AI is in each boardroom dialog, and enterprise leaders all over the place are feeling the stress to get it proper. However as adoption hastens, so do the questions.
Which use circumstances are delivering actual outcomes? How are organizations balancing velocity with governance? Are most constructing from scratch, shopping for off the shelf, or discovering a center path? And most significantly, what’s really working in observe for world enterprises?
Drawing insights from over 1000+ enterprise leaders throughout industries and areas, it paints an actual image of what AI experimentation and adoption seem like in 2025, not simply in headlines, however on the bottom.
On this weblog, you’ll get a peek into what’s prime of thoughts for world AI leaders – the priorities, challenges, investments, and expertise methods shaping the subsequent part of enterprise AI.
Let’s dive in
(Concerning the report: Surveyed in March 2025 by Paradoxes and supported by Kore.ai, ‘Sensible Insights from AI Leaders – 2025’ reveals how enterprise leaders are adopting AI, tackling challenges, investing budgets, and driving innovation to reshape enterprise and achieve a aggressive edge.
The survey gathered insights from over 1000 senior enterprise and expertise leaders throughout 12 nations, together with the U.S., UK, Germany, UAE, India, Singapore, Philippines, Japan, Korea, Australia, and New Zealand. Obtain the whole report.)
How deep AI adoption runs throughout enterprises?
Enterprises are experimenting with AI throughout a number of practical areas, however typically in silos. What’s lacking is a cohesive technique to scale AI impression throughout the enterprise.
Based on the Kore.ai survey, 71% of enterprise leaders report that their organizations are actively utilizing or piloting AI throughout a number of departments, like buyer help, IT, HR, finance, operations, and advertising and marketing.
This surge in adoption aligns with Gartner’s forecast that, by 2026, greater than 80% of enterprises may have deployed generative AI functions in manufacturing, a dramatic rise from lower than 5% in early 2023. The survey exhibits that use circumstances particular to IT help, customer support, and advertising and marketing lead in AI automation. Product, HR, finance, operations, and engineering present sturdy uptake, whereas capabilities like admin, procurement, authorized, and gross sales stay in early or experimental levels.
Regionally, North America (79%), Western Europe (70%), and India (87%) lead in AI adoption, pushed by sturdy govt help. In distinction, components of APAC, notably Japan (56%), South Korea (64%), and Southeast Asia (59%), present a slower uptake, reflecting extra cautious management. With AI adoption accelerating worldwide, the subsequent query is obvious: Which use circumstances are driving leaders to double down on AI?
What’s fueling the AI agenda within the C-suite?
Throughout boardrooms, the AI dialog is shifting from ‘why’ to ‘the place subsequent’. The analysis highlights that almost all leaders are specializing in use circumstances at present that ship tangible enterprise worth:
1. 44% are making use of AI for course of automation, masking areas like compliance, danger administration, and workflow optimization. 2. 31% of organizations are utilizing AI to reinforce office productiveness, from automating duties and surfacing insights to enabling sooner content material creation and summarization. 3. 24% are deploying AI to reinforce customer support and self-service experiences.
Know-how (77%) and monetary companies (72%) are doubling down on AI for insights and analytics, treating knowledge as a aggressive edge. Retail (77%), enterprise companies (75%), and healthcare (69%) are targeted on AI-powered buyer engagement. In the meantime, use circumstances like search and knowledge discovery are gaining floor throughout expertise (64%), finance (66%), retail (71%), and enterprise companies (62%).
Nearly all of enterprises are already seeing early wins with AI. Actually, 93% of leaders report that their pilot initiatives met or exceeded expectations. Nonetheless, transferring from profitable pilots to organization-wide AI transformation introduces a brand new set of hurdles.
The analysis means that enterprises are going through just a few challenges which might be slowing down their momentum. A few of these challenges are:
1. The AI expertise hole – This stays probably the most important problem enterprises face at present. Bain & Co. additionally recognized that 44% of executives really feel an absence of in-house experience is slowing AI adoption. 2. Excessive LLM prices – with 42% respondents citing it, ongoing token-based prices for LLMs additionally emerged as a big problem to scaling AI within the examine. This implies that usage-based prices grow to be extra related as organizations scale. 3. Knowledge safety and belief – 41% of the decision-makers within the survey reported that they face the problem of safeguarding proprietary and first-party knowledge.
Given these challenges, many organizations are rethinking their strategy to AI adoption: Ought to they construct customized options in-house, or is it more practical to purchase? 👇
Purchase or construct? Strategic trade-offs shaping enterprise AI
Let’s dive into the intriguing story revealed by Kore.ai analysis—the story of how enterprises are navigating the traditional purchase vs. construct dilemma for AI.
The survey exhibits that enterprises clearly favor simplicity and velocity over complexity. Solely 28% of organizations mentioned they’d favor to construct their very own AI options from the bottom up, whereas the remaining 72% are choosing numerous purchase-led methods. This contains ready-to-deploy options (31%), customizable third-party choices (25%), or integrating best-of-breed options (16%).
This pattern is per the McKinsey report, which says that AI methods that mix vendor instruments with inside capabilities allow enterprises to scale AI 1.5X sooner than these constructing totally personalized options.
Selecting distributors: worth over price
The selection of AI vendor is not only a procurement choice, however a make-or-break choice. The place the suitable associate can speed up outcomes and scale innovation, whereas the fallacious one can introduce friction, delays, and technical debt. Based on the analysis, decision-makers constantly prioritize output high quality and accuracy (45%), AI resolution effectivity and efficiency (34%), domain-specific experience (28%), and ease of integration with current methods (28%).
Notably, vendor pricing (24%) ranks a lot decrease on the checklist. These priorities replicate a maturing market the place leaders are on the lookout for long-term companions that may evolve with their wants, perceive their {industry}, and ship measurable worth at scale.
Need a full breakdown of which shopping for methods enterprises are utilizing for AI? Obtain the complete report for all particulars right here.
Need a full breakdown of which shopping for methods enterprises are utilizing for AI? Obtain the Full Report for all particulars.
What are hard-earned classes from previous AI initiatives?
As enterprise AI strikes past pilots, leaders are asking onerous questions: What actually issues to scale? The place are we underprepared? And what can we enhance? The analysis highlights vital areas that repeatedly emerge because the spine of profitable AI deployments:
Greater than 50% of the respondents cited knowledge high quality as an space needing critical enchancment in future AI initiatives. In any case, AI’s impression is barely as sturdy as the info it learns from.
Industries equivalent to retail, manufacturing, and expertise are doubling down on first-party knowledge, recognizing its position in enabling differentiated, AI-driven experiences. In the meantime, regulated sectors equivalent to healthcare, monetary companies, authorities, and enterprise companies are putting higher concentrate on the safe dealing with of consumer and third-party knowledge.
Safety and knowledge privateness are non-negotiable
With AI methods permeating enterprise operations, knowledge safety and privateness are greater than technical containers; they’re belief and compliance necessities. Practically 40% of leaders view safety and knowledge privateness as the highest space to strengthen in upcoming AI initiatives.
Tech infrastructure is a strategic enabler
Many organizations, within the survey, admit their present tech stacks aren’t constructed to help enterprise-grade AI. AI workloads demand important compute energy, scalable pipelines, and sturdy mannequin governance.
AI expertise is a make-or-break for AI success
Kore.ai analysis suggests that just about two-thirds of organizations admit they want stronger AI experience, however they’re divided on whether or not to rent new expertise or upskill current groups. The numbers underscore a broader expertise crunch that impacts each scale-up.
“AI success hinges on partnering knowledge and enterprise groups and constructing a data-literate tradition.” – Vanguard’s Chief Knowledge Officer.
The place are the investments headed in 2025 and past?
When requested, “How do you anticipate your AI price range will change over the subsequent three years?” A exceptional 90% leaders say their AI budgets will enhance, with 75% planning to allocate greater than half of their IT spending to AI initiatives.
The report additionally highlights industry-specific price range patterns. As an example, monetary companies and expertise sectors are main the cost with over 50% of their tech price range going in direction of AI expertise. Enterprise companies and healthcare are following intently with substantial allocations, whereas manufacturing (25%) tends to be extra conservative in its AI spending.
Remaining ideas: the enterprise AI story is simply starting
If there’s one factor this analysis makes clear, it’s that AI is changing into a core a part of how organizations work, compete, and develop.
And as extra enterprises embrace agentic AI, the numbers inform a transparent story: leaders are pushing past pilots, budgets are scaling quick, and AI is making its presence felt throughout departments, from buyer help to finance to advertising and marketing. Expertise methods are evolving, infrastructure is being modernized, and knowledge is lastly getting the eye it deserves.
However the journey is way from over.
The analysis additionally highlights that whereas enthusiasm runs excessive, so do the expectations and the stress to show worth, defend knowledge, and scale responsibly. The choices leaders make now, equivalent to what to construct, what to purchase, the place to speculate, and how one can measure success, will form the trajectory of AI for years to come back.
This weblog solely scratches the floor. The total Kore.ai Sensible Insights from AI Leaders – 2025 report dives deeper into the benchmarks, methods, and classes that at present’s decision-makers are utilizing to show AI potential into enterprise efficiency. 👇
The concept of extinction — the everlasting lack of life — is horrifying. But the stakes of dropping crops and animals are sometimes unclear. If an already-rare chicken vanishes from the forest, most individuals in all probability gained’t really feel the affect.
However a troubling scenario unfolding in Florida is totally different. Following a record-shattering warmth wave in 2023, two marine species at the moment are practically extinct within the state — and the affect of that loss on human life will probably be felt for generations.
In a brand new examine revealed this week in Science, researchers discovered that elkhorn and staghorn corals — two species as soon as elementary to the construction of Florida’s reef — at the moment are “functionally extinct” within the state. Which means these animals are so uncommon that they now not serve a perform in Florida’s marine ecosystem.
Why excessive warmth kills corals
Corals are colonies of residing animals, referred to as polyps, which have a symbiotic relationship with a form of algae that lives inside their cells. The algae give coral meals — and their shade — in change for vitamins and a spot to soak up daylight.
When the ocean will get too scorching, nevertheless, this symbiotic relationship breaks down, and the polyps expel the algae and switch white. That is bleaching. When a coral is bleached, it’s basically weak and ravenous, and if the warmth persists, it may possibly die.
Throughout excessive marine warmth waves — like what Florida noticed in summer time 2023 — corals can die in a matter of days, generally with out bleaching. Warmth shock kills the polyps and causes their comfortable tissue to slough off their skeleton.
