I used to be promoted to CTO in my late twenties, and whereas it is not uncommon to see younger CTOs main startups nowadays, it was uncommon within the ‘90s. I used to be far much less skilled again then, and nonetheless growing my enterprise acumen. Whereas I used to be a powerful software program developer, it wasn’t my structure and coding abilities that helped me transition to a C-level position.
Of all of the technical abilities I had again then, my devops abilities had been essentially the most essential. After all, we didn’t name it devops, because the time period hadn’t been invented but. We didn’t but have CI/CD pipelines or infrastructure-as-code capabilities. Nonetheless, I automated our builds, scripted the deployments, standardized infrastructure configurations, and monitored methods efficiency.
Growing that scaffolding enabled our improvement groups to give attention to constructing and testing purposes whereas operations managed infrastructure enhancements. With automation in place and a staff centered on the know-how, I used to be in a position to give attention to higher-level duties resembling understanding buyer wants, partnering with product managers, studying advertising aims, and studying about gross sales operations. When our CTO left for an additional alternative, I used to be given the possibility to step into the management position.
A federal agent shoves a girl to the bottom. A younger man walks over to assist her up. Then the agent pepper-sprays them each.
Regardless of the burning in his eyes, the younger man retains attempting to get the lady upright — till a pack of masked, camouflaged officers wrestle him to the road.
They beat him. He writhes in ache. An agent realizes that he has a firearm holstered on his waist and confiscates it. Somebody shouts, “Gun.” An officer fires a shot into the younger man’s again — then retains firing as he collapses. Now, a second agent is firing too. Bullet after bullet right into a immobile physique. Screams from bystanders as the entire world shakes.
That is what practically everybody with eyes and an web connection noticed Saturday, when Border Patrol brokers gunned down 37-year-old Alex Pretti in Minneapolis.
The ICU nurse’s closing moments had been caught on a number of cellphone movies, every depicting one of the vital horrifying “officer-involved” shootings of an period that’s seen loads, together with ICE’s killing of Renee Good in the identical metropolis, lower than three weeks earlier.
Nonetheless, administration officers selected to defend the federal government’s killing of a US citizen with incendiary lies.
The Division of Homeland Safety claimed that Pretti had “approached officers with a 9mm semi-automatic handgun,” forcing them to fireplace “defensive pictures.” DHS Secretary Kristi Noem steered that Pretti had been attempting to perpetrate an act of “home terrorism” that aimed “to inflict most harm on people and to kill regulation enforcement.”
Border Patrol Commander Gregory Bovino mentioned Pretti deliberate to “bloodbath” federal brokers.
And White Home adviser Stephen Miller declared the VA nurse a “would-be murderer” who had “tried to homicide federal regulation enforcement.”
All these remarks had the identical chilling subtext: Actuality was no constraint on the administration’s assist for violence dedicated in its agenda’s title. DHS was ready to say issues that contradicted all accessible proof, so as to shield its brokers from authorized accountability.
This proved a bit too Orwellian, even for Trump’s allies.
Many Republican senators, governors, and influencers known as for an intensive investigation into Pretti’s killing, as did the NRA. In the meantime, in interviews with CBS Information, nameless DHS officers complained that the administration was squandering its credibility by attempting to “gaslight and contradict what the general public can plainly see with their very own eyes.”
By Monday, the White Home was beating a retreat. Most importantly, the president demoted Bovino, sending him again to his previous job as chief of Border Patrol’s sector in El Centro, California. Trump additionally deployed his (seemingly extra average) border czar Tom Homan to Minnesota, in a bid to fix fences with its management. Trump subsequently mentioned he had a “excellent name” with Minnesota’s Democratic Gov. Tim Walz, saying they each wished to make situations in Minneapolis higher.
On the similar time, administration officers stopped asserting that Pretti’s killing was justified, saying as a substitute that an investigation was crucial to find out that.
These are heartening developments. It was removed from sure whether or not any substantial variety of Republican officers would publicly critique the White Home’s posture.
In any case, the administration’s practically similar response to Renee Good’s killing didn’t encourage comparable intraparty criticism. When an ICE agent killed the 37-year-old mom, the administration had smeared her as a “home terrorist,” claiming that she had deliberately run over the agent, who’d sustained life-threatening accidents within the encounter — a story blatantly contradicted by video proof.
Voters selected to consider their very own eyes. By a 54 to twenty-eight % margin, they informed a CBS Information/YouGov ballot that Good’s killing was unjustified. Nonetheless, even because the administration selected to launch a punitive investigation into Good’s widow, conservative pushback remained muted.
It’s comforting to know that there’s a diploma of depravity that Republicans received’t tolerate. And it’s equally reassuring that the White Home shouldn’t be wholly detached to in style backlash.
Nonetheless, it’s vital to withstand this administration’s newest makes an attempt to induce collective amnesia.
When the White Home says that it might’t but decide whether or not Pretti was lawfully killed, it’s admitting that our nation’s highest-ranking immigration officers shamelessly misled the American individuals, in order to defame a slain US citizen.
An administration that had any honest regrets about DHS’s perfidy would relieve Miller and Noem of their positions throughout the Cupboard, whereas denying Bovino any function inside Border Patrol.
Over the previous 48 hours, America has taken child steps again from the brink. However our republic received’t be on sound footing till Trump beats a far deeper retreat.
An enormous photo voltaic flare on our solar was powered by an avalanche of smaller magnetic disturbances, offering the clearest perception but into how power from our star is launched in a torrent of high-energy ultraviolet mild and X-rays. The invention was made by the European Area Company (ESA) Photo voltaic Orbiter mission, which is imaging the solar from nearer than any spacecraft earlier than it.
Some photo voltaic flares may end up in coronal mass ejections (CMEs) – large plumes of plasma blown off the solar’s corona and into deep house. If their trajectory away from the solar intersects with Earth‘s location, they will set off geomagnetic storms that may injury satellites and energy grids whereas disrupting communications, and dazzle us with colourful auroral lights.
The extra we study how photo voltaic flares are triggered, the higher ready we might be to foretell when a dangerous flare and CME is about to happen. Photo voltaic Orbiter’s new observations are a significant step in direction of having the ability to do that.
“This is likely one of the most enjoyable outcomes from Photo voltaic Orbiter up to now,” Miho Janvier, who’s the ESA co-Venture Scientist on Photo voltaic Orbiter, stated in a assertion. “Photo voltaic Orbiter’s observations unveil the central engine of a flare and emphasize the essential function of an avalanche-like magnetic power launch mechanism at work.”
Attending to the underside of photo voltaic flares
On Sept. 30, 2024, Photo voltaic Orbiter got here inside 27 million miles (43.3 million kilometers) of the solar, when it witnessed the eruption of a medium-class photo voltaic flare. Because of 4 of Photo voltaic Orbiter’s devices working in unison to watch the flare, scientists have, for the primary time, seen how smaller magnetic instabilities can construct up into a big flare, like an avalanche on a snowy mountainside originating from a comparatively small disturbance.
“We had been actually very fortunate to witness the precursor occasions of this massive flare in such lovely element,” analysis lead creator Pradeep Chitta of the Max Planck Institute for Photo voltaic System Analysis, Germany, stated. “We actually had been in the correct place on the proper time to catch the wonderful particulars of this flare.”
Photo voltaic flares are the product of magnetic reconnection. That is when magnetic discipline traces on the solar, laced with high-energy plasma, turn out to be taut and snap, releasing large quantities of power earlier than the sphere traces reconnect. The exact origins of photo voltaic flares, nonetheless, have been secretive. Are they a single highly effective eruption, or an accumulation of smaller reconnection occasions? For the 30 September flare at the very least, Photo voltaic Orbiter discovered the reply.
Breaking house information, the newest updates on rocket launches, skywatching occasions and extra!
Beginning with its Excessive Ultraviolet Imager (EUI), Photo voltaic Orbiter witnessed the technology of the flare over the course of 40 minutes. EUI detected adjustments within the magnetic surroundings of the solar’s corona native to the eruption level of the flare, capturing particulars as small as a number of hundred kilometers on timescales of lower than two seconds, which is the time coated in every picture body.
The spacecraft noticed an arching filament constituted of entwined magnetic fields carrying plasma and linked to a cross-shaped area of magnetic exercise laced with extra magnetic discipline traces. It watched because the area grew more and more unstable, discipline traces snapping and reconnecting, releasing bursts of power that appeared as brilliant factors of sunshine.
A snapshot of the solar captured by Photo voltaic Orbiter moments earlier than a robust photo voltaic flare was unleashed. (Picture credit score: ESA & NASA/Photo voltaic Orbiter/EUI Group)
These bursts had been the start of the avalanche. They triggered a series response of more and more highly effective reconnection occasions. At one level, the arching filament indifferent from certainly one of its anchor factors on the solar and launched out into house, blown by the ferocity of the photo voltaic wind. The cascade of smaller reconnection occasions shortly gathered steam earlier than culminating as a medium-class flare.
“These minutes earlier than the flare are extraordinarily essential, and Photo voltaic Orbiter gave us a window proper into the foot of the flare the place this avalanche course of started,” stated Chitta. “We had been stunned by how the big flare is pushed by a sequence of smaller reconnection occasions that unfold quickly in house and time.”
Three different devices aboard the Photo voltaic Orbiter – SPICE (Spectral Imaging of the Coronal Setting), STIX (X-ray spectrometer/Telescope) and PHI (Polarimetric and Helioseismic Imager) – additionally noticed the flare, measuring occasions at totally different depths within the solar’s environment, from the outer environment, the corona, all the best way all the way down to the seen floor of the solar, referred to as the photosphere. They captured waves of big blobs of plasma, which gained their power from magnetic fields, raining from the corona down onto the photosphere.
“We noticed ribbon-like options transferring extraordinarily shortly down by way of the solar’s environment, even earlier than the primary episode of the flare,” stated Chitta. “These streams of raining plasma blobs are signatures of power deposition, which get stronger and stronger because the flare progresses. Even after the flare subsides, the rain continues for a while.”
