Science is our notion of how issues work. The scientific methodology is how we decide what’s the present state of our science. Science is the product of the profitable utility of the scientific methodology. They aren’t the identical. For one factor, whereas science adjustments; the scientific methodology is fixed.
When folks say “belief the science” what they actually imply to say, or ought to imply to say, is “belief the scientific methodology.” Science is consistently in a state of flux. It’s by no means settled as a result of there are at all times new issues to be taught. Within the Nineteen Fifties, I used to be taught that there have been electrons having a unfavorable cost, protons having a constructive cost, and neutrons having no cost. My grandparents by no means realized about any of those once they went to high school, it was all too new and unsettled. As we speak, there are extra subatomic particles than I can depend. I don’t even know what’s taught about them in highschool.
There are lots of ways in which the scientific methodology could be perverted, if not ignored altogether, to supply faulty outcomes. Most analysis characterised as unhealthy science might be the results of bias on the a part of the researcher. Typically, it’s a consequence of the subject not having a theoretical foundation or being close to the boundaries of our present understanding. And, in fact, in uncommon instances, it’s intentional.
Classes of unhealthy science go by many names, all of that are pejorative. Class definitions range between sources and a few matters have been given as examples in multiple class. Typically the unfavorable connotations are used to discredit analysis that challenges mainstream scientific concepts. Like an advert hominem argument, invoking phrases associated to unhealthy science have been used to silence dissenters by stopping them from receiving monetary help or publishing in scientific journals.
Pathological science happens when a researcher holds onto a speculation regardless of legitimate opposition from the scientific neighborhood. This isn’t essentially a nasty factor. Most scientific hypotheses undergo durations when they’re ignored in favor of the accepted speculation. It’s only with persistence and additional analysis {that a} speculation shall be accepted. Typically the change is evolutionary and typically the change is revolutionary. The change from the Increasing-Earth speculation to the Continental-Drift speculation was revolutionary; the change from the Continental-Drift speculation to Plate Tectonics was evolutionary.
The pathological a part of pathological science happens when the researcher deviates from strict adherence to the scientific methodology in an effort to favor the specified speculation or incorporate wishful pondering into interpretation of the information. Often, the speculation is experimental in nature and is developed after some analysis information have been generated. The results of the outcomes are close to the boundaries of detectability. Typically, different researchers are recruited to perpetuate the delusion.
Researchers concerned in pathological science are likely to have the schooling and expertise to conduct true science so their preliminary outcomes could also be accepted as professional. Finally, although, failure to copy the outcomes damages its credibility.
Chilly fusion is taken into account by some to be an instance of pathological science as a result of all or a lot of the analysis is finished by a closed group of scientists who sponsor their very own conferences and publish their very own journals.
Pseudoscience entails hypotheses that can’t be validated by statement or experimentation, that’s, are incompatible with the scientific methodology, however nonetheless are claimed to be scientifically professional. Pseudoscience typically entails long-held beliefs that pre-date experiments, consequently, it’s typically primarily based on defective premises. Whereas much less more likely to be standard within the scientific neighborhood, pseudoscience could discover help from most people.
Examples which were characterised as pseudoscience embrace numerology, free power, dowsing, Lysenkoism, graphology , physique reminiscence, human auras, crystal therapeutic, grounding remedy, macrobiotics, homeopathy, and near-death experiences.
The time period pseudoscience is usually used as an inflammatory buzzword for dismissing opponents’ information and outcomes.
Fringe science refers to hypotheses inside a longtime discipline of examine which are extremely speculative, typically on the excessive boundaries of mainstream research. Proponents of some fringe sciences could come from exterior the mainstream of the self-discipline. However, they’re typically vital brokers in bringing about adjustments in conventional methods of desirous about science, resulting in far-reaching paradigm shifts.
Some ideas that had been as soon as rejected as fringe science have ultimately been accepted as mainstream science. Examples embrace heliocentrism (sun-centered photo voltaic system), peptic ulcers being brought on by Helicobacter pylori, and chaos principle. The time period protoscience refers to matters that had been at one level mainstream science however fell out of favor and had been changed by extra superior formulations of comparable ideas. The unique speculation then grew to become a pseudoscience. Examples of protosciences are astrology evolving into the science of astronomy, alchemy evolving into the science of chemistry, and continental drift evolving into plate tectonics.
