It is exhausting to know the place to begin with this degenerate hogwash. However that final line “ICE > MN” captures it. The ICE brokers are superior to the entire state. That is their mentalty and mannequin.
Comer
on Fox proper now urging Trump to drag ICE out of Minneapolis to
*punish* Minnesotans — will show to the state how good it was to have
ICE there! That is actually some 5-D chess
Pulling out the guard all the time has potential surprising penalties. Publicly maintaining distance from ICE is essential.
Minnesota
Nationwide Guard members have arrived at a federal constructing and had been
directed to distribute donuts, espresso, and scorching chocolate to anti-ICE
protesters. Guard members had been issued reflective vests so they might not
be mistaken for federal brokers.
Having Bessent speaking about this will characterize an all fingers on deck second inside the administration or it could simply be poor message self-discipline.
1. Wasn’t at a protest
2. Was disarmed once they shot him whereas he was face down
3. New gun rights rule: the second modification is when conservatives can carry weapons in all places, but when anybody else has a gun we will kill him on sight
Nobody has been righter on the political affect of Trump’s immigration terror marketing campaign than Elliott. When know-it-all pundits had been demanding Dems shut up about Kilmar Abrego Garcia, he pushed again with exhausting knowledge and has been totally vindicated on daily basis since. Dems have to hearken to Elliott.
Immigration
was a profitable challenge for Trump in 2024, however no challenge is so common that
it might probably’t be turned poisonous by ample evil, overreach, and
incompetence.
With out diminishing the outrage on the taking pictures, it is vital to recollect that is considered one of many horrors occurring within the twin cities.
First day of lessons at present at Harvard. Excited to show each a chance course and a course on quant strategies for undergrads.
What a recreation yesterday. I forgot what it was wish to root for a staff that was ok the place watching the sport might trigger me that a lot stress. The Tremendous Bowl will completely give me a coronary. However right here’s footage from yesterday strolling from my apt to catch the practice. I put on #99 bc cosmos advised me one once I first obtained right here that White was underrated, and I’m all about supporting the entire staff, not simply the celebs. However then White obtained traded midway via the season.
The climate is wonderful although. I like all this snow and chilly personally. Right here’s a video outdoors my residence.
Amazon employees await imminent layoffs by reflecting on an outdated Jeff Bezos adage that there ought to by no means be a staff bigger than you possibly can feed in a room with two pizzas.
Fascinating Twitter thread about Claude and the assorted sciences. One factor that jumped out at me — Claude is getting built-in into the manufacturing capabilities of society the place switching prices are excessive.
I offered at Middlebury Faculty final week. Whereas strolling throughout city, I handed a gap within the buildings and noticed this waterfall. It was my first time in Vermont which I’ve at all times regarded as one of many cool snowy states. Actually fantastic go to.
And that’s it! Hope everybody has an awesome semester.
Scott’s Mixtape Substack is a reader-supported publication. To obtain new posts and help my work, think about changing into a free or paid subscriber.
I used to be constructing a Modal element that makes use of the component’s showModal technique. Whereas testing the element, I found I might tab out of the (in modal mode) and onto the deal with bar.
And I used to be shocked — accessibility recommendation round modals have generally taught us to entice focus inside the modal. So this appears mistaken to me.
Upon additional analysis, it looks as if we now not have to entice focus inside the (even in modal mode). So, the focus-trapping is deprecated recommendation when you use .
Some notes for you
As an alternative of asking you to learn by means of your complete GitHub Challenge detailing the dialogue, I summarized a few key factors from notable individuals under.
Listed here are some feedback from Scott O’Hara that tells us in regards to the historical past and context of the focus-trapping recommendation:
WCAG is not normatively stating focus should be trapped inside a dialog. Slightly, the normative WCAG spec makes zero point out of necessities for focus conduct in a dialog.
The informative 2.4.3 focus order understanding docdoes discuss limiting focus conduct inside a dialog – however once more, that is within the context of a scripted customized dialog and was written lengthy earlier than inert or have been extensively accessible.
The aim of the APG is to show tips on how to use ARIA. And, with out utilizing native HTML options like or inert, it’s far simpler to entice focus inside the customized dialog than it’s to attain the conduct that the component has.
Each the APG modal dialog and the WCAG understanding doc have been written lengthy earlier than the inert attribute or the component have been extensively supported. And, the choice to instructing builders to entice focus within the dialog would have been to inform them that they wanted to make sure that all focusable parts within the internet web page, exterior of the modal dialog, obtained a tabindex=-1.
Léonie Watson weighs in and explains why it’s okay for a screen-reader consumer to maneuver focus to the deal with bar:
Within the web page context you possibly can select to Tab out of the underside and across the browser chrome, you should utilize a keyboard command to maneuver straight to the deal with bar or open a specific menu, you possibly can shut the tab, and so forth. This offers individuals a alternative about how, why, and what they do to flee out of the context.
It appears logical (to me no less than) for a similar choices to be accessible to individuals when in a dialog context as an alternative of a web page context.
Lastly, Matatk shared the conclusion from the W3C’s Accessible Platform Architectures (APA) Working Group that okay-ed the notion that ‘s showModal technique doesn’t have to entice focus.
We addressed this query in the middle of a number of APA conferences and got here to the conclusion that the present conduct of the native dialog component must be saved as it’s. So, which you could tab from the dialog to the browser functionalities.
We see particularly the profit that keyboard customers can, for instance, open a brand new tab to look one thing essential up or to vary a browser setting this manner. On the similar time, the dialog component thus offers an extra pure escape mechanism (i.e. shifting to the deal with bar) in, for instance, kiosk conditions the place the consumer can’t use different commonplace keyboard shortcuts.
From what I’m studying, it appears like we don’t have to fret about focus trapping if we’re correctly utilizing the Dialog API’s showModal technique!
Hope this information make it simpler so that you can construct parts. 😉
Trendy AI functions depend on clever brokers that suppose, cooperate, and execute advanced workflows, whereas single-agent methods battle with scalability, coordination, and long-term context. AgentScope AI addresses this by providing a modular, extensible framework for constructing structured multi-agent methods, enabling position task, reminiscence management, device integration, and environment friendly communication with out pointless complexity for builders and researchers alike searching for sensible steerage at this time now clearly. On this article, we offer a sensible overview of its structure, options, comparisons, and real-world use circumstances.
What’s AgentScope and Who Created It?
AgentScope is an open-source multi-agent framework for AI agent methods that are structured, scalable, and production-ready. Its primary focus is on clear abstractions, modular design together with communication between brokers relatively than ad-hoc immediate chaining.
The AI methods group’s researchers and engineers primarily created AgentScope to beat the obstacles of coordination and observability in intricate agent workflows. The truth that it may be utilized in analysis and manufacturing environments makes it a rigour-laden, reproducible and extensible framework that may nonetheless be dependable and experimental on the similar time.
As LLM functions develop extra advanced, builders more and more depend on a number of brokers working collectively. Nevertheless, many groups battle with managing agent interactions, shared state, and long-term reminiscence reliably.
AgentScope solves these issues by introducing express agent abstractions, message-passing mechanisms, and structured reminiscence administration. Its core targets embrace:
Transparency and Flexibility: The entire functioning of an agent’s pipeline, which incorporates prompts, reminiscence contents, API calls, and gear utilization, is seen to the developer. You might be allowed to cease an agent in the midst of its reasoning course of, verify or change its immediate, and proceed execution with none difficulties.
Multi-Agent Collaboration: With regards to performing difficult duties, the necessity for a number of specialised brokers is most well-liked over only one huge agent. AgentScope has built-in help for coordinating many brokers collectively.
Integration and Extensibility: AgentScope was designed with extensibility and interoperability in thoughts. It makes use of the newest requirements just like the MCP and A2A for communication, which not solely enable it to attach with exterior providers but additionally to function inside different agent frameworks.
Manufacturing Readiness: The traits of many early agent frameworks didn’t embrace the aptitude for manufacturing deployment. AgentScope aspires to be “production-ready” proper from the beginning.
In conclusion, AgentScope is designed to make the event of advanced, agent-based AI methods simpler. It supplies modular constructing blocks and orchestration instruments, thus occupying the center floor between easy LLM utilities and scalable multi-agent platforms.
Core Ideas and Structure of AgentScope
Agent Abstraction and Message Passing: AgentScope symbolizes each agent as a standalone entity with a selected perform, psychological state, and choice-making course of. Brokers don’t trade implicit secret context, thus minimizing the prevalence of unpredictable actions.
Fashions, Reminiscence, and Instruments: AgentScope divides intelligence, reminiscence, and execution into separate parts. This partitioning allows the builders to make modifications to every half with out disrupting the whole system.
Mannequin Abstraction and LLM Suppliers: AgentScope abstracts LLMs behind a consolidated interface, henceforth permitting easy transitions between suppliers. Builders can select between OpenAI, Anthropic, open-source fashions, or native inference engines.
Quick-Time period and Lengthy-Time period Reminiscence: AgentScope differentiates between short-term conversational reminiscence and long-term persistent reminiscence. Quick-term reminiscence supplies the context for speedy reasoning, whereas long-term reminiscence retains information that lasts.
Device and Operate Invocation: AgentScope offers brokers the chance to name exterior instruments by way of structured perform execution. These instruments might include APIs, databases, code execution environments, or enterprise methods.