After the flare reached peak power, throughout which X-ray ranges rose dramatically, and charged particles had been accelerated to between 40 and 50 % of the pace of sunshine, the cross-shaped magnetic area started to calm down. The plasma cooled, and particle emission decreased to regular ranges. Chitta described how utterly sudden it was that the avalanche course of may drive such high-energy particles.
The avalanche mannequin of weaker disturbances cascading into one thing extra severe had beforehand been proposed to elucidate the collective habits of a whole lot of 1000’s of flares all throughout the solar, however till now, it hadn’t actually been thought of that it may apply to a single flare.
There are two essential questions to return out of this. First, are all of the flares on the solar produced as an avalanche? “What we noticed challenges present theories for flare-energy launch,” stated David Pontin of the College of Newcastle, Australia, who was a part of the workforce analyzing the Photo voltaic Orbiter information.
Additional observations of photo voltaic flares might be required to make clear this.
Second, our solar isn’t the one star to have flares. They erupt from all stars, and a few stellar our bodies, similar to purple dwarfs, have way more highly effective and extra frequent flares than the solar.
“An fascinating prospect is whether or not this mechanism occurs in all flares, and on different flaring stars,” stated Janvier.
The outcomes from Photo voltaic Orbiter’s observations of the 30 September 2024 flare had been revealed on Jan. 21 within the journal Astronomy & Astrophysics.
JavaScript is among the most helpful programming languages for college students who need to perceive how web sites and interactive functions work. It permits learners to create dynamic content material similar to buttons, types, video games and instruments that reply to person actions. For college kids, studying JavaScript turns into a lot simpler once they apply by means of tasks as a substitute of solely studying concept or memorizing syntax. Initiatives enable the combination of ideas with sensible functions. Colleges and faculties are emphasizing skill-based studying in the course of the educational 12 months 2026 to 2027. This weblog on 20+ JavaScript challenge concepts for college students in 2026-27 contains easy, sensible, and beginner-friendly challenge concepts that assist college students enhance logic, confidence, and problem-solving abilities step-by-step.
How Initiatives Assist College students Study JavaScript Higher
Engaged on JavaScript tasks provides college students an actual studying expertise past textbooks.
Helps college students apply ideas in sensible conditions.
Improves logical considering and drawback fixing abilities.
Makes capabilities, loops and situations simpler to grasp.
Builds confidence by creating working functions.
Encourages unbiased studying.
Teaches college students methods to discover and repair errors.
Makes coding extra attention-grabbing and fulfilling.
What College students Want Earlier than Beginning JavaScript Initiatives
College students don’t want costly software program or superior techniques to start JavaScript tasks.
Create a calculator that performs primary math operations utilizing buttons. Studying End result: Capabilities, operators, and click on occasions.
2. To-Do Checklist Software
Customers can add duties, mark them full, and delete them. Studying End result: DOM manipulation and arrays.
3. Digital Clock
Mechanically updates each second and shows the present time. Studying End result: Date objects and timing capabilities.
4. Random Quote Generator
Shows a brand new quote every time a button is chosen. Studying End result: Arrays and random quantity logic.
5. Quantity Guessing Sport
This system generates a quantity and the person tries to guess it. Studying End result: Conditional statements and loops.
6. Temperature Converter
Converts values between Celsius and Fahrenheit. Studying End result: Enter dealing with and calculations.
7. Counter Software
A easy counter with improve, lower, and reset buttons. Studying End result: Occasion listeners and state modifications.
8. Quiz Software
Shows questions with choices and calculates the ultimate rating. Studying End result: Logic constructing and situations.
9. Password Generator
Generates random passwords utilizing letters and numbers. Studying End result: String manipulation and randomness.
10. Colour Picker Software
Permits customers to pick out colours and reveals colour codes. Studying End result: Enter occasions and elegance updates.
11. Picture Slider
Mechanically or manually switches between pictures. Studying End result: Timers and array indexing.
12. Phrase Counter
Counts phrases and characters entered by the person. Studying End result: String strategies and enter monitoring.
13. Login Kind Validation
Checks whether or not kind fields are crammed accurately. Studying End result: Validation logic.
14. Stopwatch
A stopwatch with begin, cease, and reset capabilities. Studying End result: Time management utilizing JavaScript.
15. Easy Climate Show
Shows pattern climate data similar to temperature. Studying End result: Object dealing with and information show.
16. Music Participant (Fundamental)
Performs and pauses audio information utilizing buttons. Studying End result: Media dealing with and occasions.
17. Expense Tracker
Tracks every day bills entered by the person. Studying End result: Information storage and calculations.
18. Typing Velocity Take a look at
Measures typing velocity and accuracy. Studying End result: Timers and textual content comparability.
19. Cube Rolling Sport
Generates random numbers like a cube. Studying End result: Math capabilities and randomness.
20. Flashcard Studying App
Reveals questions and solutions for revision. Studying End result: Toggle logic and interplay.
21. Polling System
Permits customers to vote and reveals outcomes. Studying End result: Counting logic.
22. Easy Chat Interface
Shows messages in a chat format. Studying End result: Dynamic content material updates.
Tips on how to Select the Proper JavaScript Undertaking
Choosing the proper challenge helps college students be taught successfully.
Begin with beginner-level tasks.
Keep away from complicated concepts to start with.
Select tasks you possibly can clarify clearly.
Deal with logic as a substitute of copying code.
Maintain design easy and purposeful.
Take a look at the challenge earlier than submission.
How JavaScript Initiatives Assist in Exams and Assignments
JavaScript tasks play an vital position in inner assessments and sensible exams. When college students construct tasks themselves, they perceive the logic behind the code and might clarify it confidently. This reduces examination strain and improves efficiency throughout viva or displays. Initiatives additionally assist college students keep in mind ideas longer as a result of they be taught by means of apply. Lecturers often give higher marks to college students who present understanding, even when the challenge is straightforward.
For those who face any difficulties whereas creating your JavaScript tasks, we can assist! Our JavaScript task assist guides you step-by-step and resolves any challenges you face, making certain your challenge works completely. Whether or not it’s debugging, logic points, or code implementation our group offers the assistance you have to succeed.
Presentation Suggestions for JavaScript Initiatives
Good presentation can enhance grades and confidence.
Use clear headings and labels.
Clarify the challenge step-by-step.
Present how the challenge works.
Maintain the interface clear.
Apply clarification earlier than presentation.
Reply questions confidently
Widespread Errors College students Ought to Keep away from
Many college students lose marks on account of easy errors.
Copying code with out understanding.
Selecting superior tasks too early.
Ignoring errors and warnings.
Poor variable naming
Not testing the challenge correctly.
Speeding the challenge on the final second
Conclusion
JavaScript tasks are a wonderful means for college students to maneuver from theoretical data to sensible studying. The 20+ challenge concepts for 2026–27 are easy, straightforward to grasp and appropriate for newbies and intermediate learners alike. By engaged on these tasks, college students can strengthen their coding confidence, improve logical considering and develop drawback fixing abilities. The tasks are designed to assist college students comprehend basic programming ideas which might be helpful for his or her educational pursuits and potential technical endeavors by emphasizing real-world functions. Relatively than merely memorizing syntax, learners ought to have interaction within the means of writing, testing and enhancing their very own code. Along with getting ready college students for superior coding challenges, constant challenge work enhances the engagement, effectiveness and delight of JavaScript studying.
Continuously Requested Questions (FAQs)
1. Are JavaScript tasks appropriate for newbies?
Sure, newbies can full many tasks with primary data.
2. How lengthy does it take to finish one challenge?
Easy tasks take hours superior ones take days.
3. Do college students want superior instruments to construct JavaScript tasks?
No. Fundamental instruments and a browser are sufficient.
4. Can these tasks assist in exams or assessments?
Sure, tasks construct understanding and assist with evaluations.
5. Ought to college students work alone or in teams?
Each assist. Solo work builds independence. Teams construct teamwork.
Breakthroughs, discoveries, and DIY suggestions despatched six days every week.
Whitening your enamel typically comes at a monetary and bodily price. Lots of at the moment’s hottest merchandise together with gels, strips, and rinses depend on peroxide-based bleaching options. Whereas efficient, the chemical processes generate reactive oxygen species (ROS) compounds that not solely destroy staining molecules—they’ll ultimately erode tooth enamel. Over time, this could truly make it simpler to stain once more or trigger long-term dental well being issues.
In keeping with a examine printed within the journal ACS Nano, researchers on the Chinese language Academy of Sciences have developed another resolution that not solely whitens enamel, however repairs them, too. As a substitute of harsh chemical compounds, the brand new technique depends on vibrations.
The crew swapped peroxide for his or her new ceramic powder creation known as BSCT. To make it, they heated an answer of strontium and calcium ions in addition to barium titanate. If shaken shortly sufficient (resembling with an electrical toothbrush), the combination generates a tiny electrical discipline by way of what’s known as the piezoelectric impact. Whereas generally related to guitar amplification and electrical cigarette lighters, piezoelectricity additionally creates ROS chemical reactions which can be much like peroxide bleach.
After artificially staining human enamel with espresso and tea, researchers utilized BSCT and noticed seen whitening after 4 hours of using an electrical toothbrush. By 12 hours of brushing, the enamel had been almost 50 p.c whiter than management enamel brushed with saline. Not solely that, however BSCT truly regenerated broken dentin and enamel due to therapeutic deposits of barium, calcium, and strontium layered atop the enamel.
A second experiment concerned rats fed with high-sugar diets. Researchers brushed the rodents’ enamel for one minute per day over 4 weeks, then measured their oral microbiomes. They found the BSCT powder killed frequent mouth micro organism resembling Porphyromonas gingivalis and Staphylococcus aureus whereas additionally lowering irritation.
