

{kind=link}
In case you have been operating reinforcement studying (RL) post-training on a language mannequin for math reasoning, code era, or any verifiable process, you have got nearly actually stared at a progress bar whereas your GPU cluster burns by means of rollout era. A group of researchers from NVIDIA proposes a exact repair by integrating speculative decoding into the RL coaching loop itself, and do it in a means that preserves the goal mannequin’s actual output distribution.
The analysis group built-in speculative decoding immediately into NeMo RL v0.6.0 with a vLLM backend, delivering lossless rollout acceleration at each 8B and projected 235B mannequin scales.The newest NeMo RL v0.6.0 launch formally ships speculative decoding as a supported characteristic alongside the SGLang backend, the Muon optimizer, and YaRN long-context coaching.
Why Rollout Technology is the Bottleneck
To grasp the issue, it helps to know the way a synchronous RL coaching step breaks down. In NeMo RL, every step consists of 5 phases: knowledge loading, weight synchronization and backend preparation (put together), rollout era (gen), log-probability recomputation (logprob), and coverage optimization (prepare).

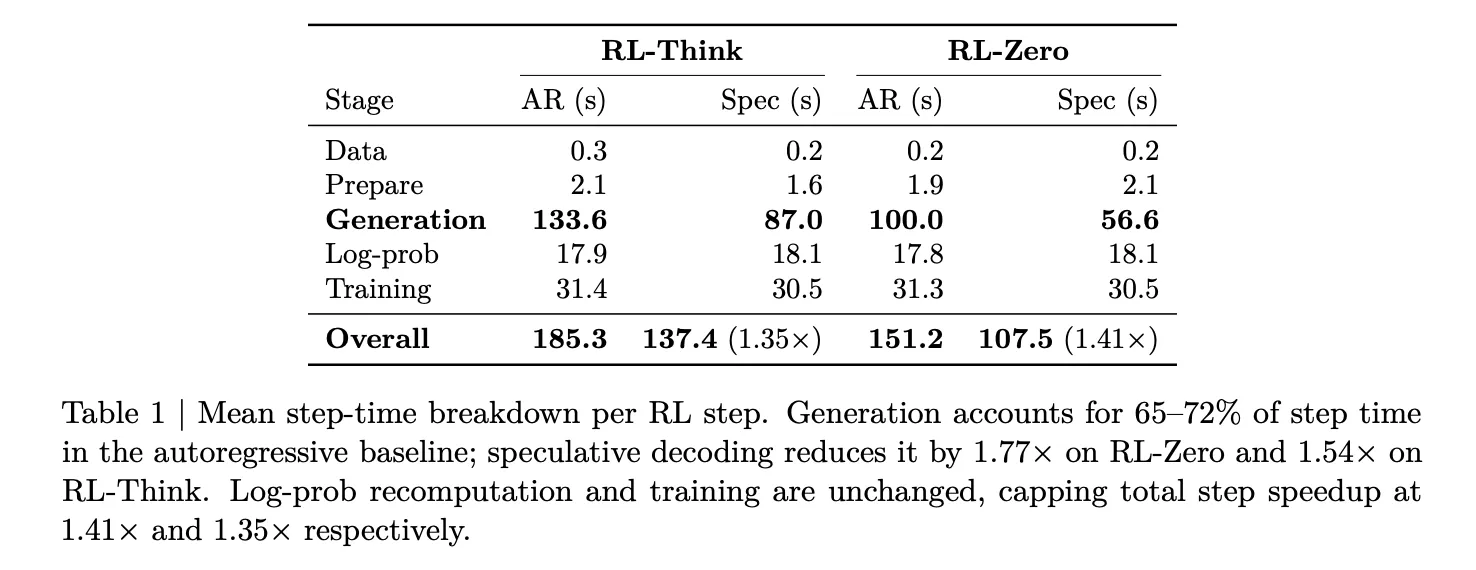
The analysis group measured this breakdown on Qwen3-8B below two workloads — RL-Suppose, which continues coaching a reasoning-capable mannequin, and RL-Zero, which begins from a base mannequin and learns reasoning from scratch. In each circumstances, rollout era accounts for 65–72% of complete step time. Log-probability recomputation and coaching collectively take solely about 27–33%. This makes era the one stage value focusing on for acceleration, and the one which determines the ceiling for any rollout-side optimization.