Different examples of fringe science embrace Feng shui, Ley strains, distant viewing, hypnotherapy and psychoanalysis, subliminal messaging, and the MBTI (Myers–Briggs Kind Indicator). Some areas of complementary drugs, akin to mind-body strategies and power therapies, could sometime develop into mainstream with persevering with scientific consideration.
The time period fringe science is taken into account to be pejorative by some folks however it isn’t meant to be.
Barely science is perhaps completely acceptable science besides that it’s too underdeveloped to be launched exterior the scientific neighborhood. Barely science could also be primarily based on a single examine, or pilot research that lack the methodological rigor of formal research, or research that don’t have sufficient samples for sufficient decision, or research that haven’t undergone formal peer overview. Researchers beneath strain to exhibit outcomes to sponsors or announce outcomes earlier than opponents are the sources. Customers see barely science greater than they know.
Junk science refers to analysis thought of to be biased by authorized, political, ideological, monetary, or in any other case unscientific motives. The idea was popularized within the Nineteen Nineties in relation to authorized instances. Forensic strategies which were criticized as junk science embrace polygraphy (lie detection), bloodstain-pattern evaluation, speech and textual content patterns evaluation, microscopic hair comparisons, arson burn sample evaluation, and roadside drug checks. Creation sciences, religion therapeutic, eugenics, and conversion remedy are thought of to be junk sciences.
Typically, characterizing analysis as junk science is just a option to discredit opposing claims. This use of the time period is a typical ploy for devaluing research involving archeology, complementary drugs, public well being, and the surroundings. Maligning analyses as junk science has been criticized for undermining public belief in actual science.
Tooth-Fairy science is analysis that may be portrayed as professional as a result of the information are reproducible and statistically vital however there isn’t any understanding of why or how the phenomenon exists. Placebos, endometriosis, yawning, out-of-place artifacts, megalithic stonework, ball lightning, and darkish matter are examples. Chiropractic, acupuncture, homeopathy, therapeutic contact, and biofield tuning can also be thought of to be tooth-fairy sciences
Cargo-cult science entails utilizing equipment, instrumentation, procedures, experimental designs, information, or outcomes with out understanding their function, operate, or limitations, in an effort to verify a speculation. Examples of cargo-cult experimentation may contain replication research that use lower-grade chemical reagents, devices not designed for discipline circumstances, or information obtained utilizing totally different populations and sampling schemes. In a case of fraudulent science involving experimental analysis on Alzheimer’s illness, over a decade of analysis efforts had been wasted by counting on the illegitimate outcomes.
Coerced science happens when researchers are compelled by authorities to review sometimes-objectionable matters in ways in which promote pace in reaching a desired consequence over scientific integrity. There are many notable examples. Throughout World Warfare II, just about each main energy pushed their scientists and engineers to realize quite a lot of desired outcomes. Within the Nineteen Sixties, JFK efficiently pressured NASA to land a person on the Moon. Within the Eighties, Reagan prioritized efforts on his Strategic Protection Initiative (SDI) despite the fact that the objective was thought of to be unachievable by specialists. Many governments limit analysis on their nation’s cultural artefacts to people who comply with extreme preconditions together with censorship of bulletins and outcomes.
Companies, particularly within the fields of drugs and pharmaceutics, place nice strain on analysis employees to realize outcomes. For instance, Elizabeth Holmes, founding father of the medical diagnostic firm Theranos, was convicted of fraud and sentenced to 111⁄4 years in jail. Companies are additionally recognized to hide information that will be of nice profit to society in the event that they had been obtainable. Examples embrace outcomes of pharmaceutical research (e.g., Tamiflu, statins) and subsurface exploration for oil and mineral assets.
Tutorial establishments predicate tenure appointments partly on journal publications and grant awards, each of which depend on researchers discovering statistical significance of their analyses (p-hacking, see Chapter 6).
