: How does GH200 differ from H100 and H200? – GH200 fuses a CPU and GPU on one module with 900 GB/s NVLink‑C2C, making a unified reminiscence pool of as much as 624 GB. H100 is a standalone GPU with 80 GB HBM, whereas H200 upgrades the H100 with 141 GB HBM3e. GH200 is healthier for reminiscence‑sure duties; H100/H200 stay robust for compute‑sure workloads and x86 compatibility.
Q3: Will I must rewrite my code to run on GH200? – Most AI frameworks (PyTorch, TensorFlow, JAX) help ARM and CUDA. Nevertheless, some libraries may have recompilation. Utilizing containerised environments (e.g., Clarifai native runner) simplifies the migration.
This fall: What about energy consumption and cooling? – GH200 nodes can eat round 1 000 W. Guarantee satisfactory energy and cooling. Good autoscaling reduces idle consumption.
Q5: When will Blackwell/B200/Rubin be extensively obtainable? – Nvidia has introduced B200 and Rubin platforms, however broad availability might arrive in late 2026 or 2027. Rubin guarantees 10× decrease inference value and 4× fewer GPUs in comparison with Blackwell. For many builders, GH200 will stay a flagship selection by 2026.
Conclusion
The Nvidia GH200 marks a turning level in AI {hardware}. By fusing a 72‑core Grace CPU with a Hopper/H200 GPU by way of NVLink‑C2C, it delivers a unified reminiscence pool as much as 624 GB and eliminates the bottlenecks of PCIe. Benchmarks present as much as 1.8× extra efficiency than the H100 and massive enhancements in value per token for LLM inference. These features stem from reminiscence: the flexibility to maintain whole fashions, key–worth caches and vector indices on chip. Whereas GH200 isn’t good—software program on ARM requires adaptation, energy consumption is excessive and provide is restricted—it presents unparalleled capabilities for reminiscence‑sure workloads.
As AI enters the period of trillion‑parameter fashions, reminiscence‑centric computing turns into important. GH200 paves the way in which for Blackwell, Rubin and past, with bigger reminiscence swimming pools and extra environment friendly NVLink interconnects. Whether or not you’re constructing chatbots, producing video, exploring scientific simulations or coaching recommender techniques, GH200 gives a strong platform. Partnering with Clarifai simplifies adoption: their compute platform presents good autoscaling, GPU fractioning and cross‑cloud orchestration, making the GH200 accessible to groups of all sizes. By understanding the structure, efficiency traits and greatest practices outlined right here, you’ll be able to harness the GH200’s potential and put together for the subsequent wave of AI innovation.
The ShinyHunters extortion gang claims it’s behind a wave of ongoing voice phishing assaults focusing on single sign-on (SSO) accounts at Okta, Microsoft, and Google, enabling menace actors to breach company SaaS platforms and steal firm information for extortion.
In these assaults, menace actors impersonate IT assist and name staff, tricking them into coming into their credentials and multi-factor authentication (MFA) codes on phishing websites that impersonate firm login portals.
As soon as compromised, the attackers acquire entry to the sufferer’s SSO account, which might present entry to different related enterprise functions and companies.
SSO companies from Okta, Microsoft Entra, and Google allow corporations to hyperlink third-party functions right into a single authentication move, giving staff entry to cloud companies, inside instruments, and enterprise platforms with a single login.
These SSO dashboards usually listing all related companies, making a compromised account a gateway into company programs and information.
Platforms generally related by SSO embrace Salesforce, Microsoft 365, Google Workspace, Dropbox, Adobe, SAP, Slack, Zendesk, Atlassian, and plenty of others.
Microsoft Entra single sign-on (SSO) dashboard Supply: Microsoft
Vishing assaults used for information theft
As first reported by BleepingComputer, menace actors have been finishing up these assaults by calling staff and posing as IT employees, utilizing social engineering to persuade them to log into phishing pages and full MFA challenges in actual time.
After having access to a sufferer’s SSO account, the attackers browse the listing of related functions and start harvesting information from the platforms out there to that consumer.
BleepingComputer is conscious of a number of corporations focused in these assaults which have since obtained extortion calls for signed by ShinyHunters, indicating that the group was behind the intrusions.
BleepingComputer contacted Okta earlier this week in regards to the breaches, however the firm declined to touch upon the information theft assaults.
Nevertheless, Okta launched a report yesterday describing the phishing kits utilized in these voice-based assaults, which match what BleepingComputer has been advised.
In response to Okta, the phishing kits embrace a web-based management panel that permits attackers to dynamically change what a sufferer sees on a phishing website whereas talking to them on the telephone. This permits menace actors to information victims by every step of the login and MFA authentication course of.
If the attackers enter stolen credentials into the actual service and are prompted for MFA, they’ll show new dialog containers on the phishing website in actual time to instruct a sufferer to approve a push notification, enter a TOTP code, or carry out different authentication steps.
A phishing package lets attackers show totally different dialogs whereas calling victims Supply: Okta
ShinyHunters declare accountability
Whereas ShinyHunters declined to touch upon the assaults final evening, the group confirmed to BleepingComputer this morning that it’s accountable for a number of the social engineering assaults.
“We affirm we’re behind the assaults,” ShinyHunters advised BleepingComputer. “We’re unable to share additional particulars at the moment, moreover the truth that Salesforce stays our main curiosity and goal, the remainder are benefactors.”
The group additionally confirmed different elements of BleepingComputer’s reporting, together with particulars in regards to the phishing infrastructure and domains used within the marketing campaign. Nevertheless, it disputed {that a} screenshot of a phishing package command-and-control server shared by Okta was for its platform, claiming as an alternative that theirs was constructed in-house.
ShinyHunters claimed it’s focusing on not solely Okta but additionally Microsoft Entra and Google SSO platforms.
Microsoft stated it has nothing to share at the moment, and Google stated it had no proof its merchandise have been being abused within the marketing campaign.
“Right now, now we have no indication that Google itself or its merchandise are affected by this marketing campaign,” a Google spokesperson advised BleepingComputer.
ShinyHunters claims to be utilizing information stolen in earlier breaches, such because the widespread Salesforce information theft assaults, to establish and phone staff. This information contains telephone numbers, job titles, names, and different particulars used to make the social-engineering calls extra convincing.
Final evening, the group relaunched its Tor information leak website, which at the moment lists breaches at SoundCloud, Betterment, and Crunchbase.
SoundCloud beforehand disclosed an information breach in December 2025, whereas Betterment confirmed this month that its electronic mail platform had been abused to ship cryptocurrency scams and that information was stolen.
Crunchbase, which had not beforehand disclosed a breach, confirmed right this moment that information was stolen from its company community.
“Crunchbase detected a cybersecurity incident the place a menace actor exfiltrated sure paperwork from our company community,” an organization spokesperson advised BleepingComputer. “No enterprise operations have been disrupted by this incident. We now have contained the incident and our programs are safe.”
“Upon detecting the incident we engaged cybersecurity consultants and contacted federal legislation enforcement. We’re reviewing the impacted data to find out if any notifications are required in line with relevant authorized necessities.”
Whether or not you are cleansing up outdated keys or setting guardrails for AI-generated code, this information helps your staff construct securely from the beginning.
Get the cheat sheet and take the guesswork out of secrets and techniques administration.