Preliminary ideas
Estimating causal relationships from knowledge is likely one of the elementary endeavors of researchers. Ideally, we might conduct a managed experiment to estimate causal relations. Nonetheless, conducting a managed experiment could also be infeasible. For instance, schooling researchers can not randomize schooling attainment and so they should study from observational knowledge.
Within the absence of experimental knowledge, we assemble fashions to seize the related options of the causal relationship we now have an curiosity in, utilizing observational knowledge. Fashions are profitable if the options we didn’t embody will be ignored with out affecting our skill to establish the causal relationship we’re involved in. Typically, nonetheless, ignoring some options of actuality ends in fashions that yield relationships that can’t be interpreted causally. In a regression framework, relying on our self-discipline or our analysis query, we give a unique identify to this phenomenon: endogeneity, omitted confounders, omitted variable bias, simultaneity bias, choice bias, and so on.
Under I present how we are able to perceive many of those issues in a unified regression framework and use simulated knowledge for example how they have an effect on estimation and inference.
Understanding omitted confounders, endogeneity, omitted variable bias, and associated ideas
Framework
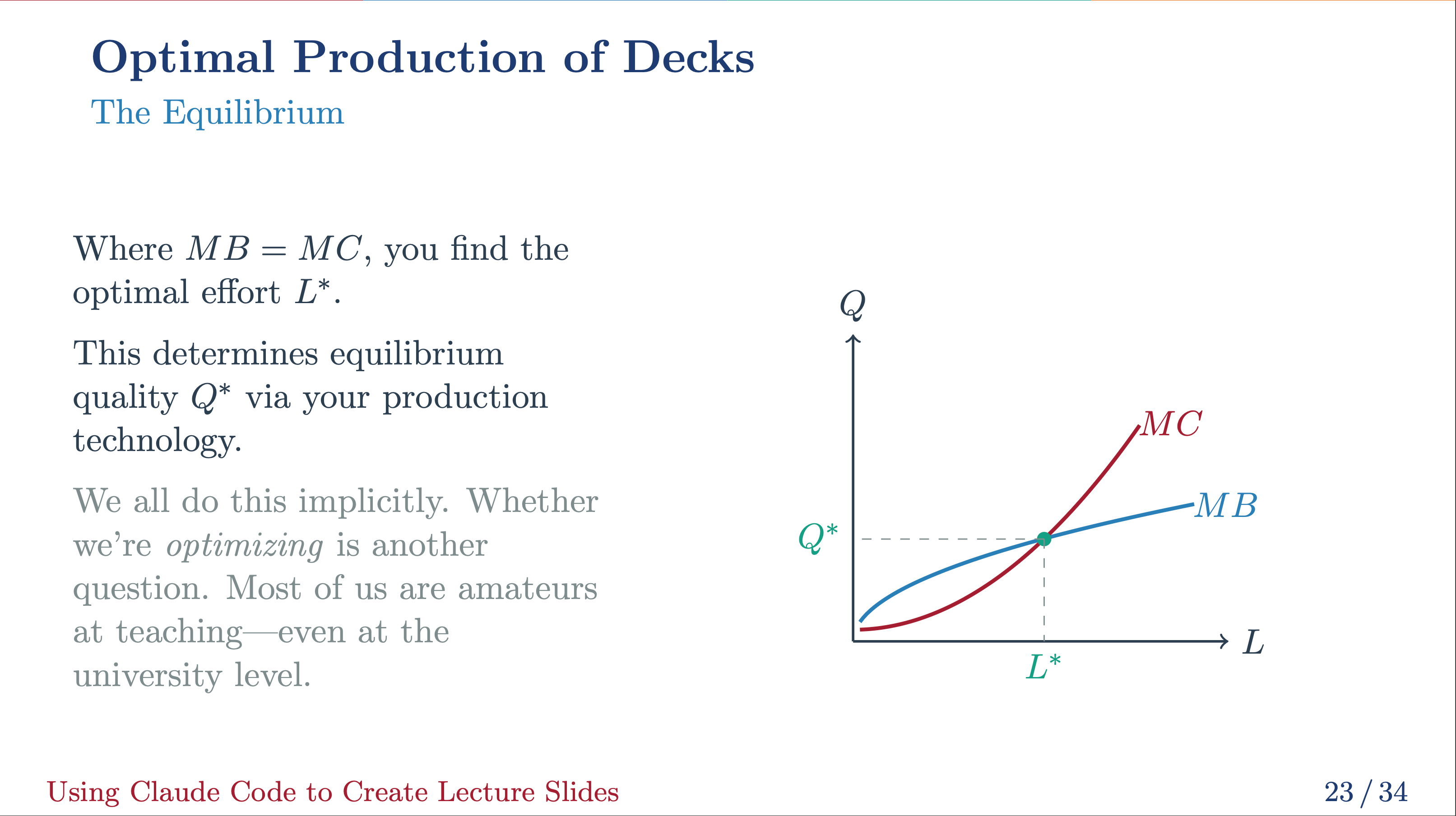
The next statements permit us to acquire a causal relationship in a regression framework.
