Abstract created by Sensible Solutions AI
In abstract:
- Macworld examines seven pivotal Apple merchandise that remodeled the corporate from near-bankruptcy to tech dominance, together with the G3 iMac, iPod, iTunes Retailer, MacBook Air, Apple Watch, AirPods, and Apple Silicon.
- These improvements addressed vital challenges and established Apple’s ecosystem technique, with merchandise just like the iPod creating seamless hardware-software integration and the iTunes Retailer proving Apple’s service capabilities.
- Initially underestimated merchandise turned business game-changers, from the ridiculed AirPods attaining international success to Apple Silicon revitalizing Mac computer systems and attracting new customers.
As Apple turns 50, it’s straightforward to deal with the most important hits, such because the Macintosh, iPod, and iPhone. However the firm by no means relied on a single blockbuster. As an alternative, its historical past is paved with a collection of bold merchandise that arrived at simply the suitable moments.
Greater than the merchandise themselves, Apple’s historical past may be divided into moments that took the corporate in main new instructions, saved it from chapter, and reinvented its id. Listed here are the seven merchandise that helped Apple keep related amid a quickly altering panorama.
iMac: The comeback
Earlier than Apple launched the G3 iMac, the corporate was going through some robust occasions. Apple was near chapter with a bloated product lineup and no clear technique for the long run. There was additionally the entire management state of affairs, with a carousel of CEOs after Jobs left in 1985.
When Jobs returned to his function as Apple’s CEO in 1997, he fully rethought the corporate’s technique. Not solely that, he knew that Apple wanted a killer product to win again its prospects.
The unique G3 iMac introduced Apple bacl from the brink of chapter.
The iMac, launched in 1998, wasn’t only a new pc. It was an entire new idea that might change Apple without end. Not like all different PCs on the time, the iMac was made of lovely translucent, colourful plastic and had a contemporary all-in-one design.
Requirements like floppy disk drives and SCSI gave approach to extra trendy applied sciences resembling CD-ROM, USB, and Ethernet. The concept was clear: a pc for the long run, prepared for the web, that was so easy to make use of that anybody would need it.
The iMac didn’t save Apple alone, nevertheless it helped the corporate get again on monitor and, extra importantly, reestablished its id as an organization targeted on the consumer expertise.
iPod: The ecosystem
Even earlier than the iPod, Apple had tried to succeed in markets past computer systems with issues like digital cameras, printers, and even a sport console. All of them failed.
However in 2001, the corporate lastly took a step in the suitable route to create a real Apple ecosystem. The primary iPod was greater than a fairly MP3 participant. It was a tool constructed to develop past the Mac. Customers may merely plug them into their Mac and mechanically sync their iTunes library.

