Macworld studies on Apple’s rumored ‘Liquid Glass’ show expertise that might function a delicate curve and practically invisible bezels for future iPhones.
This speculative innovation goals to boost visible expertise by making a extra immersive show in comparison with present Android curved screens.
The expertise might debut with Apple’s twentieth anniversary iPhone in 2027, probably redefining smartphone aesthetics and person expertise.
One of many extra divisive parts of final 12 months’s raft of Apple OS updates was the brand new Liquid Glass interface design. This shimmery aesthetic was imagined to convey cohesion throughout the iPhone, Mac, Imaginative and prescient Professional, and different Apple merchandise, however ended up inflicting legibility points and a specific amount of irritation. Fortunately, nonetheless, it seems the corporate doesn’t assume Liquid Glass as a model is past redemption.
In keeping with a Twitter/X submit by the prolific leaker Ice Universe, Apple is engaged on a next-gen iPhone show that may use the identical Liquid Glass branding because the software program it runs. In a primary for the corporate’s smartphone line, this show can be curved, however Ice stresses that the curvature can be “extraordinarily delicate,” in contrast to the curved screens we’ve seen on Android telephones over time.
“What really creates the visible influence could also be a complicated mixture of optical refraction, mild guiding constructions, and thoroughly engineered visible phantasm,” the leaker explains. “The tip end result may very well be a show the place the bezel practically disappears from sight, whereas edge viewing stays pure and undisturbed.”
From the wording of the submit (“might,” “may,” and so forth) it’s obvious that this can be a idea fairly than a particular plan. Ice Universe additionally doesn’t cite any sources or in any other case specify the place the knowledge comes from. So at this level it’s finest to treat this as hypothesis: a product idea which Apple is plausibly exploring, however isn’t near launching, nor assured to get there in any respect.
The timeframe isn’t clear from the submit both. Ice refers to it as Apple’s “next-generation show,” however it’s virtually definitely destined for Apple’s twentieth anniversary iPhone as a result of arrive in 2027. We already know the massive design change for late 2026, and that’s the folding physique of the iPhone Extremely, whereas the iPhone 18 Professional is more likely to be way more iterative upgrades on their respective predecessors. Nonetheless, it’s been closely rumored that Apple is planning to launch an iPhone with “curved glass edges throughout” to mark it’s twentieth anniversary.
As Ice Universe acknowledges, curved telephone shows have been round for some time; the primary commercially accessible Android system to supply this was the Samsung Galaxy Spherical manner again in 2013. (The Samsung Galaxy S23 Extremely, pictured above, got here out in 2023.) Apple has even performed curved shows itself: Apple Watches have screens that curve down subtly on the edges so as to disguise the bezel.
It would due to this fact be attention-grabbing to see how Apple presents it as a brand new breakthrough, if it does so in any respect. Maybe the corporate will focus, because it does so typically, on the expertise fairly than the main points. Its upcoming iPhone Extremely, for instance, will not be even near being the primary folding smartphone, however will certainly be offered as the primary to do it proper. Count on the same strategy with the Liquid Glass show.
Whenever you consider a high operating watch, sure manufacturers like Garmin and Coros most likely come to thoughts — however we will guess a high greenback that Amazfit will not be one in all them. This can be about to alter, although. The Chinese language model has simply launched its greatest operating watch but. The Amazfit Energetic 3 Premium is refreshingly glossy, surprisingly well-built and jam-packed with monitoring options — all for $169.99.
This can be a price range health tracker and isn’t superior sufficient to fulfill the wants {of professional} runners, however then it isn’t meant to. The Amazfit Energetic 3 Premium was designed primarily for health rookies and informal exercisers “working in the direction of their first clear purpose,” in line with the model. In different phrases, it’s an entry-level gadget for many who favor easy, actionable insights to the advanced, data-heavy evaluation favored by Garmin and different high-end manufacturers.
That isn’t to say the Amazfit Energetic 3 Premium will not be additionally appropriate for extra skilled runners. It is without doubt one of the hardest and best-looking smartwatches in its value vary, and it comes with offline maps and as much as 12 days of battery life, making it a worthy competitor to wearables which are two or 3 times the worth. Evidently, we have been excited to place the Amazfit Energetic 3 Premium by way of its paces.
Amazfit Energetic 3 Premium overview
Amazfit Energetic 3 Premium: Design
Compact, elegant and cozy to put on
Sturdy stainless-steel bezel and scratch-resistant sapphire glass
Vibrant 1.32-inch AMOLED show
The Amazfit Energetic 3 Premium encompasses a 1.32-inch AMOLED show. (Picture credit score: Anna Gora)
Key specs
Show: 1.32-inch AMOLED – 466 x 466
At all times-On: Sure
Dimensions (inches): 1.77 x 1.77 x 0.43
Dimensions (mm): 45 x 45 x 11 mm
Weight (with out strap): 1.34 oz (38g)
Colours: Silver, blue and white
End: Stainless-steel
Battery life: As much as 12 days
GPS: Sure, single-band
Compass: No
Altimeter: Sure
Water resistance: 5 ATM
NFC funds: Sure, Zepp Pay
Compatibility: Android 7.0 and above, iOS 14.0 and above
Storage: 4GB inside storage
At a look, the Amazfit Energetic 3 Premium appears virtually similar to the Amazfit Energetic Max we examined a few months in the past. Each watches are pleasantly compact and unobtrusive, look nice on the wrist, and include removable silicon straps and engraved-style tick markers on a spherical bezel. Nevertheless, look nearer, and you’ll spot some key variations.
To start out with, the Energetic 3 Premium has a barely smaller AMOLED show than the Energetic Max (1.32-inch vs 1.5-inch). This alone makes it look sleeker and extra like an everyday on a regular basis smartwatch than a severe health tracker. Secondly, the Energetic 3 Premium options extra buttons (4 versus the Energetic Max’s two) — a design tweak that makes it simpler to regulate with sweaty palms or gloves midway by way of a run.
The Amazfit Energetic 3 Premium is glossy, elegant and simple to regulate. (Picture credit score: Anna Gora)
The Amazfit Energetic 3 Premium can be considerably extra sturdy than the Energetic Max. That’s as a result of its bezel is product of stainless-steel, which is extra proof against shocks, corrosion and excessive temperatures than aluminium alloy. It additionally comes with scratch-resistant Sapphire glass on the display screen, whereas the Energetic Max has no show safety in any respect. They share the identical 5 ATM waterproof ranking, although. Each might be safely used for surface-level swimming and shallow-water actions, however they aren’t waterproof sufficient to resist deep dives and high-pressure water jets.
We actually loved our time with the Amazfit Energetic 3 Premium. This smartwatch is a pleasure to put on. We appreciated its elegant seems and the way gentle and cozy it was (a lot in order that we regularly forgot we have been even carrying it), and that it appeared simply pretty much as good with our activewear because it did with extra informal clothes. We might suggest the Amazfit Energetic 3 Premium to anybody bored with cumbersome, rugged wearables. That mentioned, some folks could discover this smartwatch a bit too small to go well with their fashion.
Get the world’s most fascinating discoveries delivered straight to your inbox.
Compact and light-weight, the Amazfit Energetic 3 Premium didn’t overload our wrist or get in the way in which of our clothes. (Picture credit score: Anna Gora)
We had no points with utilizing or navigating the show. It’s vibrant, vibrant and simply readable in direct daylight, and it didn’t lag or freeze throughout power-intensive duties. The one slight criticism is with extreme smudging — the Amazfit Energetic 3 Premium appears to gather extra fingerprints than different operating watches we’ve got examined. Nevertheless, it isn’t a deal-breaker, on condition that this smartwatch might be managed totally with the facet buttons.
Amazfit Energetic 3 Premium: Options
Strong exercise monitoring instruments
GPS, offline maps and turn-by-turn navigation
Fundamental smartwatch capabilities
The Amazfit Energetic 3 Premium is a health tracker by way of and thru. Whereas it does include an app ecosystem and a good number of smartwatch options, reminiscent of Bluetooth calls, music management, NFC funds by way of Zepp Pay and calendar notifications, for instance, it’s extra centered on measuring and analyzing train efficiency than maintaining with day-to-day actions. Due to that, this smartwatch doesn’t really feel overloaded with pointless widgets and area of interest options.
(Picture credit score: Anna Gora)
(Picture credit score: Anna Gora)
The Amazfit Energetic 3 Premium tracks greater than 170 totally different actions, however it’s geared predominantly to runners and race walkers. It provides a powerful vary of operating metrics, lots of which you usually tend to see in premium wearables for athletes quite than price range wearables. These embody posture monitoring (detection of overstriding, hunching or improper head place throughout operating), lactate threshold evaluation (the train depth at which lactate begins accumulating within the bloodstream sooner than it may be eliminated), floor contact stability monitoring (monitoring the symmetry between left and proper foot floor contact time) and operating rhythm evaluation (assessing whether or not your respiratory, foot strikes and physique actions are synchronized).
Regardless of providing all these stats, the Amazfit Energetic 3 Premium continues to be very beginner-friendly, that includes a mess of operating exercises and adaptive operating plans (a key promoting level for these new to this type of train). It does a comparatively good job of explaining stats with out counting on advanced terminology or over-emphasising the necessity for fixed progress — one thing that Garmin wearables get lots of slack for.
