Sadly, there isn’t a vaccine to guard towards iGAS or GAS infections. This example considerations healthcare professionals as a result of streptococcus Group A micro organism are demonstrating indicators of antibiotic resistance.
Nevertheless, different preventive measures can assist reduce the unfold.
Good hygiene practices
Wash your arms with cleaning soap and water for at the very least twenty seconds. That is notably vital after coughing, sneezing, utilizing the lavatory, or touching probably contaminated surfaces.
Use hand sanitizers with at the very least 60% alcohol when cleaning soap and water should not available. Keep away from touching your face, particularly eyes, nostril, and mouth, with unwashed arms.
Respiratory hygiene
Cowl your mouth and nostril once you cough or sneeze; keep away from utilizing your arms. Use a tissue or your elbow to attenuate the chance of unfold.
Eliminate used tissues in a closed container and wash your arms instantly. Reduce interactions with people who’ve respiratory infections, such because the flu or a chilly.
Wound care
Correctly clear and look after any cuts, scrapes, or wounds to forestall bacterial entry. Maintain wounds coated with a clear bandage till they heal.
Apply preventive well being measures to construct immunity
Eat a balanced weight loss program and get common train and satisfactory sleep to help a strong immune system. Handle continual situations underneath medical supervision.
Keep away from sharing private gadgets
Don’t share gadgets like towels, razors, or consuming utensils with others.
Vaccination towards different respiratory infections
Think about getting vaccinated towards vaccine-preventable ailments, reminiscent of influenza (flu) and pneumococcal infections, which might cut back the chance of secondary infections.
Obtain immediate medical consideration
If you happen to develop signs like fever, extreme ache, pores and skin adjustments, or any indicators of an infection, search rapid medical consideration. Early analysis and remedy are essential to handle iGAS infections successfully.
These measures can assist cut back the chance of iGAS infections and their issues. Nevertheless, full prevention can’t be assured as a result of presence of Group A Streptococcus micro organism within the atmosphere.
This morning whereas I used to be looking for a tune by Merle Haggard that I needed to learn to to my dad, he peacefully handed away after a number of years of coping with Parkinsons. He was 83 years outdated, simply wanting his 84th birthday.
I’ve been engaged on a speech for the funeral since mid August after I final noticed him. I’ve 7 minutes so I used to be attempting to determine what to say, how you can say it, what his story gave the impression to be about to me, and what he meant to me.
Dad’s dad had began and later operated with Dads older brothers a grocery retailer in Baldwin Mississippi known as Cunningham’s Grocery. Dad had a type of tales of the son who doesn’t go into the household enterprise however as an alternative goes to school. He was the primary one in his household tree to take action. He went to Mississippi State the place he majored in arithmetic. He was a lifelong Bulldogs fan. And had we stayed in Mississippi, that’s the place I might’ve gone too.
I’ve written about it on right here earlier than which was that I believe Dad was a primary “enterprise functions” laptop programmer. Not a primary technology programmer, which could require relationship again to the Second World Battle, or perhaps a bit after, however extra like this mid to late 60s when trucking firms bought computer systems and wanted manpower to function them. However there weren’t any, and so companies would rent based mostly on a willingness to be taught and pop was prepared.
So dad’s first job was at Roadway Categorical within the managerial observe, however he then instantly utilized for a programmer place, and was accepted. It was a 12 months lengthy sort of academic program. He was studying outdated machine languages, which I’ve acquired written down someplace. He was significantly good at it — he advised that candidly earlier this 12 months. He was a modest man, and it was in all probability one among a handful of instances I’d ever heard dad say one thing constructive about himself.
Dad was shy, reserved, and bookish. I’ve generally heard the phrase “bookish” to imply somebody who was a bit nerdy, which is ok I assume, however I imply dad actually was consistently with a ebook. Truly a number of books, all the time checked out from the library, and nearly all the time nonfiction biographies and histories, and often it was one thing from American politics, although generally I might see him studying books on the mafia.
It was satirically our mutual curiosity in regards to the mafia that may lead me to develop into an economist. I’ve thought that a number of instances, and sometimes recount it, however principally I grew up watching motion pictures with my dad. He, like me, preferred traditional auteur movies from the 60s and 70s like Bonny and Clyde, The Godfather, after which later, Goodfellas. Dad gave me Nicholas Pileggi’s ebook Wiseguy whereas I used to be in highschool which Scorsese would later make into the film Goodfellas. He had such a conflicted feeling in regards to the mafia as a result of he, like me, was genuinely intrigued by it. And it was part of American political historical past, plus dad being that his first job was Roadway Categorical, a trucking firm, in all probability might’ve meant he was very conscious of Jimmy Hoffa on the union. So it did all really feel prefer it got here full circle. However dad was literary, like me, and I believe he additionally simply beloved the tales, and the mafia has many nice tales, together with that Pileggi ebook. However, dad additionally discovered the mafia extremely unethical, and I believe I heard him say to me a half dozen instances that we shouldn’t be telling tales celebrating the mafia anymore than we must be telling tales celebrating the Ku Klux Klan. And I believe that was a superb level — and but dad and I might nonetheless for many years quote traces from Goodfellas.
One among my favourite recollections of father was in highschool when after we opened Christmas presents, he, my mother and me went to see the film Bugsy, starring Warren Beatty and Anette Benning. It was very nice that the three of us had such completely correlated pursuits like that as a result of I deep down needed to go to the films, and so did dad, and so did mother. As soon as we vacationed in Gulf Springs, Arkansas for per week, and it rained the whole time. So each day the three of us would go to the films, and each day I noticed Again to the Future, and each day they noticed one thing else, and on the final day all of us noticed Again to the Future collectively. My love of tales — I in all probability did get that from dad. In all probability mother too. However undoubtedly dad.
Dad additionally was the one who gave me Jack Kerouac’s On the Street. He gave me Of Mice and Males by Steinbeck. He gave me Ken Kesey’s One Flew Over the Cuckoo’s Nest. He gave me, most of all, my most treasured ebook — JD Salinger’s Catcher within the Rye. We’d speak about that one repeatedly all through my life. Like my dad, I’ve learn it a number of instances, and whereas I’m undecided if dad recognized with Holden Caufield at fairly the identical stage as I did, there will need to have be one thing in it that resonated with him for the reason that whole ebook is from Holden’s viewpoint. However he discovered so many issues Holden would say so humorous, and I want I might now keep in mind simply what they have been.
And my love of music I additionally acquired from dad. But it surely was on music that our tastes fully diverged — they have been perhaps even orthogonal. Dad beloved nation music and Elvis Presley. He didn’t love traditional rock. He didn’t love Dylan or the Beatles. He didn’t love the psychedelics interval of rock and roll in any respect, and he completely despised leisure medication. I doubt he ever drank to the purpose of intoxication. He preferred Budweiser, and I believe perhaps at most drank two of them in a single sitting, spaced out over a number of hours.
However again to music — dad didn’t like these eras. He additionally didn’t appear to essentially like Johnny Money, chopping off actually all the roads to him that I had quick access to. He beloved the outlaw nation musicians like Waylon Jennings, Merle Haggard, Willie Nelson, and a few others who I actually didn’t know very properly. After I acquired the decision that he died this morning at 9:45am CST, I had actually simply pulled up a tune by Merle Haggard that I used to be planning on studying for my speech at his funeral. It’s known as “Sing Me Again Residence”, and whereas I’m not certain it was one among his favourite, I determine he probably knew it by coronary heart. He knew all the pieces, it appeared like, by coronary heart. Not like me, he had a reminiscence like a metal entice, by no means appeared to overlook something, and so I’m certain if I might’ve learn it to him, he would’ve identified it by coronary heart too if he might’ve heard me, which he wouldn’t have been capable of.
Dad appeared to like the deeper nation songs the place the lyrics have been about issues like life and dying, laborious dwelling, unhappiness. And looking for just one tune from that catalog of outlaw nation singers that may be appropriate is like attempting to wade via a smorgasbord of positive meals, I believe I’ll do that one.
At my wedding ceremony rehearsal dinner, dad made a speech. I knew he had labored at it for some time as a result of it was memorized and he hated public talking. He went to Toastmasters with my mother (who excels at public talking) to beat his resistance to public talking, as he was a reserved personal man. And so I figured dad standing up in entrance of everybody and making a speech, of his personal creation, was an affidavit to his love for me. Or as I might say now in my sport theoretic jargon, him giving a speech at my rehearsal was “value discriminating sign” that solely somebody who actually beloved me would ever endure given his absolute wrestle to be so public in any respect, not to mention in his affection for me. And I don’t keep in mind a lot of it in any respect, however I keep in mind what he stated on the finish — he gave me some type of priestly blessing, from William Faulkner, saying merely that I ought to “go together with God”. After which he sat down.
Yesterday I talked to dad one final time on FaceTime, and as soon as once more I advised him I assumed he was going to be occurring an thrilling journey quickly, and that I couldn’t wait to see him once more and listen to all about it. I additionally learn him this Irish blessing.
Dad was a superb father to me, and I’ve one final anecdote earlier than I hit publish. Once we moved from Brookhaven, Mississippi to the suburbs of Memphis within the eighth grade, 1989, I had develop into the de facto solely baby — within the sense that my older siblings had moved on, graduated from school, and have been married. And people first few years have been fairly laborious for me. In truth, I believe it is perhaps correct to say that these first two years, and the expertise of being torn out of my homeland and friendship group, have forged a shadow over my whole life, even as much as this actual second — however the elemental downside of causal inference which states nobody actually can ever understand how one occasion in a single’s life impacts one other.
Dad was a programmer, as I stated, and we owned an IBM PS2 Mannequin 30 desktop. And we had a 2400 baud modem. So I used these first two years to pour myself into that — dialing into bulletin boards, beginning my very own bulletin board, and most of all, participating in low stage hacking actions. Dad knew it, and since he was one among these first gen enterprise programmers, he additionally knew in regards to the hacking tradition, even when he was not eager about it. Hackers choose on excessive capability varieties, and I believe dad in all probability simply acknowledged that no matter expertise that they had at hacking, he had them too, however nonetheless stored his distance.
However I didn’t. And I keep in mind a pair years in the past out of nowhere dad sharing at dinner at his home, when he was nonetheless actually lucid, that he noticed it occurring, and he truly thought it was wholesome for me, as a result of he noticed me attempting to resolve my very own social issues by creating one thing significant and making mates. I assumed it was unusually clever now on this finish of my life to be frank as a result of he was truly 100% correct that that was what I used to be doing, and step by step aged out of it too. I used to be appreciative that he noticed it, and cared sufficient to let it run its course, and that he had compassion. Although I do know I about drove him loopy with all my shenanigans too which I received’t get into right here.
So this week, I’ll end my lessons right here at Harvard. I’ll end my grading. I’ll end assembly with my TFs. I’ll end my stuff after which Thursday after class, I’ll catch a flight to Memphis, and spend the weekend with my household and prolonged household. On Saturday is the funeral. I’m wanting ahead to seeing his physique and telling him one final time I like him and all the time will love him and that I’m counting the times till I see him once more.
Few days in the past we had a chat by Gergely Neu, who offered his current work:
I am scripting this submit principally to bother him, by presenting this work utilizing tremendous hand-wavy intuitions and cartoon figures. If this is not sufficient, I’ll even discover a technique to point out GANs on this context.
However honestly, I am simply excited as a result of for as soon as, there’s a little little bit of studying concept that I half-understand, no less than at an intuitive stage, because of its reliance on KL divergences and the mutual data.
A easy guessing recreation
Let’s begin this with a easy thought experiment as an instance why and the way mutual data could also be helpful in describing an algorithm’s potential to generalize. Say we’re given two datasets, $mathcal{D}_{practice}$ and $mathcal{D}_{take a look at}$, of the identical dimension for simplicity. We play the next recreation: we each have entry to $mathcal{D}_{practice}$ and $mathcal{D}_{take a look at}$, and we each know what studying algorithm, $operatorname{Alg}$ we will use.
Now I toss a coin and I preserve the consequence (recorded as random variable $Y$) a secret. If it is heads, I run $operatorname{Alg}$ on the coaching set $mathcal{D}_{practice}$. If it is tails, I run $operatorname{Alg}$ on the take a look at knowledge $mathcal{D}_{take a look at}$ as an alternative. I do not inform you which of those I did, I solely divulge to you the ultimate parameter worth $W$. Are you able to guess, simply by $W$, whether or not I skilled on coaching or take a look at knowledge?
For those who can not guess $Y$, that implies that the algorithm returns the identical random $W$ no matter whether or not you practice it on coaching or take a look at knowledge. So the coaching and take a look at losses develop into interchangeable. This suggests that the algorithm will generalize very nicely (on common) and never overfit to the information it is skilled on.
The mutual data, on this case between $W$ and $Y$ quantifies your theoretical potential to guess $Y$ from $W$. The upper this worth is, the better it’s to inform which dataset the algorithm was skilled on. If it is simple to reverse engineer my coin toss from parameters, it implies that the algorithm’s output could be very delicate to the enter dataset it is skilled on. And that probably implies poor generalization.
Notice by: an algorithm generalizing nicely on common doesn’t suggest it really works nicely on common. It simply implies that there will not be a big hole between the anticipated coaching and anticipated take a look at error. Take for instance an algorithm returns a randomly initialized neural community, with out even touching the information. That algorithm generalizes extraordinarily nicely on common: it does simply as poorly on take a look at knowledge because it does on coaching knowledge.