Taboo science refers to areas of analysis which are restricted and even prohibited both by governments or funding organizations. Typically that is cheap and good. For instance, analysis on people has develop into increasingly restrictive after the atrocities that occurred throughout World Warfare II. Throughout the Chilly Warfare, U.S. army and intelligence companies obstructed unbiased analysis on nationwide safety matters, akin to encryption.
Some taboos, nevertheless, are promoted by special-interest teams, akin to political and non secular organizations. Examples of matters which are tough for researchers to acquire funding for embrace: effectiveness of strategies to regulate gun violence; historic civilizations, archeological websites, artefacts, and STEM capabilities; well being advantages of hashish and psychedelics; resurrecting extinct species; and a few matters in human biology akin to cloning, genetic engineering, chimeras, artificial biology, scientific features of racial and gender variations, and causes and coverings for pedophilia.
Fraudulent science consists of analysis, experimental or observational, through which information, outcomes, and even entire research are faked. Creation of false information or instances is named fabrication; misrepresentation of information or outcomes is named falsification. Plagiarism and different types of data theft, conflicts of curiosity, and moral violations are additionally thought of features of fraudulent science. The objectives of fraudulent science are normally for the researcher to amass cash together with funding and sponsorships, and improve repute and energy throughout the occupation.
Sadly, there are too many examples of fraudulent science. Maybe probably the most infamous is the 1998 case of Andrew Wakefield, a British skilled in gastroenterology, who claimed to have discovered a hyperlink between the MMR vaccine, autism and inflammatory bowel illness. His paper revealed in The Lancet, which was retracted in 2010, is believed to have prompted worldwide outbreaks on measles after a considerable decline in vaccinations. Wakefield later grew to become a frontrunner within the anti-vaxx motion within the U.S.. One other notorious instance entails faked photos in a 2006 experimental examine of reminiscence deficits in mice, which subsequently led to an unproductive diversion of funding for Alzheimer’s analysis.
Typically, fraudulent actions are refined and go unnoticed even by specialists. Examples embrace pharmaceutical research designed to intensify constructive results whereas concealing undesirable unwanted side effects. Typically, well-meaning actions have unexpected ramifications, akin to when definitions of medical circumstances are modified leading to sufferers being handled otherwise. Examples embrace weight problems, diabetes, and cardiac circumstances.
From 2000 to 2020, 37,780 skilled papers have been retracted due to fraud (The Retraction Watch Database [Internet]. New York: The Heart for Scientific Integrity. 2018. ISSN: 2692-465X. Accessed 4/13/2023. Out there at: http://retractiondatabase.org/). These retractions are thought of to symbolize solely a fraction of all fraudulent science.
Clearly, science and scientists are improper every so often even once they don’t intend to be. That’s to be anticipated. Even when the scientific methodology isn’t all that obscure it’s extremely tough to place into apply, simplified flowcharts however. As a consequence, scientific research are too typically poorly designed, poorly executed, deceptive, or misinterpreted. More often than not, that is inadvertent although typically not.
Whereas this may increasingly appear to be a reasonably dismal portrayal of science, keep in mind that the overwhelming majority of right now’s science is actual and bonafide. The distinction between unhealthy science and true science that strictly follows the scientific methodology is that true science will ultimately appropriate illegitimate outcomes.