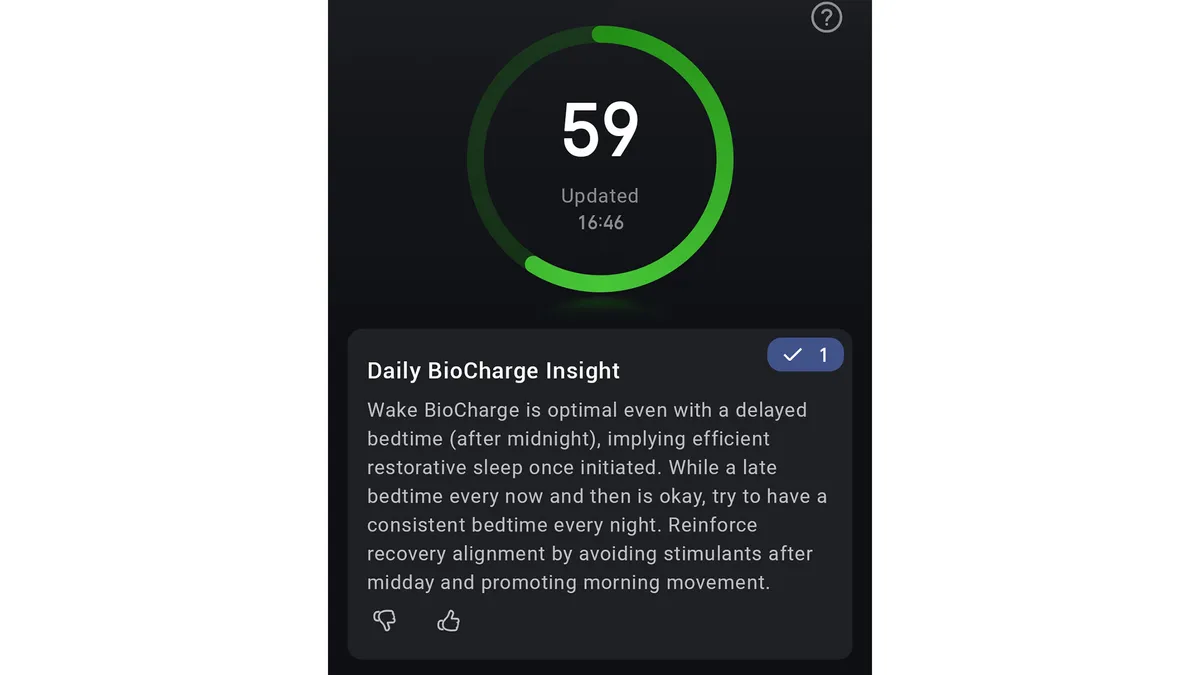
The BioCharge rating offers a complete evaluation of 1’s post-exercise restoration based mostly on sleep, HRV, stress and recorded exercise ranges. (Picture credit score: Anna Gora)
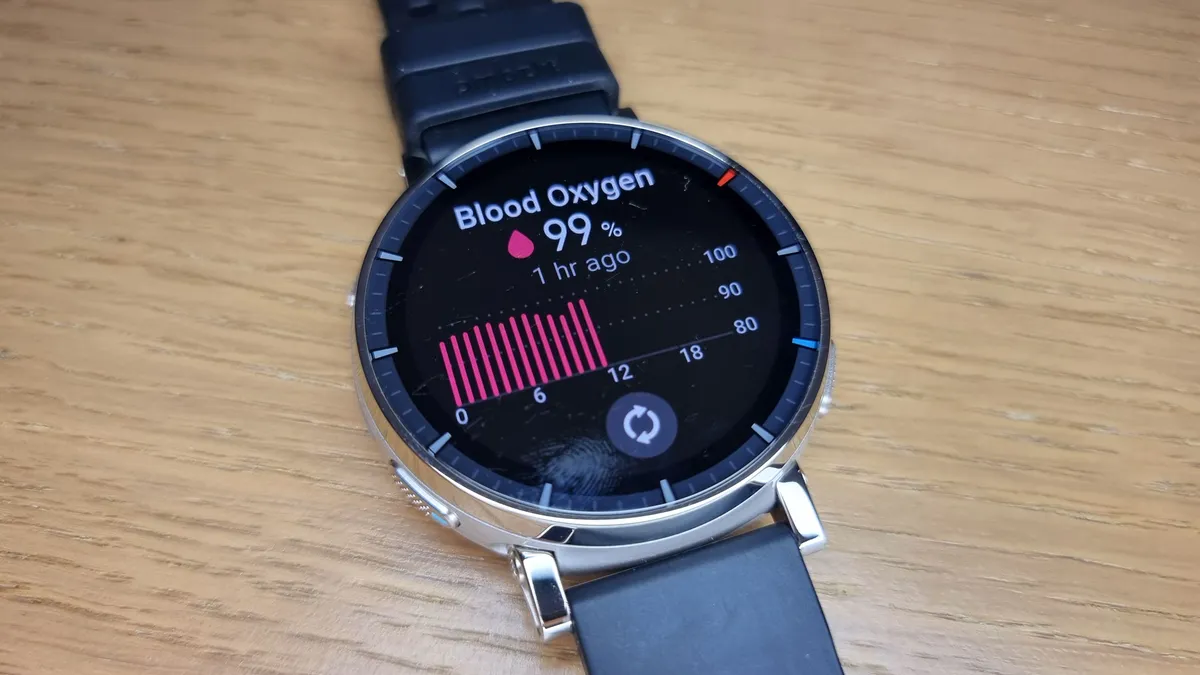
The Amazfit Energetic 3 Premium measures coronary heart fee, blood oxygen, respiratory fee and plenty of different very important well being metrics. (Picture credit score: Anna Gora)
Put merely, the Amazfit Energetic 3 Premium is sort of a pocket-sized operating coach — able to fine-tune your exercises, assist defend you from potential accidents and share your achievements with others.
The Amazfit Energetic 3 Premium additionally comes with GPS and offline maps, in addition to turn-by-turn navigation, computerized rerouting and point-to-point route planning. These options should not as detailed and superior as these we’ve got seen in Garmin and Suunto wearables, however they’re ok for primary navigation and phone-free outside exercises.
The Amazfit Energetic 3 Premium provides useful climate assessments. (Picture credit score: Anna Gora)
In accordance with the producer, the Amazfit Energetic 3 Premium has as much as 12 days of battery life with “typical use” or as much as 7 days with “heavy use”, which then drops to 24 hours within the steady GPS mode. Based mostly on our expertise, that appears about proper. Our utilization was someplace between “typical” and “heavy” — we wore the Amazfit Energetic 3 Premium through the day and at evening, tracked a minimum of 4 exercises per week, and infrequently used GPS when coaching open air. On common, our testing unit lasted round 10 days on a single cost.
The Amazfit Energetic 3 Premium lasts as much as 12 days on a single cost. (Picture credit score: Anna Gora)
Shifting on to monitoring efficiency, the Amazfit Energetic 3 Premium did a comparatively good job open air. We examined its mapping capabilities throughout two day-long hikes within the dense Welsh woodlands and when operating across the native park. The smartwatch estimated our location with sufficient accuracy to show a dependable exercise companion.
Nevertheless, the Amazfit Energetic 3 Premium’s monitoring will not be at all times very exact. It makes use of single-band GPS as a substitute of dual-band GPS, so its sign might not be as robust in additional dense, difficult environments. As such, skilled path runners and wilderness explorers could favor a smartwatch with extra superior geolocation options.
The Amazfit Energetic 3 Premium did a comparatively good job of mapping our climbing routes. (Picture credit score: Anna Gora)
(Picture credit score: Anna Gora)
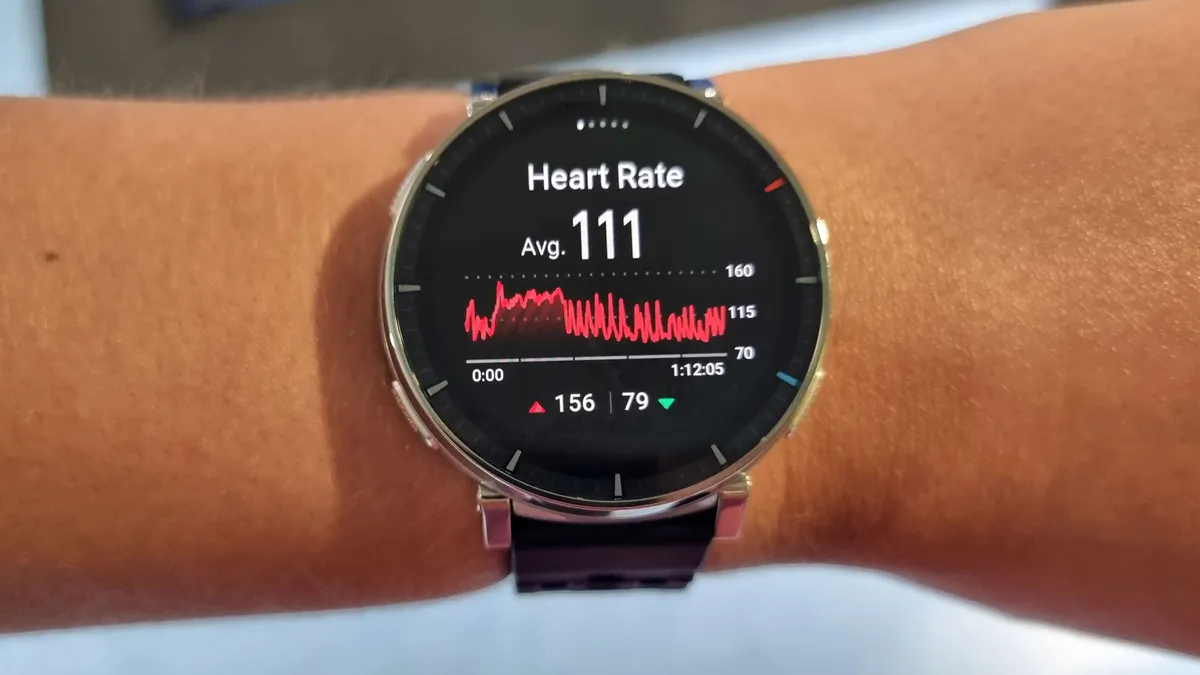
We in contrast the smartwatch’s coronary heart fee measurements with the info we obtained utilizing the Whoop MG screenless tracker, Oura Ring Gen 4 sensible ring and Polar H9 chest strap coronary heart fee monitor, and located that the center fee readings precisely mirrored the depth and coaching load of our exercises. The monitoring precision decreased throughout high-intensity actions (above 150 bpm), however that tends to be the case with most budget-friendly health trackers. Sleep and stress measurements have been fairly correct, too.
The Amazfit Energetic 3 Premium offers comparatively correct coronary heart fee measurements. (Picture credit score: Anna Gora)
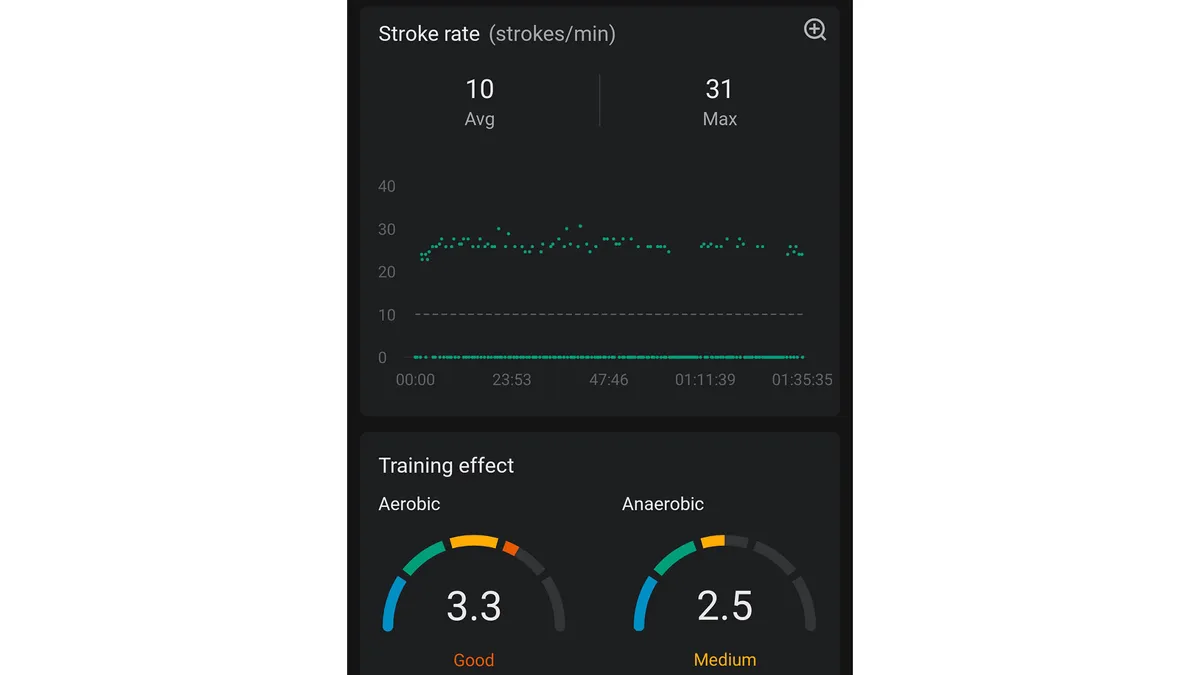
Then again, some facets of exercise monitoring might use some enchancment. The Amazfit Energetic 3 Premium tended to underestimate our steps and upper-body actions (a stroke fee in indoor rowing, for instance), and it didn’t appear to select up sure energy workouts, both. Nevertheless, this didn’t have a major impression on our total person expertise, and it isn’t one thing that we’d fret about in a wearable at this value vary.