Illustrating this in additional element
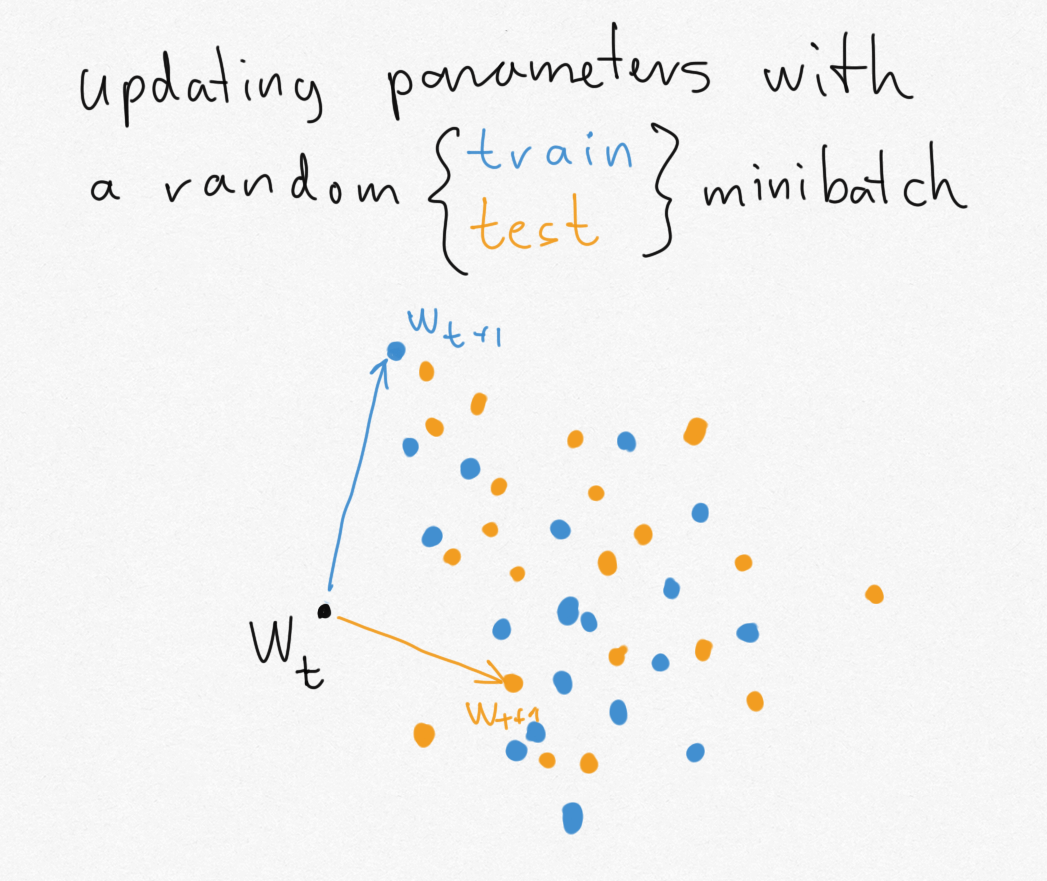
Under is an illustration of my thought experiment for SGD.
Within the high row, I doodled the distribution of the parameter $W_t$ at varied timesteps $t=0,1,2,ldots,T$ of SGD. We begin the algorithm by initializing $W$ randomly from a Gaussian (left panel). Then, every stochastic gradient replace modifications the distribution of $W_t$ a bit in comparison with the distribution of $W_{t-1}$. How the form of the distribution modifications depends upon the information we use within the SGD steps. Within the high row, for instance I ran SGD on $mathcal{D}_{practice}$ and within the backside, I run it on $mathcal{D}_{take a look at}$. The distibutions $p(W_tvert mathcal{D})$ I drew right here describe the place the SGD iterate is prone to be after $t$ steps of SGD began from random initialization. They aren’t to be confused with Bayesian posteriors, for instance.
We all know that working the algorithm on the take a look at set would produce low take a look at error. Subsequently, sampling a weight vector $W$ from $p(W_Tvert mathcal{D}_{take a look at})$ could be nice if we may do this. However in follow, we won’t practice on the take a look at knowledge, all we’ve the flexibility to pattern from is $p(W_Tvert mathcal{D}_{practice})$. So what we would like for good generalization, is that if $p(W_Tvert mathcal{D}_{take a look at})$ and $p(W_Tvert mathcal{D}_{practice})$ had been as shut as potential. The mutual data between $W_T$ and my coinflip $Y$ measures this closeness by way of the Jensen-Shannon divergence:
So, in abstract, if we are able to assure that the ultimate parameter an algorithm comes up with does not reveal an excessive amount of details about what dataset it was skilled on, we are able to hope that the algorithm has good generalization properties.
Mutual Inforrmation-based Generalization Bounds
These obscure intuitions will be formalized into actual information-theoretic generalization bounds. These had been first offered in a basic context in (Russo and Zou, 2016) and in a extra clearly machine studying context in (Xu and Raginsky, 2017). I will give a fast – and presumably considerably handwavy – overview of the principle outcomes.
Let $mathcal{D}$ and $mathcal{D}’$ be random datasets of dimension $n$, drawn i.i.d. from some underlying knowledge distribution $P$. Let $W$ be a parameter vector, which we get hold of by working a studying algorithm $operatorname{Alg}$ on the coaching knowledge $mathcal{D}$: $W = operatorname{Alg}(mathcal{D})$. The algorithm could also be non-deterministic, i.e. it could output a random $W$ given a dataset. Let $mathcal{L}(W, mathcal{D})$ denote the lack of mannequin $W$ on dataset $mathcal{D}$. The anticipated generalization error of $operatorname{Alg}$ is outlined as follows:
If we unpack this, we’ve two datasets $mathcal{D}$ and $mathcal{D}’$, the previous taking the function of the coaching dataset, the latter of the take a look at knowledge. We take a look at the anticipated distinction between the coaching and take a look at losses ($mathcal{L}(W, mathcal{D})$ and $mathcal{L}(W, mathcal{D}’)$), the place $W$ is obtained by working $operatorname{Alg}$ on the coaching knowledge $mathcal{D}$. The expectation is taken over all potential random coaching units, take a look at units, and over all potential random outcomes of the educational algorithm.
The data theoretic sure states that for any studying algorithm, and any loss operate that is bounded by $1$, the next inequality holds:
The principle time period within the RHS of this sure is the mutual infomation between the coaching knowledge mathcal{D} and the pararmeter vector $W$ the algorithm finds. It basically quantifies the variety of bits of knowledge the algorithm leaks concerning the coaching knowledge into the parameters it learns. The decrease this quantity, the higher the algorithm generalizes.
Why we won’t apply this to SGD?
The issue with making use of these good, intuitive bounds to SGD is that SGD, in truth, leaks an excessive amount of details about the precise minibatches it’s skilled on. Let’s return to my illustrative instance of getting to guess if we ran the algorithm on coaching or take a look at knowledge. Take into account the state of affairs the place we begin type some parameter worth $w_t$ and we replace both with a random minibatch of coaching knowledge (blue) or a random minibatch of take a look at knowledge (orange).
For the reason that coaching and take a look at datasets are assumed to be of finite dimension, there are solely a finite variety of potential minibatches. Every of those minibatches can take the parameter to a singular new location. The issue is, the set of areas you may attain with one dataset (blue dots) doesn’t overlap with the set of areas you may attain when you replace with the opposite dataset (orange dots). Out of the blue, if I offer you $w_{t+1}$, you may instantly inform if it is an orange or blue dot, so you may instantly reconstruct my coinflip $Y$.
Within the extra basic case, the issue with SGD within the context of information-theoretic bounds is that the quantity of knowledge SGD leaks concerning the dataset it was skilled on is excessive, and in some instances could even be infinite. That is really associated to the issue that a number of of us seen within the context of GANs, the place the true and faux distributions could have non-overlapping help, making the KL divergence infinite, and saturating out the Jensen-Shannon divergence. The primary trick we got here up with to resolve this downside was to easy issues out by including Gaussian noise. Certainly, including noise is essential what researches have been doing to use these information-theoretic bounds to SGD.
Including noise to SGD
The very first thing folks did (Pensia et al, 2018) is to review a loud cousin of SGD: stochastic gradient Langevin dynamics (SGLD). SGDL is like SGD however in every iteration we add a little bit of Gaussian noise to the parameters along with the gradient replace. To grasp why SGLD leaks much less data, take into account the earlier instance with the orange and blue level clouds. SGLD makes these level clouds overlap by convolving them with Gaussian noise.
Nonetheless, SGLD just isn’t precisely SGD, and it is not likely used as a lot in follow. In an effort to say one thing about SGD particularly, Neu (2021) did one thing else, whereas nonetheless counting on the thought of including noise. As an alternative of baking the noise in as a part of the algorithm, Neu solely provides noise as a part of the evaluation. The algorithm being analysed continues to be SGD, however after we measure the mutual data we’ll measure the mutual data between $mathbb{I}[W + xi; mathcal{D}]$, the place $xi$ is Gaussian noise.
I depart it to you to take a look at the small print of the paper. Whereas the findings fall in need of explaining whether or not SGD have any tendency to seek out options that generalise nicely, a few of the outcomes are good and interpretable: they join the generalization of SGD to the noisiness of gradients in addition to the smoothness of the loss alongside the precise optimization path that was taken.
GPU Partitioning (GPU-P) is a function in Home windows Server 2025 Hyper-V that permits a number of digital machines to share a single bodily GPU by dividing it into remoted fractions. Every VM is allotted a devoted portion of the GPU’s assets (reminiscence, compute, encoders, and so on.) as an alternative of utilizing your complete GPU. That is achieved by way of Single-Root I/O Virtualization (SR-IOV), which offers a hardware-enforced isolation between GPU partitions, guaranteeing every VM can entry solely its assigned GPU fraction with predictable efficiency and safety. In distinction, GPU Passthrough (also referred to as Discrete Machine Project, DDA) assigns a complete bodily GPU solely to at least one VM. With DDA, the VM will get full management of the GPU, however no different VMs can use that GPU concurrently. GPU-P’s potential to time-slice or partition the GPU permits greater utilization and VM density for graphics or compute workloads, whereas DDA gives most efficiency for a single VM at the price of flexibility.
GPU-P is good whenever you need to share a GPU amongst a number of VMs, comparable to for VDI desktops or AI inference duties that solely want a portion of a GPU’s energy. DDA (passthrough) is most well-liked when a workload wants the complete GPU (e.g. massive mannequin coaching) or when the GPU doesn’t assist partitioning. One other main distinction is mobility: GPU-P helps dwell VM mobility and failover clustering, which means a VM utilizing a GPU partition can transfer or restart on one other host with minimal downtime. DDA-backed VMs can not live-migrate. If that you must transfer a DDA VM, it have to be powered off after which began on a goal host (in clustering, a DDA VM will likely be restarted on a node with an accessible GPU upon failover, since dwell migration isn’t supported). Moreover, you can’t combine modes on the identical machine. A bodily GPU will be both partitioned for GPU-P or handed by by way of DDA, however not each concurrently.
Supported GPU {Hardware} and Driver Necessities
GPU Partitioning in Home windows Server 2025 is supported on choose GPU {hardware} that gives SR-IOV or related virtualization capabilities, together with acceptable drivers. Solely particular GPUs assist GPU-P and also you gained’t be capable to configure it on a client gaming GPU like your RTX 5090.
Along with the GPU itself, sure platform options are required:
Fashionable CPU with IOMMU: The host processors should assist Intel VT-d or AMD-Vi with DMA remapping (IOMMU). That is essential for mapping machine reminiscence securely between host and VMs. Older processors missing these enhancements might not totally assist dwell migration of GPU partitions.
BIOS Settings: Be certain that in every host’s UEFI/BIOS,Intel VT-d/AMD-Vi and SR-IOV are enabled. These choices could also be underneath virtualization or PCIe settings. With out SR-IOV enabled on the firmware stage, the OS won’t acknowledge the GPU as partitionable (in Home windows Admin Heart it’d present standing “Paravirtualization” indicating the driving force is succesful however the platform isn’t).
Host GPU Drivers: Use vendor-provided drivers that assist GPU virtualization. For NVIDIA, this implies putting in the NVIDIA digital GPU (vGPU) driver on the Home windows Server 2025 host (the driving force bundle that helps GPU-P). Verify the GPU vendor’s documentation for set up for specifics. After putting in, you possibly can confirm the GPU’s standing by way of PowerShell or WAC.
Visitor VM Drivers: The visitor VMs additionally want acceptable GPU drivers put in (inside the VM’s OS) to utilize the digital GPU. As an example, if utilizing Home windows 11 or Home windows Server 2025 as a visitor, set up the GPU driver contained in the VM (usually the identical data-center driver or a guest-compatible subset from the vGPU bundle) in order that the GPU is usable for DirectX/OpenGL or CUDA in that VM. Linux friends (Ubuntu 18.04/20.04/22.04 are supported) likewise want the Linux driver put in. Visitor OS assist for GPU-P in WS2025 covers Home windows 10/11, Home windows Server 2019+, and sure Ubuntu LTS variations.
After {hardware} setup and driver set up, it’s vital to confirm that the host acknowledges the GPU as “partitionable.” You should use Home windows Admin Heart or PowerShell for this: in WAC’s GPU tab, verify the “Assigned standing” of the GPU it ought to present “Partitioned” if every little thing is configured appropriately (if it exhibits “Prepared for DDA project” then the partitioning driver isn’t energetic, and if “Not assignable” then the GPU/driver doesn’t assist both methodology). In PowerShell, you possibly can run:
It will checklist every GPU machine’s identifier and what partition counts it helps. For instance, an NVIDIA A40 may return ValidPartitionCounts : {16, 8, 4, 2 …} indicating the GPU will be break up into 2, 4, 8, or 16 partitions, and likewise present the present PartitionCount setting (by default it might equal the max or present configured worth). If no GPUs are listed, or the checklist is empty, the GPU just isn’t acknowledged as partitionable (verify drivers/BIOS). If the GPU is listed however ValidPartitionCounts is clean or exhibits solely “1,” then it might not assist SR-IOV and might solely be used by way of DDA.