The iPod was Apple’s first ecosystem product.
Filipe Esposito
The iPod additionally confirmed what Apple did greatest: take an concept that was already available on the market and make it even higher. MP3 gamers had been already a factor on the time, however the iPod was smaller, higher designed, and far more intuitive than something on the market. The Click on Wheel made it in contrast to every other transportable music participant ever made.
Over time, the iPod gained assist for Home windows PCs, which made much more individuals need an iPod. It pulled new customers into Apple Shops and made iTunes a platform. However greater than the music, the iPod paved the way in which for Apple to create a whole ecosystem of merchandise that labored seamlessly with one another.
iTunes Retailer: The primary Service
What actually helped the iPod grow to be a giant hit was the iTunes Retailer. On the time, Apple was completely targeted on promoting {hardware} to make cash. However in 2003, the iTunes Retailer modified that.
In an try to assist document labels fight piracy, Steve Jobs partnered with main document labels to launch the iTunes Retailer. The concept was to let prospects buy digital variations of their favourite albums at reasonably priced costs.
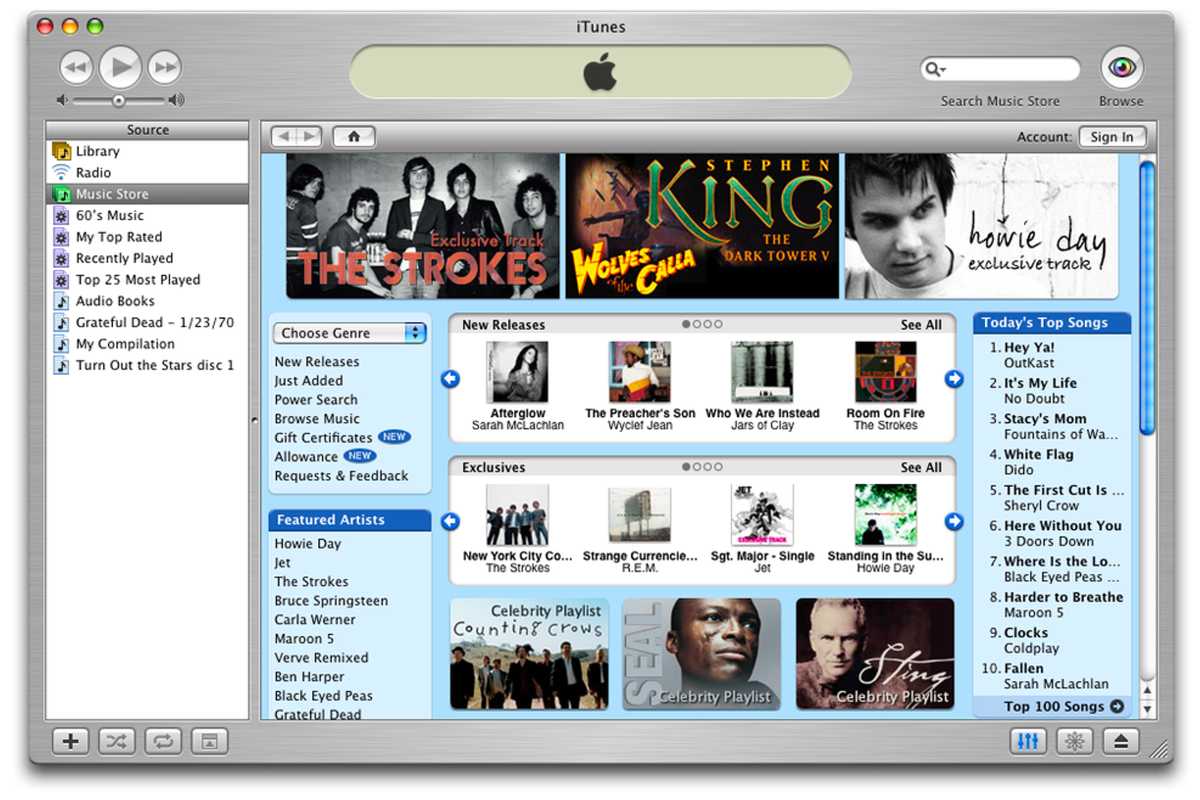
The iTunes Music Retailer confirmed the world that Apple was greater than a {hardware} firm.
Apple
Furthermore, customers may even buy a single tune for simply 99 cents, a groundbreaking innovation on the time. And naturally, bought songs had been mechanically synced to the consumer’s iPod.
The iTunes Retailer marked the start of a brand new period for Apple. It was a digital service that complemented the {hardware}, and vice versa. One made you need the opposite.
In 2010, the iTunes Retailer turned the world’s largest music vendor. Now, now we have Apple Music, Apple TV, and even the App Retailer, and it’s all as a result of Apple determined to create its personal on-line music retailer greater than twenty years in the past.
MacBook Air: The laptop computer of tomorrow
Some of the iconic moments in Apple’s historical past is undoubtedly when Steve Jobs pulled the unique MacBook Air out of an inter-office envelope in 2008. He wasn’t simply displaying how skinny the MacBook Air was, however how gentle, transportable, and versatile laptops might be.
Not like different laptops on the time, the MacBook Air was extremely skinny and light-weight. It focused prospects who didn’t want cumbersome laptops. Greater than that, it was constructed with applied sciences which have grow to be commonplace as we speak – issues like a speedy SSD, multi-touch trackpad, and naturally, its all-aluminum design.

The MacBook Air set the course for the way forward for Apple’s transportable Macs.
Apple
Similar to Apple did with the primary iMac, the MacBook Air was a press release of how Apple believed laptops must be from then on. No extra CD trays or legacy ports.
Rivals rushed to repeat it. Intel constructed the Ultrabook initiative in response. The MacBook Air quietly reshaped the PC business at a second when Apple wanted the Mac to stay related in a post-iPhone world.
Apple Watch: The following chapter
The Apple Watch was the primary really new product class launched beneath Tim Cook dinner’s management as CEO. It was additionally the primary main check to point out whether or not Apple may nonetheless innovate with out Steve Jobs.
The primary model appeared to lack a transparent focus. Apple tried to advertise the Apple Watch as a vogue accent, an iPhone companion, and in addition a health tracker. It additionally had a really sluggish processor and relied closely on the iPhone to run apps. However regardless of these points, the Apple Watch was successful and confirmed that the corporate was nonetheless in good palms.