The crew hasn’t included BSCT powder into an precise toothpaste but, however hope to experiment with mixtures sooner or later. Within the meantime, they consider their different to harsh whitening merchandise could quickly discover their manner into dentist places of work and shops.
Start line: A hurdle mannequin with a number of hurdles
In a sequence of posts, we’re going to illustrate tips on how to get hold of right normal errors and marginal results for fashions with a number of steps.
Our inspiration for this publish is an outdated Statalist inquiry about tips on how to get hold of marginal results for a hurdle mannequin with multiple hurdle (http://www.statalist.org/boards/discussion board/general-stata-discussion/basic/1337504-estimating-marginal-effect-for-triple-hurdle-model). Hurdle fashions have the interesting property that their chances are separable. Every hurdle has its personal chance and regressors. You’ll be able to estimate every one in every of these hurdles individually to acquire level estimates. Nonetheless, you can not get normal errors or marginal results this fashion.
On this publish, we present tips on how to get the marginal results and normal errors for a hurdle mannequin with two hurdles utilizing gsem. gsem is right for this objective as a result of it permits us to estimate likelihood-based fashions with a number of equations.
The mannequin
Suppose we have an interest within the imply spending on dental care, given the attribute of the people. Some individuals spend zero {dollars} on dental care in a yr, and a few individuals spend greater than zero {dollars}. Solely the people that cross a hurdle are keen to spend a constructive quantity on dental care. Hurdle fashions permit the traits of the people that spend a constructive quantity and people who spend zero to vary.
There could possibly be multiple hurdle. Within the dental-care spending instance, the second hurdle could possibly be insurance coverage protection: uninsured, fundamental insurance coverage, or premium insurance coverage. We mannequin the primary hurdle of spending zero or a constructive quantity by a probit. We mannequin the second hurdle of insurance coverage degree utilizing an ordered probit. Lastly, we mannequin the constructive quantity spent utilizing an exponential-mean mannequin.
We have an interest within the marginal results for the imply quantity spent for somebody with premium insurance coverage, given particular person traits. The expression for this conditional imply is start{eqnarray*} Eleft(textual content{expenditure}|X, {tt insurance coverage} =textual content{premium}proper) &=& Phi(X_pbeta_p)Phileft(X_obeta_o – textual content{premium}proper) expleft(X_ebeta_eright) finish{eqnarray*} The conditional imply accounts for the chances of being in numerous threshold ranges and for the expenditure preferences amongst these spending a constructive quantity.We use the subscripts (p), (o), and (e) to emphasise that the covariates and coefficients associated to the probit, ordered probit, and exponential imply are completely different.
Beneath we are going to use gsem to estimate the mannequin parameters from simulated information. spend is a binary final result for whether or not a person spends cash on dental care, insurance coverage is an ordered final result indicating insurance coverage degree, and expenditure corresponds to the quantity spent on dental care.
The estimated probit parameters are within the spend equation. The estimated ordinal-probit parameters are within the insurance coverage equation. The estimated expenditure parameters are within the expenditure equation. We might have obtained these level estimates utilizing probit, oprobit, and poisson. With gsem, we do that collectively and acquire right normal errors when computing marginal results. Within the case of the poisson mannequin, we’re utilizing gsem to acquire an exponential imply and may interpret the outcomes from a quasilikelihood perspective. Due to the quasilikelihood nature of the issue, we use the vce(sturdy) choice.
The typical of the marginal impact of x4 is start{equation*} frac{1}{N}sum_{i=1}^N frac{partial hat{E}left(textual content{expenditure}_i|X_i, {tt insurance coverage}_iright)}{partial {tt x4}_i} finish{equation*} and we estimate it by
We used the expression() choice to jot down an expression for the anticipated worth of curiosity and predict() and eta() to indicate the linear predictions for every mannequin. We use the vce(unconditional) choice to permit the covariates to be random as a substitute of mounted. In different phrases, we’re estimating a inhabitants impact as a substitute of a pattern impact.
Ultimate issues
We illustrated tips on how to use gsem to acquire the estimates and normal errors for a a number of hurdle mannequin and its marginal impact. In subsequent posts, we are going to get hold of these outcomes utilizing different Stata instruments.
Appendix
Beneath is the code used to provide the information.
On this tutorial, we introduce Phase Something Mannequin 3 (SAM 3), the shift from geometric promptable segmentation to open-vocabulary idea segmentation, and why that issues.
First, we summarize the mannequin household’s evolution (SAM-1 → SAM-2 → SAM-3), define the brand new Notion Encoder + DETR detector + Presence Head + streaming tracker structure, and describe the SA-Co information engine that enabled large-scale idea supervision.
Lastly, we arrange the event atmosphere and present single-prompt examples to show the mannequin’s primary picture segmentation workflow.
By the top of this tutorial, we’ll have a stable understanding of what makes SAM 3 revolutionary and how one can carry out primary concept-driven segmentation utilizing textual content prompts.
This lesson is the first of a 4-part collection on SAM 3:
The discharge of the Phase Something Mannequin 3 (SAM 3) marks a definitive transition in laptop imaginative and prescient, shifting the main target from purely geometric object localization to a classy, concept-driven understanding of visible scenes.
Developed by Meta AI, SAM 3 is described as the primary unified basis mannequin able to detecting, segmenting, and monitoring all situations of an open-vocabulary idea throughout photographs and movies through pure language prompts or visible exemplars.
Whereas its predecessors (i.e., SAM 1 and SAM 2) established the paradigm of Promptable Visible Segmentation (PVS) by permitting customers to outline objects through factors, packing containers, or masks, they remained semantically agnostic. Consequently, they basically functioned as high-precision geometric instruments.
SAM 3 transcends this limitation by introducing Promptable Idea Segmentation (PCS). This activity internalizes semantic recognition and permits the mannequin to “perceive” user-provided noun phrases (NPs).
This transformation from a geometrical segmenter to a imaginative and prescient basis mannequin is facilitated by a large new dataset, SA-Co (Phase Something with Ideas), and a novel architectural design that decouples recognition from localization.
The trajectory of the Phase Something venture displays a broader development in synthetic intelligence towards multi-modal unification and zero-shot generalization.
SAM 1, launched in early 2023, launched the idea of a promptable basis mannequin for picture segmentation, able to zero-shot generalization to unseen domains by utilizing easy spatial prompts.
Launched in 2024, SAM 2 prolonged this functionality to the temporal area by using a reminiscence financial institution structure to trace single objects throughout video frames with excessive temporal consistency.
Nonetheless, each fashions suffered from a standard bottleneck: they required an exterior system or a human operator to inform them the place an object was earlier than they might decide its extent.
SAM 3 addresses this foundational hole by integrating an open-vocabulary detector straight into the segmentation and monitoring pipeline. This integration permits the mannequin to resolve “what” is within the picture, successfully turning segmentation right into a query-based search interface.
For instance, whereas SAM 2 required customers to click on on each automotive in a car parking zone to section them, SAM 3 can settle for the textual content immediate “automobiles” and immediately return masks and distinctive identifiers for every particular person automotive within the scene. This evolution is summarized within the following comparability of the three mannequin generations.
Desk 1: Evolution of SAM fashions (supply: Meta AI analysis; desk by the creator)
The structure of SAM 3 represents a basic departure from earlier fashions, shifting to a unified, twin encoder-decoder transformer system.
The mannequin includes roughly 848 million parameters (relying on configuration), a major scale-up from the most important SAM 2 variants, reflecting the elevated complexity of the open-vocabulary recognition activity.
These parameters are distributed throughout 3 principal architectural pillars:
Central to SAM 3’s design is the Notion Encoder (PE), a imaginative and prescient spine that’s shared between the image-level detector and the video-level tracker.
This shared design is vital for guaranteeing that visible options are processed persistently throughout each static and temporal domains, minimizing activity interference and maximizing information scaling effectivity.
In contrast to SAM 2, which utilized the Hiera structure, SAM 3 employs a ViT-style notion encoder that’s extra simply aligned with the semantic embeddings of the textual content encoder.
The imaginative and prescient encoder accounts for about 450 million parameters and is designed to deal with high-resolution inputs (typically scaled to 1024 or 1008 pixels) to protect the spatial element mandatory for exact masks era.
The encoder’s output embeddings, usually of measurement with 1024 channels, are handed to a fusion encoder that situations them based mostly on the supplied immediate tokens.
To facilitate Promptable Idea Segmentation, SAM 3 integrates a classy textual content encoder with roughly 300 million parameters. This encoder processes noun phrases utilizing a specialised Byte Pair Encoding (BPE) vocabulary, permitting it to deal with an unlimited vary of descriptive phrases. When a person supplies a textual content immediate, the encoder generates linguistic embeddings which might be handled as “immediate tokens”.
Along with textual content, SAM 3 helps picture exemplars — visible crops of goal objects supplied by the person. These exemplars are processed by a devoted exemplar encoder that extracts visible options to outline the goal idea.
This multi-modal immediate interface permits the fusion encoder to collectively course of linguistic and visible cues, making a unified idea embedding that tells the mannequin precisely what to seek for within the picture.
Desk 2: SAM 3 Mannequin Elements and Approximate Parameter Distribution (supply: Meta AI analysis; desk by the creator)
The detection part of SAM 3 is predicated on the DEtection TRansformer (DETR) framework, which makes use of discovered object queries to work together with the conditioned picture options.
In an ordinary DETR structure, queries are accountable for each classifying an object and figuring out its location. Nonetheless, in open-vocabulary eventualities, this typically results in “phantom detections.” There are false positives the place the mannequin localizes background noise as a result of it lacks a world understanding of whether or not the requested idea even exists within the scene.