Enabling and Configuring GPU Partitioning
As soon as the {hardware} and drivers are prepared, enabling GPU Partitioning includes configuring how the GPU will likely be divided and guaranteeing all Hyper-V hosts (particularly in a cluster) have a constant setup.
Every bodily GPU have to be configured with a partition depend (what number of partitions to create on that GPU). You can’t outline an arbitrary quantity – it have to be one of many supported counts reported by the {hardware}/driver. The default is likely to be the utmost supported (e.g., 16). To set a particular partition depend, use PowerShell on every host:
Resolve on a partition depend that fits your workloads. Fewer partitions means every VM will get extra GPU assets (extra VRAM and compute per partition), whereas extra partitions means you possibly can assign the GPU to extra VMs concurrently (every getting a smaller slice). For AI/ML, you may select a average quantity – e.g. break up a 24 GB GPU into 4 partitions of ~6 GB every for inference duties.
Run the Set-VMHostPartitionableGpu cmdlet. Present the GPU’s machine ID (from the Title discipline of the sooner Get-VMHostPartitionableGpu output) and the specified -PartitionCount. For instance:
This may configure the GPU to be divided into 4 partitions. Repeat this for every GPU machine if the host has a number of GPUs (or specify -Title accordingly for every). Confirm the setting by operating:
It ought to now present the PartitionCount set to your chosen worth (e.g., PartitionCount : 4 for every listed GPU).
If you’re in a clustered atmosphere, apply the identical partition depend on each host within the cluster for all equivalent GPUs. Consistency is vital: a VM utilizing a “quarter GPU” partition can solely fail over to a different host that additionally has its GPU break up into quarters. Home windows Admin Heart will truly implement this by warning you for those who attempt to set mismatched counts on completely different nodes.
You too can configure the partition depend by way of the WAC GUI. In WAC’s GPU partitions device, choose the GPU (or a set of homogeneous GPUs throughout hosts) and select Configure partition depend. WAC will current a dropdown of legitimate partition counts (as reported by the GPU). Deciding on a quantity will present a tooltip of how a lot VRAM every partition would have (e.g., choosing 8 partitions on a 16 GB card may present ~2 GB per partition). WAC helps make sure you apply the change to all related GPUs within the cluster collectively. After making use of, it should replace the partition depend on every host mechanically.
After this step, the bodily GPUs on the host (or cluster) are partitioned into the configured variety of digital GPUs. They’re now able to be assigned to VMs. The host’s perspective will present every partition as a shareable useful resource. (Observe: You can’t assign extra partitions to VMs than the quantity configured)
Assigning GPU Partitions to Digital Machines
With the GPU partitioned on the host stage, the following step is to connect a GPU partition to a VM. That is analogous to plugging a digital GPU machine into the VM. Every VM can have at most one GPU partition machine hooked up, so select the VM that wants GPU acceleration and assign one partition to it. There are two principal methods to do that: utilizing PowerShell instructions or utilizing the Home windows Admin Heart UI. Beneath are the directions for every methodology.
So as to add the GPU Partition to the VM use the Add-VMGpuPartitionAdapter cmdlet to connect a partitioned GPU to the VM. For instance:
Add-VMGpuPartitionAdapter -VMName ""
It will allocate one of many accessible GPU partitions on the host to the desired VM. (There is no such thing as a parameter to specify which partition or GPU & Hyper-V will auto-select an accessible partition from a suitable GPU. If no partition is free or the host GPUs aren’t partitioned, this cmdlet will return an error)
You may verify that the VM has a GPU partition hooked up by operating:
It will present particulars just like the GPU machine occasion path and a PartitionId for the VM’s GPU machine. In the event you see an entry with an occasion path (matching the GPU’s PCI ID) and a PartitionId, the partition is efficiently hooked up.
Energy on the VM. On boot, the VM’s OS will detect a brand new show adapter. In Home windows friends, you must see a GPU in Machine Supervisor (it might seem as a GPU with a particular mannequin, or a digital GPU machine title). Set up the suitable GPU driver contained in the VM if not already put in, in order that the VM can totally make the most of the GPU (for instance, set up NVIDIA drivers within the visitor to get CUDA, DirectX, and so on. working). As soon as the driving force is energetic within the visitor, the VM will be capable to leverage the GPU partition for AI/ML computations or graphics rendering.
Utilizing Home windows Admin Heart:
Open Home windows Admin Heart and navigate to your Hyper-V cluster or host, then go to the GPUs extension. Guarantee you could have added the GPUs extension v2.8.0 or later to WAC.
Within the GPU Partitions tab, you’ll see an inventory of the bodily GPUs and any present partitions. Click on on “+ Assign partition”. This opens an project wizard.
Choose the VM: First select the host server the place the goal VM at present resides (WAC will checklist all servers within the cluster). Then choose the VM from that host to assign a partition to. (If a VM is greyed out within the checklist, it seemingly already has a GPU partition assigned or is incompatible.)
Choose Partition Measurement (VRAM): Select the partition dimension from the dropdown. WAC will checklist choices that correspond to the partition counts you configured. For instance, if the GPU is break up into 4, you may see an choice like “25% of GPU (≈4 GB)” or related. Guarantee this matches the partition depend you set. You can’t assign extra reminiscence than a partition accommodates.
Offline Motion (HA choice): If the VM is clustered and also you need it to be extremely accessible, verify the choice for “Configure offline motion to pressure shutdown” (if introduced within the UI).
Proceed to assign. WAC will mechanically: shut down the VM (if it was operating), connect a GPU partition to it, after which energy the VM again on. After a short second, the VM ought to come on-line with the GPU partition hooked up. Within the WAC GPU partitions checklist, you’ll now see an entry displaying the VM title underneath the GPU partition it’s utilizing.
At this level, the VM is operating with a digital GPU. You may repeat the method for different VMs, as much as the variety of partitions accessible. Every bodily GPU can solely assist a hard and fast variety of energetic partitions equal to the PartitionCount set. In the event you try to assign extra VMs than partitions, the extra VMs won’t get a GPU (or the Add command will fail). Additionally be aware {that a} given VM can solely occupy one partition on one GPU – you can’t span a single VM throughout a number of GPU partitions or throughout a number of GPUs with GPU-P.
GPU Partitioning in Clustered Environments (Failover Clustering)
One of many main advantages launched with Home windows Server 2025 is that GPU partitions can be utilized in Failover Clustering eventualities for prime availability. This implies you possibly can have a Hyper-V cluster the place VMs with digital GPUs are clustered roles, able to shifting between hosts both by dwell migration (deliberate) or failover (unplanned). To make the most of GPU-P in a cluster, you need to pay particular consideration to configuration consistency and perceive the present limitations:
Use Home windows Server 2025 Datacenter: As talked about, clustering options (like failover) for GPU partitions are supported solely on Datacenter version.
Homogeneous GPU Configuration: All hosts within the cluster ought to have equivalent GPU {hardware} and partitioning setup. Failover/Reside Migration with GPU-P does not assist mixing GPU fashions or partition sizes in a GPU-P cluster. Every host ought to have the identical GPU mannequin. The partition depend configured (e.g., 4 or 8 and so on.) have to be the identical on each host. This uniformity ensures {that a} VM anticipating a sure dimension partition will discover an equal on another node.
Home windows Server 2025 introduces assist for dwell migrating VMs which have a GPU partition hooked up. Nonetheless, there are vital caveats:
{Hardware} assist: Reside migration with GPU-P requires that the hosts’ CPUs and chipsets totally assist isolating DMA and machine state. In observe, as famous, you want Intel VT-d or AMD-Vi enabled, and the CPUs ideally supporting “DMA bit monitoring.” If that is in place, Hyper-V will try to dwell migrate the VM usually. Throughout such a migration, the GPU’s state just isn’t seamlessly copied like common reminiscence; as an alternative, Home windows will fallback to a slower migration course of to protect integrity. Particularly, when migrating a VM utilizing GPU-P, Hyper-V mechanically makes use of TCP/IP with compression (even if in case you have quicker strategies like RDMA configured). It’s because machine state switch is extra advanced. The migration will nonetheless succeed, however you could discover greater CPU utilization on the host and an extended migration time than traditional.
Cross-node compatibility: Be certain that the GPU driver variations on all hosts are the identical, and that every host has an accessible partition for the VM. If a VM is operating and also you set off a dwell migrate, Hyper-V will discover a goal the place the VM can get an equivalent partition. If none are free, the migration won’t proceed (or the VM might must be restarted elsewhere as a failover).
Failover (Unplanned Strikes): If a bunch crashes or goes down, a clustered VM with a GPU partition will likely be mechanically restarted on one other node, very similar to any HA VM. The important thing distinction is that the VM can not save its state, so it will likely be a chilly begin on the brand new node, attaching to a brand new GPU partition there. When the VM comes up on the brand new node, it should request a GPU partition. Hyper-V will allocate one if accessible. If NodeB had no free partition (say all had been assigned to different VMs), the VM may begin however not get a GPU (and certain Home windows would log an error that the digital GPU couldn’t begin). Directors ought to monitor and probably leverage anti-affinity guidelines to keep away from packing too many GPU VMs on one host if full automated failover is required.
The Definitive Information to Information Extraction Software program: The way to Select the Proper Software
TL;DR: This information gives a transparent framework for navigating the fragmented marketplace for knowledge extraction software program. It clarifies the three essential classes of instruments based mostly in your knowledge supply: ETL/ELT platforms for shifting structured knowledge between purposes and databases, internet scrapers for extracting public info from web sites, and Clever Doc Processing (IDP) for extracting knowledge from unstructured enterprise paperwork, equivalent to invoices and contracts. For many operational challenges, the perfect answer is an end-to-end IDP workflow that integrates ingestion, AI-powered seize, automated validation, and seamless ERP integration. The ROI of this strategy is strategic, serving to to stop monetary worth leakage and straight contributing to measurable good points, a $40,000 improve in Internet Working Earnings.
You’ve seemingly heard the outdated laptop science saying: “Rubbish In, Rubbish Out.” It’s the quiet purpose so many costly AI initiatives are failing to ship. The issue is not at all times the AI; it is the standard of the info we’re feeding it. A 2024 trade report discovered {that a} startling 77% of corporationsadmit their knowledge is common, poor, or very poor by way of AI readiness. The offender is the chaotic, unstructured info that flows into enterprise operations every day via paperwork like invoices, contracts, and buy orders.
Your seek for a knowledge extraction answer could have been complicated. You’d have come throughout developer-focused database instruments, easy internet scrapers, and superior doc processing platforms, all below the identical umbrella. The query is, what do you have to put money into? In the end, you have to make sense of messy, unstructured paperwork. The important thing to that is not discovering a greater device; it is asking the best query about your knowledge supply.
This information gives a transparent framework to diagnose your particular knowledge problem and presents a sensible playbook for fixing it. We’ll present you how you can overcome the constraints of conventional OCR and guide entry, constructing an AI-ready basis. The result’s a workflow that may scale back doc processing prices by as a lot as 80% and obtain over 98% knowledge accuracy, enabling the seamless stream of data trapped in your paperwork.
The info extraction spectrum: A framework for readability
The seek for knowledge extraction software program will be complicated as a result of the time period is usually used to explain three fully totally different sorts of instruments that remedy three totally different issues. The best answer relies upon solely on the place your knowledge lives. Understanding the spectrum is step one to discovering a device that really works for what you are promoting.
1. Public internet knowledge (Internet Scraping)
What it’s: This class consists of instruments designed to drag publicly accessible info from web sites mechanically. Widespread use circumstances embrace gathering competitor pricing, gathering product evaluations, or aggregating actual property listings.
Who it is for: Advertising groups, e-commerce analysts, and knowledge scientists.
Backside line:Select this class in case your knowledge is structured on public web sites.
Main options: This area is occupied by platforms like Vivid Information and Apify, which supply strong proxy networks and pre-built scrapers for large-scale public knowledge assortment. No-code instruments like Octoparse are additionally widespread for non-technical customers.
2. Structured software and database knowledge (ETL/ELT)
What it’s: This software program strikes already structured knowledge from one system to a different. The method is usually known as Extract, Rework, Load (ETL). A typical use case includes syncing gross sales knowledge from a CRM, equivalent to Salesforce, right into a central knowledge warehouse for enterprise intelligence reporting.
Who it is for: Information engineers and IT departments.
Backside line:Select this class in case your knowledge is already organized inside a database or a SaaS software.
Main options: The market leaders listed here are platforms like Fivetran and Airbyte. They focus on offering lots of of pre-built connectors to SaaS purposes and databases, automating a course of that may in any other case require important {custom} engineering.
What it’s: That is AI-powered software program constructed to learn and perceive the unstructured or semi-structured paperwork that run what you are promoting: the PDFs, emails, scans, invoices, buy orders, and contracts. It finds the precise info you want—like an bill quantity or contract renewal date—and turns it into clear, structured knowledge.
Who it is for: Finance, Operations, Procurement, Authorized, and Healthcare groups.
Backside line:Select this class in case your knowledge is trapped inside paperwork. That is the most typical and dear problem for enterprise operations.
Main options: This class incorporates specialised doc knowledge extraction software program like Nanonets, Rossum, ABBYY, and Tungsten Automation (previously Kofax). Developer-focused providers like Amazon Textract additionally match right here. In contrast to internet scrapers, these platforms are engineered with superior AI to deal with document-specific challenges like structure variations, desk extraction, and handwriting recognition.
The 2024 trade report we cited earlier additionally confirms it is probably the most important bottleneck, with over 62% of procurement processes and 59% of authorized contract administration nonetheless being extremely guide on account of doc complexity. The remainder of this information will concentrate on this matter.