Apple Watch has come a good distance since its debut in 2014.
Britta O’Boyle
The Apple Watch was so profitable that it redefined the concept of a smartwatch. The idea wasn’t new, however most of them had been ugly, clunky, and low-cost. The Apple Watch was launched with a ravishing OLED show, customizable bands, and a premium end product of aluminum, metal, and even strong gold.
Apple ultimately addressed the most important criticisms and refocused its efforts on making it a health and well being gadget. The Watch has now grow to be indispensable for hundreds of thousands of individuals, due to options resembling well being alerts, 5G, and Emergency SOS proper from their wrist.
And maybe extra importantly, it launched Apple’s wearables and equipment section, which now consists of AirPods and Imaginative and prescient Professional.
AirPods: The lock-in impact
When Apple unveiled the iPhone 7, it was lacking a port that had been on each Apple product since its first Macintosh: a headphone jack. As a replacement, Apple included a Lightning-to-3.5mm adapter within the field and launched its first pair of wi-fi earbuds aptly named AirPods.
Few Apple merchandise had been mocked as rapidly as AirPods. The really wi-fi design regarded unusual. Folks had been afraid that they might simply lose their earphones since there was no wire connecting them.

AirPods have grow to be as ubiquitous because the iPhone itself.
Andreas Bergsman
But, AirPods turned an enormous success. As soon as customers skilled instantaneous pairing and computerized gadget switching with out having to fret about tedious Bluetooth settings, there was no turning again. Quickly, everybody needed AirPods.
This additionally led rivals to speculate closely in wi-fi earbuds. Regardless of that, solely AirPods supplied so many handy options for iPhone customers. They served as delicate reminders of the benefits of staying locked into the Apple ecosystem, quite than shopping for earbuds from different manufacturers. And with out a headphone jack on the brand new iPhone, it was a pure accent pairing.
Apple continually promotes how nicely the iPhone, Apple Watch, and AirPods work collectively. Collectively, they grow to be a powerful cause for iPhone customers to not swap to Android, and even to inspire them to purchase different Apple merchandise.
Right this moment, AirPods are a phenomenon. You see them all over the place around the globe, they usually have grow to be an vital income for Apple.
Apple Silicon: The guess on the long run
Apple made a daring transfer when it transitioned Macs from Intel processors to its personal Apple Silicon chips in 2020. With the introduction of the M1 chip, Apple didn’t simply make quicker Macs. It reclaimed management over its roadmap.
For a second, it was nearly as if the Mac was turning into a distinct segment product. There have been computer systems with higher efficiency and decrease costs. On the similar time, Apple relied on Intel to plan what would come subsequent for the Mac.

Apple silicon modified the route of the Mac.
Apple
Apple Silicon chips have breathed new life into the Mac. These chips have enabled Apple to raised combine {hardware} and software program, which has additionally enabled new type elements for the Mac. The MacBook Air is now smaller and extra highly effective than ever, and the brand new, reasonably priced MacBook Neo runs full macOS on an iPhone chip.
The Mac has as soon as once more set itself other than the remainder of the business, not solely as a result of it has a greater design, however as a result of its whole structure is extra highly effective and extra environment friendly. The result’s that increasingly more individuals have been switching to the Mac in recent times.
The Mac regained credibility. Lengthy-time Mac customers regained enthusiasm. Apple Silicon Macs are actually, in a approach, what the primary iMac represented for Apple within the late ’90s.
What’s subsequent?
Wanting again, it was laborious to think about that these merchandise would grow to be so vital to Apple.
The iMac appeared like an optimistic idea, the iPod was too area of interest, the MacBook Air had too many compromises for its time, the Apple Watch lacked a transparent function, AirPods appeared like a gimmick, and Apple Silicon was a dangerous structure change.
And but, every of them solved a selected problem Apple was going through on the time and paved the way in which for the services and products now we have as we speak.
In fact, the massive query now could be what the following “quiet savior” will probably be. Apple is already investing closely in new areas resembling well being and spatial computing with units such because the Apple Imaginative and prescient Professional. Whether or not any of those efforts will grow to be the following iMac or iPod stays to be seen.
Maybe Apple’s subsequent massive factor will come from the place we least anticipate it.