Key Capabilities of AgentScope
AgentScope is an all-in-one bundle of a number of highly effective options which permits multi-agent workflows. Listed here are some principal strengths of the framework already talked about:
Multi-Agent Orchestration: AgentScope is a grasp within the orchestration of quite a few brokers working to realize both overlapping or opposing targets. Furthermore, the builders have the choice to create a hierarchical, peer-to-peer, or perhaps a coordinator-worker strategy.
async with MsgHub(
members=[agent1, agent2, agent3],
announcement=Msg("Host", "Introduce yourselves.", "assistant"),
) as hub:
await sequential_pipeline([agent1, agent2, agent3])
# Add or take away brokers on the fly
hub.add(agent4)
hub.delete(agent3)
await hub.broadcast(Msg("Host", "Wrap up."), to=[])
Device Calling and Exterior Integrations: AgentScope has a easy and simple integration with the exterior methods by way of device calling mechanisms. This function helps to show brokers from easy conversational entities into environment friendly automation parts that perform actions.
Reminiscence Administration and Context Persistence: With AgentScope, the builders have the facility of explicitly controlling the context of the brokers’ storage and retrieval. Thus, they resolve what data will get retained and what will get to be transient. The advantages of this transparency embrace the prevention of context bloating, fewer hallucinations, and reliability in the long run.
QuickStart with AgentScope
In case you observe the official quickstart, the method of getting AgentScope up and operating is kind of easy. The framework necessitates Python model 3.10 or above. Set up may be carried out both via PyPI or from the supply:
From PyPI:
Run the next instructions within the command-line:
pip set up agentscope
to put in the newest model of AgentScope and its dependencies. (In case you are utilizing the uv setting, execute uv pip set up agentscope as described within the docs)
This may set up AgentScope in your Python setting, linking to your native copy. You too can use uv pip set up -e . if utilizing an uv setting.
After the set up, it’s best to have entry to the AgentScope lessons inside Python code. The Howdy AgentScope instance of the repository presents a really primary dialog loop with a ReActAgent and a UserAgent.
AgentScope doesn’t require any further server configurations; it merely is a Python library. Following the set up, it is possible for you to to create brokers, design pipelines, and do some testing instantly.
Making a Multi-Agent Workflow with AgentScope
Let’s create a practical multi-agent system wherein two AI fashions, Claude and ChatGPT, possess totally different roles and compete with one another: Claude generates issues whereas GPT makes an attempt to resolve them. We will clarify every a part of the code and see how AgentScope truly manages to carry out this interplay.
1. Setting Up the Atmosphere
Importing Required Libraries
import os
import asyncio
from typing import Listing
from pydantic import BaseModel
from agentscope.agent import ReActAgent
from agentscope.formatter import OpenAIChatFormatter, AnthropicChatFormatter
from agentscope.message import Msg
from agentscope.mannequin import OpenAIChatModel, AnthropicChatModel
from agentscope.pipeline import MsgHub
All the mandatory modules from AgentScope and Python’s commonplace library are imported. The ReActAgent class is used to create the clever brokers whereas the formatters be sure that messages are ready accordingly for the assorted AI fashions. Msg is the communication methodology between brokers supplied by AgentScope.
This setup will assist in authenticating the API credentials for each OpenAI and Anthropic. And to entry a specific mannequin now we have to go the particular mannequin’s identify additionally.
2. Defining Knowledge Constructions for Monitoring Outcomes
Spherical Log Construction:
class RoundLog(BaseModel):
round_index: int
creator_model: str
solver_model: str
downside: str
solver_answer: str
judge_decision: str
solver_score: int
creator_score: int
This information mannequin holds all the data concerning each spherical of the competition in real-time. Taking part fashions, generated issues, solver’s suggestions, and present scores are being recorded thus making it simple to evaluate and analyze every interplay.
International Rating Construction:
class GlobalScore(BaseModel):
total_rounds: int
creator_model: str
solver_model: str
creator_score: int
solver_score: int
rounds: Listing[RoundLog]
The general competitors outcomes throughout all rounds are saved on this construction. It preserves the ultimate scores and the whole rounds historical past thus providing us a complete view of brokers’ efficiency within the full workflow.
Normalizing Agent Messages
def extract_text(msg) -> str:
"""Normalize an AgentScope message (or comparable) right into a plain string."""
if isinstance(msg, str):
return msg
get_tc = getattr(msg, "get_text_content", None)
if callable(get_tc):
textual content = get_tc()
if isinstance(textual content, str):
return textual content
content material = getattr(msg, "content material", None)
if isinstance(content material, str):
return content material
if isinstance(content material, listing):
components = []
for block in content material:
if isinstance(block, dict) and "textual content" in block:
components.append(block["text"])
if components:
return "n".be a part of(components)
text_attr = getattr(msg, "textual content", None)
if isinstance(text_attr, str):
return text_attr
messages_attr = getattr(msg, "messages", None)
if isinstance(messages_attr, listing) and messages_attr:
final = messages_attr[-1]
last_content = getattr(final, "content material", None)
if isinstance(last_content, str):
return last_content
last_text = getattr(final, "textual content", None)
if isinstance(last_text, str):
return last_text
return ""
Our perform here’s a supporting one that enables us to acquire readable textual content from agent responses with reliability whatever the message format. Totally different AI fashions have totally different buildings for his or her responses so this perform takes care of all of the totally different codecs and turns them into easy strings we are able to work with.
4. Constructing the Agent Creators
Creating the Drawback Creator Agent (Claude)
def create_creator_agent() -> ReActAgent:
return ReActAgent(
identify="ClaudeCreator",
sys_prompt=(
"You might be Claude Sonnet, performing as an issue creator. "
"Your activity: in every spherical, create ONE practical on a regular basis downside that "
"some folks may face (e.g., scheduling, budgeting, productiveness, "
"communication, private determination making). "
"The issue ought to:n"
"- Be clearly described in 3–6 sentences.n"
"- Be self-contained and solvable with reasoning and customary sense.n"
"- NOT require personal information or exterior instruments.n"
"Return ONLY the issue description, no resolution."
),
mannequin=AnthropicChatModel(
model_name=CLAUDE_MODEL_NAME,
api_key=ANTHROPIC_API_KEY,
stream=False,
),
formatter=AnthropicChatFormatter(),
)
This utility produces an assistant that takes on the position of Claude and invents practical issues of on a regular basis life that aren’t essentially such. The system immediate specifies the sort of issues to be created, primarily making it the eventualities the place reasoning is required however no exterior instruments or personal data are required for fixing them.
Creating the Drawback Solver Agent (GPT)
def create_solver_agent() -> ReActAgent:
return ReActAgent(
identify="GPTSolver",
sys_prompt=(
"You might be GPT-4.1 mini, performing as an issue solver. "
"You'll obtain a sensible on a regular basis downside. "
"Your activity:n"
"- Perceive the issue.n"
"- Suggest a transparent, actionable resolution.n"
"- Clarify your reasoning in 3–8 sentences.n"
"If the issue is unclear or inconceivable to resolve with the given "
"data, you MUST explicitly say: "
""I can't clear up this downside with the data supplied.""
),
mannequin=OpenAIChatModel(
model_name=GPT_SOLVER_MODEL_NAME,
api_key=OPENAI_API_KEY,
stream=False,
),
formatter=OpenAIChatFormatter(),
)
This device additionally offers beginning to a different agent powered by GPT-4.1 mini whose primary activity is to discover a resolution to the issue. The system immediate dictates that it should give a transparent resolution together with the reasoning, and most significantly, to acknowledge when an issue can’t be solved; this frank recognition is crucial for correct scoring within the competitors.
5. Implementing the Judging Logic
Figuring out Answer Success
def solver_succeeded(solver_answer: str) -> bool:
"""Heuristic: did the solver handle to resolve the issue?"""
textual content = solver_answer.decrease()
failure_markers = [
"i cannot solve this problem",
"i can't solve this problem",
"cannot solve with the information provided",
"not enough information",
"insufficient information",
]
return not any(marker in textual content for marker in failure_markers)
This judging perform is straightforward but highly effective. If the solver has truly supplied an answer or confessed failure the perform will verify. By trying to find sure expressions that present the solver was not capable of handle the problem, the winner of each spherical may be determined mechanically with out the necessity for human intervention.
6. Operating the Multi-Spherical Competitors
Principal Competitors Loop
async def run_competition(num_rounds: int = 5) -> GlobalScore:
creator_agent = create_creator_agent()
solver_agent = create_solver_agent()
creator_score = 0
solver_score = 0
round_logs: Listing[RoundLog] = []
for i in vary(1, num_rounds + 1):
print(f"n========== ROUND {i} ==========n")
# Step 1: Claude creates an issue
creator_msg = await creator_agent(
Msg(
position="consumer",
content material="Create one practical on a regular basis downside now.",
identify="consumer",
),
)
problem_text = extract_text(creator_msg)
print("Drawback created by Claude:n")
print(problem_text)
print("n---n")
# Step 2: GPT-4.1 mini tries to resolve it
solver_msg = await solver_agent(
Msg(
position="consumer",
content material=(
"Right here is the issue you could clear up:nn"
f"{problem_text}nn"
"Present your resolution and reasoning."
),
identify="consumer",
),
)
solver_text = extract_text(solver_msg)
print("GPT-4.1 mini's resolution:n")
print(solver_text)
print("n---n")
# Step 3: Decide the end result
if solver_succeeded(solver_text):
solver_score += 1
judge_decision = "Solver (GPT-4.1 mini) efficiently solved the issue."
else:
creator_score += 1
judge_decision = (
"Creator (Claude Sonnet) will get the purpose; solver failed or admitted failure."