The strategic operator’s playbook for doc knowledge extraction
Doc knowledge extraction has developed from a easy effectivity device right into a strategic crucial for enterprise AI adoption. As companies look to 2026’s strongest AI purposes, notably these using Retrieval-Augmented Technology (RAG), the standard of their inner knowledge turns into more and more essential. However, even superior AI fashions like Gemini, Claude, or ChatGPT battle with imperfect doc scans, and accuracy charges for these main LLMs hover round 60-70% for doc processing duties.
This actuality underscores that profitable AI implementation requires extra than simply highly effective fashions – it calls for a complete platform with human oversight to make sure dependable knowledge extraction and validation.
A contemporary IDP answer is just not a single device however an end-to-end workflow engineered to show doc chaos right into a structured, dependable, and safe asset. This playbook outlines the 4 vital levels of the workflow and gives a sensible two-week implementation plan.
Earlier than we proceed, the desk beneath gives a fast overview of the most typical and high-impact knowledge extraction purposes throughout numerous departments. It showcases the precise paperwork, the kind of knowledge extracted, and the strategic enterprise outcomes achieved.
Mitigate worth leakage by mechanically flagging off-contract spend and unfulfilled provider obligations; shift procurement from transactional work to strategic provider administration.
Healthcare & Insurance coverage
HCFA-1500/CMS-1500 Declare Types, Digital Well being Data (EHRs), Affected person Onboarding Types
Affected person ID, Process Codes (CPT), Analysis Codes (ICD), Supplier NPI, Scientific Notes
Speed up claims-to-payment cycles and scale back denials; create high-quality, structured datasets from unstructured EHRs to energy predictive fashions and enhance scientific determination assist.
Authorized
Service Agreements, Non-Disclosure Agreements (NDAs), Grasp Service Agreements (MSAs)
Scale back contract evaluate cycles and operational threat by mechanically extracting key clauses, dates, and obligations; uncover hidden worth leakage by auditing contracts for non-compliance at scale.
Manufacturing
Payments of Supplies (BOMs), High quality Inspection Stories, Work Orders, Certificates of Evaluation (CoA)
Half Quantity, Amount, Materials Spec, Cross/Fail Standing, Serial Quantity
Enhance high quality management by digitizing inspection stories; speed up manufacturing cycles by automating work order processing; guarantee compliance by verifying materials specs from CoAs.
Half A: The 4-stage trendy knowledge extraction engine for AI-ready knowledge
The evolution of data extraction from the inflexible, rule-based strategies of the previous to at this time’s adaptive, machine learning-driven methods has made true workflow automation attainable. This contemporary workflow consists of 4 important, interconnected levels.
Step 1: Omnichannel ingestion
The objective right here is to cease the limitless cycle of guide downloads and uploads by making a single, automated entry level for all incoming paperwork. That is the primary line of protection towards the info fragmentation that plagues many organizations, the place vital info is scattered throughout totally different methods and inboxes. A sturdy platform connects on to your current channels, permitting paperwork to stream right into a centralized processing queue from sources like:
A direct API connection out of your different enterprise software program.
Step 2: AI-first knowledge seize
That is the core know-how that distinguishes trendy IDP from outdated Optical Character Recognition (OCR). Legacy OCR depends on inflexible templates, which break the second a vendor adjustments their bill structure. AI-first platforms are “template-agnostic.” They’re pre-trained on tens of millions of paperwork and be taught to determine knowledge fields based mostly on context, very like a human would.
This AI-driven strategy is essential for dealing with the complexities of real-world paperwork. For example, a current examine discovered that even minor doc skew (in-plane rotation from a crooked scan) “adversely impacts the info extraction accuracy of all of the examined LLMs,” with efficiency for fashions like GPT-4-Turbo dropping considerably past a 35-degree rotation. The greatest knowledge extraction software program consists of pre-processing layers that mechanically detect and proper for skew earlier than the AI even begins extracting knowledge.
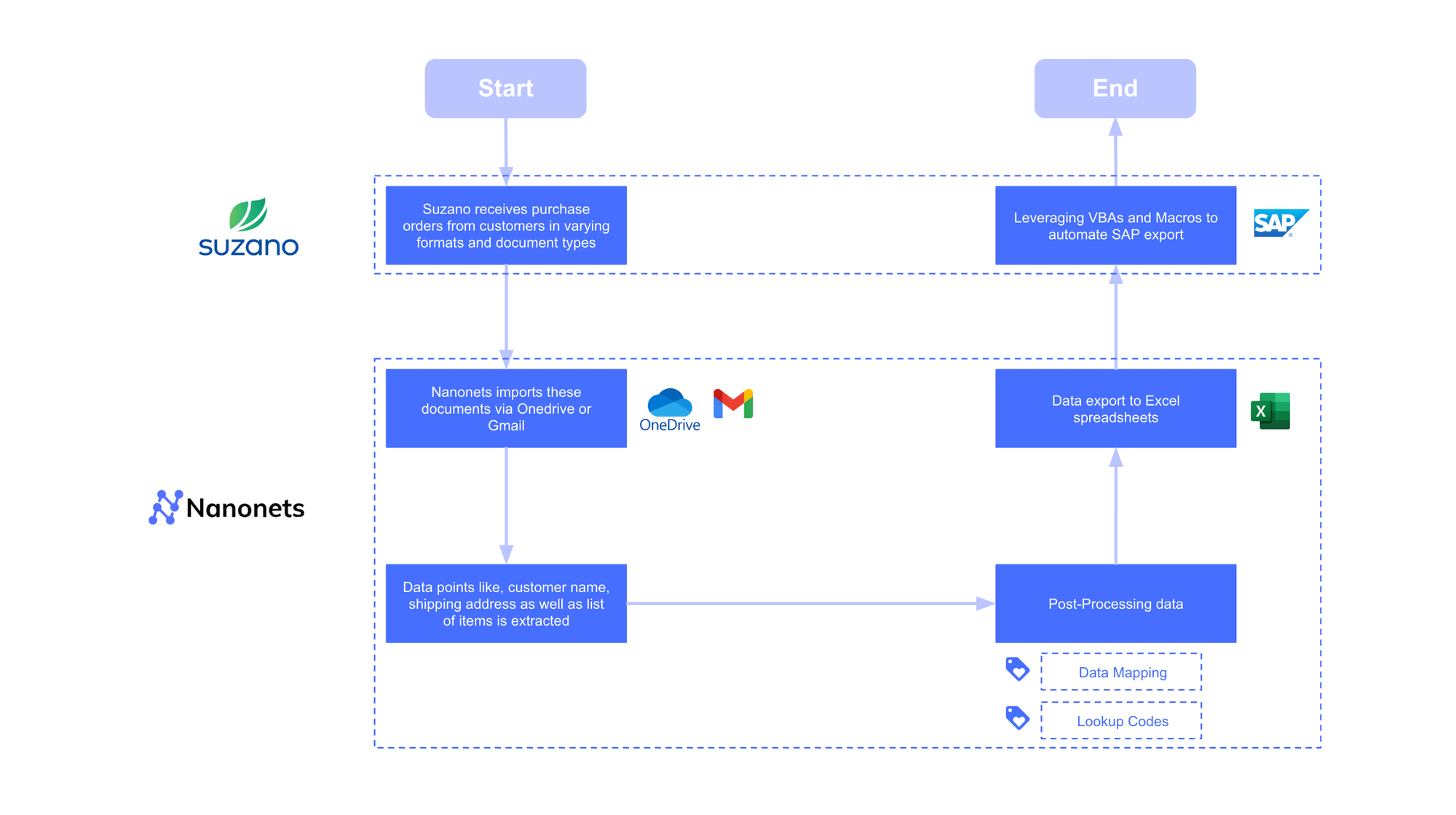
This is how Nanonets helped automate Suzano’s guide workflow. Our IDP ingests Buy Orders straight on the supply, which is Gmail or OneDrive, mechanically extracts the related knowledge factors, codecs them, and exports them as Excel Sheets. Then, the workforce leverages VBAs and Macros to automate knowledge entry into SAP.
This adaptability is confirmed at scale. Suzano Worldwide processes buy orders from over 70 prospects, every with a singular format. A template-based system would have been unmanageable. By using an AI-driven IDP platform, they effectively dealt with all variations, decreasing their processing time per order by 90%—from 8 minutes to simply 48 seconds.
🗨️
“OCR Expertise has clearly been accessible for 10-15 years. We had been testing totally different options however the distinctive facet of Nanonets, I might say, was its means to deal with totally different templates in addition to totally different codecs of the doc which is sort of distinctive from its rivals that create OCR fashions based mostly particular to a single format in a single automation. So, in our case as you may think about we might have needed to create greater than 200 totally different automations.”
~ Cristinel Tudorel Chiriac, Challenge Supervisor at Suzano.
Step 3: Automated validation and enhancement
Uncooked extracted knowledge is just not business-ready. This stage is the sensible software of the “Human-in-the-Loop” (HIL) precept that tutorial analysis has confirmed is non-negotiable for attaining dependable knowledge from AI methods. One 2024 examine on LLM-based knowledge extraction concluded there’s a “dire want for a human-in-the-loop (HIL) course of” to beat accuracy limitations.
That is what separates a easy “extractor” from an enterprise-grade “processing system.” As an alternative of guide spot-checks, a no-code rule engine can mechanically implement what you are promoting logic:
Inside consistency: Guidelines that test knowledge inside a single doc. For instance, flagging an bill if subtotal + tax_amount doesn’t equal total_amount.
Historic consistency: Guidelines that test knowledge towards previous paperwork. For instance, mechanically flagging any bill the place the invoice_number and vendor_name match a doc processed within the final 90 days to stop duplicate funds.
Exterior consistency: Guidelines that test knowledge towards your methods of document. For instance, verifying {that a} PO_number on an bill exists in your grasp Buy Order database earlier than routing for cost.
Step 4: Seamless integration and export
The ultimate step is to “shut the loop” and get rid of the final mile of guide knowledge entry. As soon as the info is captured and validated, the platform should mechanically export it into your system of document. With out this step, automation is incomplete and creates a brand new guide job: importing a CSV file.
Main IDP platforms present pre-built, two-way integrations with main ERP and accounting methods, equivalent to QuickBooks, NetSuite, and SAP, enabling the system to mechanically sync payments and replace cost statuses with out requiring human intervention.
Half B: Your 2-week implementation plan
Deploying one in all these knowledge extraction options doesn’t require a multi-month IT venture that drains sources and delays worth. With a contemporary, no-code IDP platform, a enterprise workforce can obtain important automation in a matter of weeks. This part gives a sensible two-week dash plan to information you from pilot to manufacturing, adopted by an sincere evaluation of the real-world challenges you could anticipate for a profitable deployment.
Week 1: Setup, pilot, and fine-tuning
Setup and pilot: Join your main doc supply (e.g., your AP e-mail inbox). Add a various batch of at the least 30 historic paperwork from 5-10 totally different distributors. Carry out a one-time verification of the AI’s preliminary extractions. This includes a human reviewing the AI’s output and making corrections, offering essential suggestions to the mannequin in your particular doc varieties.
Prepare and configure: Provoke a mannequin re-train based mostly in your verified paperwork. This fine-tuning course of usually takes 1-2 hours. Whereas the mannequin trains, configure your 2-3 most crucial validation guidelines and approval workflows (e.g., flagging duplicates and routing high-value invoices to a supervisor).
Week 2: Go stay and measure
Go stay: Start processing your stay, incoming paperwork via the now-automated workflow.
Monitor your key metric: A very powerful success metric is your Straight-Via Processing (STP) Fee. That is the proportion of paperwork which can be ingested, captured, validated, and exported with zero human touches. Your objective needs to be to attain an STP charge of 80% or greater. For reference, the property administration agency Hometown Holdings achieved an 88% STP charge after implementing its automated workflow.
Half C: Navigating the real-world implementation challenges
The trail to profitable automation includes anticipating and fixing key operational challenges. Whereas the know-how is strong, treating it as a easy “plug-and-play” answer with out addressing the next points is a typical explanation for failure. That is what separates a stalled venture from a profitable one.
The issue: The soiled knowledge actuality
What it’s: Actual-world enterprise paperwork are messy. Scans are sometimes skewed, codecs are inconsistent, and knowledge is fragmented throughout methods. It might probably trigger even superior AI fashions to hallucinate and produce incorrect outputs.
Actionable answer:
Prioritize a platform with strong pre-processing capabilities that mechanically detect and proper picture high quality points like skew.
Create workflows that consolidate associated paperwork earlier than extraction to supply the AI with an entire image.
The issue: The last-mile integration failure
What it’s: Many automation initiatives succeed at extraction however fail on the ultimate, essential step of getting validated knowledge right into a legacy ERP or system of document. This leaves groups caught manually importing CSV recordsdata, a bottleneck that negates a lot of the effectivity good points. This difficulty is a number one explanation for venture failure. This difficulty is a number one explanation for venture failure. A BCG report discovered that 65% of digital transformations fail to attain their targets, actually because organizations “underestimate integration complexities”.
Actionable answer:
Outline your integration necessities as a non-negotiable a part of your choice course of.
Prioritize platforms with pre-built, two-way integrations in your particular software program stack (e.g., QuickBooks, SAP, NetSuite).
The flexibility to mechanically sync knowledge is what permits true, end-to-end straight-through processing.
The issue: The governance and safety crucial
What it’s: Your doc processing platform is the gateway to your organization’s most delicate monetary, authorized, and buyer knowledge. Connecting inner paperwork to AI platforms introduces new and important safety dangers if not correctly managed. As a 2025 PwC report on AI predicts, rigorous governance and validation of AI methods will change into “non-negotiable”.