Beginning in July 2023, water temperatures in Southeast Florida, dwelling to the one barrier reef within the continental US, began rising to record-breaking ranges, partly on account of local weather change. Sensors recorded temperatures above 93 levels in some components of the reef. And corals had been finally uncovered to warmth that was as a lot as 4 instances higher than “all prior years on document,” the authors write. That worn out 97.8 p.c to 100% of staghorn and elkhorn corals within the Florida Keys, the place most of them had been discovered, in keeping with the examine, which was led by Derek Manzello, a coral researcher on the Nationwide Oceanic and Atmospheric Administration.
“What we noticed occur was an excessive warmth wave the place circumstances surpassed the thresholds of survival of an entire, whole species — two species — throughout all of Florida’s coral reef,” mentioned Ross Crafty, a coral biologist at Chicago’s Shedd Aquarium, who was carefully concerned within the analysis. “That’s one thing we haven’t seen earlier than. We had been in shock.”
These outcomes ought to alarm anybody residing in coastal Florida. Staghorn and elkhorn corals — native to Florida and the Caribbean, the place their populations have additionally plummeted — usually are not solely fairly to have a look at however assist maintain human life.
Olivia M. Williamson/Science
Olivia M. Williamson/Science
Elkhorn coral within the Florida Keys progressed from wholesome (prime left) to bleached (prime proper) to useless (backside) in a matter of months in the summertime of 2023.Dana E. Williams/Science
These species create advanced buildings that appeal to fish by offering them with a spot to cover from predators and meals to eat. These embrace fish comparable to snappers and groupers that folks catch and devour in Florida, the place one evaluation reveals fishing is a whopping $24.6 billion trade. Then there’s the worth that corals present for nature-related tourism. Diving and snorkeling generate some $900 million a yr in Southeast Florida. While you go snorkeling, there’s usually an expectation that you simply’ll see coral or the animals it helps, from eels to octopuses.
However maybe most significantly, these two coral species safeguard coastlines from flooding throughout hurricanes. Or a minimum of they did. Staghorn and elkhorn develop within the shallows, the place their many giant branches assist cut back wave power, very like a seawall. Waves with much less power are smaller and slower and don’t deal as a lot harm after they attain the shore. A 2014 meta-analysis discovered that coral reefs — which comprise different species past staghorn and elkhorn — can cut back wave power by a mean of 97 p.c. That interprets to cash: A 2019 authorities examine discovered that Florida’s coral reefs avert $675 million price of flood harm every year.
Now that these coral species are principally useless, staghorn and elkhorn skeletons in Florida will ultimately wither away, leaving the shoreline much less engaging to fish and vacationers, and extra susceptible to storms.
What occurred in Florida isn’t a one-off occasion. High scientists are assured that excessive marine warmth waves are changing into extra frequent. And whereas staghorn and elkhorn are particularly delicate to warming, they actually aren’t the one species that warmth places in danger. The planet has already misplaced roughly half of its stay coral cowl, and local weather change — and the bleaching of corals it causes — has emerged as the highest risk. In Australia, for instance, a 2024 bleaching occasion killed off roughly 1 / 4 of the corals within the northern Nice Barrier Reef, a document decline.
The state of coral reefs is so bleak, in truth, that a big, worldwide workforce of scientists just lately introduced that these ecosystems worldwide have surpassed a local weather tipping level, past which they will now not survive.
That implies that until rich economies cease burning fossil fuels, it’s unlikely that Florida will ever be capable to deliver again ample colonies of elkhorn and staghorn corals, even with aggressive restoration efforts. Certainly, most of the corals that died within the 2023 warmth wave had been planted on the reef by conservation teams. (I detailed that in a separate story right here.)
Even when the world’s prime polluters slashed their emissions instantly — which, in the mean time, seems anathema to US power coverage — coral reefs would nonetheless face dramatic losses. The ocean is already far too scorching. Restoring the life-supporting advantages that reefs as soon as supplied in locations like Florida now requires superior expertise to breed heat-tolerant corals, whereas additionally tackling different threats like overfishing and air pollution.
“We have to do one thing to throw corals a lifeline,” Crafty advised me. “We are able to’t simply cease and say, ‘Oh, the federal authorities isn’t doing what we’d prefer to see occur on this entrance, so we’re simply going to surrender.’ We are able to’t cease. We now have to maintain making an attempt.”
A scientific trial testing a diabetes medicine and an insulin nasal spray has discovered that each medicine, together and alone, safely sort out totally different facets of gentle cognitive decline that’s typically seen in early Alzheimer’s illness, with none dangerous unwanted side effects.
We all know Alzheimer’s illness and different types of dementia are extremely advanced circumstances, and a number of remedy approaches are doubtless wanted to raised handle them.
The 2 medicines examined on this trial goal a number of totally different organic processes: Empagliflozin, an current diabetes drug, reduces irritation, which has been linked to Alzheimer’s onset, amongst different issues. The insulin nasal spray, which delivers insulin straight to the mind, has additionally been proven to maintain mind cells wholesome.
Carried out within the US, the trial reveals some early indicators of progress in sustaining mind well being in these vulnerable to Alzheimer’s. It enrolled 47 older adults aged 55 to 85 years, 42 of whom accomplished remedy.
The contributors had been recognized with gentle cognitive impairment or gentle dementia, or have been cognitively nice however confirmed indicators of molecular modifications linked to Alzheimer’s illness.
They got both empagliflozin alone, the insulin spray by itself, each medicines collectively, or a placebo, for 4 weeks. The trial was too small to detect any statistically vital variations between the teams (its fundamental intention was testing security); nevertheless, some tendencies have been noticed.
“For the primary time, we discovered that empagliflozin, a longtime diabetes and coronary heart medicine, decreased markers of mind damage whereas restoring blood stream in crucial mind areas,” says neuroscientist Suzanne Craft from the Wake Forest College Faculty of Medication within the US.
“We additionally confirmed that delivering insulin on to the mind with a newly validated machine enhances cognition, neurovascular well being, and immune perform.”
One of many advantages seen with empagliflozin (EMPA-Solely) was indicators of much less tau build-up in cerebrospinal fluid (CSF). (Erichsen et al., A&D, 2025)
As a diabetes drug, empagliflozin improves the best way the physique handles glucose and sodium. This has numerous additional results, together with decrease irritation and stress on cells, higher vitality effectivity, and improved insulin sensitivity.
Right here, the medicine was proven to cut back the degrees of the tau protein in cerebrospinal fluid, a protein that we all know can kind dangerous clumps in Alzheimer’s brains. It additionally had advantages by way of blood stream and levels of cholesterol, and several other different biomarkers linked to Alzheimer’s development.
The insulin nasal spray was chosen as a result of insulin resistance has beforehand been linked to Alzheimer’s, and former analysis reveals insulin’s results on mind cells will help enhance immune responses, white matter construction, and blood stream.
On this research, contributors given the insulin spray noticed higher scores on cognitive assessments measuring reminiscence and considering. Via mind scans, the researchers noticed advantages in white matter connectivity and blood stream linked to reminiscence.
The physique’s metabolism, or the best way it turns gasoline into vitality, is essential to good well being, and these therapies focus extra on that, slightly than a few of the later, end-stage results of Alzheimer’s we see in individuals with the illness.
“Our research means that concentrating on metabolism can change the course of Alzheimer’s illness,” says Craft. “Collectively, these findings spotlight metabolism as a robust new frontier in Alzheimer’s remedy.”
This was a comparatively fast and small trial, achieved to construct on earlier analysis and run additional security assessments.
Whereas a lot additional testing is required to gauge how efficient these medicine could also be in mitigating Alzheimer’s illness, the outcomes present an encouraging stability in boosting the best way the immune system fights illness, whereas additionally reducing the danger of overactive immune responses resulting in irritation and harm.
“We plan to construct on these promising outcomes with bigger, longer research in individuals with early and preclinical Alzheimer’s illness,” says Craft.
“We consider these therapies might provide actual therapeutic potential, both on their very own or together with different Alzheimer’s therapies.”
With Leah South from QUT we’re organizing an internet workshop on the subject of “Measuring the standard of MCMC output”. The occasion web site is right here with extra data:
That is a part of ISBABayesComp part’s efforts to prepare actions whereas ready for the following “large” in-person assembly, hopefully in 2023. The occasion advantages from the beneficiant help of QUT Centre for Knowledge Science. The occasion’s web site shall be often up to date between now and the occasion in October 2021, with three reside classes:
11am-2pm UTC on Wednesday sixth October,
1pm-4pm UTC on Thursday 14th October,
3pm-6pm UTC on Friday twenty second October.
Registration is free however obligatory (kind right here) as we need to be sure the reside classes stay convivial and centered; therefore the somewhat particular theme, nevertheless it’s an thrilling matter with a number of very a lot open questions, which we hope will appeal to each practitioners and methodologists. In the meantime some materials shall be obtainable on the web site to everybody, together with video recordings of shows, and posters, in order that the workshop hopefully advantages the broader group.
In case you have recommendations for this occasion, or want to set up an identical occasion sooner or later, on one other “BayesComp” matter, don’t hesitate to get in contact. Our contact particulars are on the workshop’s web site.
Welcome to the second a part of this two-part weblog collection on the bias-variance tradeoff and its software to buying and selling in monetary markets.
Within the first half, we tried to develop an instinct for the bias-variance decomposition. On this half, we’ll lengthen our learnings from the primary half and develop a buying and selling technique.
Conditions
You probably have some primary information of Python and ML, it’s best to have the ability to learn and comprehend the article. These are some pre-requisites:
As a result of the article additionally covers time collection transformations and stationarity, you may familiarize your self with Time Sequence Evaluation. Information of dealing with monetary market knowledge and sensible expertise in technique creation, backtesting, and analysis will assist you apply the article’s learnings to your methods.
On this weblog, we’ll cowl the whole pipeline for utilizing machine studying to construct and backtest a buying and selling technique whereas utilising the bias-variance decomposition to pick the suitable prediction mannequin. So, right here goes…
The circulate of this text is as follows:
As a ritual, step one is to import the mandatory libraries.
Importing Libraries
In case you don’t have any of those put in, a ‘!pip set up’ command ought to do the trick (if you happen to don’t wish to go away the Jupyter Pocket book surroundings, or if you wish to work on Google Colab).
Downloading Knowledge
Subsequent, we outline a operate for downloading the info. We’ll use the yfinance API right here.
Discover the argument ‘multi_level_index’. Not too long ago (I’m scripting this in April 2025), there have been some modifications within the yfinance API. When downloading value stage and quantity knowledge for any safety via the required API, the ticker title of the safety will get added as a heading.
