

How can healthcare selections grow to be extra correct when affected person knowledge is scattered throughout reviews, photos, and monitoring techniques?
Regardless of advances in synthetic intelligence, most healthcare AI instruments nonetheless function in silos, limiting their real-world impression, and that is the place the Multimodal AI addresses this hole by integrating a number of knowledge varieties, corresponding to scientific textual content, medical imaging, and physiological indicators right into a unified intelligence framework.
On this weblog, we discover how multimodal AI is reworking healthcare by enabling extra context-aware diagnostics, personalised remedy methods, and environment friendly scientific workflows, whereas additionally highlighting why it represents the subsequent frontier for healthcare.
Summarize this text with ChatGPT
Get key takeaways & ask questions
What’s Multimodal AI?
Multimodal AI refers to synthetic intelligence techniques designed to course of and combine a number of kinds of knowledge concurrently. Multimodal AI can interpret mixtures of knowledge varieties to extract richer, extra contextual insights.
In healthcare, this implies analyzing scientific notes, medical photos, lab outcomes, biosignals from wearables, and even patient-reported signs collectively reasonably than in isolation.
By doing so, multimodal AI permits a extra correct understanding of affected person well being, bridging gaps that single-modality AI techniques usually go away unaddressed.
Core Modalities in Healthcare
- Scientific Textual content: This consists of Digital Well being Data (EHRs), structured doctor notes, discharge summaries, and affected person histories. It supplies the “narrative” and context of a affected person’s journey.
- Medical Imaging: Information from X-rays, MRIs, CT scans, and ultrasounds. AI can detect patterns in pixels that could be invisible to the human eye, corresponding to minute textural adjustments in tissue.
- Biosignals: Steady knowledge streams from ECGs (coronary heart), EEGs (mind), and real-time vitals from hospital displays or shopper wearables (like smartwatches).
- Audio: Pure language processing (NLP) utilized to doctor-patient conversations. This may seize nuances in speech, cough patterns for respiratory analysis, or cognitive markers in vocal tone.
- Genomic and Lab Information: Massive-scale “Omics” knowledge (genomics, proteomics) and normal blood panels. These present the molecular-level floor reality of a affected person’s organic state.
How Multimodal Fusion Permits Holistic Affected person Understanding?
Multimodal fusion is the method of mixing and aligning knowledge from completely different modalities right into a unified illustration for AI fashions. This integration permits AI to:
- Seize Interdependencies: Delicate patterns in imaging could correlate with lab anomalies or textual observations in affected person information.
- Scale back Diagnostic Blind Spots: By cross-referencing a number of knowledge sources, clinicians can detect circumstances earlier and with greater confidence.
- Help Customized Remedy: Multimodal fusion permits AI to grasp the affected person’s well being story in its entirety, together with medical historical past, genetics, way of life, and real-time vitals, enabling actually personalised interventions.
- Improve Predictive Insights: Combining predictive modalities improves the AI’s capacity to forecast illness development, remedy response, and potential issues.
Instance:
In oncology, fusing MRI scans, biopsy outcomes, genetic markers, and scientific notes permits AI to advocate focused therapies tailor-made to the affected person’s distinctive profile, reasonably than counting on generalized remedy protocols.