Actionable answer:
Select a vendor with enterprise-grade safety credentials (e.g., SOC 2, GDPR, HIPAA compliance)
Guarantee distributors have a transparent knowledge governance coverage that ensures your knowledge won’t be used to coach third-party fashions.
The ROI: From stopping worth leakage to driving revenue
A contemporary doc automation platform is just not a price heart; it is a value-creation engine. The return on funding (ROI) goes far past easy time financial savings, straight impacting your backside line by plugging monetary drains which can be typically invisible in guide workflows.
A 2025 McKinsey report identifies that probably the most important sources of worth leakage is corporations dropping roughly 2% of their whole spend to points equivalent to off-contract purchases and unfulfilled provider obligations. Automating and validating doc knowledge is without doubt one of the most direct methods to stop this.
Right here’s how this appears to be like in follow throughout totally different companies.
Instance 1: 80% price discount in property administration
Nanonets’ knowledge extraction device captures info from invoices and sends it to Ascend properties. Ascend educated the AI to extract the required info from the invoices, after which it performs checks to make sure that all fields are appropriately populated and consistent with expectations.
Ascend Properties, a quickly rising property administration agency, noticed its bill quantity develop 5x in 4 years.
Earlier than: To deal with the quantity manually, their course of would have required 5 full-time workers devoted to simply bill verification and entry.
After: By implementing an IDP platform, they now course of 400 invoices a day in simply 10 minutes with just one part-time worker for oversight.
The end result: This led to a direct 80% discount in processing prices and saved the work of 4 full-time workers, permitting them to scale their enterprise with out scaling their back-office headcount.
Instance 2: $40,000 improve in Internet Working Earnings
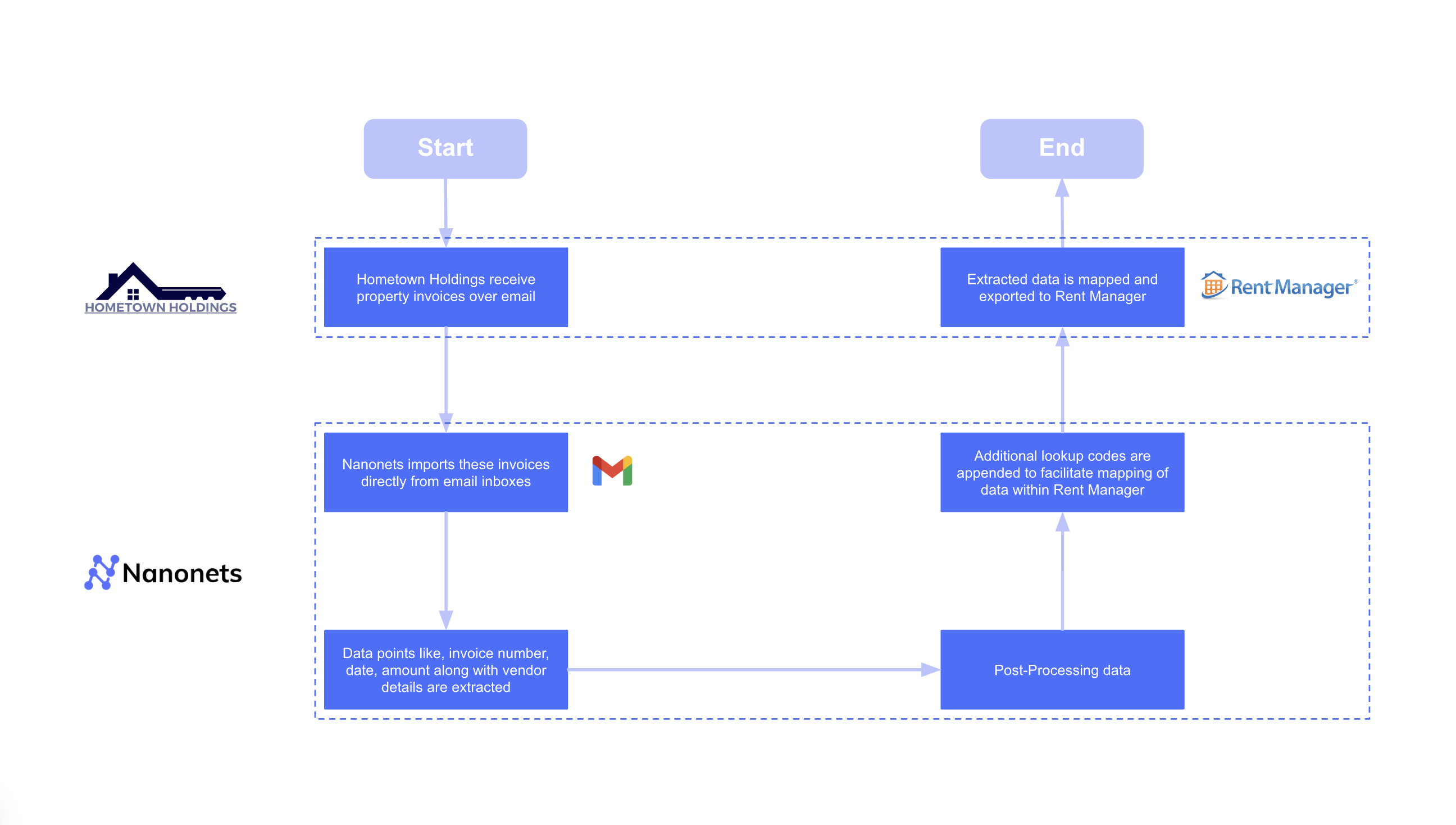
In Hometown Holding’s case, Nanonets’ knowledge extraction answer ingests Invoices straight on the supply, which is their e-mail inbox, mechanically extracts the related knowledge factors, codecs them, after which exports them into Lease Supervisor, mechanically mapping the bill to the suitable vendor.
For Hometown Holdings, one other property administration firm, the objective was not simply price financial savings however worth creation.
Earlier than: Their workforce spent 4,160 hours yearly manually getting into utility payments into their Lease Supervisor software program.
After: The automated workflow achieved an 88% Straight-Via Processing (STP) charge, almost eliminating guide entry.
The end result: Past the huge time financial savings, the elevated operational effectivity and improved monetary accuracy contributed to a $40,000 improve within the firm’s NOI.
Instance 3: 192 Hours Saved Per Month at enterprise scale
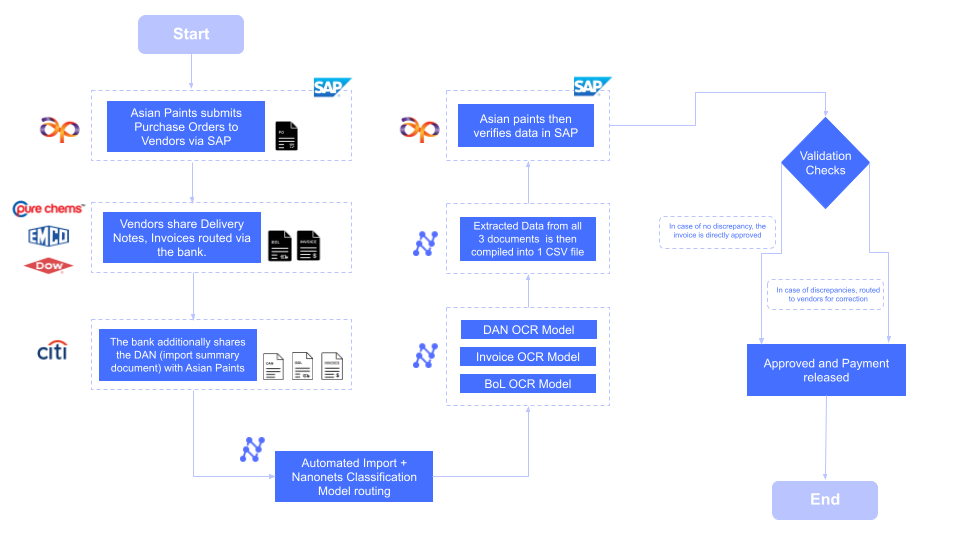
Nanonets IDP helped Asian Paints automate their whole worker reimbursement course of from finish to finish with automated knowledge extraction and export. All related knowledge factors from every particular person doc are extracted and compiled right into a single CSV file, which is mechanically imported into their SAP occasion.
The affect of automation scales with quantity. Asian Paints, one in all Asia’s largest paint corporations, manages a community of over 22,000 distributors.
Earlier than: Processing the advanced set of paperwork for every vendor—buy orders, invoices, and supply notes—took a mean of 5 minutes per doc.
After: The AI-driven workflow lowered the processing time to ~30 seconds per doc.
The end result: This 90% discount in processing time saved the corporate 192 person-hours each month, releasing up the equal of a full-time worker to concentrate on extra strategic monetary duties as a substitute of knowledge entry.
The marketplace for knowledge extraction software program is notoriously fragmented. You can’t group platforms constructed for database replication (ETL/ELT), internet scraping, and unstructured doc processing (IDP) collectively. It creates a major problem when looking for an answer that matches your precise enterprise downside. On this part, we are going to enable you consider totally different knowledge extraction instruments and choose those most fitted in your use case.
We’ll briefly cowl the main platforms for internet and database extraction earlier than inspecting IDP options designed for advanced enterprise paperwork. We may even handle the function of open-source elements for groups contemplating a {custom} “construct” strategy.
a. For software and database Extraction (ETL/ELT)
These platforms are the workhorses for knowledge engineering groups. Their main operate is to maneuver pre-structured knowledge from numerous purposes (equivalent to Salesforce) and databases (like PostgreSQL) right into a central knowledge warehouse for analytics.
1. Fivetran
Fivetran is a completely managed, automated ELT (Extract, Load, Rework) platform identified for its simplicity and reliability. It’s designed to attenuate the engineering effort required to construct and keep knowledge pipelines.
Execs:
Intuitive, no-code interface that accelerates deployment for non-technical groups.
Its automated schema administration, which adapts to adjustments in supply methods, is a key power that considerably reduces upkeep overhead.
Cons:
Consumption-based pricing mannequin, whereas versatile, can result in unpredictable and excessive prices at scale, a typical concern for enterprise customers.
As a pure ELT device, all transformations occur post-load within the knowledge warehouse, which might improve warehouse compute prices.
Pricing:
Gives a free plan for low volumes (as much as 500,000 month-to-month energetic rows).
Paid plans observe a consumption-based pricing mannequin.
Integrations:
Helps over 500 connectors for databases, SaaS purposes, and occasions.
Key options:
Absolutely managed and automatic connectors.
Automated dealing with of schema drift and normalization.
Actual-time or near-real-time knowledge synchronization.
Greatest use-cases: Fivetran’s main use case is making a single supply of reality for enterprise intelligence. It excels at consolidating knowledge from a number of cloud purposes (e.g., Salesforce, Marketo, Google Adverts) and manufacturing databases into a knowledge warehouse, equivalent to Snowflake or BigQuery.
Splendid prospects: Information groups at mid-market to enterprise corporations who prioritize velocity and reliability over the associated fee and complexity of constructing and sustaining {custom} pipelines.
2. Airbyte
Airbyte is a number one open-source knowledge integration platform that gives a extremely extensible and customizable various to completely managed options, favored by technical groups who require extra management.
Execs:
Being open-source eliminates vendor lock-in, and the Connector Improvement Equipment (CDK) permits builders to construct {custom} connectors shortly.
It has a big and quickly rising library of over 600 connectors, with a good portion contributed by its group.
Cons:
The setup and administration will be advanced for non-technical customers, and a few connectors could require guide upkeep or {custom} coding.
Self-hosted deployments will be resource-heavy, particularly throughout giant knowledge syncs. The standard and reliability also can differ throughout the various community-built connectors.
Pricing:
A free and limitless open-source model is out there.
A managed cloud plan can be accessible, priced per credit score.
Integrations:
Helps over 600 connectors, with the power to construct {custom} ones.
Key options:
Each ETL and ELT capabilities with non-compulsory in-flight transformations.
Change Information Seize (CDC) assist for database replication.
Versatile deployment choices (self-hosted or cloud).
Greatest use-cases: Airbyte is greatest fitted to integrating all kinds of knowledge sources, together with long-tail purposes or inner databases for which pre-built connectors could not exist. Its flexibility makes it excellent for constructing {custom}, scalable knowledge stacks.
Splendid prospects: Organizations with a devoted knowledge engineering workforce that values the management, flexibility, and cost-effectiveness of an open-source answer and is supplied to handle the operational overhead.
3. Qilk Talend
Qilk Talend is a complete, enterprise-focused knowledge integration and administration platform that gives a set of merchandise for ETL, knowledge high quality, and knowledge governance.
Execs:
Gives intensive and highly effective knowledge transformation and knowledge high quality options that go far past easy knowledge motion.
Helps a variety of connectors and has versatile deployment choices (on-prem, cloud, hybrid).
Cons:
Steep studying curve in comparison with newer, no-code instruments.
The enterprise version comes with excessive licensing prices, making it much less appropriate for smaller companies.
Pricing:
Gives a primary, open-source model. Paid enterprise plans require a {custom} quote.
Integrations:
Helps over 1,000 connectors for databases, cloud providers, and enterprise purposes.
Greatest use-cases: Talend is right for large-scale, enterprise knowledge warehousing initiatives that require advanced knowledge transformations, rigorous knowledge high quality checks, and complete knowledge governance.
Splendid prospects: Giant enterprises, notably in regulated industries like finance and healthcare, with mature knowledge groups that require a full-featured knowledge administration suite.
b. For internet knowledge extraction (Internet Scraping)
These instruments are for pulling public knowledge from web sites. They are perfect for market analysis, lead era, and aggressive evaluation.
1. Vivid Information
Vivid Information is positioned as an enterprise-grade internet knowledge platform, with its core power being its huge and dependable proxy community, which is important for large-scale, nameless knowledge assortment.