It appears like this when downloaded:
For individuals (like me!) who’re accustomed to not seeing this further stage of heading, eradicating it whereas downloading the info is a good suggestion. So we set the ‘multi_level_index’ argument to ‘False’.
Defining Technical Indicators as Predictor Variables
Subsequent, since we’re utilizing machine studying to construct a buying and selling technique, we should embody some options (typically known as predictor variables) on which we practice the machine studying mannequin. Utilizing technical indicators as predictor variables is a good suggestion when buying and selling within the monetary markets. Let’s do it now.
Ultimately, we’ll see the record of indicators after we name this operate on the asset dataframe.
Defining the Goal Variable
The subsequent chronological step is to outline the goal variable/s. In our case, we’ll outline a single goal variable, the close-to-close 5-day p.c return. Let’s see what this implies. Suppose at present is a Monday, and there aren’t any market holidays, barring the weekends, this week. Take into account the p.c change in tomorrow’s (Tuesday’s) closing value over at present’s closing value, which might be a close-to-close 1-day p.c return. At Wednesday’s shut, it will be the 2-day p.c return, and so forth, until the next Monday, when it will be the 5-day p.c return. Right here’s the Python implementation for a similar:
Why will we use the shift(-5) right here? Suppose the 5-day p.c return primarily based on the closing value of the next Monday over at present’s closing value is 1.2%. By utilizing shift(-5), we’re putting this worth of 1.2% within the row for at present’s OHLC value ranges, quantity, and different technical indicators. Thus, after we feed the info to the ML mannequin for coaching, it learns by contemplating the technical indicators as predictors and the worth of 1.2% in the identical row because the goal variable.
Stroll Ahead Optimization with PCA and VIF
One important consideration whereas coaching ML fashions is to make sure that they show strong generalization. Because of this the mannequin ought to have the ability to extrapolate its efficiency on the coaching dataset (typically known as in-sample knowledge) to the check dataset (typically known as out-of-sample knowledge), and its good (or in any other case) efficiency must be attributed primarily to the inherent nature of the info and the mannequin, relatively than to likelihood.
One strategy in the direction of that is combinatorial purged cross-validation with embargoing. You possibly can learn this to be taught extra.
One other strategy is walk-forward optimisation, which we’ll use (learn extra: 12).
One other important consideration whereas constructing an ML pipeline is characteristic extraction. In our case, the entire predictors we’ve got is 21. We have to extract an important ones from these, and for this, we’ll use Principal Element Evaluation and the Variance Inflation Issue. The previous extracts the highest 4 (a worth that I selected to work with; you may change it and see how the backtest modifications) combos of options that designate essentially the most variance inside the dataset, whereas the latter addresses mutual info, also referred to as multicollinearity.
Right here’s the Python implementation of constructing a operate that does the above:
Buying and selling Technique Formulation, Backtesting, and Analysis
We now come to the meaty half: the technique formulation. Listed here are the technique outlines:
Preliminary capital: ₹10,000.
Capital to be deployed per commerce: 20% of preliminary capital (₹2,000 in our case).
Lengthy situation: when the 5-day close-to-close p.c return prediction is constructive.
Brief situation: when the 5-day close-to-close p.c return prediction is unfavourable.
Entry level: open of day (N+1). Thus, if at present is a Monday, and the prediction for the 5-day close-to-close p.c returns is constructive at present, I’ll go lengthy at Tuesday’s open, else I’ll go quick at Tuesday’s open.
Exit level: shut of day (N+5). Thus, after I get a constructive (unfavourable) prediction at present and go lengthy (quick) throughout Tuesday’s open, I’ll sq. off on the closing value of the next Monday (offered there aren’t any market holidays in between).
Capital compounding: no. Because of this our income (losses) from each commerce should not getting added (subtracted) to (from) the tradable capital, which stays mounted at ₹10,000.
Right here’s the Python code for this technique:
Subsequent, we outline the features to guage the Sharpe ratio and most drawdowns of the technique and a buy-and-hold strategy.
Calling the Capabilities Outlined Beforehand
Now, we start calling a number of the features talked about above.
We’ll begin with downloading the info utilizing the yfinance API. The ticker and interval are user-driven. When operating this code, you’ll be prompted to enter the identical. I selected to work with the 10-year day by day knowledge of the NIFTY-50, the broad market index primarily based on the Nationwide Inventory Trade (NSE) of India. You possibly can select a smaller timeframe; the longer the timeframe, the longer it should take for the following codes to run. After downloading the info, we’ll create the technical indicators by calling the ‘create_technical_indicators’ operate we outlined beforehand.
Right here’s the output of the above code:
Enter a sound yfinance API ticker: ^NSEI
Enter the variety of years for downloading knowledge (e.g., 1y, 2y, 5y, 10y): 10y
YF.obtain() has modified argument auto_adjust default to True
[*********************100%***********************] 1 of 1 accomplished
Subsequent, we align the info:
Let’s test the 2 dataframes ‘indicators’ and ‘data_merged’.
The dataframe ‘indicators’ accommodates all 21 technical indicators talked about earlier.
Bias-Variance Decomposition
Now, the first goal of this weblog is to reveal how the bias-variance decomposition can help in growing an ML-based buying and selling technique. After all, we aren’t simply limiting ourselves to it; we’re additionally studying the whole pipeline of making and backtesting an ML-based technique with robustness. However let’s discuss in regards to the bias-variance decomposition now.
We start by defining six totally different regression fashions:
You possibly can add extra or subtract a pair from the above record. The extra regressor fashions there are, the longer the following codes will take to run. Decreasing the variety of estimators within the related fashions can even end in sooner execution of the following codes.
In case you’re questioning why I selected regressor fashions, it’s as a result of the character of our goal variable is steady, not discrete. Though our buying and selling technique relies on the route of the prediction (bullish or bearish), we’re coaching the mannequin to foretell the 5-day return, a steady random variable, relatively than the market motion, which is a categorical variable.
After defining the fashions, we outline a operate for the bias-variance decomposition:
You possibly can lower the worth of num_rounds to, say, 10, to make the next code run sooner. Nonetheless, the next worth offers a extra strong estimate.
This can be a good repository to search for the above code:
Let’s analyse the above desk. We’ll want to decide on a mannequin that balances bias and variance, which means it neither underfits nor overfits. The choice tree regressor finest balances bias and variance amongst all six fashions.
Nonetheless, its whole error is the very best. Bagging and RandomForest show comparable whole errors. GradientBoosting shows not simply the bottom whole error but additionally the next diploma of variance in comparison with Bagging and RandomForest; thus, its capability to generalise to unseen knowledge must be higher than the opposite two, since it will seize extra advanced patterns..
You is perhaps compelled to suppose that with such proximity of values, such in-depth evaluation isn’t apt owing to a excessive noise-to-signal ratio. Nonetheless, since we’re operating 100 rounds of the bias-variance decomposition, we may be assured within the noise mitigation that outcomes.
Lengthy story reduce quick, we’ll select to coach the GradientBoosting regressor, and use it to foretell the goal variable. You possibly can, in fact, change the mannequin and see how the technique performs below the brand new mannequin. Please word that we’re treating the ML fashions as black packing containers right here, as exploring their underlying mechanisms is exterior the scope of this weblog. Nonetheless, when utilizing ML fashions for any use case, we should always all the time concentrate on their inside workings and select accordingly.
Having mentioned all of the above, is there a method of lowering the errors of a number of of the above regressor fashions? Sure, and it’s not a mere method, however an integral a part of working with time collection. Let’s talk about this.
Stationarizing the Inputs
We’re working with time collection knowledge (learn extra), and when performing monetary modeling duties, we have to test for stationarity (learn extra). In our case, we should always test our enter variables (the predictors) for stationarity.
Let’s outline a operate to test the order of integration of the predictor variables. This operate would test whether or not we have to distinction the time collection (in our case, the predictor variables) and in that case, what number of instances (learn extra).
Let’s test the predictor variables for stationarity and apply differencing to the required predictors.
Right here’s the code:
Right here’s a snapshot of the output of the above code:
The above output signifies that 13 predictor variables don’t require stationarisation, whereas 8 do. Let’s stationarise them.
Let’s confirm whether or not the stationarising received performed as anticipated or not:
Yup, performed!
Let’s align the info once more:
Let’s test the bias-variance decomposition of the fashions with the stationarised predictors:
There you go. Simply by following Time Sequence 101, we might scale back the errors of all of the fashions. For a similar purpose that we mentioned earlier, we’ll select to run the prediction and backtesting utilizing the GradientBoosting regressor.
Operating a Prediction utilizing the Chosen Mannequin
Subsequent, we run a walk-forward prediction utilizing the chosen mannequin:
Now, we create a dataframe, ‘final_data’, that accommodates solely the open costs, shut costs, precise/realised 5-day returns, and 5-day returns predicted by the mannequin. We’d like the open and shut costs for coming into and exiting trades, and the anticipated 5-day returns, to find out the route by which we take trades. We then name the ‘backtest_strategy’ operate on this dataframe.
Checking the Commerce Logs
The dataframe ‘trades_df_differenced’ accommodates the commerce logs.
We’ll convert the decimals of the values within the dataframe for higher visibility:
Let’s test the dataframe ‘trades_df_differenced’ now:
Right here’s a snapshot of the output of this code:
From the desk above, it’s obvious that we take a brand new commerce day by day and deploy 20% of our tradeable capital on every commerce.
Fairness Curves, Sharpe, Drawdown, Hit Ratio, Returns Distribution, Common Returns per Commerce, and CAGR
Let’s calculate the fairness for the technique and the buy-and-hold strategy:
Subsequent, we calculate the Sharpe and the utmost drawdowns:
The above code requires you to enter the risk-free price of your selection. It’s usually the federal government treasury yield. You possibly can look it up on-line in your geography. I selected to work with a worth of 6.6:
Enter the risk-free price (e.g., for five.3%, enter solely 5.3): 6.6
Now, we’ll reindex the dataframes to a datetime index.
We’ll plot the fairness curves subsequent:
That is how the technique and buy-and-hold fairness curves look when plotted on the identical chart:
The technique fairness and the underlying transfer nearly in tandem, with the technique underperforming earlier than the COVID-19 pandemic and outperforming afterward. Towards the tip, we’ll talk about some lifelike concerns about this relative efficiency.