Structure Behind Multimodal Healthcare AI Techniques
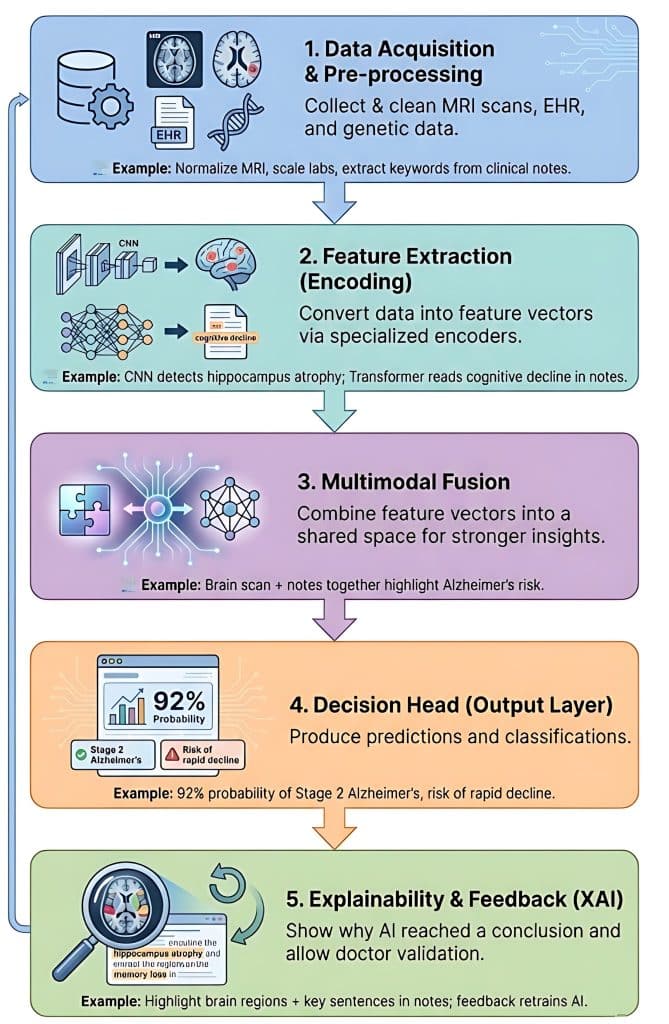
Constructing a multimodal healthcare AI system entails integrating various knowledge varieties, corresponding to medical photos, digital well being information (EHRs), and genomic sequences, to supply a complete view of a affected person’s well being.
For instance this, let’s use the instance of diagnosing and predicting the development of Alzheimer’s Illness.
1. Information Acquisition and Pre-processing
On this stage, the system collects uncooked knowledge from numerous sources. As a result of these sources converse “completely different languages,” they have to be cleaned and standardized.
- Imaging Information (Pc Imaginative and prescient): Uncooked MRI or PET scans are normalized for depth and resized.
- Structured Information (Tabular): Affected person age, genetic markers (like APOE4 standing), and lab outcomes are scaled.
- Unstructured Information (NLP): Scientific notes from neurologists are processed to extract key phrases like “reminiscence loss” or “disorientation.”
Every knowledge sort is shipped by means of a specialised encoder (a neural community) that interprets uncooked knowledge right into a mathematical illustration known as a function vector. Instance:
- The CNN encoder processes the MRI and detects “atrophy within the hippocampus.”
- The Transformer encoder processes scientific notes and identifies “progressive cognitive decline.”
- The MLP encoder processes the genetic knowledge, flagging a excessive danger because of particular biomarkers.
3. Multimodal Fusion
That is the “mind” of the structure. The system should determine how you can mix these completely different function vectors. There are three frequent methods:
- Early Fusion: Combining uncooked options instantly (usually messy because of completely different scales).
- Late Fusion: Every mannequin makes a separate “vote,” and the outcomes are averaged.
- Intermediate (Joint) Fusion: The commonest strategy, the place function vectors are projected right into a shared mathematical area to seek out correlations.
- Instance: The system notices that the hippocampal shrinkage (from the picture) aligns completely with the low cognitive scores (from the notes), making a a lot stronger “sign” for Alzheimer’s than both would alone.
4. The Resolution Head (Output Layer)
The fused data is handed to a remaining set of absolutely related layers that produce the precise scientific output wanted. The Instance: The system outputs two issues:
- Classification: “92% likelihood of Stage 2 Alzheimer’s.”
- Prediction: “Excessive danger of speedy decline inside 12 months.”
5. Explainability and Suggestions Loop (XAI)
In healthcare, a “black field” is not sufficient. The system makes use of an explainability layer (like SHAP or Consideration Maps) to indicate the physician why it reached a conclusion. Instance:
The system highlights the precise space of the mind scan and the precise sentences within the scientific notes that led to the analysis. The physician can then verify or right the output, which helps retrain the mannequin.
As multimodal AI turns into central to fashionable healthcare, there’s a rising want for professionals who can mix scientific information with technical experience.
The Johns Hopkins College’s AI in Healthcare Certificates Program equips you with expertise in medical imaging, precision medication, and regulatory frameworks like FDA and HIPAA, making ready you to design, consider, and implement secure, efficient AI techniques. Enroll at present to grow to be a future-ready healthcare AI skilled and drive the subsequent era of scientific innovation.