The Amazfit Energetic 3 Premium tended to underestimate our steps and upper-body actions. (Picture credit score: Anna Gora)
Must you purchase the Amazfit Energetic 3 Premium?
The Amazfit Energetic 3 Premium is a good budget-friendly smartwatch for novice runners and informal exercisers. It’s sturdy, comparatively correct and cozy to put on, and provides complete workout-tracking options and loads of beginner-friendly coaching insights. It seems nice, too. The Amazfit Energetic 3 Premium could not have probably the most superior GPS or mapping options, and its display screen smudges too simply, however that’s not one thing we’d anticipate at such an reasonably priced value.
✅ Purchase it if: You’re a newbie or informal runner searching for a glossy, dependable smartwatch on a price range.
❌ Don’t purchase it if: You’re a seasoned operating professional searching for a premium wearable with superior GPS and mapping capabilities.
(Picture credit score: Anna Gora)
If the Amazfit Energetic 3 Premium will not be for you
The Amazfit Energetic Max is a wonderful different to the Amazfit Energetic 3 Premium. Each watches price round $169 and include comparable options, however the former has a bigger show and longer battery life. Nevertheless, it is usually barely much less sturdy.
If you’re not a fan of Amazfit, contemplate the Coros Tempo 4 as a substitute. This glossy and light-weight smartwatch boasts good monitoring accuracy, superior workout-tracking options and as much as 19 days of battery life. Nevertheless, it lacks offline maps and prices round $80 greater than the Amazfit Energetic 3 Premium.
Searching for one thing extra premium? Then you possibly can’t go flawed with the Garmin Forerunner 965. This smartwatch prices 4 instances greater than the Amazfit Energetic 3 Premium, however that step up in value is mirrored in its specs. This flagship Garmin operating watch comes with extra superior navigation instruments, a richer app ecosystem and virtually twice as lengthy battery life.
Amazfit Energetic 3 Premium: How we examined
We spent practically a month testing the Amazfit Energetic 3 Premium. (Picture credit score: Anna Gora)
We spent practically a month testing the Amazfit Energetic 3 Premium, trying into its design, sturdiness, options, day-to-day efficiency and ease of use. We wore this smartwatch through the day and at evening, when doing gym-based exercises and whereas climbing and operating open air. We additionally in contrast the sleep, steps and coronary heart fee measurements taken by our Amazfit Energetic 3 Premium with the info we obtained utilizing the Whoop MG screenless tracker, Oura Ring Gen 4 sensible ring and Polar H9 chest strap coronary heart fee monitor.
The guide entry for xtmixed paperwork all of the official options within the command, and a number of other functions. Nevertheless, it could be not possible to deal with all of the fashions that may be fitted with this command in a guide entry. I need to present you find out how to embrace covariates in a crossed-effects mannequin.
Let me begin by reviewing the crossed-effects notation for xtmixed. I’ll use the homework dataset from Kreft and de Leeuw (1998) (a subsample from the Nationwide Training Longitudinal Research of 1988). You may obtain the dataset from the webpage for Rabe-Hesketh & Skrondal (2008) (http://www.stata-press.com/information/mlmus2.html), and run all of the examples on this entry.
If we need to match a mannequin with variable math (math grade) as end result, and two crossed results: variable area and variable city, the usual syntax can be:
(1) xtmixed math ||_all:R.area || _all: R.city
The underlying mannequin for this syntax is
math_ijk = b + u_i + v_j + eps_ijk
the place i represents the area and j represents the extent of variable city, u_i are i.i.d, v_j are i.i.d, and eps_ijk are i.i.d, and all of them are unbiased from one another.
The usual notation for xtmixed assumes that ranges are all the time nested. With a view to match non-nested fashions, we create a synthetic stage with just one class consisting of all of the observations; as well as, we use the notation R.var, which signifies that we’re together with dummies for every class of variable var, whereas constraining the variances to be the identical.
That’s, if we write
xtmixed math ||_all:R.area
we’re simply becoming the mannequin:
xtmixed math || area:
however we’re doing it in a really inefficient means. What we’re doing is strictly the next:
generate one = 1
tab area, gen(id_reg)
xtmixed math || one: id_reg*, cov(identification) nocons
That’s, as a substitute of estimating one variance parameter, we’re estimating 4, and constraining them to be equal. Subsequently, a extra environment friendly option to match our blended mannequin (1), can be:
xtmixed math ||_all:R.area || city:
It will work as a result of city is nested in one. Subsequently, if we need to embrace a covariate (also referred to as random slope) in one of many ranges, we simply want to put that stage on the finish and use the same old syntax for random slope, for instance:
xtmixed math public || _all:R.area || city: public
Now let’s assume that we need to embrace random coefficients in each ranges; how would we try this? The trick is to make use of the _all notation to incorporate a random coefficient within the mannequin. For instance, if we need to match
(2) xtmixed math meanses || area: meanses
we’re assuming that variable meanses (imply SES per college) has a distinct impact (random slope) for every area. This mannequin might be expressed as
math_ik = x_ik*b + sigma_i + alpha_i*meanses_ik
the place sigma_i are i.i.d, alpha_i are i.i.d, and sigmas and alphas are unbiased from one another. This mannequin might be fitted by producing all of the interactions of meanses with the areas, together with a random alpha_i for every interplay, and proscribing their variances to be equal. In different phrases, we are able to match mannequin (2) additionally as follows:
unab idvar: id_reg*
foreach v of native idvar{
gen inter`v' = meanses*`v'
}
xtmixed math meanses ///
|| _all:inter*, cov(identification) nocons ///
|| _all: R.area
Lastly, we are able to use all these instruments to incorporate random coefficients in each ranges, for instance:
xtmixed math parented meanses public || _all: R.area || ///
_all:inter*, cov(identification) nocons || city: public
We’ve all, sooner or later, had the thought that CSS sucks. Certainly, the overhyped buzz round the brand new pretext.js library as a “CSS killer” displays how a lot all of us need to strangle CSS at instances
Nicely, CSS, you’ve been teasing me since 2017 with the opportunity of that API, which I hoped would let me create my very own CSS syntax, however no such factor materialized.
And whereas I’m venting, since 2003 we’ve requested over and over and over for ::nth-letter, which looks like a pure suggestion. I imply, we’ve all the time had ::first-letter to imitate print results like drop caps, so we all know you can do ::nth-letter in the event you wished.
You’re only a tease, CSS, which signifies that in 2026, I nonetheless can’t write kinds like Chris Coyier’s hypothetical instance from again in 2011.
When you desire to play with an interactive instance, right here is the invalid syntax ::nth-letter working in CodePen.
And right here’s a video demo by my eight-year-old, to display that utilizing this syntax is baby’s play.
If ::nth-letter existed, we might migrate my textual content vortex scrolling impact to make use of it, after which delete the JavaScript, as seen beneath. That is Chrome/Safari-only, as a result of using the brand new sibling-index() operate.
If we had ::nth-letter, we might migrate Temani Afif’s wonderful direction-aware elastic hover, then gleefully delete all of the spans within the unique markup round every letter. The ::nth-letter code can be as proven within the CodePen beneath.
If solely ::nth-letter existed, I would make it my mission to go round upgrading each typography styling demo to make use of it.
Alas, the syntax to make this work shouldn’t be attainable with CSS and HTML. Such capabilities exist solely within the wildest realms of our creativeness. Article ends right here.
Wait, what? How do all these demos work?
Whereas we’re on the subject of doing the inconceivable, it has been stated — by Philip Walton at Google, who tried actually arduous prior to now to make production-ready CSS polyfills — that it’s not attainable to jot down a dependable polyfill for CSS. He gave up the concept, however I prefer to think about his nickname at Google turned “Polyphil,” so it wasn’t a complete loss.
Philip additionally created this deserted framework for creating CSS polyfills, which nonetheless works, though it’s so outdated that the examples present methods to polyfill flexbox. Within the decade since he stopped supporting this library, it doesn’t seem to be the feasibility of excellent CSS polyfills has improved.
To take care of our motivation for simulating ::nth-letter, I word that the shortage of a spec would possibly make implementing it simpler than writing a real polyfill. Something we create on this area will technically be a shim slightly than a polyfill. All polyfills are shims, however not all shims are polyfills — like all cows are animals, however not the opposite means round.
Having defined that, I’ll use the phrases polyfill and shim interchangeably right here, as a result of polyfill is the extra well-known time period, and since I’m anyhow about to play quick and free with what phrases imply.
Jeremy questioned what the third letter in a paragraph can be. Take this instance markup:
ABCDEF
The third letter could possibly be:
“C” as a result of that’s the third letter as it will seem whenever you learn from left to proper, whatever the DOM construction. In any case, p::first-letter would choose “A,” even when that character was deeply nested in markup inside the paragraph.
“D” or “B” if we styled the paragraph to make use of a right-to-left writing path. In a extra possible state of affairs, if the paragraph above have been modified to
אבקדפע
Hebrew characters are inherently right-to-left in Unicode — after which the reply can be completely different once more.
Isn’t life less complicated when the rigorous drafting strategy of the W3C is changed with the whims of a lone crackpot?
2. What does “letter” imply?
We touched on how different languages would have an effect on ::nth-letter. Solely half of the online makes use of English. If we’re simulating a browser characteristic, we are able to’t ignore different languages, can we?
Not solely are writing instructions completely different in languages aside from English, however some languages use a number of characters to characterize a single letter. Now, in principle, ::first-letter selects all components of such a letter. However the browser help for that’s poor. ::first-letter has another fascinating edge circumstances I wouldn’t have anticipated, resembling deciding on punctuation along with the primary letter, possibly as a result of that’s how drop caps are usually offered.
At this level, I determine that any reply I give would disappoint some folks if their thought of a letter isn’t what’s chosen by ::nth-letter. To avoid this debate, let’s say ::nth-letter is an alias for the nth character.
A bit excessive, however the examples I confirmed above of how folks think about ::nth-letter don’t appear to deal with whether or not every character is a letter. And I believe my 8-year-old would have been dissatisfied if the exclamation level he added to his rainbow textual content wasn’t coloured.
Look, in the event you don’t prefer it, return to your individual universe the place there’s no ::nth-letter in any respect. Or you’ll be able to tinker with the supply code I’ll present you subsequent.
Tips on how to write an inconceivable polyfill
I revealed this experimental library on npm. That’s what the above CodePen makes use of by way of unpckg. The ::nth-letter package deal obtained 1.3k downloads in its first week with out me promoting it, in order that was good.