Let’s take a look on the drawdowns of the technique and the buy-and-hold strategy:
Let’s check out the Sharpe ratios and the utmost drawdown by calling the respective features that we outlined earlier:
Output:
Sharpe Ratio (Technique with Stationarised Predictors): 0.89
Sharpe Ratio (Purchase & Maintain): 0.42
Max Drawdown (Technique with Stationarised Predictors): -11.28%
Max Drawdown (Purchase & Maintain): -38.44%
Right here’s the hit ratio:
Hit Ratio of Technique with Stationarised Predictors: 54.09%
That is how the distribution of the technique returns appears like:
Lastly, let’s calculate the common income (losses) per profitable (shedding) commerce:
Common Revenue for Worthwhile Trades with Stationarised Predictors: 0.0171
Common Loss Loss-Making Trades with Stationarised Predictors: -0.0146
Primarily based on the above commerce metrics, we revenue extra on common in every commerce than we lose. Additionally, the variety of constructive trades exceeds the variety of unfavourable trades. Subsequently, our technique is protected on each fronts. The utmost drawdown of the technique is proscribed to 10.48%.
The explanation: The holding interval for any commerce is 5 days, utilizing solely 20% of our obtainable capital per commerce. This additionally reduces the upside potential per commerce. Nonetheless, for the reason that common revenue per worthwhile commerce is greater than the common loss per loss-making commerce and the variety of worthwhile trades is greater than the variety of loss-making trades, the probabilities of capturing extra upsides are greater than these of capturing extra downsides.
Let’s calculate the compounded annual progress price (CAGR):
Our technique outperformed the underlying index through the post-COVID-19 crash interval and marginally outperformed the general market. Nonetheless, if you’re pondering of utilizing the skeleton of this technique to generate alphas, you’ll have to peel off some assumptions and keep in mind some lifelike concerns:
Transaction Prices: We enter and exit trades day by day, as we noticed earlier. This incurs transaction prices.
Asset Choice: We backtested utilizing the broad market index, which isn’t immediately tradable. We’ll want to decide on ETFs or derivatives with this index because the underlying. The technique’s efficiency would even be topic to the inherent traits of the asset that we determine to commerce as a proxy for the broad market index.
Slippages: We enter our trades on the market’s opening and exit at its shut. Buying and selling exercise may be excessive throughout these durations, and we could encounter appreciable slippages.
Availability of Partially Tradable Securities: Our backtest implicitly assumes the supply of fractional property. For instance, if our capital is ₹2,000 and the entry value is ₹20,000, we’ll have the ability to purchase or promote 0.1 models of the underlying, ignoring all different prices.
Taxes: Since we’re coming into and exiting trades inside very quick time frames, other than transaction fees, we might incur a big quantity of short-term capital features tax (STCG) on the income earned. This, in fact, would rely in your native laws.
Threat Administration: Within the backtest, we omitted stop-losses and take-profits. You’re inspired to incorporate them and tell us your findings on how the technique’s efficiency will get modified.
Occasion-driven Backtesting: The backtesting we carried out above is vectorized. Nonetheless, in actual life, tomorrow comes solely after at present, and we should take into account this when performing a backtest. You possibly can discover the Blueshift at https://blueshift.quantinsti.com/ and take a look at backtesting the above technique utilizing an event-driven strategy (learn extra). An event-driven backtest would additionally account for slippage, transaction prices, implementation shortfalls, and threat administration.
Technique Efficiency: The hit ratio of the technique and the mannequin’s accuracy are roughly 54% and 56%, respectively. These values are marginally higher than these of a coin toss. You must do this technique with different asset lessons and solely choose these property on which these values are at the least 60% (or greater if you happen to wanna be extra conservative). Solely after that ought to you carry out an event-driven backtesting utilizing this technique define.
A Word on the Downloadable Python Pocket book
The downloadable pocket book includes backtesting the technique and evaluating its efficiency and the mannequin’s efficiency parameters in a situation the place the predictors should not stationarised and after stationarising them (as we noticed above). Within the former, the technique considerably outperforms the underlying mannequin, and the mannequin shows higher accuracy in its predictions regardless of its greater errors displayed through the bias-variance decomposition. Thus, a well-performing mannequin needn’t essentially translate into a great buying and selling technique, and vice versa.
The Sharpe of the technique with out the predictors stationarised is 2.56, and the CAGR is sort of 27% (versus 0.94 and 14% respectively when the predictors are stationarised). Since we used GradientBoosting, a tree-based mannequin that does not essentially want the predictor variables to be stationarised, we will work with out stationarising the predictors and reap the advantages of the mannequin’s excessive efficiency with non-stationarised predictors.
Word that operating the pocket book will take a while. Additionally, the performances you get hold of will differ a bit from what I’ve proven all through the article.
There’s no ‘Good’ in Goodbye…
…but, I’ll should say so now 🙂. Check out the backtest with totally different property by altering a number of the parameters talked about within the weblog, and tell us your findings. Additionally, as we all the time say, since we aren’t a registered funding advisory, any technique demonstrated as a part of our content material is for demonstrative, academic, and informational functions solely, and shouldn’t be construed as buying and selling or funding recommendation. Nonetheless, if you happen to’re in a position to incorporate all of the aforementioned lifelike components, extensively backtest and ahead check the technique (with or with out some tweaks), generate vital alpha, and make substantial returns by deploying it within the markets, do share the excellent news with us as a remark under. We’ll be joyful in your success 🙂. Till subsequent time…
After going via the above, you may observe a number of structured studying paths if you wish to broaden and/or deepen your understanding of buying and selling mannequin efficiency, ML technique improvement, and backtesting workflows.
To grasp every part of this technique — from Python and PCA to stationarity and backtesting — discover topic-specific Quantra programs like:
For these aiming to consolidate all of this data right into a structured, mentor-led format, the Government Programme in Algorithmic Buying and selling (EPAT) presents a really perfect subsequent step. EPAT covers all the pieces from Python and statistics to machine studying, time collection modeling, backtesting, and efficiency metrics analysis — equipping you to construct and deploy strong, data-driven methods at scale.
File within the obtain:
Bias Variance Decomposition – Python pocket book
Be happy to make modifications to the code as per your consolation.
All investments and buying and selling within the inventory market contain threat. Any determination to put trades within the monetary markets, together with buying and selling in inventory or choices or different monetary devices is a private determination that ought to solely be made after thorough analysis, together with a private threat and monetary evaluation and the engagement {of professional} help to the extent you consider obligatory. The buying and selling methods or associated info talked about on this article is for informational functions solely.
Everybody is aware of what comes up in information science interviews: SQL, Python, machine studying fashions, statistics, generally a system design or case examine. If this comes up within the interviews, it’s what they check, proper? Not fairly. I imply, they positive check every thing I listed, however they don’t check solely that: there’s a hidden layer behind all these technical duties that the businesses are literally evaluating.
Picture by Writer | Imgflip
It’s nearly a distraction: whilst you assume you’re showcasing your coding abilities, employers are one thing else.
That one thing else is a hidden curriculum — the talents that may truly reveal whether or not you possibly can succeed within the function and the corporate.
Picture by Writer | Serviette AI
# 1. Can You Translate Enterprise to Knowledge (and Again)?
This is without doubt one of the largest abilities required of knowledge scientists. Employers wish to see in case you can take a imprecise enterprise drawback (e.g. “Which clients are most useful?”), flip it into a knowledge evaluation or machine studying mannequin, then flip the insights again into plain language for decision-makers.
What to Anticipate:
Case research framed loosely: For instance, “Our app’s day by day energetic customers are flat. How would you enhance engagement?”
Observe-up questions that power you to justify your evaluation: For instance, “What metric would you monitor to know if engagement is bettering?”, “Why did you select that metric as a substitute of session size or retention?”, “If management solely cares about income, how would you reframe your resolution?”
What They’re Actually Testing:
Picture by Writer | Serviette AI
Readability: Are you able to clarify your factors in plain English with out too many technical phrases?
Prioritization: Are you able to spotlight the principle insights and clarify why they matter?
Viewers consciousness: Do you modify your language relying in your viewers (technical vs. non-technical)?
Confidence with out vanity: Are you able to clarify your strategy clearly, with out getting overly defensive?
Questions like: “Would you utilize a random forest or logistic regression right here?”.
No appropriate reply: Eventualities the place each solutions may very well be proper, however they’re within the why of your selection.
What They’re Actually Testing:
Picture by Writer | Serviette AI
No universally “finest” mannequin: Do you perceive that?
Framing trade-offs: Are you able to do this in plain phrases?
Enterprise alignment: Do you present the attention to align your mannequin selection with enterprise wants, as a substitute of chasing technical perfection?
# 3. Can You Work with Imperfect Knowledge?
The datasets in interviews are hardly ever clear. There are often lacking values, duplicates, and different inconsistencies. That’s consider to mirror the precise information you’ll need to work with.
What to Anticipate:
Imperfect information: Tables with inconsistent codecs (e.g. dates present as 2025/09/19 and 19-09-25), duplicates, hidden gaps (e.g. lacking values solely in sure time ranges, for instance, each weekend), edge instances (e.g. detrimental portions in an “gadgets bought” column or clients with an age of 200 or 0)
Analytical reasoning query: Questions on the way you’d validate assumptions
What They’re Actually Testing:
Picture by Writer | Serviette AI
Your intuition for information high quality: Do you pause and query the info as a substitute of mindlessly coding?
Prioritization in information cleansing: Have you learnt which points are price cleansing first and have the largest impression in your evaluation?
Judgement below ambiguity: Do you make assumptions express so your evaluation is clear and you may transfer ahead whereas acknowledging dangers?
# 4. Do You Suppose in Experiments?
Experimentation is a big a part of information science. Even when the function isn’t explicitly experimental, you’ll need to carry out A/B assessments, pilots, and validation.
What to Anticipate:
What They’re Actually Testing:
Picture by Writer | Serviette AI
Your means to design experiments: Do you clearly outline management vs. therapy, carry out randomization, and think about pattern dimension?
Vital interpretation of outcomes: Do you think about statistical significance vs. sensible significance, confidence intervals, and secondary results when decoding the experiment’s outcomes?
# 5. Can You Keep Calm Beneath Ambiguity?
Most interviews are designed to be ambiguous. The interviewers wish to see how you use with imperfect and incomplete data and directions. Guess what, that’s exactly what you’ll get at your precise job.
What to Anticipate:
Obscure questions with lacking context: For instance, “How would you measure buyer engagement?”
Pushing again in your clarifying questions: For instance, you would possibly attempt to make clear the above by asking, “Do we would like engagement measured by time spent or variety of classes?”. Then the interviewer may put you on the spot by asking, “What would you choose if management doesn’t know?”