Excessive-Affect Use Circumstances Displaying Why Multimodal AI is The Subsequent Frontier in Healthcare

1. Multimodal Scientific Resolution Help (CDS)
Conventional scientific choice help (CDS) usually depends on remoted alerts, corresponding to a excessive coronary heart price set off. Multimodal CDS, nonetheless, integrates a number of streams of affected person data to supply a holistic view.
- Integration: It correlates real-time important indicators, longitudinal laboratory outcomes, and unstructured doctor notes to create a complete affected person profile.
- Early Detection: In circumstances like sepsis, AI can determine delicate adjustments in cognitive state or speech patterns from nurse notes hours earlier than important indicators deteriorate. In oncology, it combines pathology photos with genetic markers to detect aggressive mutations early.
- Lowering Uncertainty: The system identifies and highlights conflicting knowledge, for instance, when lab outcomes recommend one analysis however bodily exams point out one other, enabling well timed human assessment.
- Final result: This strategy reduces clinician “alarm fatigue” and helps 24/7 proactive monitoring, contributing to a measurable lower in preventable mortality.
2. Clever Medical Imaging & Radiology
Medical imaging is evolving from easy detection (“What’s on this picture?”) to patient-specific interpretation (“What does this picture imply for this affected person?”).
- Context-Pushed Interpretation: AI cross-references imaging findings with scientific knowledge, corresponding to affected person historical past, prior biopsies, and documented signs, to supply significant insights.
- Automated Prioritization: Scans are analyzed in real-time. For pressing findings, corresponding to intracranial hemorrhage, the system prioritizes these circumstances for instant radiologist assessment.
- Augmentation: AI acts as a further professional, highlighting delicate abnormalities, offering automated measurements, and evaluating present scans with earlier imaging to help radiologists in decision-making.
- Final result: This results in sooner emergency interventions and improved diagnostic accuracy, notably in complicated or uncommon circumstances, enhancing general affected person care.
3. AI-Powered Digital Care & Digital Assistants
AI-driven digital care instruments lengthen the attain of clinics into sufferers’ properties, enabling a “hospital at house” mannequin.
- Holistic Triage: Digital assistants analyze a number of inputs, voice patterns, symptom descriptions, and wearable system knowledge to find out whether or not a affected person requires an emergency go to or will be managed at house.
- Scientific Reminiscence: Not like fundamental chatbots, these techniques retain detailed affected person histories. As an illustration, a headache reported by a hypertension affected person is flagged with greater urgency than the identical symptom in a wholesome particular person.
- Steady Engagement: Publish-surgery follow-ups are automated, guaranteeing medicine adherence, monitoring bodily remedy, and detecting potential issues corresponding to an contaminated surgical website earlier than hospital readmission turns into crucial.
- Final result: This strategy reduces emergency division congestion, enhances affected person compliance, and improves satisfaction by means of personalised, steady care.
4. Precision Medication & Customized Remedy
Precision medication shifts healthcare from a “one-size-fits-all” strategy to therapies tailor-made to every affected person’s molecular and scientific profile.
- Omics Integration: AI combines genomics, transcriptomics, and radiomics to assemble a complete, multi-dimensional map of a affected person’s illness.
- Dosage Optimization: Utilizing real-time knowledge on kidney operate and genetic metabolism, AI predicts the exact chemotherapy dosage that maximizes effectiveness whereas minimizing toxicity.
- Predictive Modeling: Digital twin simulations enable clinicians to forecast how a selected affected person will reply to completely different therapies, corresponding to immunotherapy versus chemotherapy, earlier than remedy begins.
- Final result: This technique transforms beforehand terminal sicknesses into manageable circumstances and eliminates the normal trial-and-error strategy in high-risk therapies.
5. Hospital Operations & Workflow Optimization
AI applies multimodal analytics to the complicated, dynamic setting of hospital operations, treating the power as a “dwelling organism.”
- Capability Planning: By analyzing components corresponding to seasonal sickness patterns, native occasions, staffing ranges, and affected person acuity within the ER, AI can precisely forecast mattress demand and put together assets prematurely.
- Predicting Bottlenecks: The system identifies potential delays, for instance, a hold-up within the MRI suite that would cascade into surgical discharge delay,s permitting managers to proactively redirect employees and assets.