As an alternative of making an attempt to construct an ideal polyfill, there’s a sure freedom in understanding we are able to’t. We’ll subsequently do the only factor that would probably work. We rewrite the CSS and remodel the DOM so the browser can do the remainder. Right here’s a simplified model that’s 29 strains of JavaScript and works in as we speak’s browsers. As we discover the way it works, you’ll see that the brevity is achieved by leveraging what CSS can already do with minimal tampering.
import getCssData from 'get-css-data';
import { SplitText } from 'gsap/SplitText';
getCssData({
onComplete(cssText, cssArray, nodeArray) {
nodeArray.forEach(e => e.take away());
const selectors = new Set();
const nthArgs = new Set();
cssText = cssText.change(//*[sS]*?*//g, '');
// Substitute ::nth-letter with :nth-child in CSS
let rewrittenCss = cssText.change(
/([^,{{rn]+?)::?nth-letter[ t]*(([^n)]*))/gi,
(full, selector, args) => {
selector = selector.trim();
selectors.add(selector);
nthArgs.add(args);
// Use :nth-child as a substitute of ::nth-letter
return `${selector} .char:nth-child(${args})`;
}
);
doc.head.insertAdjacentHTML("beforeend", ``);
selectors.forEach(selector => {
doc.querySelectorAll(selector).forEach(el => {
if (el.hasAttribute('data-nth-letter')) return;
el.setAttribute('data-nth-letter', 'hooked up');
new SplitText(el, { sort: 'chars', charsClass: 'char' });
});
});
}
});
So much is happening on this small block of code, so let’s break down the phases.
Translating ::nth-letter into legitimate CSS
Even at this primary section, we get a way that introducing customized CSS syntax received’t be as straightforward as we’d hope. It’s much less conveniently apparent methods to do it than monkey patching JavaScript, though the dangers are corresponding to patching globals in JavaScript.
The way in which CSS is utilized to an online web page doesn’t present an excellent alternative to intercept normal CSS behaviors and customise them.
Certainly, even making the nonstandard ::nth-letter syntax accessible to our JavaScript code is tough, as a result of the CSS parser will discard invalid CSS, so if the person consists of the selector .rainbow::nth-letter(2n), that received’t be accessible to JavaScript when it accesses the stylesheets property of the DOM.
We have to collect all uncooked CSS free from judgment of validity, so let’s use get-css-data, which concatenates the uncooked contents of any type tags within the DOM and makes use of fetch to incorporate the contents of every stylesheet imported by way of hyperlink tags.
Sidenote:get-css-data received’t work if the CORS coverage doesn’t enable it, however that is without doubt one of the inherent limitations of CSS polyfills.
Subsequent, we rewrite the nonstandard CSS utilizing common expressions, which is a bit ghetto. A extra rigorous method would use one thing like PostCSS at construct time. However, we are able to get away with regex on this case, as a result of we’re not doing our personal parsing of CSS; we’re doing a comparatively easy find-replace, which regex is sweet at.
The results of the alternative will translate the invalid CSS…
This nice video concludes that the least unhealthy possibility for implementing a CSS polyfill is to “rewrite the CSS to focus on particular person parts whereas sustaining cascade order.” Philip provides that he has “by no means seen a polyfill do that. I don’t suggest it, however I believe it’s the most effective of the unhealthy choices.” Higher late than by no means to create a polyfill utilizing this technique.
Implementing the translator for ::nth-letter
The shim removes the unique kinds from the web page and replaces them with the rewritten kinds, like so:
getCssData({
onComplete(cssText, cssArray, nodeArray) {
nodeArray.forEach(e => e.take away());
const selectors = new Set();
const nthArgs = new Set();
cssText = cssText.change(//*[sS]*?*//g, '');
// Substitute ::nth-letter with :nth-child in CSS
let rewrittenCss = cssText.change(
/([^,{{rn]+?)::?nth-letter[ t]*(([^n)]*))/gi,
(full, selector, args) => {
selector = selector.trim();
selectors.add(selector);
nthArgs.add(args);
// Use :nth-child as a substitute of ::nth-letter
return `${selector} .char:nth-child(${args})`;
}
);
doc.head.insertAdjacentHTML("beforeend", ``);
}
});
At this level, now we have translated the unsupported ::nth-letter syntax into legitimate CSS. Nevertheless it nonetheless wants some DOM parts to type, or it received’t do something.
Getting ready the DOM
Since ::nth-letter doesn’t exist, my implementation is finally a handy abstraction for what I did manually in my spiral scrollytelling article. So, after gathering all the weather that require styling of particular person characters, we cut up the focused content material into div tags, utilizing the freely accessible SplitText plugin from GSAP.
It really works! The auto-magically generated CSS receives an auto-magically generated DOM to type. All of us reside fortunately ever after. Article over for actual this time.
Or is it?
Do now we have to change the DOM for this?
As talked about in a 2021 CSS-Methods e-newsletter that lamented ::nth-letter being “sadly nonetheless not a factor,” the answer of spitting the textual content into separate parts per character is “fairly gross, proper? It’s a disgrace that now we have to mess up the markup to make a comparatively easy aesthetic change.”
Additionally, if ::nth-letter have been a local characteristic, it will be a pseudo-element. It will be nice if we might simulate that, understanding there’s a danger we’ll journey over these further parts that my library provides to the DOM.
A pseudo-element might give us the most effective of each worlds for fixing the duty at hand: one thing that’s purely presentational and doesn’t pollute the DOM, however can nonetheless behave like a part of the DOM for styling functions solely. Can we implement one thing much like keep away from polluting our DOM?
Sure and no.
The tough fact is we could by no means have the ability to implement our personal customized pseudo-elements.
Earlier, I expressed the hope that the CSS Parser API would sometime assist, however even within the unlikely occasion that this API materializes, the intent wouldn’t be to permit builders to implement their very own CSS syntax or pseudo-elements. As you’ll be able to see from this 2021 unofficial draft, if we ever get this API, it will probably expose the browser’s CSS parser for programmatic use — but it surely in all probability wouldn’t assist us customise how CSS is interpreted. Customized pseudo-elements can be the area of a hypothetical CSS Renderer API, which is one thing my mind simply got here up with that no person has even proposed.
Bramus from the Chrome group has a draft doc outlining how a CSS parser extensions API would work, and that is nearer to what I imagined the hypothetical CSS parser API would possibly present, however Bramus’s doc doesn’t at the moment focus on customized psuedo-elements. There’s additionally the HTML-in-canvas API proposal which might allow us to customise the best way parts are rendered with out modifying their DOM. That’s already experimentally accessible in Chrome, however nonetheless wouldn’t give us customized psuedo-elements we might arbitrarily type utilizing CSS.
Shadow DOM model of ::nth-letter
If we’re caught with manipulating the DOM, the closest we are able to get to customized pseudo-elements is to cover the character parts within the shadow DOM of the focused parts, whereas exposing an API that lets us type chosen characters from outdoors the goal.
If we’re decided that focused parts of this new selector received’t pollute the gentle DOM with further markup, then now we have to cover that markup within the shadow DOM. If we do this, then the closest I do know of to a customized pseudo-element is the ::half pseudo-element. If we use that, then by design, we are able to’t use:
The reason being that the shadow DOM of my ingredient would appear like:
1
2
A client of my part shouldn’t have the ability to know the construction of the shadow DOM from outdoors the part utilizing CSS. That’s why “structural pseudo-classes that match based mostly on tree info, resembling :empty and :last-child, can’t be appended“ to ::half. As soon as upon a time, there was a ::shadow pseudo-element that might have allow us to type :nth-child from outdoors the shadow DOM, but it surely was deprecated a lifetime in the past.
Truly, there’s a approach to nonetheless use :nth-child along with ::half in the event you suppose laterally.
What if we populate every character’s ::half attribute based mostly on the :nth-child selectors we all know we might want to help? We all know what these are, since we created them after we have been regex changing the kinds!
By pre-calculating the :nth-child selectors as names of the shadow components which match the ::nth-letter usages our CSS has requested, we are able to choose them from outdoors, with out touching the sunshine DOM, and with out hitting a brick wall of the intentional limitations of shadow DOM.
It really works! Are we there but? Is the most effective reply to make use of shadow DOM?
Probably not, it causes a minimum of two large points:
We will’t use the emergent sibling-index() operate within the kinds for a shadow half, as a result of sibling-index() depends on understanding the construction of the DOM, similar to :nth-child does. This prevents supporting the textual content styling demos I confirmed in the beginning. These demos wouldn’t work with the shadow DOM model of ::nth-letter.
I discover that ::first-letter can be significantly restricted within the styling it helps. That’s not sufficient cause to knowingly cripple our implementation of ::nth-letter when there’s an possibility to not. I conclude the sunshine DOM model is healthier. It could be “gross” markup, however a minimum of we’re now not those who want to jot down or preserve it. And if browsers ever help ::nth-letter natively, the design of the shim is meant so we‘d hold the CSS as-is, delete the reference to my library, and by no means communicate of it once more.
The (precise) ending
Now that now we have a easy foundation for implementing issues like ::nth-letter, it will be possible so as to add ::nth-word, ::nth-last-letter, and so forth. Chris Coyier confirmed cool use circumstances for these in [his call for ::nth everything.
There are still many limitations to the ::nth-letter shim, such as:
It doesn’t work if you change the DOM or the styles on the fly, although we probably could support that.
It doesn’t work if you use ::nth-letter in a CSS selector passed to querySelectorAll, although we could monkey-patch JavaScript to make that work.
I am unsure how scalable it is.
It could lead to hard-to-diagnose bugs because it rewrites all the CSS and adds unexpected “char” divs to the DOM. I noticed that Philip Schatz’s polyfill for a crazy working draft called the “CSS Generated Content Module” requires the consumer to opt-in by using special attributes on the link or style tags. That’s an interesting compromise that might limit the blast radius by only triggering the CSS rewrites where we need them, but it seems less convenient than just referencing the library and then using the new syntax.
External stylesheets not allowed by CORS won’t work.
In summary, I’d probably use ::nth-letter and its hypothetical friends all the time if these features were built into browsers. But I must admit that, having explored the complexity of building generic support for a design we can often adequately solve with a few lines of JavaScript, I see why the browsers are reluctant to implement and maintain such a feature.
My shim might give the powers that be another reason to say native support isn’t necessary, or if lots of people use my ::nth-letter hack in the wild, the browser gods might recognize the need to implement it for real.
Either way, let’s never argue again, CSS. I understand now why you did what you did. I could never stay mad at you.
Healthcare and life sciences determination making more and more depends on multimodal information to diagnose ailments, prescribe drugs and predict remedy outcomes, develop and optimize progressive therapies precisely. Conventional approaches analyze fragmented information, resembling ‘omics for drug discovery, medical pictures for diagnostics, scientific trial studies for validation, and digital well being data (EHR) for affected person remedy. In consequence, determination makers (CxOs, VPs, Administrators) usually miss essential insights hidden within the relationships between information sorts. Latest developments in AI allow you to combine and analyze these fragmented information streams effectively to help a extra full understanding of therapeutics and affected person care.