What They’re Actually Testing:
Picture by Writer | Serviette AI
Mindset below uncertainty: Do you freeze, or keep calm and pragmatic?
Downside structuring: Are you able to impose order on a imprecise request?
Assumption-making: Do you make your assumptions express in order that they are often challenged and refined within the following evaluation iterations?
Enterprise reasoning: Do you tie your assumptions to enterprise targets or to some arbitrary guesses?
# 6. Do You Know When “Higher” Is the Enemy of “Good”?
Employers need you to be pragmatic, that means: are you able to give as helpful outcomes as rapidly and as merely as doable? A candidate who would spend six months bettering the mannequin’s accuracy by 1% isn’t precisely what they’re searching for, to place it mildly.
What to Anticipate:
Pragmatism query: Are you able to provide you with a easy resolution that solves 80% of the issue?
Probing: An interviewer pushing you to clarify why you’d cease there.
What They’re Actually Testing:
Picture by Writer | Serviette AI
Judgement: Have you learnt when to cease optimizing?
Enterprise alignment: Are you able to join options to enterprise impression?
Useful resource-awareness: Do you respect time, value, and crew capability?
Iterative mindset: Do you ship one thing helpful now, then enhance later, as a substitute of spending an excessive amount of time devising a “excellent” resolution?
# 7. Can You Deal with Pushback?
Knowledge science is collaborative, and your concepts might be challenged, so the interviews replicate that.
What to Anticipate:
Vital reasoning check: Interviewers attempting to impress you and poke holes in your strategy
Alignment check: Questions like, “What if management disagrees?”
What They’re Actually Testing:
Picture by Writer | Serviette AI
Resilience below scrutiny: Do you keep calm when your strategy is challenged?
Readability of reasoning: Are your ideas clear to you, and may you clarify them to others?
Adaptability: If the interviewer exposes a gap in your strategy, how do you react? Do you acknowledge it gracefully, or do you get offended and run out of the workplace crying and screaming expletives?
# Conclusion
You see, technical interviews aren’t actually about what you thought they have been. Take into account that all that technical screening is actually about:
Translating enterprise issues
Managing trade-offs
Dealing with messy, ambiguous information and conditions
Understanding when to optimize and when to cease
Collaborating below stress
Nate Rosidi is a knowledge scientist and in product technique. He is additionally an adjunct professor instructing analytics, and is the founding father of StrataScratch, a platform serving to information scientists put together for his or her interviews with actual interview questions from prime corporations. Nate writes on the most recent developments within the profession market, offers interview recommendation, shares information science tasks, and covers every thing SQL.
Corporations with a number of places face a connectivity problem that doesn’t exist for single-site operations. It’s not nearly getting web to every workplace—it’s about making a community that lets all these places work collectively as one cohesive enterprise. However the strategy most corporations take creates extra issues than it solves.
The everyday sample goes one thing like this: a enterprise opens a second location and treats it as a separate entity from a connectivity standpoint. They join no matter web service is obtainable at that deal with, arrange some primary networking tools, and name it achieved. Perhaps they add a VPN so the 2 workplaces can talk. This works initially, when there are solely two websites and restricted inter-office site visitors. Then the corporate grows to 3 places, then 5, then ten. The patchwork strategy that appeared high-quality early on turns into a administration nightmare.
The Supplier Fragmentation Drawback
One of many largest errors giant companies make is ending up with totally different web suppliers throughout totally different websites. It occurs naturally—every location will get arrange independently, somebody picks no matter supplier appears finest at that individual deal with, and no one thinks concerning the long-term implications.
This fragmentation creates severe administration complications. Every supplier has totally different help processes, totally different service stage agreements, totally different billing programs, totally different technical specs. When issues come up, IT groups spend time determining which supplier to name for which website, navigating totally different help buildings, and making an attempt to coordinate responses throughout suppliers who don’t talk with one another.
The efficiency inconsistency issues too. One workplace might need fiber with symmetric gigabit speeds and assured uptime. One other is perhaps caught with no matter cable web was obtainable in that space, with decrease speeds and consumer-grade reliability. Workers working in several places have dramatically totally different experiences, and purposes that rely upon inter-office communication carry out unpredictably.
Companies working throughout a number of places profit from working with suppliers who specialise in web for big companies and may ship constant service requirements no matter the place workplaces are positioned. This consistency issues extra as corporations scale—what works for 2 workplaces turns into unmanageable at ten.
Bandwidth Planning That Ignores Actuality
Corporations usually strategy bandwidth allocation for multi-site setups by asking “what does every workplace want?” after which provisioning connections primarily based on these particular person assessments. This appears logical however misses how fashionable companies truly work.
Inter-office site visitors patterns get ignored. When workplaces want to speak always—sharing information, accessing centralized programs, taking part in company-wide video calls—the bandwidth between websites issues as a lot as web speeds at every location. A setup that gives nice exterior web however horrible inter-office connectivity leaves workers annoyed and productiveness struggling.
The calculation modifications whenever you consider cloud companies, backup programs, and centralized purposes. That department workplace may solely have 15 workers, but when they’re all accessing purposes hosted in the primary workplace’s information middle, or backing as much as centralized storage, or taking part in each day video conferences with different places, their bandwidth wants are larger than the worker depend suggests.
Peak utilization patterns compound throughout a number of websites. When each workplace hits its busiest interval throughout the identical hours—which often occurs since they’re all working the identical enterprise hours—the community must deal with everybody’s peak calls for concurrently. Planning bandwidth primarily based on common utilization slightly than peak concurrent utilization results in slowdowns proper when individuals want efficiency most.
The VPN Strategy That Doesn’t Scale
The usual answer for connecting a number of workplaces is organising VPNs between places. This works as a place to begin, however VPN-based architectures create issues as networks develop.
Efficiency degrades with VPN overhead. Each packet will get encrypted, despatched by way of the web, and decrypted on the vacation spot. This provides latency and reduces efficient bandwidth. For 2 workplaces, the efficiency hit is perhaps acceptable. For ten workplaces all making an attempt to speak with one another, the overhead turns into important.
Administration complexity explodes with scale. Connecting three workplaces requires three VPN tunnels. 5 workplaces want ten tunnels. Ten workplaces require 45 separate VPN connections. Every tunnel wants configuration, monitoring, and troubleshooting when issues come up. IT groups spend rising quantities of time simply sustaining the VPN infrastructure slightly than specializing in precise enterprise wants.
Safety turns into more durable to handle, not simpler. A number of VPN tunnels imply a number of potential entry factors, a number of configurations that want to remain safe, and a number of alternatives for misconfigurations that create vulnerabilities. The extra advanced the setup, the extra doubtless one thing will get ignored.
Inconsistent Service Ranges Throughout Areas
Giant companies usually find yourself with wildly totally different service stage agreements at totally different websites. The headquarters might need enterprise-grade connectivity with 99.9% uptime ensures and four-hour response instances. Regional workplaces might need business-class service with weaker ensures. Smaller places is perhaps caught with no matter consumer-grade service was obtainable with no actual SLA in any respect.
This inconsistency creates unpredictable issues. When the primary workplace’s web goes down, everybody is aware of it’s a precedence and expects fast response. When a smaller workplace loses connectivity, they is perhaps ready days for decision as a result of their supplier treats it as a routine residential service name.
The enterprise impression varies by location in ways in which don’t align with enterprise priorities. A small workplace that handles essential customer support capabilities wants reliability simply as a lot as headquarters, however might need inferior connectivity just because somebody made choices primarily based on workplace measurement slightly than enterprise perform.
Budgeting turns into sophisticated when totally different places have totally different value buildings, totally different contract phrases, and totally different improve paths. Planning community enhancements throughout the corporate requires coordinating with a number of suppliers, every with their very own pricing and timelines.
Poor Community Structure Selections
Many companies deal with multi-site connectivity as a group of impartial workplaces that often want to speak to one another, slightly than designing an precise community structure. This lack of planning creates bottlenecks and inefficiencies.
Hub-and-spoke designs make sense for some companies however get carried out poorly. All department workplaces route by way of headquarters, which turns into a chokepoint. If the primary workplace’s web goes down, branches can’t talk with one another or entry central assets—despite the fact that all of them have working web connections regionally.
Mesh networks the place each workplace connects immediately to each different workplace sound good in principle however create administration nightmares in follow. The complexity grows exponentially with every new location, and troubleshooting issues turns into practically not possible when any given connection could possibly be taking a number of totally different paths by way of the community.
Centralized vs. distributed assets choices don’t get sufficient thought. Ought to every workplace have native servers and storage, or ought to every thing centralize? The reply impacts bandwidth necessities dramatically, however corporations usually make these choices with out contemplating connectivity implications.
Ignoring Redundancy Till It’s Too Late
Single factors of failure plague multi-site networks. One web connection per website appears adequate till that connection goes down and all the location goes offline. For companies the place each location wants to remain operational, single connections create unacceptable threat.
The issue is redundancy prices cash, and it’s onerous to justify the expense till you’ve skilled pricey downtime. Then it’s apparent that paying for backup connections would have been cheaper than the misplaced productiveness and income from outages.
However redundancy isn’t nearly having two web connections at every website. It’s about guaranteeing these connections don’t share widespread failure factors—totally different suppliers, totally different bodily infrastructure, totally different entry factors into the constructing. In any other case, the redundancy supplies false confidence when the underlying reason for failure impacts each connections concurrently.
The Migration Drawback
Corporations that notice their multi-site connectivity is a multitude face a tough problem: fixing it often requires main modifications whereas enterprise continues working. You possibly can’t simply shut down the community and rebuild it correctly.
Migration planning must account for sustaining operations throughout the transition. Every website probably must run outdated and new connectivity in parallel whereas cutover occurs. This will get costly and complex, particularly when coping with a number of suppliers and places unfold throughout totally different time zones.
Testing turns into essential. Adjustments that work high-quality in a lab atmosphere can break in manufacturing after they work together with the quirks of present programs. However testing multi-site community modifications with out affecting operations is sort of not possible, so companies find yourself making modifications throughout off-hours and hoping every thing works.
Getting It Proper From the Begin
The businesses that deal with multi-site connectivity nicely give it some thought as a unified community from the start, not a group of impartial workplaces. They set up requirements for what connectivity seems like—similar supplier the place attainable, constant service ranges, appropriate tools, centralized administration.
They plan for development slightly than simply assembly present wants. Including new places must be simple, not require rethinking all the community structure. The infrastructure ought to scale naturally because the enterprise expands.