Execs:
Its intensive community of knowledge facilities and residential IPs permits it to bypass geo-restrictions and complicated anti-bot measures.
The corporate emphasizes a “compliance-first” strategy, offering a degree of assurance for companies involved with the moral and authorized facets of internet knowledge assortment.
Cons:
Steep studying curve, with a lot of options that may be overwhelming for brand new customers.
Occasional proxy instability or blockages can disrupt time-sensitive knowledge assortment workflows.
Pricing:
Plans are usually subscription-based, with some beginning round $500/month.
Integrations:
Primarily integrates through a strong API, permitting builders to attach it to {custom} purposes.
Key options:
Giant datacenter and residential proxy networks.
Pre-built internet scrapers and different knowledge assortment instruments.
Greatest use-cases: Vivid Information is greatest for large-scale internet scraping initiatives that require excessive ranges of anonymity and geographic variety. It’s well-suited for duties like e-commerce value monitoring, advert verification, and gathering public social media knowledge.
Splendid prospects: The perfect prospects are data-driven corporations, from mid-market to enterprise, which have a steady want for big volumes of public internet knowledge and require a strong and dependable proxy infrastructure to assist their operations.
2. Apify
Apify is a complete cloud platform providing pre-built scrapers (referred to as “Actors”) and the instruments to construct, deploy, and handle {custom} internet scraping and automation options.
Execs:
The Apify Retailer incorporates over 2,000 pre-built scrapers, which might considerably speed up initiatives for widespread targets like social media or e-commerce websites.
The platform is very versatile, catering to each builders who need to construct {custom} options and enterprise customers who can leverage the pre-built Actors.
Cons:
The price can escalate for large-scale or high-frequency knowledge operations, a typical concern in person suggestions.
Whereas pre-built instruments are user-friendly, totally using the platform’s {custom} capabilities requires technical data.
Pricing:
Gives a free plan with platform credit.
Paid plans begin at $49/month and scale with utilization.
Integrations:
Integrates with Google Sheets, Amazon S3, and Zapier, and helps webhooks for {custom} integrations.
Key options:
A big market of pre-built scrapers (“Actors”).
A cloud surroundings for creating, operating, and scheduling scraping duties.
Instruments for constructing {custom} automation options.
Greatest use-cases: Automating knowledge assortment from e-commerce websites, social media platforms, actual property listings, and advertising and marketing instruments. Its flexibility makes it appropriate for each fast, small-scale jobs and complicated, ongoing scraping initiatives.
Splendid prospects: A variety of customers, from particular person builders and small companies utilizing pre-built instruments to giant corporations constructing and managing {custom}, large-scale scraping infrastructure.
3. Octoparse
Octoparse is a no-code internet scraping device designed for non-technical customers. It makes use of a point-and-click interface to show web sites into structured spreadsheets with out writing any code.
Execs:
The visible, no-code interface.
It might probably deal with dynamic web sites with options like infinite scroll, logins, and dropdown menus.
Gives cloud-based scraping and automated IP rotation to stop blocking.
Cons:
Whereas highly effective for a no-code device, it might battle with extremely advanced or aggressively protected web sites in comparison with developer-focused options.
Pricing:
Gives a restricted free plan.
Paid plans begin at $89/month.
Integrations:
Exports knowledge to CSV, Excel, and numerous databases.
Additionally affords an API for integration into different purposes.
Key options:
No-code point-and-click interface.
A whole lot of pre-built templates for widespread web sites.
Cloud-based platform for scheduled and steady knowledge extraction.
Greatest use-cases: Market analysis, value monitoring, and lead era for enterprise customers, entrepreneurs, and researchers who want to gather structured internet knowledge however don’t have coding expertise.
Splendid prospects: Small to mid-sized companies, advertising and marketing companies, and particular person entrepreneurs who want a user-friendly device to automate internet knowledge assortment.
c. For doc knowledge extraction (IDP)
That is the answer to the most typical and painful enterprise problem: extracting structured knowledge from unstructured paperwork. These platforms require specialised AI that understands not solely textual content but additionally the visible structure of a doc, making them the best selection for enterprise operators in finance, procurement, and different document-intensive departments.
1. Nanonets
Nanonets is a number one IDP platform for companies that want a no-code, end-to-end workflow automation answer. Its key differentiator is its concentrate on managing the whole doc lifecycle with a excessive diploma of accuracy and adaptability.
Execs:
Manages the whole course of from omnichannel ingestion and AI-powered knowledge seize to automated validation, multi-stage approvals, and deep ERP integration, which is a major benefit over instruments that solely carry out extraction.
The platform’s template-agnostic AI will be fine-tuned to attain very excessive accuracy (over 98% in some circumstances) and repeatedly learns from person suggestions, making it extremely adaptable to new doc codecs with out guide template creation.
The system is very versatile and will be programmed for advanced, bespoke use circumstances.
Cons:
Whereas it affords a free tier, the Professional plan’s beginning value could also be a consideration for tiny companies or startups with extraordinarily low doc volumes.
Pricing:
Gives a free plan with credit upon sign-up.
Paid plans are subscription-based per mannequin, with overages charged per subject or web page.
Integrations:
Gives pre-built, two-way integrations with main ERP and accounting methods like QuickBooks, NetSuite, SAP, and Salesforce.
Key options:
AI-powered, template-agnostic OCR that repeatedly learns.
A no-code, visible workflow builder for validation, approvals, and knowledge enhancement.
Pre-trained fashions for widespread paperwork like invoices, receipts, and buy orders.
Zero-shot fashions that use pure language to explain the info you need to extract from any doc.
Greatest use-cases: Automating document-heavy enterprise processes the place accuracy, validation, and integration are vital. This consists of accounts payable automation, gross sales order processing, and compliance doc administration. For instance, Nanonets helped Ascend Properties save the equal work of 4 FTEs by automating their bill processing workflow.
Splendid prospects: Enterprise groups (Finance, Operations, Procurement) in mid-market to enterprise corporations who want a robust, versatile, and easy-to-use platform to automate their doc workflows with out requiring a devoted workforce of builders.
2. Rossum
Rossum is a robust IDP platform with a selected concentrate on streamlining accounts payable and different document-based processes.
Execs:
Intuitive interface, which is designed to make the method of validating extracted bill knowledge very environment friendly for AP groups.
Adapts to totally different bill layouts with out requiring templates, which is its core power.
Excessive accuracy on normal paperwork.
Cons:
Its main concentrate on AP means it might be much less versatile for a variety of {custom}, non-financial doc varieties in comparison with extra general-purpose IDP platforms.
Whereas glorious at extraction and validation, it might provide much less intensive no-code workflow customization for advanced, multi-stage approval processes in comparison with some rivals.
Pricing:
Gives a free trial; paid plans are custom-made based mostly on doc quantity.
Integrations:
Integrates with quite a few ERP methods equivalent to SAP, QuickBooks, and Microsoft Dynamics.
Key options:
AI-powered OCR for bill knowledge extraction.
An intuitive, user-friendly interface for knowledge validation.
Automated knowledge validation checks.
Greatest use-cases: Automating the extraction and validation of knowledge from vendor invoices for accounts payable groups who prioritize a quick and environment friendly validation expertise.
Splendid prospects: Mid-market and enterprise corporations with a excessive quantity of invoices who need to enhance the effectivity and accuracy of their AP division.
3. Klippa DocHorizon
Klippa DocHorizon is an AI-powered knowledge extraction platform designed to automate doc processing workflows with a robust emphasis on safety and compliance.
Execs:
A key differentiator is its concentrate on safety, with options like doc verification to detect fraudulent paperwork and the power to cross-check knowledge with exterior registries.
Gives knowledge anonymization and masking capabilities, that are vital for organizations in regulated industries needing to adjust to privateness legal guidelines like GDPR.
Cons:
Documentation could possibly be extra detailed, which can current a problem for improvement groups throughout integration.
Pricing:
Pricing is out there upon request and is usually custom-made for the use case.
Integrations:
Integrates with a variety of ERP and accounting methods together with Oracle NetSuite, Xero, and QuickBooks.
Key options:
AI-powered OCR with a concentrate on fraud detection.
Automated doc classification.
Information anonymization and masking for compliance.
Greatest use circumstances: Processing delicate paperwork the place compliance and fraud detection are paramount, equivalent to invoices in finance, id paperwork for KYC processes, and expense administration.
Splendid prospects: Organizations in finance, authorized, and different regulated industries that require a excessive diploma of safety and knowledge privateness of their doc processing workflows.
4. Tungsten Automation (previously Kofax)
Tungsten Automation gives an clever automation software program platform that features highly effective doc seize and processing capabilities, typically as a part of a broader digital transformation initiative.
Execs:
Gives a broad suite of instruments that transcend IDP to incorporate Robotic Course of Automation (RPA) and course of orchestration, permitting for true end-to-end enterprise course of transformation.
The platform is very scalable and well-suited for big enterprises with a excessive quantity and number of advanced, typically world, enterprise processes.
Cons:
Preliminary setup will be advanced and will require specialised data or skilled providers. The whole price of possession is a major funding.
Whereas highly effective, it’s typically seen as a heavy-duty IT answer that’s much less agile for enterprise groups who need to shortly construct and modify their very own workflows with out developer involvement.
Pricing:
Enterprise pricing requires a {custom} quote.
Integrations:
Integrates with a variety of enterprise methods and is usually used as half of a bigger automation technique.
Key options:
AP Doc Intelligence and workflow automation.
Built-in analytics and Robotic Course of Automation (RPA).
Cloud and on-premise deployment choices.
Greatest use circumstances: Giant enterprises seeking to implement a broad clever automation technique the place doc processing is a key element of a bigger workflow that features RPA.
Splendid prospects: Giant enterprises with advanced enterprise processes which can be present process a major digital transformation and have the sources to put money into a complete automation platform.
5. ABBYY
ABBYY is a long-standing chief and pioneer within the OCR and doc seize area, providing a set of highly effective, enterprise-grade IDP instruments like Vantage and FlexiCapture.
Execs:
Extremely correct recognition engine, can deal with an unlimited variety of languages and complicated paperwork, together with these with cursive handwriting.
The software program is strong and may deal with a variety of doc varieties with spectacular accuracy, notably structured and semi-structured varieties.
It’s engineered for high-volume, mission-critical environments, providing the robustness required by giant, multinational companies for duties like world shared service facilities and digital mailrooms.
Cons:
The preliminary setup and configuration could be a important endeavor, typically requiring skilled providers or a devoted inner workforce with specialised expertise.
The whole price of possession is on the enterprise degree, making it much less accessible and infrequently prohibitive for small to mid-sized companies that don’t require its full suite of capabilities.
Pricing:
Enterprise pricing requires a {custom} quote.
Integrations:
Gives a variety of connectors and a strong API for integration with main enterprise methods like SAP, Oracle, and Microsoft.
Key options:
Superior OCR and ICR for high-accuracy handwriting extraction.
Automated doc classification and separation for dealing with advanced, multi-document recordsdata.
A low-code/no-code “ability” designer that enables enterprise customers to coach fashions for {custom} doc varieties.
Greatest use circumstances: ABBYY is right for big, multinational companies with advanced, high-volume doc processing wants. This consists of digital mailrooms, world shared service facilities for finance (AP/AR), and large-scale digitization initiatives for compliance and archiving.
Splendid prospects: The perfect prospects are Fortune 500 corporations and enormous authorities companies, notably in document-intensive sectors like banking, insurance coverage, transportation, and logistics, that require a extremely scalable and customizable platform with intensive language and format assist.
6. Amazon Textract
Amazon Textract is a machine studying service that mechanically extracts textual content, handwriting, and knowledge from scanned paperwork, leveraging the ability of the AWS cloud.
Execs:
Advantages from AWS’s highly effective infrastructure and integrates seamlessly with the whole AWS ecosystem (S3, Lambda, SageMaker), a serious benefit for corporations already on AWS.
It’s extremely scalable and goes past easy OCR to determine the contents of fields in varieties and data saved in tables.
Cons:
It’s a developer-focused API/service, not a ready-to-use enterprise software. Constructing an entire workflow with validation and approvals requires important {custom} improvement effort.
The pay-as-you-go pricing mannequin, whereas versatile, will be difficult to foretell and management for companies with fluctuating doc volumes.
Pricing:
Pay-as-you-go pricing based mostly on the variety of pages processed.
Integrations:
Deep integration with AWS providers like S3, Lambda, and SageMaker.
Key options:
Pre-trained fashions for invoices and receipts.
Superior extraction for tables and varieties.
Signature detection and handwriting recognition.
Greatest use circumstances: Organizations already invested within the AWS ecosystem which have developer sources to construct {custom} doc processing workflows powered by a scalable, managed AI service.
Splendid prospects: Tech-savvy corporations and enterprises with robust improvement groups that need to construct {custom}, AI-powered doc processing options on a scalable cloud platform.
d. Open-Supply elements
For organizations with in-house technical groups contemplating a “construct” strategy for a {custom} pipeline or RAG software, a wealthy ecosystem of open-source elements is out there. These should not end-to-end platforms however present the foundational know-how for builders. The panorama will be damaged down into three essential classes:
1. Foundational OCR engines
These are the elemental libraries for the important first step: changing pixels from a scanned doc or picture into uncooked, machine-readable textual content. They don’t perceive the doc’s construction (e.g., the distinction between a header and a line merchandise), however it’s a prerequisite for processing any non-digital doc.
Examples:
Tesseract: The long-standing, widely-used baseline OCR engine maintained by Google, supporting over 100 languages.
PaddleOCR: A preferred, high-performance various that can be famous for its robust multilingual capabilities.