AWS offers a unified atmosphere for multimodal organic basis fashions (BioFMs), enabling you to make extra assured, well timed decision-making in customized drugs. This AI system combines organic information, mannequin improvement, scalable compute, and accomplice instruments to help the drug improvement life cycle. On this put up, we’ll discover how multimodal BioFMs work, showcase real-world functions in drug discovery and scientific improvement, and contextualize how AWS permits organizations to construct and deploy multimodal BioFMs.
Multimodal organic basis fashions
Organic basis fashions (BioFMs) are AI fashions pre-trained on massive organic datasets. BioFMs show superior capabilities on particular healthcare and life sciences duties. The generally used BioFMs span drug discovery and scientific improvement domains, notably in protein construction and molecule design (~20%), omics information evaluation together with DNA, epigenetic, and RNA (~30%), medical imaging (15%), and scientific documentation (~35%) (Delile et al. 2025).
Unimodal BioFMs are skilled solely on a single information modality (for instance, amino acid sequences) for related downstream functions like predicting protein buildings; this breakthrough earned the 2024 Nobel Prize in Chemistry. Multimodal BioFMs practice throughout a number of information sorts (textual content, audio, picture, and video, hereafter “modalities”) and might concurrently infer throughout completely different streams in a single mannequin (for instance, textual content prompts to generate new pictures or match pictures to captions).
Notable multimodal BioFM examples embody:
Latent Labs’ Latent-X1 and Latent-X2 not solely predict 3D buildings of proteins, but in addition generate novel binders like antibodies, macrocyclic peptides, and miniproteins and predict how they work together with targets.
Arc Institute’s Evo 2 maps the central dogma of biology to interpret and predict the construction and performance of DNA, RNA, and proteins.
Insilco Medication’s Nach01 integrates pure language, chemical intelligence, and 3D molecular construction information to speed up drug discovery.
Bioptimus’ M-Optimus decodes histology and scientific information for wealthy organic insights, supporting a number of levels from analysis to affected person care.
Harvard and AstraZeneca’s MADRIGAL integrates structural, pathway, cell viability, and transcriptomic information to foretell drug mixture scientific final result, determine adversarial interactions, and optimize polypharmacy administration.
John Snow Lab’s imaginative and prescient language mannequin Medical VLM-24B processes scientific notes, lab studies, and imaging (X‑ray, MRI, CT) for unified, context‑conscious diagnostics.
GEHC’s 3D magnetic resonance imaging (MRI) basis mannequin, designed to allow builders to construct functions for duties resembling picture retrieval, classification, picture segmentation, and report era.
The multimodal benefit
The present frontier of fashions pushes the boundary of multimodal understanding and era capabilities. Common-purpose fashions like Amazon Nova 2 Omni can course of textual content, pictures, video, and speech inputs whereas producing each textual content and pictures. This multimodality development extends to BioFMs, the place combining a number of information sorts like medical pictures and scientific documentation achieves greater predictive accuracy and broader applicability throughout various scientific outcomes (Siam et al. 2025).
Integrating various organic information sorts yields measurable efficiency good points:
Enhanced diagnostic accuracy: Fashions integrating genomics, imaging, and scientific information yield 4-7% common good points in space underneath the curve (AUC) over unimodal baselines for diagnoses (e.g., Alzheimer’s, mind most cancers) and phenotypes (Solar et al. 2024). Furthermore, fashions integrating lab information, affected person train metrics, and scientific notes throughout affected person screening obtain 92.74% accuracy with 93.21 AUC in cardiovascular danger prediction (Guo and Wu, 2025).
Focused therapeutic methods: You should use fashions integrating genomic profiles, medical pictures, and scientific histories to information choice of efficient interventions for particular person sufferers (Parvin et al. 2025). This proves particularly impactful for most cancers sufferers the place tumor genomics and radiological imaging can facilitate therapeutic choices like chemotherapy regimens (Restrepo et al. 2023).
New illness mechanisms: Single-cell multi-omics fashions present how most cancers cells develop and resist therapies inside blood ailments like leukemia, serving to physicians enhance survival charges by recognizing hidden most cancers cells, monitoring how mutations drive illness development, and choosing customized therapies for sufferers (Kim and Takahashi, 2025).
Correct danger prediction: You should use fashions integrating lab outcomes, drugs, scientific notes, and discharge summaries and different scientific information to foretell 30-day hospital readmission danger with 76% accuracy—delivering ~$3.4 million in internet financial savings per hospital yearly whereas enhancing general scientific outcomes for high-risk coronary heart failure sufferers by means of focused interventions (Golas et al. 2018).
Predictive, Preventative, Personalised, Participatory (P4) drugs: Fashions combining wearable well being applied sciences with affected person well being information can extract goal indicators with 96-97% accuracy for diabetes and coronary heart illness prognosis (Mansour et al. 2021).
BioFMs in motion at AWS prospects
These efficiency good points clarify why main biopharma organizations are more and more adopting multimodal BioFMs. Main biopharma organizations spend money on BioFMs for analyzing biologic (Merck and Novo Nordisk), genomic (AstraZeneca), pathology (Bayer), and scientific (Roche) information. You may understand as much as 50% in value and time financial savings for drug improvement and as much as 90% in time financial savings for medical picture prognosis when utilizing these specialised AI fashions (State of the Artwork-ificial Intelligence 2025,Jeong et al. 2025). Multimodal BioFMs present promise in a number of levels of the healthcare and life sciences worth chain (Determine 1).
Determine 1. Multimodal BioFMs combine numerous organic information sorts (for instance, protein, small molecule, omics, imaging, sensors, scientific documentation) to energy functions throughout the drug improvement lifecycle (analysis, scientific improvement, manufacturing, industrial).
For a deeper dive, we’ve chosen two use circumstances: drug discovery and scientific improvement.
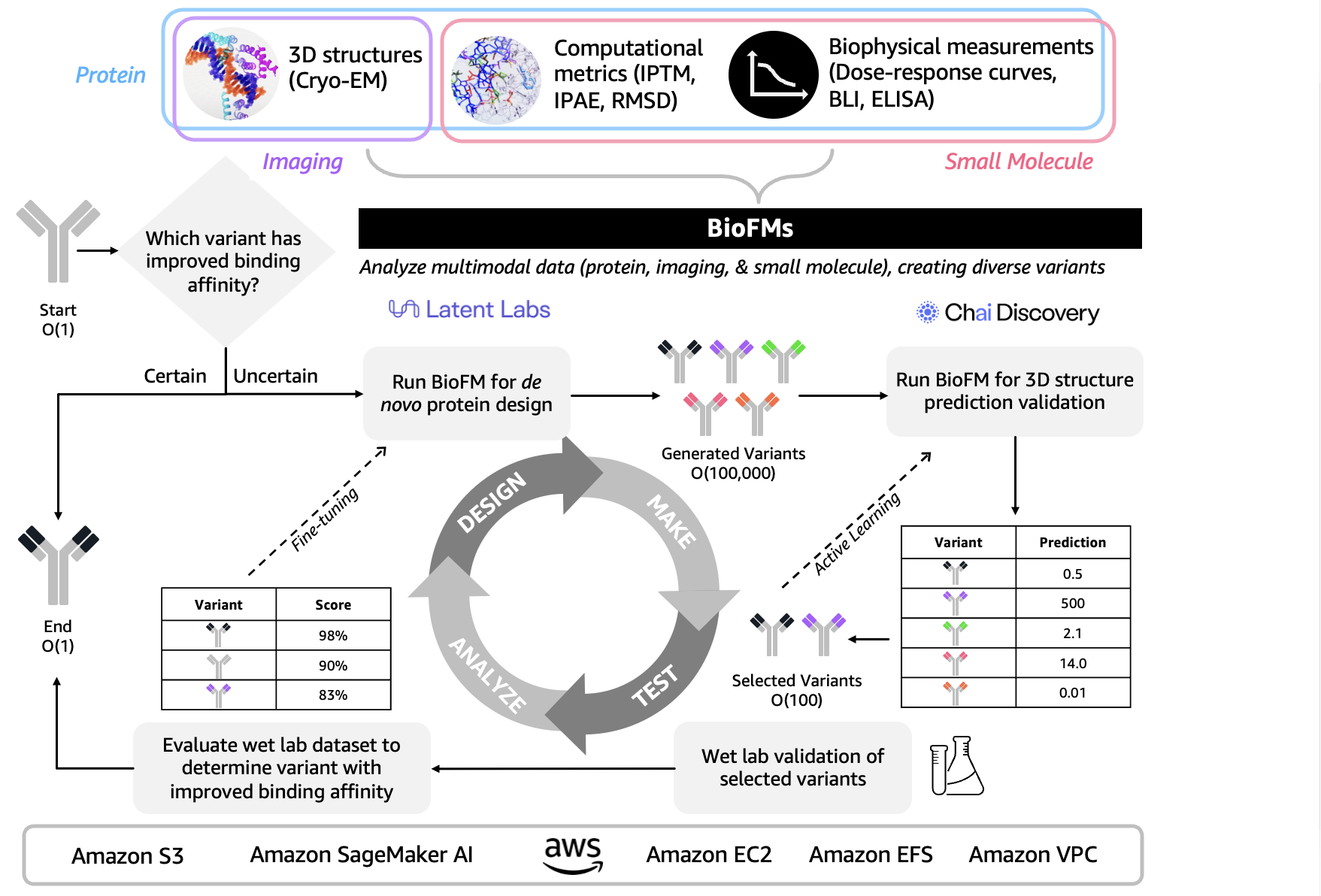
Designing therapeutic proteins for undruggable illness targets. Multimodal BioFMs integrating computational predictions, structural biology, and biophysical validation allow new approaches to beforehand inaccessible protein targets (Determine 2). Early functions predicted 3D buildings however struggled with multidomain targets that includes discontinuous epitopes. Superior drug discovery now integrates iterative design-make-test-analyze (DMTA) loops that span structural, computational, and biophysical information. The 3D protein structural information captured by means of cryo-electron microscopy (Cryo-EM) is evaluated alongside computational metrics like interface predicted template modeling rating (iPTM), interface predicted aligned error (iPAE), and root imply sq. deviation (RMSD) then validated in opposition to biophysical measurements resembling dose-response curves, biolayer interferometry (BLI), and enzyme-linked immunosorbent assay (ELISA) to speed up and de-risk drug discovery. For instance, Onava’s built-in “AI-human-wet lab” loop represents a step ahead on this house by combining generative AI for de novo protein design with fast experimental validation by means of an “epitope growth” technique, compressing design-to-validation timelines from months to weeks (Calman et al. bioRxiv 2025). It’s possible you’ll develop next-generation biologics utilizing multimodal BioFMs like Latent Labs Latent-X2 and Chai Discovery Chai-2 by means of AWS providers together with Amazon Bio Discovery, Amazon SageMaker AI for coaching generative fashions, Amazon Elastic Compute Cloud (EC2) for mannequin inference, Amazon Easy Storage Service (Amazon S3) for storing structural and experimental information, Amazon Elastic File System (EFS) for shared design libraries, and Amazon Digital Personal Cloud (VPC) for safe infrastructure.
Determine 2. Multimodal BioFMs combine 3D protein construction, computational metrics, and biophysical measurements by means of iterative design-validation loops to speed up therapeutic protein discovery for undruggable multidomain illness targets.