They put money into correct community design upfront slightly than patching issues later. Skilled community structure for multi-site companies prices cash however prevents the costly mess of making an attempt to repair a patchwork system that grew organically with out planning.
Most essential, they acknowledge that connectivity between websites issues as a lot as connectivity to the web. Fashionable companies don’t function as remoted places that occur to share an organization title—they perform as built-in organizations the place data flows always between places. The community infrastructure must help that actuality, not battle in opposition to it.
Espresso beans collected from the faeces of civets have a novel chemistry that will clarify why such beans are prized for his or her flavour.
Asian palm civets (Paradoxurus hermaphroditus) are mongoose-like animals native to South and South-East Asia. Civet espresso, also called kopi luwak, is without doubt one of the world’s most useful and strangest luxurious drinks. A kilogram of beans which have handed via a civet’s digestive tract will be price over $1000.
Kopi luwak is produced primarily in Indonesia, the Philippines and Vietnam, however it is usually made on a smaller scale in different nations, together with India and East Timor. Nevertheless, animal welfare teams urge shoppers to keep away from the business, accusing it of preserving 1000’s of civets caged in horrible circumstances.
To learn the way espresso beans are remodeled after passing via a civet, Palatty Allesh Sinu at Central College of Kerala, India, and his colleagues collected espresso samples from 5 coffee-growing farms close to Kodagu within the Western Ghats mountain vary of India.
Civets stay wild inside these farms, and not one of the operations maintain the animals caged. Staff routinely acquire the beans from the scats after which add them to the harvest of tree-grown espresso beans. “The locations we labored have a harmonious interplay between planters and civets,” says Sinu. “We need to convey the details in regards to the chemical composition to the planters.”
The researchers collected almost 70 civet scats containing espresso beans and in addition manually harvested beans from the plantations’ robusta espresso bushes, earlier than operating a set of checks that checked out key chemical parts, like fat and caffeine.
Whole fats was considerably larger within the civet beans than in these harvested from the bushes, whereas caffeine, protein and acid content material had been barely decrease. The decrease acidity was possible because of the fermentation throughout digestion, the researchers say.
The risky natural compounds within the civet espresso additionally confirmed important variations relative to common espresso beans. A few of these parts, that are routinely present in common espresso beans, had been both lacking outright from the civet beans or current in solely minimal portions.
The staff means that the upper fats content material in civet espresso could contribute to its distinctive aroma and flavour profile, and the decrease degree of proteins could end in decreased bitterness.
Sinu says caging civets to make kopi luwak is merciless, and the hope is that additional work might assist develop synthetic fermentation processes that end in espresso with an equivalent chemical composition.
“We assume that the intestine microbiome may assist a way within the fermentation course of,” Sinu says. “As soon as we all know the enzymes concerned in digestion and fermentation, we could possibly artificially make civet espresso.”
The Problem: Why Your Qualitative Outcomes Chapter Feels Overwhelming
Qualitative Outcomes
Outcomes
Statistical Evaluation
The method of growing a qualitative outcomes chapter presents a singular set of difficulties that may make it really feel like a monumental job. College students usually grapple with the sheer quantity and complexity of their information, the subjective nature of interpretation, and the strain to supply findings which are each significant and methodologically sound. These qualitative evaluation challenges are usually not merely procedural hurdles; they are often vital sources of stress and may impede progress towards finishing the dissertation. Understanding these widespread ache factors is step one towards recognizing the worth of specialised help.
Navigating the Labyrinth of Qualitative Knowledge
Dissertation college students steadily encounter a number of particular struggles when confronted with their qualitative information:
Knowledge Overload:Qualitative analysis usually generates huge quantities of textual, audio, or visible information. Managing, organizing, and systematically reviewing these giant datasets—be it hours of interview transcripts or pages of area notes—could be extremely time-consuming and overwhelming earlier than evaluation even begins. The sheer quantity could make it tough to see the forest for the bushes.
Figuring out Significant Patterns: Shifting from familiarization with the info to figuring out genuinely vital themes and patterns that straight handle the analysis questions is a complicated analytical leap. It requires a capability to discern delicate nuances and connections, distilling “key themes” and articulating their broader significance past mere description. That is usually the place college students really feel essentially the most uncertainty.
Subjectivity and Bias: A core concern in qualitative analysis is the potential for researcher bias to affect information interpretation. Whereas strategies like reflexivity (acknowledging and inspecting one’s personal views) and bracketing (setting apart preconceived notions) are designed to mitigate this, successfully implementing them requires cautious apply and self-awareness, which could be difficult to keep up in isolation.
Structuring a Coherent Narrative: As soon as themes are recognized, organizing them right into a logical, flowing chapter that tells a compelling and clear story from the info is one other vital hurdle. The outcomes chapter should “objectively and neutrally current the findings”, however crafting this neutrality into a fascinating narrative requires talent.
Guaranteeing Rigor and Trustworthiness: Qualitative analysis is judged by its adherence to standards akin to credibility, transferability, dependability, and confirmability. Reaching this requires “precision, care, and a spotlight to element” at each stage of the analysis course of, a regular that may really feel formidable to uphold independently.
Need assistance conducting your evaluation? Leverage our 30+ years of expertise and low-cost service to make progress in your outcomes!
Schedule now utilizing the calendar under.
Click on under to see a testimonial from a glad Intellectus buyer!
These challenges spotlight that the issue is just not merely in doing the evaluation, however in doing it effectively, below tutorial strain, and sometimes with out steady, specialised steerage. The iterative nature of qualitative evaluation, involving a number of readings, coding cycles, and theme refinement, can really feel countless if a transparent path ahead is just not established. This underscores the necessity for help that addresses not simply job completion, but in addition high quality assurance and the discount of scholar stress.
The Stress to Produce Excessive-High quality Outcomes
The qualitative outcomes chapter is not only one other part; it’s the place the “core findings” of the analysis are laid naked, forming the spine of the dissertation’s contribution to data. Consequently, dissertation committees maintain excessive expectations for the depth of research, the readability of presentation, and the methodological soundness demonstrated on this chapter. The strain to satisfy these expectations, coupled with the inherent complexities of qualitative information, could be immense. Many college students can also lack specialised, in-depth coaching in superior qualitative methodologies or the nuances of the newest analytical software program, making a data and expertise hole. This hole is exactly the place professional providers, significantly these leveraging subtle instruments, can present essential help, bridging the divide between the scholar’s information and a cultured, defensible outcomes chapter. Don’t let qualitative evaluation challenges stop you from graduating- we can assist!
Get Your Dissertation Accepted
We work with graduate college students every single day and know what it takes to get your analysis accredited.
Nothing I am about to say or have ever stated about housing ought to be taken as a blanket condemnation of YIMBY concepts and proposals. I occur to agree with most of them, even the overly simplistic ones featured in The New York Occasions.
If this had been only a query of being proper — or no less than being directionally proper — nearly all of the time, I would not have wasted all this time writing a seemingly infinite sequence of posts on the topic. Sadly there’s extra to it..
The housing discourse is embarrassingly dysfunctional even by the abysmal requirements of the 2020s. The usual narrative is introduced with out query as absolute fact, regardless of being simplistic, typically monocausal, closely reliant on outliers and unrepresentative knowledge, and unforgivably gradual to acknowledge conflicting knowledge even when it significantly threatens the main tenets of the arguments.
Working example, the fixation on zoning together with hypocritical liberals as the first large bads of the story. In case you assume I am misrepresenting their case.
Here is Krugman with an early and fewer shrill) model of the zoning argument. [Emphasis added.]
Many bubble deniers level to common costs for the nation as an entire, which look worrisome however not completely loopy. Relating to housing, nevertheless, the USA is actually two nations, Flatland and the Zoned Zone.
In Flatland, which occupies the center of the nation, it’s straightforward to construct homes. When the demand for homes rises, Flatland metropolitan areas, which don’t actually have conventional downtowns, simply sprawl some extra. Consequently, housing costs are principally decided by the price of building. In Flatland, a housing bubble can’t even get began.
However within the Zoned Zone, which lies alongside the coasts, a mix of excessive inhabitants density and land-use restrictions – therefore “zoned” – makes it exhausting to construct new homes. So when individuals turn out to be keen to spend extra on homes, say due to a fall in mortgage charges, some homes get constructed, however the costs of current homes additionally go up. And if individuals assume that costs will proceed to rise, they turn out to be keen to spend much more, driving costs nonetheless larger, and so forth. In different phrases, the Zoned Zone is vulnerable to housing bubbles.
Do not get me improper, there are actually some horrible zoning legal guidelines out
there and there is not any query that they make the housing disaster worse,
maybe a lot worse, however if you attempt to make tearing them down your
panacea, you run into knowledge like this.
A brand new actual property report confirms one thing that Houstonians fairly
a lot already knew: Town of Houston noticed a big enhance in
housing costs amongst U.S. cities inside the final decade, with median
residence costs skyrocketing as much as 86 p.c.
The report
by on-line actual property database PropertyShark analyzed median residence sale
costs in 41 of probably the most populous U.S. cities and locales in 2014 and
2023. In keeping with the research, the median sale value of a house in Houston
in 2014 was $142,000. A decade later, median housing costs within the metropolis
almost doubled, touchdown at $264,000 in 2023.
So is Houston a kind of few closely zoned crimson state cities? Not simply “no,” however “Hell, No.”
Why doesn’t Houston have zoning?
In contrast to different cities, Houston by no means efficiently voted to place zoning restrictions in place.
“The dearth of zoning began on the Huge Bang, the creation of the universe,” joked Matthew Festa,
South Houston Faculty of Regulation professor and land use lawyer. “…We’ve
by no means had zoning, so it didn’t actually begin. It simply by no means occurred.”
The metropolis constitution requires
a binding referendum vote from residents or a six-month ready interval
for public remark and debate of a zoning ordinance. Houston officers
introduced it to the poll in 1948, 1962 and 1993. Voters rejected it every time.
For Christian Menefee, the county lawyer, the dearth of zoning makes
his work tougher. Simply this 12 months, the Harris County Legal professional’s
Workplace – led by Menefee – sued the Texas Fee on Environmental High quality for approving a allow for a concrete batch plant throughout from a hospital in Kashmere Gardens. A transfer that will be far tougher or unimaginable with zoning legal guidelines.
“We now have quite a few concrete batch crops in Fifth Ward and Close to North
Facet,” stated Menefee. “(No zoning) makes our lives preventing these
conditions troublesome as a result of then we have now to go and try to search each
authorized treatment on the state stage.”