start{eqnarray*}
y &=& gleft(Xright) + varepsilon
Eleft(varepsilon|Xright) &=& 0
finish{eqnarray*}
Within the expression above, (y) is the end result vector of curiosity, (X) is a matrix of covariates, (varepsilon) is a vector of unobservables, and (gleft(Xright)) is a vector-valued operate. The assertion (Eleft(varepsilon|Xright) = 0) implies that after we account for all the data within the covariates, what we didn’t embody in our mannequin, (varepsilon), doesn’t give us any info, on common. It additionally implies that, on common, we are able to infer the causal relationship of our final result of curiosity and our covariates. In different phrases, it implies that
start{equation*}
Eleft(y|Xright) = gleft(Xright)
finish{equation*}
The other happens when
start{eqnarray*}
y &=& gleft(Xright) + varepsilon
Eleft(varepsilon|Xright) &neq& 0
finish{eqnarray*}
The expression (Eleft(varepsilon|Xright) neq 0) implies that it doesn’t suffice to regulate for the covariates (X) to acquire a causal relationship as a result of the unobservables should not negligible after we incorporate the data of the covariates in our mannequin.
Under I current three examples that fall into this framework. Within the examples beneath, (gleft(Xright)) is linear, however the framework extends past linearity.
Instance 1 (omitted variable bias and confounders). The true mannequin is given by
start{eqnarray*}
y &=& X_1beta_1 + X_2beta_2 + varepsilon
Eleft(varepsilon| X_1, X_2right)&=& 0
finish{eqnarray*}
Nonetheless, the researcher doesn’t embody the covariate matrix (X_2) within the mannequin and believes that the connection between the covariates and the end result is given by
start{eqnarray*}
y &=& X_1beta_1 + eta
Eleft(eta|X_1right)&=& 0
finish{eqnarray*}
If (Eleft(eta|X_1right)= 0), the researcher will get appropriate inference about (beta_1) from linear regression. Nonetheless, (Eleft(eta|X_1right)= 0) will solely occur if (X_2) is irrelevant as soon as we incorporate the data of (X_1). In different phrases, this occurs if (Eleft(X_2|X_1right)=0). To see this, we write
start{eqnarray*}
Eleft(eta|X_1right)&=& Eleft(X_2beta_2 + varepsilon| X_1right)
&=& Eleft(X_2|X_1right)beta_2 + Eleft(varepsilon| X_1right)
&=& Eleft(X_2|X_1right)beta_2
finish{eqnarray*}
If (Eleft(eta|X_1right) neq 0), we now have omitted variable bias, which on this case comes from the connection between the included and omitted variable, that’s, (Eleft(X_2|X_1right)). Relying in your self-discipline, you’d additionally consult with (X_2) as an omitted confounder.
Under I simulate knowledge that exemplify omitted variable bias.
clear seize set seed 111 quietly set obs 20000 native rho = .5 // Producing correlated regressors generate x1 = rnormal() generate x2 = `rho'*x1 + rnormal() // Producing Mannequin quietly generate y = 1 + x1 - x2 + rnormal()
In line 4, I set a parameter that correlates the 2 regressors within the mannequin. In traces 6-8 I generate correlated regressors. In line 12, I generate the end result variable. Under I estimate the mannequin excluding one of many regressors.
. regress y x1, vce(sturdy)
Linear regression Variety of obs = 20,000
F(1, 19998) = 2468.92
Prob > F = 0.0000
R-squared = 0.1086
Root MSE = 1.4183
--------------------------------------------------------------------------
| Strong
y | Coef. Std. Err. t P>|t| [95% Conf. Interval]
---------+----------------------------------------------------------------
x1 | .4953172 .0099685 49.69 0.000 .4757781 .5148563
_cons | 1.006971 .0100287 100.41 0.000 .9873138 1.026628
--------------------------------------------------------------------------
The estimated coefficient is 0.495, however we all know that the true worth is 1. Additionally, our confidence interval means that the true worth is someplace between 0.476 and 0.515. Estimation and inference are deceptive.