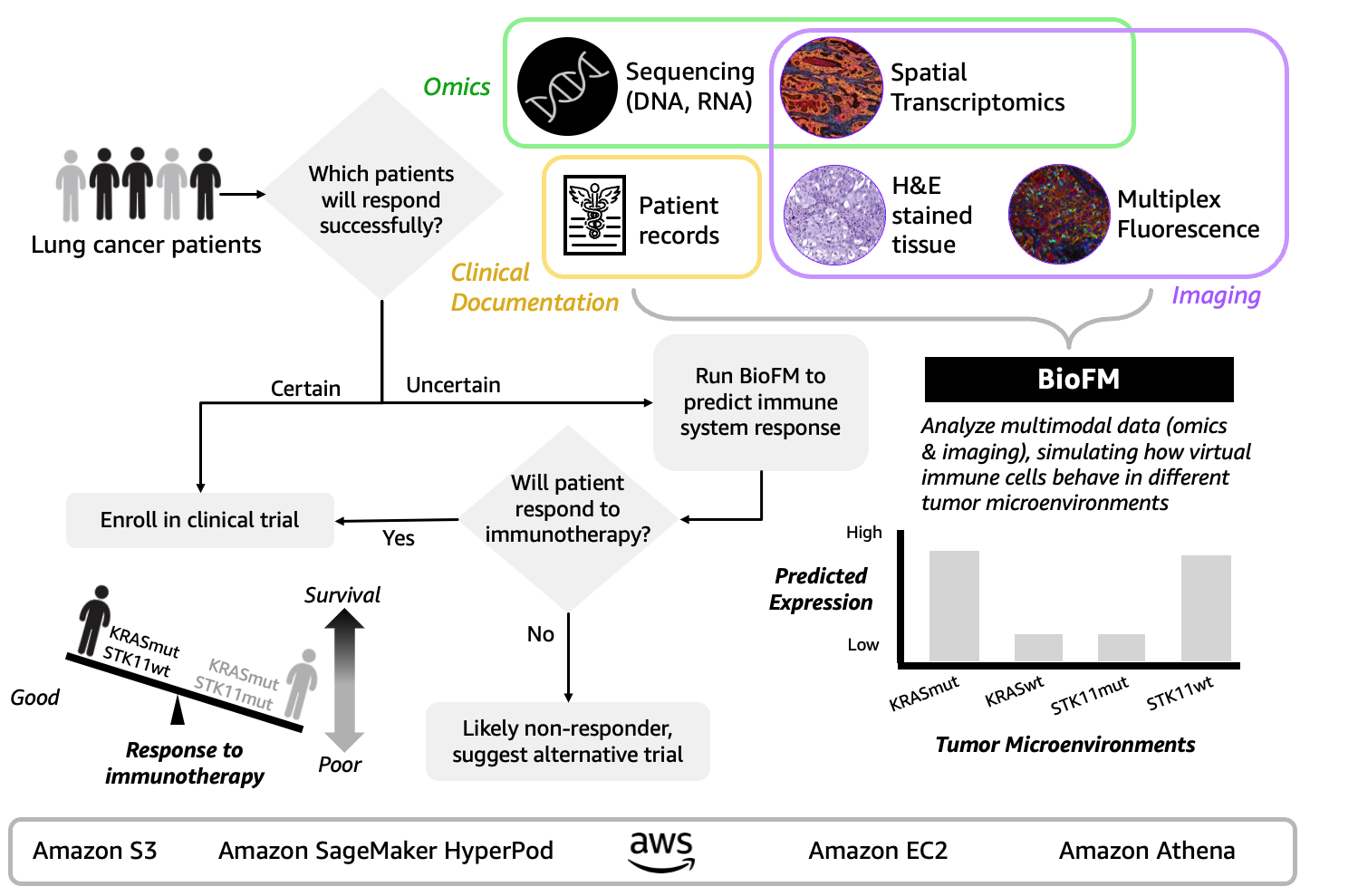
Predicting immunotherapy resistance in most cancers sufferers throughout scientific improvement. Multimodal BioFM builders work in the direction of addressing oncology’s 90% scientific trial failure fee. At present’s multimodal BioFMs simulate tumor microenvironments by integrating sequencing, single-cell information, spatial biology, and affected person data to find resistance mechanisms that cut back affected person drop-offs from ineffective therapies and uncover new therapeutic targets for beforehand untreatable affected person subgroups (Determine 3). For instance, Noetik’s Oncology Counterfactual Therapeutics Oracle (OCTO) simulated 873,000 digital immune cells throughout 1,399 affected person tumors and revealed why lung most cancers sufferers with KRAS and STK11 gene mutations develop “immune chilly” environments blocking immunotherapy effectiveness (Xie et al. Poster offered at SITC 2025). Notably, Noetik achieved 40% sooner coaching time and doubled processing pace by means of Amazon SageMaker HyperPod’s fault-tolerant infrastructure on AWS with NVIDIA H100 GPUs. You may construct your personal multimodal BioFMs can take the same strategy utilizing Amazon SageMaker HyperPod for distributed AI coaching throughout GPUs, Amazon Elastic Compute Cloud (EC2) for compute capability, Amazon Easy Storage Service (Amazon S3) for information storage, and Amazon Athena for analyzing petabytes of affected person information.
Determine 3. Multimodal BioFM strategy combines sequencing, spatial transcriptomics, pathology, and affected person data to simulate tumor microenvironments and prioritize affected person subpopulations, probably lowering early-phase trial failures
Answer: AWS atmosphere for multimodal BioFMs
AWS offers a unified atmosphere for constructing, coaching, and deploying multimodal BioFMs that aid you convert healthcare and life science information into actionable insights. This atmosphere includes 4 layers: an AI resolution for mannequin improvement, a unified information basis for organic information administration, scalable infrastructure for compute and storage, and accomplice integrations that stretch capabilities throughout the drug improvement lifecycle.
AI System
Amazon Bio Discovery offers scientists direct entry AI brokers choosing the suitable BioFMs, optimizing inputs, evaluating candidates, sending to lab companions for testing, and mechanically returning outcomes for refinement in a lab-in-the-loop cycle that builds institutional information.
Amazon SageMaker HyperPod delivers distributed coaching infrastructure for large-scale fashions. Amazon SageMaker AI compliments this with built-in explainability instruments, bias detection, and complete audit trails to help regulatory confidence wanted from mannequin improvement by means of manufacturing deployment.
Amazon Nova Forge,launched at AWS re:Invent 2025, makes use of the Amazon Nova mannequin household as a place to begin to coach at optimum factors to maximise proprietary information set studying whereas minimizing coaching and continued pretraining.
Amazon Bedrock AgentCore consists of the Runtime service to host long-running deep analysis brokers and the Gateway service to securely join brokers to BioFM fashions and different domain-specific instruments.
Unified Knowledge Basis
AWS HealthOmics can orchestrate multi-step AI workflows and deal with omics information (DNA, RNA, proteomics) on the petabyte scale, serving as a organic information spine that powers multimodal BioFM workflows.
AWS HealthLake and AWS HealthImaging mixture heterogeneous information into ruled lakehouses, automating harmonization throughout scientific data and medical imaging (radiology, pathology).
AWS Knowledge Change and AWS Lake Formation present “search, store, serve” entry to federated datasets from Epic, Snowflake, and proprietary sources – revealing illness mechanisms throughout most cancers, uncommon ailments, and scientific trials with out guide integration. AWS Clear Rooms allow federated studying whereas sustaining information sovereignty.
Scalable Infrastructure
AWS Associate options and implementation help
You may deploy pre-built multimodal BioFMs from companions like NVIDIA instantly by means of AWS. Mix these production-ready NVIDIA NIM microservices with AWS HIPAA-eligible imaging providers, multimodal reasoning capabilities, and parallel genomics pipelines to construct end-to-end discovery-to-clinic functions. Instance accomplice multimodal BioFMs embody:
MONAI Multimodal: Fashions mix various healthcare information—together with CT, MRI, X-ray, ultrasound, EHRs, scientific documentation, DICOM requirements, video streams, and entire slide imaging—to allow multimodal evaluation for researchers and builders.
NVIDIA Cosmos: Massive Multimodal Fashions for Science and Medication. Fashions like NVIDIA Cosmos Purpose-1-7B may very well be used for surgical robotics coaching by producing artificial datasets that mix 3D anatomical fashions, physics-based sensor information (ultrasound/RGB cameras), and procedural variation.
La-Proteina: Makes use of each protein sequence and atom-level 3D structural info to design massive, exact proteins, so it might fairly be described as a multimodal protein mannequin (sequence + construction).
You may seek the advice of with implementation companions like Loka, Deloitte, and Accenture on transitioning from proof-of-concept to manufacturing deployment for multimodal BioFMs use circumstances. These companions carry specialised experience in bioinformatics, cloud structure, and regulatory compliance to speed up time-to-value. Go to the AWS Associate Community to discover further certified companions with healthcare and life sciences competencies.
Conclusion
Multimodal BioFMs are reimagining what we will uncover about illness, remedy, and human well being. By integrating omics information, medical imaging, and scientific info, these fashions reveal hidden insights that have been beforehand troublesome to detect by means of conventional strategies. Choice makers can now make extra correct, assured choices throughout illness prognosis, remedy prediction, and therapeutic optimization.
AWS offers a unified atmosphere to beat the technical limitations of constructing and deploying multimodal BioFMs at scale. Reasonably than investing in fragmented, single-use AI options for every therapeutic space or scientific software, you’ll be able to leverage reusable basis fashions that adapt throughout therapeutics and affected person care. This method reduces time-to-value whereas preserving the flexibleness to adapt as new information sources and use circumstances emerge for multimodal BioFMs throughout therapeutics and affected person care.
To study extra about utilizing AWS for BioFM coaching or inference in a therapeutic or medical context, please contact an AWS Life Sciences consultant.
CIOs who spearhead AI adoption and worth creation can face an uphill, lonely battle as the remainder of the C-suite expects near-term outcomes from the hassle. PwC’s April 2026 C-Suite Outlook report discovered that 81% of executives say that their organizations are “not less than a 12 months away from seeing significant returns past effectivity.” The race to realize these returns is aggressive and CIOs danger dropping with out confederates of their nook.
The human component stays a big issue within the potential success of AI, as with different rising applied sciences. Different CIOs, C-suite friends and board members may be invaluable assets to determine what works and what would not on the street to AI worth creation.
“It will be irresponsible to not speak to different individuals concerning the adoption of this expertise,” statedSteve Santana, CIO of ETS, an training and expertise options group.
Santana and two different CIOs discuss how they’re tapping into their private networks to assist form their method to AI.
Navigating information governance and safety issues
Making use of AI on the enterprise degree comes with numerous huge, elementary questions. Early on within the adoption of AI at DeVry College, CIO Chris Campbell reached out to his community to debate governance and the information administration. Later, the dialog centered on use circumstances and scale.
“I have been in a number of conversations the place we have labored via: How do you discover measurable affect? How do you scale outcomes?” stated Campbell.
For Santana, early conversations along with his community gave him the angle he wanted to mood his management’s eagerness to leap into AI experimentation. He talked to his peer group about how they took safety into consideration when exploring AI and the way they had been having these discussions with their CEOs and CFOs.