Simply to reiterate, a number of zoning legal guidelines are dangerous. Similar to a number of simplistic narratives about housing.


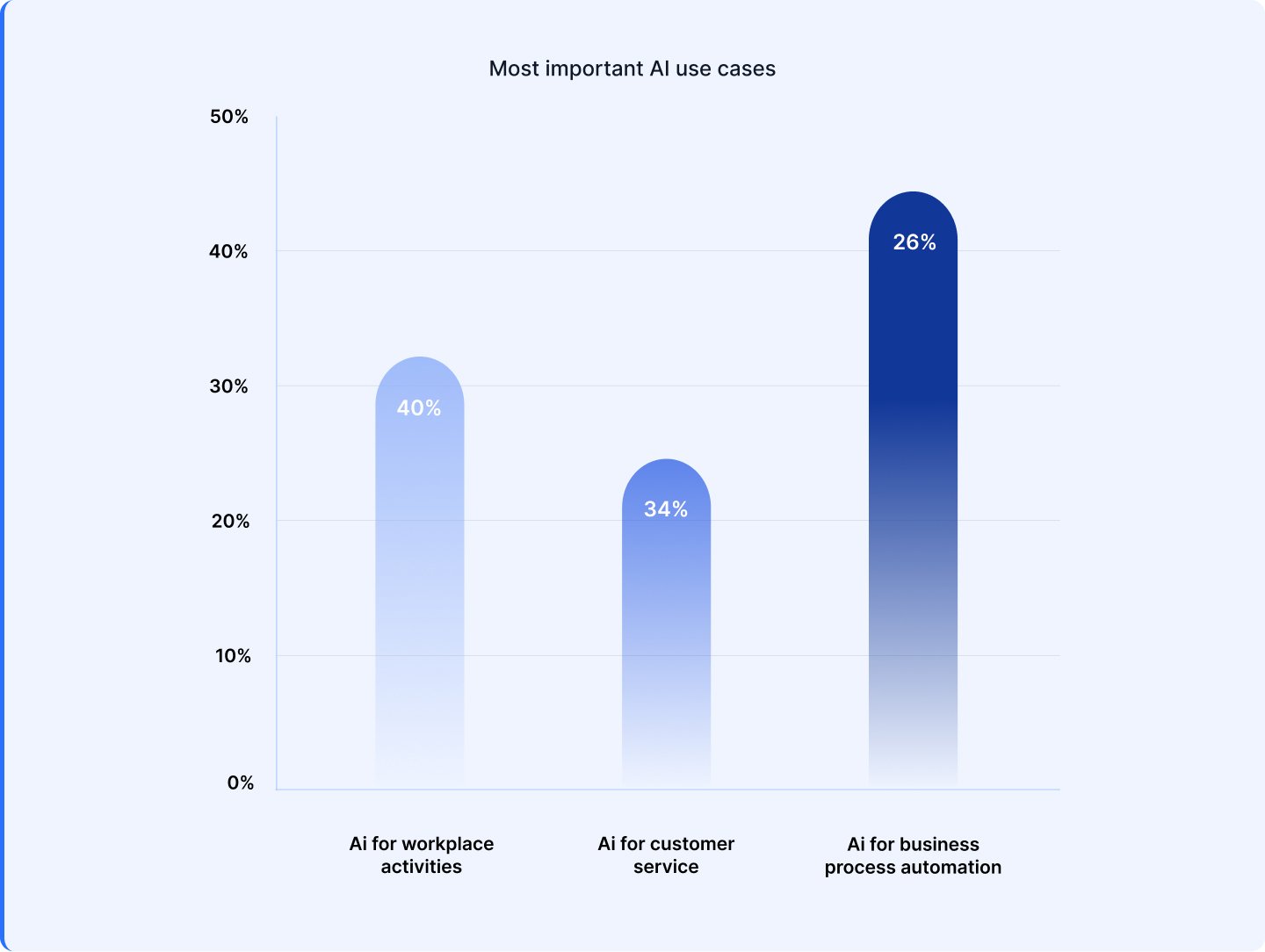
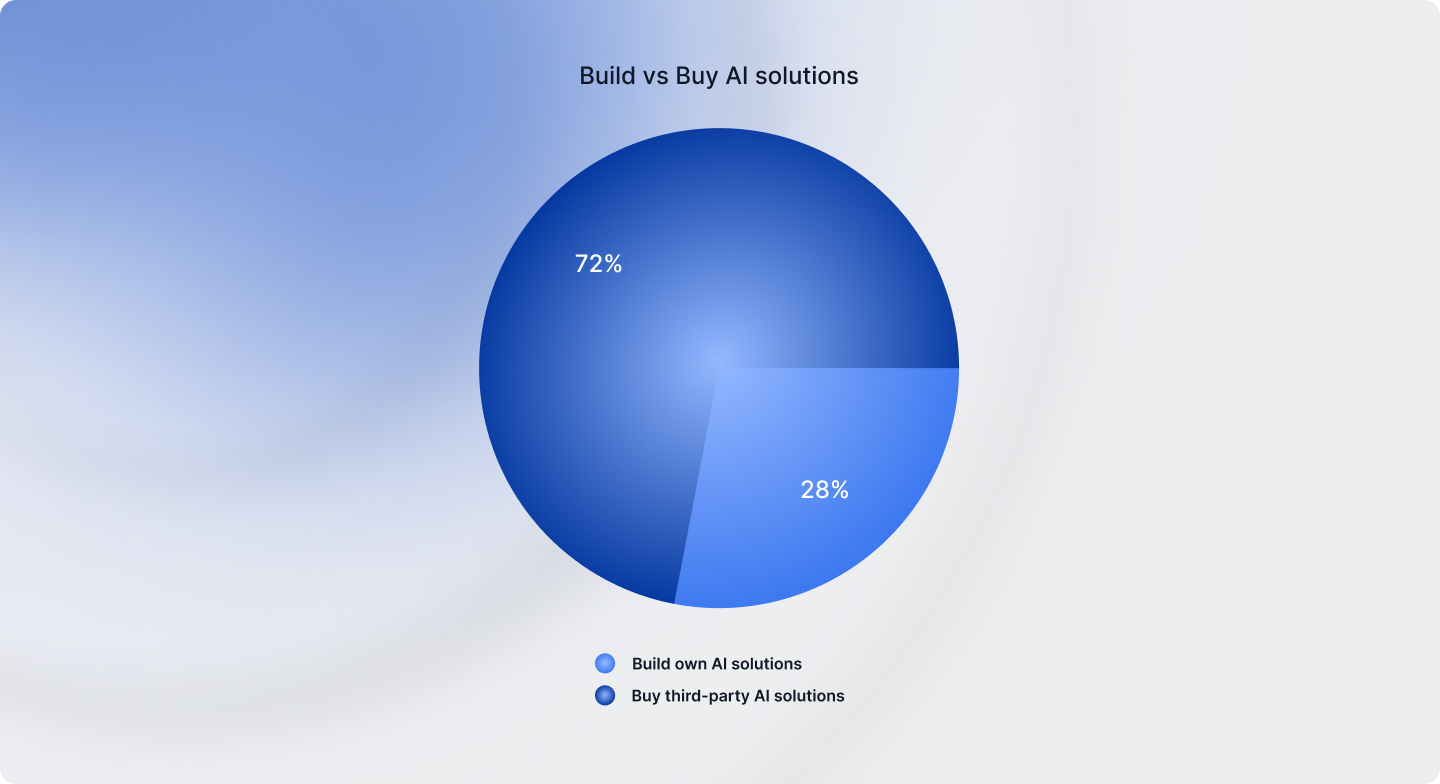
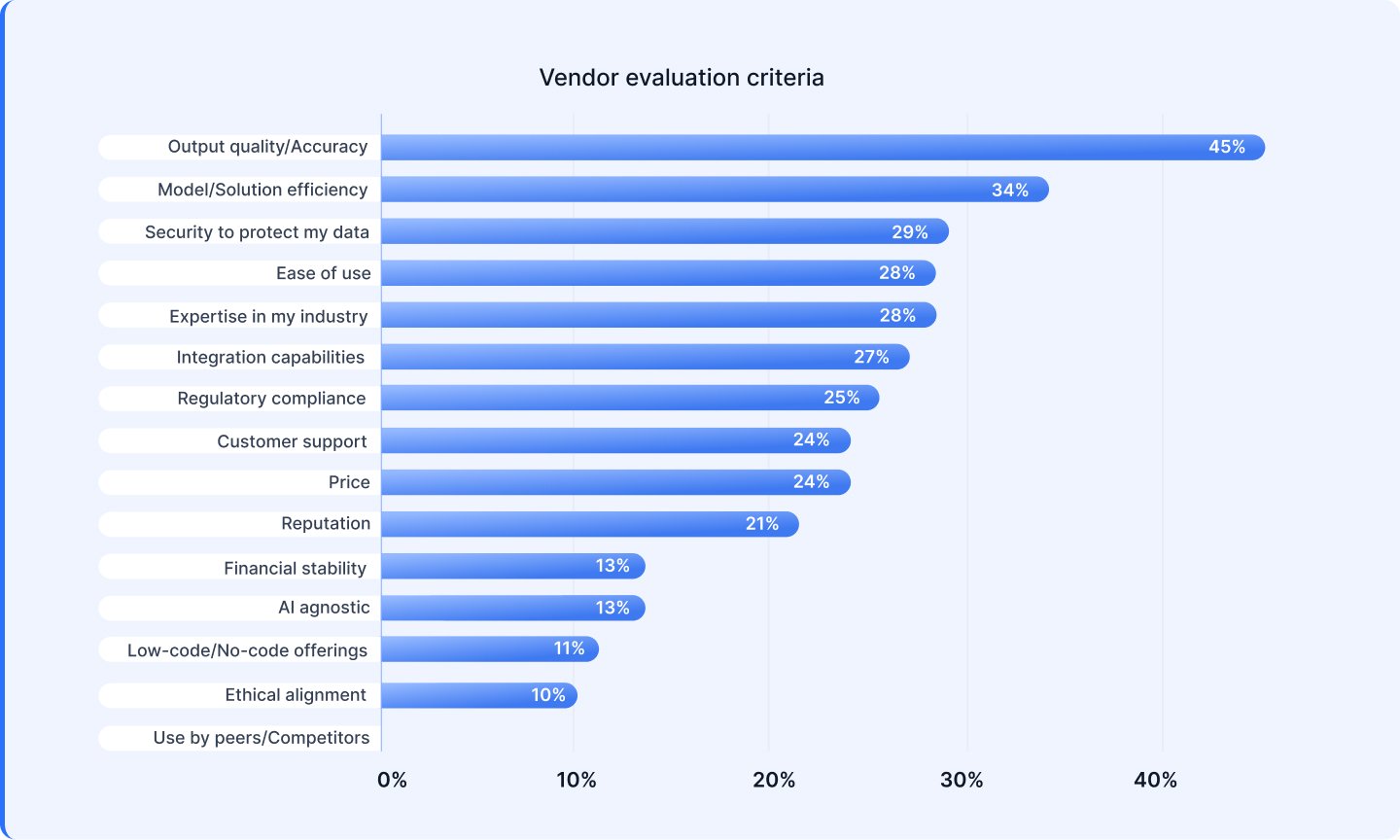
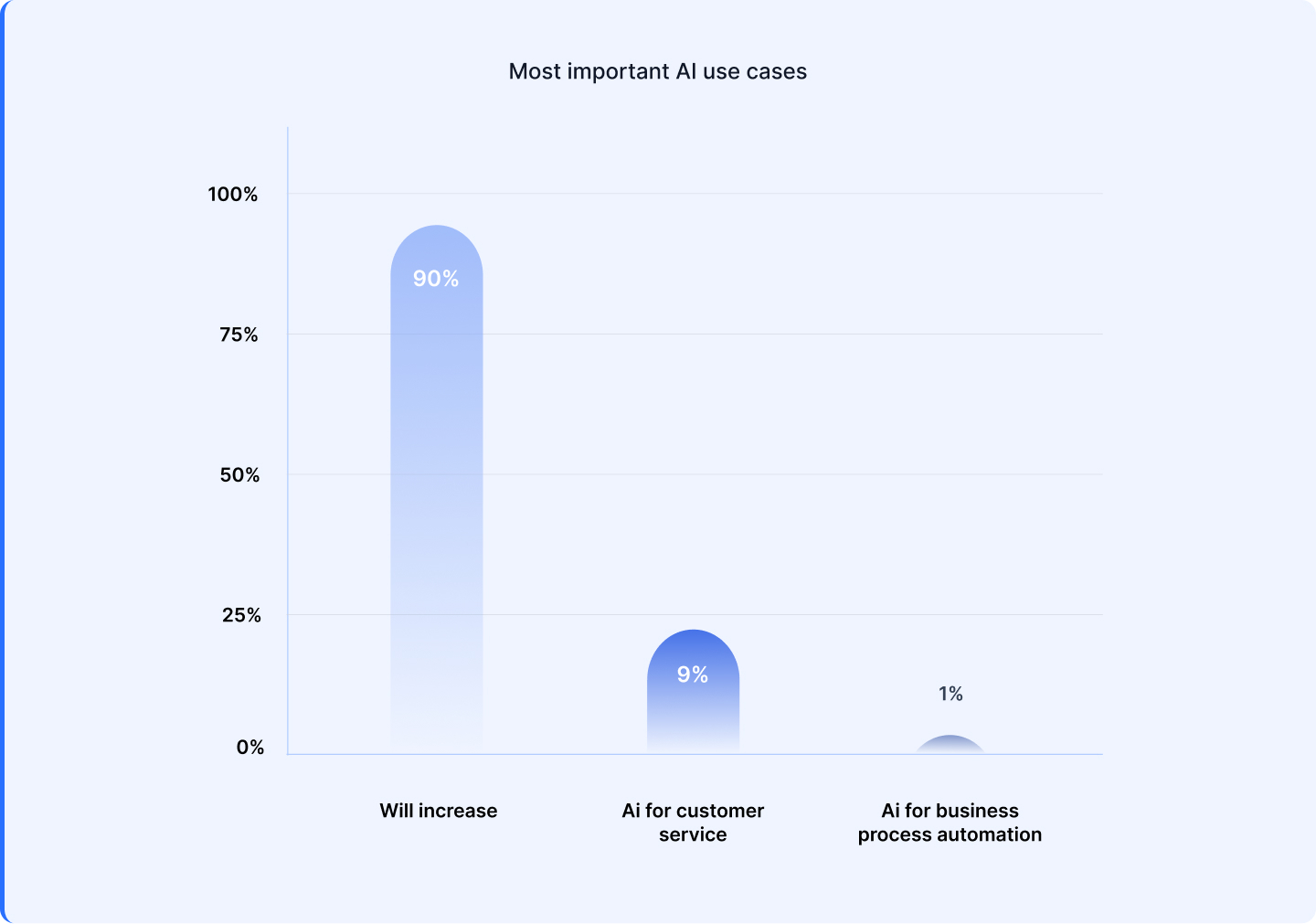