To resolve this, SAM 3 introduces the Presence Head, a novel architectural innovation that decouples recognition from localization. The Presence Head makes use of a discovered world token that attends to the complete picture context and predicts a single scalar “presence rating” () between 0 and 1. This rating represents the likelihood that the prompted idea is current wherever within the body. The ultimate confidence rating for any particular person object question is then calculated as:
the place is the rating produced by the person question’s native detection. If the Presence Head determines {that a} “unicorn” shouldn’t be within the picture (rating ≈ 0.01), it suppresses all native detections, stopping hallucinations throughout the board. This mechanism considerably improves the mannequin’s calibration, significantly on the Picture-Stage Matthews Correlation Coefficient (IL_MCC) metric.
For video processing, SAM 3 integrates a tracker that inherits the reminiscence financial institution structure from SAM 2 however is extra tightly coupled with the detector via the shared Notion Encoder.
On every body, the detector identifies new situations of the goal idea, whereas the tracker propagates present “masklets” (i.e., object-specific spatial-temporal masks) from earlier frames utilizing self- and cross-attention.
The system manages the temporal id of objects via an identical and replace stage. Propagated masks are in contrast with newly detected masks to make sure consistency, permitting the mannequin to deal with occlusions or objects that quickly exit the body.
If an object disappears behind an obstruction and later reappears, the detector supplies a “recent” detection that the tracker makes use of to re-establish the item’s historical past, stopping id drift.
The introduction of Promptable Idea Segmentation (PCS) is the defining attribute of SAM 3, reworking it from a device for “segmenting that factor” to a system for “segmenting every thing like that”. SAM 3 unifies a number of segmentation paradigms (i.e., single-image, video, interactive refinement, and concept-driven detection) below a single spine.
The mannequin’s main interplay mode is thru textual content prompts. In contrast to conventional object detectors which might be restricted to a hard and fast set of lessons (e.g., the 80 lessons in COCO), SAM 3 is open-vocabulary.
As a result of it has been skilled on over 4 million distinctive noun phrases, it could perceive particular descriptions (e.g., “delivery container,” “striped cat,” or “gamers sporting pink jerseys”). This permits researchers to question datasets for particular attributes with out retraining the mannequin for each new class.
Exemplar prompting permits customers to offer visible examples as an alternative of or along with textual content.
By drawing a field round an instance object, the person tells the mannequin to “discover extra of those”. That is significantly helpful in specialised fields the place textual content descriptions could also be ambiguous (e.g., figuring out a particular sort of business defect or a uncommon organic specimen).
The mannequin additionally helps hybrid prompting, the place a textual content immediate is used to slim the search and visible prompts are used for refinement. As an illustration, a person can immediate for “helmets” after which use unfavorable exemplars (packing containers round bicycle helmets) to pressure the mannequin to solely section building onerous hats.
This iterative refinement loop maintains the interactive “spirit” of the unique SAM whereas scaling it to hundreds of potential objects.
Desk 3: Prompting Modes Supported by SAM 3 and Their Major Use Circumstances (supply: Meta AI analysis; desk by the creator)
The success of SAM 3 is basically pushed by its coaching information. Meta developed an modern information engine to create the SA-Co (Phase Something with Ideas) dataset, which is the most important high-quality open-vocabulary segmentation dataset so far. This dataset accommodates roughly 5.2 million photographs and 52.5 thousand movies, with over 4 million distinctive noun phrases and 1.4 billion masks.
The SA-Co information engine follows a classy semi-automated suggestions loop designed to maximise each range and accuracy.
Media Curation: The engine curates numerous media domains, shifting past homogeneous net information to incorporate aerial, doc, medical, and industrial imagery.
Label Curation and AI Annotation: By leveraging a fancy ontology and multimodal massive language fashions (MLLMs) reminiscent of Llama 3.2 to function “AI annotators,” the system generates a large variety of distinctive noun phrases for the curated media.
High quality Verification: AI annotators are deployed to verify masks high quality and exhaustivity. Apparently, these AI programs are reported to be 5× quicker than people at figuring out “unfavorable prompts” (ideas not current within the scene) and 36% quicker at figuring out “constructive prompts”.
Human Refinement: Human annotators are used strategically, stepping in just for essentially the most difficult examples the place the AI fashions battle (e.g., fine-grained boundary corrections or resolving semantic ambiguities).
The ensuing dataset is categorized into coaching and analysis units that cowl a variety of real-world eventualities.
SA-Co/HQ: 5.2 million high-quality photographs with 4 million distinctive NPs.
SA-Co/SYN: 38 million artificial phrases with 1.4 billion masks, used for massive-scale pre-training.
SA-Co/VIDEO: 52.5 thousand movies containing over 467,000 masklets, guaranteeing temporal stability.
The analysis benchmark (SA-Co Benchmark) is especially rigorous, containing 214,000 distinctive phrases throughout 126,000 photographs and movies — over 50× the ideas present in present benchmarks (e.g., LVIS). It contains subsets (e.g., SA-Co/Gold), the place every image-phrase pair is annotated by three totally different people to ascertain a baseline for “human-level” efficiency.
Notion Encoder Pre-training: The imaginative and prescient spine is pre-trained to develop a strong function illustration of the world.
Detector Pre-training: The detector is skilled on a mixture of artificial information and high-quality exterior datasets to ascertain foundational idea recognition.
Detector Positive-tuning: The mannequin is fine-tuned on the SA-Co/HQ dataset, the place it learns to deal with exhaustive occasion detection, and the Presence Head is optimized utilizing difficult unfavorable phrases.
Tracker Coaching: Lastly, the tracker is skilled whereas the imaginative and prescient spine is frozen, permitting the mannequin to study temporal consistency with out degrading the detector’s semantic precision.
The coaching course of leverages fashionable engineering methods to deal with the huge dataset and parameter rely.
Precision: Use of PyTorch Computerized Combined Precision (AMP) (float16/bfloat16) to optimize reminiscence utilization on massive GPUs (e.g., the H200).
Gradient Checkpointing: Enabled for decoder cross-attention blocks to cut back reminiscence overhead through the coaching of the 848M-parameter mannequin.
Instructor Caching: In distillation eventualities (e.g., EfficientSAM3), trainer encoder options are cached to cut back the I/O bottleneck, considerably accelerating the coaching of smaller “scholar” fashions.
The LVIS dataset is an ordinary benchmark for long-tail occasion segmentation. SAM 3 achieves a zero-shot masks common precision (AP) of 47.0 (or 48.8 in some experiences), representing a 22% enchancment over the earlier better of 38.5. This means a vastly improved means to acknowledge uncommon or specialised classes with out specific coaching on these labels.
On the brand new SA-Co benchmark, SAM 3 achieves a 2× efficiency acquire over present programs. On the Gold subset, the mannequin reaches 88% of human-level efficiency, establishing it as a extremely dependable device for automated labeling.
Desk 4: Impression of Picture Exemplars on SA-Co Benchmark Efficiency (supply: Meta AI analysis; desk by the creator)
The mannequin’s means to rely and motive about objects can be a significant spotlight. In counting duties, SAM 3 achieves an accuracy of 93.8% and a Imply Absolute Error (MAE) of simply 0.12, outperforming huge fashions (e.g., Gemini 2.5 Professional and Qwen2-VL-72B) on exact visible grounding benchmarks.
Desk 5: Object Counting Efficiency Comparability Throughout Imaginative and prescient-Language Fashions (supply: Meta AI analysis; desk by the creator)
For advanced reasoning duties (ReasonSeg), the place directions is perhaps “the leftmost individual sporting a blue vest,” SAM 3, when paired with an MLLM agent, achieves 76.0 gIoU (Generalized Intersection over Union), a 16.9% enchancment over the prior state-of-the-art.
Creators can now use pure language to use results to particular topics in movies. For instance, a video editor can immediate “apply a sepia filter to the blue chair” or “blur the faces of all bystanders,” and the mannequin will deal with the segmentation and monitoring all through the clip. This performance is being built-in into instruments (e.g., Vibes on the Meta AI app and media modifying flows on Instagram).
As SAM 3 is computationally heavy (working at 30 ms per picture on an H200), its most rapid industrial affect is in scaling information annotation. Groups can use SAM 3 to robotically label thousands and thousands of photographs with high-quality occasion masks after which use this “floor reality” to coach smaller, quicker fashions like YOLO or EfficientSAM3 for real-time use on the sting (e.g., in drones or cellular apps).
SAM 3 is being utilized in Aria Gen 2 analysis glasses to assist section and observe palms and objects from a first-person perspective. This helps contextual AR analysis, the place a wearable assistant can acknowledge {that a} person is “holding a screwdriver” or “taking a look at a leaky pipe” and supply related holographic overlays or directions.
Regardless of its breakthrough efficiency, a number of analysis frontiers stay for the Phase Something household.
Instruction Reasoning: Whereas SAM 3 handles atomic ideas, it nonetheless depends on exterior brokers (MLLMs) to interpret long-form or advanced directions. Future iterations (e.g., SAM 3-I) are working to combine this instruction-level reasoning natively into the mannequin.
Effectivity and On-Gadget Use: The 848M parameter measurement restricts SAM 3 to server-side environments. The event of EfficientSAM3 via progressive hierarchical distillation is essential for bringing concept-aware segmentation to real-time, on-device purposes.
Positive-Grained Context: In duties involving fine-grained organic constructions or context-dependent targets, textual content prompts can generally fail or present coarse boundaries. Positive-tuning with adapters (e.g., SAM3-UNet) stays an important analysis path for adapting the muse mannequin to specialised scientific and medical domains.
Would you want rapid entry to three,457 photographs curated and labeled with hand gestures to coach, discover, and experiment with … free of charge? Head over to Roboflow and get a free account to seize these hand gesture photographs.
To comply with this information, it’s essential to have the next libraries put in in your system.
!pip set up --q git+https://github.com/huggingface/transformers supervision jupyter_bbox_widget
We set up the transformers library to load the SAM 3 mannequin and processor, the supervision library for annotation, drawing, and inspection, which we use later to visualise bounding packing containers and segmentation outputs. We additionally set up jupyter_bbox_widget, which provides us an interactive widget. This widget runs inside a pocket book and lets us click on on the picture so as to add factors or draw bounding packing containers.