- Autonomous Coordination: AI can routinely set off transport groups or housekeeping as soon as a affected person discharge is recorded within the digital well being report, decreasing mattress turnaround occasions and sustaining clean affected person circulate.
- Final result: Hospitals obtain greater affected person throughput, decrease operational prices, and decreased clinician burnout, optimizing general effectivity with out compromising high quality of care.
Implementation Challenges vs. Finest Practices
| Problem | Description | Finest Apply for Adoption |
| Information High quality & Modality Imbalance | Discrepancies in knowledge frequency (e.g., 1000’s of vitals vs. one MRI) and “noisy” or lacking labels in scientific notes. | Use “Late Fusion” methods to weight modalities in a different way and make use of artificial knowledge era to fill gaps in rarer knowledge varieties. |
| Privateness & Regulatory Compliance | Managing consent and safety throughout various knowledge streams (voice, video, and genomic) underneath HIPAA/GDPR. | Prepare fashions throughout decentralized servers so uncooked affected person knowledge by no means leaves the hospital, and make the most of automated redaction for PII in unstructured textual content/video. |
| Explainability & Scientific Belief | The “Black Field” downside: clinicians are hesitant to behave on AI recommendation if they can not see why the AI correlated a lab end result with a picture. | Implement “Consideration Maps” that visually spotlight which a part of an X-ray or which particular sentence in a observe triggered the AI’s choice. |
| Bias Propagation | Biases in a single modality (e.g., pulse oximetry inaccuracies on darker pores and skin) can “infect” all the multimodal output. | Conduct “Subgroup Evaluation” to check mannequin efficiency throughout completely different demographics and use algorithmic “de-biasing” through the coaching section. |
| Legacy System Integration | Most hospitals use fragmented EHRs and PACS techniques that weren’t designed to speak to high-compute AI fashions. | Undertake Quick Healthcare Interoperability Sources (FHIR) APIs to create a standardized “knowledge freeway” between previous databases and new AI engines. |
What’s Subsequent for Multimodal AI in Healthcare?
1. Multimodal Basis Fashions as Healthcare Infrastructure
By 2026, multimodal basis fashions (FMs) would be the core intelligence layer of implementing AI in healthcare.
These fashions present cross-modal illustration studying throughout imaging, scientific textual content, biosignals, and lab knowledge, changing fragmented, task-specific AI instruments.
Working as a scientific “AI working system,” they permit real-time inference, shared embeddings, and synchronized danger scoring throughout radiology, pathology, and EHR platforms.
2. Steady Studying in Scientific AI Techniques
Healthcare AI is shifting from static fashions to steady studying architectures utilizing methods corresponding to Elastic Weight Consolidation (EWC) and on-line fine-tuning.
These techniques adapt to knowledge drift, inhabitants heterogeneity, and rising illness patterns whereas stopping catastrophic forgetting, guaranteeing sustained scientific accuracy with out repeated mannequin redeployment.
3. Agentic AI for Finish-to-Finish Care
Agentic AI introduces autonomous, goal-driven techniques able to multi-step scientific reasoning and workflow. Leveraging instrument use, planning algorithms, and system interoperability, AI brokers coordinate diagnostics, knowledge aggregation, and multidisciplinary decision-making, considerably decreasing clinician cognitive load and operational latency.
4. Adaptive Regulatory Frameworks for Studying AI
Regulatory our bodies are enabling adaptive AI by means of mechanisms corresponding to Predetermined Change Management Plans (PCCPs). These frameworks enable managed post-deployment mannequin updates, steady efficiency monitoring, and bounded studying, supporting real-world optimization whereas sustaining security, auditability, and compliance.
The subsequent frontier of healthcare AI is cognitive infrastructure. Multimodal, agentic, and constantly studying techniques will fade into the background—augmenting scientific intelligence, minimizing friction, and turning into as foundational to care supply as scientific instrumentation.
Conclusion
Multimodal AI represents a basic shift in how intelligence is embedded throughout healthcare techniques. By unifying various knowledge modalities, enabling steady studying, and care by means of agentic techniques, it strikes AI from remoted prediction instruments to a scalable scientific infrastructure. The true impression lies not in changing clinicians however in decreasing cognitive burden, enhancing choice constancy, and enabling sooner, extra personalised care.