What Speculative Decoding Truly Does
Speculative decoding is a method the place a smaller, sooner draft mannequin proposes a number of tokens without delay, and the bigger goal mannequin (the one you’re truly coaching) verifies them utilizing a rejection sampling process. The important thing property and why it issues for RL, is that the rejection process is mathematically assured to supply the identical output distribution as if the goal mannequin had generated these tokens autoregressively. No distribution mismatch, no off-policy corrections wanted, no change to the coaching sign.
That is essential as a result of in RL post-training, the coaching reward depends upon the coverage’s personal samples. Strategies like asynchronous execution, off-policy replay, or low-precision rollouts all commerce some quantity of coaching constancy for throughput. Speculative decoding trades nothing: the rollouts are an identical in distribution to what the goal mannequin would have generated by itself, simply produced sooner.
The System Integration Problem
Including a draft mannequin to a serving backend is simple. Including one to an RL coaching loop just isn’t. Each time the coverage updates, the rollout engine should obtain new weights. The draft mannequin should stay aligned with the evolving coverage. Log-probabilities, KL penalties, and the GRPO coverage loss should all be computed towards the goal (verifier) coverage not the draft or the optimization goal is silently corrupted.
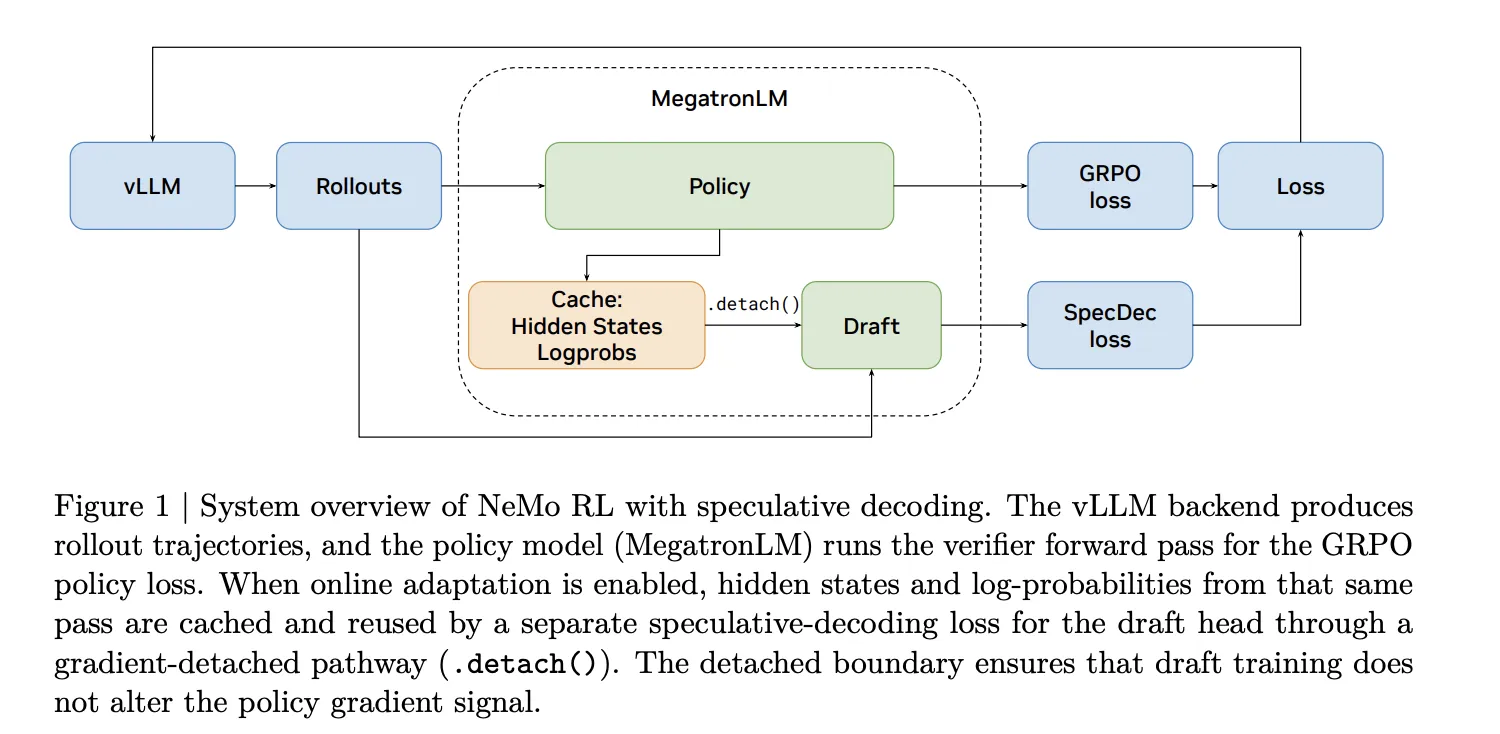
The NVIDIA analysis group handles this in NeMo RL with a two-path structure. The final path makes use of EAGLE-3, a drafting framework that works with any pretrained mannequin with out requiring native multi-token prediction (MTP) assist. A local path can also be accessible for fashions that ship with built-in MTP heads. When on-line draft adaptation is enabled, the hidden states and log-probabilities from the MegatronLM verifier ahead move are cached and reused to oversee the draft head through a gradient-detached pathway, so draft coaching by no means interferes with the coverage gradient sign.