We additionally cross the --q flag to cover set up logs. This retains pocket book output clear.
Want Assist Configuring Your Improvement Atmosphere?
Having bother configuring your improvement atmosphere? Need entry to pre-configured Jupyter Notebooks working on Google Colab? Make sure to be part of PyImageSearch College — you may be up and working with this tutorial in a matter of minutes.
All that stated, are you:
Quick on time?
Studying in your employer’s administratively locked system?
Desirous to skip the trouble of preventing with the command line, package deal managers, and digital environments?
Able to run the code instantly in your Home windows, macOS, or Linux system?
Acquire entry to Jupyter Notebooks for this tutorial and different PyImageSearch guides pre-configured to run on Google Colab’s ecosystem proper in your net browser! No set up required.
And better of all, these Jupyter Notebooks will run on Home windows, macOS, and Linux!
As soon as put in, we transfer on to import the required libraries.
import io
import torch
import base64
import requests
import matplotlib
import numpy as np
import ipywidgets as widgets
import matplotlib.pyplot as plt
from google.colab import output
from speed up import Accelerator
from IPython.show import show
from jupyter_bbox_widget import BBoxWidget
from PIL import Picture, ImageDraw, ImageFont
from transformers import Sam3Processor, Sam3Model, Sam3TrackerProcessor, Sam3TrackerModel
We import the next:
io: Python’s built-in module to deal with in-memory picture buffers later when changing PIL photographs to base64 format
torch: to run the SAM 3 mannequin, ship tensors to the GPU, and work with mannequin outputs
base64: module to transform our photographs into base64 strings in order that the BBox widget can show them within the pocket book
requests: library to obtain photographs straight from a URL; this retains our workflow easy and avoids handbook file uploads
We import a number of helper libraries.
matplotlib.pyplot: helps us visualize masks and overlays
numpy: offers us quick array operations
ipywidgets: permits interactive components contained in the pocket book
We import the output utility from Colab. Later, we use it to allow interactive widgets. With out this step, our bounding field widget is not going to render. We import Accelerator from Hugging Face to run the mannequin effectively on both CPU or GPU with the identical code. It additionally simplifies gadget placement.
We import the show perform to render photographs and widgets straight in pocket book cells, and BBoxWidget acts because the core interactive device that enables us to click on and draw bounding packing containers or factors on high of a picture. We use this as our immediate enter system.
We additionally import 3 lessons from Pillow:
Picture: hundreds RGB photographs
ImageDraw: helps us draw shapes on photographs
ImageFont: offers us textual content rendering help for overlays
Lastly, we import our SAM 3 instruments from transformers.
Sam3Processor: prepares inputs for the segmentation mannequin
Sam3Model: performs segmentation from textual content and field prompts
Sam3TrackerProcessor: prepares inputs for point-based or monitoring prompts
Sam3TrackerModel: runs point-based segmentation and masking
First, we verify if a GPU is offered within the atmosphere. If PyTorch detects CUDA (Compute Unified Gadget Structure), then we use the GPU for quicker inference. In any other case, we fall again to the CPU. This verify ensures our code runs effectively on any machine (Line 1).
Subsequent, we load the Sam3Processor. The processor is accountable for making ready all inputs earlier than they attain the mannequin. It handles picture preprocessing, bounding field formatting, textual content prompts, and tensor conversion. In any case, it makes our uncooked photographs appropriate with the mannequin (Line 3).
Lastly, we load the Sam3Model from Hugging Face. This mannequin takes the processed inputs and generates segmentation masks. We instantly transfer the mannequin to the chosen gadget (GPU or CPU) for inference (Line 4).
Right here, we obtain a couple of photographs from the Roboflow media server utilizing the wget command and use the -q flag to suppress output and preserve the pocket book clear.
This helper overlays segmentation masks, bounding packing containers, labels, and confidence scores straight on high of the unique picture. We use it all through the pocket book to visualise mannequin predictions.
def overlay_masks_boxes_scores(
picture,
masks,
packing containers,
scores,
labels=None,
score_threshold=0.0,
alpha=0.5,
):
picture = picture.convert("RGBA")
masks = masks.cpu().numpy()
packing containers = packing containers.cpu().numpy()
scores = scores.cpu().numpy()
if labels is None:
labels = ["object"] * len(scores)
labels = np.array(labels)
# Rating filtering
preserve = scores >= score_threshold
masks = masks[keep]
packing containers = packing containers[keep]
scores = scores[keep]
labels = labels[keep]
n_instances = len(masks)
if n_instances == 0:
return picture
# Colormap (one colour per occasion)
cmap = matplotlib.colormaps.get_cmap("rainbow").resampled(n_instances)
colours = [
tuple(int(c * 255) for c in cmap(i)[:3])
for i in vary(n_instances)
]
First, we outline a perform named overlay_masks_boxes_scores. It accepts the unique RGB picture and the mannequin outputs: masks, packing containers, and scores. We additionally settle for elective labels, a rating threshold, and a transparency issue alpha (Strains 1-9).
Subsequent, we convert the picture into RGBA format. The additional alpha channel permits us to mix masks easily on high of the picture (Line 10). We transfer the tensors to the CPU and convert them to NumPy arrays. This makes them simpler to govern and appropriate with Pillow (Strains 12-14).
If the person doesn’t present labels, we assign a default label string to every detected object (Strains 16 and 17). We convert labels to a NumPy array so we are able to filter them later, together with masks and scores (Line 19). We filter out detections beneath the rating threshold. This permits us to cover low-confidence masks and cut back muddle within the visualization (Strains 22-26). If nothing survives filtering, we return the unique picture unchanged (Strains 28-30).
We choose a rainbow colormap and pattern one distinctive colour per detected object. We convert float values to RGB integer tuples (0-255 vary) (Strains 33-37).
Right here, we loop via every mask-color pair. For every masks, we create a grayscale masks picture, convert it right into a clear RGBA overlay, and mix it onto the unique picture. The alpha worth controls transparency. This step provides gentle, coloured areas over segmented areas (Strains 42-46).
Right here, we put together a drawing context to overlay rectangles and textual content (Line 51). We try to load a default font. If unavailable, we fall again to no font (Strains 53-56). We loop over every object and extract its bounding field coordinates (Strains 58 and 59).
We draw two rectangles: The primary one (black) improves visibility, and the second makes use of the assigned object colour (Strains 62 and 63). We format the label and rating textual content, then compute the textual content field measurement (Strains 66-68). We draw a coloured background rectangle behind the label textual content (Strains 71-74). We draw black textual content on high. Black textual content supplies a robust distinction towards brilliant overlay colours (Strains 77-82).
Lastly, we return the annotated picture (Line 84).
First, we load a check picture from the COCO (Widespread Objects in Context) dataset. We obtain it straight through URL, convert its bytes right into a PIL picture, and guarantee it’s in RGB format utilizing Picture from Pillow. This supplies a standardized enter for SAM 3 (Strains 2 and three).
Subsequent, we put together the mannequin inputs. We cross the picture and a single textual content immediate — the key phrase "ear". The processor handles all preprocessing steps (e.g., resizing, normalization, and token encoding). We transfer the ultimate tensors to our chosen gadget (GPU or CPU) (Line 6).
Then, we run inference. We disable gradient monitoring utilizing torch.no_grad(). This reduces reminiscence utilization and quickens ahead passes. The mannequin returns uncooked segmentation outputs (Strains 8 and 9).
After inference, we convert uncooked mannequin outputs into usable instance-level segmentation predictions utilizing processor.post_process_instance_segmentation (Strains 12-17).
We apply a threshold to filter weak detections.
We apply mask_threshold to transform predicted logits into binary masks.
We resize masks again to their unique dimensions.
We index [0] as a result of this output corresponds to the primary (and solely) picture within the batch (Line 17).
We print the variety of detected occasion masks. Every masks corresponds to at least one “ear” discovered within the picture (Line 19).
Under is the variety of objects detected within the picture.
This block of code is similar to the earlier instance. The one change is that we now load a native picture (birds.jpg) as an alternative of downloading one from COCO. We additionally replace the segmentation immediate from "ear" to "fowl".
Under is the variety of objects detected within the picture.
This block of code is similar to the earlier instance. The one change is that we now load a native picture (traffic_jam.jpg) as an alternative of downloading one from COCO. We additionally replace the segmentation immediate from "fowl" to "taxi".
Under is the variety of objects detected within the picture.
Course info:
86+ complete lessons • 115+ hours hours of on-demand code walkthrough movies • Final up to date: January 2026 ★★★★★ 4.84 (128 Scores) • 16,000+ College students Enrolled
I strongly imagine that for those who had the appropriate trainer you would grasp laptop imaginative and prescient and deep studying.
Do you assume studying laptop imaginative and prescient and deep studying must be time-consuming, overwhelming, and sophisticated? Or has to contain advanced arithmetic and equations? Or requires a level in laptop science?
That’s not the case.
All it’s essential to grasp laptop imaginative and prescient and deep studying is for somebody to clarify issues to you in easy, intuitive phrases. And that’s precisely what I do. My mission is to vary training and the way advanced Synthetic Intelligence subjects are taught.
For those who’re severe about studying laptop imaginative and prescient, your subsequent cease needs to be PyImageSearch College, essentially the most complete laptop imaginative and prescient, deep studying, and OpenCV course on-line in the present day. Right here you’ll learn to efficiently and confidently apply laptop imaginative and prescient to your work, analysis, and initiatives. Be a part of me in laptop imaginative and prescient mastery.