“I may have been rolled over by management on how I deployed expertise early,” stated Santana. “I felt emboldened to place up these partitions to guarantee that we did it safely, and that is paid off invaluably.”
When CIOs flip to trusted members of their networks, they’ll get frank perception into what different organizations are spending on AI, what their implementation timelines appear to be and the outcomes that they’re seeing. CIOs can open these conversations as much as friends exterior of their enterprises, even to CIOs of competing firms.
Rivals, naturally won’t reveal proprietary data to at least one one other, however a big quantity of labor enterprises do with AI is broadly relevant.
“I’d verify, sure, we’re doing related issues that you simply’re chasing down. I’d additionally speak concerning the affect normally phrases,” stated Santana.
In fact, CIOs could discover they want somebody to speak to when drilling into specifics of how AI can enhance margins in a use case. Then, it is likely to be time to show to board members. Eliot Pikoulis, CIO of CFA Institute, a nonprofit that gives training to funding professionals, defined how he had an AI brainstorming session with one of many institute’s board members who additionally runs an AI middle of excellence inside a monetary providers trade resolution. Pikoulis offered his agentic technique to the board member and was capable of garner helpful suggestions.
Selecting AI providers by way of knowledgeable suggestions
The sheer quantity of AI distributors and instruments obtainable out there is staggering. A CIO alone can not feasibly sift via and consider their choices.
“When you speak to the distributors, all you hear is that we’re one of the best factor that is ever occurred. You want perspective from individuals who’ve used the merchandise,” Pikoulis stated.
In actual fact, Pikoulis was one of many individuals Santana reached out to when contemplating deploying Microsoft Copilot in his group; the 2 CIOs beforehand labored collectively and remained in contact. “Copilot appeared prefer it was a superb alternative. And I immediately began speaking to as many CEOs, CIOs, former CIOs I can get my arms on. One in all them was truly at a competitor,” Santana shared. “They’d the very same thought course of I had. It is the simpler, safer guess to go together with.” That fast suggestions gave Santana the boldness to current his management with a directive to take motion.
Pikoulis additionally talks along with his friends concerning the plethora of agentic enterprise options out there. He desires the pliability of utilizing completely different parts with an enterprise layer, reasonably than going all in with one firm.
“It is nice to speak to any person about Glean. It is in all probability one of the best enterprise agentic resolution on the market in the meanwhile as a result of it is received connectors into just about all the information sources you need to work with, however it’s a small area of interest firm,” he stated. There could also be an assumption that huge gamers would dominate this market, and that’s the place enter from different CIOs is available in. “You’d assume that the massive gamers are going to ultimately take up this market. So, then you definately begin to marvel: Which huge participant ought to I be partnering with? Who appears like they’re extra prone to come to the fore? And that is the place you need to speak to different CIOs.”
Whereas Pikoulis thinks about completely different distributors and instruments, he stays much more centered on the underlying structure, asking questions like “Who owns the information?”
“The precise structure and construction of the way you do that is, in the meanwhile, far more necessary than the precise distributors and the standard of the fashions that they are utilizing,” he stated. “That is a fantastic dialogue to have with any person.”
Campbell appears towards a future formed by agentic AI and occupied with how governance might want to adapt to account for the proliferation of brokers throughout complete enterprise ecosystems.
“How are we going to know what they’re, what they’re doing and who provides them permissions?” he stated. “That’s going to be a spot I will be spending numerous time with my peer group.”
CIOs are additionally occupied with what AI means for the way forward for the human workforce. Will it’s a instrument that augments staff, or is it going to gasoline increasingly more layoffs? They don’t seem to be going to be the only real decisionmakers for his or her enterprises’ method to automation, however they’re key stakeholders in these conversations.
“That moral setup to what you are doing and why you are doing it is a huge dialogue that now we have inside the expertise group,” stated Pikoulis.
Samsung Galaxy Z Fold 8 might shrink its selfie digicam cutout from 3.7mm to 2.5mm, and the identical could possibly be seen on the Huge model.
Each telephones are anticipated to make use of a 10MP selfie digicam, so don’t count on higher photograph high quality.
Launch is anticipated round late July alongside the Galaxy Z Flip 8.
Samsung might need a intelligent transfer deliberate for the Galaxy Z Fold 8. In response to latest rumors, the book-style foldable’s entrance digicam cutout might shrink from 3.7mm on the Fold 7 to simply 2.5mm, supplying you with just a little extra display screen on the duvet show. Now, a brand new rumor says the Z Fold 8 Huge might get the identical replace.
A Weibo submit by dependable leaker Ice Universe says the Galaxy Z Fold 8 Huge will use the identical improved selfie digicam because the common Fold 8. This implies a smaller 2.5mm digicam cutout, which is a small however welcome change that trims the bezel and offers you a bit extra display screen area.
The rumor additionally says each telephones can have a 10MP selfie digicam, similar to the Galaxy Z Fold 7. So, you would be sensible to not maintain your breath for an enormous soar in picture high quality.
Article continues beneath
The Galaxy Z Flip 8 would possibly get neglected
However Samsung’s selections look a bit complicated right here. The Galaxy Z Flip 8 doesn’t appear to be getting any digicam enhancements. Why give the big-screen fashions a cleaner entrance however depart the Flip out? We don’t have a solution both.
The leaker suggests Samsung would possibly deliver again under-display selfie cameras in future fashions. Samsung dropped this strategy with the Fold 7 final 12 months after utilizing it by way of the Fold 6. The reason being easy: hiding a digicam underneath the display screen hurts picture high quality, making pictures look hazy and smooth, which isn’t ok for video calls or selfies.
Samsung received’t deliver again under-display cameras simply to indicate off. The corporate will wait till the know-how is prepared. For now, a smaller gap punch is the center floor.
You possibly can count on the Galaxy Z Fold 8 and Fold 8 Huge to be launched in late July, together with the Flip 8.
Get the most recent information from Android Central, your trusted companion on this planet of Android
Android Central’s Take
A smaller digicam cutout is a pleasant contact, however you most likely received’t discover it a lot when watching YouTube or scrolling by way of X. Nonetheless, that’s not likely innovation; it’s only a minor design tweak. Consumers deserve greater than a “barely much less intrusive selfie cutout” as the principle characteristic. Nonetheless, no less than the Huge model will get the identical replace. It’s a small win.
AI picture processing has sped up evaluation of information from NASA’s James Webb House Telescope from years to mere days or much less, ushering in an avalanche of ground-breaking discoveries which will in any other case by no means have been made.
And now, the expertise might be used to boost the standard of photos taken by the Chile-based Vera C. Rubin Observatory, the latest astronomy energy home, to make them seem as sharp as if they’ve been taken from house.
The Vera C. Rubin Observatory, named after the American astronomer who found one of many key items of proof for the existence of darkish matter, sits atop the 8,770-feet (2,673 meters ) Cerro Pachón within the Chilean Andes. The telescope started operations final 12 months. It scans the complete sky each three nights, aiming to create a 10-year timelapse of the motions of objects within the sky.
Its place in Chile’s Atacama Desert, probably the most parched area on the planet, permits the observatory to learn from a dry environment and a year-round clear sky. Nonetheless, Rubin’s observations endure from vital distortions, as gentle from distant celestial objects should go by means of Earth’s environment earlier than it hits the telescope’s detectors.
A brand new AI algorithm developed by researchers from the College of California, Santa Cruz (UCSC) will now try to take away this distortion and enhance the decision of the pictures to make them look as if they’ve been taken from house.
“Floor-based telescopes endure from blurring owing to atmospheric turbulence as the sunshine comes by means of,” Brant Robertson, a professor of astronomy and astrophysics at UCSC, whose staff developed the brand new AI mannequin, informed House.com. “We spend some huge cash on high-performance expertise to take away that atmospheric distortion, however we are able to additionally prepare AI machine studying fashions to take out a few of that blurring.”
The researchers skilled the generative mannequin, referred to as Neo, utilizing photos taken by the Subaru Telescope in Japan and snaps of the identical sections of the sky captured by the Hubble House Telescope. The duty for the mannequin was to learn to fill the main points lacking within the photos taken from Earth. The outcomes had been spectacular. The researchers mentioned in a paper that the Neo mannequin “improves the accuracy of measured morphological parameters by elements of 2-10.”
Breaking house information, the most recent updates on rocket launches, skywatching occasions and extra!
In apply, meaning an elevated decision that reveals an unlimited amount of particular person stars and exact shapes of galaxies the place earlier than one would discover solely imprecise smudges.
“The mannequin improves the spatial high quality of that information and recovers, in a statistical sense, the properties of galaxies that you just see in these photos as in the event that they had been seen by a telescope in house,” Robertson mentioned.
The expertise, he added, super-charges discovery and permits the scientific group to maximise the scientific return on cash invested into cutting-edge astronomical telescopes. The Vera C. Rubin Observatory in Chile, fitted with a 27.6-foot (8.4 m) mirror, price $800 million to construct. That, nevertheless, remains to be solely a fraction of the price of space-based telescopes similar to Hubble and James Webb, each of which price billions to construct and function.
“We spend some huge cash, enormous quantities of sources, on astronomical observatories, and we want to leverage that funding by the general public and by the group to get every part that we are able to out of the info,” mentioned Robertson.
Comparability of photos taken by (from left to proper) an Earth-based telescope, the Hubble House Telescope and people improved by the Neo AI community. (Picture credit score: NAOJ/NASA/UCSC)
The Neo mannequin is a Conditional Generative Adversarial Community, a collaboration of two neural networks, steadily used for AI picture technology. Within the case of Neo, the primary community generates improved photos from the captured images; the opposite evaluates their high quality.
The mannequin relies on an earlier expertise Robertson’s staff developed to hurry up processing of photos from Webb. The $10 billion astronomical powerhouse produces such huge portions of information that it is unattainable to maintain on prime of it utilizing simply visible evaluation by human astronomers. AI algorithms, just like the one developed by Robertson and his colleagues, accomplish what would have taken people years, in mere days.
“We’re being inundated with such an quantity of information that it’s extremely troublesome to maintain up with,” mentioned Robertson. “Our commonplace approaches to analyzing these photos are simply actually not ample.”
The algorithm, working on NVIDIA’s GPU-powered supercomputers, has made among the most jaw-dropping discoveries within the Webb period, together with recognizing complicated galaxies within the earliest universe, which astronomers didn’t count on.
“The mannequin analyzes each pixel and distinguishes whether or not it is a part of the sky or part of an object,” mentioned Robertson. “And if it is an object, is it part of a disk galaxy or a spheroid galaxy or part of a star?”
(Picture credit score: NVIDIA/UCSC/Robertson et al)
Robertson added that the algorithm shouldn’t be changing astronomers. Relatively, it helps them make discoveries quicker, and in addition detect patterns that they could overlook.
“AI shouldn’t be going to be pure or full, however in fact, neither are people and conventional methodologies. All of them have completely different strengths and advantages,” he mentioned.
The astronomers are making the processed photos obtainable to different groups and the general public to discover.
The paper describing the Leo mannequin, which can assist enhance the decision of photos from the Vera Rubin Observatory, has been accepted for publication within the Astrophysical Journal.
Most information scientists study pandas by studying tutorials and copying patterns that work.