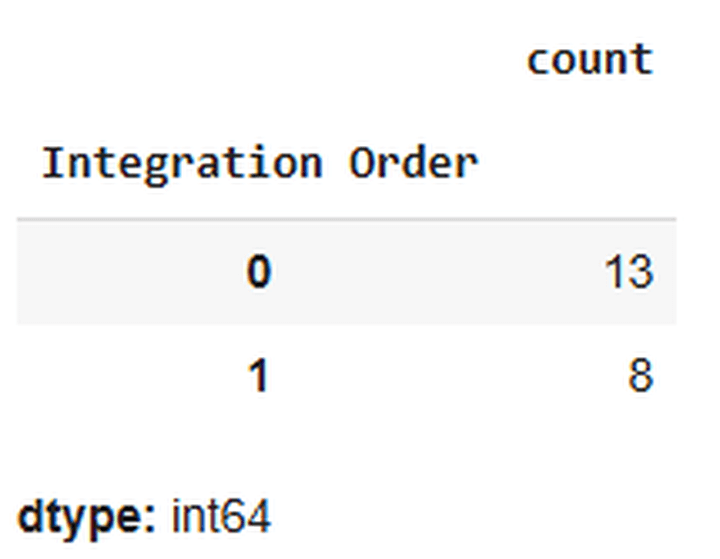
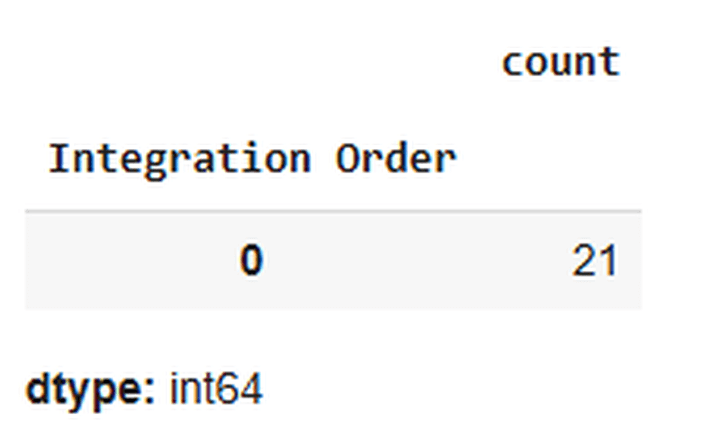
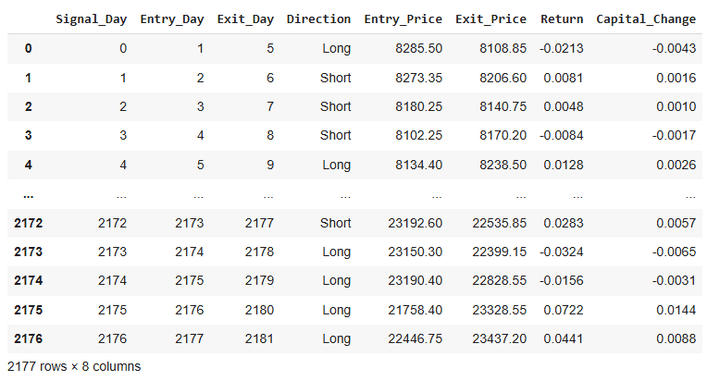
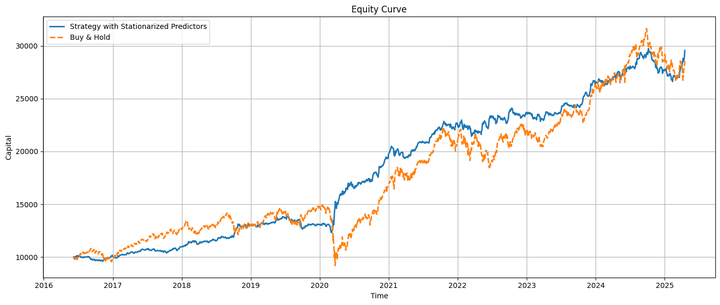
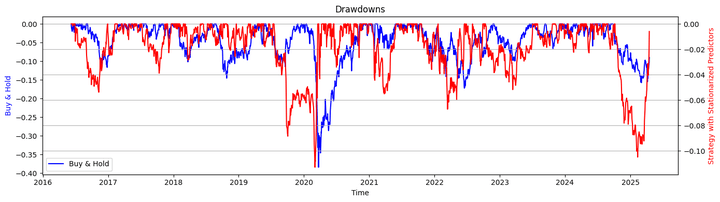
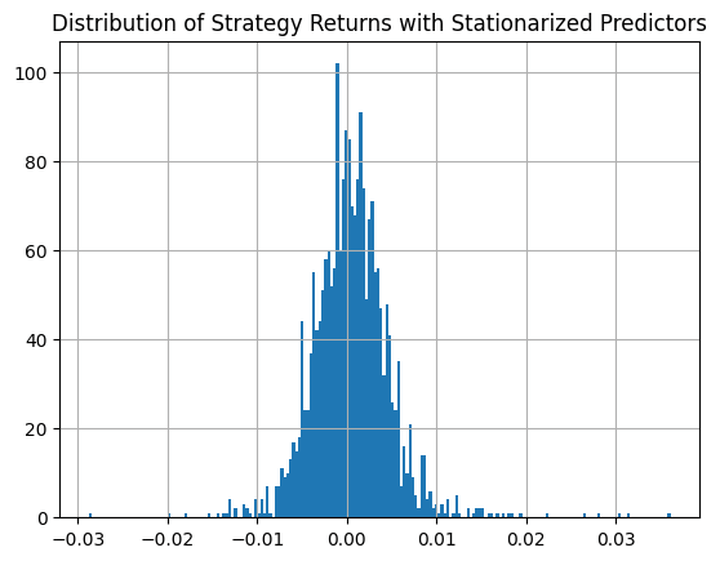

















{kind=link}