Inside PyImageSearch College you may discover:
&verify; 86+ programs on important laptop imaginative and prescient, deep studying, and OpenCV subjects
&verify; 86 Certificates of Completion
&verify; 115+ hours hours of on-demand video
&verify; Model new programs launched usually, guaranteeing you possibly can sustain with state-of-the-art methods
&verify; Pre-configured Jupyter Notebooks in Google Colab
&verify; Run all code examples in your net browser — works on Home windows, macOS, and Linux (no dev atmosphere configuration required!)
&verify; Entry to centralized code repos for all 540+ tutorials on PyImageSearch
&verify; Straightforward one-click downloads for code, datasets, pre-trained fashions, and many others.
&verify; Entry on cellular, laptop computer, desktop, and many others.
On this tutorial, we explored how the discharge of Phase Something Mannequin 3 (SAM 3) represents a basic shift in laptop imaginative and prescient — from geometry-driven segmentation to concept-driven visible understanding. In contrast to SAM 1 and SAM 2, which relied on exterior cues to determine the place an object is, SAM 3 internalizes semantic recognition and permits customers to straight question what they wish to section utilizing pure language or visible exemplars.
We examined how this transition is enabled by a unified structure constructed round a shared Notion Encoder, an open-vocabulary DETR-based detector with a Presence Head, and a memory-based tracker for movies. We additionally mentioned how the huge SA-Co dataset and a fastidiously staged coaching pipeline permit SAM 3 to scale to thousands and thousands of ideas whereas sustaining sturdy calibration and zero-shot efficiency.
Via sensible examples, we demonstrated how one can arrange SAM 3 in your improvement atmosphere and implement single textual content immediate segmentation throughout varied eventualities — from detecting ears on a cat to figuring out birds in a flock and taxis in site visitors.
In Half 2, we’ll dive deeper into superior prompting methods, together with multi-prompt segmentation, bounding field steerage, unfavorable prompts, and absolutely interactive segmentation workflows that offer you pixel-perfect management over your outcomes. Whether or not you’re constructing annotation pipelines, video modifying instruments, or robotics purposes, Half 2 will present you how one can harness SAM 3’s full potential via refined immediate engineering.
Thakur, P. “SAM 3: Idea-Based mostly Visible Understanding and Segmentation,” PyImageSearch, P. Chugh, S. Huot, G. Kudriavtsev, and A. Sharma, eds., 2026, https://pyimg.co/uming
@incollection{Thakur_2026_sam-3-concept-based-visual-understanding-and-segmentation,
creator = {Piyush Thakur},
title = {{SAM 3: Idea-Based mostly Visible Understanding and Segmentation}},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Susan Huot and Georgii Kudriavtsev and Aditya Sharma},
12 months = {2026},
url = {https://pyimg.co/uming},
}
To obtain the supply code to this put up (and be notified when future tutorials are printed right here on PyImageSearch), merely enter your electronic mail tackle within the type beneath!
Obtain the Supply Code and FREE 17-page Useful resource Information
Enter your electronic mail tackle beneath to get a .zip of the code and a FREE 17-page Useful resource Information on Laptop Imaginative and prescient, OpenCV, and Deep Studying. Inside you may discover my hand-picked tutorials, books, programs, and libraries that will help you grasp CV and DL!
ComfyUI has modified how creators and builders strategy AI-powered picture technology. In contrast to conventional interfaces, the node-based structure of ComfyUI offers you unprecedented management over your artistic workflows. This crash course will take you from a whole newbie to a assured person, strolling you thru each important idea, function, and sensible instance you might want to grasp this highly effective device.
Picture by Creator
ComfyUI is a free, open-source, node-based interface and the backend for Secure Diffusion and different generative fashions. Consider it as a visible programming surroundings the place you join constructing blocks (known as “nodes”) to create complicated workflows for producing pictures, movies, 3D fashions, and audio.
Key benefits over conventional interfaces:
You’ve gotten full management to construct workflows visually with out writing code, with full management over each parameter.
It can save you, share, and reuse total workflows with metadata embedded within the generated information.
There aren’t any hidden prices or subscriptions; it’s fully customizable with customized nodes, free, and open supply.
It runs domestically in your machine for quicker iteration and decrease operational prices.
It has prolonged performance, which is sort of limitless with customized nodes that may meet your particular wants.
# Selecting Between Native and Cloud-Primarily based Set up
Earlier than exploring ComfyUI in additional element, you will need to resolve whether or not to run it domestically or use a cloud-based model.
Native Set up
Cloud-Primarily based Set up
Works offline as soon as put in
Requires a relentless web connection
No subscription charges
Might contain subscription prices
Full knowledge privateness and management
Much less management over your knowledge
Requires highly effective {hardware} (particularly a great NVIDIA GPU)
No highly effective {hardware} required
Handbook set up and updates required
Automated updates
Restricted by your pc’s processing energy
Potential pace limitations throughout peak utilization
If you’re simply beginning, it is strongly recommended to start with a cloud-based resolution to study the interface and ideas. As you develop your abilities, take into account transitioning to a neighborhood set up for larger management and decrease long-term prices.
# Understanding the Core Structure
Earlier than working with nodes, it’s important to know the theoretical basis of how ComfyUI operates. Consider it as a multiverse between two universes: the crimson, inexperienced, blue (RGB) universe (what we see) and the latent area universe (the place computation occurs).
// The Two Universes
The RGB universe is our observable world. It comprises common pictures and knowledge that we are able to see and perceive with our eyes. The latent area (AI universe) is the place the “magic” occurs. It’s a mathematical illustration that fashions can perceive and manipulate. It’s chaotic, crammed with noise, and comprises the summary mathematical construction that drives picture technology.
// Utilizing the Variational Autoencoder
The variational autoencoder (VAE) acts as a portal between these universes.
Encoding (RGB — Latent) takes a visual picture and converts it into the summary latent illustration.
Decoding (Latent — RGB) takes the summary latent illustration and converts it again to a picture we are able to see.
This idea is vital as a result of many nodes function inside a single universe, and understanding it is going to enable you to join the correct nodes collectively.
// Defining Nodes
Nodes are the basic constructing blocks of ComfyUI. Every node is a self-contained perform that performs a particular process. Nodes have:
Inputs (left aspect): The place knowledge flows in
Outputs (proper aspect): The place processed knowledge flows out
Parameters: Settings you modify to regulate the node’s habits
// Figuring out Coloration-Coded Knowledge Sorts
ComfyUI makes use of a shade system to point what sort of knowledge flows between nodes:
Understanding these colours is essential. They let you know immediately whether or not nodes can join to one another.
// Exploring Vital Node Sorts
Loader nodes import fashions and knowledge into your workflow:
CheckPointLoader: Masses a mannequin (usually containing the mannequin weights, Contrastive Language-Picture Pre-training (CLIP), and VAE in a single file).
Load Diffusion Mannequin: Masses mannequin parts individually (for newer fashions like Flux that don’t bundle parts).
VAE Loader: Masses the VAE decoder individually.
CLIP Loader: Masses the textual content encoder individually.
Processing nodes remodel knowledge:
CLIP Textual content Encode converts textual content prompts into machine language (conditioning).
KSampler is the core picture technology engine.
VAE Decode converts latent pictures again to RGB.
Utility nodes help workflow administration:
Primitive Node: Permits you to enter values manually.
Reroute Node: Cleans up workflow visualization by redirecting connections.
Load Picture: Imports pictures into your workflow.
Save Picture: Exports generated pictures.
# Understanding the KSampler Node
The KSampler is arguably an important node in ComfyUI. It’s the “robotic builder” that really generates your pictures. Understanding its parameters is essential for creating high quality pictures.
// Reviewing KSampler Parameters
Seed (Default: 0) The seed is the preliminary random state that determines which random pixels are positioned at first of technology. Consider it as your place to begin for randomization.
Fastened Seed: Utilizing the identical seed with the identical settings will all the time produce the identical picture.
Randomized Seed: Every technology will get a brand new random seed, producing totally different pictures.
Worth Vary: 0 to 18,446,744,073,709,551,615.
Steps (Default: 20) Steps outline the variety of denoising iterations carried out. Every step progressively refines the picture from pure noise towards your required output.
Low Steps (10-15): Quicker technology, much less refined outcomes.
Medium Steps (20-30): Good stability between high quality and pace.
Excessive Steps (50+): Higher high quality however considerably slower.
CFG Scale (Default: 8.0, Vary: 0.0-100.0) The classifier-free steerage (CFG) scale controls how strictly the AI follows your immediate.
Analogy — Think about giving a builder a blueprint:
Low CFG (3-5): The builder glances on the blueprint then does their very own factor — artistic however might ignore directions.
Excessive CFG (12+): The builder obsessively follows each element of the blueprint — correct however might look stiff or over-processed.
Balanced CFG (7-8 for Secure Diffusion, 1-2 for Flux): The builder principally follows the blueprint whereas including pure variation.
Sampler Title The sampler is the algorithm used for the denoising course of. Widespread samplers embody Euler, DPM++ 2M, and UniPC.
Scheduler Controls how noise is scheduled throughout the denoising steps. Schedulers decide the noise discount curve.
Regular: Normal noise scheduling.
Karras: Typically offers higher outcomes at decrease step counts.
Denoise (Default: 1.0, Vary: 0.0-1.0) That is certainly one of your most vital controls for image-to-image workflows. Denoise determines what proportion of the enter picture to exchange with new content material:
0.0: Don’t change something — output might be an identical to enter
0.5: Hold 50% of the unique picture, regenerate 50% as new
1.0: Fully regenerate — ignore the enter picture and begin from pure noise
# Instance: Producing a Character Portrait
Immediate: “A cyberpunk android with neon blue eyes, detailed mechanical elements, dramatic lighting.”
Settings:
Mannequin: Flux
Steps: 20
CFG: 2.0
Sampler: Default
Decision: 1024×1024
Seed: Randomize
Adverse immediate: “low high quality, blurry, oversaturated, unrealistic.”
// Exploring Picture-to-Picture Workflows
Picture-to-image workflows construct on the text-to-image basis, including an enter picture to information the technology course of.