That’s high-quality for getting began, nevertheless it usually ends in newcomers growing unhealthy habits. Using iterrows() loops, intermediate variable assignments, and repetitive merge() calls are some examples of code that’s technically correct however slower than obligatory and harder to learn than it must be.
The patterns under should not edge circumstances. They cowl the most typical each day operations in information science, resembling filtering, reworking, becoming a member of, grouping, and computing conditional columns.
In every of them, there’s a widespread strategy and a greater strategy, and the excellence is usually one in all consciousness moderately than complexity.
These six have the best affect: methodology chaining, the pipe() sample, environment friendly joins and merges, groupby optimizations, vectorized conditional logic, and efficiency pitfalls.
# Methodology Chaining
Intermediate variables could make code really feel extra organized, however usually simply add noise. Methodology chaining permits you to write a sequence of transformations as a single expression, which reads naturally and avoids naming objects that don’t want distinctive identifiers.
When chaining, the present state of the DataFrame can’t be accessed by identify; it’s a must to use a lambda to consult with it. Essentially the most frequent explanation for chains breaking is forgetting this, which usually ends in a NameError or a stale reference to a variable that was outlined earlier within the script.
One different mistake value figuring out is using inplace=True inside a series. Strategies with inplace=True return None, which breaks the chain instantly. In-place operations must be averted when writing chained code, as they provide no reminiscence benefit and make the code more durable to comply with.
# The Pipe() Sample
When one in all your transformations is sufficiently complicated to deserve its personal separate perform, utilizing pipe() means that you can keep it contained in the chain.
pipe() passes the DataFrame as the primary argument to any callable:
This retains complicated transformation logic inside a named, testable perform whereas preserving the chain. Every piped perform may be individually examined, which is one thing that turns into difficult when the logic is hidden inline inside an intensive chain.
The sensible worth of pipe() extends past look. Dividing a processing pipeline into labeled capabilities and linking them with pipe() permits the code to self-document. Anybody studying the sequence can perceive every step from the perform identify without having to parse the implementation.
It additionally makes it straightforward to swap out or skip steps throughout debugging: should you remark out one pipe() name, the remainder of the chain will nonetheless run easily.
# Environment friendly Joins And Merges
One of the vital generally misused capabilities in pandas is merge(). The 2 errors we see most frequently are many-to-many joins and silent row inflation.
If each dataframes have duplicate values within the be a part of key, merge() performs a cartesian product of these rows. For instance, if the be a part of key will not be distinctive on not less than one facet, a 500-row “customers” desk becoming a member of to an “occasions” desk may end up in tens of millions of rows.
This doesn’t increase an error; it simply produces a DataFrame that seems appropriate however is bigger than anticipated till you look at its form.
This raises a MergeError instantly if the many-to-one assumption is violated. Use “one_to_one”, “one_to_many”, or “many_to_one” relying on what you count on from the be a part of.
The indicator=True parameter is equally helpful for debugging:
This parameter provides a _merge column exhibiting whether or not every row got here from “left_only”, “right_only”, or “each”. It’s the quickest technique to catch rows that failed to hitch whenever you anticipated them to match.
In circumstances the place each dataframes share an index, be a part of() is faster than merge() since it really works immediately on the index as a substitute of looking by a specified column.
# Groupby Optimizations
When utilizing a GroupBy, one underused methodology is remodel(). The distinction between agg() and remodel() comes right down to what form you need again.
The agg() methodology returns one row per group. Then again, remodel() returns the identical form as the unique DataFrame, with every row crammed with its group’s aggregated worth. This makes it best for including group-level statistics as new columns with out requiring a subsequent merge. Additionally it is sooner than the handbook mixture and merge strategy as a result of pandas doesn’t must align two dataframes after the very fact:
This immediately provides the common income for every phase to every row. The identical consequence with agg() would require computing the imply after which merging again on the phase key, utilizing two steps as a substitute of 1.
For categorical groupby columns, at all times use noticed=True:
With out this argument, pandas computes outcomes for each class outlined within the column’s dtype, together with combos that don’t seem within the precise information. On giant dataframes with many classes, this ends in empty teams and pointless computation.
# Vectorized Conditional Logic
Utilizing apply() with a lambda perform for every row is the least environment friendly technique to calculate conditional values. It avoids the C-level operations that pace up pandas by operating a Python perform on every row independently.
For binary circumstances, NumPy‘s np.the place() is the direct alternative:
The np.choose() perform maps on to an if/elif/else construction at vectorized pace by evaluating circumstances so as and assigning the primary matching choice. That is normally 50 to 100 occasions sooner than an equal apply() on a DataFrame with one million rows.
For numeric binning, conditional task is totally changed by pd.minimize() (equal-width bins) and pd.qcut() (quantile-based bins), which mechanically return a categorical column with out the necessity for NumPy. Pandas takes care of every thing, together with labeling and dealing with edge values, whenever you cross it the variety of bins or the bin edges.
# Efficiency Pitfalls
Some widespread patterns decelerate pandas code greater than anything.
For instance, iterrows() iterates over DataFrame rows as (index, Collection) pairs. It’s an intuitive however sluggish strategy. For a DataFrame with 100,000 rows, this perform name may be 100 occasions slower than a vectorized equal.
The shortage of effectivity comes from constructing an entire Collection object for each row and executing Python code on it separately. Each time you end up writing for _, row in df.iterrows(), cease and think about whether or not np.the place(), np.choose(), or a groupby operation can exchange it. More often than not, one in all them can.
Utilizing apply(axis=1) is quicker than iterrows() however shares the identical drawback: executing on the Python stage for every row. For each operation that may be represented utilizing NumPy or pandas built-in capabilities, the built-in methodology is at all times sooner.
Object dtype columns are additionally an easy-to-miss supply of slowness. When pandas shops strings as object dtype, operations on these columns run in Python moderately than C. For columns with low cardinality, resembling standing codes, area names, or classes, changing them to a categorical dtype can meaningfully pace up groupby and value_counts().
df['status'] = df['status'].astype('class')
Lastly, keep away from chained task. Utilizing df[df['revenue'] > 0]['label'] = 'constructive' might alter the preliminary DataFrame, relying on whether or not pandas generated a duplicate behind the scenes. The habits is undefined. Make the most of .loc alongside a boolean masks as a substitute:
That is unambiguous and raises no SettingWithCopyWarning.
# Conclusion
These patterns distinguish code that works from code that works effectively: environment friendly sufficient to run on actual information, readable sufficient to take care of, and structured in a manner that makes testing straightforward.
Methodology chaining and pipe() deal with readability, whereas the be a part of and groupby patterns deal with correctness and efficiency. Vectorized logic and the pitfall part deal with pace.
Most pandas code we evaluate has not less than two or three of those points. They accumulate quietly — a sluggish loop right here, an unvalidated merge there, or an object dtype column no one seen. None of them causes apparent failures, which is why they persist. Fixing them separately is an inexpensive place to begin.
Nate Rosidi is a knowledge scientist and in product technique. He is additionally an adjunct professor educating analytics, and is the founding father of StrataScratch, a platform serving to information scientists put together for his or her interviews with actual interview questions from high firms. Nate writes on the most recent tendencies within the profession market, offers interview recommendation, shares information science tasks, and covers every thing SQL.
A brand new Xbox 360 emulator for Android has surfaced on-line, though you may’t obtain it but.
An unofficial video provides us an in-depth have a look at the so-called X360 Cell app, displaying the setup course of and a wide range of video games.
The developer might doubtlessly launch an alpha model of the app to the general public on the finish of Might.
Xbox 360 emulation on Android was a pipe dream till final yr, when the aX360e emulator arrived on the platform. Nevertheless, one other Xbox 360 emulator is within the works for Android, and whereas we’re nonetheless considerably skeptical, this could be the true deal.
YouTube movies purportedly displaying an emulator dubbed X360 Cell have surfaced within the final two weeks. The clips declare to indicate numerous video games in motion on the AYN Odin 3 handheld. We had been extraordinarily skeptical at first, because it’s not unusual to see faux or mispresented YouTube movies of this nature. Moreover, the channel claims that the emulator remains to be in growth and never obtainable for obtain simply but.
Don’t wish to miss one of the best from Android Authority?
Nevertheless, Spanish YouTube channel El Poder del Androide Verde apparently acquired their arms on a working model of X360 Cell from the nameless developer. The channel posted an intensive video together with a deep dive on their web site, that includes a prolonged Q&A with the developer. It additionally seems to be just like the developer could be the supply of the aforementioned YouTube movies, as they verify that they’re certainly utilizing an Odin 3 handheld to create the emulator.
The developer insists through the interview that X360 Cell isn’t a fork of the sooner aX360e emulator, however is definitely primarily based on the Xenia Canary Arm construct. The aX360e emulator relies on the usual Xenia Arm model however purportedly incorporates “many of the code” from the Canary model.
The outlet’s video provides us have a look at the app’s interface, which includes a nice Metro-style UI. The host additionally runs X360 Cell by means of an antivirus verify in an try to assuage malware considerations. Moreover, we get a have a look at the setup course of, and it seems that the app certainly helps customized Turnip drivers.
What about gameplay, then? The outlet’s video reveals a wide range of titles operating by way of the emulator on a Galaxy S25 Extremely, with various levels of efficiency. Video games like Fortress Crashers, Arkanoid, and Rayman Origins ran very easily. In the meantime, titles like Ace Fight Assault Horizon and Forza Horizon had been a step above slideshows and never playable for most individuals. The video host additionally notes that no less than one sport (Dragon Ball: Raging Blast 2) which was proven to run at ~60fps on the developer’s YouTube channel solely runs at ~30fps on their Samsung handset. This means that Samsung software program could possibly be the problem. The developer’s official web site additionally incorporates a compatibility record. Nevertheless, I’d take this with a grain of salt as some “playable” video games run at a slideshow’s tempo in YouTube clips.
The developer additionally revealed system necessities on their web site, confirming that you just want a Snapdragon chipset with Adreno 600 to 800 collection graphics, no less than 6GB of RAM, Android 12 or newer, and customized Turnip drivers for playable efficiency. Nevertheless, they particularly name for a Snapdragon 8 Gen 1 processor and 8GB of RAM for one of the best expertise. A earlier launch launched compatibility with Mali GPUs, however the developer clarifies that that is solely “partial” assist. So don’t anticipate your MediaTek-powered telephone to run video games any time quickly.
Do be cautious of any web sites claiming to supply the app, although, because it’s apparently restricted to simply 4 personal testers proper now. The Spanish outlet experiences that an alpha model (v0.5) could possibly be launched to the general public by way of the official web site on the finish of Might. Moreover, the developer goals to finally supply the app by way of the Google Play Retailer.
Once more, we’re nonetheless a little bit skeptical about X360 Cell, particularly within the period of vibe-coded apps. Moreover, the developer is outwardly undecided about whether or not or not this shall be an open-source undertaking. An open-source strategy could be the way in which to go for safety functions, as it will permit anybody to comb by means of the code. Nevertheless, we do recall seeing different builders preserve elements of their undertaking closed-source. In any occasion, we’d undoubtedly advocate you take a look at the El Poder del Androide Verde article and YouTube video for many extra particulars about this undertaking.
Thanks for being a part of our group. Learn our Remark Coverage earlier than posting.