)
print("Decide determination:", judge_decision)
print(f"Present rating -> Claude: {creator_score}, GPT-4.1 mini: {solver_score}")
round_logs.append(
RoundLog(
round_index=i,
creator_model=CLAUDE_MODEL_NAME,
solver_model=GPT_SOLVER_MODEL_NAME,
downside=problem_text,
solver_answer=solver_text,
judge_decision=judge_decision,
solver_score=solver_score,
creator_score=creator_score,
)
)
global_score = GlobalScore(
total_rounds=num_rounds,
creator_model=CLAUDE_MODEL_NAME,
solver_model=GPT_SOLVER_MODEL_NAME,
creator_score=creator_score,
solver_score=solver_score,
rounds=round_logs,
)
# Ultimate abstract print
print("n========== FINAL RESULT ==========n")
print(f"Whole rounds: {num_rounds}")
print(f"Creator (Claude Sonnet) rating: {creator_score}")
print(f"Solver (GPT-4.1 mini) rating: {solver_score}")
if solver_score > creator_score:
print("nOverall winner: GPT-4.1 mini (solver)")
elif creator_score > solver_score:
print("nOverall winner: Claude Sonnet (creator)")
else:
print("nOverall end result: Draw")
return global_score
This represents the core of our multi-agent course of. Each spherical Claude proposes a difficulty, GPT tries to resolve it, and we resolve the scores are up to date and every part is logged. The async/await sample makes the execution easy, and after all of the rounds are over, we current the entire outcomes that point out which AI mannequin was total higher.
This single assertion is the start line of the whole multi-agent competitors for five rounds. Since we’re utilizing await, this runs completely in Jupyter notebooks or different async-enabled environments, and the global_result variable will retailer all of the detailed statistics and logs from the whole competitors
Actual-World Use Instances of AgentScope
AgentScope is a extremely versatile device that finds sensible functions in a variety of areas together with analysis, automation, and company markets. It may be deployed for each experimental and manufacturing functions.
Analysis and Evaluation Brokers: The very first space of utility is analysis evaluation brokers. AgentScope is likely one of the finest options to create a analysis assistant agent that may gather data with none assist.
Knowledge Processing and Automation Pipelines: One other potential utility of AgentScope is within the space of knowledge processing and automation. It might handle pipelines the place the info goes via totally different levels of AI processing. In this type of system, one agent may clear information or apply filters, one other may run an evaluation or create a visible illustration, and a 3rd one may generate a abstract report.
Enterprise and Manufacturing AI Workflows: Lastly, AgentScope is created for high-end enterprise and manufacturing AI functions. It caters to the necessities of the actual world via its options which can be built-in:
Observability
Scalability
Security and Testing
Lengthy-term Initiatives
When to Select AgentScope
AgentScope is your go-to resolution once you require a multi-agent system that’s scalable, maintainable, and production-ready. It’s a good selection for groups that have to have a transparent understanding and oversight. It could be heavier than the light-weight frameworks however it can undoubtedly repay the hassle when the methods change into extra difficult.
Venture Complexity: In case your utility actually requires the cooperation of a number of brokers, such because the case in a buyer help system with specialised bots, or a analysis evaluation pipeline, then AgentScope’s built-in orchestration and reminiscence will assist you a large number.
Manufacturing Wants: AgentScope places a terrific emphasis on being production-ready. In case you want robust logging, Kubernetes deployment, and analysis, then AgentScope is the one to decide on.
Expertise Preferences: In case you’re utilizing Alibaba Cloud or want help for fashions like DashScope, then AgentScope might be your excellent match because it supplies native integrations. Furthermore, it’s suitable with most typical LLMs (OpenAI, Anthropic, and so forth.).
Management vs Simplicity: AgentScope offers very detailed management and visibility. If you wish to undergo each immediate and message, then it’s a really appropriate alternative.
Extra Examples to Attempt On
Builders take the chance to experiment with concrete examples to get essentially the most out of AgentScope and get an perception into its design philosophy. Such patterns signify typical situations of agentic behaviors.
Analysis Assistant Agent: The analysis assistant agent is able to find sources, condensing the outcomes, and suggesting insights. Assistant brokers confirm sources or present counter arguments to the conclusions.
Device-Utilizing Autonomous Agent: The autonomous tool-using agent is ready to entry APIs, execute scripts and modify databases. A supervisory agent retains monitor of the actions and checks the outcomes.
Multi-Agent Planner or Debate System: The brokers working as planners give you methods whereas the brokers concerned within the debate problem the assumptions. A decide agent amalgamates the ultimate verdicts.
Conclusion
AgentScope AI is the right device for making scalable and multi-agent methods which can be clear and have management. It’s the finest resolution in case a number of AI brokers have to carry out the duty collectively, with no confusion in workflows and mastery of reminiscence administration. It’s using express abstractions, structured messaging, and modular reminiscence design that brings this know-how ahead and solves a number of points which can be generally related to prompt-centric frameworks.
By following this information; you now have an entire comprehension of the structure, set up, and capabilities of AgentScope. For groups constructing large-scale agentic functions, AgentScope acts as a future-proof strategy that mixes flexibility and engineering self-discipline in fairly a balanced approach. That’s how the multi-agent methods would be the primary a part of AI workflows, and frameworks like AgentScope would be the ones to set the usual for the following technology of clever methods.
Steadily Requested Questions
Q1. What’s AgentScope AI?
A. AgentScope AI is an open-source framework for constructing scalable, structured, multi-agent AI methods. pasted
Q2. Who created AgentScope?
A. It was created by AI researchers and engineers targeted on coordination and observability. pasted
Q3. Why was AgentScope developed?
A. To unravel coordination, reminiscence, and scalability points in multi-agent workflows.
Howdy! I am Vipin, a passionate information science and machine studying fanatic with a powerful basis in information evaluation, machine studying algorithms, and programming. I’ve hands-on expertise in constructing fashions, managing messy information, and fixing real-world issues. My aim is to use data-driven insights to create sensible options that drive outcomes. I am wanting to contribute my abilities in a collaborative setting whereas persevering with to be taught and develop within the fields of Knowledge Science, Machine Studying, and NLP.
Login to proceed studying and revel in expert-curated content material.
Working with video datasets, notably with respect to detection of AI-based pretend objects, could be very difficult on account of correct body choice and face detection. To strategy this problem from R, one could make use of capabilities supplied by OpenCV, magick, and keras.
Our strategy consists of the next consequent steps:
learn all of the movies
seize and extract photos from the movies
detect faces from the extracted photos
crop the faces
construct a picture classification mannequin with Keras
Let’s shortly introduce the non-deep-learning libraries we’re utilizing. OpenCV is a pc imaginative and prescient library that features:
Then again, magick is the open-source image-processing library that can assist to learn and extract helpful options from video datasets:
Learn video information
Extract photos per second from the video
Crop the faces from the pictures
Earlier than we go into an in depth rationalization, readers ought to know that there isn’t any must copy-paste code chunks. As a result of on the finish of the put up one can discover a hyperlink to Google Colab with GPU acceleration. This kernel permits everybody to run and reproduce the identical outcomes.
Information exploration
The dataset that we’re going to analyze is supplied by AWS, Fb, Microsoft, the Partnership on AI’s Media Integrity Steering Committee, and varied lecturers.
It incorporates each actual and AI-generated pretend movies. The full measurement is over 470 GB. Nevertheless, the pattern 4 GB dataset is individually obtainable.
The movies within the folders are within the format of mp4 and have varied lengths. Our activity is to find out the variety of photos to seize per second of a video. We often took 1-3 fps for each video.
Notice: Set fps to NULL if you wish to extract all frames.
We noticed simply the primary body. What about the remainder of them?
Wanting on the gif one can observe that some fakes are very simple to distinguish, however a small fraction appears to be like fairly sensible. That is one other problem throughout knowledge preparation.
Face detection
At first, face areas must be decided through bounding bins, utilizing OpenCV. Then, magick is used to robotically extract them from all photos.
# get face location and calculate bounding fieldlibrary(opencv)unconf<-ocv_read('frame_1.jpg')faces<-ocv_face(unconf)facemask<-ocv_facemask(unconf)df=attr(facemask, 'faces')rectX=(df$x-df$radius)rectY=(df$y-df$radius)x=(df$x+df$radius)y=(df$y+df$radius)# draw with crimson dashed line the fieldimh=image_draw(image_read('frame_1.jpg'))rect(rectX, rectY, x, y, border ="crimson", lty ="dashed", lwd =2)dev.off()
If face areas are discovered, then it is vitally simple to extract all of them.
After dataset preparation, it’s time to construct a deep studying mannequin with Keras. We will shortly place all the pictures into folders and, utilizing picture turbines, feed faces to a pre-trained Keras mannequin.
Be happy to strive these choices on the Deepfake detection problem and share your ends in the feedback part!
Thanks for studying!
Corrections
In the event you see errors or need to recommend modifications, please create a problem on the supply repository.
Reuse
Textual content and figures are licensed below Artistic Commons Attribution CC BY 4.0. Supply code is obtainable at https://github.com/henry090/Deepfake-from-R, except in any other case famous. The figures which were reused from different sources do not fall below this license and might be acknowledged by a observe of their caption: “Determine from …”.
Quotation
For attribution, please cite this work as
Abdullayev (2020, Aug. 18). Posit AI Weblog: Deepfake detection problem from R. Retrieved from https://blogs.rstudio.com/tensorflow/posts/2020-08-18-deepfake/
BibTeX quotation
@misc{abdullayev2020deepfake,
creator = {Abdullayev, Turgut},
title = {Posit AI Weblog: Deepfake detection problem from R},
url = {https://blogs.rstudio.com/tensorflow/posts/2020-08-18-deepfake/},
12 months = {2020}
}
Apple providers have not all the time remained locked contained in the walled backyard. In truth, Apple first made a reputation for itself within the shopper tech house with the iPod and iTunes, which have been each appropriate with Home windows PCs along with Macs. Apple Music is following go well with, because the music streaming service is now extensively out there on platforms like Android, Home windows, Google TV, and ChromeOS. There’s additionally an online app for Apple Music that may be accessed on just about any gadget.