State of affairs: You’ve gotten {a photograph} of a panorama and wish it in an oil portray type.
Set up PyTorch: Comply with platform-specific directions on your GPU.
Set up Dependencies: pip set up -r necessities.txt
Add Fashions: Place mannequin checkpoints in fashions/checkpoints.
Run: python major.py
# Working With Totally different AI Fashions
ComfyUI helps quite a few state-of-the-art fashions. Listed below are the present high fashions:
Flux (Beneficial for Realism)
Secure Diffusion 3.5
Older Fashions (SD 1.5, SDXL)
Wonderful for photorealistic pictures
Nicely-balanced high quality and pace
Extensively fine-tuned by the neighborhood
Quick technology
Helps numerous kinds
Huge low-rank adaptation (LoRA) ecosystem
CFG: 1-3 vary
CFG: 4-7 vary
Nonetheless wonderful for particular workflows
# Advancing Workflows With Low-Rank Diversifications
Low-rank diversifications (LoRAs) are small adapter information that fine-tune fashions for particular kinds, topics, or aesthetics with out modifying the bottom mannequin. Widespread makes use of embody character consistency, artwork kinds, and customized ideas. To make use of one, add a “Load LoRA” node, choose your file, and join it to your workflow.
// Guiding Picture Technology with ControlNets
ControlNets present spatial management over technology, forcing the mannequin to respect pose, edge maps, or depth:
Drive particular poses from reference pictures
Keep object construction whereas altering type
Information composition primarily based on edge maps
Respect depth data
// Performing Selective Picture Modifying with Inpainting
Inpainting lets you regenerate solely particular areas of a picture whereas preserving the remaining intact.
Workflow: Load picture — Masks portray — Inpainting KSampler — End result
// Rising Decision with Upscaling
Use upscale nodes after technology to extend decision with out regenerating all the picture. Well-liked upscalers embody RealESRGAN and SwinIR.
# Conclusion
ComfyUI represents an important shift in content material creation. Its node-based structure offers you energy beforehand reserved for software program engineers whereas remaining accessible to learners. The educational curve is actual, however each idea you study opens new artistic prospects.
Start by making a easy text-to-image workflow, producing some pictures, and adjusting parameters. Inside weeks, you may be creating subtle workflows. Inside months, you may be pushing the boundaries of what’s doable within the generative area.
Shittu Olumide is a software program engineer and technical author keen about leveraging cutting-edge applied sciences to craft compelling narratives, with a eager eye for element and a knack for simplifying complicated ideas. You may also discover Shittu on Twitter.
A brand new malware-as-a-service (MaaS) referred to as ‘Stanley’ guarantees malicious Chrome extensions that may clear Google’s overview course of and publish them to the Chrome Net Retailer.
Researchers at end-to-end knowledge safety firm Varonis named the challenge Stanley after the alias of the vendor, who advertises straightforward phishing assaults by intercepting navigation and masking a webpage with an iframe with content material of the attacker’s alternative.
The brand new MaaS providing is for malicious Chrome extensions that may cowl a webpage with a full-screen iframe containing phishing content material of the attacker’s alternative. Stanley additionally advertises silent auto-installation on Chrome, Edge, and Courageous browsers and assist for customized tweaks.
The MaaS has a number of subscription tiers, the most costly one being the Luxe Plan, which additionally affords an internet panel and full assist for publishing the malicious extension to the Chrome Net Retailer.
Stanley promoted on cybercrime portals Supply: Varonis
BleepingComputer has contacted Google to request a touch upon these claims, and we’ll replace this publish once we hear again.
Varonis stories that Stanley works by overlaying a full-screen iframe with malicious content material whereas the sufferer’s browser handle bar stays untouched, exhibiting the official area.
Perform that generates the misleading iframe Supply: Varonis
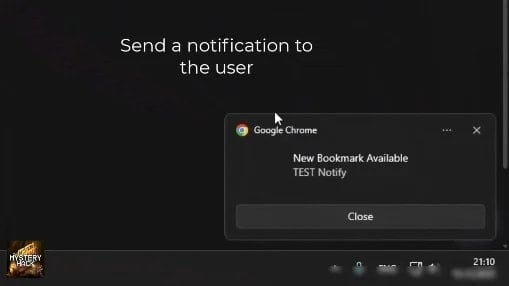
Operators who’ve entry to Stanley’s panel can allow or disable hijacking guidelines on demand, and even push notifications straight within the sufferer’s browser to lure them to particular pages, pushing the phishing course of extra aggressively.
Producing a customized notification Supply: Varonis
Stanley helps IP-based sufferer identification and permits geographic concentrating on and correlation throughout classes and gadgets.
Furthermore, the malicious extension performs persistent command-and-control (C2) polling each 10 seconds, and it could actually additionally carry out backup area rotation to supply resilience in opposition to takedowns.
Varonis feedback that, from a technical perspective, Stanley lacks superior options and as a substitute opts for an easy method to implementing well-known strategies.
Its code is reportedly “tough” at locations, that includes Russian feedback, empty catch blocks, and inconsistent error dealing with.
What actually makes this new MaaS stand out is its distribution mannequin, particularly the promise to go the Chrome Net Retailer overview and get malicious extensions onto the most important platform of trusted browser add-ons.
On condition that such extensions proceed to slide via the cracks, as lately highlighted in two separate stories by Symantec and LayerX, customers ought to set up solely the minimal variety of extensions they want, learn consumer evaluations, and ensure the writer’s trustworthiness.
As MCP (Mannequin Context Protocol) turns into the usual for connecting LLMs to instruments and knowledge, safety groups are shifting quick to maintain these new providers secure.
This free cheat sheet outlines 7 finest practices you can begin utilizing at this time.
A federal decide on Monday declined to right away curb the federal operation that has put armed brokers on the streets of Minneapolis and St. Paul, however ordered the federal government to file a brand new briefing by Wednesday night answering a central declare in the case: that the surge is getting used to punish Minnesota and pressure state and native authorities to alter their legal guidelines and cooperate with the concentrating on of native immigrants.
The order leaves the operation’s scope and techniques in place for now, however requires the federal authorities to elucidate whether or not it’s utilizing armed raids and avenue arrests to strain Minnesota into detaining immigrants and handing over delicate state information.
In a written order, Choose Kate Menendez directed the federal authorities to immediately tackle whether or not Operation Metro Surge was designed to “punish Plaintiffs for adopting sanctuary legal guidelines and insurance policies.” The courtroom ordered the Division of Homeland Safety to answer allegations that the surge was a device to coerce the state to alter legal guidelines, share public help information and different state data, divert native sources to help immigration arrests, and maintain folks in custody “for longer durations of time than in any other case allowed.”
The decide stated the extra briefing was required as a result of the coercion declare grew to become clearer solely after current developments, together with public statements by senior administration officers made after Minnesota sought emergency aid.
A key issue within the courtroom’s evaluation is a January 24 letter from US lawyer common Pam Bondi to Minnesota governor Tim Walz, which Minnesota described as an “extortion.” In it, Bondi accuses Minnesota officers of “lawlessness” and calls for what she calls “easy steps” to “restore the rule of legislation,” together with turning over state welfare and voter information, repealing sanctuary insurance policies, and directing native officers to cooperate with federal immigration arrests. She warned that the federal operations would proceed if the state didn’t comply.
Immigration and Customs Enforcement and the Division of Justice didn’t instantly reply to a request for remark.
The case—State of Minnesota v. Noem—was introduced by Minnesota lawyer common Keith Ellison, Minneapolis, and St. Paul towards Homeland Safety secretary Kristi Noem and senior DHS, ICE, CBP, and Border Patrol officers.
On the listening to on Monday, legal professionals for Minnesota and the cities argued that the federal deployment had crossed from investigating immigration violations into sustained avenue policing and “unlawful” habits, producing an ongoing public-safety disaster that warranted fast limits. They pointed to deadly shootings by federal brokers, using chemical brokers in crowded areas, colleges canceling courses or shifting on-line, mother and father protecting kids residence, and residents avoiding streets, shops and public buildings out of concern.
The plaintiffs argued that these weren’t accidents of the previous however ongoing harms, and that ready to litigate particular person circumstances would depart the cities to soak up the violence, concern and disruption of an operation they don’t management. The authorized struggle, they stated, activates whether or not the Structure permits a federal operation to impose these prices and dangers on state and native governments, and whether or not the conduct described within the report was remoted or so widespread that solely fast, court-ordered limits might restore fundamental order.
In filings, the plaintiffs describe an operation that DHS has publicly promoted because the “largest” of its sort in Minnesota, with the division claiming it deployed greater than 2,000 brokers into the Twin Cities; greater than the mixed variety of sworn officers in Minneapolis and St. Paul. They argue the federal presence became day-to-day patrols in in any other case sleepy neighborhoods, with brokers pulling over residents at random, detaining them on sidewalks, and making sweeping detentions with out suspecting prison conduct.