 – Geometry")
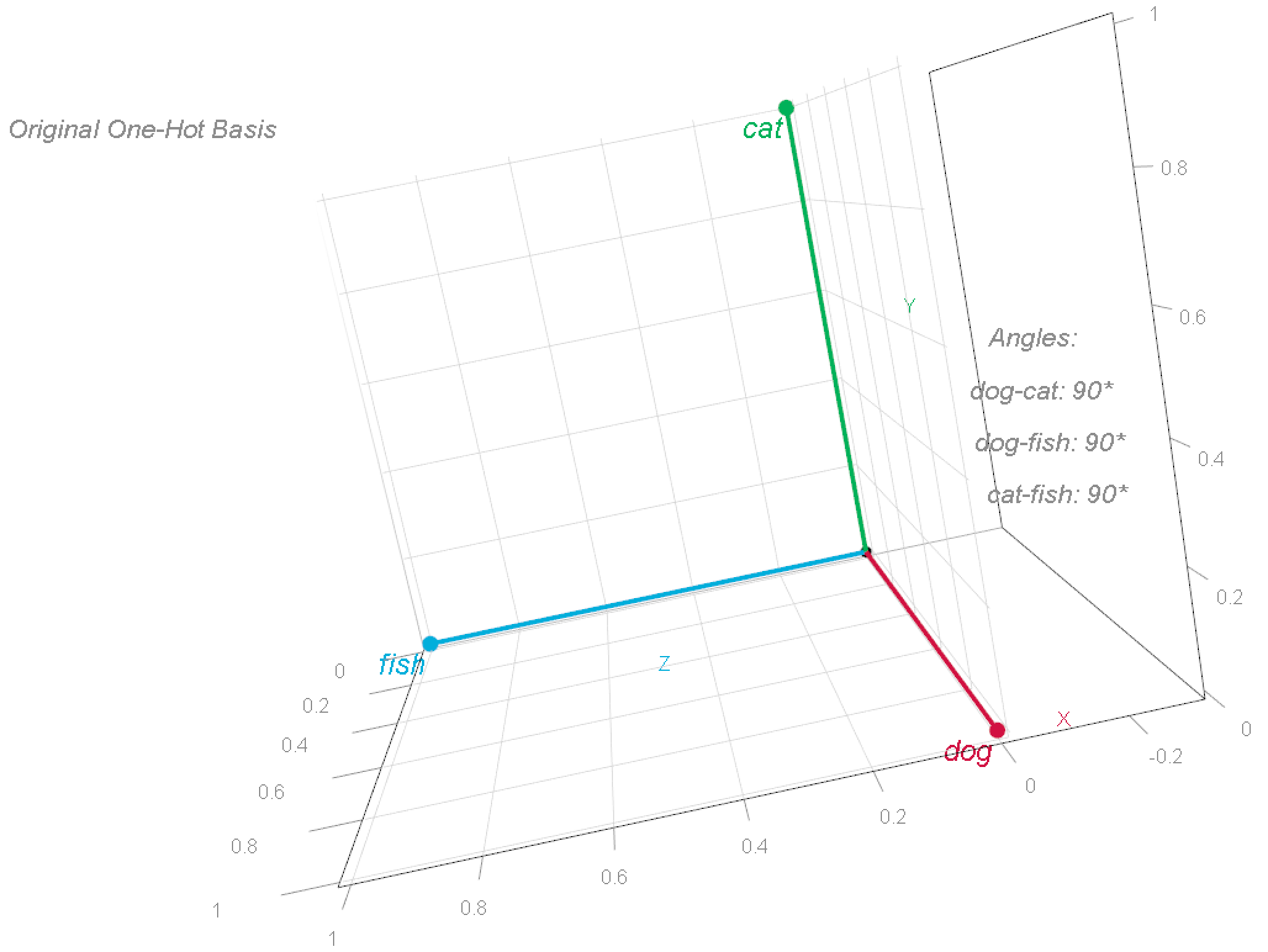
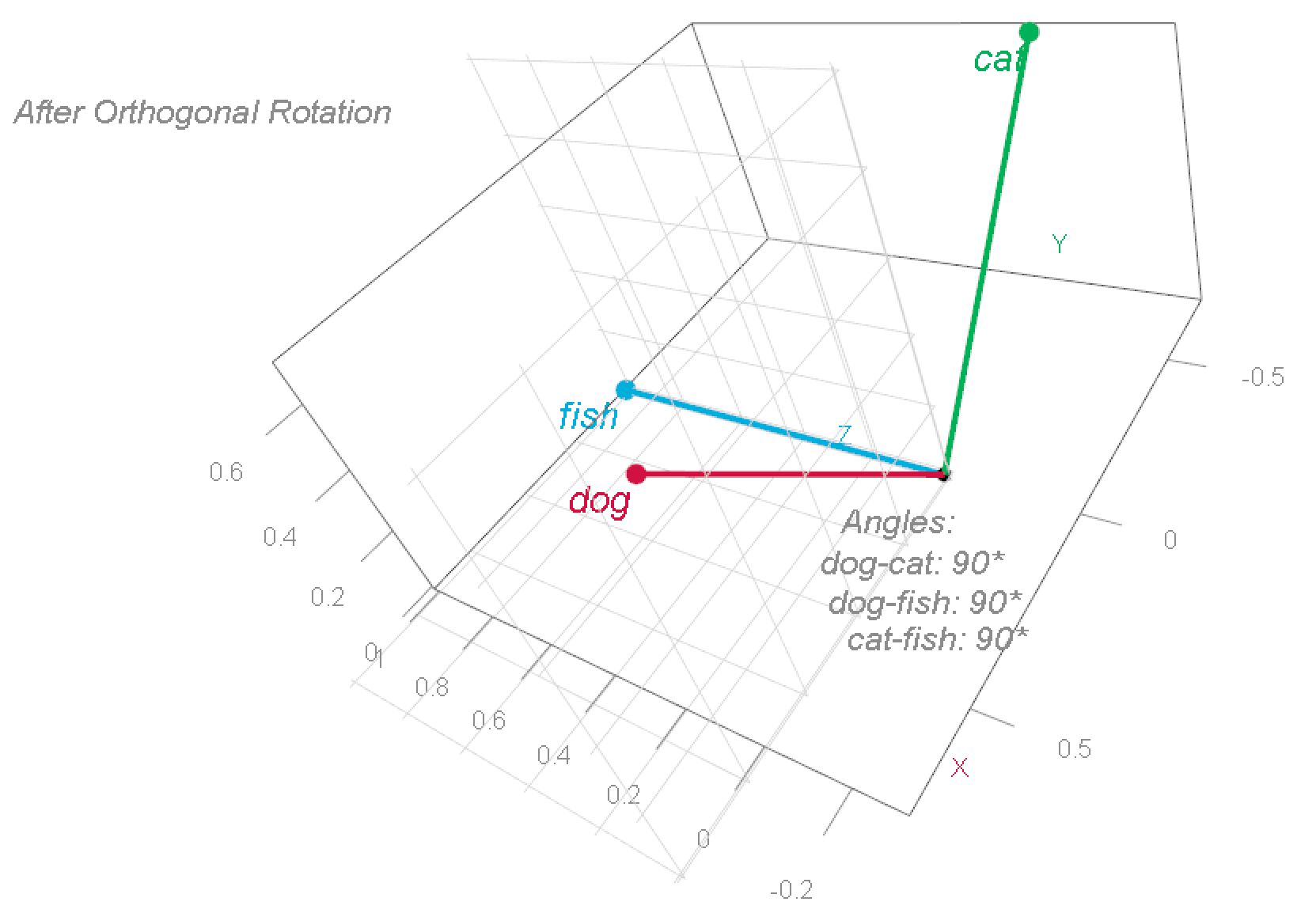
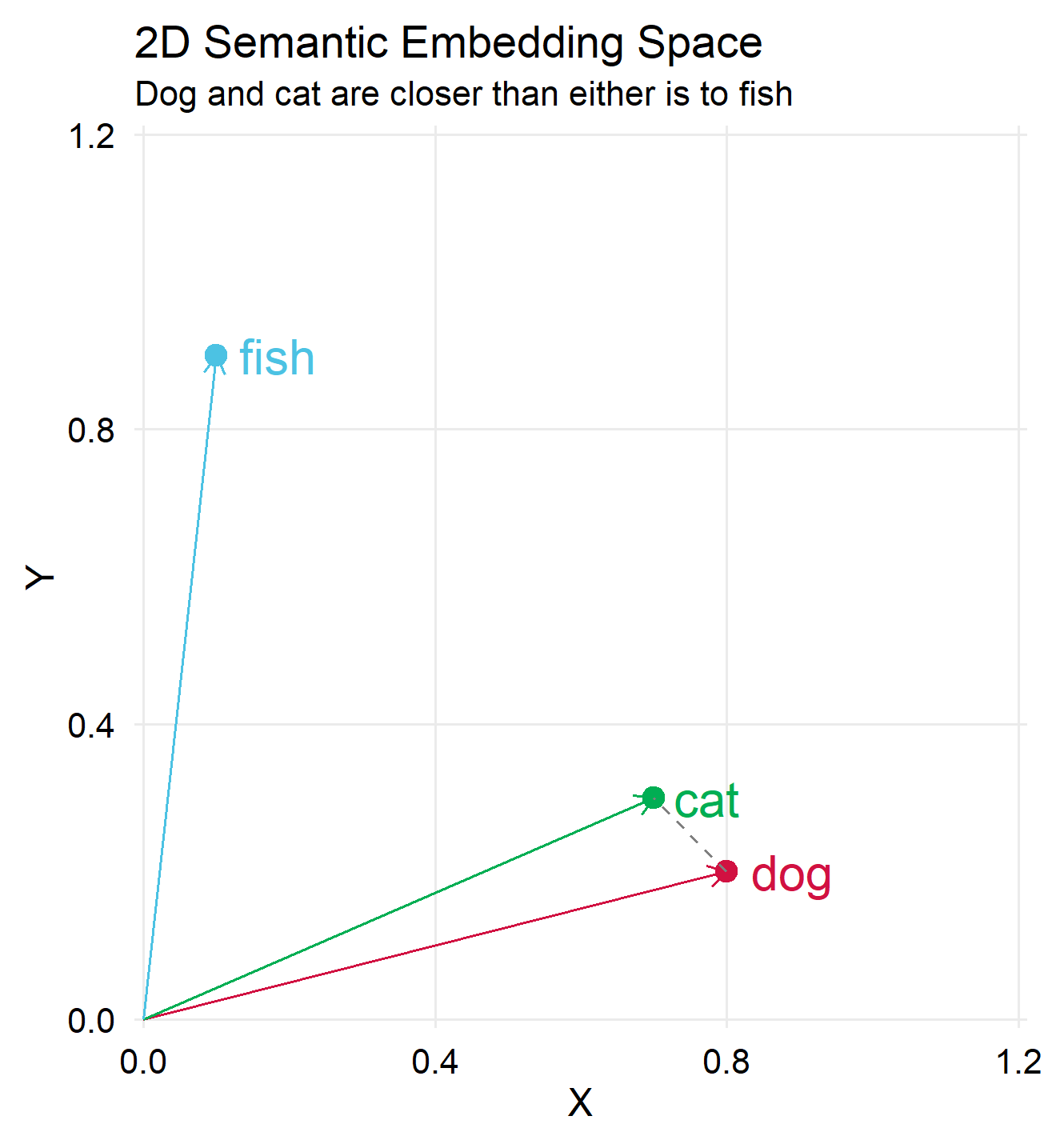
![[begin{pmatrix} text{dog:} & 0.8 & 0.2 & 0.3 text{cat:} & 0.7 & 0.3 & 0.4 text{fish:} & 0.1 & 0.9 & 0.2 end{pmatrix}]](https://eranraviv.com/wp-content/ql-cache/quicklatex.com-3eb0537e2b314e83096cd7f1af6cad70_l3.svg "Rendered by QuickLaTeX.com")

![[ (1 - varepsilon) |a - b|^2 leq |f(a) - f(b)|^2 leq (1 + varepsilon) |a - b|^2, ]](https://eranraviv.com/wp-content/ql-cache/quicklatex.com-4b2a22c397d712dc0e272690002ff866_l3.svg "Rendered by QuickLaTeX.com")
![[frac{log_2(100,000) approx 17}{0.1^2} approx 1700.]](https://eranraviv.com/wp-content/ql-cache/quicklatex.com-ff306c84d76bb0945c799629391becd3_l3.svg "Rendered by QuickLaTeX.com")