I have been a fan of Apple Music because it was known as Beats Music earlier than the Apple acquisition. Since then, the music streaming service continued to win me over, including options like Dolby Atmos and lossless audio assist whereas protecting costs low. I’ve acknowledged that Spotify and YouTube Music have been higher choices for Android customers prior to now, however it’s getting tougher and tougher to make that argument.
Particularly, Spotify’s constant value hikes and YouTube Music’s lacking assist for high-fidelity audio make them more durable to suggest, even for Android customers. If these two streamers aren’t the most suitable choice for Android customers, their subsequent choose is likely to be Tidal or Amazon Music Limitless. Each are high quality choices that stay aggressive with Apple Music. However I would guess that if Apple Music have been made by another firm, it might be an on the spot Android hit.
The place Spotify is falling brief
(Picture credit score: Andrew Myrick / Android Central)
Spotify is the most important music streaming service, with over 700 million month-to-month energetic customers and roughly 281 million subscribers as of 2025. It is a music streaming large in each sense, with over 100 million songs out there for listening and downloading. Spotify can be extremely costly, with the corporate’s most up-to-date value hike elevating costs by a greenback or extra throughout all of its subscription tiers.
Spotify was already one of many costlier streaming providers. The platform’s particular person plan now prices two {dollars} extra per thirty days than the likes of YouTube Music, Apple Music, and Tidal. Amazon Music Limitless is $1 cheaper month-to-month for everybody and $2 cheaper for Prime members. It is a comparatively small premium to pay, however over time, the additional prices add up.
Folks usually flock to Spotify for its glorious algorithms and proposals. The platform’s social options, together with the well-known Spotify Wrapped expertise, are one other interesting facet of the service for followers. I are inclined to view these extras as each a blessing and a curse. Whereas they’re typically neat, others are pointless — like Spotify DMs — and add bloat to an already-overloaded music app.
I might ignore them, however the bigger concern right here is that Spotify is paying somebody to develop and keep these options. If my music streaming invoice is $2 increased every month in order that my music app is cluttered with one other messaging inbox, I will not be completely satisfied.
Get the newest information from Android Central, your trusted companion on the earth of Android
What about YouTube Music?
(Picture credit score: Android Central)
If Spotify is out, YouTube Music seems like the following wise possibility for Android customers. YouTube Music is a streaming service that is laborious to evaluate, primarily as a result of it’s bundled with YouTube Premium for $13.99 per thirty days. Whilst you can subscribe to YouTube Music Premium individually for $10.99 month-to-month, the YouTube Premium bundle is actually the higher worth. With that being stated, YouTube Music Premium is an excellent perk of subscribing to YouTube Premium, however it struggles to face by itself.
Those that thought Spotify was bloated is likely to be much more disillusioned with YouTube Music. It now serves as Google’s main distribution channel for podcasts, cluttering the app. It’s also possible to discover audiobooks on YouTube Music, for the reason that platform faucets into the YouTube database. This comes with advantages and disadvantages — yow will discover area of interest content material that is not out there wherever else, however you may also be distracted by it.
(Picture credit score: Derrek Lee / Android Central)
The massive cause YouTube Music’s standing as a critical music streamer is unsure is its low music high quality. I will be the primary to confess that lossless high quality is pointless with out the best gear. Nonetheless, YouTube Music’s mere assist for as much as 256kbps AAC or Opus is missing even by lossy requirements. It simply is not ok, particularly when it is lacking Dolby Atmos too.
For those who already deliberate to subscribe to YouTube Premium and are content material with what YouTube Music Premium affords without cost, by all means, hold utilizing it. It is a superb add-on to YouTube Premium. However till the streamer’s sound high quality and music options enhance, it is not possible for me to suggest it as a standalone subscription.
Then there’s Apple Music, a totally featured, noncontroversial music streaming app for Android. The service prices simply $10.99 per thirty days whereas providing hi-res, lossless audio as much as 24-bit/192 kbps (sure, that is increased high quality than Spotify). There’s additionally Dolby Atmos assist, so you possibly can take your choose of a lossless or immersive audio format.
Crucially, the app helps each function Android customers care about, together with Google Solid.
I like that the Apple Music app is not suffering from pointless AI options or different media, like podcasts or audiobooks. It is all about music. There’s a stunning quantity of customization out there, because the app permits customers to handle animations, lyrics, listening historical past, quantity normalization, crossfade, and audio high quality.
Better of all, Apple Music helps importing libraries from YouTube Music, Spotify, Amazon Music, Deezer, and Tidal. For those who’re sticking with Spotify regardless of the worth hike over fears of shedding your library, concern not.
I have been a loyal Apple Music person for a decade and possibly will not ever change. I am unable to say it is the very best music streaming service for everybody. Nonetheless, it does supply the very best music high quality and have set for the worth level ($10.99/mo). For those who’ve prevented the streaming service as a result of it is hosted by Apple, you is likely to be lacking out.
A steal
Apple Music affords hi-res lossless audio, Dolby Atmos assist, and extra for a similar value as YouTube Music and two {dollars} cheaper than Spotify per thirty days. It is absolutely supported on Android, Home windows, and the net, making it a succesful possibility — even for these exterior the Apple ecosystem.
The next essay is reprinted with permission from The Dialog, an internet publication overlaying the newest analysis.
It’s a mistake you hopefully solely make as soon as. In your morning rush to prepare, you sweep your tooth earlier than you head to the kitchen and down a giant glass of orange juice. Yuck!
What makes your clear, minty mouth style so gross when it meets OJ?
On supporting science journalism
If you happen to’re having fun with this text, contemplate supporting our award-winning journalism by subscribing. By buying a subscription you might be serving to to make sure the way forward for impactful tales in regards to the discoveries and concepts shaping our world right now.
The brief reply is that toothpaste accommodates a detergent that dissolves fats. And since your style buds are partly fabricated from fats, they’re disrupted everytime you brush your tooth.
Earlier than you determine you could cease brushing your tooth to save lots of your style buds, know that this disruption is non permanent, lasting just a few minutes. Brushing with toothpaste remains to be necessary on your well being.
However how does this modification in style occur? And the way are the style receptors which might be all around the floor of your tongue alleged to work?
All the cells in your physique are held collectively by an outer layer, often called the membrane, that’s made up of fat known as lipids. And in candy or bitter style receptor cells, the cell membranes additionally include a particular molecule known as a G protein-coupled receptor, or GPCR.
Some GPCRs are designed to detect candy tastes. They tune out all compounds that aren’t candy and reply solely to the sugars your physique can use. Others detect bitter tastes, tuning in to the big variety of compounds in nature which might be toxic. They act as a built-in alarm system.
Salty chips and bitter candies
Your notion of saltiness and sourness occurs just a little in a different way. These tastes are detected when positively charged ions known as cations go via tiny openings within the cell membrane of your salty and bitter receptors.
Within the case of saltiness, the cation is the positively charged sodium present in sodium chloride – frequent desk salt.
For acidic, or bitter, tastes, the cation is a positively charged hydrogen ion. Whereas several types of acids might include totally different chemical compounds, all of them include the hydrogen cation.
While you eat potato chips, the positively charged sodium cations from the salt go via particular openings in a receptor’s membrane, producing the salty style. Equally, the hydrogen cations in your favourite bitter sweet slip via different particular openings in your bitter receptor’s membrane and ship a “bitter” sign to your mind.
Toothpaste and OJ
The orange juice that many individuals wish to drink with breakfast is of course excessive in sugar. However it additionally accommodates citric acid, with its hydrogen cations. Consequently, it’s a scrumptious mixture of each candy and just a little bitter.
However in the event you brush your tooth earlier than breakfast, your OJ tastes horrible. What’s modified?
It’s not simply that minty tastes conflict with candy ones. Toothpaste accommodates the detergent sodium lauryl sulfate, which helps take away dental plaque out of your tooth. Plaque is the sticky movie of germs that may trigger cavities and make your breath scent dangerous.
If you happen to ever do the dishes, you’ve most likely seen what occurs whenever you squirt detergent right into a sink filled with greasy water: The detergent breaks up the greasy fats, making it simple to wipe it off the dishes and rinse them clear.
However there’s one other sort of fats in your mouth that the detergent in toothpaste disrupts – the lipids within the cell membranes of your style receptors. Brushing your tooth breaks up that layer of lipids, quickly altering the way you understand style.
Testing it out
Again in 1980, I performed a research with a few my colleagues who have been learning chemistry. We needed to know the way the tongue responds to candy, bitter, salty and bitter after being uncovered to sodium lauryl sulfate, the detergent in toothpaste.
We performed an experiment with seven pupil volunteers at Yale. They tasted very excessive concentrations of candy sucrose, bitter citric acid, salt and bitter quinine, each earlier than and after holding an answer (0.05%) of sodium lauryl sulfate of their mouths for one minute.
You may conduct your personal model of this experiment with one thing candy like sugar, just a little desk salt, orange juice and tonic water. Style them earlier than you sweep your tooth after which after, and see what occurs!
We discovered that the depth of the tastes of sucrose, salt and quinine have been decreased by a small quantity, however a very powerful change was {that a} bitter style was added to the bitter style of citric acid.
This is the reason, as a substitute of tasting candy with a little bit of good tanginess, your OJ tastes bitter after you sweep your tooth.