Instance 2 (endogeneity in a projection mannequin). The projection mannequin offers us appropriate inference if
start{eqnarray*}
y &=& X_1beta_1 + X_2beta_2 + varepsilon
Eleft(X_j’varepsilon proper)&=& 0 quad textual content{for} quad j in{1,2}
finish{eqnarray*}
If (Eleft(X_j’varepsilon proper) neq 0), we are saying that the covariates (X_j) are endogenous. The legislation of iterated expectations states that (Eleft(varepsilon|X_jright) = 0) which yields (Eleft(X_j’varepsilon proper) = 0). Thus, if (Eleft(X_j’varepsilon proper) neq 0), we now have that (Eleft(varepsilon|X_jright) neq 0). Say (X_1) is endogenous; then, we are able to write the mannequin below endogeneity inside our framework as
start{eqnarray*}
y &=& X_1beta_1 + X_2beta_2 + varepsilon
Eleft(varepsilon| X_1 proper)&neq& 0
Eleft(varepsilon| X_2 proper)&=& 0
finish{eqnarray*}
Under I simulate knowledge that exemplify endogeneity:
clear seize set seed 111 quietly set obs 20000 // Producing Endogenous Elements matrix C = (1, .5 .5, 1) quietly drawnorm e v, corr(C) // Producing Regressors generate x1 = rnormal() generate x2 = v // Producing Mannequin generate y = 1 + x1 - x2 + e
In traces 7–10 I generate correlated unobservable variables. In line 14, I generate a covariate that’s correlated to one of many unobservables, x2. In line 18, I generate the end result variable. The covariate x2 is endogenous, and its coefficient needs to be far-off from the true worth (on this case, (-1)). Under we observe precisely this:
. regress y x1 x2, vce(sturdy)
Linear regression Variety of obs = 20,000
F(2, 19997) = 17126.12
Prob > F = 0.0000
R-squared = 0.6292
Root MSE = .86244
--------------------------------------------------------------------------
| Strong
y | Coef. Std. Err. t P>|t| [95% Conf. Interval]
---------+----------------------------------------------------------------
x1 | 1.005441 .0060477 166.25 0.000 .9935867 1.017295
x2 | -.4980092 .006066 -82.10 0.000 -.5098991 -.4861193
_cons | .9917196 .0060981 162.63 0.000 .9797669 1.003672
--------------------------------------------------------------------------
The estimated coefficient is (-0.498), and our confidence interval means that the true worth is someplace between (-0.510) and (-0.486). Estimation and inference are deceptive.
Instance 3 (choice bias). On this case, we solely observe our final result of curiosity for a subset of the inhabitants. The subset of the inhabitants we observe will depend on a rule. As an example, we observe (y) if (y_2geq 0). On this case, the conditional expectation of our final result of curiosity is given by
start{equation*}
Eleft(y|X_1, y_2 geq 0right) = X_1beta + Eleft(varepsilon|X_1, y_2 geq 0 proper)
finish{equation*}
Choice bias arises if (Eleft(varepsilon|X_1, y_2 geq 0 proper) neq 0). This means that the choice rule is said to the unobservables in our mannequin. If we outline (X equiv (X_1, y_2 geq 0)), we are able to rewrite the issue by way of our common framework:
start{eqnarray*}
Eleft(y|Xright) &=& X_1beta + Eleft(varepsilon|X proper)
Eleft(varepsilon|Xright) &neq & 0
finish{eqnarray*}
Under I simulate knowledge that exemplify choice on unobservables:
clear seize set seed 111 quietly set obs 20000 // Producing Endogenous Elements matrix C = (1, .8 .8, 1) quietly drawnorm e v, corr(C) // Producing exogenous variables generate x1 = rbeta(2,3) generate x2 = rbeta(2,3) generate x3 = rnormal() generate x4 = rchi2(1) // Producing final result variables generate y1 = x1 - x2 + e generate y2 = 2 + x3 - x4 + v exchange y1 = . if y2<=0
In traces 7 and eight, I generate correlated unobservable variables. In traces 12–15 I generate the exogenous covariates. In traces 19 and 20, I generate the 2 outcomes and drop observations in response to the choice rule in line 21. If we use linear regression, we receive
. regress y1 x1 x2, vce(sturdy) noconstant
Linear regression Variety of obs = 14,847
F(2, 14845) = 808.75
Prob > F = 0.0000
R-squared = 0.0988
Root MSE = .94485
--------------------------------------------------------------------------
| Strong
y1 | Coef. Std. Err. t P>|t| [95% Conf. Interval]
---------+----------------------------------------------------------------
x1 | 1.153796 .0291331 39.60 0.000 1.096692 1.210901
x2 | -.7896144 .0288036 -27.41 0.000 -.846073 -.7331558
--------------------------------------------------------------------------
As within the earlier instances, the purpose estimates and confidence intervals lead us to incorrect conclusions.
Concluding remarks
I’ve introduced a common regression framework to know most of the issues that don’t permit us to interpret our outcomes causally. I additionally illustrated the consequences of those issues on our level estimates and confidence intervals utilizing simulated knowledge.


























")