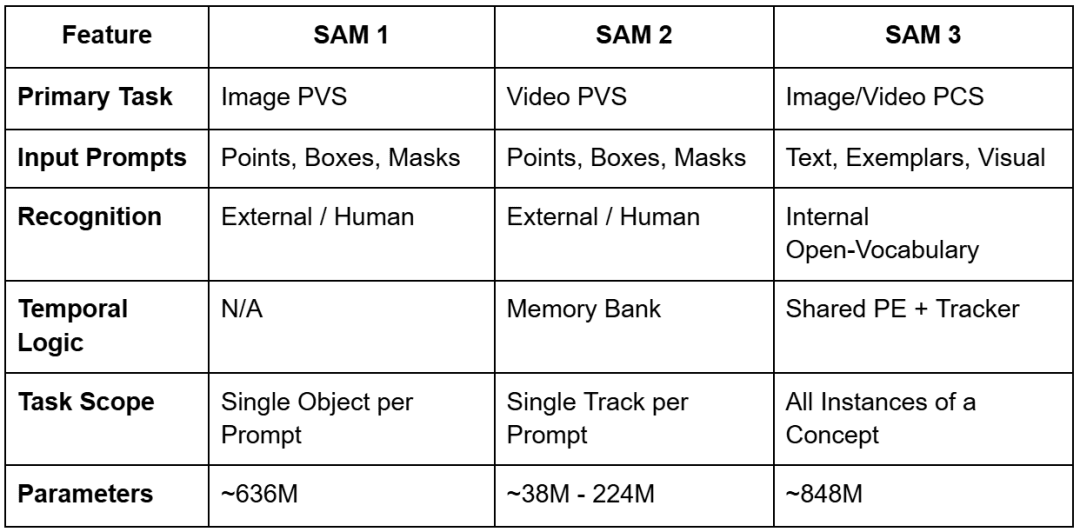
") with 1024 channels, are handed to a fusion encoder that situations them based mostly on the supplied immediate tokens.
with 1024 channels, are handed to a fusion encoder that situations them based mostly on the supplied immediate tokens.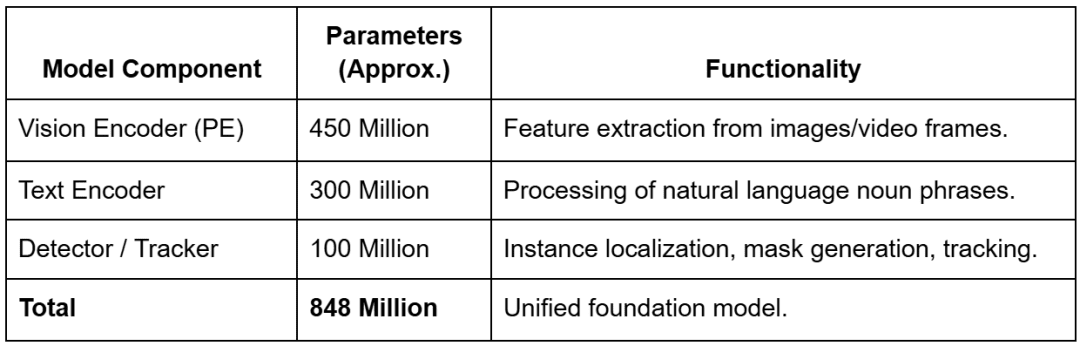
 ) between 0 and 1. This rating represents the likelihood that the prompted idea is current wherever within the body. The ultimate confidence rating for any particular person object question is then calculated as:
) between 0 and 1. This rating represents the likelihood that the prompted idea is current wherever within the body. The ultimate confidence rating for any particular person object question is then calculated as:
 is the rating produced by the person question’s native detection. If the Presence Head determines {that a} “unicorn” shouldn’t be within the picture (rating ≈ 0.01), it suppresses all native detections, stopping hallucinations throughout the board. This mechanism considerably improves the mannequin’s calibration, significantly on the Picture-Stage Matthews Correlation Coefficient (IL_MCC) metric.
is the rating produced by the person question’s native detection. If the Presence Head determines {that a} “unicorn” shouldn’t be within the picture (rating ≈ 0.01), it suppresses all native detections, stopping hallucinations throughout the board. This mechanism considerably improves the mannequin’s calibration, significantly on the Picture-Stage Matthews Correlation Coefficient (IL_MCC) metric.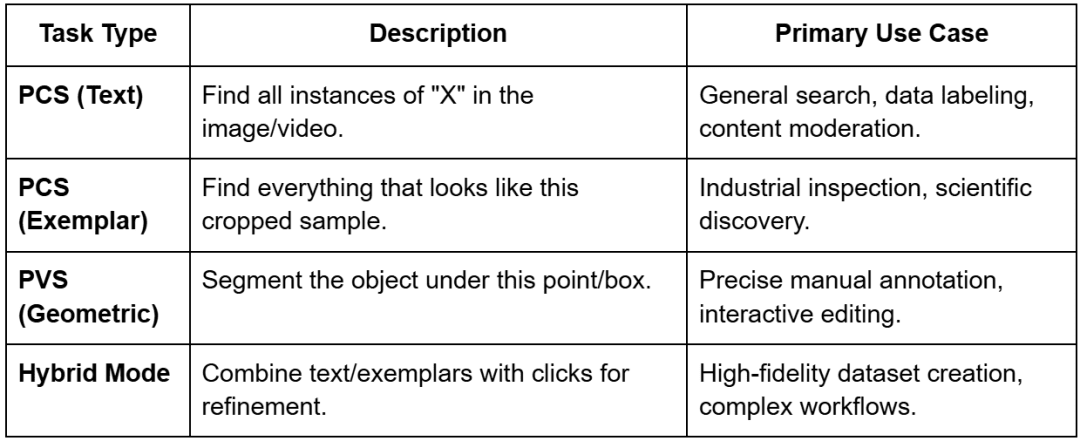
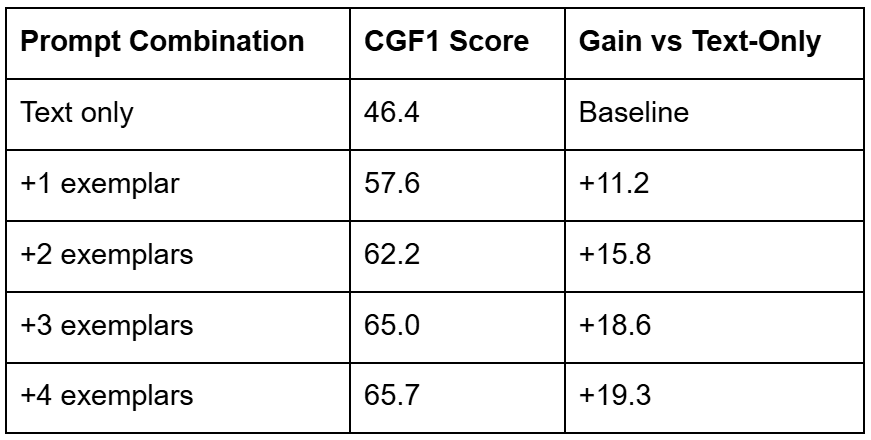
 30 ms per picture on an H200), its most rapid industrial affect is in scaling information annotation. Groups can use SAM 3 to robotically label thousands and thousands of photographs with high-quality occasion masks after which use this “floor reality” to coach smaller, quicker fashions like YOLO or EfficientSAM3 for real-time use on the sting (e.g., in drones or cellular apps).
30 ms per picture on an H200), its most rapid industrial affect is in scaling information annotation. Groups can use SAM 3 to robotically label thousands and thousands of photographs with high-quality occasion masks after which use this “floor reality” to coach smaller, quicker fashions like YOLO or EfficientSAM3 for real-time use on the sting (e.g., in drones or cellular apps).
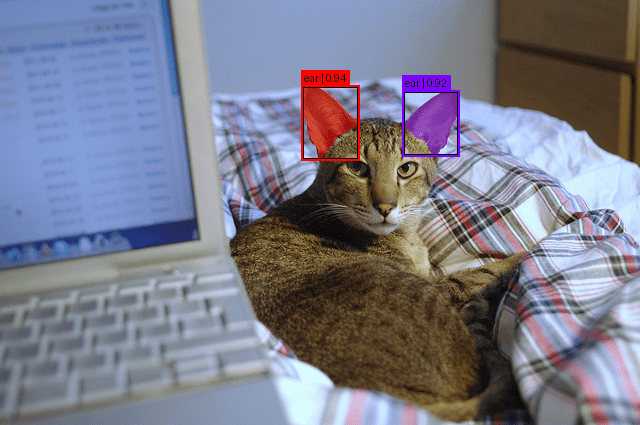








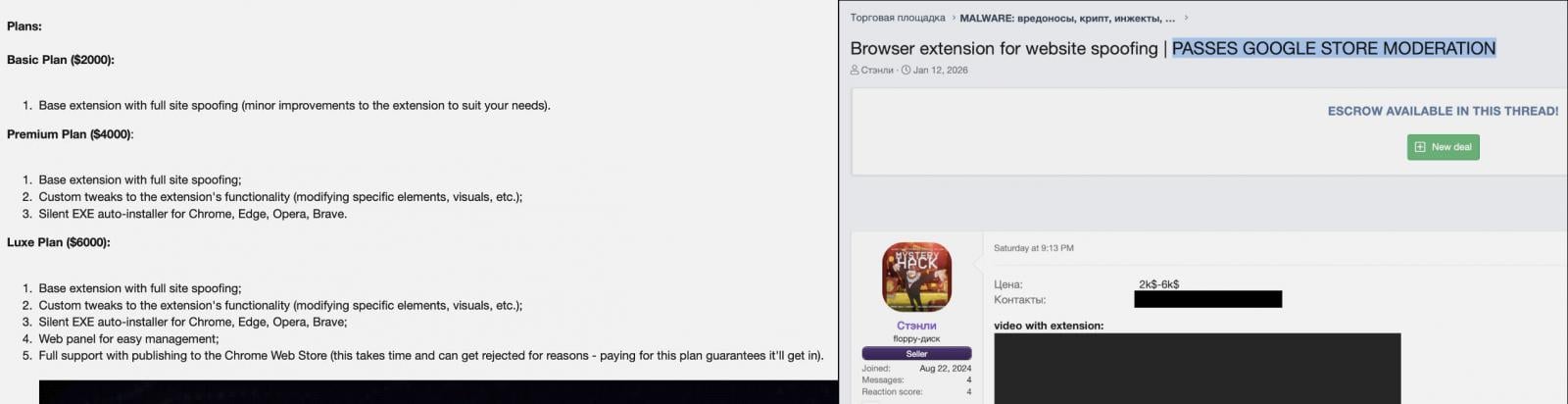
.jpg)