The Amazon.com Catalog is the muse of each buyer’s buying expertise—the definitive supply of product info with attributes that energy search, suggestions, and discovery. When a vendor lists a brand new product, the catalog system should extract structured attributes—dimensions, supplies, compatibility, and technical specs—whereas producing content material equivalent to titles that match how prospects search. A title isn’t a easy enumeration like coloration or dimension; it should steadiness vendor intent, buyer search conduct, and discoverability. This complexity, multiplied by hundreds of thousands of every day submissions, makes catalog enrichment a really perfect proving floor for self-learning AI.
On this submit, we reveal how the Amazon Catalog Staff constructed a self-learning system that repeatedly improves accuracy whereas decreasing prices at scale utilizing Amazon Bedrock.
The problem
In generative AI deployment environments, enhancing mannequin efficiency requires fixed consideration. As a result of fashions course of hundreds of thousands of merchandise, they inevitably encounter edge circumstances, evolving terminology, and domain-specific patterns the place accuracy might degrade. The normal method—utilized scientists analyzing failures, updating prompts, testing adjustments, and redeploying—works however is resource-intensive and struggles to maintain tempo with real-world quantity and selection. The problem isn’t whether or not we will enhance these programs, however the best way to make enchancment scalable and computerized somewhat than depending on handbook intervention. At Amazon Catalog, we confronted this problem head-on. The tradeoffs appeared inconceivable: giant fashions would ship accuracy however wouldn’t scale effectively to our quantity, whereas smaller fashions struggled with the complicated, ambiguous circumstances the place sellers wanted probably the most assist.
Resolution overview
Our breakthrough got here from an unconventional experiment. As a substitute of selecting a single mannequin, we deployed a number of smaller fashions to course of the identical merchandise. When these fashions agreed on an attribute extraction, we might belief the consequence. However after they disagreed—whether or not from real ambiguity, lacking context, or one mannequin making an error—we found one thing profound. These disagreements weren’t all the time errors, however they had been nearly all the time indicators of complexity. This led us to design a self-learning system that reimagines how generative AI scales. A number of smaller fashions course of routine circumstances by consensus, invoking bigger fashions solely when disagreements happen. The bigger mannequin is carried out as a supervisor agent with entry to specialised instruments for deeper investigation and evaluation. However the supervisor doesn’t simply resolve disputes; it generates reusable learnings saved in a dynamic information base that helps stop total courses of future disagreements. We invoke extra highly effective fashions solely when the system detects excessive studying worth at inference time, whereas correcting the output. The result’s a self-learning system the place prices lower and high quality will increase—as a result of the system learns to deal with edge circumstances that beforehand triggered supervisor calls. Error charges fell repeatedly, not by retraining however by gathered learnings from resolved disagreements injected into smaller mannequin prompts. The next determine exhibits the structure of this self-learning system.
Within the self-learning structure, product knowledge flows by generator-evaluator employees, with disagreements routed to a supervisor for investigation. Put up-inference, the system additionally captures suggestions indicators from sellers (equivalent to itemizing updates and appeals) and prospects (equivalent to returns and destructive opinions). Learnings from the sources are saved in a hierarchical information base and injected again into employee prompts, making a steady enchancment loop.
The next describes a simplified reference structure that demonstrates how this self-learning sample could be carried out utilizing AWS companies. Whereas our manufacturing system has further complexity, this instance illustrates the core parts and knowledge flows.
This technique could be constructed with Amazon Bedrock, which offers the important infrastructure for multi-model architectures. The flexibility of Amazon Bedrock to entry various basis fashions permits groups to deploy smaller, environment friendly fashions like Amazon Nova Lite as employees and extra succesful fashions like Anthropic Claude Sonnet as supervisors—optimizing each price and efficiency. For even higher price effectivity at scale, groups can even deploy open supply small fashions on Amazon Elastic Compute Cloud (Amazon EC2) GPU cases, offering full management over employee mannequin choice and batch throughput optimization. For productionizing a supervisor agent with its specialised instruments and dynamic information base, Bedrock AgentCore offers the runtime scalability, reminiscence administration, and observability wanted to deploy self-learning programs reliably at scale.
Our supervisor agent integrates with Amazon’s in depth Choice and Catalog Methods. The above diagram is a simplified view displaying the important thing options of the agent and among the AWS companies that make it attainable. Product knowledge flows by generator-evaluator employees (Amazon EC2 and Amazon Bedrock Runtime), with agreements saved straight and disagreements routed to a supervisor agent (Bedrock AgentCore). The educational aggregator and reminiscence supervisor make the most of Amazon DynamoDB for the information base, with learnings injected again into employee prompts. Human evaluation (Amazon Easy Queue Service (Amazon SQS)) and observability (Amazon CloudWatch) full the structure. Manufacturing implementations will doubtless require further parts for scale, reliability, and integration with current programs.
However how did we arrive at this structure? The important thing perception got here from an surprising place.
The perception: Turning disagreements into alternatives
Our perspective shifted throughout a debugging session. When a number of smaller fashions (equivalent to Nova Lite) disagreed on product attributes—decoding the identical specification in a different way based mostly on how they understood technical terminology—we initially noticed this as a failure. However the knowledge instructed a distinct story: merchandise the place our smaller fashions disagreed correlated with circumstances requiring extra handbook evaluation and clarification. When fashions disagreed, these had been exactly the merchandise that wanted further investigation. The disagreements had been surfacing studying alternatives, however we couldn’t have engineers and scientists deep-dive on each case. The supervisor agent does this mechanically at scale. And crucially, the purpose isn’t simply to find out which mannequin was proper—it’s to extract learnings that assist stop comparable disagreements sooner or later. That is the important thing to environment friendly scaling. Disagreements don’t simply come from AI employees at inference time. Put up-inference, sellers categorical disagreement by itemizing updates and appeals—indicators that our authentic extraction may need missed vital context. Clients disagree by returns and destructive opinions, typically indicating that product info didn’t match expectations. These post-inference human indicators feed into the identical studying pipeline, with the supervisor investigating patterns and producing learnings that assist stop comparable points throughout future merchandise. We discovered a candy spot: attributes with reasonable AI employee disagreement charges yielded the richest learnings—excessive sufficient to floor significant patterns, low sufficient to point solvable ambiguity. When disagreement charges are too low, they sometimes replicate noise or basic mannequin limitations somewhat than learnable patterns—for these, we think about using extra succesful employees. When disagreement charges are too excessive, it indicators that employee fashions or prompts aren’t but mature sufficient, triggering extreme supervisor calls that undermine the effectivity positive aspects of the structure. These thresholds will differ by activity and area; the bottom line is figuring out your personal candy spot the place disagreements signify real complexity price investigating, somewhat than basic gaps in employee functionality or random noise.
Deep dive: The way it works
On the coronary heart of our system are a number of light-weight employee fashions working in parallel—some as turbines extracting attributes, others as evaluators assessing these extractions. These employees could be carried out in a non-agentic manner with mounted inputs, making them batch-friendly and scalable. The generator-evaluator sample creates productive pressure, conceptually just like the productive pressure in generative adversarial networks (GANs), although our method operates at inference time by prompting somewhat than coaching. We explicitly immediate evaluators to be important, instructing them to scrutinize extractions for ambiguities, lacking context, or potential misinterpretations. This adversarial dynamic surfaces disagreements that signify real complexity somewhat than letting ambiguous circumstances cross by undetected. When the generator and evaluator agree, now we have excessive confidence within the consequence and course of it at minimal computational price. This consensus path handles most product attributes. After they disagree, we’ve recognized a case price investigating—triggering the supervisor to resolve the dispute and extract reusable learnings.
Our structure treats disagreement as a common studying sign. At inference time, worker-to-worker disagreements catch ambiguity. Put up-inference, vendor suggestions catches misalignments with intent and buyer suggestions catches misalignments with expectations. The three channels feed the supervisor, which extracts learnings that enhance accuracy throughout the board. When employees disagree, we invoke a supervisor agent—a extra succesful mannequin that resolves the dispute and investigates why it occurred. The supervisor determines what context or reasoning the employees lacked, and these insights turn out to be reusable learnings for future circumstances. For instance, when employees disagreed about utilization classification for a product based mostly on sure technical phrases, the supervisor investigated and clarified that these phrases alone had been inadequate—visible context and different indicators wanted to be thought of collectively. The supervisor generated a studying about the best way to correctly weight completely different indicators for that product class. This studying instantly up to date our information base, and when injected into employee prompts for comparable merchandise, helped stop future disagreements throughout 1000’s of things. Whereas the employees might theoretically be the identical mannequin because the supervisor, utilizing smaller fashions is essential for effectivity at scale. The architectural benefit emerges from this asymmetry: light-weight employees deal with routine circumstances by consensus, whereas the extra succesful supervisor is invoked solely when disagreements floor high-value studying alternatives. Because the system accumulates learnings and disagreement charges drop, supervisor calls naturally decline—effectivity positive aspects are baked straight into the structure. This worker-supervisor heterogeneity additionally permits richer investigation. As a result of supervisors are invoked selectively, they’ll afford to tug in further indicators—buyer opinions, return causes, vendor historical past—that may be impractical to retrieve for each product however present essential context when resolving complicated disagreements. When these indicators yield generalizable insights about how prospects need product info introduced—which attributes to spotlight, what terminology resonates, the best way to body specs—the ensuing learnings profit future inferences throughout comparable merchandise with out retrieving these resource-intensive indicators once more. Over time, this creates a suggestions loop: higher product info results in fewer returns and destructive opinions, which in flip displays improved buyer satisfaction.