Measured Outcomes at 8B Scale
On 32 GB200 GPUs (8 GB200 NVL72 nodes, 4 GPUs per node), EAGLE-3 reduces era latency from 100 seconds to 56.6 seconds on RL-Zero — a 1.8× era speedup. On RL-Suppose, it drops from 133.6 seconds to 87.0 seconds, a 1.54× speedup. As a result of log-probability re-computation and coaching are unchanged, these generation-side beneficial properties translate to general step speedups of 1.41× on RL-Zero and 1.35× on RL-Suppose. Validation accuracy on AIME-2024 evolves identically below autoregressive and speculative decoding all through coaching, confirming that the lossless assure holds in observe.
The analysis group additionally checks n-gram drafting as a model-free speculative baseline. Regardless of reaching acceptance lengths of two.47 on RL-Zero and a couple of.05 on RL-Suppose, n-gram drafting is slower than the autoregressive baseline in each settings — 0.7× and 0.5× respectively. This can be a essential discovering for practitioners: a optimistic acceptance size is critical however not ample. If the verification overhead is excessive sufficient, hypothesis makes issues worse.
Three Configuration Choices That Decide Realized Speedup
The analysis group isolates three operational selections that practitioners should get proper.
Draft initialization issues greater than generic drafting capacity. An EAGLE-3 draft initialized on the DAPO post-training dataset achieves a 1.77× era speedup on RL-Zero, whereas a draft initialized on the general-purpose UltraChat and Magpie datasets achieves just one.51× on the identical draft size. The draft should be aligned with the precise rollout distribution encountered throughout RL, not only a broad chat distribution.