2. Format-aware and LLM-ready conversion libraries
This contemporary class of instruments goes past uncooked OCR. They use AI fashions to grasp a doc’s visible structure (headings, paragraphs, tables) and convert the whole doc right into a clear, structured format like Markdown or JSON. This output preserves the semantic context and is taken into account “LLM-ready,” making it excellent for feeding into RAG pipelines.
Examples:
3. Specialised extraction libraries
Some open-source instruments are constructed to unravel one particular, troublesome downside very effectively, making them invaluable additions to a custom-built workflow.
Examples:
Tabula: A go-to utility, ceaselessly really helpful in person boards, for the precise job of extracting knowledge tables from text-based (not scanned) PDFs right into a clear CSV format.
Stanford OpenIE: A well-regarded tutorial device for a special type of extraction: figuring out and structuring relationships (subject-verb-object triplets) from sentences of plain textual content.
Shopping for an off-the-shelf product is usually thought of the quickest path to worth, whereas constructing a {custom} answer avoids vendor lock-in however requires a major upfront funding in expertise and capital. The basis explanation for many failed digital transformations is that this “overly simplistic binary selection.” As an alternative, the best selection typically relies upon solely on the issue being solved and the group’s particular circumstances.
🗨️
What about general-purpose AI fashions? It’s possible you’ll surprise why you may’t merely use ChatGPT, Gemini, or some other fashions for doc knowledge extraction. Whereas these LLMs are spectacular and do energy trendy IDP methods, they’re greatest understood as reasoning engines slightly than full enterprise options.
Analysis has recognized three vital gaps that make uncooked LLMs inadequate for enterprise doc processing:
1. Common-purpose fashions battle with the messy actuality of enterprise paperwork; even barely crooked scans may cause hallucinations and errors. 2. LLMs lack the structured workflows wanted for enterprise processes, with research exhibiting that they want human validation to attain dependable accuracy. 3. Utilizing public AI fashions for delicate paperwork poses important safety dangers.
Wrapping up: Your path ahead
Automated knowledge extraction is now not nearly decreasing guide entry or digitizing paper. The know-how is quickly evolving from a easy operational device right into a core strategic operate. The following wave of innovation is ready to redefine how all enterprise departments—from finance to procurement to authorized—entry and leverage their Most worthy asset: the proprietary knowledge trapped of their paperwork.
Rising developments to look at
The rise of the “knowledge extraction layer”: As seen in probably the most forward-thinking enterprises, corporations are shifting away from ad-hoc scripts and level options. As an alternative, they’re constructing a centralized, observable knowledge extraction layer. This unified platform handles all kinds of knowledge ingestion, from APIs to paperwork, making a single supply of reality for downstream methods.
From extraction to augmentation (RAG): Essentially the most important pattern of 2025 is the shift from simply extracting knowledge to utilizing it to enhance Giant Language Fashions in real-time. The success of Retrieval-Augmented Technology is solely depending on the standard and reliability of this extracted knowledge, making high-fidelity doc processing a prerequisite for reliable enterprise AI.
Self-healing and adaptive pipelines: The following frontier is the event of AI brokers that not solely extract knowledge but additionally monitor for errors, adapt to new doc codecs with out human intervention, and be taught from the corrections made through the human-in-the-loop validation course of. This can additional scale back the guide overhead of sustaining extraction workflows.
Strategic affect on enterprise operations
As dependable knowledge extraction turns into a solved downside, its possession will shift. It can now not be seen as a purely technical or back-office job. As an alternative, it’s going to change into a enterprise intelligence engine—a supply of real-time insights into money stream, contract threat, and provide chain effectivity.
The most important shift is cultural: groups in Finance, Procurement, and Operations will transfer from being knowledge gatherers to knowledge shoppers and strategic analysts. As famous in a current McKinsey report on the way forward for the finance operate, automation is what permits groups to evolve from “quantity crunching to being a greater enterprise companion”.
Key takeaways:
Readability is step one: The market is fragmented. Choosing the proper device begins with appropriately figuring out your main knowledge supply: a web site, a database, or a doc.
AI readiness begins right here: Excessive-quality, automated knowledge extraction is the non-negotiable basis for any profitable enterprise AI initiative, particularly for constructing dependable RAG methods.
Concentrate on the workflow, not simply the device: The most effective options present an end-to-end, no-code workflow—from ingestion and validation to ultimate integration—not only a easy knowledge extractor.
Closing thought: Your path ahead is to not schedule a dozen demos. It is designed to conduct a easy but highly effective check.
First, collect 10 of your most difficult paperwork from at the least 5 totally different distributors.
Then, your first query to any IDP vendor needs to be: “Can your platform extract the important thing knowledge from these paperwork proper now, with out me constructing a template?”
Their reply, and the accuracy of the stay end result, will let you know the whole lot you have to know. It can immediately separate the good, template-agnostic platforms from the inflexible, legacy methods that aren’t constructed for the complexity of recent enterprise.
FAQs
How is knowledge extracted from handwritten paperwork?
Information is extracted from handwriting utilizing a specialised know-how referred to as Clever Character Recognition (ICR). In contrast to normal OCR, which is educated on printed fonts, ICR makes use of superior AI fashions which have been educated on tens of millions of various handwriting samples. This permits the system to acknowledge and convert numerous cursive and print kinds into structured digital textual content, a key functionality for processing paperwork like handwritten varieties or signed contracts.
How ought to a enterprise measure the accuracy of an IDP platform?
Accuracy for an IDP platform is measured at three distinct ranges. First is Subject-Stage Accuracy, which checks if a single piece of knowledge (e.g., an bill quantity) is right. Second is Doc-Stage Accuracy, which measures if all fields on a single doc are extracted appropriately. A very powerful enterprise metric, nonetheless, is the Straight-Via Processing (STP) Fee—the proportion of paperwork that stream from ingestion to export with zero human intervention.
What are the widespread pricing fashions for IDP software program?
The pricing fashions for IDP software program usually fall into three classes: 1) Per-Web page/Per-Doc, a easy mannequin the place you pay for every doc processed; 2) Subscription-Based mostly, a flat price for a set quantity of paperwork monthly or 12 months, which is widespread for SaaS platforms; and 3) API Name-Based mostly, widespread for developer-focused providers like Amazon Textract the place you pay per request. Most enterprise-level plans are custom-quoted based mostly on quantity and complexity.
Can these instruments deal with advanced tables that span a number of pages?
This can be a identified, troublesome problem that primary extraction instruments typically fail to deal with. Nevertheless, superior IDP platforms use subtle, vision-based AI fashions to grasp desk constructions. These platforms will be educated to acknowledge when a desk continues onto a subsequent web page and may intelligently “sew” the partial tables collectively right into a single, coherent dataset.
What’s zero-shot knowledge extraction?
Zero-shot knowledge extraction refers to an AI mannequin’s means to extract a subject of knowledge that it has not been explicitly educated to seek out. As an alternative of counting on pre-labeled examples, the mannequin makes use of a pure language description (a immediate) of the specified info to determine and extract it. For instance, you might instruct the mannequin to seek out the policyholder’s co-payment quantity. This functionality dramatically reduces the time wanted to arrange new or uncommon doc varieties.
How does knowledge residency (e.g., GDPR, CCPA) have an effect on my selection of a knowledge extraction device?
Information residency and privateness are vital concerns. When selecting a device, particularly a cloud-based platform, you could guarantee the seller can course of and retailer your knowledge in a selected geographic area (e.g., the EU, USA, or APAC) to adjust to knowledge sovereignty legal guidelines like GDPR. Search for distributors with enterprise-grade safety certifications (like SOC 2 and HIPAA) and a transparent knowledge governance coverage. For max management over delicate knowledge, some enterprise platforms additionally provide on-premise or non-public cloud deployment choices.
The Samsung Galaxy S26 Plus is predicted to come back with quite a few sensible enhancements equivalent to a quicker and extra energy-efficient SoC, a greater major sensor for enhanced images, and a good higher battery endurance.
Professionals
Qualcomm Snapdragon 8 Elite Gen 5 for considerably higher basic and AI efficiency
Silicon-carbon battery and MagSafe help anticipated
Android 16 (with One UI 8.5) and 7 years of OS & safety updates
Cons
No vital design adjustments anticipated
Nonetheless rumored to come back with 45W charging
Does all of it
The Samsung Galaxy S25 Plus stays a well-balanced Android flagship that provides a vibrant high-resolution show, top-notch {hardware} specs, and a flexible triple-lens digicam setup. It’s going to even be supported for years to come back.
Professionals
Qualcomm Snapdragon 8 Elite continues to be highly effective but thermally environment friendly
All-day battery life
Improbable digicam efficiency with Log video help
Cons
Digicam {hardware} unchanged over the previous couple of generations
No built-in magnets for correct Qi2 help
In the event you’re out there for a well-rounded Android flagship, the Galaxy S25 Plus is a straightforward selection. From a beautiful high-resolution show to top-of-the-line cameras to all-day battery life, it gives nearly all the pieces, and you will recognize the balanced nature of the Galaxy S25 Plus, particularly in comparison with different gadgets just like the Galaxy S25 Edge. It is clearly the darkish horse of the whole Galaxy S25 line-up.
That stated, we’re quick approaching the launch of the Galaxy S26 collection, and if the regular stream of leaks and rumors is to be believed, Samsung appears set to introduce some huge adjustments to its top-tier smartphones.
So, what precisely are you able to anticipate from the Galaxy S26 Plus (if it is even known as that!) when it goes official? Extra importantly, is it price ready for, or do you have to simply purchase the Galaxy S25 Plus that is out there now? We take a speculative take a look at the Samsung Galaxy S26 Plus vs. Galaxy S25 Plus and attempt to reply these questions.
Samsung Galaxy S26 Plus vs. Galaxy S25 Plus: Naming, worth, and availability
(Picture credit score: Derrek Lee / Android Central)
The previous few months have seen a barrage of conflicting data surfacing on-line about Samsung’s plans for the Galaxy S26 line-up. Lots of the earlier leaks claimed that the corporate was planning on introducing the Galaxy S26 Professional to succeed the Galaxy S25, in addition to launching the Galaxy S26 Edge to take over the mantle from the Galaxy S25 Plus, with the Galaxy S26 Extremely changing the Galaxy S25 Extremely as the usual bearer of the brand new collection.
Nonetheless, in line with the newest rumors, the chaebol will probably be sticking to its regular naming scheme and introduce the bottom Galaxy S26, the larger Galaxy S26 Plus, and the stylus-toting Galaxy S26 Extremely. The rationale for this choice is alleged to be the Galaxy S25 Edge’s lackluster gross sales, which have failed to draw consumers. Actually, Samsung would possibly even discontinue the super-slim ‘Edge’ collection altogether after only one mannequin.
(Picture credit score: Derrek Lee / Android Central)
No matter its title, the Galaxy S26 Plus is prone to have the identical beginning worth of $999 for the 256GB storage model. That stated, you may need to attend a bit longer to get your arms on Samsung’s new flagships, as a current leak claims the collection’ launch has been postponed to March, relatively than the same old January 2026 timeline.
Samsung Galaxy S26 Plus vs. Galaxy S25 Plus: Design, show, and {hardware}
(Picture credit score: Derrek Lee / Android Central)
Barring this yr’s Galaxy S25 Extremely, the design of Samsung’s top-tier telephones has remained largely unchanged over the previous couple of generations. Nonetheless, if some CAD renders shared by tipster OnLeaks (through Android Headlines) are something to go by, we would lastly have some visible updates, even when they’re actually minor.
Get the newest information from Android Central, your trusted companion on the planet of Android
In these renders, the three rear cameras of the bottom Galaxy S26 (and presumably the Galaxy S26 Plus, since they’re going to share the identical design) might be seen sitting atop a vertical pill-shaped island, relatively than instantly on the again panel like they’re with the Galaxy S25 collection.
Additionally, leaked renders of the Galaxy S26 Extremely counsel the identical design change is perhaps utilized to all members of the Galaxy S26 line-up. Clearly, the inspiration for this comes from the Galaxy S25 Edge and the Galaxy Z Fold 7. We’d see barely extra rounded corners and slimmer bezels too, however aside from that, the brand new telephones will retain their regular boxy design with flat sides, all-glass back and front panels, and IP68 certification.
(Picture credit score: Android Headlines)
The Galaxy S26 Plus would possibly get a touch bigger and brighter show, however that display screen will not be a lot totally different than what its soon-to-be predecessor has. That is an excellent factor, because the Galaxy S25 Plus’s 6.7-inch Dynamic LTPO AMOLED panel is an absolute delight to take a look at. From the 120Hz adaptive refresh fee to the super-high pixel density, it has all the pieces!
Swipe to scroll horizontally
Specs
Class
Samsung Galaxy S26 Plus (Rumored/anticipated)
Samsung Galaxy S25 Plus
Dimensions
158.4 x 75.8 x 7.3 mm (6.24 x 2.98 x 0.29 in)
158.4 x 75.8 x 7.3 mm (6.24 x 2.98 x 0.29 in)
Sturdiness & Case Materials(s)
IP68 score for mud and water resistance, Corning Gorilla Glass Victus 2 (back and front), Aluminum body
IP68 score for mud and water resistance, Corning Gorilla Glass Victus 2 (back and front), Aluminum body
Android 16 with One UI 8.5 (preinstalled), seven years of OS and safety updates
Android 15 with One UI 7 (preinstalled), seven years of OS and safety updates
Coming to specs, that is the place we are able to anticipate some main adjustments. The S-series smartphones have at all times packed in one of the best {hardware} within the enterprise, and the Galaxy S25 Plus isn’t any totally different. It is powered by Qualcomm’s Snapdragon 8 Elite (for Galaxy) SoC, together with 12GB of RAM and as much as 512GB of blazing-fast storage.