The information base: Making learnings scalable
The supervisor investigates disagreements on the particular person product degree. With hundreds of thousands of things to course of, we’d like a scalable solution to remodel these product-specific insights into reusable learnings. Our aggregation technique adapts to context: high-volume patterns get synthesized into broader learnings, whereas distinctive or important circumstances are preserved individually. We use a hierarchical construction the place a big language mannequin (LLM)-based reminiscence supervisor navigates the information tree to position every studying. Ranging from the foundation, it traverses classes and subcategories, deciding at every degree whether or not to proceed down an current path, create a brand new department, merge with current information, or substitute outdated info. This dynamic group permits the information base to evolve with rising patterns whereas sustaining logical construction. Throughout inference, employees obtain related learnings of their prompts based mostly on product class, mechanically incorporating area information from previous disagreements. The information base additionally introduces traceability—when an extraction appears incorrect, we will pinpoint precisely which studying influenced it. This shifts auditing from an unscalable activity to a sensible one: as an alternative of reviewing a pattern of hundreds of thousands of outputs—the place human effort grows proportionally with scale—groups can audit the information base itself, which stays comparatively mounted in dimension no matter inference quantity. Area consultants can straight contribute by including or refining entries, no retraining required. A single well-crafted studying can instantly enhance accuracy throughout 1000’s of merchandise. The information base bridges human experience and AI functionality, the place automated learnings and human insights work collectively.
Classes realized and finest practices
When this self-learning structure works finest:
Excessive-volume inference the place enter variety drives compounded studying
High quality-critical functions the place consensus offers pure high quality assurance
Evolving domains with new patterns and terminology continually rising
It’s much less appropriate for low-volume eventualities (inadequate disagreements for studying) or use circumstances with mounted, unchanging guidelines.
Essential success components:
Defining disagreements: With a generator-evaluator pair, disagreement happens when the evaluator flags the extraction as needing enchancment. With a number of employees, scale thresholds accordingly. The bottom line is sustaining productive pressure between employees. If disagreement charges fall exterior the productive vary (too low or too excessive), think about extra succesful employees or refined prompts.
Monitoring studying effectiveness: Disagreement charges should lower over time—that is your major well being metric. If charges keep flat, examine information retrieval, immediate injection, or evaluator criticality.
Data group: Construction learnings hierarchically and preserve them actionable. Summary steerage doesn’t assist; particular, concrete learnings straight enhance future inferences.
Frequent pitfalls
Specializing in price over intelligence: Value discount is a byproduct, not the purpose
Rubber-stamp evaluators: Evaluators that merely approve generator outputs gained’t floor significant disagreements—immediate them to actively problem and critique extractions
Poor studying extraction: Supervisors should determine generalizable patterns, not simply repair particular person circumstances
Data rot: With out group, learnings turn out to be unsearchable and unusable
The important thing perception: deal with declining disagreement charges as your north star metric—they present the system is actually studying.
Deployment methods: Two approaches
Study-then-deploy: Begin with primary prompts and let the system be taught aggressively in a pre-production setting. Area consultants then audit the information base—not particular person outputs—to verify realized patterns align with desired outcomes. When permitted, deploy with validated learnings. That is superb for brand new use circumstances the place you don’t but know what good seems like—disagreements assist uncover the correct patterns, and information base auditing permits you to form them earlier than manufacturing.
Deploy-and-learn: Begin with refined prompts and good preliminary high quality, then repeatedly enhance by ongoing studying in manufacturing. This works finest for well-understood use circumstances the place you’ll be able to outline high quality upfront however nonetheless need to seize domain-specific nuances over time.
Each approaches use the identical structure—the selection relies on whether or not you’re exploring new territory or optimizing acquainted floor.
Conclusion
What began as an experiment in catalog enrichment revealed a basic reality: AI programs don’t must be frozen in time. By embracing disagreements as studying indicators somewhat than failures, we’ve constructed an structure that accumulates area information by precise utilization. We watched the system evolve from generic understanding to domain-specific experience. It realized industry-specific terminology. It found contextual guidelines that adjust throughout classes. It tailored to necessities no pre-trained mannequin would encounter—all with out retraining, by learnings saved in a information base and injected again into employee prompts. For groups operationalizing comparable architectures, Amazon Bedrock AgentCore presents purpose-built capabilities:
AgentCore Runtime handles fast consensus choices for routine circumstances whereas supporting prolonged reasoning when supervisors examine complicated disagreements
AgentCore Observability offers visibility into which learnings drive affect, serving to groups refine information propagation and keep reliability at scale
The implications lengthen past catalog administration. Excessive-volume AI functions may gain advantage from this course of—and the flexibility of Amazon Bedrock to entry various fashions makes this structure easy to implement. The important thing perception is that this: we’ve shifted from asking “which mannequin ought to we use?” to “how can we construct programs that be taught our particular patterns? “Whether or not you learn-then-deploy for brand new use circumstances or deploy-and-learn for established ones, the implementation is simple: begin with employees suited to your activity, select a supervisor, and let disagreements drive studying. With the correct structure, each inference can turn out to be a possibility to seize area information. That’s not simply scaling—that’s constructing institutional information into your AI programs.
Acknowledgement
This work wouldn’t have been attainable with out the contributions and assist from Ankur Datta (Senior Principal Utilized Scientist – chief of science in On a regular basis Necessities Shops), Zhu Cheng (Utilized Scientist), Xuan Tang (Software program Engineer), Mohammad Ghasemi (Utilized Scientist). We sincerely recognize the contributions in designs, implementations, quite a few fruitful brain-storming periods, and all of the insightful concepts and strategies.
In regards to the authors
Tarik Arici is a Principal Scientist at Amazon Choice and Catalog Methods (ASCS), the place he pioneers self-learning generative AI programs design for catalog high quality enhancement at scale. His work focuses on constructing AI programs that mechanically accumulate area information by manufacturing utilization—studying from buyer opinions and returns, vendor suggestions, and mannequin disagreements to enhance high quality whereas decreasing prices. Tarik holds a PhD in Electrical and Pc Engineering from Georgia Institute of Expertise.
Sameer Thombare is a Senior Product Supervisor at Amazon with over a decade of expertise in Product Administration, Class/P&L Administration throughout various industries, together with heavy engineering, telecommunications, finance, and eCommerce. Sameer is keen about growing repeatedly enhancing closed-loop programs and leads strategic initiatives inside Amazon Choice and Catalog Methods (ASCS) to construct a complicated self-learning closed-loop system that synthesize indicators from prospects, sellers, and provide chain operations to optimize outcomes. Sameer holds an MBA from the Indian Institute of Administration Bangalore and an engineering diploma from Mumbai College.
Amin Banitalebi acquired his PhD within the Digital Media on the College of British Columbia (UBC), Canada, in 2014. Since then, he has taken numerous utilized science roles spanning over areas in laptop imaginative and prescient, pure language processing, suggestion programs, classical machine studying, and generative AI. Amin has co-authored over 90 publications and patents. He’s at present an Utilized Science Supervisor in Amazon On a regular basis Necessities.
Puneet Sahni is a Senior Principal Engineer at Amazon Choice and Catalog Methods (ASCS), the place he has spent over 8 years enhancing the completeness, consistency, and correctness of catalog knowledge. He focuses on catalog knowledge modeling and its software to enhancing Promoting Accomplice and buyer experiences, whereas utilizing ML/DL and LLM-based enrichment to drive enhancements in catalog knowledge high quality.
Erdinc Basci joined Amazon in 2015 and brings over 23 years of know-how {industry} expertise. At Amazon, he has led the evolution of Catalog system architectures—together with ingestion pipelines, prioritized processing, and site visitors shaping—in addition to catalog knowledge structure enhancements equivalent to segmented presents, product specs for manufacture-on-demand merchandise, and catalog knowledge experimentation. Erdinc has championed a hands-on efficiency engineering tradition throughout Amazon companies unlocking $1B+ annualized price financial savings and 20%+ latency wins throughout core Shops companies. He’s at present centered on enhancing generative AI software efficiency and GPU effectivity throughout Amazon. Erdinc holds a BS in Pc Science from Bilkent College, Turkey, and an MBA from Seattle College, US.
Mey Meenakshisundaram is a Director in Amazon Choice and Catalog Methods, the place he leads progressive GenAI options to ascertain Amazon’s worldwide catalog because the best-in-class supply for product info. His crew pioneers superior machine studying strategies, together with multi-agent programs and huge language fashions, to mechanically enrich product attributes and enhance catalog high quality at scale. Excessive-quality product info within the catalog is important for delighting prospects find the correct merchandise, empowering promoting companions to checklist their merchandise successfully, and enabling Amazon operations to cut back handbook effort.
Clawdbot is an open supply private AI assistant that you simply run by yourself {hardware}. It connects giant language fashions from suppliers akin to Anthropic and OpenAI to actual instruments akin to messaging apps, recordsdata, shell, browser and good dwelling units, whereas protecting the orchestration layer below your management.
The attention-grabbing half is just not that Clawdbot chats. It’s that the mission ships a concrete structure for native first brokers, and a typed workflow engine referred to as Lobster that turns mannequin calls into deterministic pipelines.
Structure: Gateway, Nodes and Expertise
On the middle of Clawdbot is the Gateway course of. The Gateway exposes a WebSocket management aircraft on ws://127.0.0.1:18789 and an area HTTP interface for the management UI and internet chat.
Your messages from WhatsApp, Telegram, Sign, Slack, Discord, iMessage and different channels are delivered to the Gateway. The Gateway decides which agent ought to deal with the message, which instruments it could name, and which mannequin supplier to make use of. It then sends the reply again over the identical channel.
The runtime is cut up into a couple of core ideas:
Gateway: Routing, mannequin calls, instrument invocation, periods, presence and scheduling.