Draft size has a non-obvious optimum. At draft size okay=3, RL-Zero achieves 1.77× speedup and RL-Suppose achieves 1.53×. Rising to okay=5 raises the acceptance size however drops speedup to 1.44× on RL-Zero and 0.84× on RL-Suppose — the latter already slower than autoregressive. At okay=7, RL-Zero drops additional to 1.21× and RL-Suppose to 0.71×. The distinction issues: RL-Zero’s rollouts are generated from a base mannequin beginning with quick outputs, making them simpler for the draft to foretell even at excessive okay. RL-Suppose’s totally developed reasoning traces are tougher to take a position over, so the overhead of longer drafts erases the profit sooner. Extra speculative work per step can erase the advantage of greater acceptance completely, particularly in tougher era regimes.
On-line draft adaptation — updating the draft throughout RL utilizing rollouts generated by the present coverage helps most when the draft is weakly initialized. For a DAPO-initialized draft, offline and on-line configurations carry out practically identically (1.77× vs. 1.78× on RL-Zero). For a UltraChat-initialized draft, on-line updating improves speedup from 1.51× to 1.63× on RL-Zero.
Interplay with asynchronous execution was additionally examined immediately at 8B scale not simply in simulation. The analysis group ran RL-Suppose at coverage lag 1 in a 16-node non-colocated configuration, with 12 nodes devoted to era and 4 to coaching. In asynchronous mode, most of rollout era is already hidden behind log-probability re-computation and coverage updates, so the related amount is the uncovered era time that is still on the essential path. Speculative decoding reduces that uncovered era time from 10.4 seconds to 0.6 seconds per step and lowers efficient step time from 75.0 seconds to 60.5 seconds (1.24×). The achieve is smaller than in synchronous RL — anticipated, since asynchronous overlap already hides a lot of the rollout price — nevertheless it confirms that the 2 mechanisms are genuinely complementary somewhat than redundant.
Projected Positive aspects at 235B Scale
Utilizing a proprietary GPU efficiency simulator calibrated to device-level compute, reminiscence, and interconnect traits, the analysis group projected speculative decoding beneficial properties at bigger scales. For Qwen3-235B-A22B operating synchronous RL on 512 GB200 GPUs, draft size okay=3 with an acceptance size of three tokens yields a 2.72× rollout speedup and a 1.70× end-to-end speedup.
On the most favorable simulated working level — Qwen3-235B-A22B on 2048 GB200 GPUs with asynchronous RL at coverage lag 2 — rollout speedup reaches roughly 3.5×, translating to a projected 2.5× end-to-end coaching speedup. Speculative decoding and asynchronous execution are described as complementary: hypothesis reduces the price of every particular person rollout, whereas asynchronous overlap hides the remaining era time behind coaching and log-probability computation.
Key Takeaways
- Rollout era is the dominant bottleneck in RL post-training, accounting for 65–72% of complete step time in synchronous RL workloads — making it the one stage the place acceleration has significant impression on end-to-end coaching pace.
- Speculative decoding through EAGLE-3 delivers lossless rollout acceleration, reaching 1.8× era speedup at 8B scale (1.41× general step speedup) with out altering the goal mannequin’s output distribution — in contrast to asynchronous execution, off-policy replay, or low-precision rollouts, which all commerce coaching constancy for throughput.
- Draft initialization high quality issues greater than draft size, with in-domain (DAPO-trained) drafts outperforming normal chat-domain drafts by a significant margin; longer draft lengths (okay≥5) constantly backfire in tougher reasoning workloads, making okay=3 the dependable default.
- Simulator projections present beneficial properties scale up considerably, reaching ~3.5× rollout speedup and a projected ~2.5× end-to-end coaching speedup at 235B scale on 2048 GB200 GPUs — and the approach is already accessible in NeMo RL v0.6.0 below Apache 2.0.
Try the Full Paper and Nemo RL Repo. Additionally, be happy to comply with us on Twitter and don’t neglect to affix our 130k+ ML SubReddit and Subscribe to our E-newsletter. Wait! are you on telegram? now you may be part of us on telegram as nicely.
Must associate with us for selling your GitHub Repo OR Hugging Face Web page OR Product Launch OR Webinar and many others.? Join with us