As famous by Android Central’s Derrek Lee in his Galaxy S25 Plus assessment, the smartphone makes fast work of even essentially the most demanding of video games and apps, all whereas staying thermally environment friendly. In fact, that is all to be anticipated from a smartphone of its caliber.
(Picture credit score: Derrek Lee / Android Central)
Now, the Galaxy S26 Plus (and all its siblings) are all however confirmed to be pushed by the Snapdragon 8 Elite Gen 5, which is Qualcomm’s latest top-tier chipset. In comparison with the last-gen mannequin, it claims to ship a leap of as much as 25% in single-core efficiency and a lift of as much as 20% in multi-core workloads. You can too anticipate some strong good points in gaming and AI workflows.
It is also price mentioning right here that Samsung would possibly revert to a dual-chipset strategy with the Galaxy S26 line-up, with its upcoming flagships utilizing a homegrown SoC, the Exynos 2600, in some markets. And it would really be an excellent factor this time round, as a current report claims that the brand new chipset will pack some critical punch, with efficiency which may put it in the identical league because the freshest SoCs from Qualcomm and Apple.
It goes with out saying that the Galaxy S26 Plus will possible include all the same old connectivity and I/O choices, together with Wi-Fi 7, multi-band 5G, and USB Kind-C 3.2 with DisplayPort performance.
As implausible as all that’s, newer {hardware} should not be your “solely” cause to select the Galaxy S26 Plus. The Galaxy S25 Plus continues to be among the many finest Android telephones cash can purchase, and it will stay so for a really very long time, even when it is now not the most recent factor on the town.
Samsung Galaxy S26 Plus vs. Galaxy S25 Plus: Cameras, software program, and battery
(Picture credit score: Derrek Lee / Android Central)
It ought to come as no shock that the Samsung Galaxy S25 Plus ranks among the many finest Android digicam telephones out there out there now. The triple-lens system is comprised of a 50MP major sensor, a 10MP telephoto unit with 3x optical zoom, and a 12MP ultrawide module.
The setup helps you to seize strong photographs with a number of element and dynamic vary, and low-light efficiency is nice too. For movies, you rise up to 8K recording and Log video seize performance. Add to it the same old assortment of modifying choices and AI-based options, and you’ve got a wonderful on a regular basis digicam array.
However even with all that goodness, the digicam {hardware} is precisely the identical because it has been during the last a number of generations. In keeping with rumors, this development is prone to proceed with the Galaxy S26 Plus, because it’ll carry ahead the identical triple-lens association but once more, though the 50MP major sensor would possibly get an replace.
Even so, the brand new telephone would possibly get a greater digicam efficiency because of its improved processing, however that is one thing we’ll solely be capable of take a look at as soon as we get our arms on the Galaxy S26 Plus and we put it via its paces.
(Picture credit score: Smartprix)
Speaking about software program, it is all however sure that the Galaxy S26 Plus and all of its siblings will launch with Android 16 out of the field. Samsung has already began rolling out the newest model of the working system to the Galaxy S25 collection of telephones, and the rollout is predicted to succeed in different gadgets quickly.
The corporate’s construct of Android 16 comes spruced up with the One UI 8 customized overlay, which incorporates options like enhanced multitasking, extra highly effective AI capabilities, and enhancements to the ‘Now Bar’ and ‘Now Transient’ modules. As for the Galaxy S26 lineup, it would launch with One UI 8.5, which is already in beta testing and can carry options equivalent to AI-based notification summaries, precedence notifications, and extra.
In fact, all these options may even make their strategy to the Galaxy S25 collection smartphones and different eligible gadgets.
(Picture credit score: Derrek Lee / Android Central)
Rounding off the spectacular specs of the Galaxy S25 Plus is its unbelievable battery life. Regardless of having the identical battery dimension as its predecessor, the Galaxy S25 Plus can go a full day earlier than needing a top-up.
There is not a lot details about what the Galaxy S26 Plus would possibly carry to the desk on this division, but when the rumors concerning the Galaxy S26 getting an even bigger battery maintain any weight, it is not unreasonable to anticipate Samsung to provide the identical remedy to the ‘Plus’ mannequin.
Some leaks have hinted on the Galaxy S26 smartphones getting silicon-carbon batteries, one thing we might like to see since many Chinese language flagships (e.g., Vivo X200 Professional) have already adopted the know-how. We might like the whole Galaxy S26 collection to get 65W quick charging as effectively, however Samsung’s unlikely to try this.
(Picture credit score: Derrek Lee / Android Central)
The Galaxy S26 Plus ought to hopefully embrace built-in magnets for correct MagSafe wi-fi charging, however we aren’t certain whether or not it should help the newer Qi2 25W customary. Nonetheless, the Galaxy S26 Plus ought to have higher battery life (theoretically) over the Galaxy S25 Plus because of its newer and extra power-efficient internals.
Samsung Galaxy S26 Plus vs. Galaxy S25 Plus: Is ready price it?
(Picture credit score: Android Headlines)
Though the leaks and rumors to this point have been (and proceed to be) everywhere, there isn’t any denying that the upcoming launch of the Galaxy S26 collection is shaping as much as be a hotly anticipated one. And whereas nothing’s confirmed but, the main points we have now to this point level to the Galaxy S26 line-up being a bit extra than simply one other incremental replace. So, the actual query is, should you’ve been fascinated with getting the Galaxy S25 Plus, do you have to simply purchase one or watch for the Galaxy S26 Plus?
The reply to that query depends upon many components, equivalent to your use case, funds, and the way urgently you want a brand new smartphone. In the event you’re an influence person who takes numerous photographs along with your smartphone and plan on utilizing your subsequent system for a very long time, ready for the Galaxy S26 Plus is smart, even when which means having to carry on to your present telephone for a bit longer.
Alternatively, should you want a feature-laden Android flagship that’ll final you years and could not care much less concerning the newest chipset or the most recent assortment of AI instruments, getting the Galaxy S25 Plus now (and even higher, in the course of the festive-season promotions like Black Friday) is the precise selection. It has nearly all the pieces you might need in a top-of-the-line Android smartphone and can get software program help for years to come back.
New and improved
The upcoming Galaxy S26 Plus is predicted to characteristic Qualcomm’s latest top-tier chipset, together with an up to date major digicam sensor, a large assortment of AI-powered instruments, and MagSafe help.
Ticks all of the bins
About to be a last-generation mannequin quickly, the Samsung Galaxy S25 Plus continues to be a powerhouse that provides cutting-edge {hardware}, nice cameras, years software program help, and a battery that may go all day.
A fossil unearthed on Japanese Europe’s Crimean Peninsula has divulged the strongest genetic clues but about Neandertals’ long-distance journeys into the guts of Asia.
After figuring out a bone fragment beforehand excavated at Crimea’s Starosele rock-shelter as Neandertal, researchers extracted bits of mitochondrial DNA from the discover. That genetic materials shows shut hyperlinks to corresponding DNA segments already obtained from Neandertal fossils at three websites within the Altai area of Russian Siberia, say archaeologist Emily Pigott and colleagues. Mitochondrial DNA sometimes will get handed from moms to their kids.
“Lengthy-distance migrations by Neandertals facilitated contact and interbreeding with Homo sapiens and Denisovans in numerous elements of the world,” says Pigott, of the College of Vienna.
Protein analyses helped researchers determine a Crimean fossil (the possible leg bone seen right here from two views) as that of a Neandertal. DNA from the fossil confirmed hyperlinks to Neandertals who lived 3,000 kilometers to the east.Emily Pigott
Radiocarbon courting places the Crimean Neandertal fossil, in all probability a part of an higher leg bone, at between roughly 46,000 and 45,000 years outdated. Neandertal treks from Europe to Siberia and maybe so far as East Asia occurred in periods of warming temperatures, Pigott’s workforce suspects. Geologic research place one such travel-friendly interval at about 120,000 to 100,000 years in the past. One other began round 60,000 years in the past.
1000’s of fossils excavated at Starosele are too fragmentary to categorise as species by visible inspection. Analyses of protein residues in 150 Starosele bone fragments recognized most because the stays of horses. An abundance of horse fossils on the Crimean rock-shelter aligns with proof that Neandertals hunted wild horses.
I just lately noticed somebody put up [1] that 987654321/123456789 could be very practically 8, particularly 8.0000000729.
I puzzled whether or not there’s something distinct about base 10 on this. For instance, would the ratio of 54321six and 12345six be near an integer? The ratio is 4.00268, which is fairly near 4.
What a few bigger base? Let’s strive base 16. The expression
0xFEDCBA987654321 / 0x123456789ABCDEF
in Python returns 14. The precise ratio is just not 14, however it’s as near 14 as a regular floating level quantity might be.
For a base b, let denom(b) to be the quantity fashioned by concatenating all of the digits in ascending order and let num(b) be the quantity fashioned by concatenating all of the digits in descending order.
Then for b > 2 we now have
The next Python code demonstrates [2] that that is true for b as much as 1000.
num = lambda b: sum([k*b**(k-1) for k in range(1, b)])
denom = lambda b: sum([(b-k)*b**(k-1) for k in range(1, b)])
for b in vary(3, 1001):
n, d = num(b), denom(b)
assert(n // d == b-2)
assert(n % d == b-1)
So for any base the ratio is almost an integer, specifically b − 2, and the fractional half is roughly 1/bb−2.
When b = 16, as within the instance above, the result’s roughly
14 + 16−14 = 8 + 4 + 2 + 2−56
which might take 60 bits to symbolize precisely, however a floating level fraction solely has 53 bits. That’s why our calculation returned precisely 14 with no fractional half.
[1] I noticed @ColinTheMathmo put up it on Mastodon. He mentioned he noticed it on Fermat’s Library someplace. I assume it’s a really outdated commentary and that the evaluation I did above has been carried out many occasions earlier than.
[2] Why embody a script moderately than a proof? One motive is that the proof is straight-forward however tedious and the script is compact.
A extra normal motive that I give computational demonstrations of theorems is that applications are complementary to proofs. Packages and proofs are each topic to bugs, however they’re not prone to have the identical bugs. And since applications made particulars express by necessity, a program would possibly fill in gaps that aren’t sufficiently spelled out in a proof.
R’s method syntax is extraordinarily highly effective however could be complicated for novices.
This put up is a fast reference masking all the symbols which have a “particular” which means within an R method: ~, +, ., -, 1, :, *, ^, and I().
You might by no means use a few of these in observe, but it surely’s good to know that they exist.
It was a few years earlier than I noticed that I might merely sort y ~ x * z as a substitute of the lengthier y ~ x + z + x:z, for instance.
Whereas R formulation crop up in quite a lot of locations, they’re in all probability most acquainted as the primary argument of lm().
For that reason, my verbal explanations assume a easy linear regression setting through which we hope to foretell y utilizing various regressors x, z, and w.
~
separate LHS and RHS of method
y ~ x
regress y on x
+
add variable to a method
y ~ x + z
regress y on xandz
.
denotes “all the pieces else”
y ~ .
regress y on all different variables in a knowledge body
-
take away variable from a method
y ~ . - x
regress y on all different variables besidesx
1
denotes intercept
y ~ x - 1
regress y on xwith out an intercept
:
assemble interplay time period
y ~ x + z + x:z
regress y on x, z, and the product x instances z
*
shorthand for ranges plus interplay
y ~ x * z
regress y on x, z, and the product x instances z
^
larger order interactions
y ~ (x + z + w)^3
regress y on x, z, w, all two-way interactions, and the three-way interactions
I()
“as-is” – override particular meanings of different symbols from this desk
As of mid-2019, Dropbox introduced that they not assist symlinks that time exterior of the primary Dropbox folder. On this tutorial, we present a workaround on Linux that permits us to retailer in Dropbox any file, even when it isn’t positioned inside the primary Dropbox folder.
What
is the limitation and why it’s an issue?
Think about that you’ve got a bunch of information that you just wish to synchronize throughout your gadgets, however they’re saved exterior of your Dropbox folder. For instance, assume that your primary Dropbox folder is positioned at ~/Dropbox however your paperwork reside within the ~/Paperwork folder. As much as lately, you had the choice so as to add these information in Dropbox with out bodily transferring them by making a symlink:
ln -s ~/Paperwork ~/Dropbox/Paperwork
Sadly this function received deprecated by Dropbox. Each folder/file that was a symlink is now copied and the “(Symlink Backup Copy)” is appended to it. Which means any adjustments you make to your authentic exterior folders will not be seen to Dropbox.
Working across the limitation utilizing mount
Fortunately there’s a fast and simple resolution to work across the limitation on Linux. Under I clarify how this may be achieved on Ubuntu, however the course of ought to be much like different Linux distributions.
To realize the identical
impact, we’re going to use “bind mount”. A bind mount permits us
to create an alternate view of the unique listing tree in a brand new
location. Any modification on one facet is straight away mirrored on
the opposite, successfully permitting us to share the identical information.
To create a bind
mount you should utilize the next instructions:
# Create mounting level in Dropbox folder
mkdir -p ~/Dropbox/Paperwork
# Hyperlink the exterior folder in Dropbox
sudo mount --bind ~/Paperwork ~/Dropbox/Paperwork
That’s it! Dropbox ought to be capable of begin synchronizing the information. Sadly the mount command doesn’t persist between restarts. To make the change everlasting we have to modify the /and so forth/fstab file by appending:
WARNING: Enhancing your fstab file incorrectly can render your pc unbootable. It’s easy to recuperate from this downside however earlier than enhancing the file, you might be suggested to do some studying.
# Add one line for each exterior Dropbox folder
/residence/YOUR_USERNAME_HERE/Paperwork
/residence/YOUR_USERNAME_HERE/Dropbox/Paperwork none
defaults,bind,x-gvfs-hide 0 0
Observe that including the x-gvfs-hide possibility will permit make Nautilus file supervisor to cover the mounting factors.


 Claymon Cunningham (1941")