Nodes: Processes that give Clawdbot entry to native sources akin to file system, browser automation, microphone, digital camera or platform particular APIs on macOS, Home windows, Linux, iOS and Android.
Channels: Integrations for chat methods like WhatsApp, Telegram, Discord, Slack, Sign, Microsoft Groups, Matrix, Zalo and extra. These are configured as channel backends that connect to the Gateway.
Expertise and plugins: Instruments that the agent can name, described in a typical SKILL.md format and distributed by way of ClawdHub.
This separation permits you to run the Gateway on a 5 greenback digital server or a spare machine at dwelling, whereas protecting heavy mannequin compute on distant APIs or native mannequin backends when wanted.
Expertise and the SKILL.md commonplace
Clawdbot makes use of an open expertise format described in SKILL.md. A talent is outlined in Markdown with a small header and an ordered process. For instance, a deployment talent would possibly specify steps akin to checking git standing, working exams and deploying solely after success.
---
title: deploy-production
description: Deploy the present department to manufacturing. Use solely after exams cross.
disable-model-invocation: true
---
1. Test git standing guaranteeing clear working listing.
2. Run `npm check`
3. If exams cross, run `npm run deploy`
The Gateway reads these definitions and exposes them to brokers as instruments with specific capabilities and security constraints. Expertise are revealed to ClawdHub and could be put in or composed into bigger workflows.
Which means that operational runbooks can transfer from ad-hoc wiki pages into machine executable expertise, whereas nonetheless being auditable as textual content.
Lobster: Typed Workflow Runtime for Brokers
Lobster is the workflow runtime that powers Native Lobster and plenty of superior Clawdbot automations. It’s described as a typed workflow shell that lets Clawdbot run multi step instrument sequences as a single deterministic operation with specific approval gates.
As an alternative of getting the mannequin name many instruments in a loop, Lobster strikes orchestration right into a small area particular runtime:
Pipelines are outlined as JSON or YAML, or as a compact shell like pipeline string.
Steps alternate typed JSON information, not unstructured textual content.
The runtime enforces timeouts, output limits and sandbox insurance policies.
Workflows can pause on negative effects and resume later with a resumeToken.
A easy inbox triage workflow appears to be like like this:
Clawdbot treats this file as a talent. Whenever you ask it to wash your inbox, it calls one Lobster pipeline as an alternative of improvising many instrument calls. The mannequin decides when to run the pipeline and with which parameters, however the pipeline itself stays deterministic and auditable.
Native Lobster is the reference agent that makes use of Lobster to drive native workflows and is described in protection as an open supply agent that redefines private AI by pairing native first workflows with proactive habits.
Proactive native first habits
A key purpose Clawdbot is trending and visual on X and in developer communities is that it behaves like an operator, not only a chat window.
As a result of the Gateway can run scheduled jobs and observe state throughout periods, widespread patterns embrace:
Each day briefings that summarize calendars, duties and essential mail.
Periodic recaps akin to weekly shipped work summaries.
Displays that look ahead to circumstances, then message you first in your most well-liked channel.
File and repository automations that run regionally however are triggered by pure language.
All of this runs with routing and gear coverage in your machine or server. Mannequin calls nonetheless go to suppliers like Anthropic, OpenAI, Google, xAI or native backends, however the assistant mind, reminiscence and integrations are below your management.
Set up and developer workflow
The mission gives a one line installer that fetches a script from clawd.bot and bootstraps Node, the Gateway and core elements. For extra management, you may set up through npm or clone the TypeScript repository and construct with pnpm.
Typical steps:
curl -fsSL https://clawd.bot/set up.sh | bash
# or
npm i -g clawdbot
clawdbot onboard
After onboarding you join a channel akin to Telegram or WhatsApp, select a mannequin supplier and allow expertise. From there you may write your personal SKILL.md recordsdata, construct Lobster workflows and expose them by way of chat, internet chat or the macOS companion software.
Some Examples
Simply had Clawdbot arrange Ollama with an area mannequin. Now it handles web site summaries and easy duties regionally as an alternative of burning API credit.
Clawdbot is controlling LMStudio remotely from telegram, downloading Qwen, which it would then use to energy a few of my duties with Clawdbot. 🤯🤯 pic.twitter.com/ll2adg19Za
Michal Sutter is a knowledge science skilled with a Grasp of Science in Information Science from the College of Padova. With a stable basis in statistical evaluation, machine studying, and information engineering, Michal excels at remodeling complicated datasets into actionable insights.
Android 17 is alleged to be shifting away from flat design towards translucent, blur-heavy visuals.
Google might roll out a frosted-glass look throughout core UI parts, together with the quantity slider and energy menu.
Dynamic Coloration will reportedly tint blurred panels, serving to the brand new transparency results mix together with your wallpaper and theme.
Android 17 continues to be months from its official launch, nevertheless it’s clear that Google plans to alter how you employ your cellphone. After years of flat, strong colours, the subsequent model — codenamed “Cinnamon Bun” — is alleged to deal with translucent, blurry backgrounds.
We noticed the seeds of this variation planted final yr with the introduction of Materials 3 Expressive, which introduced delicate blurs to the notification shade and the Fast Settings panel. Google needed to create a way of depth in order that the consumer interface felt light-weight somewhat than like a heavy, opaque wall of coloration blocking your view.
By blurring the background as an alternative of hiding it completely, you keep conscious of the app you have been simply utilizing whereas specializing in the duty at hand. It creates a hierarchy that feels extra pure to the human eye, and Android 17 is ready to take that idea to the subsequent stage.
Don’t wish to miss the most effective from Android Authority?
Within the subsequent model, Google goes all-in on the frosted-glass look throughout the system. Inside builds seen by 9to5Google present this translucent impact showing in almost each a part of the UI. One huge change is the quantity bar, which now makes use of a translucent slider so your wallpaper or app icons present via.
This method additionally applies to the ability menu and different system overlays. The blurs are reportedly tinted by your Dynamic Coloration theme, serving to the entire OS really feel unified.
Whereas some would possibly level out that this look follows Apple’s Liquid Glass design on iOS or Samsung’s latest UI tweaks, Google’s implementation is reportedly extra delicate and refined.
We’ll possible discover these modifications most when the primary Android 17 Developer Preview arrives, anticipated in early 2026. The blur impact is anticipated to look principally in system menus, nevertheless it’s unclear if Google will carry this look to third-party apps with new Materials Design pointers.