.jpg)













")






 Roger Wang is a Senior Answer Architect at AWS. He’s a seasoned architect with over 20 years of expertise within the software program business. He helps New Zealand and international software program and SaaS corporations use cutting-edge expertise at AWS to unravel complicated enterprise challenges. Roger is captivated with bridging the hole between enterprise drivers and technological capabilities and thrives on facilitating conversations that drive impactful outcomes.
Roger Wang is a Senior Answer Architect at AWS. He’s a seasoned architect with over 20 years of expertise within the software program business. He helps New Zealand and international software program and SaaS corporations use cutting-edge expertise at AWS to unravel complicated enterprise challenges. Roger is captivated with bridging the hole between enterprise drivers and technological capabilities and thrives on facilitating conversations that drive impactful outcomes. Melanie Li, PhD, is a Senior Generative AI Specialist Options Architect at AWS based mostly in Sydney, Australia, the place her focus is on working with clients to construct options leveraging state-of-the-art AI and machine studying instruments. She has been actively concerned in a number of Generative AI initiatives throughout APJ, harnessing the ability of Massive Language Fashions (LLMs). Previous to becoming a member of AWS, Dr. Li held knowledge science roles within the monetary and retail industries.
Melanie Li, PhD, is a Senior Generative AI Specialist Options Architect at AWS based mostly in Sydney, Australia, the place her focus is on working with clients to construct options leveraging state-of-the-art AI and machine studying instruments. She has been actively concerned in a number of Generative AI initiatives throughout APJ, harnessing the ability of Massive Language Fashions (LLMs). Previous to becoming a member of AWS, Dr. Li held knowledge science roles within the monetary and retail industries. Frank Huang, PhD, is a Senior Analytics Specialist Options Architect at AWS based mostly in Auckland, New Zealand. He focuses on serving to clients ship superior analytics and AI/ML options. All through his profession, Frank has labored throughout quite a lot of industries akin to monetary providers, Web3, hospitality, media and leisure, and telecommunications. Frank is raring to make use of his deep experience in cloud structure, AIOps, and end-to-end answer supply to assist clients obtain tangible enterprise outcomes with the ability of knowledge and AI.
Frank Huang, PhD, is a Senior Analytics Specialist Options Architect at AWS based mostly in Auckland, New Zealand. He focuses on serving to clients ship superior analytics and AI/ML options. All through his profession, Frank has labored throughout quite a lot of industries akin to monetary providers, Web3, hospitality, media and leisure, and telecommunications. Frank is raring to make use of his deep experience in cloud structure, AIOps, and end-to-end answer supply to assist clients obtain tangible enterprise outcomes with the ability of knowledge and AI. Saurabh Gupta is an information science and AI skilled at Pushpay based mostly in Auckland, New Zealand, the place he focuses on implementing sensible AI options and statistical modeling. He has intensive expertise in machine studying, knowledge science, and Python for knowledge science purposes, with specialised expertise coaching in database brokers and AI implementation. Previous to his present function, he gained expertise in telecom, retail and monetary providers, creating experience in advertising analytics and buyer retention applications. He has a Grasp’s in Statistics from College of Auckland and a Grasp’s in Enterprise Administration from the Indian Institute of Administration, Calcutta.
Saurabh Gupta is an information science and AI skilled at Pushpay based mostly in Auckland, New Zealand, the place he focuses on implementing sensible AI options and statistical modeling. He has intensive expertise in machine studying, knowledge science, and Python for knowledge science purposes, with specialised expertise coaching in database brokers and AI implementation. Previous to his present function, he gained expertise in telecom, retail and monetary providers, creating experience in advertising analytics and buyer retention applications. He has a Grasp’s in Statistics from College of Auckland and a Grasp’s in Enterprise Administration from the Indian Institute of Administration, Calcutta. Todd Colby is a Senior Software program Engineer at Pushpay based mostly in Seattle. His experience is targeted on evolving complicated legacy purposes with AI, and translating consumer wants into structured, high-accuracy options. He leverages AI to extend supply velocity and produce innovative metrics and enterprise choice instruments.
Todd Colby is a Senior Software program Engineer at Pushpay based mostly in Seattle. His experience is targeted on evolving complicated legacy purposes with AI, and translating consumer wants into structured, high-accuracy options. He leverages AI to extend supply velocity and produce innovative metrics and enterprise choice instruments.{kind=link}