Thanks for being a part of our group. Learn our Remark Coverage earlier than posting.











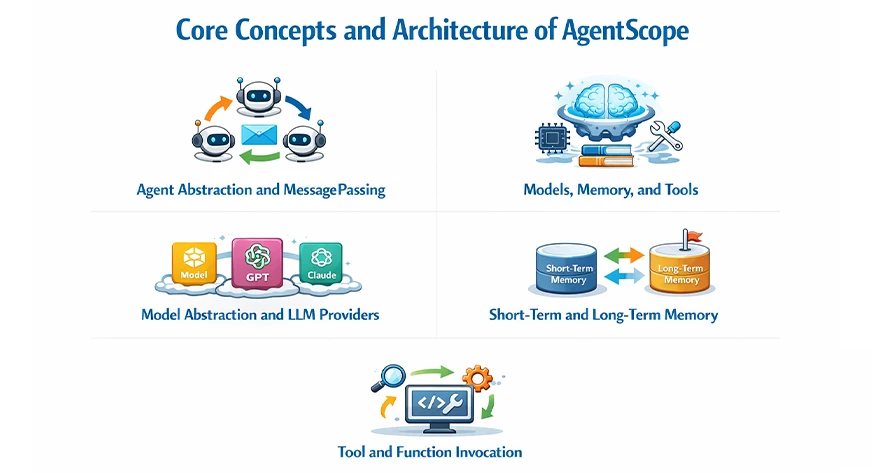
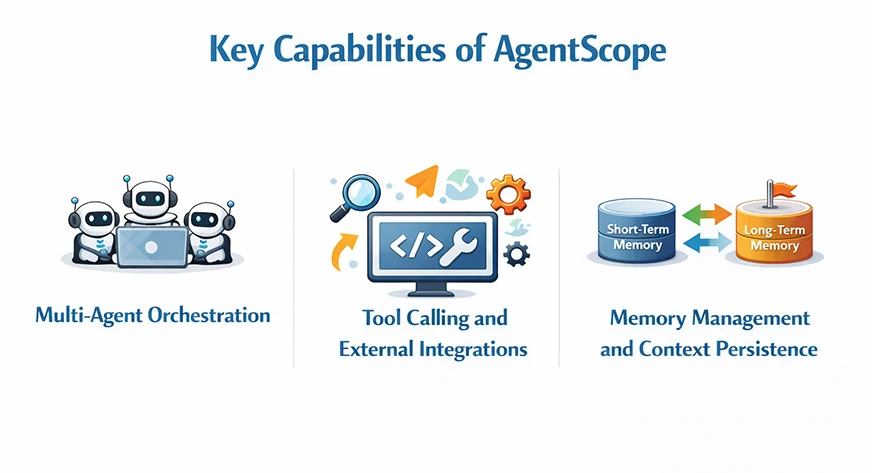

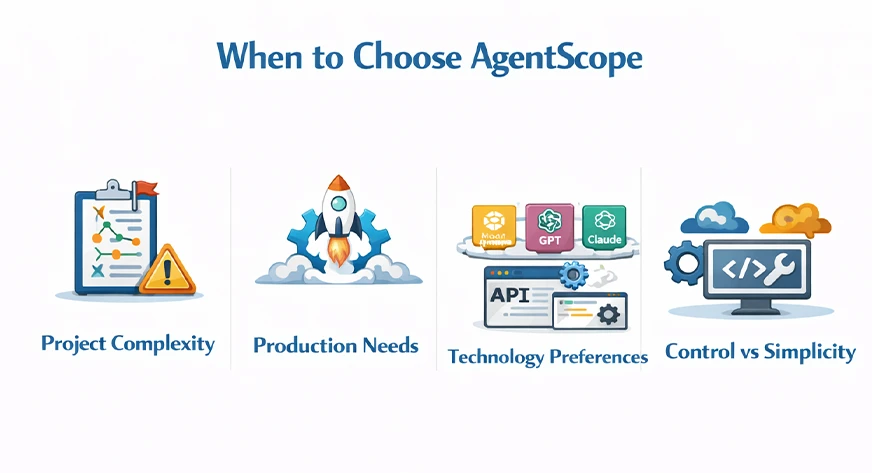
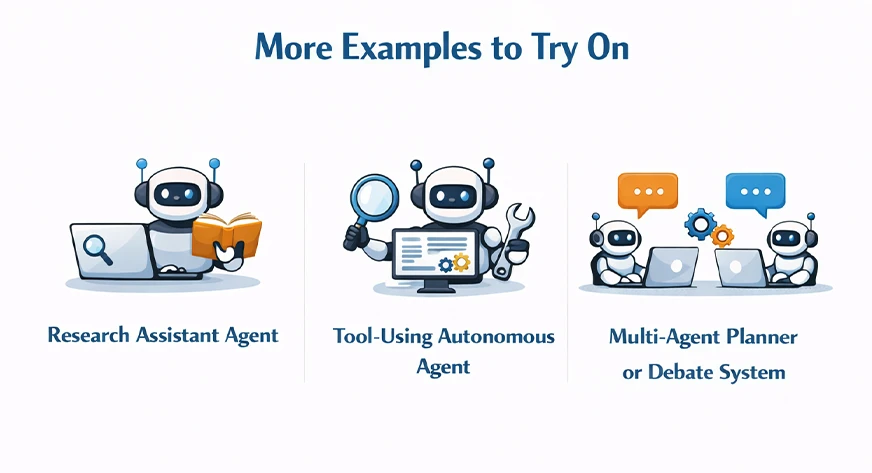








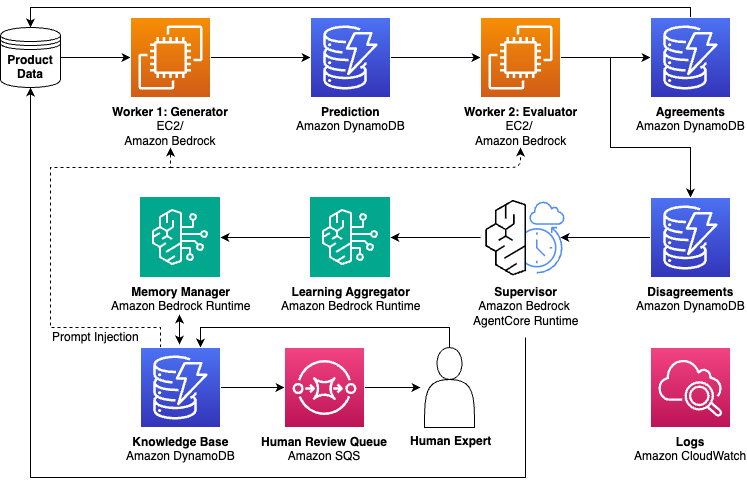
 Tarik Arici is a Principal Scientist at Amazon Choice and Catalog Methods (ASCS), the place he pioneers self-learning generative AI programs design for catalog high quality enhancement at scale. His work focuses on constructing AI programs that mechanically accumulate area information by manufacturing utilization—studying from buyer opinions and returns, vendor suggestions, and mannequin disagreements to enhance high quality whereas decreasing prices. Tarik holds a PhD in Electrical and Pc Engineering from Georgia Institute of Expertise.
Tarik Arici is a Principal Scientist at Amazon Choice and Catalog Methods (ASCS), the place he pioneers self-learning generative AI programs design for catalog high quality enhancement at scale. His work focuses on constructing AI programs that mechanically accumulate area information by manufacturing utilization—studying from buyer opinions and returns, vendor suggestions, and mannequin disagreements to enhance high quality whereas decreasing prices. Tarik holds a PhD in Electrical and Pc Engineering from Georgia Institute of Expertise. Sameer Thombare is a Senior Product Supervisor at Amazon with over a decade of expertise in Product Administration, Class/P&L Administration throughout various industries, together with heavy engineering, telecommunications, finance, and eCommerce. Sameer is keen about growing repeatedly enhancing closed-loop programs and leads strategic initiatives inside Amazon Choice and Catalog Methods (ASCS) to construct a complicated self-learning closed-loop system that synthesize indicators from prospects, sellers, and provide chain operations to optimize outcomes. Sameer holds an MBA from the Indian Institute of Administration Bangalore and an engineering diploma from Mumbai College.
Sameer Thombare is a Senior Product Supervisor at Amazon with over a decade of expertise in Product Administration, Class/P&L Administration throughout various industries, together with heavy engineering, telecommunications, finance, and eCommerce. Sameer is keen about growing repeatedly enhancing closed-loop programs and leads strategic initiatives inside Amazon Choice and Catalog Methods (ASCS) to construct a complicated self-learning closed-loop system that synthesize indicators from prospects, sellers, and provide chain operations to optimize outcomes. Sameer holds an MBA from the Indian Institute of Administration Bangalore and an engineering diploma from Mumbai College. Amin Banitalebi acquired his PhD within the Digital Media on the College of British Columbia (UBC), Canada, in 2014. Since then, he has taken numerous utilized science roles spanning over areas in laptop imaginative and prescient, pure language processing, suggestion programs, classical machine studying, and generative AI. Amin has co-authored over 90 publications and patents. He’s at present an Utilized Science Supervisor in Amazon On a regular basis Necessities.
Amin Banitalebi acquired his PhD within the Digital Media on the College of British Columbia (UBC), Canada, in 2014. Since then, he has taken numerous utilized science roles spanning over areas in laptop imaginative and prescient, pure language processing, suggestion programs, classical machine studying, and generative AI. Amin has co-authored over 90 publications and patents. He’s at present an Utilized Science Supervisor in Amazon On a regular basis Necessities. Puneet Sahni is a Senior Principal Engineer at Amazon Choice and Catalog Methods (ASCS), the place he has spent over 8 years enhancing the completeness, consistency, and correctness of catalog knowledge. He focuses on catalog knowledge modeling and its software to enhancing Promoting Accomplice and buyer experiences, whereas utilizing ML/DL and LLM-based enrichment to drive enhancements in catalog knowledge high quality.
Puneet Sahni is a Senior Principal Engineer at Amazon Choice and Catalog Methods (ASCS), the place he has spent over 8 years enhancing the completeness, consistency, and correctness of catalog knowledge. He focuses on catalog knowledge modeling and its software to enhancing Promoting Accomplice and buyer experiences, whereas utilizing ML/DL and LLM-based enrichment to drive enhancements in catalog knowledge high quality. Erdinc Basci joined Amazon in 2015 and brings over 23 years of know-how {industry} expertise. At Amazon, he has led the evolution of Catalog system architectures—together with ingestion pipelines, prioritized processing, and site visitors shaping—in addition to catalog knowledge structure enhancements equivalent to segmented presents, product specs for manufacture-on-demand merchandise, and catalog knowledge experimentation. Erdinc has championed a hands-on efficiency engineering tradition throughout Amazon companies unlocking $1B+ annualized price financial savings and 20%+ latency wins throughout core Shops companies. He’s at present centered on enhancing generative AI software efficiency and GPU effectivity throughout Amazon. Erdinc holds a BS in Pc Science from Bilkent College, Turkey, and an MBA from Seattle College, US.
Erdinc Basci joined Amazon in 2015 and brings over 23 years of know-how {industry} expertise. At Amazon, he has led the evolution of Catalog system architectures—together with ingestion pipelines, prioritized processing, and site visitors shaping—in addition to catalog knowledge structure enhancements equivalent to segmented presents, product specs for manufacture-on-demand merchandise, and catalog knowledge experimentation. Erdinc has championed a hands-on efficiency engineering tradition throughout Amazon companies unlocking $1B+ annualized price financial savings and 20%+ latency wins throughout core Shops companies. He’s at present centered on enhancing generative AI software efficiency and GPU effectivity throughout Amazon. Erdinc holds a BS in Pc Science from Bilkent College, Turkey, and an MBA from Seattle College, US. Mey Meenakshisundaram is a Director in Amazon Choice and Catalog Methods, the place he leads progressive GenAI options to ascertain Amazon’s worldwide catalog because the best-in-class supply for product info. His crew pioneers superior machine studying strategies, together with multi-agent programs and huge language fashions, to mechanically enrich product attributes and enhance catalog high quality at scale. Excessive-quality product info within the catalog is important for delighting prospects find the correct merchandise, empowering promoting companions to checklist their merchandise successfully, and enabling Amazon operations to cut back handbook effort.
Mey Meenakshisundaram is a Director in Amazon Choice and Catalog Methods, the place he leads progressive GenAI options to ascertain Amazon’s worldwide catalog because the best-in-class supply for product info. His crew pioneers superior machine studying strategies, together with multi-agent programs and huge language fashions, to mechanically enrich product attributes and enhance catalog high quality at scale. Excessive-quality product info within the catalog is important for delighting prospects find the correct merchandise, empowering promoting companions to checklist their merchandise successfully, and enabling Amazon operations to cut back handbook effort.
